Pythonで重い処理を高速化したいとき、関数の結果を一時的に保存して再利用するメモ化はとても強力なテクニックです。
Python標準ライブラリのfunctools.lru_cacheを使えば、複雑な実装なしにメモ化を安全かつ効率的に利用できます。
本記事では、lru_cacheの仕組み・使い方・注意点を、図解をまじえながら丁寧に解説していきます。
Python高速化の基本:lru_cacheとメモ化とは
メモ化(memoization)とは何か
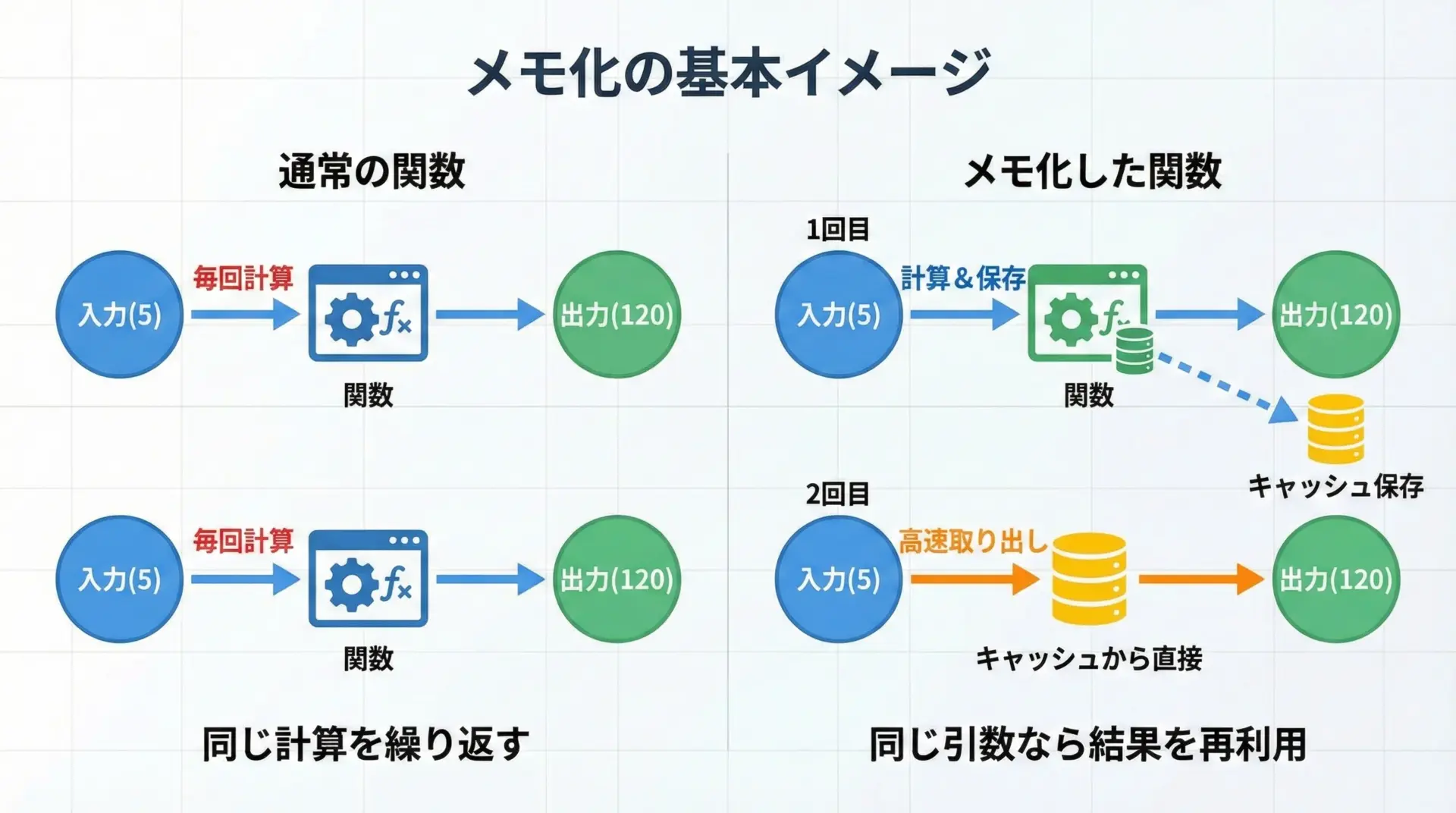
メモ化(memoization)とは、同じ引数に対する関数の結果を保存しておき、次回以降は保存済みの結果を再利用することで高速化する手法です。
特に、次のような処理で効果を発揮します。
- 同じ引数で何度も呼び出される関数
- 計算コストが高い(時間がかかる)関数
- 再帰的な計算(フィボナッチ数列、動的計画法など)
メモ化の基本的なアイデアはとてもシンプルです。
プログラム中に「引数 → 結果」の対応表を持ち、関数が呼ばれたときに、まずその表を調べます。
すでに結果があればそれを返し、なければ計算して表に保存しておきます。
この対応表は通常、Pythonではdict(辞書)で実装されます。
キーとして引数の値を使い、値として関数の戻り値を保存します。
これにより、同じ引数での2回目以降の呼び出しは、ほぼ辞書アクセスの速度で結果を返すことができます。
lru_cacheとは何か
Python標準ライブラリfunctoolsが提供するlru_cacheは、メモ化を簡単に使うためのデコレータです。
特徴をまとめると次のようになります。
- デコレータとして関数に付けるだけでメモ化が有効になる
- 引数の組み合わせをキーにして結果を自動で保存してくれる
- キャッシュサイズ(
maxsize)を指定でき、古いデータから自動的に捨ててくれる - Python本体に最適化された実装で、高速かつスレッドセーフ
@lru_cacheをつけると、元の関数は「キャッシュ機能付きのラッパー関数」に置き換えられます。
呼び出し時には、まずキャッシュを調べ、該当するエントリがあればそれを返し、なければ計算してキャッシュに保存します。
lru_cacheと手動メモ化の違い
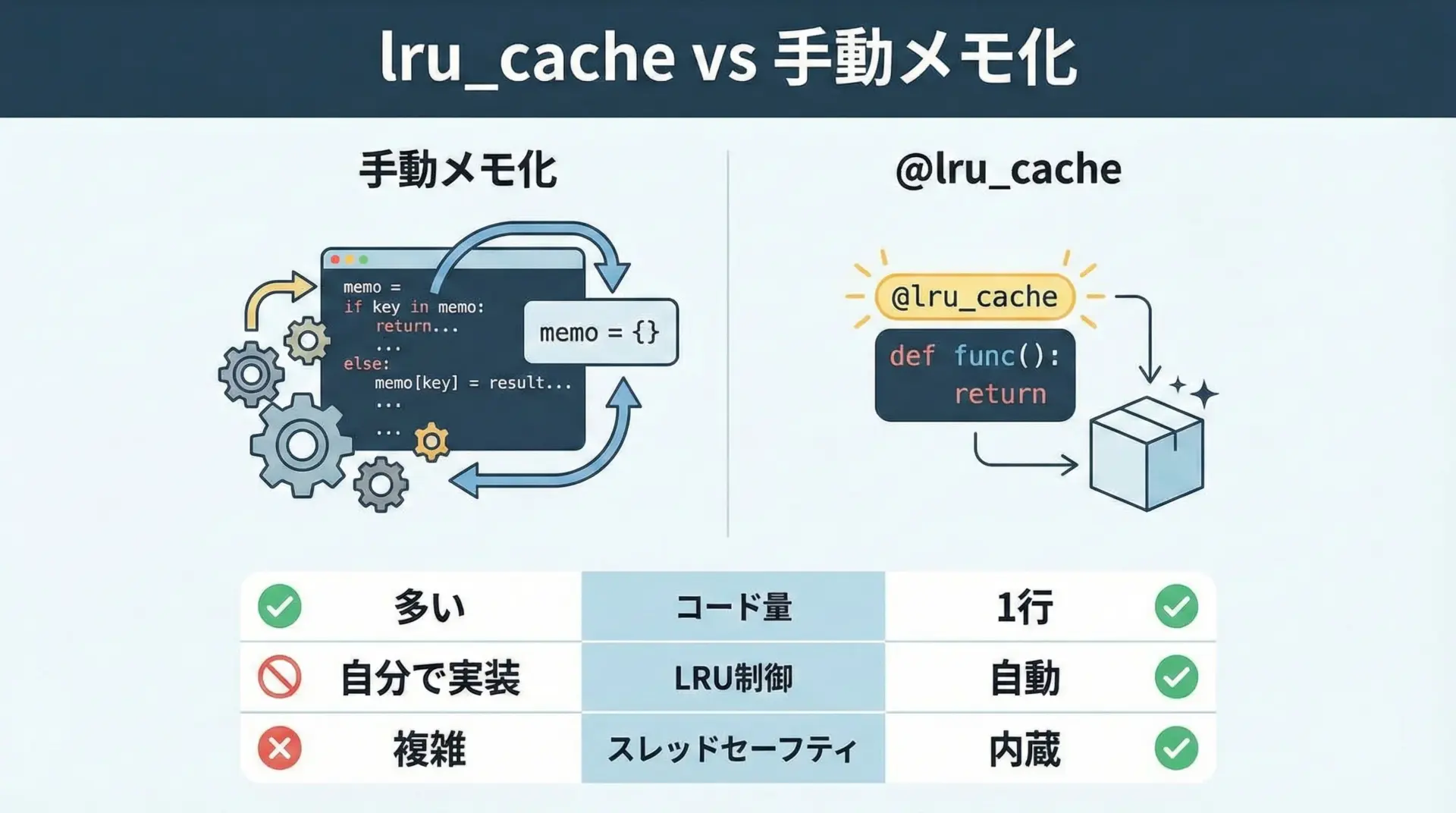
自分でdictを使ってメモ化を実装することも可能ですが、lru_cacheを使う方が安全で楽な場面が多くあります。
手動メモ化では、次のような処理を自分で書く必要があります。
- キャッシュ用の
dictの用意 - 「キャッシュにあるかどうか」を毎回チェック
- 必要に応じて古いエントリの削除
- スレッドから同時にアクセスされた場合の排他制御
一方、lru_cacheはこれらをすべて内部で処理してくれます。
特にLRU方式の削除(後述)やスレッドセーフな実装を自前で正しく書くのは意外と大変です。
ただし、手動メモ化には以下のようなメリットもあります。
- キャッシュの構造やキーの設計を柔軟に制御できる
- 「一部だけキャッシュする」「条件付きでキャッシュする」など細かいポリシーを実装しやすい
このため、基本はlru_cacheを使い、特殊な要件があるときにだけ手動メモ化を検討するのがおすすめです。
図解で理解するlru_cacheの仕組み
関数呼び出しとキャッシュの流れ
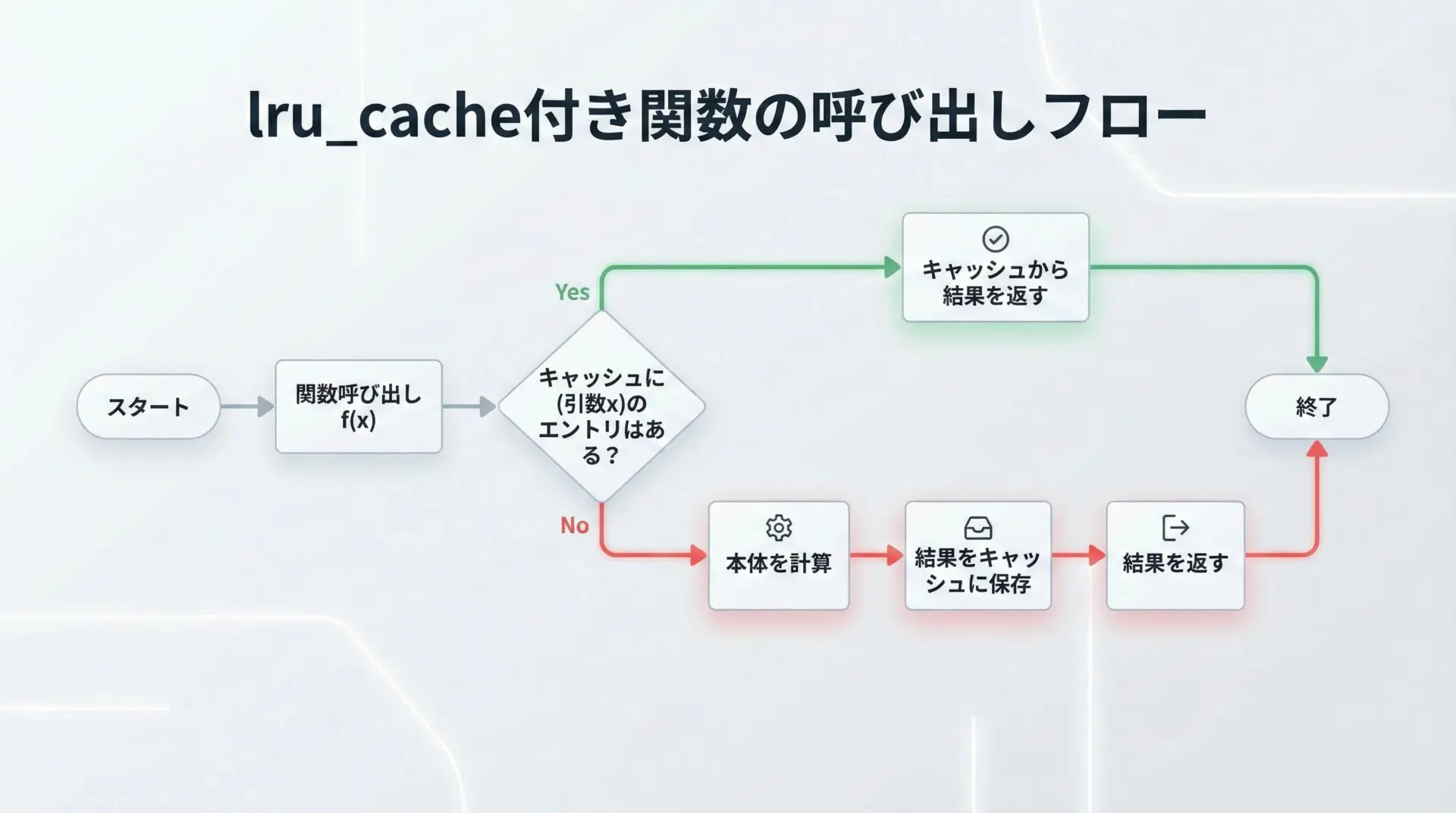
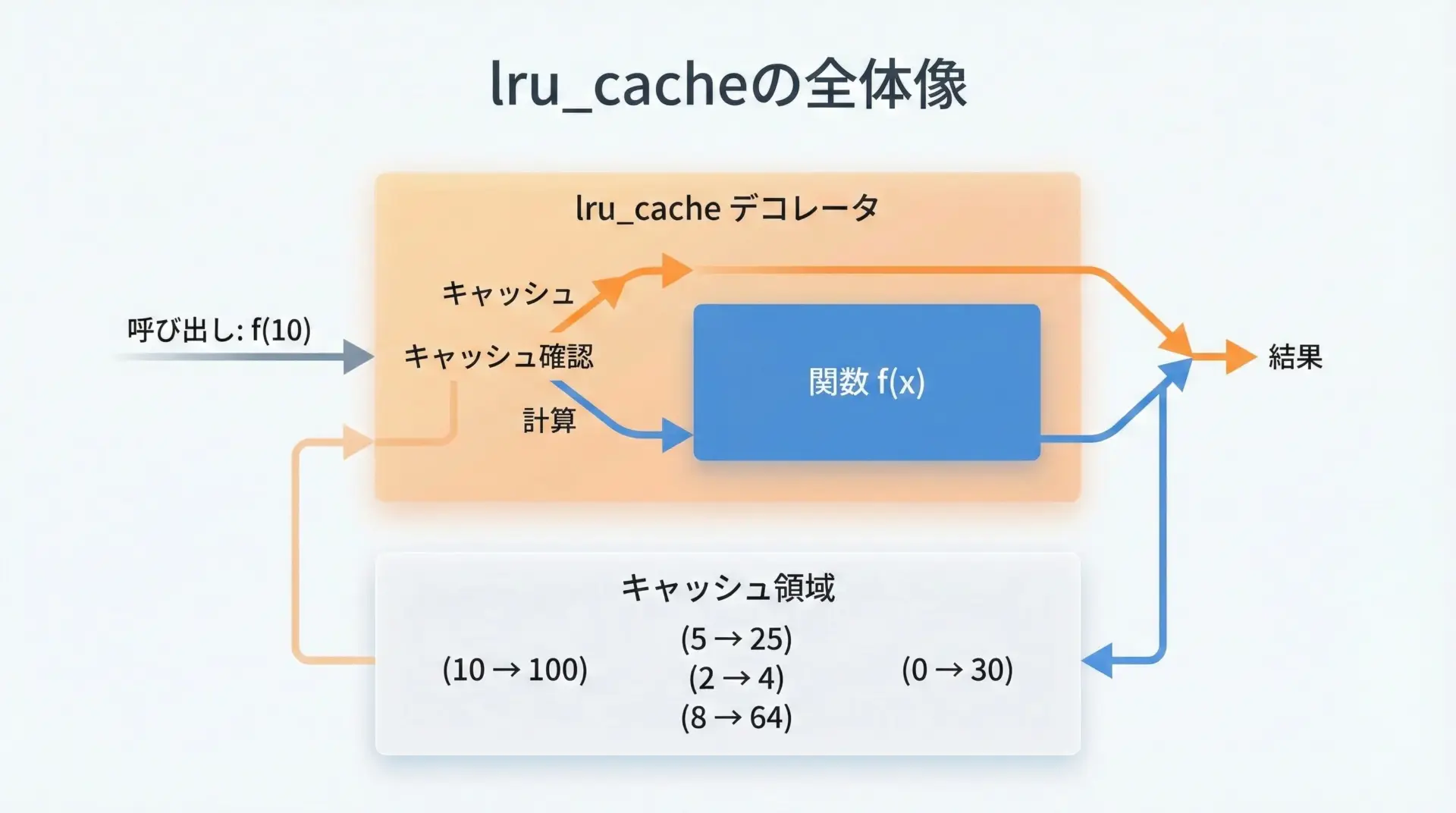
lru_cacheが付いた関数を呼び出すときの流れは、概ね次のようになります。
- 呼び出し
- 例えば
f(10, 20)のように関数が呼び出されます。
- 例えば
- キャッシュキーの生成
- 引数から
(10, 20)のようなタプルが作られます。
- 引数から
- キャッシュの確認
- 内部のキャッシュ辞書に、そのキーが存在するかどうかを調べます。
- ヒットした場合
- すでに結果が保存されているので、計算を行わずにその値を返します。
- ミスした場合
- 元の関数本体を実行し、結果を得ます。
- 次回以降のため、その結果をキャッシュに保存します。
- 計算した結果を返します。
ポイントは、キャッシュの存在を完全に透明化したラッパー関数になっていることです。
利用者は単に関数を呼ぶだけでよく、キャッシュの存在を意識する必要はありません。
引数タプルをキーにしたキャッシュの構造
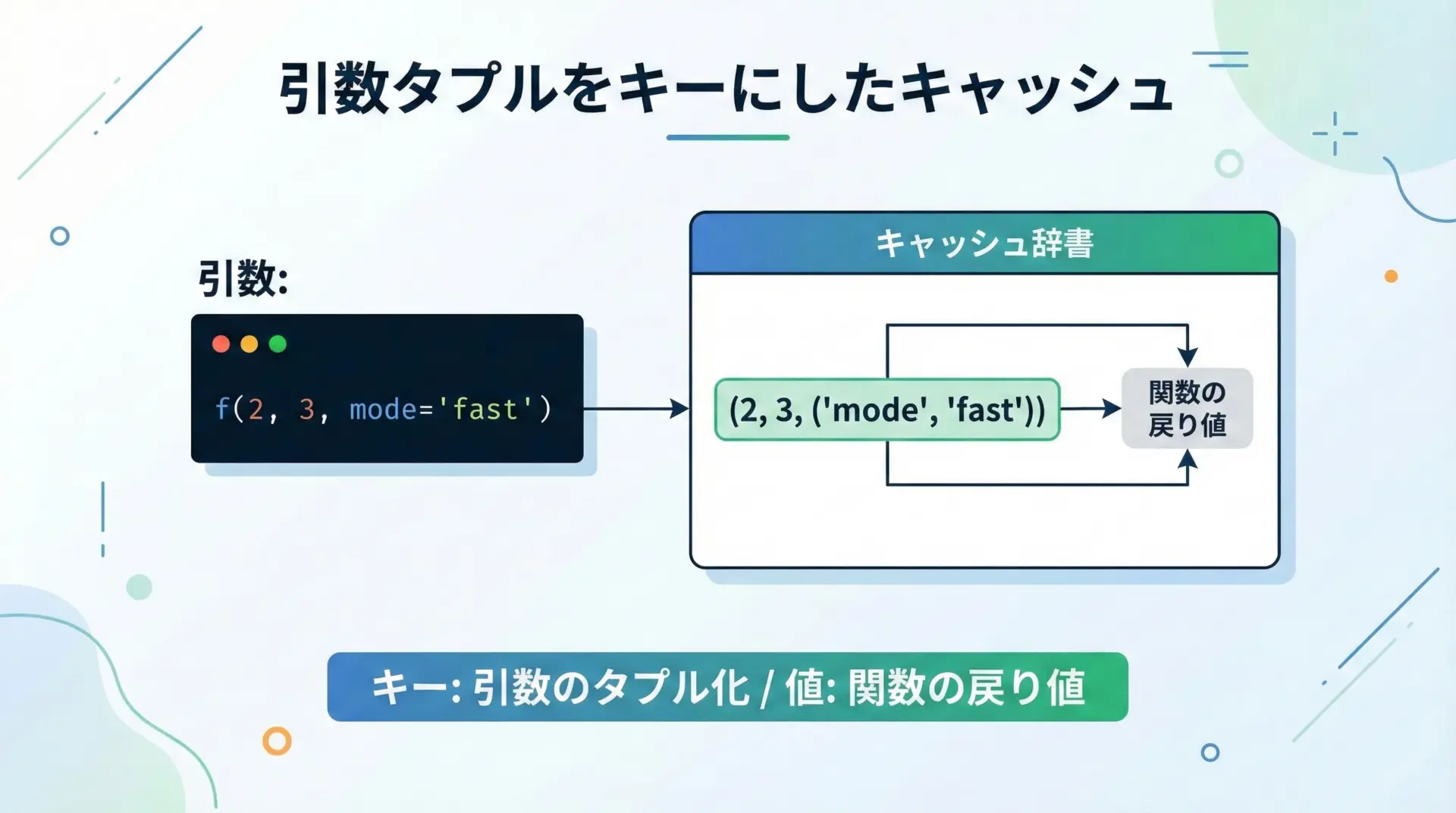
lru_cacheの内部では、関数の引数がタプルにまとめられ、それがキャッシュのキーとして使われます。
たとえば次のような関数呼び出しを考えます。
- 位置引数だけ:
f(1, 2)→ キーは(1, 2) - キーワード引数あり:
f(1, y=3)→ キーは概ね(1, (('y', 3),))のような形
実際の内部表現はCPythonの実装に依存しますが、「すべての引数をハッシュ可能な1つのオブジェクト(タプル)にまとめ、そのハッシュ値を使って辞書にアクセスする」という大枠は変わりません。
この仕組みのおかげで、同じ引数の組み合わせに対しては、常に同じキャッシュキーが生成され、正しくキャッシュが利用されます。
逆に言えば、引数がハッシュ不可能なオブジェクトだとキャッシュに使えないことになります。
これは後ほど詳しく解説します。
LRU(Least Recently Used)方式での削除ルール
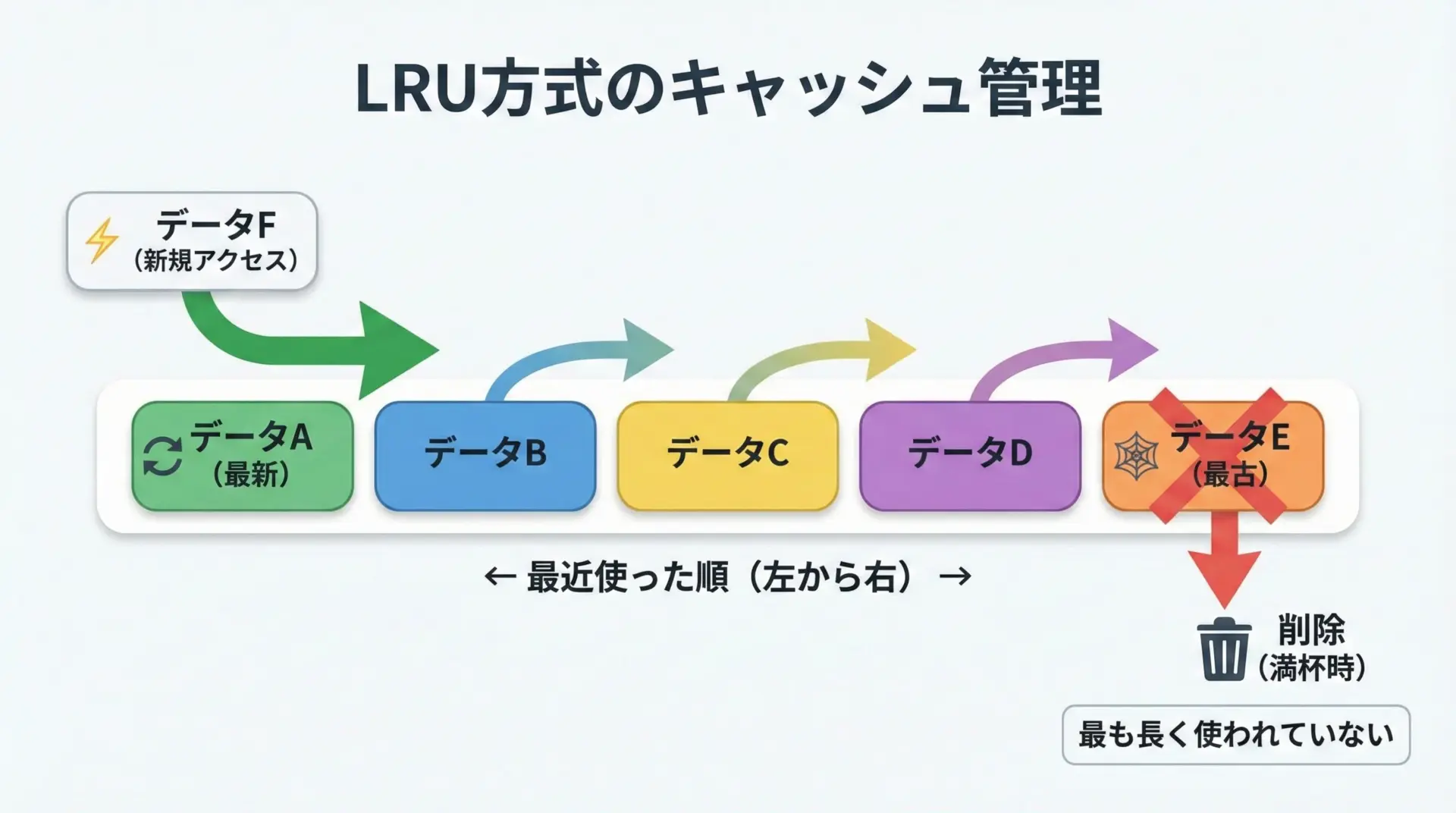
lru_cacheの「LRU」はLeast Recently Usedの略で、「最近あまり使われていないものから順に捨てていく」キャッシュ戦略を意味します。
基本ルールは次の通りです。
- 各エントリは「最後に使われた時刻(順序)」を持つイメージで管理されます。
- キャッシュにアクセス(ヒット・新規追加)されたエントリは「最新」として扱われます。
- キャッシュが
maxsizeで指定した上限数に達した状態で新しいエントリを追加するとき、最も長いあいだ使われていなかったエントリ(最古のエントリ)が自動的に削除されます。
この戦略は「直近で使われているエントリは今後も使われやすい」という仮定に基づいています。
実際のアプリケーションでも、最近アクセスしたデータに再びアクセスするケースは多いため、実用性の高い方式です。
キャッシュヒット・ミスとは
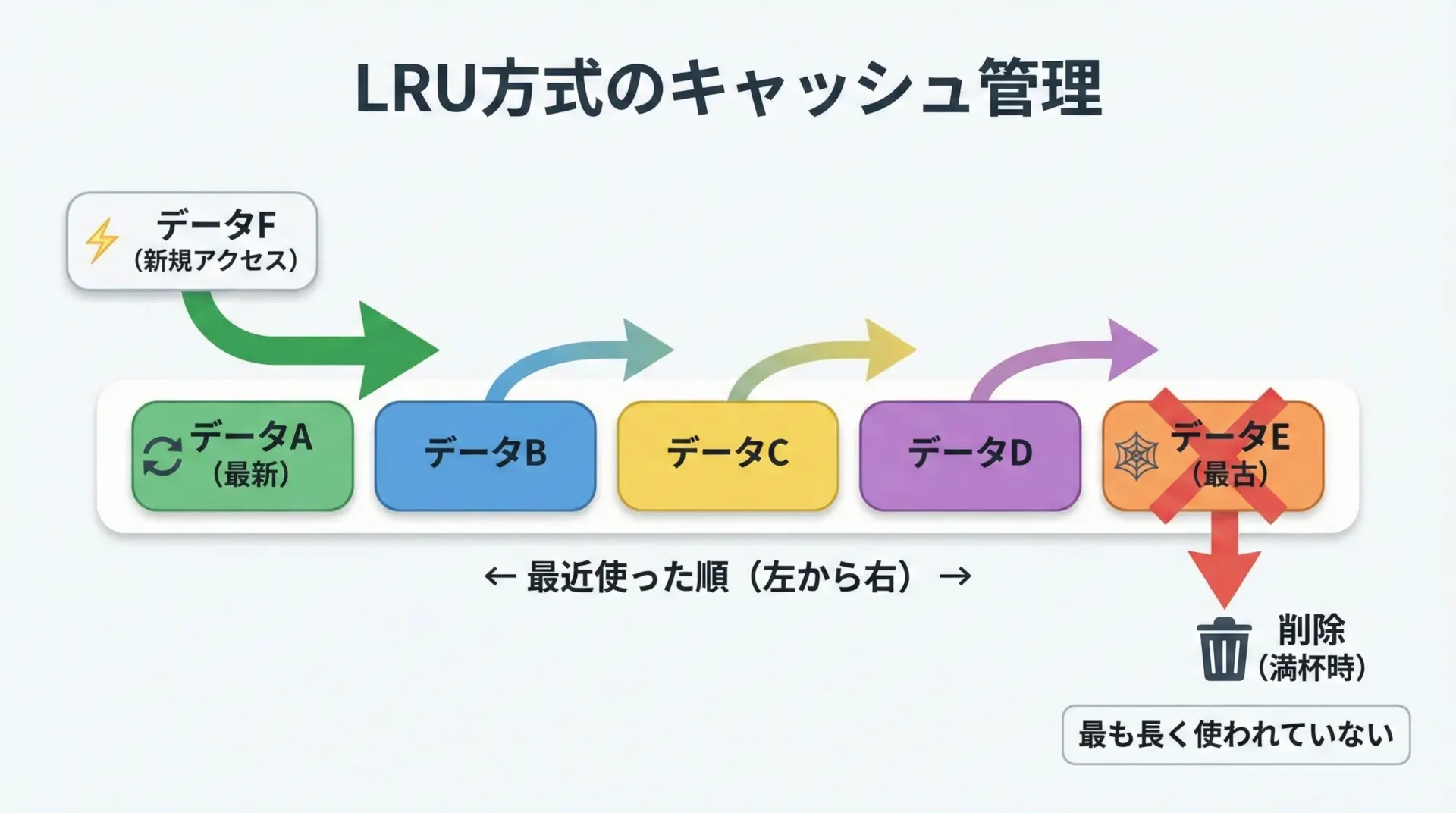
キャッシュヒットとは、関数が呼ばれたときに、対応する引数の結果がすでにキャッシュ内に存在し、それをそのまま再利用できた状態です。
このときは関数本体の計算がスキップされるため、処理は非常に高速になります。
一方、キャッシュミスとは、キャッシュにまだ結果が存在しない、またはLRUによってすでに捨てられてしまったため、改めて関数本体を実行しなければならない状態です。
ミスが起こると、その呼び出しについては高速化のメリットは得られません。
キャッシュの性能を評価するときには、しばしばキャッシュヒット率という指標を使います。
- ヒット率 = ヒット回数 ÷ 総呼び出し回数
この値が高いほど、メモ化による高速化の効果が大きくなります。
Pythonでのlru_cacheとメモ化の使い方
functools.lru_cacheの基本的な使い方
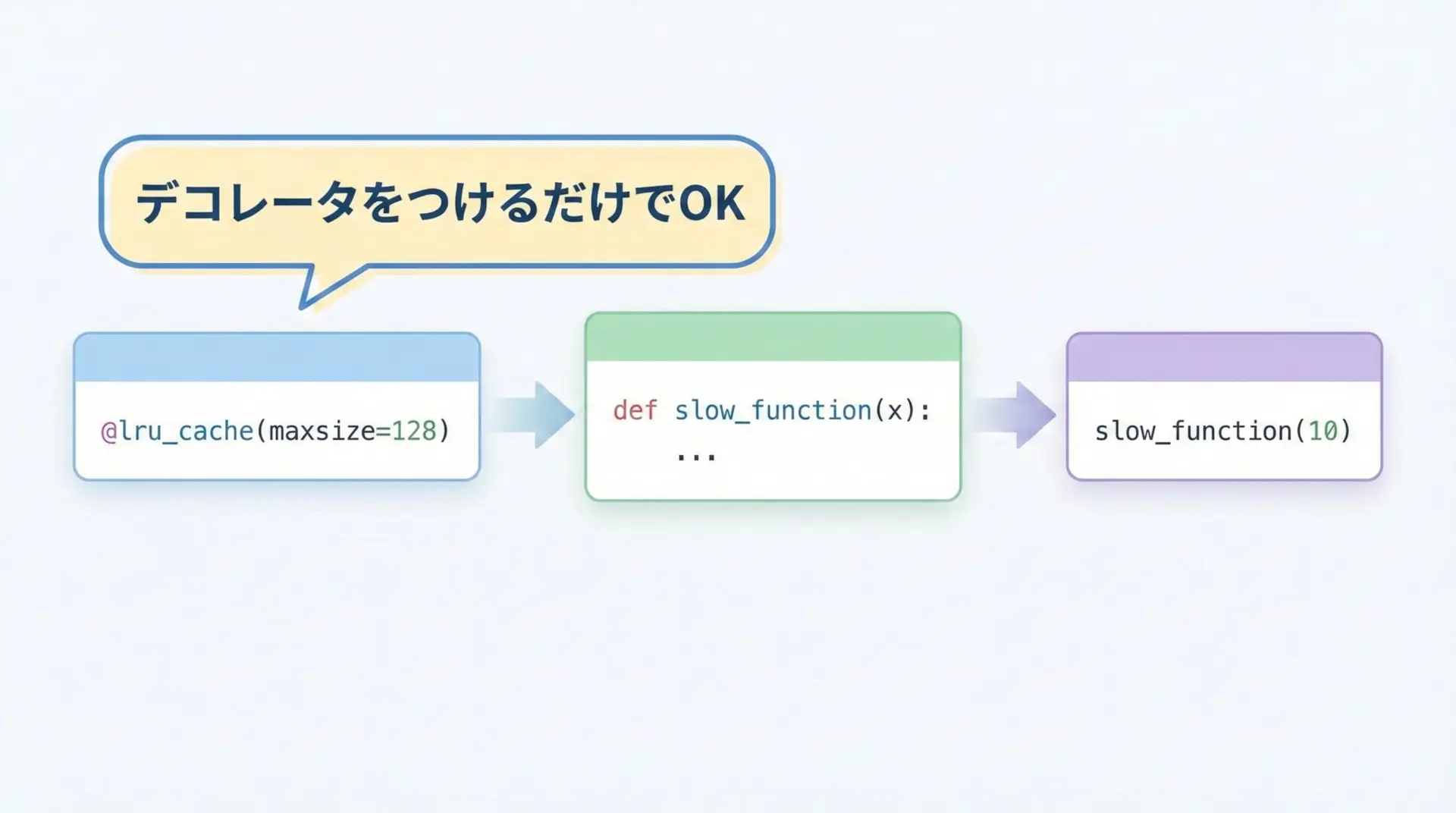
Pythonでlru_cacheを使うには、対象の関数定義の直前にデコレータを付けるだけです。
最小限の例を見てみます。
from functools import lru_cache
import time
# 遅い処理を模した関数に lru_cache を適用
@lru_cache(maxsize=128) # maxsize はキャッシュできるエントリの最大数
def slow_add(a, b):
"""わざと1秒待ってから a + b を返す関数"""
time.sleep(1) # 重い処理の代わりにスリープ
return a + b
if __name__ == "__main__":
start = time.time()
print(slow_add(3, 5)) # 1回目はキャッシュミス → 1秒かかる
print(f"1回目: {time.time() - start:.3f}秒")
start = time.time()
print(slow_add(3, 5)) # 2回目はキャッシュヒット → ほぼ一瞬
print(f"2回目: {time.time() - start:.3f}秒")8
1回目: 1.00x秒
8
2回目: 0.00x秒このように、同じ引数の2回目以降の呼び出しは、時間がほとんどかからなくなります。
コードの変更はデコレータ1行だけで済むため、既存コードにも適用しやすいです。
maxsize引数とキャッシュサイズの決め方
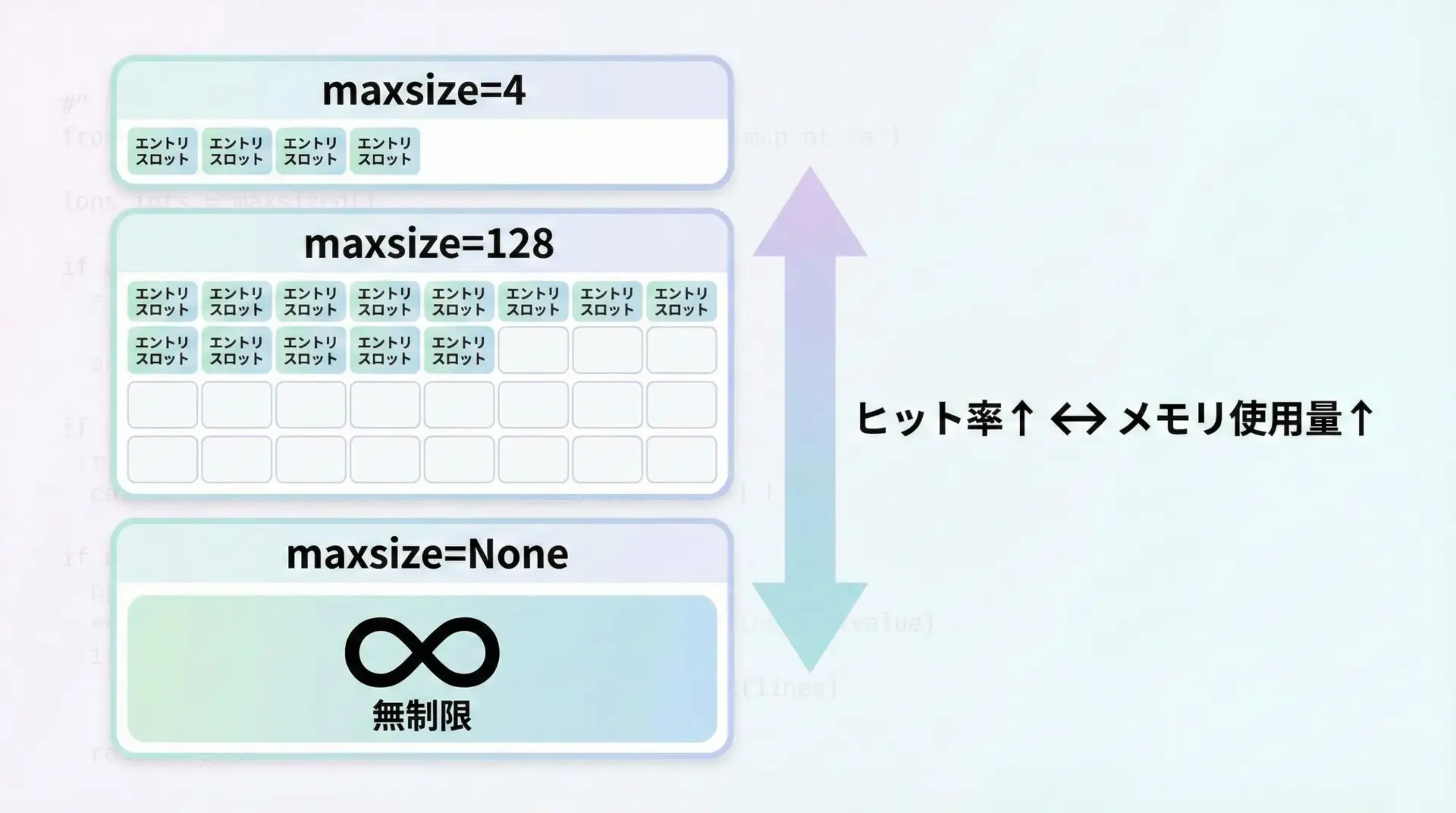
@lru_cacheの主な引数の1つがmaxsizeです。
これは、キャッシュに保持する「引数の組み合わせ」の最大数を指定します。
maxsize=128(デフォルトの1つの例): 128通りまでキャッシュmaxsize=None: 無制限にキャッシュ(理論上はメモリが許す限り)maxsize=1: 直近1回分だけを保持(常に最新の1件が残る)
maxsize=Noneは一見便利ですが、長時間動くプログラムではメモリを圧迫する危険があります。
特に、引数のパターンが非常に多い関数では、キャッシュがどんどん膨れ上がってしまう可能性があります。
おおまかな目安としては、次のように考えるとよいでしょう。
- 引数のバリエーションが少ない・上限が決まっている関数
→maxsizeをやや大きめ(数百~数千)にしても良い - Web APIなど、引数のパターンが多様になりがちな関数
→maxsizeを抑えめ(数十~数百)にし、メモリを守る - テストやスクリプト用途で、動作時間が短く影響が限定的
→maxsize=Noneで最大限のヒット率を優先する
再帰処理(フィボナッチなど)の高速化例
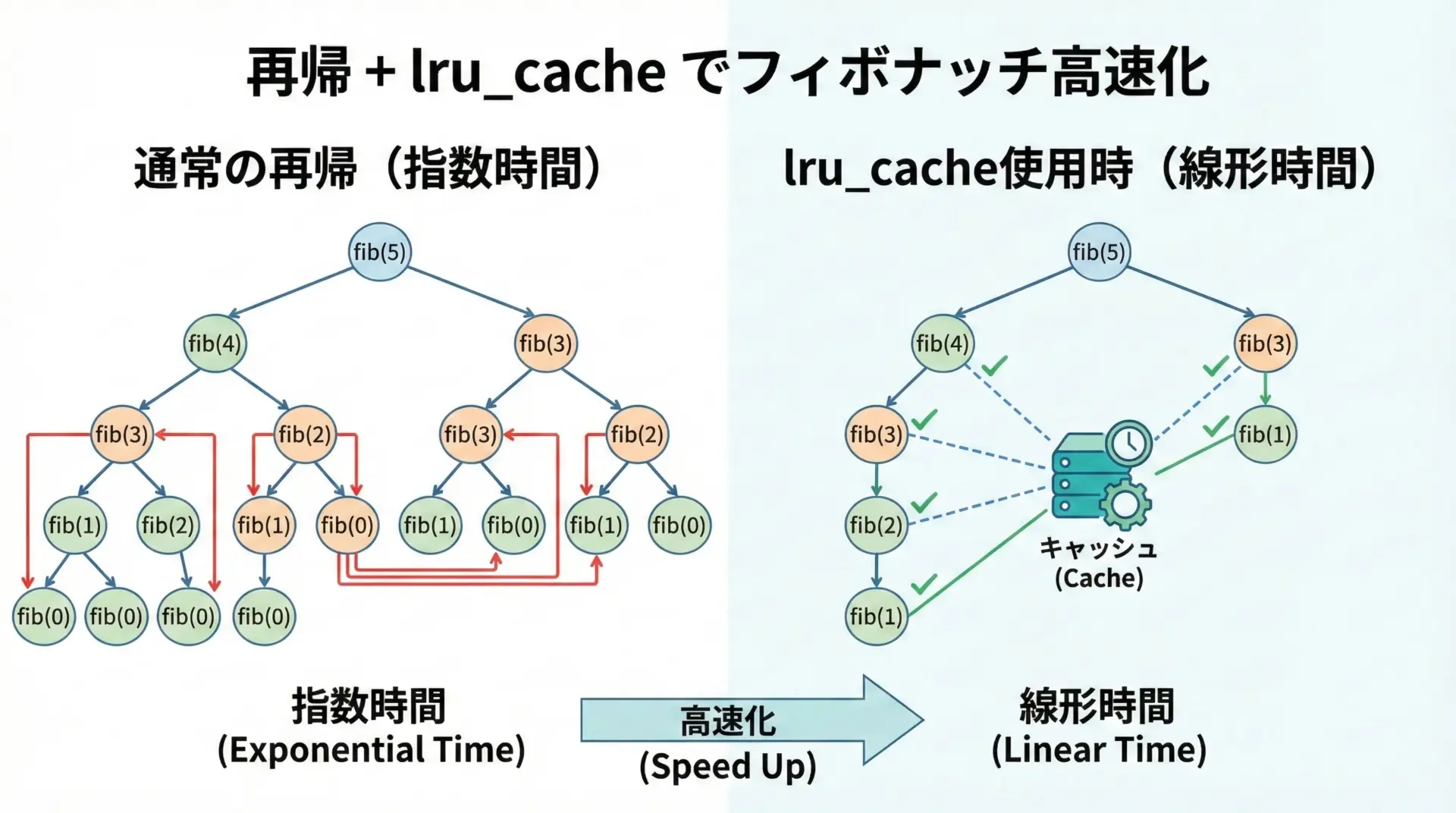
フィボナッチ数列は、メモ化による高速化の典型例です。
まず、メモ化なしの素直な再帰実装を見てみます。
import time
def fib_plain(n):
"""メモ化なしの素直な再帰フィボナッチ"""
if n <= 1:
return n
return fib_plain(n - 1) + fib_plain(n - 2)
if __name__ == "__main__":
start = time.time()
print(f"fib_plain(35) = {fib_plain(35)}")
print(f"実行時間(メモ化なし): {time.time() - start:.3f}秒")fib_plain(35) = 9227465
実行時間(メモ化なし): 数秒程度(環境による)この実装では、同じフィボナッチ数を何度も再計算してしまうため、計算量が指数関数的に増えます。
ここにlru_cacheを適用すると、劇的に速くなります。
from functools import lru_cache
import time
@lru_cache(maxsize=None) # 無制限にキャッシュしても n に応じて個数は線形
def fib_memo(n):
"""lru_cache を使ったメモ化付きフィボナッチ"""
if n <= 1:
return n
return fib_memo(n - 1) + fib_memo(n - 2)
if __name__ == "__main__":
start = time.time()
print(f"fib_memo(35) = {fib_memo(35)}")
print(f"実行時間(lru_cacheあり): {time.time() - start:.6f}秒")fib_memo(35) = 9227465
実行時間(lru_cacheあり): 0.0000x秒同じ問題を解いているにもかかわらず、メモ化の有無で数千倍以上の差になることも珍しくありません。
再帰的なDP(動的計画法)パターンでは、まずlru_cacheの適用を検討すると良いでしょう。
クラスメソッド・インスタンスメソッドでの使い方
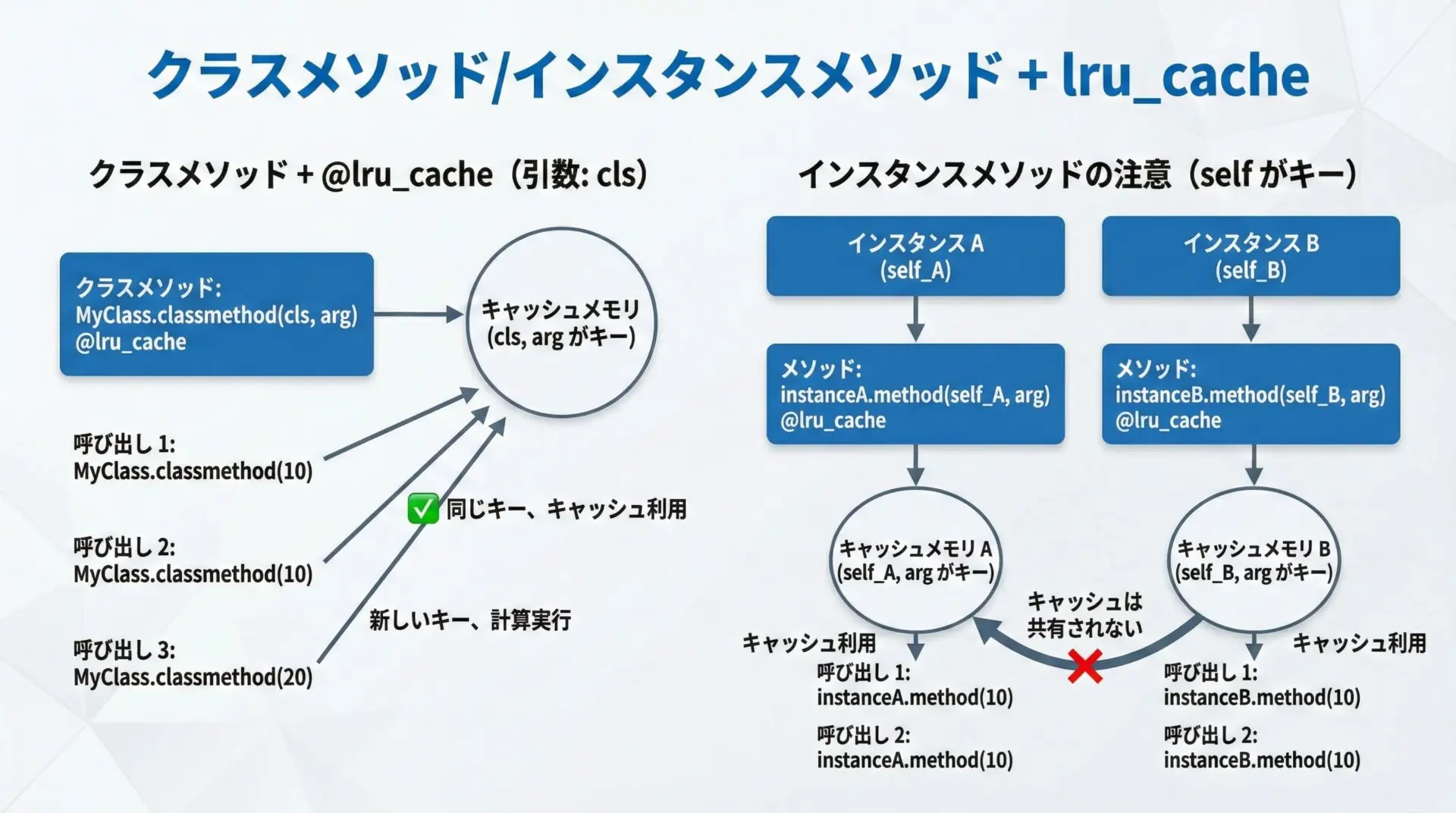
lru_cacheは、関数だけでなくメソッドにも使えます。
ただし、インスタンスメソッドではselfがキャッシュキーに含まれるなど、いくつか注意点があります。
クラスメソッドでの利用
クラスメソッドは@classmethodで定義され、最初の引数はclsです。
lru_cacheを併用する場合、デコレータの順序に注意が必要です。
from functools import lru_cache
class MathUtils:
@classmethod
@lru_cache(maxsize=128) # classmethod より後につけるとエラーになる
def heavy_calc(cls, x):
"""クラスメソッド + lru_cache (この順序はNG例)"""
return x * x上のような順序だと、lru_cacheがclassmethodオブジェクトをラップしてしまい、正しく動作しません。
正しくは次のように、lru_cacheを内側、classmethodを外側にします。
from functools import lru_cache
class MathUtils:
@lru_cache(maxsize=128)
@classmethod
def heavy_calc(cls, x):
"""クラスメソッド + lru_cache の正しい順序"""
return x * x
if __name__ == "__main__":
print(MathUtils.heavy_calc(10))
print(MathUtils.heavy_calc(10)) # 2回目はキャッシュヒット100
100インスタンスメソッドでの利用とself
インスタンスメソッドでは、最初の引数selfもキャッシュキーの一部になります。
つまり、インスタンスごとにキャッシュが分かれることになります。
from functools import lru_cache
class Example:
def __init__(self, base):
self.base = base
@lru_cache(maxsize=64)
def calc(self, x):
"""インスタンスメソッドに lru_cache を適用"""
return self.base * x
if __name__ == "__main__":
e1 = Example(10)
e2 = Example(20)
print(e1.calc(3)) # base=10
print(e1.calc(3)) # キャッシュヒット (e1, 3)
print(e2.calc(3)) # e2 は別インスタンスなので別キャッシュ (e2, 3)30
30
60このように、インスタンスが増えると、その分だけキャッシュも増えることになります。
大量のインスタンスを生成するクラスに安易にlru_cache付きメソッドを持たせると、メモリを圧迫するおそれがあります。
「インスタンスの状態に依存しない計算」をキャッシュしたい場合は、インスタンスメソッドではなくスタティックメソッド(@staticmethod)やモジュールレベル関数として定義し、そこでlru_cacheを使う設計も検討してください。
手動メモ化(dict)との実装比較
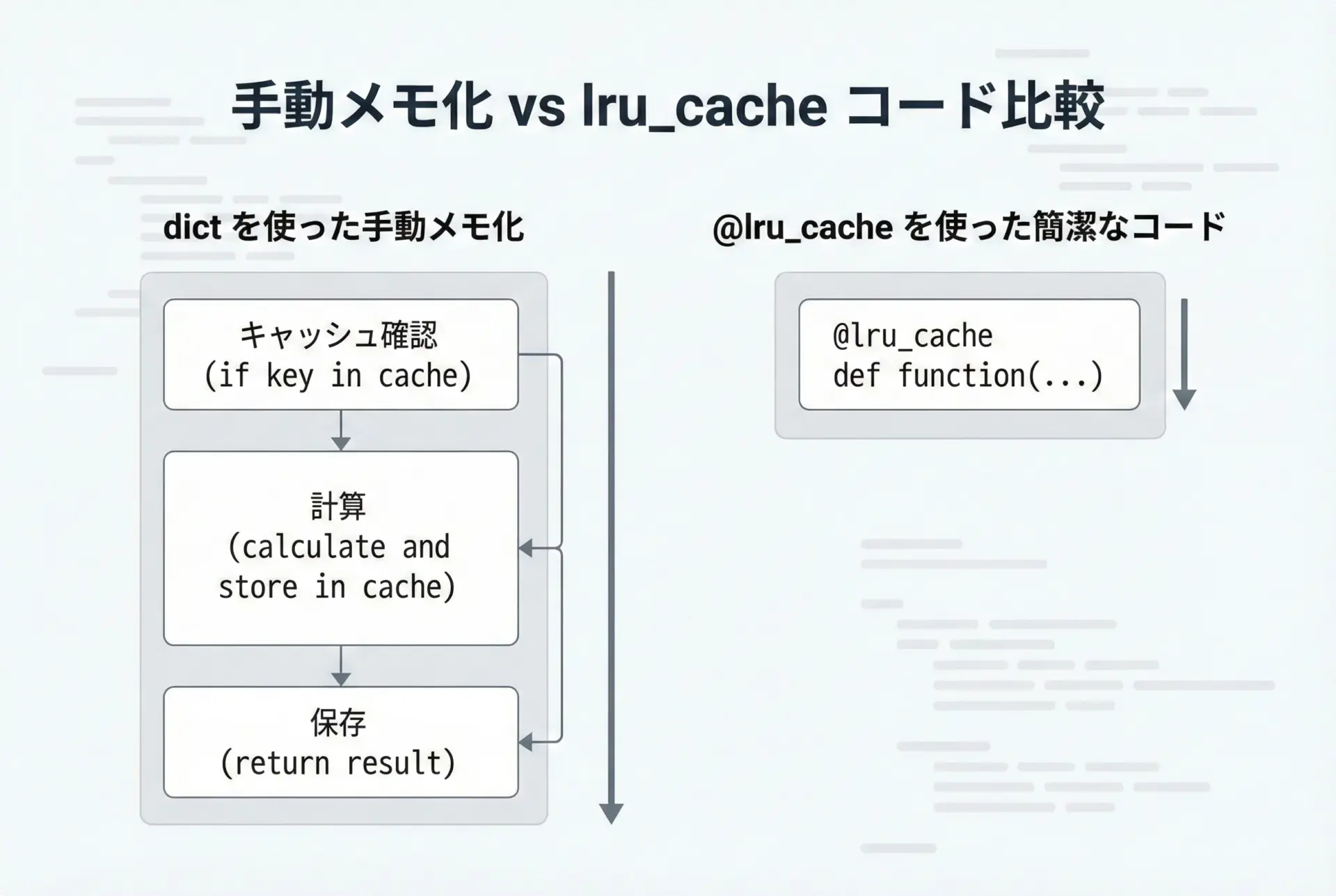
同じメモ化を、あえて手動でdictを使って実装してみると、lru_cacheの便利さがよくわかります。
まずは手動メモ化の例です。
import time
_cache = {} # グローバルなキャッシュ辞書
def slow_square_manual(n):
"""手動メモ化を行う n^2 関数"""
# 1. キャッシュ確認
if n in _cache:
return _cache[n]
# 2. 計算 (重い処理を想定)
time.sleep(1)
result = n * n
# 3. キャッシュ保存
_cache[n] = result
return result
if __name__ == "__main__":
print(slow_square_manual(5)) # 1回目は1秒
print(slow_square_manual(5)) # 2回目は即時25
25これに対して、lru_cacheを使った場合は次の通りです。
from functools import lru_cache
import time
@lru_cache(maxsize=128) # 手動の _cache が不要になる
def slow_square_auto(n):
"""lru_cache による自動メモ化"""
time.sleep(1)
return n * n
if __name__ == "__main__":
print(slow_square_auto(5)) # 1回目は1秒
print(slow_square_auto(5)) # 2回目は即時25
25コード量が減るだけでなく、LRU管理やスレッドセーフティまで面倒を見てくれる点で、lru_cacheは非常に実用的です。
特殊なキャッシュポリシーが不要であれば、基本的にはlru_cacheを利用することをおすすめします。
lru_cache・メモ化の注意点とベストプラクティス
キャッシュできる引数(ハッシュ可能オブジェクト)の制約
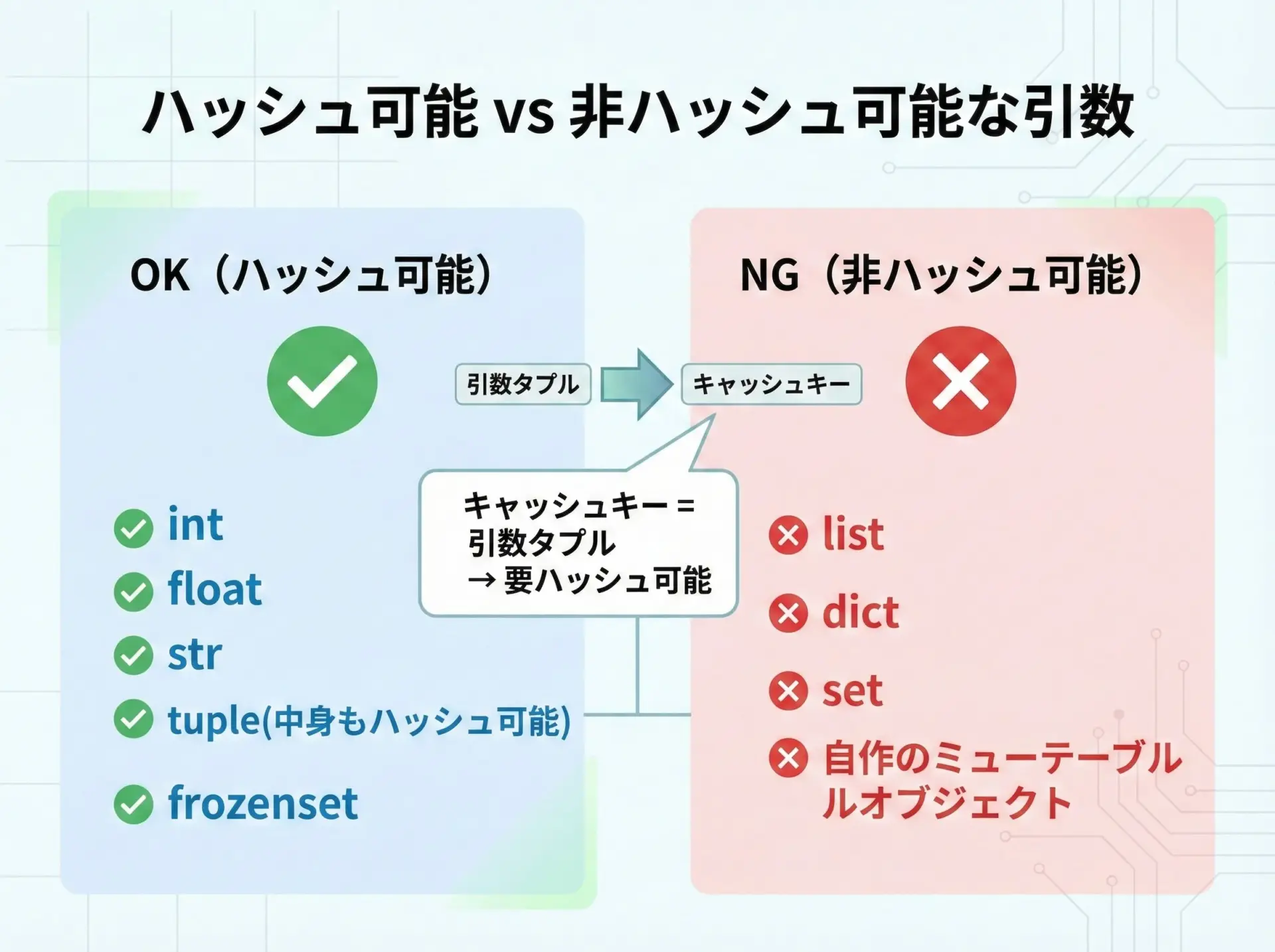
lru_cacheは内部で辞書を使っているため、引数は「ハッシュ可能(hashable)」でなければなりません。
ハッシュ可能とは、簡単に言えばdictのキーに使えるかどうかです。
代表的な例を挙げると、次のようになります。
- ハッシュ可能(キャッシュに使える)
int,float,strtuple(中身もハッシュ可能である必要あり)frozenset
- ハッシュ不可能(そのままでは使えない)
list,dict,set- 通常のユーザー定義クラスのインスタンス(デフォルトではハッシュ可能だが、内容が変化する場合は危険)
たとえば、次のようにリストを引数にするとエラーになります。
from functools import lru_cache
@lru_cache(maxsize=128)
def sum_list(values):
return sum(values)
if __name__ == "__main__":
print(sum_list([1, 2, 3])) # list はハッシュ不可能なのでエラーTypeError: unhashable type: 'list'このような場合は、引数をタプルに変換するなどの工夫を行います。
from functools import lru_cache
@lru_cache(maxsize=128)
def sum_list_safe(values_tuple):
"""タプルを受け取り、内部で sum する関数"""
return sum(values_tuple)
if __name__ == "__main__":
data = (1, 2, 3)
print(sum_list_safe(data)) # OK
print(sum_list_safe(data)) # キャッシュヒット6
6キャッシュ対象の関数設計時には、引数がハッシュ可能かどうかを必ず意識するようにしてください。
ミューテーブルな引数・副作用のある関数の危険性
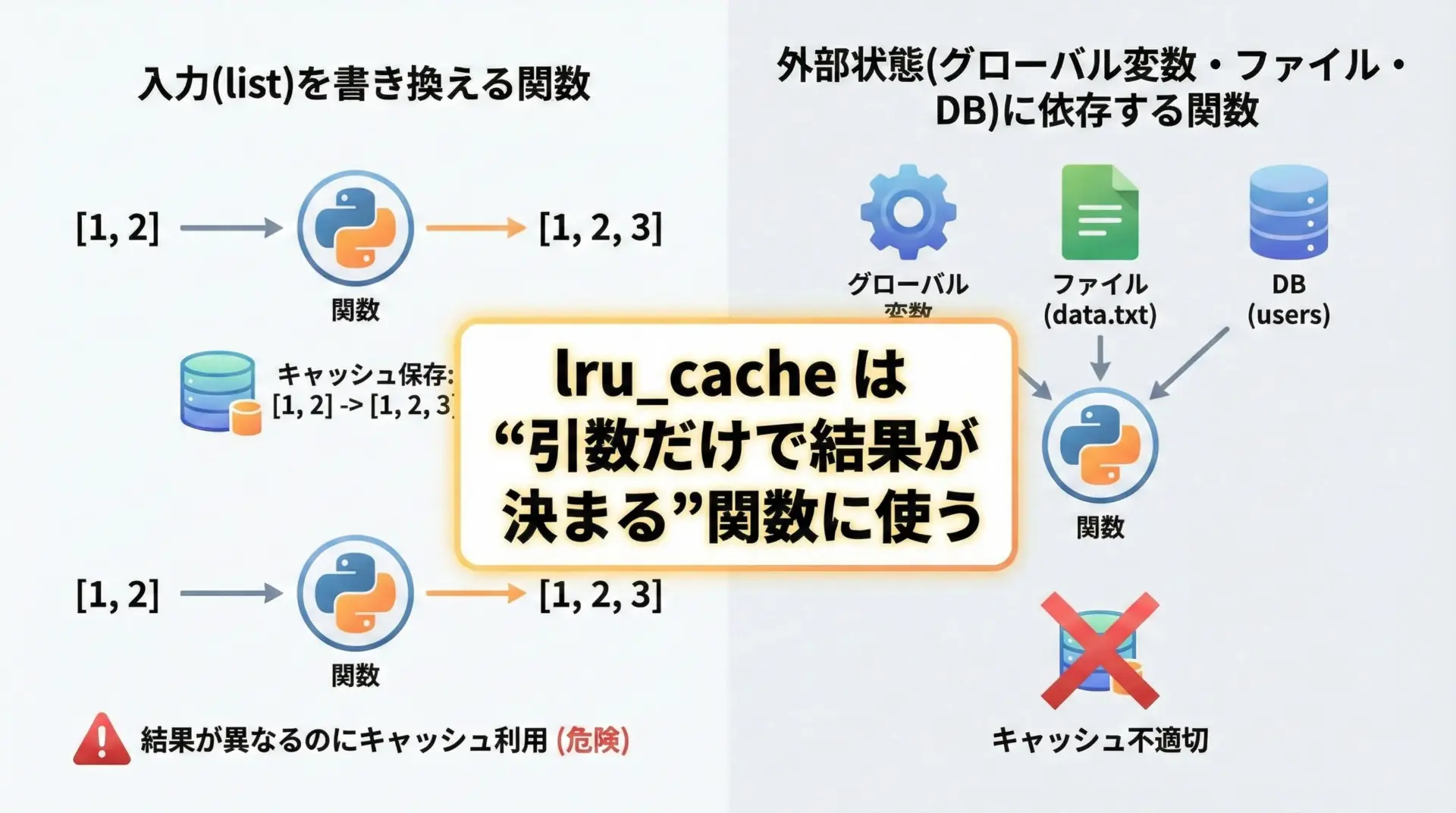
lru_cacheは、「同じ引数なら常に同じ結果を返す」関数を前提としています。
したがって、次のような関数に適用すると、正しく動作しない・バグの原因になることがあります。
- 引数のオブジェクトを書き換える(ミューテーブル操作)関数
- グローバル変数・外部ファイル・データベースなど、外部状態に依存する関数
- ランダム値や現在時刻を返す関数
たとえば次のようなコードを考えます。
from functools import lru_cache
@lru_cache(maxsize=128)
def append_and_sum(values_tuple):
# 危険な例: タプルをリストに変換して書き換える
lst = list(values_tuple)
lst.append(100)
return sum(lst)
if __name__ == "__main__":
t = (1, 2, 3)
print(append_and_sum(t)) # 1回目 → 106
print(append_and_sum(t)) # 2回目も 106 (キャッシュ)106
106この例はまだ結果が安定していますが、もし元のvalues_tupleが外部と共有され、別の場所で変更されてしまうような設計の場合、「引数が実質的に変わっているのに、キャッシュされた古い結果を返してしまう」危険があります。
また、次のように外部状態に依存する関数をキャッシュすると、値が変わっても更新されません。
from functools import lru_cache
import time
@lru_cache(maxsize=1)
def get_current_time():
"""現在時刻を返す(が、lru_cacheにより固定されてしまう)"""
return time.time()
if __name__ == "__main__":
print(get_current_time())
time.sleep(2)
print(get_current_time()) # 2秒後でも同じ値が返る1700000000.123456
1700000000.123456このように、副作用がある関数や外部状態に依存する関数にlru_cacheを使うのは危険です。
「純粋な関数(入力が同じなら出力も必ず同じになる関数)」にのみ適用するのが基本的なベストプラクティスです。
メモリ使用量とmaxsize設定のトレードオフ
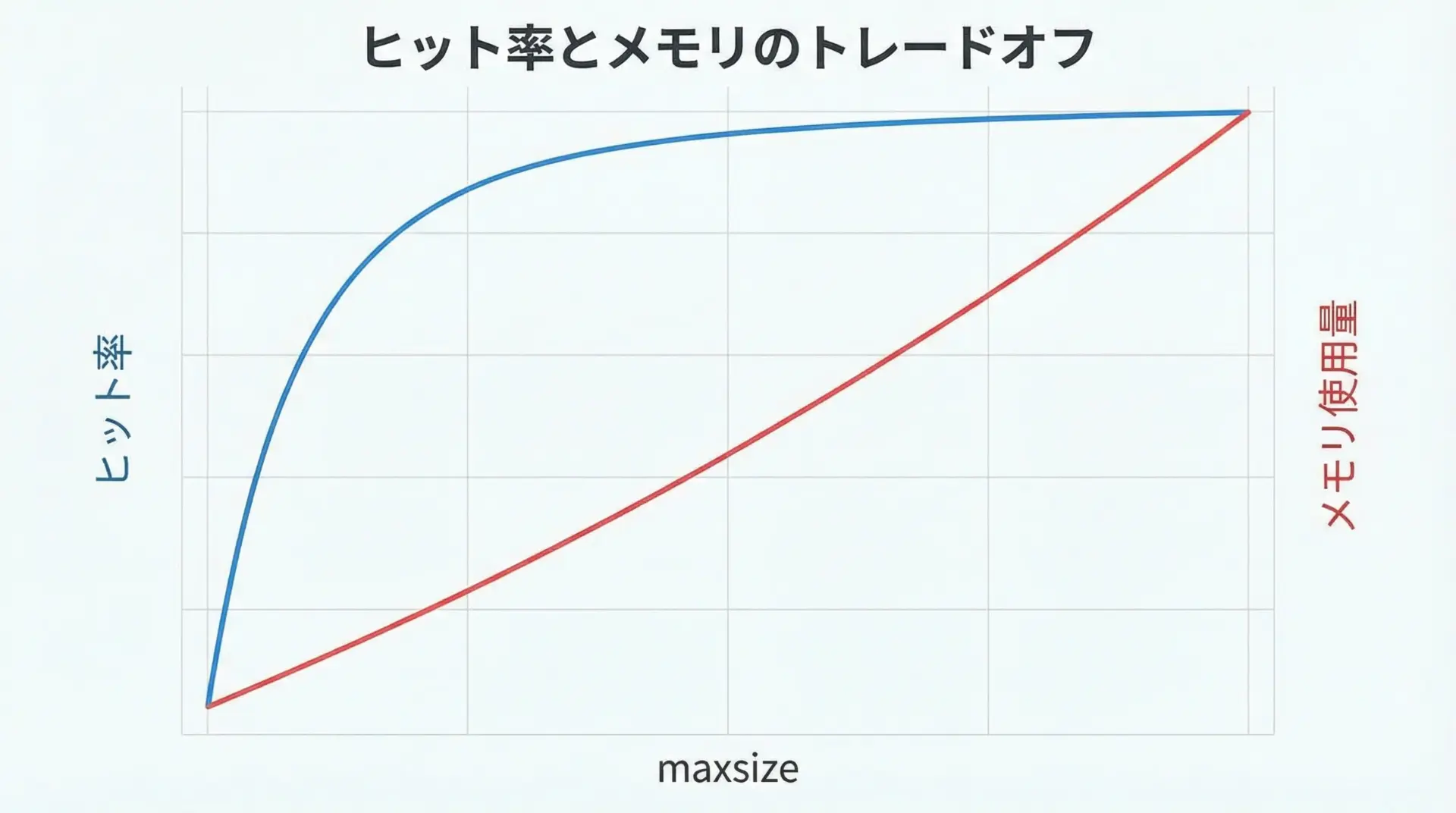
キャッシュは高速化には役立ちますが、メモリを消費することも忘れてはいけません。
- maxsizeを大きくすると、
- より多くの結果を保存できるため、ヒット率が上がりやすい
- しかし、メモリ使用量も増加する
- maxsizeを小さくすると、
- メモリの消費は抑えられる
- ただし、古いエントリがすぐに捨てられ、ヒット率が下がる可能性がある
特に、長時間稼働するサーバーアプリケーションやバッチ処理では、キャッシュの肥大化がシステム全体のメモリ不足につながるリスクがあります。
実運用では、次のような方針で検討すると良いでしょう。
- まずは保守的な
maxsize(例えば64や128)で始める - 実行時のメモリ使用量と処理速度をモニタリングする
- 必要に応じて
maxsizeを増減させ、バランスをとる
「何となく大きくしておく」のではなく、実際のアクセスパターンとメモリ制約を見ながら調整するのがポイントです。
スレッドセーフティ・パフォーマンスへの影響
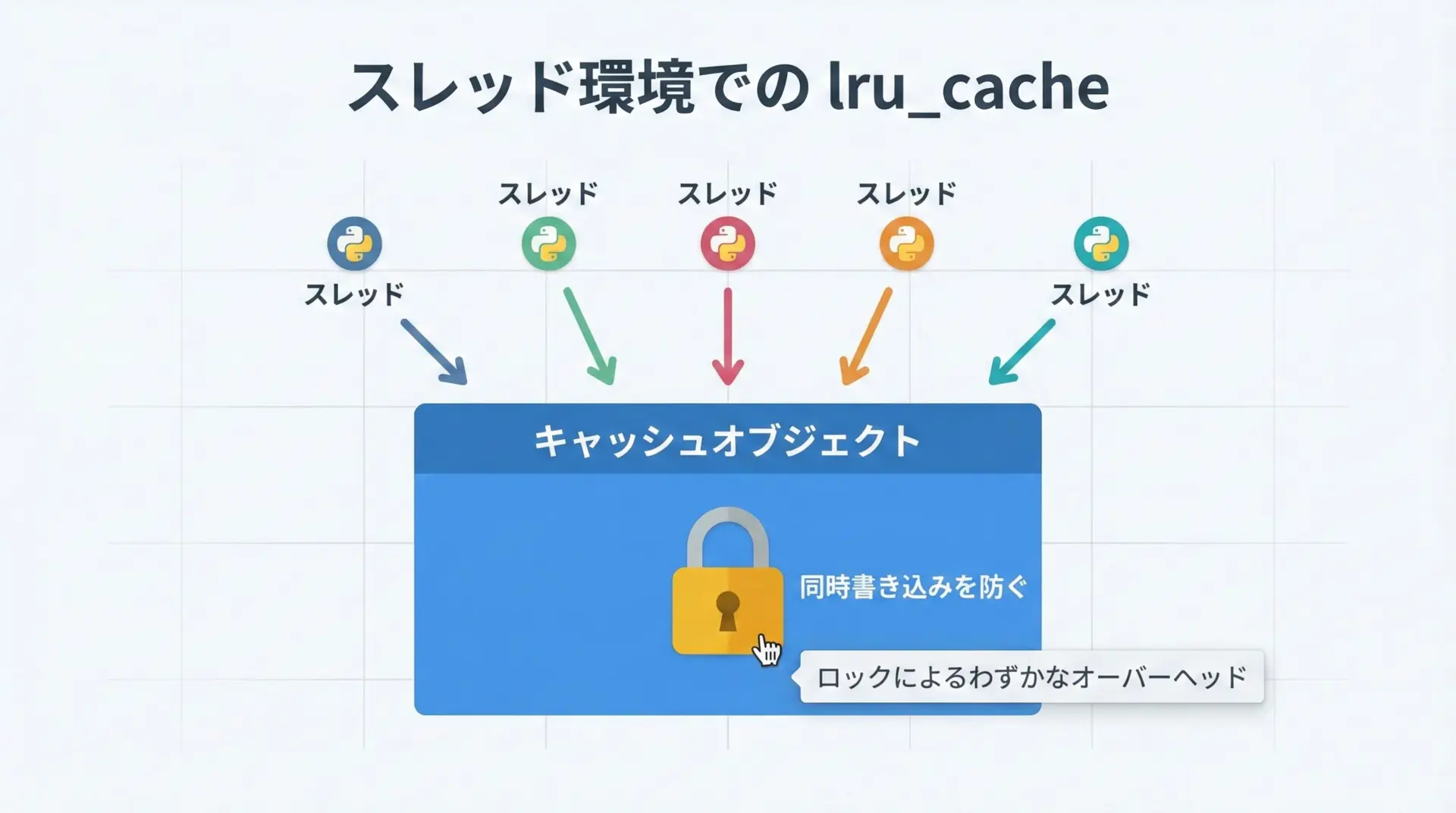
lru_cacheは、CPython実装ではスレッドセーフになるように設計されています。
内部でロックを使い、複数のスレッドが同時にキャッシュを書き換えないようにしているため、基本的にはマルチスレッド環境でも安心して使えます。
ただし、このロックによって、ごくわずかなオーバーヘッドが発生します。
通常の用途では気にならない程度ですが、次のような場合には影響を検討した方が良いこともあります。
- 非常に頻繁に呼ばれる超軽量な関数
- 複数スレッドが高頻度で同じキャッシュにアクセスするケース
このような場合、
- メモ化そのものが本当に必要か
- キャッシュをスレッドごとに分ける設計はできないか
といった観点から再検討するとよいでしょう。
とはいえ、多くの現実的なアプリケーションでは、lru_cacheによる高速化のメリットの方が、ロックオーバーヘッドを大きく上回ることがほとんどです。
キャッシュの無効化(clear_cache)と運用のコツ
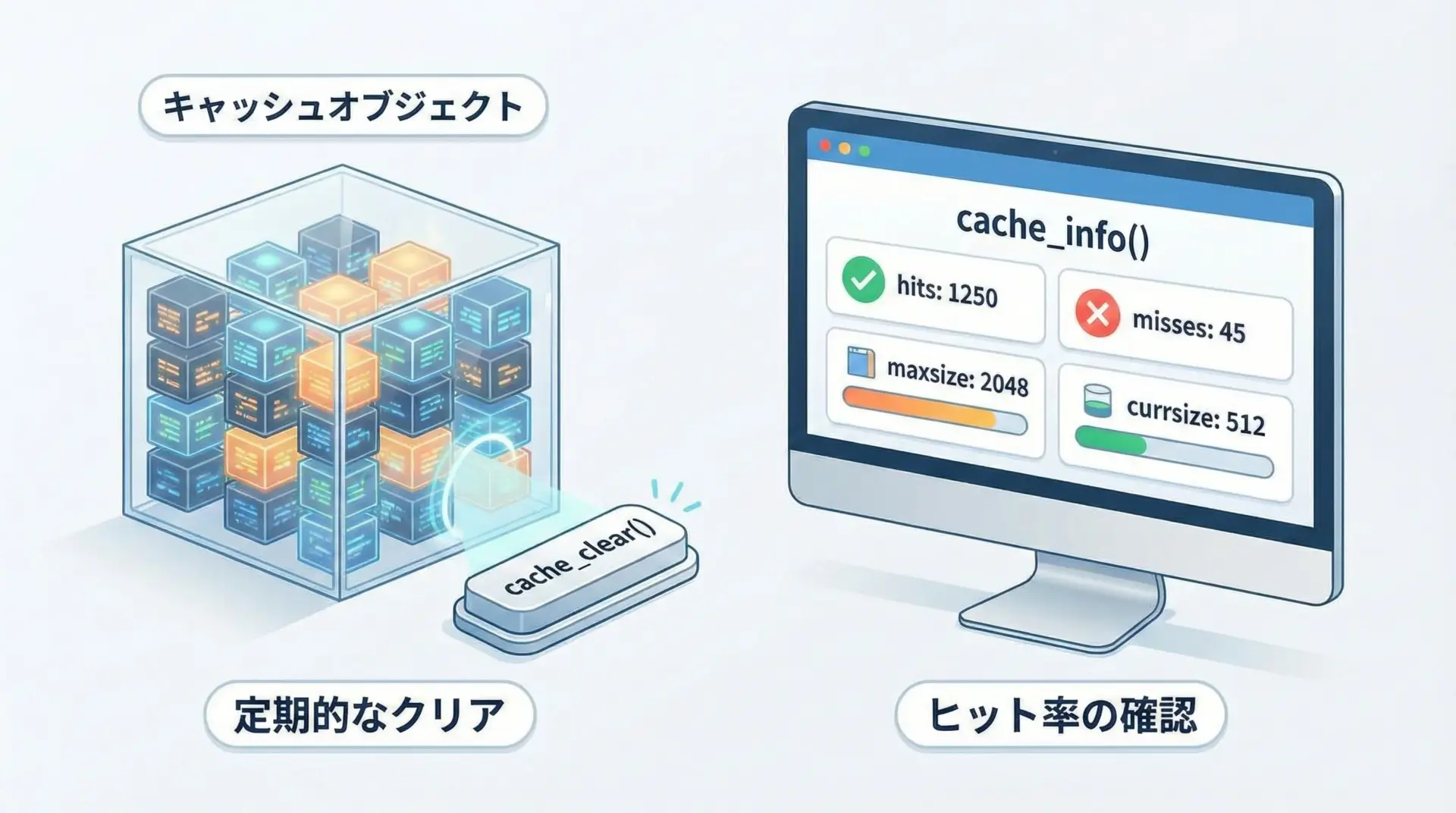
lru_cacheでメモ化した関数には、キャッシュ操作用のメソッドが自動的に生えます。
代表的なのがcache_clear()とcache_info()です。
cache_clearでキャッシュを消す
cache_clear()を呼ぶと、その関数用のキャッシュがすべて消去されます。
from functools import lru_cache
@lru_cache(maxsize=4)
def square(n):
print(f"計算しています: {n}")
return n * n
if __name__ == "__main__":
square(2)
square(3)
print("---- cache_clear 呼び出し ----")
square.cache_clear() # キャッシュを全削除
square(2) # 再び計算が行われる計算しています: 2
計算しています: 3
---- cache_clear 呼び出し ----
計算しています: 2長時間動くアプリケーションでは、定期的にキャッシュをクリアしてメモリを解放する戦略をとることもあります。
たとえば、一定時間ごと・特定のイベント発生時などにcache_clear()を呼ぶなどです。
cache_infoでヒット率を確認する
cache_info()を使うと、その関数のキャッシュ状況(ヒット数・ミス数など)を確認できます。
from functools import lru_cache
@lru_cache(maxsize=4)
def add(a, b):
return a + b
if __name__ == "__main__":
add(1, 2)
add(1, 2)
add(2, 3)
print(add.cache_info())CacheInfo(hits=1, misses=2, maxsize=4, currsize=2)ここで、
hits: キャッシュヒットした回数misses: キャッシュミスした回数maxsize: 設定された最大エントリ数currsize: 現在キャッシュされているエントリ数
がわかります。
ヒット率を見て、maxsizeが適切かどうかを調整するといった運用にも役立ちます。
まとめ
lru_cacheとメモ化は、Pythonで計算を高速化するための非常に強力な標準機能です。
デコレータ1行を追加するだけで、同じ引数の重い計算結果を自動的にキャッシュしてくれます。
本記事では、内部で引数タプルをキーとした辞書とLRU方式が使われていること、maxsizeやcache_clear、cache_infoの実用的な使い方、そしてハッシュ可能な引数・純粋な関数に限定して利用すべきといった注意点を解説しました。
再帰処理や繰り返し計算の多い箇所では、まずlru_cacheの適用を検討し、ヒット率とメモリ使用量のバランスを見ながら、賢く高速化していきましょう。
