
Pythonで大量のデータから要素数を数える場面はとても多いです。
1つ1つループを書いてカウントしていくのは面倒なだけでなく、バグの原因にもなります。
そこで活躍するのがcollections.Counterです。
標準ライブラリだけで強力な集計ができ、文字列解析やログ解析、データ分析まで幅広く使えます。
この記事では、基礎から実務レベルの応用まで、丁寧に解説していきます。
collections.Counterとは
Counterの基本概要と特徴
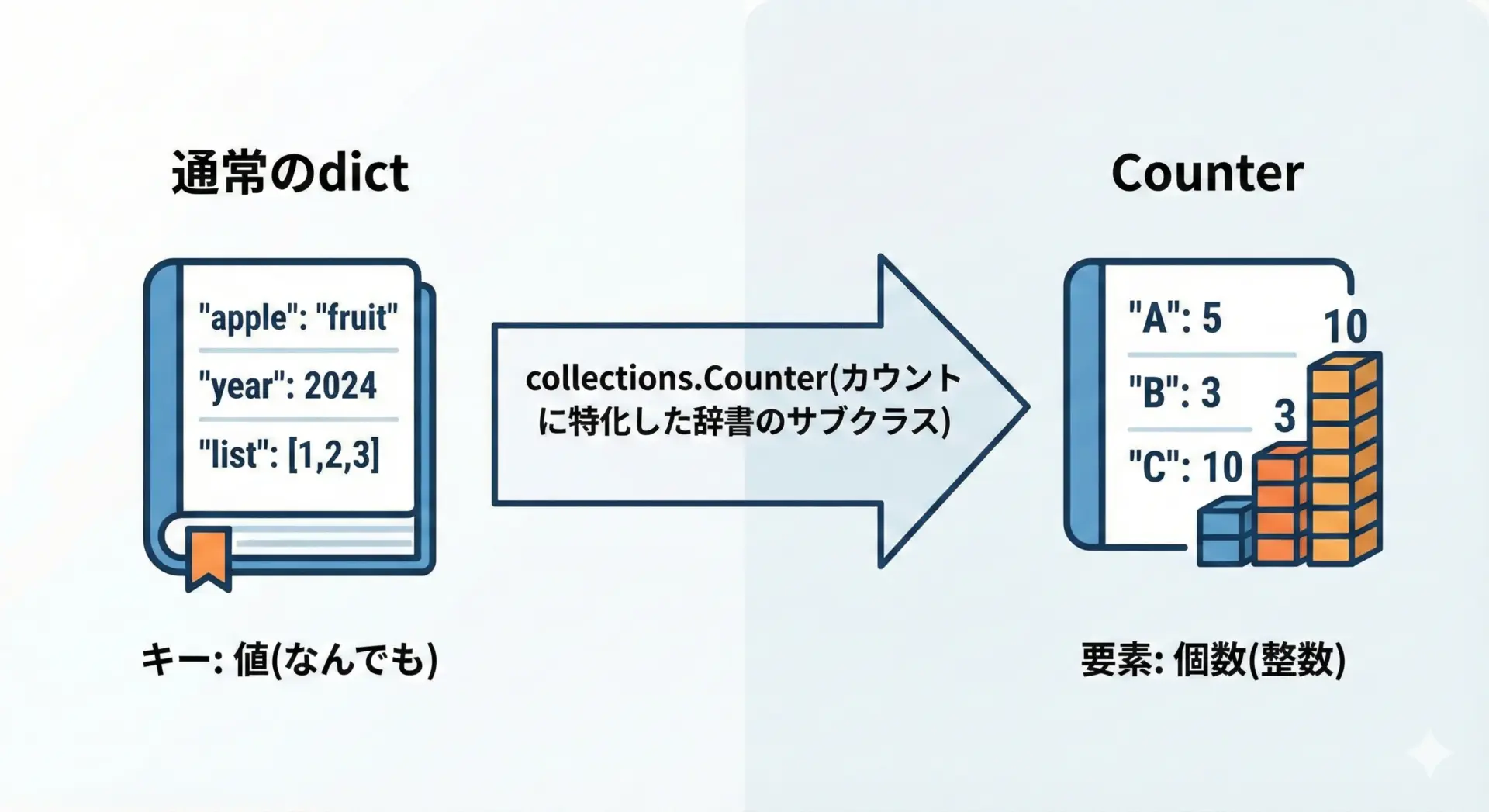
Pythonのcollections.Counterは、要素の出現回数を数えることに特化した辞書(dict)のサブクラスです。
内部的には辞書と同じようにキーと値のペアを持ちますが、次のような特徴があります。
まず、値として整数のカウントを持つことを前提に設計されています。
これにより、頻度分析や集計処理をシンプルなコードで実現できます。
また、イテラブル(listやstrなど)を渡すだけで、各要素の個数を自動的に数えてくれます。
自分でループを書いてカウントを増やしていく必要はありません。
さらに、頻出要素の抽出やカウントの加算・減算、Counter同士の演算といった集計に便利な機能を多数備えています。
これらは通常の辞書にはない専用のインターフェースで、複雑な処理も短いコードで表現できます。
まとめると、「カウント処理を簡潔かつ高速に書ける、辞書ベースの便利ツール」と捉えると理解しやすいです。
listやstrでの要素数カウントの基本例
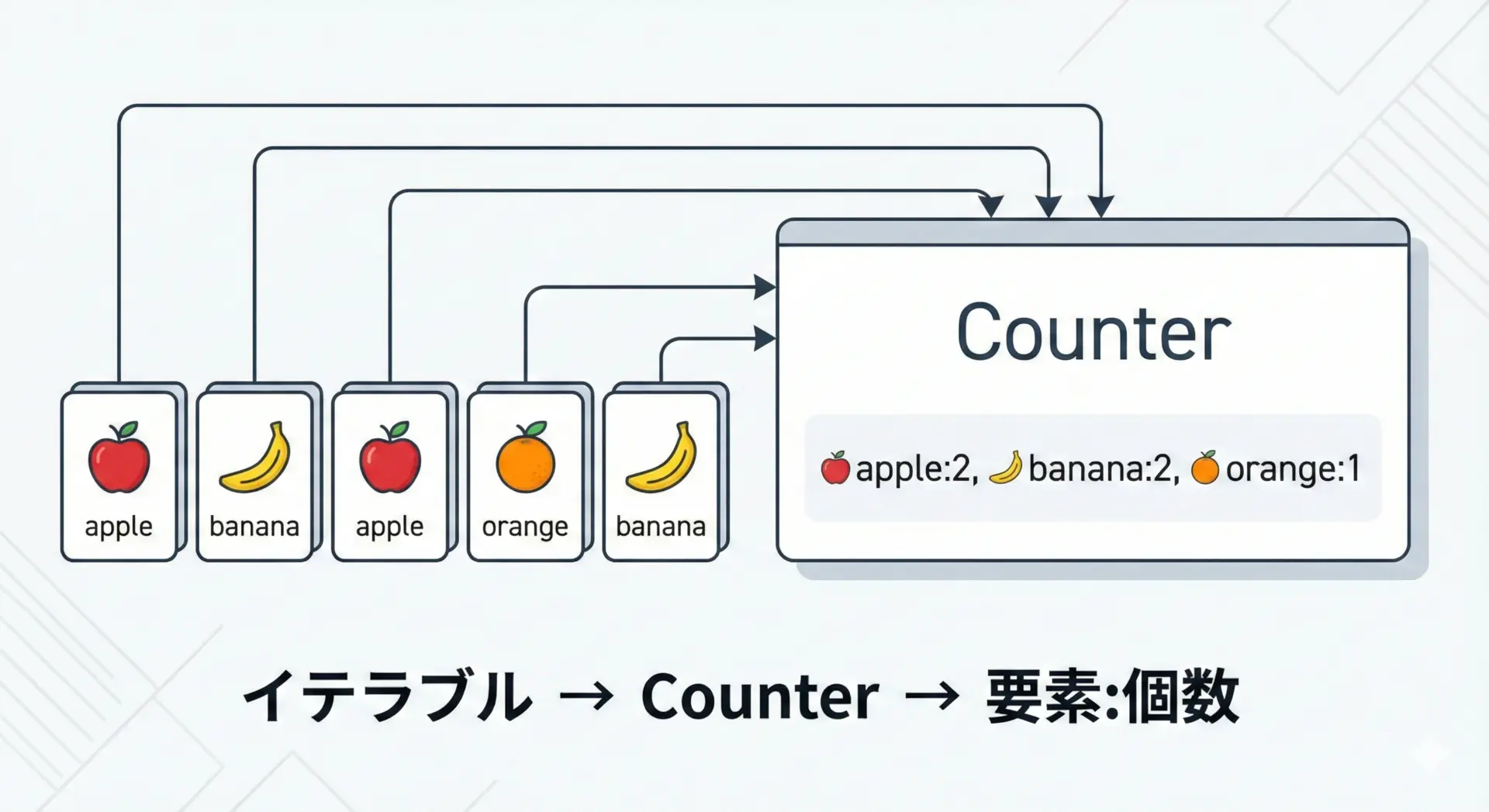
最も典型的な使い方は、リストや文字列の要素数を数える場面です。
実際のコードを見てみましょう。
from collections import Counter
# リストの要素数カウント
fruits = ["apple", "banana", "apple", "orange", "banana"]
# Counterにリストを渡すだけで、各要素の出現回数を集計してくれる
fruit_counter = Counter(fruits)
print(fruit_counter)
print(fruit_counter["apple"]) # 特定の要素の個数を取得
print(fruit_counter["grape"]) # 存在しない要素は0として扱われるCounter({'apple': 2, 'banana': 2, 'orange': 1})
2
0文字列の各文字の頻度を知りたい場合も、同じ要領です。
from collections import Counter
text = "mississippi"
# 文字列をそのまま渡すと、1文字ずつを要素としてカウントする
char_counter = Counter(text)
print(char_counter)
print(char_counter["s"]) # 's'が何回出てくるかCounter({'i': 4, 's': 4, 'p': 2, 'm': 1})
4このように、イテラブルを渡すだけで一発集計できる点が、Counterの大きな魅力です。
辞書型(dict)との違いと使い分け
Counterは辞書の一種ですが、役割が少し異なります。
ここで一度、違いと使い分けを整理しておきます。
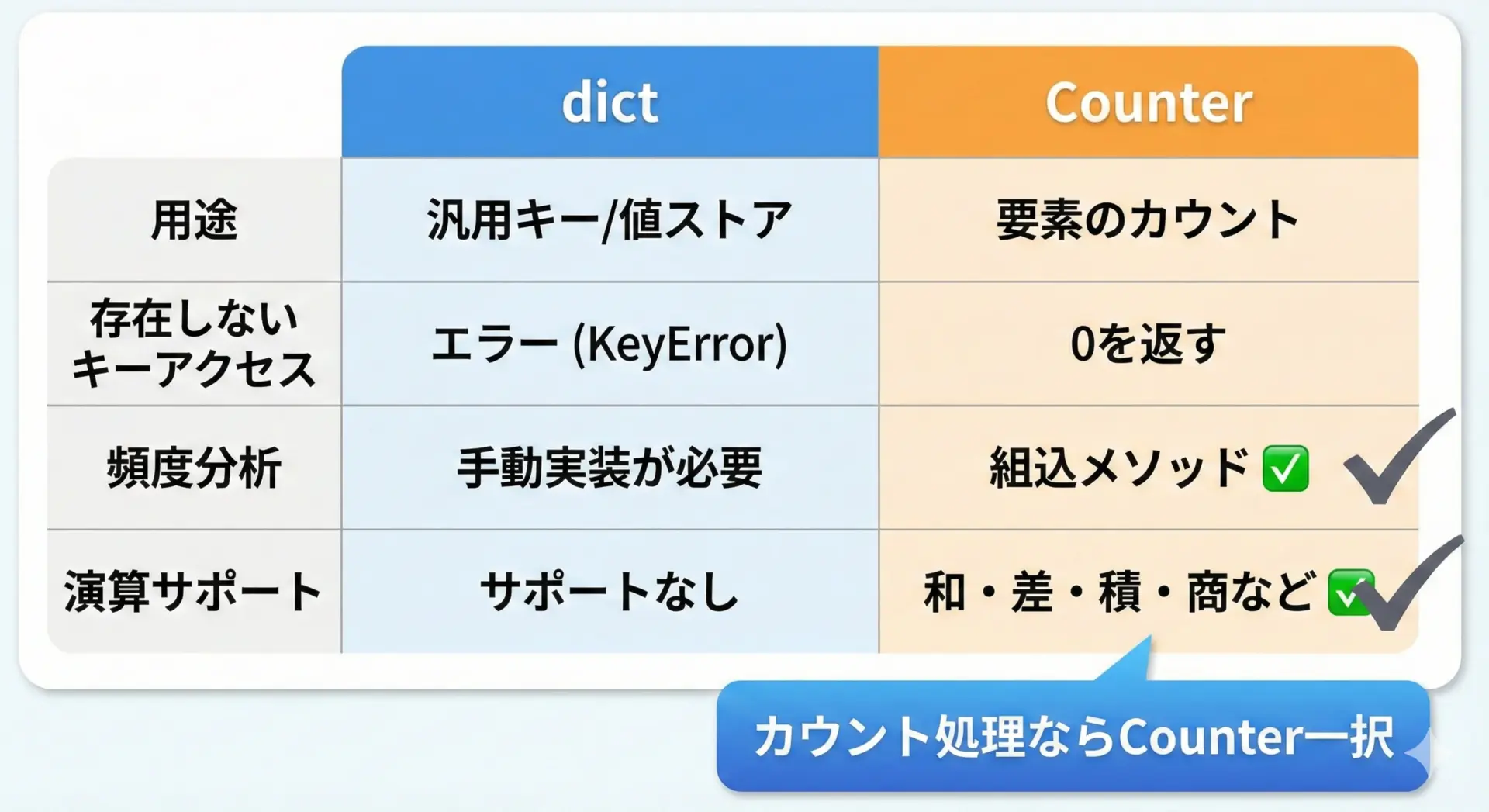
まず、通常のdictは「キーと値の汎用的なマッピング」を提供します。
値は数値でも文字列でもオブジェクトでもよく、「カウント」という用途に限定されません。
一方でCounterは、値として整数のカウントを想定し、カウント操作を簡単にする機能に特化しています。
挙動の違いも重要です。
通常の辞書では、存在しないキーにアクセスするとKeyErrorが発生しますが、Counterでは0として扱われる点が大きな違いです。
また、Counterはmost_commonメソッドや、加算・減算などの演算に対応しており、頻度分析や集計処理に向いています。
使い分けの目安としては、「ある集合の要素が、それぞれ何回出てくるかを知りたい」という目的があるならCounterを選ぶとよいです。
逆に、設定情報やオブジェクトのIDとインスタンスの紐付けなど、一般的なキー・値のマッピングが目的なら、通常のdictを使うのが適切です。
Counterの基本的な使い方
Counterの生成方法と初期化のパターン
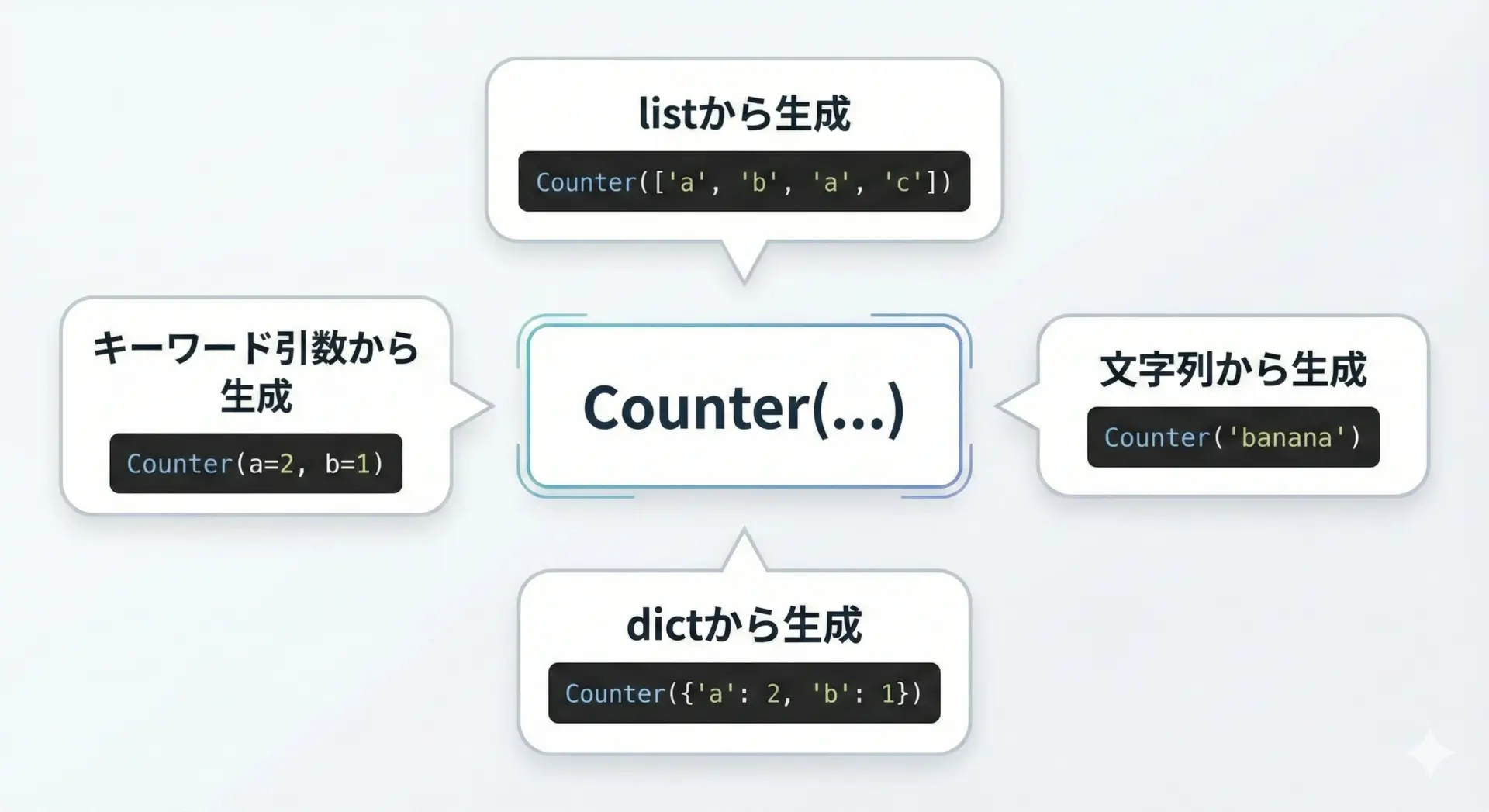
Counterの便利さは、さまざまな形のデータから柔軟に生成できるところにもあります。
代表的な初期化パターンをまとめて見ていきます。
from collections import Counter
# 1. リストなどのイテラブルから生成
fruits = ["apple", "banana", "apple"]
c1 = Counter(fruits) # 各要素の個数を自動でカウント
# 2. 文字列から生成(1文字ずつカウント)
text = "hello"
c2 = Counter(text)
# 3. 既存の辞書から生成(値をカウントとして扱う)
initial_dict = {"apple": 2, "banana": 3}
c3 = Counter(initial_dict)
# 4. キーワード引数で生成
c4 = Counter(apple=2, banana=3)
print(c1)
print(c2)
print(c3)
print(c4)Counter({'apple': 2, 'banana': 1})
Counter({'l': 2, 'h': 1, 'e': 1, 'o': 1})
Counter({'banana': 3, 'apple': 2})
Counter({'banana': 3, 'apple': 2})このように、すでにカウント済みの辞書がある場合はそのまま渡せますし、イテラブルから一気に集計することもできます。
「どこかで数えた結果をCounterにまとめ直す」といった用途にも使いやすいです。
most_commonで頻出要素を取得する方法
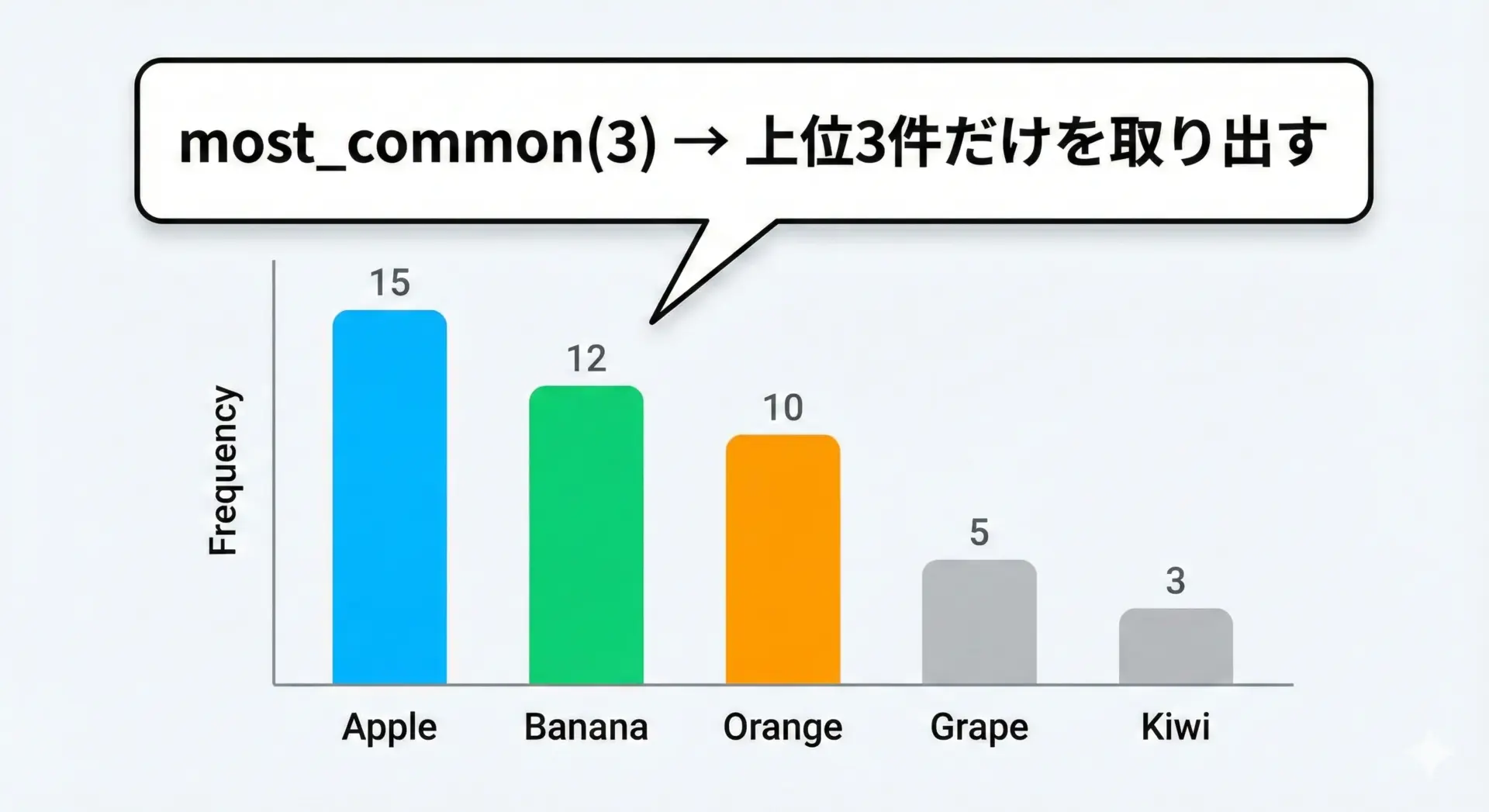
集計した結果から、頻出する要素だけを取り出したい場面はとても多いです。
Counterではmost_commonメソッドを使うことで、簡単に上位の要素を取得できます。
from collections import Counter
words = ["python", "java", "python", "go", "python", "java"]
counter = Counter(words)
# 上位2件を取得
top2 = counter.most_common(2)
print(top2) # 要素とカウントのタプルのリスト
print(top2[0][0]) # 最も多い要素
print(top2[0][1]) # その出現回数[('python', 3), ('java', 2)]
python
3most_common()に引数を渡さない場合は、すべての要素を多い順に並べたリストが返ります。
ランキング表示や、上位N件だけをグラフに表示するといった用途で、そのまま使える構造になっています。
要素数の更新(update)と減算の使い方
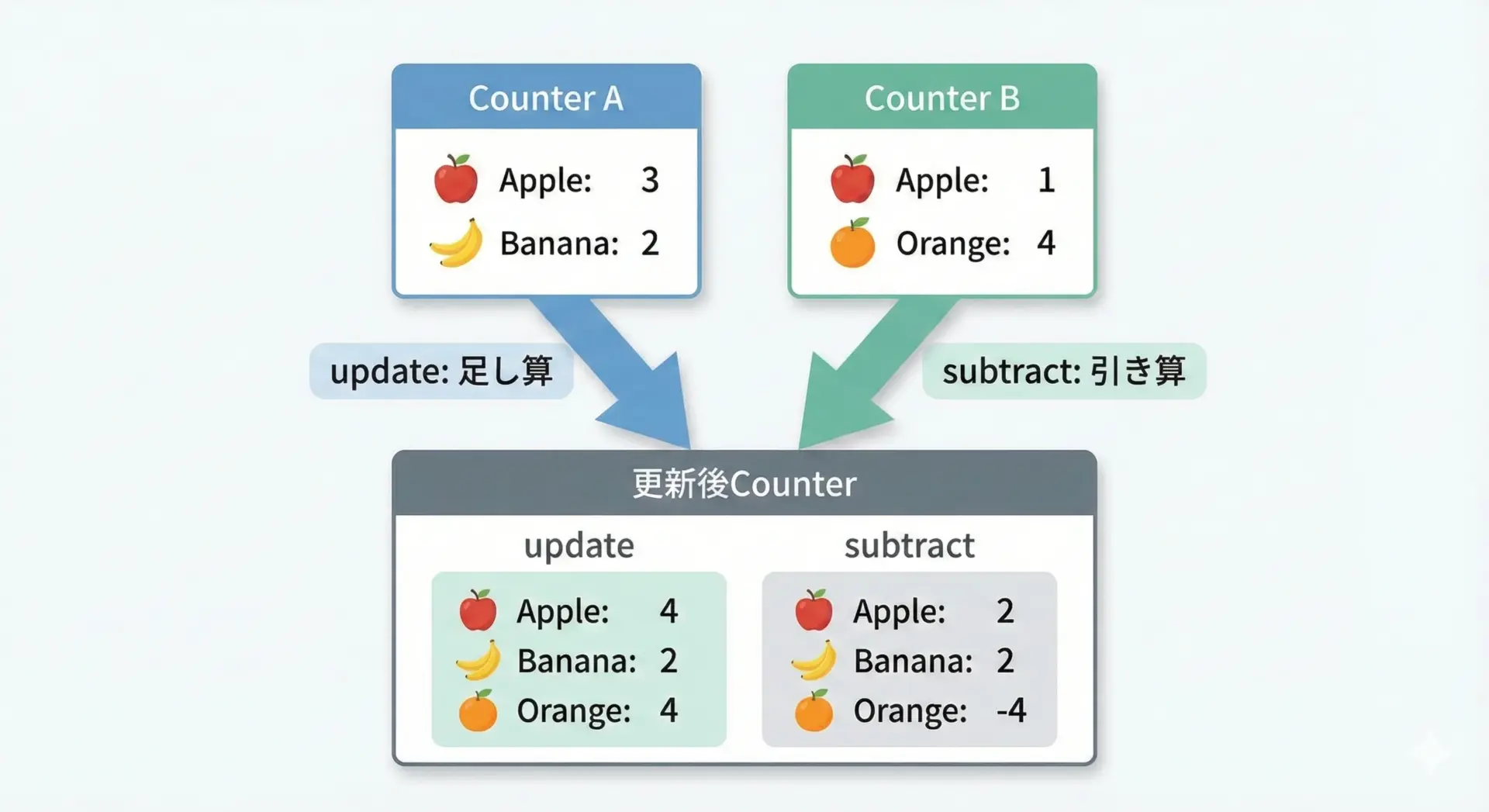
Counterの真価は、あとからカウントをどんどん更新できるところにあります。
新しいデータが届いたときに加算したり、不要になったデータを減算したりすることが簡単にできます。
from collections import Counter
counter = Counter({"apple": 2, "banana": 1})
# 新しくカウントした結果を足し合わせる
new_counts = Counter({"apple": 1, "orange": 3})
counter.update(new_counts) # appleが+1, orangeが+3される
print(counter)
# 逆に、あるカウントを減らしたい場合はsubtractを使う
remove_counts = Counter({"apple": 1, "orange": 1})
counter.subtract(remove_counts) # appleが-1, orangeが-1される
print(counter)Counter({'orange': 3, 'apple': 3, 'banana': 1})
Counter({'orange': 2, 'apple': 2, 'banana': 1})updateは、イテラブル(listやstrなど)を渡しても利用できます。
新たなリストを処理するたびにupdateすれば、ストリーム的なデータを逐次集計することも可能です。
存在しないキーの扱いと0カウントの注意点
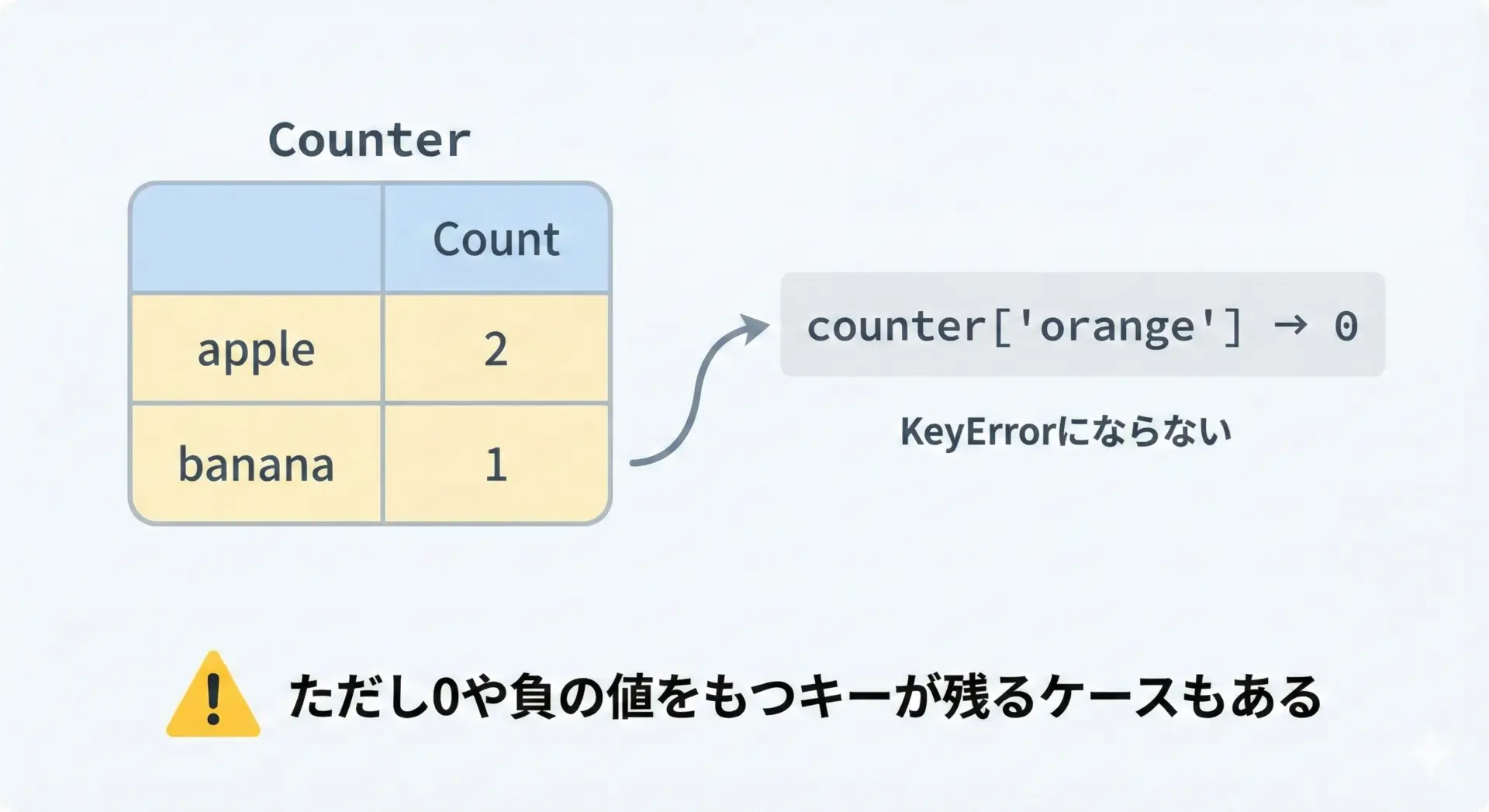
Counterでは、存在しないキーにアクセスしたときにKeyErrorにならないのが大きな特徴です。
これは、カウントのロジックを簡潔にしてくれます。
from collections import Counter
counter = Counter({"apple": 2})
# 存在しないキーでも0が返る
print(counter["banana"])
# 直接インクリメントしてもOK
counter["banana"] += 1
print(counter)0
Counter({'apple': 2, 'banana': 1})ただし、0や負の値を持つキーがInternalに残り続けることには注意が必要です。
減算や演算をしたあとに、不要なキーを取り除きたい場合は+演算などを活用します。
これについては後ほど、Counter同士の演算の節で詳しく解説します。
実践で役立つCounterの応用テクニック
文字列解析での頻度分析
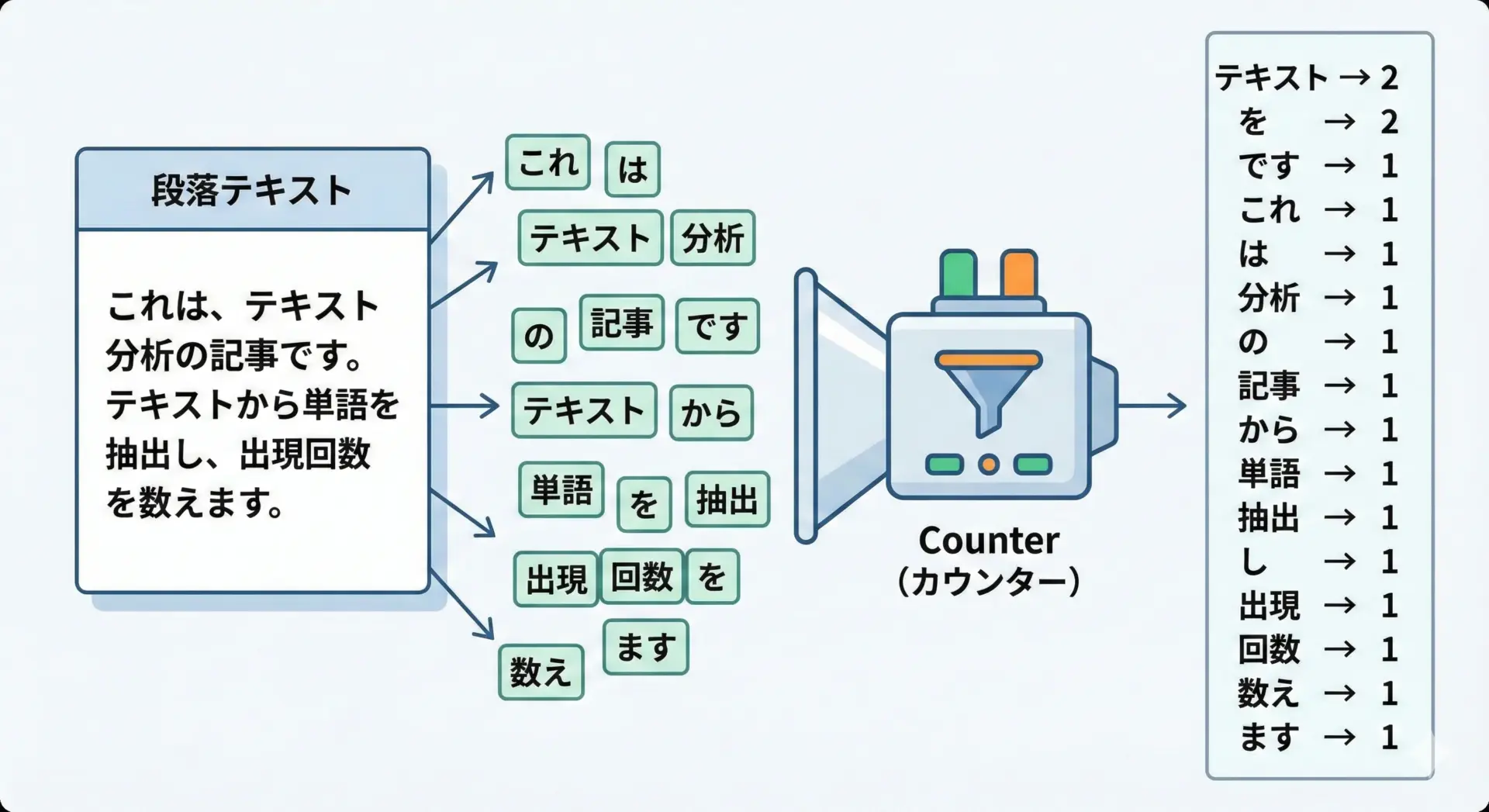
テキスト解析では、単語や文字の頻度分析が頻出タスクです。
Counterを使うと、単語カウントを簡単に実装できます。
from collections import Counter
import re
text = """
Pythonはシンプルで読みやすい言語です。
Pythonはデータ分析やWeb開発にもよく使われます。
"""
# 日本語と英数字を単純に分ける簡易トークナイズ(本格的にはJanomeなどを利用)
# ここでは単語らしきまとまりを抽出するイメージです
words = re.findall(r"[A-Za-z]+|[一-龥ぁ-んァ-ン]+", text)
counter = Counter(words)
# 頻出単語トップ5を表示
for word, count in counter.most_common(5):
print(f"{word}: {count}")Python: 2
シンプル: 1
で: 1
読みやすい: 1
言語: 1このように、文章からの単語抽出と組み合わせることで、簡易なテキストマイニングが行えます。
英語であれば、スペースで分割してからカウントするだけでも、十分な分析が可能です。
リストの重複チェックと集計レポート作成
大量のIDや値が入ったリストから、重複している要素やその回数を知りたい場面でもCounterが役立ちます。
from collections import Counter
user_ids = [100, 101, 100, 102, 103, 101, 100]
counter = Counter(user_ids)
print("=== 全ユーザーのアクセス回数 ===")
for user_id, count in counter.items():
print(f"user {user_id}: {count}回")
print("=== 複数回アクセスしたユーザー ===")
for user_id, count in counter.items():
if count > 1:
print(f"user {user_id}: {count}回")=== 全ユーザーのアクセス回数 ===
user 100: 3回
user 101: 2回
user 102: 1回
user 103: 1回
=== 複数回アクセスしたユーザー ===
user 100: 3回
user 101: 2回このように、Counterを使うと「重複チェック + 回数レポート」が1ステップで実現できます。
ログ解析やアクセス分析、アンケートの集計など、さまざまな場面で応用できます。
Counter同士の和・差・積集合的な演算
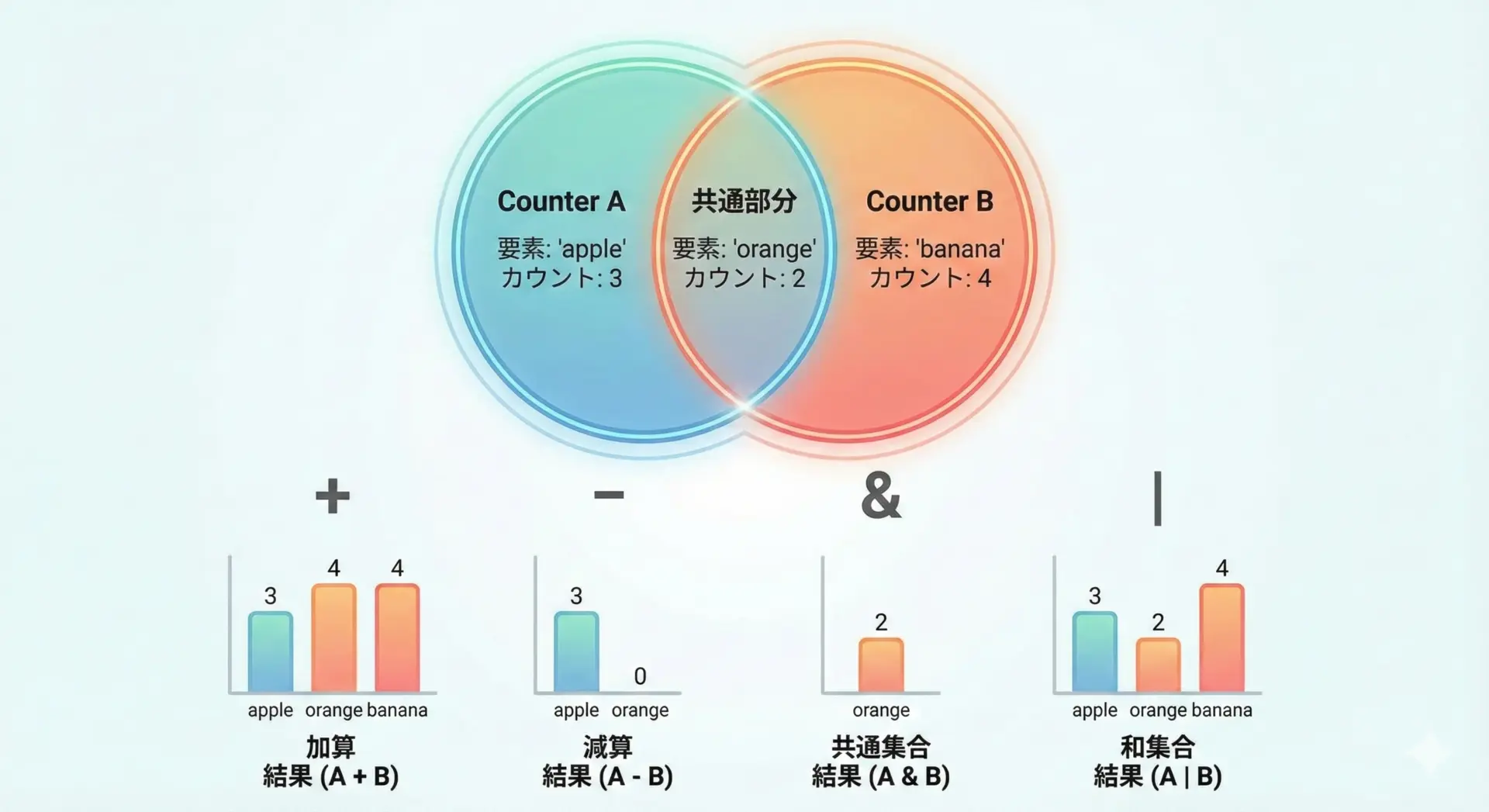
Counterは、数学的な集合演算に似た操作をサポートしています。
複数の集計結果を組み合わせたいときに非常に便利です。
from collections import Counter
c1 = Counter(A=3, B=1, C=1)
c2 = Counter(A=1, B=2, D=4)
print("c1:", c1)
print("c2:", c2)
# 和: 各要素のカウントを足し合わせる
print("c1 + c2:", c1 + c2)
# 差: c1からc2を引く(負の値や0は除外される)
print("c1 - c2:", c1 - c2)
# 積集合的な最小値: 共通要素について、カウントの小さい方を取る
print("c1 & c2:", c1 & c2)
# 和集合的な最大値: どちらかで出てくる最大カウントを取る
print("c1 | c2:", c1 | c2)c1: Counter({'A': 3, 'B': 1, 'C': 1})
c2: Counter({'D': 4, 'B': 2, 'A': 1})
c1 + c2: Counter({'D': 4, 'A': 4, 'B': 3, 'C': 1})
c1 - c2: Counter({'A': 2, 'C': 1})
c1 & c2: Counter({'A': 1, 'B': 1})
c1 | c2: Counter({'D': 4, 'A': 3, 'B': 2, 'C': 1})ポイントは、引き算-や論理演算&、|では負の値や0は自動的に取り除かれることです。
これにより、不要なキーを綺麗に消した結果だけを得ることができます。
先ほど触れた「0カウントのキーを掃除したい」場面でも、counter + Counter()のような書き方で正のカウントだけを残せます。
データ集計やログ解析での実用サンプル
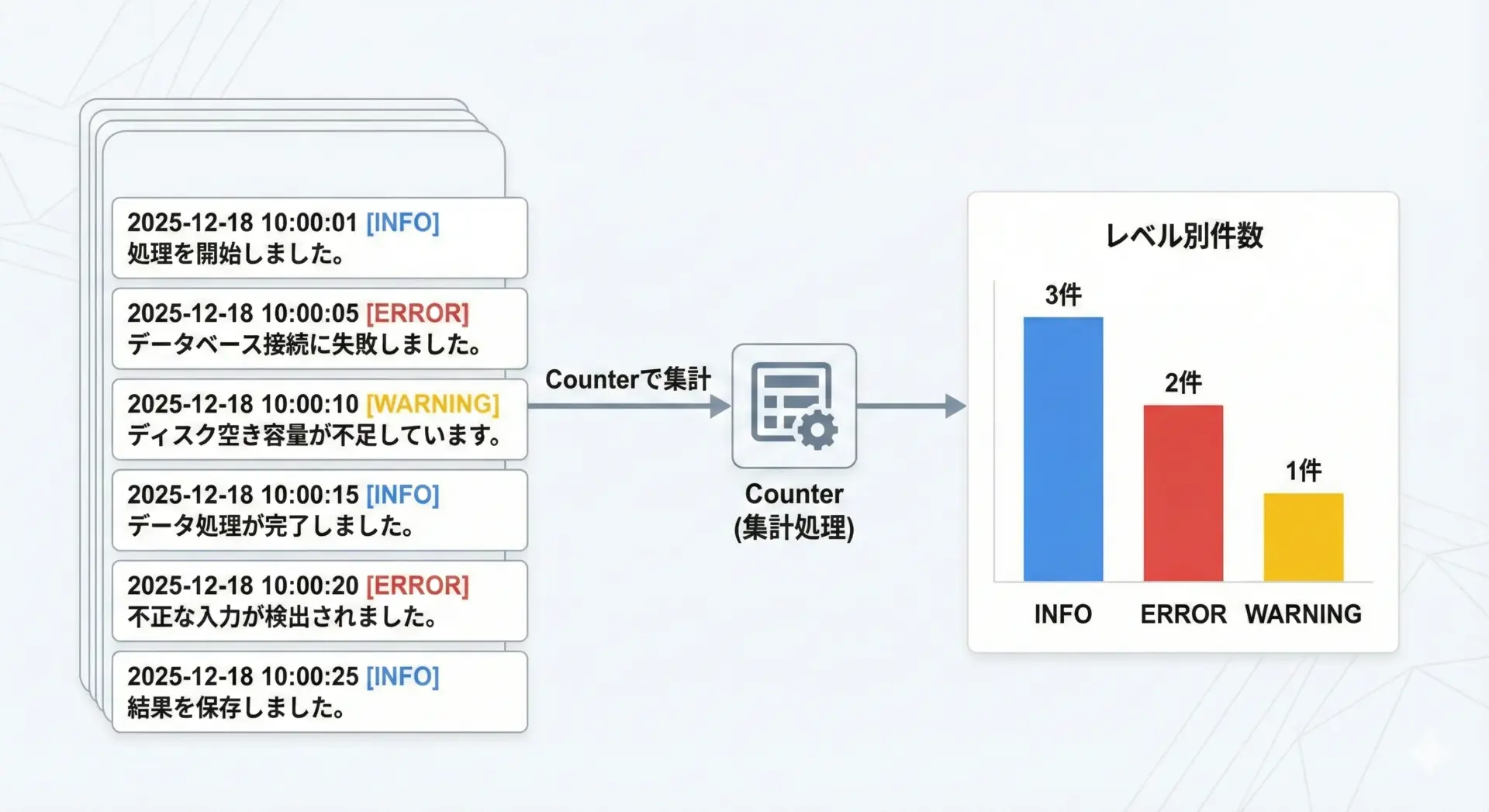
実務では、ログファイルの解析にCounterを使うケースが非常に多いです。
ここでは、シンプルなログ形式を想定した例を示します。
from collections import Counter
logs = [
"2025-01-01 10:00:00 [INFO] Start process",
"2025-01-01 10:00:01 [ERROR] Failed to connect",
"2025-01-01 10:00:02 [WARNING] Retry connect",
"2025-01-01 10:00:03 [INFO] Process running",
"2025-01-01 10:00:04 [ERROR] Timeout",
]
level_counter = Counter()
for line in logs:
# ログレベルは [] の中にあると仮定
left = line.find("[")
right = line.find("]")
if left != -1 and right != -1:
level = line[left + 1:right]
level_counter[level] += 1
print("=== ログレベル別件数 ===")
for level, count in level_counter.most_common():
print(f"{level}: {count}件")=== ログレベル別件数 ===
ERROR: 2件
INFO: 2件
WARNING: 1件ログレベルだけでなく、IPアドレスごとのアクセス回数や、エラーコードの出現頻度なども、同じパターンでカウントできます。
実際にはファイルから1行ずつ読み込んでupdateしていけば、大量データでも順次集計が可能です。
pandasやcollections.defaultdictとの組み合わせ方
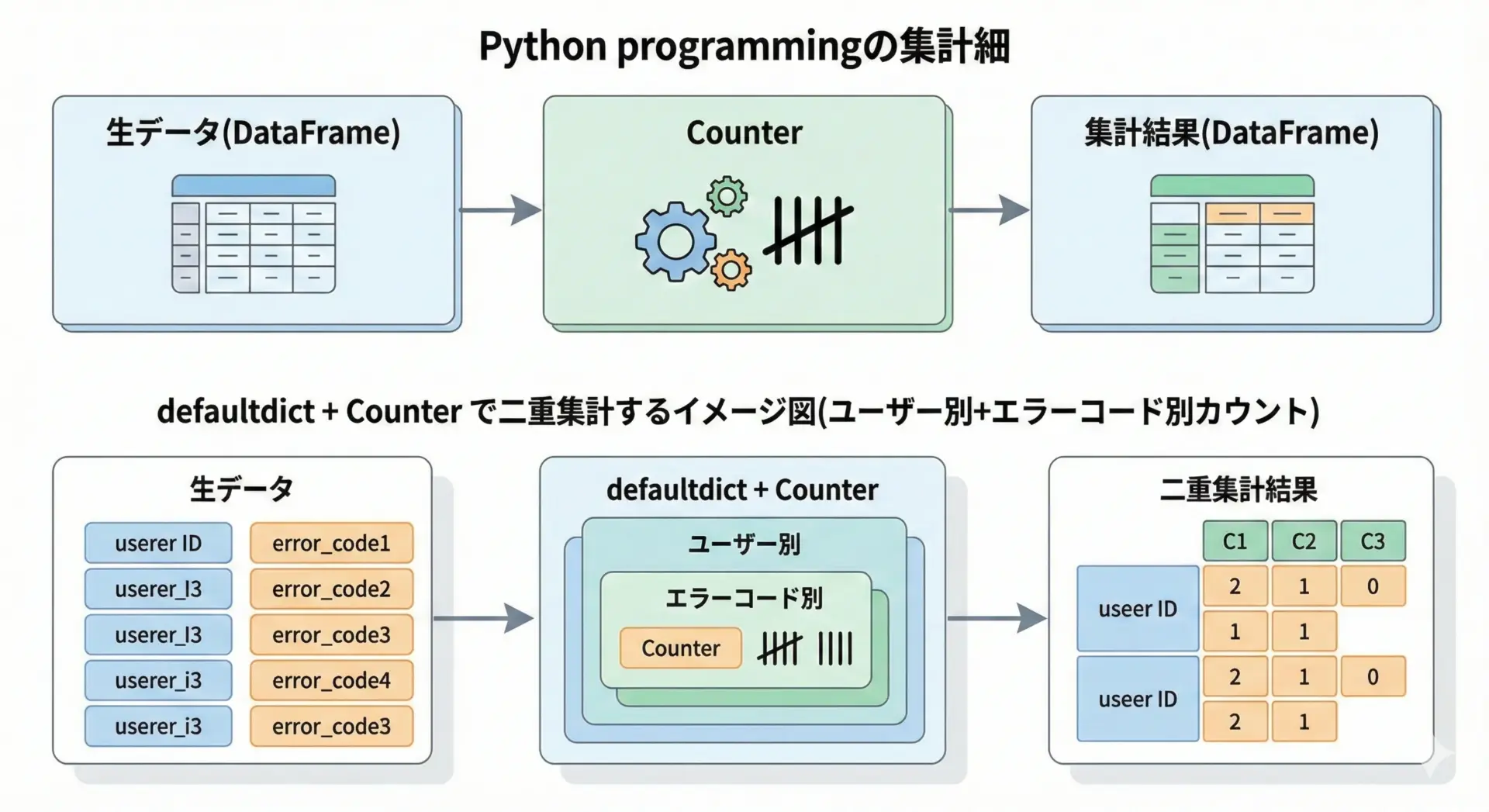
実務では、Counter単体だけでなく、pandasやdefaultdictと組み合わせて使う場面も多いです。
まず、pandasとの連携例です。
pandasにはvalue_countsという似た機能がありますが、Counterを介すると、より柔軟な処理が可能です。
import pandas as pd
from collections import Counter
data = {
"user": ["A", "B", "A", "C", "B", "A"],
"action": ["login", "login", "logout", "login", "logout", "login"],
}
df = pd.DataFrame(data)
# action列の頻度をCounterで集計
action_counter = Counter(df["action"])
print(action_counter)
# CounterからDataFrameに変換してレポート化
report_df = pd.DataFrame(
action_counter.items(), columns=["action", "count"]
).sort_values("count", ascending=False)
print(report_df)Counter({'login': 4, 'logout': 2})
action count
0 login 4
1 logout 2次に、defaultdictとの組み合わせです。
例えば「ユーザーごとに、発生したエラーコードの回数を数える」といった二重集計には、defaultdict(Counter)というパターンがよく使われます。
from collections import Counter, defaultdict
logs = [
{"user": "A", "error": "E001"},
{"user": "A", "error": "E002"},
{"user": "B", "error": "E001"},
{"user": "A", "error": "E001"},
]
# userごとにCounterを持つ構造
user_errors = defaultdict(Counter)
for log in logs:
user = log["user"]
error = log["error"]
user_errors[user][error] += 1
for user, counter in user_errors.items():
print(f"user {user}: {dict(counter)}")user A: {'E001': 2, 'E002': 1}
user B: {'E001': 1}このように、Counterは他のデータ構造と組み合わせることで、多次元の集計や高度な分析にも対応できます。
パフォーマンスとベストプラクティス
手書きループとの速度比較とメリット
Counterは見た目のシンプルさだけでなく、速度面でも優れた選択肢です。
手書きで辞書にカウントしていくコードと、Counterを使うコードを比べてみましょう。
from collections import Counter
import time
data = [i % 100 for i in range(1_000_00)] # 同じ値が繰り返されるリスト
# 手書きループによるカウント
start = time.time()
manual = {}
for x in data:
# dict.getを使って初期値0を扱うパターン
manual[x] = manual.get(x, 0) + 1
end = time.time()
print(f"手書きループ: {end - start:.4f}秒")
# Counterによるカウント
start = time.time()
c = Counter(data)
end = time.time()
print(f"Counter: {end - start:.4f}秒")手書きループ: 0.xxxx秒
Counter: 0.xxxx秒実際の数値は環境によって異なりますが、Counterの方が短く・読みやすく・しばしば高速です。
内部実装が最適化されていることに加え、「バグを生みやすいループ処理」を自前で書かなくて済む点も、実務では大きなメリットになります。
大量データでのメモリ・速度の注意点
大量のデータに対してCounterを使う場合、メモリと速度のバランスを意識する必要があります。
全データを一度にリストに読み込んでからCounterに渡すと、メモリを大量に消費してしまう可能性があります。
このような場合は、データを逐次的に読み込みながらupdateするのがポイントです。
from collections import Counter
def read_large_file(path):
# 実際にはファイルを開いて1行ずつyieldするなど
# ここではイメージのために固定データを返すだけ
for line in ["apple", "banana", "apple"]:
yield line.strip()
counter = Counter()
for item in read_large_file("bigdata.txt"):
counter[item] += 1 # 1件ずつカウントを増やす
print(counter)Counter({'apple': 2, 'banana': 1})この方法であれば、全データをリストに保持せずにカウントできるため、メモリ使用量を抑えられます。
速度面でも、I/Oとカウント処理を並行して進められるため、実効時間を短縮できることが多いです。
読みやすく保守しやすいコードの書き方
Counterを使うことで、コードの意図をそのまま表現できるようになります。
「カウントしている」という事実が一目でわかるため、保守性が上がります。
以下のような方針を意識するとよいです。
まず、変数名で目的を明確にすることが大切です。
例えばcounterよりもerror_countsやword_freqなど、何を数えているかがわかる名前にすると、後から読んだ人にも意図が伝わりやすくなります。
次に、集計処理を関数に切り出すことも有効です。
Counterを返す関数にしておけば、テストや再利用が簡単になります。
from collections import Counter
def count_words(text: str) -> Counter:
"""テキスト中の単語頻度をカウントして返す関数"""
words = text.split()
return Counter(words)
sample = "python python java go python"
word_freq = count_words(sample)
print(word_freq.most_common())[('python', 3), ('java', 1), ('go', 1)]このようにCounterを中心に処理を組み立てることで、簡潔で意図の伝わるコードを書くことができます。
まとめ
collections.Counterは、要素数を直感的かつ高速に集計できる、辞書ベースの強力なツールです。
listやstrからの一発集計、most_commonによる頻出要素の取得、updateや演算子を使った柔軟なカウント操作など、標準ライブラリだけとは思えないほど多機能です。
文字列解析やログ解析、pandasとの連携、defaultdictとの二重集計など、実務でも活躍の場は非常に広いです。
カウント処理が出てきたら、まずはCounterで書けないかを検討する習慣をつけると、コードの品質と生産性が大きく向上します。
