
テキストファイルを扱っていると、BOM(Byte Order Mark)という言葉に一度は出会います。
特にUTF-8では「BOMあり」「BOMなし」という表現が出てきて、どちらを選ぶべきか迷う方も多いのではないでしょうか。
この記事では、BOMの役割とUTF-8との関係を整理しながら、BOMが付いていることで具体的に何が変わるのか、そして実務でどのように扱うべきかを、図解を交えて丁寧に解説します。
BOM(Byte Order Mark)とは
BOMの基本的な意味と役割
BOM(Byte Order Mark)とは、テキストファイルの先頭に付く「このファイルは何のエンコーディングで書かれているか」を示す目印のようなものです。
特にUTF-16やUTF-32といったマルチバイト文字コードでは、バイト順序(エンディアン)を伝えるためのフラグとしても使われます。
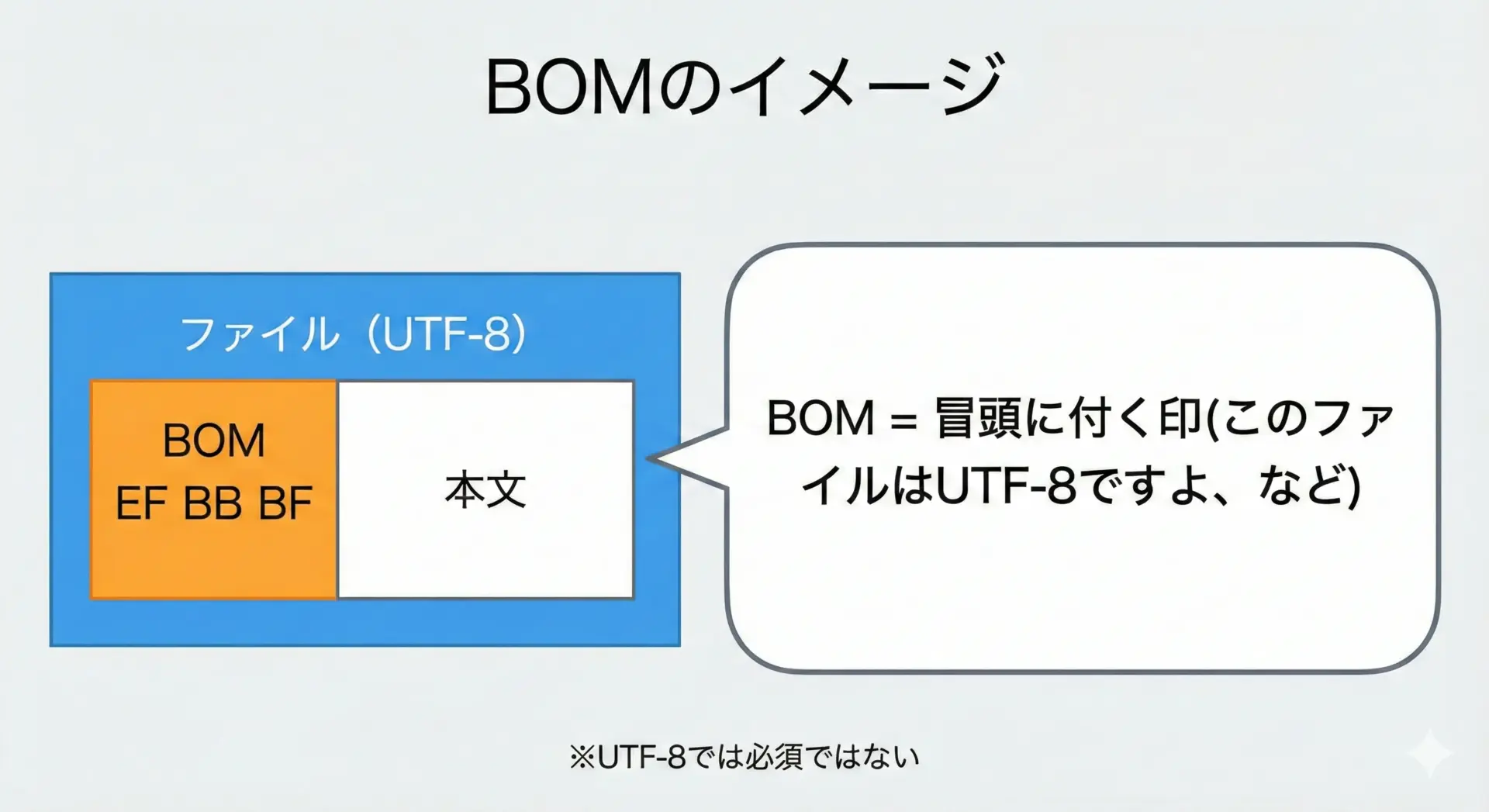
テキストファイルは本来、単なるバイト列に過ぎません。
BOMが付いていると、ファイルを開いたプログラムが「このファイルは特定のUnicodeエンコーディングで書かれている」と判断しやすくなります。
特に区別したい情報は次の2点です。
- どのUnicodeエンコーディング形式か(UTF-8 / UTF-16 / UTF-32など)
- (UTF-16, UTF-32の場合) ビッグエンディアンかリトルエンディアンか
このように、BOMは「エンコーディングを自己申告するための目印」と捉えると理解しやすくなります。
テキストファイルにBOMが付くタイミング
BOMは、自動的に発生する魔法の情報ではなく、「書き出し時の設定」や「使用するライブラリの仕様」によって付くかどうかが決まります。
代表的なタイミングは次のようなものです。
- エディタで「UTF-8 (BOM付き)」などの保存形式を選んだ場合
- プログラムでテキストを書き出すライブラリが、デフォルトでBOMを出力する仕様になっている場合
- IDEやビルドツールのテンプレートが、BOM付きのソースファイルを生成する場合
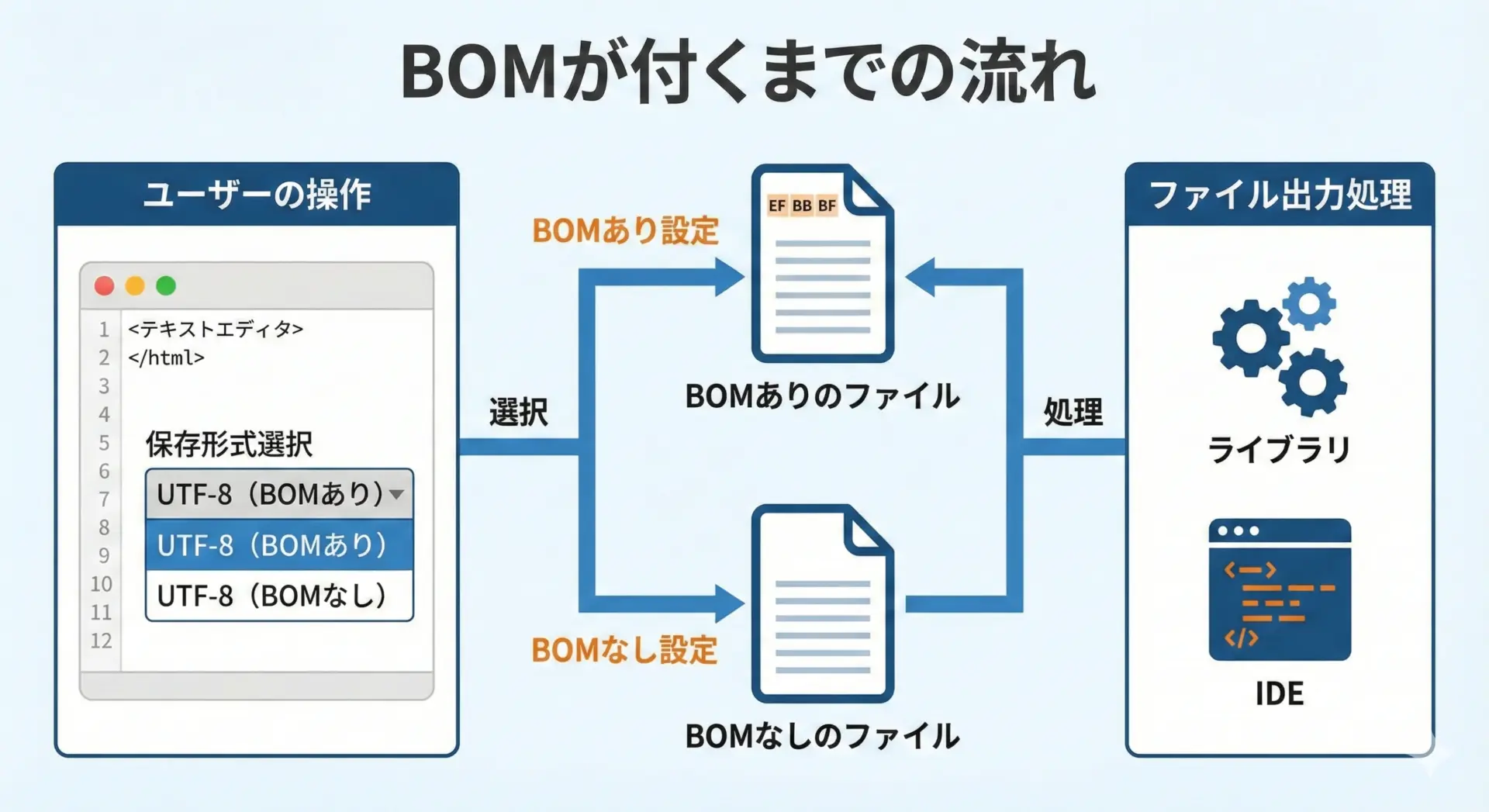
多くのテキストエディタでは、「UTF-8」「UTF-8 (BOM付き)」といった選択肢を明示的に切り替えられます。
一方で、初期設定のまま使っていると気付かないうちにBOM付きで保存されていることも少なくありません。
BOMが付くファイルと付かないファイルの違い
BOMが付くかどうかで、ファイルの「中身の先頭」が変化します。
UTF-8の場合、先頭に3バイト分のEF BB BFが入るかどうかだけが違いです。
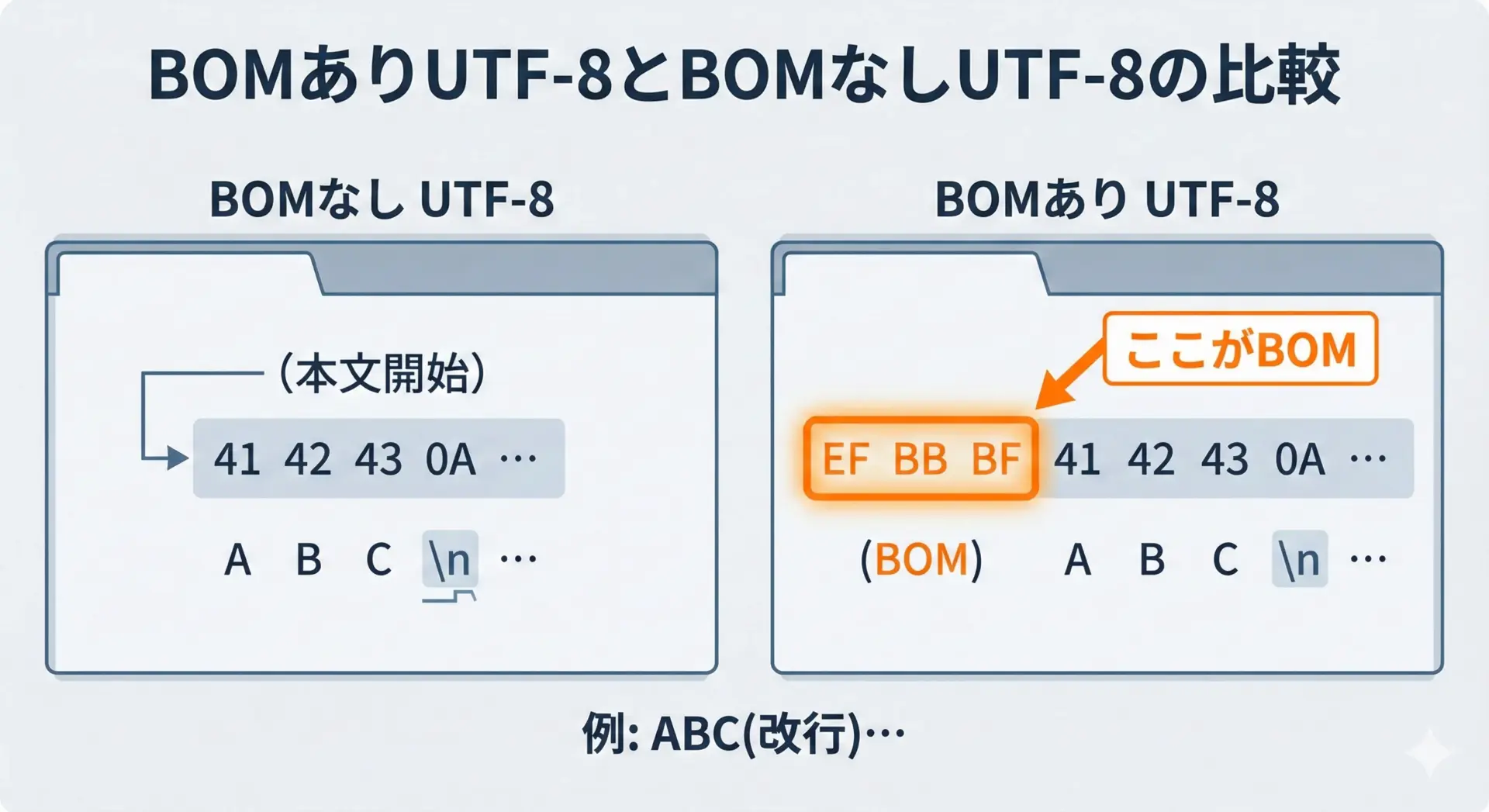
人間がエディタで開いて読む分には、BOMの有無は通常意識されませんが、機械がファイルを解釈する場面では、この3バイトがあるかどうかが挙動に影響を与えることがあります。
とくに次のような場面では、BOMの有無が差として顕在化します。
- プログラムソースコードとしてコンパイル・実行するとき
- スクリプト言語のインタプリタで読み込むとき
- バイナリ形式と組み合わせて使うとき(先頭数バイトに特定の意味を持たせるプロトコルなど)
BOMとUTF-8の関係
UTF-8におけるBOMのバイト列
UTF-8でのBOMは、固定の3バイトEF BB BFです。
この3バイト列は、UnicodeのU+FEFFという特殊なコードポイントをUTF-8でエンコードした結果に対応します。
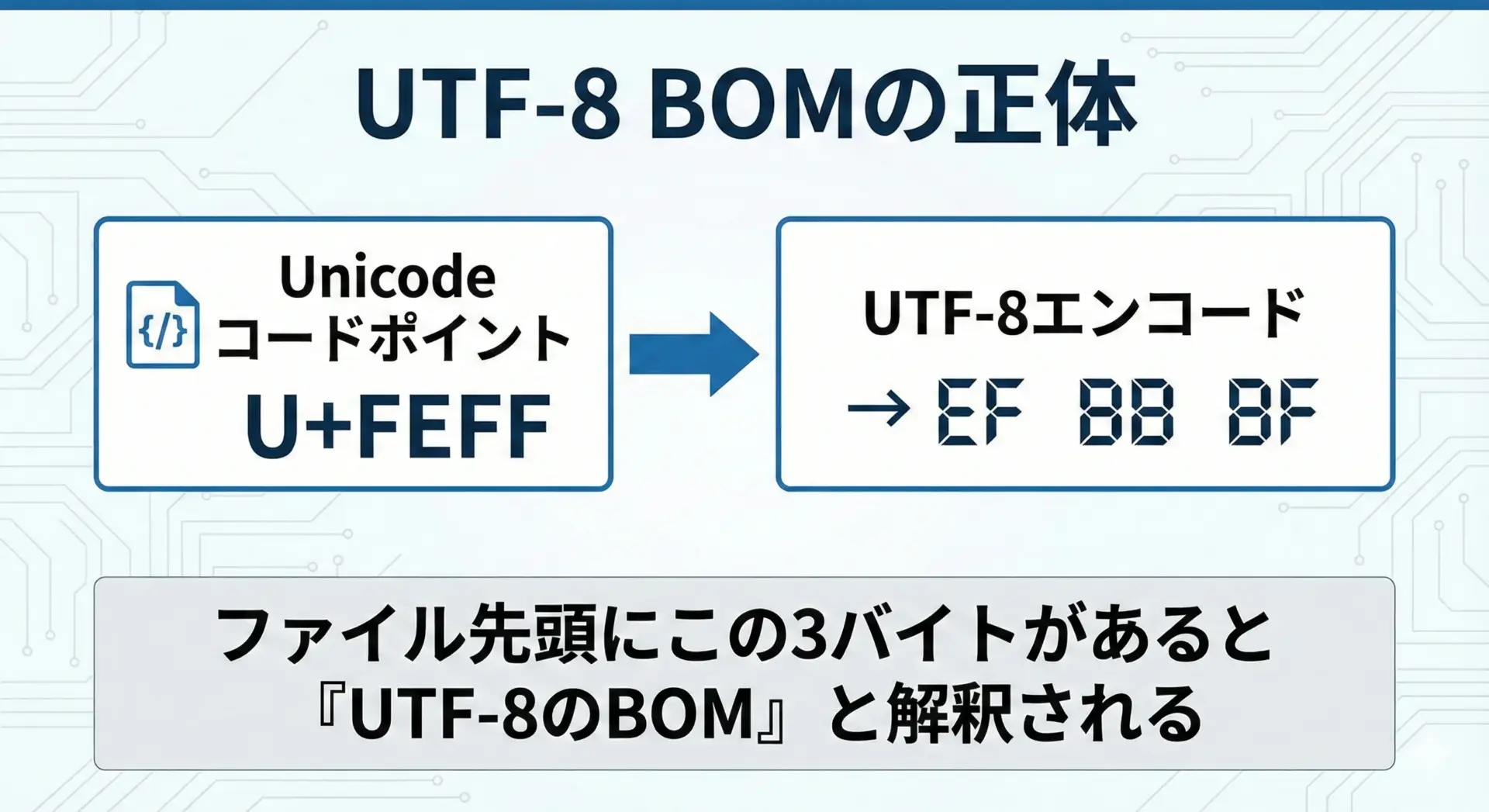
もともとU+FEFFは「ゼロ幅の非表示文字」として定義されていましたが、テキスト途中で使うことは禁止され、現在はBOM用途に限定されているという歴史的な背景があります。
UTF-8はBOMなしでも判別できる理由
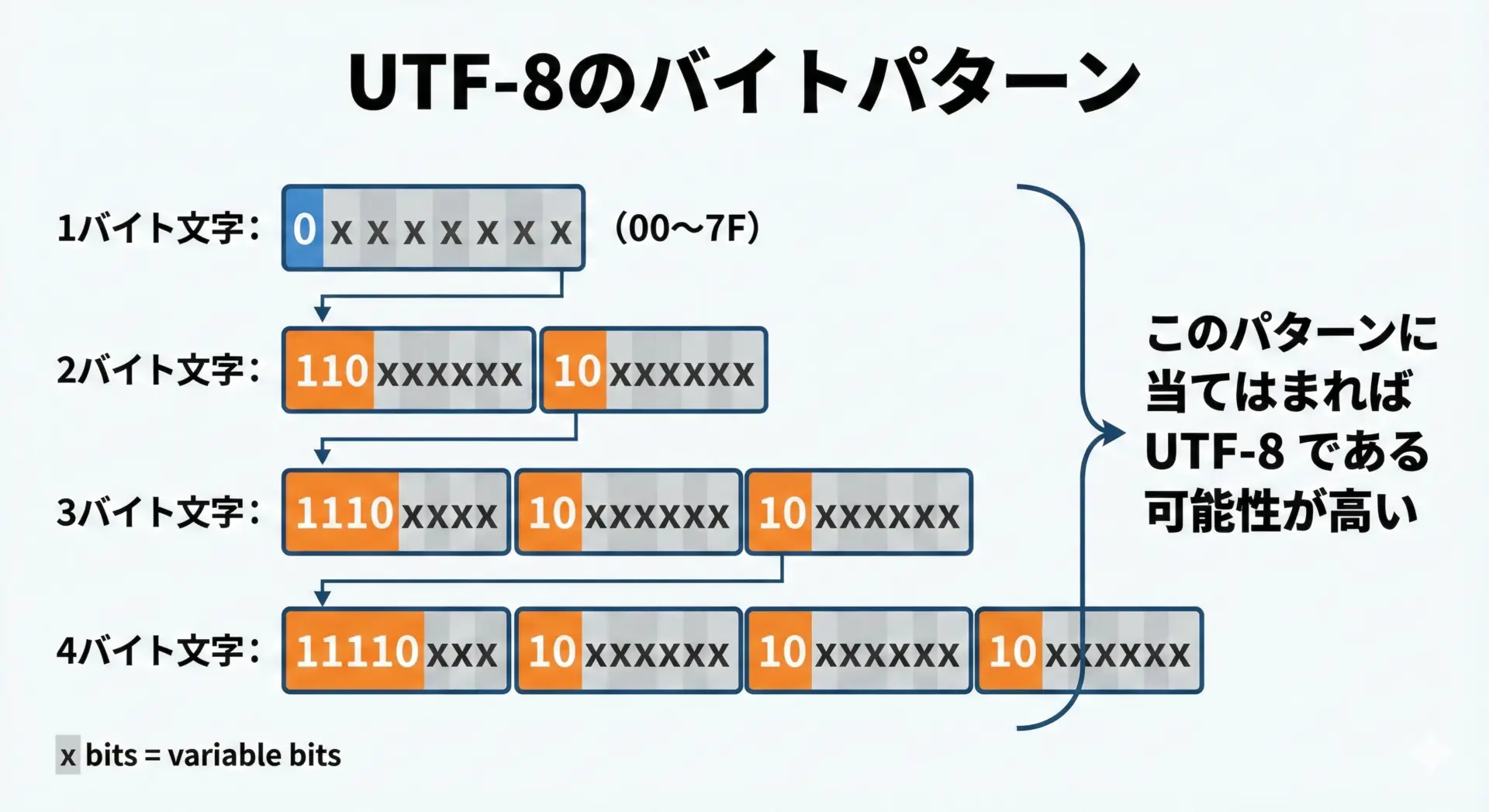
UTF-8は、BOMがなくてもパターンから判別しやすいように設計されています。
主な理由は以下の通りです。
- 1バイト文字は
00〜7Fの範囲(ASCII互換)に収まる - マルチバイト文字は
C2〜F4から始まり、続くバイトは80〜BFに限定される - その結果、「ASCIIテキスト」と「UTF-8テキスト」は多くの場合両立する
多くのエディタやブラウザは、実際のバイト列を読みながら「これはUTF-8っぽい」「これはShift_JISっぽい」と推測します。
そのため、UTF-8ではBOMが必須とされておらず、むしろBOMなしで使うのが一般的です。
UTF-16・UTF-32とBOMの違い
UTF-8と違い、UTF-16やUTF-32では、BOMがより重要な役割を持ちます。
これらは1コードポイントを2バイト(UTF-16)または4バイト(UTF-32)で表現するため、バイト順序(ビッグエンディアン/リトルエンディアン)が問題になります。
代表的なBOMは次の通りです。
| エンコーディング | エンディアン | BOMバイト列 |
|---|---|---|
| UTF-8 | なし(概念上) | EF BB BF |
| UTF-16 | BE | FE FF |
| UTF-16 | LE | FF FE |
| UTF-32 | BE | 00 00 FE FF |
| UTF-32 | LE | FF FE 00 00 |
UTF-16やUTF-32では、BOMがないと、同じバイト列でも全く異なる文字列として解釈されてしまう可能性があります。
そのため、これらのエンコーディングではBOMの有無が実質的に必須レベルで重要です。
一方で、UTF-8はエンディアンに依存しないため、BOMの意義は「このファイルはUTF-8ですよ」という宣言にとどまります。
BOM付きUTF-8で「何が変わる」のか
エディタでの表示や文字化けへの影響
一般的なテキストエディタやIDEは、UTF-8 BOMを正しく認識し、表示時にはBOMを見せないように実装されています。
この場合、ユーザーからはBOMの存在はほとんど意識されません。
しかし、すべてのツールがBOMを理解しているとは限りません。
古いツールや簡易なビューアでは、BOMをそのまま文字として表示してしまい、先頭に謎の文字が現れるケースがあります。
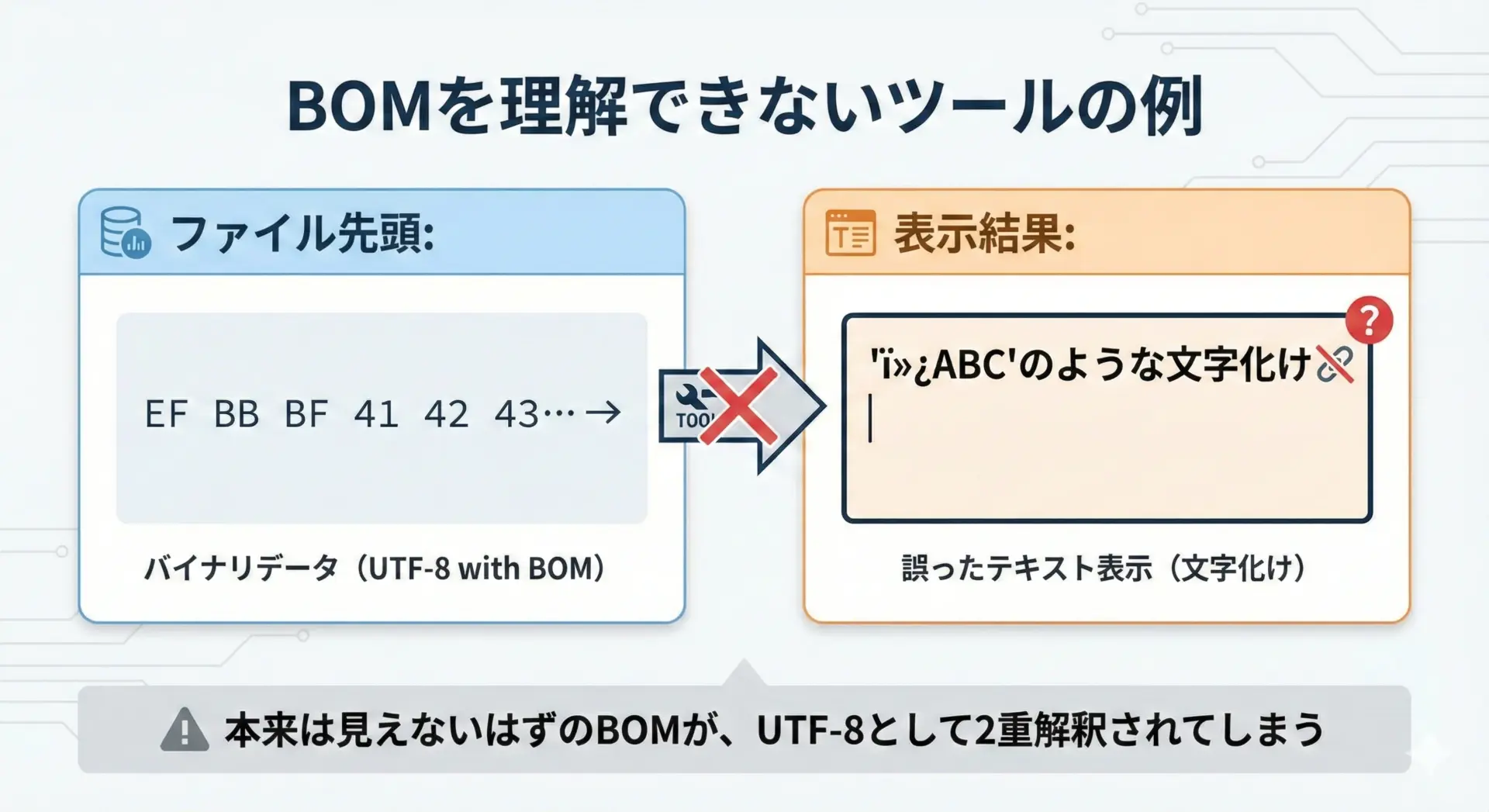
このような問題は最近では減っているものの、レガシーな環境や特殊なビューアを使うときには意識しておく必要があります。
Webブラウザの文字コード判定とBOM
Webの世界では、ブラウザがHTMLやCSSの文字コードをどのように判定するかが重要になります。
判定ルールは仕様である程度決まっており、その中にBOMも含まれています。
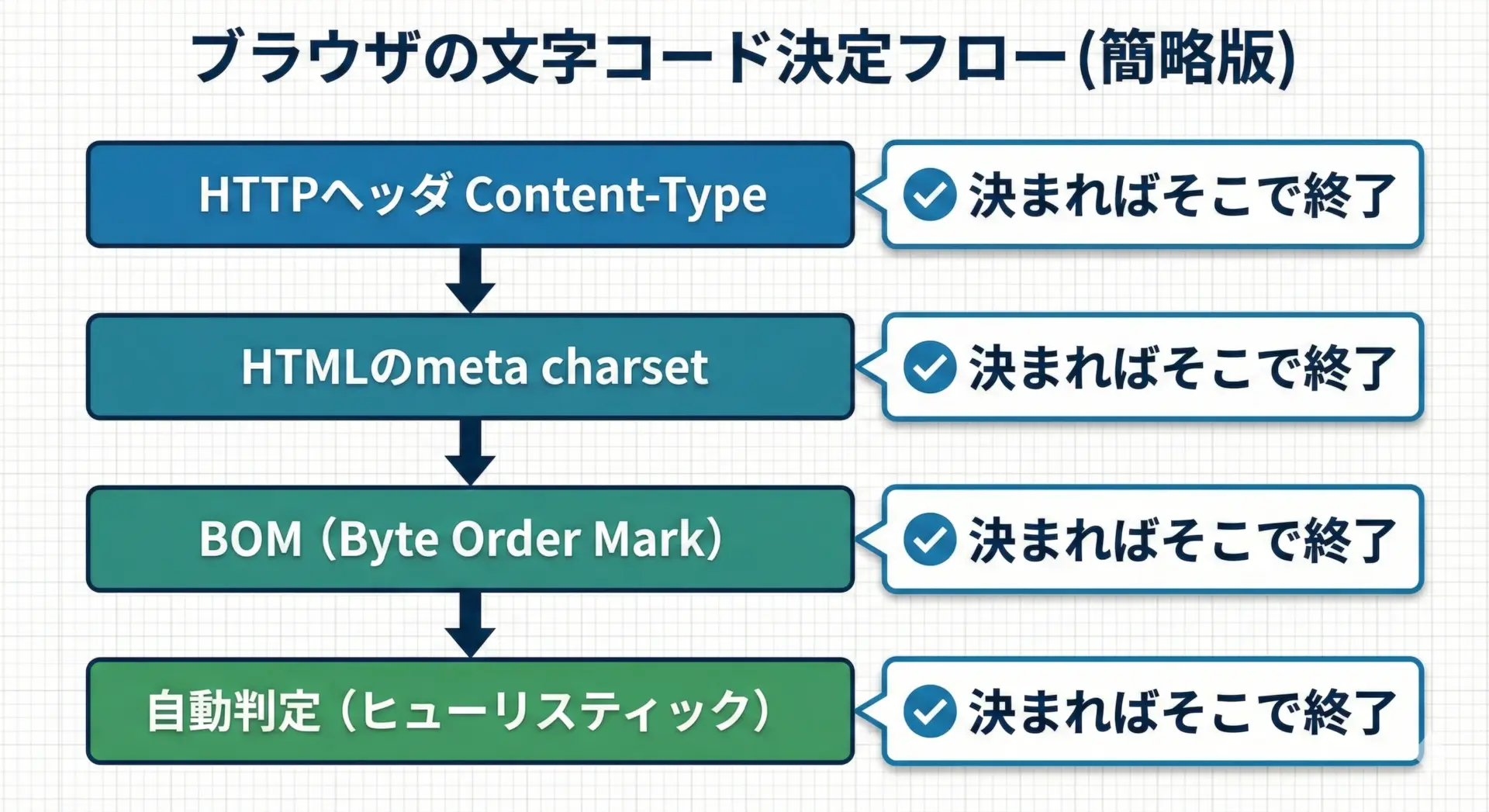
簡略化すると、ブラウザは次のような優先順位で文字コードを決めます。
- HTTPヘッダの
Content-Typeに含まれるcharset - HTML内の
<meta charset="..."> - ファイル先頭のBOM
- 内容を見ての自動判定
このため、UTF-8 BOMを付けておくと、HTTPヘッダやmetaタグが不十分な場合でもブラウザがUTF-8として解釈しやすくなるという利点があります。
一方で、最近ではサーバ設定やビルドツールでcharset=UTF-8を明示するのが一般的になっており、BOMに頼らずにUTF-8を宣言する構成が主流です。
シェルスクリプトやバッチでの実行エラー
BOM付きUTF-8が最もトラブルを起こしやすいのが、シェルスクリプトやバッチファイルです。
スクリプトは通常「1行目の先頭文字から」構文として解釈されるため、行頭に余計な3バイトがあるとパースに失敗することがあります。
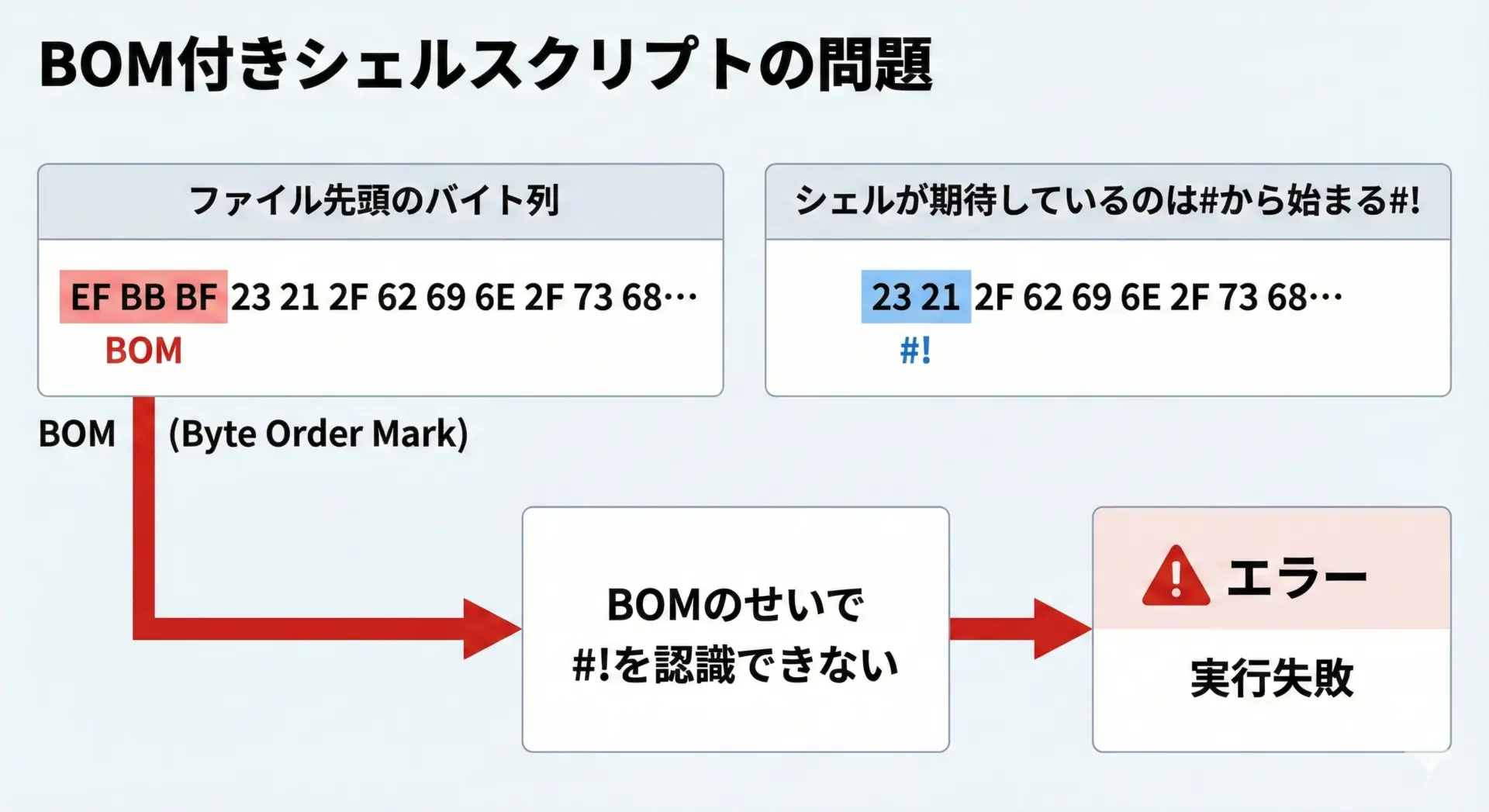
たとえば、Unix系環境での#!/bin/sh行(シバン)は、ファイルの先頭2バイトが#と!である必要があります。
ここにBOMが入ると、実際にはEF BB BF 23 21となってしまい、システムはこれをシバン行として認識できません。
Windowsバッチファイル(.bat, .cmd)でも、先頭のBOMがコマンド解釈を乱し、予期しないエラーを引き起こすことがあります。
そのため、スクリプトファイルは基本的に「UTF-8 (BOMなし)」で保存するのが実務上の定石です。
プログラムでの読み込み時に起こる不具合例
プログラムやライブラリがBOMに対応していない場合、BOMが通常の文字データとして扱われ、不具合の原因になることがあります。
具体的な例をいくつか挙げます。
- 設定ファイルの先頭キーが壊れる
INIやYAML, JSONなどの設定ファイルを自前のパーサで読み込むとき、EF BB BFをそのまま文字として受け取ってしまうと、最初のキー名の先頭に不可視文字が入り、「キーが見つからない」といった現象が起こります。
- CSVファイルの1列目に謎の文字が混入
Excelなどが出力したUTF-8 BOM付きCSVを、BOM非対応のCSVパーサで読み込むと、1行目1列目の値にBOMが付いたままになることがあります。これにより、カラム名の比較が失敗し、マッピングに不具合が出ます。
- HTTPレスポンスの先頭に余計なバイトが付く
Webアプリケーションがレスポンスボディを組み立てる際に、テンプレートファイルのBOMをそのまま送信してしまうと、JSONやXMLのパースエラーの原因になります。特にJSONは先頭に{や[が来ることを期待するため、その前にBOMがあると仕様上は不正な文書になります。
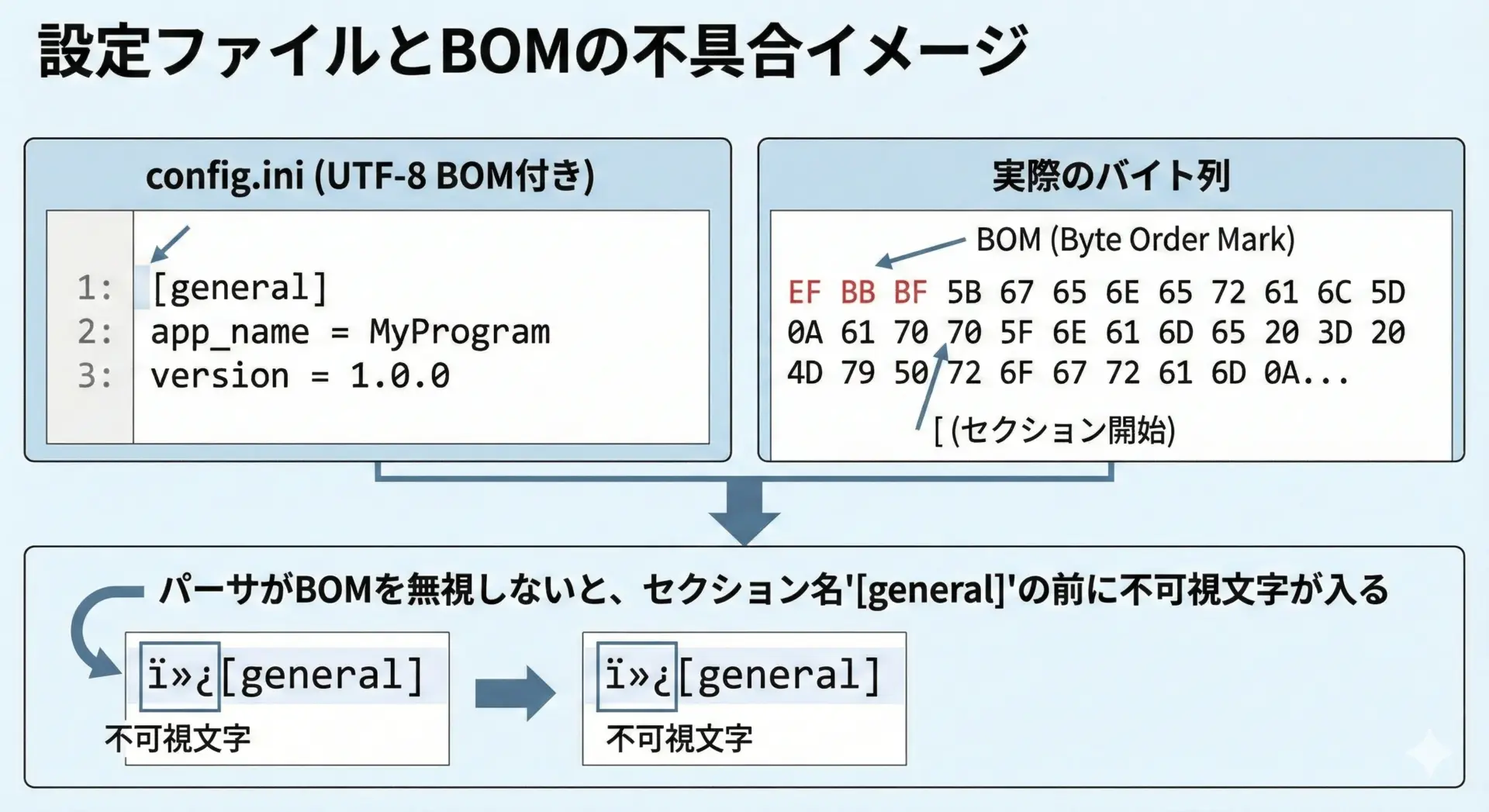
このような問題を避けるには、読み込み側でBOMを明示的に処理するか、そもそもBOMなしUTF-8を前提にするかのどちらかを、プロジェクトの方針として決めておくことが重要です。
BOMの扱い方と実践的な注意点
BOM付きとBOMなしを選ぶ判断基準
実務の観点からは、UTF-8のBOMをどう扱うかについて、次のような指針を持っておくと整理しやすくなります。
基本方針としては「UTF-8はBOMなしで運用し、例外的な用途のみBOM付きにする」ことが多いです。
BOMなしを推奨できるケース:
- ソースコード全般(C/C++, Java, JavaScript, Python, Go など)
- シェルスクリプト、バッチファイル、Makefileなど
- JSON, YAML, XML, CSVなどのデータ交換フォーマット
- 設定ファイル(アプリケーション構成ファイルなど)
BOM付きが有利になり得るケース:
- UTF-8を前提としていないレガシー環境で、「とにかくUTF-8だと気付いてほしい」場合
- Excelなど、BOM付きUTF-8を期待しているアプリケーションへの受け渡し用CSV
- Windows環境で、メモ帳(旧バージョン)などBOMに依存してUTF-8を判定するツールと連携するとき
ただし、近年は多くのツールや言語がUTF-8 (BOMなし)をデファクト標準として扱うようになっているため、「よほどの理由がなければBOMなし」という判断が現実的です。
エディタでBOMを付ける・外す設定方法のポイント
テキストエディタやIDEには、保存時のエンコーディングとBOMの有無を切り替える設定が用意されています。
具体的な操作はツールごとに異なりますが、共通して押さえるべきポイントは次の通りです。
- デフォルトの文字コードプロファイルを確認する
プロジェクトで統一したい設定(例: UTF-8, BOMなし)を、新規ファイルのデフォルトにしておきます。 - 既存ファイルのBOM有無を確認できるようにする
ステータスバーやファイル情報ビューにUTF-8 with BOM/UTF-8などと表示してくれる機能をオンにしておくと、誤保存に気付きやすくなります。 - 明示的な変換操作を覚えておく
ファイル単位で「BOM付きUTF-8 → BOMなしUTF-8」に変換する機能を把握しておき、スクリプトや設定ファイルをコミットする前に確認するようにします。
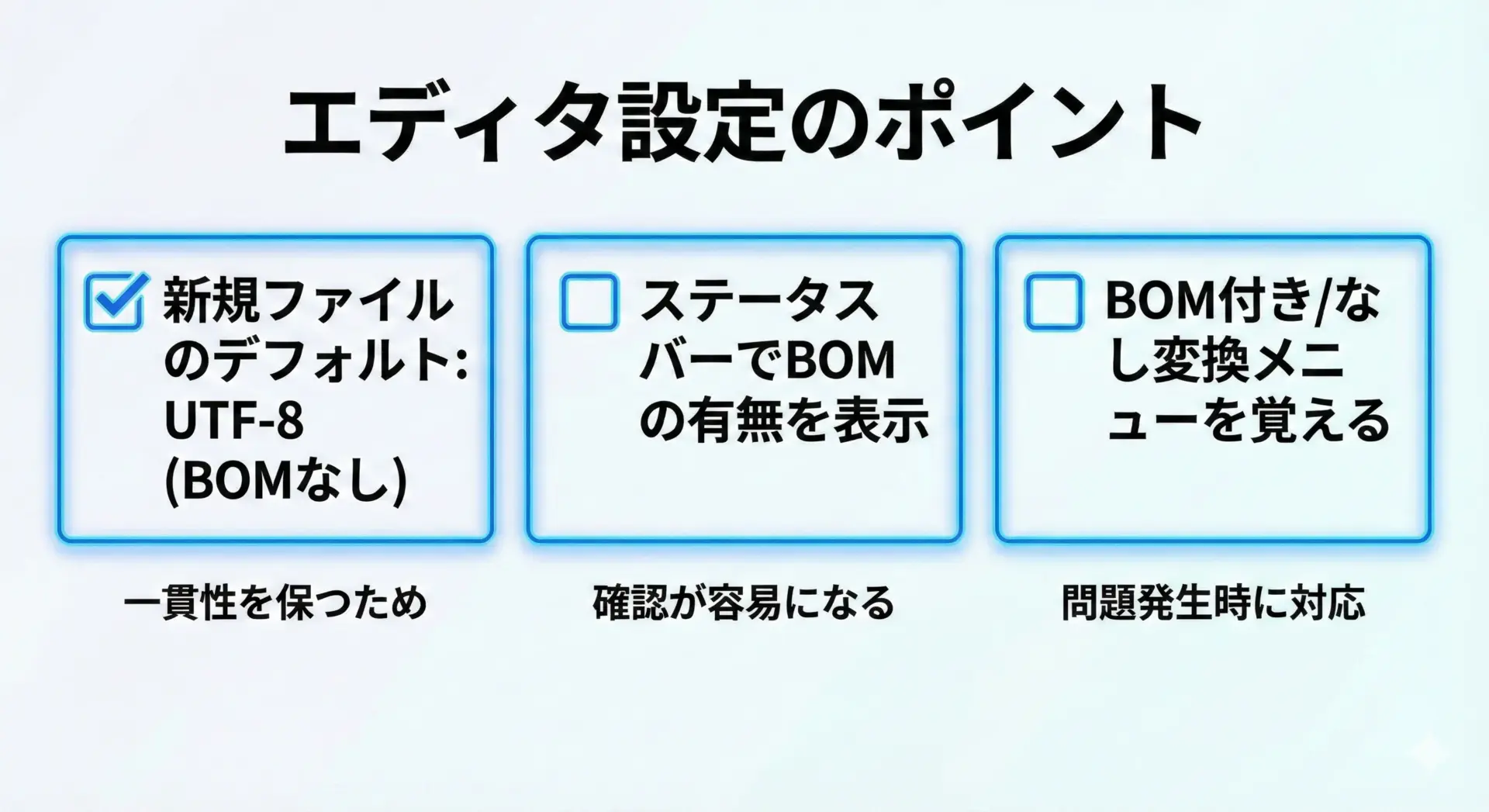
具体的な手順は、VS CodeやIntelliJ、Vim、Emacsなどツールごとに大きく異なりますが、「プロジェクトとしてBOMポリシーを決め、エディタ側を合わせる」という発想が重要です。
Gitや差分ツールでのBOMの扱い
バージョン管理システムや差分ツールでも、BOMはときに「ノイズ」となります。
UTF-8 BOMは先頭3バイトの差分として認識されるため、次のような問題を引き起こすことがあります。
- ファイルをBOM付きで保存し直しただけで、大きな差分が出たように見える
- 差分ツールがテキストと見なせず、バイナリとして扱ってしまう
- 1行目の変更として常にハイライトされてしまい、実質的な差分が見づらくなる

これらを避けるために、Gitでは次のような運用が考えられます。
- .gitattributesで特定の種類のファイル(スクリプト、設定ファイルなど)を「UTF-8 (BOMなし)」で統一するルールを決める
- レビューのルールとして「BOMの追加/削除だけの変更を避ける」「必要であればコミットメッセージで明記する」
プロジェクト全体で「UTF-8はBOMなしで統一する」と決めておけば、BOMに起因する差分ノイズを大幅に減らすことができます。
プログラムからBOMを検出・削除する基本方針
既にBOM付きのファイルが存在しており、それをプログラムで扱わざるを得ない場面もあります。
その場合、読み込み処理の入口でBOMを検出して取り除いておくのが基本方針です。
手順のイメージは次の通りです。
- ファイル先頭の数バイトを読み込む
EF BB BF(UTF-8 BOM)に一致するかチェックする- 一致すれば、その3バイトをスキップして残りをテキストとして扱う
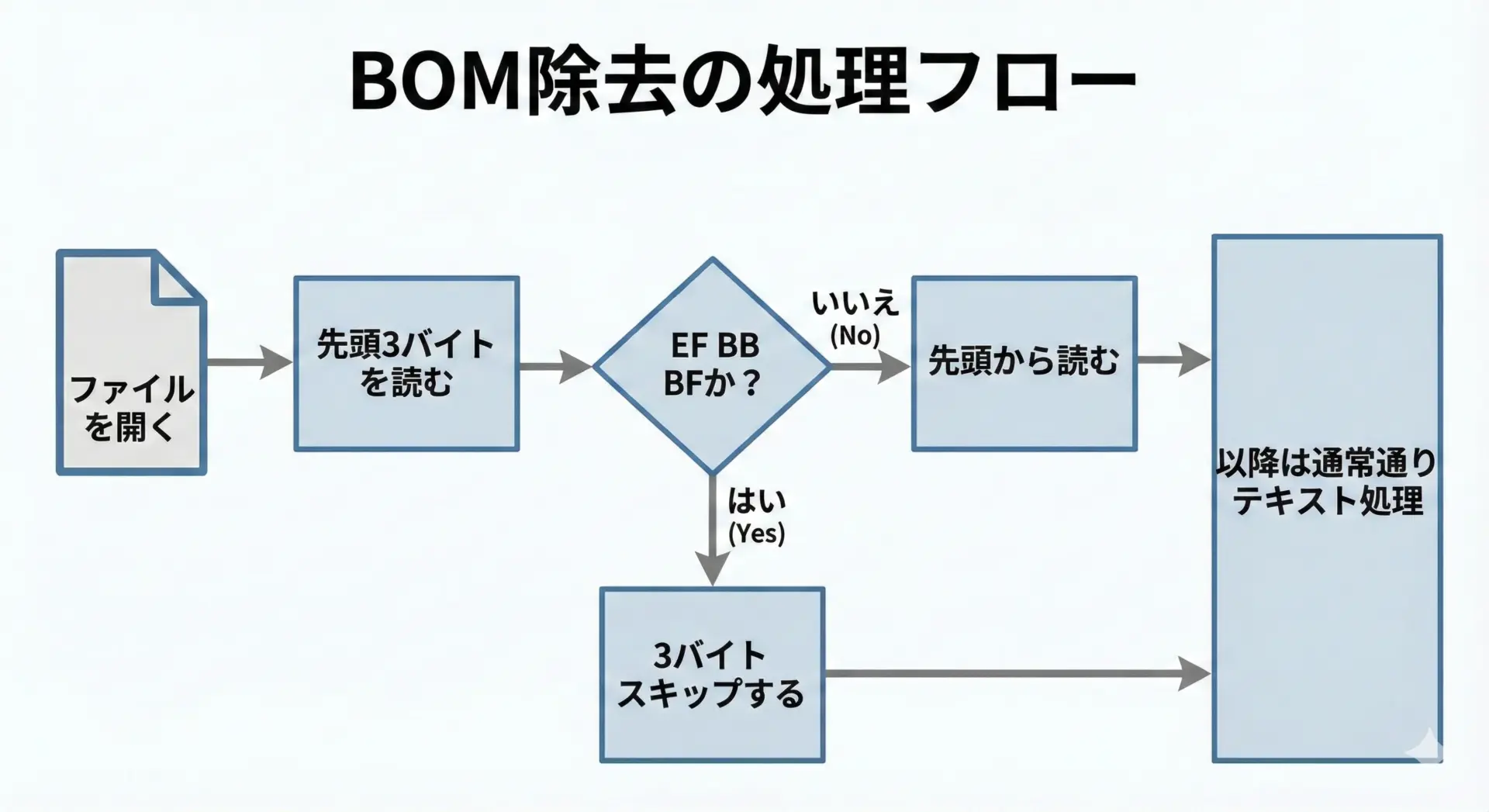
言語やフレームワークによっては、BOMを自動的に処理してくれるAPIが用意されています。
その場合は、そのAPIを利用するのが最も安全です。
自前で処理する必要があるときは、次の点に注意します。
- UTF-8以外のBOM(UTF-16, UTF-32)も考慮するかどうかを、要件に応じて決める
- バイナリフォーマットに対して誤って「BOM除去」を行わないように、対象ファイルを明確に限定する
- 読み込みと同時に「内部表現はUTF-8(BOMなし)に正規化する」という方針で統一する
このように、BOMは「入口で正しく扱い、内部では存在しない前提にしておく」と、後続処理でのトラブルを大幅に減らすことができます。
まとめ
BOM(Byte Order Mark)は、テキストファイルの先頭に付く「このファイルはどのUnicodeエンコーディングか」を示す目印です。
UTF-16やUTF-32ではバイト順序の判別に不可欠な存在ですが、UTF-8におけるBOMは必須ではなく、「あってもなくてもよい」ものとして位置付けられています。
しかし、UTF-8 BOMが付いているかどうかは、次のような点で実際の挙動に影響を与えます。
- 古いエディタやビューアで、BOMが文字化けとして見えてしまう
- ブラウザの文字コード判定に影響し、UTF-8として認識させやすくなる
- シェルスクリプトやバッチファイルで、先頭行の解釈を壊し実行エラーを引き起こす
- 設定ファイルやCSV、JSONなどで、先頭キーやカラム名に不可視文字が混入し、バグの原因になる
こうした事情から、現代の開発現場では「UTF-8はBOMなし」を標準とし、例外的な用途に限ってBOM付きUTF-8を選ぶという方針が主流になっています。
その上で、エディタの設定やGitの運用、プログラム側の読み込み処理を通して、BOMを「正しく理解し、必要に応じて検出・除去できる」状態を整えておくことが重要です。
BOMの仕組みと影響範囲を一度きちんと整理しておけば、「BOM付きUTF-8って何が違うの?」という疑問に迷わされることはぐっと少なくなります。
今後は、プロジェクトの方針やツール設定を決める際に、ここで紹介したポイントを踏まえてBOMの扱いを検討してみてください。
