
Pythonで実務レベルのコードを書くためには、関数の定義(def)をしっかり理解することが欠かせません。
本記事では、関数の基礎から、実務で役立つ関数設計・分割・テストまでを体系的に解説します。
初心者の方はもちろん、独学で何となく書いてきた方が「設計のコツ」を学び直すのにも役立つ内容です。
Pythonの関数(def)とは何か
関数(def)の基本概念とメリット
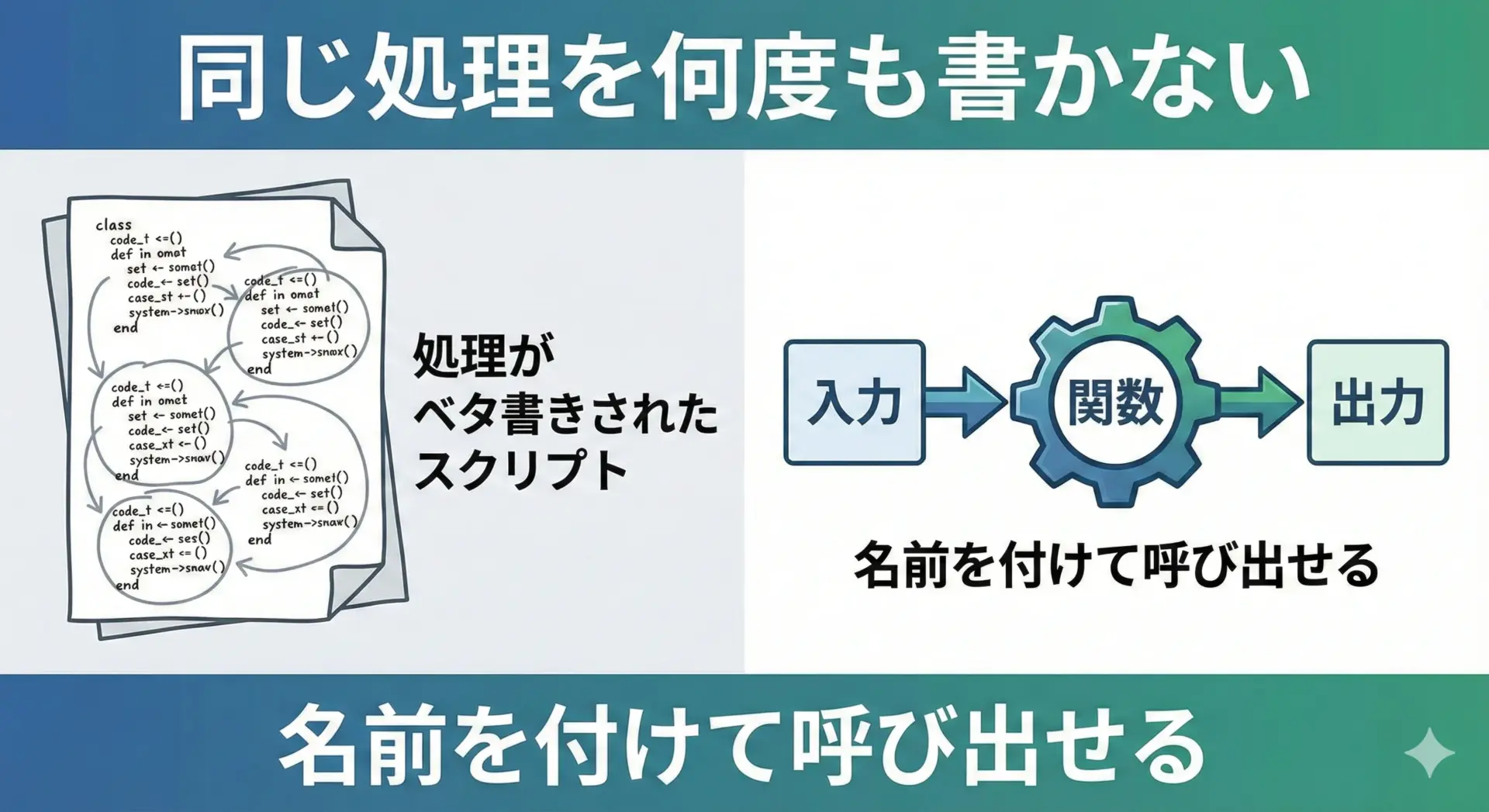
関数とは、一定の処理に名前を付けてまとめたものです。
Pythonではdefキーワードを使って関数を定義します。
関数を使うことで、同じ処理を何度も書かずに済み、コードが読みやすく、変更にも強くなります。
もう少し具体的に言うと、関数は「入力(引数)」を受け取り、「処理」を行い、「結果(戻り値)」を返す、小さな部品のようなものです。
このように処理を部品化することには、次のようなメリットがあります。
- コードの再利用がしやすくなる
- バグが発生したときに原因の切り分けがしやすくなる
- 役割ごとに処理を分けることで、仕様変更に強くなる
よく使う処理・意味のあるひとかたまりの処理は、関数に切り出して名前を付けるという意識が大切です。
関数とメソッドの違い
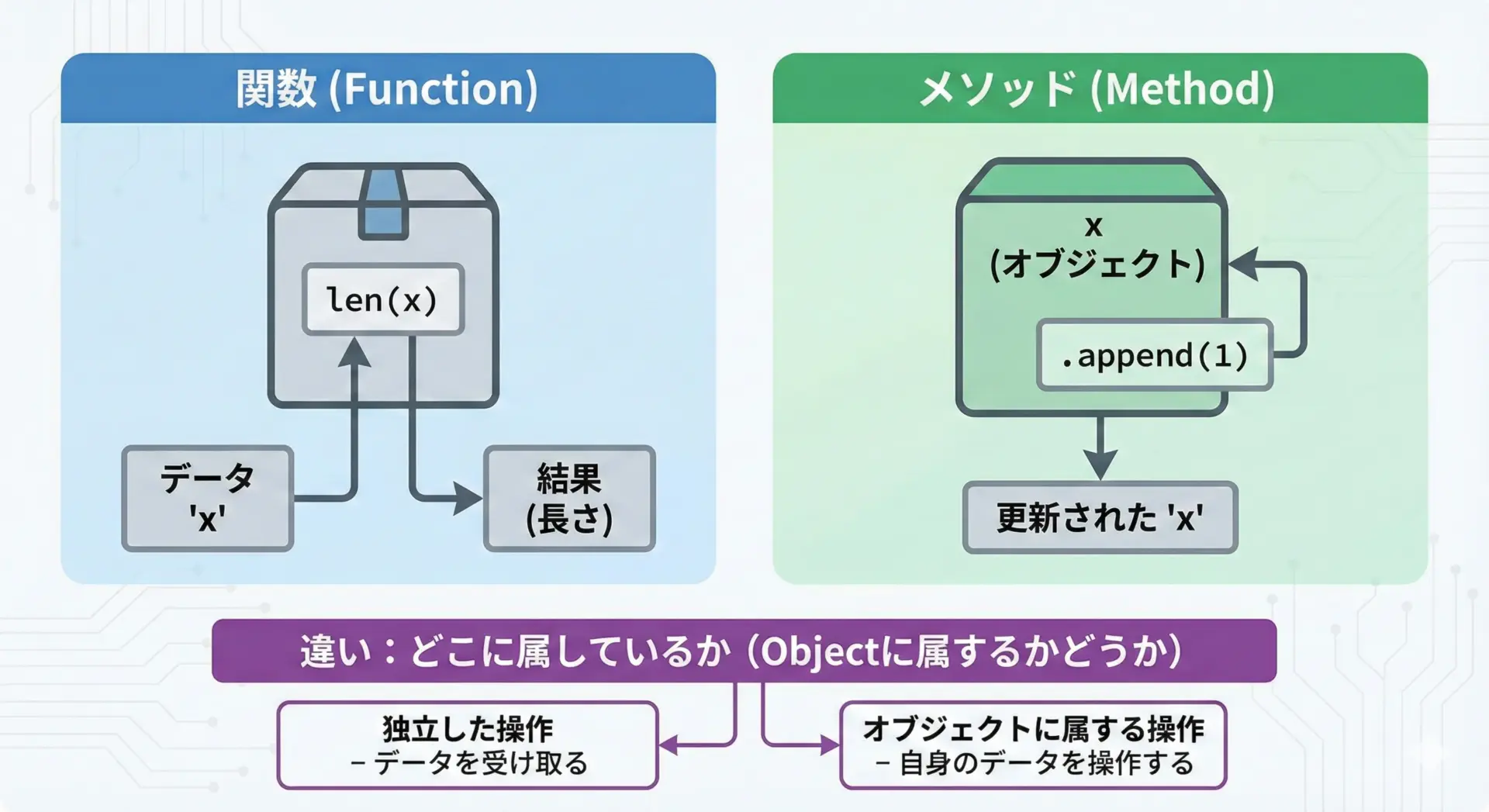
Pythonでは、似た概念として「メソッド」があります。
どちらも「名前の付いた処理」ですが、次の点が異なります。
- 関数: どのオブジェクトにも属さない、独立した処理
- 例:
len("abc")、print("Hello")
- 例:
- メソッド: あるオブジェクト(インスタンス)に属する処理
- 例:
text.upper()、numbers.append(10)
- 例:
表にすると次のようになります。
| 種類 | 呼び出し方 | 属するもの | 例 |
|---|---|---|---|
| 関数 | func(x) | 何にも属さない | len(s) |
| メソッド | obj.method(x) | オブジェクトに属する | lst.append(1) |
実務でコードを読むときは、「これはクラス(オブジェクト)のメソッドか」「単なる関数か」を意識すると、設計の意図を理解しやすくなります。
関数定義と呼び出しの流れ
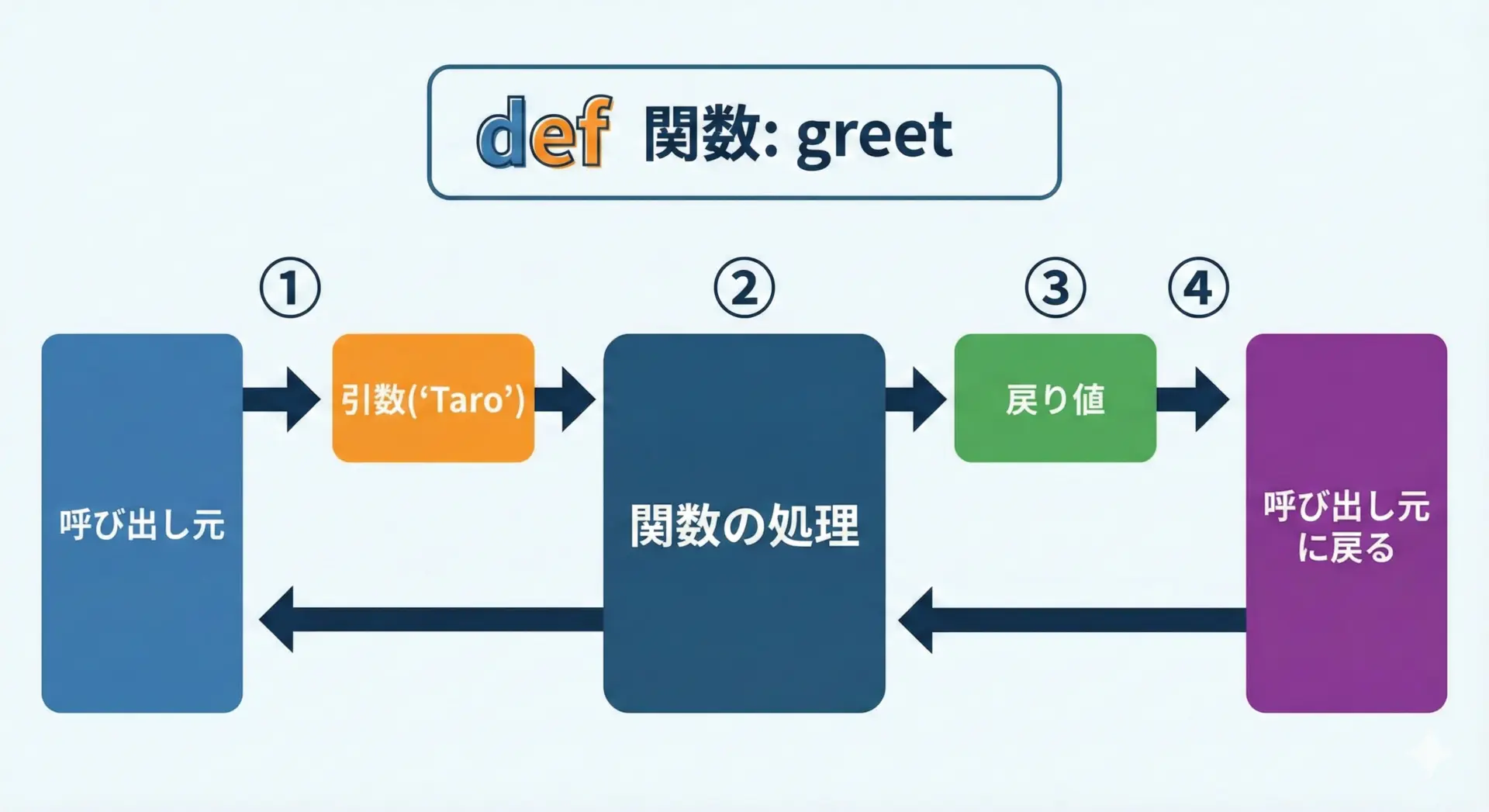
Pythonで関数を使う流れは、次のように整理できます。
defで関数を定義する- 必要な場所で、その関数を「呼び出す」
- 引数があれば、呼び出し時に値を渡す
- 関数が
returnで結果を返す - 呼び出し元は、その結果を変数に受け取って利用する
具体的な例をCUIで確認してみます。
# 挨拶文を作る関数を定義
def make_greeting(name):
# f文字列で「こんにちは, 誰々さん!」というメッセージを作成
message = f"こんにちは、{name}さん!"
return message # 呼び出し元に結果を返す
# 関数の呼び出し
result = make_greeting("太郎") # 引数に "太郎" を渡す
print(result) # 戻り値を表示こんにちは、太郎さん!この流れを理解すると、以降の「引数」「戻り値」「エラー処理」などもイメージしやすくなります。
defによる関数の書き方
最もシンプルな関数定義とreturn

Pythonの関数定義は、次のような基本構造で書きます。
def 関数名(引数1, 引数2, ...):
処理
return 戻り値最もシンプルな例として、2つの数値を足し算する関数を定義してみます。
# 2つの数値を足し算する関数
def add(a, b):
result = a + b # a と b を足し算
return result # 計算結果を戻り値として返す
# 関数の呼び出し例
x = add(3, 5) # 3 + 5 の結果が x に入る
print(x)8なお、returnを書かない場合、Pythonの関数は自動的にNoneを返します。
処理だけ行って、特に結果を返さない関数(ログ出力だけ行う関数など)では、この形もよく使われます。
# メッセージを表示するだけの関数(戻り値なし)
def show_message():
print("処理を開始します")
value = show_message()
print("戻り値:", value) # None が入っている処理を開始します
戻り値: None引数あり関数
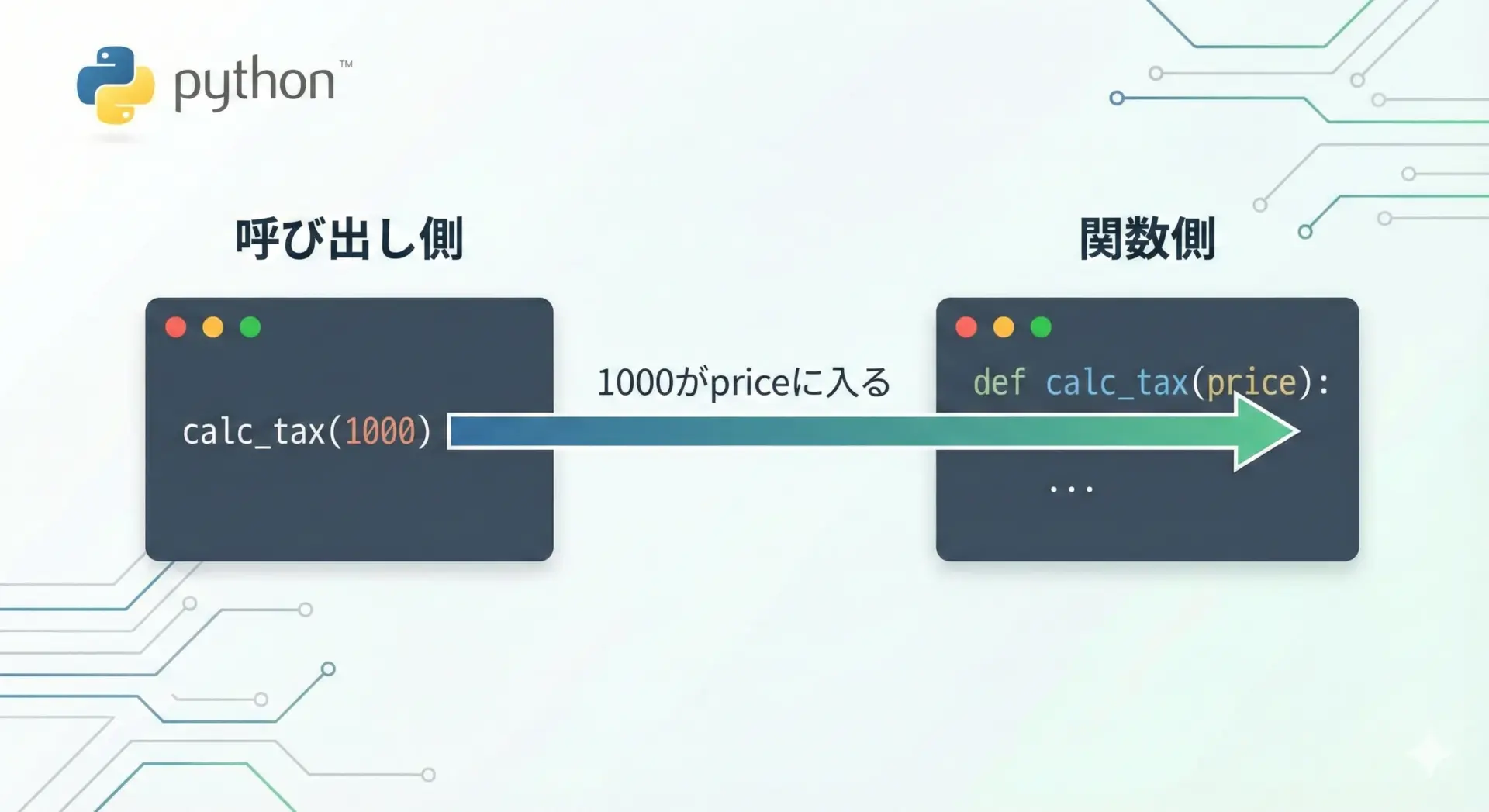
引数は、関数に渡す入力データです。
引数を使うことで、同じロジックをさまざまな値に対して適用できます。
# 税込価格を計算する関数
def calc_tax(price, tax_rate):
"""価格と税率から税込価格を計算する"""
tax = price * tax_rate
total = price + tax
return total
# 関数の呼び出し例
total1 = calc_tax(1000, 0.1) # 1000円に10%の税
total2 = calc_tax(5000, 0.08) # 5000円に8%の税
print(total1)
print(total2)1100.0
5400.0ここでのポイントは、関数の外で決まる値を、関数の外から明示的に渡すことです。
関数の中でグローバル変数を勝手に参照するよりも、引数として渡す方が、テストしやすくバグも少なくなります。
デフォルト引数とキーワード引数
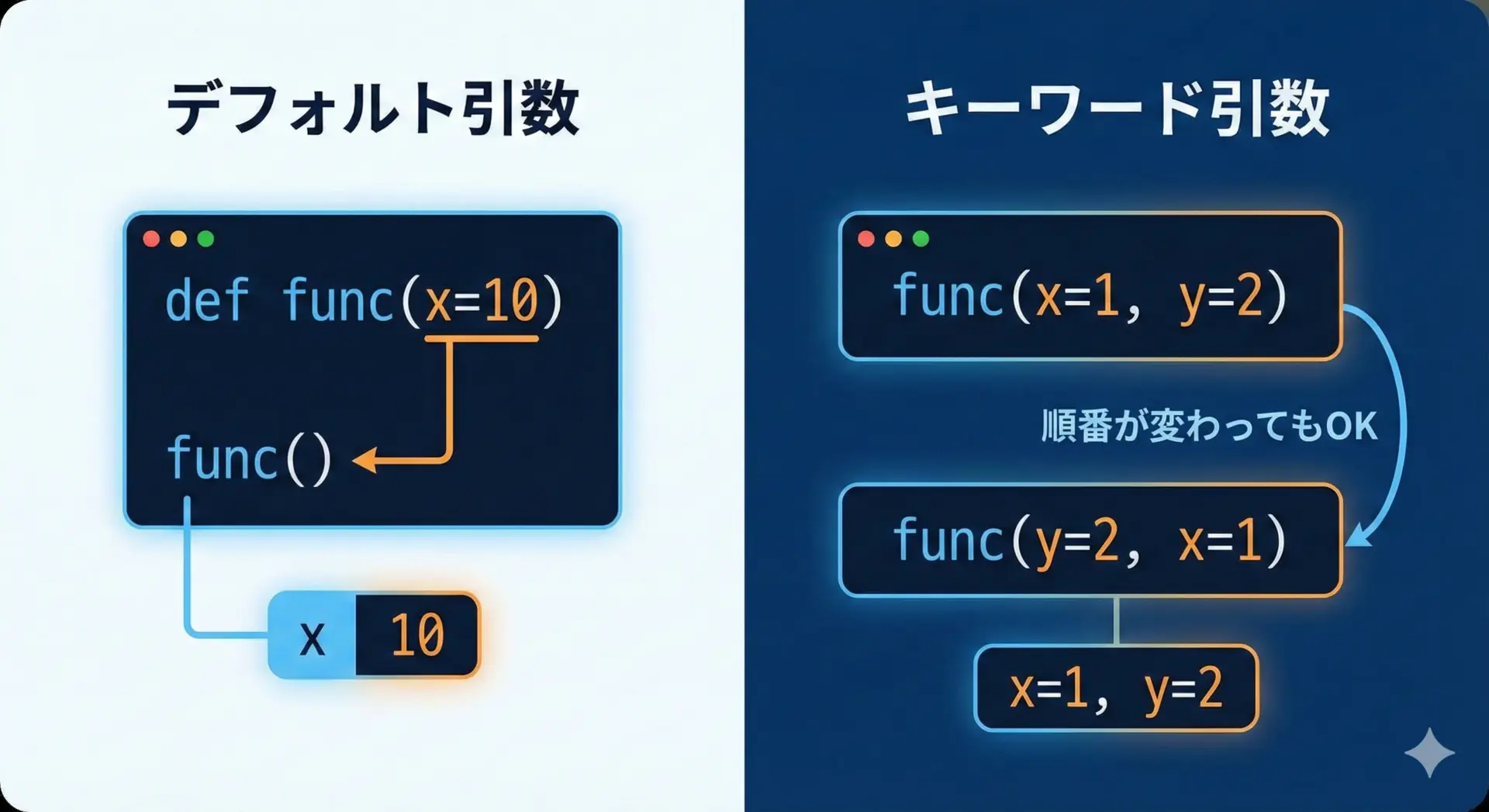
実務では、「ほとんどの場合は同じ値を使うが、必要に応じて変えたい」というケースがよくあります。
このときに便利なのがデフォルト引数です。
# デフォルト引数を持つ関数
def calc_tax(price, tax_rate=0.1):
"""税率のデフォルト値を10%にしたバージョン"""
return price * (1 + tax_rate)
print(calc_tax(1000)) # tax_rate を省略 → 0.1 が使われる
print(calc_tax(1000, 0.08)) # tax_rate を明示的に指定1100.0
1080.0次に、キーワード引数です。
これは、引数名を指定して渡す呼び出し方で、引数の順番を気にせずに呼び出せるメリットがあります。
def format_name(family_name, given_name, separator=" "):
"""姓名を指定の区切り文字で結合する"""
return family_name + separator + given_name
# 位置引数での呼び出し(順番に注意が必要)
print(format_name("山田", "太郎"))
# キーワード引数での呼び出し(順番を入れ替えてもOK)
print(format_name(given_name="太郎", family_name="山田"))
# デフォルト引数とキーワード引数の併用
print(format_name("山田", "太郎", separator="・"))山田 太郎
山田 太郎
山田・太郎引数が増えてきたら、積極的にキーワード引数で呼び出すようにすると、読みやすさが大きく向上します。
可変長引数
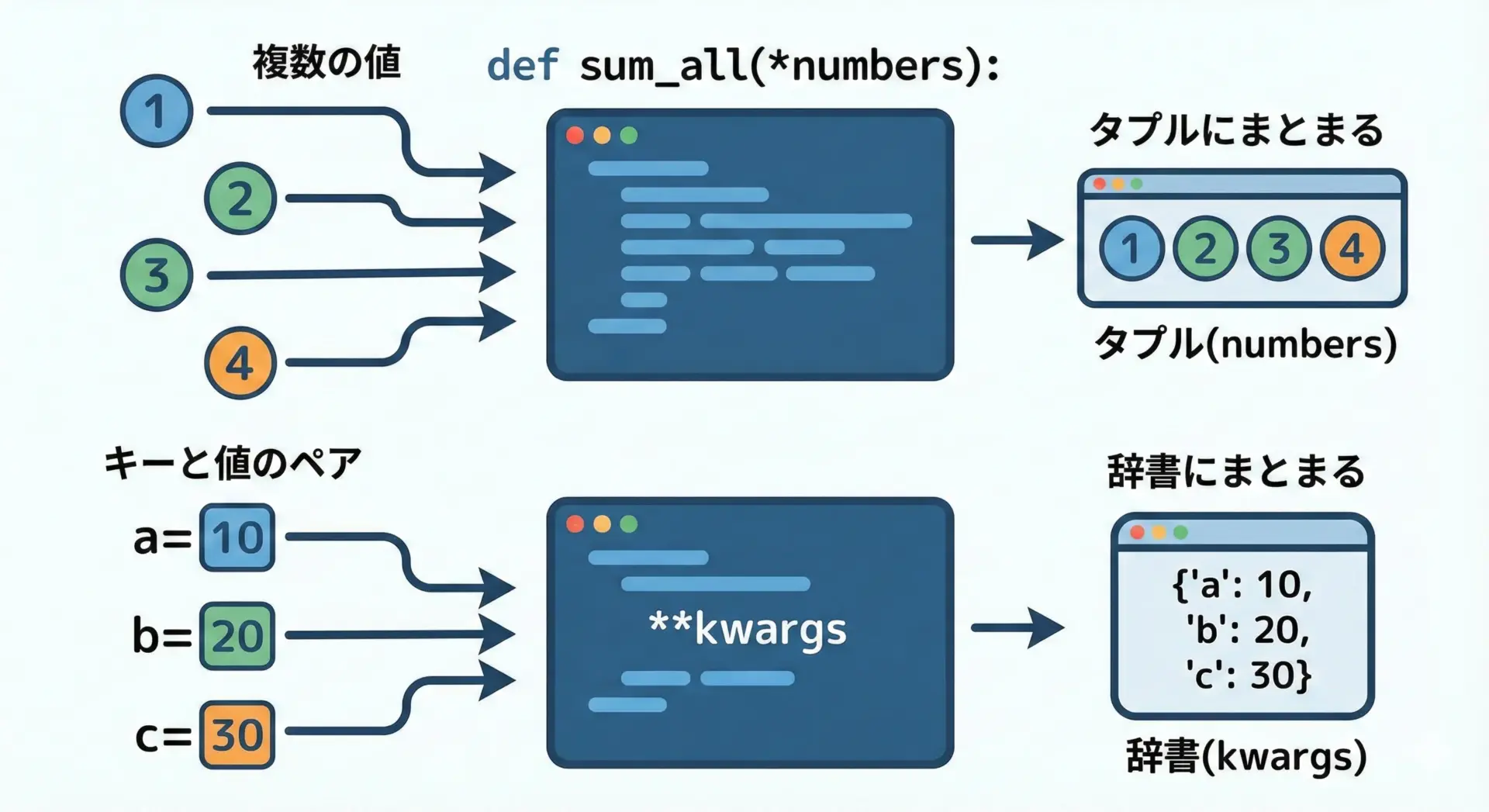
可変長引数は、引数の数が呼び出しごとに変わる場合に使います。
代表的なのは*argsと**kwargsです。
# 任意の数の数値を足し算する関数
def sum_all(*numbers):
"""渡された数値をすべて合計する"""
total = 0
for n in numbers:
total += n
return total
print(sum_all(1, 2, 3))
print(sum_all(10, 20, 30, 40, 50))6
150*numbersは、渡された引数をタプルとして受け取ります。
次に**kwargsを見てみます。
# 任意のキーワード引数を受け取ってログ出力する関数
def debug_log(**info):
"""キーバリュー形式のデータをまとめて表示する"""
for key, value in info.items():
print(f"{key} = {value}")
debug_log(user="taro", action="login", success=True)user = taro
action = login
success = True**infoは、キーワード引数を辞書として受け取ります。
実務コードでは、設定値をまとめて受け取る関数などでよく使われます。
ドキュストリングと型ヒント

実務では、関数を定義するときにドキュストリング(docstring)と型ヒント(type hint)を書いておくと、保守性が大きく向上します。
def calc_bmi(weight_kg: float, height_m: float) -> float:
"""
BMI(Body Mass Index)を計算する。
BMI = 体重(kg) / 身長(m)^2
Args:
weight_kg: 体重(kg)
height_m: 身長(m)
Returns:
BMIの値
"""
bmi = weight_kg / (height_m ** 2)
return bmi
result = calc_bmi(60.0, 1.7)
print(result)20.761245674740486ポイントをまとめると次の通りです。
- 型ヒント
引数名: 型の形で引数の型を示す)-> 戻り値の型:で関数の戻り値の型を示す- 実行時に型チェックされるわけではありませんが、静的解析ツールやIDEが補完・検査に利用します
- ドキュストリング
- 関数の最初の文字列リテラルが自動的に関数の説明として利用される
help(calc_bmi)で参照したり、ドキュメント自動生成に使える
人に読まれる・長く使われる関数には、型ヒントとドキュストリングを書くことを習慣にすると良いです。
実務で使うPython関数
データ処理で使う関数の書き方
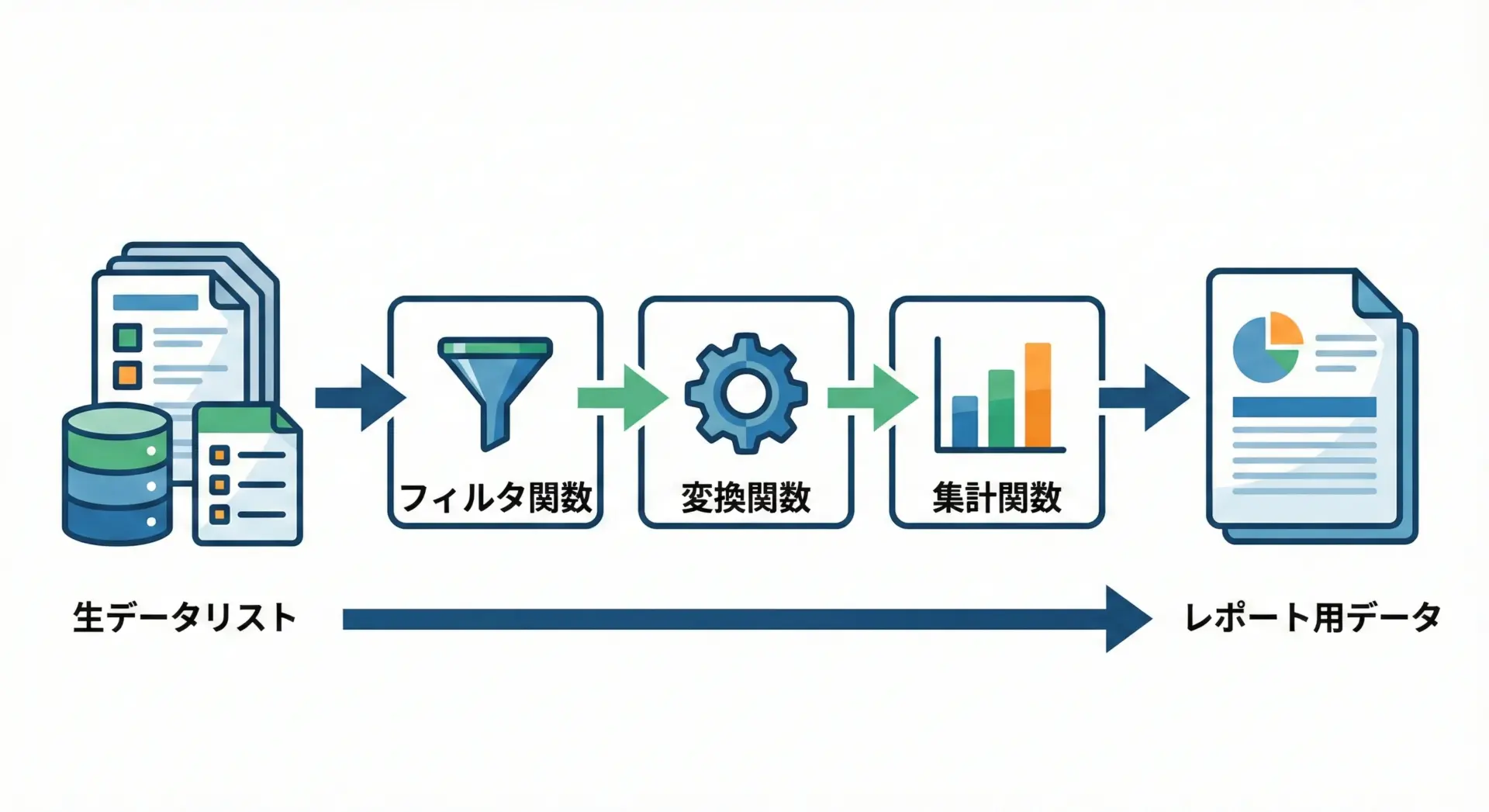
データ処理では、「フィルタ」「変換」「集計」などの役割ごとに関数を分けると、処理の意図が非常にわかりやすくなります。
from statistics import mean
def filter_valid_scores(scores):
"""0〜100点の範囲に収まるスコアだけを残す"""
return [s for s in scores if 0 <= s <= 100]
def convert_to_grade(score):
"""点数をA〜Dの評価に変換する"""
if score >= 80:
return "A"
elif score >= 65:
return "B"
elif score >= 50:
return "C"
else:
return "D"
def summarize_scores(scores):
"""スコアの平均と評価分布をまとめて返す"""
valid_scores = filter_valid_scores(scores)
avg = mean(valid_scores) if valid_scores else None
grades = [convert_to_grade(s) for s in valid_scores]
distribution = {
"A": grades.count("A"),
"B": grades.count("B"),
"C": grades.count("C"),
"D": grades.count("D"),
}
return avg, distribution
# 実行例
raw_scores = [95, 82, 70, 58, 45, 110, -5]
average, dist = summarize_scores(raw_scores)
print("平均点:", average)
print("分布:", dist)平均点: 70
分布: {'A': 2, 'B': 1, 'C': 1, 'D': 1}このように、1つの大きな処理を小さな関数に分割しておくと、後から「集計だけ仕様変更したい」「評価の基準だけ変えたい」といったニーズにも柔軟に対応できます。
バリデーション関数とエラーハンドリング
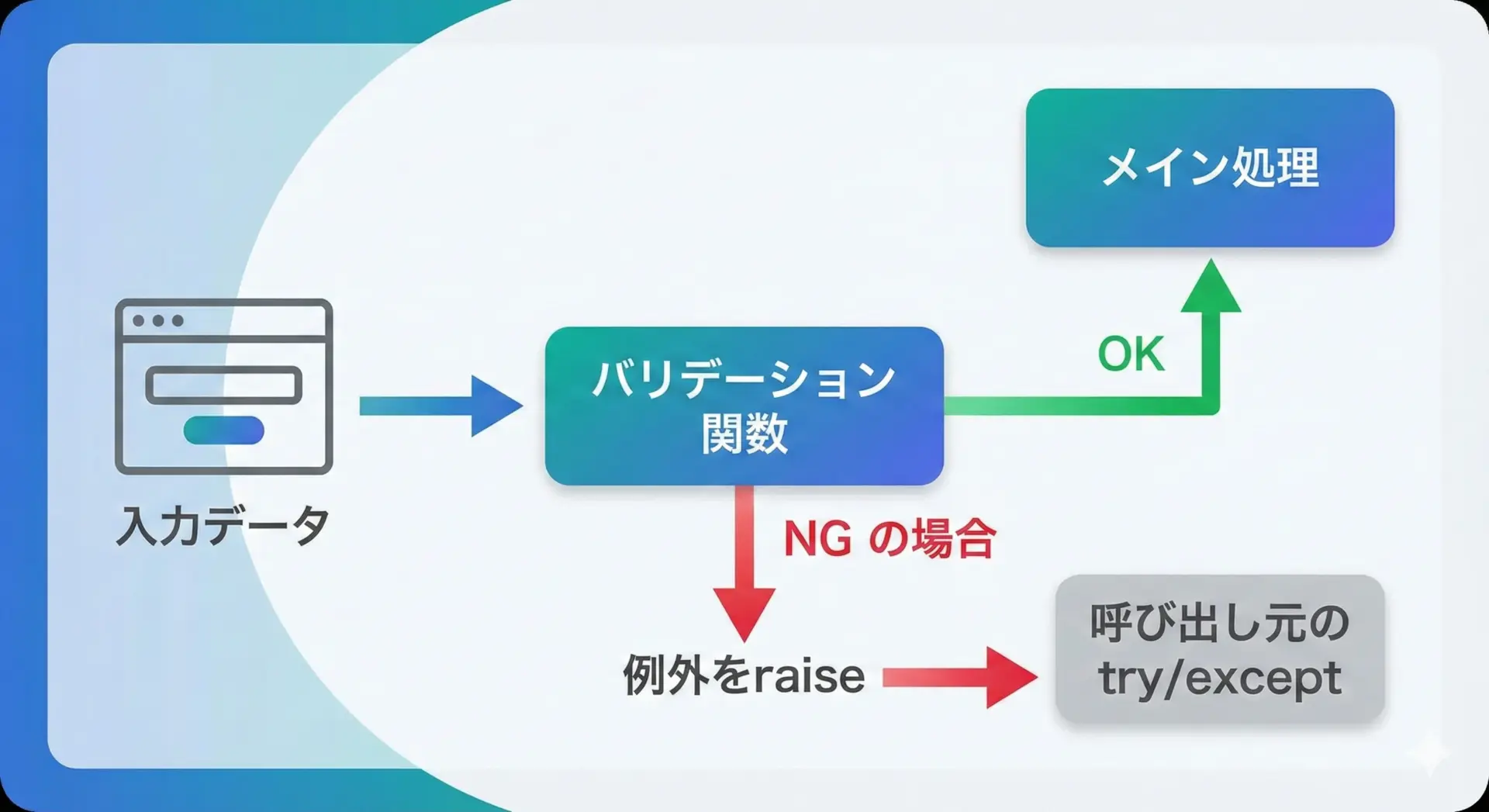
実務では、外部から受け取るデータ(ユーザー入力、ファイル、APIレスポンスなど)が前提条件を満たしているかを検証することが重要です。
この検証処理(バリデーション)を、専用の関数に切り出しておくと、コードがすっきりします。
class ValidationError(Exception):
"""入力値が不正な場合に投げる例外"""
pass
def validate_age(age: int) -> None:
"""年齢が0〜120の範囲に収まっているかチェックする"""
if not isinstance(age, int):
raise ValidationError("年齢は整数で指定してください")
if age < 0 or age > 120:
raise ValidationError("年齢は0〜120の範囲で指定してください")
def register_user(name: str, age: int) -> None:
"""ユーザー登録処理"""
validate_age(age) # まずバリデーション
print(f"ユーザーを登録しました: name={name}, age={age}")
try:
register_user("太郎", 150)
except ValidationError as e:
print("入力エラー:", e)入力エラー: 年齢は0〜120の範囲で指定してくださいバリデーション関数は「チェックしかしない」「エラーを投げるか、静かに終わるか」のどちらかに徹すると、責務がはっきりし、呼び出し側の実装もわかりやすくなります。
クリーンコードのための関数分割
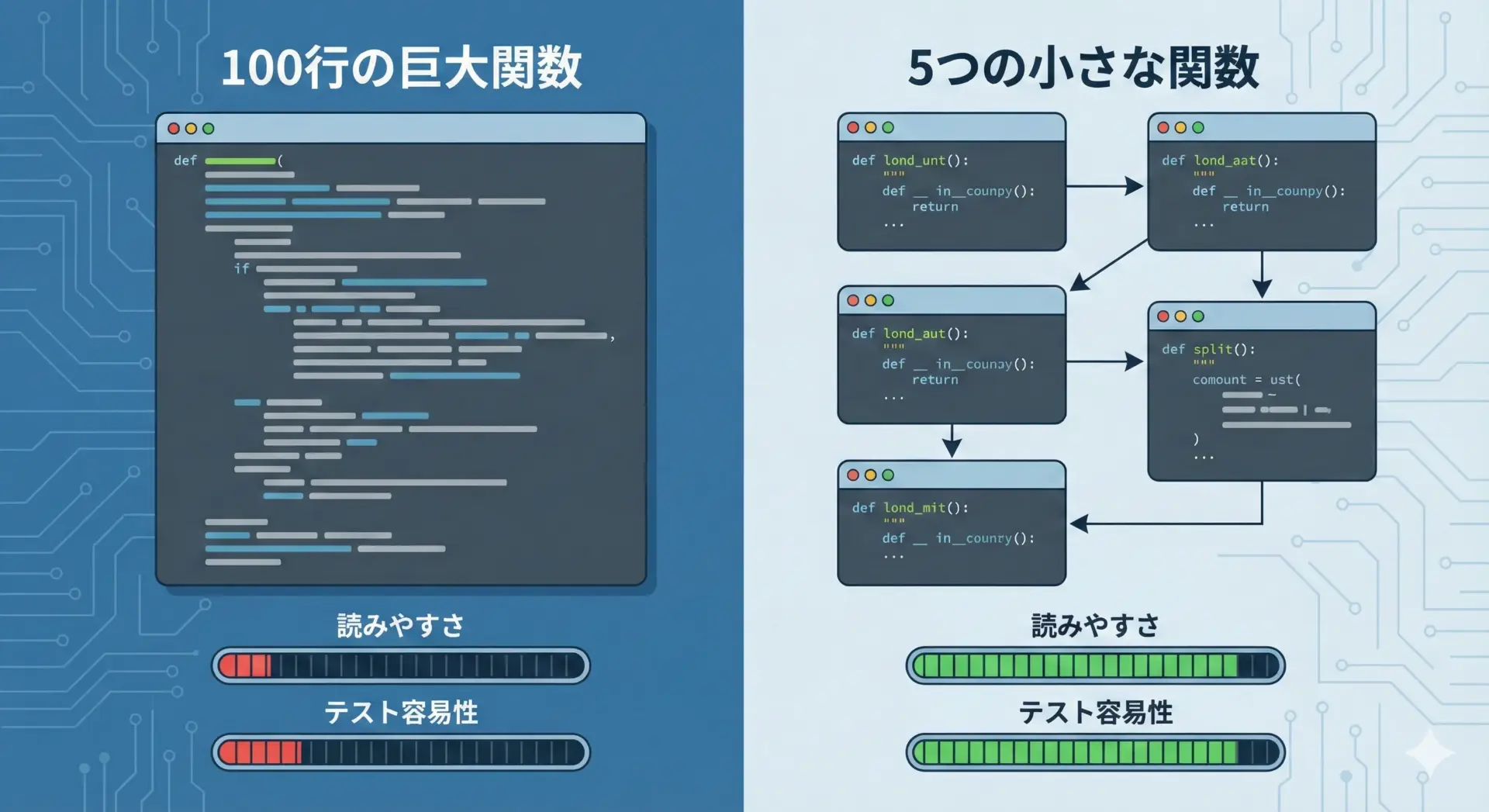
1つの関数が長くなると、コードの見通しが悪くなり、修正時にバグを埋め込みやすくなります。
「1つの関数は1つの責務」に絞るのが、クリーンコードの基本です。
例として、注文処理のコードを大きな関数と分割された関数で比較します。
# 悪い例: すべてを1つの関数でやってしまう
def process_order(order):
# 合計金額計算
total = 0
for item in order["items"]:
total += item["price"] * item["quantity"]
# 割引
if order.get("vip"):
total *= 0.9
# 送料加算
if total < 5000:
total += 500
# 請求書の作成と表示
print("=== 請求書 ===")
for item in order["items"]:
print(item["name"], item["quantity"], item["price"])
print("合計:", total)# 良い例: 責務ごとに関数を分割
def calc_subtotal(order):
total = 0
for item in order["items"]:
total += item["price"] * item["quantity"]
return total
def apply_discount(total, is_vip):
return total * 0.9 if is_vip else total
def add_shipping(total):
return total if total >= 5000 else total + 500
def print_invoice(order, total):
print("=== 請求書 ===")
for item in order["items"]:
print(item["name"], item["quantity"], item["price"])
print("合計:", total)
def process_order(order):
subtotal = calc_subtotal(order)
discounted = apply_discount(subtotal, order.get("vip", False))
final_total = add_shipping(discounted)
print_invoice(order, final_total)このように分割すると、個々の関数を単体でテストでき、ビジネスルールの変更にも素早く対応できます。
再利用性の高いユーティリティ関数
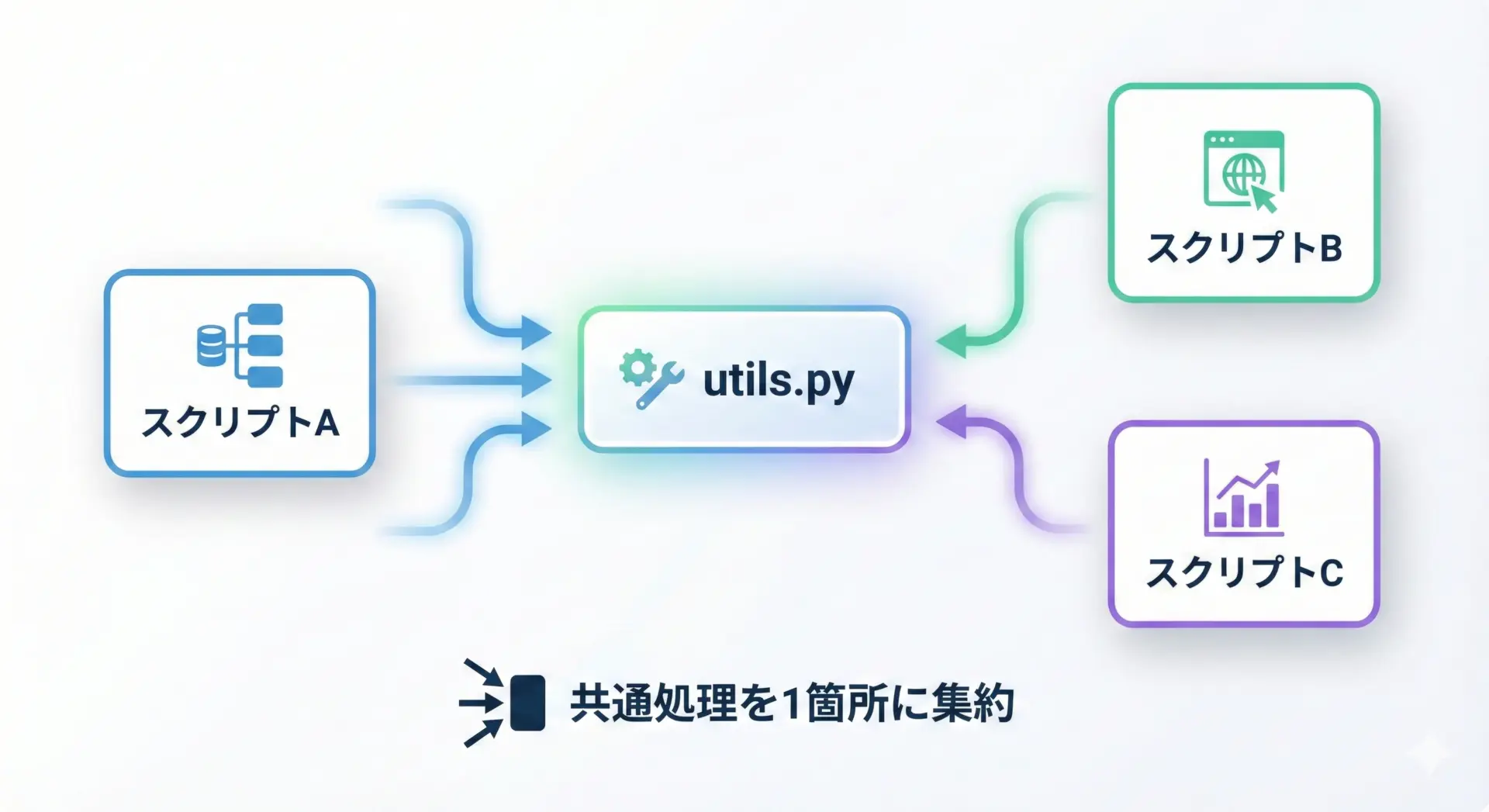
実務では、複数のスクリプトやモジュールで同じ処理を使い回すことがあります。
そのような処理は、ユーティリティ関数として専用モジュールにまとめると便利です。
# utils.py
from datetime import datetime, timezone, timedelta
JST = timezone(timedelta(hours=9))
def now_jst() -> datetime:
"""JST(日本時間)の現在時刻を返す"""
return datetime.now(JST)
def to_int_safe(value, default=0):
"""
値を安全にintに変換する。
失敗した場合はdefaultを返す。
"""
try:
return int(value)
except (TypeError, ValueError):
return default# main.py
from utils import now_jst, to_int_safe
print("現在時刻(JST):", now_jst())
age_str = "20歳"
age = to_int_safe(age_str, default=-1)
print("年齢:", age)現在時刻(JST): 2025-12-14 12:34:56+09:00 # 実行時の現在時刻が表示される
年齢: -1ユーティリティ関数は、「プロジェクトのどこからでも使いたい小さな便利処理」をまとめる場所です。
ただし、何でもかんでも詰め込むと逆に分かりづらくなるため、用途ごとにファイル(モジュール)を分けるのがおすすめです。
関数を使ったロジック共通化の例
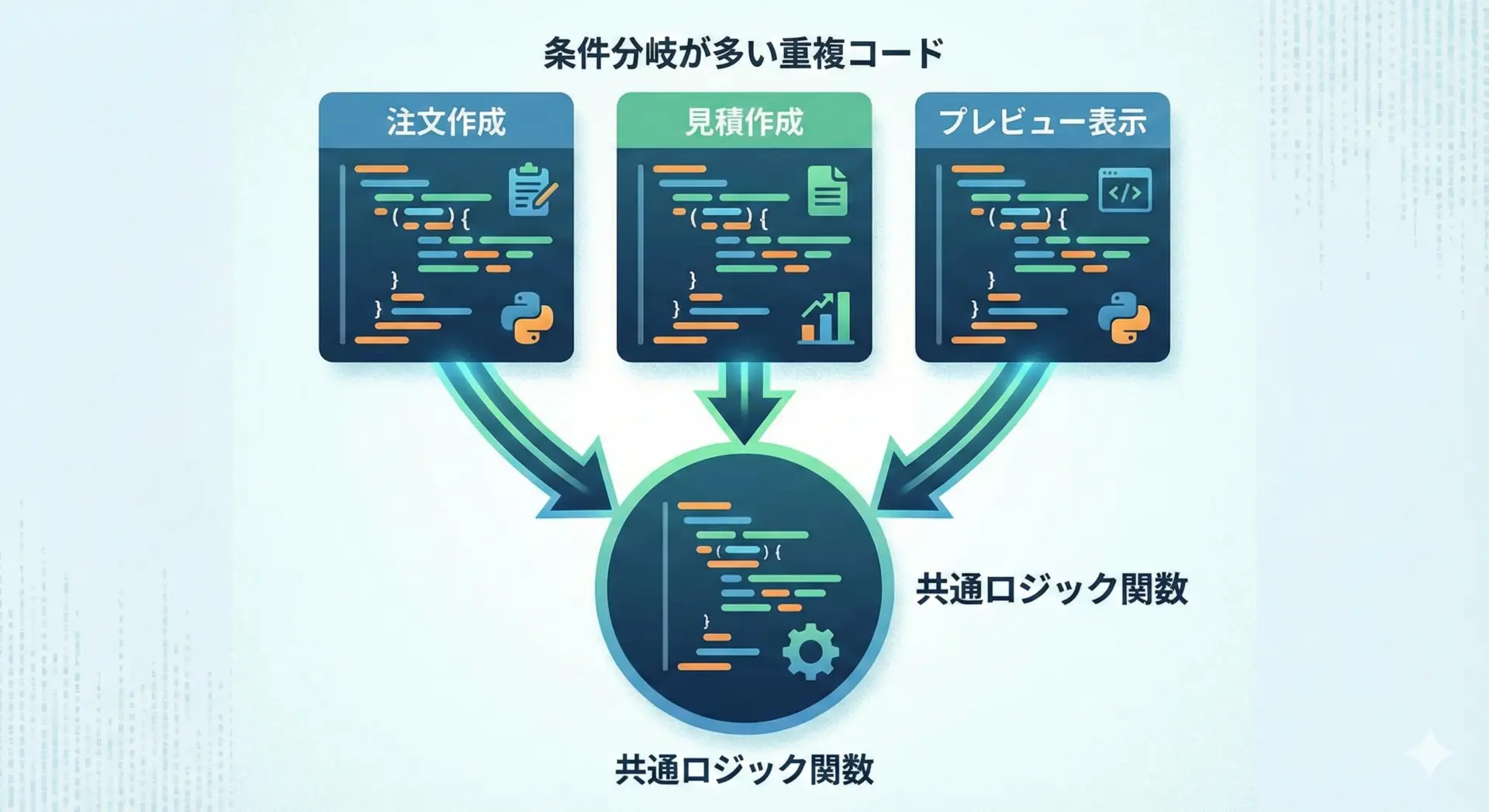
実務でありがちな「ほぼ同じロジックが、少しだけ違う形で複数箇所に書かれている」状態は、バグや不整合の温床になります。
関数として共通化しておくと、修正も1箇所で済みます。
def calc_order_total(items, discount_rate=0.0, with_shipping=True):
"""
注文金額を計算する共通関数。
Args:
items: {"price": 価格, "quantity": 数量} のリスト
discount_rate: 割引率(0.1 なら10%引き)
with_shipping: 送料を含めるかどうか
Returns:
合計金額
"""
subtotal = sum(item["price"] * item["quantity"] for item in items)
discounted = subtotal * (1 - discount_rate)
if with_shipping and discounted < 5000:
discounted += 500
return discounted
def create_order(items):
return {
"items": items,
"total": calc_order_total(items, discount_rate=0.0, with_shipping=True),
}
def create_quote(items, discount_rate):
return {
"items": items,
"total": calc_order_total(items, discount_rate=discount_rate, with_shipping=False),
}
def preview_cart(items):
preview_total = calc_order_total(items, discount_rate=0.0, with_shipping=False)
print("カートの参考金額:", preview_total)同じロジックを複数箇所に分散して書くのではなく、共通部分を関数にまとめてから、用途ごとの差分だけを外側で指定することが重要です。
一歩進んだPython関数テクニック
ラムダ式とdefの使い分け
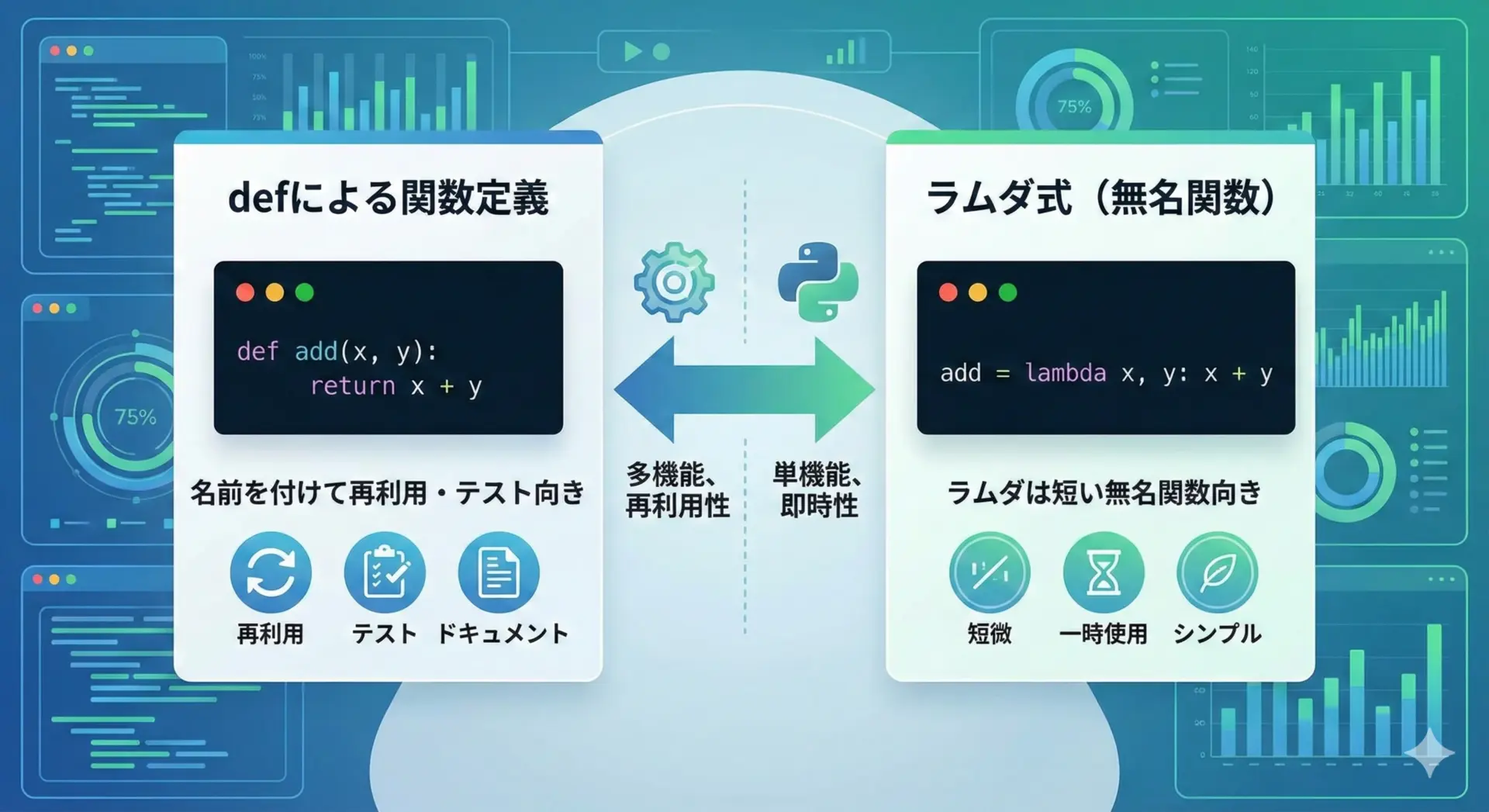
ラムダ式(lambda)は、1行で書ける小さな無名関数です。
構文は次のようになります。
# ラムダ式で足し算関数を定義(変数に代入)
add = lambda x, y: x + y
print(add(3, 5))8ただし、ラムダ式には次のような制限があります。
- 1行でしか書けない(複雑な処理には不向き)
- ドキュストリングや型ヒントが付けにくい
- デバッグやログで関数名がわかりにくい
そのため、ラムダ式は次のような場面に限定して使うのがおすすめです。
- 高階関数に渡す、短いコールバック(例:
sortedのキー関数) - 1回しか使わない簡単な変換関数
# 文字列リストを長さでソートする例
words = ["Python", "AI", "Data", "Function"]
# ラムダ式をkeyに指定
sorted_words = sorted(words, key=lambda w: len(w))
print(sorted_words)['AI', 'Data', 'Python', 'Function']少しでもロジックが複雑になる場合や、再利用したい場合は、迷わずdefで関数を定義した方が読みやすさ・保守性の面で有利です。
関数を引数にする高階関数

高階関数とは、関数を引数として受け取ったり、関数を戻り値として返す関数のことです。
Pythonでは、関数も「値」として扱えるため、次のような書き方ができます。
def apply_to_all(values, func):
"""リスト内のすべての要素にfuncを適用する"""
return [func(v) for v in values]
def square(x):
return x * x
def to_str(x):
return f"[{x}]"
numbers = [1, 2, 3, 4]
print(apply_to_all(numbers, square))
print(apply_to_all(numbers, to_str))[1, 4, 9, 16]
['[1]', '[2]', '[3]', '[4]']標準ライブラリにも、高階関数を前提とした関数がいくつかあります。
numbers = [1, 2, 3, 4, 5, 6]
# filter: 条件を満たす要素だけを残す
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
# map: 各要素に関数を適用
squared = list(map(lambda x: x * x, numbers))
print(even_numbers)
print(squared)[2, 4, 6]
[1, 4, 9, 16, 25, 36]ただし、Pythonでは内包表記の方が読みやすいことが多いため、mapやfilterよりもリスト内包表記を優先するのが一般的です。
デコレータで関数処理を拡張する
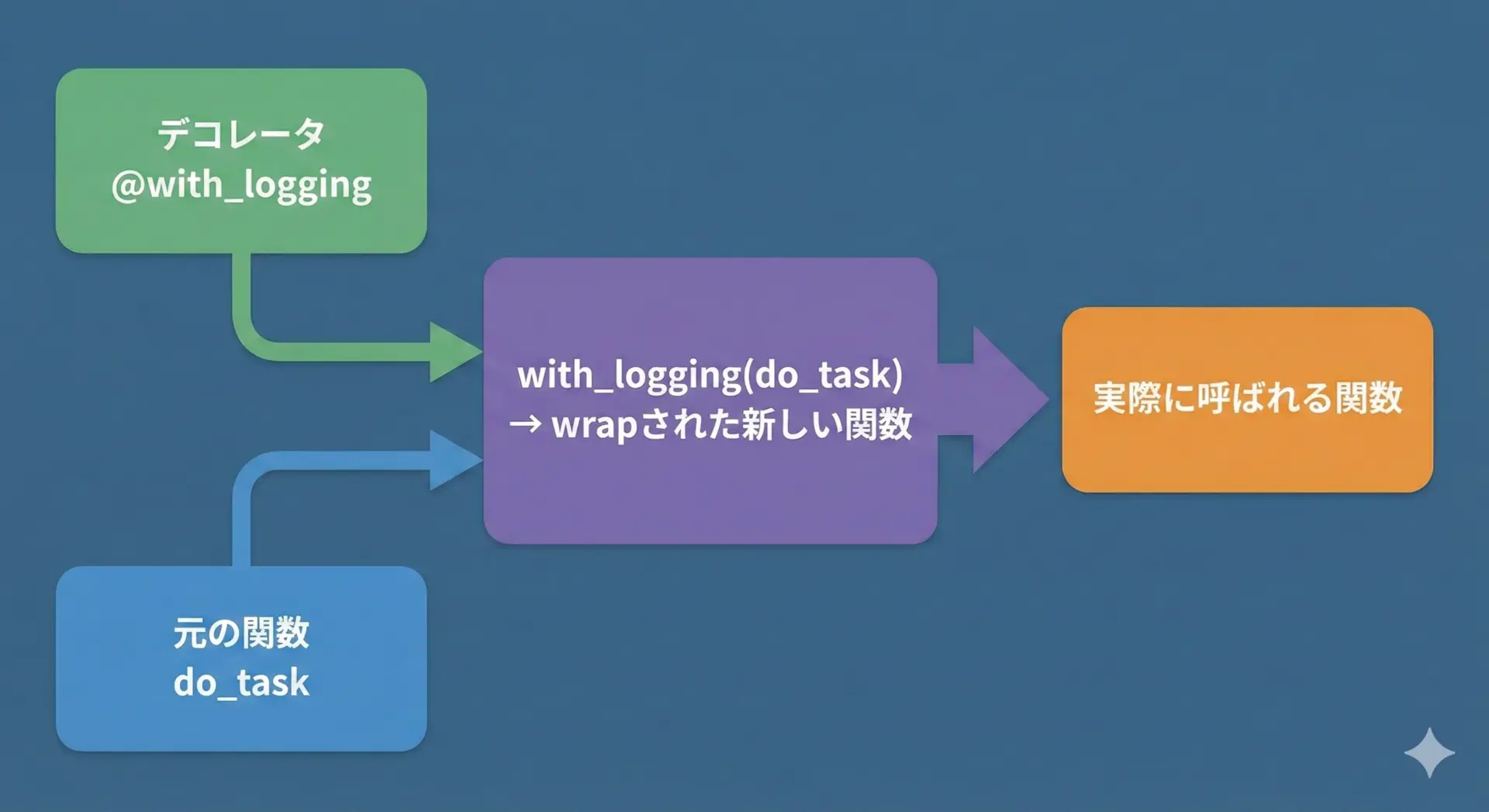
デコレータは、既存の関数に対して、前後処理などの共通ロジックを簡潔に追加するための仕組みです。
ログ出力や実行時間計測などでよく使われます。
import time
from functools import wraps
def timeit(func):
"""関数の実行時間を計測して表示するデコレータ"""
@wraps(func)
def wrapper(*args, **kwargs):
start = time.time()
try:
return func(*args, **kwargs)
finally:
elapsed = time.time() - start
print(f"{func.__name__} took {elapsed:.4f} seconds")
return wrapper
@timeit
def slow_task():
"""わざと時間のかかる処理"""
total = 0
for i in range(1_000_000):
total += i
return total
result = slow_task()
print("結果:", result)slow_task took 0.0XXX seconds
結果: 499999500000@timeitという1行を付けるだけで、その関数に「実行時間計測」の機能を追加できています。
実務では次のような用途がよくあります。
- ログ出力(
@log_execution) - リトライ制御(
@retry) - キャッシュ(
@lru_cacheなど標準ライブラリ) - 認可チェック(
@require_loginなどWebフレームワーク)
デコレータは少し難しく感じるかもしれませんが、「関数を受け取り、関数を返す高階関数」であるという視点から理解すると整理しやすくなります。
テストしやすい関数設計とユニットテスト
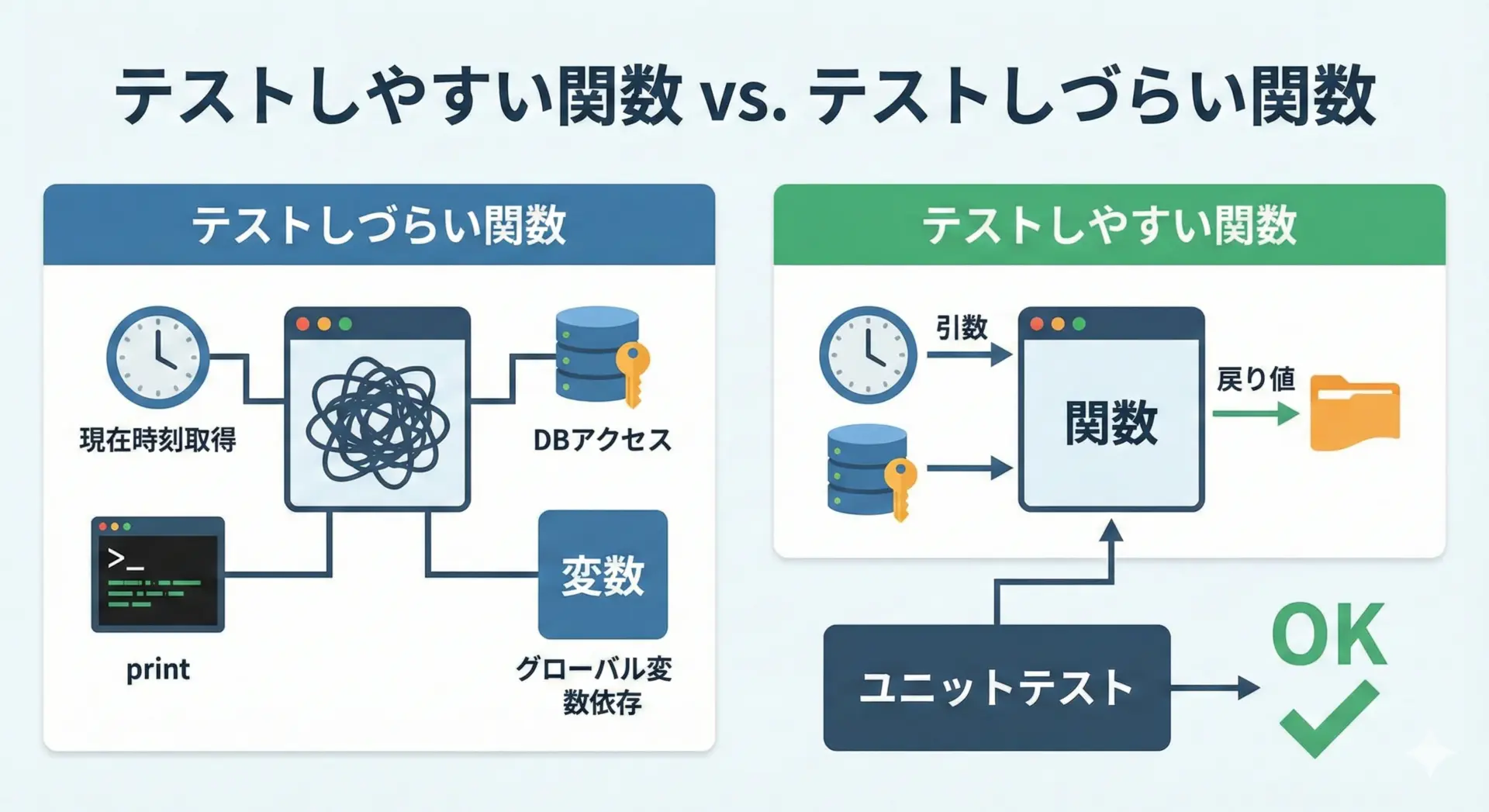
テストしやすい関数の特徴は、次のようにまとめられます。
- 入力(引数)と出力(戻り値)がはっきりしている
- グローバル変数や外部リソース(DB、API、現在時刻など)に直接依存しない
- 処理が1つの責務に絞られていて、シンプル
テストコードの例として、unittestを使った簡単なユニットテストを書いてみます。
# calculator.py
def add(a: int, b: int) -> int:
"""2つの整数を足し算する"""
return a + b
def divide(a: int, b: int) -> float:
"""a を b で割る。b が0のときは ValueError を投げる。"""
if b == 0:
raise ValueError("b must not be zero")
return a / b# test_calculator.py
import unittest
from calculator import add, divide
class TestCalculator(unittest.TestCase):
def test_add(self):
self.assertEqual(add(2, 3), 5)
self.assertEqual(add(-1, 1), 0)
def test_divide_normal(self):
self.assertAlmostEqual(divide(10, 2), 5.0)
def test_divide_zero(self):
with self.assertRaises(ValueError):
divide(10, 0)
if __name__ == "__main__":
unittest.main()...
----------------------------------------------------------------------
Ran 3 tests in 0.000s
OKこのように、関数の責務を小さくし、外部依存を減らすと、ユニットテストが書きやすくなり、結果として信頼性の高いコードになります。
まとめ
Pythonのdefによる関数定義は、単なる文法要素ではなく、読みやすく・変更に強く・テストしやすいコードを書くための中心的な道具です。
基本的な引数やreturnに始まり、デフォルト引数・可変長引数・ドキュストリング・型ヒントを押さえることで、実務レベルでも通用する関数を書けるようになります。
さらに、関数分割やユーティリティ化、高階関数やデコレータといったテクニックを身に付ければ、複雑な要件にも柔軟に対応できます。
日々のコーディングで意識的に関数設計を磨き、再利用性と保守性の高いPythonコードを目指していきましょう。
