Pythonではメソッドのオーバーロードは、JavaやC++などと比べると少し独特な扱いになります。
ただし、工夫することで関数・メソッド・演算子の「オーバーロード的な振る舞い」を柔軟に実現できます。
本記事では、Pythonの考え方に沿いながら、実装パターンを図解とコード例で丁寧に解説していきます。
Pythonのメソッドオーバーロードとは
オーバーロードの基本概念とメリット
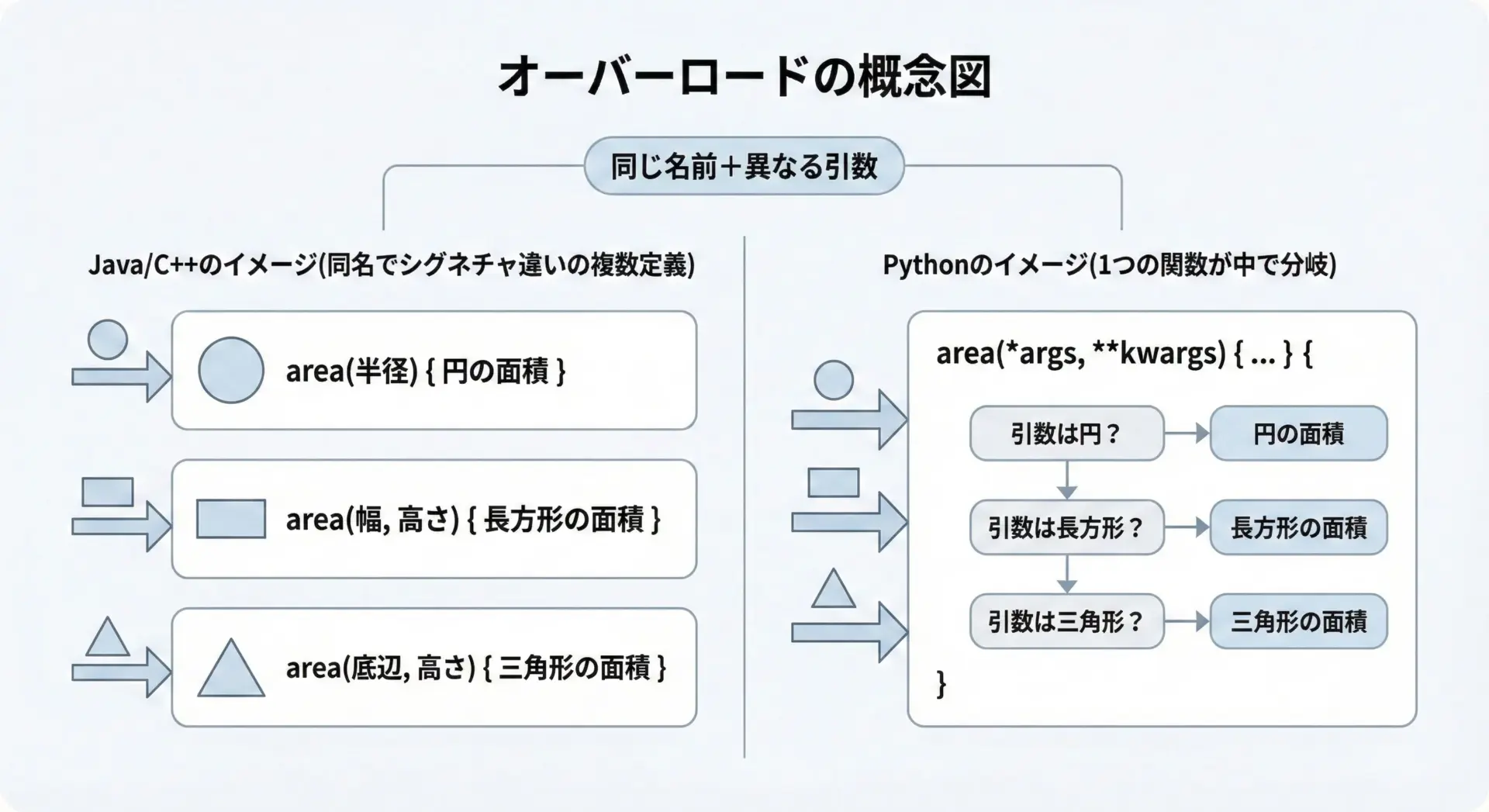
オーバーロード(overload)とは、同じ名前の関数(メソッド)を、引数の個数や型を変えて複数定義する機能のことです。
呼び出し時の引数に応じて、最適な実装が自動的に選ばれるという考え方です。
たとえば、図形の面積を求めるareaという関数を考えると、円用、長方形用、三角形用といった複数のバリエーションを、同じ名前areaで提供できると便利です。
オーバーロードを使うメリットとしては、次のような点があります。
文章で整理すると、コードを使う側の視点と、作る側の視点の両面から有効です。
- 使う側は「何をしたいか」に集中でき、関数名を覚える負担が減る
- 作る側は、1つの概念を1つの名前に集約でき、APIの設計がシンプルになる
- 型ごとに処理を分けても、呼び出し側のコードは統一したままにできる
PythonがJavaやC++と違う点
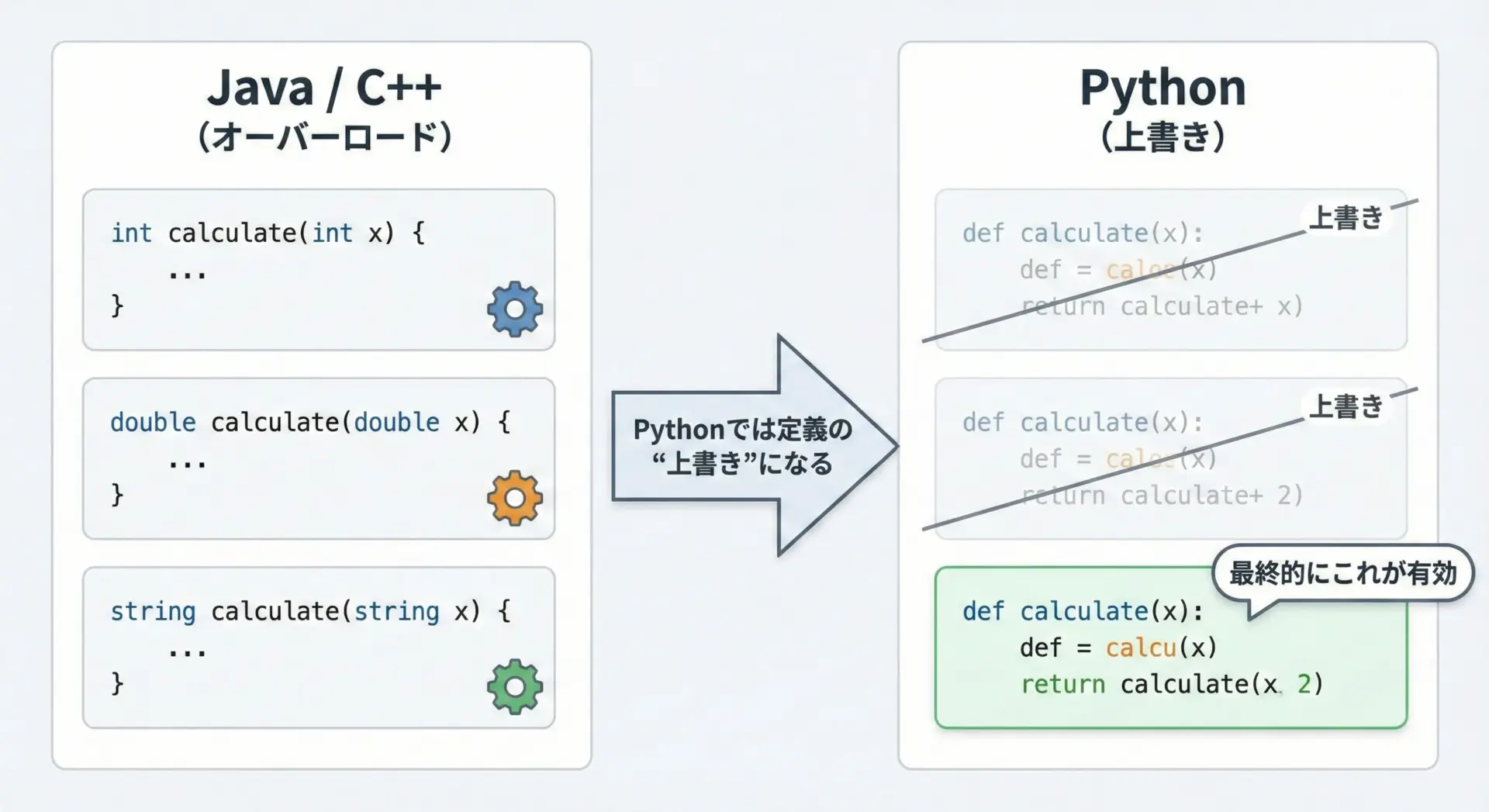
JavaやC++では、次のように同じ名前のメソッドを複数定義できます。
// Javaの例
int add(int a, int b) { ... }
double add(double a, double b) { ... }
String add(String a, String b) { ... }しかしPythonでは、同じ名前の関数やメソッドを複数定義すると、後から定義したものが前の定義を上書きしてしまいます。
def add(a, b):
return a + b
def add(a, b, c):
return a + b + c
print(add(1, 2)) # これはどうなる?上のコードはエラーになります。
なぜなら、2つ目のadd定義によって、最初のaddが完全に上書きされており、Pythonから見えるadd関数は「引数3つを期待するもの」だけになっているからです。
このように、PythonにはJava/C++のような「シグネチャによる自動切り替え」は存在しません。
その代わり、引数の扱い方を工夫してオーバーロード的な振る舞いを実現します。
関数・メソッド・演算子オーバーロードの関係
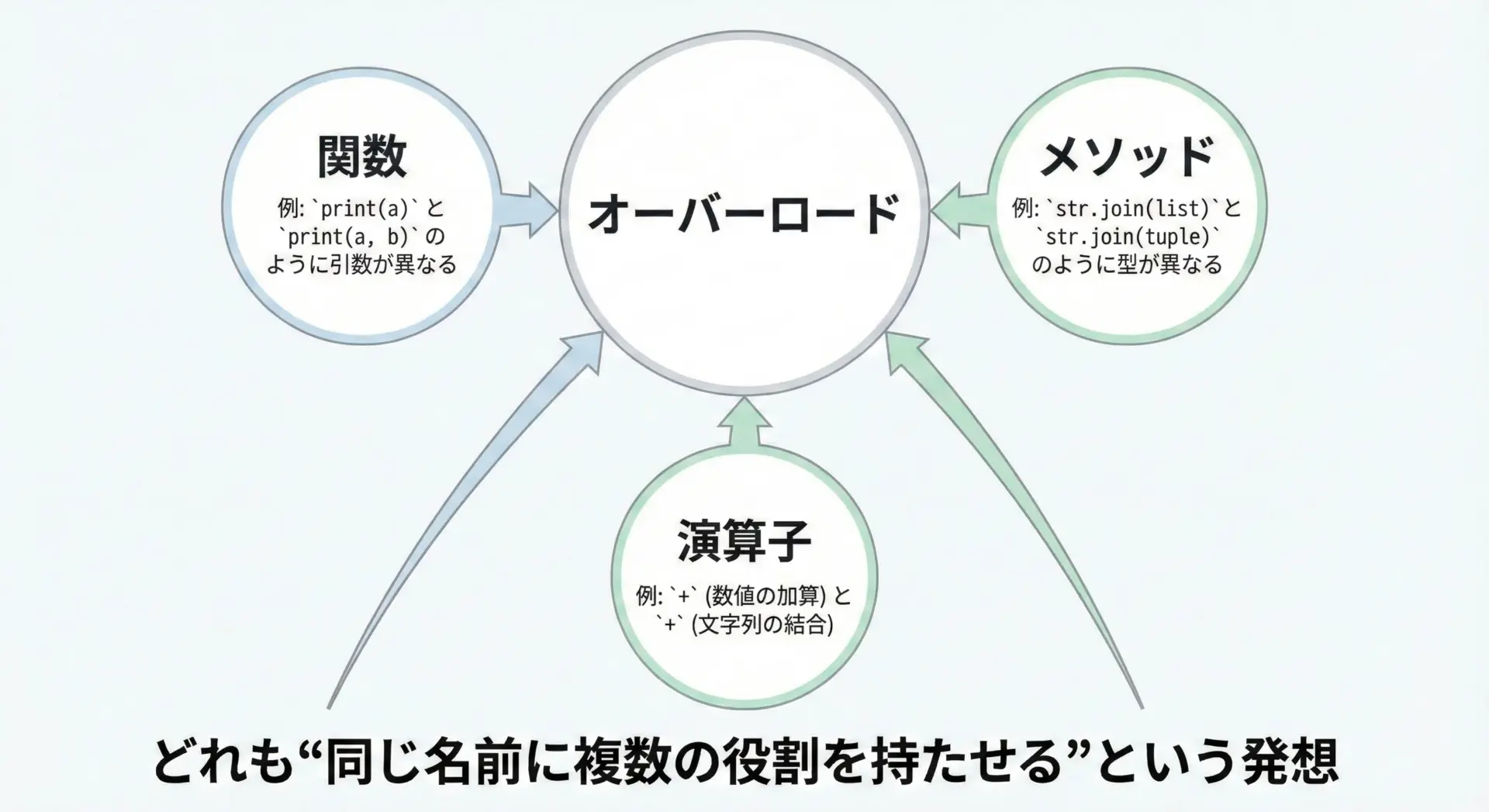
Pythonでは、オーバーロードと呼ばれるものが大きく3つの場面で登場します。
- 関数オーバーロード
- メソッドオーバーロード
- 演算子オーバーロード
どれも「同じ名前に複数の役割を持たせる」という共通の発想に基づいています。
ただし、実際の仕組みや書き方は少しずつ異なります。
- 関数オーバーロード
デフォルト引数、*args、**kwargs、functools.singledispatchなどを使って、1つの関数で引数に応じて処理を分岐します。 - メソッドオーバーロード
クラスのメソッドでも基本は関数と同じ考え方ですが、selfや@classmethod、@staticmethodなどとの組み合わせを意識する必要があります。 - 演算子オーバーロード
__add__や__eq__といった特殊メソッドを定義することで、+や==といった演算子に独自の意味を持たせます。
次のセクションから、それぞれを具体的に見ていきます。
Pythonの関数オーバーロード
Pythonに公式な関数オーバーロードはあるか

Pythonには、Javaのような「シグネチャによる関数オーバーロード」の仕組みは標準では備わっていません。
同名の関数を複数定義することはできず、最後に定義したものだけが有効になります。
def greet():
print("Hello")
def greet(name):
print(f"Hello, {name}")
greet() # TypeError になるこの場合、2つ目のgreet(name)だけが有効で、Pythonはgreet()を「引数が足りない呼び出し」とみなしてTypeErrorを出します。
実行例を確認してみます。
def greet():
print("Hello")
def greet(name):
print(f"Hello, {name}")
try:
greet()
except TypeError as e:
print("TypeError:", e)
greet("Alice")TypeError: greet() missing 1 required positional argument: 'name'
Hello, Aliceこのように、Pythonでは「複数定義」ではなく「1つの関数で柔軟に受ける」という発想に切り替えることが重要です。
デフォルト引数で擬似オーバーロードを実装
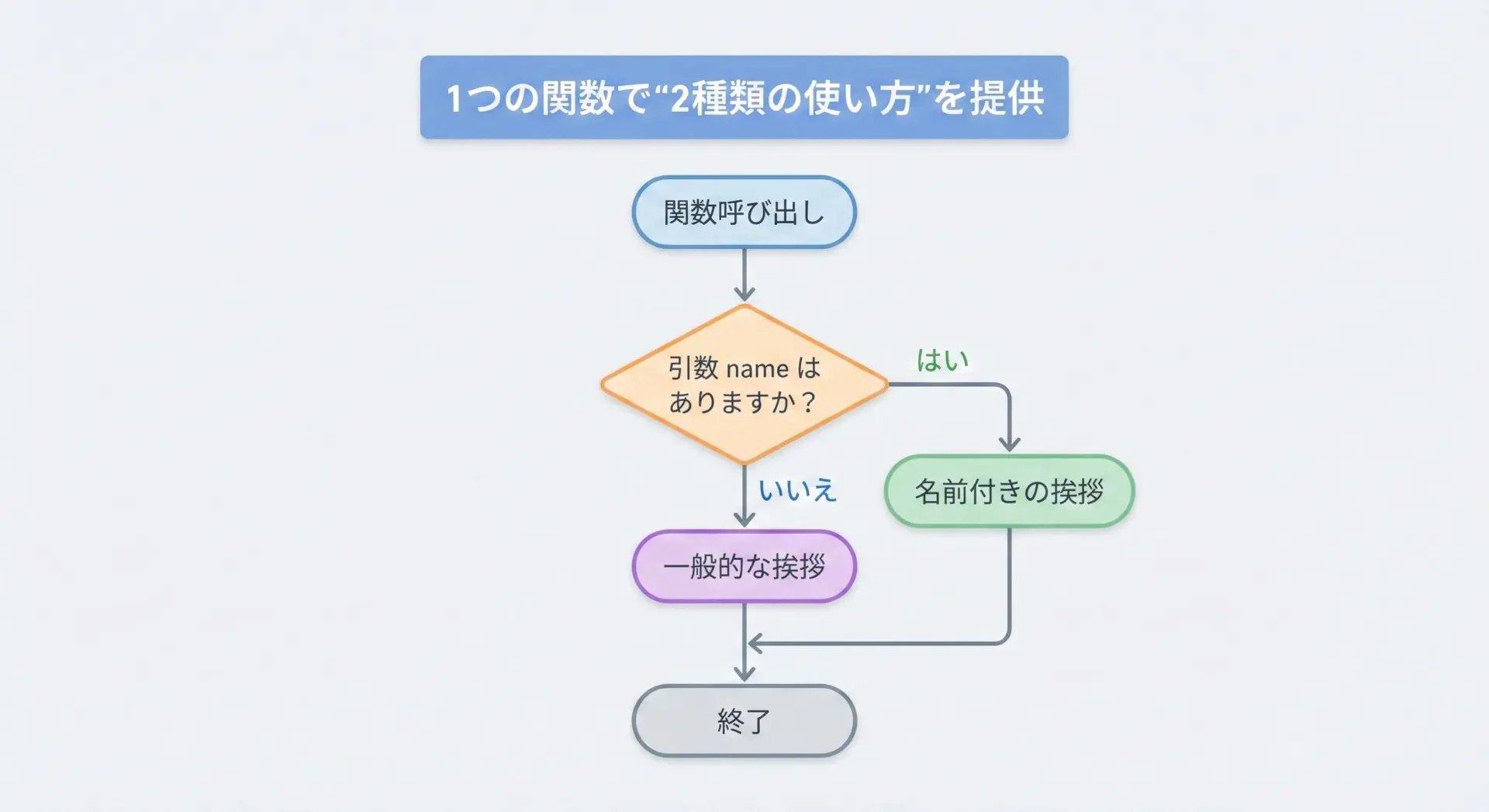
もっともシンプルな「擬似オーバーロード」の方法は、デフォルト引数を利用することです。
引数にデフォルト値を設定し、呼び出し時に引数が省略されたかどうかで処理を分けます。
def greet(name=None):
"""name があれば名前付きで、なければ一般的な挨拶をする関数"""
if name is None:
print("Hello")
else:
print(f"Hello, {name}")
greet() # 引数なし
greet("Bob") # 引数ありHello
Hello, Bobこの書き方では、呼び出し側は2種類の使い方を選べる一方で、実装側は1つの関数だけを管理すればよいという利点があります。
応用として、引数の数が少し違うケースもデフォルト引数で吸収できます。
def power(base, exp=2):
"""べき乗を計算する。exp を省略すると 2 乗として扱う"""
return base ** exp
print(power(3)) # 3^2
print(power(2, 3)) # 2^39
8このように、「単純に引数が増えるだけ」のようなケースは、デフォルト引数だけで十分にオーバーロード的な振る舞いを表現できます。
*argsや**kwargsで柔軟な引数を受け取る
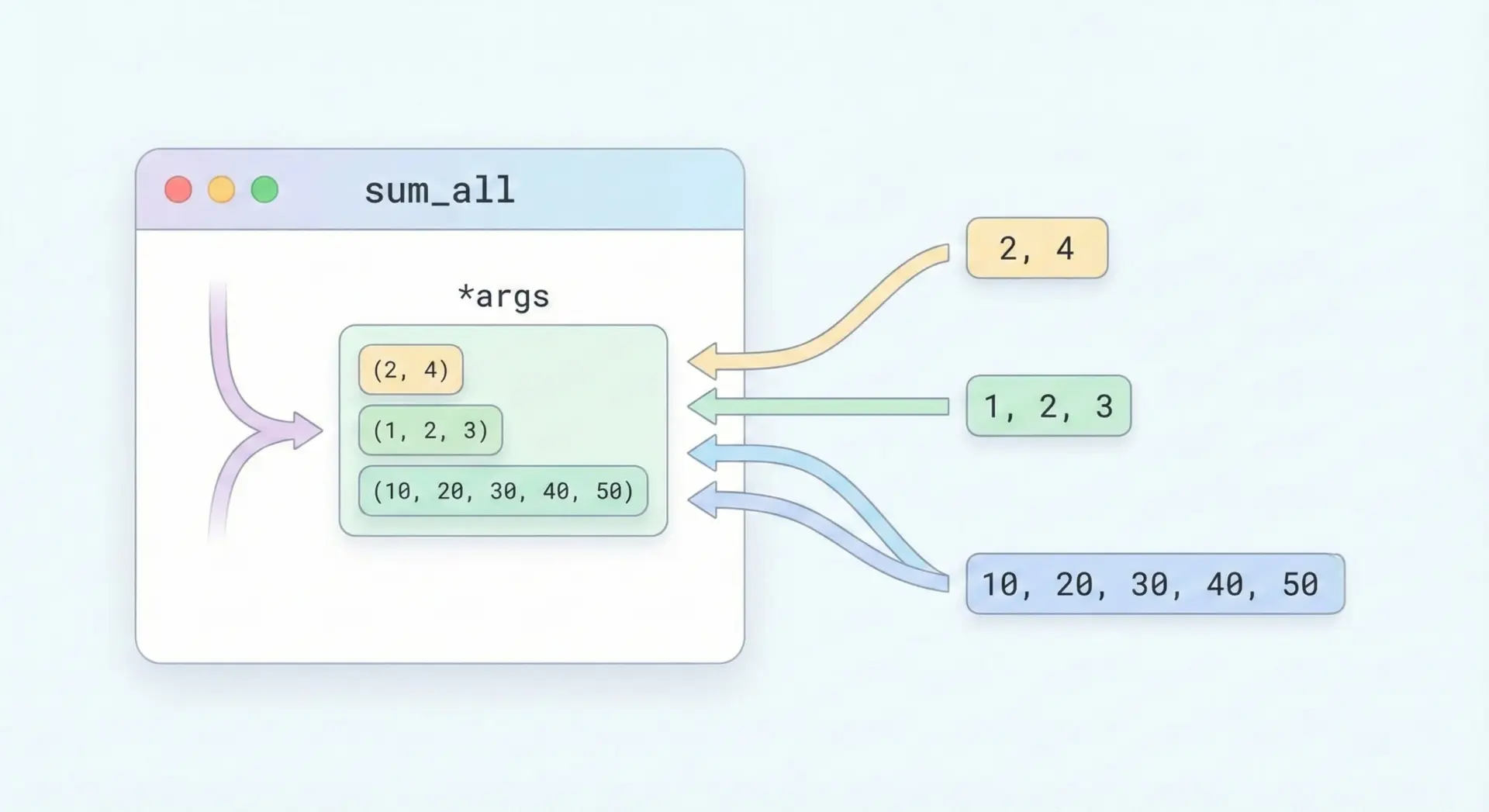
*argsや**kwargsを使うと、「引数の個数や名前が異なるさまざまな呼び出し」を1つの関数で受け止めることができます。
def describe_person(name, *traits, **extra):
"""
name: 名前(必須)
*traits: 性格や特徴(任意個)
**extra: 年齢や職業などの追加情報(キーワード引数)
"""
print(f"Name: {name}")
if traits:
print("Traits:", ", ".join(traits))
if extra:
for key, value in extra.items():
print(f"{key.capitalize()}: {value}")
# いろいろな呼び出し方
describe_person("Alice")
print("-----")
describe_person("Bob", "kind", "smart")
print("-----")
describe_person("Charlie", "active", age=30, job="Engineer")Name: Alice
-----
Name: Bob
Traits: kind, smart
-----
Name: Charlie
Traits: active
Age: 30
Job: Engineerこのように*argsと**kwargsを組み合わせることで、「複数パターンの呼び出し」を1つの関数に集約できます。
Javaなどでシグネチャを分けていた設計も、多くの場合このようにまとめられます。
ただし、あまりにも柔軟にしすぎると、「関数の使い方がわかりにくくなる」というデメリットもあります。
そのため、仕様をドキュメントや型ヒントで丁寧に説明することが大切です。
functools.singledispatchによる関数オーバーロード
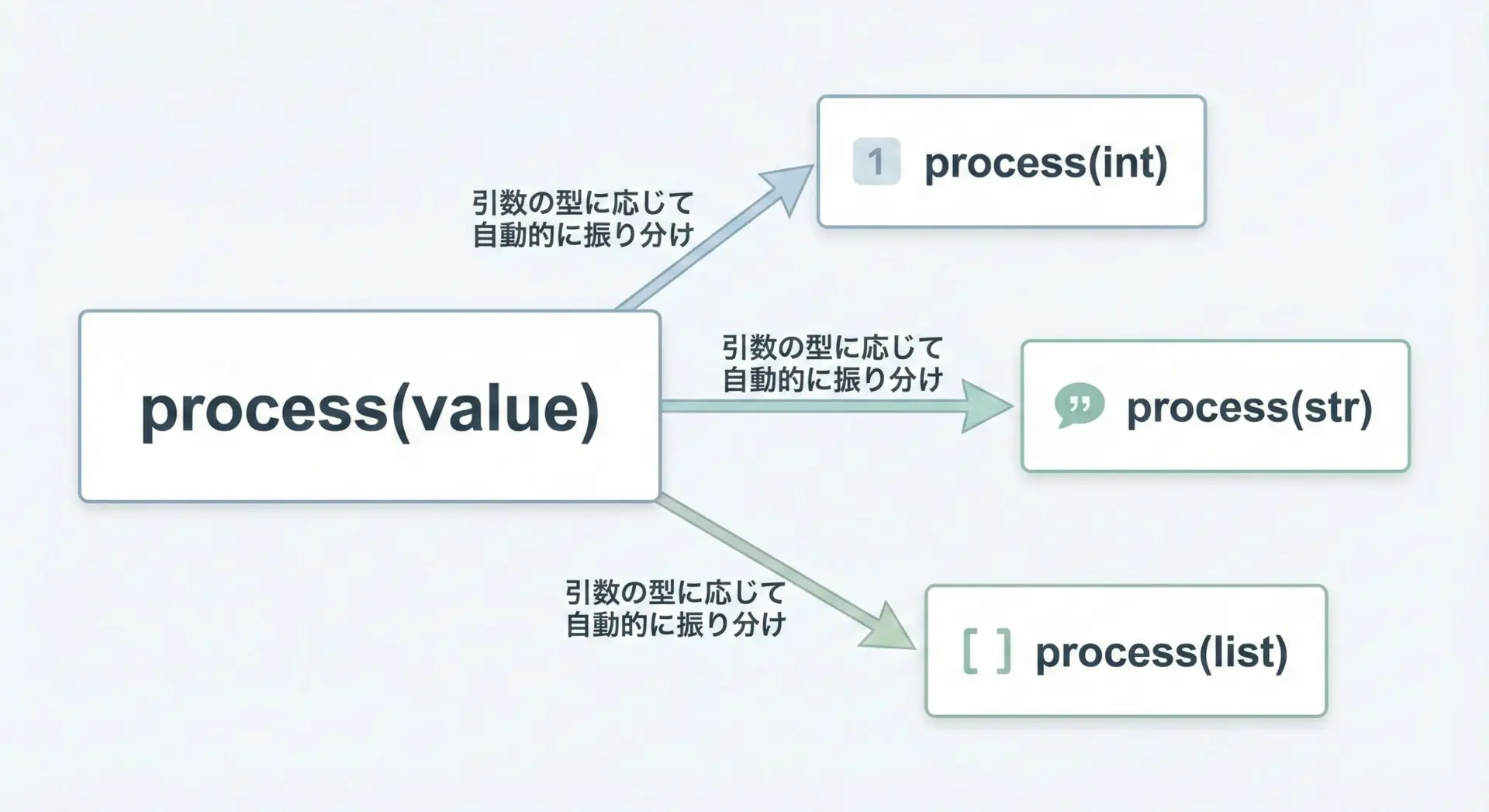
Python 3.4以降では、functools.singledispatchを使って「型に応じた関数オーバーロード的な動作」を実現できます。
これは「最初の引数の型」に応じて、適切な実装を呼び出す仕組みです。
from functools import singledispatch
@singledispatch
def show(value):
"""デフォルトの実装(対応する型がなければこれが使われる)"""
print(f"[default] {value!r}")
@show.register
def _(value: int):
print(f"[int] {value} (二倍: {value * 2})")
@show.register
def _(value: str):
print(f"[str] '{value}' (長さ: {len(value)})")
@show.register
def _(value: list):
print(f"[list] 要素数: {len(value)}, 中身: {value}")
show(10)
show("hello")
show([1, 2, 3])
show(3.14) # 対応していない型(float)はデフォルト実装が呼ばれる[int] 10 (二倍: 20)
[str] 'hello' (長さ: 5)
[list] 要素数: 3, 中身: [1, 2, 3]
[default] 3.14ここでは、1つの関数名showに対して、型ごとの実装を登録しています。
singledispatchを使うときのポイント
@singledispatchを付けた関数は「デフォルト実装」になります。- 型ごとの実装は
@show.registerで登録し、引数の型ヒントでどの型に対応するかを指定します。 - オーバーロードの基準になるのは最初の引数の型だけです。
クラスメソッド版のsingledispatchmethodも存在しますが、ここでは関数版に絞って説明しました。
後のセクションのメソッドオーバーロードと合わせて理解すると、より強力に活用できます。
Pythonのメソッドオーバーロード
クラス内でのメソッドオーバーロードの考え方
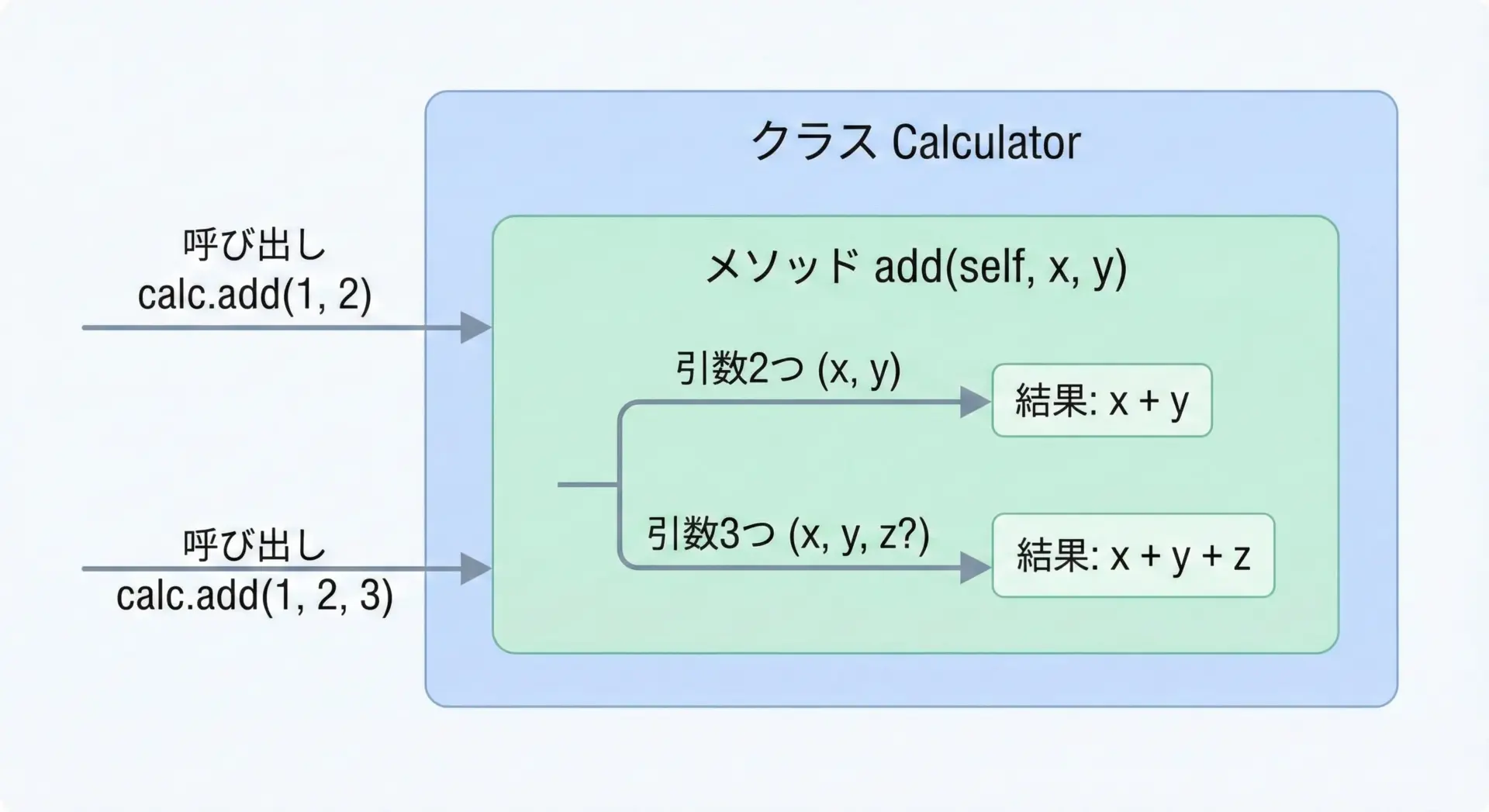
クラスのメソッドも関数と同じく、同じ名前を複数定義すると上書きされてしまいます。
そのため、Pythonにおける「メソッドオーバーロード」も、実際には1つのメソッドで引数を柔軟に扱うことで表現します。
class Calculator:
def add(self, *args):
"""引数の個数に応じて加算を行うメソッド"""
if not args:
return 0
elif len(args) == 2:
a, b = args
return a + b
elif len(args) == 3:
a, b, c = args
return a + b + c
else:
# それ以外の個数はエラーにする
raise TypeError("add() は 0, 2, 3 個の引数にのみ対応しています")
calc = Calculator()
print(calc.add())
print(calc.add(1, 2))
print(calc.add(1, 2, 3))0
3
6このようにクラスのメソッドでも*argsやデフォルト引数を組み合わせて「オーバーロード的な挙動」を実現できます。
実装の基本方針は、関数オーバーロードと同じです。
メソッドオーバーロードとオーバーライドの違い
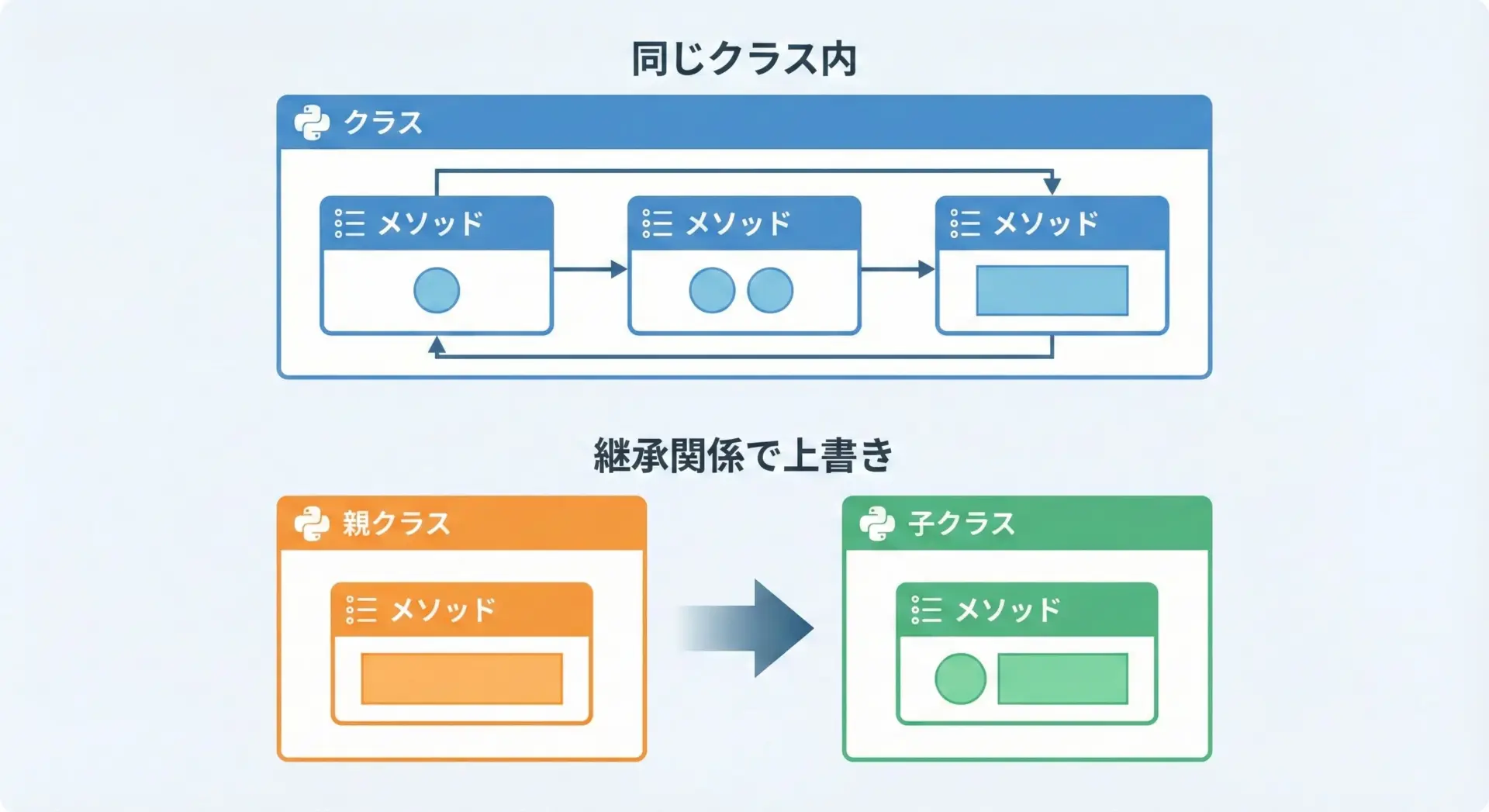
ここで混同しやすい概念がオーバーロード(overload)とオーバーライド(override)です。
Pythonでは、どちらもよく登場しますが、意味は明確に異なります。
- オーバーロード
同じクラス(またはモジュール)内で、同じ名前の関数やメソッドを「引数違い」で複数用意する考え方です。Pythonでは前述の通り、形式的なオーバーロード構文はなく、1つの関数で分岐する形を取ります。 - オーバーライド
親クラスに定義されたメソッドを、子クラスで同じ名前のメソッドとして定義し直す(上書きする)ことです。こちらはPythonでも一般的に行われます。
class Animal:
def speak(self):
print("...")
class Dog(Animal):
def speak(self):
# 親クラスの speak を「オーバーライド」している
print("Woof!")
animal = Animal()
dog = Dog()
animal.speak() # ...
dog.speak() # Woof!...
Woof!この例では、Dog.speakがAnimal.speakをオーバーライドしています。
Pythonのオブジェクト指向では、オーバーライドは頻繁に登場する重要な仕組みなので、オーバーロードと混同しないようにしましょう。
@classmethodや@staticmethodとオーバーロード
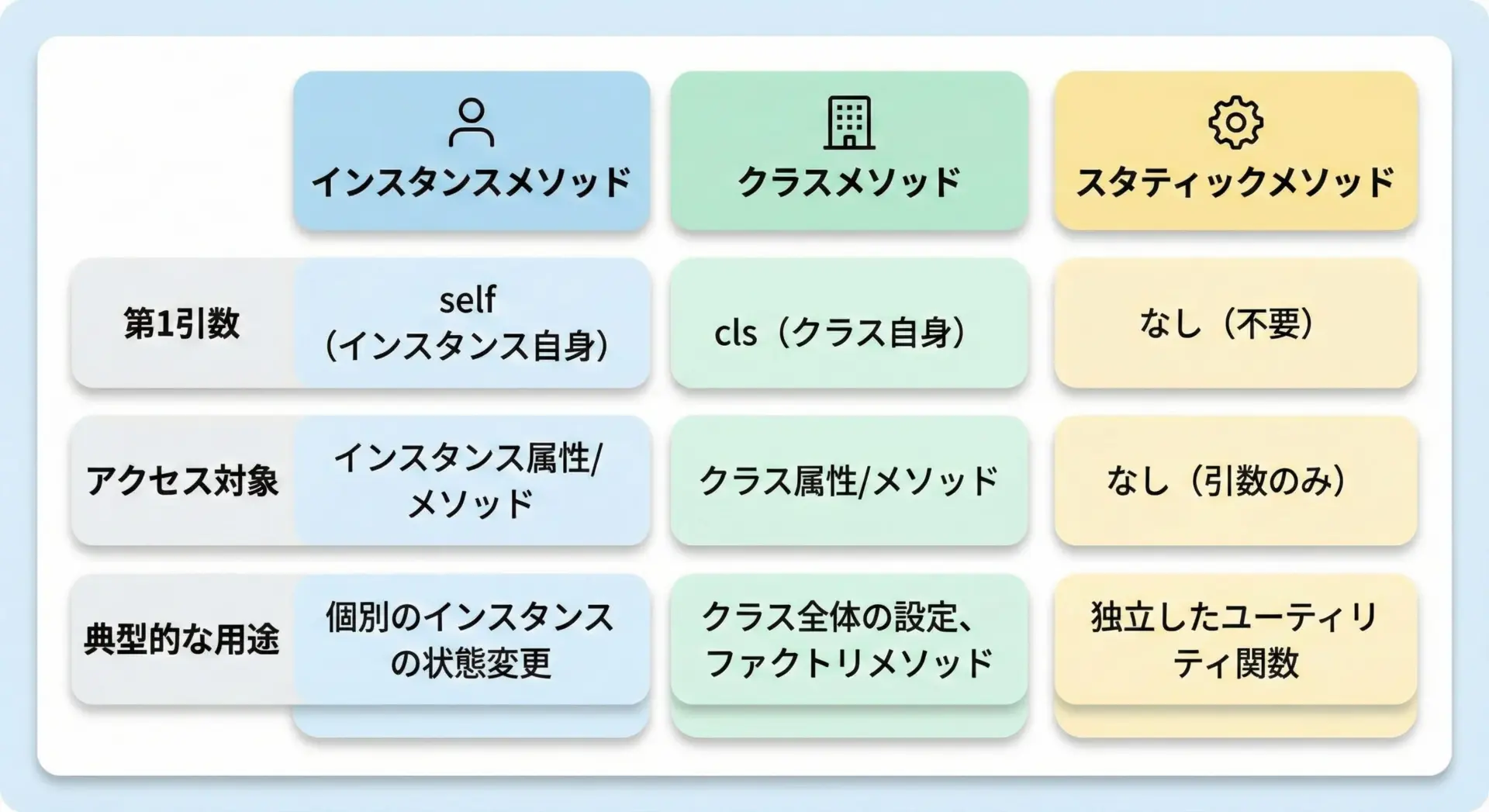
Pythonでは、クラスのメソッドには大きく3種類あります。
- インスタンスメソッド(通常のメソッド)
- クラスメソッド(
@classmethod) - スタティックメソッド(
@staticmethod)
まとめると、次のような違いがあります。
| 種類 | デコレータ | 第1引数 | 主な用途 |
|---|---|---|---|
| インスタンスメソッド | なし | self | 個々のインスタンスの状態に基づく処理 |
| クラスメソッド | @classmethod | cls | クラス全体に関する処理、別コンストラクタ |
| スタティックメソッド | @staticmethod | なし | クラスに関連する汎用関数 |
これらそれぞれで、デフォルト引数や*argsを使った「オーバーロード的なメソッド」を実装できます。
class Person:
def __init__(self, name):
self.name = name
# 別コンストラクタのようなクラスメソッド
@classmethod
def from_fullname(cls, first, last):
return cls(f"{first} {last}")
# ユーティリティ的なスタティックメソッド
@staticmethod
def format_name(name, upper=False):
if upper:
return name.upper()
return name
p1 = Person("Alice")
p2 = Person.from_fullname("Bob", "Smith") # クラスメソッドの利用
print(Person.format_name(p1.name))
print(Person.format_name(p2.name, upper=True))Alice
BOB SMITHここでは、format_nameメソッドが引数upperの有無によって挙動を変える「擬似オーバーロード」になっています。
型ヒントとオーバーロード
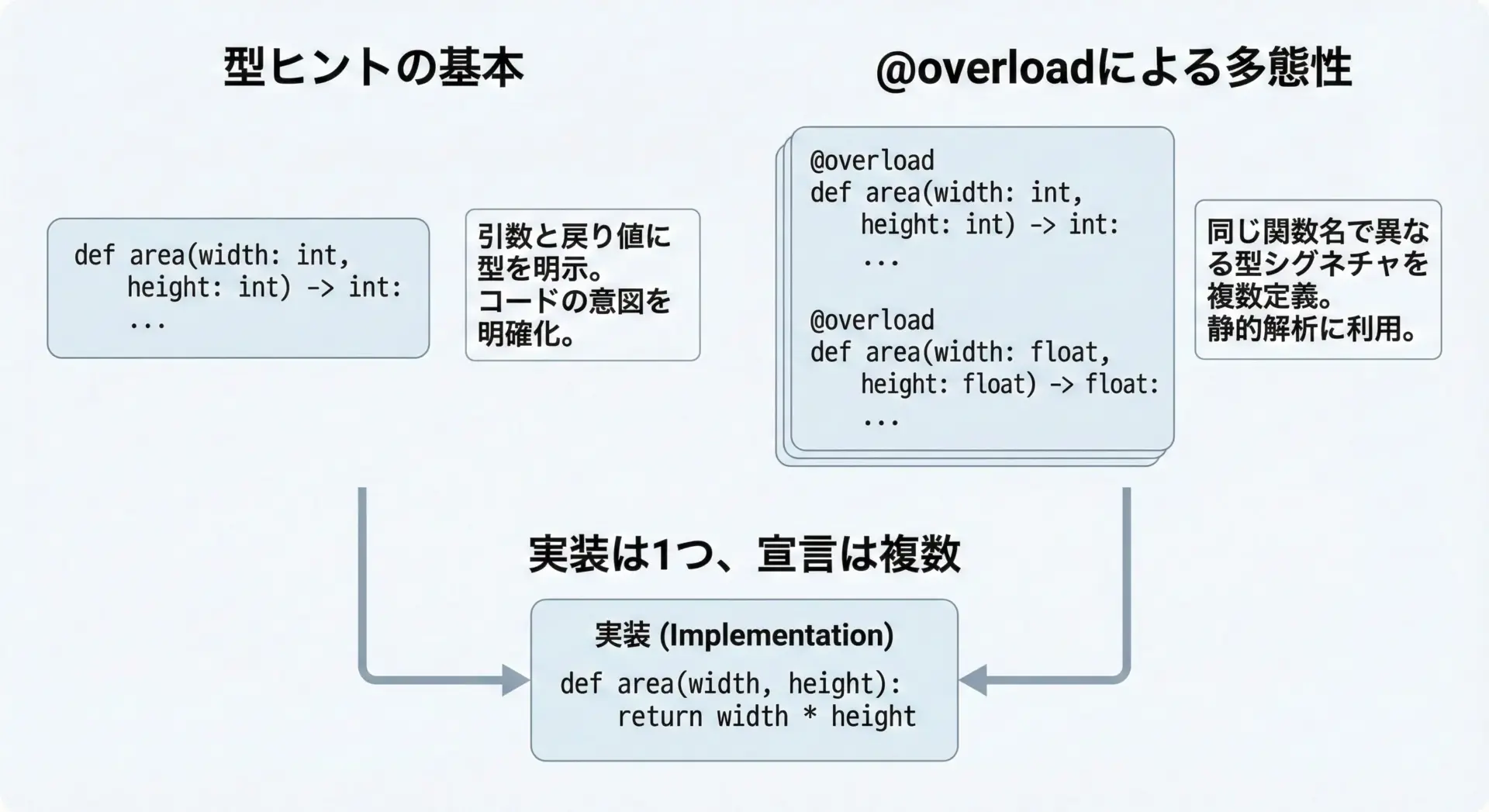
Pythonの型ヒント(typing)を使うと、静的型チェッカ(例: mypy)向けに「オーバーロード宣言」を行うことができます。
ここでは、typing.overloadを利用します。
ポイントは、実行時には「実装は1つだけ」という点です。
複数の@overloadは、あくまで型チェッカに対する宣言であり、実体となる実装は最後に1つだけ定義します。
from typing import overload, Union
@overload
def repeat(value: int, times: int) -> list[int]:
...
@overload
def repeat(value: str, times: int) -> list[str]:
...
def repeat(value, times):
"""value の型に応じて、同じ値を times 回並べたリストを返す"""
return [value] * times
print(repeat(1, 3))
print(repeat("a", 4))[1, 1, 1]
['a', 'a', 'a', 'a']ここでの流れは次の通りです。
@overload付きの2つのrepeatは、「型チェック用の宣言」として扱われます。- その後に定義した
repeat(value, times)が、実際に実行される関数です。 - IDEやmypyなどは、
@overloadの宣言を読み取り、引数と戻り値の型を推論します。
このパターンを使うと、実装はシンプルに保ちつつ、利用側には「オーバーロードされたAPI」として見せることができます。
Pythonの演算子オーバーロード
演算子オーバーロードの基本と用途
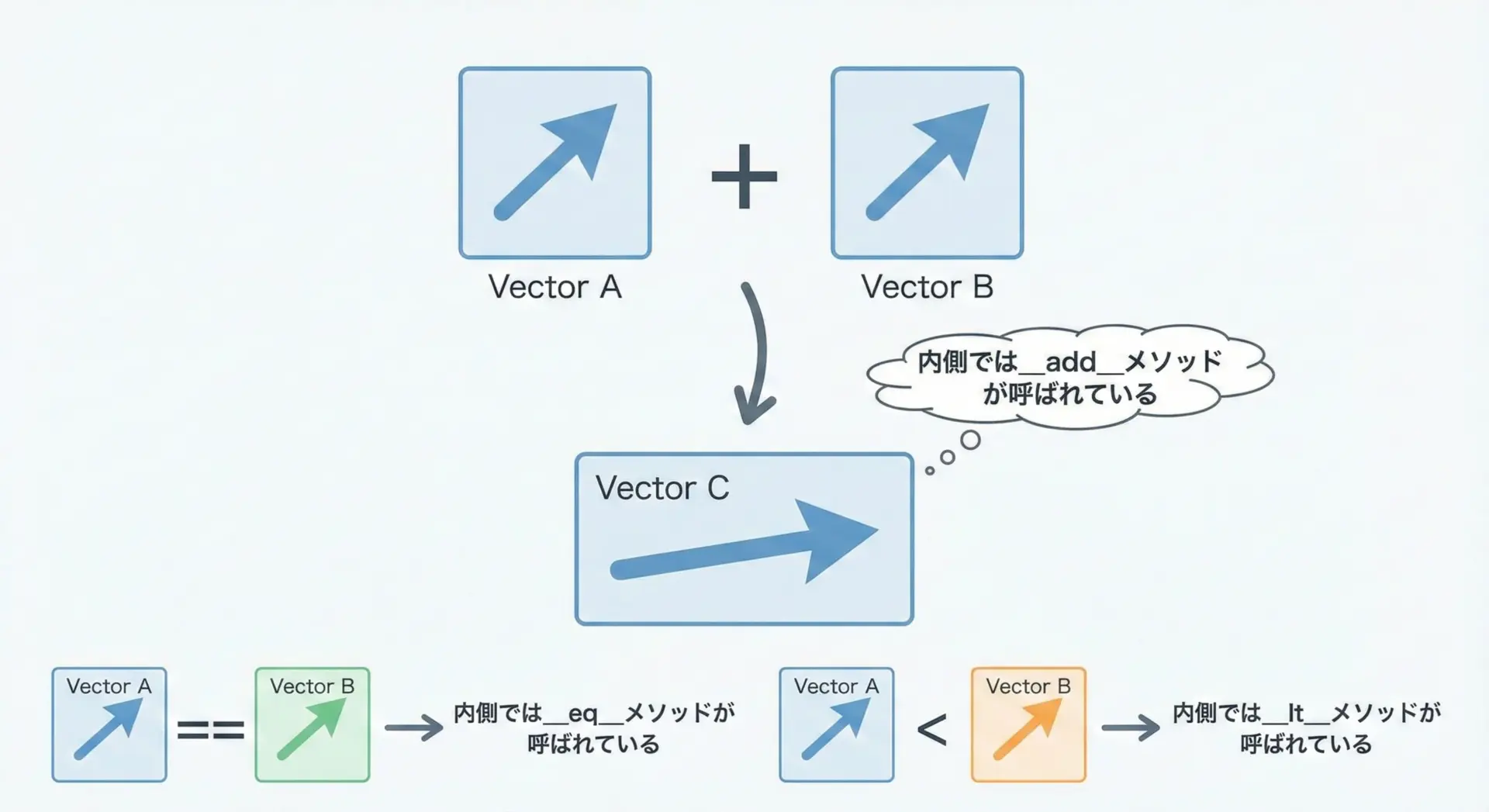
演算子オーバーロードとは、自作クラスに対して+や==などの演算子の動作を定義することです。
Pythonでは、クラスの特殊メソッドを定義することで実現します。
よく使われる用途としては、次のようなものがあります。
- ベクトルや行列などの数学的オブジェクトを
+や*で操作できるようにする - 金額や単位付きの値を、数値と似た感覚で扱えるようにする
- ドメイン固有のオブジェクト(例えば日付範囲、期間など)に直感的な演算子を提供する
演算子オーバーロードの利点は、「利用側のコードが非常に読みやすくなる」ことです。
ただし、本来の意味からかけ離れた挙動を定義すると混乱を招くため、設計には注意が必要です。
__add__などの特殊メソッドで演算子をオーバーロード
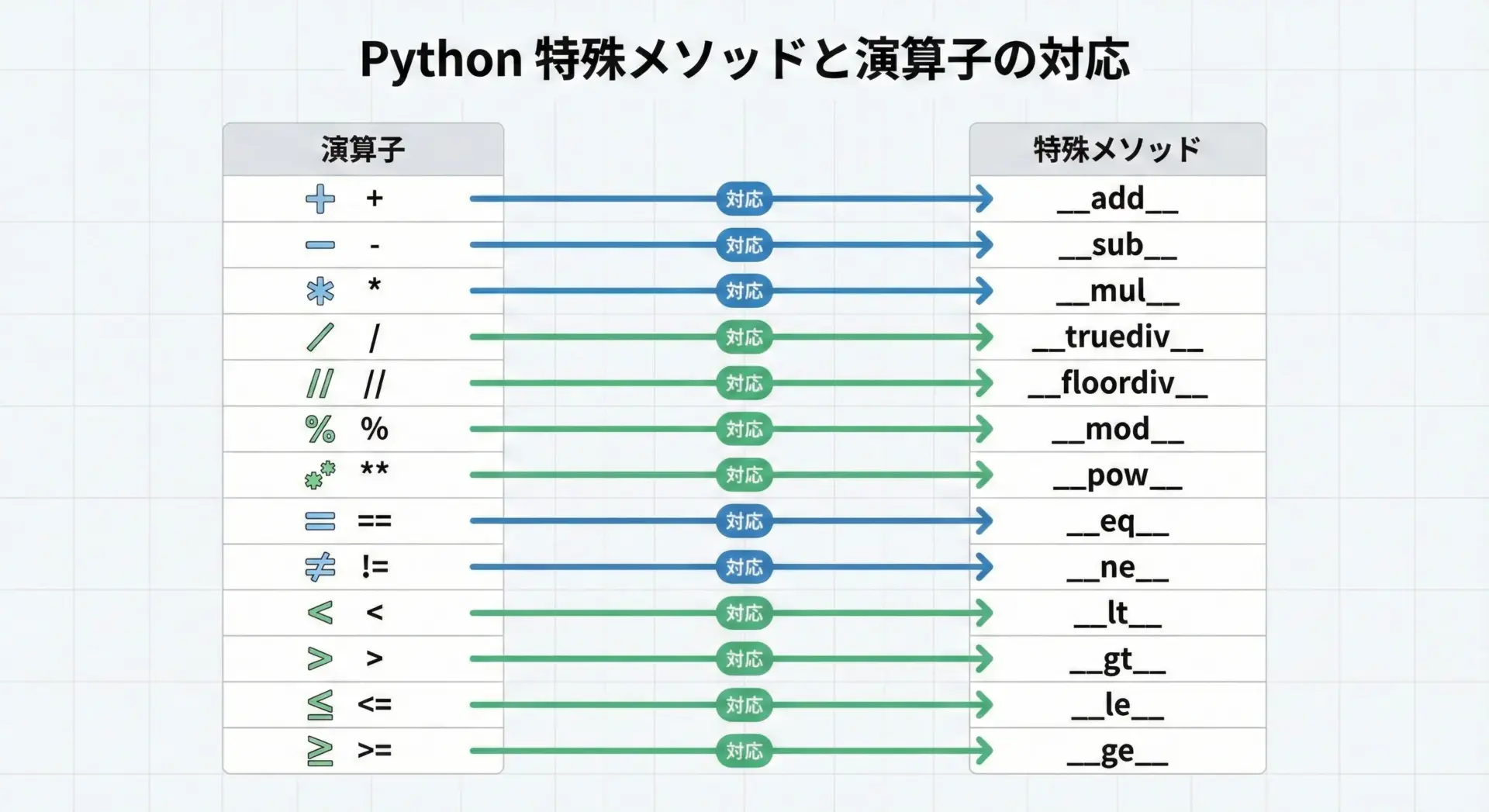
Pythonでは、演算子と特殊メソッドの対応が決まっています。
例えば+は__add__、-は__sub__です。
ベクトルクラスを例に、+演算子をオーバーロードしてみましょう。
class Vector2D:
"""2次元ベクトルを表すクラス"""
def __init__(self, x, y):
self.x = x
self.y = y
def __add__(self, other):
"""self + other の挙動を定義する"""
if not isinstance(other, Vector2D):
return NotImplemented # 他の型との加算には対応しない
return Vector2D(self.x + other.x, self.y + other.y)
def __repr__(self):
return f"Vector2D({self.x}, {self.y})"
v1 = Vector2D(1, 2)
v2 = Vector2D(3, 4)
v3 = v1 + v2 # 内部的には v1.__add__(v2) が呼ばれる
print(v3)Vector2D(4, 6)ここではv1 + v2という直感的な記述でベクトルの加算ができるようになりました。
内部的にはv1.__add__(v2)が呼ばれています。
NotImplemented を返す理由
__add__内で、対応していない型の相手が来たときにはNotImplementedを返しています。
これはPythonに「この組み合わせの演算はこのクラス側では対応していない」と伝えるための特別な値です。
これを返すことで、Pythonは次に「相手側の__radd__を試す」など、別の候補を検討できます。
比較演算子オーバーロード
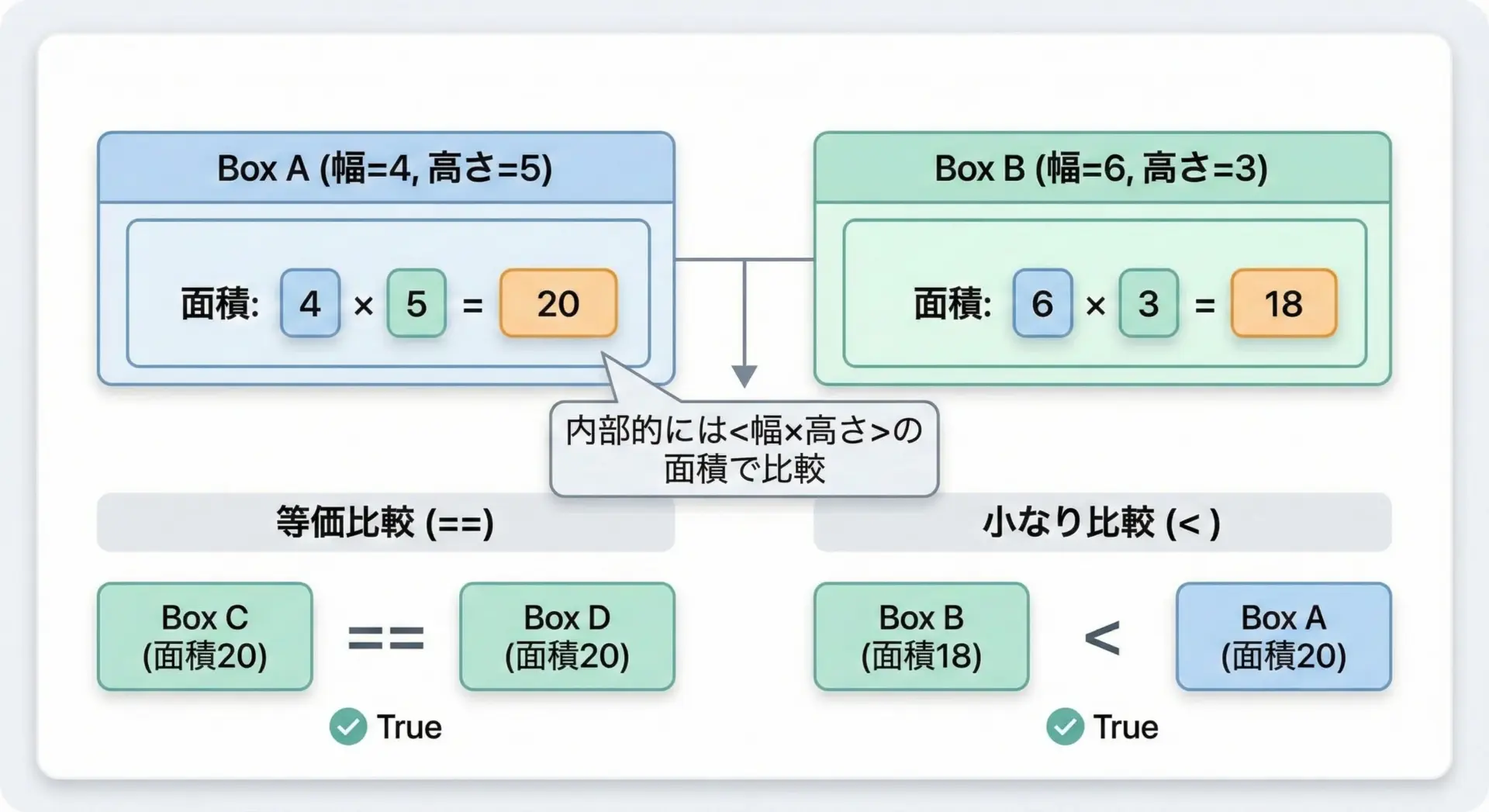
比較演算子==や<なども、特殊メソッドでオーバーロードできます。
代表的な対応は次の通りです。
| 演算子 | 特殊メソッド |
|---|---|
== | __eq__ |
!= | __ne__ |
< | __lt__ |
<= | __le__ |
> | __gt__ |
>= | __ge__ |
たとえば、面積で比較できるRectangleクラスを定義してみます。
class Rectangle:
"""長方形を表すクラス"""
def __init__(self, width, height):
self.width = width
self.height = height
@property
def area(self):
return self.width * self.height
def __eq__(self, other):
if not isinstance(other, Rectangle):
return NotImplemented
return self.area == other.area
def __lt__(self, other):
if not isinstance(other, Rectangle):
return NotImplemented
return self.area < other.area
def __repr__(self):
return f"Rectangle({self.width}, {self.height})"
r1 = Rectangle(2, 3) # 面積 6
r2 = Rectangle(1, 6) # 面積 6
r3 = Rectangle(3, 3) # 面積 9
print(r1 == r2) # 面積が同じ
print(r1 < r3) # 6 < 9
print(r3 > r2) # 9 > 6True
True
Trueこのように独自クラス同士の「自然な比較」を提供できます。
ただし、比較の意味が直感とズレないように設計することが重要です。
実用例で学ぶ演算子オーバーロードのパターン
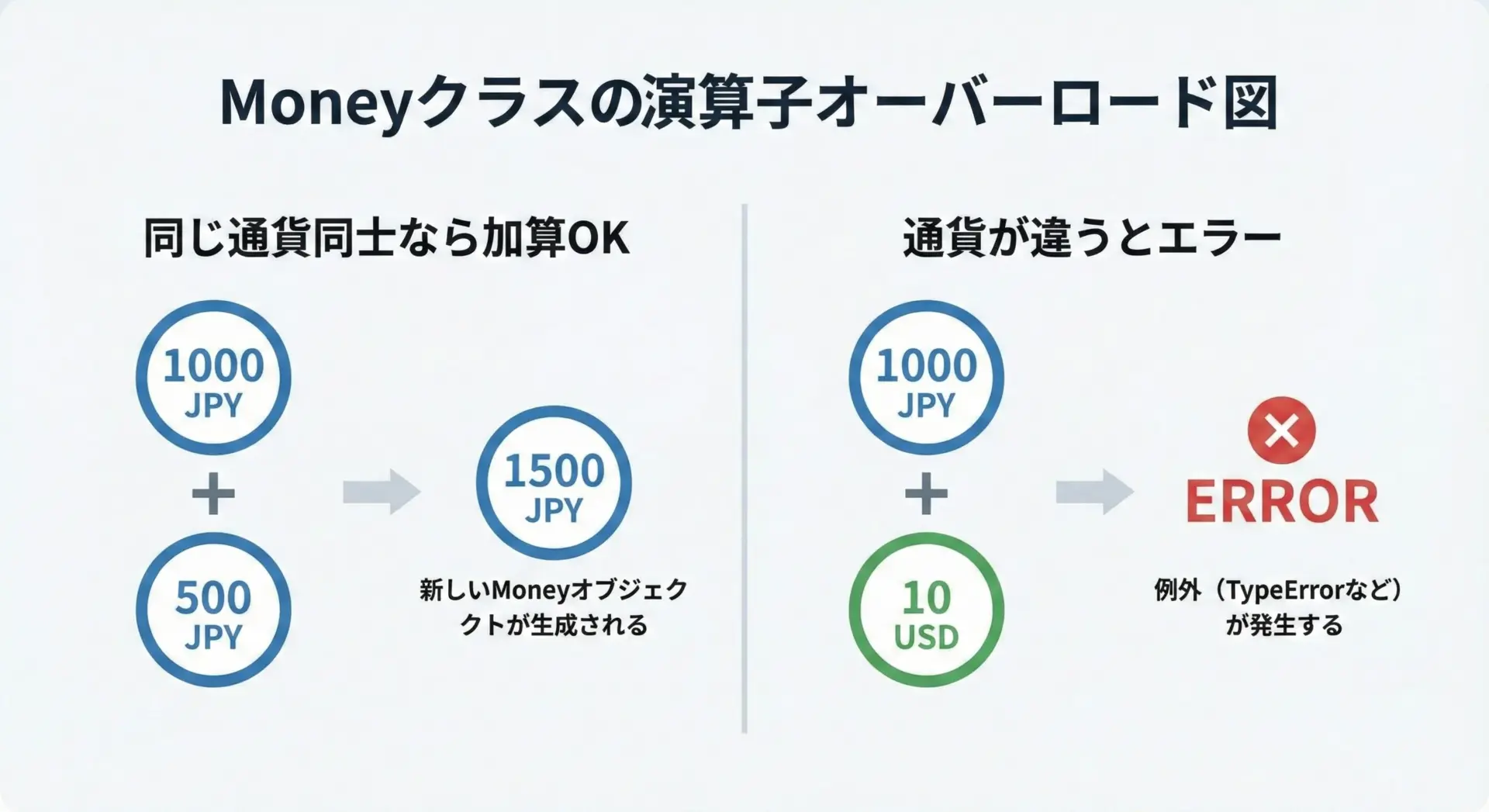
演算子オーバーロードは、実際のアプリケーションでも多用されます。
ここでは金額を扱うMoneyクラスを例に、+や*などの演算子をオーバーロードしてみます。
class Money:
"""通貨付き金額を表すクラス"""
def __init__(self, amount, currency="JPY"):
self.amount = amount
self.currency = currency
def __add__(self, other):
"""同じ通貨同士の加算のみ許可する"""
if not isinstance(other, Money):
return NotImplemented
if self.currency != other.currency:
raise ValueError("通貨が異なる Money 同士は加算できません")
return Money(self.amount + other.amount, self.currency)
def __mul__(self, factor):
"""金額 × 倍率(数値)"""
if not isinstance(factor, (int, float)):
return NotImplemented
return Money(self.amount * factor, self.currency)
def __rmul__(self, factor):
"""倍率 × 金額 も許可する(右側版の演算)"""
return self.__mul__(factor)
def __repr__(self):
return f"Money({self.amount}, '{self.currency}')"
salary = Money(200000) # 20万円
bonus = Money(50000) # 5万円
total = salary + bonus # 内部的には salary.__add__(bonus)
double = 2 * salary # __rmul__ が使われる
triple = salary * 3 # __mul__ が使われる
print(total)
print(double)
print(triple)
# 通貨が異なる場合
usd = Money(100, "USD")
try:
print(salary + usd)
except ValueError as e:
print("エラー:", e)Money(250000, 'JPY')
Money(400000, 'JPY')
Money(600000, 'JPY')
エラー: 通貨が異なる Money 同士は加算できませんこの例では、次のようなパターンを確認できます。
- 同じ通貨同士の
Moneyは+で自然に加算できる - 倍数との掛け算
金額 * 倍率と倍率 * 金額の両方をサポートするために、__mul__と__rmul__を実装している - 通貨が異なる
Money同士の加算には明確にエラーを出すことで、安全性を高めている
このような設計は、金額や単位など、ビジネスロジックで重要なルールを「演算子の振る舞い」としてカプセル化したいときに非常に有効です。
まとめ
Pythonでは、JavaやC++のような「シグネチャによる正式なオーバーロード構文」はありませんが、デフォルト引数・*args/**kwargs・functools.singledispatch・typing.overload・特殊メソッドなどを組み合わせることで、関数・メソッド・演算子のオーバーロード的な振る舞いを柔軟に実現できます。
ポイントは、「1つの名前に複数の使い方を集約する」と同時に、挙動が直感から外れないように注意深く設計することです。
本記事で紹介したパターンを理解しておけば、Pythonらしいスタイルで分かりやすく拡張性の高いAPIを設計できるようになります。
