Pythonの内包表記は便利だとよく聞きますが、いざ辞書内包表記やセット内包表記を見てみると、記号が多くて「ひと目ではよく分からない…」と感じる方が多いです。
本記事では、Python初心者がつまずきやすいポイントに焦点を当てながら、辞書内包表記とセット内包表記を具体的なサンプルコードと図解を使ってやさしく解説します。
辞書内包表記・セット内包表記とは
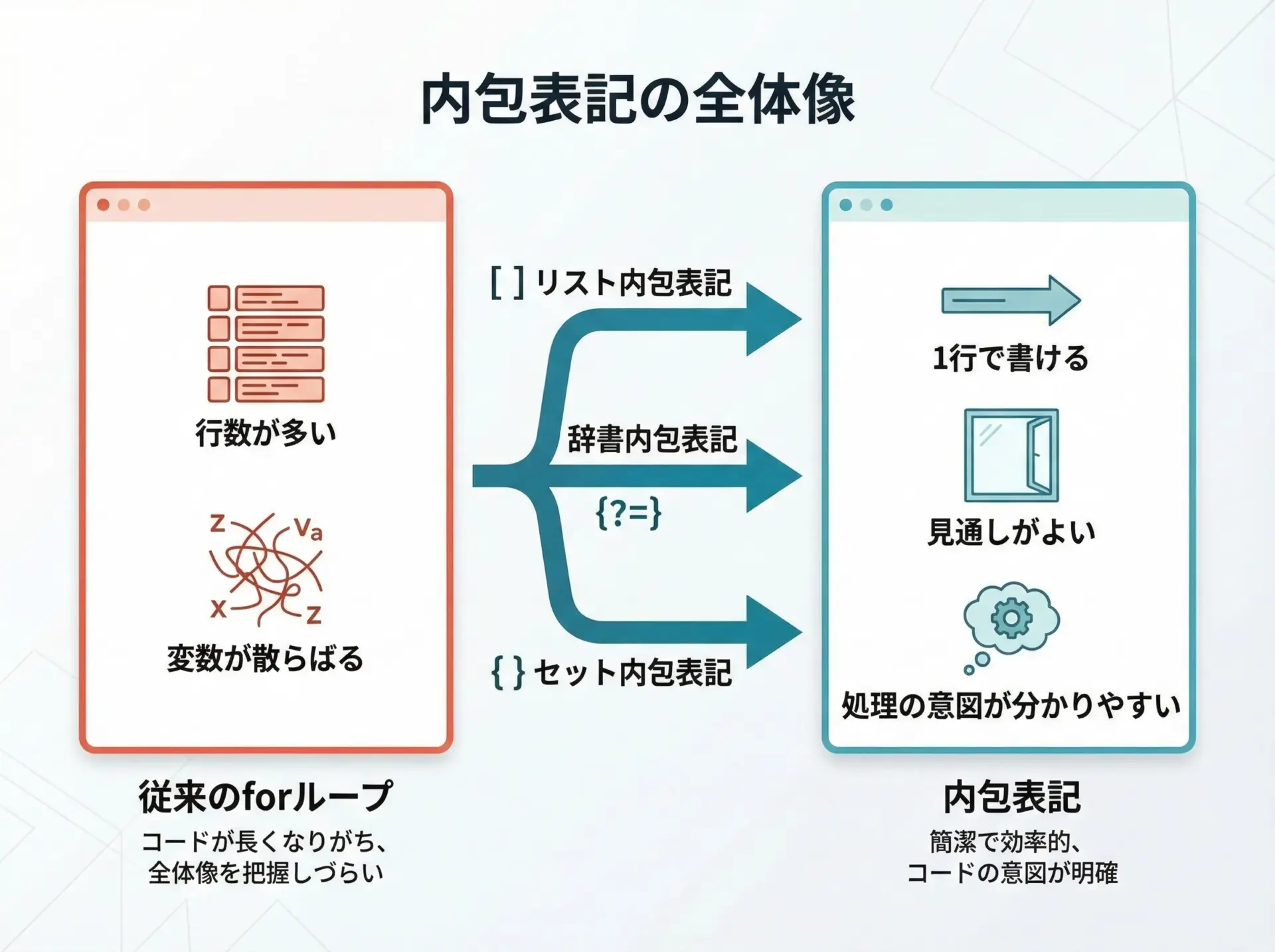
Python内包表記の基本とメリット
Pythonの内包表記(comprehension)とは、リストや辞書、セットなどのコレクションを1行で簡潔に生成するための構文です。
代表的なものとして、次の3種類があります。
- リスト内包表記(list comprehension)
- 辞書内包表記(dict comprehension)
- セット内包表記(set comprehension)
通常のforループと比べたメリットは、主に次の3つです。
1つ目は、コード量を減らせることです。
ループで新しいリストや辞書を作る処理を、1行で表現できることが多くなります。
2つ目は、「何を作っているか」がひと目で分かりやすくなることです。
ループの途中で変数を書き換える形より、「この要素を集めて新しいコレクションを作っている」と意識しやすくなります。
3つ目は、場合によってはパフォーマンスが良くなることです。
特にリスト内包表記は、同じ処理をforループで書くより高速になることが多いです。
リスト内包表記との違い
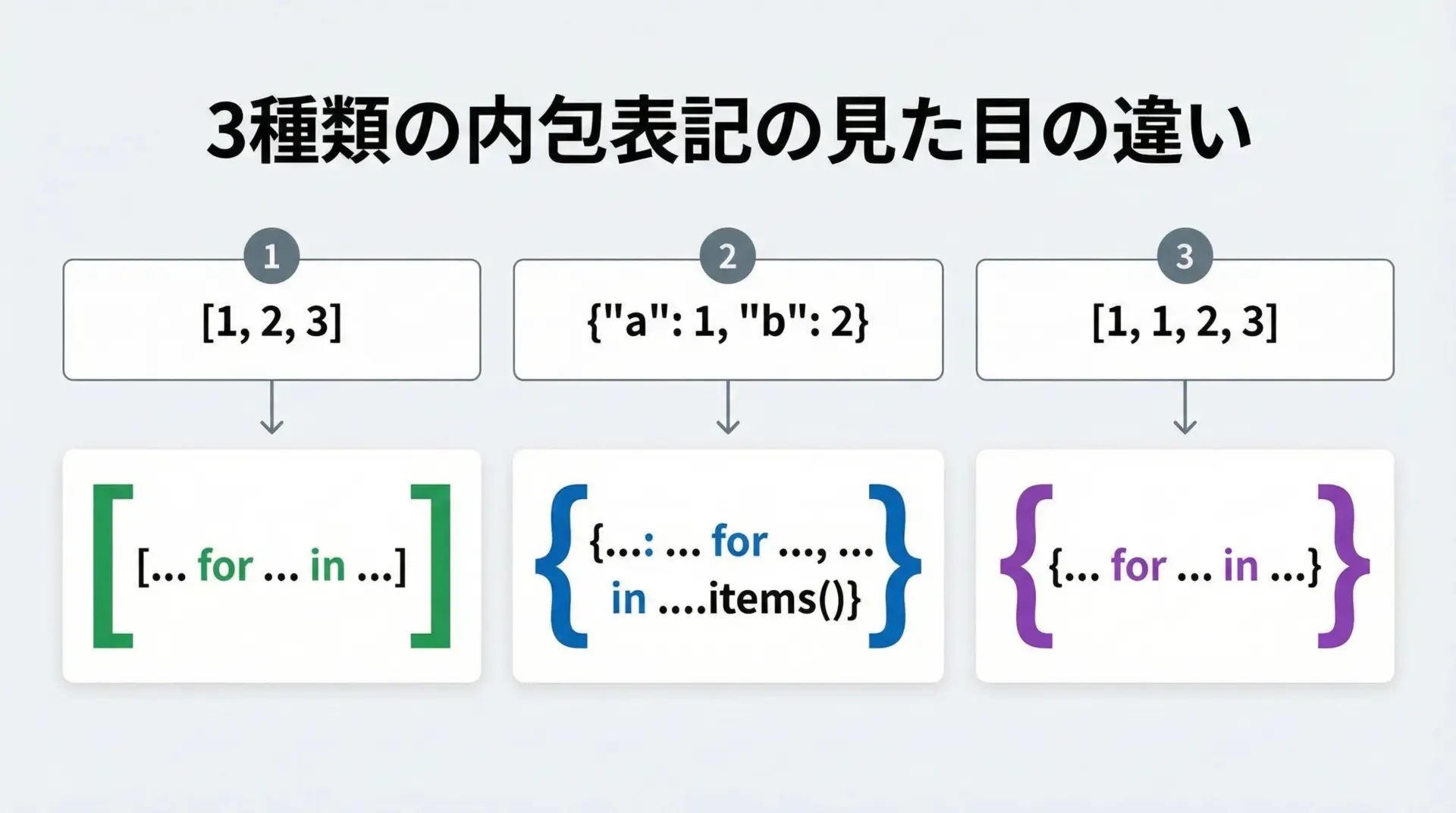
最初に押さえておきたいのは、3種類の内包表記の「かたち」の違いです。
ざっくり比較すると次のようになります。
| 種類 | 使う括弧 | 要素の書き方 | 主な用途 |
|---|---|---|---|
| リスト内包表記 | [] | 値1つ | 順番付きの列を作る |
| セット内包表記 | {} | 値1つ | 重複なしの集合を作る |
| 辞書内包表記 | {} | キー: 値 | キーと値のペアを作る |
見た目の最大の違いは「中に:があるかどうか」です。
{式 for ...}のように:がなければセット内包表記{キー: 値 for ...}のように:があれば辞書内包表記
ここを意識しておくと、後で混乱しにくくなります。
Python初心者がつまずく辞書内包表記
辞書内包表記の基本構文
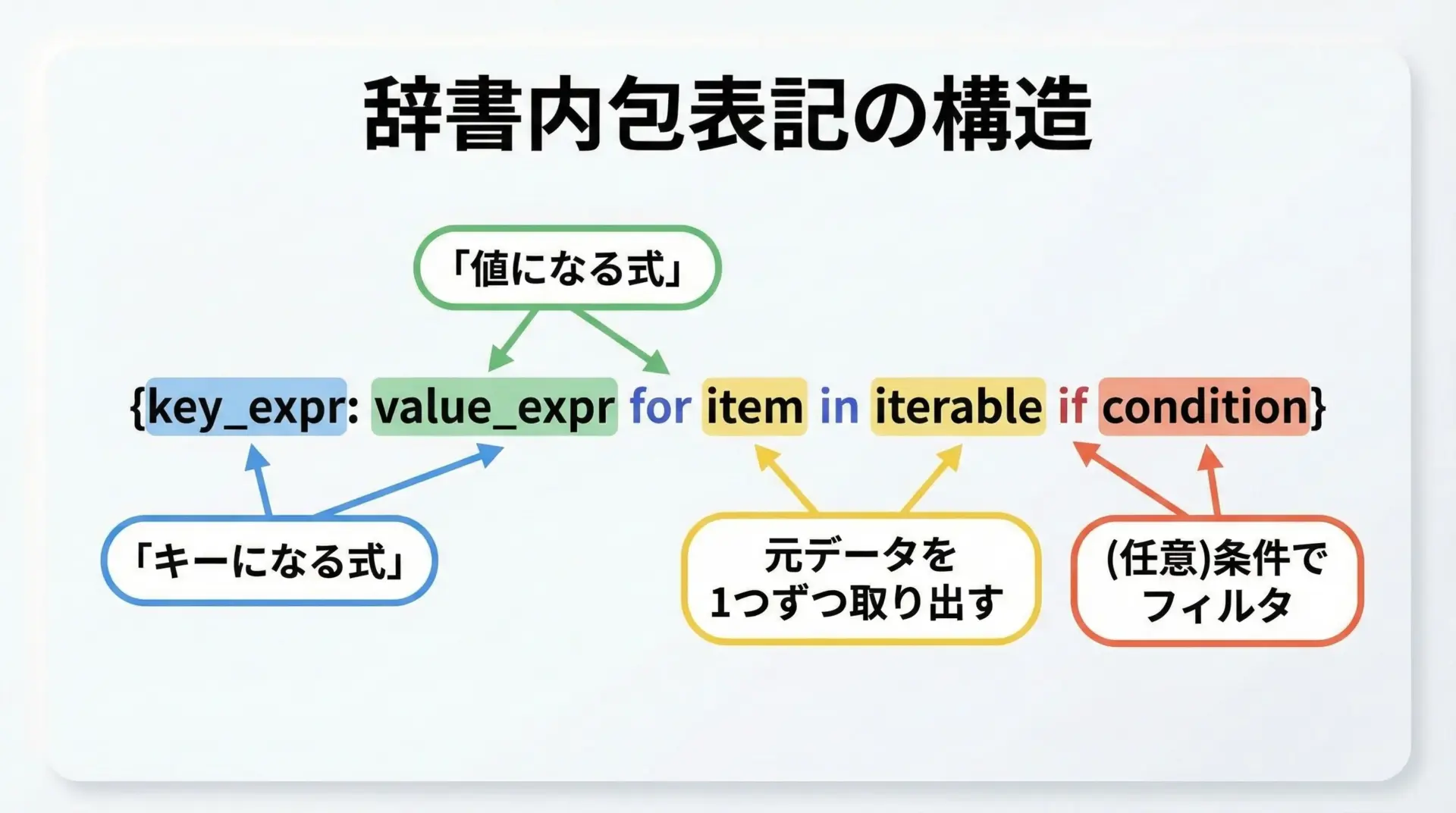
辞書内包表記の基本形は、次のような構文です。
{キーの式: 値の式 for 変数 in イテラブル if 条件}もう少し具体的なコードで見てみます。
# 元のリスト
keys = ["apple", "banana", "orange"]
# 各キーに長さを対応させる辞書を作る
length_dict = {k: len(k) for k in keys}
print(length_dict){'apple': 5, 'banana': 6, 'orange': 6}この例では、キーの式がk、値の式がlen(k)です。
for文はfor k in keysとなり、keysから1つずつ値を取り出して、新しい辞書を作っています。
「どの値をキーにするか」「どの値を値にするか」を意識するのが、辞書内包表記を理解するコツです。
キーと値を入れ替える辞書内包表記の実例
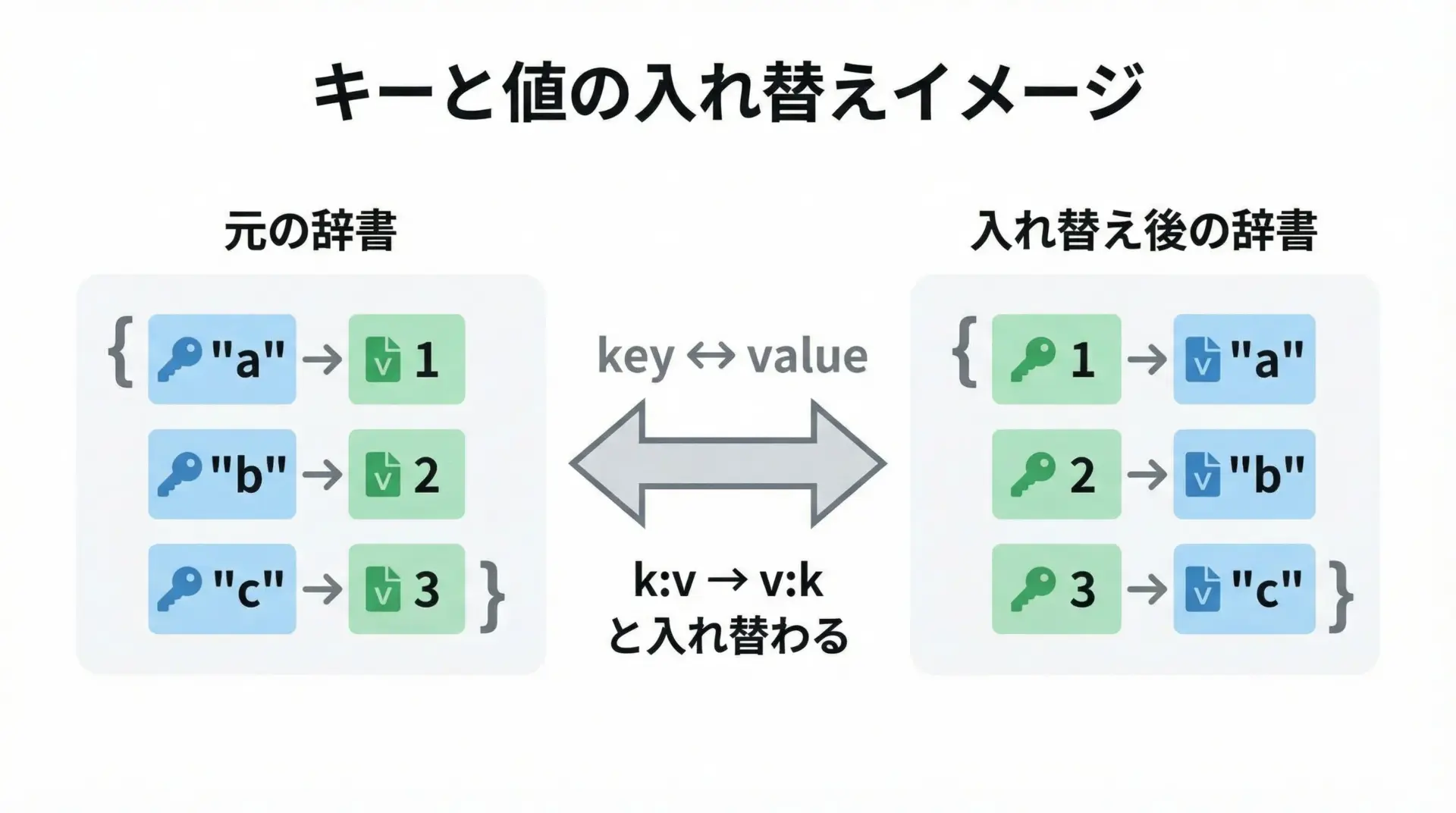
既存の辞書から、キーと値を入れ替えた新しい辞書を作るパターンはよく使われます。
例えば次のようなケースです。
# 元の辞書
eng_to_jp = {
"apple": "りんご",
"banana": "バナナ",
"orange": "オレンジ",
}
# キーと値を入れ替える
jp_to_eng = {jp: eng for eng, jp in eng_to_jp.items()}
print(jp_to_eng){'りんご': 'apple', 'バナナ': 'banana', 'オレンジ': 'orange'}ここでのポイントは2つあります。
1つ目は、for eng, jp in eng_to_jp.items()で、元の辞書から「キーと値のペア」を取り出していることです。
.items()を使うと、(キー, 値)のタプルとして受け取れます。
2つ目は、{jp: eng for eng, jp in ...}のように、内包表記の左側で順番を入れ替えることです。
「.items()で取り出し」「左側のキー:値で並べ替え」という流れを理解しておくと、応用が効くようになります。
なお、元の辞書の値が重複していると、新しい辞書ではキーの重複により情報が失われる可能性があるので注意が必要です。
条件付き辞書内包表記(if文)の書き方

辞書内包表記では、末尾にif 条件を付けることで、要素をフィルタリングできます。
例えばテストの点数から、合格者だけを抽出する場合を考えてみます。
scores = {
"Alice": 85,
"Bob": 62,
"Charlie": 90,
"Dave": 58,
}
# 70点以上だけを取り出す辞書を作る
passed = {name: score for name, score in scores.items() if score >= 70}
print(passed){'Alice': 85, 'Charlie': 90}ここでは、if score >= 70がフィルタ条件です。
辞書内包表記のifは「入れるかどうかを決める条件」であり、値そのものを変えるif式(三項演算子のようなもの)とは違うことに注意します。
値を条件によって変えたい場合は、if ... else ...を値の式側に書きます。
例えば次のようになります。
scores = {
"Alice": 85,
"Bob": 62,
"Charlie": 90,
"Dave": 58,
}
# 合否を文字列で表す辞書を作る
result = {
name: ("pass" if score >= 70 else "fail")
for name, score in scores.items()
}
print(result){'Alice': 'pass', 'Bob': 'fail', 'Charlie': 'pass', 'Dave': 'fail'}このように、「要素を入れるかどうか」を決めるifと、「値をどう計算するか」を決めるifがある点が、少し紛らわしいところです。
ネストしたforで複雑な辞書を作るサンプル
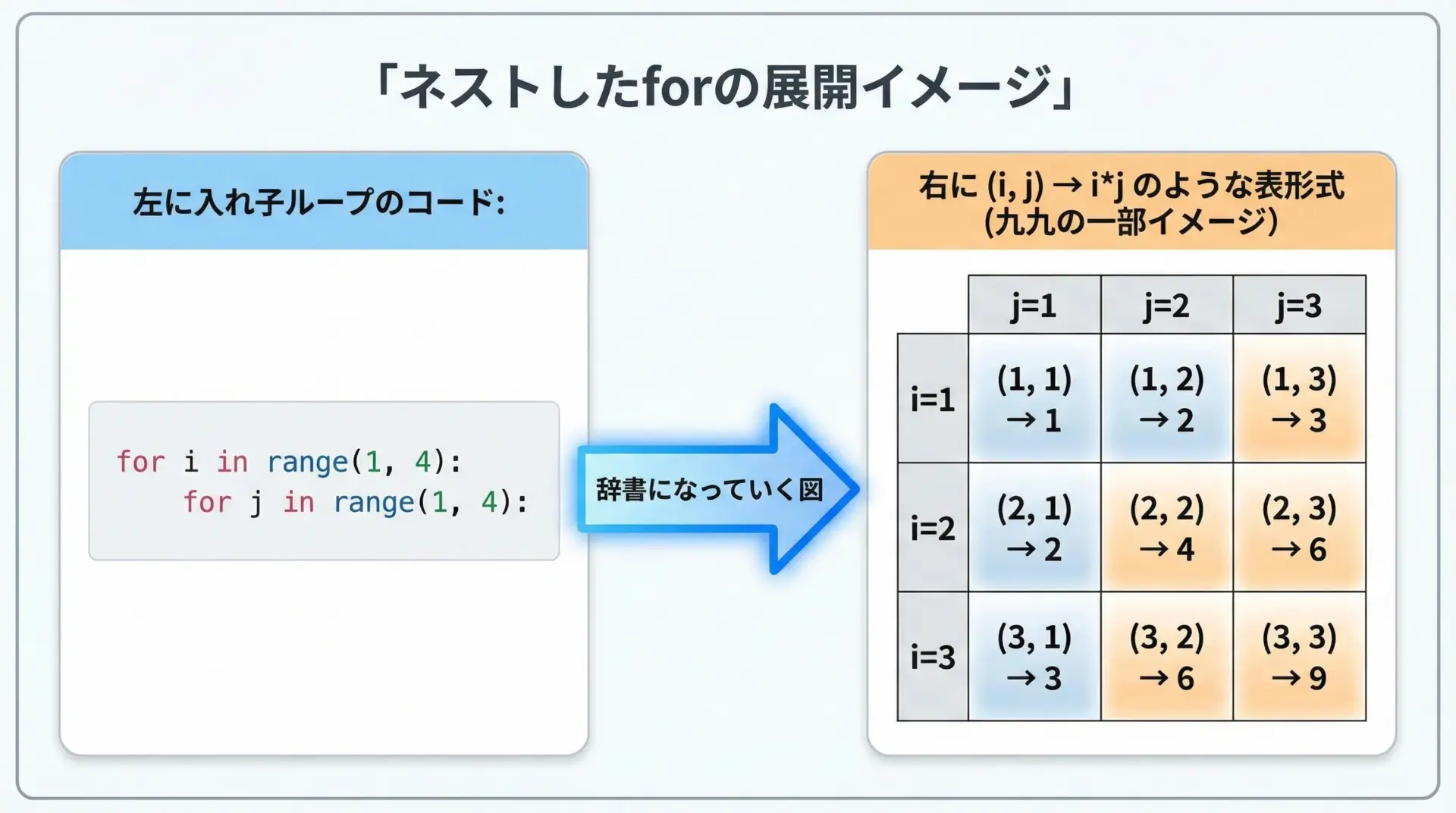
辞書内包表記では、forをネスト(複数並べる)して、少し複雑な辞書を作ることもできます。
例えば、2つのリストの組み合わせに対して値を割り当てるようなケースです。
rows = [1, 2, 3]
cols = [1, 2, 3]
# (行, 列) をキー、行×列を値にした辞書を作る
table = {
(r, c): r * c
for r in rows
for c in cols
}
print(table){(1, 1): 1, (1, 2): 2, (1, 3): 3, (2, 1): 2, (2, 2): 4, (2, 3): 6, (3, 1): 3, (3, 2): 6, (3, 3): 9}ネストしたforの読み方のコツは、「普通のforループに展開してから考える」ことです。
上のコードは、次のように書き換えられます。
rows = [1, 2, 3]
cols = [1, 2, 3]
table = {}
for r in rows:
for c in cols:
table[(r, c)] = r * c
print(table){(1, 1): 1, (1, 2): 2, (1, 3): 3, (2, 1): 2, (2, 2): 4, (2, 3): 6, (3, 1): 3, (3, 2): 6, (3, 3): 9}「forを上から順に読む」「最後のforが一番内側のループ」というルールさえ押さえれば、ネストした辞書内包表記も理解しやすくなります。
辞書内包表記でよくあるエラーと原因
辞書内包表記では、書き方を少し間違えるとエラーになりやすいです。
初心者が特につまずきやすいパターンをいくつか挙げます。
1. コロン:の書き忘れ
# 間違い: コロンがない
# new_dict = {k v for k, v in d.items()}このように{k v for ...}と書いてしまうと、SyntaxErrorになります。
辞書内包表記では、必ずキー: 値の形にする必要があります。
# 正しい書き方
new_dict = {k: v for k, v in {"a": 1, "b": 2}.items()}
print(new_dict){'a': 1, 'b': 2}2. アンパックの数が合わない
d = {"a": 1, "b": 2}
# 間違い: items()を使わず、キーだけ取り出そうとしている
# for k, v in d:
# ...
# 辞書内包表記でも同様のミスをしがち
# new_dict = {k: v for k, v in d}このように、for k, v in dと書くと、ValueError: too many values to unpackのようなエラーになることがあります。
辞書をそのままループするとキーだけが取り出されるため、k, vの2つに分解できないからです。
d = {"a": 1, "b": 2}
# 正しい書き方: .items() で (キー, 値) を取り出す
new_dict = {k: v for k, v in d.items()}
print(new_dict){'a': 1, 'b': 2}3. ifの位置を間違える
d = {"a": 1, "b": 2, "c": 3}
# 間違い: if の位置が不適切
# new_dict = {k: v if v % 2 == 0 for k, v in d.items()}このような書き方は構文エラーになります。
フィルタ用のifはforの後ろに、値を変えるif式は値の式の中に書きます。
d = {"a": 1, "b": 2, "c": 3}
# フィルタ用のif
even_only = {k: v for k, v in d.items() if v % 2 == 0}
# 値を変えるif式
even_or_odd = {k: ("even" if v % 2 == 0 else "odd") for k, v in d.items()}
print(even_only)
print(even_or_odd){'b': 2}
{'a': 'odd', 'b': 'even', 'c': 'odd'}Python初心者がつまずくセット内包表記
セット内包表記の基本構文
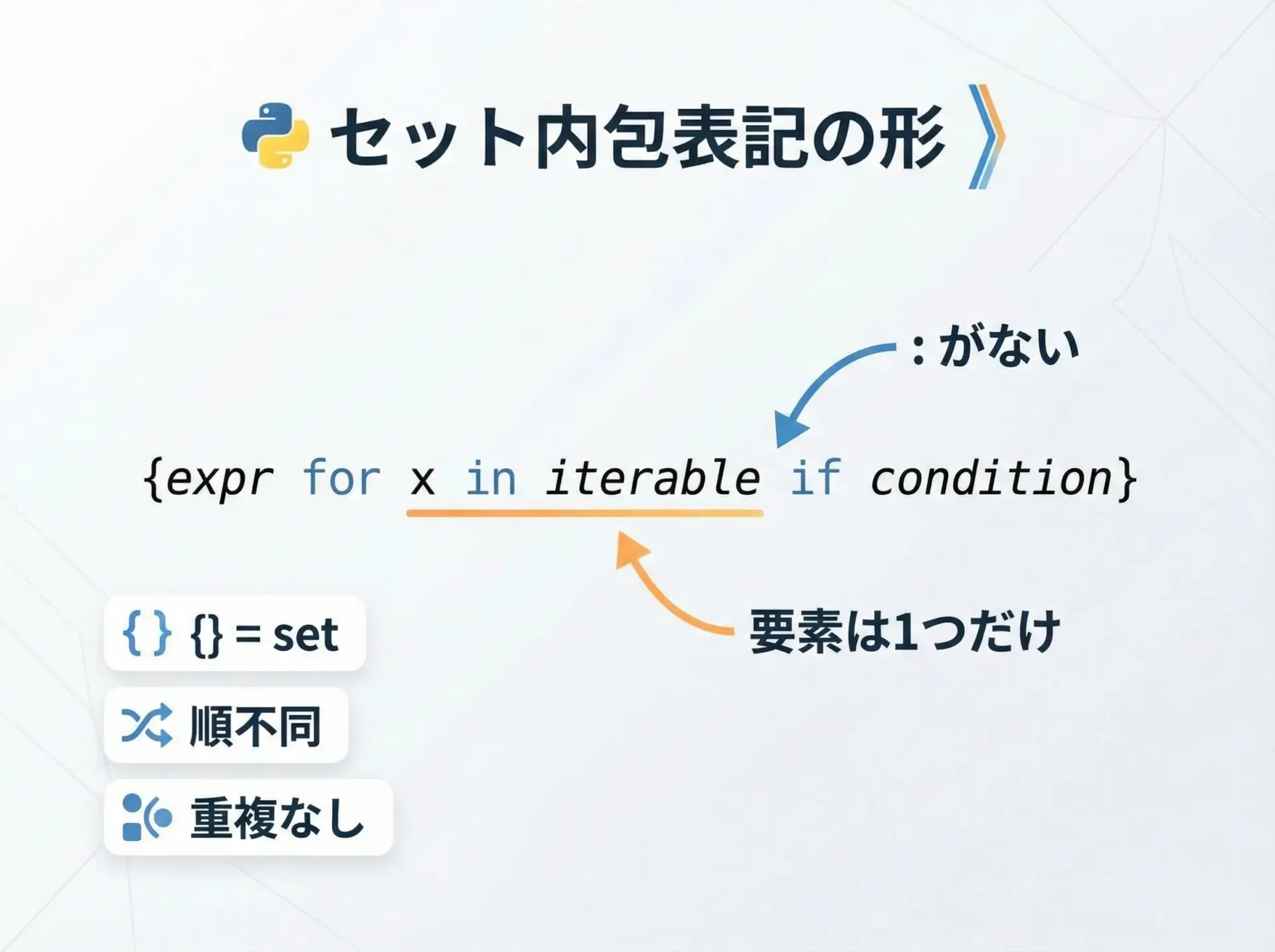
セット内包表記の基本形は、次のような構文です。
{値の式 for 変数 in イテラブル if 条件}辞書内包表記と似ていますが、中に:が存在しない点が決定的に違います。
セットは「重複のない要素の集まり」なので、キーや値ではなく、「1種類の値」だけを扱います。
簡単な例を見てみます。
nums = [1, 2, 2, 3, 3, 3]
# 2乗した結果の集合を作る
squares = {n ** 2 for n in nums}
print(squares){1, 4, 9}元のリストには重複がありますが、セット内包表記で作られたsquaresは重複を自動的に取り除いた集合になります。
重複除去で力を発揮するセット内包表記の実例
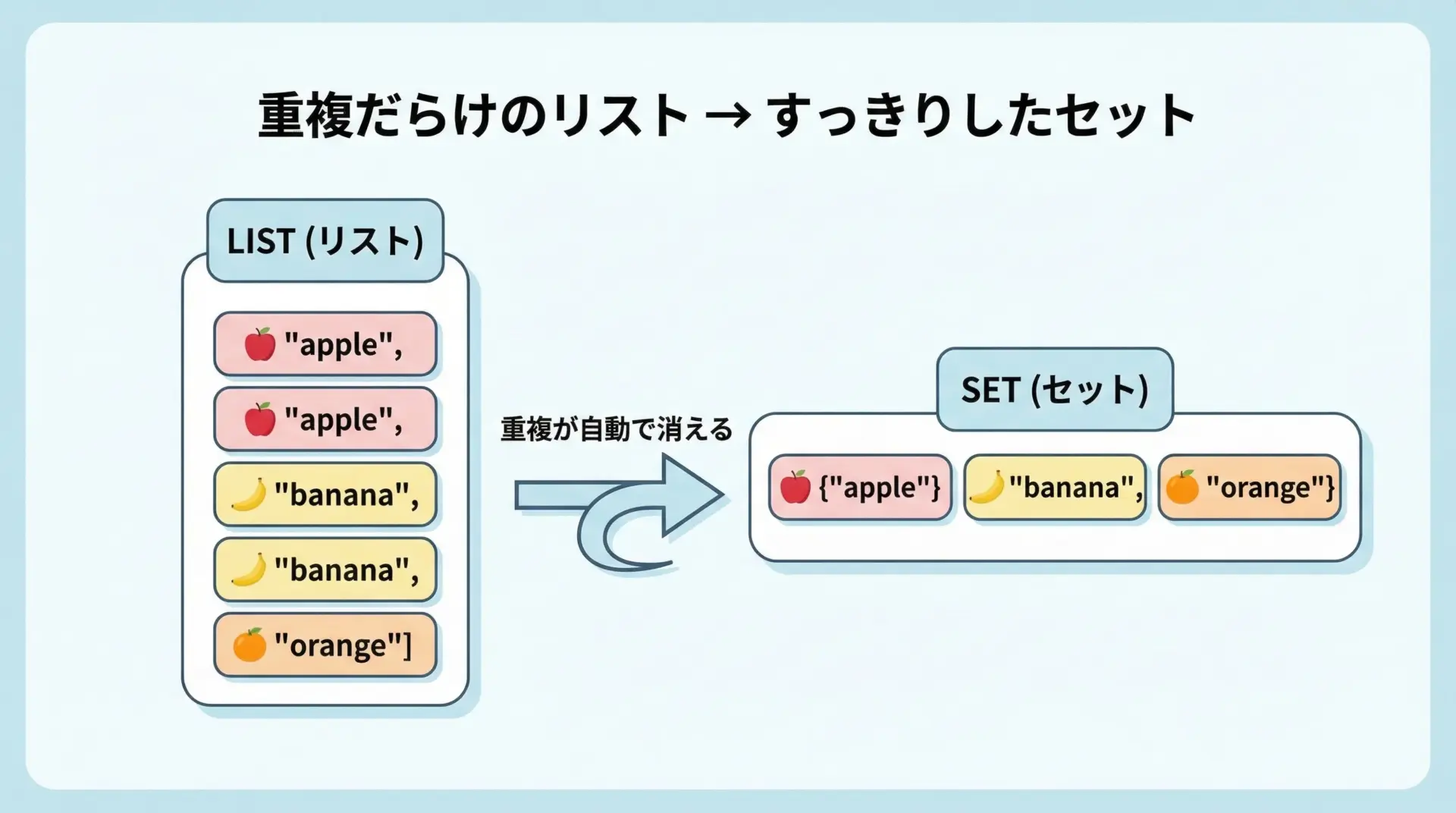
セット内包表記の最大の強みは、重複した値を自動的に落としてくれることです。
例えば、ユーザーの入力履歴から「登場したことがあるキーワードの一覧」だけを取り出したいときに便利です。
keywords = [
"python",
"django",
"python",
"flask",
"python",
"pandas",
"django",
]
# 登場したことがあるキーワードの集合
unique_keywords = {word for word in keywords}
print(unique_keywords){'flask', 'django', 'python', 'pandas'}セットは順番を持たないので、出力順序は環境によって変わる可能性がありますが、「重複がない」という性質が重要です。
また、文字列を正規化してから重複を取り除くといった使い方もよくあります。
raw_words = ["Python", "python", "PYTHON", "Flask", "flask"]
# 小文字にそろえてから重複を除去
normalized = {w.lower() for w in raw_words}
print(normalized){'flask', 'python'}このように、何らかの変換 → 重複を除去という流れを1行で書けるのが、セット内包表記の分かりやすい用途です。
条件付きセット内包表記でフィルタリング

セット内包表記でも、末尾にif 条件を書くことでフィルタリングができます。
例えば、偶数だけを集めたセットを作る例を見てみます。
nums = [1, 2, 2, 3, 4, 4, 5, 6]
# 偶数だけの集合
even_set = {n for n in nums if n % 2 == 0}
print(even_set){2, 4, 6}ここでのif n % 2 == 0は、「この要素をセットに入れてよいかどうか」を決める条件です。
条件を満たさない要素は、そもそもセットに追加されません。
もう少し実用的な例として、ある文字を含む単語だけを集めるようなケースも考えられます。
words = ["apple", "banana", "cherry", "date", "grape", "avocado"]
# "a" を含む単語だけの集合
a_words = {w for w in words if "a" in w}
print(a_words){'banana', 'grape', 'avocado', 'apple', 'date'}このような「条件でフィルタ + 重複除去」の組み合わせは、セット内包表記の典型的な活用パターンです。
辞書内包表記との違いで混乱しないコツ

辞書内包表記とセット内包表記は、どちらも{}を使うため見た目が非常に似ています。
混乱を避けるために、次の2点を常にチェックする習慣を付けるとよいです。
1つ目は、「中に:があるかどうか」です。
キー: 値のようにコロンがあれば辞書、なければセットです。
2つ目は、「forの左側に2つの情報を書いていないか」という点です。
辞書ならキー: 値の2つが必要ですが、セットは「値1つ」だけになります。
| 種類 | 例 | 覚え方 |
|---|---|---|
| 辞書内包表記 | {k: v for k, v in d.items()} | コロン:がある、ペア(キー・値)を扱う |
| セット内包表記 | {x for x in nums} | コロンがない、値1つだけを扱う |
「コロンが出てきたら辞書、出てこなければセット」というくらいシンプルに覚えてしまうと、迷いにくくなります。
辞書内包表記・セット内包表記の実践パターン
リストから辞書を生成するパターン集
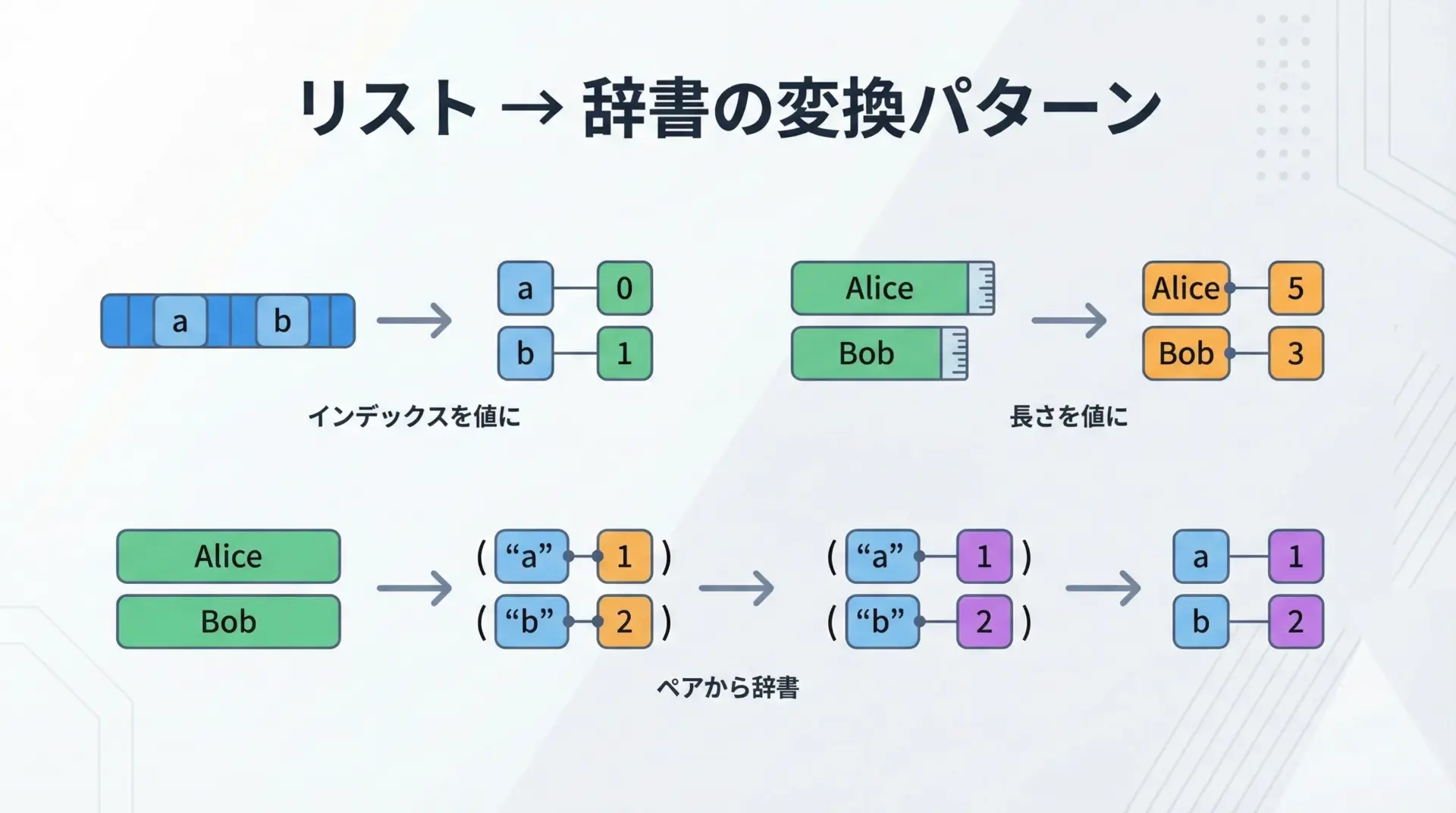
リストから辞書を作る処理は、実務でも頻繁に登場します。
ここでは、よくあるパターンをいくつかまとめて紹介します。
1. 要素をキーに、インデックスを値にする
names = ["Alice", "Bob", "Charlie"]
# 名前 → インデックス(順番)の辞書
index_map = {name: i for i, name in enumerate(names)}
print(index_map){'Alice': 0, 'Bob': 1, 'Charlie': 2}enumerate()と組み合わせることで、元の順番情報を辞書に変換できます。
2. 要素をキーに、長さなどの属性を値にする
words = ["python", "java", "go", "javascript"]
# 単語 → 文字数 の辞書
length_map = {w: len(w) for w in words}
print(length_map){'python': 6, 'java': 4, 'go': 2, 'javascript': 10}このように、要素から計算した値を辞書に保存するのもよくあるパターンです。
3. (キー, 値) 形式のタプルのリストから辞書を作る
pairs = [("apple", 100), ("banana", 80), ("orange", 120)]
# タプルのリスト → 辞書
price_map = {k: v for k, v in pairs}
print(price_map){'apple': 100, 'banana': 80, 'orange': 120}組み込みのdict(pairs)でも同じことができますが、途中でフィルタや変換を挟みたいときには辞書内包表記が便利です。
pairs = [("apple", 100), ("banana", 80), ("orange", 120)]
# 100円以上の商品だけを10%値上げして辞書を作る
increased = {
name: int(price * 1.1)
for name, price in pairs
if price >= 100
}
print(increased){'apple': 110, 'orange': 132}リストからセットを生成するパターン集
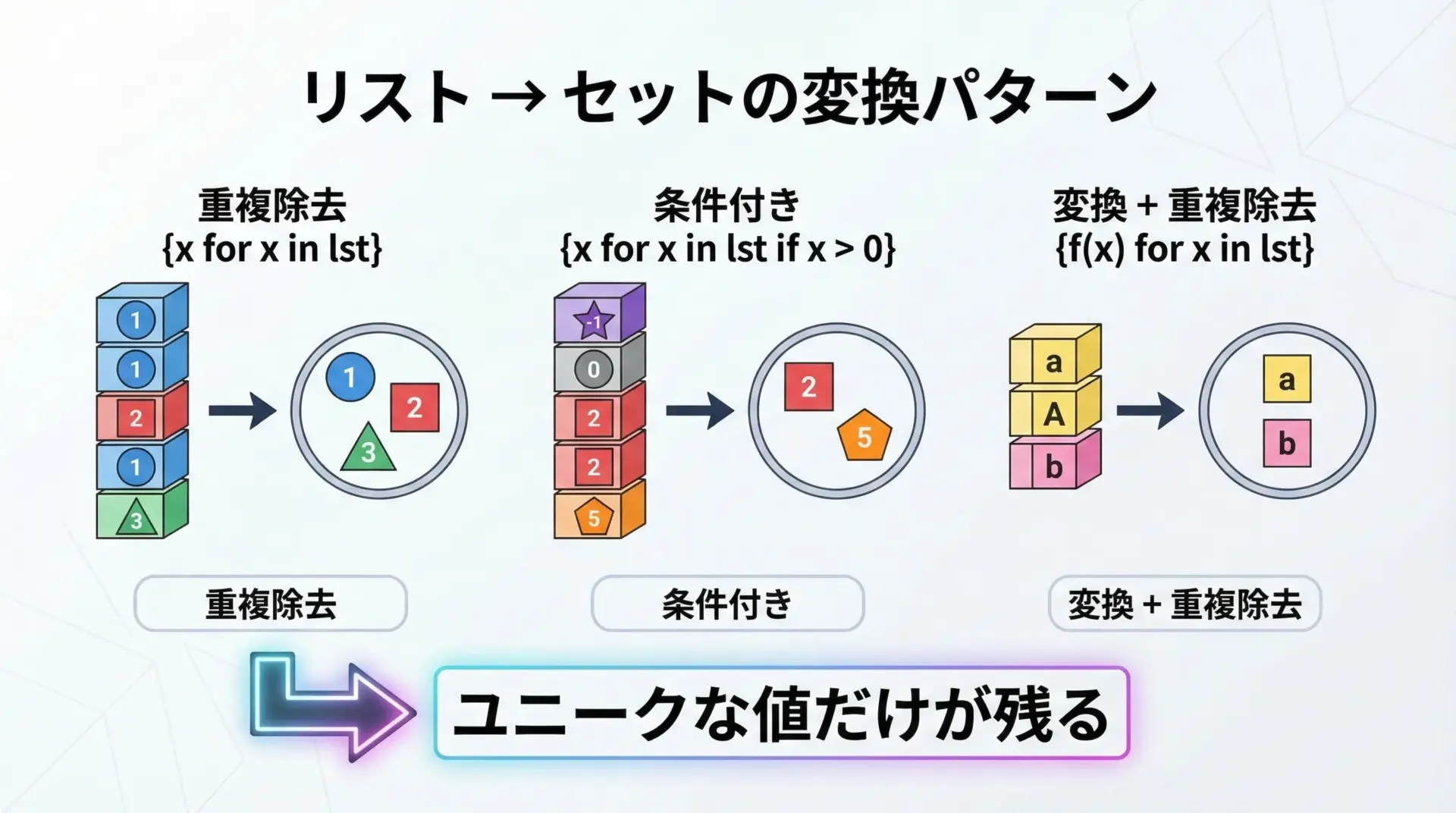
次に、リストからセットを作るときに役立つパターンを紹介します。
1. 単純な重複除去
nums = [1, 1, 2, 3, 3, 4]
unique = {n for n in nums}
print(unique){1, 2, 3, 4}この役割だけならset(nums)でも同じですが、内包表記にすることで次のような「条件」や「変換」を同時に書けます。
2. 条件付きでの重複除去
nums = [1, -1, 2, -2, 3, -3, 2, -2]
# 正の数だけを取り出し、かつ重複を除去
positive = {n for n in nums if n > 0}
print(positive){1, 2, 3}3. 変換した結果について重複を除去
words = ["Python", "python", "PYTHON", "Java", "JAVA"]
# 小文字に揃えた上での、ユニークな言語名
unique_langs = {w.lower() for w in words}
print(unique_langs){'java', 'python'}このように、「変換 → 重複除去」という流れを1行で書けるのが、セット内包表記の強みです。
ループより内包表記を使うべきケース
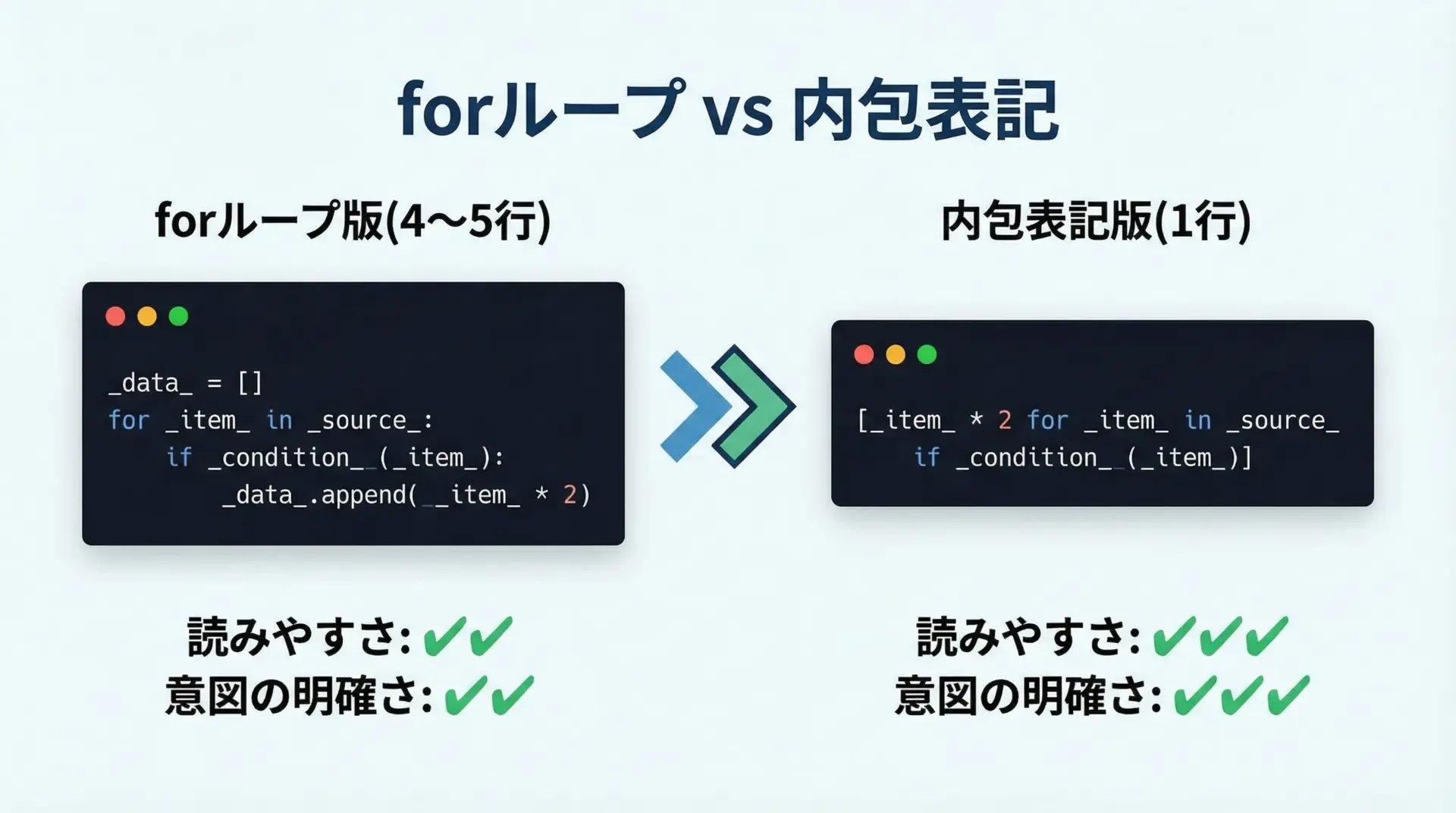
いつでも内包表記を使えばよいわけではありませんが、次のようなケースでは内包表記を優先して検討すると良いです。
1つ目は、「あるコレクションから新しいコレクションを作る」だけの処理である場合です。
副作用(ファイル出力やprintなど)がなく、単に変換やフィルタリングだけを行うなら、内包表記の方が処理の意図が明確になります。
# forループ版
nums = [1, 2, 3, 4, 5]
squares = []
for n in nums:
if n % 2 == 0:
squares.append(n ** 2)
# 内包表記版
squares2 = [n ** 2 for n in nums if n % 2 == 0]
print(squares)
print(squares2)[4, 16]
[4, 16]2つ目は、処理内容が1〜2つの簡単な操作で表せる場合です。
文字列の長さを取る、数値を2乗する、条件に合うものだけ残す、といった単純なものが向いています。
3つ目は、コードの見通しが良くなる場合です。
短くできても、読みやすさが落ちるようなら内包表記にこだわらない方がよいですが、「こういうリスト(辞書・セット)が欲しい」という意図が1行で伝わるなら、内包表記は非常に有効です。
初心者が避けたい書きすぎな内包表記の例
内包表記は便利ですが、何でもかんでも1行に詰め込むと逆に読みづらくなります。
初心者のうちは特に、次のような「書きすぎパターン」は避けた方が安全です。
1. ネストが深すぎる内包表記
# (あえての悪い例)
# 3重のループ + 条件2つを1行に詰め込んでいる
# result = {
# (i, j, k): i * j * k
# for i in range(1, 5)
# for j in range(1, 5) if j != i
# for k in range(1, 5) if k != i and k != j
# }このように、forが3つ以上、ifも複数になってくると、「一目で理解できる」という内包表記の利点が失われてしまいます。
まずは普通のforループで正しく書けることを確認し、その上で内包表記にするか検討する方がよいです。
result = {}
for i in range(1, 5):
for j in range(1, 5):
if j == i:
continue
for k in range(1, 5):
if k == i or k == j:
continue
result[(i, j, k)] = i * j * k
print(len(result))24このように複雑なロジックは、まずは通常のforループで書いてから、必要なら一部だけ内包表記に置き換えるという方針がおすすめです。
2. 副作用を含む内包表記
# (悪い例) print やファイル出力などの副作用を内包表記で行う
# [print(x) for x in range(10)]内包表記は新しいコレクションを生成するための構文なので、副作用だけを目的に使うのは避けた方がよいとされています。
読み手が「このリスト(やセット)は何に使うのだろう?」と混乱してしまうからです。
このような処理は、素直にforループで書く方が明確です。
for x in range(10):
print(x)3. 条件や計算が複雑すぎる場合
# (悪い例) 条件や計算がゴチャゴチャしていて読みにくい
# filtered = {
# k: complex_calculation(v) if is_valid(v) else default_value(v)
# for k, v in data.items()
# if check1(v) and not check2(v) or check3(v) > 10
# }このように、条件や計算ロジックが複雑な場合は、関数として切り出すか、一旦forループに戻す方が保守性が高くなります。
初心者のうちは「1つの内包表記には、1つのシンプルな目的だけ」というルールを意識してみるとよいです。
まとめ
辞書内包表記とセット内包表記は、最初は記号が多くて戸惑いますが、「何をキーにするか(あるいは値だけなのか)」「コロン:があるかどうか」に注目すると、すっきり理解しやすくなります。
リストから辞書やセットを作るよくあるパターンを押さえつつ、シンプルな変換やフィルタリングから少しずつ使い始めてみてください。
無理に1行に詰め込まず、読みやすさを優先しながら内包表記を活用していくことが、Pythonコードをきれいに保つコツです。
