
Pythonで文字列処理をしていると、「特定のパターンに合う文字だけ抜き出したい」「メールアドレスっぽい文字列だけ検出したい」などの場面がたくさん出てきます。
そうしたときに強力な武器になるのが正規表現です。
本記事では、Pythonのreモジュールを使ってパターンマッチングを行う方法を、match/search/subの3つの代表的な関数に絞って、図解とサンプルコードつきで丁寧に解説します。
Pythonの正規表現(reモジュール)とは
正規表現の基本とPythonで使う場面
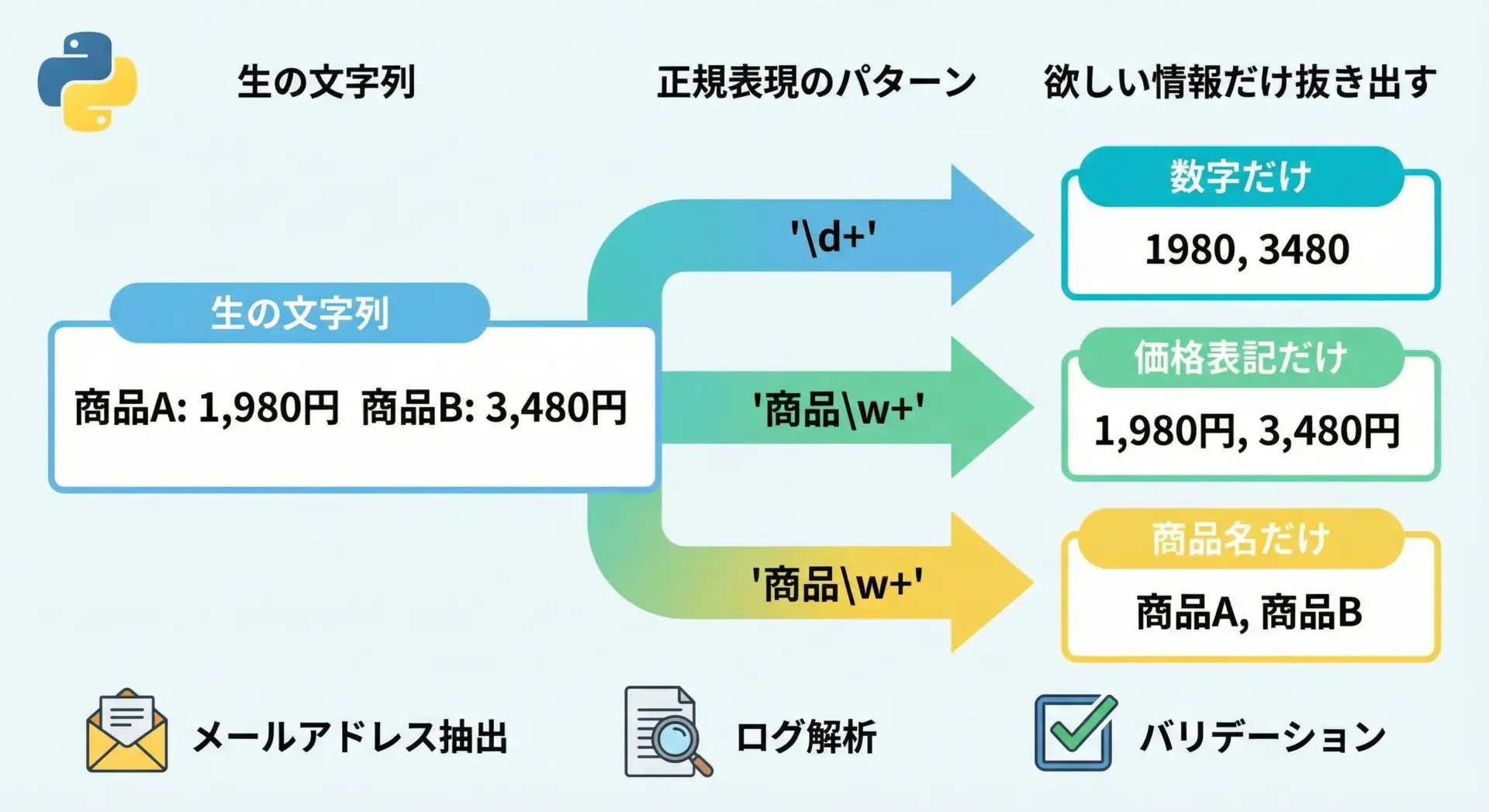
正規表現は、文字列の中から「パターンに合う部分」を見つけ出すためのミニ言語です。
単なる文字列検索では「この文字がそのまま入っているか」しか確認できませんが、正規表現を使うと、例えば次のような条件で柔軟に検索ができます。
- 1文字以上の数字が連続している部分をすべて見つける
- メールアドレスのような形をしている文字列だけを抜き出す
- 郵便番号(例: 123-4567)の形式に合うものだけをチェックする
Pythonでは、この正規表現を扱うためにreモジュールが標準ライブラリとして用意されています。
追加インストールなどは不要で、import reと書くだけで今すぐ使い始めることができます。
reモジュールでできること一覧
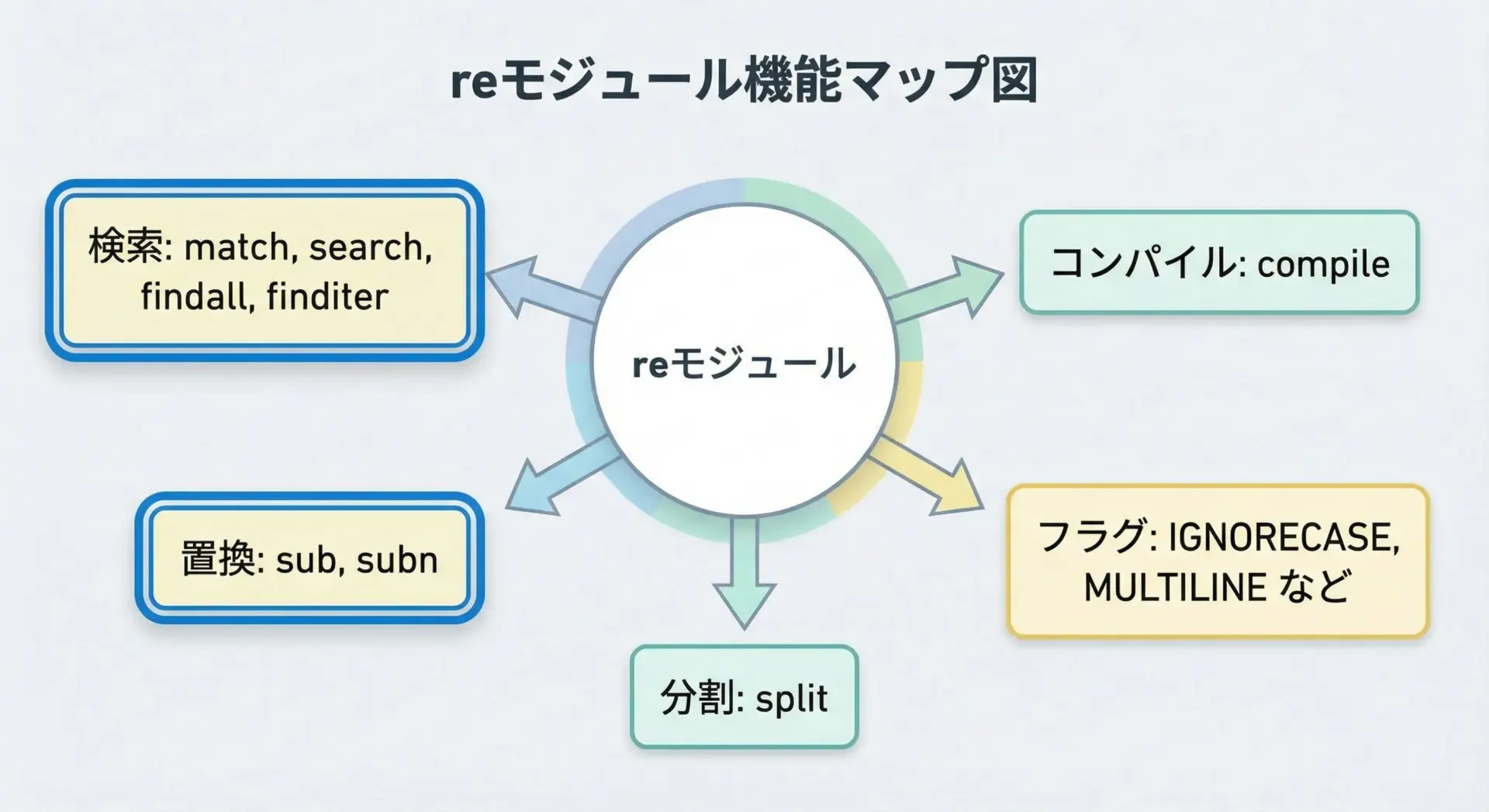
reモジュールは、文字列の検索や置換をパターンベースで行うための機能をひとまとめにしたモジュールです。
その中でも、まず押さえておきたい代表的な関数は次の3つです。
re.match()
文字列の先頭からパターンがマッチするかどうかを調べます。re.search()
文字列全体をなめて最初にマッチした部分を返します。re.sub()
パターンにマッチした部分を別の文字列や関数の結果で置換します。
その他にもre.findall()やre.split()など便利な関数がたくさんありますが、本記事ではこの3つに焦点を当てることで、正規表現の「基本操作」をしっかり身につけていただきます。
なお、Pythonで正規表現を使うときは、次のようにreモジュールをインポートしてから各関数を呼び出します。
import re
# 例: 数字にマッチするかどうか調べる
pattern = r"\d+" # 正規表現パターン (数字が1文字以上)
text = "価格は1500円です"
m = re.search(pattern, text)
if m:
print("見つかりました:", m.group())見つかりました: 1500ここではパターン文字列にr"\d+"のように先頭にrを付けています。
これはraw文字列リテラルと呼ばれ、バックスラッシュ\をPythonのエスケープとして解釈させず、そのまま文字として扱うために付けています。
正規表現では\dや\wなどバックスラッシュを多用するので、Pythonの正規表現パターンには基本的にr"..."を使うと覚えておくと安全です。
re.matchの使い方と注意点
re.matchの基本構文と戻り値
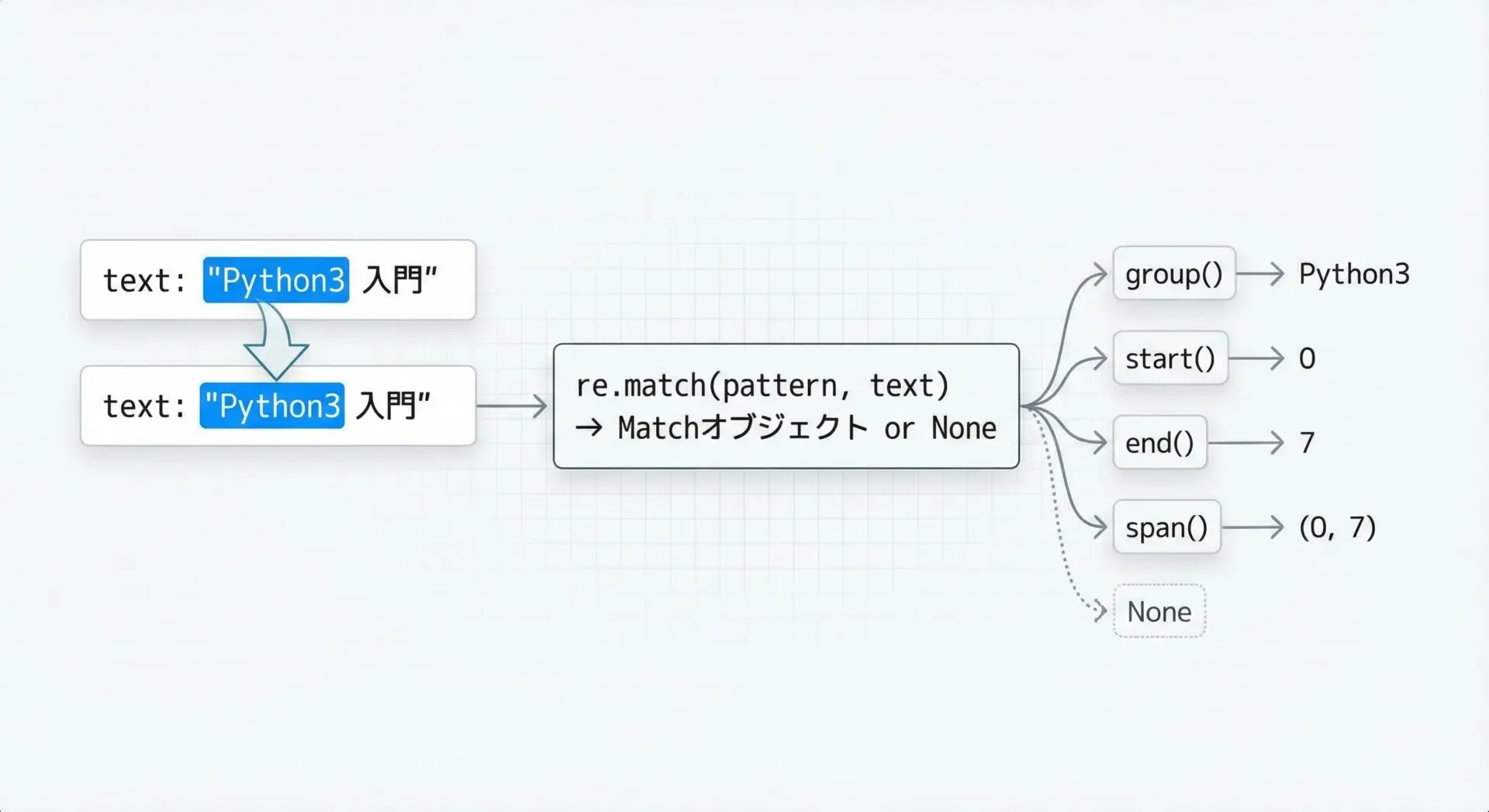
re.match()は、文字列の先頭がパターンにマッチするかどうかを調べる関数です。
基本の構文は次の通りです。
re.match(pattern, string, flags=0)pattern: 正規表現パターン(文字列)string: 対象となる文字列flags: 大文字小文字を無視するre.IGNORECASEなどのオプション(省略可)
戻り値はMatchオブジェクトかNoneのどちらかです。
マッチに成功するとMatchオブジェクトが返され、失敗するとNoneが返されます。
実際の挙動を簡単な例で確認してみます。
import re
pattern = r"Python" # 先頭が "Python" かどうかを確認
text_ok = "Python入門"
text_ng = "私はPythonが好きです"
m1 = re.match(pattern, text_ok)
m2 = re.match(pattern, text_ng)
print("text_ok:", m1) # マッチしているので Match オブジェクト
print("text_ng:", m2) # マッチしていないので Nonetext_ok: <re.Match object; span=(0, 6), match='Python'>
text_ng: Noneこのように先頭がパターンに合っている文字列に対してのみMatchオブジェクトが返ることが分かります。
先頭のみマッチする挙動を理解する

re.match()の最大の特徴は、文字列の「先頭」からしかマッチを試さないことです。
途中にいくらパターンに合う文字列があったとしても、先頭がパターンに合っていなければNoneが返ります。
import re
pattern = r"Python"
text = "私はPythonが好きです"
m = re.match(pattern, text)
print(m) # None になるNone一方、まったく同じパターンでもre.search()を使うと結果は変わります。
import re
pattern = r"Python"
text = "私はPythonが好きです"
m = re.search(pattern, text)
print(m) # 最初にマッチした箇所の Match オブジェクト
print(m.group()) # 実際にマッチした文字列<re.Match object; span=(2, 8), match='Python'>
Pythonこのように「文字列全体から探したいときはre.search()」「先頭からきっちり特定の形式で始まっているか確認したいときはre.match()」という使い分けを意識するとよいです。
例えば、次のような用途ではre.match()が有効です。
- ユーザー入力が「abc-1234」のような決まった形式で始まっているかのバリデーション
- 行頭だけに注目して処理したいログ解析(ただし複数行を扱う場合は
re.MULTILINEフラグと組み合わせることもあります)
マッチオブジェクトから情報を取り出す
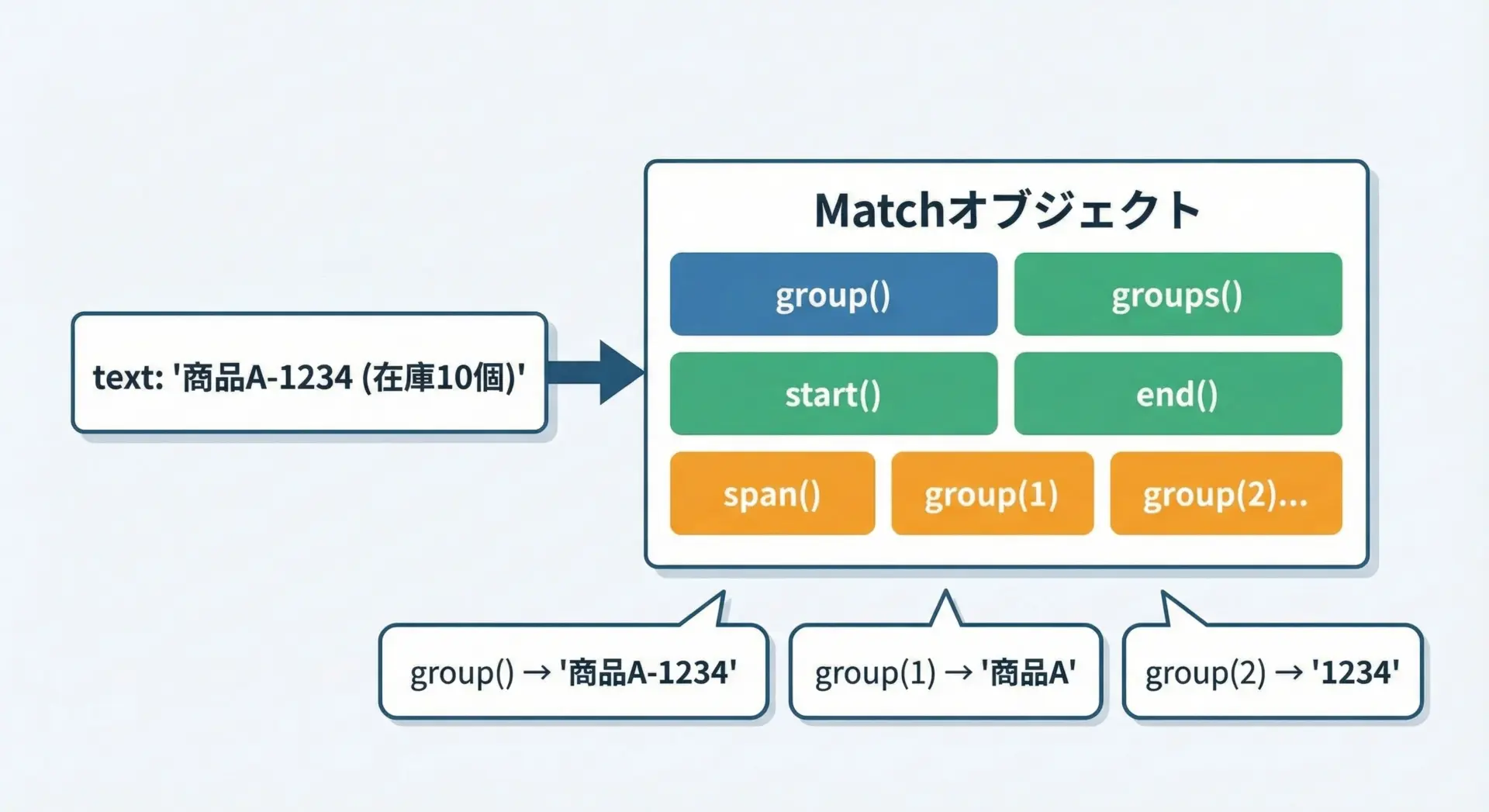
re.match()やre.search()の戻り値であるMatchオブジェクトは、どこがどのようにマッチしたのかを教えてくれる多くのメソッドを持っています。
代表的なものを見ていきます。
group()でマッチした文字列を取得する
group()メソッドは、マッチした文字列そのものを返します。
import re
pattern = r"Python\d+" # "Python" に続いて 1 文字以上の数字
text = "Python3入門"
m = re.match(pattern, text)
if m:
print("マッチした文字列:", m.group())マッチした文字列: Python3グルーピング(括弧()を使った部分パターン)を含めている場合、group(1)やgroup(2)のように、各グループごとのマッチ結果も取り出せます。
import re
pattern = r"(Python)(\d+)" # 1つ目のグループ: "Python" / 2つ目: 数字
text = "Python3入門"
m = re.match(pattern, text)
if m:
print("全体:", m.group(0)) # group(0) または group() は全体
print("1番目のグループ:", m.group(1))
print("2番目のグループ:", m.group(2))
print("全グループ:", m.groups()) # タプルで取得全体: Python3
1番目のグループ: Python
2番目のグループ: 3
全グループ: ('Python', '3')start()/end()/span()で位置情報を取得する
Matchオブジェクトには、マッチした部分の開始位置と終了位置も格納されています。
import re
pattern = r"Python"
text = "私はPythonが好きです"
m = re.search(pattern, text)
if m:
print("開始位置:", m.start()) # 2
print("終了位置:", m.end()) # 8
print("範囲:", m.span()) # (2, 8)
print("スライスで確認:", text[m.start():m.end()])開始位置: 2
終了位置: 8
範囲: (2, 8)
スライスで確認: Pythonこの位置情報を使うと、マッチした部分の前後を別々に処理したり、複数のマッチ位置を頼りに文字列を分割したりすることも容易になります。
re.searchで文字列全体から検索する
re.searchの基本構文と使い分け
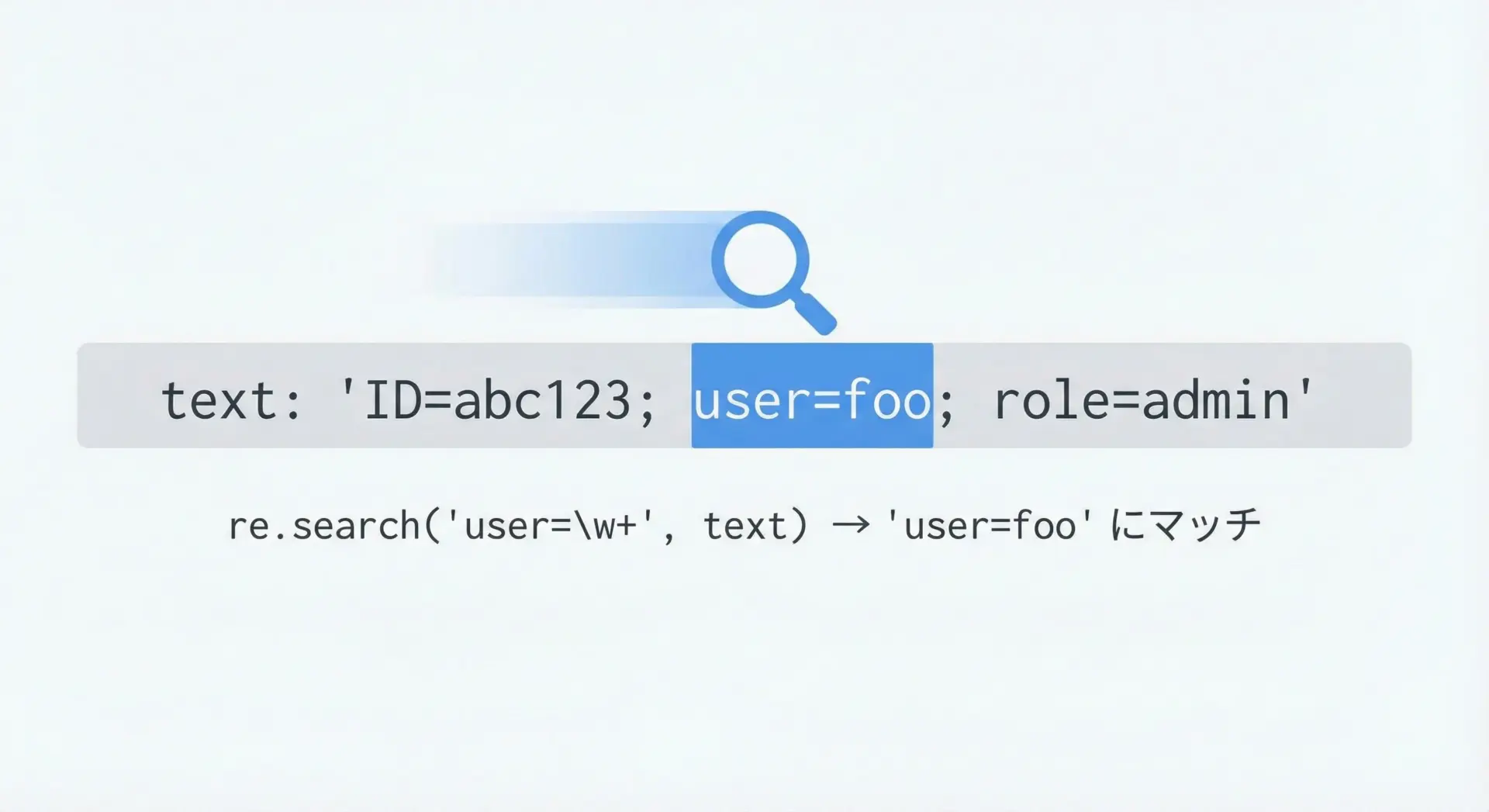
re.search()は、文字列全体を頭から順に走査し、最初にマッチした部分を返す関数です。
構文はre.match()とほぼ同じです。
re.search(pattern, string, flags=0)返り値も同じく、マッチした場合はMatchオブジェクト、マッチしなかった場合はNoneになります。
次の例では、文字列の中から最初に出てくる数字の並びを探しています。
import re
pattern = r"\d+" # 数字が 1 文字以上
text = "商品Aは1500円、商品Bは2980円です"
m = re.search(pattern, text)
if m:
print("最初に見つかった数字:", m.group())最初に見つかった数字: 1500ここで「最初に見つかった」という点が重要です。
re.search()は最初の 1 件だけを返すので、すべてのマッチが欲しい場合はre.findall()やre.finditer()を使う必要があります。
matchとの違いと使いどころ
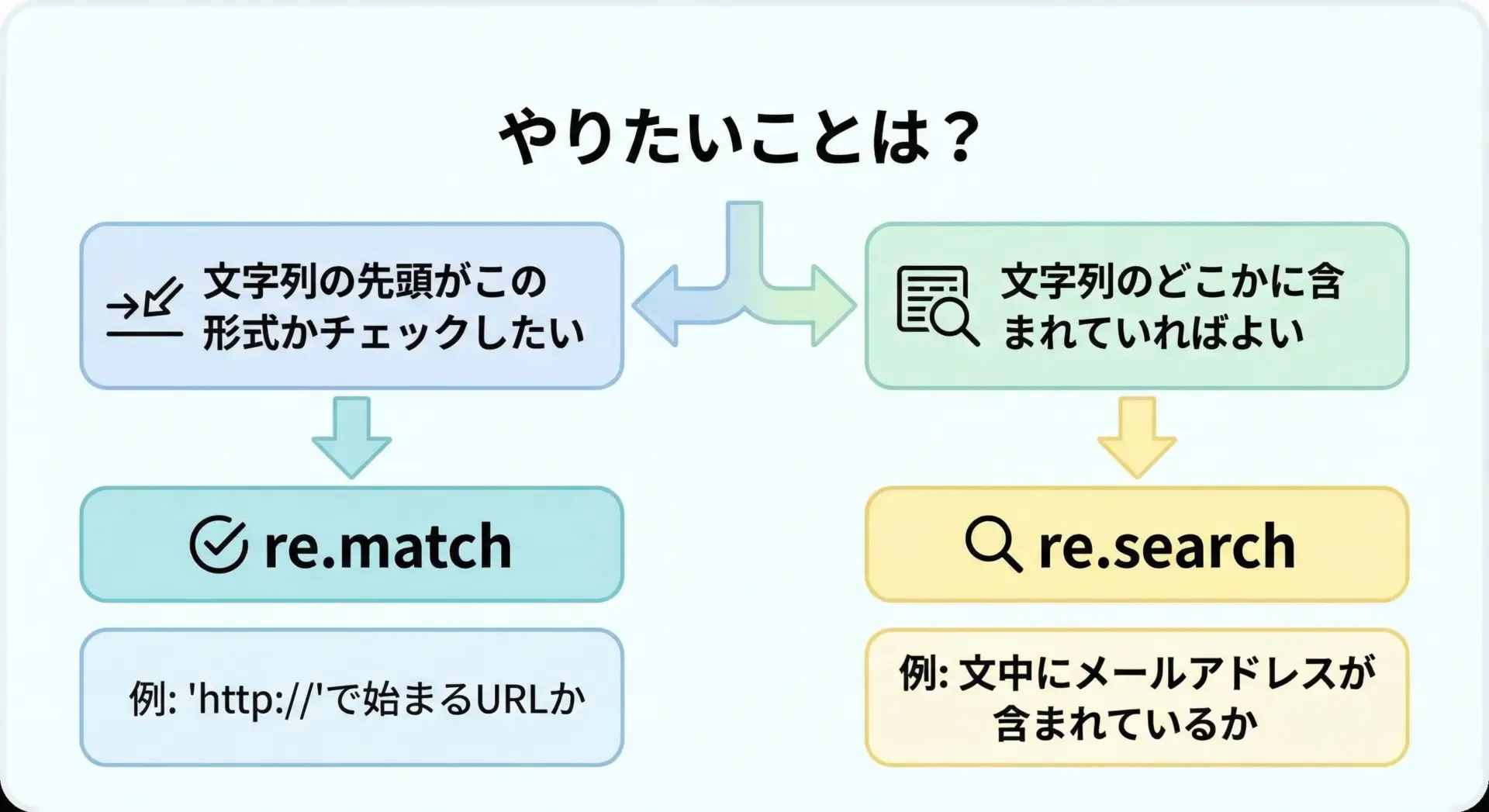
re.match()とre.search()はしばしば混同されますが、用途がはっきり違うので整理しておきます。
- re.match()
文字列先頭がパターンにマッチするかを確認します。
例: 入力値が「郵便番号の形式で始まっているか」をチェック。 - re.search()
文字列全体を探索し、どこかにパターンが含まれていれば OK。
例: メール文面に「重要」「至急」などの単語が含まれているか。
コード上の挙動の違いをもう一度確認してみます。
import re
pattern = r"cat"
text = "The black cat is sleeping."
m_match = re.match(pattern, text)
m_search = re.search(pattern, text)
print("match:", m_match)
print("search:", m_search, "→", m_search.group() if m_search else None)match: None
search: <re.Match object; span=(10, 13), match='cat'> → cat「先頭限定かどうか」が両者の決定的な違いです。
re.search()は、文章全体からキーワードを探したいときや、ログの1行のなかにエラーコードが含まれているかどうかをチェックしたいときなどに適しています。
グルーピングとキャプチャで部分一致を取得する
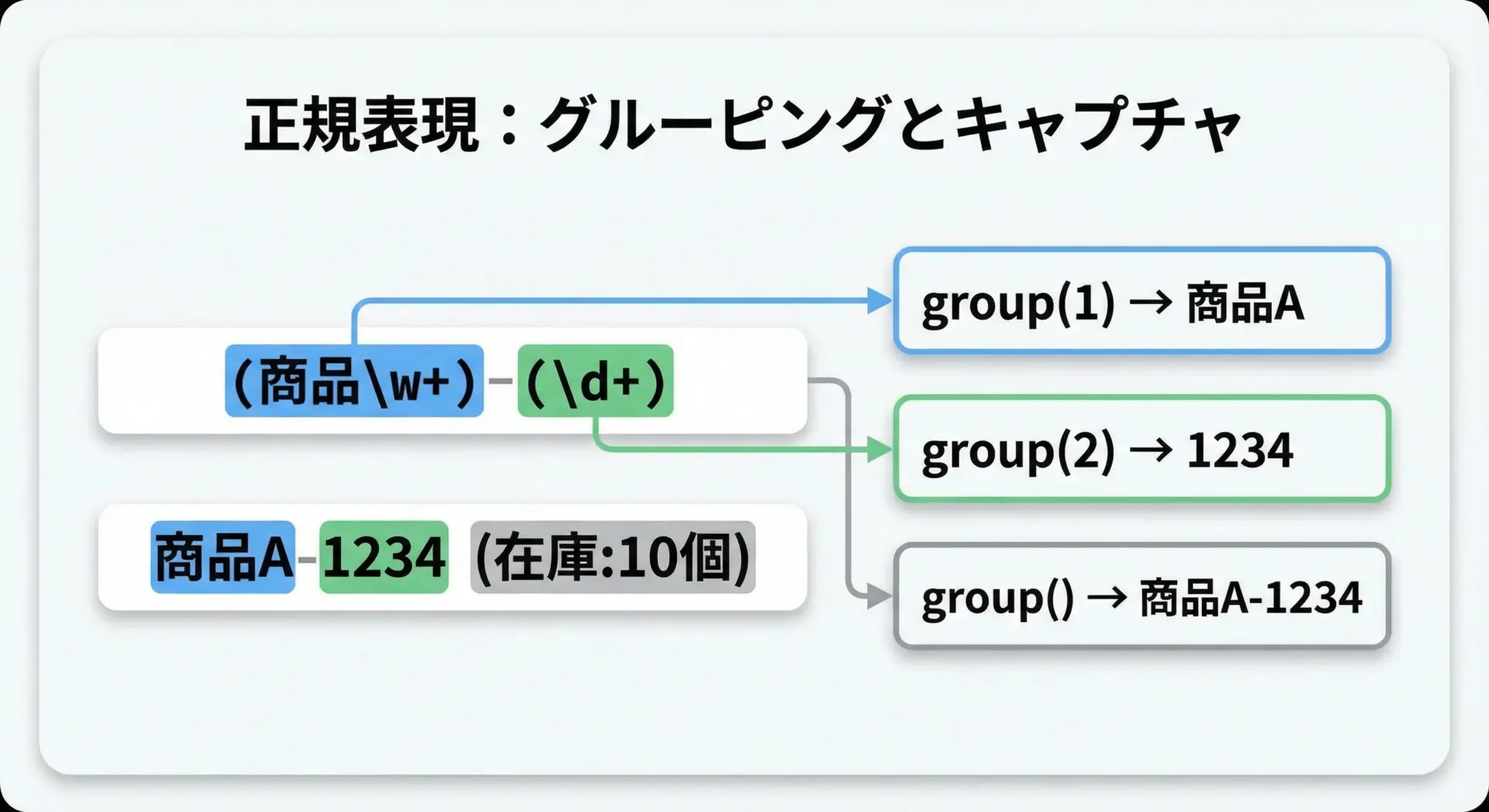
正規表現の強力な機能のひとつがグルーピングです。
括弧()で囲んだ部分は「グループ」として扱われ、group(1)やgroup(2)で個別に取り出すことができます。
次の例では、商品コードから商品名部分と数値コード部分を分離して取得しています。
import re
pattern = r"(商品\w+)-(\d+)" # グループ1: 商品名, グループ2: 数値コード
text = "本日の目玉は商品A-1234です"
m = re.search(pattern, text)
if m:
print("全体:", m.group()) # "商品A-1234"
print("商品名部分:", m.group(1))
print("コード部分:", m.group(2))
print("全グループ:", m.groups())全体: 商品A-1234
商品名部分: 商品A
コード部分: 1234
全グループ: ('商品A', '1234')また、グループには名前を付けることもできます。
名前付きグループを使うと、group("name")のようにして読みやすくアクセスできるため、パターンが複雑になっても理解しやすくなります。
import re
pattern = r"(?P<name>商品\w+)-(?P<code>\d+)"
text = "本日の目玉は商品A-1234です"
m = re.search(pattern, text)
if m:
print("商品名:", m.group("name"))
print("コード:", m.group("code"))
print("辞書形式:", m.groupdict())商品名: 商品A
コード: 1234
辞書形式: {'name': '商品A', 'code': '1234'}グルーピングとキャプチャは、この後説明するre.sub()と組み合わせた高度な置換でも活躍します。
re.subで文字列を置換する
re.subの基本構文
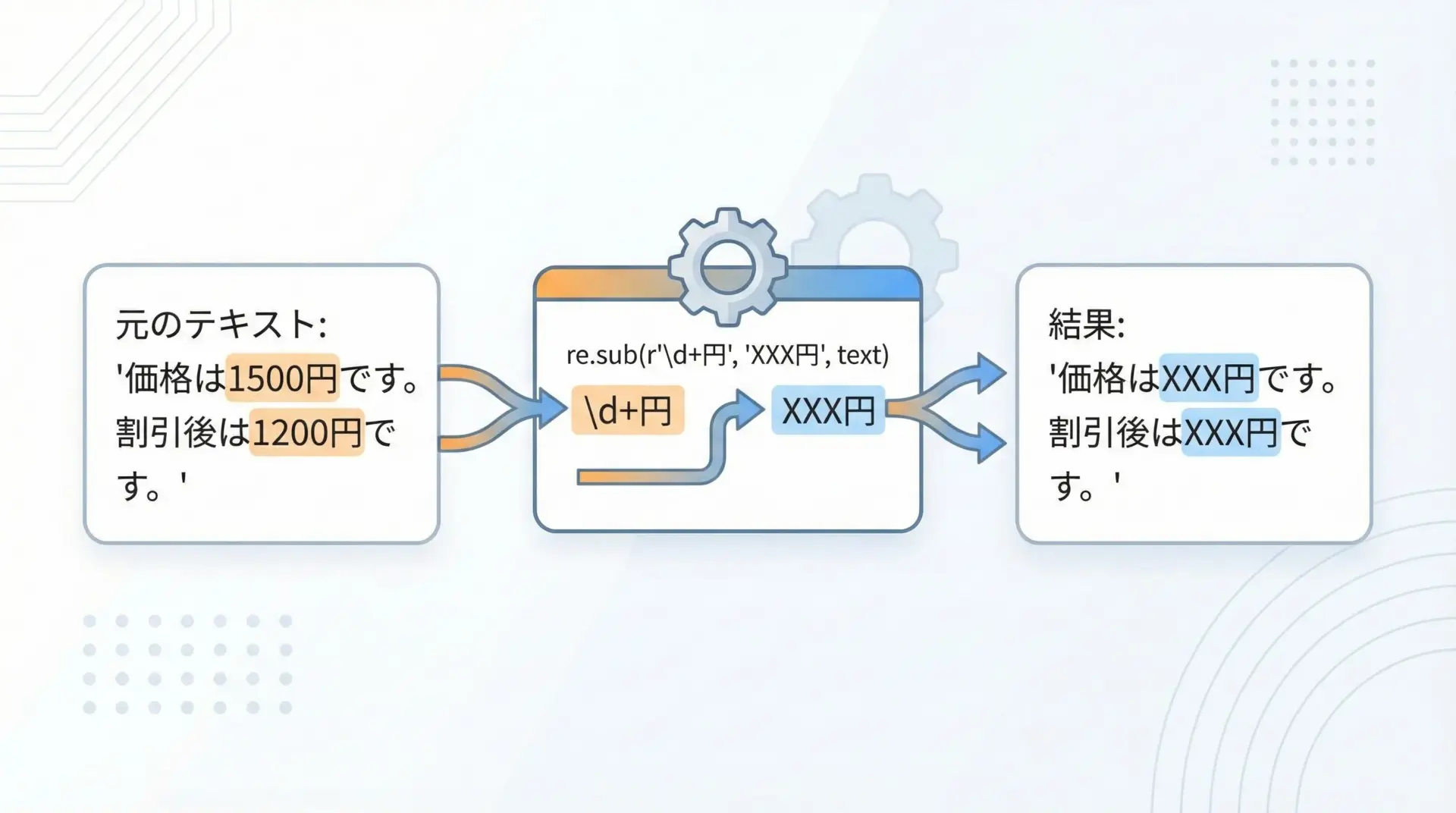
re.sub()は、パターンにマッチした部分を別の文字列に置き換えるための関数です。
構文は次の通りです。
re.sub(pattern, repl, string, count=0, flags=0)pattern: 置換対象を指定する正規表現パターンrepl: 置換後の文字列、または関数string: 元の文字列count: 置換する回数(0は無制限、デフォルト)flags: オプションフラグ(省略可)
基本的な使い方は次のようになります。
import re
pattern = r"\d+円" # 「数字 + 円」の部分を置換
text = "価格は1500円です。割引後は1200円です。"
result = re.sub(pattern, "XXX円", text)
print("元の文字列:", text)
print("置換後:", result)元の文字列: 価格は1500円です。割引後は1200円です。
置換後: 価格はXXX円です。割引後はXXX円です。パターンにマッチしたすべての箇所が一度に置換されていることが分かります。
特定の回数だけ置換したい場合はcount引数を指定します。
import re
pattern = r"\d+円"
text = "価格は1500円です。割引後は1200円です。"
# 最初の 1 回だけ置換
result_once = re.sub(pattern, "XXX円", text, count=1)
print("1回だけ置換:", result_once)1回だけ置換: 価格はXXX円です。割引後は1200円です。グループ参照を使った柔軟な置換方法
re.sub()では、マッチしたグループを置換後の文字列の中で再利用することができます。
これをグループ参照と呼びます。
書き方には主に2種類あります。
\1, \2, ...のように番号で参照\g<1>, \g<name>のように\g<...>形式で参照
(こちらの方が読みやすく、安全です)
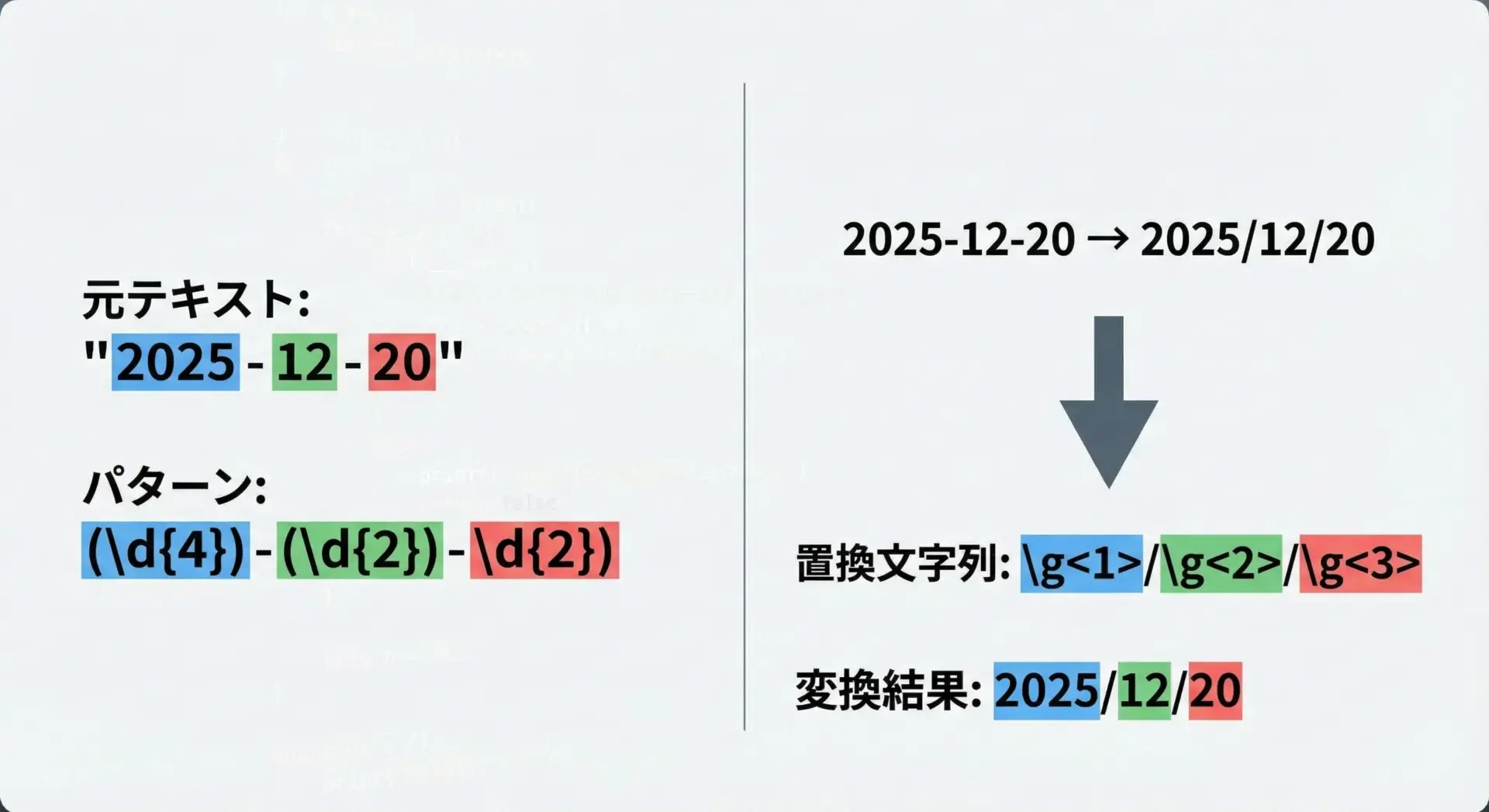
例えば、日付の表記を「YYYY-MM-DD」から「YYYY/MM/DD」に変換したい場合は次のように書けます。
import re
pattern = r"(\d{4})-(\d{2})-(\d{2})" # 年-月-日
text = "今日は2025-12-20です。"
# グループ1, 2, 3を / 区切りで並べ替える
result = re.sub(pattern, r"\1/\2/\3", text)
print("元:", text)
print("置換後:", result)元: 今日は2025-12-20です。
置換後: 今日は2025/12/20です。同じことを\g<番号>形式で書くと次の通りです。
import re
pattern = r"(\d{4})-(\d{2})-(\d{2})"
text = "今日は2025-12-20です。"
result = re.sub(pattern, r"\g<1>/\g<2>/\g<3>", text)
print(result)今日は2025/12/20です。名前付きグループと名前付き参照を組み合わせると、さらに読みやすくなります。
import re
pattern = r"(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})"
text = "今日は2025-12-20です。"
# \g<year>, \g<month>, \g<day> で参照
result = re.sub(pattern, r"\g<year>/\g<month>/\g<day>", text)
print(result)今日は2025/12/20です。置換文字列の中でバックスラッシュ\を使う場合は、r"..."のraw文字列にしておくと、Pythonのエスケープと正規表現のエスケープが混ざらず安全です。
関数を使った高度なre.subの例
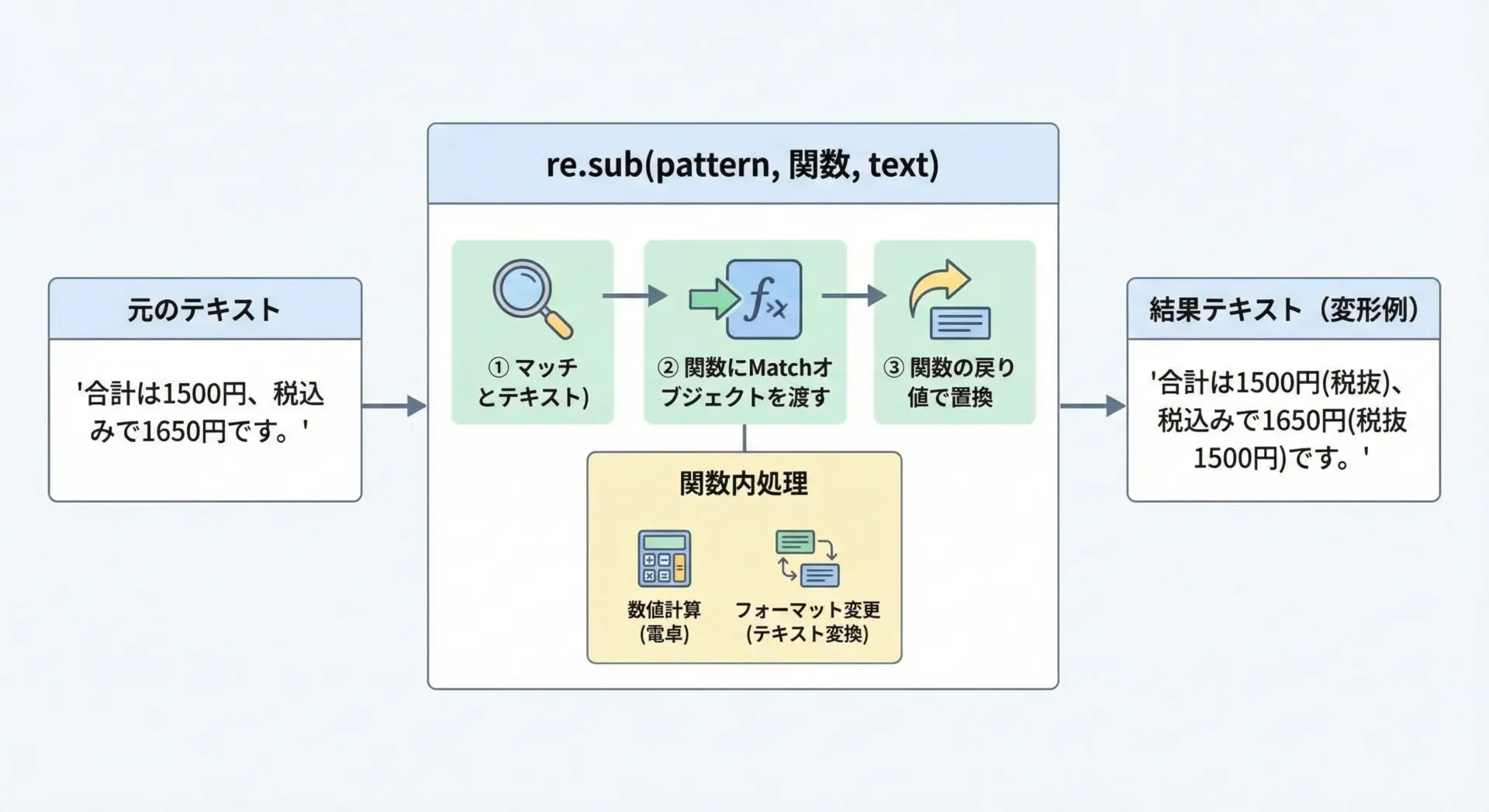
re.sub()のrepl引数には、文字列だけでなく関数を渡すことができます。
これにより、マッチした内容に応じて動的に置換結果を決めることが可能になります。
仕組みとしては、パターンにマッチするたびにそのMatchオブジェクトを引数として関数が呼び出され、その戻り値が置換後の文字列として使われるという動きになります。
次の例では、文中に出てくる数字(円)をすべて税抜価格に変換して注釈を付けるという処理を行ってみます。
ここでは簡単のため、消費税を10%と仮定し「税込価格 → 税抜価格」を計算します。
import re
text = "合計は1650円、特価は1100円です。"
def to_without_tax(m):
"""税込価格から税抜価格を計算して '(税抜XXXX円)' を返す関数"""
price_str = m.group(1) # グループ1に数字部分が入っている
price = int(price_str)
without_tax = round(price / 1.1) # 税抜に変換 (四捨五入)
# もとの価格 + 税抜価格の注釈を返す
return f"{price}円(税抜{without_tax}円)"
pattern = r"(\d+)円"
result = re.sub(pattern, to_without_tax, text)
print("元の文字列:", text)
print("置換後:", result)元の文字列: 合計は1650円、特価は1100円です。
置換後: 合計は1650円(税抜1500円)、特価は1100円(税抜1000円)です。この例では、次のような流れで置換が行われています。
r"(\d+)円"で、数字+円というパターンにマッチするたびに、
Matchオブジェクトを引数にしてto_without_tax()が呼ばれます。- 関数内で
m.group(1)から金額を取得し、税抜価格を計算します。 - 「元の価格 + 税抜価格の注釈」を文字列として返し、その文字列に置き換えます。
関数を使うと、単純な文字列置換では難しい、次のような処理も実現できます。
- 数値を使った計算(割引・税計算・単位変換)
- 大文字小文字の変換や、書式の統一
- 条件によって置換内容を変える(一定以上の金額だけマークを付ける、など)
もうひとつ簡単な例として、メール本文中のURLをすべて<URL>というマスク表現に変える処理を関数で書いてみます。
import re
text = "詳細は https://example.com/docs を参照してください。質問は http://support.example.com へ。"
url_pattern = r"https?://[^\s]+" # http または https で始まり、空白以外が続く部分
def mask_url(m):
url = m.group()
# URL の一部だけ見せてマスクする
return "<URL:" + url[:15] + "...>"
result = re.sub(url_pattern, mask_url, text)
print("元の文字列:", text)
print("置換後:", result)元の文字列: 詳細は https://example.com/docs を参照してください。質問は http://support.example.com へ。
置換後: 詳細は <URL:https://exam...> を参照してください。質問は <URL:http://support...> へ。このようにMatchオブジェクトを自由に料理できるため、re.sub()は正規表現の中でもとても応用範囲の広い機能になっています。
まとめ
Pythonのreモジュールを使うことで、文字列から複雑なパターンを検出したり、柔軟な置換処理を行ったりできるようになります。
本記事では、特に使用頻度の高いre.match・re.search・re.subの3つに焦点を当てて、「先頭限定のmatch」「全文探索のsearch」「文字列置換のsub」という役割分担を押さえました。
また、グルーピングやグループ参照、関数による動的な置換など、実践で役立つテクニックも紹介しました。
まずは簡単なパターンから試し、徐々に正規表現の表現力に慣れていくことで、日常の文字列処理を大幅に効率化できるようになります。
