
Pythonの辞書は、設定やAPIレスポンスの加工など、現代のPythonコードで頻繁に登場するデータ構造です。
そのため、複数の辞書を「結合」「マージ」する方法を理解しておくことはとても重要です。
本記事では、Pythonで辞書を結合・マージするさまざまな方法と、バージョンごとの違い、演算子+=や|の違いについて、図解とサンプルコードを交えながら詳しく解説します。
辞書の結合・マージの基本
辞書の結合・マージとは
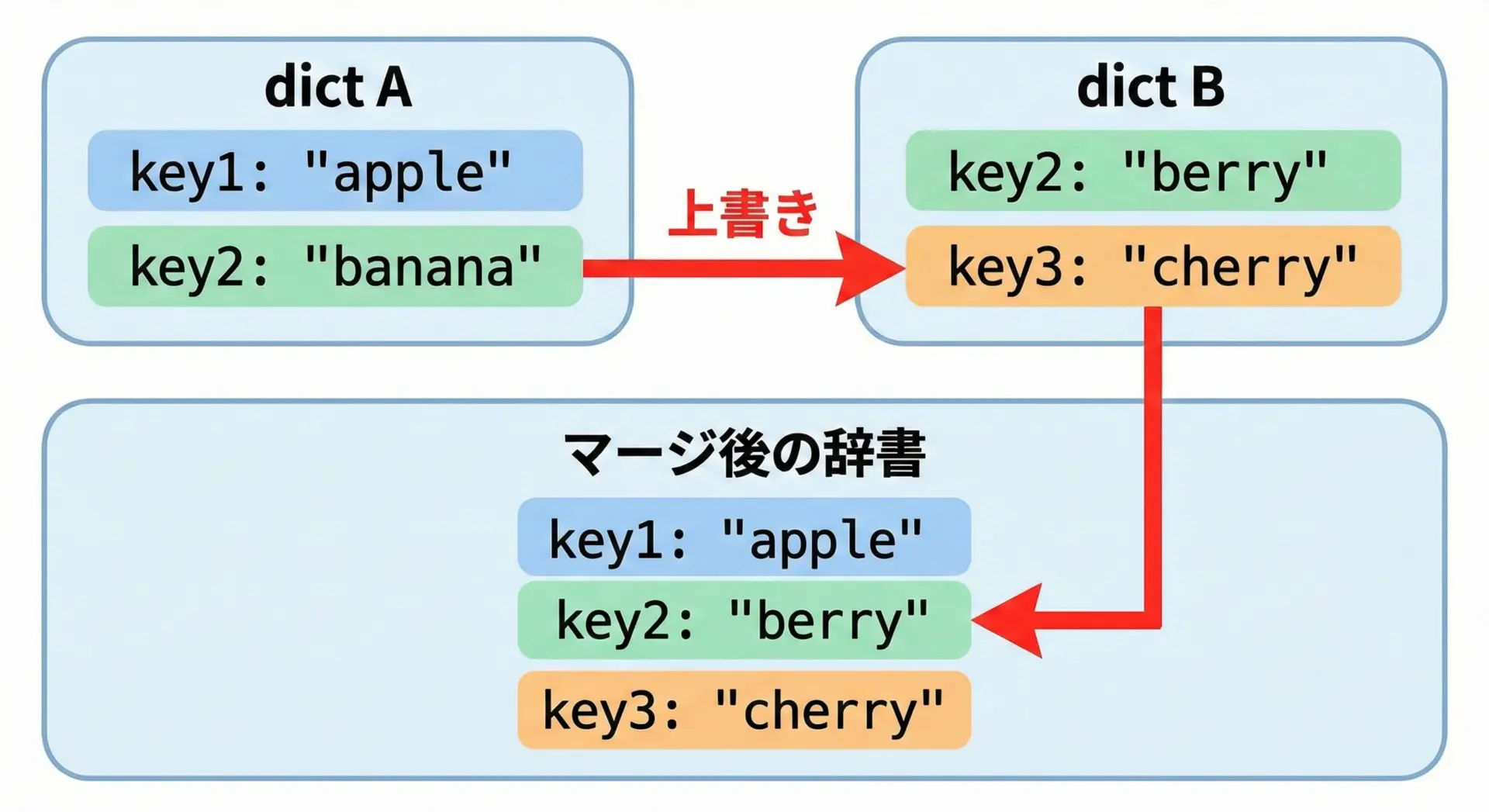
辞書の結合・マージとは、複数の辞書をまとめて1つの辞書として扱えるようにする操作のことです。
多くの場合、次のようなケースで利用します。
- 設定ファイルや環境ごとのパラメータをまとめて1つの設定辞書にしたい場合
- デフォルト値を定義した辞書に、ユーザー入力などの上書き設定を適用したい場合
- APIから取得した複数のレスポンスを1つの辞書に統合したい場合
辞書のマージで特に重要なのは、同じキーが複数の辞書に存在する場合にどちらの値を優先するかです。
一般的には、「後からマージした側」が優先され、元の辞書の値は上書きされます。
Pythonでは、このマージ処理を行う方法が複数あり、メソッドを使う方法、演算子を使う方法、構文を利用する方法などが存在します。
それぞれの挙動や対応バージョンが異なるため、目的に応じた使い分けが大切です。
Pythonのバージョンによる違い
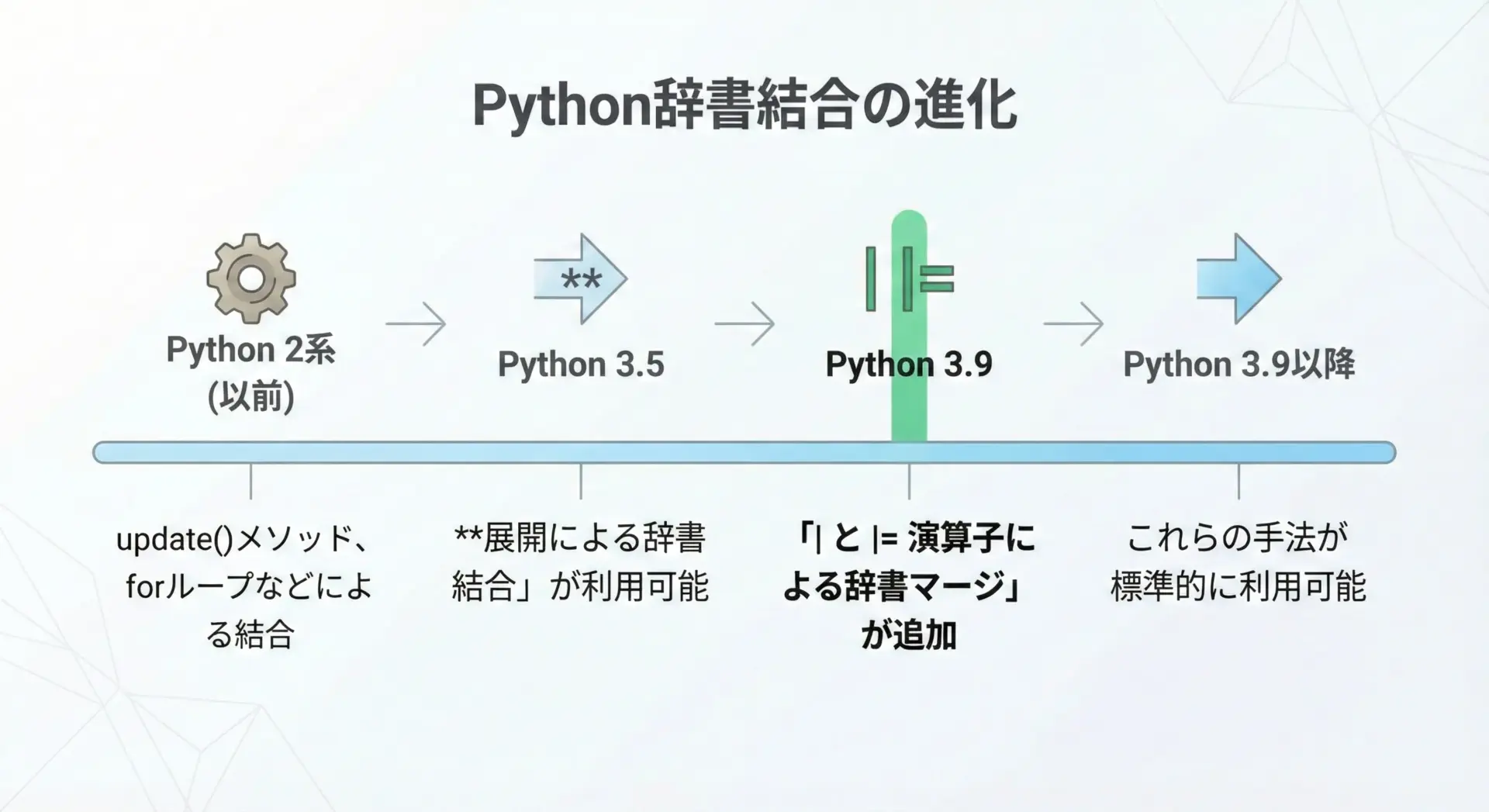
Pythonの辞書マージ機能は、バージョンによって使える構文や演算子が異なります。
主な変化点を簡単に整理します。
- Python 3.5以降
辞書のアンパック構文**による結合が利用できます。
例えばdict_c = {**dict_a, **dict_b}のように書くことができます。 - Python 3.9以降
辞書に対する|と|=演算子が追加されました。
これにより、dict_c = dict_a | dict_bのような直感的な書き方が可能になりました。 - 全バージョンで利用できる方法
dict.updateメソッドやforループを使った手動マージは、古いPythonでも使えます。
特にライブラリやツール開発で古いPythonをサポートしたい場合は、これらの方法が重要です。
このように、「どのPythonバージョンを対象にするか」によって、選べる書き方が変わります。
以降のセクションでは、バージョン差にも触れながら、それぞれの方法を詳しく説明します。
辞書を更新する基本の結合方法
dict.updateで辞書を上書き結合する方法
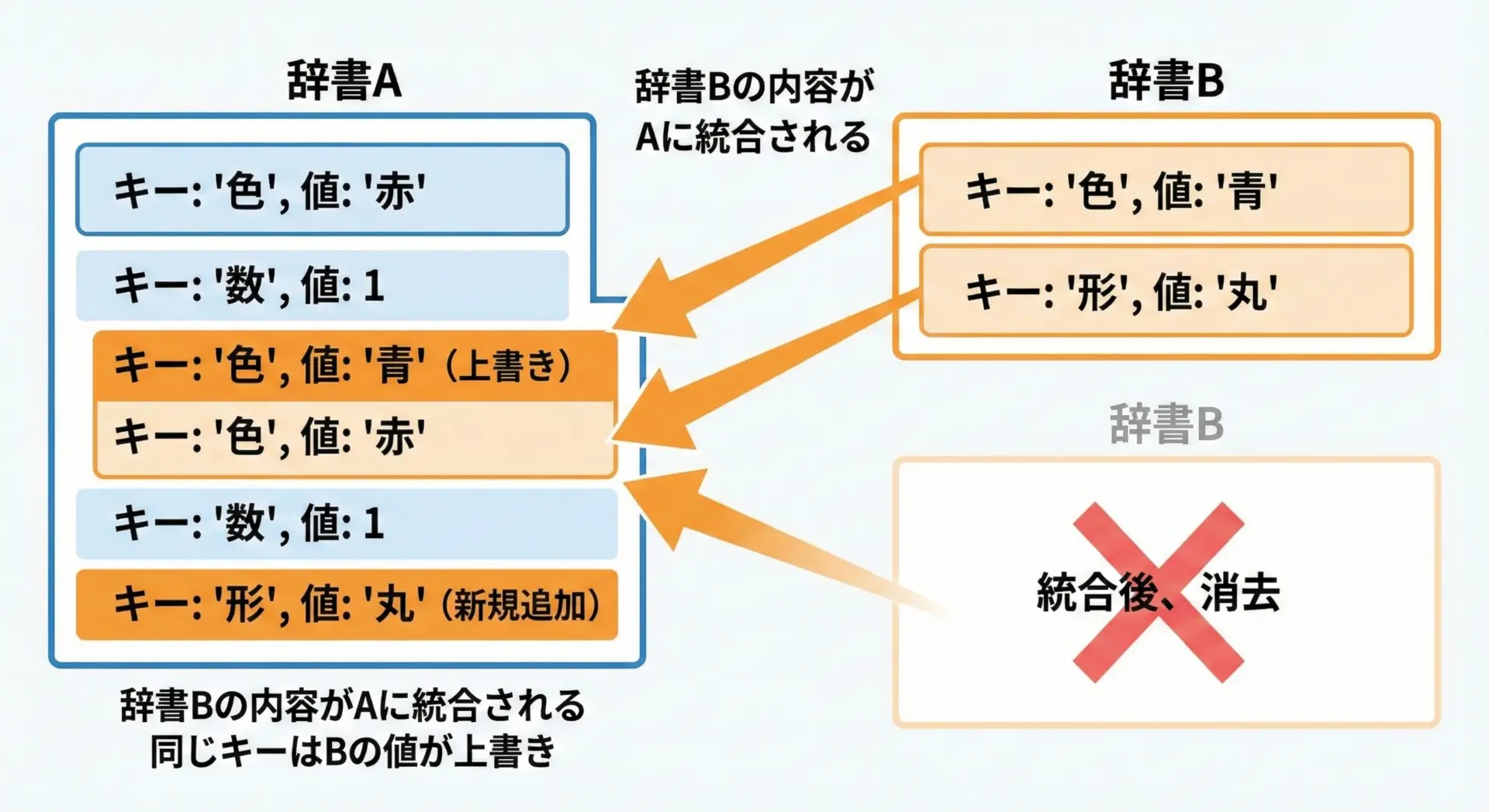
最も基本的な辞書のマージ方法はdict.updateメソッドを使うやり方です。
これは、既存の辞書を破壊的に更新する(元の辞書の内容を書き換える)点がポイントです。
dict.updateの基本的な使い方
# dict.updateを使った基本的な辞書のマージ例
base = {"host": "localhost", "port": 8000}
override = {"port": 8080, "debug": True}
# baseをoverrideで更新(破壊的変更)
base.update(override)
print(base) # {'host': 'localhost', 'port': 8080, 'debug': True}{'host': 'localhost', 'port': 8080, 'debug': True}この例では、同じキー"port"がoverride側の値8080で上書きされ、さらに"debug"という新しいキーが追加されています。
破壊的更新であることに注意
updateは元の辞書を書き換えます。
そのため、元の辞書を残しておきたい場合には、コピーを取ってからupdateする必要があります。
default_config = {"timeout": 10, "retries": 3}
user_config = {"timeout": 5}
# 元のdefault_configを残したい場合
merged = default_config.copy() # dict()でもOK
merged.update(user_config)
print("default_config:", default_config)
print("merged:", merged)default_config: {'timeout': 10, 'retries': 3}
merged: {'timeout': 5, 'retries': 3}このように「元の辞書を保持したいか」「直接書き換えてよいか」で、updateをそのまま使うか、コピーとセットで使うかを決めることが大切です。
forループでキーと値を手動マージする方法
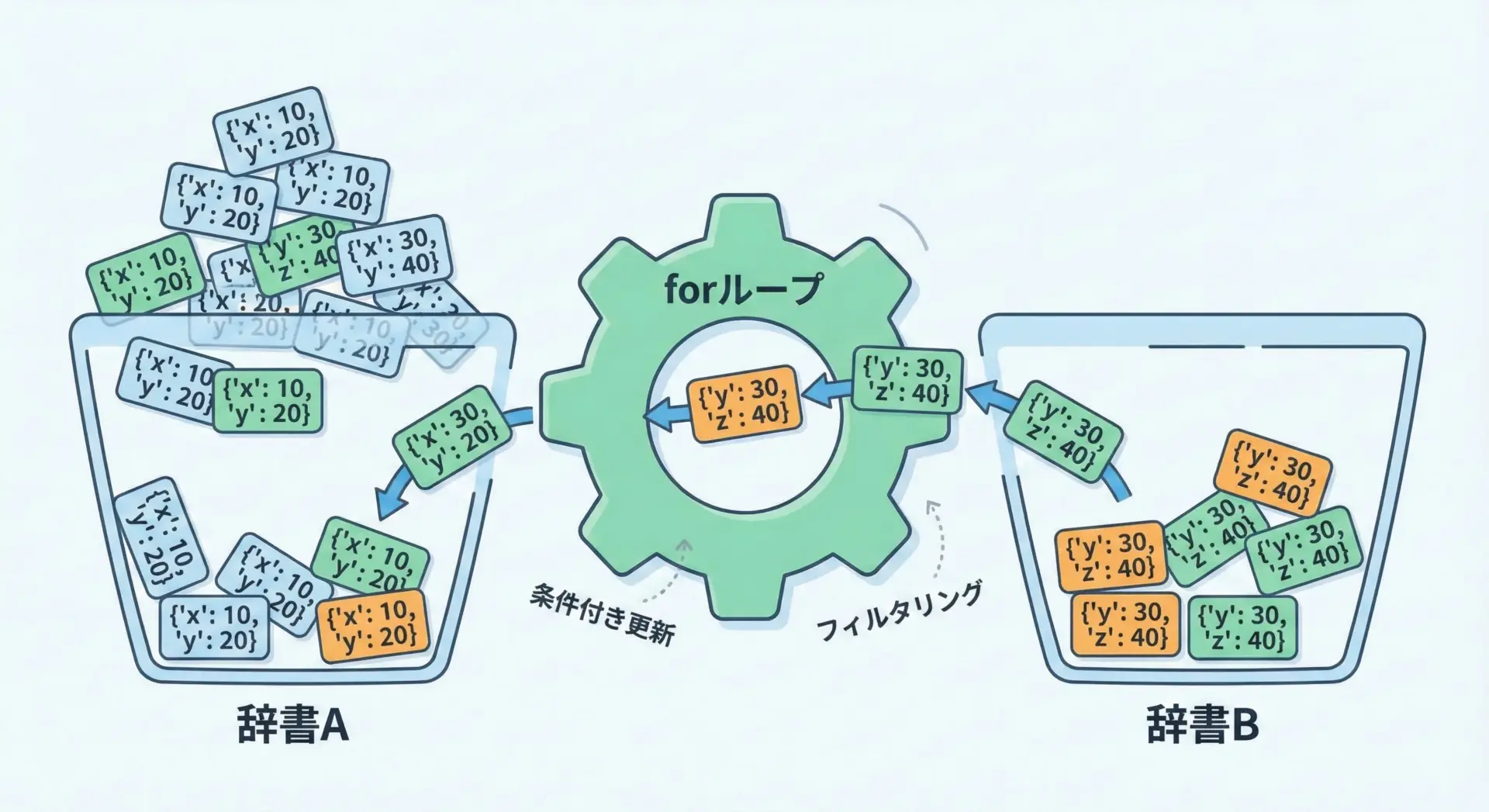
より柔軟な制御が必要な場合、forループを用いてキーと値を手動でマージする方法が役立ちます。
例えば、特定のキーだけマージしたい場合や、既にあるキーは上書きしたくない場合などです。
すべてのキーをシンプルに上書きする場合
# forループでシンプルにマージする例
a = {"x": 1, "y": 2}
b = {"y": 999, "z": 3}
for key, value in b.items():
# bのキー・値でaを更新する
a[key] = value
print(a){'x': 1, 'y': 999, 'z': 3}これは実質的にa.update(b)と同じ動きですが、forループを使うことで、途中に条件を差し込めるようになります。
既存のキーは上書きせず、新しいキーだけ追加する例
# 既に存在するキーはそのまま残し、新しいキーだけ追加する例
dest = {"id": 1, "role": "user"}
source = {"role": "admin", "active": True}
for key, value in source.items():
# destに存在しないキーだけ追加する
if key not in dest:
dest[key] = value
print(dest){'id': 1, 'role': 'user', 'active': True}このように、forループによる手動マージは、カスタムルールを実装するときに非常に強力です。
後述する「ネストした辞書の再帰的マージ」でも、forループによる処理が基本となります。
dict(**a, **b)で辞書を結合する方法
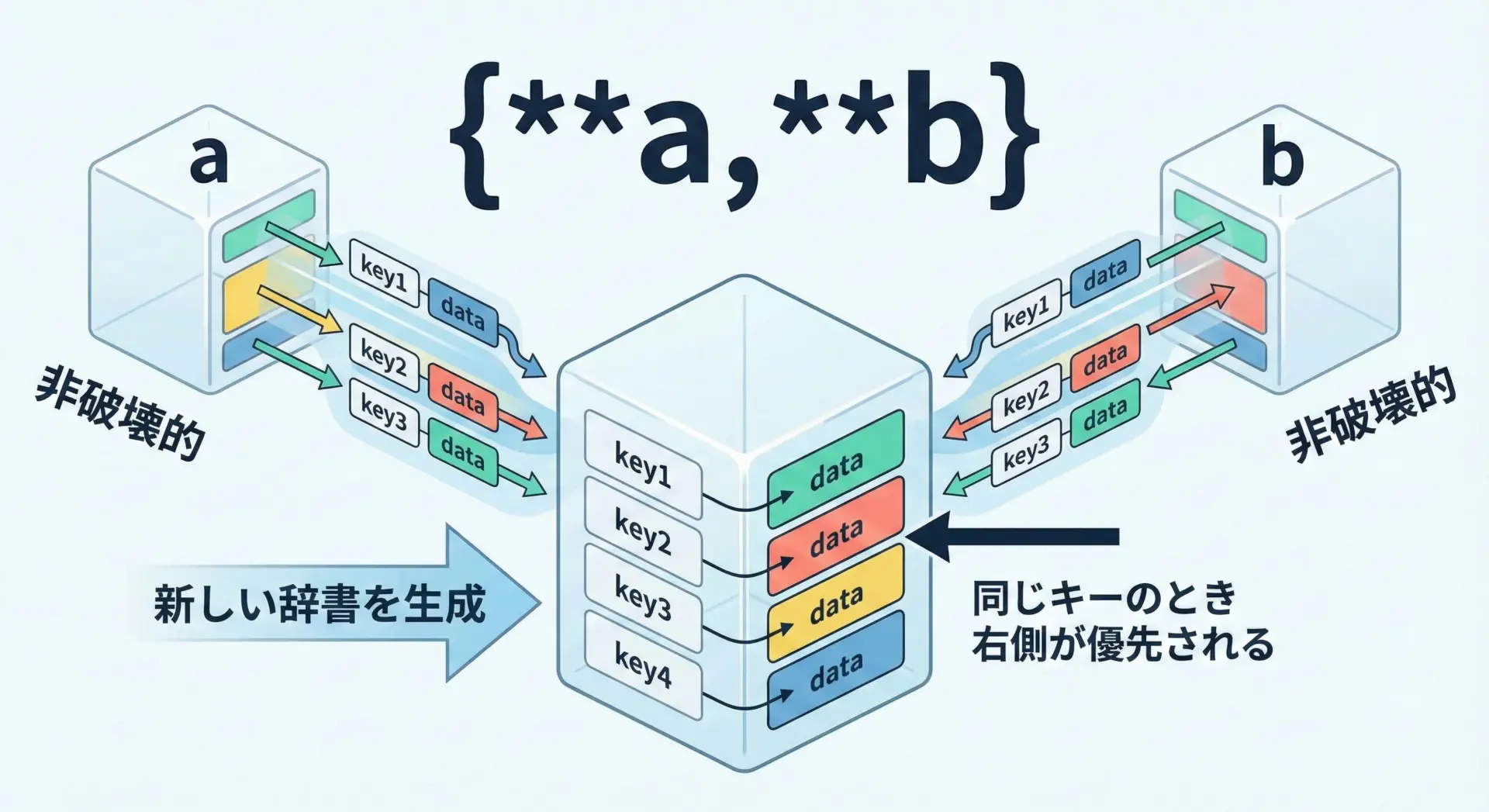
Python 3.5以降では、辞書のアンパック構文**を使って、新しい辞書を簡潔に作成できます。
この方法は非破壊的であり、元の辞書を変更しません。
基本的な使い方
# 辞書のアンパック構文(**)による結合
a = {"name": "Alice", "age": 20}
b = {"age": 21, "city": "Tokyo"}
merged = {**a, **b}
print("a:", a)
print("b:", b)
print("merged:", merged)a: {'name': 'Alice', 'age': 20}
b: {'age': 21, 'city': 'Tokyo'}
merged: {'name': 'Alice', 'age': 21, 'city': 'Tokyo'}右側に書かれた辞書bの同名キーageが優先される点が重要です。
複数の辞書をまとめて結合する
アンパック構文は複数回並べられるため、3つ以上の辞書を一気に結合することもできます。
default = {"timeout": 10, "retries": 3}
env = {"timeout": 5}
user = {"retries": 10}
# 左から順に、右側の辞書で上書きされていく
merged = {**default, **env, **user}
print(merged){'timeout': 5, 'retries': 10}この方法は、「新しい辞書を作りたい」「もとの辞書を一切触りたくない」という場合にとても便利です。
ただし、Python 3.5以前では使用できないため、対象バージョンに注意する必要があります。
演算子による辞書のマージ
+=演算子で辞書を結合する仕組みと注意点
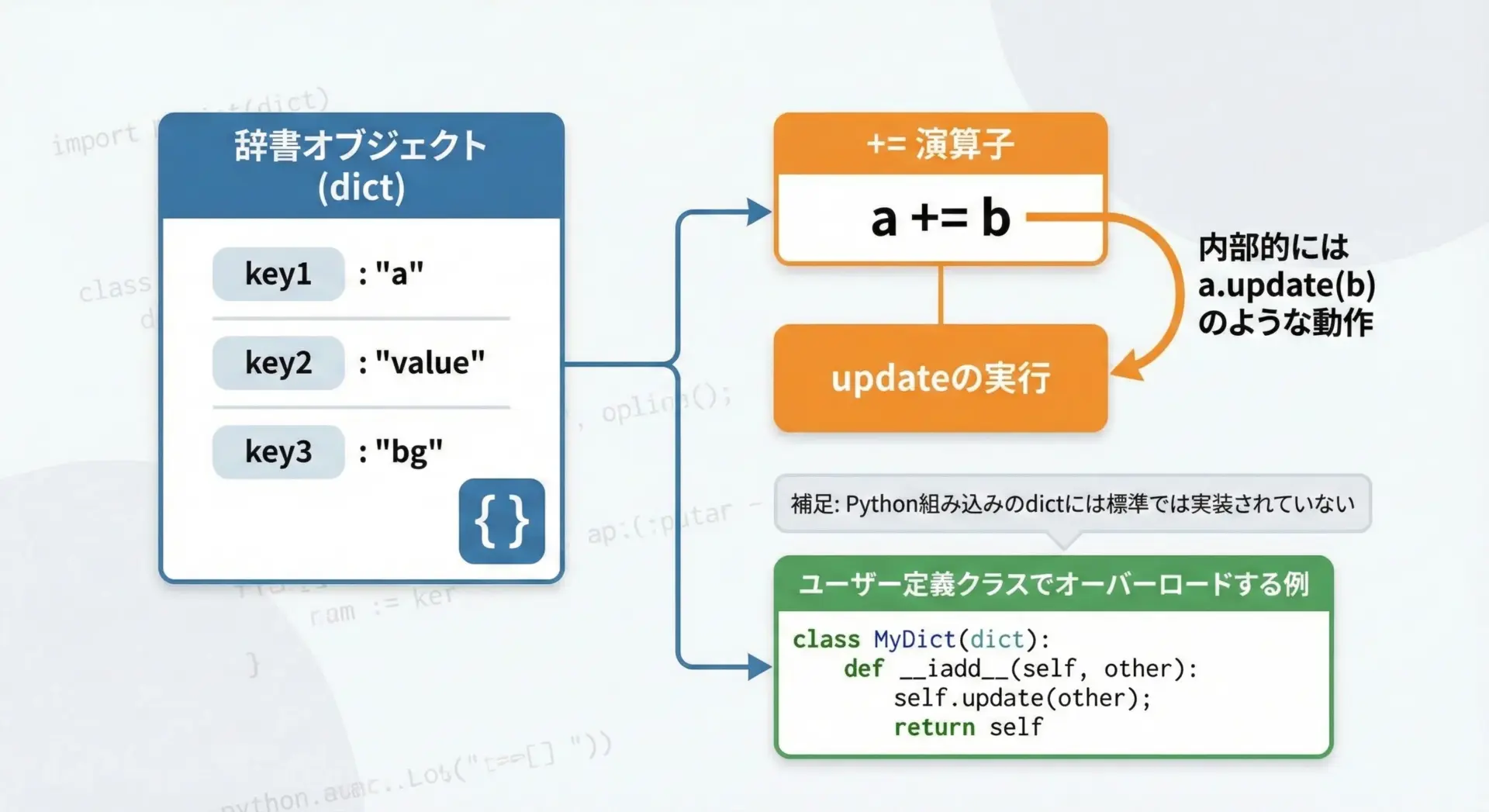
まず重要な点として、Python標準の組み込み辞書dict型には+=によるマージは定義されていません。
そのため、次のようなコードはエラーになります。
a = {"x": 1}
b = {"y": 2}
# Python組み込みのdictではこれはエラーになる
a += b # TypeErrorTypeError: unsupported operand type(s) for +=: 'dict' and 'dict'ではなぜ「辞書の結合に+=を使う」という話題が出てくるのかというと、これはユーザー定義クラスやサブクラスで__iadd__を定義している場合の話です。
カスタム辞書クラスで+=を実装する例
# カスタム辞書クラスで+=を辞書マージとして定義する例
class MergeDict(dict):
def __iadd__(self, other):
# += が呼ばれた時に self.update を行う
if isinstance(other, dict):
self.update(other)
return self
return NotImplemented
a = MergeDict({"x": 1})
b = {"y": 2}
a += b # 実体は a.__iadd__(b) の呼び出し
print(a){'x': 1, 'y': 2}このように、「辞書風のクラス」であれば、+=をマージ用途に使えるようにオーバーロードできます。
しかし、組み込みのdict型では+=は使えないため、通常のPythonコードではdict.updateや|などを利用することになります。
|演算子で新しい辞書をマージ作成する方法
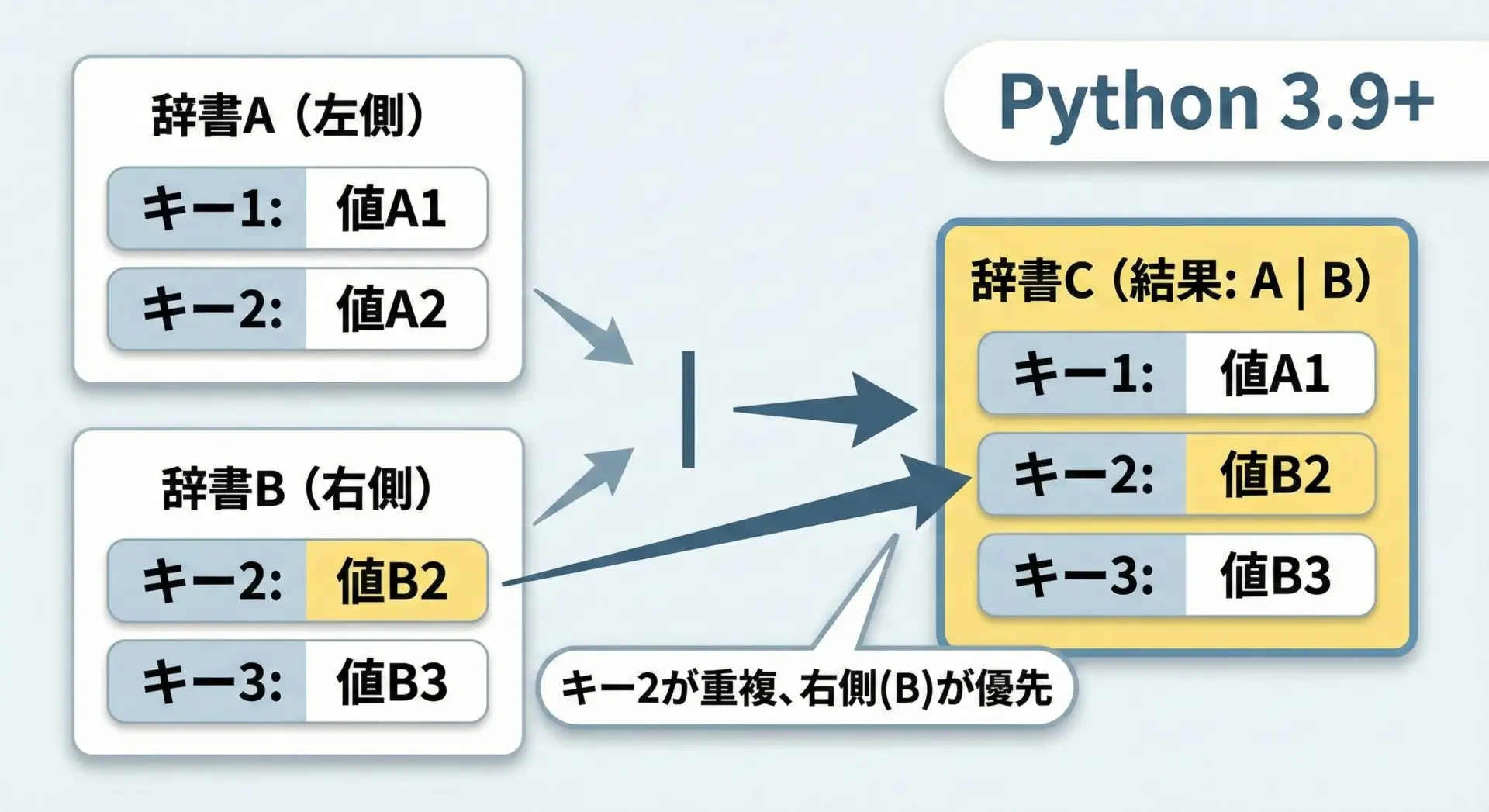
Python 3.9以降では、辞書に対して|演算子を使うことで、新しい辞書を簡潔に作成できます。
この演算子は非破壊的であり、左右の元の辞書は変更されません。
基本的な使い方
# | 演算子による辞書マージ (Python 3.9+)
a = {"id": 1, "name": "Alice"}
b = {"name": "Bob", "active": True}
c = a | b # 新しい辞書を返す
print("a:", a)
print("b:", b)
print("c:", c)a: {'id': 1, 'name': 'Alice'}
b: {'name': 'Bob', 'active': True}
c: {'id': 1, 'name': 'Bob', 'active': True}右側の辞書bの同名キー"name"が優先されていることがわかります。
左結合で連鎖的にマージする
|は演算子なので、複数の辞書を連鎖的にマージできます。
base = {"a": 1}
env = {"b": 2}
user = {"a": 10}
merged = base | env | user
print(merged){'a': 10, 'b': 2}この場合、右側に近い辞書の値ほど優先されます。
複数のレイヤー(デフォルト → 環境 → ユーザー設定など)を扱う設定マージに便利です。
|=演算子で既存の辞書をマージ更新する方法
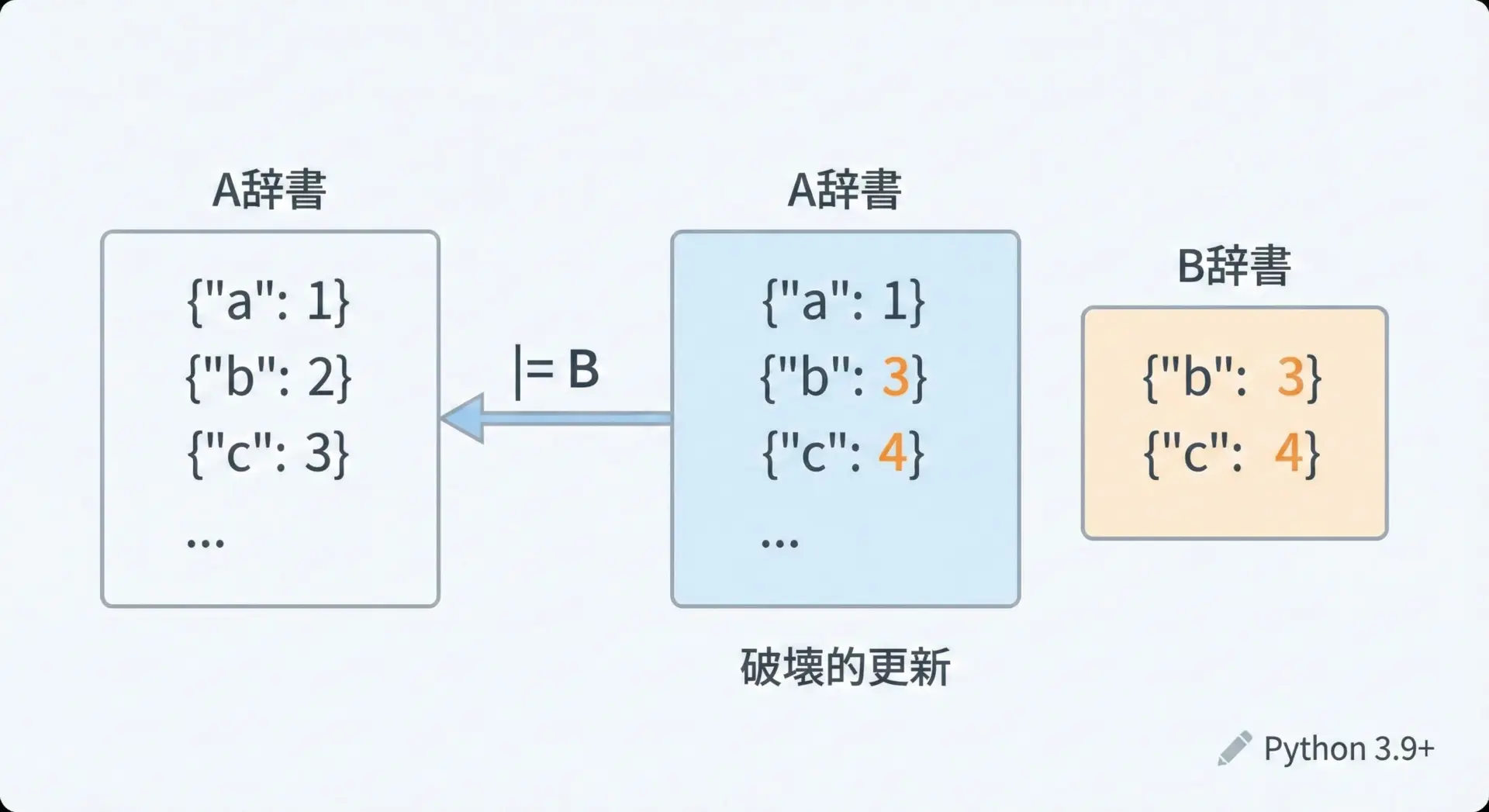
|=演算子は、左辺の辞書を破壊的に更新します。
内部的にはupdateに近い動作をしますが、式として書けるのが利点です。
基本的な使い方
# |= 演算子による破壊的辞書マージ (Python 3.9+)
config = {"timeout": 10, "retries": 3}
override = {"timeout": 5}
config |= override # configを破壊的に更新
print(config){'timeout': 5, 'retries': 3}これはconfig.update(override)とほぼ同じ意味ですが、式として記述しやすいという特徴があります。
代入表現の中で活用する例
# if文の条件や他の式の中で |= を使う例
config = {"mode": "dev"}
extra = {"debug": True}
if (config := config | extra): # 代入式(walrus)と組み合わせた例
print(config){'mode': 'dev', 'debug': True}このように、式コンテキストで辞書マージを行いたい場合に|や|=は有効です。
+= と |・|= の違いと使い分けのポイント
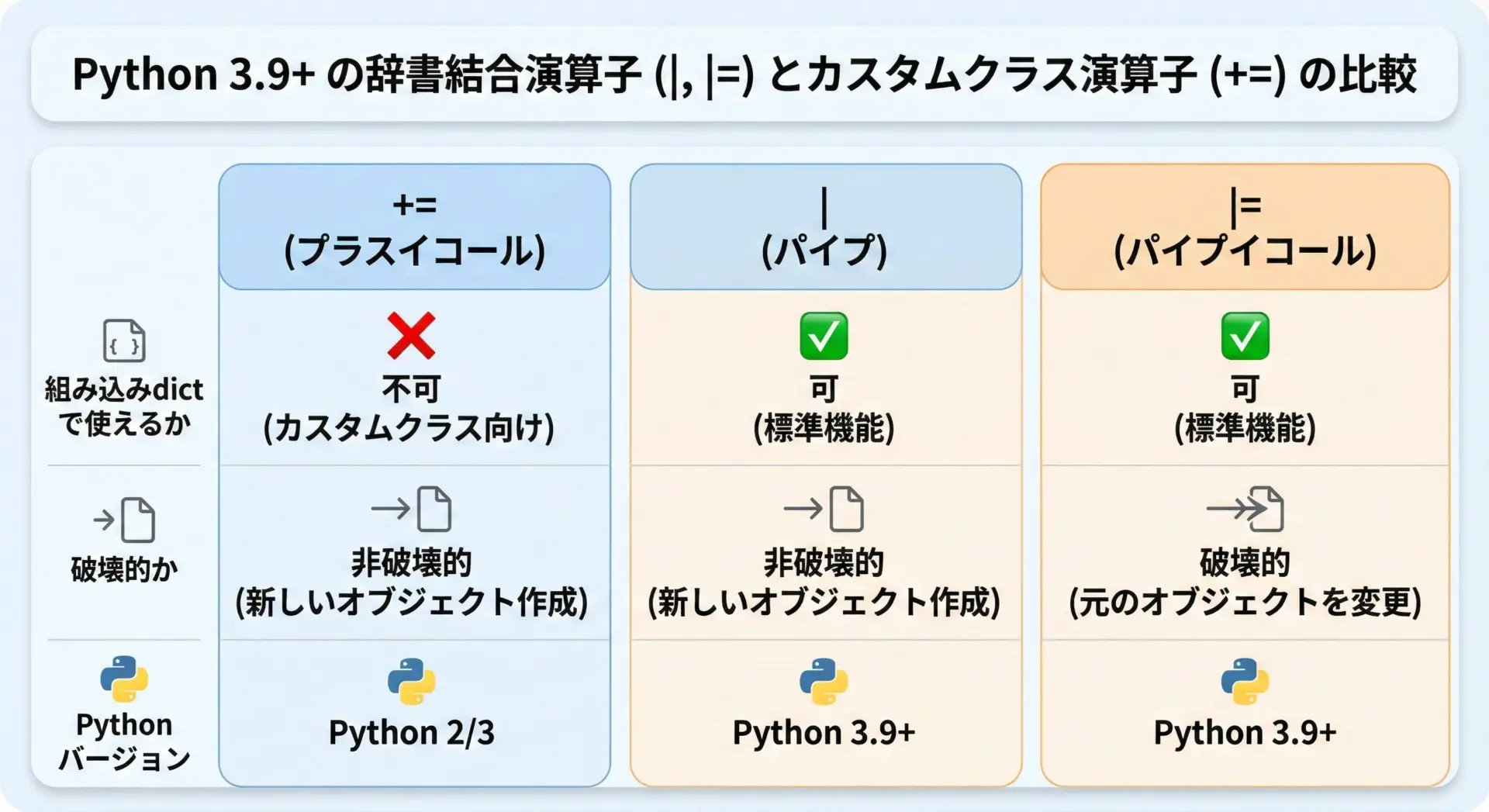
ここまでの内容を踏まえ、辞書マージに関する+=と|・|=の違いを整理します。
以下のように考えるとわかりやすくなります。
+=- 組み込みの
dictでは利用不可(TypeError) - ユーザー定義クラスでオーバーロードして使うためのもの
- 通常の辞書マージでは、あえて使う必要はほとんどありません
- 組み込みの
|- Python 3.9+ で利用可能
- 非破壊的マージ(新しい辞書を返す)
- 「元の辞書を変えたくない」ケースに最適
|=- Python 3.9+ で利用可能
- 破壊的マージ(左の辞書を書き換える)
- 「その場で辞書を更新して使い続けたい」ケースに向いています
まとめると、通常のコードでは|と|=を使い分け、古いPythonをサポートする必要がある場合にはupdateや{**a, **b}を選ぶのが実践的です。
+=は、特殊なカスタムクラス実装時にのみ検討すれば十分です。
辞書マージの実践的な使いどころ
設定ファイル(dict)のマージパターン
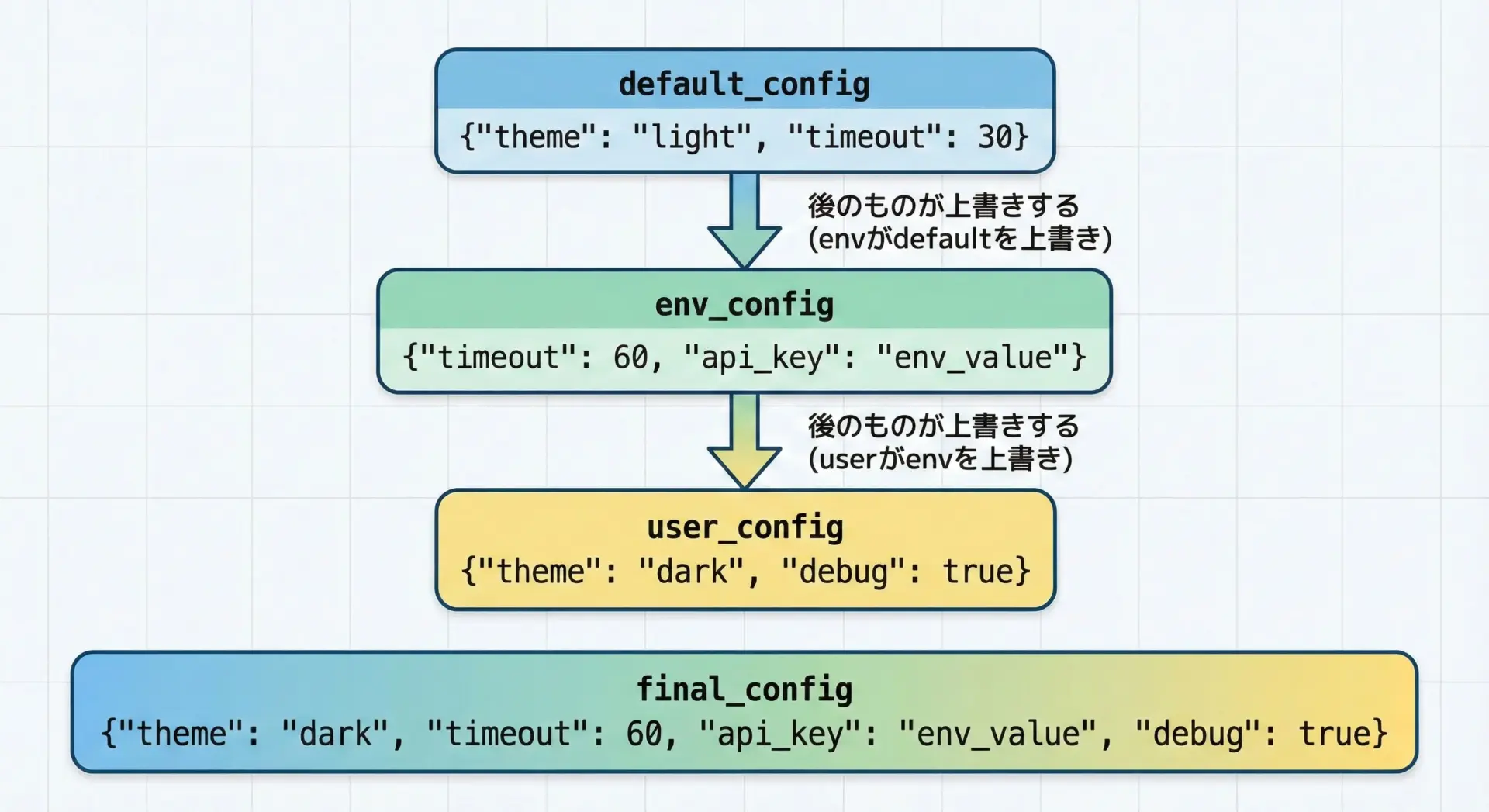
現場のコードで最もよく見かけるのが、設定(config)を辞書で表現し、それを段階的にマージして最終設定を得るパターンです。
例えば、次の3つのレイヤーがあるとします。
default_config: アプリのデフォルト設定env_config: 環境(開発、本番など)ごとの設定user_config: ユーザー指定の上書き設定
Python 3.9+ での書き方例
default_config = {
"timeout": 10,
"retries": 3,
"log_level": "INFO",
}
env_config = {
"log_level": "DEBUG",
}
user_config = {
"timeout": 5,
}
# デフォルト → 環境 → ユーザー の順に、右側が優先される
final_config = default_config | env_config | user_config
print(final_config){'timeout': 5, 'retries': 3, 'log_level': 'DEBUG'}「右に行くほど優先度が高い」というルールにすると、可読性も高く、意図もわかりやすくなります。
古いPythonバージョンでの書き方例
default_config = {
"timeout": 10,
"retries": 3,
"log_level": "INFO",
}
env_config = {"log_level": "DEBUG"}
user_config = {"timeout": 5}
# 辞書アンパック(**)を使う(Python 3.5+)
final_config = {**default_config, **env_config, **user_config}
print(final_config){'timeout': 5, 'retries': 3, 'log_level': 'DEBUG'}もしPython 3.4以下をサポートする必要がある場合は、copy+updateの組み合わせを使います。
final_config = default_config.copy()
final_config.update(env_config)
final_config.update(user_config)
print(final_config){'timeout': 5, 'retries': 3, 'log_level': 'DEBUG'}このように、設定マージでは「どの層がどれを上書きするか」を明確にしておくことが非常に重要です。
ネストした辞書を再帰的にマージする方法
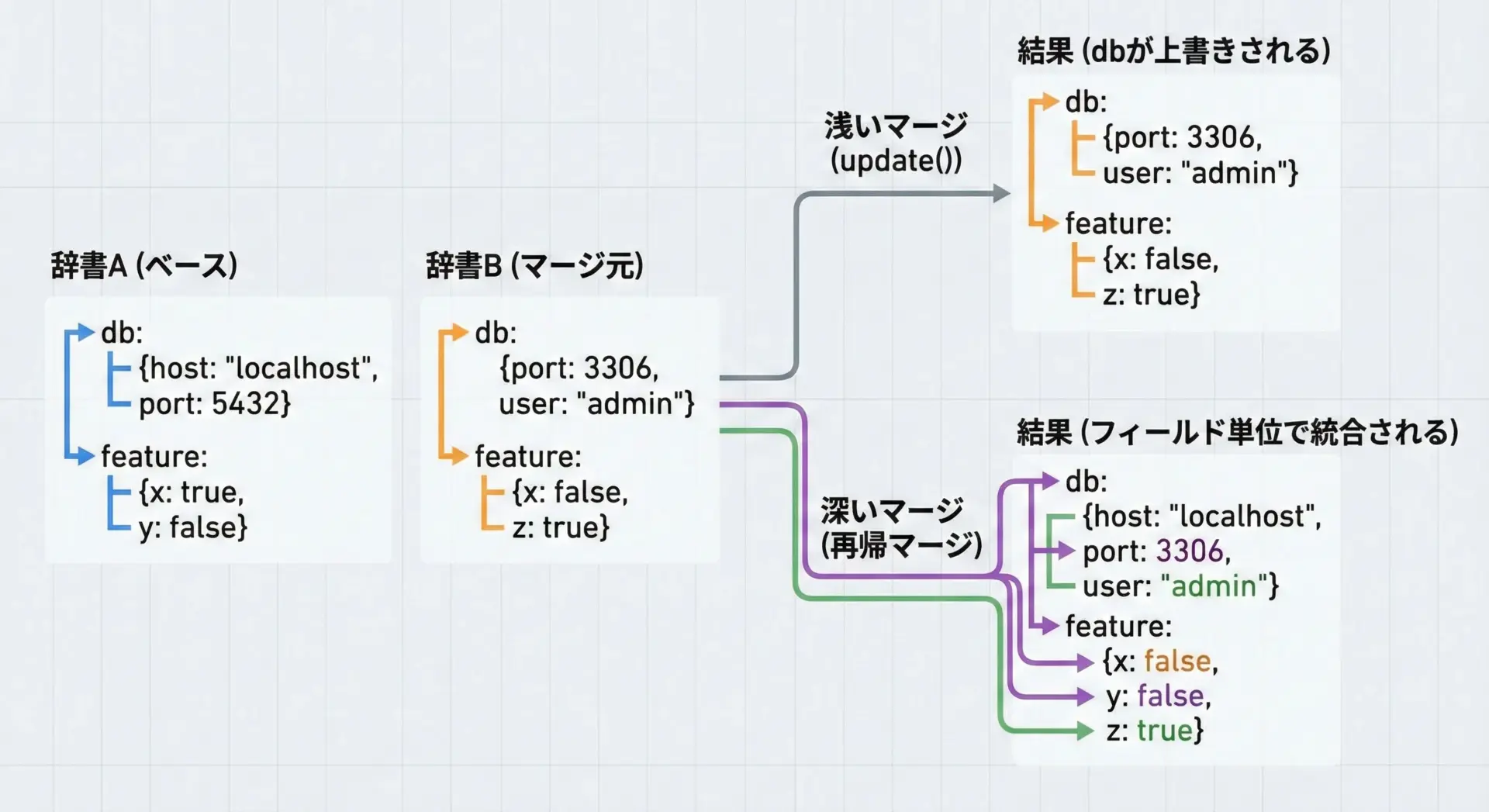
これまで説明してきたupdateや|によるマージは、「浅い」マージです。
つまり、トップレベルのキー単位での上書きしか行いません。
ネストした辞書を扱う場合、「同じキーに辞書が入っているときは、その中身を再帰的にマージしたい」というニーズがよくあります。
浅いマージの問題点
a = {
"db": {"host": "localhost", "port": 5432},
"feature": {"x": True}
}
b = {
"db": {"port": 5433}, # portだけ変えたい
}
# 浅いマージだと db ごと上書きされる
shallow = a | b # または a.update(b)
print(shallow){'db': {'port': 5433}, 'feature': {'x': True}}このように、dbのhost情報が失われてしまうのが浅いマージの問題です。
再帰的(ディープ)マージの実装例
# ネストした辞書を再帰的にマージする関数の例
def deep_merge_dict(dest, src):
"""
destをsrcで再帰的に更新する(破壊的更新)。
同じキーにdict同士が入っている場合は、その中身をマージする。
それ以外の場合はsrcの値で上書きする。
"""
for key, value in src.items():
if (
key in dest
and isinstance(dest[key], dict)
and isinstance(value, dict)
):
# 両方とも辞書なら、さらに内側をマージ
deep_merge_dict(dest[key], value)
else:
# それ以外は上書き
dest[key] = value
return dest
a = {
"db": {"host": "localhost", "port": 5432},
"feature": {"x": True}
}
b = {
"db": {"port": 5433},
"feature": {"y": False}
}
merged = deep_merge_dict(a.copy(), b)
print(merged){'db': {'host': 'localhost', 'port': 5433}, 'feature': {'x': True, 'y': False}}この再帰的マージ(ディープマージ)は、設定ファイルやYAMLなどの複雑な構造をマージするときに非常に役立ちます。
ただし、挙動を明確にドキュメント化しておかないと、想定外の上書きが起きたときに原因がわかりにくくなる点には注意が必要です。
パフォーマンスと可読性で選ぶ辞書結合テクニック
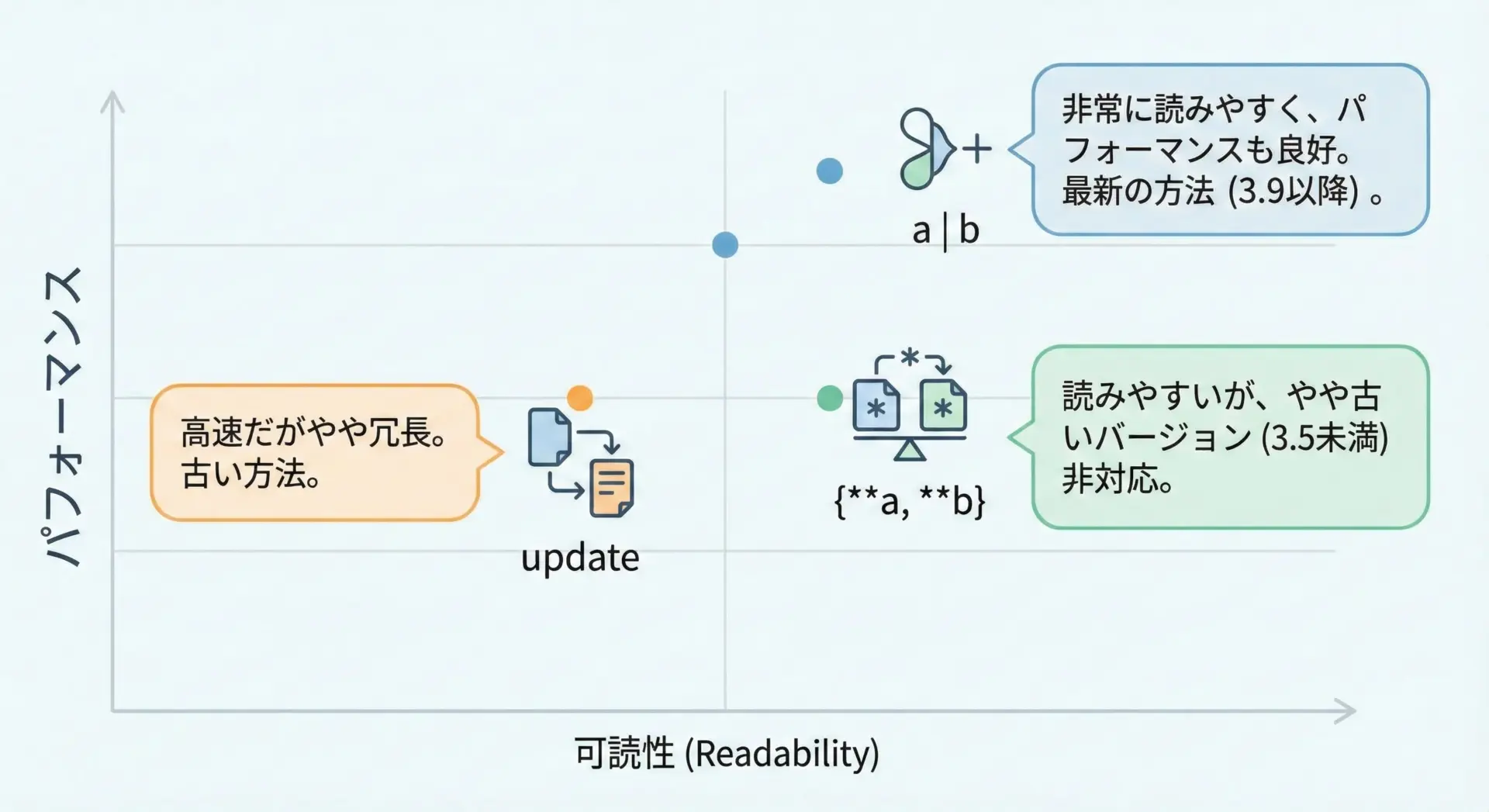
辞書結合の方法はいくつもありますが、実際の選択では「パフォーマンス」と「可読性」のバランスが重要になります。
また、サポートするPythonバージョンも大きな要素です。
代表的な方法の整理
下表は、よく使われる方法の特徴を比較したものです。
| 方法 | 特徴 | 破壊的か | Pythonバージョン目安 |
|---|---|---|---|
update | 古くからある基本的な方法 | はい | 2.x 〜 現在 |
copy()+update | 非破壊的に新しい辞書を得られる | いいえ | 2.x 〜 現在 |
{**a, **b} | 簡潔で読みやすい非破壊的マージ | いいえ | 3.5 〜 現在 |
a | b | 最も直感的な非破壊的マージ (3.9+) | いいえ | 3.9 〜 現在 |
a |= b | 破壊的な更新を式として書ける | はい | 3.9 〜 現在 |
| 再帰的マージ(自作関数) | ネストした構造に対応できる | 実装次第 | 実装次第(関数なので任意) |
実務での選び方の指針
- Python 3.9+ が前提のプロジェクト
- 非破壊的マージなら
a | b - 破壊的マージなら
a |= b
を第一候補にすると、コードが読みやすくなります。
- 非破壊的マージなら
- Python 3.5〜3.8 を含むプロジェクト
{**a, **b}を優先し、必要に応じてcopy()+updateを併用します。
- さらに古いバージョンを含む、幅広いサポートが必要なライブラリ
updateとcopy()を基本とし、ネストマージが必要なら専用のヘルパー関数を用意するのが堅実です。
パフォーマンス面では、updateや|=による破壊的更新は、新しい辞書を毎回生成しないため比較的効率的です。
一方、a | bや{**a, **b}は新しい辞書を作るコストがかかりますが、可読性が高く、安全に扱いやすいという利点があります。
まとめ
Pythonの辞書マージには、dict.updateによる古典的な方法から、{**a, **b}や|・|=といった新しい構文まで、さまざまな手段があります。
重要なのは、「破壊的か非破壊的か」「対応すべきPythonバージョン」「浅いマージか再帰的マージか」を意識して使い分けることです。
設定マージやネストした辞書の扱いなど、実務でよくあるパターンを押さえておけば、辞書結合のコードをより安全かつ読みやすく書けるようになります。
今回紹介したテクニックを、自分のプロジェクトの要件に合わせて選択してみてください。
