
Pythonで大規模なデータ処理やストリーム処理を行う際、メモリを節約しながら柔軟にデータを扱うために不可欠なのがyieldです。
本記事では、yieldの基礎から仕組み、実践的な使い方、注意点やベストプラクティスまでを、サンプルコードと図解を交えながら詳しく解説します。
初心者の方でも、読み終える頃には自分でジェネレータを設計できるレベルを目指します。
Pythonのyieldとは?基本の意味と役割
yieldの基礎概念
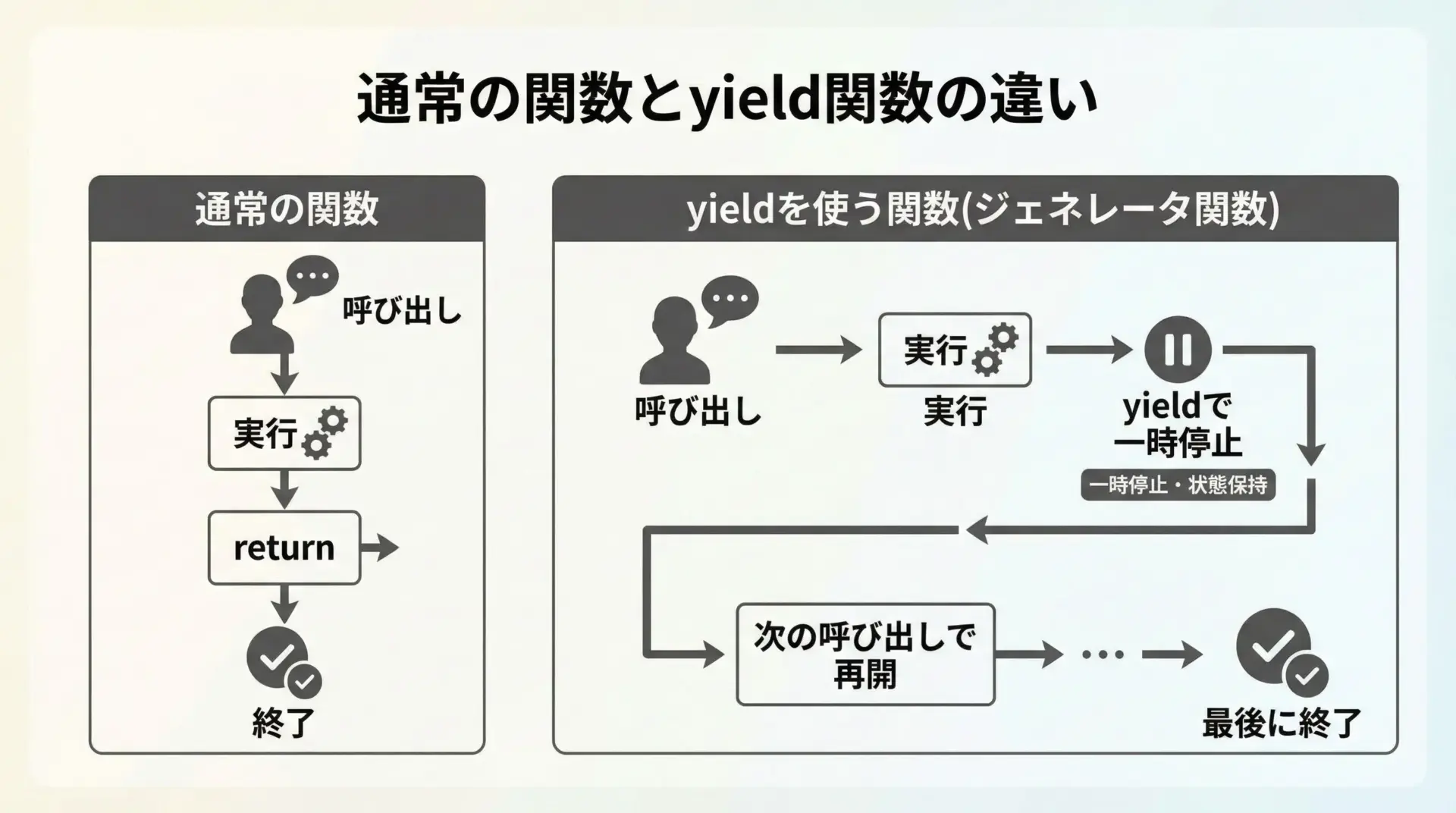
Pythonにおけるyieldは、関数の中で使うキーワードで、「値を返して一時停止する」役割を持ちます。
通常の関数がreturnで値を返すとそこで完全に終了してしまうのに対し、yieldを使う関数は「続きをあとで再開できる関数」になります。
このようにyieldを含む関数のことをジェネレータ関数(generator function)と呼び、その呼び出しによって得られるオブジェクトをジェネレータオブジェクト(generator)と呼びます。
ジェネレータはイテレータの一種であり、for文で繰り返し処理ができるオブジェクトです。
returnとの違い
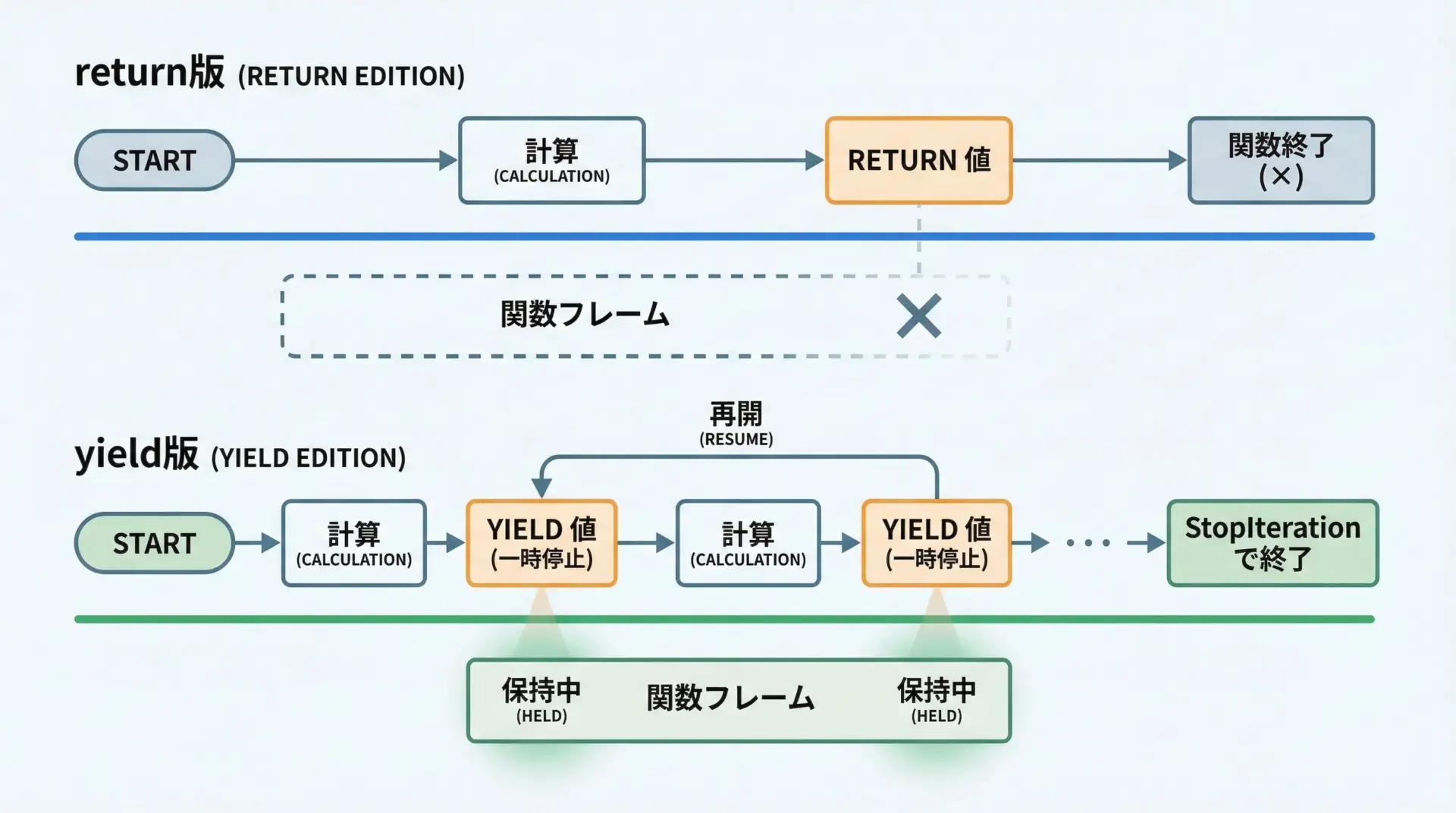
returnとyieldのもっとも大きな違いは、関数のライフサイクルにあります。
return: 値を返した時点で関数は完全に終了し、ローカル変数などの状態は破棄されます。yield: 値を1つ返したあとも関数は終了せず、「どこまで実行したか」と「ローカル変数の状態」を保持したまま一時停止します。
そのため、yieldを1回でも使うと、その関数は「1度に1つずつ値を返しながら、再開可能な処理」として振る舞います。
この性質により、大量データを一括でメモリに載せず、必要な分だけ順番に処理する、といった使い方が可能になります。
Pythonでyieldが使われる典型的な場面
yieldは次のような場面でよく利用されます。
- 大量データやストリームデータの逐次処理(メモリ節約)
- 巨大ファイルの行を1行ずつ処理する
- 無限に続くようなシーケンス(連番、フィボナッチ数列など)の生成
- パイプライン処理(処理ステップを段階的につなぐ)
- コルーチン的な双方向通信(
sendを使う高度なパターン)
このように、yieldは「すべてを一気に用意しないで、必要になったときに順次生成する」スタイルのプログラミングを支える重要な仕組みです。
yieldの仕組みを理解する
generator関数とgeneratorオブジェクトの関係
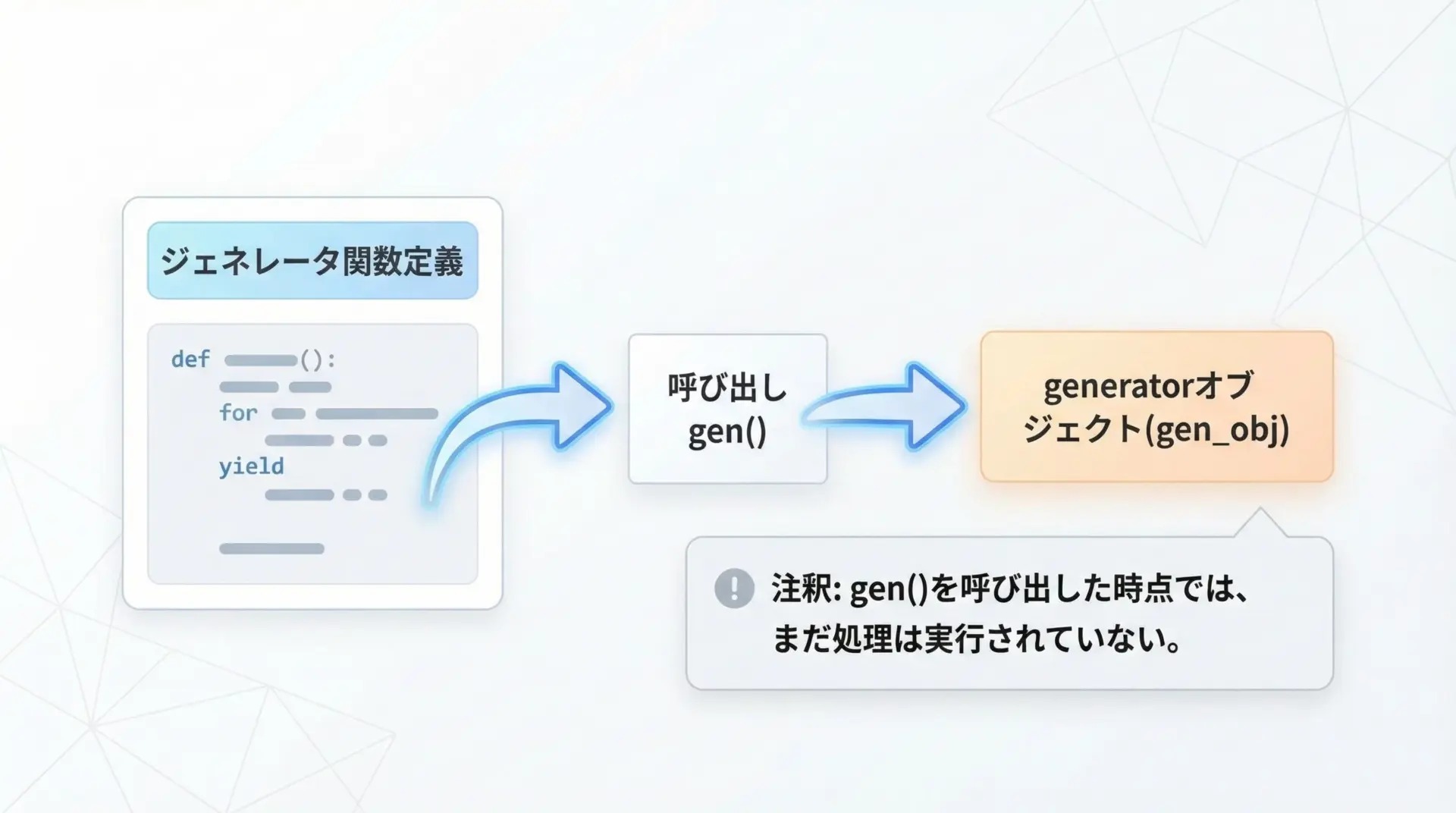
yieldを含む関数を定義しただけでは、まだ何も起きません。
その関数を呼び出したときにジェネレータオブジェクトが生成されます。
def simple_gen():
# 最初に呼び出されたときにここから実行される
yield 1
yield 2
g = simple_gen() # ここではまだ何も実行されない
print(g) # <generator object ...> のような表示このようにsimple_gen()を呼び出すと、通常の関数呼び出しとは異なり、すぐには実行されず、反復処理可能なジェネレータオブジェクトが返される点が重要です。
ジェネレータオブジェクトは、next()関数やfor文から値を1つずつ取り出すと、そのたびに内部の関数が再開され、次のyieldまで進みます。
イテレーションの流れ
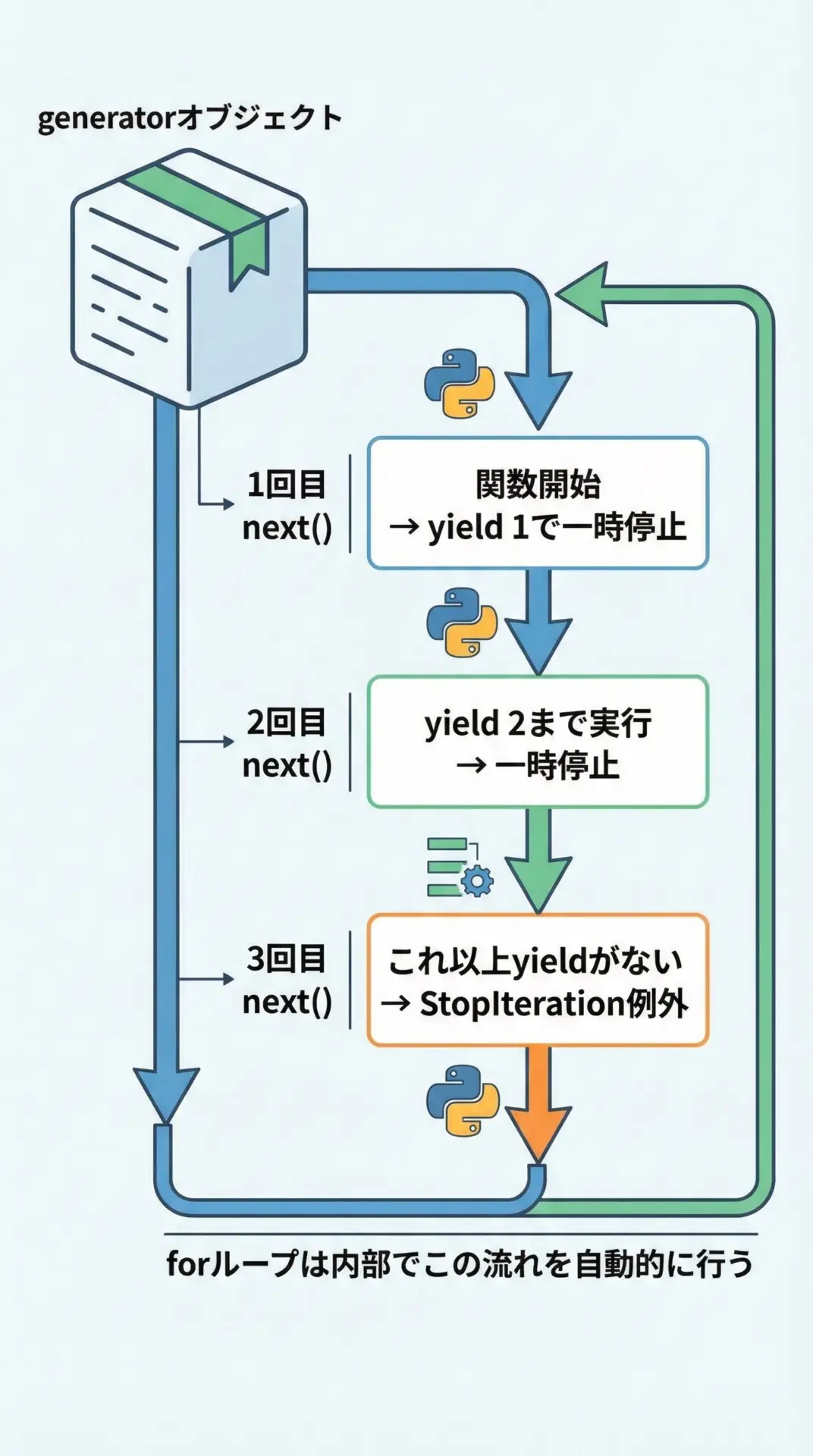
具体的なイテレーションの流れを、簡単なコードで確認します。
def simple_gen():
print("start")
yield 1
print("between")
yield 2
print("end")
# ジェネレータオブジェクトを作成
g = simple_gen()
print("first next()")
print(next(g)) # 1つ目のyieldまで実行
print("second next()")
print(next(g)) # 2つ目のyieldまで実行
print("third next()")
try:
print(next(g)) # これ以上yieldがないのでStopIteration
except StopIteration:
print("StopIterationが発生しました")first next()
start
1
second next()
between
2
third next()
end
StopIterationが発生しましたこの例からわかるように、next()が呼ばれるたびに、前回のyieldの直後から処理が再開され、次のyieldまで進むことが確認できます。
状態保持の仕組み
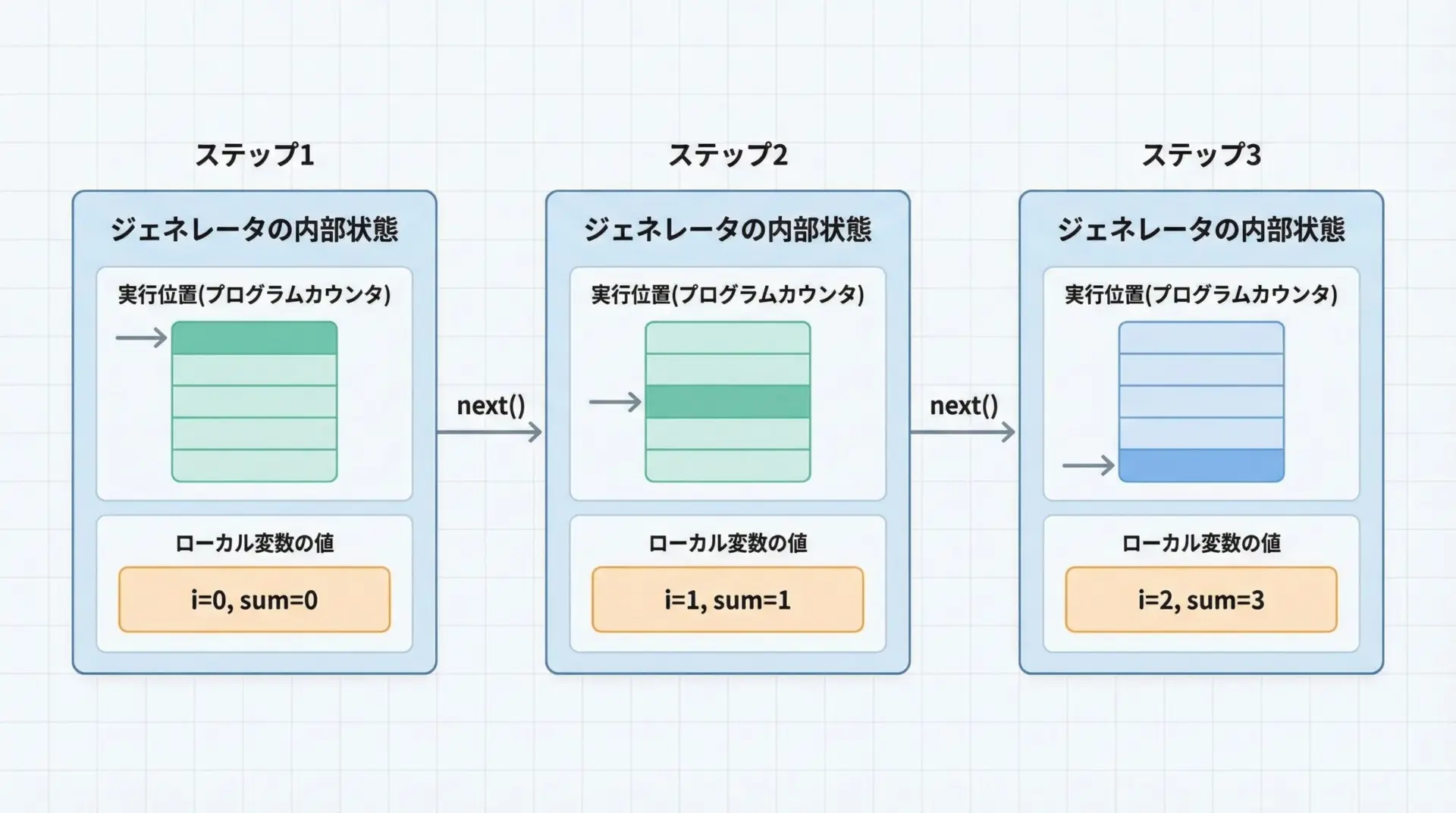
yieldが強力なのは、関数のローカル変数や実行位置が自動的に保存される点です。
開発者が状態管理用のクラスやインデックスを自前で持たなくても、言語機能として状態保持をしてくれます。
def counter():
n = 0 # このローカル変数nの値が、yieldのたびに保持される
while n < 3:
yield n
n += 1 # 次回再開時はインクリメントされた値からスタート
c = counter()
print(next(c)) # 0
print(next(c)) # 1
print(next(c)) # 2このコードでは、nが関数内部で更新され続けていますが、その状態はジェネレータオブジェクトに紐づいて保持されています。
同じジェネレータ関数から複数のジェネレータオブジェクトを作れば、それぞれ独立した状態を持つことになります。
for文とyieldの連携
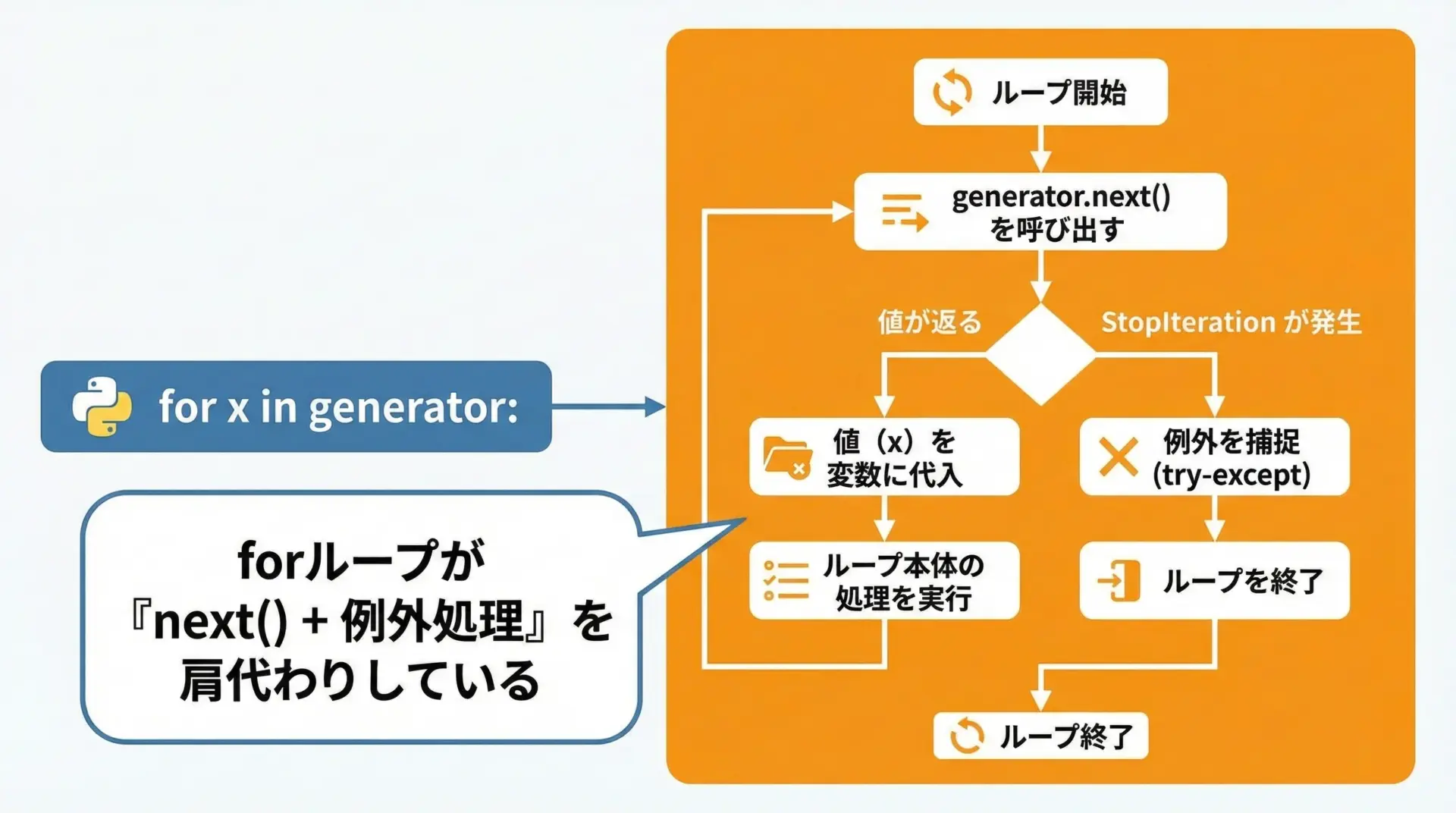
実務でジェネレータを使う場合、ほとんどはfor文と組み合わせます。
for文は、内部で次のような処理を自動的に行っています。
- イテレータ(ジェネレータ)から
next()で値を取得する。 - 取得した値をループ変数に代入して、ループ本体を実行する。
- StopIteration例外が発生したらループを終了する。
def numbers():
print("ジェネレータ開始")
for i in range(3):
print(f"yield前: i = {i}")
yield i
print(f"yield後: i = {i}")
print("ジェネレータ終了")
for x in numbers():
print(f"forループ側: x = {x}")ジェネレータ開始
yield前: i = 0
forループ側: x = 0
yield後: i = 0
yield前: i = 1
forループ側: x = 1
yield後: i = 1
yield前: i = 2
forループ側: x = 2
yield後: i = 2
ジェネレータ終了このように、for文はジェネレータと非常に相性が良く、yieldを使ったコードのほとんどはfor文で消費されると言っても過言ではありません。
yieldの具体的な使い方
シンプルなgenerator関数の例
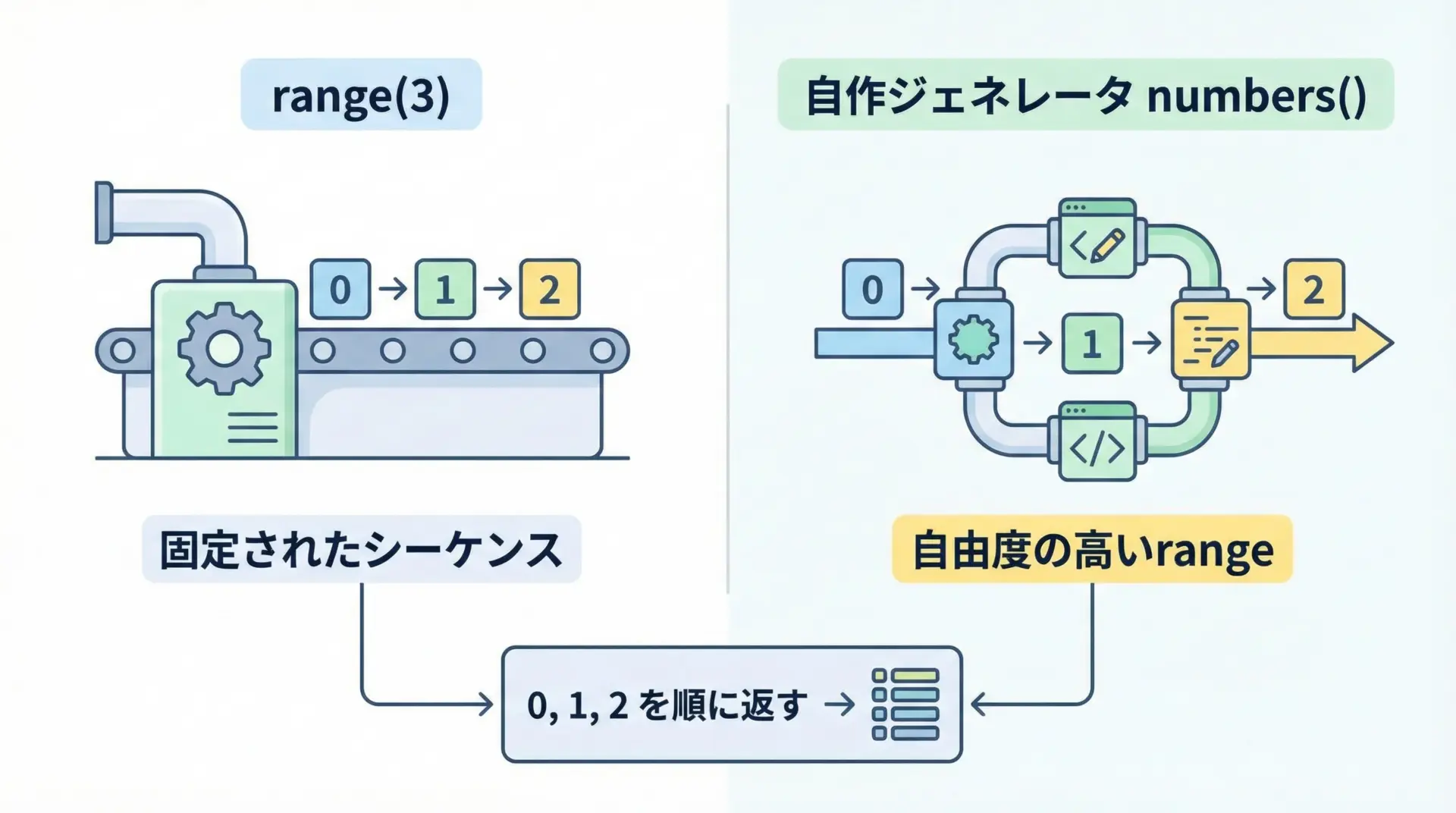
まずは基本形として、簡単なジェネレータ関数をいくつか見ていきます。
def numbers(n):
"""0からn-1までの整数を順番に返すジェネレータ"""
i = 0
while i < n:
# 現在のiを返して、一時停止
yield i
# 次回再開時はここから
i += 1
for x in numbers(5):
print(x)0
1
2
3
4このnumbers()関数は、動作としてはrange()に似ていますが、自分でロジックを組めるため、条件付きのスキップや複雑なフィルタリングを容易に実装できます。
大量データ処理でのyield活用
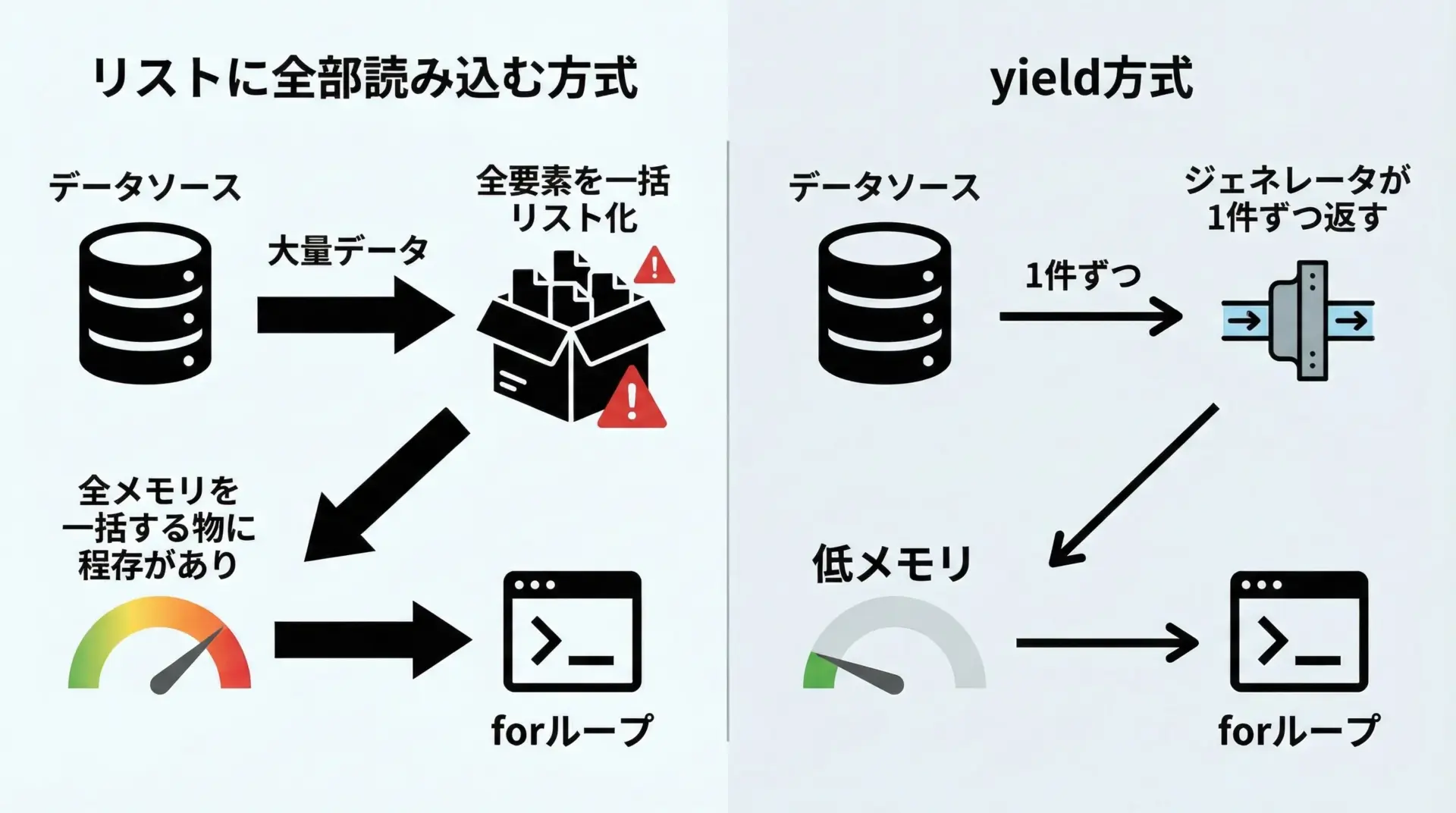
大量データを処理する場合、すべてをリストに格納してから処理すると、メモリを大量に消費してしまいます。
ジェネレータを使えば、必要な分だけ順にデータを生成し、その都度処理していくことができます。
def read_large_dataset():
"""
大量データを想定した疑似ジェネレータ。
実際にはDBや外部API、巨大リストなどから
1件ずつ読み込んでいくイメージです。
"""
for i in range(10**7): # 1,000万件を仮想的に生成
yield {"id": i, "value": i * 2}
def process():
total = 0
# 必要な分だけ1件ずつ取り出して集計する
for record in read_large_dataset():
total += record["value"]
return total
# 実際に実行すると時間はかかりますが、
# メモリを一気に使い切ることはありません。このようにyieldを使うことで、「大きすぎてリストに格納できない」規模のデータでも扱えるようになります。
実務では、ログ解析やストリーム処理などでよく使われるパターンです。
ファイル処理でのyieldの使い方
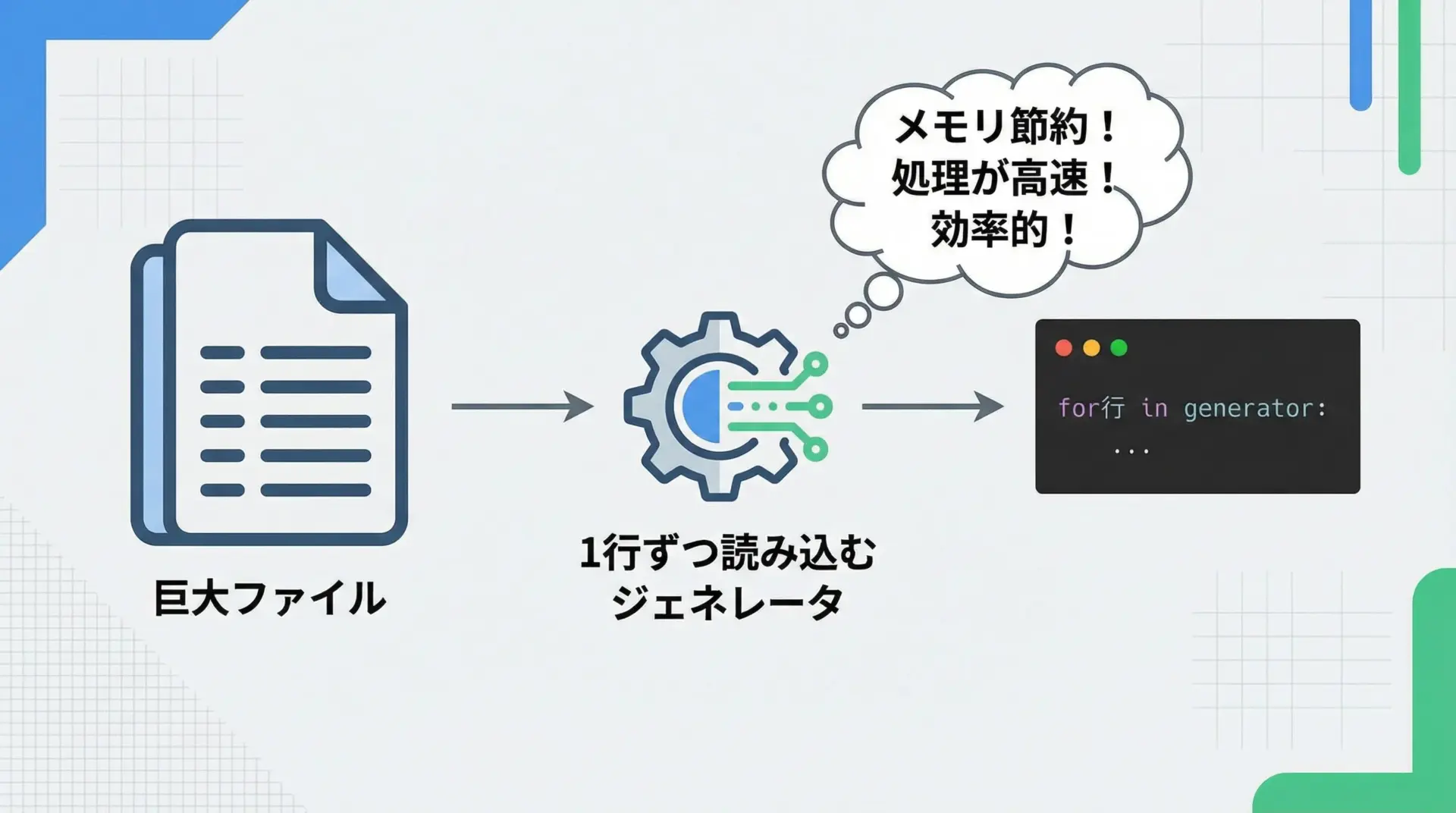
ファイル処理はyieldの典型的な活用例です。
特に大きなテキストファイルを扱う場合、全行をリストに読み込むのではなく、1行ずつジェネレータで処理すると効率的です。
def read_lines(filepath):
"""ファイルを1行ずつyieldするジェネレータ"""
with open(filepath, encoding="utf-8") as f:
for line in f:
# strip()で改行を取り除いて返す
yield line.rstrip("\n")
def count_error_lines(filepath):
"""'ERROR'を含む行数をカウントする例"""
count = 0
for line in read_lines(filepath):
if "ERROR" in line:
count += 1
return count
# 使い方の例
# error_count = count_error_lines("server.log")
# print(error_count)with文の中でyieldして大丈夫なのかと疑問に思うかもしれませんが、ジェネレータが最後まで使い切られ、forループが終わった時点で、ファイルはクローズされます。
途中でループを抜けた場合は注意が必要ですが、Python 3.3以降ではガーベジコレクションやジェネレータクローズ時にファイルが閉じられるよう配慮されています。
より厳密に管理したい場合は、contextlib.contextmanagerを使う方法もあります。
無限シーケンスをyieldで実装する方法
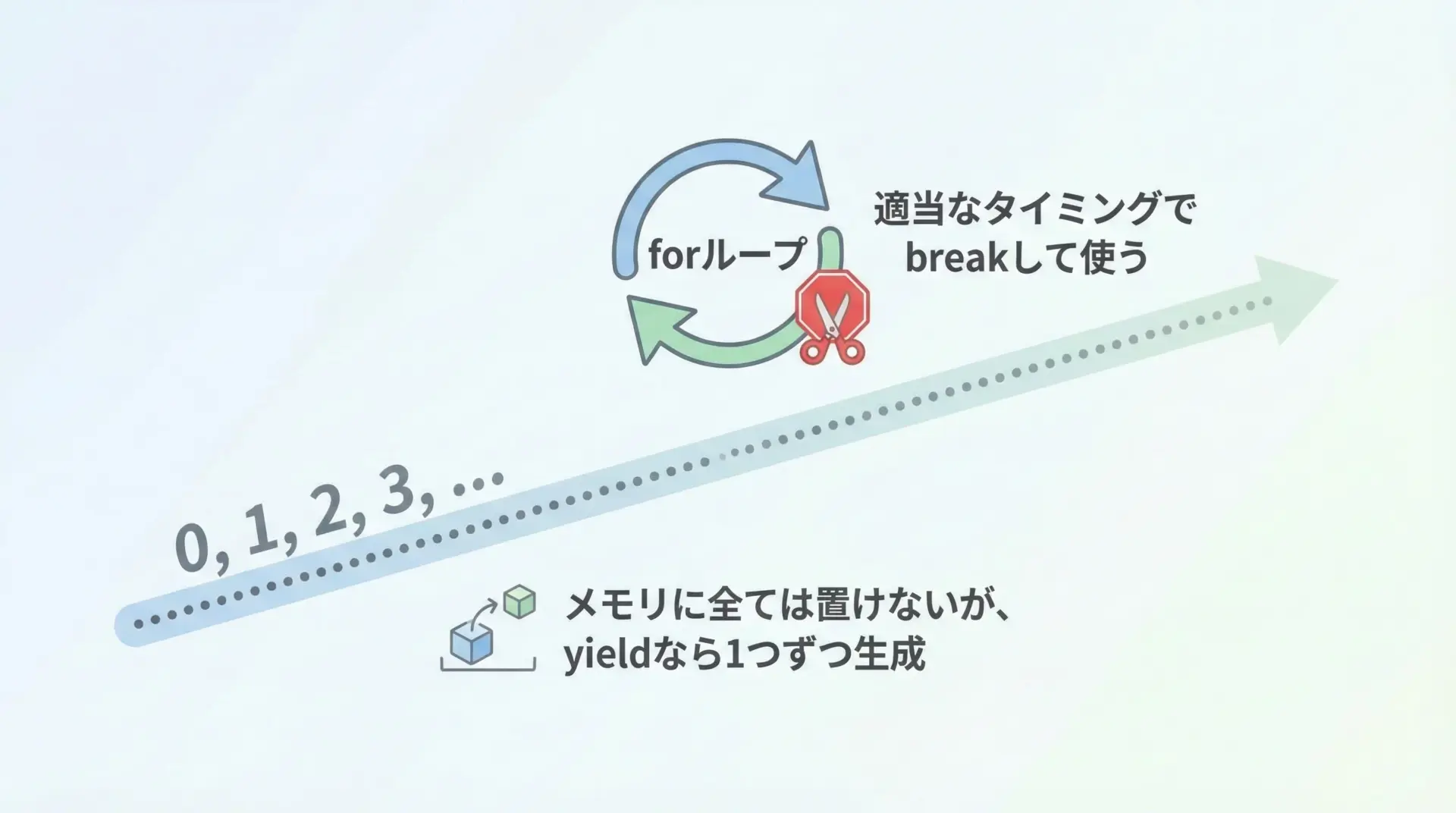
yieldは無限に続くシーケンスにも非常に向いています。
無限リストを作ることはできませんが、ジェネレータなら必要な分だけ取り出せます。
def infinite_counter(start=0, step=1):
"""startからstepずつ増える無限カウンタ"""
n = start
while True: # 無限ループ
yield n
n += step
# 0から2ずつ増えるカウンタから、最初の5個だけ取り出す例
cnt = infinite_counter(start=0, step=2)
for _ in range(5):
print(next(cnt))0
2
4
6
8for文で使う場合は、次のようにbreakで適当なところで抜ける形になります。
for n in infinite_counter():
if n > 10:
break
print(n)このように、「終わりが決まっていないもの」や「理論上無限に続くもの」を表現するのにもyieldは便利です。
複数値をyieldする
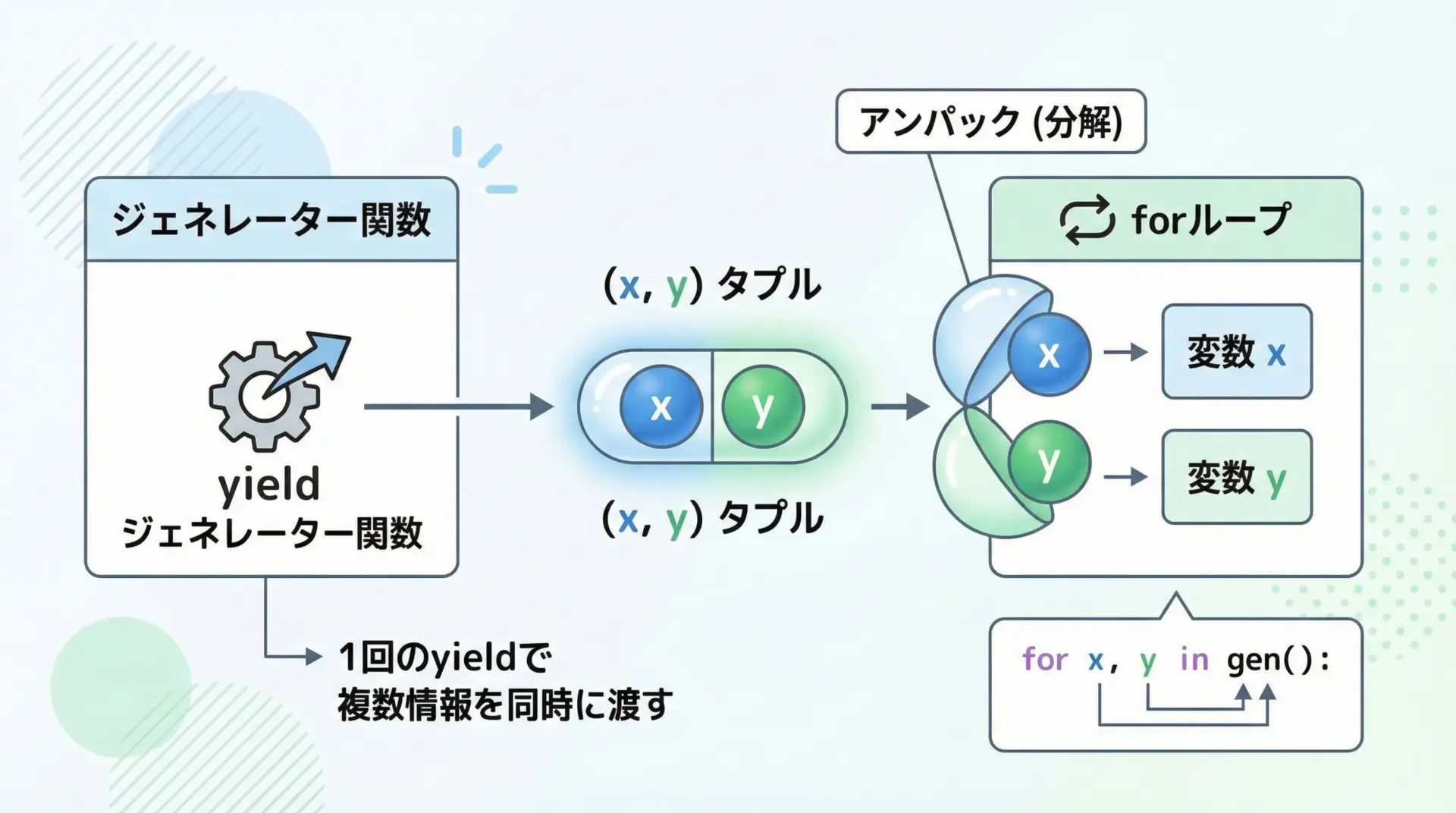
yieldは1つのオブジェクトを返すので、タプルや辞書を返すことで間接的に複数の値を渡せます。
def enumerate_lines(filepath):
"""
ファイルの各行に対して、
(行番号, 行の内容) をyieldする例
"""
with open(filepath, encoding="utf-8") as f:
for lineno, line in enumerate(f, start=1):
# 1回のyieldで2つの情報をまとめて返す
yield lineno, line.rstrip("\n")
# 行番号と内容を同時に受け取る
# for lineno, text in enumerate_lines("sample.txt"):
# print(lineno, text)同様に、辞書を返せば「フィールド名付き」で値を返すこともできます。
def points():
"""2次元座標を連続で返す例"""
for x in range(3):
for y in range(3):
# 辞書で複数の値を返す
yield {"x": x, "y": y}
for p in points():
print(f"({p['x']}, {p['y']})")(0, 0)
(0, 1)
(0, 2)
(1, 0)
(1, 1)
(1, 2)
(2, 0)
(2, 1)
(2, 2)sendを使ったyieldと双方向通信のパターン
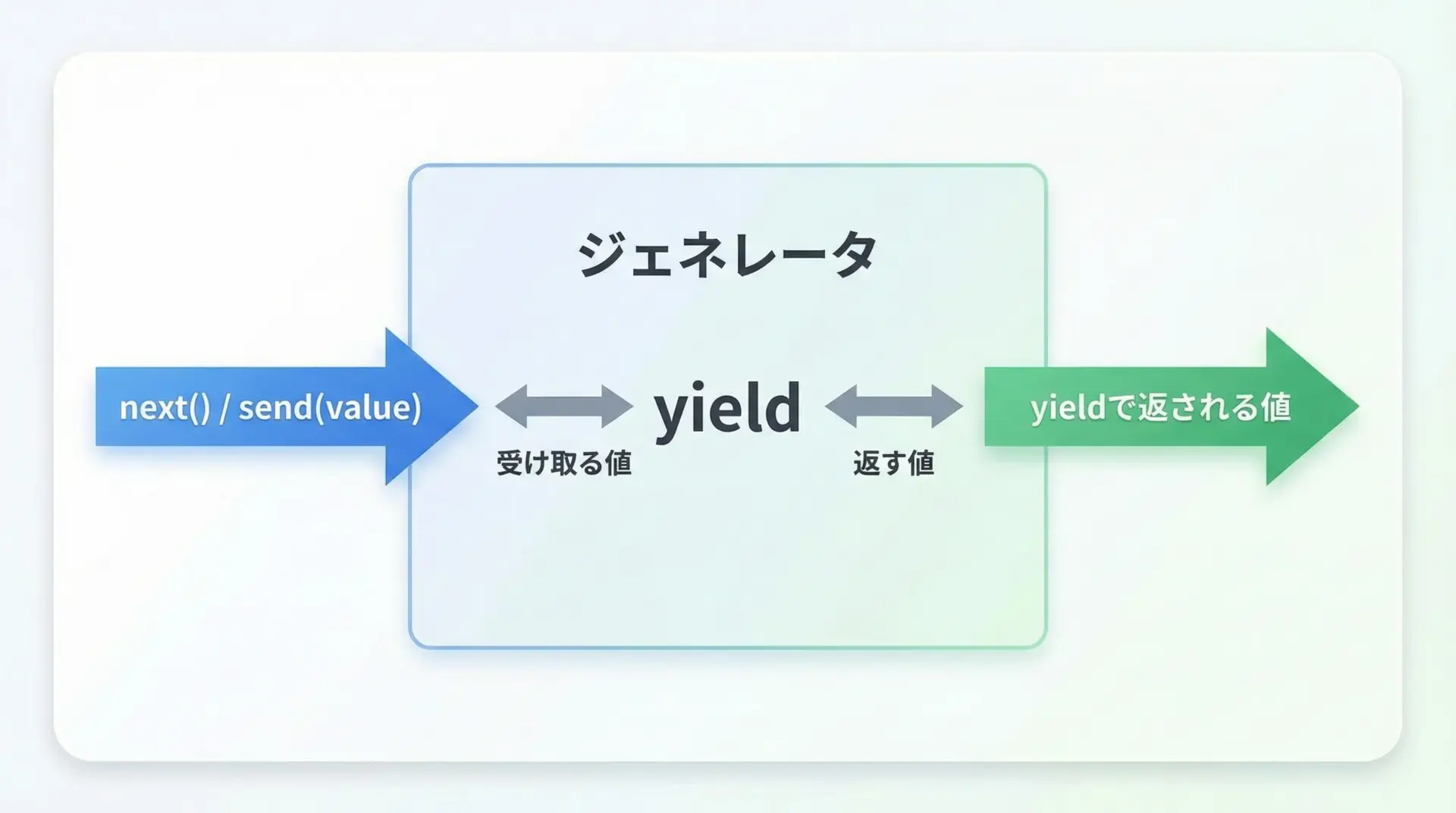
yieldには、send()メソッドを使うことで外部から値を送り込みつつ、内部からも値を返すという、双方向通信のような使い方もあります。
これはやや高度なパターンですが、コルーチン的な処理を書きたいときに便利です。
def accumulator():
"""
外部から送られてきた数値を累積していくコルーチン的ジェネレータ。
初回はnext()で起動し、それ以降はsend(value)で値を送る。
"""
total = 0
while True:
# 外部から値が送られてくるのを待つ
value = yield total # 現在のtotalを返しつつ、一時停止
if value is None:
# Noneが送られたら何もしない
continue
total += value
# ジェネレータを作成
acc = accumulator()
# 最初の起動。最初のyieldまで進める必要があるため、next()を呼ぶ
print(next(acc)) # total = 0 が返る
# ここからsendで値を送り込む
print(acc.send(10)) # total += 10 → 10を返す
print(acc.send(5)) # total += 5 → 15を返す
print(acc.send(-3)) # total += -3 → 12を返す0
10
15
12この例では、yield totalに対してsend(値)を呼ぶことで、value変数に送った値が代入されます。
同時に、yield式自体はtotalを返しているので、外側のコードでは「累計値」を受け取れます。
注意点として、最初にジェネレータを起動する際はnext()を1回呼ぶ必要があることが挙げられます。
初回からsend()を呼ぶと、TypeErrorになります。
yieldを使う際の注意点とベストプラクティス
yieldとreturnの併用時の注意点
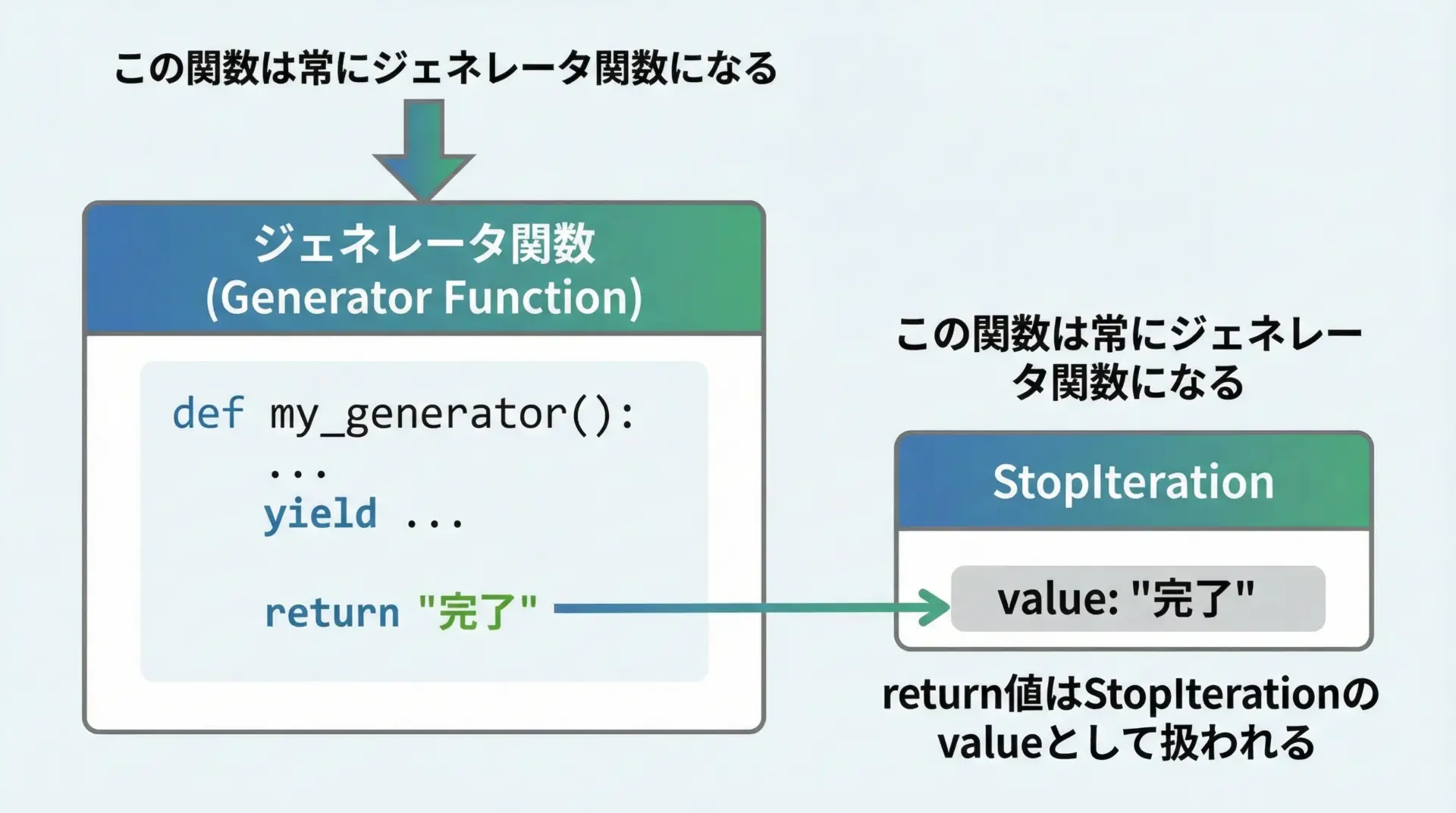
yieldを1つでも含む関数は、必ずジェネレータ関数になります。
そのため、returnの挙動も通常の関数とは少し異なります。
def sample():
yield 1
yield 2
return 999 # ここでジェネレータは終了する
g = sample()
try:
print(next(g)) # 1
print(next(g)) # 2
print(next(g)) # StopIteration
except StopIteration as e:
print("StopIteration.value =", e.value)1
2
StopIteration.value = 999このように、ジェネレータ関数のreturn値は、StopIteration例外のvalueとして内部的に渡される仕組みになっています。
通常はこの値を直接扱うことは少ないですが、yield from構文などでは意味を持ちます。
また、次のようにreturnに値を書かずに使うのは「ジェネレータの終了」を意味します。
def gen():
for i in range(5):
if i == 3:
return # ここで終了
yield iyieldとreturnを混在させると読みづらくなりやすいため、終了目的以外のreturnは避け、最終的な結果は別の方法で返す設計をおすすめします。
例外処理とyield
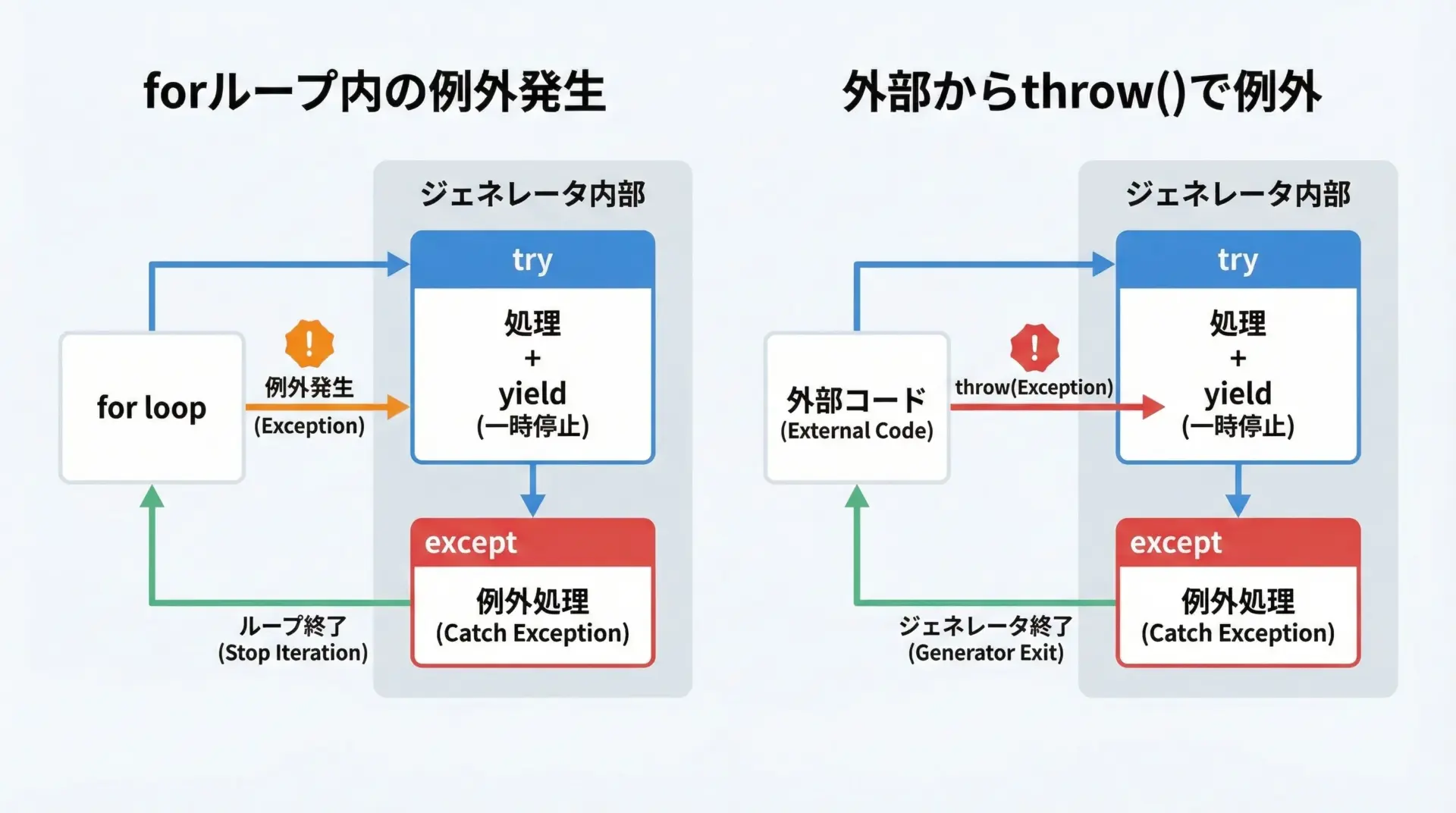
ジェネレータでも通常の関数と同様にtry/except/finallyが使えますが、yieldをまたいだ例外処理については少し意識しておくと安全です。
def safe_divider(numbers, divisor):
"""
0除算を避けつつ、1件ずつ結果をyieldする例。
例外は内部で処理し、ログを出してスキップするイメージ。
"""
for n in numbers:
try:
result = n / divisor
except ZeroDivisionError:
print("0除算が発生しました。値をスキップします。")
continue
else:
yield result
finally:
# 共通後処理がある場合はここに書く
pass
data = [10, 20, 30]
for r in safe_divider(data, 10):
print(r)1.0
2.0
3.0一方、外部からthrow()メソッドを使ってジェネレータに例外を投げ込むこともできますが、かなり特殊な使い方であり、通常の業務コードではあまり多用すべきではありません。
def gen():
try:
while True:
value = yield
print("受信:", value)
except ValueError as e:
print("ジェネレータ内でValueErrorを捕捉:", e)
g = gen()
next(g) # 起動
g.send(1)
g.throw(ValueError("エラー発生"))受信: 1
ジェネレータ内でValueErrorを捕捉: エラー発生このようなパターンは、コルーチン的な高度な制御が必要な場合に限定し、基本的には外側で例外処理を行う方が読みやすいコードになります。
デバッグしづらいyieldコードの避け方
ジェネレータは状態を内部に持つため、制御フローが見えづらく、デバッグが難しくなりがちです。
以下のような工夫で、読みやすくバグの少ないコードを心がけると良いです。
役割ごとに関数を分割する
1つのジェネレータ関数の中にロジックを詰め込みすぎると、どこで何が起きているか把握しづらくなります。
処理を「データ取得」「変換」「フィルタリング」のように分け、複数のジェネレータをパイプライン的につなぐ書き方がおすすめです。
def read_numbers(filepath):
"""ファイルから整数を1行ずつ読み込む"""
with open(filepath) as f:
for line in f:
yield int(line.strip())
def filter_positive(numbers):
"""正の数だけを通す"""
for n in numbers:
if n > 0:
yield n
def square(numbers):
"""2乗する"""
for n in numbers:
yield n * n
# パイプラインとしてつなげて使う
# nums = read_numbers("nums.txt")
# positives = filter_positive(nums)
# squared = square(positives)
# for x in squared:
# print(x)ログやprintでステップを確認する
ジェネレータ内に適宜print()を挿入し、どのタイミングで再開・一時停止しているかを確認すると、挙動がつかみやすくなります。
開発中はloggingモジュールを使って、デバッグログを出すのも有効です。
パフォーマンス観点でのyieldのメリット・デメリット
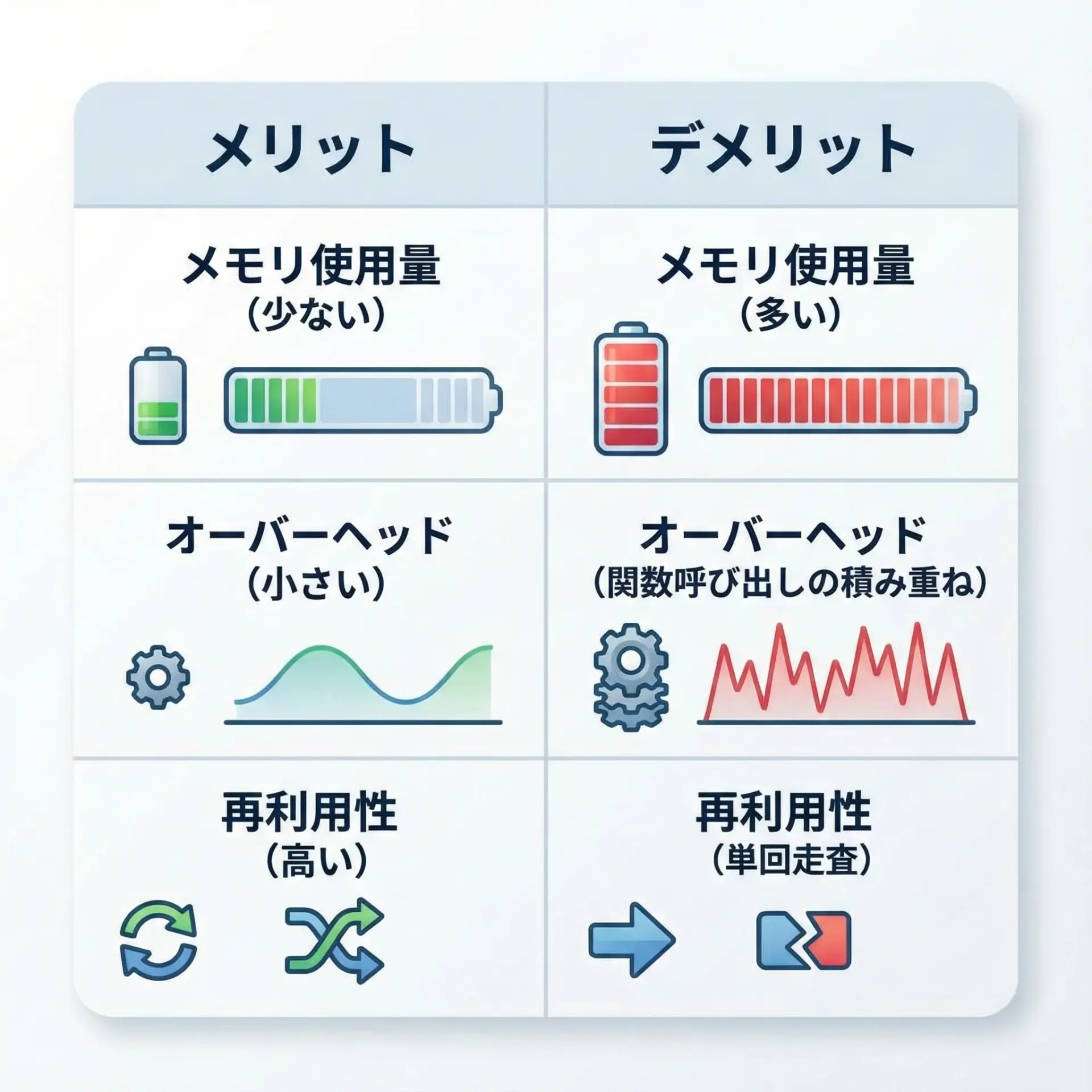
yieldのパフォーマンス面での特徴を整理します。
空行を挟んでから表を挿入します。
| 観点 | yield(ジェネレータ) | リストなどの一括生成 |
|---|---|---|
| メモリ使用量 | 必要な要素だけ保持。非常に少ない | 要素数に比例して増加。大きいデータで問題になりやすい |
| 計算タイミング | 要求されたときにその都度計算(遅延評価) | 作成時に全要素を一気に計算 |
| 処理速度 | 1要素ごとのオーバーヘッドがやや大きい場合もある | 小さなデータでは一括計算の方が速いことが多い |
| 再利用性 | 一度使い切ると再利用不可(再度生成が必要) | リストを何度でも繰り返し走査できる |
| 実装の複雑さ | 状態管理が暗黙でわかりづらくなることも | 単純で理解しやすいことが多い |
大きなデータ・ストリームデータではyieldの利点が非常に大きい一方、小さなデータや単純な処理では、リスト内包表記などの方がわかりやすく、速い場合も多いです。
パフォーマンスだけでなく、コードの読みやすさと保守性も含めて選択することが重要です。
yieldを使うべきケースと使わない方がよいケース
最後に、どのような場面でyieldを積極的に使うべきか、また避けるべきかを整理します。
yieldを使うべきケース
- データ量が大きく、全件をメモリに載せると重い・危険な場合
- ファイル・ネットワーク・DBなどのストリームデータを逐次処理する場合
- 無限シーケンスや、終了条件が外部にあるループを表現したい場合
- 複数の処理ステップをパイプラインのようにつなげたい場合
- 前処理やフィルタを段階的に適用し、遅延評価したい場合
yieldを使わない方がよいケース
- データ量が少なく、単純にリストで扱った方が読みやすい場合
- 一度に全件を必要とし、ランダムアクセスやインデックス指定が必要な場合
- ロジックが複雑で、yieldを使うと制御フローが分かりにくくなる場合
- パフォーマンスよりも実装の簡潔さを優先したい小規模スクリプトの場合
「とりあえず何でもyieldにする」のではなく、データ量・アクセスパターン・可読性を考慮して使い分けることが重要です。
まとめ
yieldは、Pythonでメモリ効率の良い処理やストリーム処理を実現するための強力なキーワードです。
通常の関数を「一時停止・再開可能な関数」に変え、ジェネレータとして1要素ずつ値を返すことで、大量データや無限シーケンスを安全に扱えるようになります。
本記事で紹介した基本的な仕組み、ファイル処理や無限カウンタ、sendを使った双方向通信のパターン、そして注意点やベストプラクティスを押さえておけば、多くの場面でyieldを活用できるはずです。
実際に小さなジェネレータから書いてみて、挙動を体感しながら慣れていくことをおすすめします。
