
Pythonでのテキストファイル読み込みは、もっとも頻繁に使われる基本テクニックの1つです。
本記事では「一行ずつ読む」「全部まとめて読む」「リスト化する」といった実務でよく使うパターンを、サンプルコード付きで丁寧に解説します。
文字化け対策や大きなファイルを扱う際の注意点も押さえ、今日からすぐに使える読み込みコードを身につけましょう。
Pythonでテキストファイルを読み込む基本
まずは、Pythonでテキストファイルを扱ううえで必須となるopen関数とwith構文、そして文字コード(encoding)の考え方から整理していきます。
Pythonでテキストファイルを開く(open関数の基本)
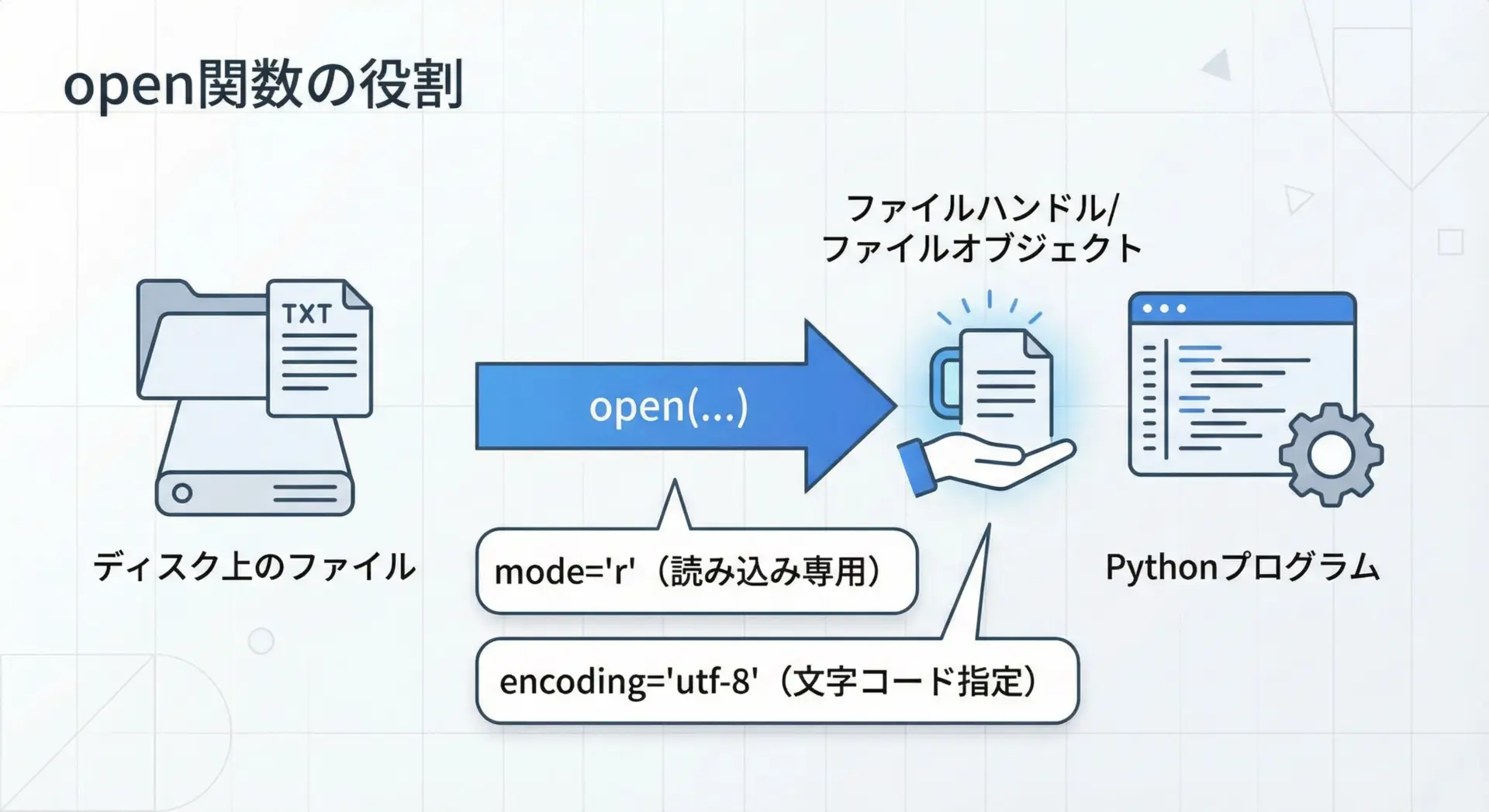
Pythonでファイルを読み込むときは、まずopen関数でファイルを開きます。
open関数は「ファイルへの入り口」を作るもので、この戻り値である「ファイルオブジェクト」を通じて読み書きを行います。
open関数の基本的な使い方
# sample_open_basic.py
# ファイルパスは自分の環境にあるテキストファイルに置き換えてください
file_path = "example.txt"
# ファイルを開く(読み込みモード)
f = open(file_path, mode="r", encoding="utf-8")
# ファイル全体を読み込む
content = f.read()
# 読み込んだ内容を表示
print(content)
# ファイルを閉じる(とても重要)
f.close()上記のコードでは、以下の3点が基本的なポイントです。
1つ目はopen(file_path, mode="r", encoding="utf-8")でファイルを開き、戻り値fが「ファイルオブジェクト」だということです。
2つ目はf.read()のように、このファイルオブジェクトのメソッドを使って中身を読み込むことです。
3つ目は必ずclose()でファイルを閉じる必要があるという点です。
modeパラメータの代表的な種類
テキストファイルを読む場合にまず覚えておくべきmodeは次の通りです。
| mode | 意味 | 主な用途 |
|---|---|---|
| r | 読み込み専用(read) | テキストを読むときの基本 |
| w | 書き込み専用(write・上書き) | 新規作成や上書き保存 |
| a | 追記(append) | 既存ファイルの末尾に追加 |
| r+ | 読み書き両用 | 既存ファイルを読みつつ更新 |
テキスト読み込みであればmode="r"がほとんどです。
バイナリファイルを扱う場合には"rb"のようにbをつけますが、今回はテキストファイルに絞って説明します。
with構文でファイルを安全に閉じる方法

ファイル操作では「開いたら必ず閉じる」ことが重要です。
closeし忘れがあると、OSのリソースを無駄に消費したり、他のプログラムからファイルを編集できなくなることがあります。
Pythonではwith構文を使うことで、処理が終わったタイミングで自動的にファイルを閉じることができます。
with構文でのサンプルコード
# sample_with_open.py
file_path = "example.txt"
# with構文でファイルを開く
# withブロックを抜けたときに、自動的に close() が呼ばれます
with open(file_path, mode="r", encoding="utf-8") as f:
# ファイルの内容を読み込む
content = f.read()
print(content)
# ここに来た時点で f.close() 済みなので、安全にファイルを扱えますPythonではファイルを開くときは基本的にwith構文を使うと覚えておくと良いです。
複雑なエラー処理を書かなくても、例外が起こった場合でも確実にファイルが閉じられます。
encoding指定と文字化け対策(UTF-8など)
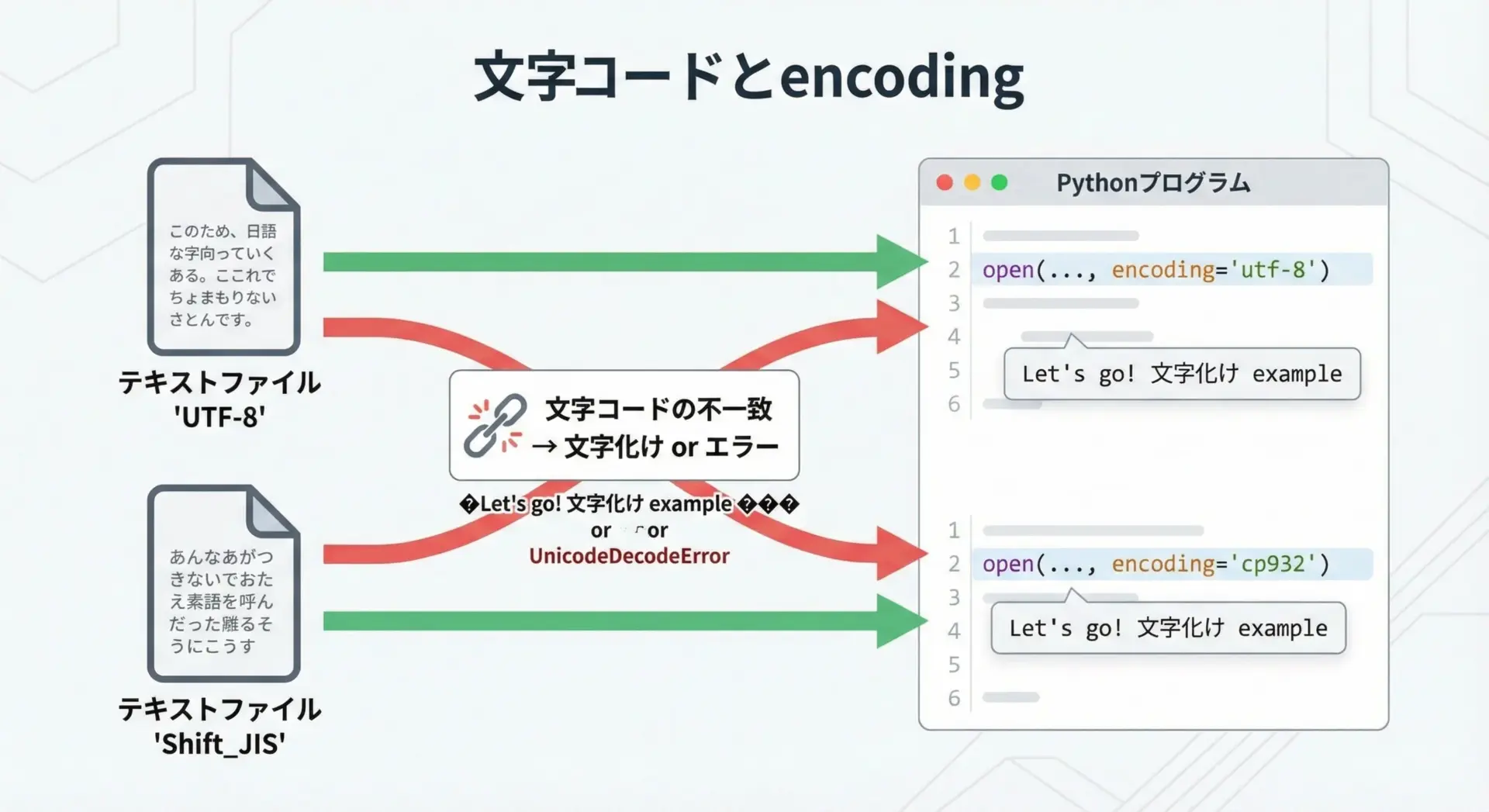
日本語を含むテキストファイルを扱うときに、もっともトラブルになりやすいのが文字コード(encoding)の違いです。
Pythonで開くときに、実際のファイルの文字コードとencodingの指定が合っていないと、文字化けやエラーが発生します。
よく使われる文字コード
代表的な文字コードと用途を簡単に整理します。
| 文字コード | Pythonでの指定例 | 主な用途・特徴 |
|---|---|---|
| UTF-8 | encoding=”utf-8″ | 現在の標準。Web・Linux・Macなどほぼすべてで主流 |
| Shift_JIS | encoding=”shift_jis” | 古いWindowsアプリや一部の日本語ファイルで使用 |
| CP932(Windows) | encoding=”cp932″ | Windows標準の日本語コード(実質Shift_JIS拡張) |
新しく自分で作るテキストファイルや、他の人と共有する前提のファイルであればUTF-8で統一するのがもっとも安全です。
Windowsメモ帳などで保存する際も、エンコードをUTF-8にしておくとPythonから扱いやすくなります。
encoding指定付きのサンプル
# sample_encoding.py
file_path = "example_utf8.txt"
# UTF-8で保存されたテキストファイルを読み込む場合
with open(file_path, mode="r", encoding="utf-8") as f:
text = f.read()
print(text)もし、Windowsの古いアプリなどが出力したShift_JIS系のファイルを読む場合は、次のようにします。
# sample_encoding_sjis.py
file_path = "example_sjis.txt"
# Shift_JIS系(Windows標準)で保存されたファイルを読み込む
with open(file_path, mode="r", encoding="cp932") as f:
text = f.read()
print(text)「どの文字コードで保存されているか分からない」場合は、テキストエディタ(Visual Studio Code、サクラエディタなど)で開き、ステータスバーなどに表示される文字コードを確認してから、同じencodingをPython側でも指定するのが確実です。
一行ずつテキストファイルを読み込む方法
テキストファイルを「一行ずつ」読み込む方法は、ログファイルや大きなデータを扱うときに非常に便利です。
この章では、for文による読み込みとreadline()メソッドの使い方を整理し、それぞれの違いやメリットを説明します。
for文で一行ずつ読み込む(readlineを使わない基本パターン)
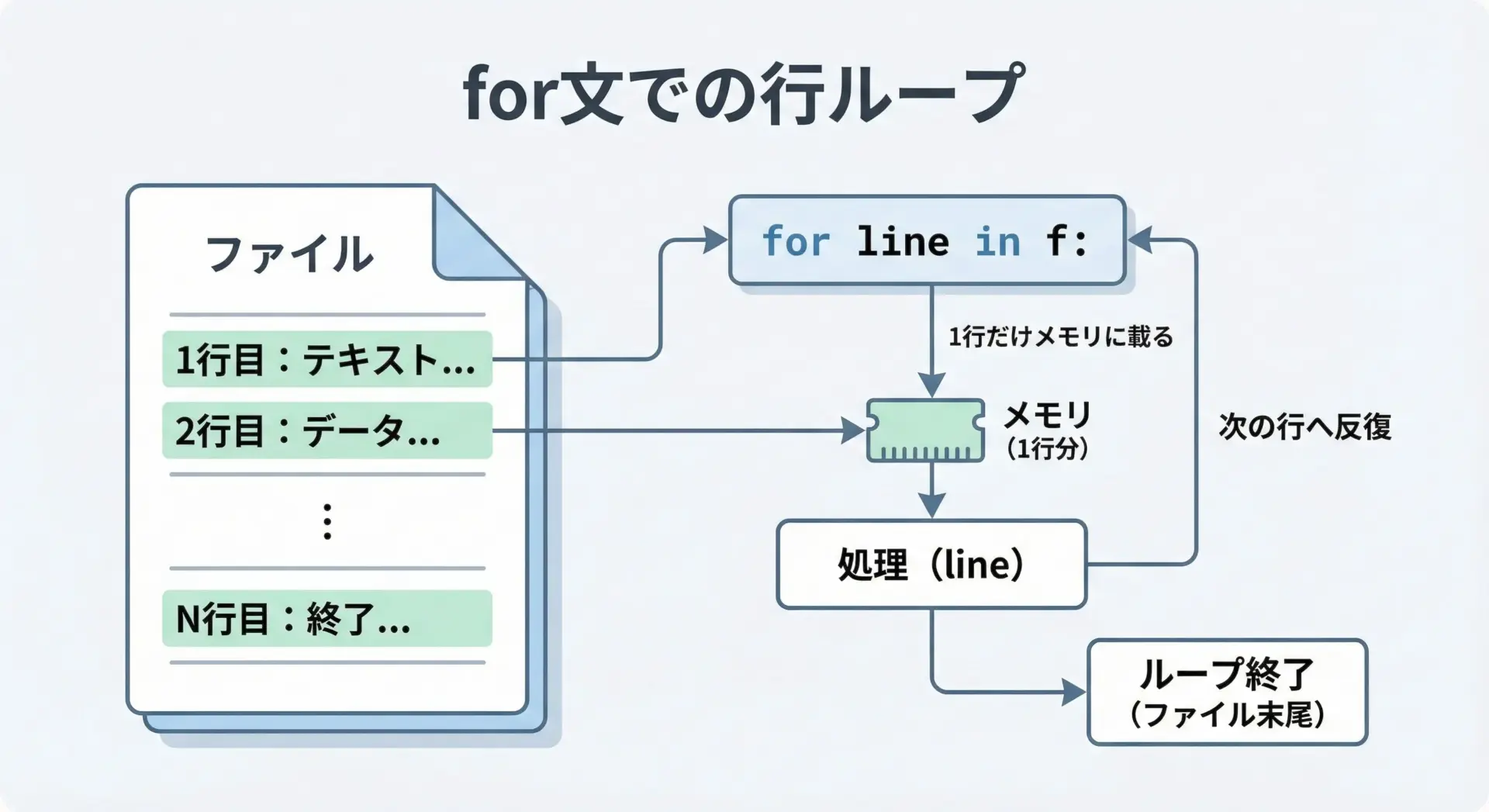
ファイルオブジェクトはイテラブルなので、for文を使うだけで自動的に1行ずつ読み込むことができます。
これはPythonらしく読みやすく、かつ大きなファイルにも向いた非常によく使われるパターンです。
for文による一行ずつ読み込みサンプル
# sample_read_line_by_for.py
file_path = "data.txt"
# with構文でファイルを開き、for文で1行ずつ処理します
with open(file_path, mode="r", encoding="utf-8") as f:
# f は「ファイルオブジェクト」で、for文に渡すと1行ずつ取り出されます
for line in f:
# line には、行末の改行文字(\n)も含まれていることが多いです
# print関数には end="" を指定して、余計な改行を入れないようにしています
print(line, end="")実行例(ファイルdata.txtの内容が以下の場合):
1行目
2行目
3行目1行目
2行目
3行目このパターンは読みやすく、メモリ効率も良いため、大きなファイルを扱う際にはまず最初に検討すべき方法です。
readlineで一行ずつ読み込むサンプルコード

readline()メソッドを使うと、「明示的に1行ずつ読み込む」処理を書けます。
ループの制御を自分で細かく行いたい場合や、1行読んだら別の処理を挟みたいときなどに便利です。
readlineを使ったサンプル
# sample_readline.py
file_path = "data.txt"
with open(file_path, mode="r", encoding="utf-8") as f:
# 最初の1行を読み込む
line = f.readline()
# 読み込んだ行が空文字("")になるまで繰り返す
# ファイル末尾(EOF)に達すると readline() は "" を返します
while line != "":
# 行末の改行を取り除いてから表示したい場合は strip() を使います
print(line.strip())
# 次の1行を読み込む
line = f.readline()実行結果(ファイルdata.txtが同じ内容の場合):
1行目
2行目
3行目for文によるループとreadline()の違いとしては、for文のほうがシンプルでPythonらしく、エラーも起こりにくいです。
一方、readline()は途中でループを抜けたり、次の行を読まずに別の処理をしたりしやすいため、柔軟な制御が必要な場合に向いています。
大きなファイルを一行ずつ処理するメリットと注意点

ログファイルや大量のデータを扱う場合、ファイルサイズが数百MB〜数GBに達することがあります。
そのようなファイルを一度に全て読み込もうとすると、メモリ不足を引き起こす危険があります。
一行ずつ読み込む方式の主なメリットは次の通りです。
1つ目はメモリ使用量が小さく抑えられることです。
常に「今処理している1行分」しかメモリに載らないため、ファイルサイズがどれだけ大きくても、メモリ消費はほぼ一定です。
2つ目は、処理しながら逐次的に結果を書き出したり、集計したりできるため、「読み込みが終わるまで何もできない」という状態を避けられます。
一方で注意点として、ランダムアクセス(特定の行だけすぐ読みたい)には向かないことがあります。
たとえば「100万行目だけ読みたい」というときでも、先頭から順番に読み進める必要があります。
また、ネットワークドライブや遅いストレージ上のファイルでは、行ごとの読み込みに時間がかかることもあるため、処理時間にも注意が必要です。
全行を一度に読み込む方法
小さめのファイルや、シンプルな処理で済む場合は、ファイル全体を一度に読み込む方法が簡単です。
この章ではread()とreadlines()の違いと使い分けを見ていきます。
readメソッドでテキスト全体を文字列として取得
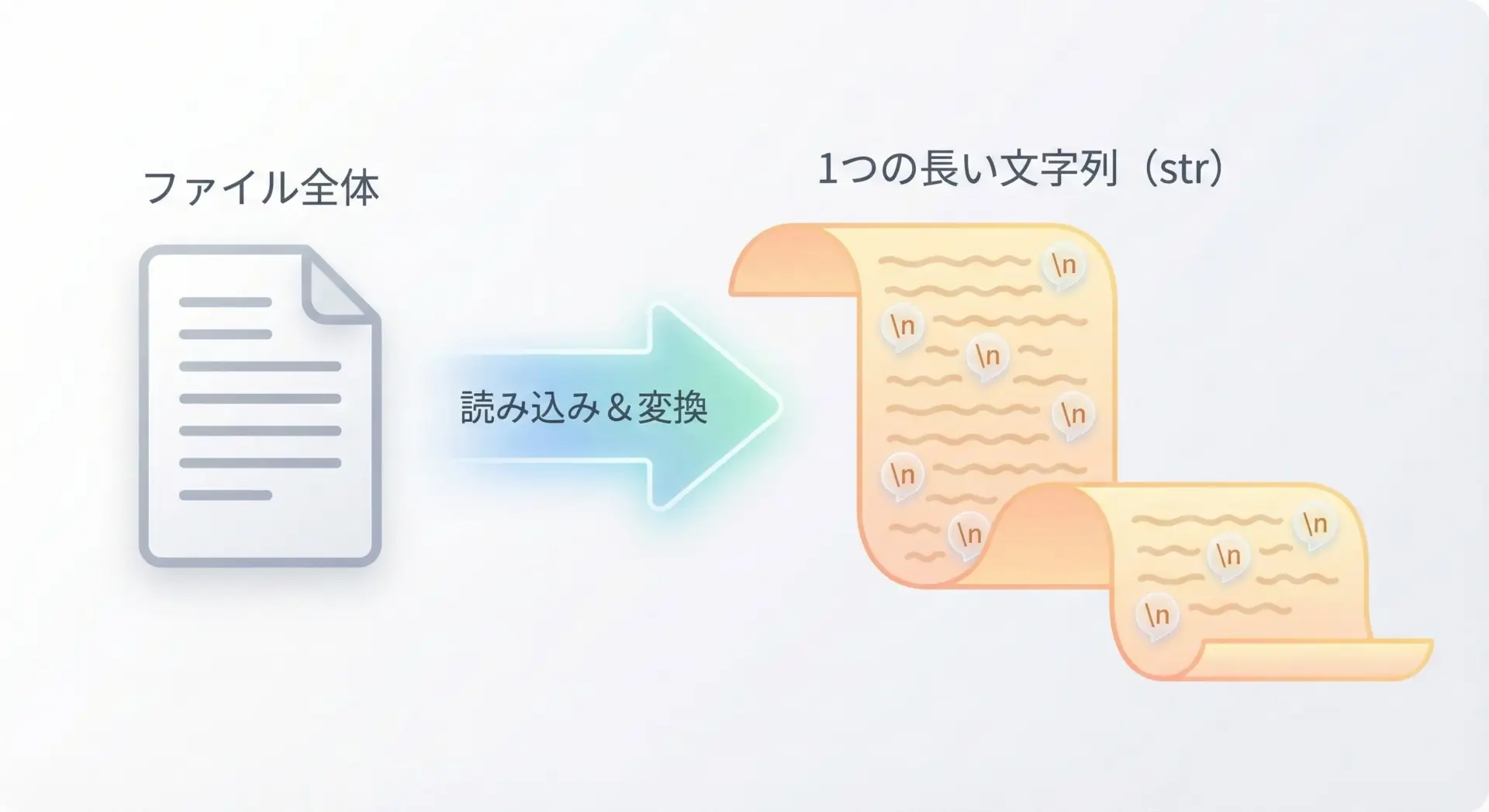
read()メソッドは、ファイル全体を1つの文字列として取得するメソッドです。
内容をまとめて処理したい場合や、単純に画面に表示したい場合に便利です。
read()のサンプル
# sample_read_all.py
file_path = "data_small.txt"
with open(file_path, mode="r", encoding="utf-8") as f:
# ファイル全体を1つの文字列として読み込みます
text = f.read()
print("---- ファイルの中身 ----")
print(text)
print("---- 文字数:", len(text), "----")---- ファイルの中身 ----
1行目
2行目
3行目
---- 文字数: 9 ----このようにread()は非常にシンプルですが、大きなファイルを一気に読み込むと、その分メモリを消費する点には注意が必要です。
readlinesで全行をリストとして取得

readlines()メソッドは、全ての行をまとめてリストとして取得します。
各要素は「1行分の文字列」であり、多くの場合\n(改行文字)を含んでいます。
readlines()のサンプル
# sample_readlines.py
file_path = "data_small.txt"
with open(file_path, mode="r", encoding="utf-8") as f:
# 全行をリストとして取得
lines = f.readlines()
print("---- 行リスト ----")
print(lines)
print("要素数:", len(lines))---- 行リスト ----
['1行目\n', '2行目\n', '3行目\n']
要素数: 3このように、インデックスでlines[0]やlines[1]などと行にアクセスしたい場合には、readlines()がとても便利です。
ファイルサイズ別の読み込み方法の使い分け

テキストファイルの読み込み方は、ファイルサイズや用途に応じて使い分けるのがポイントです。
ざっくりとした目安は次のようになります。
1つ目に、数MB程度までの小さなファイルであれば、read()やreadlines()で一括読み込みして問題ないことが多いです。
コードもシンプルになり、処理の記述も分かりやすくなります。
2つ目に、数百MB〜GBクラスの大きなファイルでは、一括読み込みは避け、for文またはreadline()による逐次処理を行うほうが安全です。
3つ目に、途中の行だけをインデックスで扱いたい場合には、多少大きめでもreadlines()でリスト化してしまったほうがコードが分かりやすくなるケースもあり、実際のファイルサイズやメモリ容量とのバランスを見て決めるとよいです。
テキストファイルの内容をリスト化する方法
テキストファイルを扱うときには、「各行をリストの要素にしたい」という場面が非常によくあります。
さらに一歩進んで、CSVやスペース区切りをsplit()で分割し、二次元リストとして扱うことも多いです。
ここでは、代表的なリスト化のパターンを一つずつ見ていきます。
行ごとにリスト化する基本サンプル(readlines・splitlines)

readlines()とsplitlines()はいずれも「行ごとにリスト化する」ための手段ですが、改行文字を含むかどうかが重要な違いになります。
readlines()でリスト化
# sample_list_readlines.py
file_path = "data_small.txt"
with open(file_path, mode="r", encoding="utf-8") as f:
# 各要素に改行文字(\n)を含む行リストが得られます
lines = f.readlines()
print(lines)想定される出力:
['1行目\n', '2行目\n', '3行目\n']splitlines()でリスト化
# sample_list_splitlines.py
file_path = "data_small.txt"
with open(file_path, mode="r", encoding="utf-8") as f:
# まずファイル全体を文字列として読み込みます
text = f.read()
# splitlines() は、改行コードを区切りとして分割し、改行文字を含まないリストを返します
lines = text.splitlines()
print(lines)想定される出力:
['1行目', '2行目', '3行目']「改行を含んだまま扱いたいか、消したいか」によってどちらを使うか決めると良いです。
細かく制御したい場合は、次で説明するstrip()と組み合わせる方法もよく使われます。
stripで改行コードを除去してリスト化する
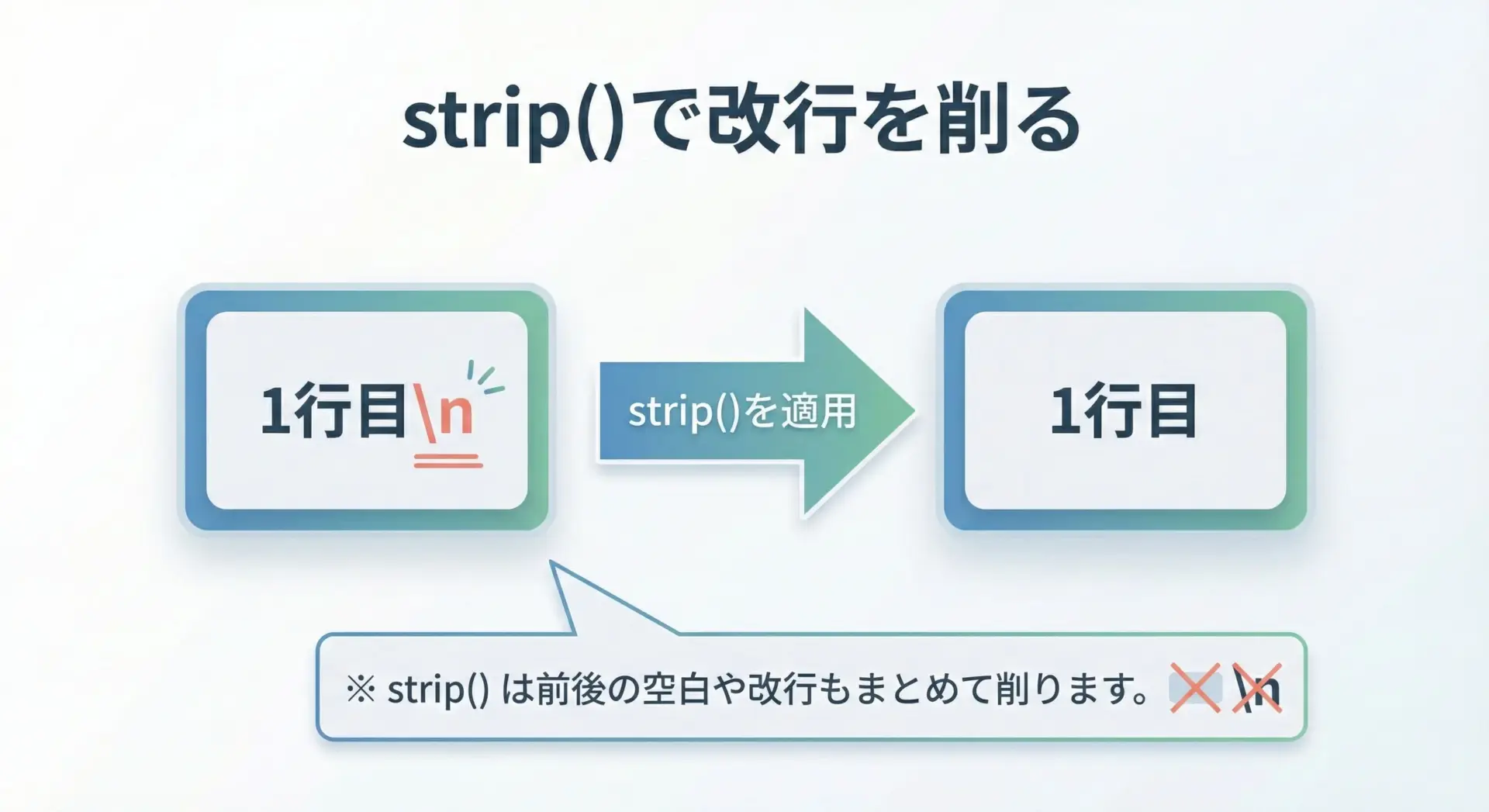
strip()メソッドを使うと、文字列の前後にある空白や改行をまとめて削除できます。
これを利用して、「行リストを作りつつ、改行は含めない」形に整形するのが実務ではよく使われるパターンです。
改行を削ってリスト化するサンプル
# sample_strip_lines.py
file_path = "data_small.txt"
clean_lines = []
with open(file_path, mode="r", encoding="utf-8") as f:
for line in f:
# strip() で前後の空白文字や改行文字(\n, \r)を取り除きます
clean_line = line.strip()
clean_lines.append(clean_line)
print(clean_lines)想定される出力:
['1行目', '2行目', '3行目']このようにfor文 + strip() + append()という形で書いておくと、あとから行ごとの追加処理を差し込みやすくなり、柔軟なコードになります。
CSVやスペース区切りをsplitして2次元リストに変換する
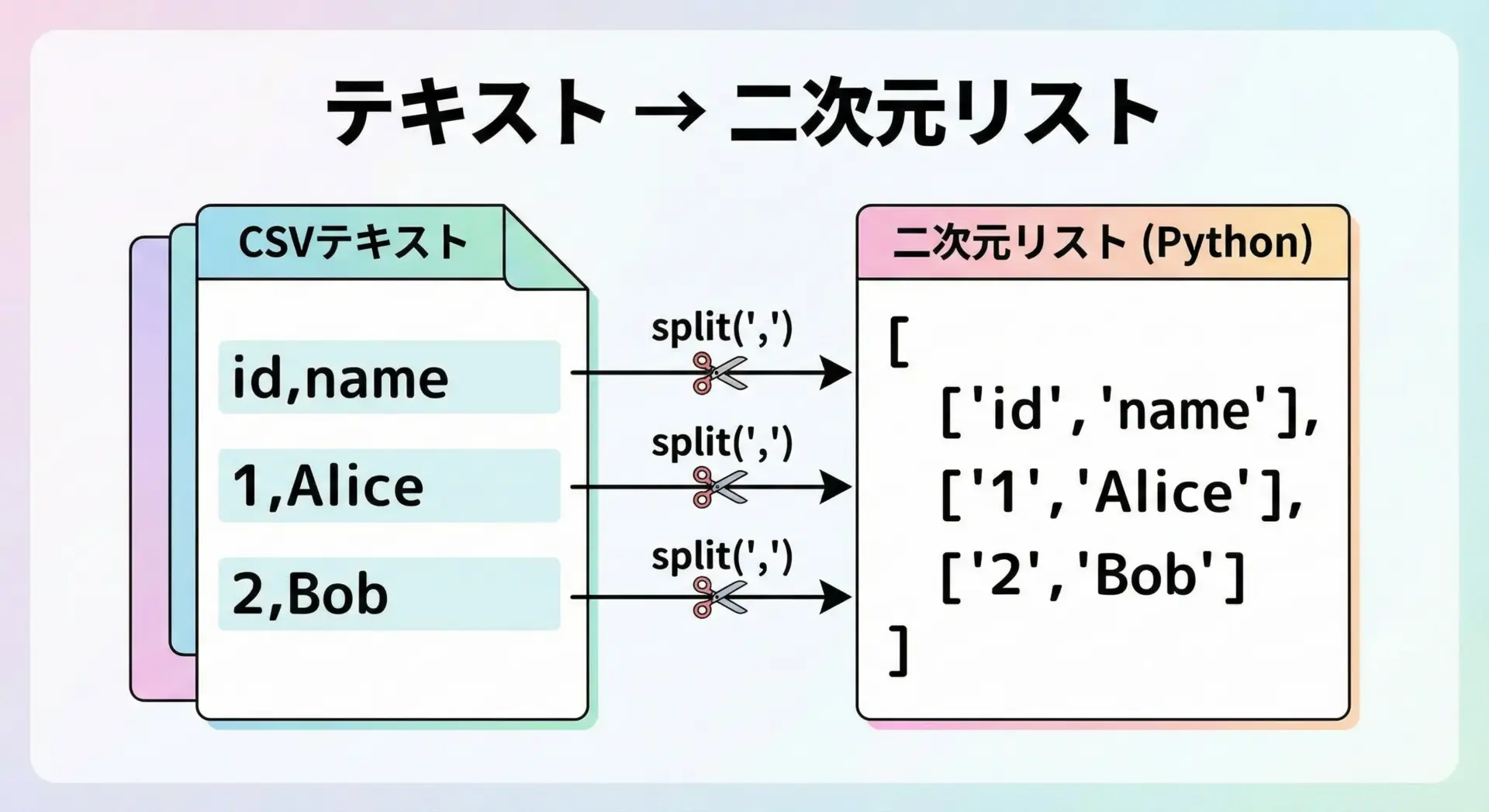
CSVやスペース区切りのテキストを扱う場合、各行を区切り文字で分割して、二次元リストとして扱うことが一般的です。
Pythonにはcsvモジュールもありますが、ここではsplit()を使った素朴な方法を紹介します。
カンマ区切り(CSV風)を二次元リストにする例
# sample_csv_like_split.py
file_path = "data.csv"
rows = []
with open(file_path, mode="r", encoding="utf-8") as f:
for line in f:
# 改行を削除
line = line.strip()
# 空行はスキップしたい場合は以下のようにチェックします
if line == "":
continue
# カンマで分割してリストを作成
columns = line.split(",")
rows.append(columns)
# 結果を確認
for row in rows:
print(row)入力ファイルdata.csvが次のような内容だとします。
id,name,age
1,Alice,23
2,Bob,30['id', 'name', 'age']
['1', 'Alice', '23']
['2', 'Bob', '30']このようにして「行のリスト(外側)」と「列のリスト(内側)」からなる二次元リストを作ることができます。
スペース区切りを二次元リストにする例
# sample_space_split.py
file_path = "data_space.txt"
rows = []
with open(file_path, mode="r", encoding="utf-8") as f:
for line in f:
# 不要な前後スペースや改行を削除
line = line.strip()
if line == "":
continue
# デフォルトの split() は空白文字(スペース・タブなど)を区切りにします
columns = line.split()
rows.append(columns)
for row in rows:
print(row)入力ファイルdata_space.txt:
1 Alice 23
2 Bob 30['1', 'Alice', '23']
['2', 'Bob', '30']このような二次元リストにしておくと、後続の処理(集計や検索、Pandasへの変換など)が非常にやりやすくなります。
実務でも最初の前処理として、このようなリスト化を行うケースが多く見られます。
まとめ
本記事では、Pythonでテキストファイルを読み込む基本から、一行ずつの処理、全行一括読み込み、さらにリスト化や二次元リスト化までを解説しました。
小さなファイルにはread/readlines、大きなファイルにはfor行ループやreadline、文字化け対策にはencoding指定という使い分けを押さえておけば、多くの場面に対応できます。
実際の業務で扱うテキストファイルに合わせて、本記事のサンプルコードを参考にしながら、自分なりの読み込みパターンを組み立ててみてください。
