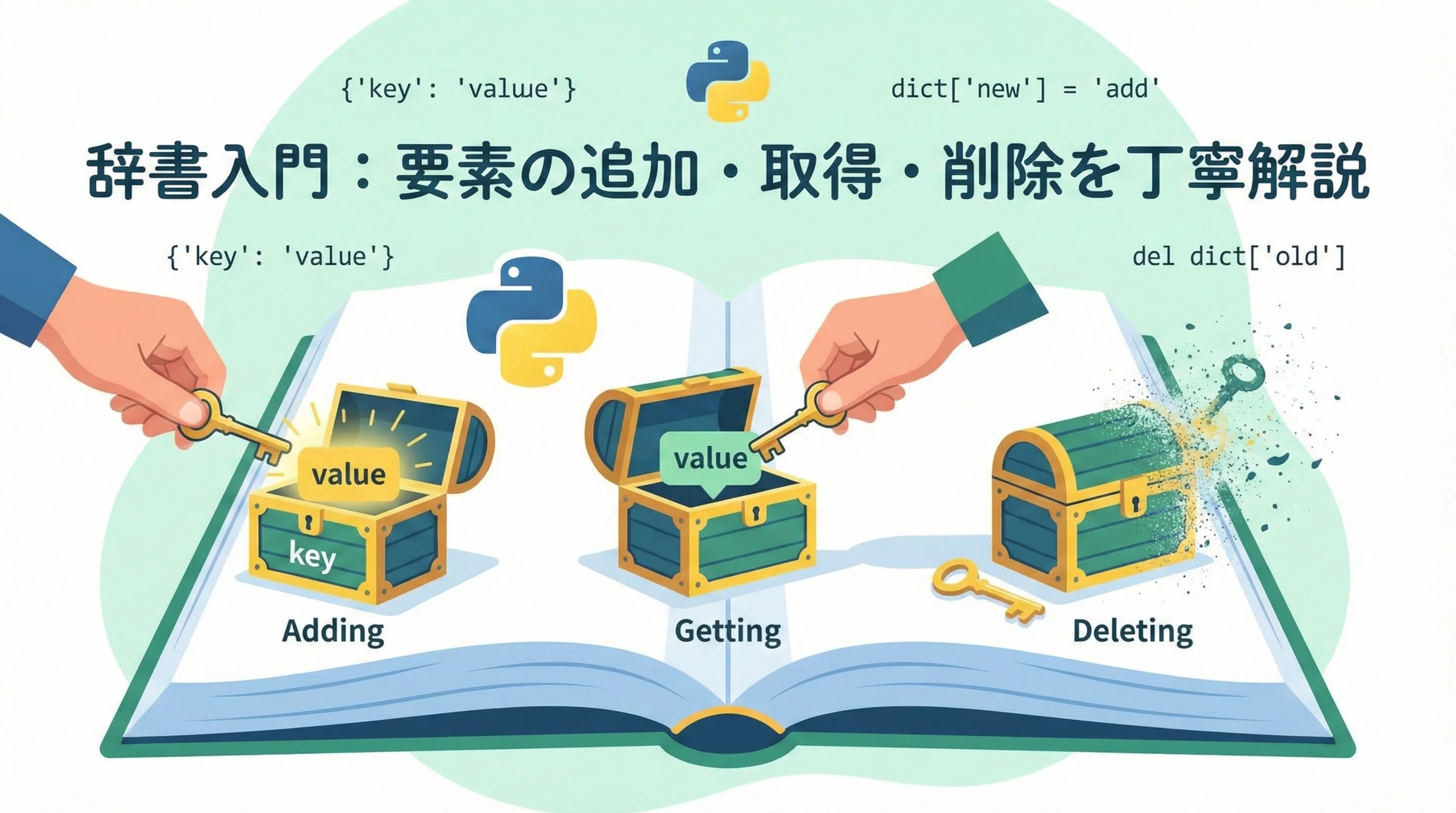
Pythonの辞書(dict)は、現代のPythonプログラミングに欠かせない重要なデータ構造です。
値を名前付きで管理できるため、設定情報やAPIレスポンス、データベースの1レコードなど、さまざまな場面で活躍します。
本記事では辞書の入門として「追加・取得・削除」を軸に、図解とコード例を交えながら丁寧に解説していきます。
辞書(dict)の基礎
辞書(dict)とは何か
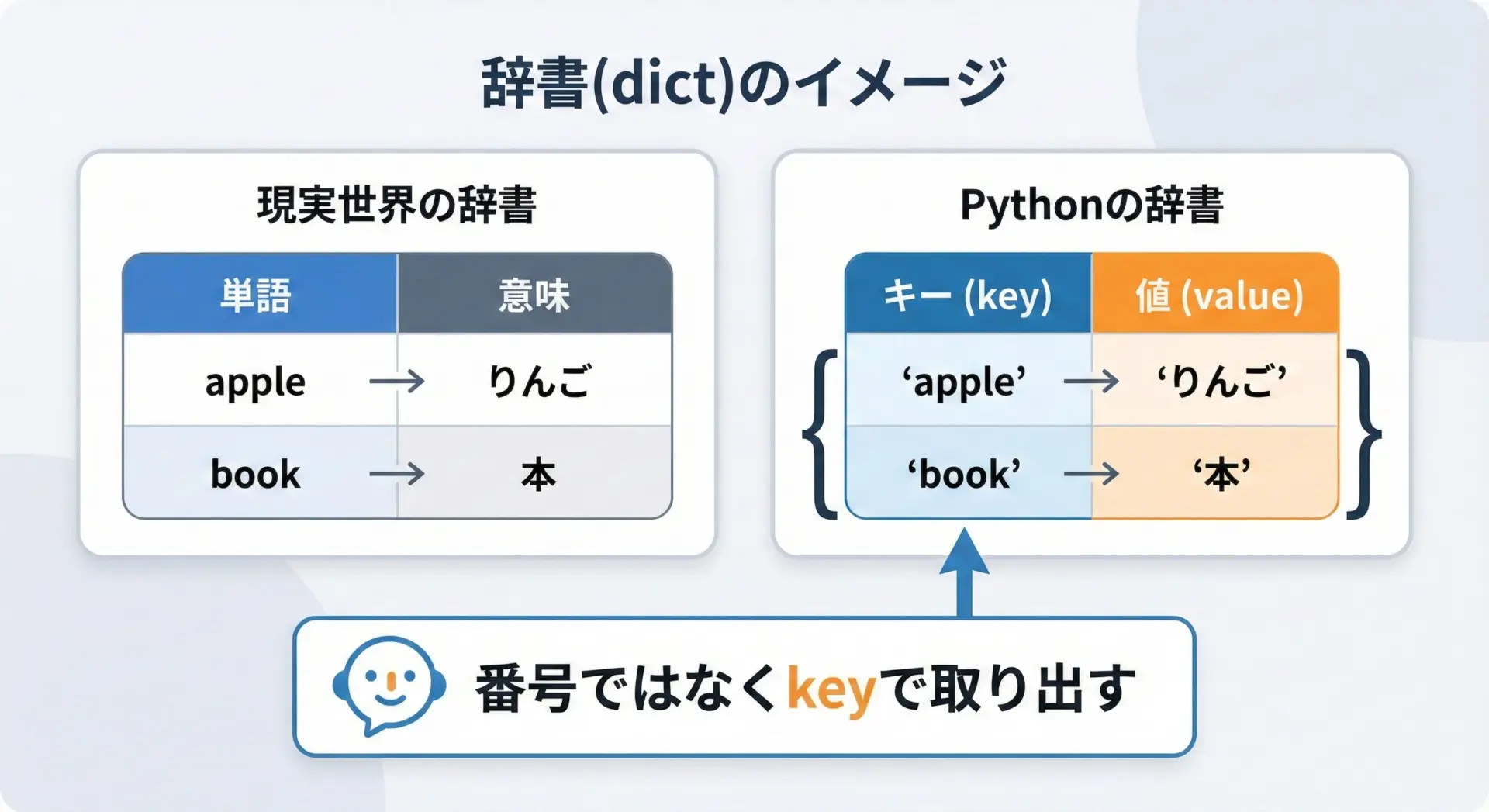
Pythonの辞書(dict)は、keyとvalueの組み合わせを扱うデータ構造です。
現実世界の「単語帳」や「電話帳」をイメージすると理解しやすくなります。
単語をkey、その意味をvalueとした対応関係を、プログラムの中でそのまま扱えるようにしたものが辞書です。
リストやタプルのように番号でアクセスするのではなく、自分で決めた名前(key)で値にアクセスできるため、コードの可読性が上がり、データ構造を直感的に扱えるという特徴があります。
辞書の典型的な利用シーン
文章中でよく使われる使い方として、次のようなものがあります。
- ユーザー情報(例: 名前、年齢、メールアドレス)を1つの辞書でまとめる
- 設定値(例: タイムアウト秒数、フラグ)を
keyで扱う - JSON形式のデータ(APIレスポンスなど)をそのまま辞書として扱う
このように「属性名 → 値」の対応を持つデータは、ほぼそのまま辞書にマッピングできるため、Pythonでは非常に出番が多いです。
リストとの違い
辞書を理解するうえで、リストと比較するのが効果的です。
ここでは、インデックスとキー、順序性などを中心に違いを整理します。
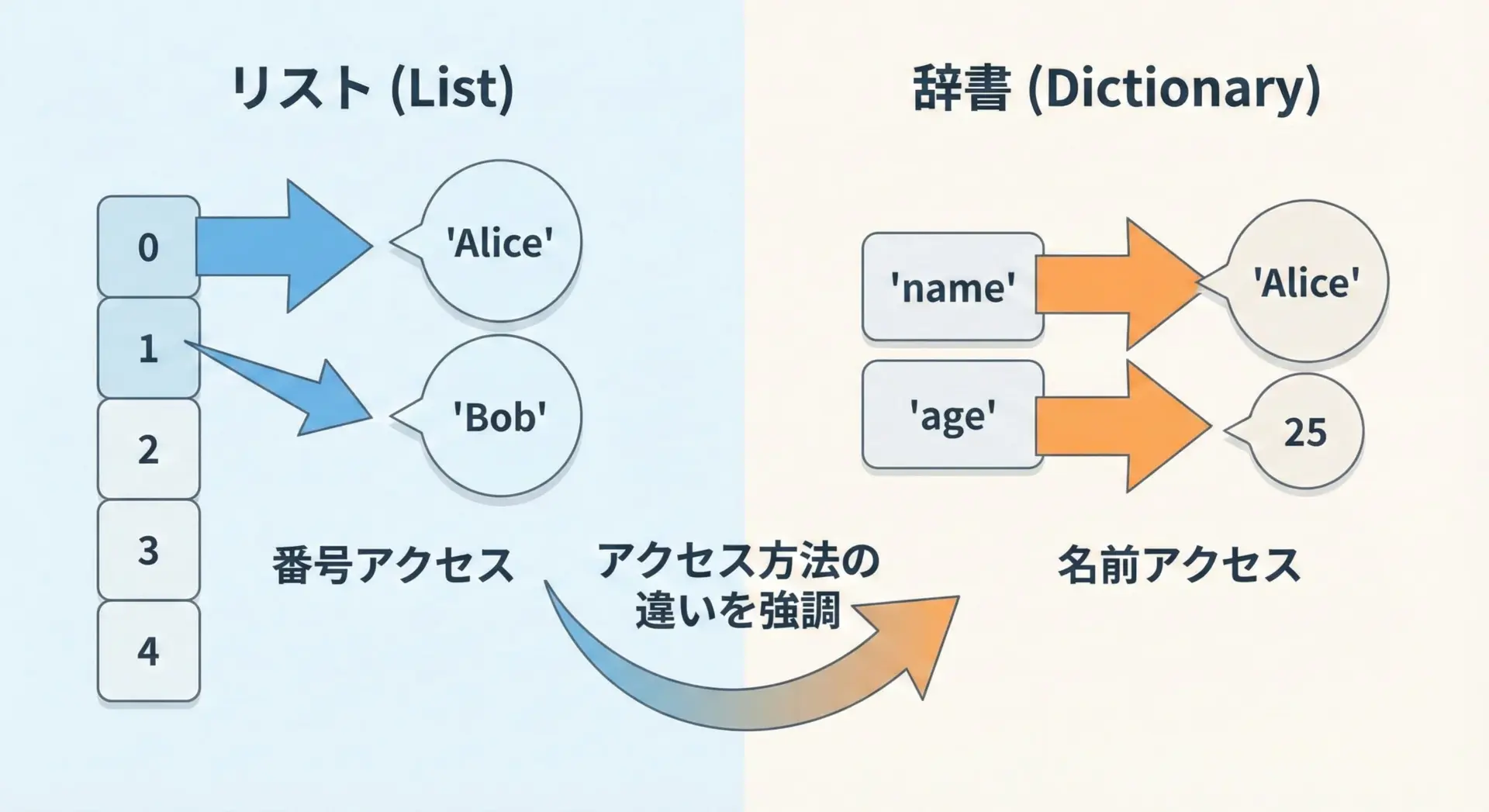
インデックス(番号)とkey(名前)の違い
リストは0から始まる整数インデックスでアクセスします。
一方で辞書は任意の不変オブジェクト(多くは文字列)をkeyとしてアクセスします。
# リストの例
names = ["Alice", "Bob", "Charlie"]
print(names[0]) # 0番目の要素を取得
# 辞書の例
user = {
"name": "Alice",
"age": 25
}
print(user["name"]) # "name"というkeyで値を取得Alice
Aliceリストでは「何番目か」が重要ですが、辞書では「どの名前(key)か」が重要になります。
順序性と用途の違い
Python 3.7以降では、辞書も「挿入順」を保持する仕様ですが、用途や設計思想はリストと異なります。
- リストは順番の意味が強いデータ列に向いています(例: タイムライン、ランキング)
- 辞書は名前付きフィールドを持つ1件分の情報に向いています(例: ユーザー1人分のプロフィール)
この違いを意識すると、どちらを選ぶべきか迷いにくくなります。
Pythonでの辞書の基本的な書き方
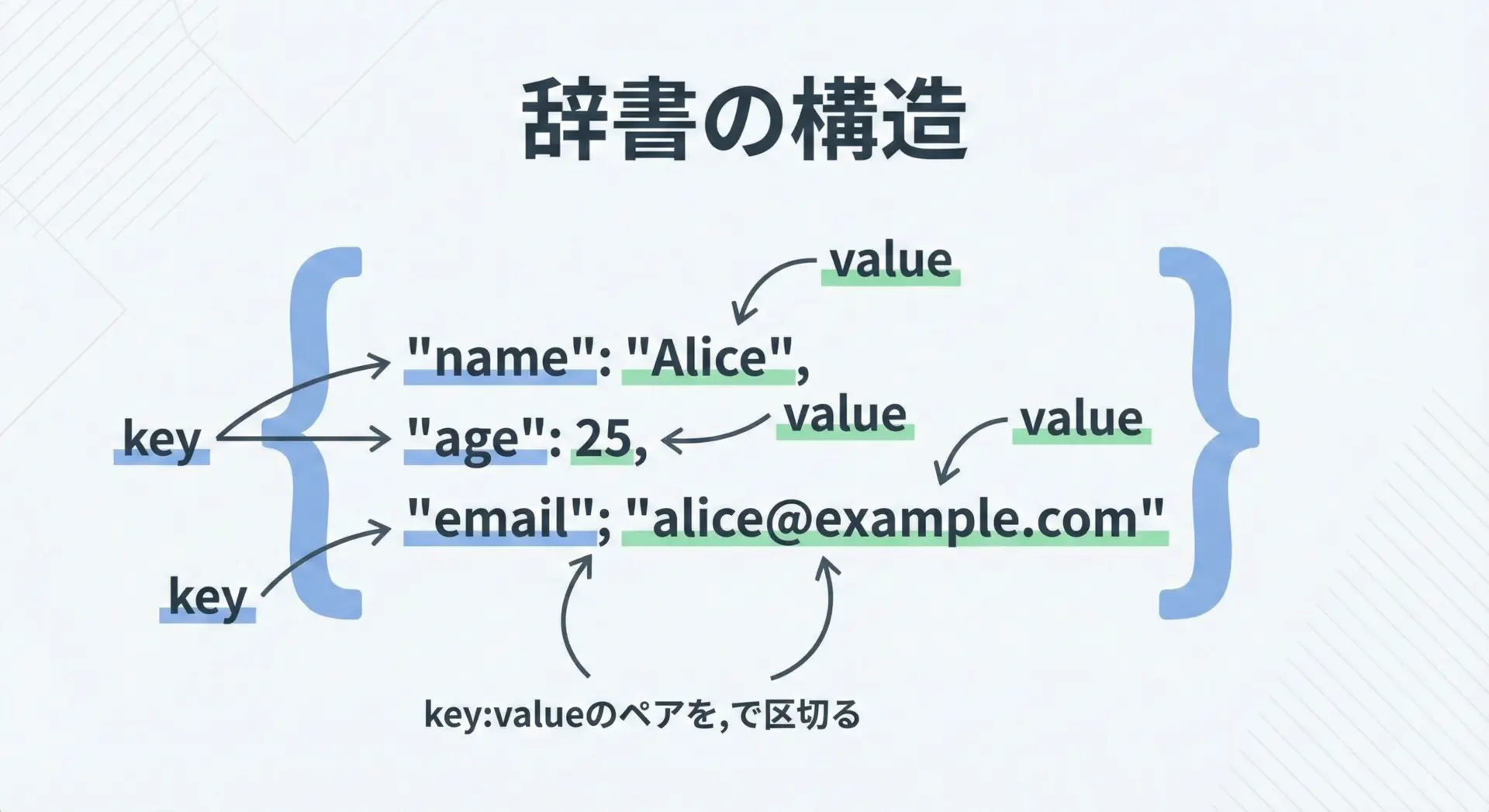
Pythonでは、中括弧{}を使って辞書を定義します。
基本形は{"key": value}というペアをカンマ区切りで並べるだけです。
# 基本的な辞書の定義
user = {
"name": "Alice", # key: "name", value: "Alice"
"age": 25, # key: "age", value: 25
"email": "alice@example.com" # key: "email", value: 文字列
}
print(user)
print(type(user)){'name': 'Alice', 'age': 25, 'email': 'alice@example.com'}
<class 'dict'>空の辞書を作る2つの方法
空の辞書は、次のどちらの書き方でも作れます。
empty1 = {} # 中括弧を使う書き方
empty2 = dict() # dictコンストラクタを使う書き方
print(empty1, type(empty1))
print(empty2, type(empty2)){} <class 'dict'>
{} <class 'dict'>実務では中括弧{}で書くことが多いですが、どちらを使っても動作は同じです。
辞書への要素の追加
新しいkeyとvalueを追加する方法
辞書への要素追加は、とてもシンプルです。
存在しないkeyを代入すると、新しい要素として追加されます。

user = {
"name": "Alice"
}
# 存在しないkey "age" を指定して代入 → 追加される
user["age"] = 25
# さらに新しいkeyを追加
user["email"] = "alice@example.com"
print(user){'name': 'Alice', 'age': 25, 'email': 'alice@example.com'}ここでもし同じkeyがすでに存在している場合、新しい値で上書きされます。
これは「追加」ではなく「更新」になります。
user = {
"name": "Alice",
"age": 25
}
# 既に存在するkey "age" に新しい値を代入 → 値が更新される
user["age"] = 26
print(user){'name': 'Alice', 'age': 26}dict.update()でまとめて要素を追加する方法
dict.update()は、複数のkeyとvalueをまとめて追加・更新したいときに便利なメソッドです。
引数に別の辞書やkey=value形式を渡すことで、一度に操作できます。
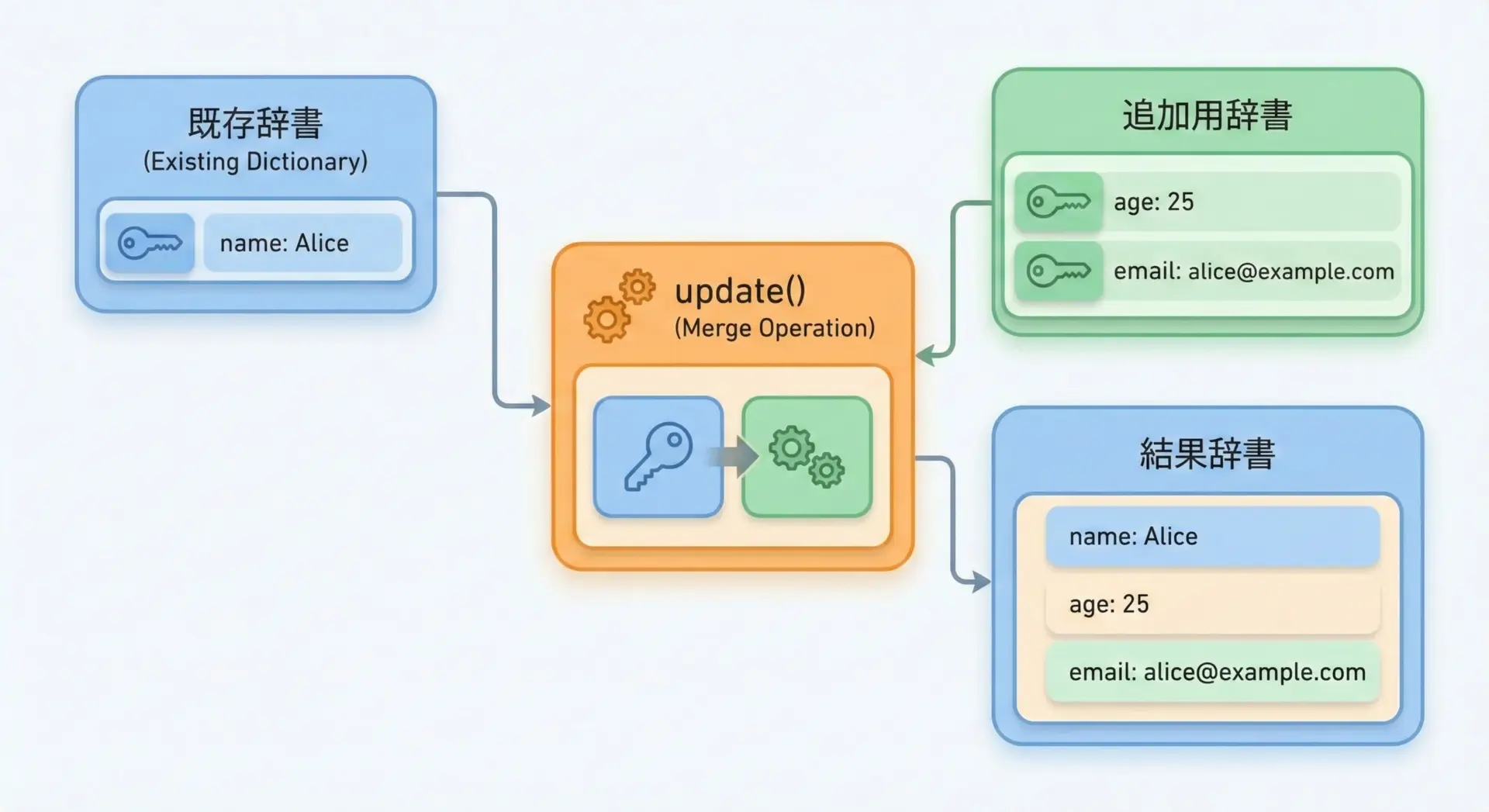
user = {
"name": "Alice"
}
# 別の辞書を使って一括で追加・更新
user.update({
"age": 25,
"email": "alice@example.com"
})
print(user){'name': 'Alice', 'age': 25, 'email': 'alice@example.com'}キーワード引数を使った書き方
update()は、キーワード引数を使うこともできます。
ただし、keyが有効な識別子である必要があることに注意してください(ハイフンなどは使えません)。
config = {
"timeout": 10
}
# キーワード引数で更新
config.update(retry=3, debug=True)
print(config){'timeout': 10, 'retry': 3, 'debug': True}setdefault()で存在確認しながら追加する方法
dict.setdefault()は、keyが存在しないときだけ、指定した値を追加してくれるメソッドです。
すでにそのkeyが存在している場合は、追加せずに元の値を返します。
「なければ追加、あればそのまま使う」という処理を1行で書けるので、カウンタや初期化処理などでよく利用されます。
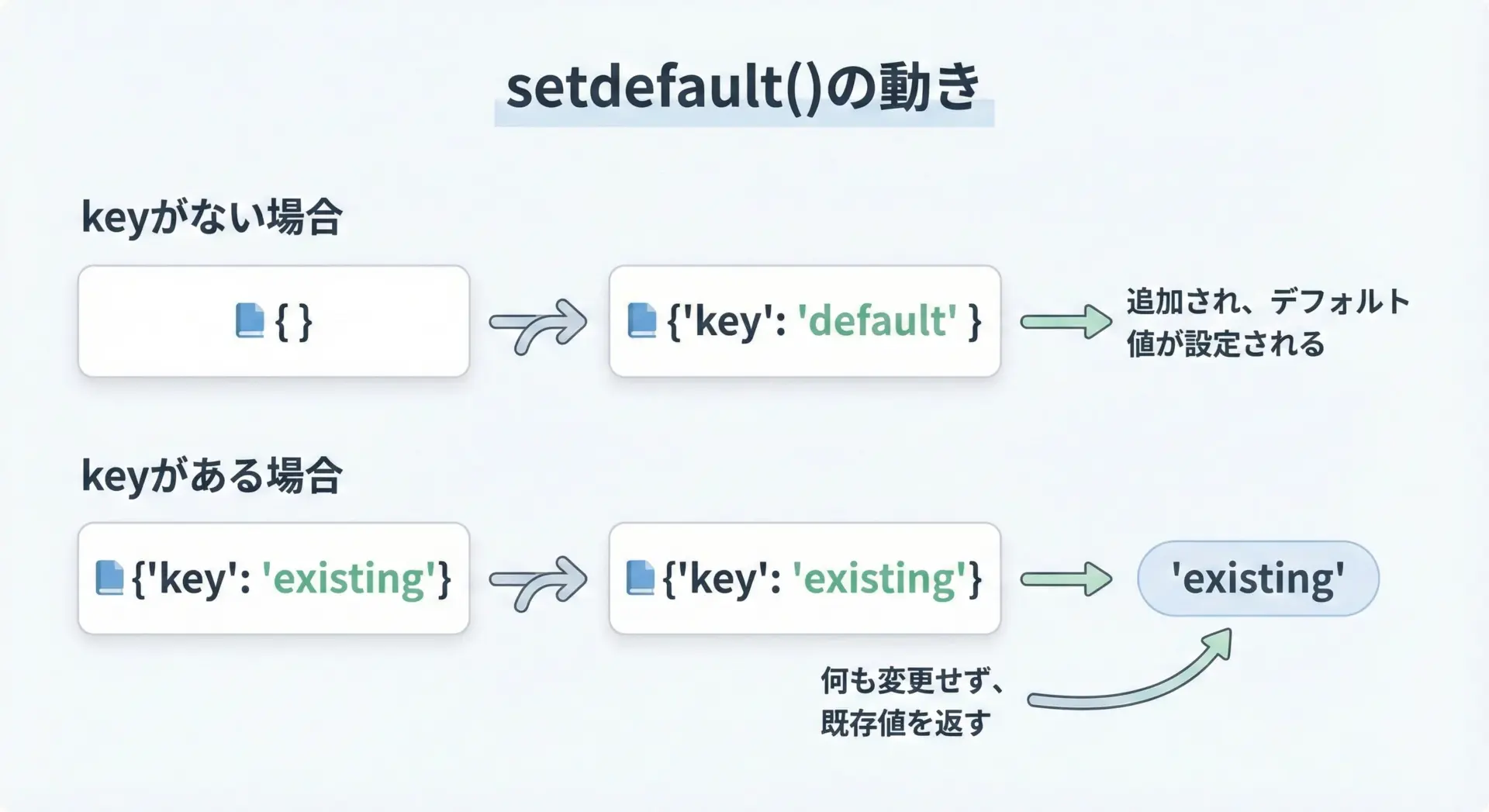
user = {
"name": "Alice"
}
# "age"がなければ 0 を設定し、その値を返す
age = user.setdefault("age", 0)
print("age:", age)
print("user:", user)
# すでに"age"がある状態でsetdefaultを呼ぶ
age_again = user.setdefault("age", 99) # ここでは99は無視される
print("age_again:", age_again)
print("user:", user)age: 0
user: {'name': 'Alice', 'age': 0}
age_again: 0
user: {'name': 'Alice', 'age': 0}2回目のsetdefault("age", 99)では、すでに”age”があるため値は変更されません。
返ってくるのも元の値0です。
ネストした辞書への要素追加
辞書のvalueに、さらに辞書を入れたものをネストした辞書と呼びます。
JSONデータなどではごく一般的な形です。
ネストした辞書に要素を追加する場合、一段ずつたどりながらkeyを指定します。
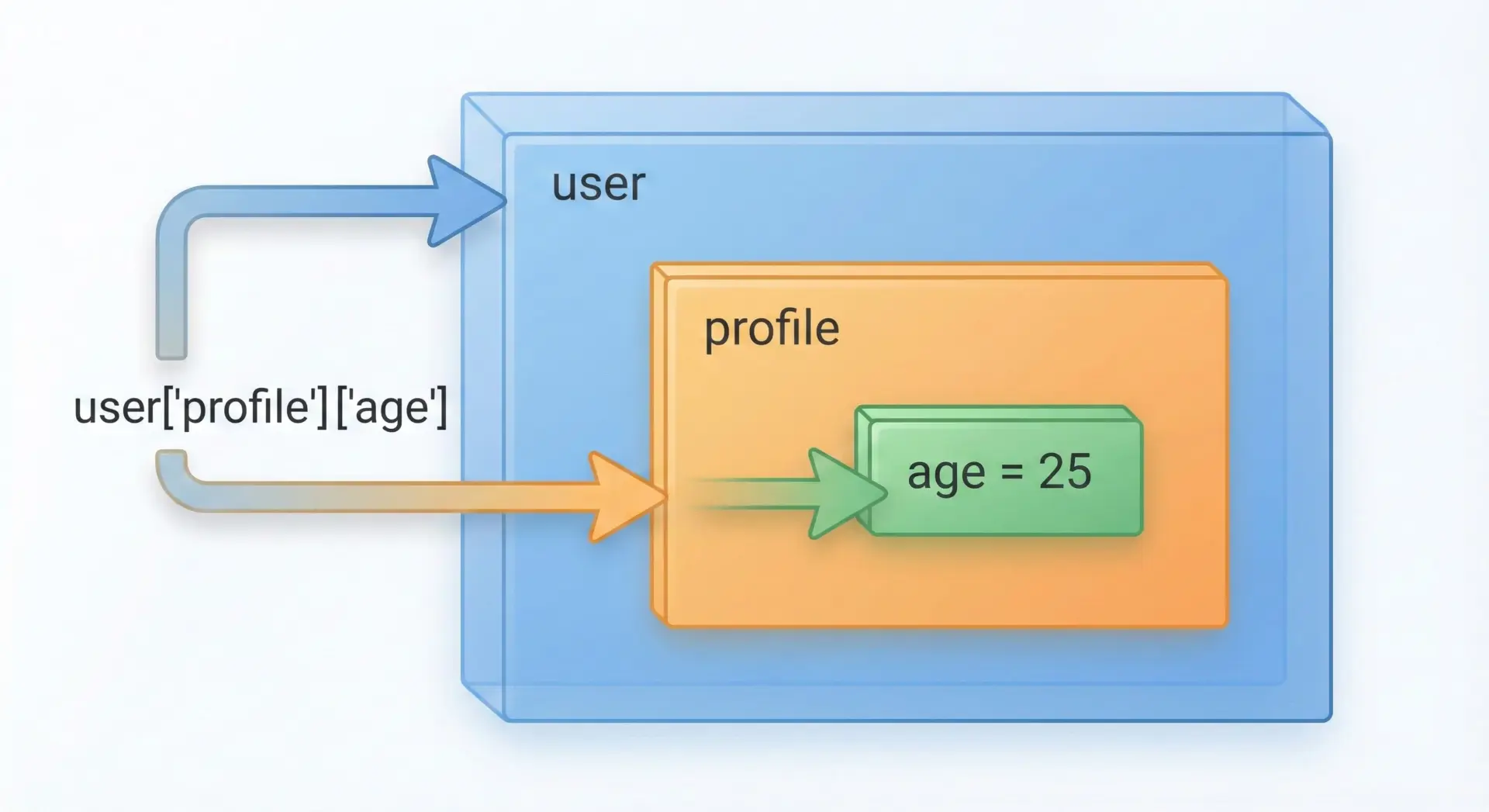
user = {
"name": "Alice",
"profile": {
"age": 25,
"country": "Japan"
}
}
# ネストした辞書への追加
user["profile"]["city"] = "Tokyo"
print(user){'name': 'Alice', 'profile': {'age': 25, 'country': 'Japan', 'city': 'Tokyo'}}ネストを段階的に作りながら追加する例
最初からネストした辞書が存在しない場合は、先に空の辞書を入れておくと安全です。
user = {
"name": "Bob"
}
# まず"profile"というkeyに空の辞書を入れる
user["profile"] = {}
# そのあとでネストした要素を追加する
user["profile"]["age"] = 30
user["profile"]["country"] = "USA"
print(user){'name': 'Bob', 'profile': {'age': 30, 'country': 'USA'}}存在しないネスト先に直接アクセスするとKeyErrorになるので、空辞書で初期化しておくのがポイントです。
辞書からの要素の取得
key指定で値を取得する基本の書き方
辞書から値を取り出す基本は、辞書名[key]という形でアクセスすることです。
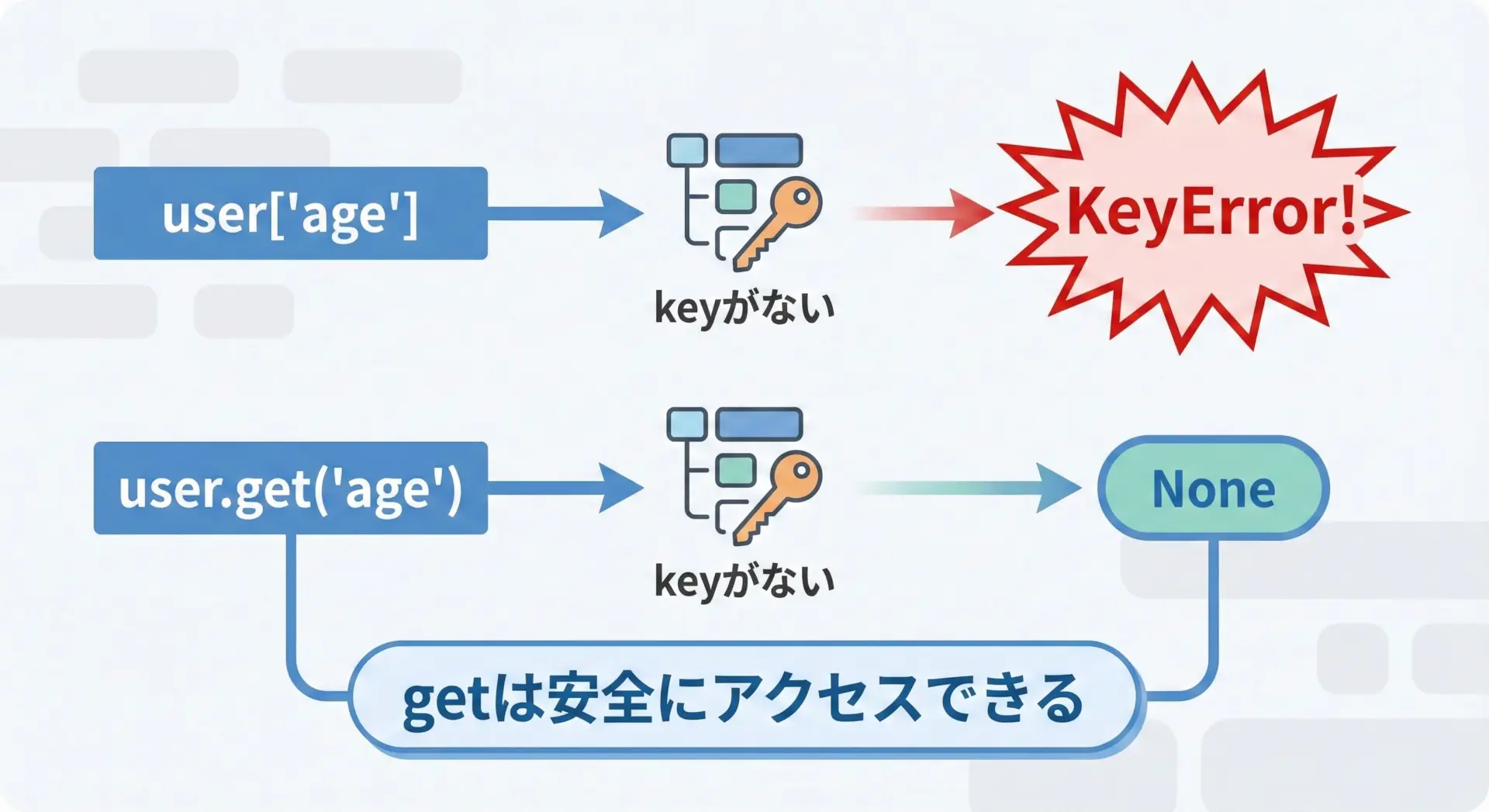
これは最もシンプルで直感的な方法ですが、存在しないkeyを指定するとKeyErrorになります。
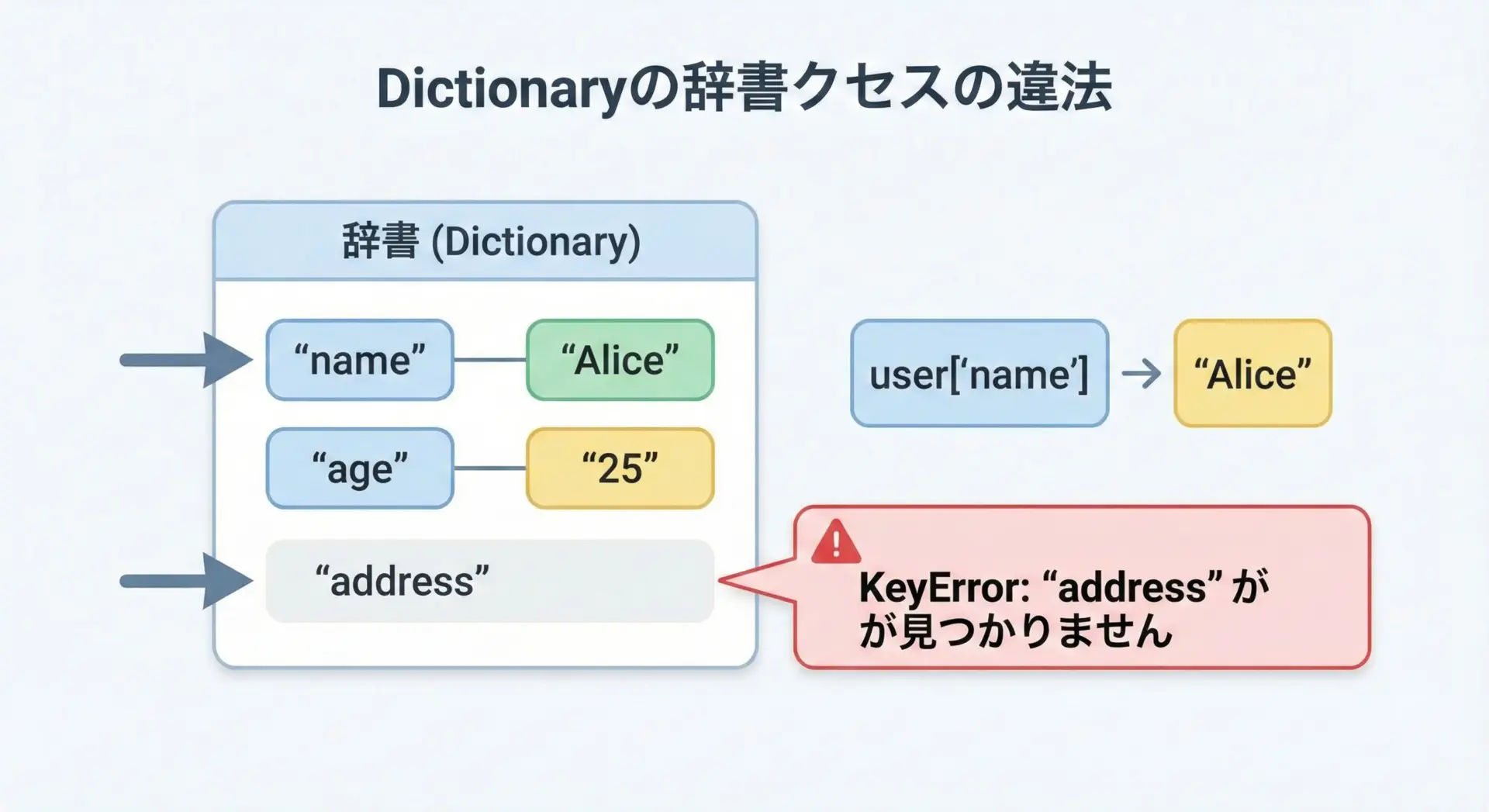
user = {
"name": "Alice",
"age": 25
}
# 存在するkeyで取得
print(user["name"])
print(user["age"])Alice
25存在しないkeyにアクセスすると、次のようにエラーになります。
user = {
"name": "Alice"
}
# 存在しないkey "age" にアクセス → KeyError
print(user["age"])Traceback (most recent call last):
...
KeyError: 'age'dict.get()で安全に値を取得する方法
dict.get()は、keyが存在しない場合でもエラーを出さずにNoneを返してくれる安全な取得メソッドです。
存在チェックと取得を分けて書く必要がないため、コードをスッキリ書けます。
user = {
"name": "Alice"
}
# get() を使うと、存在しないkeyでもエラーにならない
age = user.get("age")
print("age:", age) # 何も設定されていないので None が返るage: None「keyがあるかもしれないが、なかったとしてもそのまま処理を続けたい」という場合にはget()を使うのが定石です。
get()のデフォルト値を使ったパターン
get()は、第2引数にデフォルト値を指定できます。
keyが存在しなかった場合、その値が返されます。
これによって「なければ0」「なければ空リスト」のような初期値を1行で表現できます。
user = {
"name": "Alice",
"age": 25
}
# "age"があればその値、なければ0を返す
age = user.get("age", 0)
# "country"がなければ "Unknown" を返す
country = user.get("country", "Unknown")
print("age:", age)
print("country:", country)age: 25
country: Unknownこのパターンは、集計処理やアクセス回数カウントなどで頻繁に使われます。
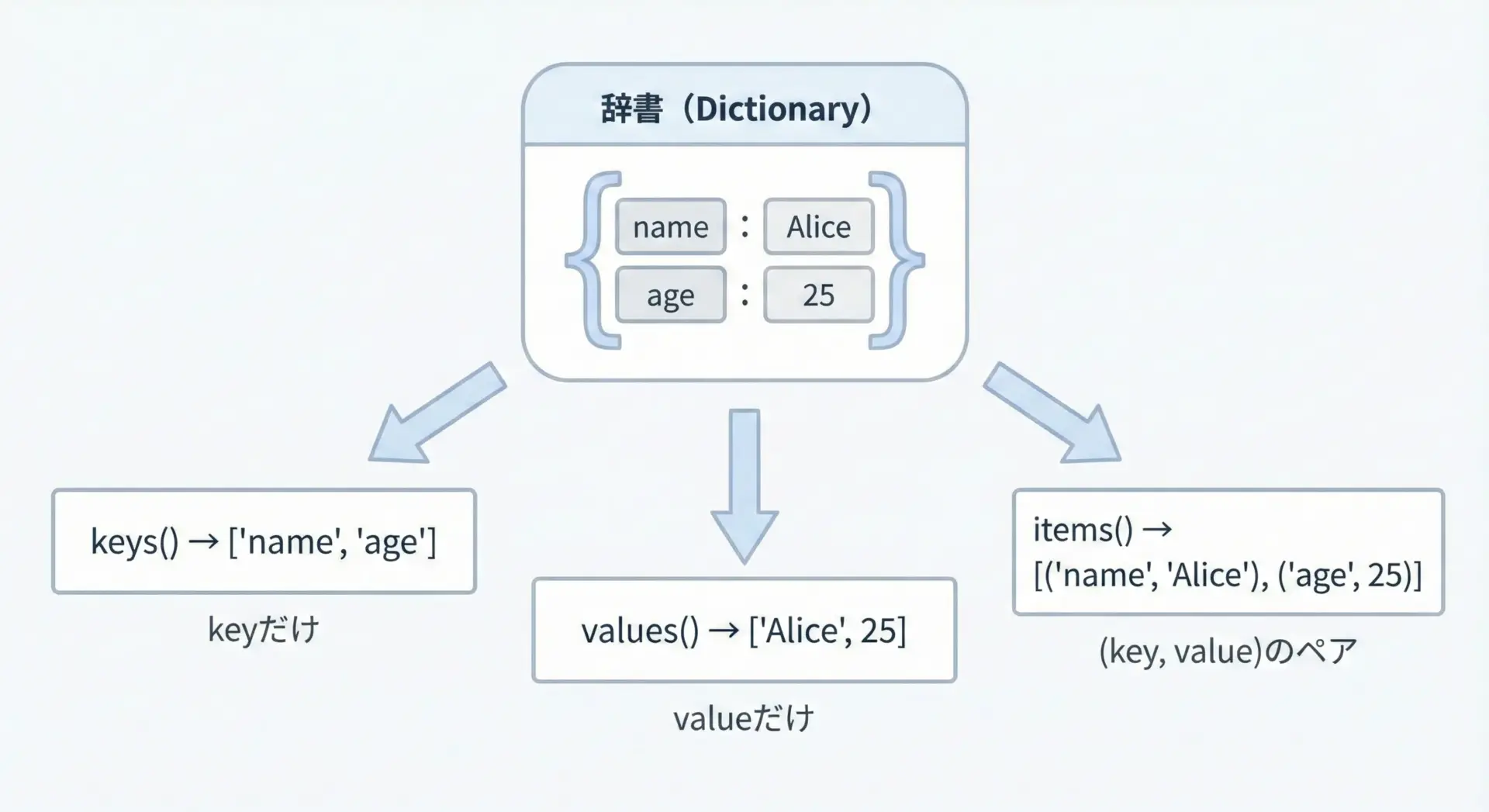
keys・values・itemsで要素一覧を取得する方法
辞書全体の中身を確認したいときには、keys()・values()・items()の3つのメソッドが役立ちます。
user = {
"name": "Alice",
"age": 25,
"country": "Japan"
}
print("keys:", user.keys())
print("values:", user.values())
print("items:", user.items())keys: dict_keys(['name', 'age', 'country'])
values: dict_values(['Alice', 25, 'Japan'])
items: dict_items([('name', 'Alice'), ('age', 25), ('country', 'Japan')])これらは見た目はリストのようですが、実際には「ビューオブジェクト」と呼ばれる特別なオブジェクトです。
リストとして使いたい場合はlist()で変換します。
user = {
"name": "Alice",
"age": 25
}
keys_list = list(user.keys())
print(keys_list)['name', 'age']for文で辞書をループ処理する方法
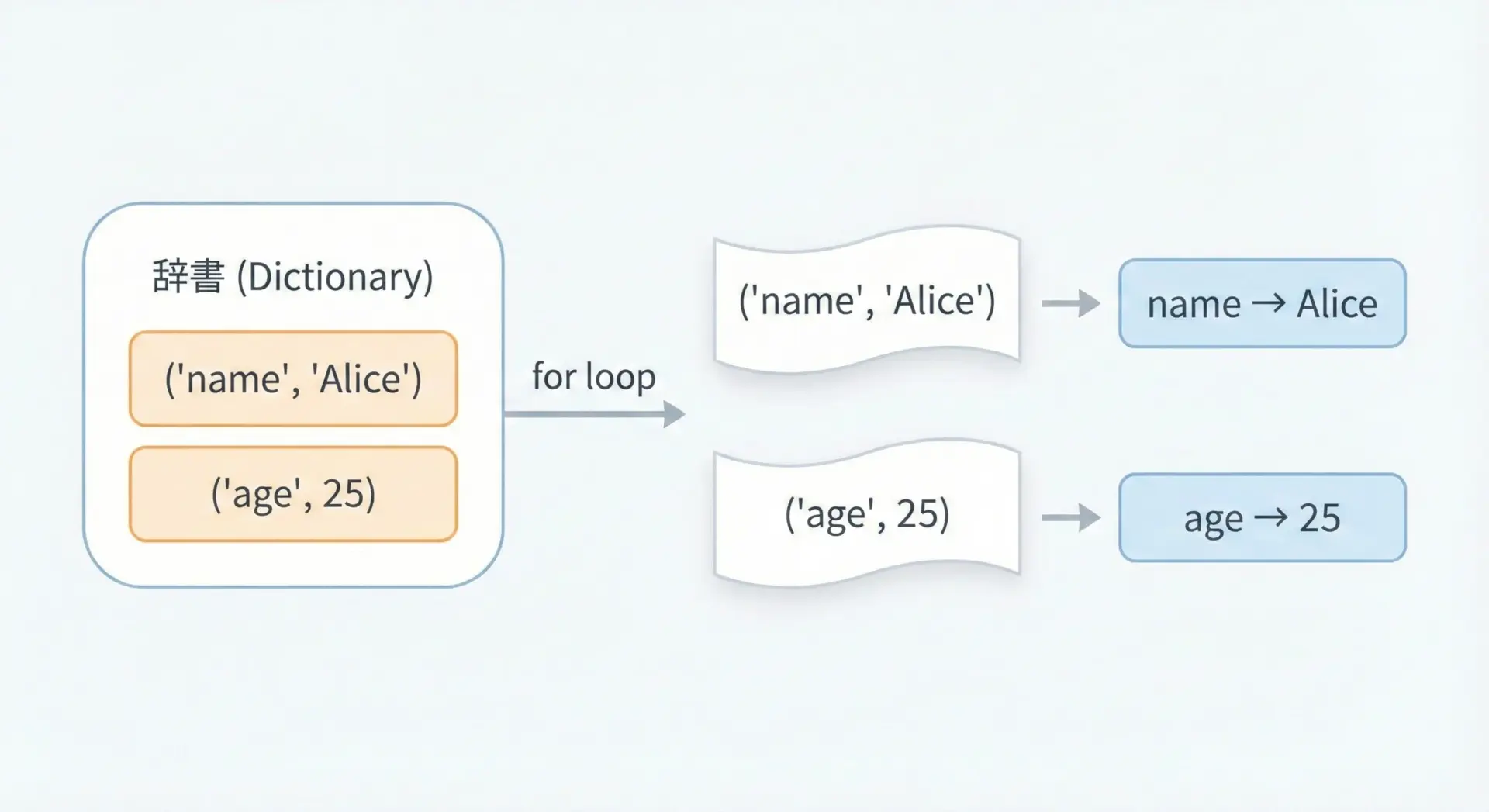
辞書の全要素を処理したいときには、for文とitems()の組み合わせが最もよく使われます。
これは(key, value)のペアを1つずつ取り出してループする方法です。
user = {
"name": "Alice",
"age": 25,
"country": "Japan"
}
# key と value を同時に取り出しながらループ
for key, value in user.items():
print(key, "=>", value)name => Alice
age => 25
country => Japankeyだけループしたい場合はfor key in user:と書けることも覚えておくと便利です。
これはfor key in user.keys():と同じ意味になります。
user = {
"name": "Alice",
"age": 25
}
for key in user: # user.keys() と同じ
print("key:", key, "value:", user[key])key: name value: Alice
key: age value: 25辞書からの要素の削除
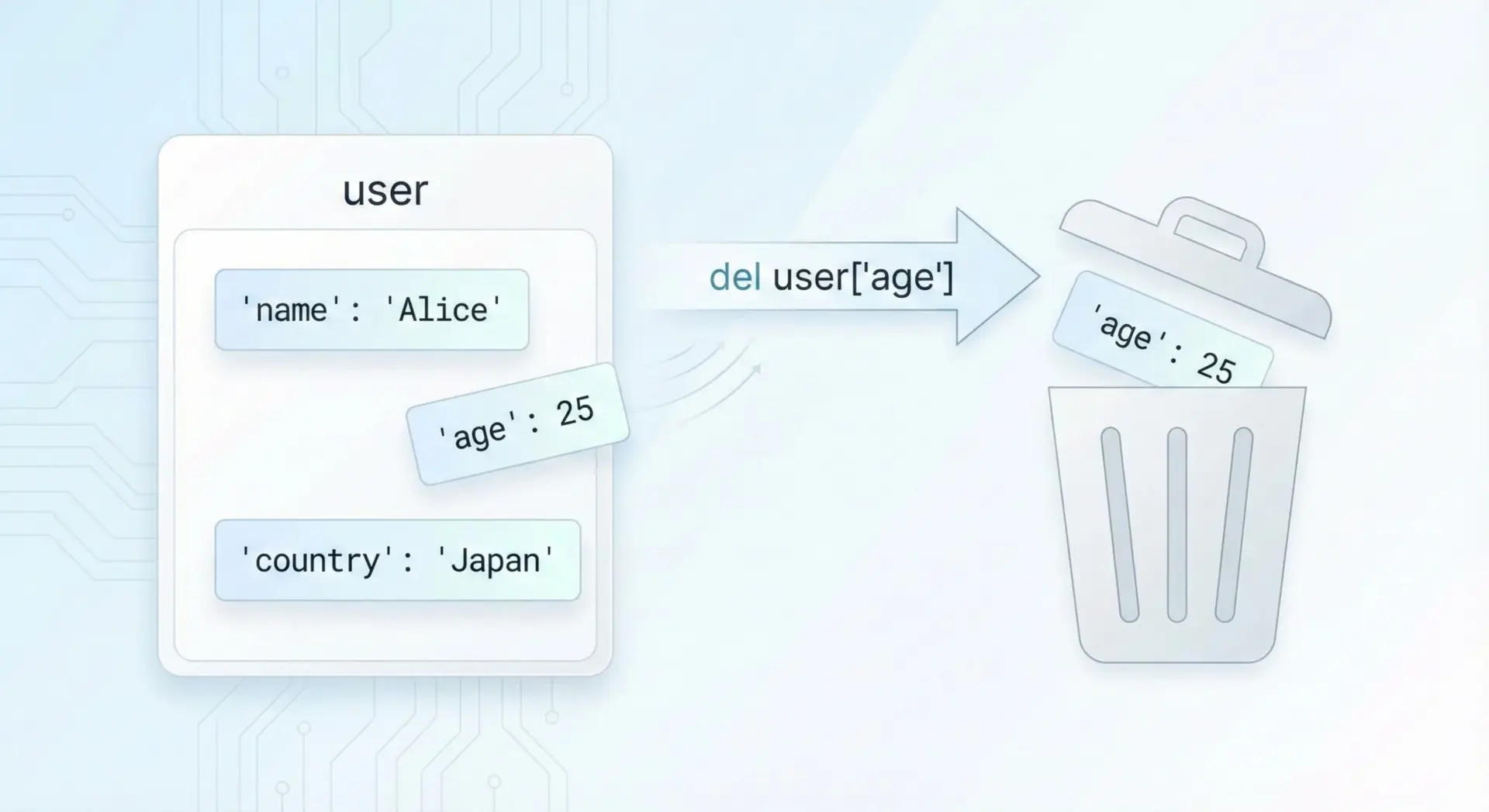
del文で辞書の要素を削除する方法
del文を使うと、特定のkeyとそのvalueを辞書から削除できます。
削除対象のkeyを指定して使います。
user = {
"name": "Alice",
"age": 25,
"country": "Japan"
}
# "age" を削除
del user["age"]
print(user){'name': 'Alice', 'country': 'Japan'}存在しないkeyを指定するとKeyErrorになるため、削除前に存在チェックをするか、後述のpop()をうまく使うと安全です。
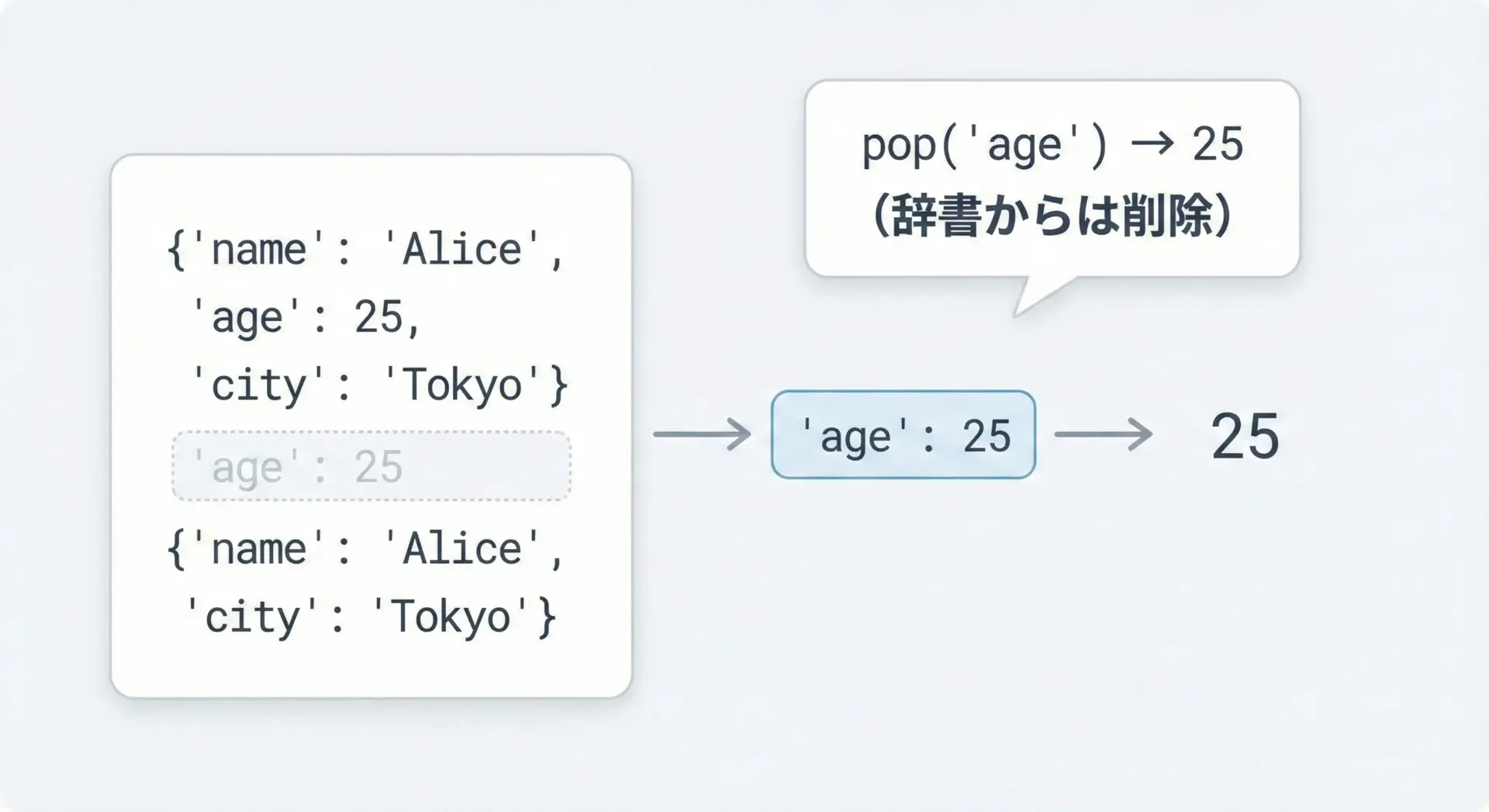
pop()で値を取り出しながら削除する方法
dict.pop()は、要素を削除しつつ、そのvalueを返してくれるメソッドです。
削除した値を変数に保持したい場合に非常に便利です。
user = {
"name": "Alice",
"age": 25,
"country": "Japan"
}
# "age" を取り出しつつ削除
age = user.pop("age")
print("popped age:", age)
print("user:", user)popped age: 25
user: {'name': 'Alice', 'country': 'Japan'}デフォルト値を指定して安全にpopする
pop()もget()と同様に、第2引数にデフォルト値を指定できます。
keyが存在しない場合、その値が返され、例外は発生しません。
user = {
"name": "Alice"
}
# "age" が存在しないので、デフォルト値 -1 が返る
age = user.pop("age", -1)
print("age:", age)
print("user:", user)age: -1
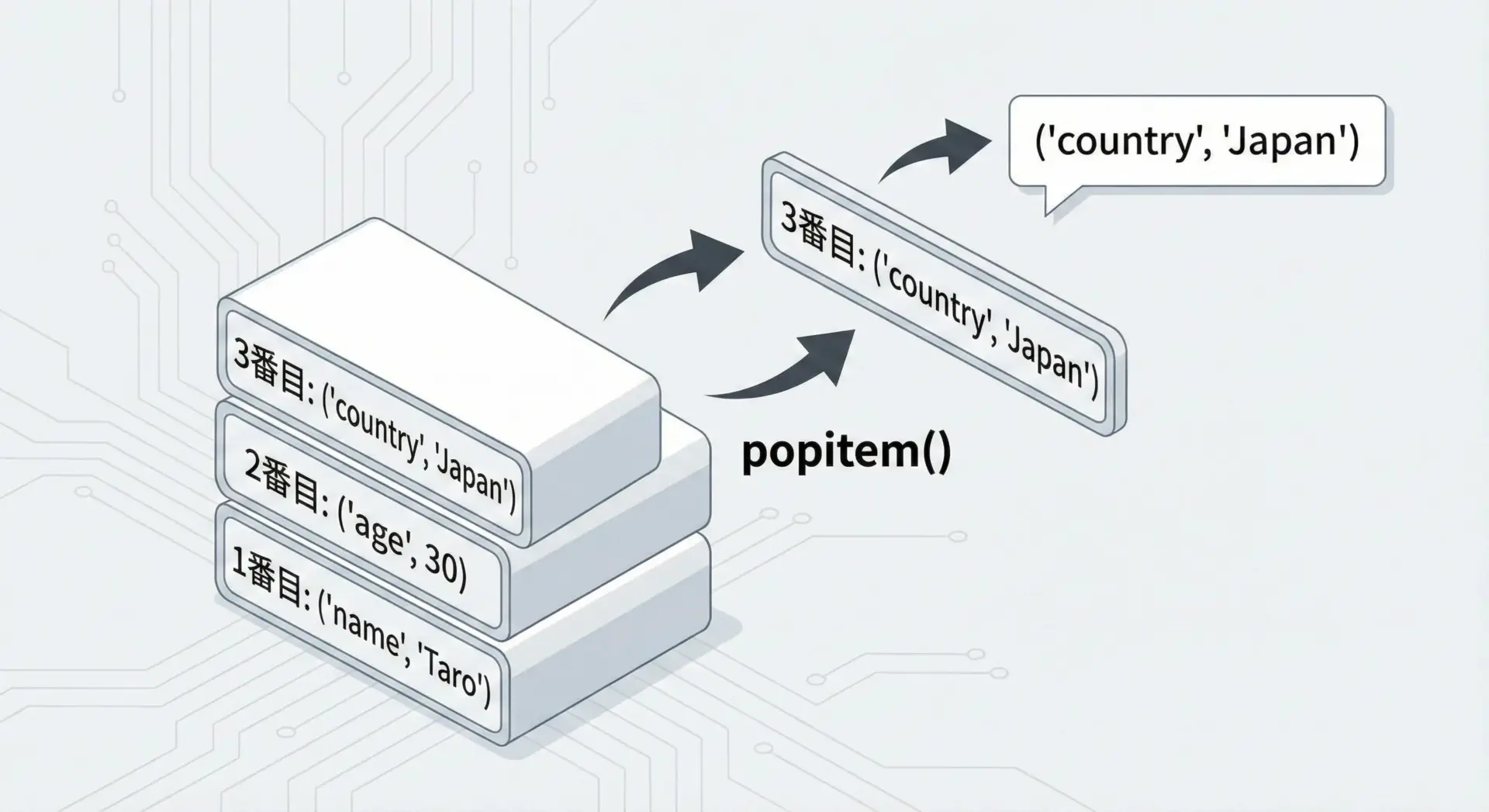
user: {'name': 'Alice'}popitem()で最後の要素を削除する方法
dict.popitem()は、辞書の最後の要素を削除し、その(key, value)のペアをタプルで返すメソッドです。
スタック的に「最後に追加したものから取り出す」ような処理に向いています。
user = {
"name": "Alice",
"age": 25,
"country": "Japan"
}
item = user.popitem()
print("popped item:", item) # ('country', 'Japan') など
print("user:", user)popped item: ('country', 'Japan')
user: {'name': 'Alice', 'age': 25}辞書が空の状態でpopitem()を呼ぶとKeyErrorになりますので、要素数を確認してから呼ぶか、例外処理を行う必要があります。
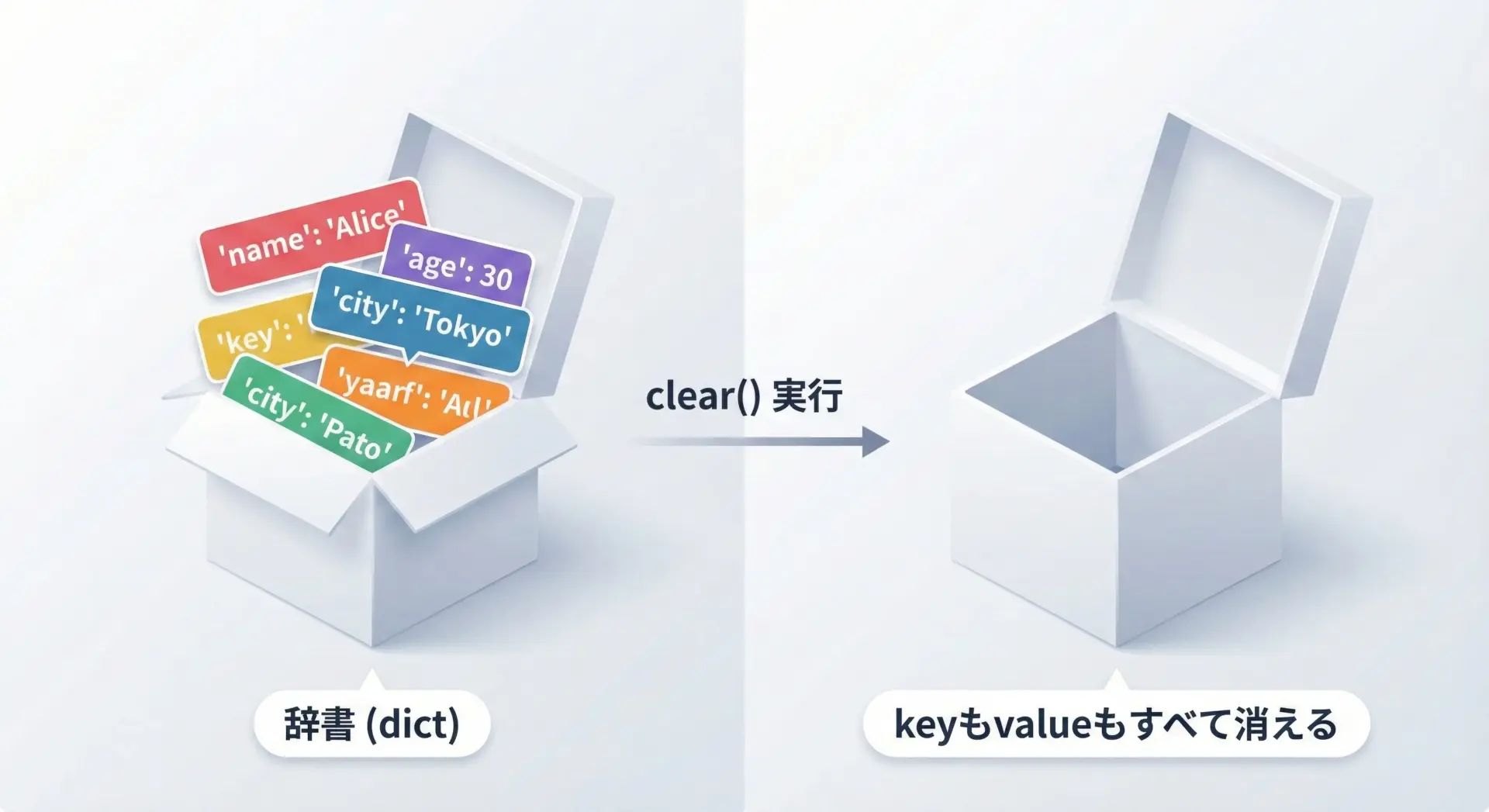
clear()で辞書を空にする方法
dict.clear()は、辞書の中身をすべて削除して空にするメソッドです。
設定をリセットしたいときや、一度使い終わったバッファとしての辞書を再利用したいときなどに使えます。
user = {
"name": "Alice",
"age": 25
}
user.clear()
print(user){}このメソッドは辞書そのものを消すわけではなく「中身」だけを消す点がポイントです。
変数user自体は引き続き辞書として使えます。
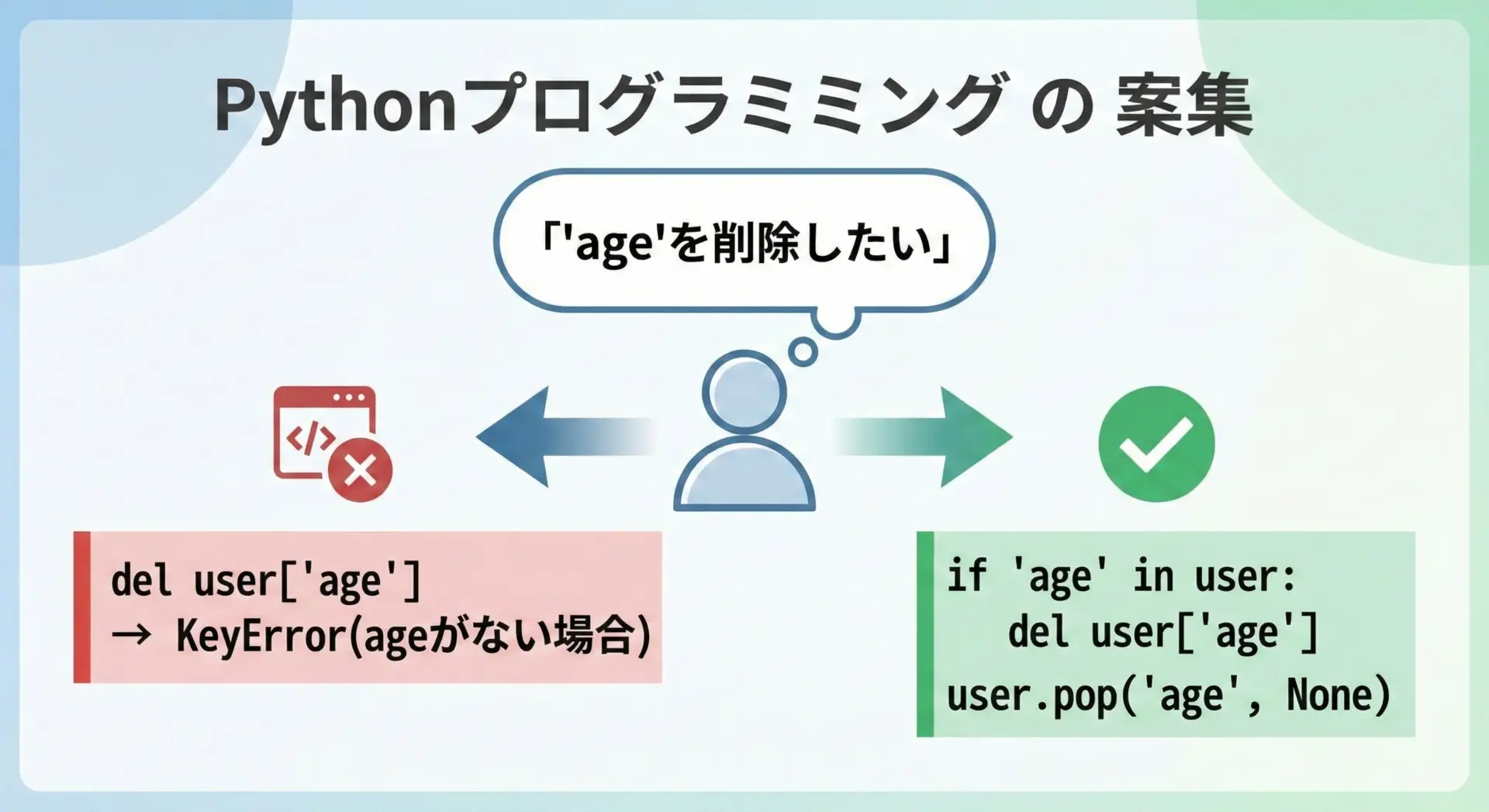
存在しないkeyを削除する際のエラー対策
存在しないkeyをdelやpop()で削除しようとするとKeyErrorが発生します。
これを防ぐための代表的なパターンをいくつか紹介します。
in演算子で存在チェックしてから削除する
user = {
"name": "Alice"
}
# 削除前に存在チェック
if "age" in user:
del user["age"]
else:
print("'age' は存在しませんでした")
print(user)'age' は存在しませんでした
{'name': 'Alice'}pop()のデフォルト値を利用して安全に削除する
存在しない場合でもエラーにしたくないときは、pop()にデフォルト値を指定する方法が簡潔です。
user = {
"name": "Alice"
}
# "age" がなくてもエラーにならない
removed_age = user.pop("age", None)
print("removed_age:", removed_age)
print(user)removed_age: None
{'name': 'Alice'}「エラーにはしたくないが、削除できたかどうかは知りたい」という場合は、戻り値がNoneかどうかで判定できます。
まとめ
Pythonの辞書(dict)は、keyとvalueの対応を扱う、非常に表現力の高いデータ構造です。
本記事では、基本構文からスタートし、要素の追加(=代入・update()・setdefault())、取得([]・get()・keys()など)、削除(del・pop()・clear()など)まで、実務でよく使う操作を一通り解説しました。
ここまでの内容をマスターすれば、設定管理やJSON処理など多くの場面で辞書を自在に活用できるようになります。
ぜひ、実際に手を動かしてコードを書きながら、辞書操作に慣れていってください。
