
Pythonのdataclassesは、データ中心のクラスを簡潔かつ安全に記述できる機能です。
従来のクラス定義では、コンストラクタや比較メソッドなどの定型コードが多くなりがちでしたが、dataclassesを使うことで、宣言的に「データ構造」を表現できます。
本記事では、基本的な使い方からメリット、落とし穴まで詳しく解説します。
Pythonのdataclassesとは
dataclassesの基本概要と役割

Pythonのdataclassesは、Python 3.7以降で標準ライブラリに追加されたデータ構造専用のクラス定義を簡略化する仕組みです。
モジュール名はdataclassesで、クラス定義の上に@dataclassデコレータを付けることで、以下のようなメソッドを自動生成してくれます。
- コンストラクタ(cst-code>__init__)
- 文字列表現(cst-code>__repr__)
- 比較メソッド(cst-code>__eq__、必要に応じて
__lt__など)
これにより、クラスの本質的な「フィールド定義」に集中でき、データモデルの宣言がシンプルかつ明確になります。
通常クラスとdataclassの比較イメージ
まずはイメージを掴むために、通常クラスとdataclassを比較してみます。
# 通常のクラス定義の場合
class User:
def __init__(self, user_id: int, name: str, is_active: bool = True) -> None:
self.user_id = user_id
self.name = name
self.is_active = is_active
def __repr__(self) -> str:
return f"User(user_id={self.user_id}, name={self.name!r}, is_active={self.is_active})"
def __eq__(self, other: object) -> bool:
if not isinstance(other, User):
return NotImplemented
return (
self.user_id == other.user_id
and self.name == other.name
and self.is_active == other.is_active
)# dataclassを使った場合
from dataclasses import dataclass
@dataclass
class User:
user_id: int
name: str
is_active: bool = True同じ機能を実現しつつ、dataclass版は非常に短くなっていることが分かります。
「属性の宣言」そのものがクラス定義の中心になっており、データ構造の意図が読み取りやすくなります。
dataclassesが導入された背景
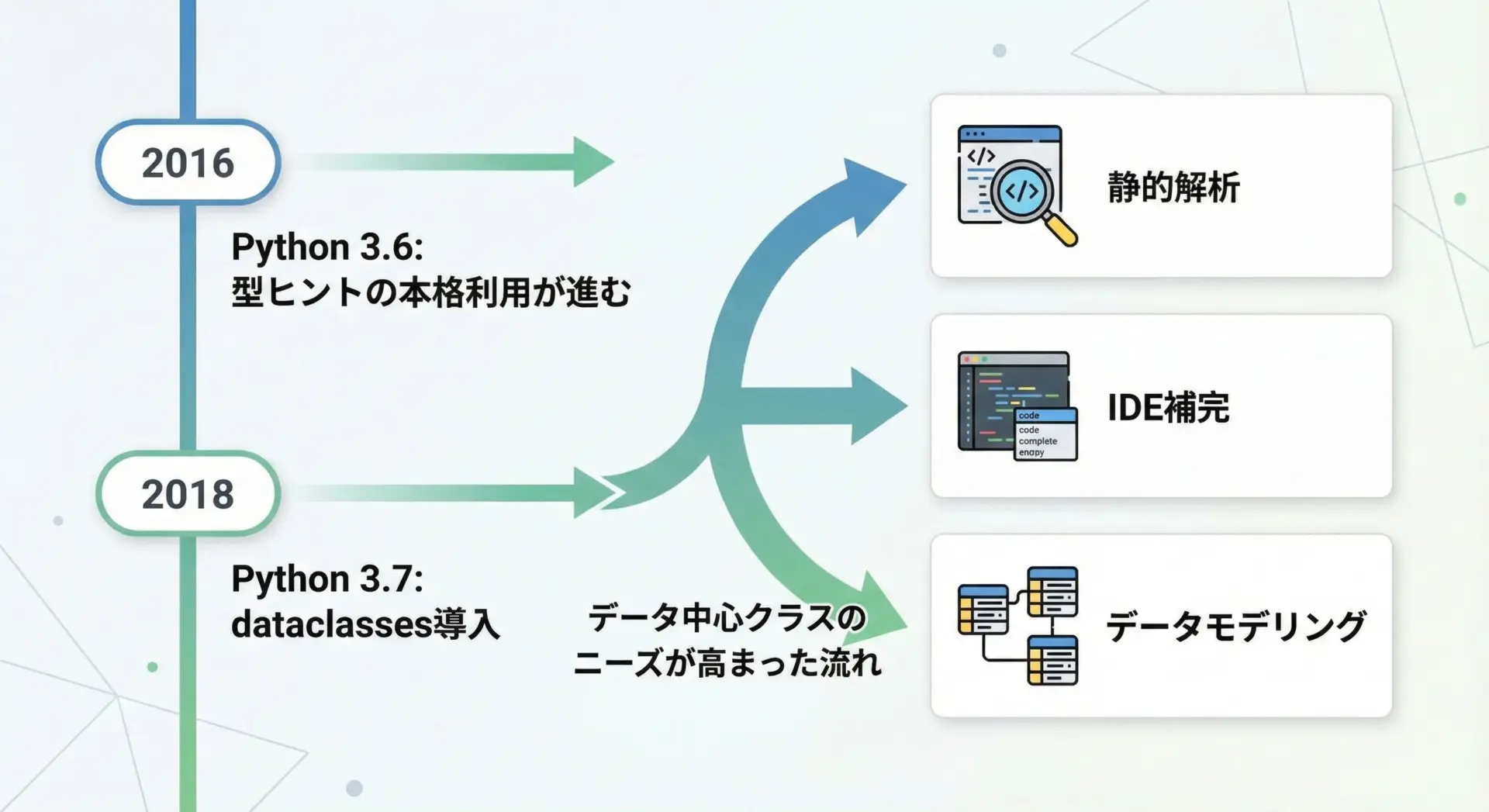
dataclassesが導入された背景には、Pythonコミュニティでの型ヒント(type hints)の普及があります。
Python 3.5以降、型ヒントが標準仕様として整備され、エディタや静的解析ツール(mypy、Pyrightなど)が活発に利用されるようになりました。
この流れの中で、次のようなニーズが高まりました。
- データを運ぶだけのクラス(いわゆるDTOやValue Objectなど)を簡潔に書きたい
- 辞書やタプルではなく、型付きの名前付きフィールドを持つ構造体のようなものが欲しい
- 既に
attrsなどの外部ライブラリで広まっていたパターンを、標準ライブラリとして提供したい
こうした要望に応える形で、Python 3.7でdataclassesが標準モジュールとして追加されました。
これにより、追加ライブラリに依存せずに、軽量なデータ構造クラスを簡単に定義できるようになりました。
dataclassesの基本的な使い方
@dataclassデコレータの書き方と基本構文
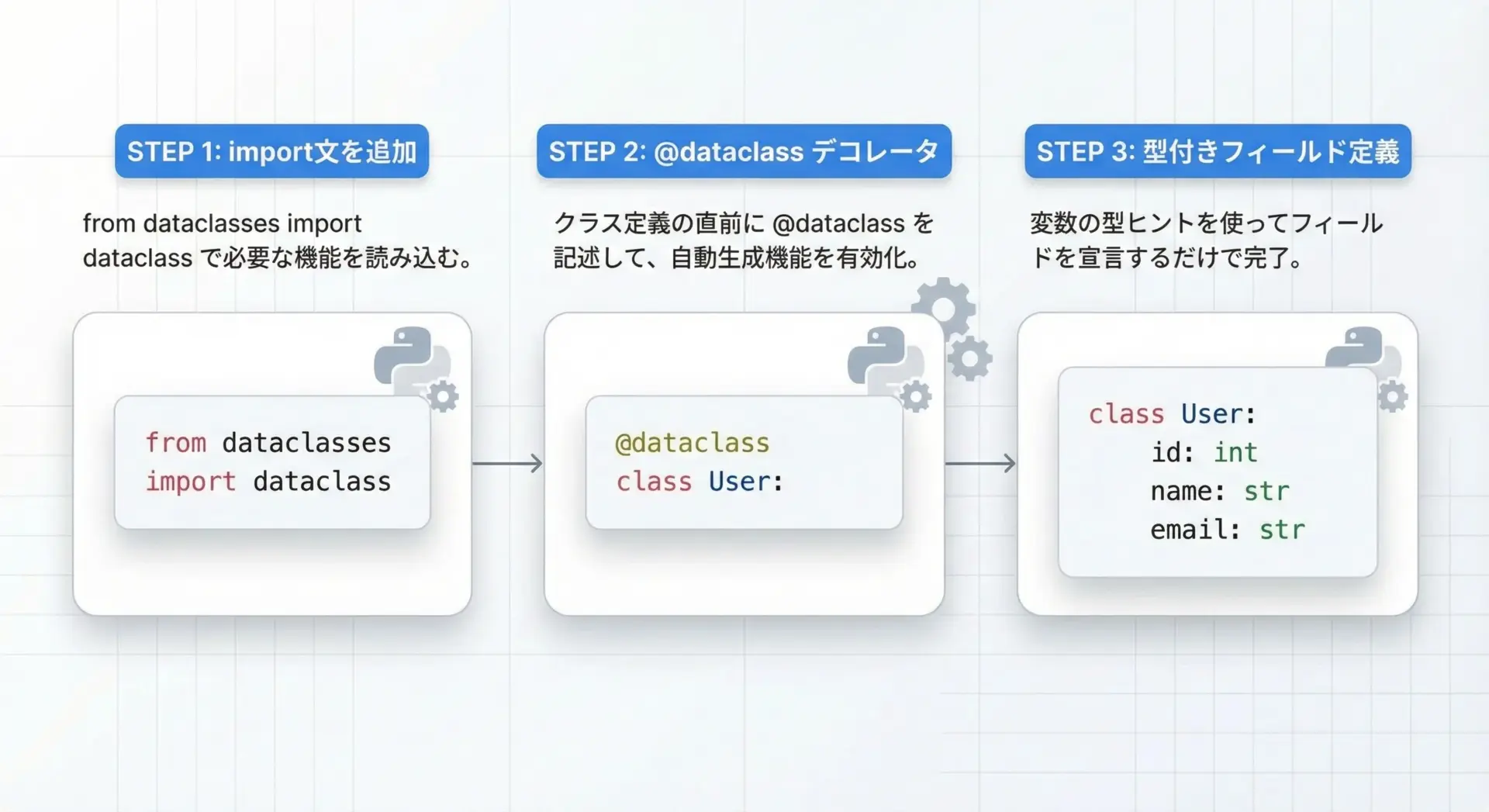
dataclassesを使うための最小限の手順はとてもシンプルです。
必要なのは、@dataclassデコレータをクラスの前に付けることだけです。
from dataclasses import dataclass
@dataclass
class Point:
# x座標 (整数)
x: int
# y座標 (整数)
y: int上記のクラス定義だけで、内部的には以下のようなメソッドが自動生成されます。
__init__(self, x: int, y: int)__repr__(self)__eq__(self, other)
実際の動きを確認してみます。
from dataclasses import dataclass
@dataclass
class Point:
x: int
y: int
p1 = Point(1, 2)
p2 = Point(1, 2)
p3 = Point(2, 3)
print(p1) # __repr__の出力
print(p1 == p2) # __eq__による比較
print(p1 == p3)Point(x=1, y=2)
True
Falseこのように、データ構造として自然な挙動が自動で手に入ることが、dataclassesの大きな特徴です。
フィールド定義(field)と型ヒントの指定
dataclassesでは、クラスの属性(フィールド)は型ヒント付きで宣言するのが基本です。
型ヒントは必須ではありませんが、型ヒントがあることでdataclassesはその属性を「フィールド」として認識し、自動生成メソッドに反映します。
もっともシンプルなフィールド定義は次のようになります。
from dataclasses import dataclass
@dataclass
class Book:
title: str # 書籍タイトル
price: int # 価格
in_stock: bool # 在庫の有無この場合、すべてのフィールドはコンストラクタの引数として必須になります。
オプション項目にしたい場合は、デフォルト値を指定します。
from dataclasses import dataclass
@dataclass
class Book:
title: str
price: int
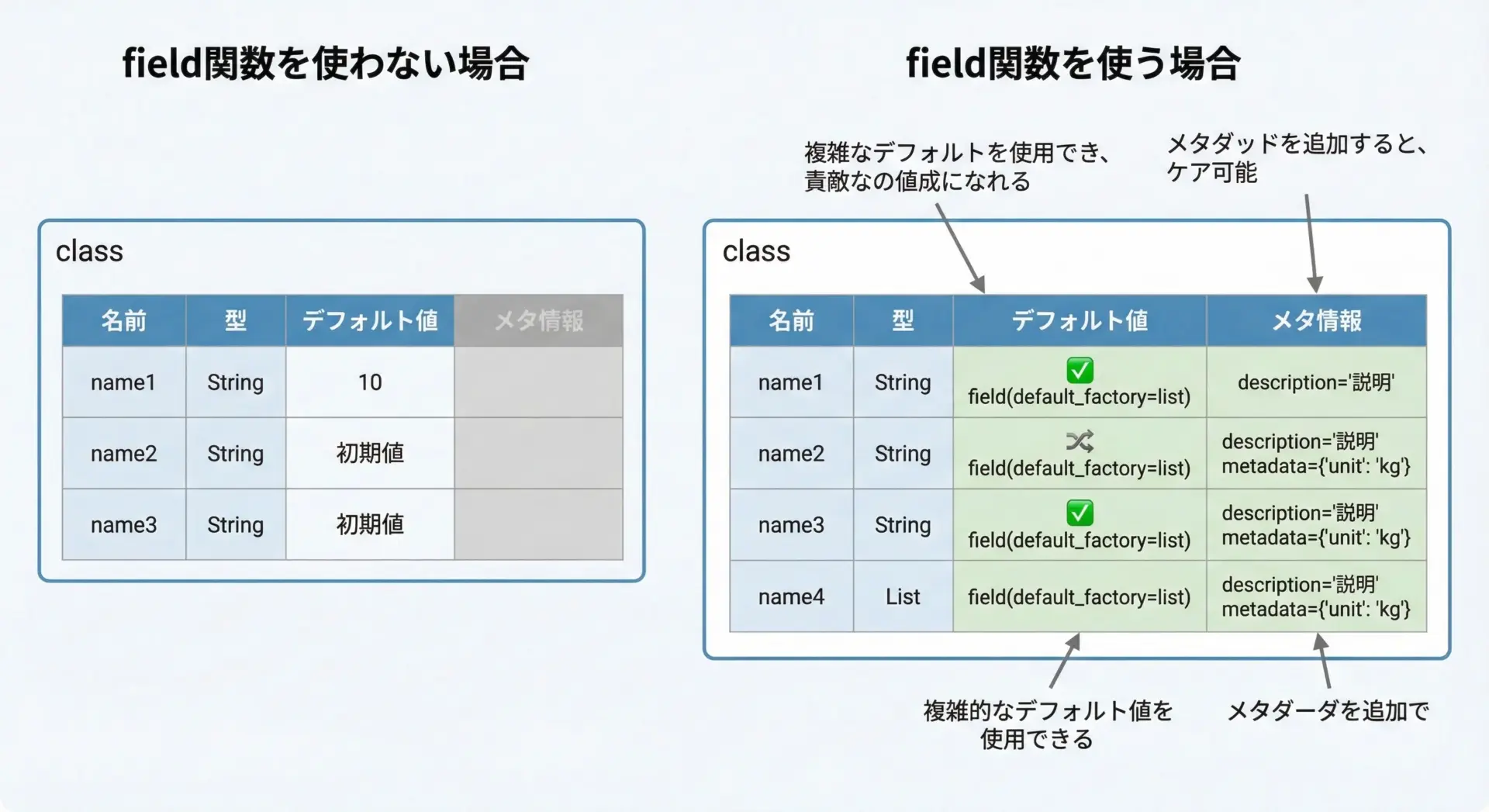
in_stock: bool = True # デフォルトで在庫ありとするさらに詳細な設定をしたい場合はfield関数を使います。
from dataclasses import dataclass, field
@dataclass
class Book:
title: str
price: int
# reprには表示したくないフラグをfieldで制御
internal_code: str = field(repr=False, default="N/A")このようにfieldを使うことで、reprに出す・出さないなどの細かな振る舞いをコントロールできるようになります。
デフォルト値とdefault_factoryの使い分け
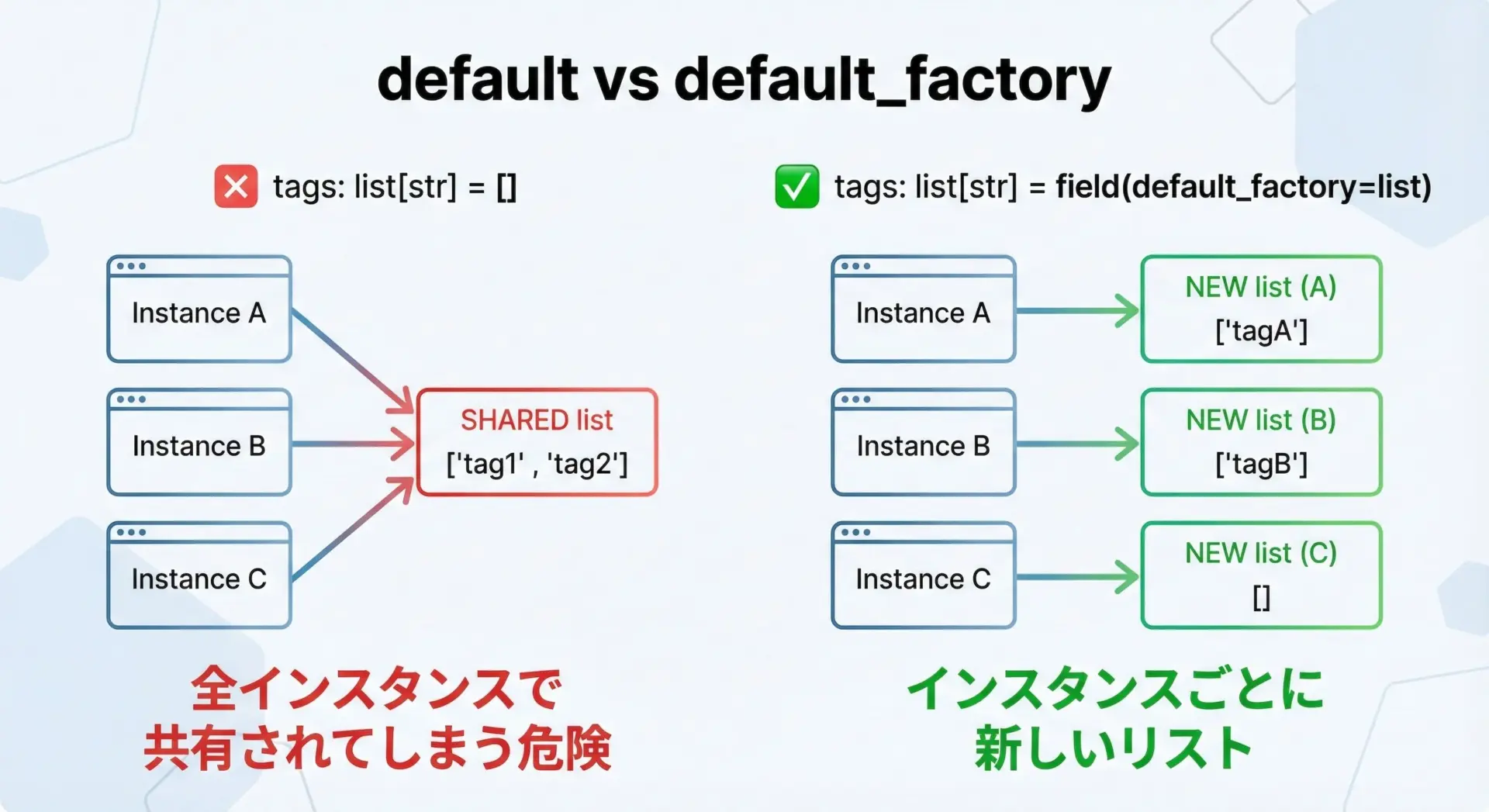
デフォルト値の指定では、可変オブジェクト(リストや辞書など)をそのままデフォルト値に書くとバグのもとになります。
そのため、dataclassesではdefaultとdefault_factoryを使い分けることが重要です。
default(値そのものを指定)
イミュータブルな値(整数、文字列、タプルなど)のときは、単純にデフォルト値を書くかdefaultを使います。
from dataclasses import dataclass, field
@dataclass
class User:
name: str
is_active: bool = True # シンプルな書き方
role: str = field(default="user") # fieldを使った書き方これらはほぼ同じ意味で、各インスタンスが同じデフォルト値を持ちますが、値自体がイミュータブルなので共有されても問題ありません。
default_factory(インスタンスごとに新しい値を生成)
リストや辞書などの可変オブジェクトをデフォルトにしたい場合は、default_factoryを使います。
これはインスタンス生成ごとに関数を呼び出して新しいオブジェクトを作るための指定です。
from dataclasses import dataclass, field
from typing import List
@dataclass
class BlogPost:
title: str
# 各インスタンスごとに空リストが生成される
tags: List[str] = field(default_factory=list)間違った書き方と比較してみましょう。
from dataclasses import dataclass
from typing import List
@dataclass
class BadBlogPost:
title: str
# 間違った例: 全インスタンスで同じリストを共有してしまう
tags: List[str] = []# 動作確認用コード
from dataclasses import dataclass, field
from typing import List
@dataclass
class BadBlogPost:
title: str
tags: List[str] = [] # NGな例
@dataclass
class GoodBlogPost:
title: str
tags: List[str] = field(default_factory=list) # OKな例
bad1 = BadBlogPost("post1")
bad2 = BadBlogPost("post2")
bad1.tags.append("python")
good1 = GoodBlogPost("post1")
good2 = GoodBlogPost("post2")
good1.tags.append("python")
print("Bad:", bad1.tags, bad2.tags)
print("Good:", good1.tags, good2.tags)Bad: ['python'] ['python']
Good: ['python'] []BadBlogPostの2つのインスタンスで同じリストが共有されてしまっていることが分かります。
可変オブジェクトをデフォルトにしたい場合は、必ずdefault_factoryを使うようにしましょう。
自動生成されるメソッド

dataclassesは、クラス定義に基づいていくつかのメソッドを自動生成します。
主なものは次の通りです。
__init__: フィールドを引数として受け取り、属性に代入するコンストラクタ__repr__: デバッグ用に読みやすい文字列表現を返す__eq__: フィールドごとの値に基づいて等価比較を行う- オプション指定により
__lt__などの順序比較メソッド
実際にどのような挙動をするのか、簡単なサンプルで確認します。
from dataclasses import dataclass
@dataclass
class Product:
name: str
price: int
in_stock: bool = True
p1 = Product("Keyboard", 3000)
p2 = Product("Keyboard", 3000)
p3 = Product("Mouse", 2000)
# __repr__ の例
print(p1)
# __eq__ の例
print(p1 == p2)
print(p1 == p3)Product(name='Keyboard', price=3000, in_stock=True)
True
Falseまた、order=Trueオプションを指定することで、__lt__などの比較メソッドも自動生成されます。
from dataclasses import dataclass
@dataclass(order=True)
class UserScore:
score: int
name: str
u1 = UserScore(80, "Alice")
u2 = UserScore(90, "Bob")
print(u1 < u2) # scoreが小さい方が小さいと判定されるTrueこのように、データ構造として自然に欲しくなるメソッドを、ほぼ自動で賄ってくれるのがdataclassesの魅力です。
dataclassesを使うメリット
クラス定義のボイラープレート削減

dataclassesの最大のメリットは、定型的なコード(ボイラープレート)を大幅に削減できることです。
通常クラスであれば、次のようなコードを書かなければならない場合が多いです。
- 引数を受け取って属性に代入する
__init__ - デバッグしやすくするための
__repr__ - 値の等価性を比較する
__eq__
dataclassesを使えば、これらは自動的に生成されます。
その結果、クラス定義が「何を表現するデータ構造か」に集中したシンプルなものになり、読みやすさと保守性が向上します。
特にビジネスロジックが複雑なプロジェクトでは、データ構造自体の定義はシンプルであればあるほど理解しやすく、レビューや仕様変更への対応が楽になるという副次的な効果も生まれます。
型ヒントと静的解析との相性の良さ
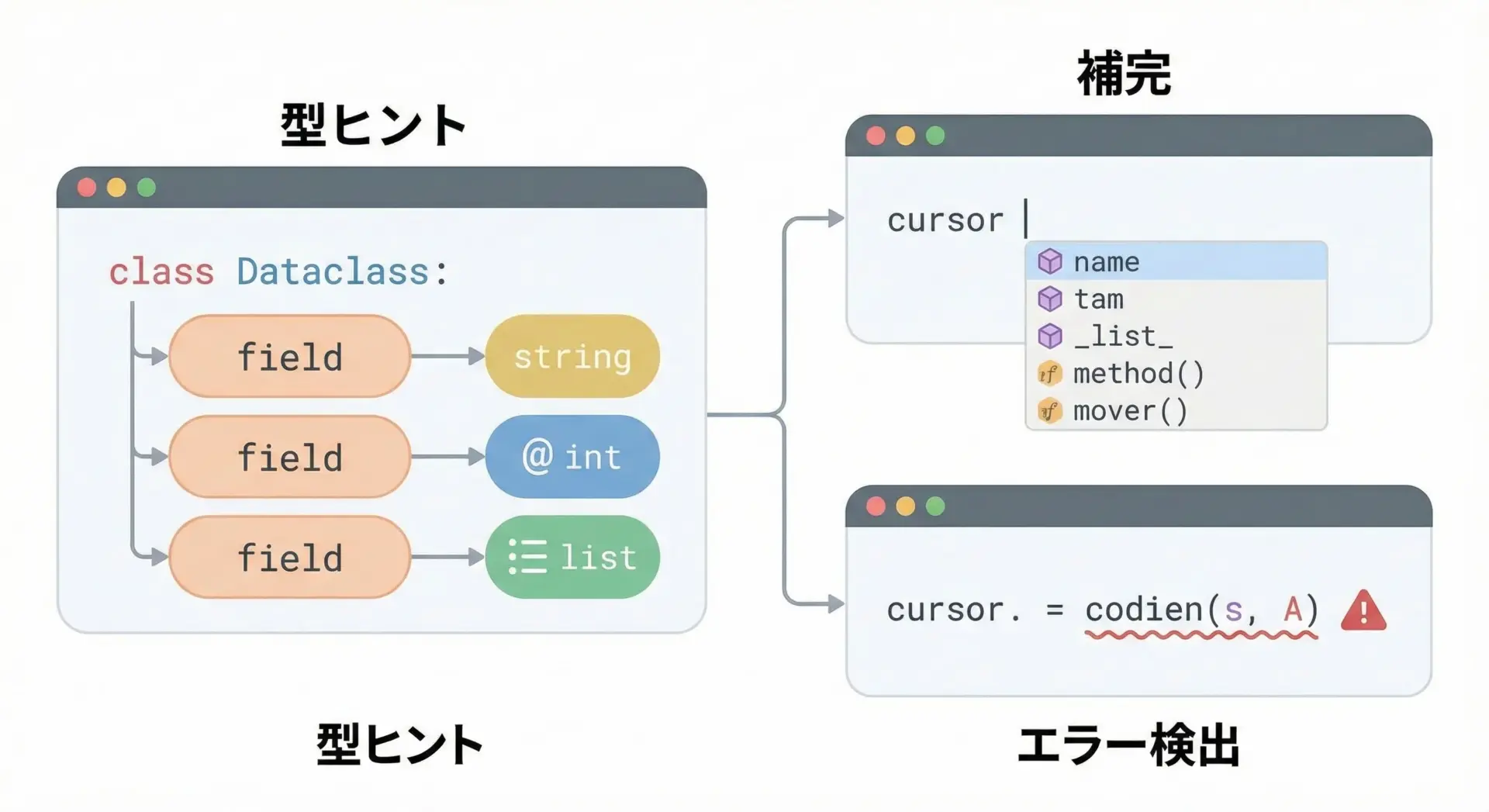
dataclassesは、型ヒントと非常に相性が良い設計になっています。
フィールド定義で必ず型ヒントを指定することが推奨されているため、次のようなメリットがあります。
- IDEでのオートコンプリートが正確に効く
- 静的解析ツール(mypyなど)が属性の型を正しく推論できる
- リファクタリング時に型エラーとして不整合を検出しやすい
たとえば、次のようなdataclassを考えます。
from dataclasses import dataclass
from typing import List
@dataclass
class Order:
order_id: int
user_id: int
item_ids: List[int]
total_price: intこのクラスを使う側のコードでは、IDEがorder.item_idsがList[int]であることを認識できるため、要素が整数である前提の補完や警告が効きます。
型ヒントとdataclassesを組み合わせることで、動的言語でありながら型安全性をある程度担保できるようになります。
辞書やタプルとの比較とdataclassの優位性
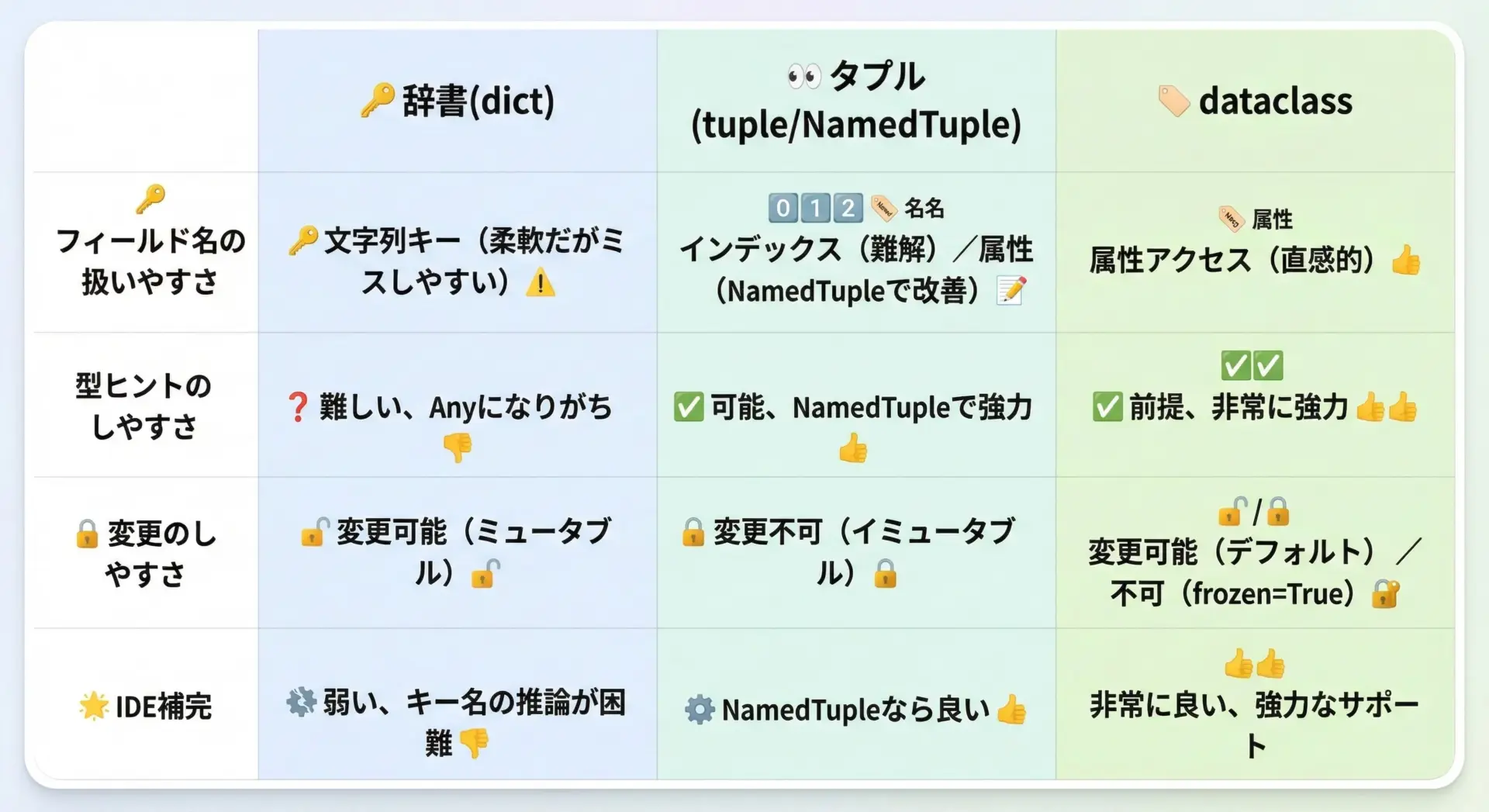
Pythonでは、データ構造を表すのに辞書やタプルを使うことも多いですが、dataclassesはそれらに対していくつかの優位性を持ちます。
代表的な違いを表にまとめます。
| 特性 | dict | tuple/NamedTuple | dataclass |
|---|---|---|---|
| フィールド名の安全性 | 文字列キーで自由だがミスしやすい | インデックス/名前付き | 属性アクセスで安全・明確 |
| 型ヒントの書きやすさ | TypedDictなどが必要 | NamedTupleで可能 | クラス定義にそのまま書ける |
| 変更しやすさ | どこでもキー追加可能 | 基本イミュータブル | 通常はミュータブル(凍結も可) |
| IDE補完・リファクタリング | キー名は補完されにくい | NamedTuple名は補完される | クラス属性として強力に補完される |
| 自動メソッド(__repr__など) | 自前実装が必要 | 一部自動 | 豊富に自動生成 |
辞書は柔軟ですが、キー名のスペルミスなどが実行時まで気付きにくいという問題があります。
一方で、dataclassは通常のクラスと同じように属性アクセスできるため、IDEや静的解析ツールがミスを早期に検出してくれます。
また、NamedTupleも強力な手段ですが、フィールドのデフォルト値設定や、後からの拡張性の面でやや扱いづらい場合があります。
dataclassesはこの中間に位置し、「クラスの分かりやすさ」と「宣言的なデータ定義」の両方をバランスよく提供してくれます。
frozen(イミュータブル)オプションの利点
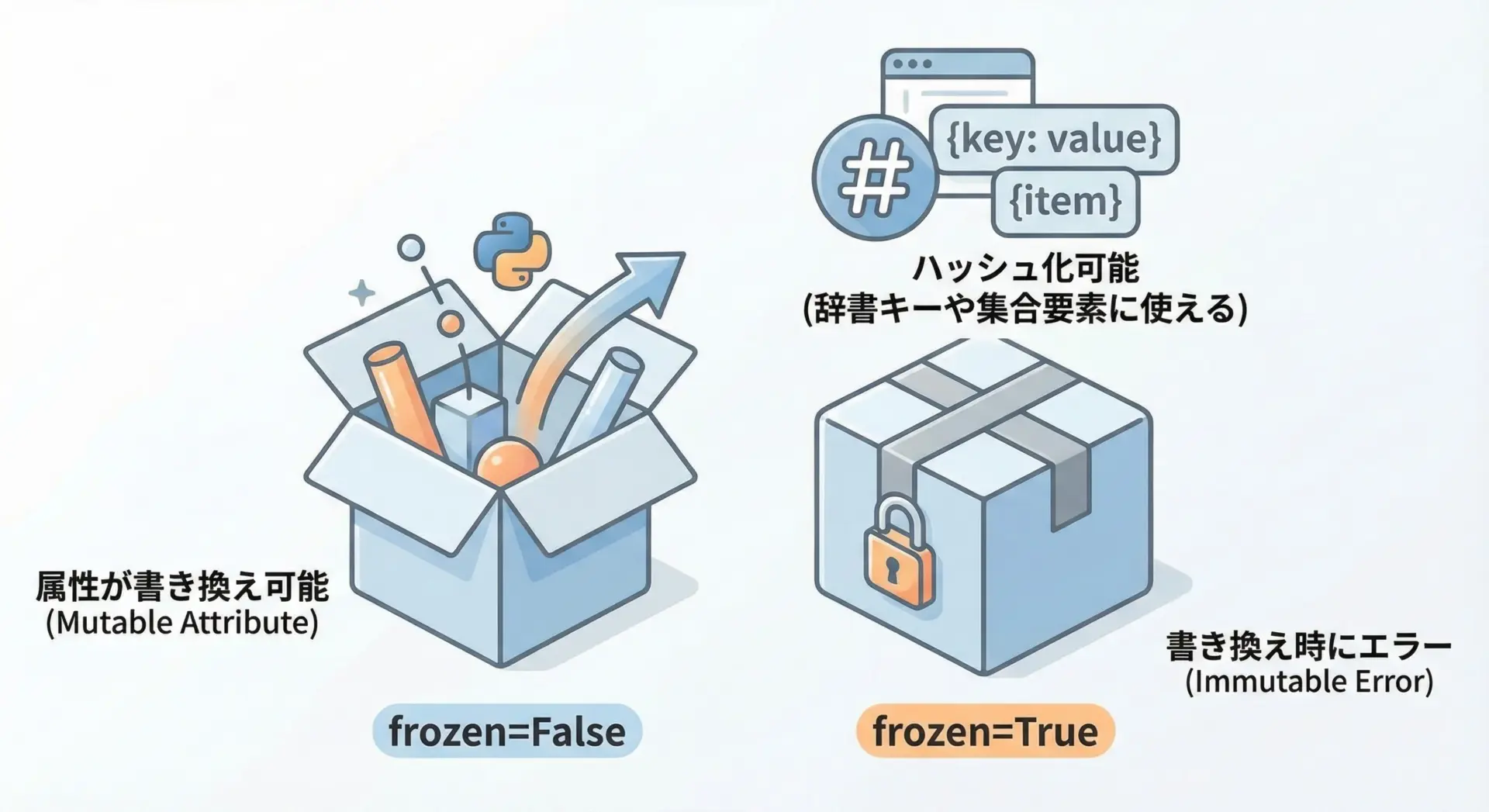
dataclassesにはfrozen=Trueというオプションがあり、これを指定するとイミュータブル(変更不可)なデータクラスを定義できます。
from dataclasses import dataclass
@dataclass(frozen=True)
class Config:
host: str
port: int
cfg = Config("localhost", 5432)
print(cfg.host)
# cfg.host = "example.com" # これは例外が発生するlocalhostfrozen=Trueを指定すると、属性を書き換えようとしたときにFrozenInstanceErrorが発生します。
これにより、意図せぬ変更を防ぎ、「値オブジェクト」として安全に扱えるようになります。
また、イミュータブルであることから、ハッシュ可能になり、辞書のキーや集合の要素として利用しやすくなるという利点もあります。
ただし、フィールドに含まれるオブジェクト自体も実質的にイミュータブルであることが望ましいため、その点は設計上意識する必要があります。
dataclassesの注意点とよくある落とし穴
可変オブジェクトとdefault値の注意点
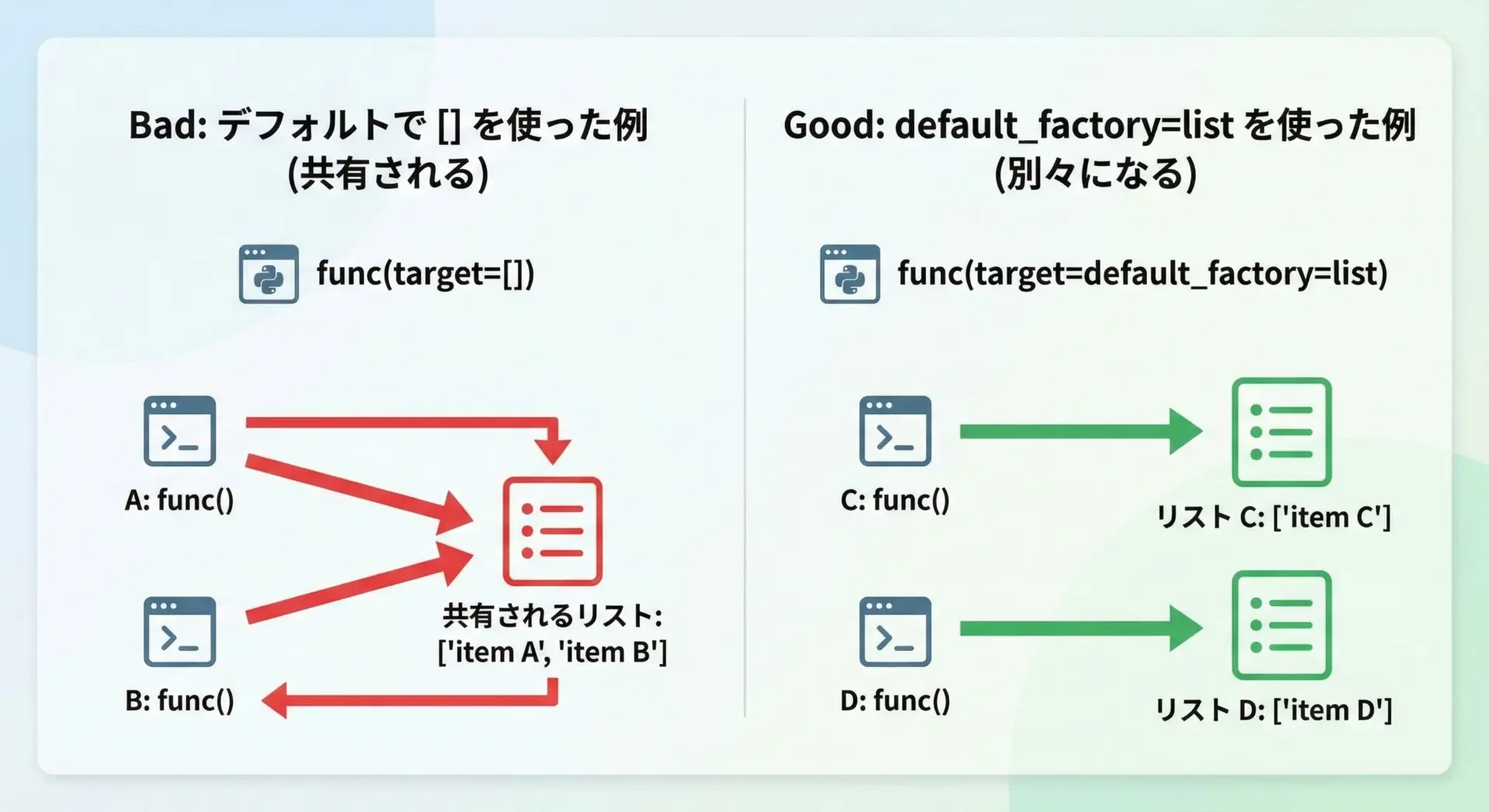
前述の通り、可変オブジェクトをそのままデフォルト値として指定するのは危険です。
これはdataclassesに限らずPython全般の仕様ですが、dataclassesではフィールド定義が集中しているため、特にミスが目立ちやすくなります。
典型的な落とし穴は次のようなパターンです。
from dataclasses import dataclass
from typing import List
@dataclass
class BadSettings:
# 可変オブジェクトを直接デフォルトに指定している(バグのもと)
plugins: List[str] = []この場合、全インスタンスでpluginsが共有されてしまいます。
必ずfield(default_factory=list)を使うようにしましょう。
from dataclasses import dataclass, field
from typing import List
@dataclass
class GoodSettings:
# 各インスタンスごとに新しいリストを生成
plugins: List[str] = field(default_factory=list)このルールは、list、dict、set、カスタムクラスなど、状態を持つオブジェクト全般に当てはまります。
イミュータブルなタプルであっても、要素がミュータブルなら同様の配慮が必要になる場合があるため、慎重に設計してください。
継承や組み合わせ時の注意点
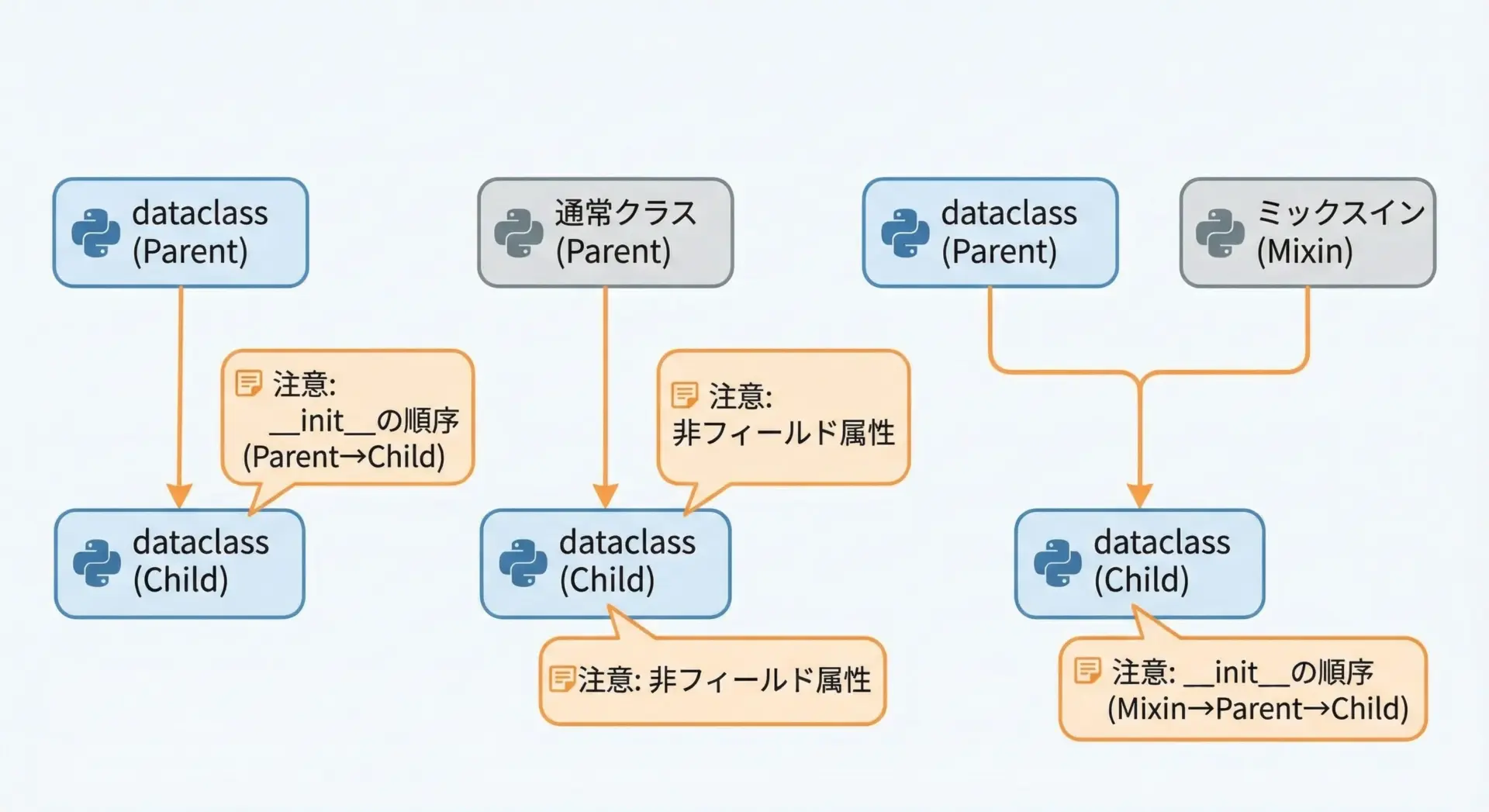
dataclassesは継承にも対応していますが、フィールドの順序や初期化の順番など、いくつか注意すべき点があります。
親クラスと子クラスのフィールド順
dataclass同士を継承した場合、親クラスのフィールドが先、その後に子クラスのフィールドという順序で__init__の引数が決まります。
from dataclasses import dataclass
@dataclass
class BaseUser:
id: int
name: str
@dataclass
class AdminUser(BaseUser):
# BaseUserのフィールドに続けて定義される
admin_level: int = 1
admin = AdminUser(1, "Alice", 3)
print(admin)AdminUser(id=1, name='Alice', admin_level=3)このように、親クラスのフィールドとの間でデフォルト引数の有無などに矛盾があると、TypeError: non-default argument follows default argumentのようなエラーが出ることがあります。
「デフォルトのないフィールド」→「デフォルトのあるフィールド」という順序を常に意識してください。
dataclassと通常クラスの組み合わせ
通常クラスから継承してdataclassを定義することも可能ですが、その場合、init=Falseなどの細かな制御が必要になることがあります。
また、mixin的なクラス(メソッドだけを提供するクラス)をdataclassに混ぜる場合は、mixin側でフィールド定義を行わないようにするなど、責務の分離を意識することが重要です。
slot付きdataclass(slots=True)の制約
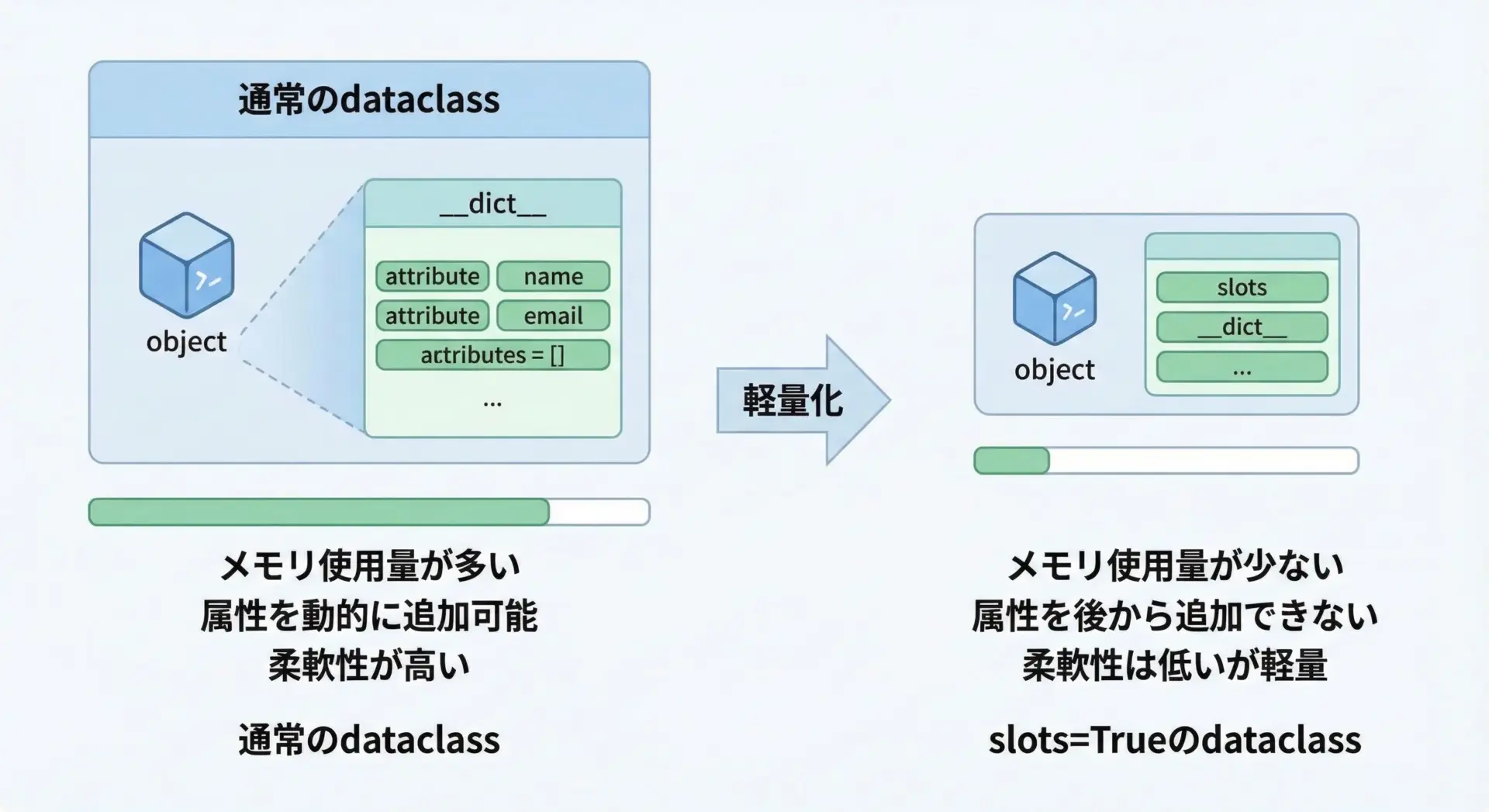
Python 3.10以降では、@dataclassにslots=Trueオプションを指定することで、__slots__を利用した軽量なdataclassを定義できます。
from dataclasses import dataclass
@dataclass(slots=True)
class Point:
x: int
y: intslotsを有効にすると、主に次のような特徴があります。
- インスタンスごとの
__dict__を持たないため、メモリ消費が少なくなる - 属性アクセスが若干高速になることがある
- 動的に新しい属性を追加できなくなる
最後の点が特に重要で、次のようなコードはエラーになります。
from dataclasses import dataclass
@dataclass(slots=True)
class User:
name: str
u = User("Alice")
# u.age = 20 # AttributeError: 'User' object has no attribute 'age'柔軟性とのトレードオフになるため、大量のインスタンスを扱う性能重視の場面など、用途を選んで使うことが大切です。
pydanticやattrsとの使い分けと選び方
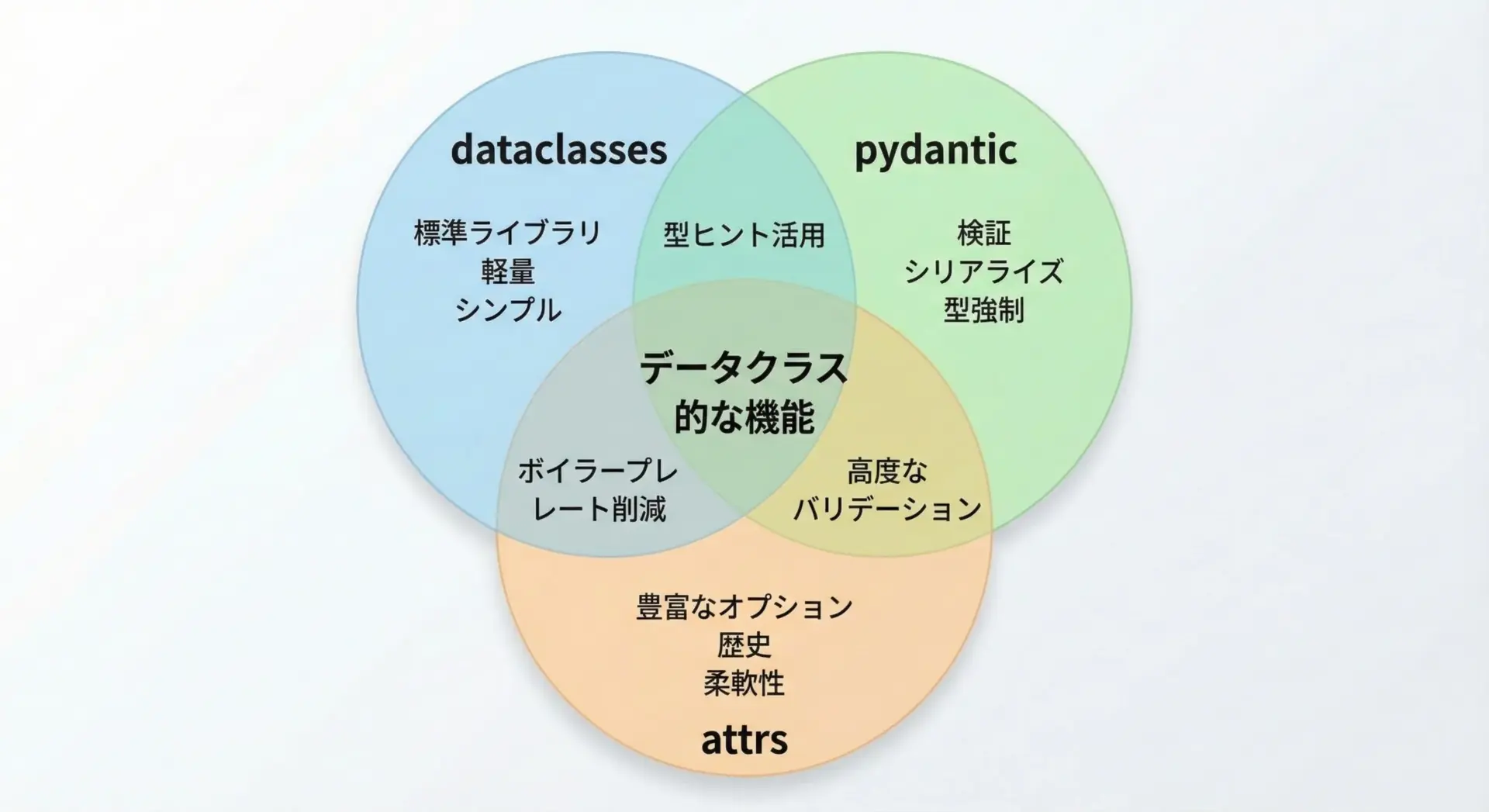
dataclassesと似たコンセプトを持つライブラリとして、pydanticやattrsがあります。
それぞれの特徴を整理して、使い分けの目安を考えてみます。
| ライブラリ | 主な用途・特徴 |
|---|---|
| dataclasses | 標準ライブラリ。軽量・シンプル。検証機能は自前実装が基本 |
| pydantic | バリデーションとシリアライズが強力。設定やAPIスキーマに最適 |
| attrs | dataclassesの先行ライブラリ。より細かい制御や豊富なオプション |
目安としては、次のように考えると分かりやすいです。
- 「標準ライブラリだけで済ませたい」「軽量で十分」 → dataclasses
- 「入力データのバリデーション・変換が重要」「JSONとの相互変換が多い」 → pydantic
- 「dataclassesでは足りない細かな制御が欲しい」「既存のattrsコードベースがある」 → attrs
特にWeb APIのリクエスト/レスポンスモデルや設定ファイルの読み込みなど、外部入力の検証が必須な場面ではpydanticの方が適していることが多いです。
一方で、アプリ内部のシンプルなデータ構造を表現するだけなら、dataclassesで十分なことがほとんどです。
まとめ
dataclassesは、「データ構造をシンプルかつ型安全に表現したい」というニーズに応える、Python標準の強力なツールです。
@dataclassデコレータと型ヒントを使うだけで、コンストラクタや比較メソッドなどの定型コードを自動生成でき、クラス定義をデータモデルそのものに集中させることができます。
一方で、可変オブジェクトのデフォルト値や継承時のフィールド順など、押さえておくべき注意点も存在します。
用途に応じてfrozenやslots、外部ライブラリ(pydanticやattrs)との使い分けを意識しながら活用すれば、Pythonでのデータモデリングがより安全で読みやすいものになります。
