Pythonでクラスを定義するとき、__str__と__repr__を正しく設計できるかどうかは、デバッグ効率やログの品質、さらにはセキュリティにまで大きく影響します。
この記事では、両者の違いや役割を明確にしながら、実務でそのまま使えるベストプラクティスとアンチパターンを詳しく解説します。
図解やコード例も豊富に用意していますので、実装のイメージを持ちながら読み進めていただけます。
Pythonの__str__と__repr__とは何か
__str__と__repr__の基本的な役割
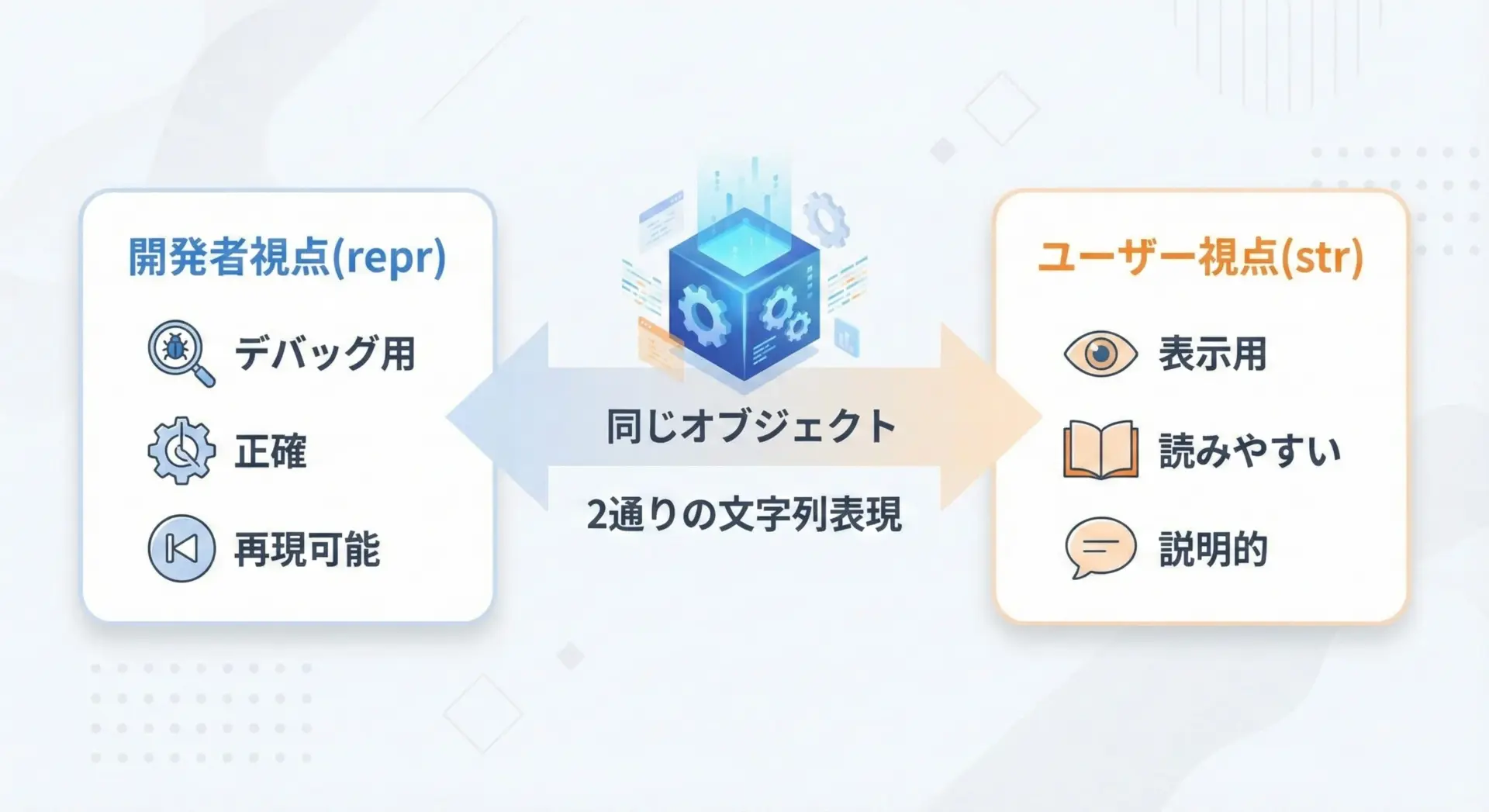
Pythonのオブジェクトには、2種類の「文字列表現」を返す仕組みが用意されています。
それが__str__と__repr__という特殊メソッドです。
__repr__の役割
__repr__は、主に開発者向けの文字列表現を返すためのメソッドです。
代表的な特徴は次のようになります。
- オブジェクトをできるだけ正確に表現する
- 可能であれば、その文字列を
evalなどで評価することで同じオブジェクトを再構築できることを目指します - 対話シェルやデバッガ、ログでの出力など、開発時に自動的に呼び出されることが多いです
Pythonの組み込み関数repr(obj)を呼び出すと、この__repr__が実行されます。
__str__の役割
一方で__str__は、主に人間のユーザーに見せるための「きれいな」文字列表現を返すメソッドです。
- 画面表示やエラーメッセージ、ログのカスタムメッセージなどでの利用を想定しています
- 読みやすさや意味の分かりやすさを優先し、内部状態の完全さにはこだわらないことも多いです
組み込み関数str(obj)やprint(obj)を呼ぶと、この__str__が呼び出されます。
なぜPythonクラス設計で__str__と__repr__が重要なのか
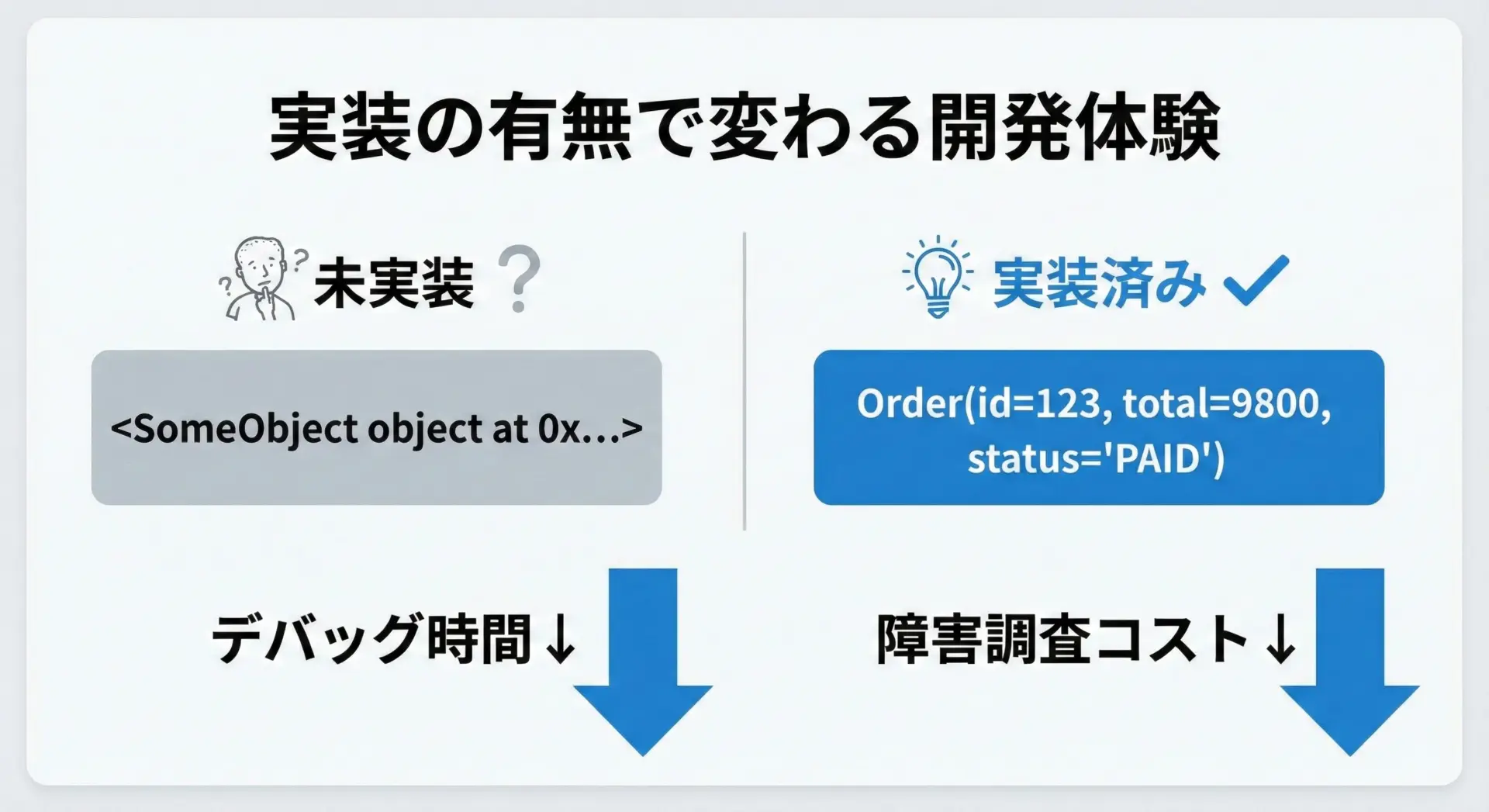
クラスを自作するときに__str__と__repr__</ccode>をきちんと設計しておくと、日々の開発や運用で次のようなメリットがあります。
1つ目はデバッグ効率の向上です。
オブジェクトの中身をログに出したり、対話シェルで確認したりするときに、わかりやすい__repr__があれば、状態把握が一瞬で済みます。
2つ目はログの品質向上です。
障害発生時のログを見たとき、<MyClass object at 0x7f...>のような情報しか出ていないと、原因究明が非常に困難になります。
逆に、MyClass(id=10, status='failed')のように出ていれば、状況を素早く再現できます。
3つ目はユーザー体験の向上です。
CLIツールやWebアプリのエラーメッセージで__str__が適切に実装されていれば、ユーザーにとって意味のある説明を簡単に行えます。
組み込み型における__str__と__repr__の例

Pythonの組み込み型では、__str__と__repr__がすでに実装されており、その違いを確認することができます。
文字列(str)の場合
text = "hello\nworld"
print(str(text)) # __str__ が呼ばれる
print(repr(text)) # __repr__ が呼ばれるhello
world
'hello\nworld'strは「実際に表示される文字」をそのまま出すのに対して、reprは「Pythonコードとして意味のある形」になるよう、改行を\nとしてエスケープし、クォートで囲んでいることが分かります。
リスト(list)の場合
nums = [1, 2, 3]
print(str(nums))
print(repr(nums))[1, 2, 3]
[1, 2, 3]リストではstrとreprが同じ出力になります。
このように、型によっては両者が同じ実装を共有していることもあります。
日付(datetime)の場合の一例
from datetime import datetime
dt = datetime(2024, 1, 2, 3, 4, 5)
print(str(dt))
print(repr(dt))2024-01-02 03:04:05
datetime.datetime(2024, 1, 2, 3, 4, 5)ここでも、strは人間にとって読みやすい形式、reprはコードとして再現可能な形式になっていることが分かります。
__str__と__repr__の違いを理解する
開発者向け表現(repr)とユーザー向け表現
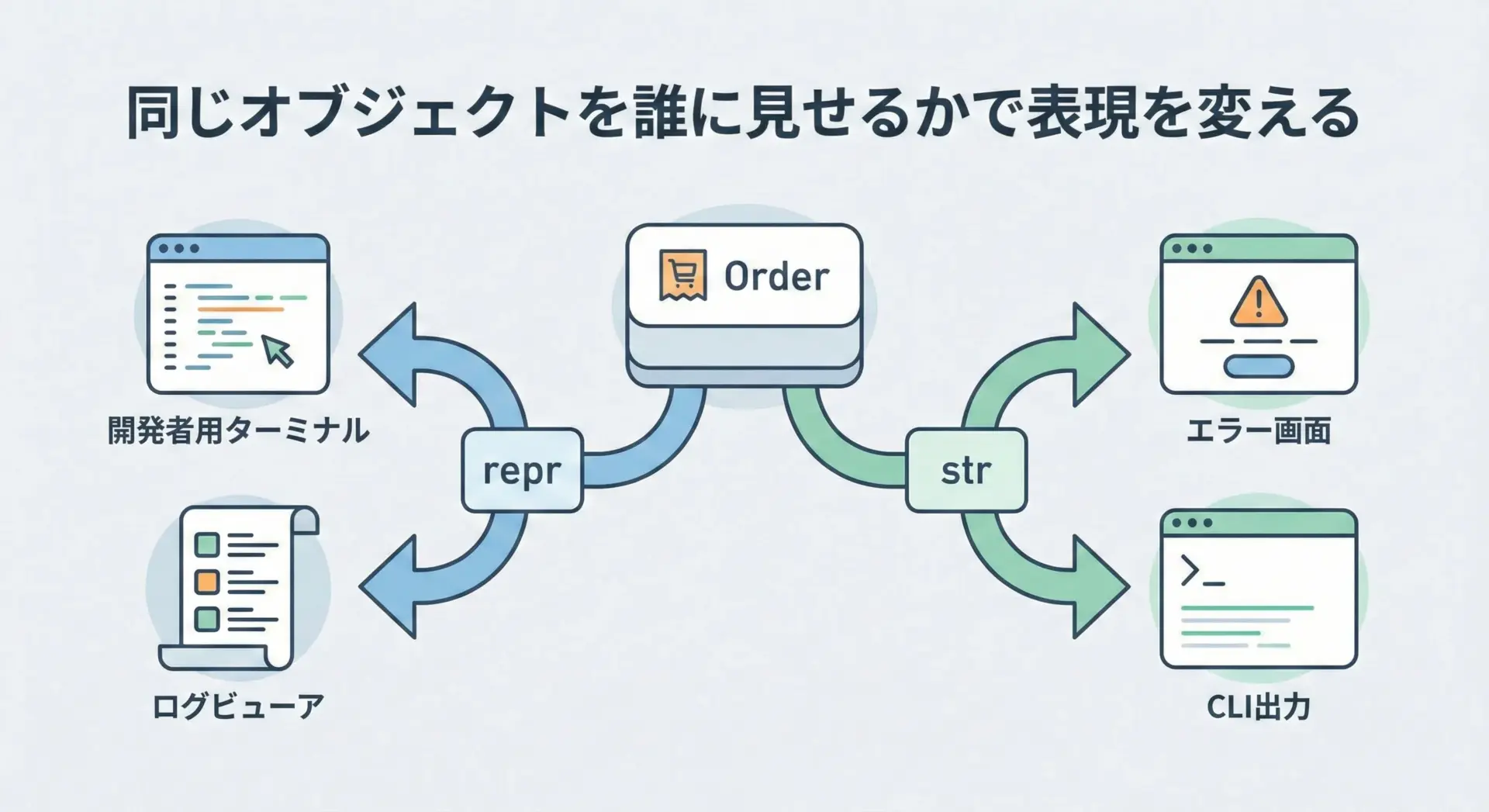
__repr__は開発者、__str__はユーザーという視点でとらえると、設計の指針が明確になります。
開発者は、バグの原因やオブジェクトの状態を正確に知りたいので、値が欠けていたり、見た目のために丸められていると困ります。
一方ユーザーは、型名や内部IDといった情報は不要で、今何が起きているのかが理解できれば十分です。
この違いは、同じオブジェクトでも__repr__と__str__で別々の文字列を返したくなる動機になります。
__repr__は「再現可能な文字列表現」を目指す理由

__repr__の理想形は、eval(repr(obj)) == objが成り立つことです。
これは公式ドキュメントでも推奨されている考え方です。
もちろん、全てのオブジェクトで完全にこの理想を満たすのは難しい場合があります。
たとえば、データベース接続やネットワークソケットなど、再構築に外部状態が必要なオブジェクトでは、単純な文字列からの復元はできません。
それでも、「可能な範囲で再現可能に近づける」ことが、分かりやすい__repr__の基本方針になります。
この方針には、次のようなメリットがあります。
- ログから
reprをコピペしてevalすれば、似た状態のオブジェクトをすぐ再現できる reprを見るだけで、どのクラスのコンストラクタにどんな引数が渡されたのかを類推しやすい- コードリーディング時に、データフローの追跡がしやすくなる
__str__は「読みやすさ」を優先するケース
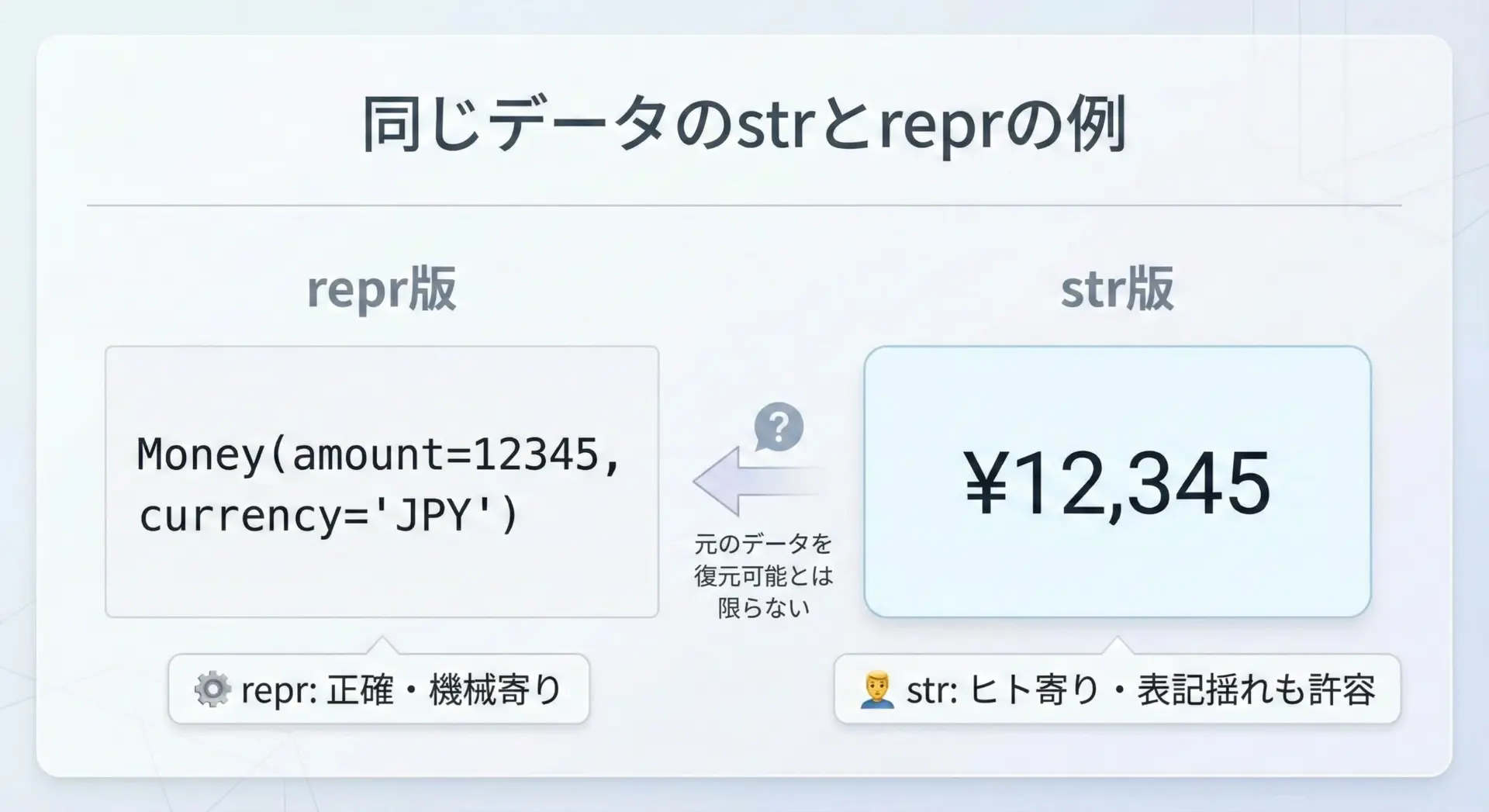
__str__では、人間にとっての読みやすさや慣習的な表記を優先できます。
例えば金額を表すクラスMoneyを考えてみます。
__repr__ではMoney(amount=12345, currency='JPY')のように、属性名と値を正確に表示__str__では¥12,345や12,345 JPYのように、実務でよく使われるフォーマットで表示
このように、__str__は「見た目優先」でも構わないという点が、__repr__との大きな違いになります。
__str__と__repr__が同じになる場合・ならない場合
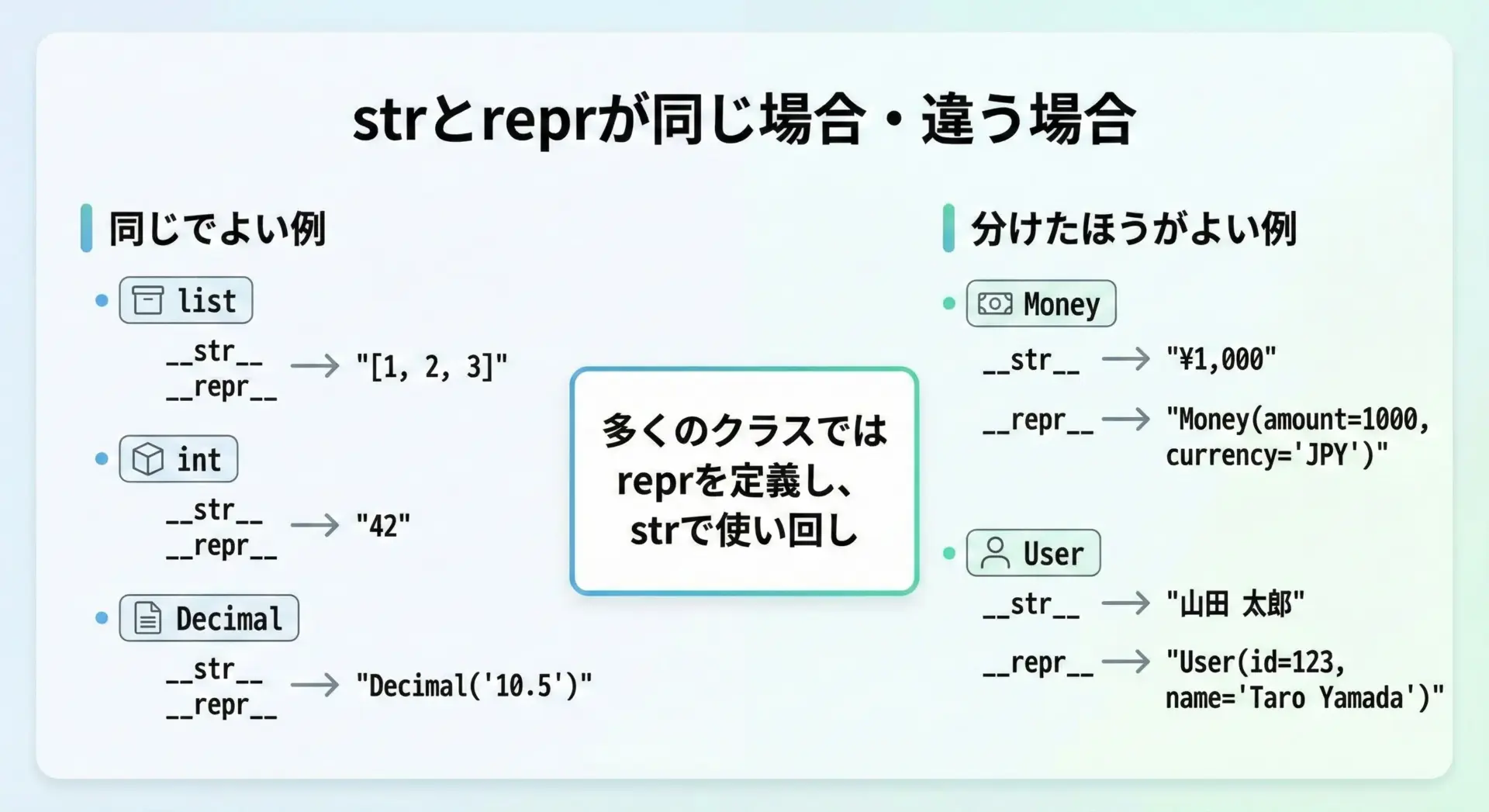
全てのクラスで__str__と__repr__を分けなければならないわけではありません。
設計上、次のようなパターンが考えられます。
どちらも同じでよいケース
- 単純な値オブジェクト
- 型名を表示する必要があまりなく、reprがすでに十分読みやすい場合
- デバッグ用と表示用の情報粒度を分ける必要がない場合
この場合、__repr__だけ実装し、__str__は__repr__を使い回す設計がよく使われます。
具体的な実装例は後ほど詳しく取り上げます。
役割を分けた方がよいケース
- ドメインオブジェクト(注文、ユーザー、請求書など)
- 表示フォーマットと内部表現にギャップがあるクラス(時間、通貨、座標など)
- ユーザーに見せたくない内部情報(トークン、IDなど)を持つオブジェクト
このような場合には、__repr__は詳しく正確に、__str__は簡潔でユーザー向けにと役割を分けるのが望ましいです。
Pythonクラス設計におけるベストプラクティス
__repr__を優先して実装し__str__で使い回す設計
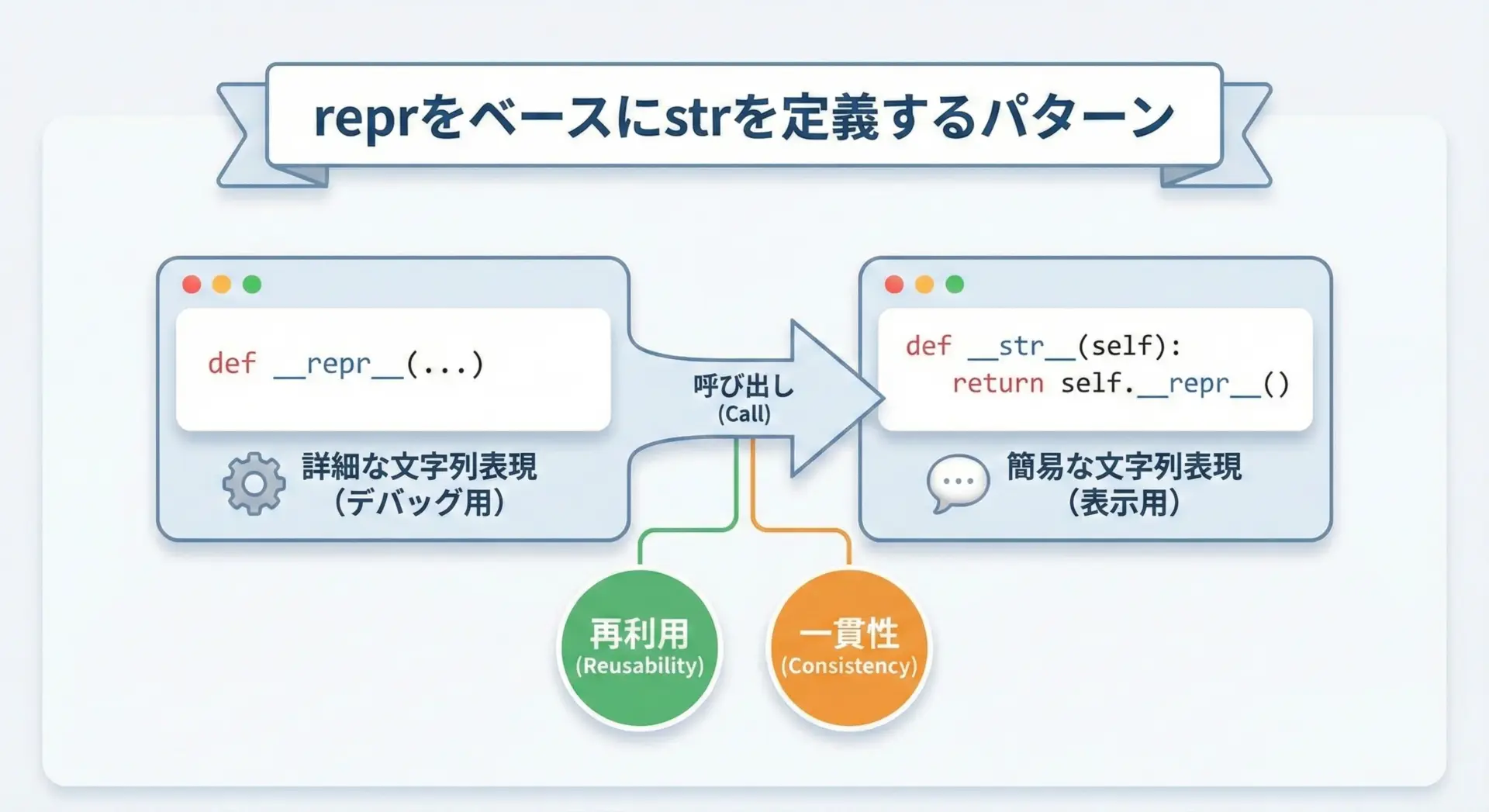
基本戦略としては「まず__repr__をしっかり書き、必要なら__str__でそれを利用する」という順番が実務ではおすすめです。
代表的なパターンは次のような実装です。
class Point:
def __init__(self, x: float, y: float) -> None:
self.x = x
self.y = y
def __repr__(self) -> str:
# 再現可能な形を目指す
return f"Point(x={self.x!r}, y={self.y!r})"
def __str__(self) -> str:
# 表示用をシンプルにしたい場合は別実装
return f"({self.x}, {self.y})"もし__str__で特別なフォーマットを必要としないなら、次のように__repr__をそのまま使い回すことができます。
class Point:
def __init__(self, x: float, y: float) -> None:
self.x = x
self.y = y
def __repr__(self) -> str:
return f"Point(x={self.x!r}, y={self.y!r})"
def __str__(self) -> str:
# reprをそのまま利用
return self.__repr__()この設計の利点は、デバッグ用と表示用で一貫性を保ちつつ、必要な場合だけ__str__をカスタムできることです。
デバッグしやすい__repr__の書き方

デバッグしやすい__repr__を書くためには、いくつかの実務的なコツがあります。
1. クラス名を含める
どのクラスのインスタンスなのかは、ログ分析やデバッグ時にとても重要です。
__repr__には、必ずクラス名を含めるようにします。
2. 主要な属性を引数風に並べる
コンストラクタの引数に対応する形でname=valueのペアを並べると、どういう状態のオブジェクトなのかが一目で分かります。
class User:
def __init__(self, user_id: int, name: str, is_active: bool) -> None:
self.user_id = user_id
self.name = name
self.is_active = is_active
def __repr__(self) -> str:
# f文字列でname=value形式にする
return (f"User(user_id={self.user_id!r}, "
f"name={self.name!r}, is_active={self.is_active!r})")
user = User(1, "Alice", True)
print(repr(user))User(user_id=1, name='Alice', is_active=True)3. !r を積極的に使う
f文字列の{value!r}という書き方は、その値のreprを使う指定です。
これにより、文字列やサブオブジェクトもreprとして展開され、一貫して「開発者向け」の形式を保てます。
ユーザー向けに分かりやすい__str__の設計
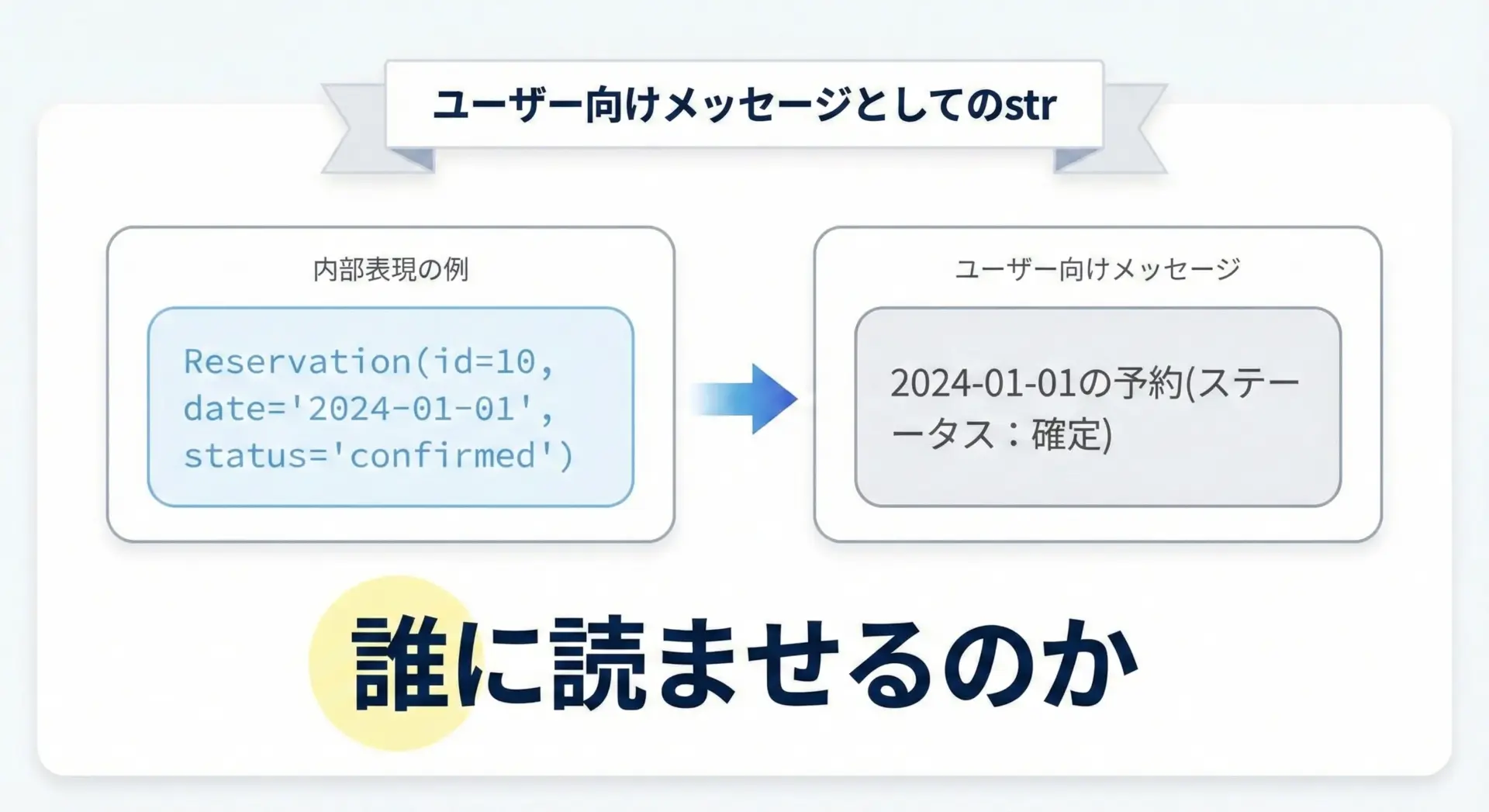
__str__は、ユーザーに見せるメッセージのテンプレートだと考えると設計しやすくなります。
次のような方針が有効です。
- 技術用語よりも、ユーザーが日常的に使う言葉で表現する
- 型名や内部IDではなく、ユーザーに意味のある情報を優先する
- 複雑なオブジェクトであれば、要約情報だけを出す
class Reservation:
def __init__(self, reservation_id: int, date: str, status: str) -> None:
self.reservation_id = reservation_id
self.date = date
self.status = status
def __repr__(self) -> str:
return (f"Reservation(reservation_id={self.reservation_id!r}, "
f"date={self.date!r}, status={self.status!r})")
def __str__(self) -> str:
# ユーザー向けの読みやすいメッセージ
return f"{self.date}の予約(ステータス: {self.status})"
r = Reservation(10, "2024-01-01", "確定")
print(str(r))
print(repr(r))2024-01-01の予約(ステータス: 確定)
Reservation(reservation_id=10, date='2024-01-01', status='確定')このように、__str__と__repr__が明確に異なるメッセージを持つことで、開発者とユーザーの両方にとって扱いやすい設計になります。
データクラス(dataclass)での__repr__と__str__の扱い
Pythonのdataclassesモジュールを使うと、__repr__が自動生成されます。
これは、フィールド名と値をname=value形式で並べる、非常に実用的な実装です。
from dataclasses import dataclass
@dataclass
class Point:
x: float
y: float
p = Point(1.0, 2.0)
print(repr(p))
print(str(p)) # デフォルトでは repr と同じPoint(x=1.0, y=2.0)
Point(x=1.0, y=2.0)データクラスでは、次のことを押さえておくと便利です。
@dataclassのrepr引数をFalseにすると、__repr__を自動生成しません__str__は自動生成されないため、定義しなければstrはreprと同じになります- ユーザー向けの表示をカスタムしたい場合は、__str__だけを実装すればよいことが多いです
from dataclasses import dataclass
@dataclass(repr=True)
class User:
user_id: int
name: str
def __str__(self) -> str:
# ユーザー向けに簡潔に
return self.name
u = User(1, "Alice")
print(str(u)) # Alice
print(repr(u)) # User(user_id=1, name='Alice')ログ出力で__str__と__repr__を使い分けるコツ

ログ出力では、ログレベルや用途に応じて__str__と__repr__を使い分けると便利です。
一般的な指針としては、次のように考えることができます。
- DEBUGログ: reprを優先し、内部状態を詳しく残す
- INFO以上のログ: strを優先し、ユーザーや運用担当者にも読みやすい形にする
Pythonのloggingモジュールでは、通常%sでstr、%rでreprが呼ばれます。
import logging
logging.basicConfig(level=logging.DEBUG)
class User:
def __init__(self, user_id: int, name: str) -> None:
self.user_id = user_id
self.name = name
def __repr__(self) -> str:
return f"User(user_id={self.user_id!r}, name={self.name!r})"
def __str__(self) -> str:
return self.name
user = User(1, "Alice")
logging.debug("Debug user=%r", user) # repr
logging.info("User logged in: %s", user) # strDEBUG:root:Debug user=User(user_id=1, name='Alice')
INFO:root:User logged in: Aliceこのように、ログフォーマット側で%sと%rを使い分けることで、同じオブジェクトでも出力の粒度をコントロールできます。
セキュリティとプライバシーを考慮した文字列表現の注意点

__repr__や__str__に機密情報を含めてしまうと、ログやエラーメッセージ経由で漏洩するリスクがあります。
特に次のような情報は慎重に扱う必要があります。
- パスワードやアクセストークン
- クレジットカード番号や個人情報
- 内部システムのシークレットや鍵
推奨される対策としては、以下のようなものがあります。
- 機密フィールドはreprに含めない、またはマスクする
- strではユーザー向けになおさら機密情報を出さない
- ログレベルによっては、reprを使わず、必要最低限の情報だけを手動で組み立てる
class Credentials:
def __init__(self, username: str, password: str) -> None:
self.username = username
self.password = password
def __repr__(self) -> str:
# パスワードは絶対にそのまま出さない
return f"Credentials(username={self.username!r}, password='***')"
def __str__(self) -> str:
# ユーザー向けにもパスワードは出さない
return f"Credentials for {self.username}"「reprはデバッグ用だから出してもよい」と考えてしまうのは危険です。
ログは長期間保存され、共有されることも多いため、最初から機密情報を含めない設計を徹底する必要があります。
実践的なコード例とアンチパターン
シンプルなクラスでの__str__と__repr__実装例
ここでは、現実的なドメインオブジェクトを想定したサンプルを示します。
class Product:
def __init__(self, product_id: int, name: str, price: int) -> None:
self.product_id = product_id
self.name = name
self.price = price # 税込価格(円)
def __repr__(self) -> str:
# デバッグ・ログ用: 正確な内部状態を表示
return (f"Product(product_id={self.product_id!r}, "
f"name={self.name!r}, price={self.price!r})")
def __str__(self) -> str:
# ユーザー向け: 分かりやすい商品表示
return f"{self.name} (¥{self.price:,})"
p = Product(1, "Coffee", 480)
print("str(p):", str(p))
print("repr(p):", repr(p))
print("p:", p) # print は __str__ を使うstr(p): Coffee (¥480)
repr(p): Product(product_id=1, name='Coffee', price=480)
p: Coffee (¥480)この例では、__repr__は内部状態を完全に、__str__はユーザー向けに簡潔に表現しています。
エラーになりやすい__repr__実装のアンチパターン
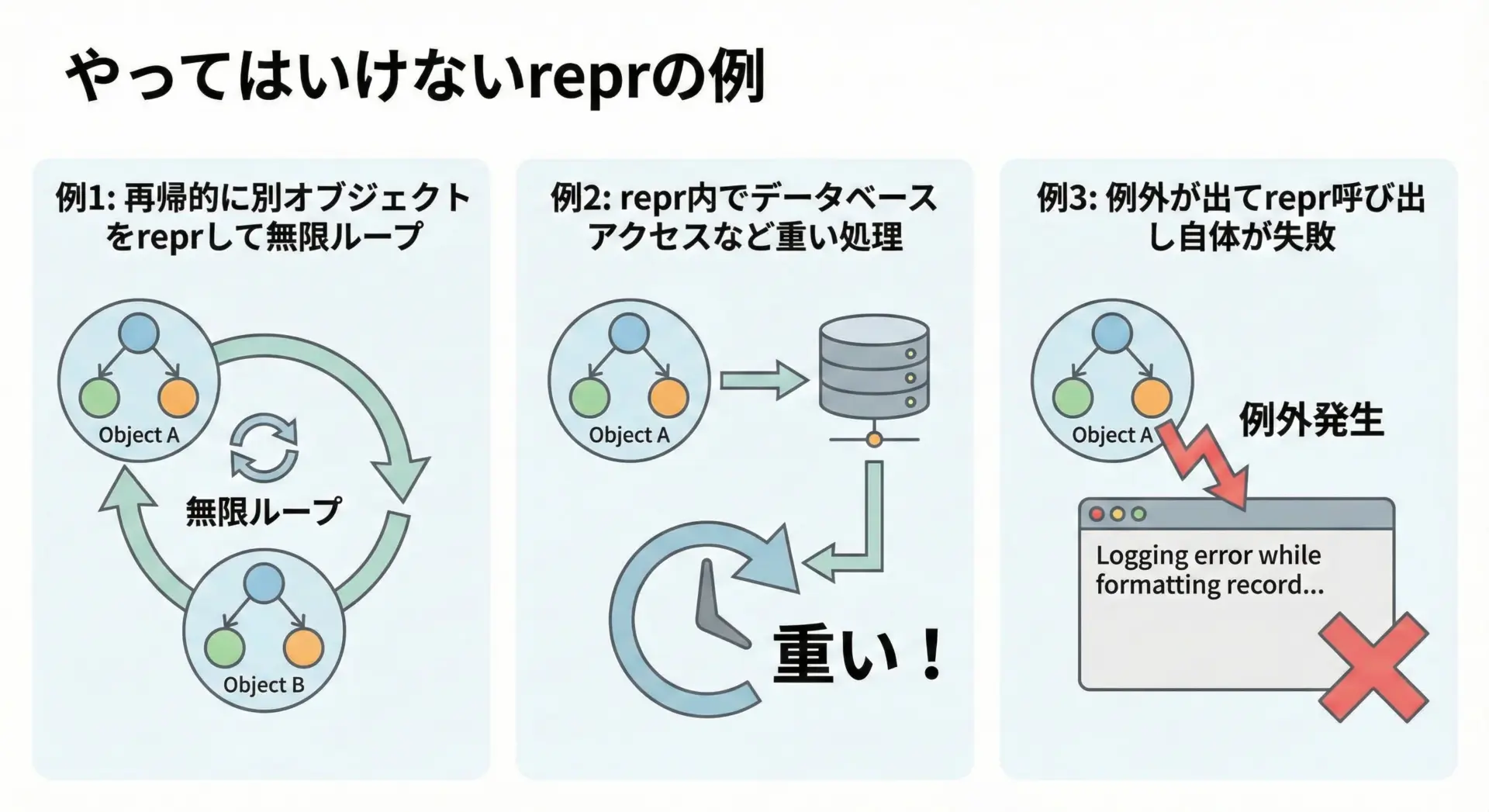
__repr__の実装を誤ると、デバッグどころか新たな不具合の原因になってしまうことがあります。
代表的なアンチパターンをいくつか紹介します。
1. __repr__内で例外を投げてしまう
__repr__は、デバッガやログ出力中に<cmst-strong>意図せず呼ばれることがあります。
その際に例外が出ると、本来追いたかったエラーの情報が隠れてしまうことがあります。
class BadRepr:
def __init__(self, value: int) -> None:
self.value = value
def __repr__(self) -> str:
# value が負の時に例外を投げてしまう悪い例
if self.value < 0:
raise ValueError("value must be non-negative")
return f"BadRepr(value={self.value})"
obj = BadRepr(-1)
print("Start")
print(repr(obj)) # ここで ValueError が発生しうる
print("End")Start
Traceback (most recent call last):
...
ValueError: value must be non-negativeこのように、本来はreprを出したいだけなのにreprでエラーが起きてしまうと、トラブルシューティングが難しくなります。
reprは可能な限り「安全に」動作するように心がけることが大切です。
2. 重い処理を行う
__repr__内でデータベースアクセスやネットワーク通信など、重い処理を行うのも避けるべきです。
デバッグ用ログ一つ出すのに数秒かかるようでは、実用に耐えません。
reprは常に軽量であるべきです。
3. 相互参照で無限再帰に陥る
相互に参照しあうオブジェクトがそれぞれreprの中で相手のreprを呼ぶと、無限再帰になります。
必要に応じて、IDだけを出す、一覧は長さだけ出すなどの工夫で回避します。
class Node:
def __init__(self, name: str) -> None:
self.name = name
self.parent = None # type: Node | None
self.children = [] # type: list[Node]
def __repr__(self) -> str:
# 親や子ノードのreprをそのまま使うのは危険
return (f"Node(name={self.name!r}, "
f"parent={self.parent.name if self.parent else None!r}, "
f"children={len(self.children)} children)")このように、reprは「ほどほど」に情報を含めることも大切です。
大規模プロジェクトで統一した__str__と__repr__設計ルールを決める方法

プロジェクトが大きくなると、開発者ごとに__str__ / __repr__の設計方針がバラバラになりがちです。
そうなると、ログの読みやすさやデバッグ効率が大きく落ちます。
そのため、チームとしてのルールを決めておくことが重要です。
代表的なガイドラインの例を挙げます。
- データを持つクラスでは、原則として__repr__を必ず実装する
ただし@dataclassなどにより自動生成される場合は例外とする。 - __repr__は「クラス名 + 主要フィールドのname=valueの列挙」を基本とする
クラス名を省略したり、'some object'のような抽象的な文字列は避ける。 - __str__は、ユーザー向け表示が必要なドメインオブジェクトにだけ実装する
特に必要がないクラスでは、__str__を定義せずreprをそのまま使う。 - パスワードやトークンなど機密情報は、repr/strともにマスクする
「***」や「<hidden>」など、機密であることがわかる表現を使う。 - repr内では副作用のある処理を行わない
例外を投げる可能性のある処理、IO処理、外部サービス呼び出しなどは避ける。
このようなルールを、プロジェクトのコーディング規約やLintルールとして明文化しておくと、長期的な保守性が高まります。
まとめ
__str__と__repr__は、Pythonクラス設計において「人にどう見せるか」「コードとしてどう扱うか」を決める重要なインターフェースです。
__repr__は開発者向けに正確で再現可能な表現を目指し、__str__はユーザー向けに読みやすく意味の伝わる表現を目指します。
実務では、まず__repr__をしっかり設計し、必要に応じて__str__を追加する戦略が有効です。
また、ログやデバッグのしやすさと同時に、機密情報の漏洩を防ぐセキュリティ面も忘れてはいけません。
この記事で紹介したベストプラクティスとアンチパターンを押さえておけば、プロジェクト全体の可読性と保守性が大きく向上します。
