Pythonで多数のオブジェクトを扱う場合、1インスタンスあたりのメモリ使用量は無視できない問題になります。
本記事では、クラス設計の段階から__slots__を活用してメモリを削減するテクニックを体系的に解説します。
通常クラスとの違い、継承やdataclassとの組み合わせ、導入判断の基準まで、実戦で迷いやすいポイントを具体例とともに整理します。
__slots__とは何か
Pythonの__slots__とは
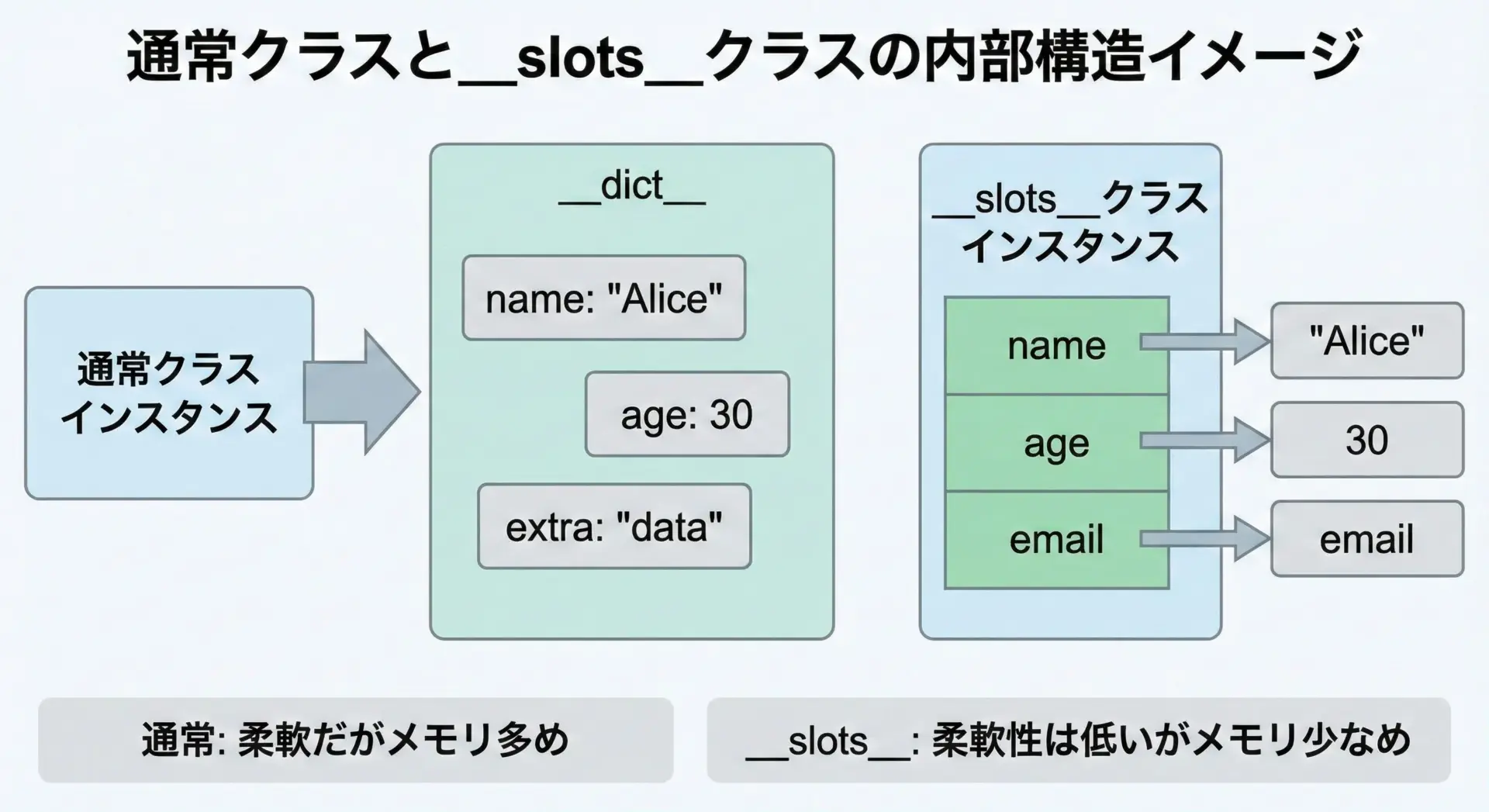
Pythonのクラスでは、通常インスタンスごとに__dict__が作られ、属性名をキーとした辞書として値が格納されます。
これに対して__slots__は、クラス定義時に「このクラスのインスタンスが持てる属性名を事前に列挙する仕組み」です。
クラスの中で次のように__slots__を指定すると、その属性以外は原則としてインスタンスに追加できなくなり、インスタンスは__dict__を持たない特殊なレイアウトになります。
class User:
__slots__ = ("name", "age") # この2つ以外の属性は追加できない
def __init__(self, name: str, age: int) -> None:
self.name = name
self.age = ageこの制約の代わりに、インスタンスごとのメモリ使用量を抑えたり、属性アクセスが高速になることがあります。
通常のクラス(dictベース)との違い
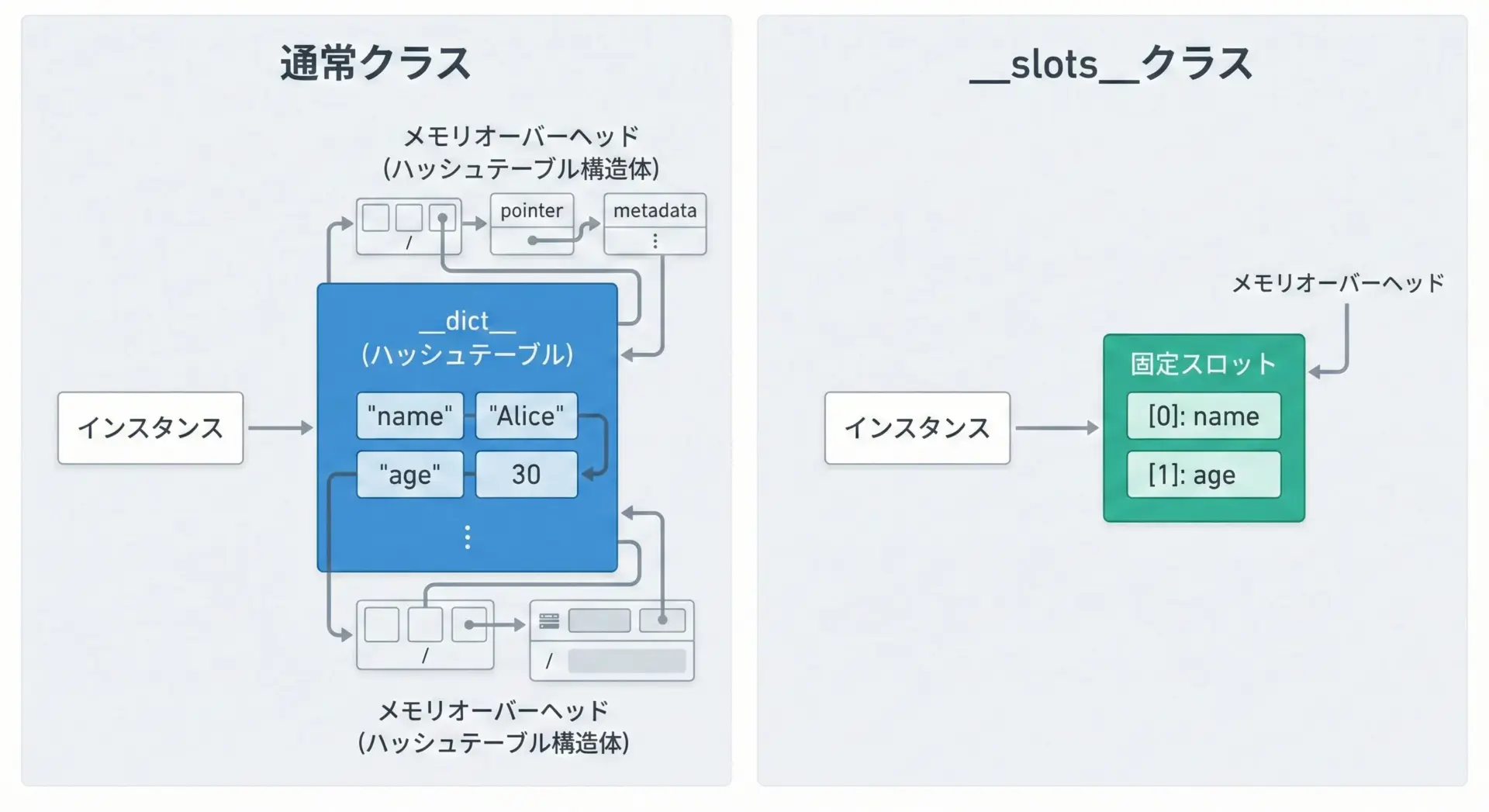
通常のクラスと__slots__を利用したクラスの主な違いを整理します。
インスタンスの内部構造の違い
通常クラスでは、各インスタンスは次のような構造を持ちます。
- インスタンス本体(型情報など)
- インスタンス属性を保持する
__dict__(辞書オブジェクト) - 必要なら
__weakref__
__dict__はハッシュテーブル構造を持つため柔軟ですが、属性数が少なくても一定のオーバーヘッドがあります。
一方__slots__付きクラスでは、インスタンスは固定長の「スロット」として属性値を保持し、原則として__dict__を持ちません。
そのため、属性名やハッシュテーブルに伴うオーバーヘッドが省かれます。
動的な属性追加可否の違い
通常クラスでは、どのタイミングでも新しい属性を追加できます。
class NormalUser:
def __init__(self, name: str) -> None:
self.name = name
u = NormalUser("Alice")
u.age = 30 # 後から自由に追加できる__slots__を定義したクラスでは、定義済みのスロット以外の属性を追加しようとするとAttributeErrorになります。
class SlottedUser:
__slots__ = ("name",)
def __init__(self, name: str) -> None:
self.name = name
u = SlottedUser("Alice")
u.age = 30 # AttributeError: 'SlottedUser' object has no attribute 'age'__slots__によるメモリ削減の概要
__slots__のメモリ削減効果は、特に「同じクラスのインスタンスを大量に生成する場合」に顕著です。
1インスタンスあたり数十バイト〜百数十バイトの差が、数十万〜数百万インスタンス規模になると、数十MB〜数百MBの差として効いてきます。
簡単な実験コードのイメージを示します。
import sys
class NormalPoint:
def __init__(self, x: float, y: float) -> None:
self.x = x
self.y = y
class SlottedPoint:
__slots__ = ("x", "y")
def __init__(self, x: float, y: float) -> None:
self.x = x
self.y = y
p1 = NormalPoint(1.0, 2.0)
p2 = SlottedPoint(1.0, 2.0)
print("NormalPoint size:", sys.getsizeof(p1))
print("SlottedPoint size:", sys.getsizeof(p2))出力例(実際の値はPythonの実装や環境により異なります)。
NormalPoint size: 48
SlottedPoint size: 48この差に加え、通常クラスではインスタンスごとに__dict__オブジェクト自体(内部配列を含む)も必要になるため、実際のメモリ差はさらに大きくなります。
__slots__の書き方とclass設計
単一クラスでの__slots__の基本的な定義方法
最も基本的なパターンは、クラス定義の直下で__slots__にタプルまたはリストで属性名を列挙する方法です。
class Point:
# このクラスのインスタンスは x, y 属性だけを持つ
__slots__ = ("x", "y") # タプルで指定するのが一般的
def __init__(self, x: float, y: float) -> None:
# __slots__で定義した属性にだけ代入できる
self.x = x
self.y = y
def move(self, dx: float, dy: float) -> None:
self.x += dx
self.y += dy定義時の注意点
- 属性名は
文字列で書きます。 - 重複する属性名を入れないようにします。
- 慣習としてタプルで書くケースが多いですが、リストでも動作します。
- スロット名に
"__dict__"や"__weakref__"を含める特別なケースもあります(後述)。
継承クラスと__slots__の組み合わせ方
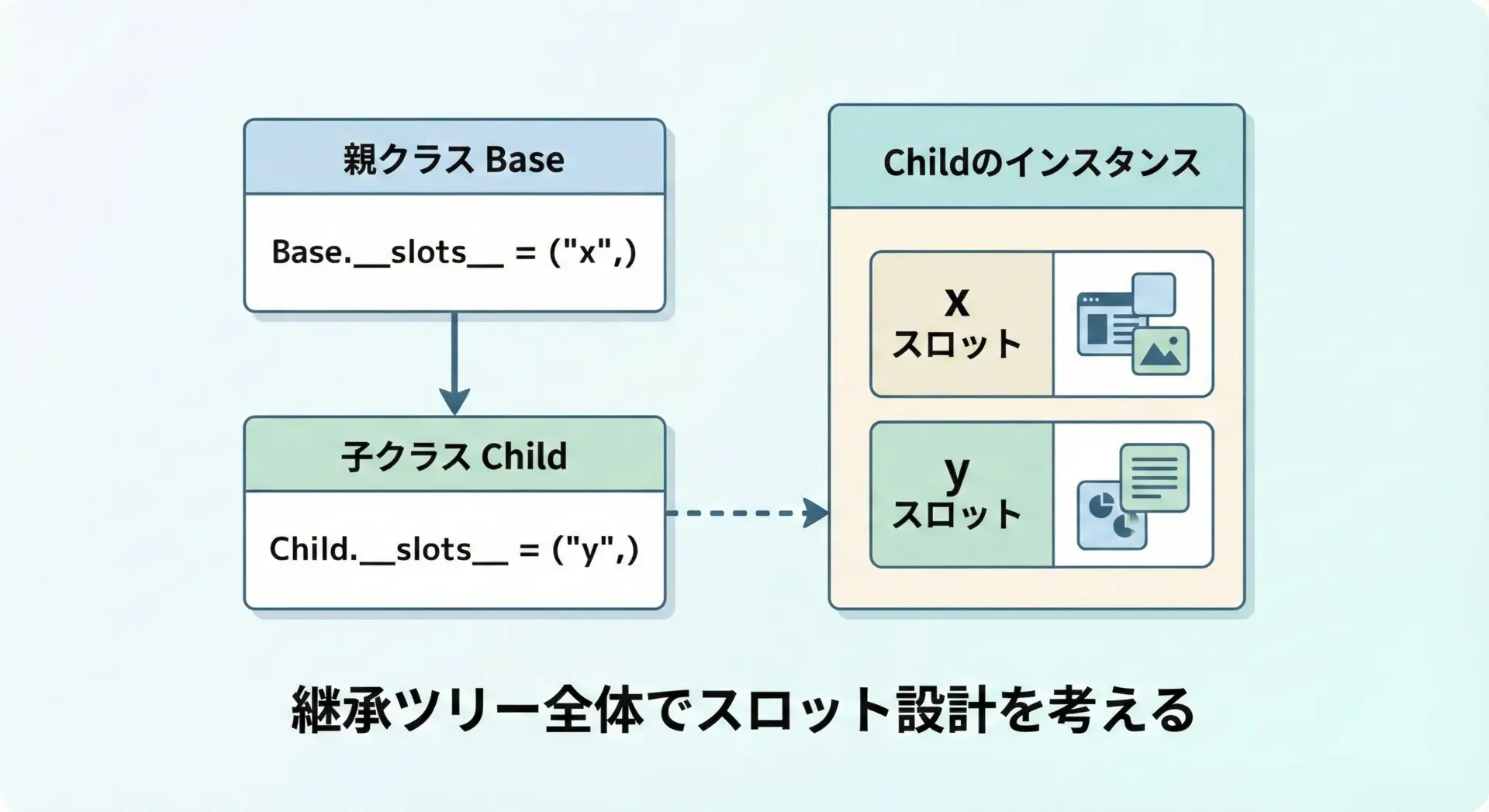
継承を伴うと__slots__の設計は少し複雑になります。
ポイントは親クラスと子クラスそれぞれで__slots__を定義し、全体として持てる属性名を管理することです。
親子両方で__slots__を定義する例
class Base:
__slots__ = ("x",)
def __init__(self, x: int) -> None:
self.x = x
class Child(Base):
__slots__ = ("y",)
def __init__(self, x: int, y: int) -> None:
super().__init__(x)
self.y = yこの場合、Childインスタンスはxとyの2つのスロットを持ちます。
親クラスと子クラスがそれぞれ固定スロットを持ち、インスタンスはそれらを合成したメモリレイアウトになります。
親に__slots__がなく、子だけに定義した場合
class Base:
# __slots__ を定義していない
def __init__(self, x: int) -> None:
self.x = x
class Child(Base):
__slots__ = ("y",)この場合、Baseが__dict__を持っているため、Childインスタンスも__dict__を持ちます。
__slots__で節約されるのはChildで追加した部分だけです。
しっかりメモリ削減したい場合は、継承階層の上から順に__slots__を導入することが重要です。
多重継承時の注意点
多重継承で__slots__を使うと、スロットの解決規則やメモリレイアウトがさらに複雑になります。
原則として多重継承と__slots__の組み合わせは慎重に検討するべきで、必要性が高い場合以外は避ける設計も選択肢です。
dataclassと__slots__を併用する方法

Python 3.10以降では、@dataclassと__slots__を非常に簡単に併用できます。
Python 3.10以降: slots=True を使う
from dataclasses import dataclass
@dataclass(slots=True)
class Point:
x: float
y: floatこの指定により、dataclassが自動的に__slots__を生成し、通常のdataclassよりメモリ効率の良いインスタンスになります。
属性はフィールド定義に限定され、動的な属性追加はできなくなります。
それ以前のバージョンでのパターン
Python 3.9以前では、@dataclassと手動__slots__を組み合わせるパターンが使われていました。
from dataclasses import dataclass
@dataclass
class Point:
__slots__ = ("x", "y")
x: float
y: floatただし実装の細かい挙動や将来の互換性を考えると、可能ならPython 3.10以降のslots=Trueを使うことをおすすめします。
__slots__とプロパティ(property)の設計ポイント
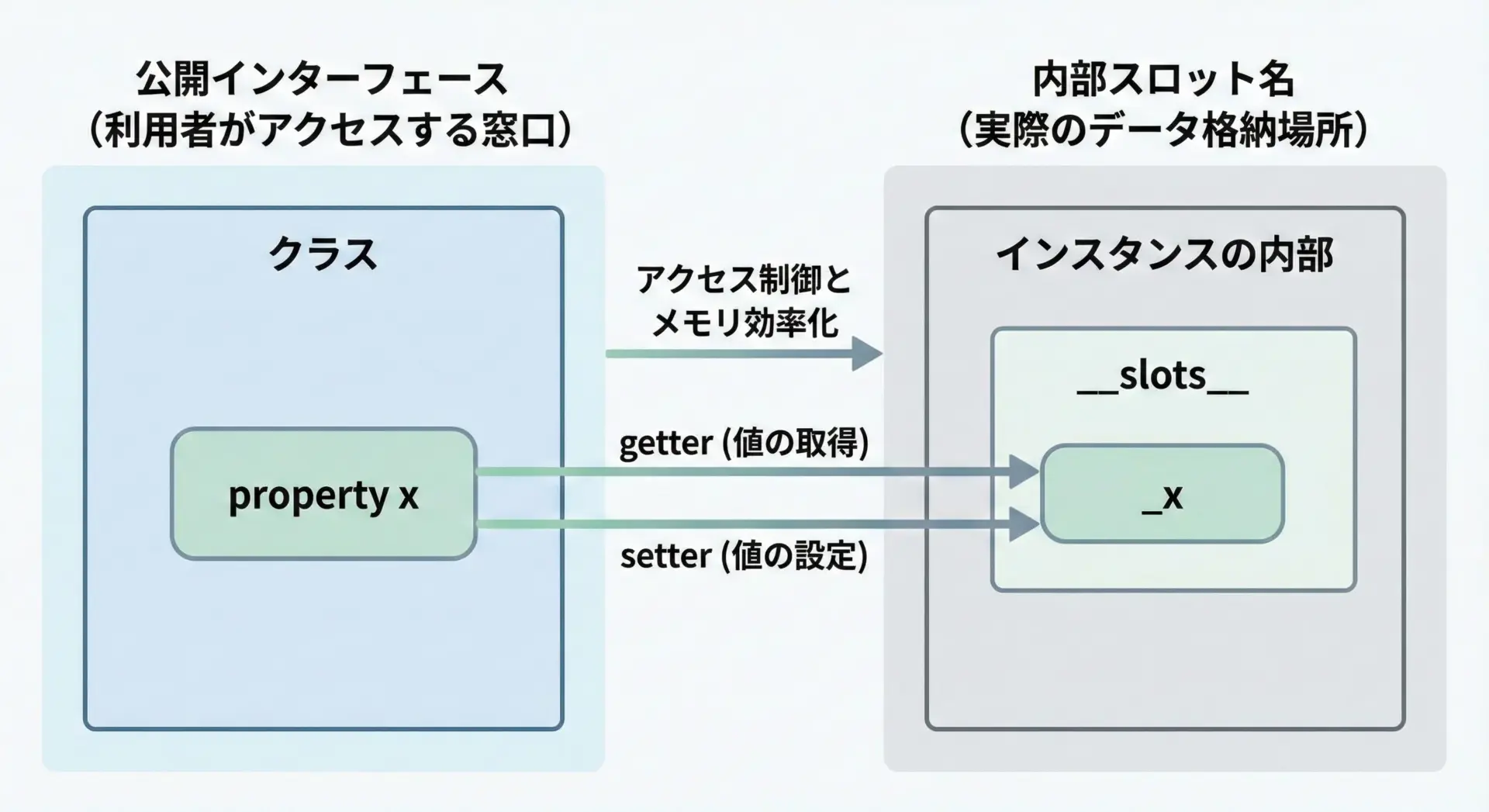
__slots__とpropertyは非常に相性が良く、クリーンなAPIと効率的な内部表現を両立できます。
内部名と公開名を分ける
次のように、実際のスロット名は"_x"とし、propertyでxという公開インターフェースを提供するのが定石です。
class Temperature:
__slots__ = ("_celsius",)
def __init__(self, celsius: float) -> None:
self._celsius = celsius
@property
def celsius(self) -> float:
return self._celsius
@celsius.setter
def celsius(self, value: float) -> None:
if value < -273.15:
raise ValueError("絶対零度未満にはできません")
self._celsius = value
@property
def fahrenheit(self) -> float:
return self._celsius * 9 / 5 + 32このようにすることで、内部スロット名は実装詳細として隠蔽しつつ、プロパティで表現力の高いAPIを設計できます。
propertyで動的な計算結果を返す場合
プロパティは元々属性値ではなく関数呼び出しなので、__slots__とは直接競合しません。
必要なデータだけをスロットに持ち、その他はプロパティで計算して返せば、メモリ使用量を抑えつつAPIをリッチにできます。
__slots__とクラス変数・インスタンス変数の整理
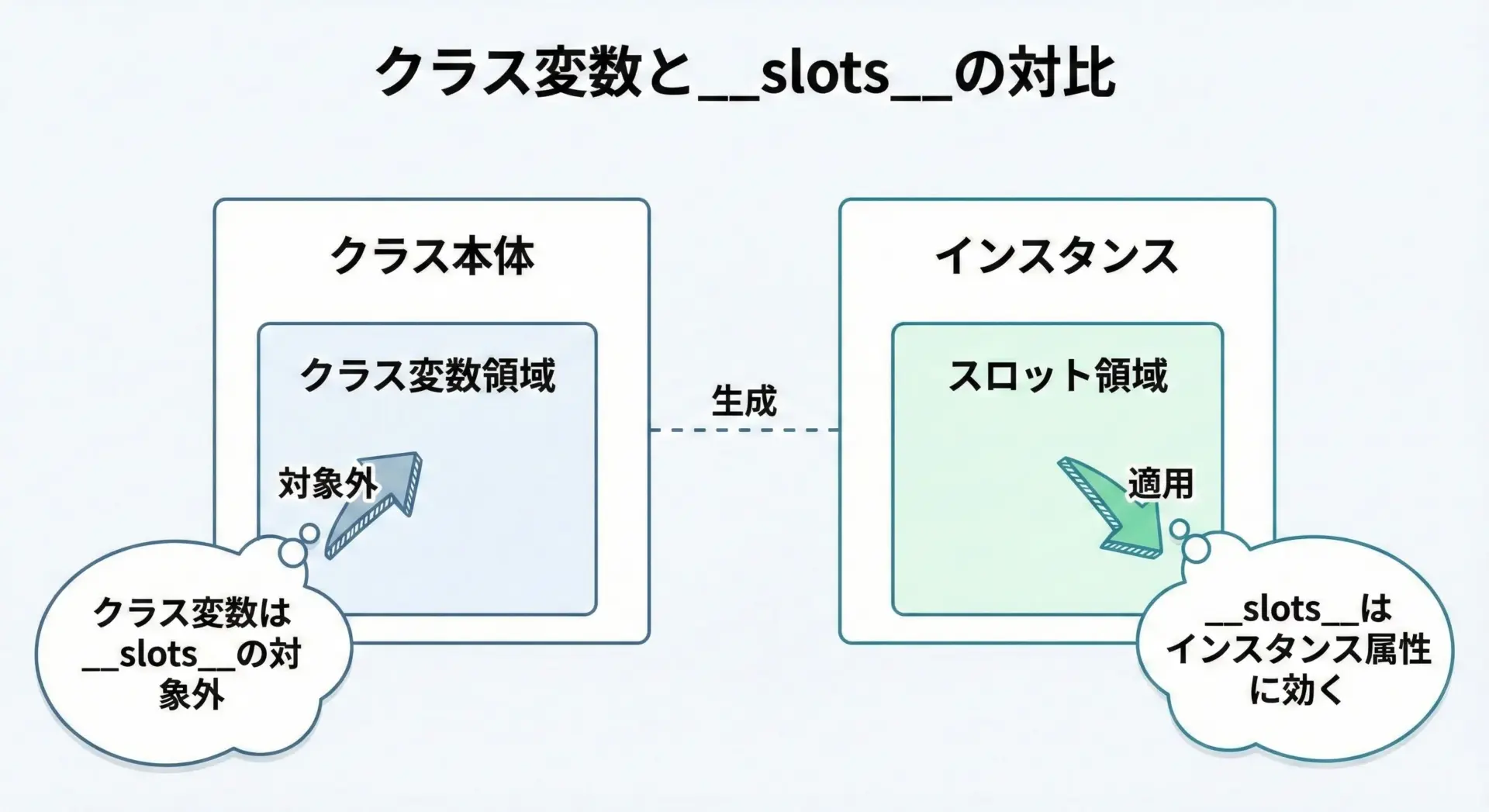
__slots__が制御するのは「インスタンス変数」だけであり、クラス変数には影響しません。
class Config:
# クラス変数(全インスタンスで共有)
DEFAULT_TIMEOUT = 10
# インスタンス変数を slots で制限
__slots__ = ("timeout",)
def __init__(self, timeout: int | None = None) -> None:
self.timeout = timeout or self.DEFAULT_TIMEOUTこの例でDEFAULT_TIMEOUTはクラス変数として定義されており、__slots__の対象ではありません。
一方、timeoutはインスタンスごとに持つ値であり、スロットとして管理されます。
クラス設計時には「共有したい値はクラス変数」「インスタンスごとに異なる値はスロット」と役割を明確に分けることで、構造が分かりやすくなります。
__slots__のメリットとデメリット
大量インスタンスでのメモリ削減効果

具体例を使って、メモリ削減効果のイメージをつかみます。
import sys
class NormalUser:
def __init__(self, name: str, age: int) -> None:
self.name = name
self.age = age
class SlottedUser:
__slots__ = ("name", "age")
def __init__(self, name: str, age: int) -> None:
self.name = name
self.age = age
def estimate_memory(cls, n: int) -> int:
users = [cls(f"user{i}", i) for i in range(n)]
# オブジェクト本体のサイズ + 属性の一部しか見えないため
# 実際の全メモリはもっと多いが、相対比較には有効
return sum(sys.getsizeof(u) for u in users)
N = 10000
print("Normal:", estimate_memory(NormalUser, N))
print("Slotted:", estimate_memory(SlottedUser, N))出力例(概念的な値)。
Normal: 480000
Slotted: 400000この差に加え、通常クラスでは__dict__や属性名文字列、それらを保持する内部構造によるオーバーヘッドも生じるため、大規模なインスタンス数になるほどメモリ削減効果は増大します。
属性アクセス速度とパフォーマンスへの影響

__slots__は主にメモリ削減目的の機能ですが、属性アクセスがわずかに高速になることも多いです。
理由は、通常クラスでは__dict__というハッシュテーブルを介して属性を検索するのに対し、__slots__では固定インデックスの配列を直接参照できるためです。
ただし、パフォーマンス改善はケースバイケースであり、Pythonの実装やCPUキャッシュの挙動によっては差が小さい、あるいは逆転することもあります。
性能目的で__slots__を導入する場合は、必ずtimeitやベンチマークツールで事前測定することが重要です。
__dict__や__weakref__が使えない制約
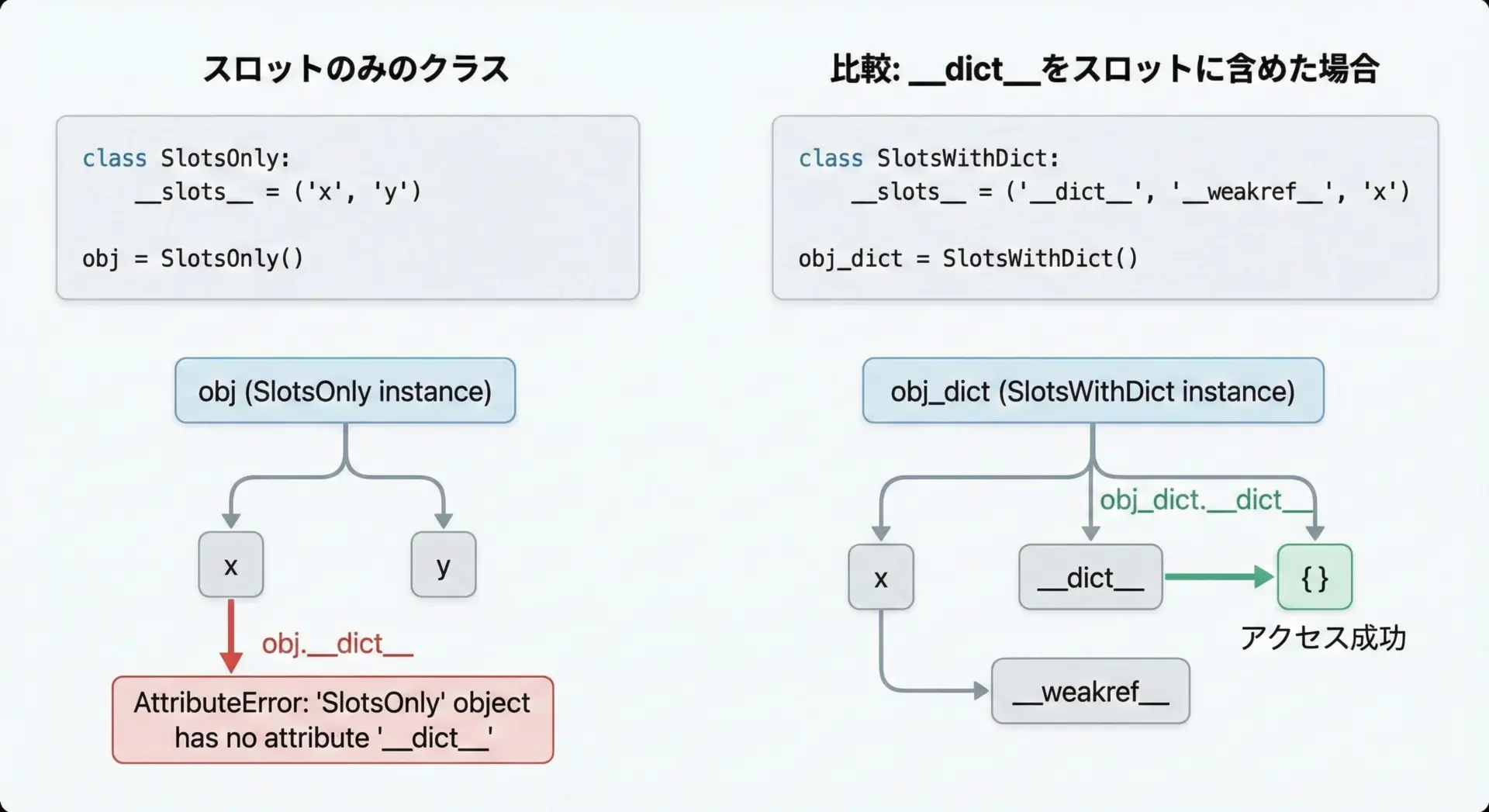
通常の__slots__付きクラスでは、インスタンスに__dict__や__weakref__属性が存在しません。
そのため次のようなコードはエラーになります。
class User:
__slots__ = ("name",)
u = User()
u.name = "Alice"
print(u.__dict__) # AttributeErrorもしどうしても__dict__や__weakref__を使いたい場合は、それ自体をスロットとして明示する必要があります。
class FlexibleUser:
__slots__ = ("__dict__", "__weakref__", "name")
def __init__(self, name: str) -> None:
self.name = name
u = FlexibleUser("Alice")
u.age = 30 # __dict__ があるので動的属性追加が可能
print(u.__dict__)ただしこの場合、メモリ削減効果の多くが失われるため、基本的にはおすすめできません。
デバッグ・動的属性追加が難しくなる注意点
__slots__は柔軟性を犠牲にしているため、次のような場面では扱いづらさを感じることがあります。
- デバッグ時に
obj.__dict__を直接見て調査できない。 - 一時的なデバッグ用属性(例:
obj._debug_info)を気軽に追加できない。 - ライブラリ利用者が後付けで属性を生やすメタプログラミング的な使い方ができない。
デバッグのしやすさと柔軟性をどこまで犠牲にできるかを考えたうえで、__slots__の利用可否を判断する必要があります。
__slots__を使うべきケースと避けるべきケース

使うべきケースの典型例は次のようなものです。
- 数万〜数百万インスタンスを生成するデータ構造(グラフノード、ログレコード、座標点など)。
- ライブラリ内部の隠蔽されたクラスで、APIが固定されており柔軟性を必要としないもの。
- 組み込み用途やメモリ制約の厳しい環境で動作させるコード。
一方、避けるべきケースは次のような状況です。
- インスタンス数が少なく、メモリ削減のメリットが小さいアプリケーションロジック層のクラス。
- 利用者が自由に属性を増やしたり、ミドルウェアが動的に属性を付与するような拡張性重視のクラス。
- デバッグ時にインスタンスへ自由に情報を追加したい場面が多いコードベース。
__slots__は「何となくパフォーマンスが良さそうだから」という理由で乱用するものではなく、具体的な要件とトレードオフを見たうえで導入するのが重要です。
Python class設計ベストプラクティス
__slots__を導入する判断基準
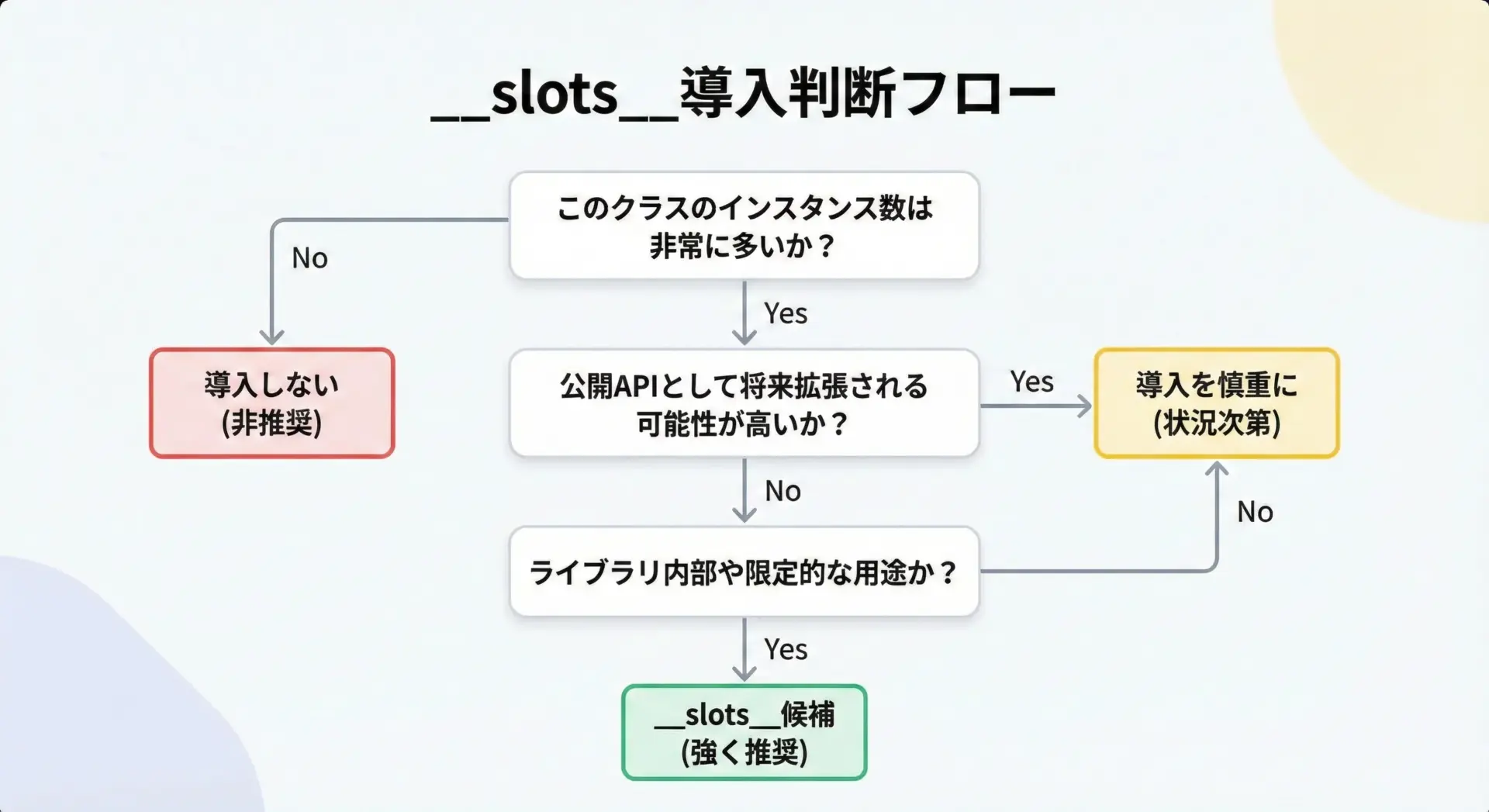
判断基準を文章で整理します。
導入を強く検討すべき条件としては、次のようなものがあります。
- このクラスのインスタンスを10万個以上生成する可能性がある。
- メモリ使用量がボトルネックとなっている、もしくはなり得る。
- クラスの属性構造はほぼ固定であり、大きく変わる予定がない。
- クラスは主にライブラリ内部や限定的なスコープで使われる。
逆に、次の条件が多く当てはまる場合、__slots__は見送った方が無難です。
- インスタンス数は数百〜数千程度にとどまる。
- 仕様変更が頻繁で、属性がよく増減する。
- 拡張ポイントとしてユーザーが動的に属性を追加する設計である。
「メモリプロファイルを測定した結果、特定クラスが支配的なメモリを消費している」ことが確認できたタイミングで、ピンポイントに__slots__を適用するのが実務的なアプローチです。
ライブラリ・API公開クラスにおける__slots__の扱い
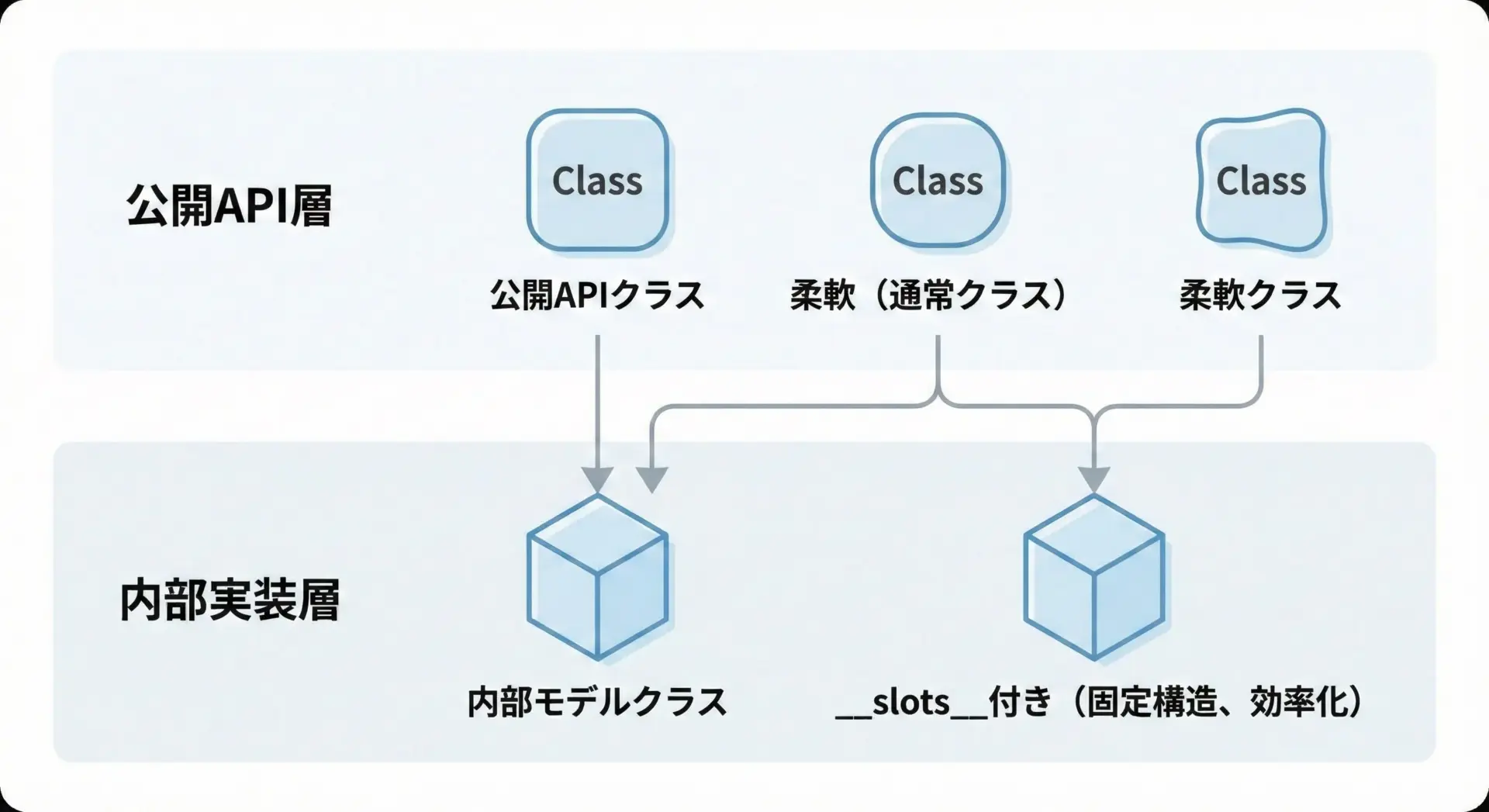
ライブラリやフレームワークが提供する公開APIクラスに__slots__を使うかどうかは、慎重に検討する必要があります。
- 公開クラスに__slots__を定義すると、ユーザーはそのクラスの属性を動的に拡張できません。
- 既存の公開クラスに後から__slots__を導入するのは、後方互換性を壊す可能性が高い変更です。
そのため、次のような方針が実用的です。
- 外部に直接公開するモデルクラスには、原則として__slots__を使わない。
- 内部でのみ使用するデータホルダーやキャッシュ用オブジェクトなど、ライブラリ内部の詳細にとどまるクラスで積極的に__slots__を活用する。
- どうしても公開クラスでメモリが厳しい場合は、ドキュメントで制約を明示し、メジャーバージョンアップ時に導入する。
型ヒントと__slots__を組み合わせた設計パターン

型ヒントと__slots__を組み合わせることで、静的チェックしやすく、かつメモリ効率の良いクラスを設計できます。
手書きクラスでのパターン
class User:
__slots__ = ("name", "age", "active")
name: str
age: int
active: bool
def __init__(self, name: str, age: int, active: bool = True) -> None:
self.name = name
self.age = age
self.active = activeこの例では、__slots__とクラスレベルの変数アノテーションを揃えることで、「どの属性を持つインスタンスなのか」が一目で分かるようになります。
mypyなどの型チェッカーもクラス属性としての型を理解できます。
dataclass(slots=True, frozen=True)などの複合パターン
イミュータブルな値オブジェクトでは、次のような構成がよく使われます。
from dataclasses import dataclass
@dataclass(slots=True, frozen=True)
class Point:
x: float
y: floatslots=Trueでメモリ効率の良いインスタンス。frozen=Trueでイミュータブルにし、ハッシュ可能な値オブジェクトとして扱える。- 型ヒントで属性型が明示されており、静的解析がしやすい。
このように、値オブジェクトやドメインモデルでは「dataclass + slots + 型ヒント」の組み合わせが強力です。
既存コードに__slots__を導入する際のリファクタリング手順
既存コードへ__slots__を導入する場合は、次のような手順で進めると安全です。
1. 候補クラスの選定
まず、プロファイラやメモリダンプから、メモリを多く消費しているクラスを特定します。
その中から、次の条件を満たすものを候補にします。
- インスタンス数が非常に多い。
- 外部に公開されていない、あるいは利用範囲が限定的。
- 動的属性追加を行っていない。
2. 実際に使われている属性の洗い出し
IDEの機能やgrep、静的解析ツールなどを使って、そのクラスに対してどの属性が読み書きされているかを洗い出します。
テストコードも含めて調査し、__slots__に列挙する属性リストを作ります。
3. __slots__を追加し、テストを実行
候補クラスに__slots__を追加し、既存のテストスイートを実行します。
class User:
__slots__ = ("name", "age", "active")
...この段階で、動的に追加していた属性や、テストコードでの一時的な属性追加があれば、AttributeErrorとして表面化します。
それらを修正し、必要であれば設計自体を見直します。
4. メモリと性能の計測
__slots__を導入したブランチと導入前のブランチで、同じシナリオを実行してメモリ使用量と速度を比較します。
期待したほど効果がない、あるいは副作用が大きい場合は導入を見直します。
5. 段階的な適用とドキュメント整備
問題がなければ、影響範囲の小さいクラスから順に__slots__を導入していきます。
同時に、開発者向けドキュメントに「このクラスは__slots__を持ち、動的属性追加はできない」ことを明記し、今後の変更時に誤った拡張が行われないようにします。
まとめ
__slots__は、Pythonのクラスにおけるインスタンス構造を「固定スロット」に制約することで、メモリ使用量を削減し、場合によっては属性アクセスも高速化できる仕組みです。
一方で、動的属性追加や__dict__参照ができなくなるなど、柔軟性とデバッグのしやすさを犠牲にします。
そのため、インスタンス数が非常に多い内部用クラスや値オブジェクト、dataclass(slots=True)など、メリットが明確な場面に絞って活用するのがベストプラクティスです。
型ヒントやプロパティと組み合わせた堅牢な設計と、メモリ・性能の事前計測を行いながら、あなたのプロジェクトにとって最適な__slots__活用戦略を検討してみてください。
