
プログラムを書いていて、日本語が「???」や「ア・テスト」のように崩れてしまった経験はないでしょうか。
原因は多くの場合、難しいバグではなく文字コードの食い違いです。
本記事では、はじめて文字化けに遭遇した人でも理解しやすいように、仕組みからよくある原因、そしてシンプルで実践しやすい直し方までを順番に解説していきます。
文字化けとは何かを理解しよう
文字化けとは
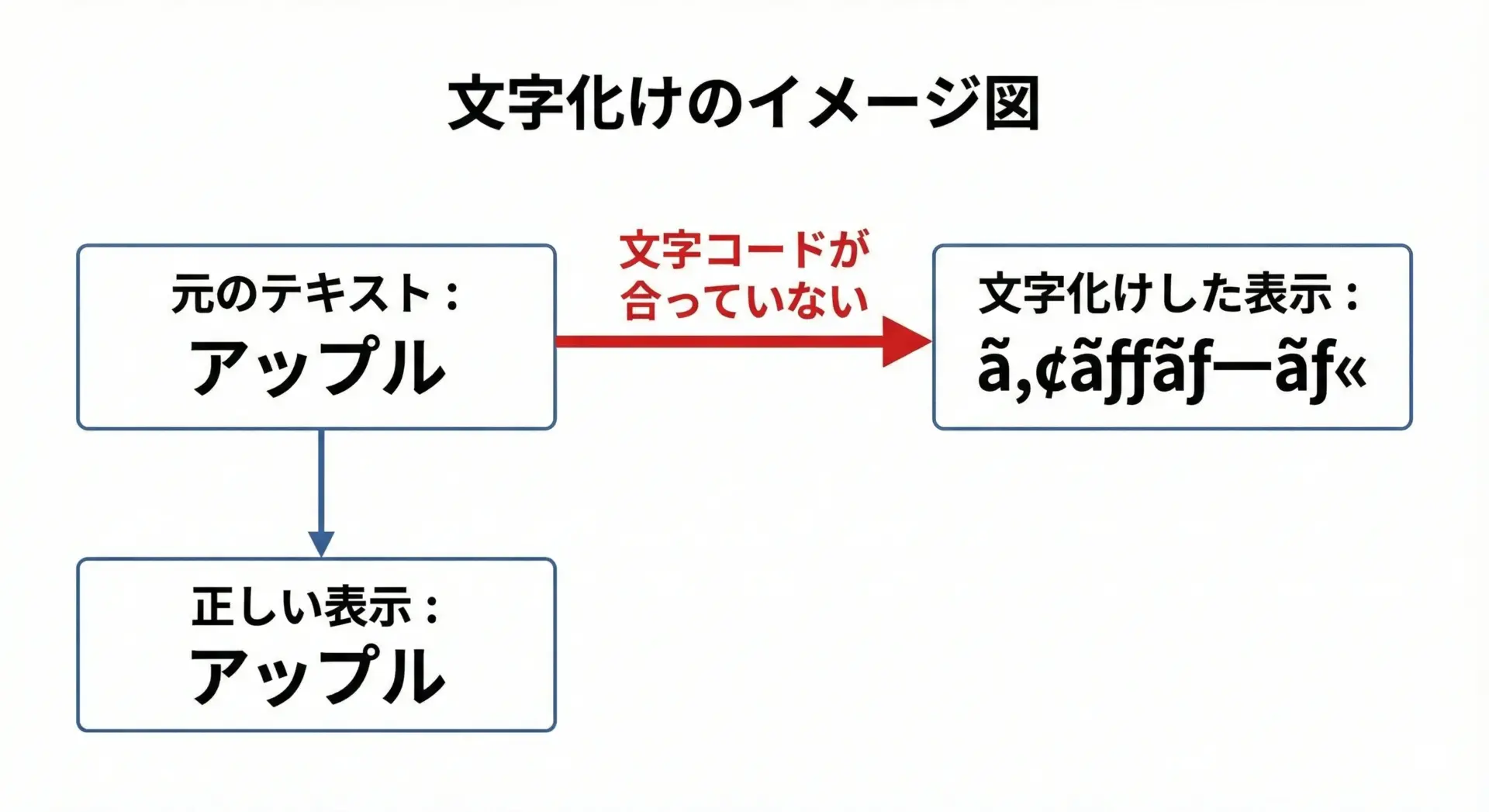
文字化けとは、本来表示したい文字列が、意味不明な記号や文字列に置き換わってしまう現象のことです。
日本語テキストを扱うときに頻繁に起きやすく、「さっきまで大丈夫だったのに、急に表示がおかしくなった」という形で現れることが多いです。
この現象は、文字そのものが壊れたというよりも、「どうやって文字を数値として扱うか」というルールが合っていないことによって起こります。
つまり、送り手と受け手で「文字コードの約束ごと」がずれている状態です。
文字コードとエンコーディングの基本
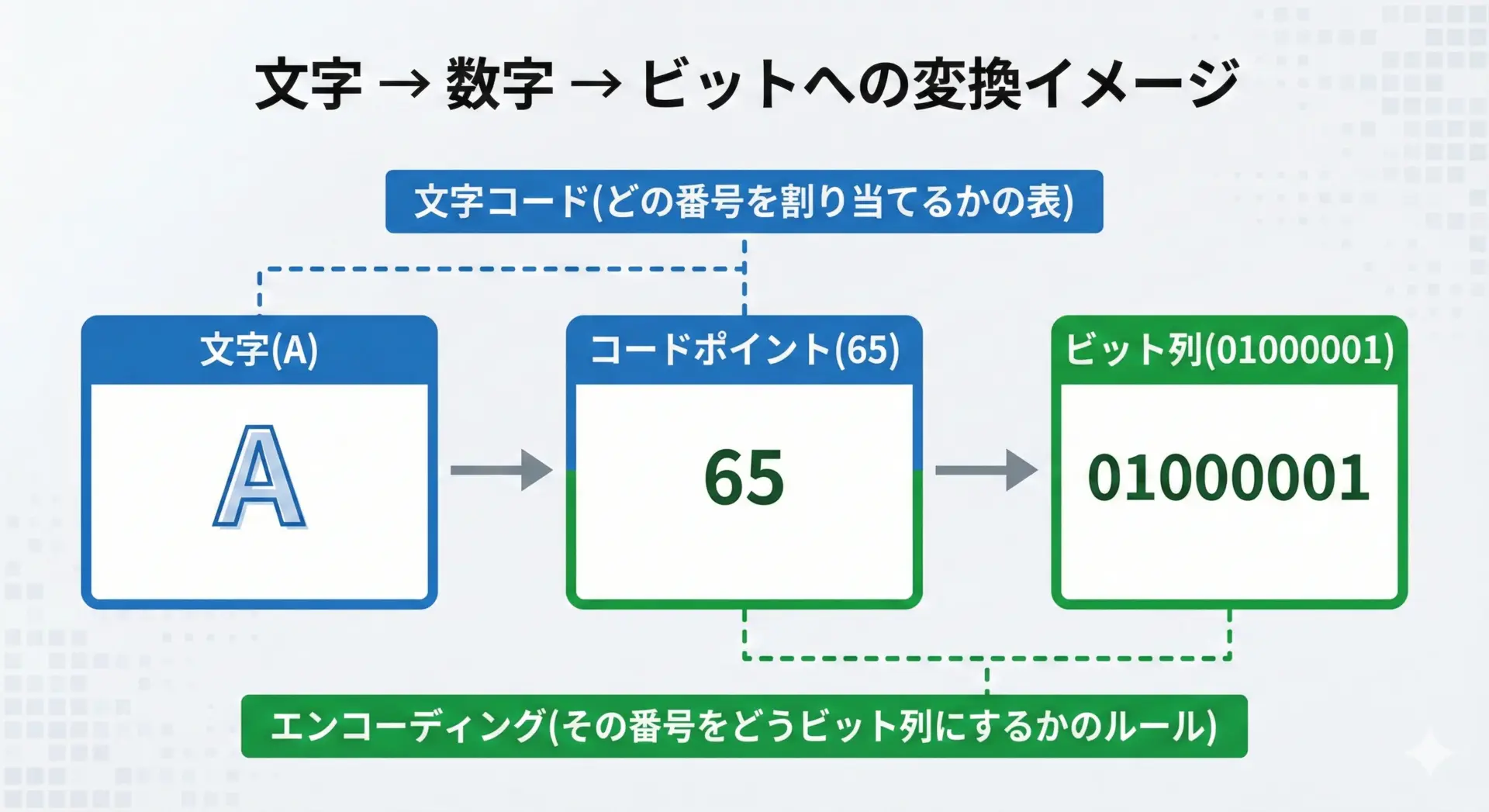
コンピュータは文字をそのまま扱えないため、文字に番号(数値)を割り当てて管理しています。
この番号を決めた表が文字コード(キャラクタセット)です。
有名な例として ASCII や Unicode があります。
一方、エンコーディング(符号化方式)は、「その番号をどのようなビット列として保存・通信するか」というルールです。
例えば、同じ Unicode の番号でも、UTF-8 と UTF-16 では保存されるビット列が異なります。
- 文字コード(キャラクタセット):
- どの文字に何番の番号を振るかの一覧表
- 例: Unicode では「A」は U+0041、「あ」は U+3042
- エンコーディング(符号化方式):
- 上記の番号を、実際のファイルや通信でどんなビット列にするかの方式
- 例: UTF-8, UTF-16, Shift_JIS など
文字化けの多くは、「このファイルは UTF-8 ですよ」と伝えているのに、ブラウザが「Shift_JIS だな」と勘違いして解読してしまうことで発生します。
よく出る文字コード
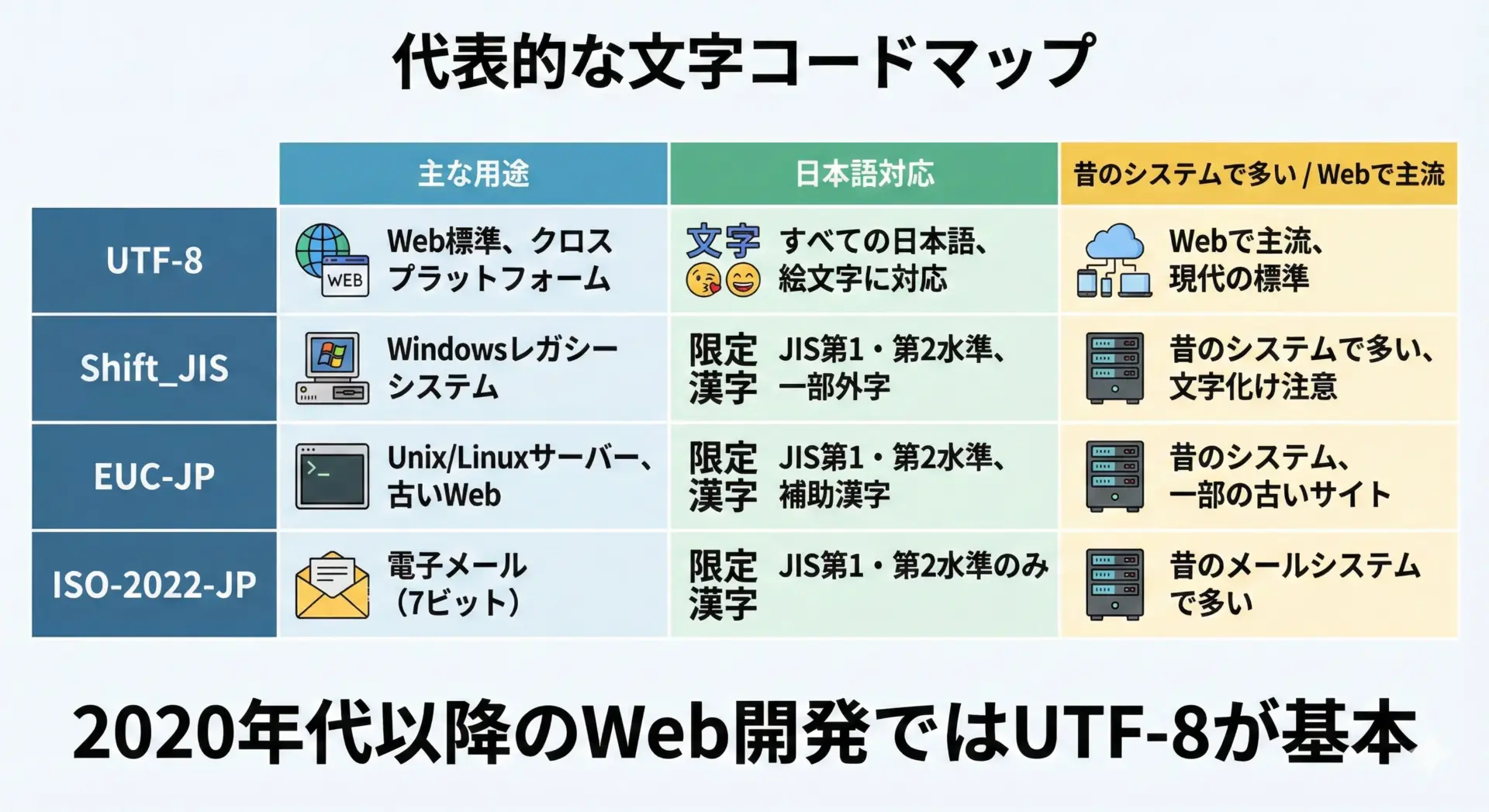
代表的な文字コードとして、次のようなものがあります。
- UTF-8
現在の Web 開発では事実上の標準となっているエンコーディングです。Unicode を可変長のバイト列で表現し、ASCII と後方互換があります。新規開発では、基本的に UTF-8 一択と考えて問題ありません。 - Shift_JIS
かつて日本語環境で広く使われていた文字コードです。Windows 系の古いアプリや、古い社内システムで今でも見かけることがあります。UTF-8 と Shift_JIS の取り違えは、現在でもよくある文字化け原因です。 - EUC-JP, ISO-2022-JP
主に古い UNIX 系環境や、メール関連の仕様で使われてきた文字コードです。最近の新規プロジェクトで採用されることは少ないものの、レガシーシステムとの連携時に遭遇するケースがあります。
このように、日本語を表現できる文字コードが複数存在していることが、文字化けトラブルの温床になっています。
文字化けの主な原因を知る
文字コードの不一致が起こるパターン
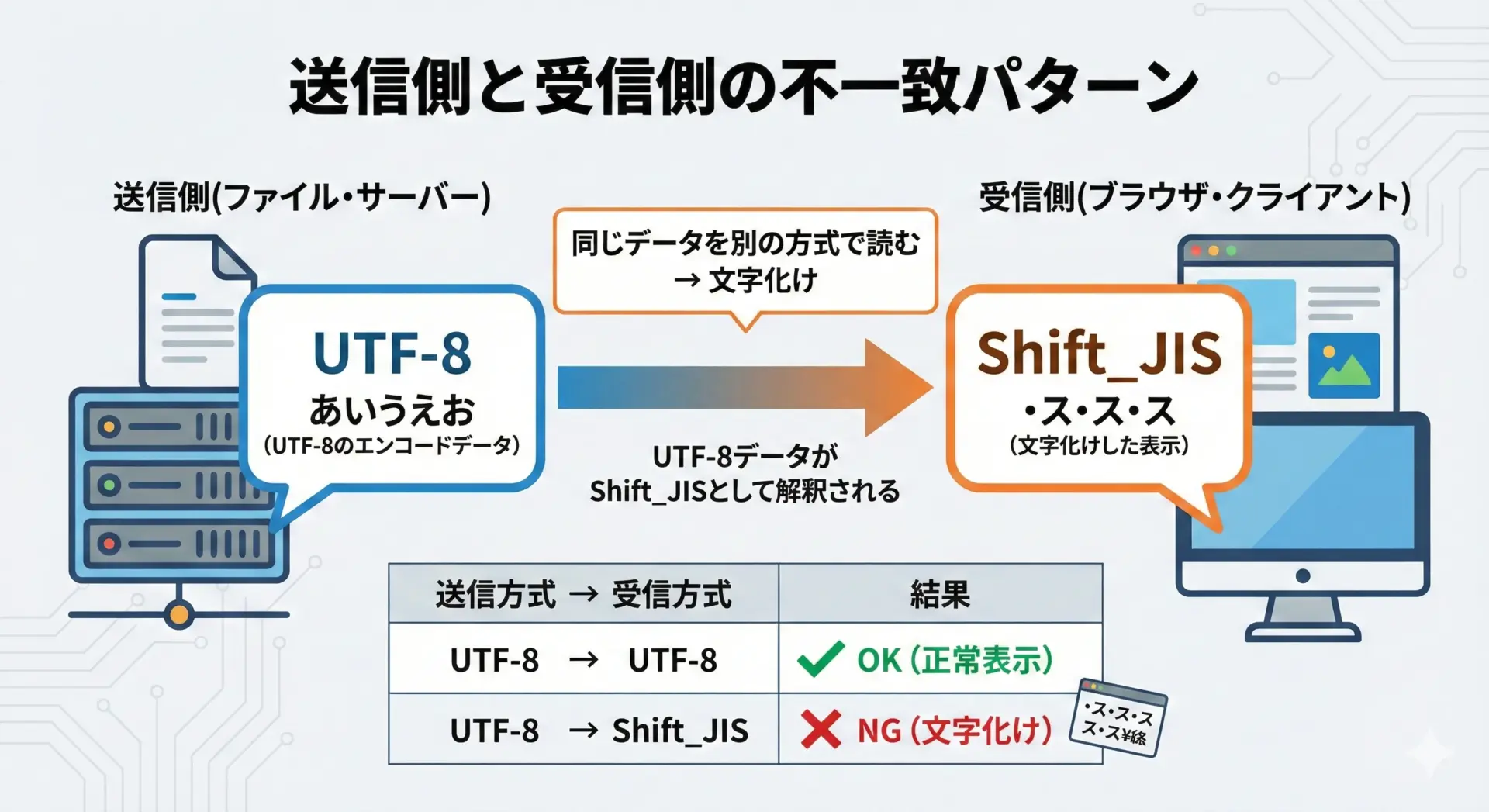
文字化けの根本原因はシンプルで、「書かれた文字コード」と「読もうとしている文字コード」が一致していないことです。
つまり、送り手は UTF-8 で保存したのに、受け手が Shift_JIS として読み込んでしまうなど、解釈ルールのズレが発生しています。
この不一致は、ファイルの保存時、ブラウザの解釈時、サーバーのレスポンスヘッダ、データベースの接続設定など、さまざまなレイヤーで起こりえます。
そのため、どこか1箇所でも違う文字コードが混ざると文字化けが発生すると考えてください。
ファイル保存時の文字コード設定ミス
エディタでソースコードやテキストファイルを保存するとき、文字コードを明示的に選べる場合が多くあります。
ここで無意識のうちに Shift_JIS や EUC-JP を選んでしまったり、デフォルト設定が UTF-8 になっていないと、後から他のツールで開いたときに文字化けが発生します。
特に、次のようなケースで起きやすいです。
- チームメンバーごとにエディタのデフォルト文字コード設定がバラバラ
- 古いテンプレートファイルをコピーして編集し、そのテンプレートが Shift_JIS だった
- エディタで「BOM あり UTF-8」と「BOM なし UTF-8」が混在している
まずは「自分のエディタが何で保存しているか」を理解し、プロジェクト内で統一することが重要です。
ブラウザ表示時の文字コード指定ミス
HTML をブラウザで表示するときは、ブラウザが「このページは何の文字コードか」を判断します。
その判断材料は主に次の2つです。
- HTTPレスポンスヘッダの
Content-Typeのcharsetパラメータ - HTML 内の
<meta charset="...">タグ
もし HTML ファイルそのものは UTF-8 で書かれているのに、サーバーが charset=Shift_JIS を返していたり、<meta charset="EUC-JP"> と書かれていれば、ブラウザはその指定に従って誤った解釈をしてしまいます。
逆に、これらの情報が欠けていると、ブラウザは「自動判別」を試みますが、完全ではないため、特に日本語ページで誤判定による文字化けが起こりがちです。
サーバーとファイルの文字コード差異
Web アプリケーションでは、
- テンプレートファイル(HTML, テキスト)
- アプリケーションコード(PHP, Ruby, Python, JavaScriptなど)
- サーバー設定(Apache, Nginx など)
- フレームワークのデフォルト設定
がそれぞれ文字コードに関する設定を持っている場合があります。
例えば、次のような組み合わせで文字化けが起こります。
- テンプレートは UTF-8 で保存している
- しかし Apache の設定で
AddDefaultCharset Shift_JISが有効になっている - 結果として、サーバーヘッダは Shift_JIS と宣言してしまい、ブラウザ側で文字化け
また、PHP などでは内部文字エンコーディングの設定や、マルチバイト対応関数の設定値がずれていると、文字列操作の途中で予期せぬ変換が行われ、文字化けにつながるケースもあります。
コピペで起こる文字化け
意外と多いのが、コピー&ペーストによる文字化けです。
特に以下のような場面が危険です。
- ブラウザ上のフォームに入力された文字を、そのままコンソールや別ツールへコピペ
- Word, Excel などオフィスソフトからソースコードや設定ファイルへコピペ
- チャットツールやメールから設定ファイルへ貼り付け
このとき、コピペ元とコピペ先のアプリケーションで文字コードやフォントが異なると、貼り付けた結果が文字化けしたり、見た目は同じでも別の文字(全角・半角違い、似た文字)が混入することがあります。
特に、中黒(・)、全角スペース、機種依存文字(丸付き数字、特殊記号)などは化けやすく、設定ファイルやコード中に混入すると予期せぬ挙動を招きます。
外部ライブラリやAPIレスポンスの文字コード違い
自分のアプリケーションはすべて UTF-8 で統一していても、外部のライブラリやAPIのレスポンスが別の文字コードで返ってくるケースがあります。
例えば、
- 古い日本の Web API が Shift_JIS で JSON を返す
- 外部ライブラリが内部的に EUC-JP を使っている
- CSV ダウンロード API が Shift_JIS でエクスポートする仕様
などです。
これらを UTF-8 前提の処理にそのまま流し込むと、途中で文字化けしたままデータベースに保存されるなど、状況が複雑になりがちです。
この場合は、「受け取った瞬間に期待する文字コードに変換しておく」ことが重要になります。
開発環境別の文字化け対策
エディタでの文字コード設定の確認と変更
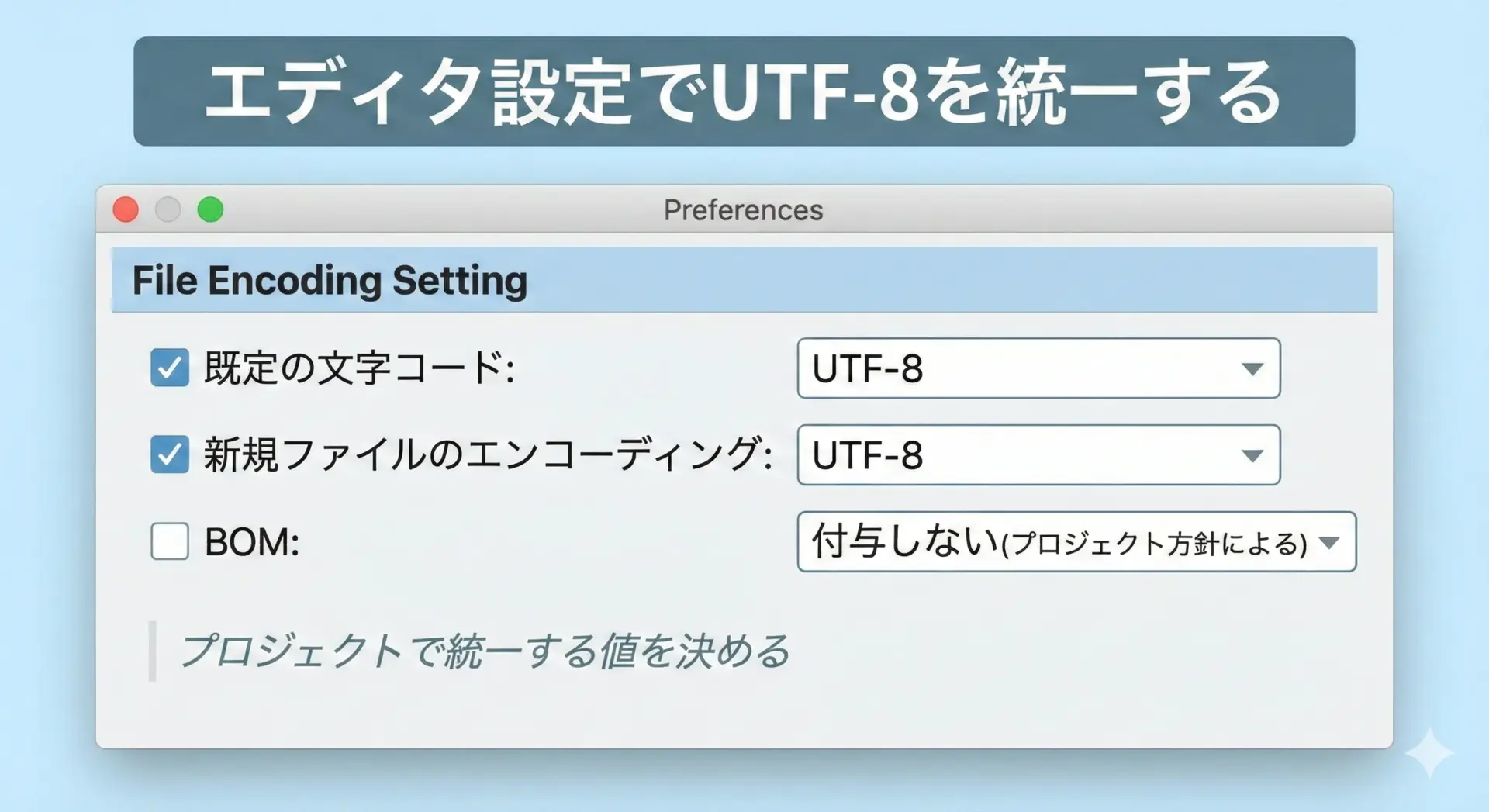
文字化け対策の第一歩は、開発で使用するエディタの文字コード設定を統一することです。
代表的なポイントは以下の通りです。
- デフォルト文字コードを UTF-8 にする
新規ファイル作成時や、文字コード不明なファイルを開くときのデフォルトを UTF-8 に設定します。 - BOM の扱いを決める
UTF-8 には「BOM あり」と「BOM なし」があります。Web 開発では「BOM なし UTF-8」を標準にするケースが多いため、プロジェクトとして方針を決めておくと安心です。 - ファイル個別の文字コードを確認する
既存ファイルを開いたとき、エディタが画面のどこかに「UTF-8」「Shift_JIS」などと表示しているはずです。怪しいファイルは、ここを必ずチェックします。
エディタ側で一元管理しておけば、「誰かだけShift_JISで保存していた」という事故をかなり防げます。
HTMLでの文字コード指定

HTML ページでは、必ず文字コードを明示的に指定しましょう。
最もシンプルで推奨される書き方は次の通りです。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>サンプルページ</title>
</head>
<body>
...
</body>
</html>ポイントは、<head> の先頭付近で <meta charset=”UTF-8″> を指定することです。
これにより、ブラウザはページの読み込み開始時点で「UTF-8 だ」と判断できます。
古い書き方である
<meta http-equiv="Content-Type" content="text/html; charset=Shift_JIS">のような記述は、新規開発では避け、UTF-8 に置き換えることをおすすめします。
CSSやJavaScriptで気をつけるポイント
CSS や JavaScript ファイルも、基本的には UTF-8 で保存するのが安全です。
特に日本語コメントや日本語の文字列リテラルを含む場合、文字コードが揃っていないと、ブラウザやツールチェーンのどこかで文字化けする可能性があります。
注意すべき点としては、次のようなものがあります。
- ビルドツール(webpack, Vite など)やトランスパイラ(Babel, TypeScript)の入出力エンコーディング設定
- CSS や JS を動的に生成するサーバーサイドのテンプレートエンジンの文字コード
- JS 内で扱う AJAX / Fetch API のレスポンス文字コード(特にテキストレスポンス)
フロントエンドのすべての静的ファイルを UTF-8 に統一しておくことで、後からのトラブルをかなり軽減できます。
サーバー設定での文字コード指定

Web サーバー(Apache, Nginx など)やアプリケーションフレームワークは、HTTP レスポンスヘッダに文字コードを含めて返します。
ここが HTML 内の設定や実際のファイルの文字コードと一致していないと、文字化けの原因になります。
たとえば Apache では、次のような設定があります。
AddDefaultCharset UTF-8古い設定のままだと、ここが Shift_JIS になっている場合があります。
アプリケーションが UTF-8 を前提としているなら、サーバーも UTF-8 に統一しましょう。
フレームワーク(Rails, Laravel, Spring, Express など)を使っている場合も、デフォルトのレスポンス文字コードが何かをドキュメントで確認し、HTML・テンプレートファイル・サーバー設定と整合性をとることが重要です。
データベースの文字コード設定
データベース(MySQL, PostgreSQL など)も、内部の文字セットとクライアント接続時の文字セットを持っています。
ここがずれると、保存時あるいは取得時に文字化けが発生します。
代表的な注意ポイントは次の通りです。
- データベース全体の文字セット(例: MySQL の
character_set_server) - テーブル・カラムごとの文字セット(例:
utf8mb4に統一) - クライアント接続時の文字セット(例:
SET NAMES utf8mb4;)
特に MySQL では、「utf8」と「utf8mb4」が別物であることに注意が必要です。
絵文字などを含めた日本語を安全に扱うなら、utf8mb4 を選択するのが現在のベストプラクティスです。
コンソール(ターミナル)での文字化け対策
コンソールやターミナルでも、フォント設定と文字コード設定が関わります。
特に Windows 環境では、次のような状況で文字化けしやすいです。
- コマンドプロンプトの既定コードページが Shift_JIS(CP932)
- Git や各種 CLI ツールは UTF-8 を出力している
- 結果として、日本語のログやファイル名が文字化け
対策としては、
- ターミナルの文字コードを UTF-8 に変更する
- あるいはツール側を Shift_JIS 出力に合わせる(推奨度は低い)
などがあります。
最近の Windows Terminal や VS Code の統合ターミナルでは、UTF-8 を前提とした設定が推奨されているため、環境構築時に最初に見直しておくとよいでしょう。
Gitでの日本語文字化け(ログ・ファイル名)対策
Git でも、日本語のコミットメッセージやファイル名が文字化けすることがあります。
特に Windows 環境では、
- Git が UTF-8 を扱う
- コンソールが Shift_JIS 前提
- さらに Git 設定
core.quotepathの影響
などが絡み合います。
代表的な対策としては、
- Git の出力を UTF-8 に固定し、ターミナルを UTF-8 に揃える
git config --global core.quotepath falseで日本語ファイル名を読みやすくする
などが挙げられます。
「Git は UTF-8が前提」という前提を押さえ、クライアント側の設定を合わせにいくと覚えておくと整理しやすくなります。
文字化けトラブルのシンプルな直し方手順
まず確認するチェックリスト
文字化けが起きたときに、いきなりあちこち設定を変えるのではなく、決まった順番で確認するとスムーズに原因を特定できます。
最低限、次のポイントを順に見ていきましょう。
- どこで文字化けしているかを特定する
- ブラウザ表示だけか
- ログ出力も化けているか
- DB 内のデータそのものが化けているか
- 元のファイルやデータの文字コードを確認する
- エディタの表示
- 文字コード判定ツール(iconv, nkf など)の結果
- サーバーやアプリの設定を確認する
- HTTP レスポンスヘッダの
charset - フレームワークのデフォルトエンコーディング
- DB の文字セット
- HTTP レスポンスヘッダの
- 最終的に表示する側の設定を確認する
- ブラウザ、コンソール、クライアントアプリの文字コード設定
「どこからどこまでが正しくて、どこから先が化けるのか」を線引きすると、切り分けがぐっと楽になります。
ファイルの文字コードを変換して直す方法
既に保存されたファイルの文字コードが原因の場合は、一度正しい文字コードに変換して保存し直す必要があります。
代表的な方法は次の通りです。
- エディタ機能で変換する
- メニューから「文字コードを指定して再読み込み」
- 正しく読める文字コードを選ぶ
- その状態で「UTF-8 として保存」を実行
- コマンドラインツールを使う
- Linux / macOS では
iconv - 例: Shift_JIS から UTF-8 へ変換する場合
iconv -f SHIFT_JIS -t UTF-8 input.txt > output.txt - Windows では
nkfなどがよく使われます
- Linux / macOS では
重要なのは、「まず正しい文字コードで読み取れる状態にしてから、UTF-8 などに変換する」ことです。
すでに文字化けした状態のファイルを変換しても、元には戻りません。
HTMLとサーバーヘッダの文字コードを揃える
ブラウザ表示の文字化けでは、HTML 側とサーバーヘッダ側の charset を揃えることが最重要ポイントになります。
具体的な手順は次の通りです。
- ブラウザの開発者ツールや curl などで、HTTP レスポンスヘッダを確認
Content-Type: text/html; charset=UTF-8になっているか
- HTML ファイルの先頭を確認
<meta charset="UTF-8">になっているか- ファイル自体も UTF-8 で保存されているか
- サーバーやフレームワークの設定を見直す
- Apache / Nginx のデフォルト charset
- フレームワークが返す charset の設定
「ヘッダ」「HTMLメタタグ」「ファイル実体」の3箇所をすべて同じ charset にするという意識で確認すると、取りこぼしを防ぎやすくなります。
プログラムの文字コード設定を統一するコツ
アプリケーションコード内では、「扱う文字列はすべて UTF-8」に統一するのが、現代の実務では最もトラブルが少ない方針です。
そのために意識しておきたいコツをまとめます。
- ソースコードファイルを UTF-8 で保存する
コメントや文字列リテラルに日本語が含まれる場合は特に重要です。 - フレームワークやランタイムのデフォルトエンコーディングを確認する
- 例: Ruby の
Encoding.default_external/Encoding.default_internal - Java の
file.encoding - PHP のマルチバイト設定
- 例: Ruby の
- 外部から受け取るデータは、受信時に UTF-8 に変換する
- API レスポンス
- CSV / テキストファイルのインポート
- メールやログの読み込み
このように、「アプリケーションの内側を UTF-8 で統一し、外との境界で変換する」と考えると、設計として整理しやすくなります。
それでも直らないときの切り分け方法と相談の仕方

ここまでの確認をしても原因が分からない場合は、切り分けをより細かく行い、第三者に相談できる情報を整理することが重要です。
切り分けの例としては、次のようなステップがあります。
- 元データの生のバイト列を確認する
- 16進ダンプ(hexdump など)を取り、どのようなバイト列になっているかを確認
- 正しい UTF-8 のバイト列か、Shift_JIS らしきバイト列か
- 各レイヤーごとに「正しい/間違っている」をチェック
- ファイルをエディタで直接開いたときは正しいか
- サーバーからのレスポンスはどうか
- DB の中身を CLI で直接見たときはどうか
- 相談するときに最低限共有したい情報
- どの環境(OS、ブラウザ、言語、フレームワーク)で発生しているか
- どの画面・どのログでどういう文字化けが起きているかの具体例
- 文字コードに関わる設定値(HTML meta、レスポンスヘッダ、DB 文字セット、エディタ設定など)
これらを整理しておくと、チームメンバーやコミュニティに質問したときに、原因特定までの時間を大きく短縮できます。
まとめ
文字化けは、一見すると不可解なトラブルのように思えますが、その正体は「送り手と受け手で文字コードの約束が合っていない」という単純な問題です。
本記事では、文字コードとエンコーディングの基本から、よく使われる文字コード、文字化けが発生しやすい具体的なパターンを整理しました。
また、エディタ・HTML・サーバー・データベース・コンソール・Git といった各環境ごとの対策と、実際に文字化けが起きたときのシンプルなチェック手順も紹介しました。
実務でのコツは、「プロジェクト全体をUTF-8で統一し、境界でだけ変換する」という方針を徹底することです。
そのうえで、ファイル保存時、レスポンスヘッダ、DB 設定、コンソール設定など、文字コードに関わるポイントを意識しておけば、多くの文字化けトラブルは未然に防げます。
もしそれでも問題が解決しない場合は、どこでどのように化けているか、どのレイヤーまでは正しく見えているかを丁寧に切り分けながら、周囲に相談してみてください。
文字化けは、仕組みを理解してしまえば決して怖いトラブルではありません。
今回紹介した考え方と手順をベースに、落ち着いて原因を探っていきましょう。
