Python3.8から導入されたウォルラス演算子:=は、コードを短く書ける一方で、使い方を誤ると読みづらくなってしまいます。
本記事では、「ウォルラス演算子とは何か」「どのように書くのか」「どんな場面で使うと便利なのか」を、初心者の方でも理解しやすいように基礎から丁寧に解説していきます。
ウォルラス演算子とは?Pythonの代入式を基礎から解説
ウォルラス演算子(:=)の概要と役割
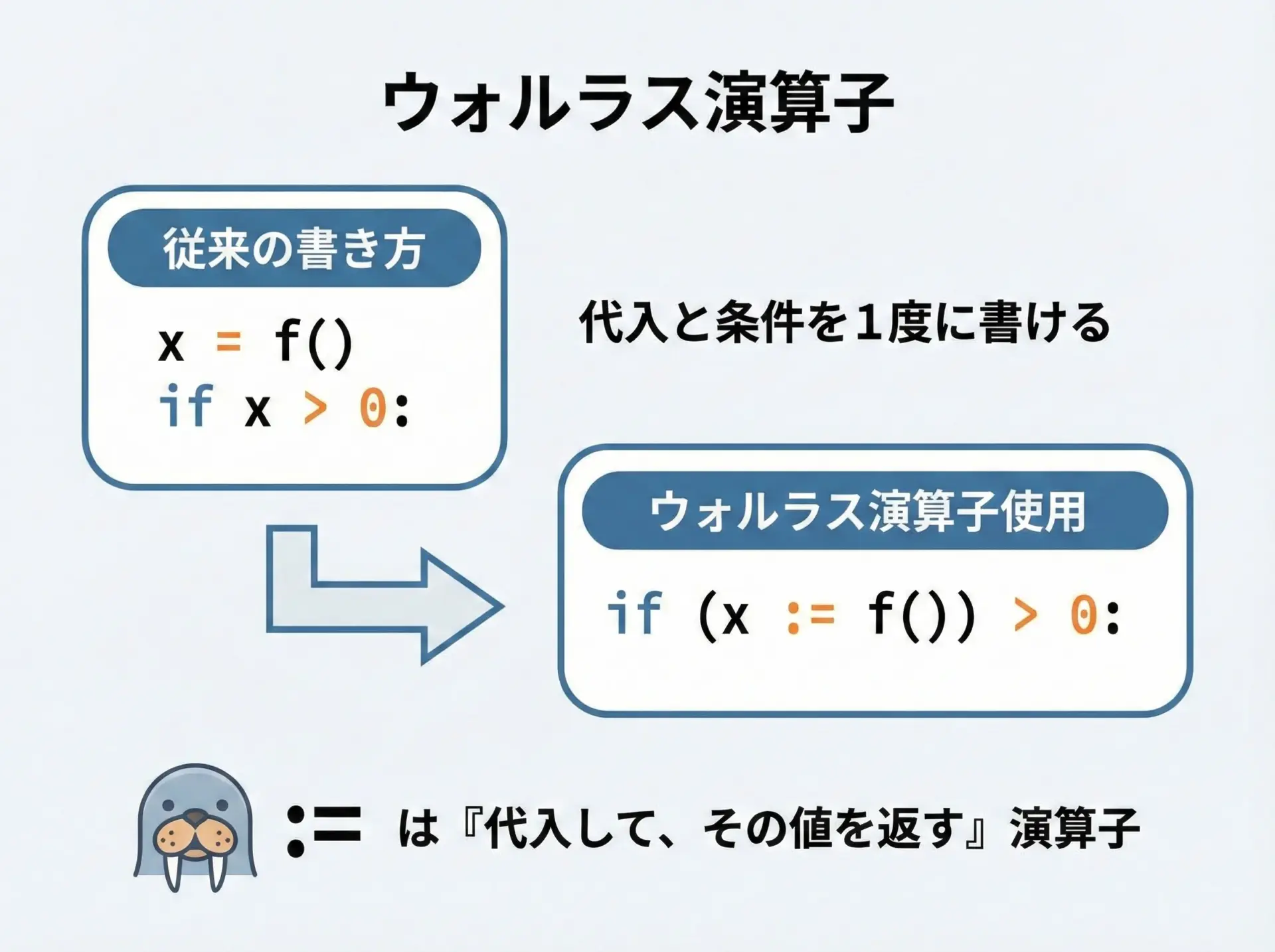
ウォルラス演算子:=は、「代入しながら、その値を式としてその場で使える」特殊な演算子です。
正式名称は代入式(assignment expression)と呼ばれます。
通常、Pythonで値を変数に代入するときは=を使いますが、この=は文(statement)であり、式(expression)としては使えません。
一方でウォルラス演算子:=は「式として値を返す代入」なので、ifやwhileの条件、内包表記の中など、式しか書けない場所で代入と評価を同時に行えるようになります。
ウォルラス演算子と代入演算子(=)の違い

ウォルラス演算子:=と、従来の=の違いを整理すると、次のようになります。
| 項目 | = (代入演算子) | := (ウォルラス演算子) |
|---|---|---|
| 正式名称 | 代入文 | 代入式(assignment expression) |
| 分類 | 文(statement) | 式(expression) |
| 使える場所 | 行の先頭など文として書く場所 | 式が書ける場所(条件式など) |
| 返り値 | 返り値を持たない | 代入した値をそのまま返す |
| 導入バージョン | Python1.0から | Python3.8以降 |
たとえば、次のようなコードはエラーになります。
# これは構文エラー(syntax error)
if x = 10: # if の中で = は使えない
print(x)一方、ウォルラス演算子を使うと、条件式の中で値を代入しつつ、その値を使うことができます。
# これはOK
if (x := 10): # x に 10 を代入し、その 10 を条件として評価
print(x)このように、「値を返すかどうか」「式として書けるかどうか」が決定的な違いになります。
Pythonでウォルラス演算子が導入された背景
ウォルラス演算子は、Python3.8でPEP 572により導入されました。
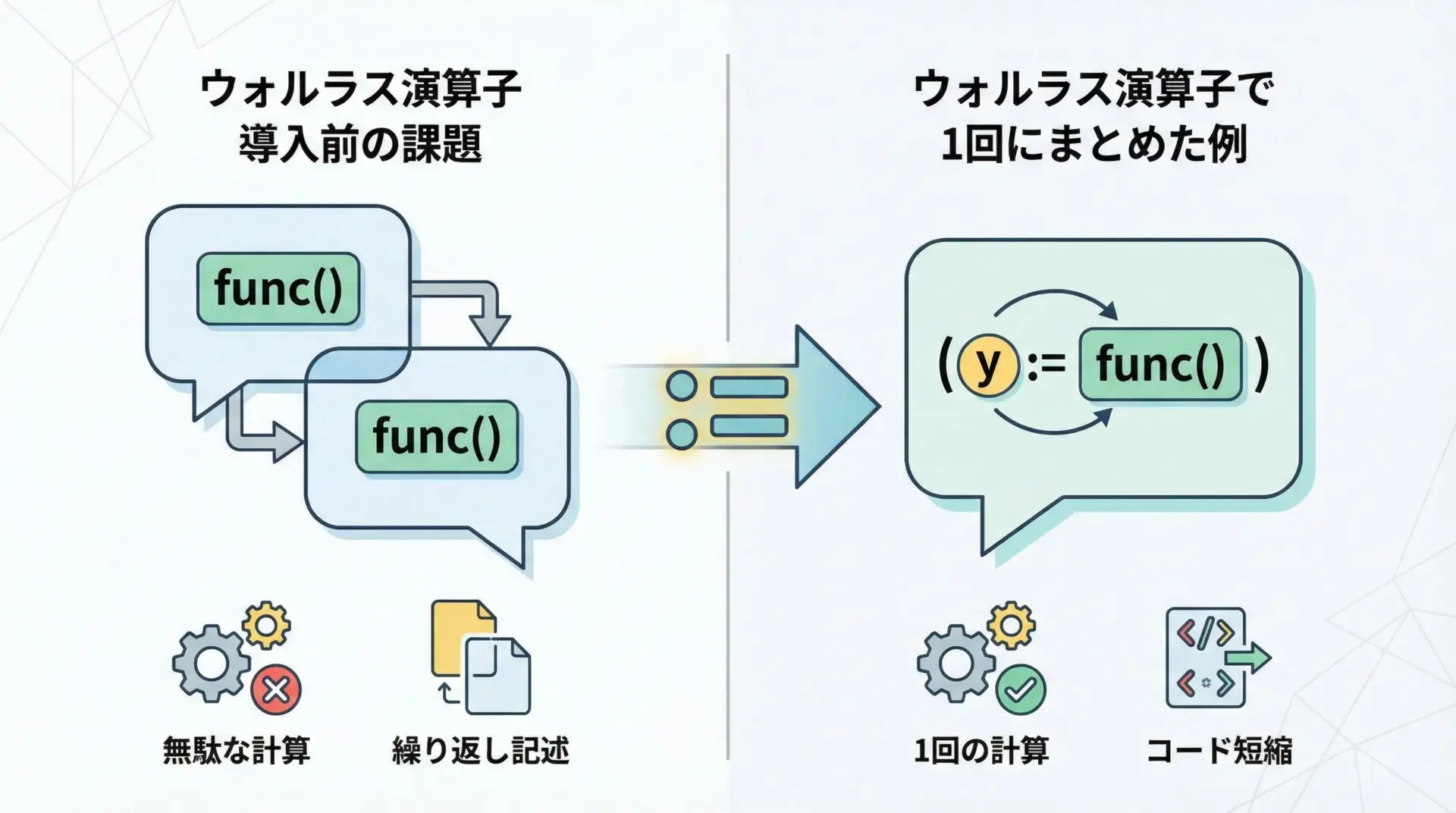
その背景には、「同じ計算や入力を何度も書かないといけない不便さ」がありました。
例えば、ユーザー入力をwhileループで受け取り続ける典型的なコードは、ウォルラス演算子導入前には次のように書かれていました。
line = input(">>> ")
while line != "":
# 何らかの処理
print("入力:", line)
line = input(">>> ")同じinput呼び出しを2回書く必要があり、コードが間延びしてしまいます。
ウォルラス演算子を使えば、次のように書けるようになります。
while (line := input(">>> ")) != "":
print("入力:", line)このように、「重複する計算や入力処理を1回にまとめて、コードを簡潔にしたい」というニーズからウォルラス演算子が生まれました。
ただし、Pythonは「読みやすさ」を非常に重視する言語であるため、導入当初から「使いすぎると分かりにくくなる」という懸念も議論されています。
ウォルラス演算子の基本構文
ウォルラス演算子(代入式)の書き方と文法ルール
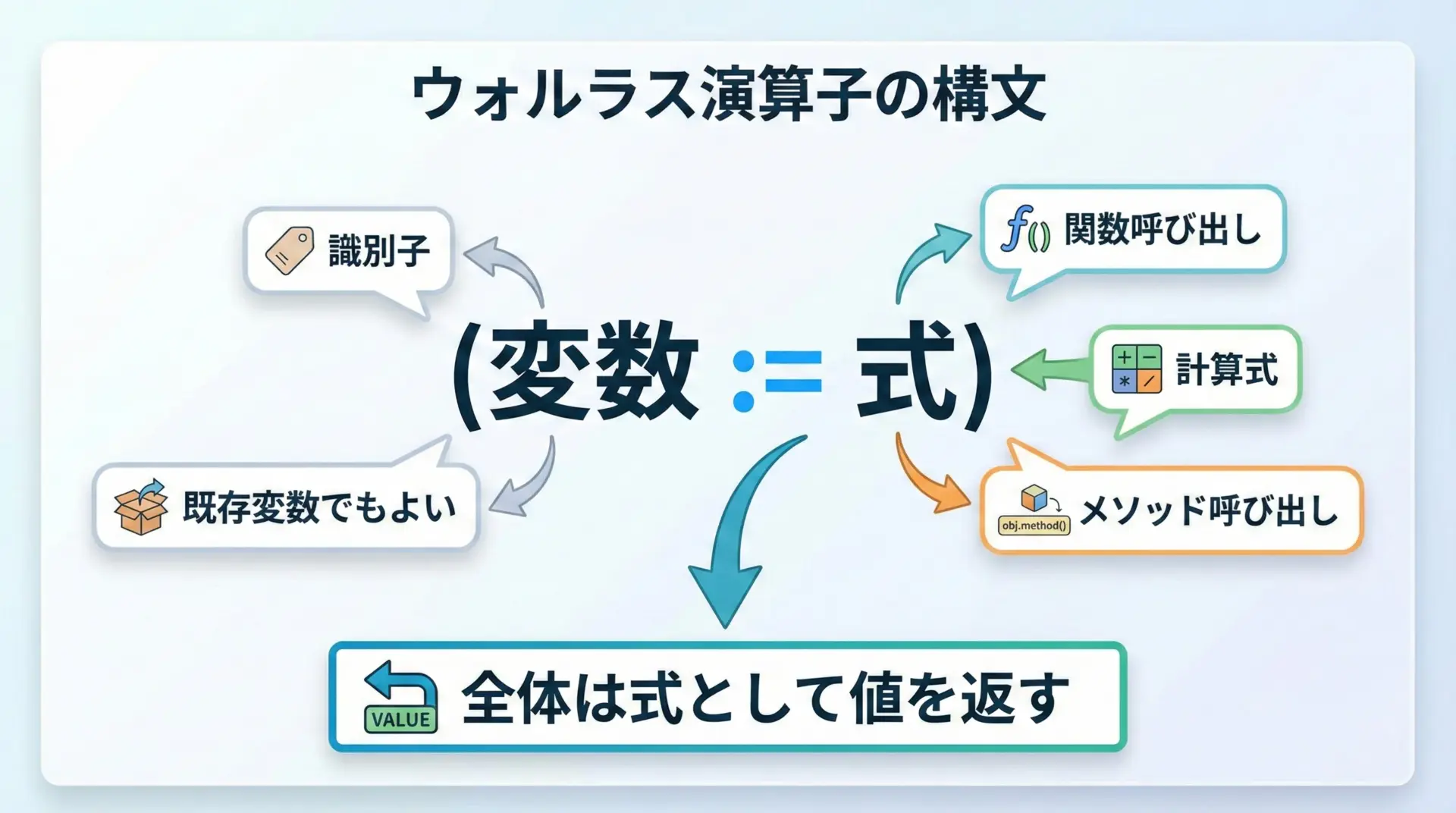
ウォルラス演算子の基本的な書き方は、次のようになります。
変数名 := 式多くの場合、丸括弧で囲んで使うのが実務的な定石です。
(変数名 := 式)Pythonの優先順位ルールの関係で、括弧を省くと意図しない解釈になることがあるため、「基本的には括弧で包む」と覚えておくと安全です。
簡単な例を見てみます。
# x に 1 + 2 の結果を代入し、その結果を y に代入
y = (x := 1 + 2)
print("x:", x)
print("y:", y)x: 3
y: 3この例では、(x := 1 + 2)が「x に 3 を代入し、同時に 3 を返す式」として機能しています。
その返り値をさらにyに代入しているイメージです。
どんな値に使える?変数・式とウォルラス演算子

ウォルラス演算子は、右辺にはほぼ任意の式を置くことができます。
例えば次のような使い方が可能です。
# 関数の戻り値
if (result := some_function()) is not None:
...
# 計算式
if (half := n / 2) > 10:
...
# メソッド呼び出し
if (cleaned := text.strip()):
...
# 組み込み関数
while (line := input(">>> ")).strip() != "exit":
...一方、左辺に書けるのは「単純な変数名」だけです。
次のようなコードはエラーになります。
# NG例: 左辺にインデックス指定や属性は不可
# (lst[i] := 10) # SyntaxError
# (obj.attr := value) # SyntaxErrorウォルラス演算子の左辺は、「通常の代入で左辺に書けるもののうち、単純変数に限定されたもの」と理解するとよいです。
ウォルラス演算子が使える場所と使えない場所
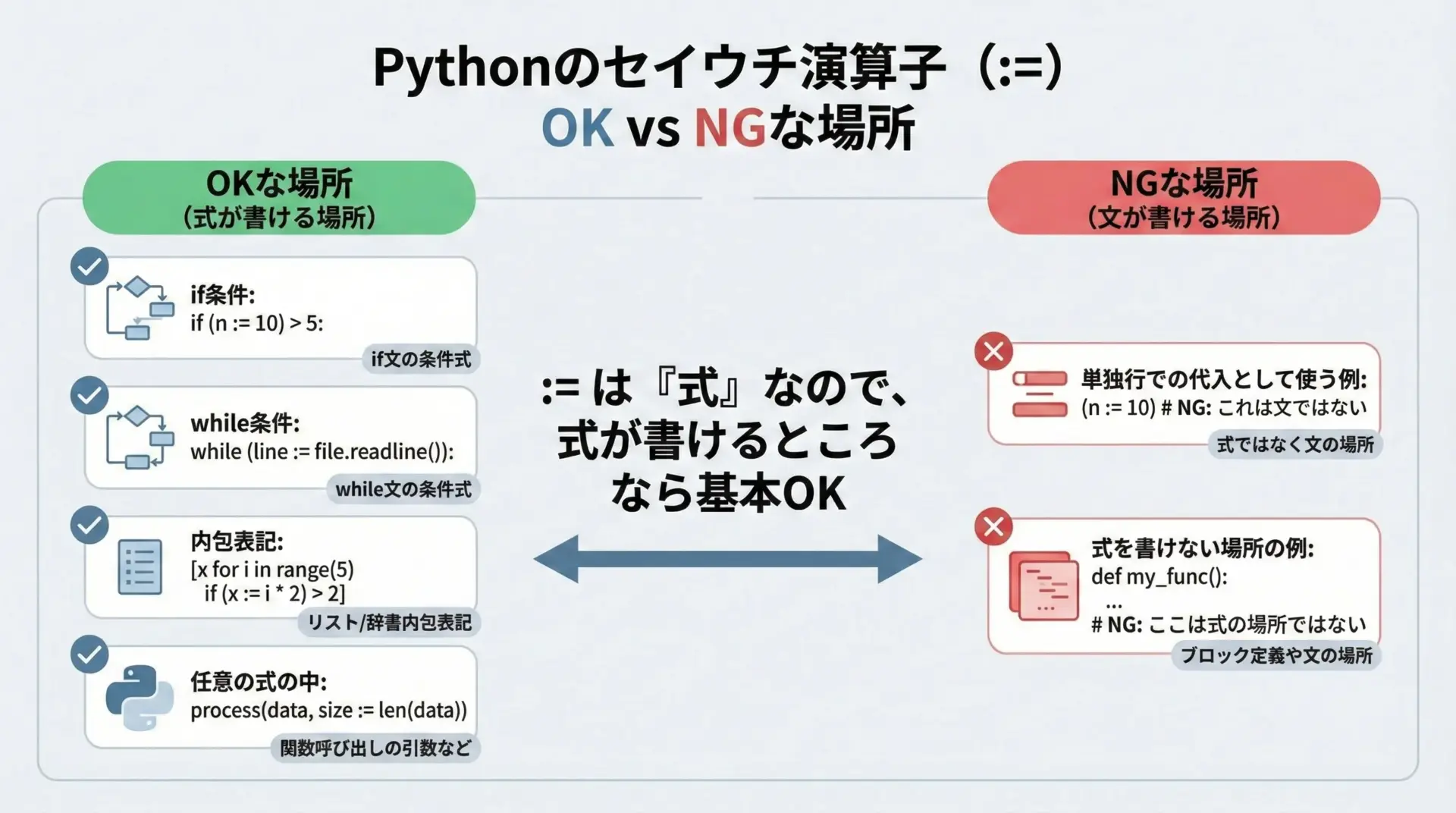
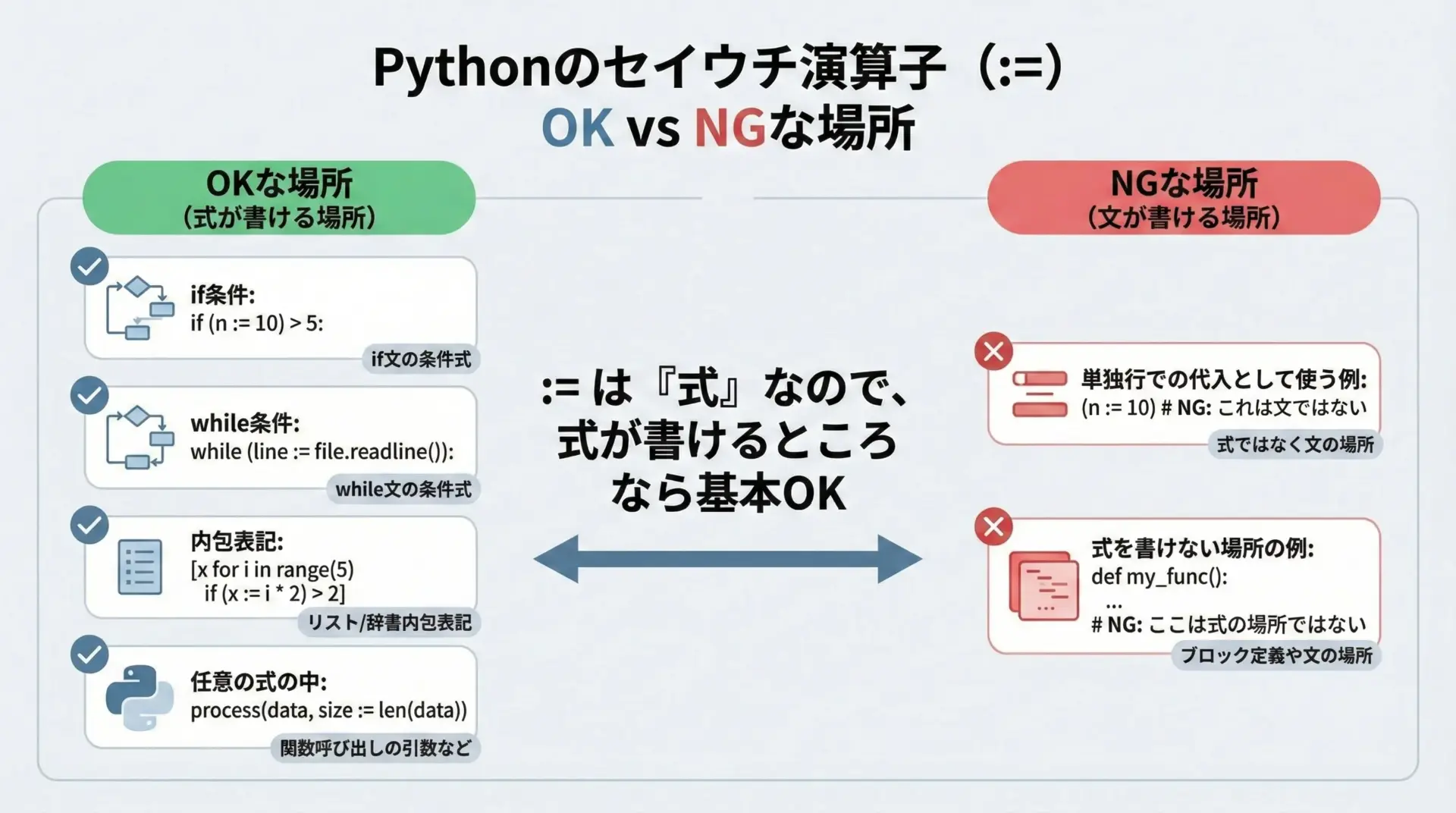
ウォルラス演算子は「式」なので、「式を書ける場所なら基本的に使える」と考えてよいです。
代表的な例を挙げます。
使える場所の例
if文の条件式while文の条件式elifの条件- リスト内包表記やジェネレータ式の中
- 代入式の結果を他の式に埋め込む場合(例:
printの引数)
# if の条件
if (n := len(items)) > 10:
print("要素数が多いです:", n)
# while の条件
while (line := input("> ")).strip() != "exit":
print("入力:", line)
# 内包表記
squares = [y for x in data if (y := x * x) > 10]使わない(意味がない・違和感がある)場所
ウォルラス演算子は式であるため、「代入文として単独で使う」ことも構文としては可能ですが、実務上は避けるべきです。
# 構文としてはOKだが、普通は = を使うべき
(x := 10) # こう書くより
x = 10 # こう書く方が明らかに読みやすいまた、Pythonの構文ルール上、lambda式の中など、一部ではウォルラス演算子は使えません。
これは、「無理に使うと読みづらくなる場所」をあえて制限しているとも言えます。
ウォルラス演算子の具体例とよくある使い方
while文での入力ループを簡潔に書く例
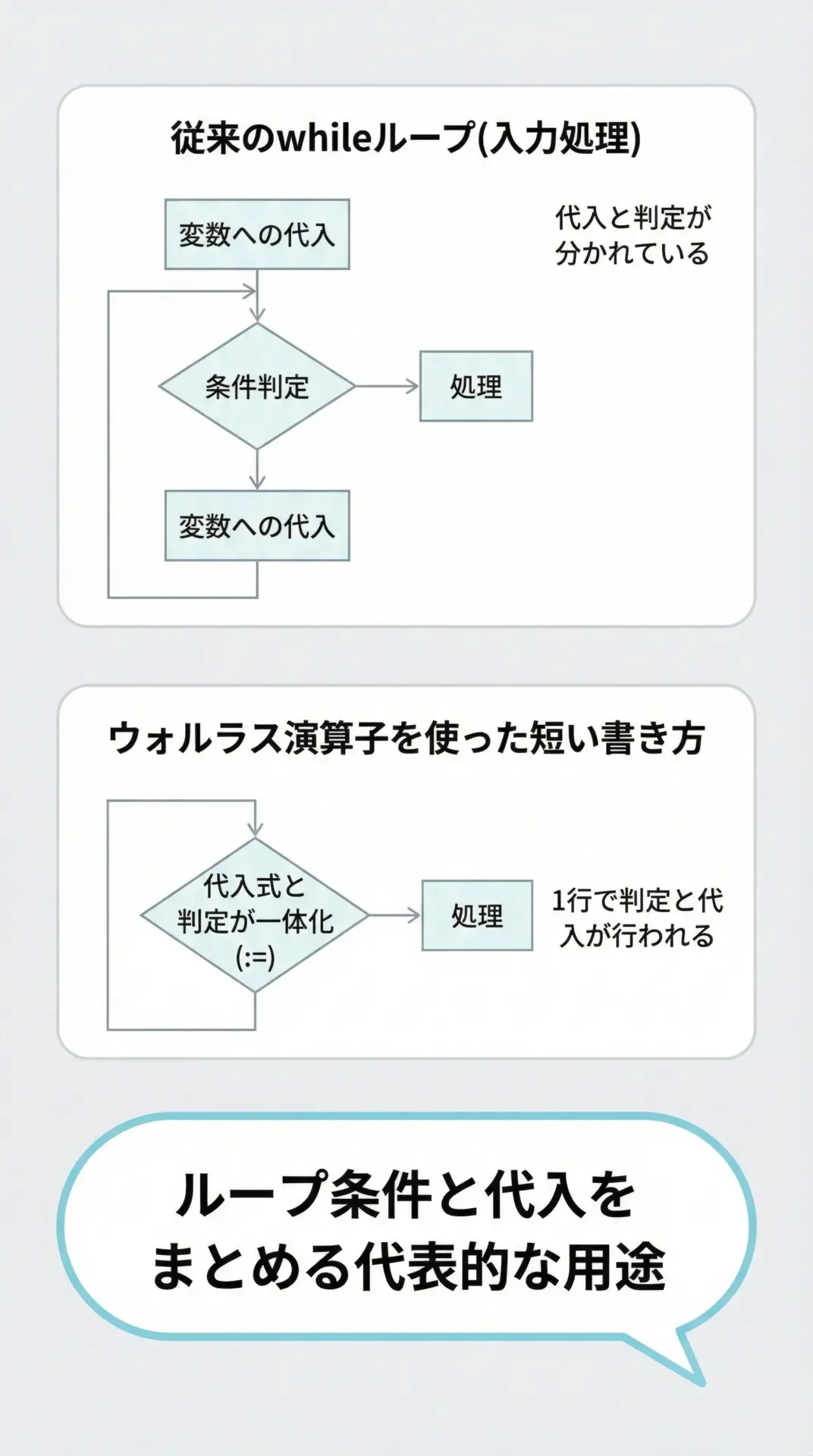
ユーザーから空行が入力されるまで繰り返し処理を行うケースを例に、ウォルラス演算子の威力を見てみます。
まずはウォルラス演算子を使わない場合です。
# ウォルラス演算子を使わない while ループ
while True:
line = input("入力(空行で終了): ")
if line == "":
break
print("入力された文字列:", line)入力(空行で終了): hello
入力された文字列: hello
入力(空行で終了): world
入力された文字列: world
入力(空行で終了):これをウォルラス演算子で書き直すと、次のようになります。
# ウォルラス演算子を使った while ループ
while (line := input("入力(空行で終了): ")) != "":
print("入力された文字列:", line)入力(空行で終了): hello
入力された文字列: hello
入力(空行で終了): world
入力された文字列: world
入力(空行で終了):1回のinput呼び出しで、入力取得と終了条件の判定を同時に行えるので、ループ全体が非常にすっきりします。
if文での条件判定と代入を同時に行う例

ファイルからデータを読み込み、そのサイズに応じて処理を変えるようなケースでは、ウォルラス演算子が自然に使えます。
# if の条件と代入を同時に行う例
data = b"1234567890" * 150 # 仮のデータ
# data の長さを測り、1KBを超えているかを判定
if (size := len(data)) > 1024:
print("データサイズが大きいです:", size, "bytes")
else:
print("データサイズは許容範囲です:", size, "bytes")データサイズが大きいです: 1500 bytesサイズ計算len(data)を1回だけ書けばよいので、計算の重複もなくなり、コードも簡潔になります。
後続のprintでsizeを再利用できる点もメリットです。
リスト内包表記・ジェネレータ式でのウォルラス演算子の例
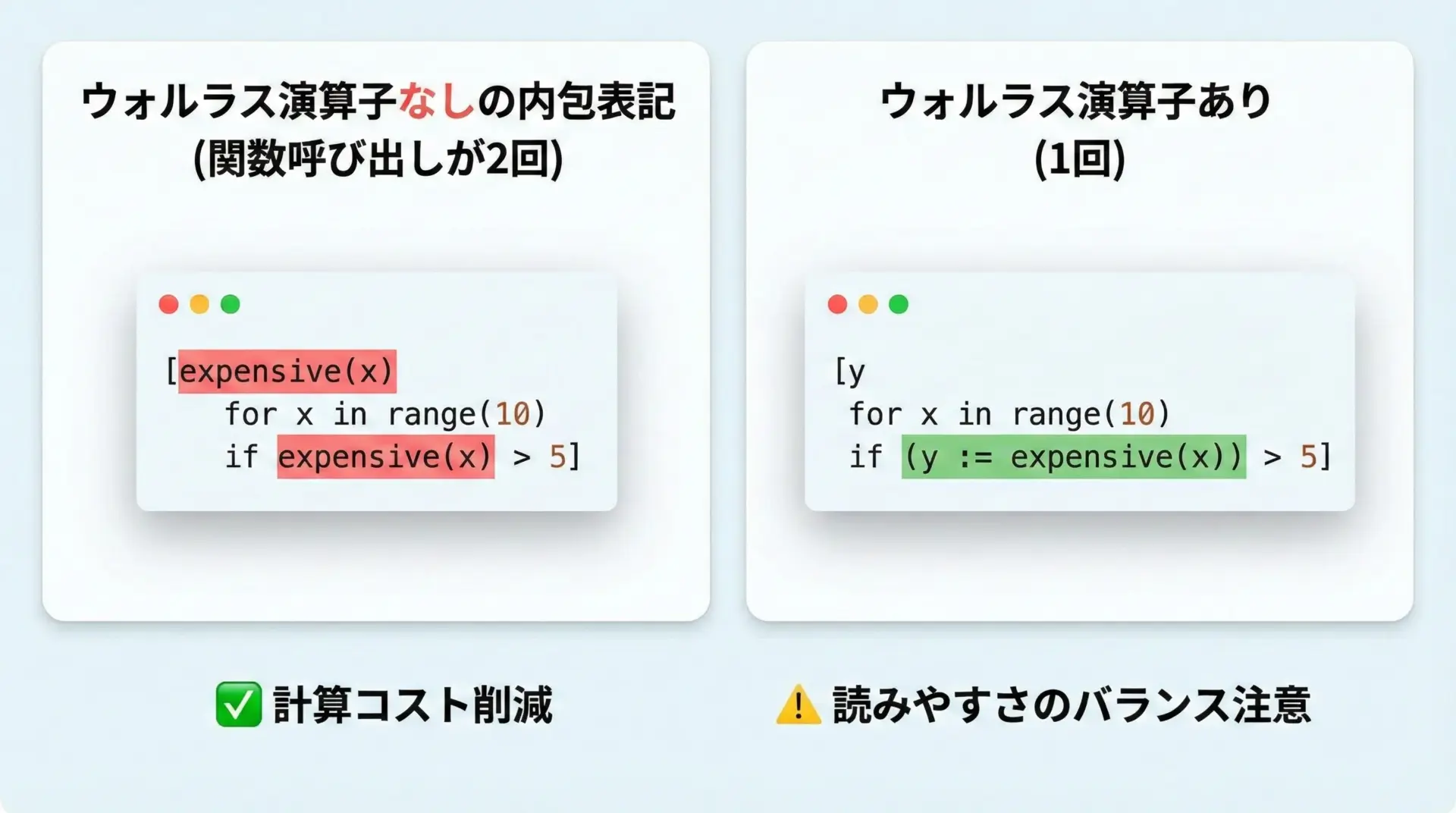
内包表記の中で、要素ごとに重い計算を行いつつ、その結果を使ってフィルタするような場面でもウォルラス演算子は便利です。
def expensive(x: int) -> int:
"""重い計算をする関数(ここでは見かけだけ)"""
print(f"expensive({x}) を計算中...")
return x * x
# ウォルラス演算子なしの書き方
results1 = [expensive(x) for x in range(5) if expensive(x) > 5]
print("results1:", results1)expensive(0) を計算中...
expensive(0) を計算中...
expensive(1) を計算中...
expensive(1) を計算中...
expensive(2) を計算中...
expensive(2) を計算中...
expensive(3) を計算中...
expensive(3) を計算中...
expensive(4) を計算中...
expensive(4) を計算中...
results1: [9, 16]このように、expensive(x)が2回ずつ呼び出されてしまいます。
ウォルラス演算子を使うと、次のように1回にまとめられます。
def expensive(x: int) -> int:
"""重い計算をする関数(ここでは見かけだけ)"""
print(f"expensive({x}) を計算中...")
return x * x
# ウォルラス演算子ありの書き方
results2 = [y for x in range(5) if (y := expensive(x)) > 5]
print("results2:", results2)expensive(0) を計算中...
expensive(1) を計算中...
expensive(2) を計算中...
expensive(3) を計算中...
expensive(4) を計算中...
results2: [9, 16]各xに対してexpensive(x)が1回だけ呼ばれるようになり、無駄な計算が減ります。
ただし、内包表記の中でウォルラス演算子を多用すると、一目では何をしているのか分かりにくくなりがちです。
複雑なロジックを内包表記の1行に詰め込みすぎないように注意してください。
正規表現(re)のマッチ結果を再利用する例
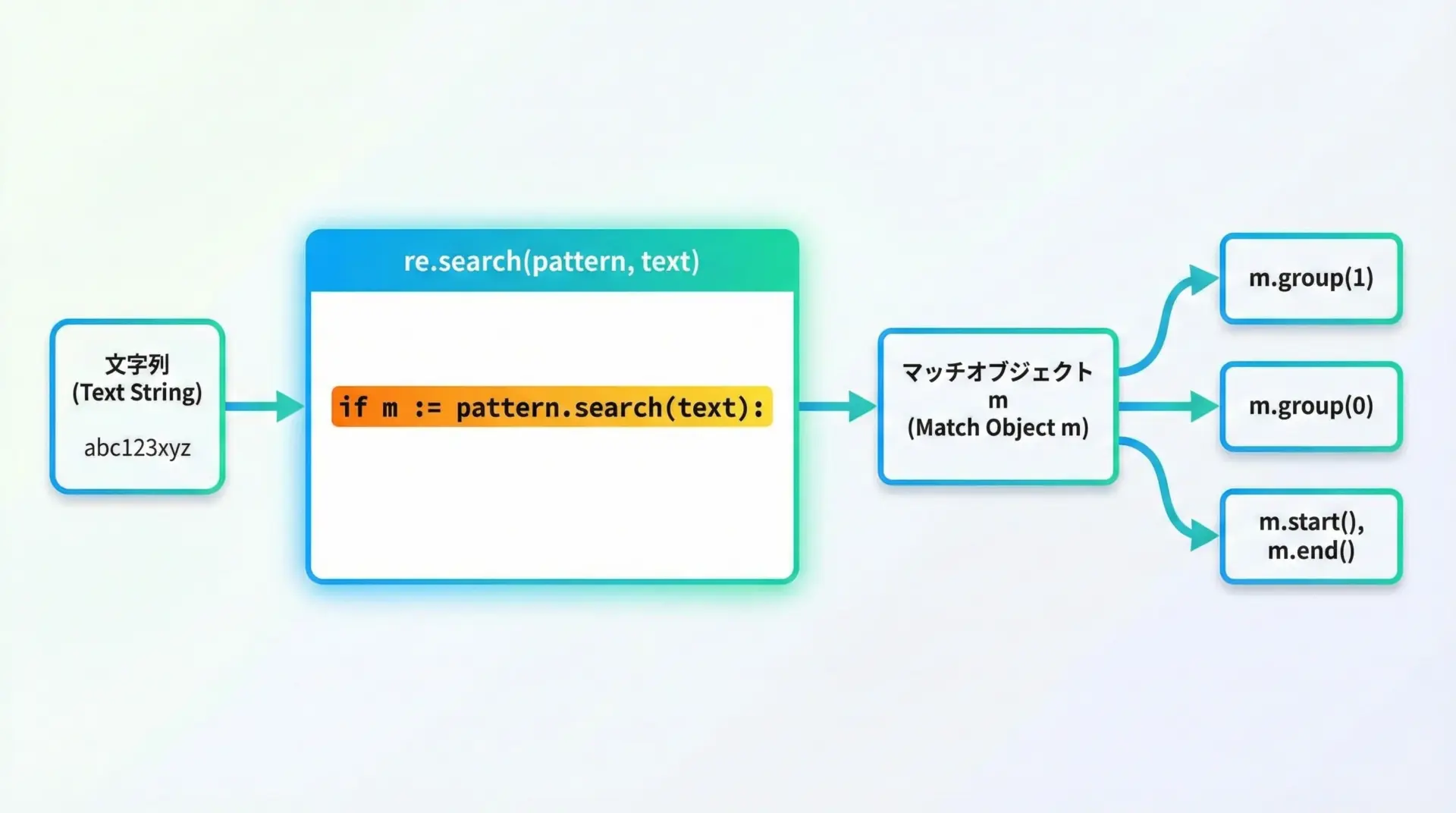
Pythonのreモジュールで正規表現マッチングを行う場合、ウォルラス演算子は非常に相性がよい使い方の1つです。
import re
pattern = re.compile(r"Name:\s*(\w+)")
text_list = [
"Name: Alice",
"No name here",
"Name: Bob",
]
for text in text_list:
# 正規表現のマッチ結果を m に代入しつつ、マッチしたかどうかを判定
if m := pattern.search(text):
# m は None ではなく、マッチオブジェクト
print("見つかった名前:", m.group(1))
else:
print("名前は見つかりませんでした:", text)見つかった名前: Alice
名前は見つかりませんでした: No name here
見つかった名前: Bobpattern.search(text)を1回だけ呼び出し、その結果をifの条件とブロック内処理の両方で使えるため、記述がかなりすっきりします。
同様のパターンはre.matchやre.fullmatchなどでも使えます。
計算結果を変数に保持して再利用する例
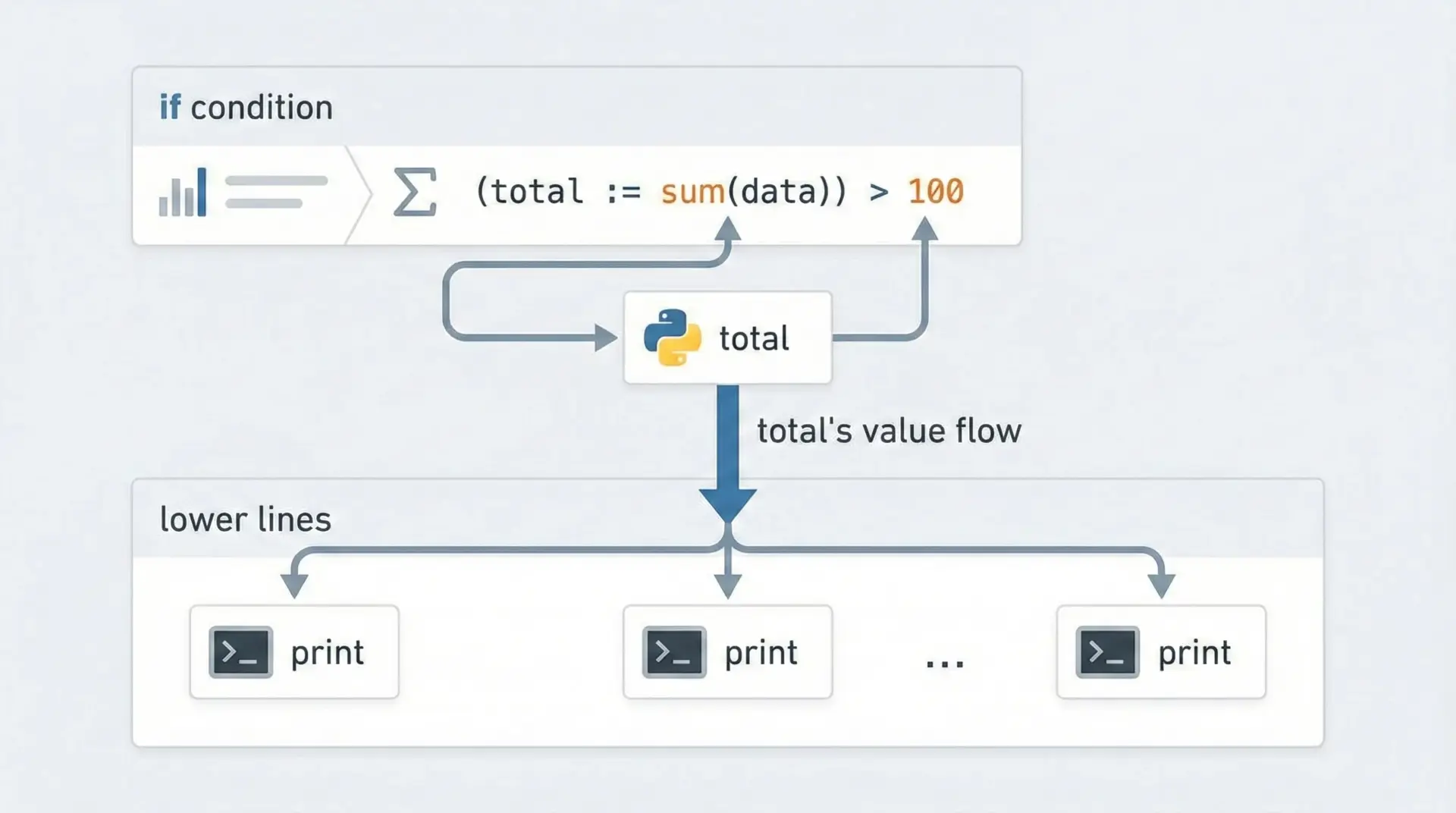
ある配列の合計を計算し、その大きさに応じてメッセージを変えながら、いくつかの出力で同じ合計値を使いたい場合を考えます。
data = [10, 20, 30, 40, 50]
# ウォルラス演算子を使わない場合
total = sum(data)
if total > 100:
print("合計値は 100 を超えています:", total)
else:
print("合計値は 100 以下です:", total)
print("最終的な合計値:", total)これでも十分読みやすいですが、ifの条件と同時に書きたい場合はウォルラス演算子を使えます。
data = [10, 20, 30, 40, 50]
# ウォルラス演算子を使う場合
if (total := sum(data)) > 100:
print("合計値は 100 を超えています:", total)
else:
print("合計値は 100 以下です:", total)
print("最終的な合計値:", total)合計値は 100 以下です: 150
最終的な合計値: 150このように、「条件判定に使う値を、そのまま後続処理でも使いたい」場面では、ウォルラス演算子が自然に馴染みます。
ウォルラス演算子を使うときの注意点とベストプラクティス
ウォルラス演算子のメリットと読みやすさのバランス
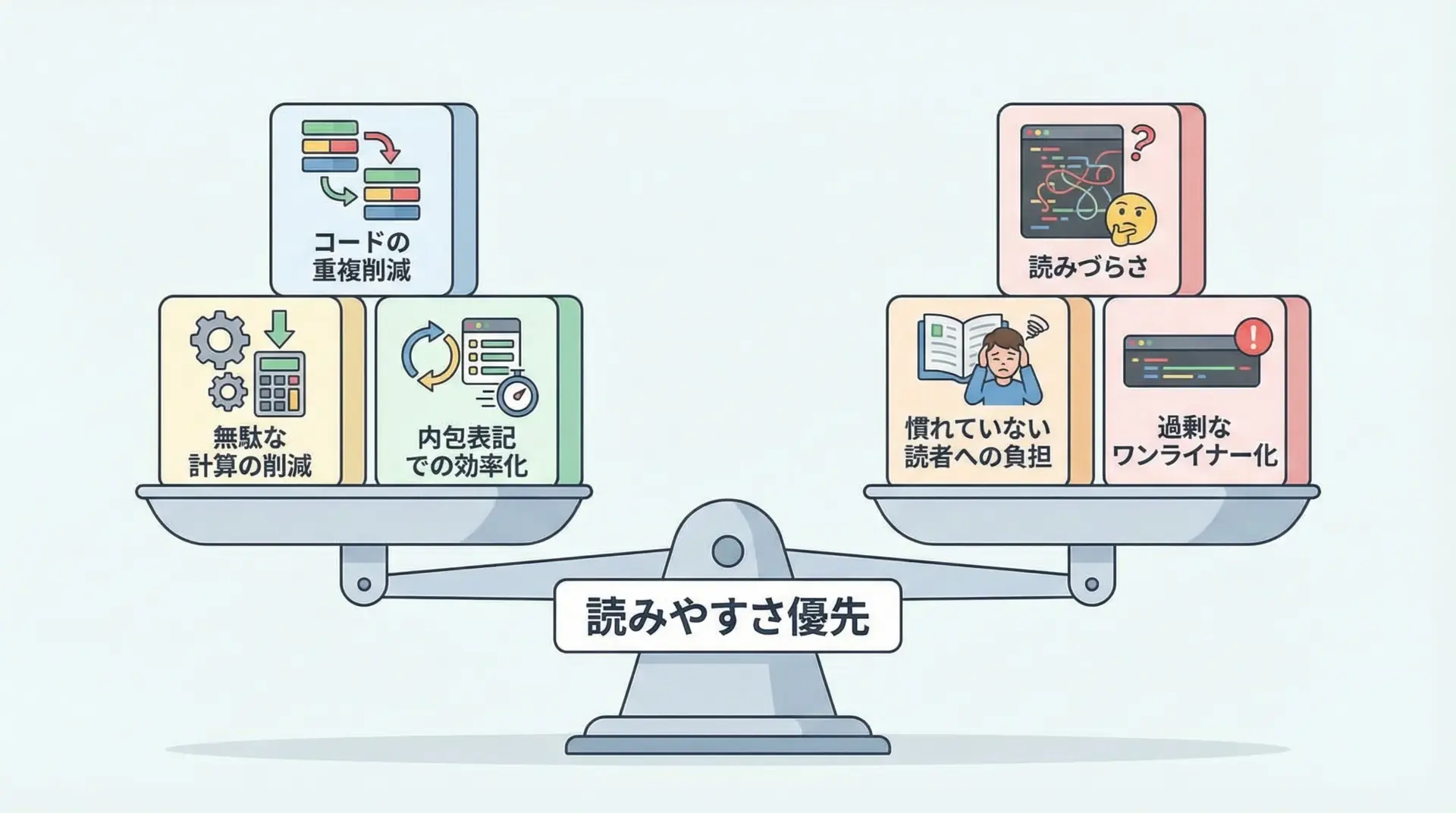
ウォルラス演算子の主なメリットは、次のようにまとめられます。
- 同じ式を何度も書かずに済むため、コードが短くなり、間違いも減る
- 重い処理(ファイル読み込みや正規表現、外部APIなど)を1回だけ実行できる
- if/while の条件と、その結果の利用を1か所にまとめられる
一方で、デメリットもはっきりしています。
- Python初心者には見慣れない記法で、読みづらく感じやすい
- 1行に多くの意味を詰め込みすぎると、バグの原因や理解の妨げになる
そのため、「行数が1行減るから」「かっこよく見えるから」という理由だけで使わないことが重要です。
あくまで、「重複した計算を減らしつつ、コードの意図がより明確になる場合」に限定して使うのがおすすめです。
初心者がやりがちな書き方のミスとエラー例
ウォルラス演算子を使い始めたばかりのときに起こりがちなミスをいくつか挙げます。
1.= と := を書き間違える
# やりがちな誤り: if の中で = を使ってしまう
value = 10
# if value = 10: # SyntaxError: invalid syntax
# print("10です")ifやwhileの中で=を使うと構文エラーになります。
「条件と同時に代入したい場合だけ :=、単純な代入は =」と整理しておきましょう。
2. 括弧を付け忘れて意図しない挙動になる
n = 5
# 意図:
# (count := n + 1) > 5 を評価したい
# しかし括弧を忘れると、別の意味に読み取られる可能性がある
# if count := n + 1 > 5: # 推奨されない書き方
# ...このような書き方は、演算子の優先順位の理解が必要になり、非常に読みにくくなります。
ウォルラス演算子を使うときは、常に丸括弧で囲むと決めてしまうと安全です。
if (count := n + 1) > 5:
print("count は 5 より大きいです:", count)3. 左辺にインデックスや属性を書いてしまう
lst = [1, 2, 3]
# (lst[0] := 10) # SyntaxError: cannot use assignment expressions with subscript
# obj.attr のような属性も同様にNG
# (obj.attr := 10) # SyntaxErrorウォルラス演算子の左側に書けるのは「単純な変数名だけ」です。
インデックス代入や属性代入を行いたい場合は、通常の=を使う必要があります。
既存コードにウォルラス演算子を導入するときのポイント
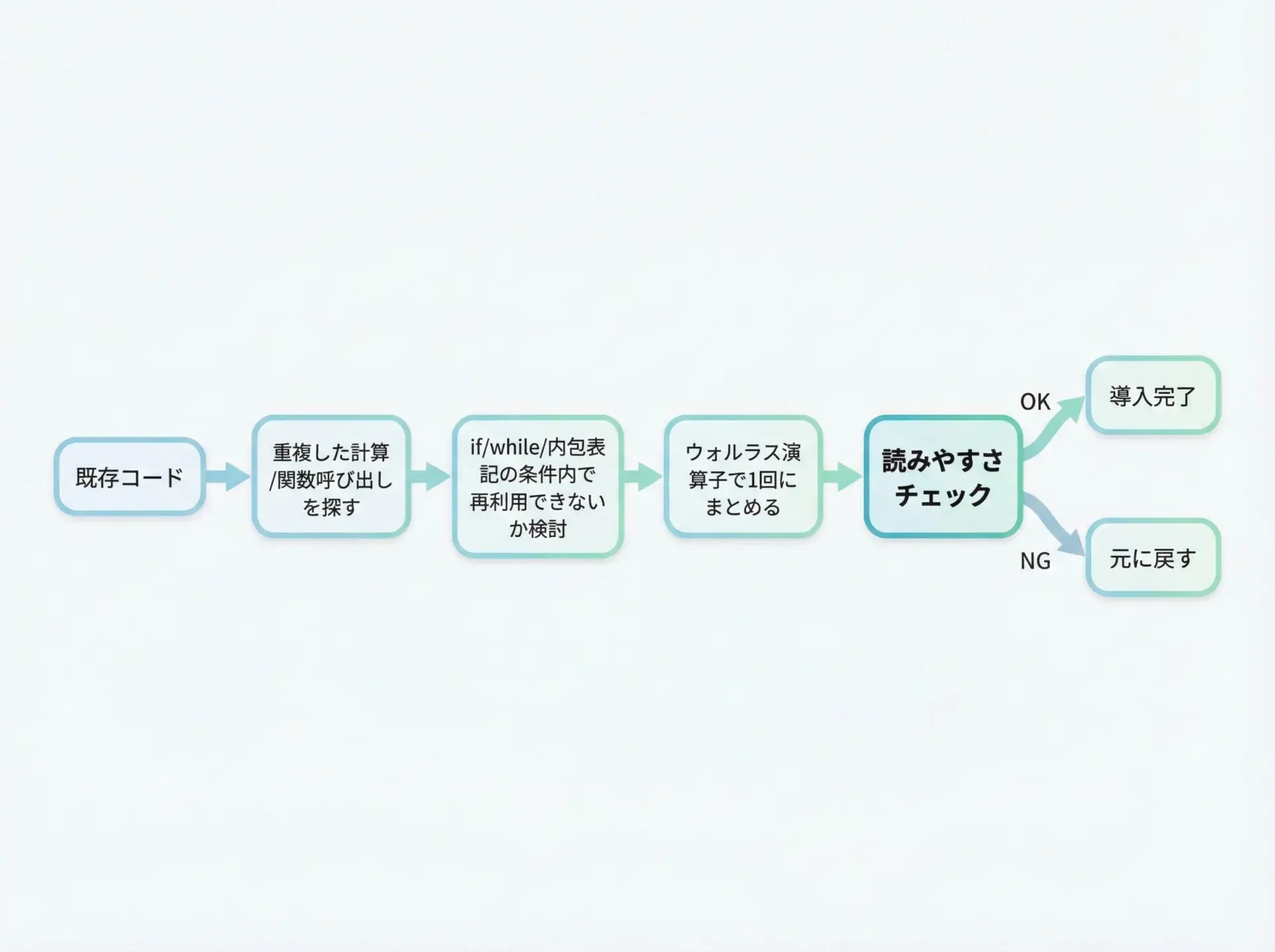
既存のコードベースにウォルラス演算子を取り入れるときには、次のようなポイントを意識すると安全です。
1. まずは「重複している計算・呼び出し」を探す
同じlen(x)やre.search(...)、input()といった関数呼び出しが、すぐ近くの行で何度も繰り返し現れる場所は、ウォルラス演算子の候補です。
2. if/while の条件と結果利用をまとめられるか検討する
条件式の中でその計算を行い、そのまま評価結果や戻り値を使っている場合は、ウォルラス演算子によって「1回の呼び出しで条件判定と結果利用の両方を行える」可能性があります。
# 変更前
m = pattern.search(text)
if m:
use(m)
# 変更後(候補)
if m := pattern.search(text):
use(m)3. ウォルラス演算子に置き換えたあと、「読む側の気持ち」で見直す
変換後のコードを、Pythonに詳しくないチームメンバーが見たときに理解しやすいかを考えてみることが重要です。
- 行数が減っても、かえって理解しづらくなっていないか
- ウォルラス演算子を知らない人にとって、コードの意図が追いにくくなっていないか
もし少しでも違和感がある場合は、無理にウォルラス演算子を使わず、通常の代入に戻すほうが健全です。
4. チームのコーディング規約に従う
プロジェクトによってはウォルラス演算子の使用を禁止・制限している場合もあります。
チームのスタイルガイドやコーディング規約を確認し、それに従って導入範囲を決めることも大切です。
まとめ
ウォルラス演算子:=は、「代入しながらその値を式として利用できる」Python3.8以降の新しい機能です。
特に、whileループでの入力処理、if文での条件と結果の再利用、内包表記や正規表現のマッチ結果の再利用などで、同じ計算を何度も書かずに済む利点があります。
一方で、読みづらさや誤用のリスクもあるため、「コードが短くなるだけでなく、意図も明確になる場合」に限定して使うのがポイントです。
この記事で紹介したパターンを参考に、まずはシンプルな場面からウォルラス演算子を試してみてください。
