
Pythonのtry文はエラー処理の基本構文ですが、実はelseまで正しく使いこなしている人は多くありません。
本記事では、初心者の方にも分かるように、try・except・else・finallyの違いや役割を整理しつつ、「いつelseを書くべきか」「どんな処理をelseに入れるべきか」を具体例とコードで丁寧に解説します。
try elseとは何かを初心者向けに整理
Pythonのtry文の基本構造
まず、Pythonのtry文の全体像から整理します。
Pythonのtry文は、次の4つのブロックを組み合わせて使います。
try: 例外が発生するかもしれない処理を書くexcept: 例外が発生したときの対処を書くelse: 例外が発生しなかった場合だけ実行する処理を書くfinally: 例外の有無に関わらず、最後に必ず実行したい処理を書く
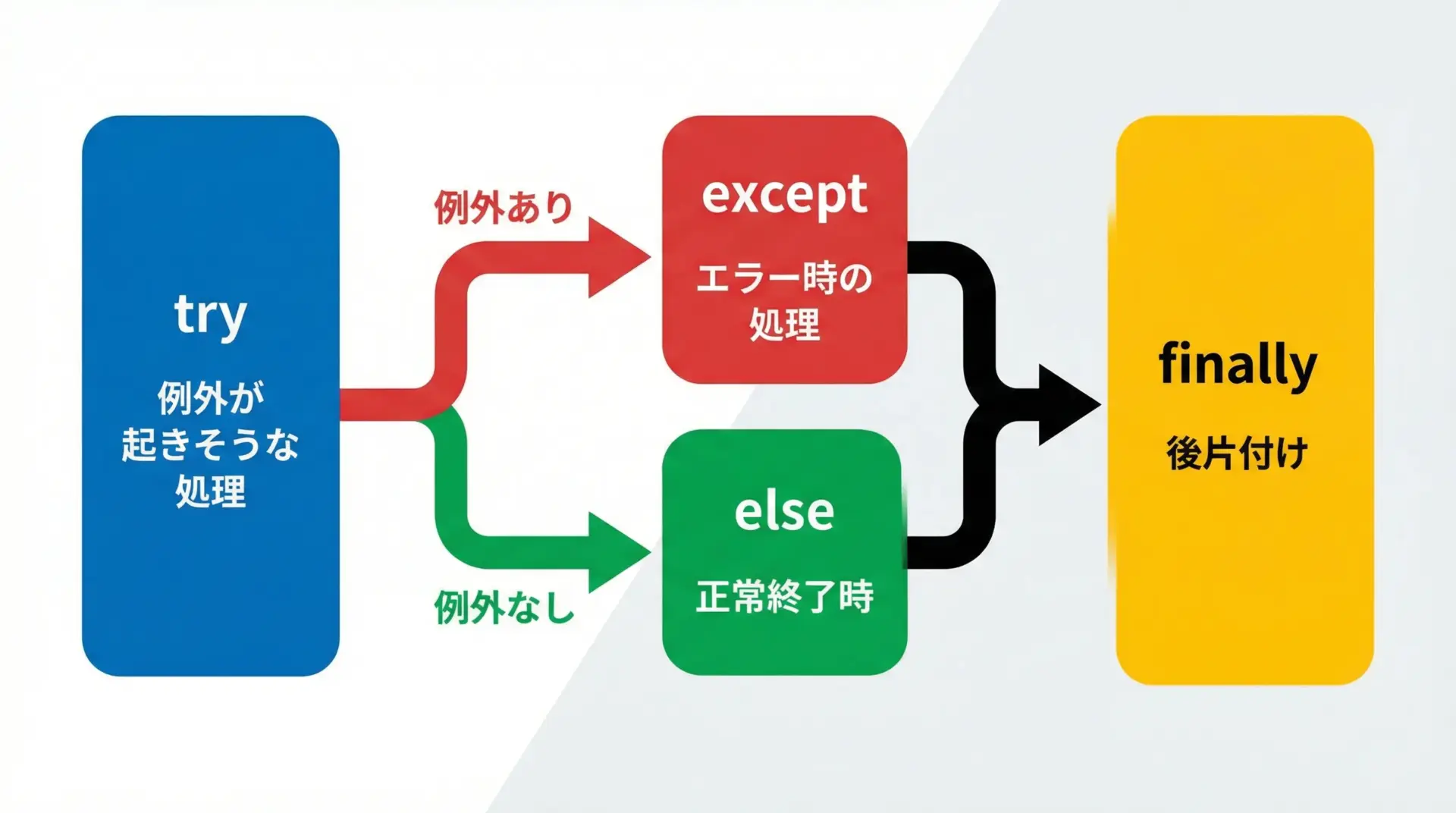
この4つをすべて書いた場合の基本構造は、次のようになります。
try:
# 例外が発生するかもしれない処理
...
except SomeError:
# 例外(SameErrorなど)が発生したときの処理
...
else:
# 例外が1つも発生しなかったときだけ実行される処理
...
finally:
# 例外の有無に関係なく、最後に必ず実行される処理
...多くの入門書ではtryとexceptしか出てこないことが多く、そのためelseやfinallyの存在に気付いていない方も少なくありません。
try elseの役割と実行タイミング
try ... else構文のポイントは、tryブロックの中で例外が発生しなかったときだけ、elseブロックが実行されるという点です。
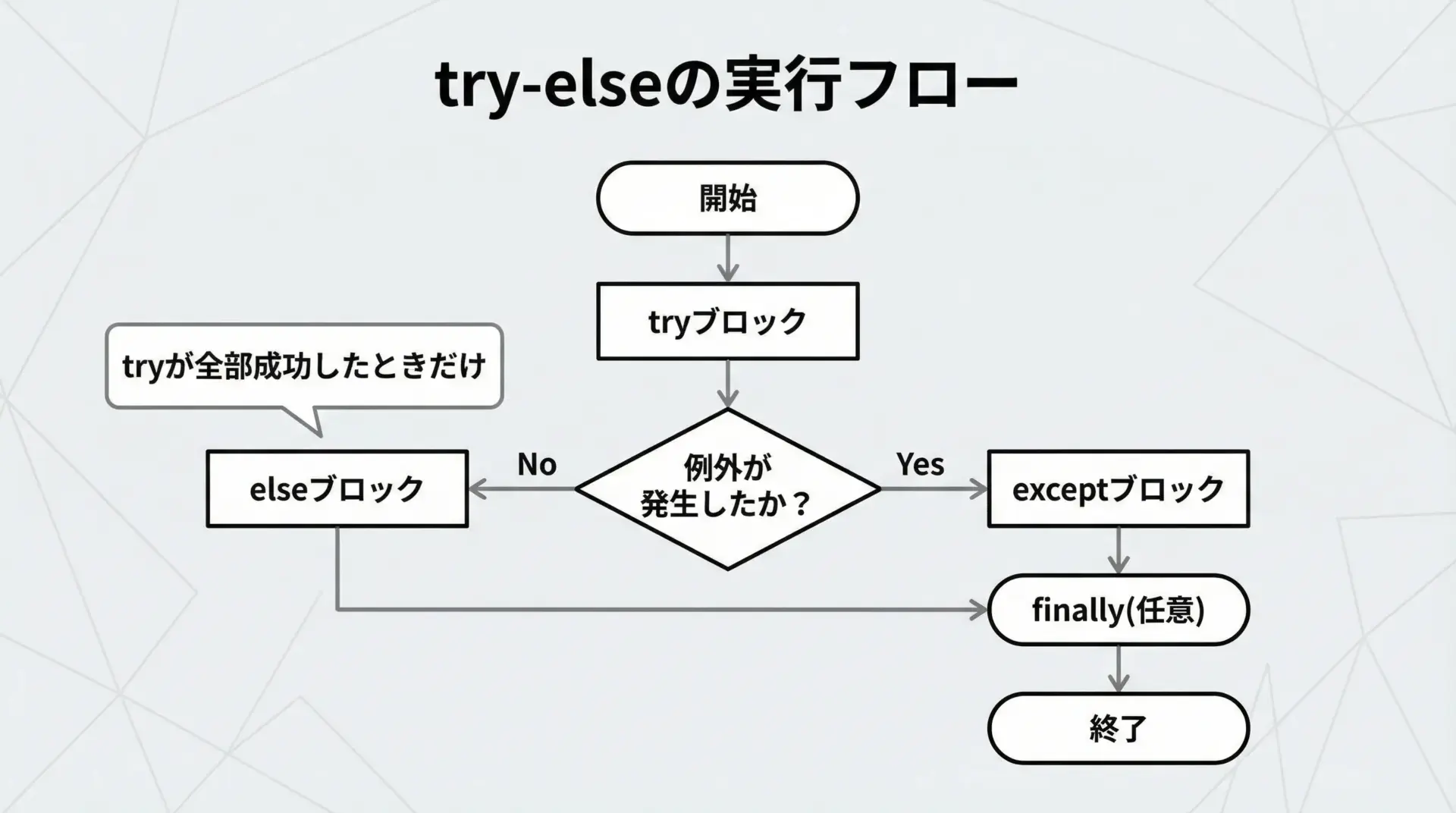
この挙動を簡単なコードで確認してみます。
def divide(a, b):
print("関数開始")
try:
print("try開始")
result = a / b # ここでゼロ除算などの例外が起きる可能性がある
print("try終了")
except ZeroDivisionError:
print("except: ゼロ除算が起きました")
else:
# tryの中で例外が一度も発生しなかったときだけ実行される
print("else: 正常に割り算できました")
print("結果は", result)
finally:
print("finally: ここは必ず通ります")
print("関数終了")
divide(10, 2)
print("----")
divide(10, 0)関数開始
try開始
try終了
else: 正常に割り算できました
結果は 5.0
finally: ここは必ず通ります
関数終了
----
関数開始
try開始
except: ゼロ除算が起きました
finally: ここは必ず通ります
関数終了ここで確認しておきたい重要ポイントは次の2つです。
1つ目は、elseはtryの処理がすべて成功したときだけ実行されるということです。
途中で1つでも例外が発生するとelseはスキップされます。
2つ目は、exceptとelseはどちらか一方しか実行されないということです。
例外が出たらexcept、出なければelseという関係です。
try exceptとの違いをコードで比較
tryとexceptだけでもコードは書けますが、「正常終了時だけ実行したい処理」がある場合、elseを使うと構造が明確になります。
ここでは、2パターンを見比べてみます。
パターン1: try-exceptだけで書く場合
def read_int_from_str(s):
try:
value = int(s) # 数値に変換を試みる
print("変換成功:", value)
# 正常終了時の後続処理
print("ここでDBに保存します")
except ValueError:
# 変換に失敗したとき
print("整数に変換できません:", s)
read_int_from_str("123")
print("----")
read_int_from_str("abc")変換成功: 123
ここでDBに保存します
----
整数に変換できません: abcこの書き方でも問題はありませんが、「例外処理」と「正常時の後続処理」がtryブロックの中に混在しているため、どこまでが「例外が起きそうな処理」なのかが分かりづらくなります。
パターン2: try-except-elseで分離して書く場合
def read_int_from_str(s):
try:
value = int(s) # 例外が起きそうな最小限の処理だけ書く
except ValueError:
print("整数に変換できません:", s)
else:
# tryが成功したときだけ通る「正常系の後続処理」
print("変換成功:", value)
print("ここでDBに保存します")
read_int_from_str("123")
print("----")
read_int_from_str("abc")変換成功: 123
ここでDBに保存します
----
整数に変換できません: abc後者のコードでは、tryブロックには「例外が起きうる部分だけ」が書かれており、elseブロックに「成功時だけ続けて行いたい処理」がまとまっています。
このように、elseを使うことで「例外処理」と「正常系ロジック」をきれいに分離できることが、のちほど説明する最大のメリットになります。
try elseの正しい使い方と注意点
成功時の処理をelseに分けるメリット
elseを使う最大のメリットは、「例外処理のためのコード」と「正常に処理が終わったあとのコード」を視覚的に分けられることです。
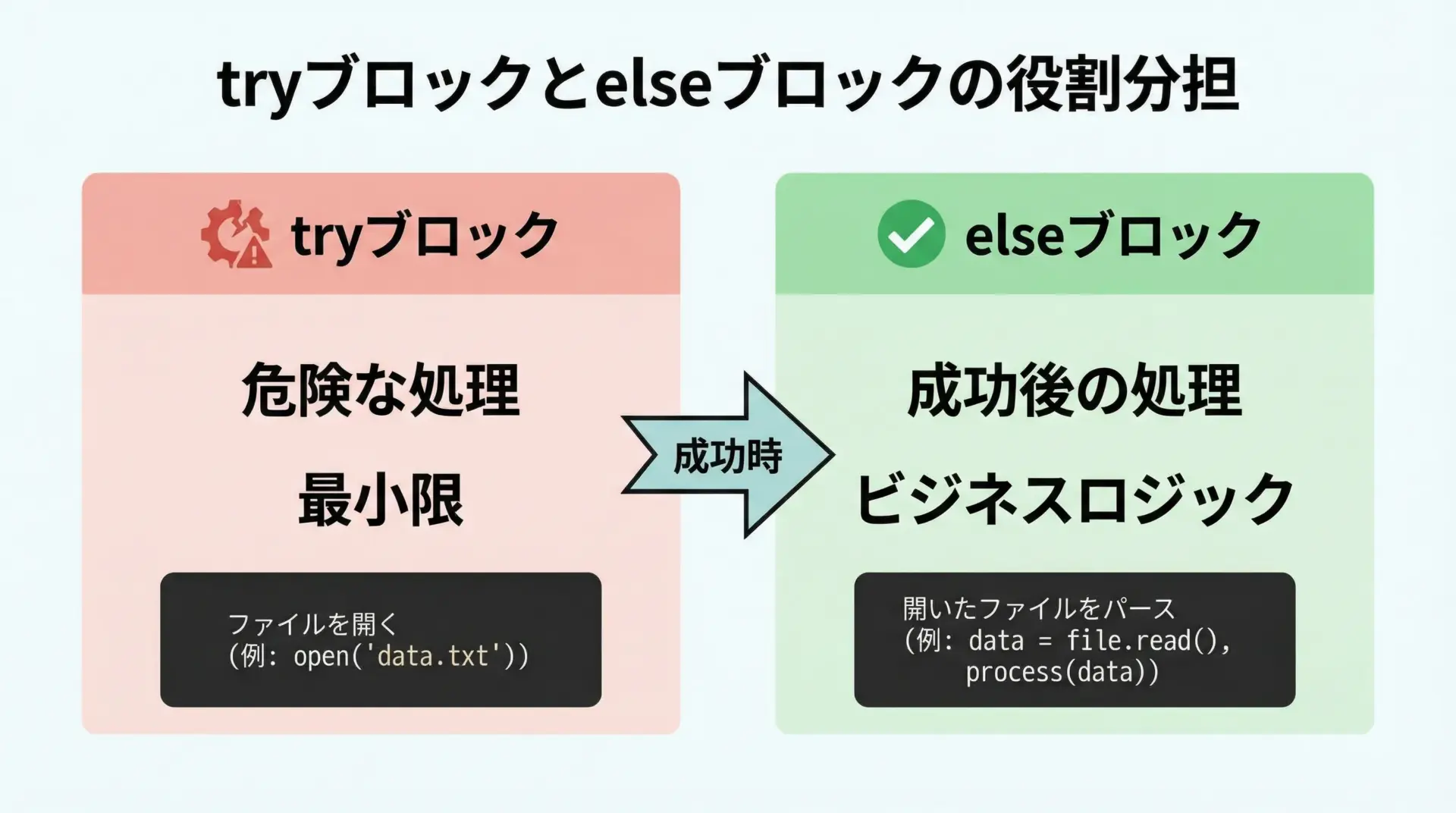
メリットをまとめると、次のようになります。
1つ目は、読みやすさの向上です。
tryの中に「成功時の長い処理」が含まれていると、「どこまでが例外の可能性がある処理なのか」が一目で分かりにくくなります。
elseに移すことで、例外が起きそうな部分の範囲がはっきりします。
2つ目は、バグの原因を切り分けやすくなることです。
tryの中に余計な処理を書かないようにすると、「どこで例外が発生したのか」を特定しやすくなります。
3つ目は、テストしやすさです。
tryブロックとelseブロックを分けておくことで、「例外が起こるケース」「正常終了するケース」の両方をテストしやすくなります。
例外処理と正常系ロジックを分離する方法
実際にどう分けるか、もう少し具体的な例で見てみます。
たとえば「ファイルを開いて中身をパースし、結果を処理する」という流れを考えます。
NG例: tryの中に全部詰め込む
def process_config(path):
try:
# ファイルを開いて
with open(path, "r", encoding="utf-8") as f:
# 読み込んで
text = f.read()
# JSONとしてパースして
import json
config = json.loads(text)
# 結果を使って処理する
print("設定値:", config["name"])
print("バージョン:", config["version"])
except Exception as e:
print("設定ファイルの処理でエラーが発生しました:", e)このコードでは、open・read・パース・後続処理がすべてtryの中に入っており、どこでエラーが起きたのかが分かりづらくなります。
改善例: 例外が起こりうる最小限をtryに、後続処理をelseに
import json
def process_config(path):
try:
with open(path, "r", encoding="utf-8") as f:
text = f.read()
config = json.loads(text) # 読み込み・パースまで
except FileNotFoundError:
print("設定ファイルが見つかりません:", path)
return
except json.JSONDecodeError as e:
print("設定ファイルの形式が不正です:", e)
return
else:
# 読み込みとパースに成功した場合だけ、ここに進む
print("設定値:", config.get("name"))
print("バージョン:", config.get("version"))このようにtryには「ファイルの読み込みとパース」まで、elseには「パースされた結果を使ったビジネスロジック」を書くことで、コードの意図がはっきりします。
tryブロックには「例外が起きそうな最小範囲」だけを書く
tryブロックは広げすぎないことが、良いコードを書くための重要なポイントです。
tryの範囲が広いと、次のような問題が起こりやすくなります。
- 本来意図していない場所の例外まで
exceptで拾ってしまう - どの行で例外が発生したのか特定しづらくなる
- バグの原因調査が難しくなる
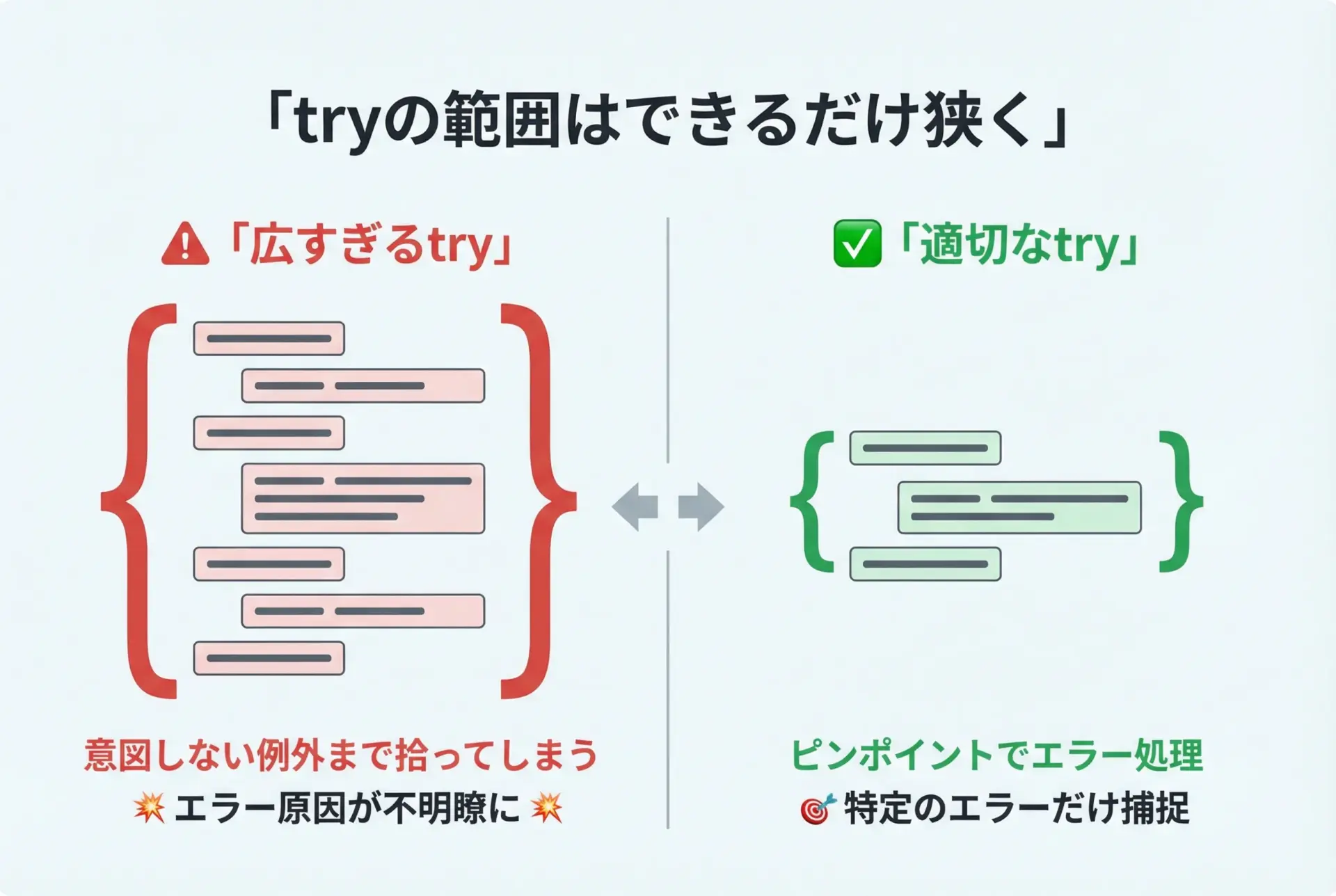
次のような2つのパターンを比較するとイメージしやすくなります。
# 悪い例: tryの範囲が広すぎる
try:
value = int(input("数字を入力してください: "))
print("2倍:", value * 2)
print("さらに+10:", value * 2 + 10)
except ValueError:
print("整数を入力してください")# 良い例: 例外が起きうる部分だけをtryにする
try:
value = int(input("数字を入力してください: "))
except ValueError:
print("整数を入力してください")
else:
print("2倍:", value * 2)
print("さらに+10:", value * 2 + 10)後者では、入力値の変換だけが「例外が起こりうる操作」としてtryに限定されているため、ValueErrorがどこから出てきたのかを迷わずに済みます。
elseブロックに書くべき処理・書くべきでない処理
elseに書くべきものは、「tryブロックが最後まで成功したときだけ実行したい、正常系の処理」です。
具体的には、次のような処理が当てはまります。
- 成功した結果を使った計算や出力
- 成功したことを前提にした後続のビジネスロジック
- 「成功したときだけログを出す」といった補助的な処理
逆に、elseに書かないほうがよいものもあります。
- また別の例外が発生しそうな「危険な処理」
- 成否に関係なく必ず行うべき後片付け処理(
finallyに書く)
簡単な例で確認してみます。
def safe_divide(a, b):
try:
result = a / b
except ZeroDivisionError:
print("0で割ることはできません")
else:
# 割り算が成功したときだけ行いたい処理
print("結果は:", result)
if result > 10:
print("結果が大きい値です")このように、「resultが存在することを前提とする処理」はelseに書くのが自然です。
もしtryの中に書いてしまうと、例外の発生箇所が増え、コードの意図も見えにくくなります。
finallyとの組み合わせ方
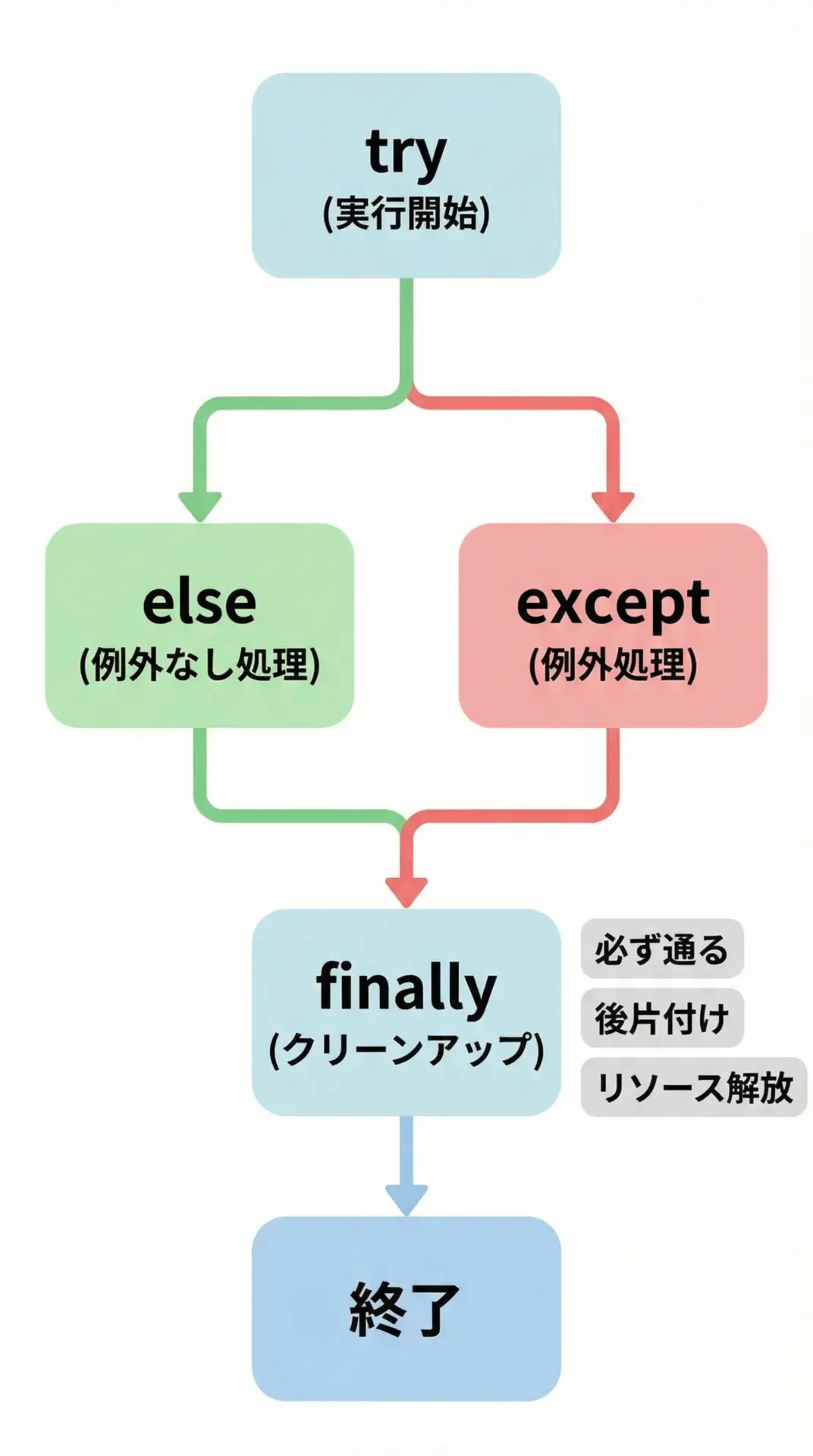
finallyブロックは、例外の有無にかかわらず必ず実行されるブロックです。
try・except・elseと組み合わせることで、次のような構造を取ることができます。
def example():
try:
print("try: 処理開始")
x = 1 / 1 # ここを 1 / 0 に変えると、例外パターンになる
except ZeroDivisionError:
print("except: 0で割りました")
else:
print("else: 正常に完了しました")
finally:
print("finally: 後片付けをします")
example()try: 処理開始
else: 正常に完了しました
finally: 後片付けをします1 / 0に変更すると、次のようになります。
try: 処理開始
except: 0で割りました
finally: 後片付けをしますこのようにfinallyは、例外があってもなくても必ず実行されるため、ファイルやネットワーク接続のクローズ処理など、リソースの解放を書く場所としてよく使われます。
try elseとtry exceptの使い分け
try exceptだけで書く場合との読みやすさの違い
tryとexceptだけで書くか、elseまで使うかは、「正常系の後続処理を、例外が起きそうな処理から分離したいかどうか」で決めるとよいです。
例として、ユーザー入力を検証して、その結果に応じて処理を分けるコードを見てみます。
# その1: try-exceptだけで書く
def handle_input(raw):
try:
value = int(raw)
print("正常系: 変換に成功しました:", value)
# ここから先も全部tryの中に書いてしまう
if value < 0:
print("負の値は受け付けません")
else:
print("値を登録しました")
except ValueError:
print("整数を入力してください")# その2: try-except-elseで分けて書く
def handle_input(raw):
try:
value = int(raw)
except ValueError:
print("整数を入力してください")
else:
print("正常系: 変換に成功しました:", value)
if value < 0:
print("負の値は受け付けません")
else:
print("値を登録しました")後者の方が、「検証(パース)の部分」と「値に基づくビジネスロジック」が自然に分かれていることが分かります。
例外が出なかった時だけ実行したい処理の書き方
elseが本領を発揮するのは、「例外が起きなかったときだけ何かをしたい」というパターンです。
次のようなケースが典型的です。
- ファイルの読み込みに成功したときだけ、内容を解析して表示する
- ネットワーク通信が成功したときだけ、レスポンスをパースして処理する
- DBトランザクションが問題なく完了したときだけ、コミットを行う
たとえば「ログファイルを開いて、開けた場合だけログを読む」という処理は、次のように書けます。
def read_log(path):
try:
f = open(path, "r", encoding="utf-8")
except FileNotFoundError:
print("ログファイルがありません:", path)
else:
# ファイルが正常に開けたときだけ実行
with f:
for line in f:
print(line.rstrip())このように「前段の処理が成功したことを前提に、後続の処理を進めたい」ときはelseを使うと、意図をコードに反映しやすくなります。
ネストしたtry exceptよりtry elseで整理するパターン
try文の中にさらにtry文をネストしてしまうと、コードが一気に読みづらくなります。
こうした場合、elseを使うことでフラットな構造にできることがあります。
NG例: tryの中にtryをネストしている
def process_value(raw):
try:
value = int(raw)
try:
result = 100 / value
except ZeroDivisionError:
print("0では割れません")
else:
print("結果:", result)
except ValueError:
print("整数を入力してください")このコードは、tryが2段になっていて、どのexceptがどのtryに対応しているのか、ぱっと見で分かりにくくなっています。
改善例: try-elseを使ってフラットに
def process_value(raw):
try:
value = int(raw)
except ValueError:
print("整数を入力してください")
return
# ここまで来たということは、valueは整数に変換できている
try:
result = 100 / value
except ZeroDivisionError:
print("0では割れません")
else:
print("結果:", result)あるいは、場合によっては次のようにelseを組み合わせて書くこともできます。
def process_value(raw):
try:
value = int(raw)
except ValueError:
print("整数を入力してください")
else:
try:
result = 100 / value
except ZeroDivisionError:
print("0では割れません")
else:
print("結果:", result)このように「1つ目の処理が成功したときだけ2つ目の処理を行いたい」場合、elseを使うことで、ネストを浅く保ちながら意図を表現できます。
初心者が陥りやすいアンチパターンと改善例
ここでは、初心者の方がよくやってしまうアンチパターンと、その直し方をいくつか紹介します。
アンチパターン1: とりあえず全部tryの中に入れてしまう
def do_something(path):
try:
f = open(path)
data = f.read()
# ここから先は実は例外がほぼ起きない処理
processed = data.strip().upper()
print(processed)
except Exception:
print("何かエラーが起きました")この書き方では、どの処理でエラーが起きたのか分からないうえに、Exceptionを丸ごと捕まえてしまっているため、バグの隠れ場所になりやすいです。
改善例は次のようになります。
def do_something(path):
try:
with open(path) as f:
data = f.read()
except FileNotFoundError:
print("ファイルが見つかりません:", path)
return
else:
processed = data.strip().upper()
print(processed)ここでは「ファイル操作だけ」をtryに入れ、「読み込み結果に対する処理」はelseに分離しています。
アンチパターン2: elseを使わずにフラグ変数で管理する
def process(raw):
ok = False
try:
value = int(raw)
ok = True
except ValueError:
print("整数を入力してください")
if ok:
print("処理を続行します:", value)これは動作としては正しいのですが、「成功したときだけ処理を続行したい」という意図はelseで素直に書けるため、次のようにシンプルにできます。
def process(raw):
try:
value = int(raw)
except ValueError:
print("整数を入力してください")
else:
print("処理を続行します:", value)このようにフラグ変数で「成功か失敗か」を管理しているコードは、elseを使って書き直せないか検討してみる価値があります。
try elseの具体的な使いどころ
ファイル読み込みとパース処理におけるtry elseの使い方
ファイル処理はtry ... elseがもっとも分かりやすく活躍する場面の1つです。
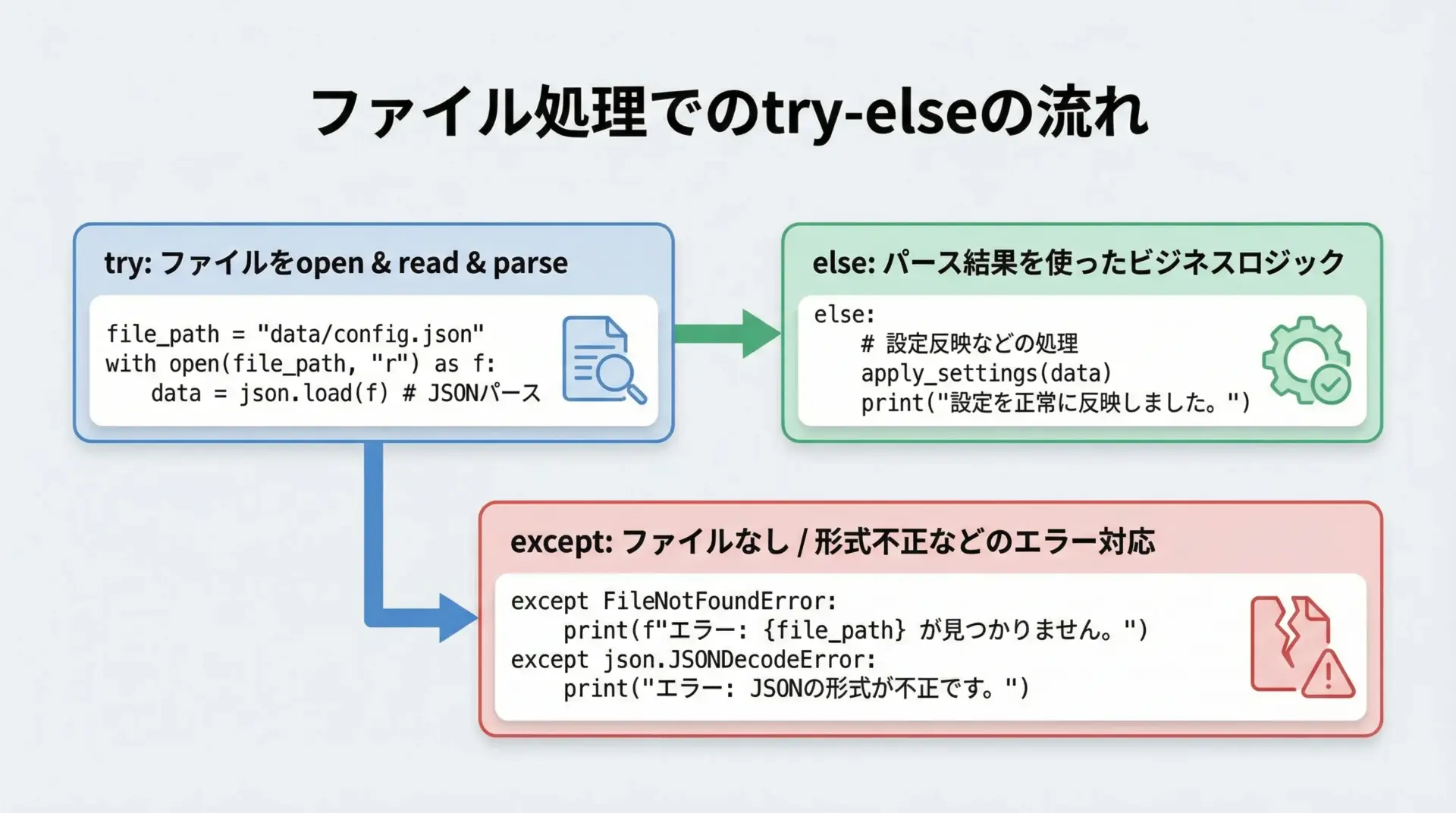
例として、JSON設定ファイルを読み込んで処理する場合を考えます。
import json
def load_and_use_config(path):
try:
with open(path, "r", encoding="utf-8") as f:
text = f.read()
config = json.loads(text)
except FileNotFoundError:
print("設定ファイルが見つかりません:", path)
return
except json.JSONDecodeError as e:
print("設定ファイルがJSONとして不正です:", e)
return
else:
# 読み込み + JSONパースが成功したときだけ、ここに進む
mode = config.get("mode", "production")
debug = config.get("debug", False)
print("モード:", mode)
print("デバッグ:", debug)このように、「ファイル読み込み」と「内容のパース」までをtry、「パースした結果を使う処理」をelseに分けるのが、ファイル処理での定番パターンです。
ユーザー入力バリデーションでのtry elseの活用
ユーザー入力は「文字列として受け取り、数値や日付などに変換し、さらにビジネスルールに合うかどうかチェックする」という流れを踏むことが多いです。
このとき、「変換に失敗した場合」と「変換には成功したが値として不適切な場合」を分けるのにelseが役立ちます。
def validate_age(raw):
try:
age = int(raw)
except ValueError:
print("年齢は整数で入力してください")
return
else:
# 整数に変換できた場合だけ、値の範囲チェックを行う
if not (0 <= age <= 120):
print("年齢として不正な値です:", age)
else:
print("年齢が登録されました:", age)このコードでは、「型的におかしい入力」(文字列を整数にできない)と「ビジネスルール的におかしい入力」(年齢が0〜120以外)を明確に分けて処理しています。
外部APIやネットワーク処理でのtry elseのパターン
外部APIやネットワーク通信では、「通信が成功したかどうか」と「レスポンス内容が期待どおりか」を分けて扱うことが重要です。
ここでもelseが使えます。
例として、requestsライブラリを使ったHTTPリクエストを考えます(インストールされている想定です)。
import requests
def fetch_user(user_id):
url = f"https://example.com/api/users/{user_id}"
try:
response = requests.get(url, timeout=5)
response.raise_for_status() # HTTPステータスコードのチェック
except requests.exceptions.Timeout:
print("タイムアウトしました")
return
except requests.exceptions.RequestException as e:
# 接続エラーやHTTPエラーなど
print("通信エラーが発生しました:", e)
return
else:
# 通信が成功し、ステータスコードもOKだった場合のみ
data = response.json()
print("ユーザー名:", data.get("name"))
print("メール:", data.get("email"))このように「通信レイヤの例外処理」と「レスポンス内容の処理」をtryとelseで分離することで、ネットワーク系のコードを整理しやすくなります。
データベース処理とトランザクションでのtry else利用例
データベース処理では、「クエリの実行が成功したときだけコミットしたい」「例外が出たらロールバックしたい」というパターンがよくあります。
try ... else ... finallyを組み合わせると、典型的なトランザクション処理を分かりやすく書けます。
ここでは、一般的なDB API風の疑似コードでイメージを示します。
def update_user_email(conn, user_id, new_email):
cursor = conn.cursor()
try:
# 例外が起きる可能性があるのは、このクエリ実行部分
cursor.execute(
"UPDATE users SET email = %s WHERE id = %s",
(new_email, user_id),
)
except Exception as e:
# 何か問題があればロールバック
print("更新に失敗しました。ロールバックします:", e)
conn.rollback()
else:
# ここまで来たということは、クエリ実行は成功
conn.commit()
print("メールアドレスを更新しました")
finally:
cursor.close()このパターンでは、「例外発生時はロールバック」「例外がなかった場合だけコミット」「どちらにしてもカーソルはクローズ」という、トランザクション処理の基本パターンを素直に表現できています。
まとめ
Pythonのtry文はexceptだけでなくelseやfinallyまで含めて使うことで、「例外処理」と「正常系ロジック」をきれいに分離できるようになります。
特にelseは、「例外が発生しなかったときだけ実行したい処理」を明示するための重要な道具です。
ファイル処理、ユーザー入力、外部API、データベースなど、実務で頻出する場面でtry ... elseを意識して使うと、コードの読みやすさと保守性が大きく向上します。
まずは「例外が起きそうな最小範囲だけをtryに入れ、成功時の処理をelseに書く」というルールを意識して、少しずつ取り入れてみてください。
