
Pythonでクラスを継承していると、親クラスのメソッドをどう呼び出すべきか迷ってしまうことがよくあります。
特にsuperの正しい使い方や多重継承のときの挙動は、なんとなく動いている状態のまま放置されがちです。
この記事では、Pythonのsuperと親クラス呼び出しについて、基本から多重継承、よくある落とし穴までを、図解とサンプルコードを交えながら丁寧に解説していきます。
Pythonのsuperとは何か
superの基本的な役割と仕組み
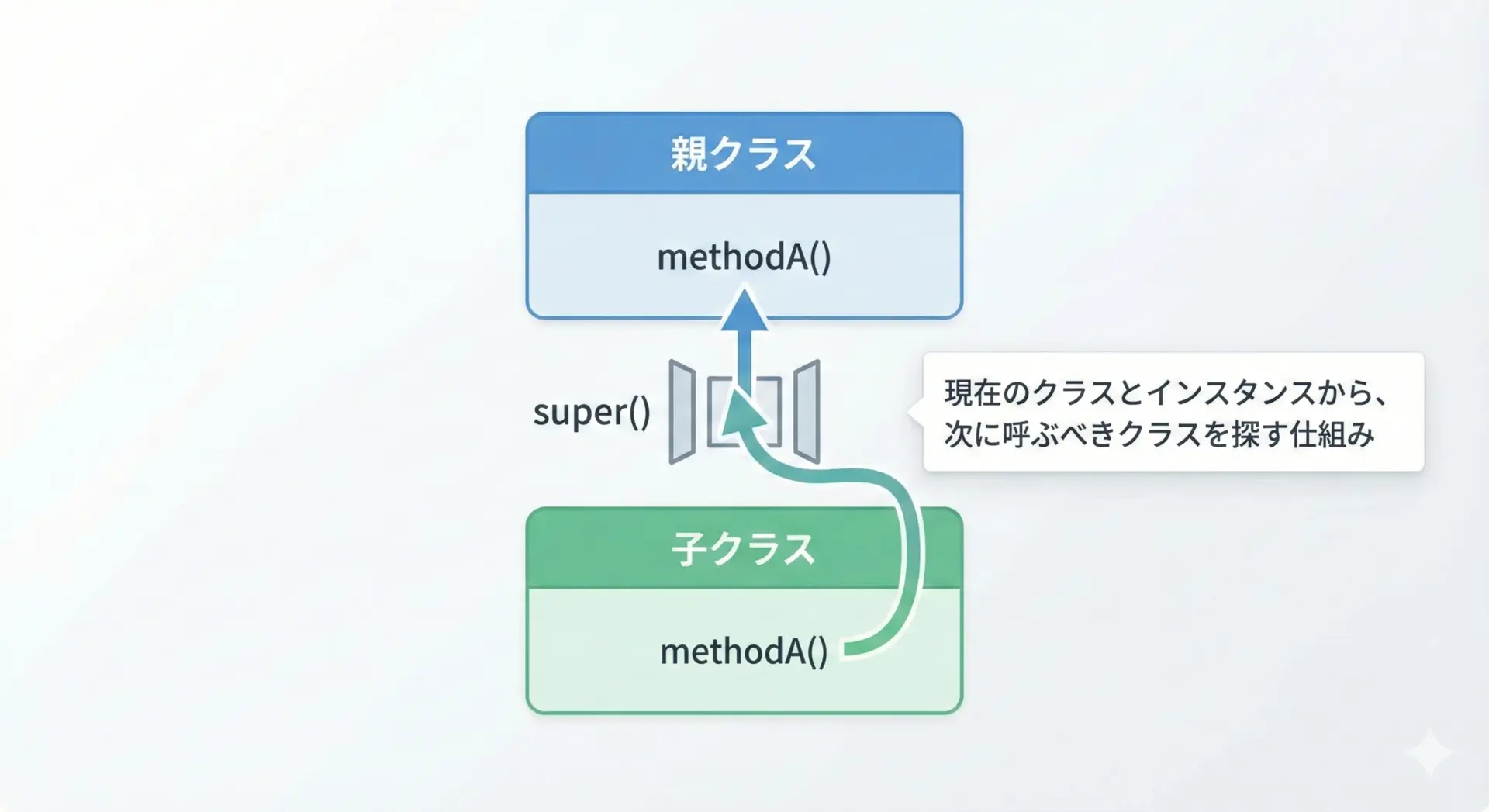
Pythonのsuperは、継承関係にあるクラス同士で「次に呼ぶべきメソッド」を自動で見つけてくれる仕組みです。
よく「親クラスのメソッドを呼び出すもの」と説明されますが、正確にはMRO(Method Resolution Order: メソッド解決順序)に従って、次に来るクラスのメソッドを呼び出すためのヘルパーです。
superの最もシンプルな例
class Parent:
def greet(self):
print("Parent: こんにちは")
class Child(Parent):
def greet(self):
# super()で親クラス(この場合はParent)のgreetを呼び出す
super().greet()
print("Child: やっほー")
c = Child()
c.greet()Parent: こんにちは
Child: やっほーこの例ではsuper().greet()が実行されると、PythonはChildクラスのMROに基づいてParent.greetを探し当てています。
継承が単純な場合は「親クラスを呼んでいる」と考えても問題ありませんが、後で見るように多重継承ではもう少し複雑に動作します。
superが解決してくれること
superを使うことで、次のような問題を避けることができます。
- 子クラスから
Parent.method(self)のように親クラス名を直書きしなくてよくなる - 多重継承で、どの順番でメソッドを呼ぶべきかを自分で管理しなくてよくなる
- 親クラス名を変更しても、子クラス側のコードを書き換えずに済む
つまり、superは「次のクラスを自動で辿るためのナビゲーションシステム」のような役割を果たします。
継承とメソッド解決順序(MRO)の関係
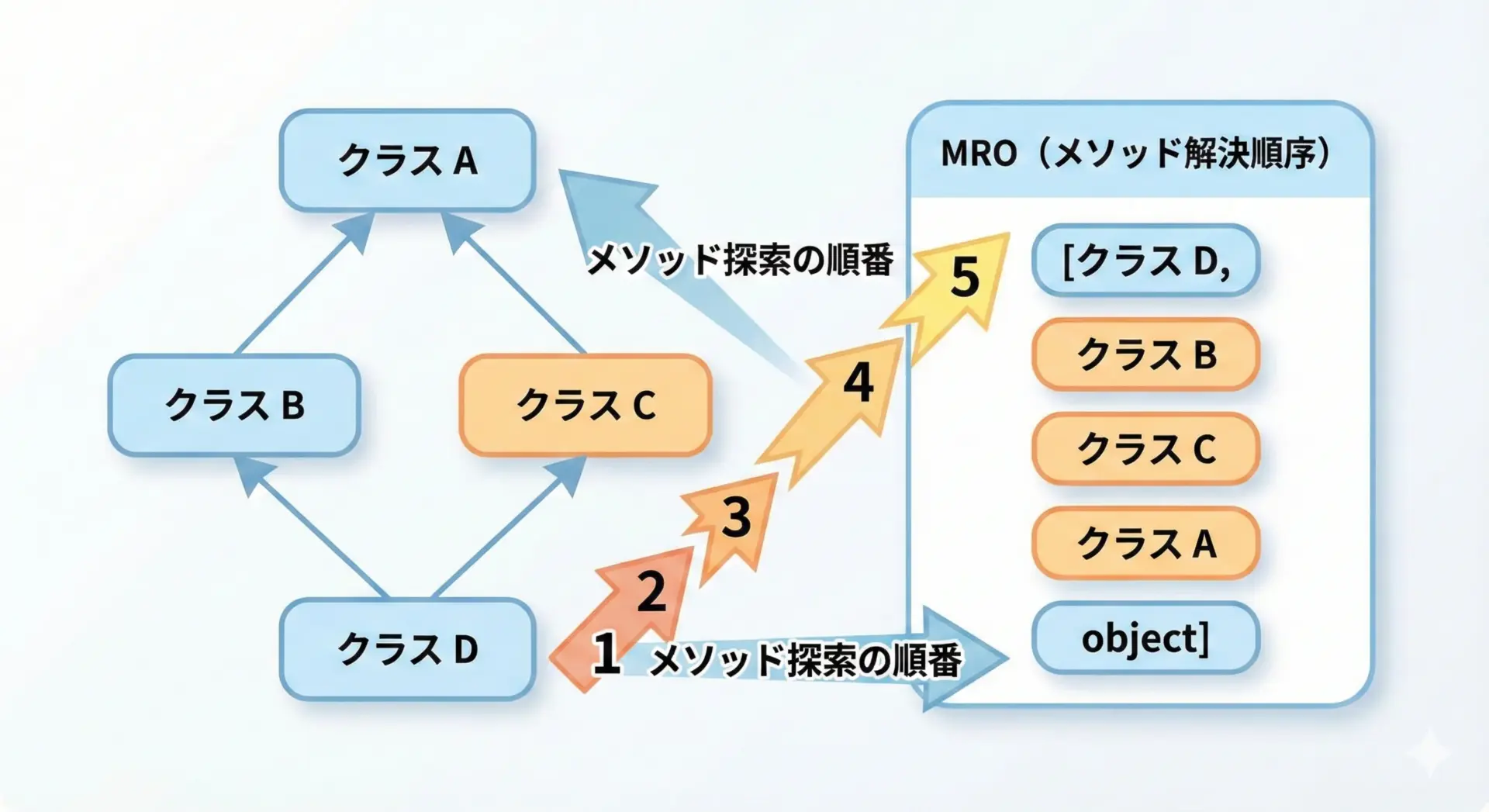
Pythonのクラスには、MRO(Method Resolution Order)という「メソッドをどの順番で探すか」を表すリストが存在します。
superはこのMROを利用して、次に呼ぶべきメソッドを決めています。
MROを確認する方法
class A:
def whoami(self):
print("A")
class B(A):
def whoami(self):
print("B")
super().whoami()
class C(A):
def whoami(self):
print("C")
super().whoami()
class D(B, C):
pass
# DクラスのMROを確認
print(D.mro())[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]このD.mro()の結果は、「Dクラスのインスタンスでメソッドを探すときに、どの順番でクラスを辿るか」を表しています。
superは、このMROの中で現在のクラスの次に位置するクラスを見つけ、そのクラスのメソッドを呼び出します。
ポイントは、superは「親クラスを直接指定するもの」ではなく、「MROに従って次のクラスを探す仕組み」だという点です。
superの正しい使い方
親クラスのメソッドを呼び出す基本パターン
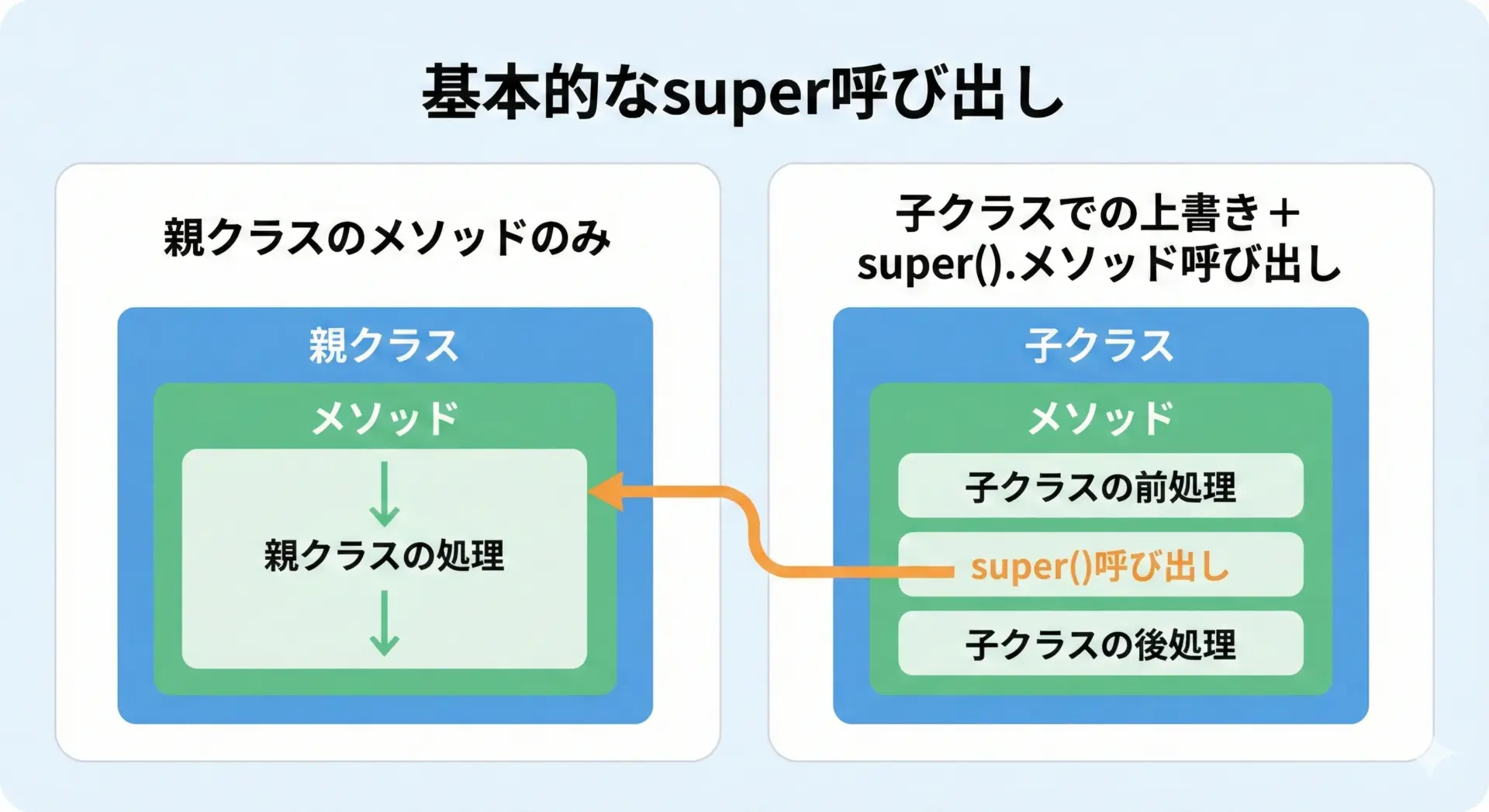
継承したクラスでメソッドをオーバーライドするとき、まずは親クラスの処理を呼び出し、その後に子クラス独自の処理を追加するというパターンがよく使われます。
典型的な基本パターン
class Logger:
def log(self, message):
print(f"[LOG] {message}")
class CustomLogger(Logger):
def log(self, message):
# 先に親クラスのlogを呼ぶ
super().log(message)
# その後で追加の処理を行う
print(f"[Custom] ログメッセージの長さ: {len(message)}")
logger = CustomLogger()
logger.log("superの基本パターンを理解する")[LOG] superの基本パターンを理解する
[Custom] ログメッセージの長さ: 18上書きしたメソッドの中でsuper().メソッド名(...)を呼ぶことで、親クラスの元の処理を簡潔に再利用できます。
親クラスの処理を前後どちらで呼ぶか
状況によっては、次のようなパターンもあります。
- 子クラス側で事前にチェックを行い、その後で
super()を呼ぶ - 先に
super()で共通処理を終え、その後で子クラスの固有処理を行う - 親クラスの処理を利用しない場合は、あえて
super()を呼ばない
「共通処理をまとめたいのか」「子クラスで完全に独自の動きをさせたいのか」を明確にして、superを使うかどうかを決めることが重要です。
__init__での親クラス呼び出しと注意点
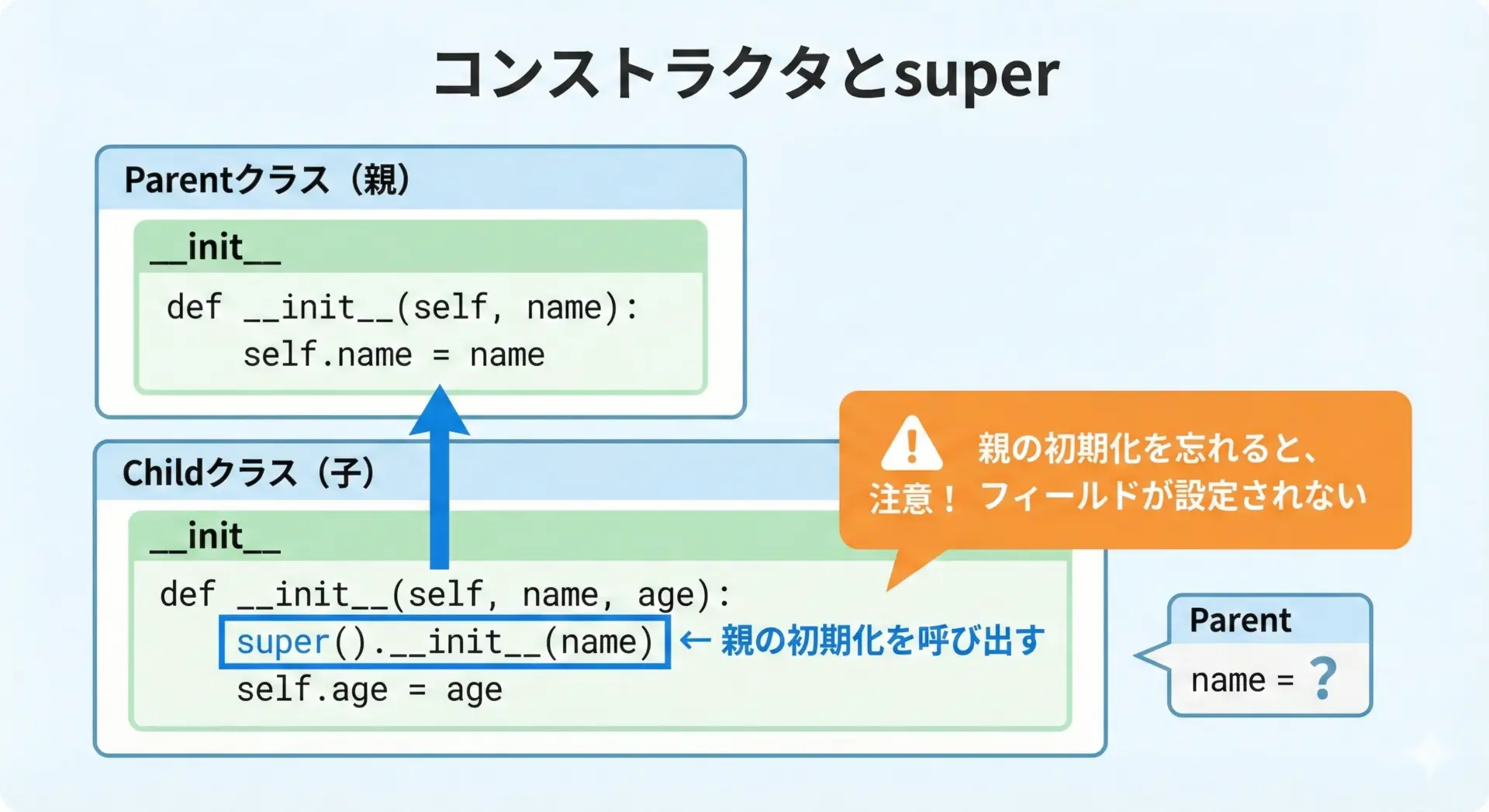
コンストラクタである__init__は、インスタンスの初期化処理を行う特別なメソッドです。
継承したクラスで__init__をオーバーライドした場合、親クラスの__init__を呼び出さないと、親クラス側の初期化が行われないという問題が発生します。
__init__での基本パターン
class User:
def __init__(self, name):
# 共通の初期化処理
self.name = name
class AdminUser(User):
def __init__(self, name, level):
# 親クラスの__init__でnameを初期化
super().__init__(name)
# 子クラス独自の初期化
self.level = level
admin = AdminUser("Alice", 10)
print(admin.name, admin.level)Alice 10ここでもしsuper().__init__(name)を呼び忘れると、self.nameが設定されず、後でAttributeErrorが発生してしまいます。
__init__での注意点
1つの継承階層で複数のクラスが__init__を持つ場合、全ての__init__が正しく呼ばれるように設計することが重要です。
特に多重継承では、各クラスの__init__がsuper()を通じて連鎖的に呼ばれるようにしておく必要があります。
この点は後ほど「多重継承」のセクションで詳しく説明します。
クラスメソッド・スタティックメソッドでのsuper
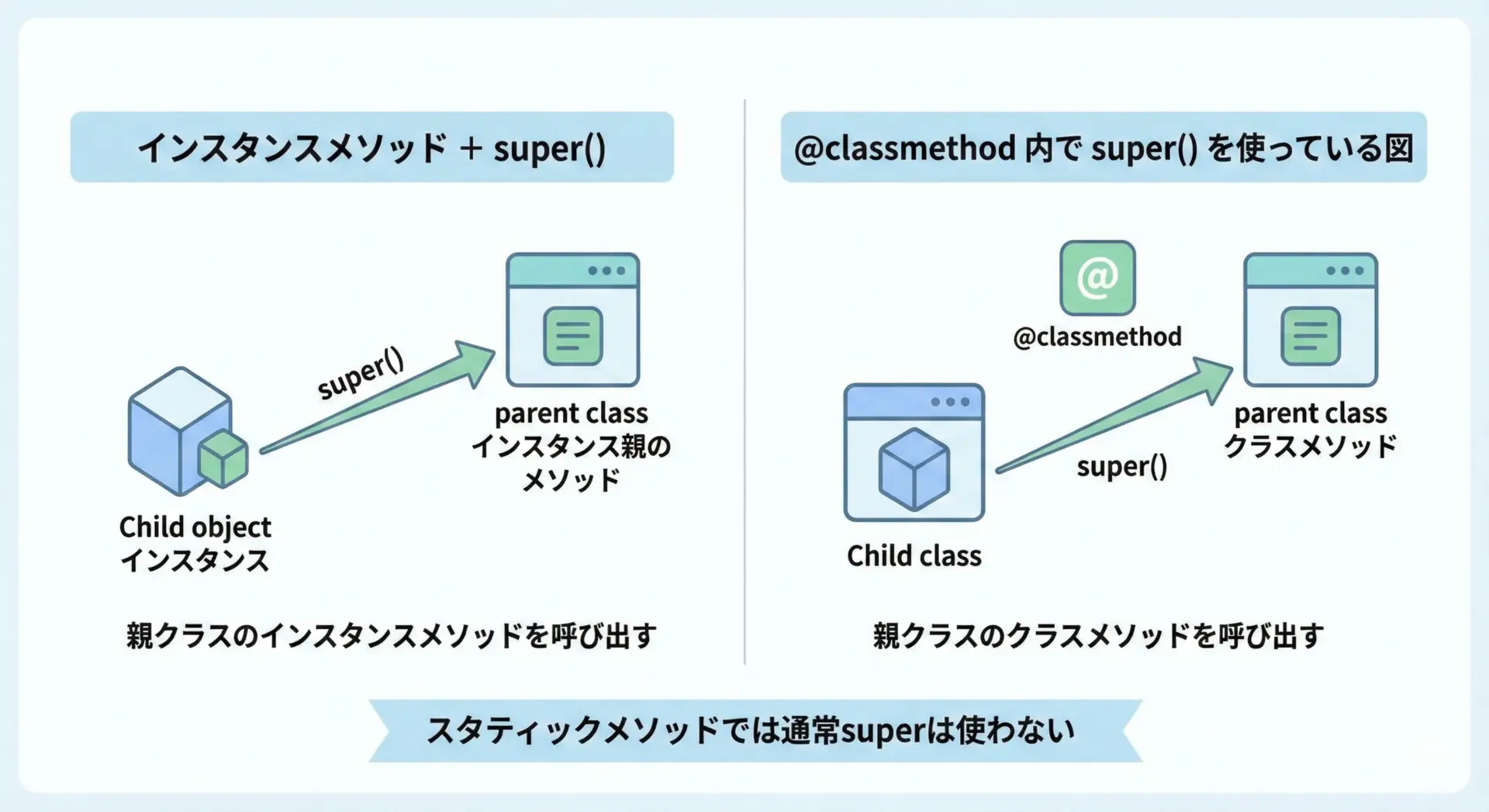
インスタンスメソッドだけでなく、クラスメソッドでもsuper()は利用できます。
ただし、クラスメソッドではクラスオブジェクトを渡すことがポイントです。
クラスメソッドでのsuper
class Base:
@classmethod
def description(cls):
print(f"Base: {cls.__name__}の説明です")
class Sub(Base):
@classmethod
def description(cls):
# super()で親クラスのクラスメソッドを呼び出す
super().description()
print(f"Sub: {cls.__name__}固有の説明を追加します")
Sub.description()Base: Subの説明です
Sub: Sub固有の説明を追加しますここでは、Base.descriptionのclsにもSubが渡されていることが分かります。
superを使うことで、「現在のクラスを維持したまま」親クラスのクラスメソッドを呼び出せるというメリットがあります。
スタティックメソッドとsuper
スタティックメソッドはclsやselfを受け取らないため、通常はsuper()を使うことはありません。
もし共通の処理を共有したい場合は、スタティックメソッド同士で直接呼び出すか、モジュールレベルの関数として定義することが多いです。
多重継承でのsuperの使い方と注意点
ダイヤモンド継承とsuperの動作
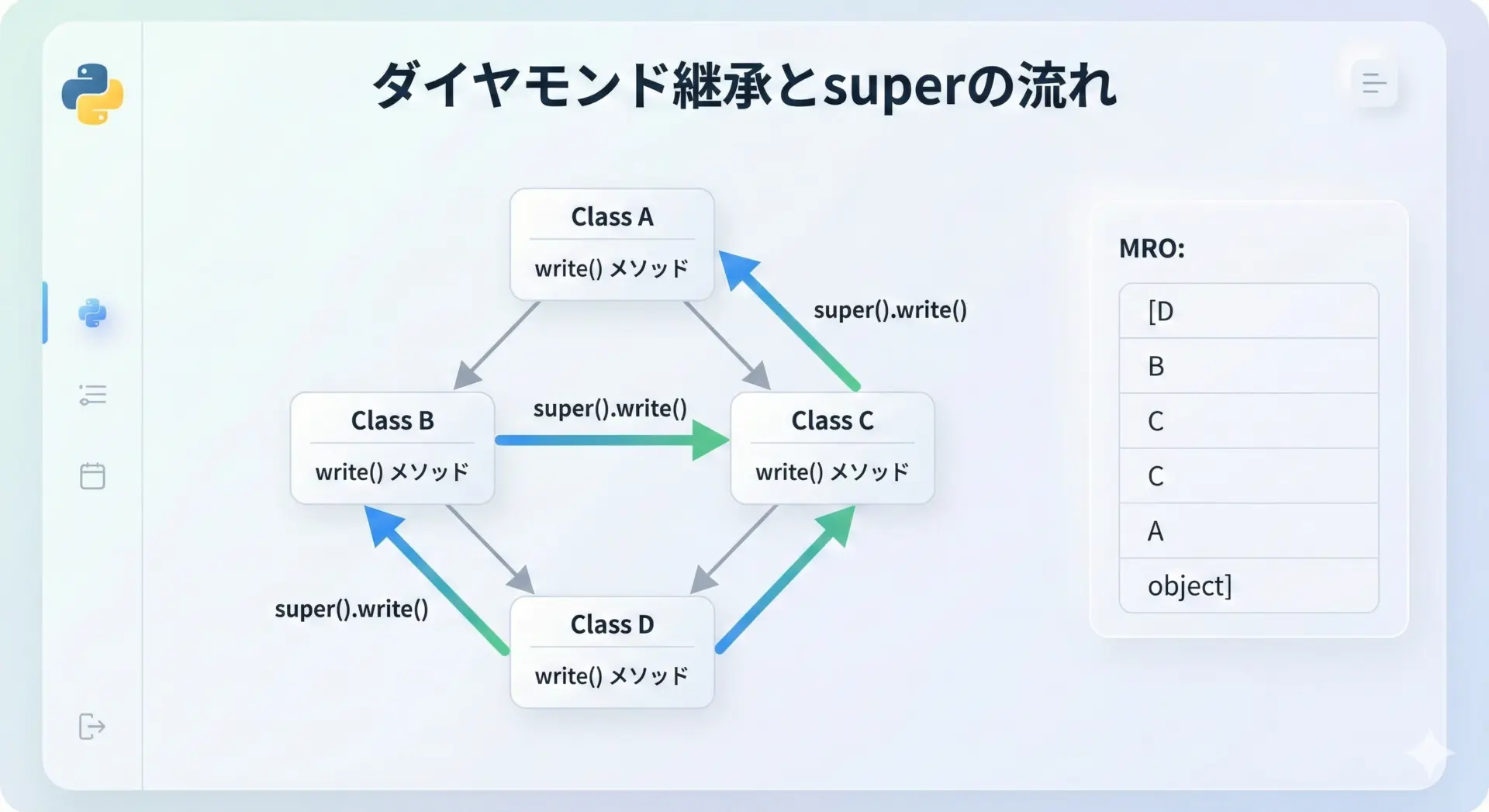
多重継承の代表的な例として「ダイヤモンド継承」があります。
これは、次のような継承関係です。
class A:
def process(self):
print("A")
super().process()
class B(A):
def process(self):
print("B")
super().process()
class C(A):
def process(self):
print("C")
super().process()
class D(B, C):
def process(self):
print("D")
super().process()
class Final(D):
def process(self):
print("Final")
# 末端でobject.processは存在しないので、ここではsuperを呼ばないことにする
# Aの末端にダミーのprocessを追加してチェーンを完結させる例
class ACompleted:
def process(self):
print("ACompleted")
# objectにはprocessがないのでsuperは呼ばないこのままだとobjectにprocessがないため最後でエラーになります。
実際に動く例として、末端で処理を止めるクラスを用意したバージョンを示します。
class A:
def process(self):
print("A")
# ここではsuperを呼ばないことでチェーンを終わらせる
class B(A):
def process(self):
print("B")
super().process()
class C(A):
def process(self):
print("C")
super().process()
class D(B, C):
def process(self):
print("D")
super().process()
d = D()
d.process()
print("MRO:", [cls.__name__ for cls in D.mro()])D
B
C
A
MRO: ['D', 'B', 'C', 'A', 'object']出力結果を見ると、D → B → C → Aという順番でprocessが呼ばれていることが分かります。
これはまさにD.mro()の順番に従ってsuper()が次々と呼び出されているためです。
ダイヤモンド継承でsuperを使うメリット
もし各クラスでsuper()を使わずに親クラス名.method(self)という形で親クラスを直接呼んでしまうと、次のような問題が発生します。
- 同じクラスのメソッドが複数回呼ばれてしまう
- クラスの順番を入れ替えたときに、呼び出し順が破綻する
- 別の開発者がサブクラスを追加したときに、予期しない挙動になる
多重継承で安全にメソッドチェーンを構築するためには、各クラスが「自分の処理をして、super()でバトンを渡す」スタイルを守ることが重要です。
明示的な親クラス呼び出しとの違い
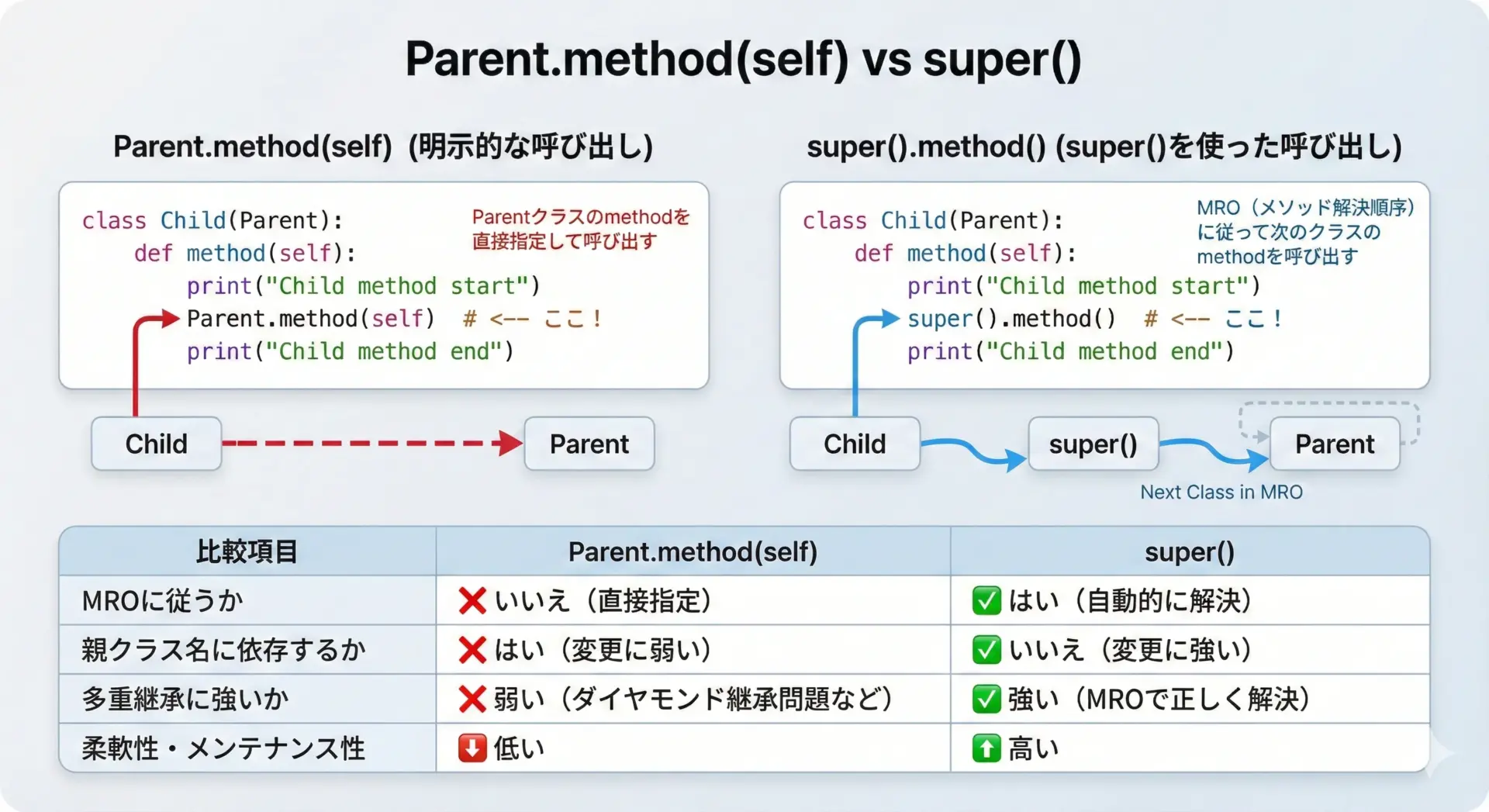
親クラスのメソッドを呼ぶ方法は、主に2つあります。
Parent.method(self, ...)と親クラス名を直接書くsuper().method(...)とsuperを使う
動作の違いを比較する表
以下の表で、両者の違いを整理します。
| 観点 | Parent.method(self, …) | super().method(…) |
|---|---|---|
| 参照先 | 指定したParentクラス | MRO上の「次」のクラス |
| 多重継承 | 重複呼び出しが起こりやすい | 安全にチェーンしやすい |
| 親クラス名変更 | 子クラスを書き換える必要あり | 変更不要 |
| 実装の一貫性 | 各クラスで個別対応が必要 | superチェーンで統一しやすい |
特に多重継承の場合は、Parent.method(self)のような明示的な呼び出しは、ほぼ確実にトラブルの元になります。
シンプルな単一継承であっても、将来的な拡張を考えるとsuper()に揃えておくほうが無難です。
superを使う時・使わない時の判断基準
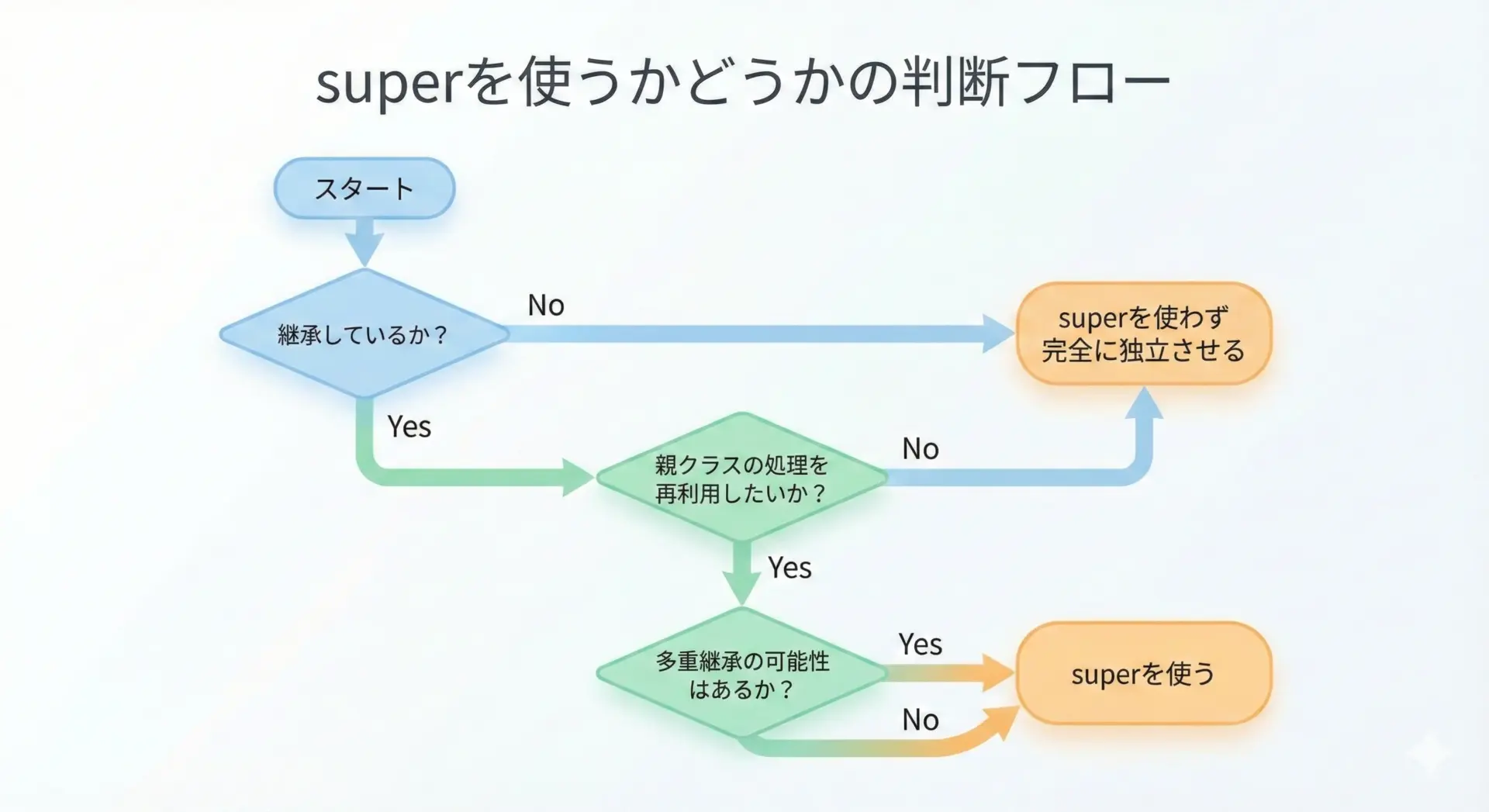
常にsuperを使えば良い、というわけではありません。
次の観点で判断すると分かりやすくなります。
superを使うべきケース
- 親クラスのメソッド処理をベースに、追加・拡張したい場合
- ライブラリやフレームワークのクラスを継承してカスタマイズする場合
- 多重継承やミックスインのように、複数のクラスから機能を合成している場合
これらのケースでは、「共通のパイプラインの一部として自分のクラスが動く」と考えられるため、superでバトンを繋ぐことが重要になります。
superを使わないほうがよいケース
- 親クラスと子クラスで、全く別物の振る舞いをさせたい場合
- 継承関係自体が「実装を流用するための手段」ではなく、「型としての関係性」を示すだけのとき
- 単純なPOJO(Plain Old Python Object)のような場面で、将来的にも多重継承の予定がないと判断できる場合
このようなケースでは、親クラスのメソッドを一切呼ばずに、子クラスで独自に実装してしまったほうが、かえって分かりやすくなることがあります。
よくある間違いとベストプラクティス
superの引数ありと引数なし

Python3では、引数なしのsuper()が一般的です。
ただし、過去のPython2との互換性や一部の特殊な場面では、super(SubClass, self)のように明示的に引数を渡す書き方も存在します。
引数なしsuper(Python3推奨スタイル)
class Base:
def show(self):
print("Base")
class Sub(Base):
def show(self):
print("Sub")
# 引数なしsuper: Python3で推奨される書き方
super().show()
sub = Sub()
sub.show()Sub
Baseこのスタイルは、クラス定義の中(メソッドの中)であれば、Pythonが自動的に現在のクラスとインスタンスを推測してくれるため、簡潔で読みやすくなります。
引数ありsuper(古いスタイル)
class Base:
def show(self):
print("Base")
class Sub(Base):
def show(self):
print("Sub")
# 引数ありsuper: super(Sub, self)
super(Sub, self).show()
sub = Sub()
sub.show()Sub
Baseこの書き方は、Python2との互換性や、super()をクラス定義の外で使うような特殊なケースで必要になることがありますが、現代のPythonコードでは、まず引数なしsuper()を使う、というルールで統一して問題ありません。
superがうまく動かない典型パターン
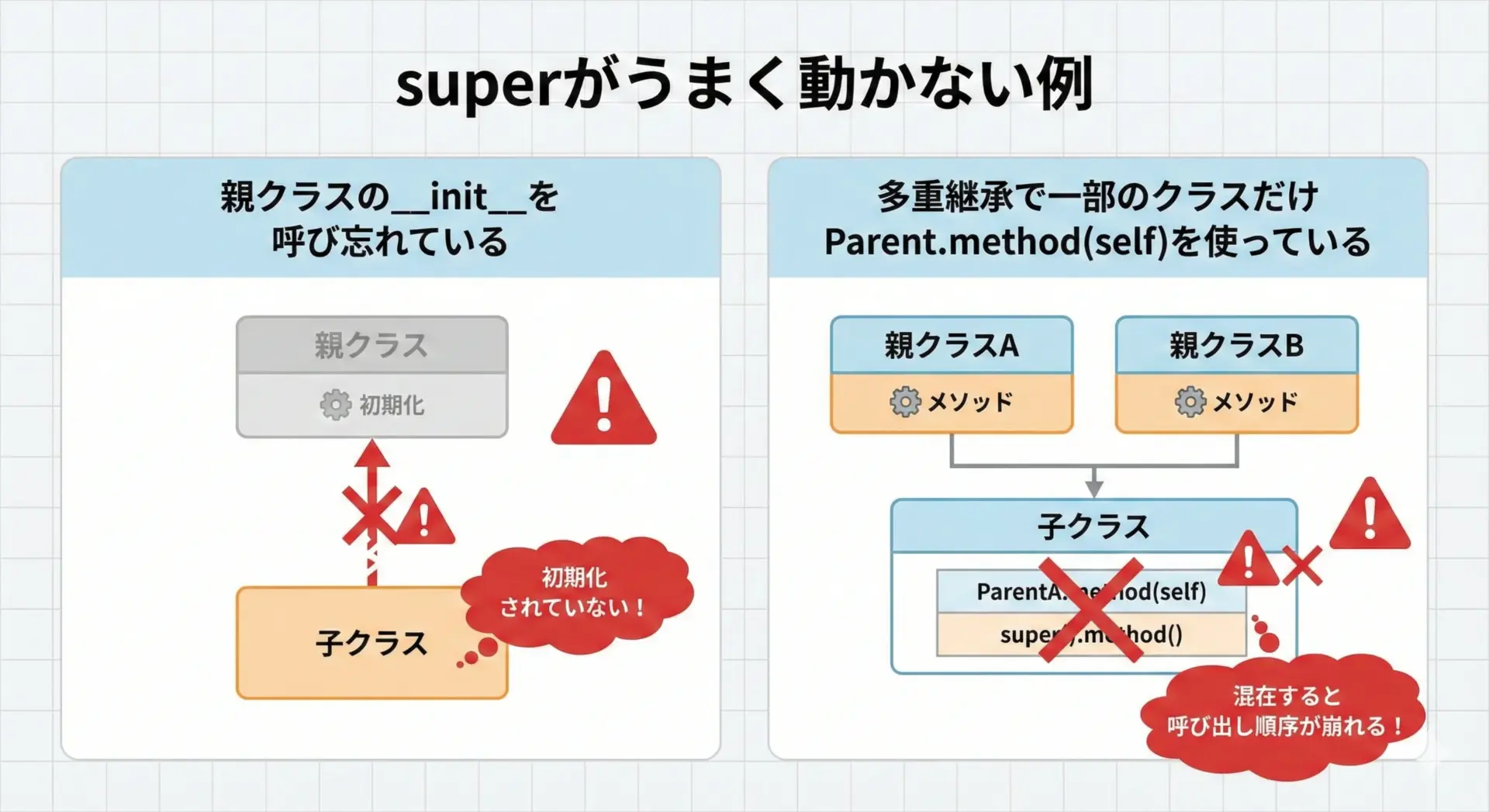
superが「うまく動かない」と感じる多くの場合は、コード側の設計や呼び出し方に問題があります。
代表的なパターンを見てみます。
親クラスの__init__を呼び忘れる
class Base:
def __init__(self):
self.value = 42
class Sub(Base):
def __init__(self):
# super().__init__() を呼び忘れている
self.extra = 100
sub = Sub()
print(sub.extra)
# print(sub.value) # ここでAttributeErrorになるこの例では、Base.__init__が呼ばれていないためself.valueが定義されません。
インスタンスを使っているときには一見問題なく動いているように見えるため、バグの発見が遅れやすい点に注意が必要です。
多重継承で一部のクラスだけParent.method(self)を使う
class A:
def process(self):
print("A")
# super().process() は呼ばない
class B(A):
def process(self):
print("B")
super().process()
class C(A):
def process(self):
print("C")
# super()ではなく、直接A.processを呼んでしまう
A.process(self)
class D(B, C):
pass
d = D()
d.process()B
C
A
Aここでは、Aのprocessが2回呼ばれています。
これは、C.process内でA.process(self)を直接呼び出しているためです。
多重継承でsuperチェーンを設計するときには、関係する全てのクラスが一貫してsuper()を使うことが大切です。
可読性を保つためのクラス設計と命名ルール

superを正しく使えていても、クラス設計や命名が分かりにくいと、コード全体の理解が難しくなります。
可読性を保つためのポイントを整理します。
クラス名と役割を明確にする
クラス名から、そのクラスがどのような責任を持っているのかが分かるようにします。
特にミックスインクラスは*Mixinという名前にしておくと、「単体では使わず、他のクラスに機能を追加するためのクラス」だと分かりやすくなります。
class TimestampMixin:
def add_timestamp(self, data):
from datetime import datetime
return {"data": data, "timestamp": datetime.now().isoformat()}
class JsonLogger(TimestampMixin):
def log(self, message):
import json
record = self.add_timestamp({"message": message})
print(json.dumps(record, ensure_ascii=False))このように、TimestampMixinという名前から「タイムスタンプ付与の機能だけを提供するクラス」であると読み取ることができます。
継承階層を深くしすぎない
継承が3段、4段と深くなると、superチェーンを追いかけるのが難しくなります。
可能であれば、継承よりもコンポジション(別クラスのインスタンスを持つ)を使うことも検討すべきです。
また、多重継承を使う場合も、「1つの継承階層で、2〜3クラス程度の組み合わせ」に抑えると、理解しやすい設計になります。
メソッド名を統一する
superチェーンで同じメソッド名を書き換えていく場合、メソッド名の意味がクラスごとにずれていないかを確認することが大切です。
例えばprocessという名前が、あるクラスでは「入力検証」、別のクラスでは「DB書き込み」を意味していると、読んでいる人は混乱してしまいます。
メソッド名が「同じ処理フェーズ」を指すように揃えることが、superを活かしたわかりやすいクラス設計につながります。
まとめ
この記事では、Pythonのsuperと親クラス呼び出しについて、基本的な役割・MRO・__init__での使い方・多重継承での注意点までを体系的に解説しました。
特に多重継承では、全てのクラスが一貫してsuper()を使うことと、クラス設計と命名を分かりやすく保つことが重要です。
superを「親クラスを直接呼ぶ道具」ではなく、「MROに沿って次のクラスへ処理をバトンする仕組み」と理解することで、もうsuperで迷うことはほとんどなくなるはずです。
