
Pythonでリストや文字列を繰り返し処理するとき、「今何番目を処理しているか」と「その要素の中身」を同時に扱いたい場面はとても多いです。
こうした場面で威力を発揮するのがenumerate関数です。
本記事では、enumerateの基本から実践テクニック、ベストプラクティスまで、実務レベルで迷わない使い方を丁寧に解説します。
enumerateとは
enumerateの役割とメリット

Pythonのenumerateは、「イテラブル(リストやタプル、文字列など)にインデックスを自動で付けてくれる仕組み」です。
通常のforループでは要素だけを取り出しますが、enumerateを使うと、インデックスと要素をセットで受け取ることができます。
これにより、次のようなメリットがあります。
1つ目は、インデックス用の変数を手作業で管理する必要がなくなることです。
カウンタ変数を初期化したり、ループの最後でi += 1と書く必要がなくなります。
2つ目は、コードの意図が分かりやすくなり、バグを防ぎやすくなることです。
enumerateという名前を見るだけで、「インデックス付きでイテレートしている」ことが一目で伝わります。
rangeとの違いと使い分け
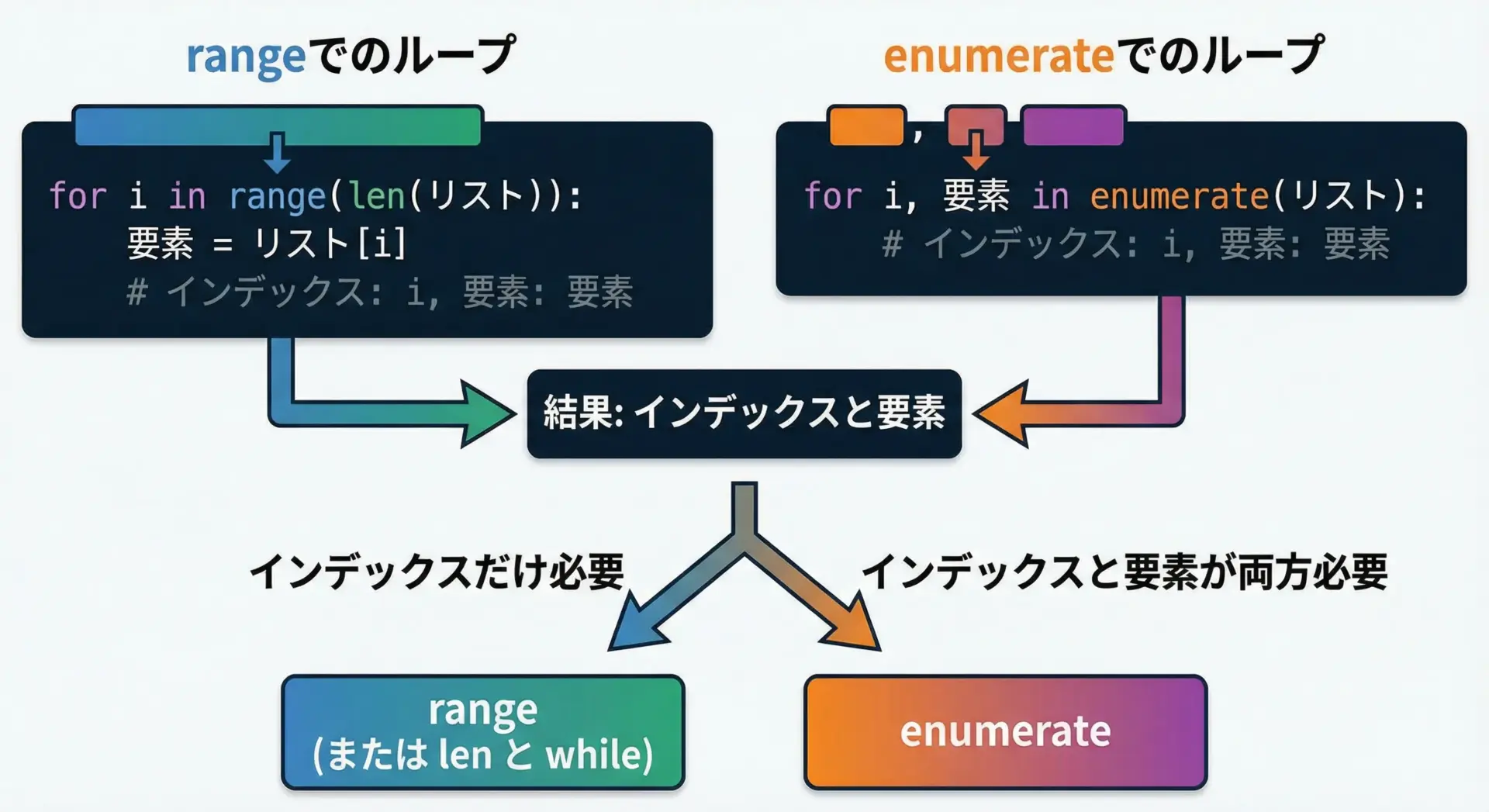
Pythonでは、インデックスを扱う方法としてrangeもよく使われます。
例えば次のようなコードです。
fruits = ["apple", "banana", "cherry"]
for i in range(len(fruits)):
print(i, fruits[i])これに対してenumerateを使うと、次のように書けます。
fruits = ["apple", "banana", "cherry"]
for i, fruit in enumerate(fruits):
print(i, fruit)どちらも同じ結果になりますが、役割の違いを整理すると次のようになります。
| 目的 | 使うもの | 向いているケース |
|---|---|---|
| 連番や範囲の数字だけが欲しい | range | 0〜9まで繰り返す、インデックスは使うが配列は別で参照する場合 |
| インデックスと要素を同時に使いたい | enumerate | リストやタプルの要素を処理しつつ、その位置も使いたい場合 |
インデックスだけが必要ならrange、インデックスと要素の両方が必要ならenumerate、という使い分けを覚えておくとよいです。
enumerateの基本構文
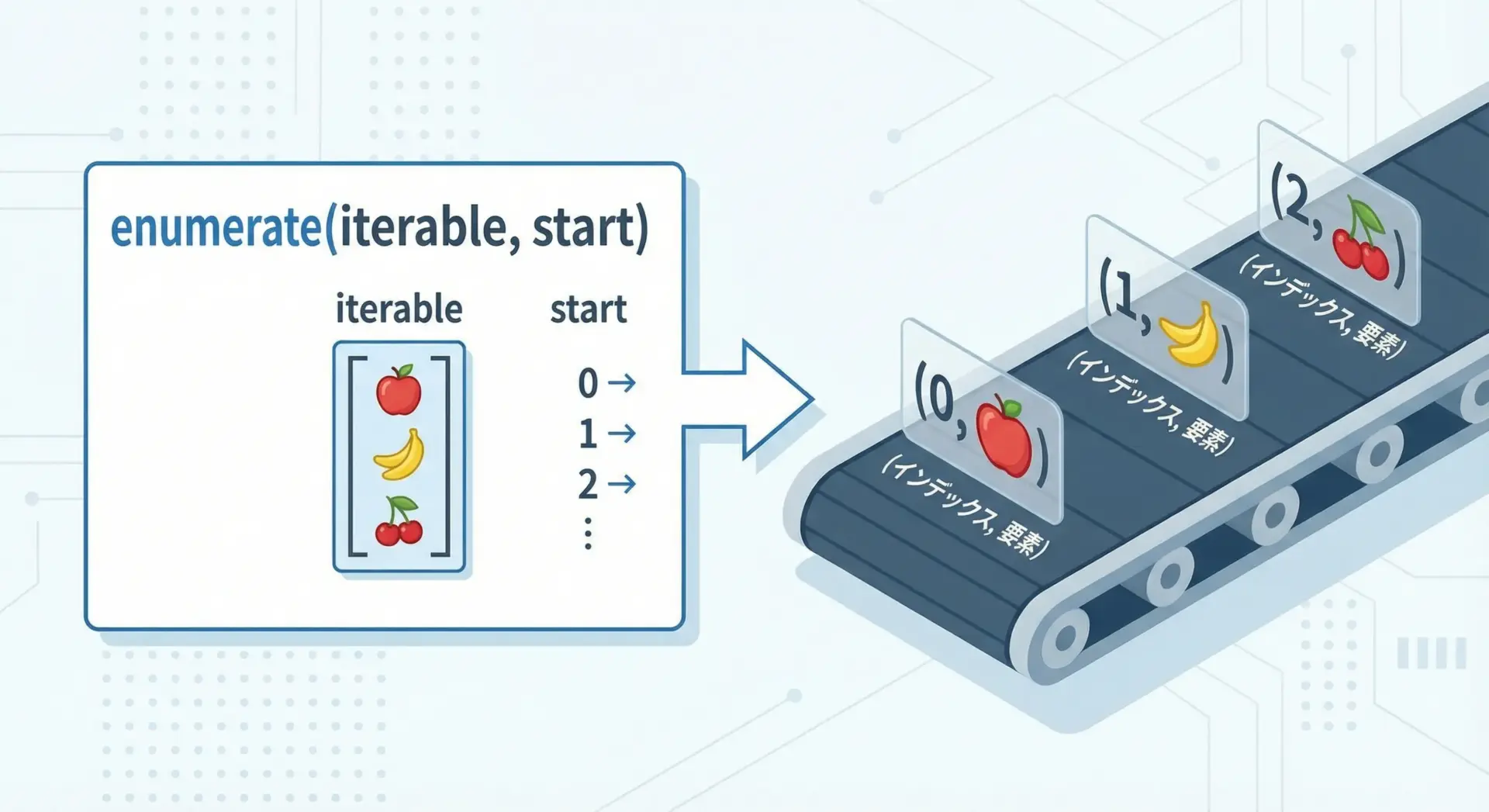
enumerateの基本構文はとてもシンプルです。
enumerate(イテラブル, start=0)主な引数は2つだけです。
1つ目の引数イテラブルには、リストやタプル、文字列など、繰り返し処理できるオブジェクトを渡します。
2つ目の引数startは省略可能で、インデックスの開始値を指定します。
省略した場合は0から始まります。
enumerateの戻り値は、「(インデックス, 要素)のタプルを順番に返すイテレータ」です。
forループの中でこの2つを同時に受け取って使います。
Pythonのenumerateの基本的な使い方
インデックスと要素を同時に取得する基本パターン
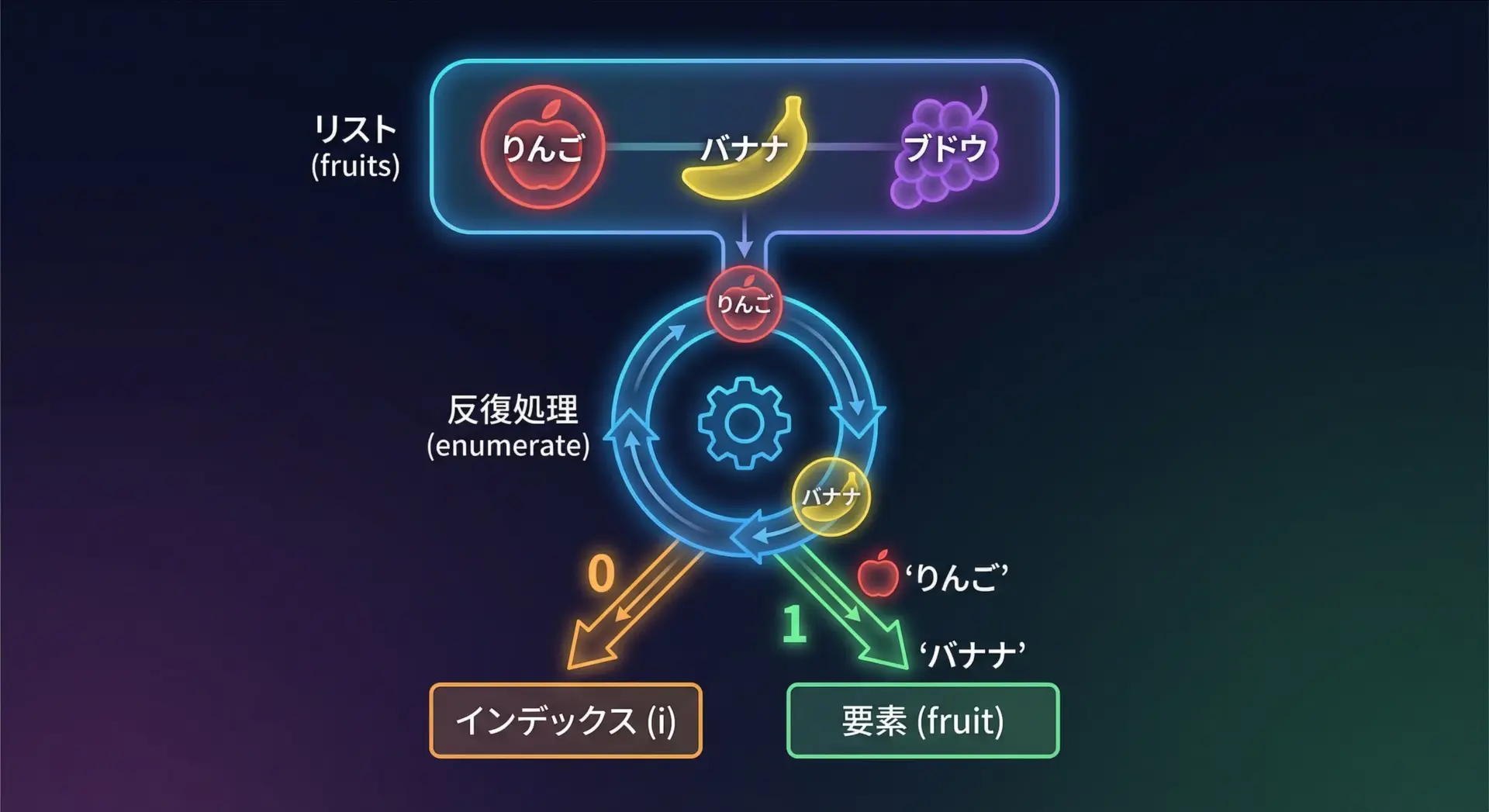
もっとも基本的な使い方は、forループの中でインデックスと要素を同時に受け取るパターンです。
fruits = ["apple", "banana", "cherry"]
# enumerateを使ってインデックスと要素を同時に取り出す
for index, fruit in enumerate(fruits):
# indexには0, 1, 2...が入る
# fruitには"apple", "banana", "cherry"...が入る
print(index, fruit)0 apple
1 banana
2 cherryこのように、インデックスも要素も必要なループは、まずenumerateを検討する、という習慣を持つとPythonらしいコードになります。
start引数でインデックスの開始値を変更する

レポートやログ出力などでは、インデックスを1から始めたいことがよくあります。
そのようなときはstart引数を使います。
students = ["Alice", "Bob", "Charlie"]
# 出席番号を1から振りたい場合
for number, name in enumerate(students, start=1):
# number: 1, 2, 3...
# name: "Alice", "Bob", "Charlie"...
print(f"{number}番: {name}")1番: Alice
2番: Bob
3番: Charlieこのように、プログラム内部では0始まり、ユーザーに見せる番号は1始まりとしたいときなどに、start引数が役立ちます。
タプルのアンパックでコードを読みやすくする
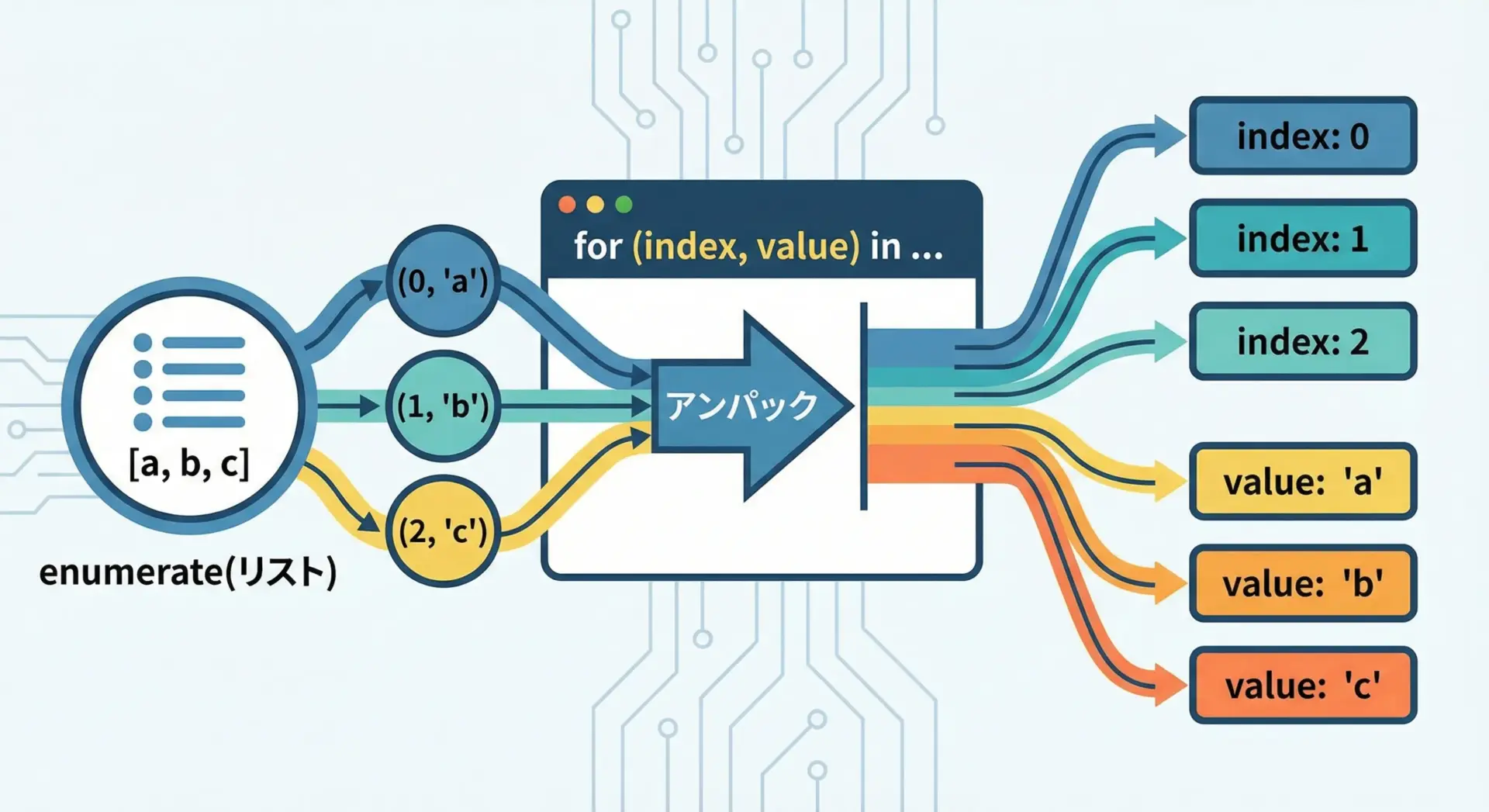
enumerateが返すのはタプルです。
そのため、forループのヘッダ部分で、タプルのアンパックを利用してインデックスと要素を分けて受け取ります。
languages = ["Python", "Java", "C++"]
# (index, lang) ← ここでタプルをアンパックしている
for index, lang in enumerate(languages):
print(f"index={index}, lang={lang}")index=0, lang=Python
index=1, lang=Java
index=2, lang=C++もしアンパックを使わず、タプルのまま受け取ると次のようになります。
languages = ["Python", "Java", "C++"]
for pair in enumerate(languages):
# pair は (index, lang) のタプル
print(pair)(0, 'Python')
(1, 'Java')
(2, 'C++')しかしこの書き方では、あとでpair[0]やpair[1]とインデックス指定する必要があり、可読性が下がります。
基本的にはアンパックして2つの変数に分ける書き方が推奨です。
enumerateの実践テクニック
list(range(len()))をenumerateで置き換えるリファクタリング

Python初心者がよく書いてしまうパターンとして、次のようなコードがあります。
fruits = ["apple", "banana", "cherry"]
# よくあるが、やや冗長な書き方
for i in range(len(fruits)):
fruit = fruits[i]
print(i, fruit)このコードは、次のようにenumerateを使ってリファクタリングできます。
fruits = ["apple", "banana", "cherry"]
# enumerateを使ったPythonicな書き方
for i, fruit in enumerate(fruits):
print(i, fruit)出力はいずれも同じです。
0 apple
1 banana
2 cherry「list(range(len(x))) と書いていたら、まずenumerateを疑う」という意識を持つと、よりPythonらしいコードになります。
ネストしたループでのenumerateの使い方
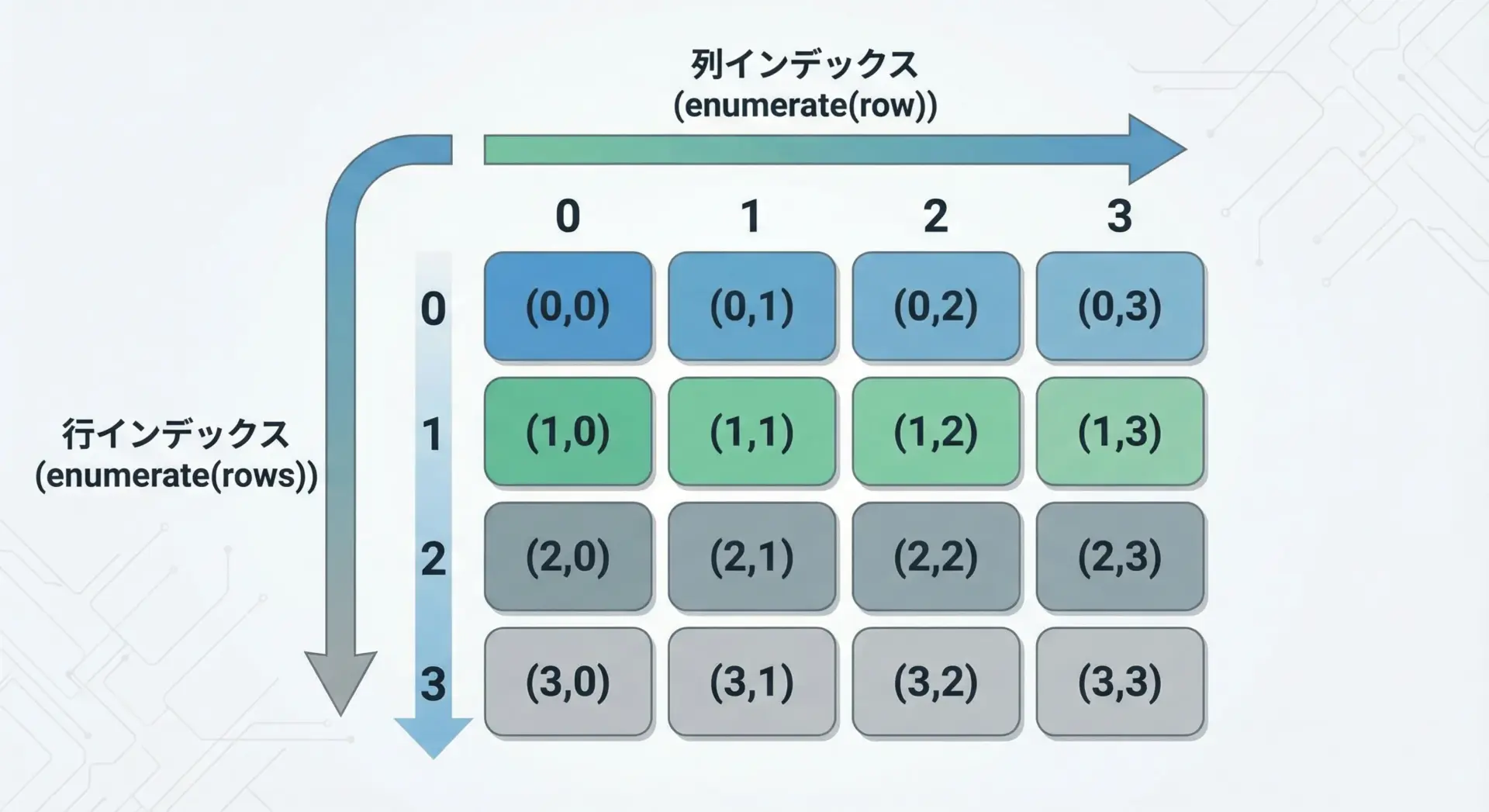
2次元リストなど、ネストしたループでもenumerateは有効です。
例えば、行列の中身を「行番号・列番号付き」で表示したい場合を考えます。
matrix = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
]
# 行番号と列番号をそれぞれenumerateで取得
for row_index, row in enumerate(matrix):
for col_index, value in enumerate(row):
print(f"row={row_index}, col={col_index}, value={value}")row=0, col=0, value=1
row=0, col=1, value=2
row=0, col=2, value=3
row=1, col=0, value=4
row=1, col=1, value=5
row=1, col=2, value=6
row=2, col=0, value=7
row=2, col=1, value=8
row=2, col=2, value=9このように、多次元構造でも各レベルでenumerateを使うことで、位置情報を明確に管理できます。
条件分岐(if)と組み合わせたインデックス付きループ

enumerateは、特定の条件を満たす要素がどの位置にあるかを調べたいときにも便利です。
numbers = [3, 8, 15, 2, 10, 7]
# 値が10以上の要素のインデックスと値を出力する
for index, value in enumerate(numbers):
if value >= 10: # 条件
print(f"index={index}, value={value}")index=2, value=15
index=4, value=10また、最初に条件を満たす要素の位置だけが知りたい場合は、breakと組み合わせることもあります。
numbers = [3, 8, 15, 2, 10, 7]
found_index = None
for index, value in enumerate(numbers):
if value >= 10:
found_index = index
break # 最初に見つかった位置でループを抜ける
print(found_index)2このように、「条件にマッチした要素の位置」を手軽に取得できるのもenumerateの大きな利点です。
辞書やセットとenumerateを組み合わせる実践例
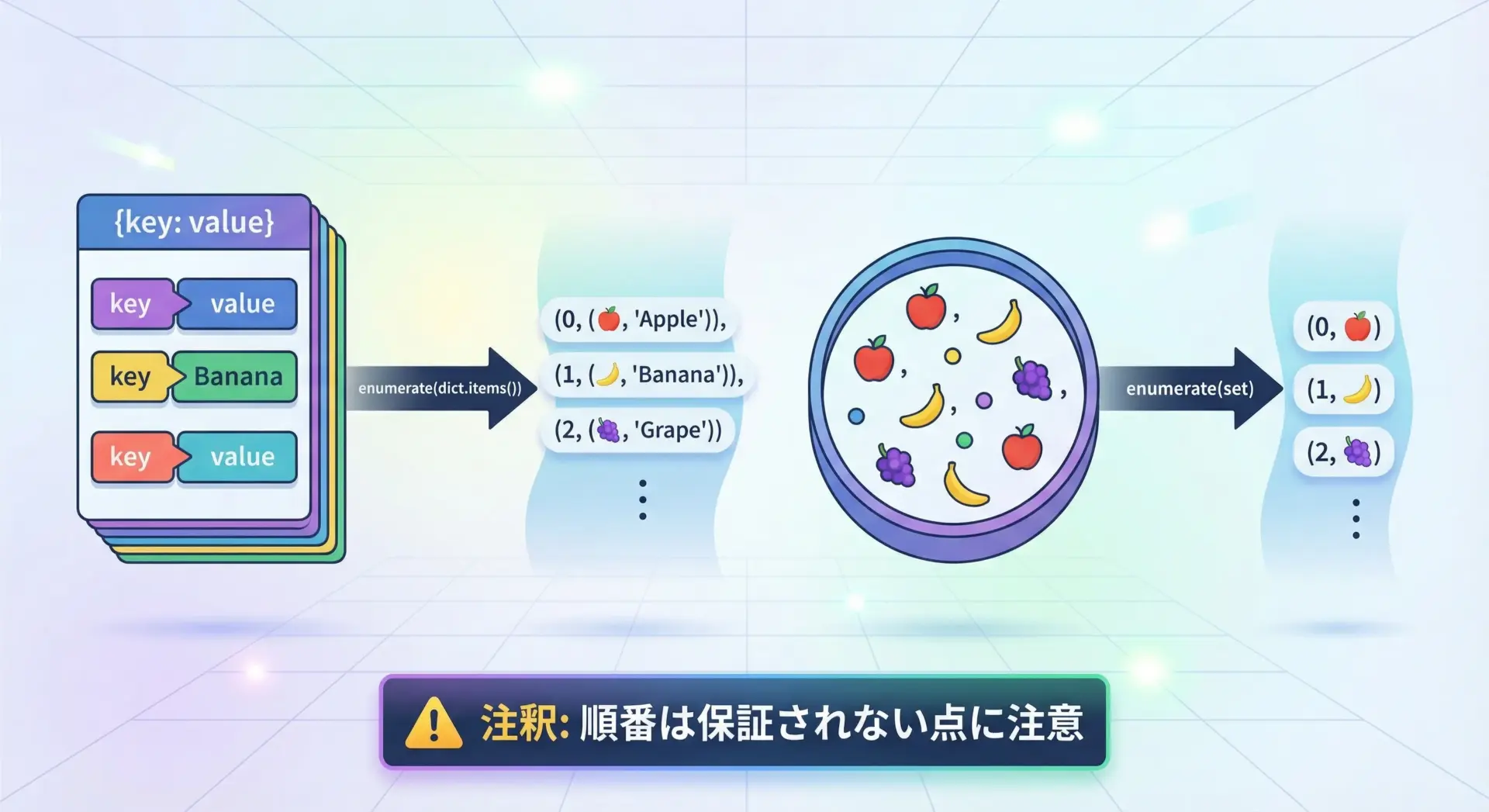
enumerateはリスト以外のイテラブルにも使えます。
辞書やセットと組み合わせる例を見てみます。
辞書(dict)とenumerate
辞書はキーと値のペアを持ちますが、そのペアに番号を振りたい場合があります。
scores = {"Alice": 85, "Bob": 92, "Charlie": 78}
# items() で (key, value) のペアを取り出し、それに対してenumerateを使う
for idx, (name, score) in enumerate(scores.items(), start=1):
print(f"{idx}. {name}: {score}")出力例(順番は辞書の実装依存ですが、Python 3.7以降は基本的に挿入順):
1. Alice: 85
2. Bob: 92
3. Charlie: 78ここでは、for idx, (name, score) in ...のように、ネストしたタプルのアンパックを行っている点がポイントです。
セット(set)とenumerate
セットにもenumerateは使えますが、セットは順序を持たない集合である点に注意が必要です。
番号を振ることはできますが、その順序に意味はありません。
tags = {"python", "enumerate", "loop"}
for idx, tag in enumerate(tags, start=1):
print(f"{idx}: {tag}")出力例(順序は毎回変わる可能性があります):
1: loop
2: python
3: enumerate「順番に意味を持たせたいときはリスト」「順番が不要なときはセット」という前提を忘れないようにすると、enumerateと集合型を安全に組み合わせられます。
リスト内包表記とenumerateでスマートに変換する
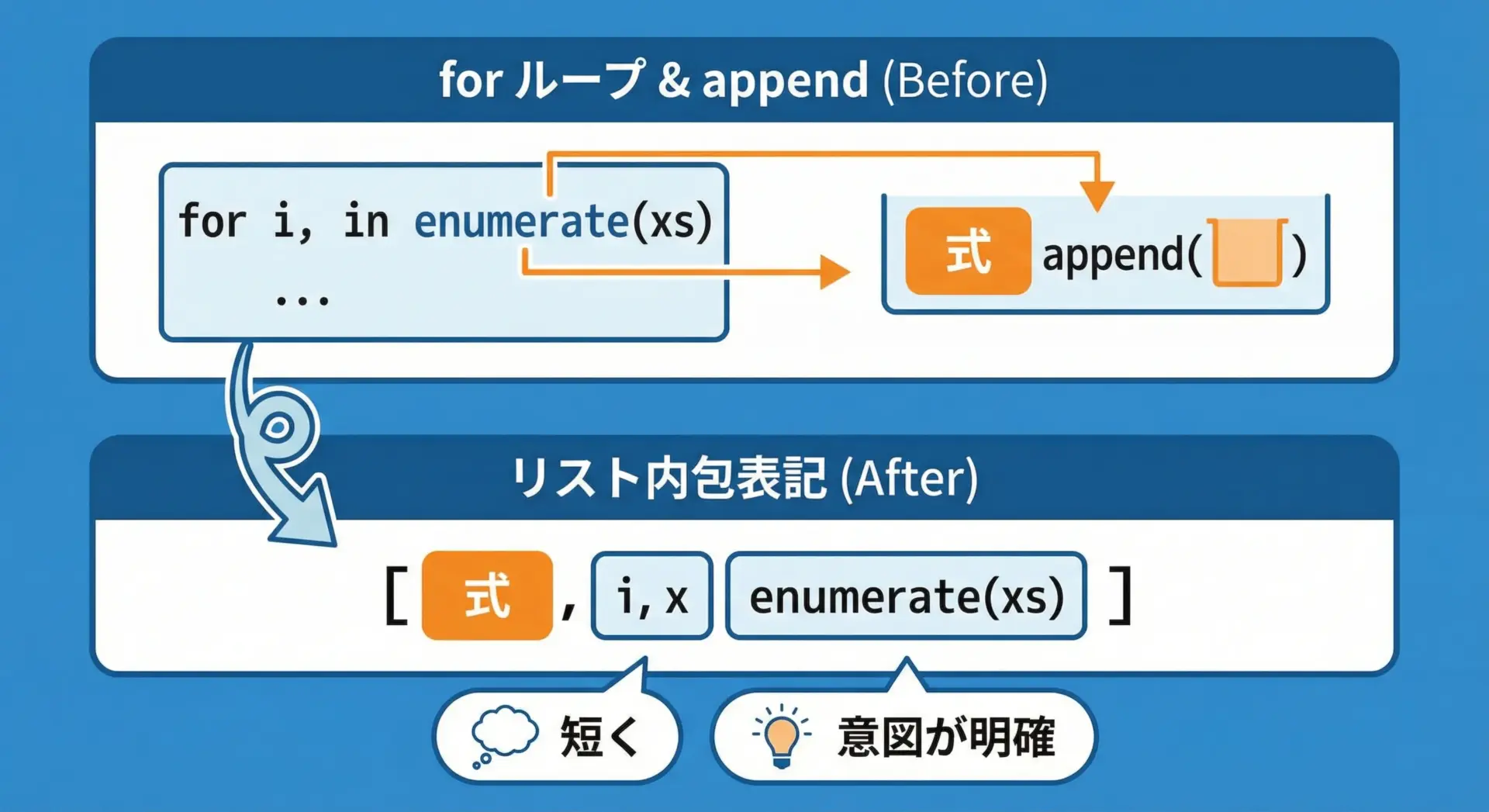
enumerateはリスト内包表記と組み合わせても便利です。
例えば、インデックス付きの文字列に変換するケースを考えます。
fruits = ["apple", "banana", "cherry"]
# 通常のforループで新しいリストを作る
labeled = []
for i, fruit in enumerate(fruits, start=1):
labeled.append(f"{i}: {fruit}")
print(labeled)['1: apple', '2: banana', '3: cherry']これと同じ処理は、リスト内包表記を使えば次のように書けます。
fruits = ["apple", "banana", "cherry"]
# リスト内包表記 + enumerate で1行にまとめる
labeled = [f"{i}: {fruit}" for i, fruit in enumerate(fruits, start=1)]
print(labeled)出力結果は同じです。
['1: apple', '2: banana', '3: cherry']処理内容が単純で、一目で意図が読み取れる場合は、このようにenumerateとリスト内包表記を組み合わせると、よりコンパクトでPythonicなコードになります。
enumerateを使う際の注意点とベストプラクティス
インデックスが必要ない時はenumerateを使わない
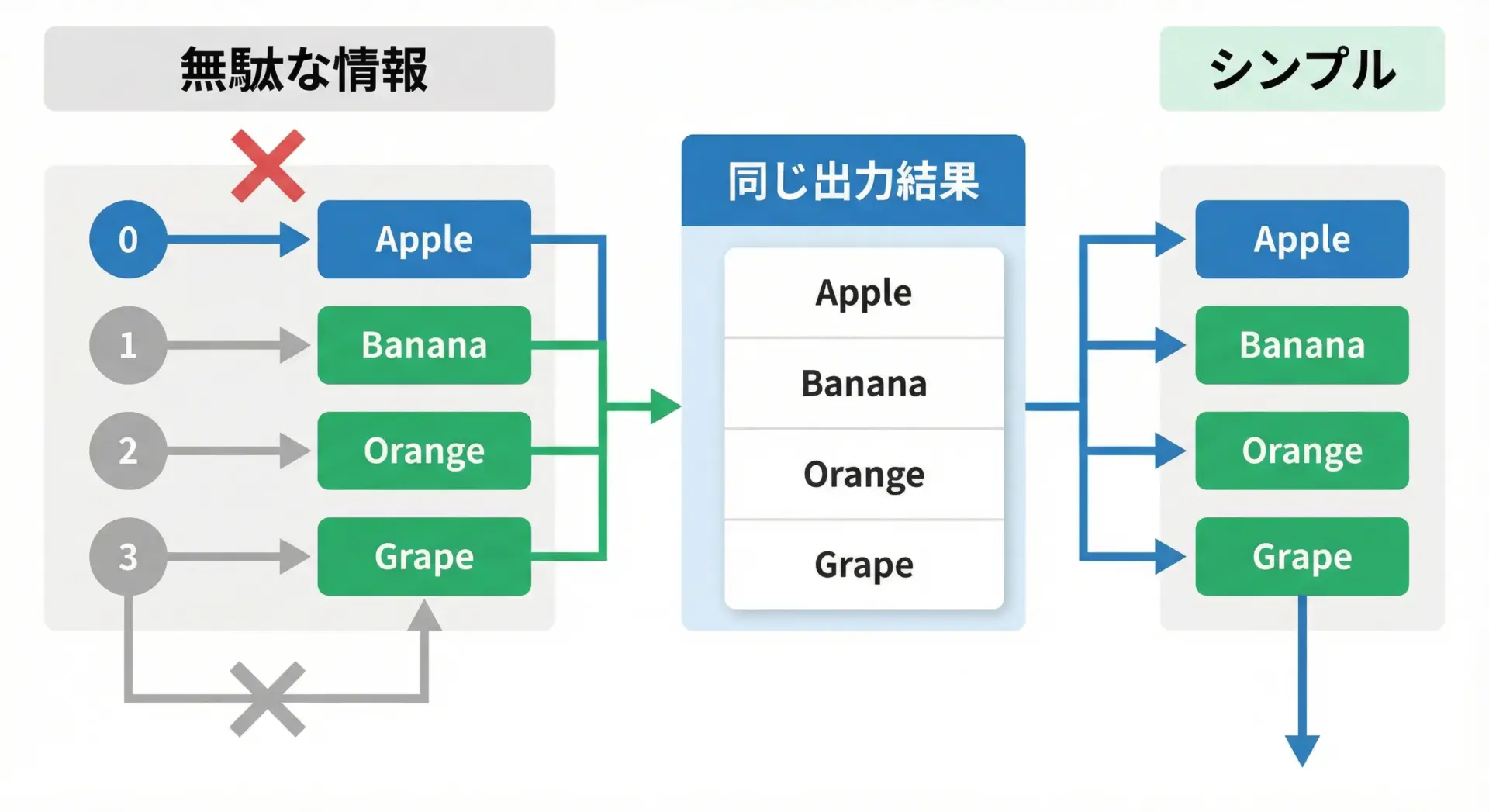
enumerateは便利ですが、インデックスを使わないのにenumerateを使うのは逆効果です。
例えば次のようなコードは避けるべきです。
fruits = ["apple", "banana", "cherry"]
# indexをまったく使っていないのにenumerateしている悪い例
for index, fruit in enumerate(fruits):
print(fruit)この場合、インデックスは不要なので、通常のforループで十分です。
fruits = ["apple", "banana", "cherry"]
# シンプルで読みやすい良い例
for fruit in fruits:
print(fruit)「本当にインデックスが必要か」を自問してからenumerateを使うことで、無駄のないコードになります。
可読性を上げるための変数名の付け方
enumerateを使うとき、変数名の付け方も重要です。
名前から役割が分かるように付けると、コードの可読性が大きく向上します。
悪い例:
data = ["Alice", "Bob", "Charlie"]
for i, x in enumerate(data):
print(i, x)このコードでは、iやxが何を表しているかが分かりにくいです。
良い例:
users = ["Alice", "Bob", "Charlie"]
for index, name in enumerate(users, start=1):
print(f"{index}: {name}")このように、indexやnameのような意味のある名前を付けることで、コードを読む人にとって理解しやすくなります。
特に、次のような名前はよく使われます。
| 用途 | 変数名の例 |
|---|---|
| インデックス | index, idx, i |
| 要素(一般) | item, value |
| 特定のドメイン | user, row, name など具体的な意味のある名前 |
抽象的な名前より、できるだけ具体的な名前を選ぶことが、長期的なメンテナンス性を高めてくれます。
enumerateを使ったPythonicな書き方のまとめ

enumerateを使いこなす上でのポイントを簡潔にまとめます。
まず、インデックスと要素を同時に扱う場面ではenumerateを優先して使うのが良い習慣です。
従来のfor i in range(len(seq))という書き方は、Pythonではあまり推奨されません。
次に、インデックスが最初から1始まりで必要な場合は、ためらわずstart引数を使うとコードがすっきりします。
出席番号や行番号など、人間に見せる番号に特に有効です。
さらに、タプルのアンパックを使って、インデックスと要素を明確な名前の変数に分けて受け取ることで、意図がはっきりしたPythonicなコードになります。
辞書のitems()など、ネストしたタプルも積極的にアンパックしましょう。
最後に、「インデックスが本当に必要か」を常に意識し、不要なときはenumerateを使わないことも重要です。
シンプルで読みやすいコードこそが、Pythonらしい美しいコードといえます。
まとめ
enumerateは、Pythonにおける「インデックス付きループ」の標準解といえる存在です。
インデックスと要素を同時に扱うシーンでは、rangeとlenの組み合わせよりも、enumerateを使った方がコードは短く、意図も明確になります。
start引数で開始値を変更したり、タプルのアンパックと組み合わせることで、さらに読みやすく表現できます。
インデックスが必要なときだけenumerateを使い、変数名にも意味を持たせることで、Pythonicで保守しやすいコードを自然と書けるようになります。
