
Pythonでコードを書くとき、リストを生成する処理はとても頻繁に登場します。
そのたびにfor文を書いていると、コードが長くなり読みづらくなってしまいます。
そんなときに役立つのが、リスト内包表記(list comprehension)です。
本記事では、基本構文から条件式、多重forまで、Pythonのリスト内包表記を体系的に解説し、読みやすい書き方のコツもあわせて紹介します。
Pythonのリスト内包表記とは
リスト内包表記の基本構文と特徴
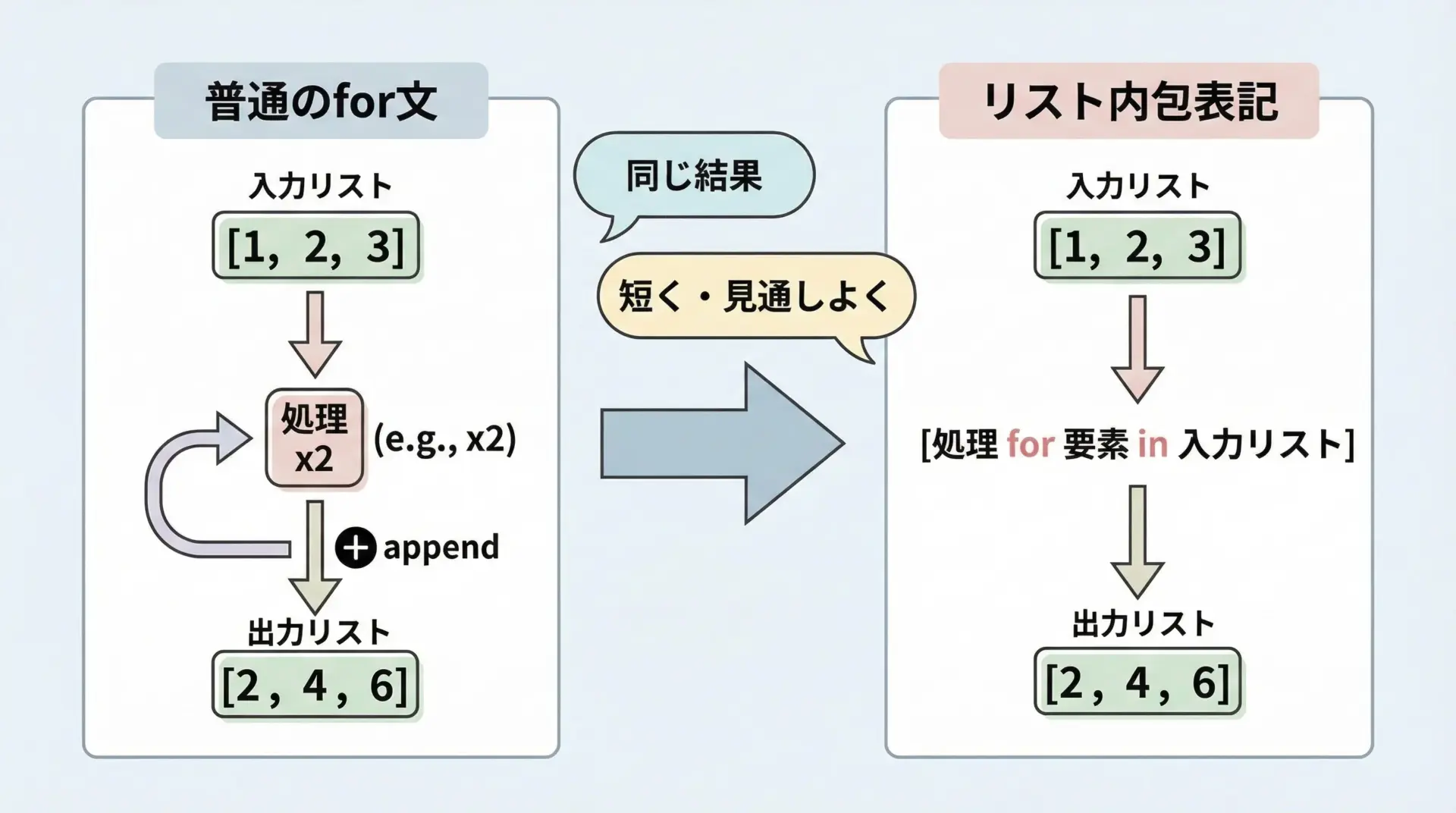
リスト内包表記(list comprehension)とは、既存のシーケンスから新しいリストを、1行の式で生成するための構文です。
Pythonの特徴である「簡潔で読みやすいコード」を体現しており、リストの生成や変換、フィルタリングなどを非常にコンパクトに書くことができます。
もっとも基本的な構文は次のようになります。
# 基本構文のイメージ
[新しい要素の式 for 変数 in イテラブル]たとえば、1〜5までの2乗のリストを作りたい場合は次のように書けます。
# 1〜5までの2乗をリスト内包表記で作成
squares = [n * n for n in range(1, 6)]
print(squares)[1, 4, 9, 16, 25]このように、「どのデータから(for部分)」「どのような値を作るか(先頭の式)」が1行でまとまっていることが主な特徴です。
リスト内包表記の基本構文まとめ
代表的なパターンを表に整理します。
| 用途 | 構文例 |
|---|---|
| 単純な変換 | [式 for x in iterable] |
| 条件でフィルタリング | [式 for x in iterable if 条件] |
| 条件に応じて値を分けて生成 | [式1 if 条件 else 式2 for x in iterable] |
| 多重for(ネスト) | [式 for x in iterable1 for y in iterable2] |
構文はシンプルですが、ifの位置・forの順番などで読みやすさが変わるため、後半で丁寧に解説していきます。
通常のfor文との違いとメリット

通常のfor文と比べたとき、リスト内包表記にはいくつかの大きなメリットがあります。
コードが短く、意図が一目でわかる
# 通常のfor文
numbers = [1, 2, 3, 4, 5]
squares = [] # 空リストを用意
for n in numbers: # 1つずつ取り出す
squares.append(n * n) # 2乗して追加
print(squares)[1, 4, 9, 16, 25]同じ処理をリスト内包表記で書くと、次のようになります。
# リスト内包表記
numbers = [1, 2, 3, 4, 5]
squares = [n * n for n in numbers]
print(squares)[1, 4, 9, 16, 25]「どのリストから」「どんな新しいリストを作っているか」が1行で把握しやすいことがわかります。
バグを生みにくい(初期化忘れやappendミスの防止)
通常のfor文では、次のようなミスをしがちです。
- リストの初期化を忘れる
appendを書き忘れる、または間違った位置に書く- 変数名をうっかり別の名前で書く
リスト内包表記では、「リストを作るための1つの式」として完結しているため、これらのミスが起きにくくなります。
パフォーマンス面のメリット
状況にもよりますが、リスト内包表記は通常のfor文よりも高速になることが多いです。
これは、リスト内包表記が内部的に最適化されているためです。
特に、単純な変換・フィルタリングであれば、リスト内包表記は「短く書けて速い」ことが多いと覚えておくとよいです。
リスト内包表記の書き方
単純なforを使ったリスト内包表記の例
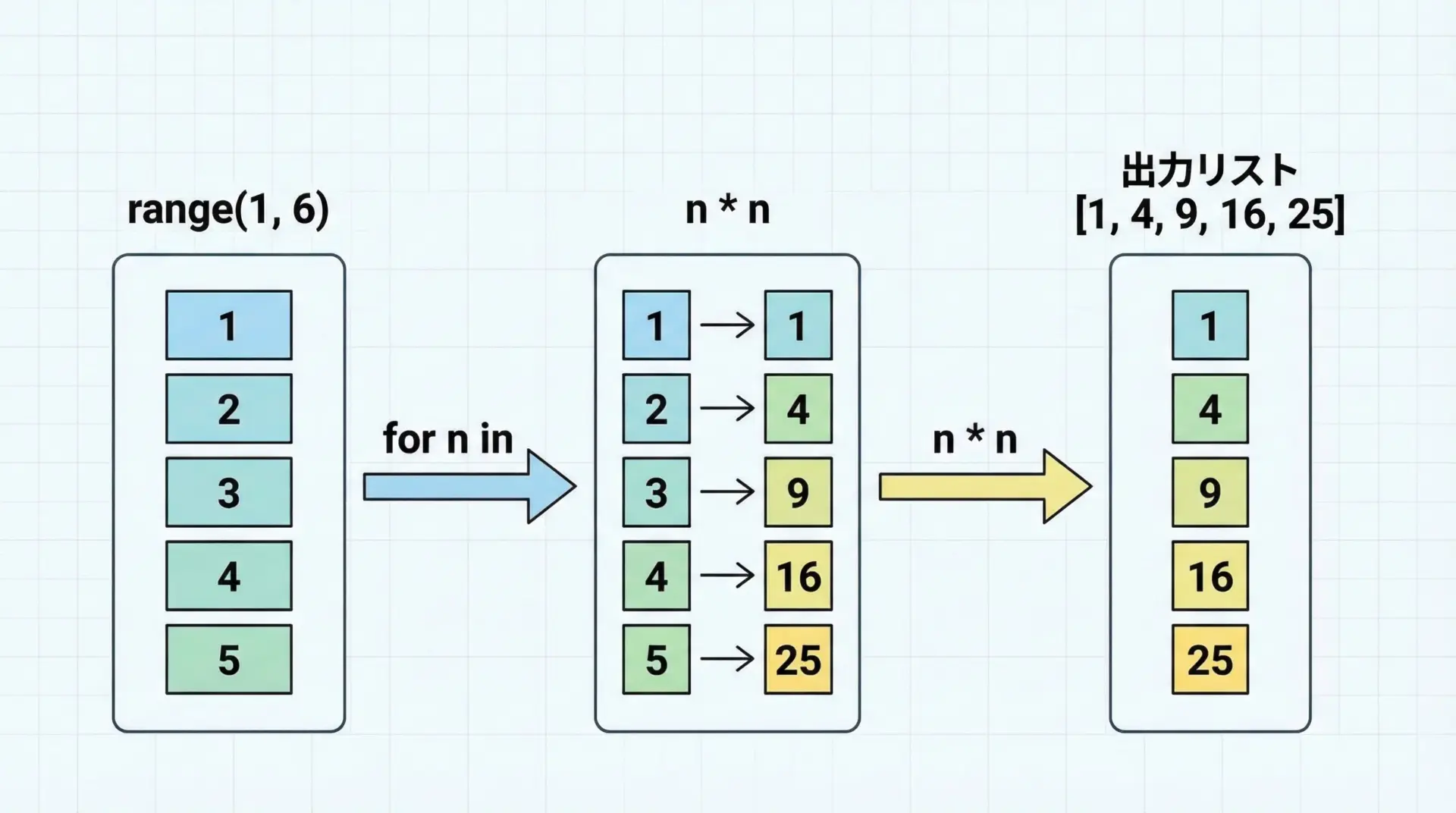
まずは、最も基本的な「単純なfor」を使った例をいくつか見ていきます。
1から10までの偶数を2倍したリストを作る
# 1〜10までの偶数を2倍した値をリストにする
doubled_evens = [n * 2 for n in range(1, 11) if n % 2 == 0]
print(doubled_evens)[4, 8, 12, 16, 20]ここでは、for n in range(1, 11)で1〜10の数を順番に取り出し、if n % 2 == 0で偶数だけに絞り込み、n * 2を新しいリストの要素にしています。
文字列リストの長さをリストにする
# 文字列の長さをリストにする
words = ["apple", "banana", "kiwi"]
lengths = [len(w) for w in words]
print(lengths)[5, 6, 4]このように、「元の要素を受け取って、関数や演算を適用する」処理とリスト内包表記は非常に相性がよいです。
インデックスを使わないPythonicな書き方
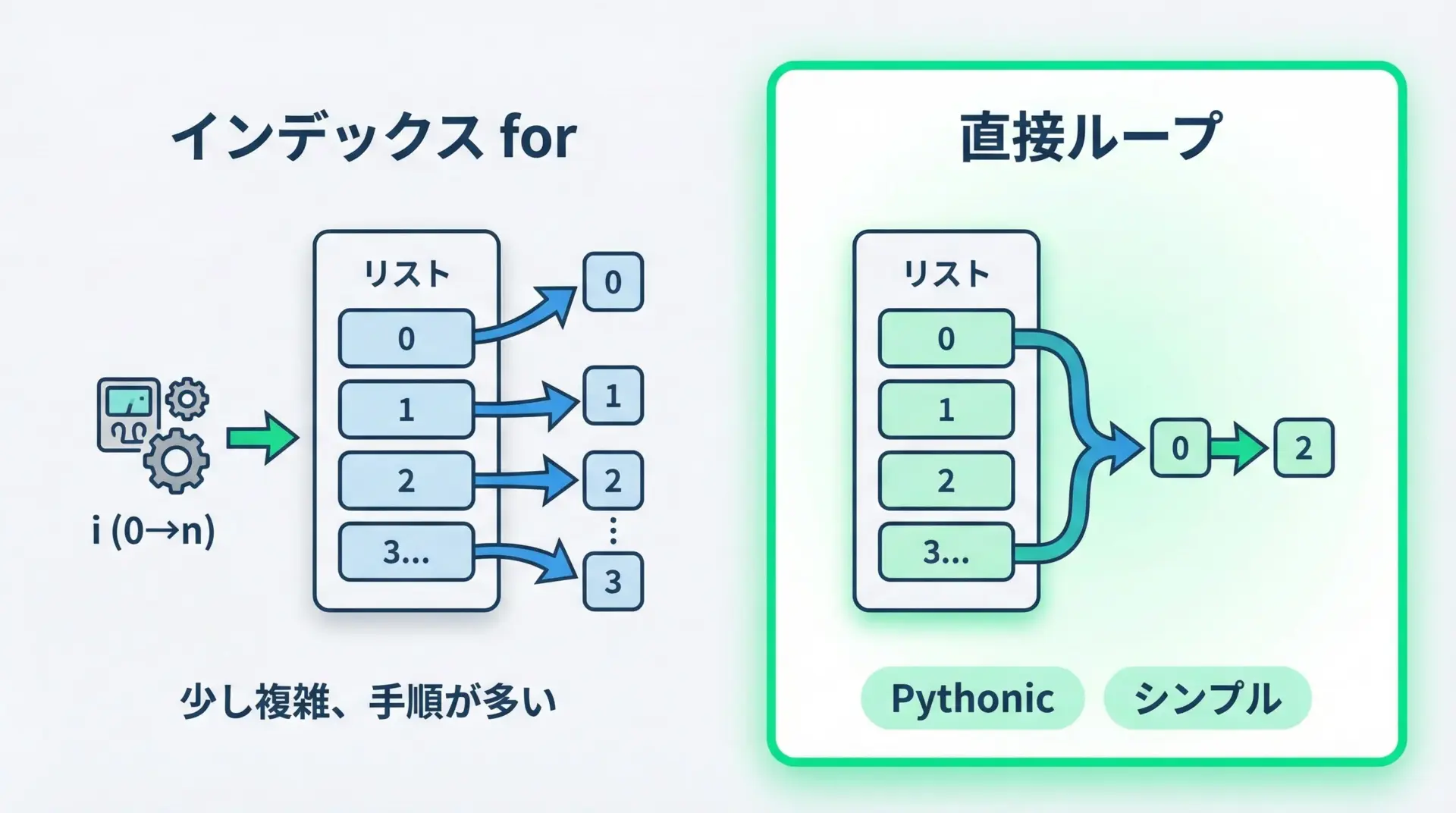
Pythonでは、C言語などでよくあるfor i in range(len(list))スタイルよりも、「要素そのもの」を直接取り出す書き方が推奨されます。
リスト内包表記でも同じ考え方が大切です。
インデックスを使う非Pythonicな書き方
# あまりPythonicではない書き方(インデックスを多用)
numbers = [1, 2, 3, 4, 5]
squares = [numbers[i] * numbers[i] for i in range(len(numbers))]
print(squares)[1, 4, 9, 16, 25]動作はしますが、余計なインデックス操作が入り、読みづらくなっています。
Pythonicな書き方
# Pythonicな書き方(要素を直接扱う)
numbers = [1, 2, 3, 4, 5]
squares = [n * n for n in numbers]
print(squares)[1, 4, 9, 16, 25]このように、「何をしているか」が素直に読めるコードを心がけることで、バグを減らし、チーム開発でも理解されやすいコードになります。
可読性を保つための書き方のコツ
リスト内包表記は便利ですが、やりすぎると一気に読みにくくなるというデメリットもあります。
ここでは、可読性を保つための主なコツを紹介します。
コツ1: 1行を長くしすぎない
複数の関数呼び出しや長い条件式を1行に詰め込むと、すぐに可読性が落ちます。
# 読みにくい例(いろいろ詰め込みすぎ)
result = [process(x).strip().lower() for x in items if x is not None and check_condition(x) and len(x) > 10]このような場合は、あえて通常のfor文に戻して段階的に処理するか、処理を関数に切り出して式を短くする方がよいです。
# 関数に切り出して読みやすくする例
def normalize(x: str) -> str:
# 文字列を正規化する処理
return process(x).strip().lower()
result = [
normalize(x)
for x in items
if x is not None and check_condition(x) and len(x) > 10
]Pythonでは、1行に収めつつも、行継続(改行)を使って縦方向に整えることで読みやすくできます。
コツ2: ネストが深くなったら素直にfor文へ戻す
多重forや複雑な条件式を組み合わせすぎると、リスト内包表記は一気に難解になります。
「自分で一度読んで理解しにくい」と感じたら、通常のfor文に戻すのが賢明です。
コツ3: 変数名を意味のある名前にする
たとえば、for x in dataよりも、for user in usersの方が、コードを見ただけで何の処理か想像しやすくなります。
リスト内包表記は1行であるがゆえに、変数名による情報量が重要になります。
条件式付きリスト内包表記
if条件を使った要素フィルタリング
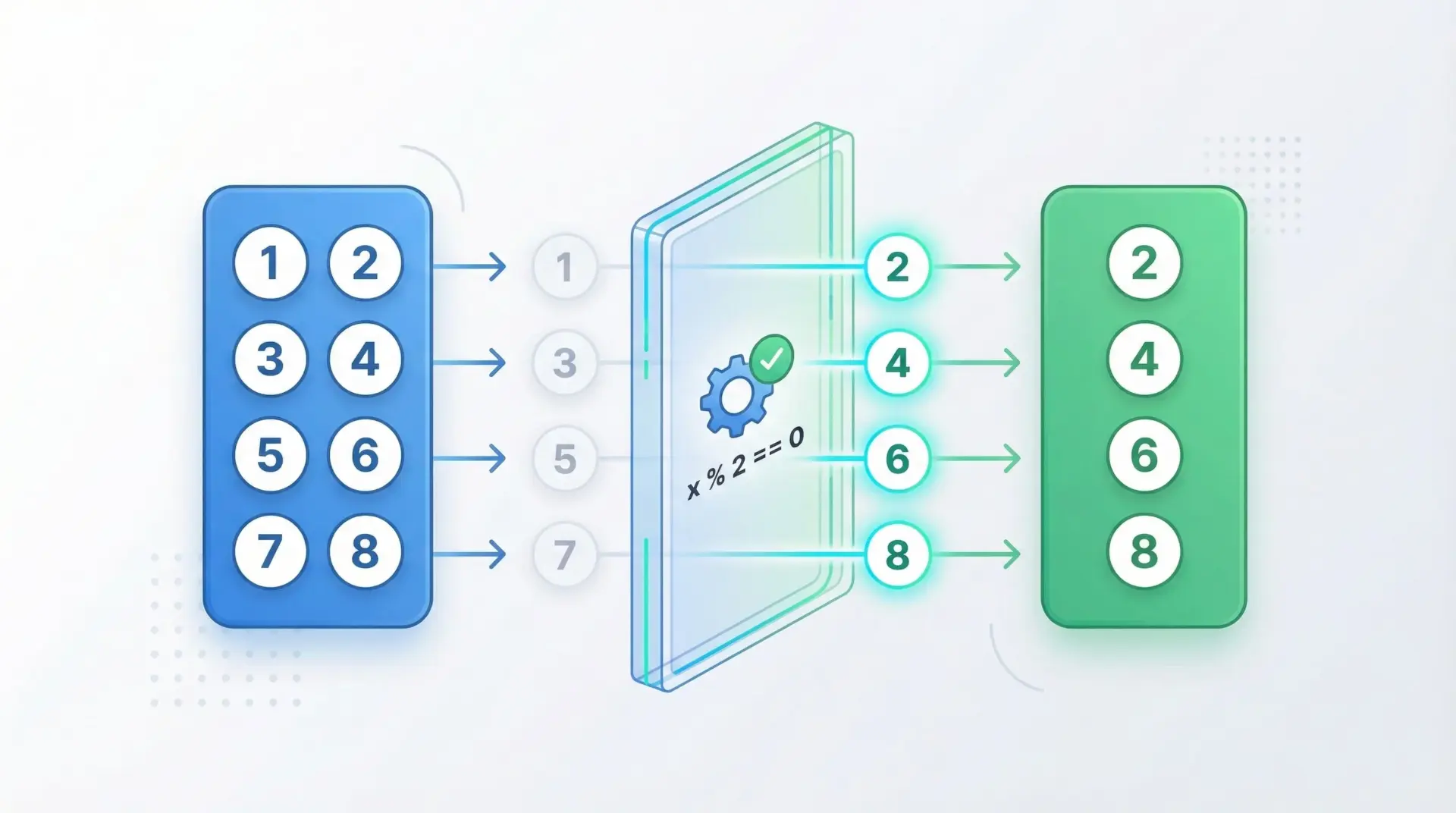
リスト内包表記では、forの後ろにif条件を書くことで、要素をフィルタリングできます。
構文は次の通りです。
[式 for 変数 in イテラブル if 条件]偶数だけを集める例
# 偶数だけを集める
numbers = list(range(1, 11))
even_numbers = [n for n in numbers if n % 2 == 0]
print(even_numbers)[2, 4, 6, 8, 10]ここでは、if n % 2 == 0で「偶数であるものだけ」を新しいリストに含めています。
文字列の長さが3以上のものだけを抽出
# 長さが3以上の文字列だけを抽出
words = ["a", "an", "the", "apple", "to", "see"]
long_words = [w for w in words if len(w) >= 3]
print(long_words)['the', 'apple', 'see']このように、ifを使うことで、「元のデータから必要なものだけを抽出する」処理を簡潔に書けます。
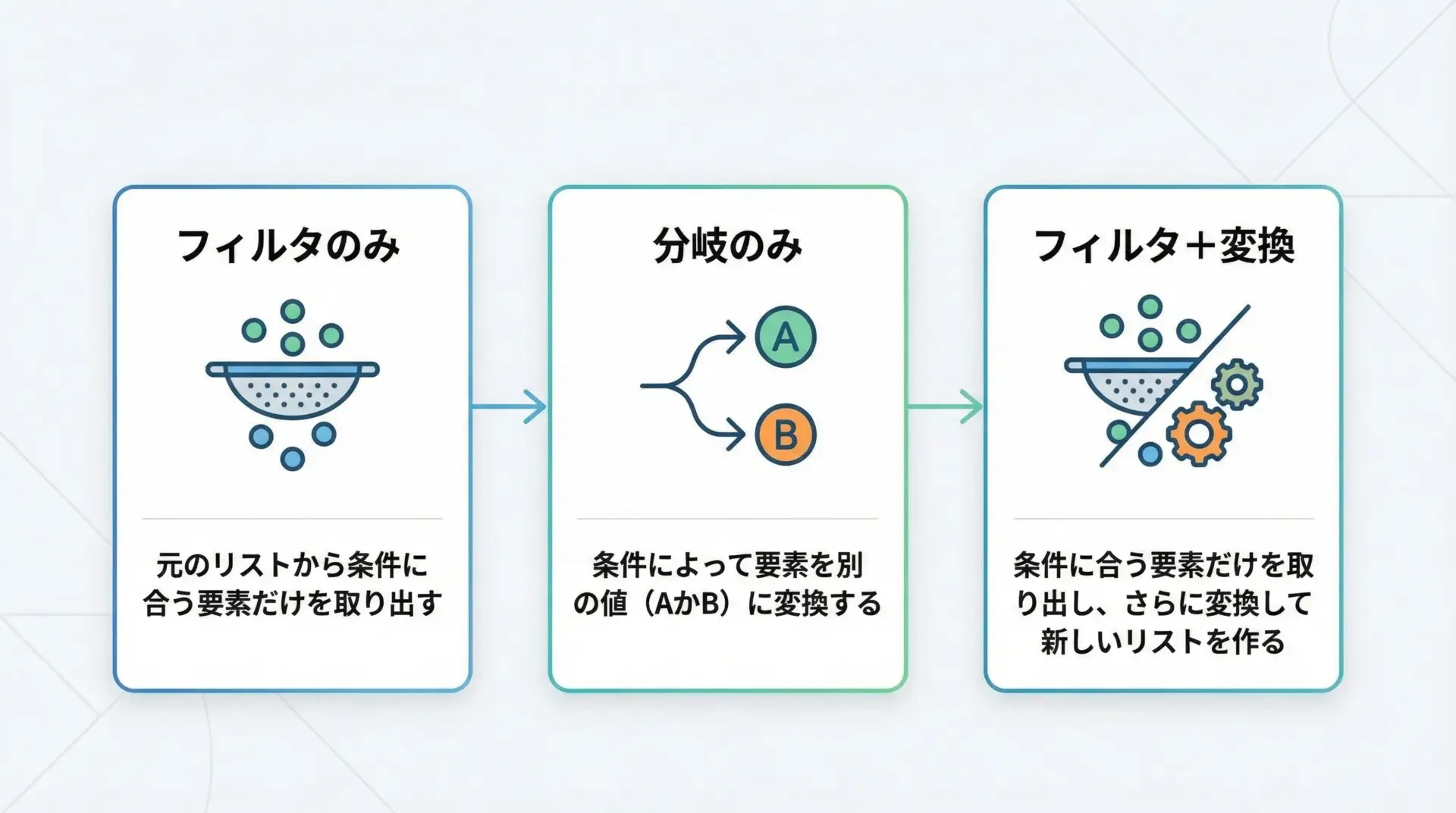
if-elseを使った値の分岐と書き方の注意点

要素をフィルタリングするだけでなく、条件によって異なる値をリストに入れたい場合は、if-elseを使います。
ここで重要なのは、if-else は「式の中」に書くという点です。
正しい構文
[式1 if 条件 else 式2 for 変数 in イテラブル]間違いやすい構文
# これは構文エラー: if-else を for の後ろに書いてはいけない
# [式 for 変数 in イテラブル if 条件 else 式2]正負で値を分ける例
# 正の数ならそのまま、負の数なら0にする
numbers = [3, -1, 0, 5, -7]
normalized = [n if n > 0 else 0 for n in numbers]
print(normalized)[3, 0, 0, 5, 0]このように、「条件に合えばA、そうでなければB」という処理を1行で書けるのがif-else付きリスト内包表記です。
条件式付きリスト内包表記の具体例
具体的な使い方をいくつかまとめて見てみましょう。
1. 負数を除外し、2倍した値のリストを作る
# 負数を除外し、残りを2倍したリスト
numbers = [-3, -1, 0, 2, 5]
processed = [n * 2 for n in numbers if n >= 0]
print(processed)[0, 4, 10]ここでは、if n >= 0でフィルタリングを行い、その後にn * 2という変換をかけています。
2. 偶数なら”even”、奇数なら”odd”という文字列リストを作る
# 偶数・奇数を文字列で表すリスト
numbers = range(1, 6)
labels = ["even" if n % 2 == 0 else "odd" for n in numbers]
print(labels)['odd', 'even', 'odd', 'even', 'odd']ここでは、if-elseで「値そのものを変換する」例になっています。
3. 辞書リストから特定条件を満たすユーザー名だけ取り出す
# 辞書リストから条件を満たす値を抽出
users = [
{"name": "Alice", "age": 25},
{"name": "Bob", "age": 17},
{"name": "Charlie", "age": 30},
]
# 20歳以上のユーザー名だけをリストにする
adult_names = [user["name"] for user in users if user["age"] >= 20]
print(adult_names)['Alice', 'Charlie']このように、実務でよくある「リストの中の辞書から条件に合う情報を取り出す」処理にも、リスト内包表記はとても便利です。
多重forのリスト内包表記
ネストしたfor文を1行で書く方法
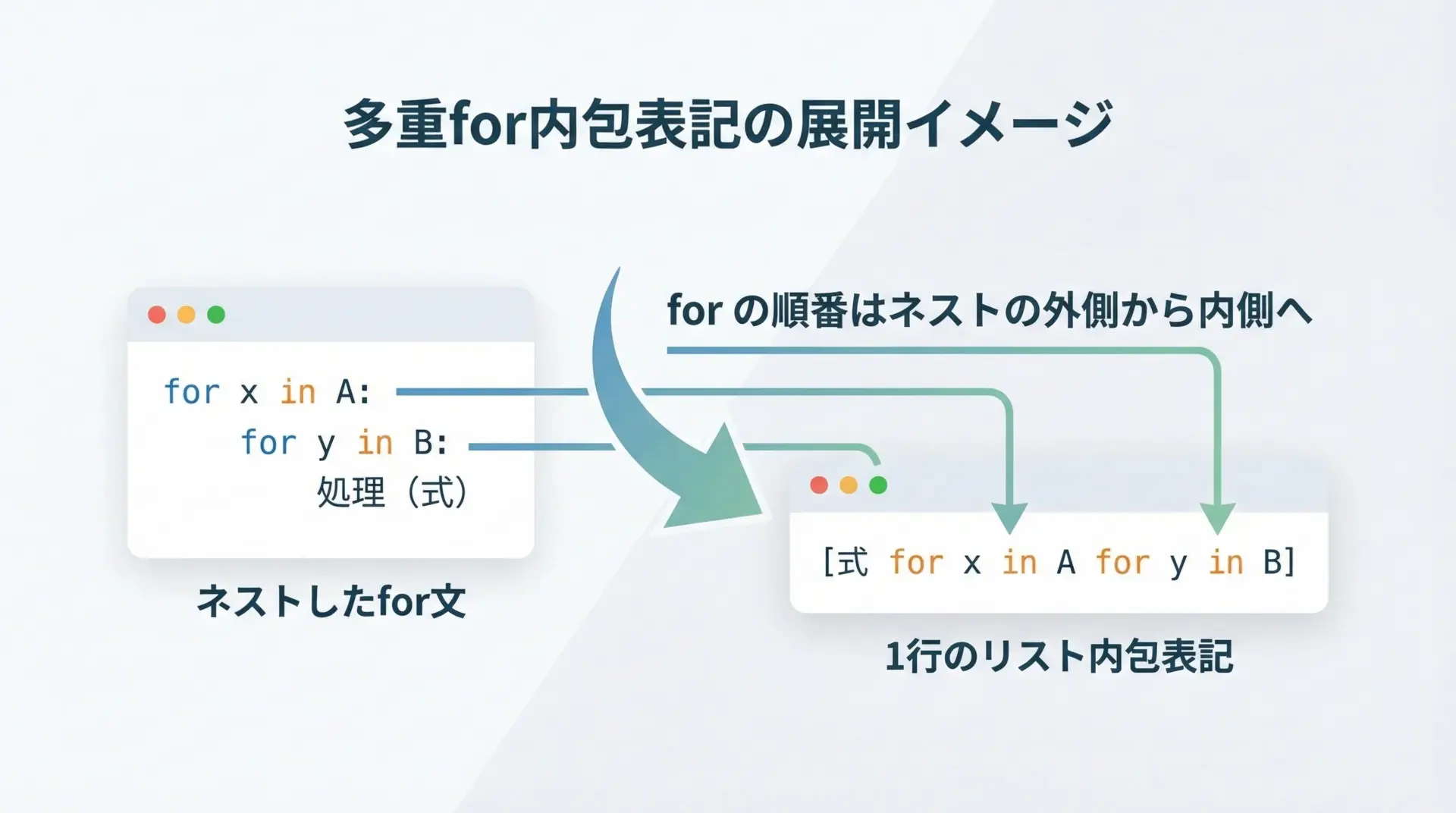
リスト内包表記では、複数のforを連ねて書くことができます。
これは、通常のネストしたfor文を1行にしたものだと考えると理解しやすいです。
通常のネストしたfor文
# 通常のネストしたfor文
pairs = []
for x in [1, 2, 3]:
for y in ["a", "b"]:
pairs.append((x, y))
print(pairs)[(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b'), (3, 'a'), (3, 'b')]多重forのリスト内包表記
# 多重forを使ったリスト内包表記
pairs = [(x, y) for x in [1, 2, 3] for y in ["a", "b"]]
print(pairs)[(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b'), (3, 'a'), (3, 'b')]ここで重要なのは、forの順番は「外側のfor → 内側のfor」の順で書くという点です。
これは、通常のネストしたfor文と同じ順序になります。
二次元リストを作るリスト内包表記の書き方
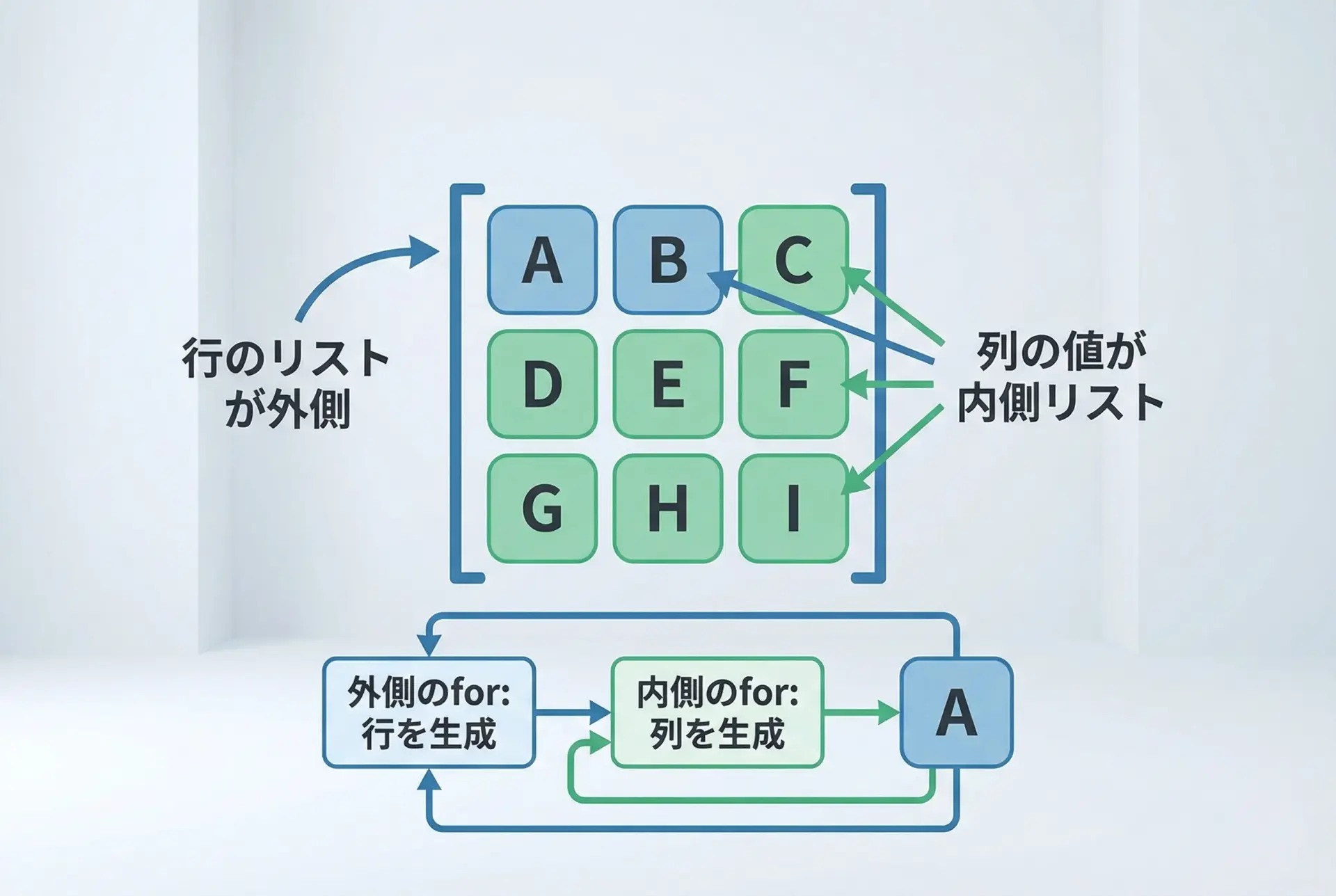
多重forのリスト内包表記を使うと、二次元リスト(リストのリスト)も簡単に生成できます。
3×3のゼロ行列を作る
# 3×3のゼロ行列を作る
rows = 3
cols = 3
matrix = [[0 for _ in range(cols)] for _ in range(rows)]
print(matrix)[[0, 0, 0], [0, 0, 0], [0, 0, 0]]ここでは、
- 外側の
for _ in range(rows)が「行の数」を決める - 内側の
[0 for _ in range(cols)]が「1行分の要素」を生成する
という構造になっています。
行番号と列番号を要素に入れた表を作る
# 各要素に(行番号, 列番号)を入れた2次元リスト
rows = 2
cols = 3
grid = [[(i, j) for j in range(cols)] for i in range(rows)]
print(grid)[[(0, 0), (0, 1), (0, 2)], [(1, 0), (1, 1), (1, 2)]]この例では、二次元の添字をデータとして持たせたいときに便利なパターンです。
多重forと条件式を組み合わせた応用例
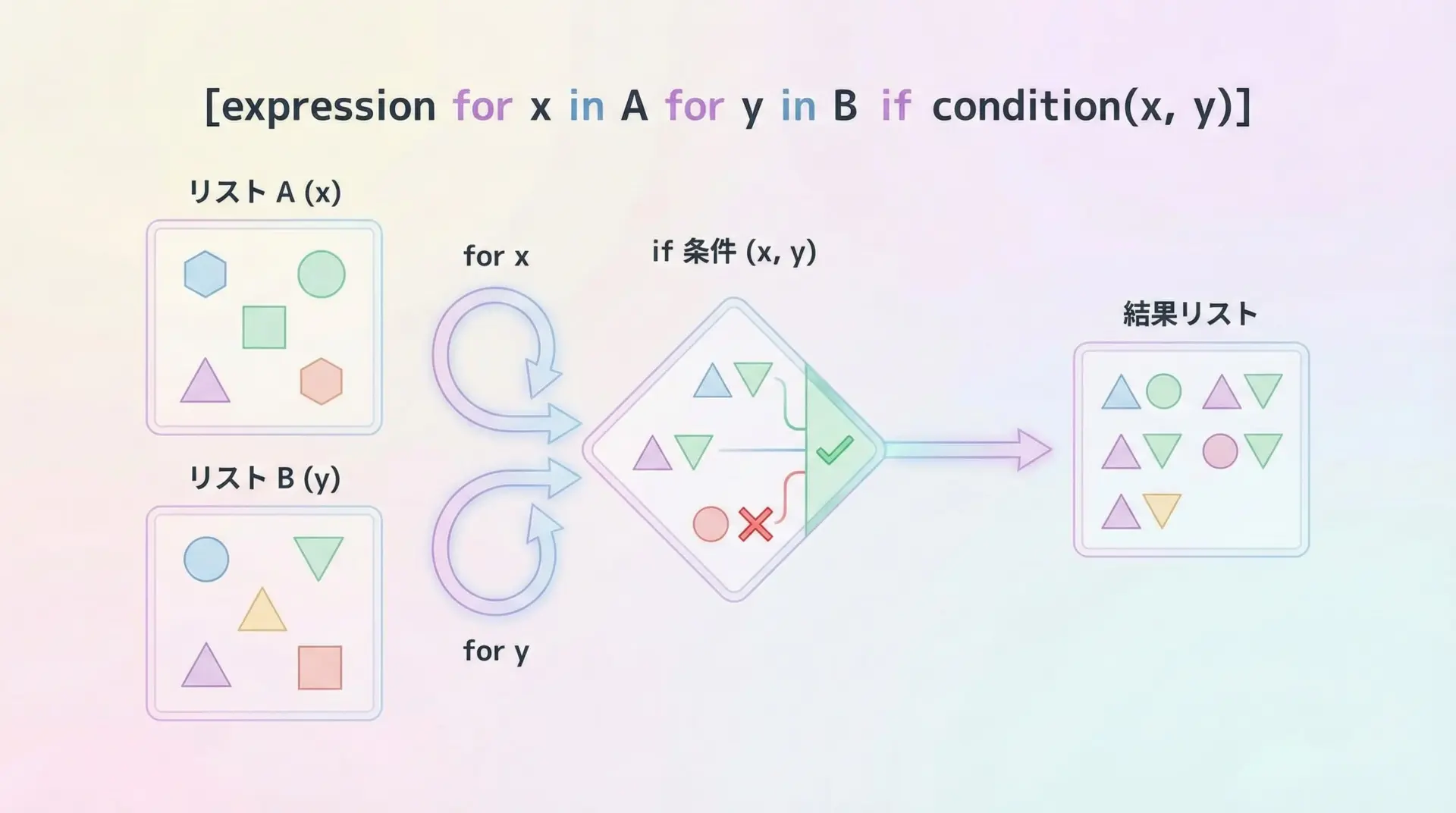
多重forに条件式を組み合わせると、「組み合わせの中から条件を満たすペアだけを取り出す」といった処理をコンパクトに記述できます。
1〜3と1〜3の全ての組み合わせのうち、和が4以下のペアだけ取り出す
# 和が4以下の(x, y)ペアだけを取り出す
pairs = [(x, y) for x in range(1, 4) for y in range(1, 4) if x + y <= 4]
print(pairs)[(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (3, 1)]このコードは、通常のfor文で書くと次のようになります。
# 同じ処理を通常のfor文で書く
pairs = []
for x in range(1, 4):
for y in range(1, 4):
if x + y <= 4:
pairs.append((x, y))
print(pairs)[(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (3, 1)]比較すると、リスト内包表記の方が「何をしたいコードか」が端的に表現されていることがわかります。
文字列の組み合わせから特定条件を満たすものだけを選ぶ
# アルファベット2文字の組み合わせのうち、先頭が 'a' か 'b' のものだけ
first = ["a", "b", "c"]
second = ["x", "y"]
pairs = [f + s for f in first for s in second if f in ("a", "b")]
print(pairs)['ax', 'ay', 'bx', 'by']ここでは、for f in first、for s in secondの後にif f in ("a", "b")を続けることで、多重forで生成される組み合わせを条件でフィルタリングしています。
注意: 複雑になりすぎたら通常のfor文を検討する
多重forと条件式を組み合わせると、強力である一方、可読性を損ないやすいという側面もあります。
たとえば、3重以上のforや、複数の条件式(かつ・または)が入り乱れるようであれば、通常のfor文に展開し、
- ロジックをコメントで説明する
- 条件を変数に分割する
- 一部処理を関数化する
といった工夫をした方が、長期的に保守しやすいコードになります。
まとめ
リスト内包表記は、Pythonで「リストの生成・変換・フィルタリング」を簡潔に書くための強力な構文です。
単純なforから始め、ifによるフィルタリング、if-elseによる値の分岐、多重forによる二次元リストや組み合わせの生成まで、幅広く活用できます。
一方で、1行に詰め込みすぎると可読性が落ちるため、「自分や他人が後で読んで理解しやすいか」を基準に、通常のfor文と使い分けることが大切です。
この記事のサンプルを手元で動かしながら、Pythonicな書き方を自然に身につけていきましょう。
