Pythonではと**がさまざまな場面で登場します。
リストの展開、辞書のマージ、柔軟な関数引数など、どれも実務で頻出です。
しかし文脈によって意味が変わるため、最初は混乱しがちです。
本記事では、アンパッキングと関数引数に焦点を当てて、Pythonのと**を体系的に解説します。
コードと図解を交えながら、実務でそのまま使えるパターンを整理していきます。
Pythonの*と**とは何か
*(アスタリスク)と**(ダブルアスタリスク)の基本
まずは、Pythonにおける*と**の役割をざっくり整理します。
ここではまだ細かい文法ではなく、「何をするための記号なのか」という直感をつかむことが大事です。
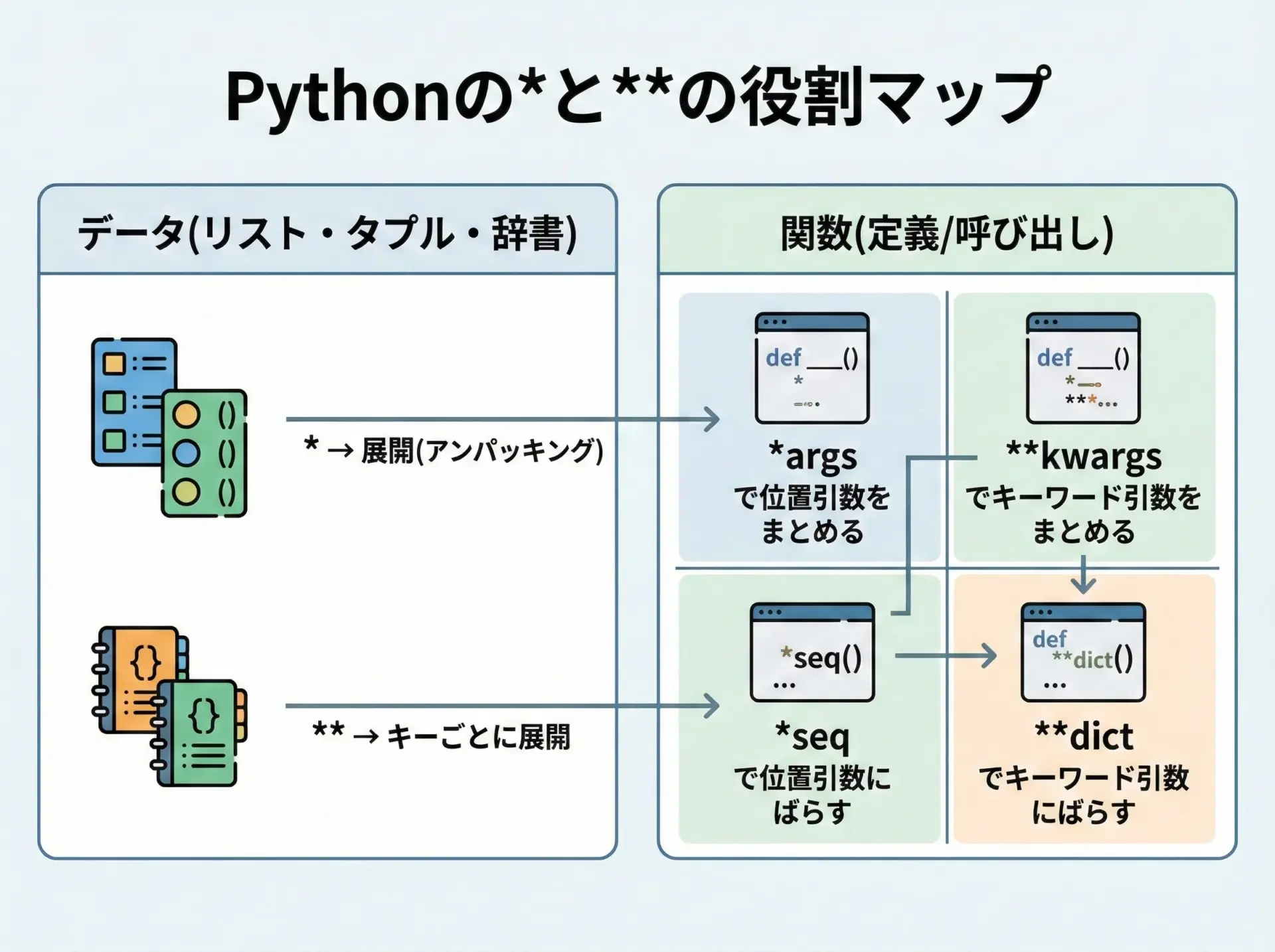
Pythonでは「どこで使うか」によって意味が変化します。
ざっくりいうと、次の2軸で考えると整理しやすくなります。
1つ目は対象です。
*はシーケンス(リスト、タプルなど)に対して、**は辞書に対して使われるのが基本です。
2つ目は位置です。
関数の定義側に置かれるか、呼び出し側に置かれるかで意味が変わります。
これを組み合わせると、次のような役割に分類できます。
- データ操作でのアンパッキング/マージ
*seq: リストやタプルなどを「ばらす」**dict: 辞書を「キーと値のペアにばらす」
- 関数定義での引数の「まとめ」
*args: 余った位置引数をタプルにまとめる**kwargs: 余ったキーワード引数を辞書にまとめる
- 関数呼び出しでの引数の「展開」
*seq: シーケンスを複数の位置引数として渡す**dict: 辞書を複数のキーワード引数として渡す
Pythonにおけるアンパッキングの意味
アンパッキングとは、1つのまとまりになっているオブジェクト(シーケンスや辞書)を、複数の要素として取り出すことです。
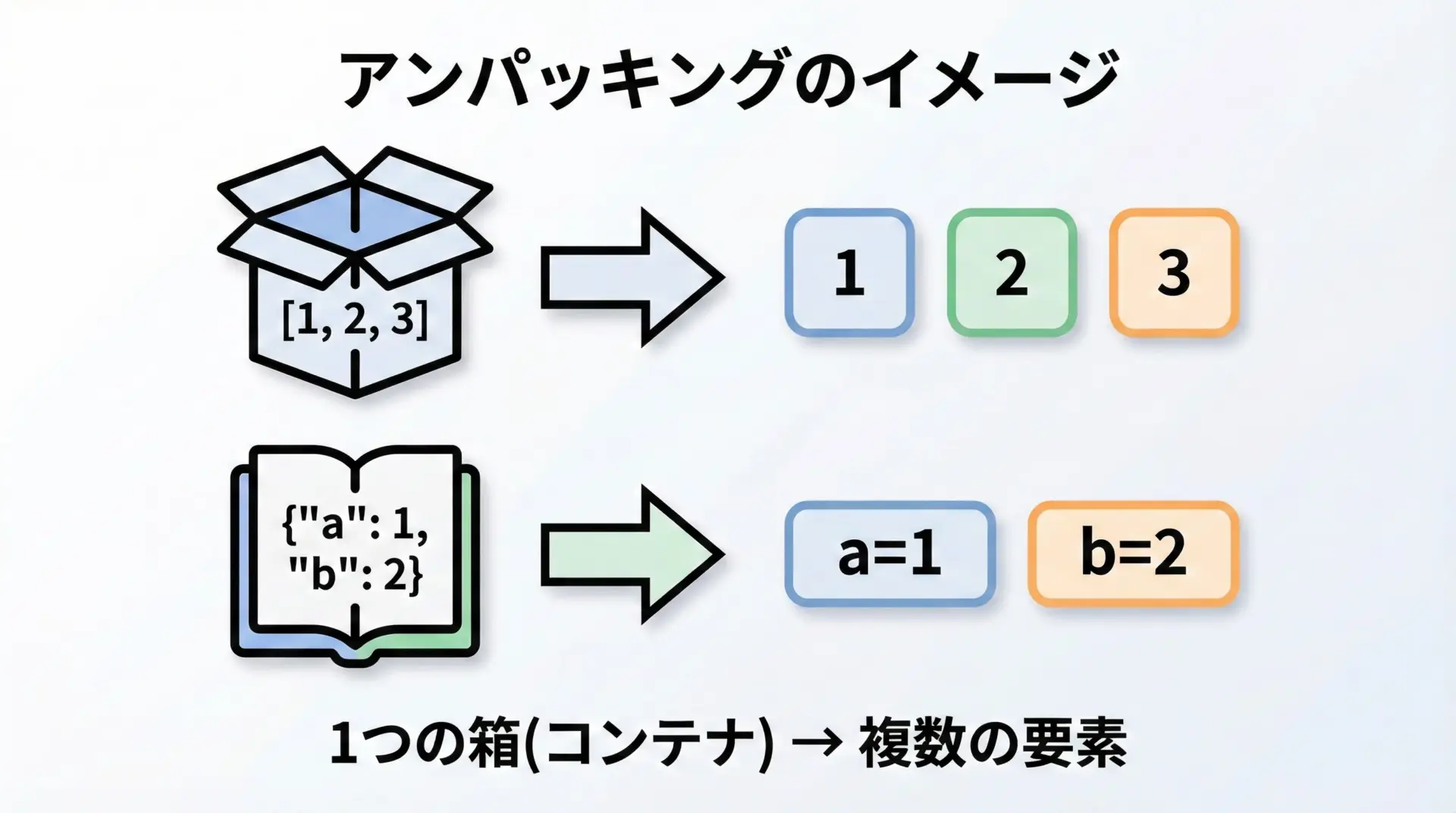
Pythonでは、次のような場面でアンパッキングが行われます。
- 複数代入でタプルやリストの要素を変数に取り出す
- 関数に引数として渡す際に、リストや辞書をそのまま「ばらす」
- リストや辞書を結合するときに、内部要素を展開する
ポイントは、「アンパッキングは文脈によって結果の形が変わる」ことです。
同じ*でも、代入の左辺か、関数呼び出しか、リストリテラルの中かによって、挙動や受け取り方が変わってきます。
関数定義と関数呼び出しでの役割の違い
最も混乱しやすいのが、関数定義側と呼び出し側での使い分けです。
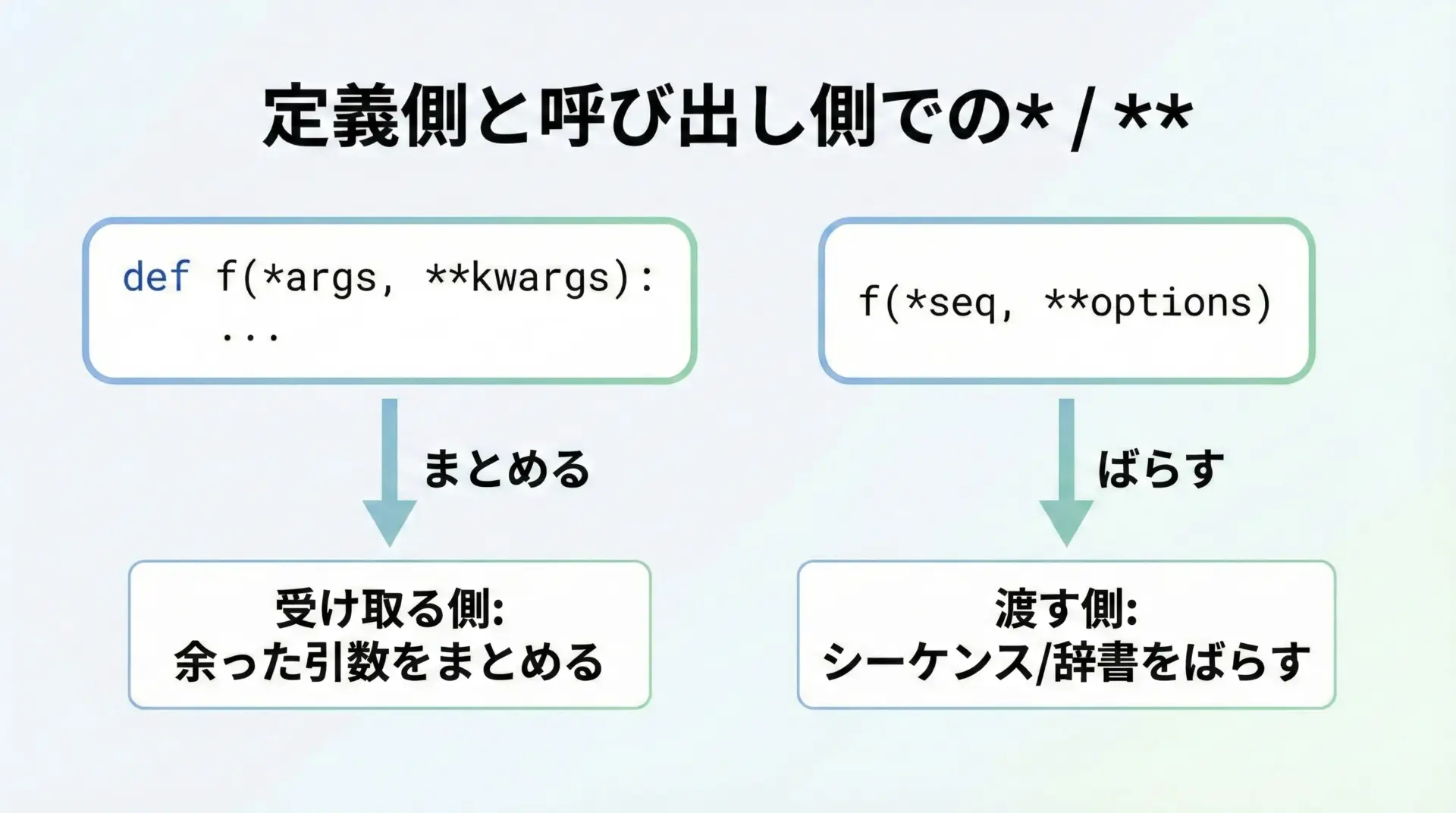
関数定義では、*や**は「余ったものをまとめる」ために使われます。
def f(*args):
渡された位置引数がargsというタプルにまとまります。def f(**kwargs):
渡されたキーワード引数がkwargsという辞書にまとまります。
一方、関数呼び出しでは逆に、*や**は「まとめてあるものをばらす」ために使われます。
f(*seq): シーケンスseqを位置引数に展開するf(**d): 辞書dをキーワード引数に展開する
この対比を押さえておくと、以降の説明がかなり理解しやすくなります。
*の使い方
リスト・タプルのアンパッキング
基本的なアンパッキング代入
*を使わない基本形から確認します。
タプルやリストは、位置ごとに変数へ展開できます。
# タプルのアンパッキング代入
pair = (10, 20)
x, y = pair # 左辺と右辺の要素数が一致している必要がある
print(x) # 10
print(y) # 2010
20このとき(10, 20)は、内部的にはアンパッキングされて、それぞれxとyに代入されています。
リストの場合も同様です。
data = [1, 2, 3]
a, b, c = data
print(a, b, c)1 2 3*を使った柔軟なアンパッキング
要素数が固定でない場合、通常のアンパッキングでは「値が多すぎる/少なすぎる」エラーになります。
ここで*が役立ちます。
numbers = [1, 2, 3, 4, 5]
# 先頭2つだけを取り出し、残りはrestにまとめる
first, second, *rest = numbers
print(first) # 1
print(second) # 2
print(rest) # [3, 4, 5]1
2
[3, 4, 5]1つだけ付き変数を含めることで、「残り全部」をリストとして受け取ることができます。
ただし、restには必ずリストが入る点に注意します。
複数代入での*
先頭・末尾を扱うパターン
*付き変数は、先頭や末尾にも配置できます。
これにより、「頭だけ」「尻だけ」を取り出すパターンが直感的に書けます。
values = [10, 20, 30, 40, 50]
# 先頭だけ取り出し、残り全部
head, *tail = values
print(head) # 10
print(tail) # [20, 30, 40, 50]
# 末尾だけ取り出し、前半全部
*body, last = values
print(body) # [10, 20, 30, 40]
print(last) # 5010
[20, 30, 40, 50]
[10, 20, 30, 40]
50先頭と末尾の両方を固定し、真ん中をまとめて受け取ることも可能です。
values = [1, 2, 3, 4, 5]
first, *middle, last = values
print(first) # 1
print(middle) # [2, 3, 4]
print(last) # 51
[2, 3, 4]
5関数定義での可変長引数*args
*argsの基本
関数定義の中で*を用いると、任意個数の位置引数を1つのタプルにまとめて受け取ることができます。
慣習としてargsという名前がよく使われます。
def average(*numbers):
"""任意個数の数値の平均を計算する関数"""
# numbers はタプルとして受け取られる
total = sum(numbers)
count = len(numbers)
return total / count
print(average(10, 20))
print(average(1, 2, 3, 4, 5))15.0
3.0*args は「余った位置引数全部」を受け取る仕組みです。
通常の引数と組み合わせることもできます。
def greet(greeting, *names):
"""最初の引数はあいさつ文、残りは名前を任意個受け取る"""
for name in names:
print(f"{greeting}, {name}!")
greet("Hello", "Alice", "Bob", "Charlie")Hello, Alice!
Hello, Bob!
Hello, Charlie!*argsの位置に関するルール
関数定義では、引数の順序にルールがあります。
大まかには次のような順序を守ります。
- 位置引数(必須)
- デフォルト値付き引数
*args- キーワード専用引数
**kwargs
詳細は後述しますが、*args は1つの関数定義につき1回だけであり、かつ、ほかの位置引数より後ろに来る必要があります。
関数呼び出しでのシーケンス展開
リストやタプルを位置引数として渡す
関数呼び出し側で*を使うと、リストやタプルの中身を「ばらして」複数の位置引数として渡すことができます。
def area(width, height):
return width * height
params = [3, 5]
# params をそのまま渡すと 1つの引数として扱われてしまう
# area(params) ではエラーになる
# *params で 3, 5 の2つの引数として展開して渡す
result = area(*params)
print(result)15同じく、タプルや任意の反復可能オブジェクトも展開できます。
def show_three(a, b, c):
print(a, b, c)
values = (1, 2, 3)
show_three(*values) # 1 2 31 2 3複数のシーケンスをまとめて展開
複数の*を使って、それぞれのシーケンスを展開して渡すことも可能です。
def show_numbers(*nums):
print(nums)
a = [1, 2]
b = (3, 4)
show_numbers(*a, *b)(1, 2, 3, 4)ここではaが1, 2、bが3, 4となり、それらがまとめてnumsタプルに入っています。
*を使ったリスト結合・コピーのパターン
リストを結合する
リストリテラルの中で*を使うと、複数のリストを展開して結合する書き方が可能です。
a = [1, 2]
b = [3, 4]
c = [5]
# リストの結合
merged = [*a, *b, *c]
print(merged)[1, 2, 3, 4, 5]従来であればa + b + cと書いていたところを、[*a, *b, *c]と表現できるため、「リストリテラル」内ですべて完結するのが利点です。
シャローコピー(浅いコピー)を作る
*を使ってシンプルにリストの浅いコピーを作ることもできます。
original = [1, 2, 3]
copy_list = [*original]
print(copy_list) # [1, 2, 3]
print(original is copy_list) # False (別オブジェクト)[1, 2, 3]
Falseもちろんlist(original)やoriginal.copy()と同様に浅いコピーであるため、リスト内にリストがあるようなネスト構造では、内側の参照は共有されます。
この点は通常のコピーと同じです。
**の使い方
辞書のアンパッキング(**dict)の基本
**は辞書を「キー=値」という形に展開するために使われます。
辞書リテラルの中で使うと、複数の辞書をマージできます。
defaults = {"color": "blue", "size": "M"}
overrides = {"size": "L"}
settings = {**defaults, **overrides}
print(settings){'color': 'blue', 'size': 'L'}ここではdefaultsとoverridesが展開され、右側の辞書が同じキーを上書きしています。
関数定義での可変長キーワード引数**kwargs
**kwargsの基本
関数定義で**を使うと、任意個数のキーワード引数を辞書にまとめて受け取ることができます。
慣習としてkwargsという名前が使われることが多いです。
def describe_person(name, **info):
"""名前は必須、その他の属性は任意のキーワード引数で受け取る"""
print(f"name: {name}")
for key, value in info.items():
print(f"{key}: {value}")
describe_person("Alice", age=30, city="Tokyo")name: Alice
age: 30
city: Tokyoここで通常の引数(name)以外のキーワード引数がすべてinfoという辞書に入っていることが分かります。
*argsとの組み合わせ順序
*argsと**kwargsを同時に使う場合、順序は次のようになります。
def func(pos1, pos2, *args, key1, key2="default", **kwargs):
...この順序を守らないとシンタックスエラーになるので、ルールとして覚えておくことが大切です。
関数呼び出しでのキーワード引数アンパッキング
辞書をキーワード引数として展開する
関数呼び出し側で**を使うと、辞書の中身をキーワード引数としてばらして渡すことができます。
def connect(host, port, timeout=10):
print(f"host={host}, port={port}, timeout={timeout}")
params = {"host": "localhost", "port": 5432, "timeout": 20}
connect(**params)host=localhost, port=5432, timeout=20辞書paramsのキーが関数の引数名と一致している必要がある点に注意します。
一致しないキーが含まれているとTypeErrorになります。
params = {"host": "localhost", "port": 5432, "user": "admin"}
# connect(**params) # TypeError: connect() got an unexpected keyword argument 'user'明示的な引数と**を組み合わせる
一部は明示的に指定しつつ、残りを辞書から渡すこともよくあります。
def connect(host, port, timeout=10):
print(f"host={host}, port={port}, timeout={timeout}")
params = {"port": 5432, "timeout": 5}
# host は明示的に指定し、残りは辞書で補う
connect("example.com", **params)host=example.com, port=5432, timeout=5複数の辞書を**でマージする方法
シンプルなマージ
先ほども登場しましたが、{**d1, **d2}で複数の辞書をマージできます。
base = {"a": 1, "b": 2}
extra = {"b": 20, "c": 3}
merged = {**base, **extra}
print(merged){'a': 1, 'b': 20, 'c': 3}右側の辞書が優先されるので、後ろに書いたものほど強いと覚えるとよいです。
リスト中でのマージやコピー
**は辞書リテラル中だけでなく、リストなどのコンテナの中で辞書を構成する際にもよく使われます。
common = {"enabled": True, "timeout": 10}
configs = [
{**common, "name": "task1"},
{**common, "name": "task2", "timeout": 20}, # 一部上書き
]
print(configs)[{'enabled': True, 'timeout': 10, 'name': 'task1'}, {'enabled': True, 'timeout': 20, 'name': 'task2'}]このように共通設定 + 差分だけ上書きというパターンは、実務コードで頻繁に使われます。
*と**を組み合わせた実践テクニック
*argsと**kwargsを同時に使う関数定義
すべての引数を受け取る「何でも屋」関数
*argsと**kwargsを同時に指定することで、位置引数もキーワード引数もすべて受け取れる関数が定義できます。
def debug_log(*args, **kwargs):
"""呼び出し時の位置引数とキーワード引数をそのまま表示する"""
print("args:", args)
print("kwargs:", kwargs)
debug_log(1, 2, 3, user="alice", verbose=True)args: (1, 2, 3)
kwargs: {'user': 'alice', 'verbose': True}このパターンは、ラッパー関数やデコレータを書くときに非常に重要です。
通常の引数と合わせた例
def send_message(channel, *messages, **options):
"""最初の引数でチャネルを指定し、複数のメッセージとオプションを受け取る"""
print(f"channel: {channel}")
print("messages:", messages)
print("options:", options)
send_message("email", "Hello", "How are you?", priority="high", retries=3)channel: email
messages: ('Hello', 'How are you?')
options: {'priority': 'high', 'retries': 3}ラッパー関数・デコレータでの引数転送
ラッパー関数で元の関数に引数をそのまま渡す
ラッパー関数やデコレータでは、受け取った引数をそのまま別の関数に渡すことが頻繁にあります。
その際に*argsと**kwargsが必須です。
import time
def timing(func):
"""関数の実行時間を計測するデコレータ"""
def wrapper(*args, **kwargs):
start = time.time()
# 受け取った args/kwargs をそのまま func に転送
result = func(*args, **kwargs)
end = time.time()
print(f"{func.__name__} took {end - start:.4f} seconds")
return result
return wrapper
@timing
def slow_add(a, b, delay=1):
time.sleep(delay)
return a + b
print(slow_add(3, 5, delay=0.5))slow_add took 0.500x seconds
8ここでwrapper が引数を「受け取る」と「渡す」の両方に * / ** を使っていることに注目してください。
def wrapper(*args, **kwargs):で「まとめて受け取る」func(*args, **kwargs)で「ばらして渡す」
このパターンは、Pythonでデコレータを実装する際の基本形です。
型ヒントと*/**の書き方
*argsと**kwargsの型ヒント
Python 3.5以降では、*argsと**kwargsにも型ヒントを付けられます。
基本形は次のようになります。
from typing import Any
def func(*args: int, **kwargs: str) -> None:
# args は int のタプル
# kwargs は 値が str の辞書
print(args, kwargs)ただし、この書き方だと「args は int のタプル」「kwargs は値が str の辞書」という意味になり、キーの型はstr前提(キーワード引数なので妥当)です。
より厳密には、Python 3.11以降やtyping_extensionsを使ってParamSpecなどを利用する方法もありますが、基本的な文脈では上記の書き方で十分なことが多いです。
実務でよく使うパターン
from typing import Any
def log_event(event: str, *details: Any, **metadata: Any) -> None:
print(f"event={event}")
if details:
print("details:", details)
if metadata:
print("metadata:", metadata)ここでは、event は必須の文字列、それ以外は何でも受け付けるという意味合いを型ヒントで表しています。
よくあるエラーとアンパッキングの注意点
要素数が合わないアンパッキング
*を使わないアンパッキング代入では、左辺と右辺の要素数が一致している必要があります。
values = [1, 2, 3]
# a, b = values # ValueError: too many values to unpack (expected 2)これを回避したい場合は、*付き変数で「残り全部」を受け取るようにします。
a, *rest = values # OK関数呼び出しでの引数の重複
*や**を使った関数呼び出しで同じ引数を2回渡してしまうと、TypeErrorになります。
def f(x, y):
print(x, y)
params = {"x": 1, "y": 2}
# f(1, **params) は NG: x が二重指定
# TypeError: f() got multiple values for argument 'x'明示的な引数と**paramsで同じ名前の引数を使わないよう注意が必要です。
**dictのキーが文字列(識別子)でない
**で展開する辞書のキーは、有効な識別子(変数名として使える文字列)でなければなりません。
params = {1: "one"}
# f(**params) # TypeError: keywords must be stringsキーにハイフン"max-value"などが含まれている場合も同様にエラーになります。
引数の順序に関するシンタックスエラー
関数定義での引数の順序を誤ると、シンタックスエラーになります。
# NG 例
# def f(*args, x, y, **kwargs, z): # *args のあとに **kwargs より後ろの引数は置けない
# pass
# OK 例
def f(a, b=0, *args, x, y=1, **kwargs):
pass順序を整理して覚えておきましょう。
まとめ
Pythonのと**は、アンパッキング(ばらす)とパッキング(まとめる)の両方を担う、とても重要な記号です。
は主にシーケンス(リストやタプル)、は辞書に対して働きますが、関数定義側では「余りをまとめる」、呼び出し側では「まとめたものを展開する」という対比を押さえると理解がスムーズです。
記事で紹介した*args/kwargs、リストや辞書のマージ、ラッパー関数やデコレータでの引数転送などは、実務で頻出のテクニックですので、コードを書きながら手を動かして慣れていくことをおすすめします。
