
Pythonの辞書型(dict)は、データを「名前と値」の組み合わせで管理できる、とても便利なデータ構造です。
本記事では、辞書型の基礎から、作成・追加・更新・削除・ループ処理、そして実務で役立つ便利メソッドまでを一通り解説します。
初心者の方でも理解しやすいように、図解とサンプルコードを交えながら丁寧に説明しますので、最後まで読むことで辞書型を自信を持って使いこなせるようになります。
辞書型とは?基本の使い方
辞書型(dict)の特徴とリストとの違い
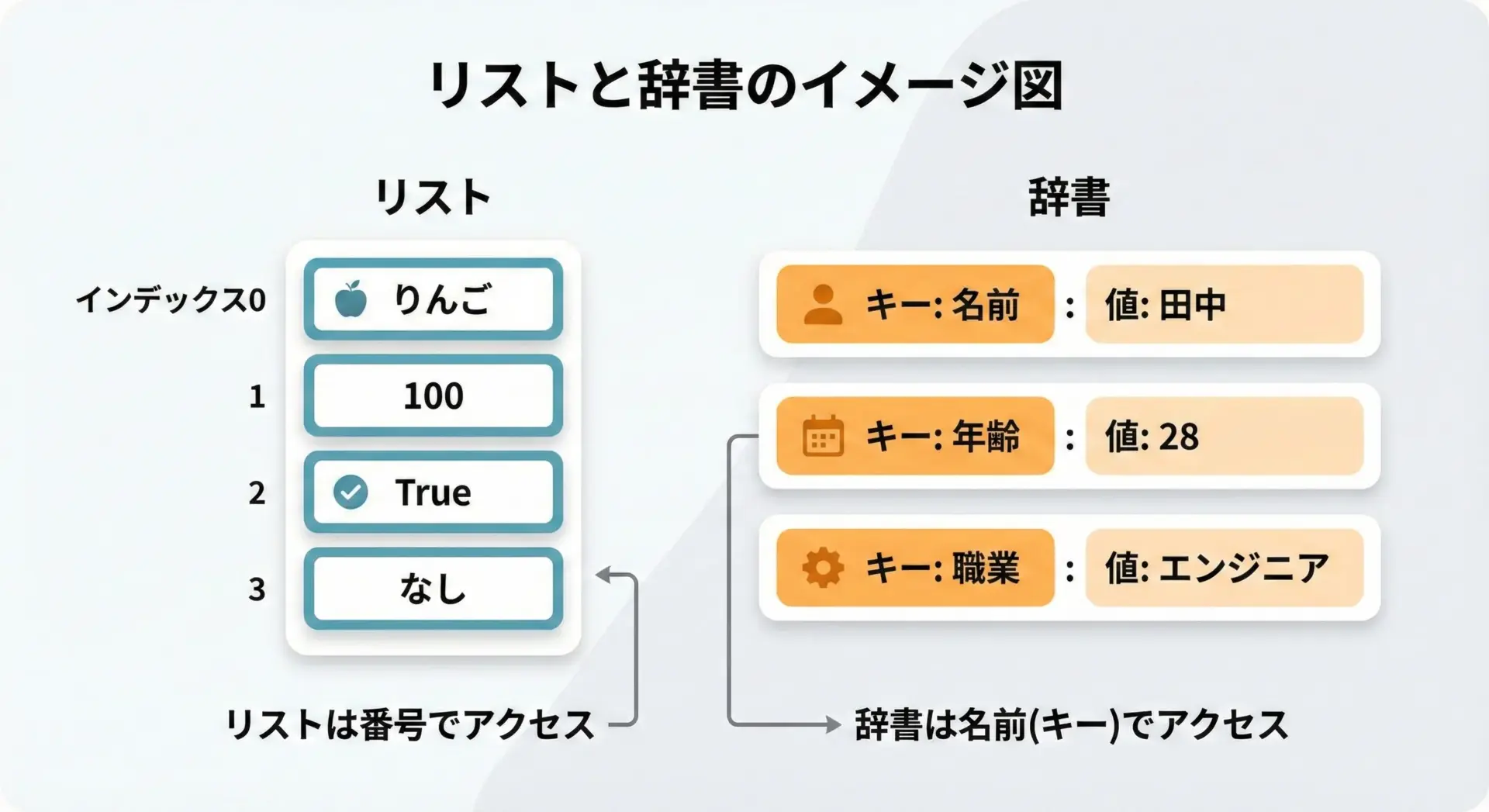
Pythonの辞書型(dict)は、「キー(key)」と「値(value)」の組み合わせでデータを管理するデータ型です。
イメージとしては、現実の「単語帳」や「住所録」に近く、「○○さんの電話番号」「商品コードと価格」などをひも付けて管理します。
リストとの主な違いを、まずはイメージから整理します。
- リスト(list)は「0番目、1番目、2番目…」という番号(インデックス)でアクセスします。
- 辞書(dict)は「name」「age」「price」などの名前(キー)でアクセスします。
次の表で両者の特徴を比べてみます。
| 特徴 | リスト(list) | 辞書(dict) |
|---|---|---|
| アクセス方法 | インデックス(0,1,2,…) | キー(key)でアクセス |
| データの構造 | 値だけが並ぶ | キーと値のペアが並ぶ |
| 主な用途 | 順番が重要なデータ、単純な列 | ラベル付きのデータ、属性のまとまり |
| アクセスのわかりやすさ | people[0] が誰かはコードだけだとわかりにくい | person["name"] なら「名前」と分かる |
| キー(インデックス)の種類 | 整数インデックスのみ | 文字列、数値、タプルなど(条件あり) |
例えば、1人のユーザー情報を扱うとき、リストで書くと次のようになります。
# リストでユーザー情報を管理する例
user_list = ["Taro", 25, "Tokyo"] # [名前, 年齢, 住所]
print(user_list[0]) # 0番目: 名前
print(user_list[1]) # 1番目: 年齢
print(user_list[2]) # 2番目: 住所この書き方だと、「0番目が名前」「1番目が年齢」と人間が覚えておく必要があるため、可読性が下がります。
辞書型を使うと、次のように書けます。
# 辞書でユーザー情報を管理する例
user_dict = {
"name": "Taro",
"age": 25,
"address": "Tokyo",
}
print(user_dict["name"]) # キー "name" で名前にアクセス
print(user_dict["age"]) # キー "age" で年齢にアクセス
print(user_dict["address"]) # キー "address" で住所にアクセスTaro
25
Tokyoこのように辞書型は「データの意味」をコードに直接書けるため、規模が大きくなっても理解しやすくなります。
キーと値(key,value)の基本ルール
辞書は「キー: 値」(key: value)の組み合わせで構成されます。
Pythonの文法では、次のように書きます。
dictionary = {
キー1: 値1,
キー2: 値2,
...
}キー(key)のルール
キーは次のようなルールを持ちます。
- 重複してはいけない(同じキーを2回書くと後の値で上書きされる)
- 変更できない(イミュータブル)型である必要がある
代表的な例は次の通りです。- 文字列(str)
- 数値(int, float)
- タプル(tuple)(中身もイミュータブルであること)
一方で、リスト(list)や別の辞書(dict)など、変更可能なオブジェクトはキーには使えません。
# 有効なキーの例
valid_dict = {
"name": "Taro", # 文字列
1: "one", # 整数
3.14: "pi", # 浮動小数点
(1, 2): "point", # タプル
}
print(valid_dict["name"])
print(valid_dict[1])
print(valid_dict[(1, 2)])Taro
one
point値(value)のルール
値に関しては特に制限はなく、どんなオブジェクトでも格納できます。
- 文字列、数値、リスト、辞書、そのほか自作クラスのインスタンスなど、あらゆる値を格納できます。
- 値が辞書の中にさらに辞書を持つ、という入れ子構造も可能です。
# 値にさまざまな型を持つ辞書の例
person = {
"name": "Taro",
"age": 25,
"languages": ["Python", "JavaScript"], # リスト
"address": {
"city": "Tokyo",
"zip": "100-0001",
}, # 辞書の中に辞書
}
print(person["languages"])
print(person["address"]["city"]) # ネストした辞書へのアクセス['Python', 'JavaScript']
Tokyo辞書型が便利な代表的な場面
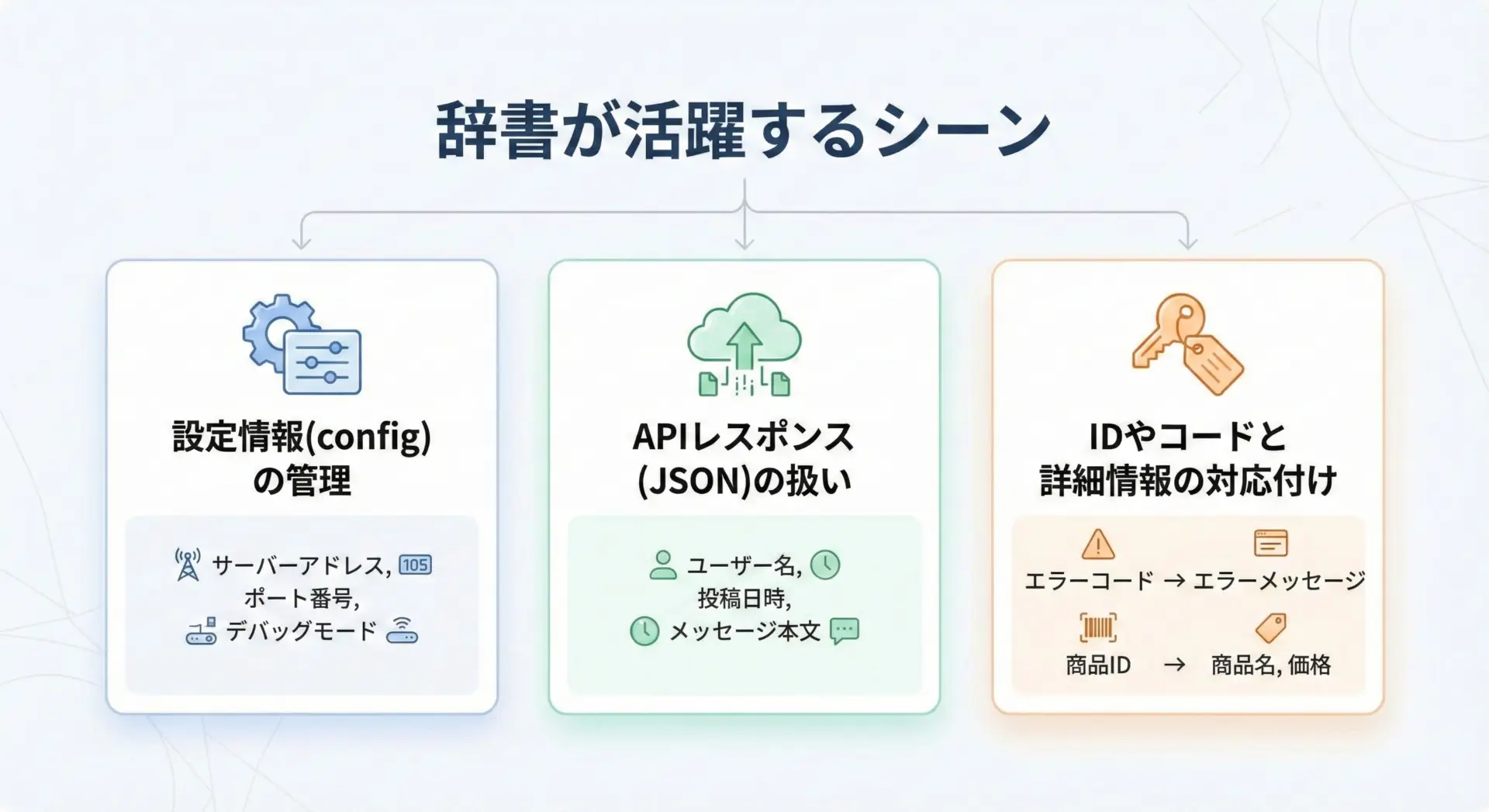
辞書型は、現実世界の多くのデータ構造に自然に対応しているため、さまざまな場面で利用されます。
代表的な例をいくつか紹介します。
設定情報の管理
アプリケーションの設定をまとめて管理したい場合、辞書が非常に便利です。
config = {
"debug": True,
"max_users": 100,
"timeout": 30,
}キーが設定項目名になっているため、設定の意味が一目でわかるというメリットがあります。
APIレスポンス(JSON)の扱い
Web APIから返ってくるJSONデータは、Pythonではほとんどが辞書として扱われます。
例えば、ユーザー情報のJSONを取得した場合、次のような辞書になります。
user = {
"id": 123,
"name": "Taro",
"email": "taro@example.com",
}これをuser["email"]のように扱うのが一般的です。
IDやコードと詳細情報の対応付け
商品コードと商品名、ステータスコードと説明文など、「コード」と「説明」の組み合わせは辞書で表現すると分かりやすくなります。
status_messages = {
200: "OK",
404: "Not Found",
500: "Internal Server Error",
}このように辞書型は、「ラベル付きのデータ」を直感的に扱えるため、実務で頻繁に使われる重要なデータ型です。
辞書型の作成と要素の追加
辞書型を作成する基本構文
辞書型を作る基本的な書き方は、{}(波かっこ)を使う方法です。
# 基本的な辞書リテラルの書き方
user = {
"name": "Taro",
"age": 25,
"city": "Tokyo",
}
print(user){'name': 'Taro', 'age': 25, 'city': 'Tokyo'}カンマと最後の要素について
Pythonでは、最後の要素の後ろにカンマを書いても問題ありません。
複数行で書く場合、変更があったときに差分が分かりやすくなるため、次のようなスタイルもよく使われます。
settings = {
"debug": True,
"log_level": "INFO",
"retries": 3,
}空の辞書を作成する方法
辞書を最初は空の状態で用意しておき、あとから値を追加したい場面がよくあります。
空の辞書を作る方法は2つあります。
1つ目は{}を使う方法です。
# {} を使って空の辞書を作成
data = {}
print(data)
print(type(data)){}
<class 'dict'>2つ目はdict()コンストラクタを使う方法です。
# dict() を使って空の辞書を作成
data = dict()
print(data)
print(type(data)){}
<class 'dict'>どちらも結果は同じです。
一般には{}のほうが短くてよく使われますが、コードのスタイルに応じて使い分けて構いません。
要素を1つずつ追加する方法
空の辞書を用意してから、要素を1つずつ追加するコード例を見てみます。
# 空の辞書を作成
user = {}
# 1つずつキーと値を追加していく
user["name"] = "Taro"
user["age"] = 25
user["city"] = "Tokyo"
print(user){'name': 'Taro', 'age': 25, 'city': 'Tokyo'}辞書への追加は、辞書[キー] = 値 という形式で行います。
存在しないキーに代入すると「追加」になり、既にあるキーに代入すると「更新」になります。
更新については後の章でも詳しく説明します。
dictコンストラクタと内包表記で辞書を作成
辞書には、dictコンストラクタと辞書内包表記という、少し高度で便利な作成方法があります。
dictコンストラクタで作成する
dict()コンストラクタは、いくつかの特殊な書き方で辞書を作成できる機能です。
1つ目は、キー=値の形式で指定する方法です。
この場合、キーは文字列として扱われます。
# dict(キー=値, ...) の形式で辞書を作成
user = dict(name="Taro", age=25, city="Tokyo")
print(user){'name': 'Taro', 'age': 25, 'city': 'Tokyo'}2つ目は、[(キー, 値), (キー, 値), ...]のようなリスト(またはタプル)から辞書を生成する方法です。
# (キー, 値) のタプルのリストから辞書を作成
pairs = [("apple", 100), ("banana", 200), ("orange", 150)]
prices = dict(pairs)
print(prices){'apple': 100, 'banana': 200, 'orange': 150}辞書内包表記で作成する
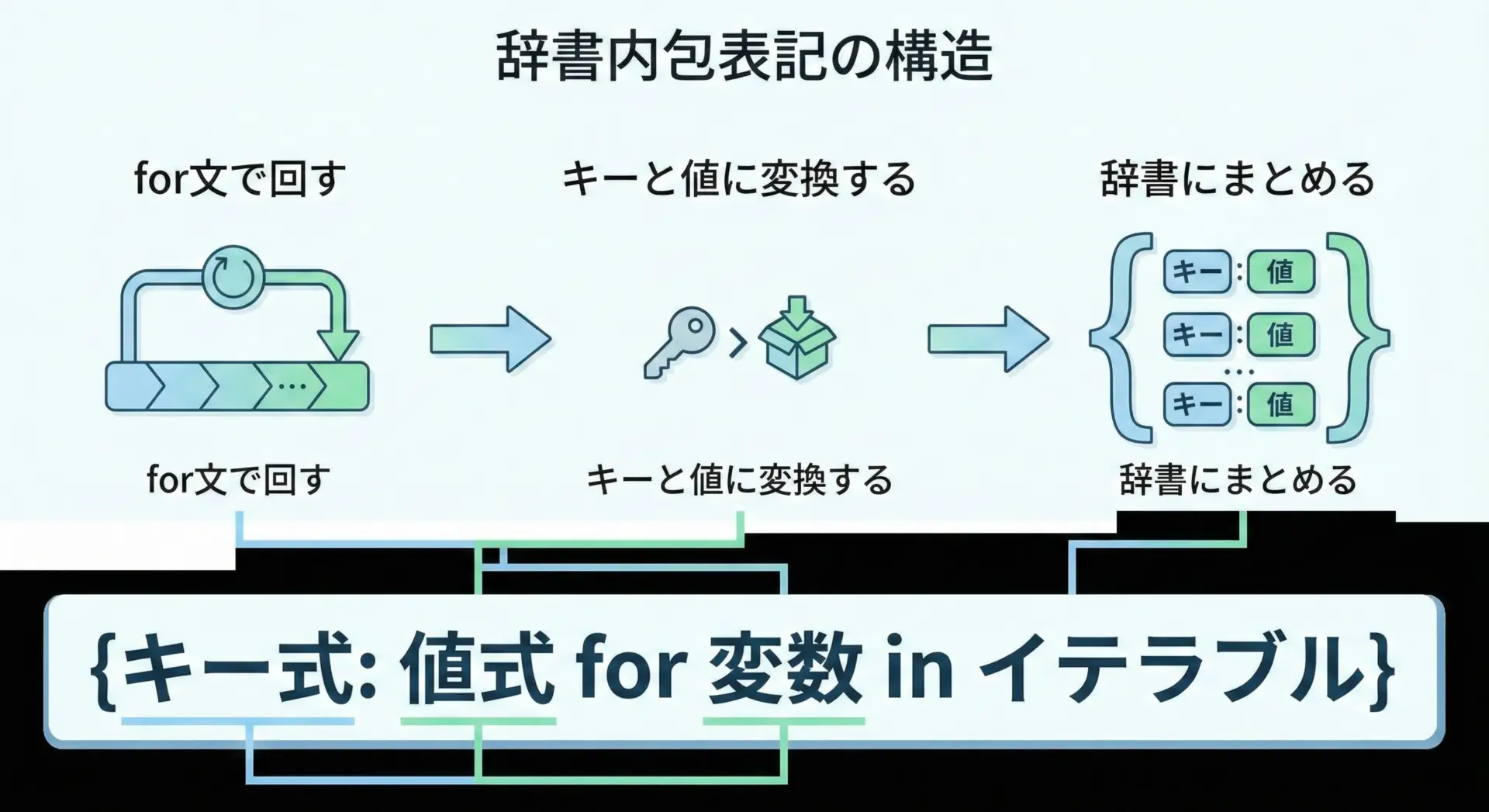
辞書内包表記は、リスト内包表記の辞書版のようなもので、規則に従って辞書を一気に作成したいときに便利です。
基本形は次のようになります。
{キーの式: 値の式 for 変数 in 反復可能オブジェクト}具体例を見てみましょう。
1から5までの整数をキー、その2乗を値とする辞書を作成します。
# 辞書内包表記の例: 1〜5の数値をキー、その2乗を値にする
squares = {x: x**2 for x in range(1, 6)}
print(squares){1: 1, 2: 4, 3: 9, 4: 16, 5: 25}条件を加えて、偶数だけを辞書に含めることもできます。
# 偶数のみを対象にした辞書内包表記の例
even_squares = {x: x**2 for x in range(1, 11) if x % 2 == 0}
print(even_squares){2: 4, 4: 16, 6: 36, 8: 64, 10: 100}辞書内包表記はやや高度な構文ですが、データ変換やマッピングを行う処理をコンパクトに書けるため、覚えておくと便利です。
辞書型の更新・取得・削除
要素の値を更新する
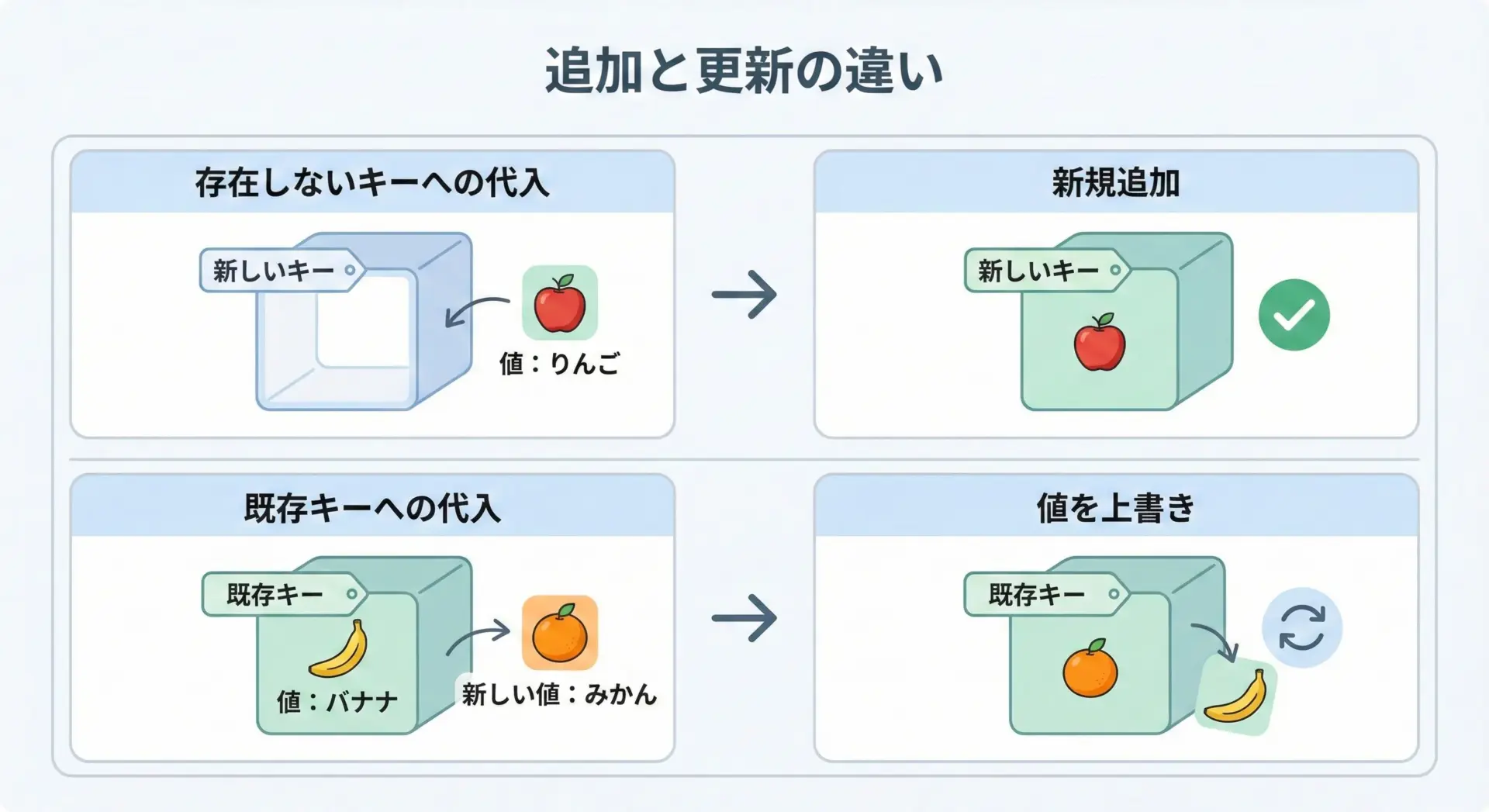
辞書の要素は、代入演算子=を使うだけで簡単に更新できます。
先ほど説明したように、存在しないキーなら「追加」、既に存在するキーなら「更新」として扱われます。
user = {
"name": "Taro",
"age": 25,
}
# 既存キー "age" の値を更新
user["age"] = 26
# 新しいキー "city" を追加
user["city"] = "Tokyo"
print(user){'name': 'Taro', 'age': 26, 'city': 'Tokyo'}複数の値を一度に更新したい場合は、update()メソッドが便利です。
後の「便利メソッド」の節でも取り上げますが、ここで簡単に使い方を見ておきます。
user = {
"name": "Taro",
"age": 25,
}
# update() で複数のキーをまとめて追加・更新
user.update({
"age": 26, # 更新
"city": "Tokyo", # 追加
})
print(user){'name': 'Taro', 'age': 26, 'city': 'Tokyo'}キーから値を取得する
辞書の値の取得は、基本的に辞書[キー]という形式で行います。
user = {
"name": "Taro",
"age": 25,
}
print(user["name"])
print(user["age"])Taro
25存在しないキーを指定した場合
辞書[キー]で存在しないキーを指定するとKeyErrorが発生します。
user = {"name": "Taro"}
# 存在しないキー "age" を指定
print(user["age"])Traceback (most recent call last):
...
KeyError: 'age'このエラーを避けながら値を取得したい場合は、get()メソッドを使う方法があります。
user = {"name": "Taro"}
# get() を使うと、キーがなくてもエラーにならない
print(user.get("age")) # デフォルトは None
print(user.get("age", 0)) # 見つからないときは 0 を返す
print(user.get("name", "N/A")) # 見つかればその値を返すNone
0
Taroget()は「キーが存在しないかもしれないが、とりあえず値が欲しい」場面でとても便利です。
キーの存在確認
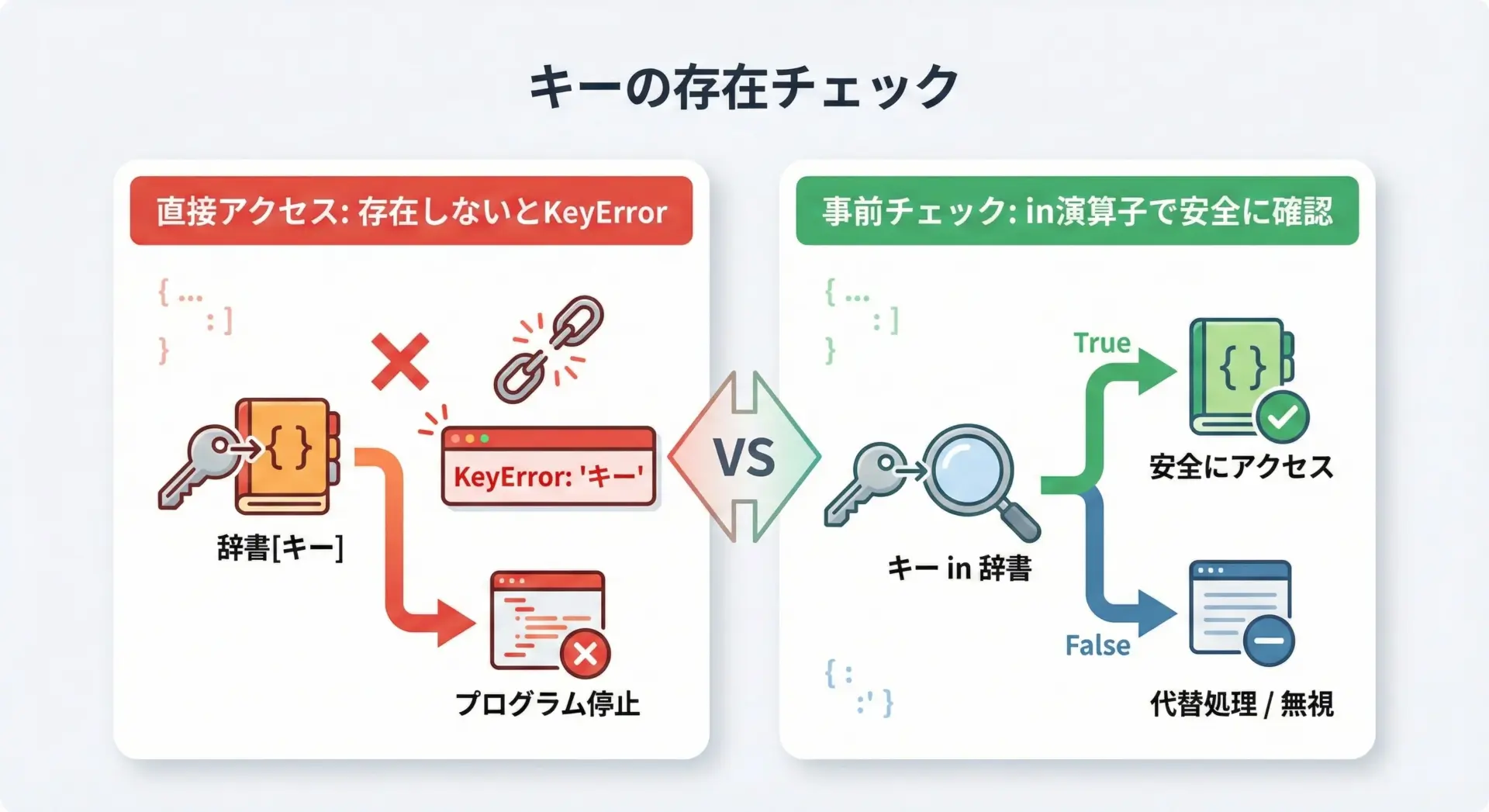
辞書に特定のキーが存在するかどうかを調べるには、in演算子を使います。
user = {
"name": "Taro",
"age": 25,
}
print("name" in user) # True
print("city" in user) # FalseTrue
Falseこの書き方は、存在確認をしたうえで安全にアクセスしたいときによく使われます。
user = {"name": "Taro"}
if "age" in user:
print("age:", user["age"])
else:
print("age は登録されていません")age は登録されていませんinはキーの存在をチェックするもので、値の存在をチェックするものではない点に注意してください。
値の存在を調べたい場合はvalue in dict.values()のようにしますが、パフォーマンス面などを考えると、値で検索する場面は設計自体を見直すことも検討した方がよい場合があります。
popとdelで要素を削除する方法
辞書から要素を削除するには、主にpop()メソッドかdel文を使います。
pop()メソッド
pop(key)は、指定したキーの要素を削除し、その値を返すメソッドです。
user = {
"name": "Taro",
"age": 25,
"city": "Tokyo",
}
# "age" を削除して、その値を受け取る
age = user.pop("age")
print("削除された age の値:", age)
print("削除後の辞書:", user)削除された age の値: 25
削除後の辞書: {'name': 'Taro', 'city': 'Tokyo'}存在しないキーをpop()で指定すると、通常はKeyErrorになりますが、第二引数にデフォルト値を指定すると、エラーを避けられます。
user = {"name": "Taro"}
# 存在しないキー "age" を pop するが、デフォルト値を指定
age = user.pop("age", None)
print(age) # None
print(user) # 変更なしNone
{'name': 'Taro'}del文
del文を使うと、指定したキーを辞書から削除できます。
返り値はありません。
user = {
"name": "Taro",
"age": 25,
"city": "Tokyo",
}
del user["city"]
print(user){'name': 'Taro', 'age': 25}存在しないキーをdelで指定するとKeyErrorになります。
必要に応じてinで存在確認を行ってから削除すると安全です。
user = {"name": "Taro"}
if "city" in user:
del user["city"]
else:
print("city は登録されていません")city は登録されていませんclearで辞書を空にする
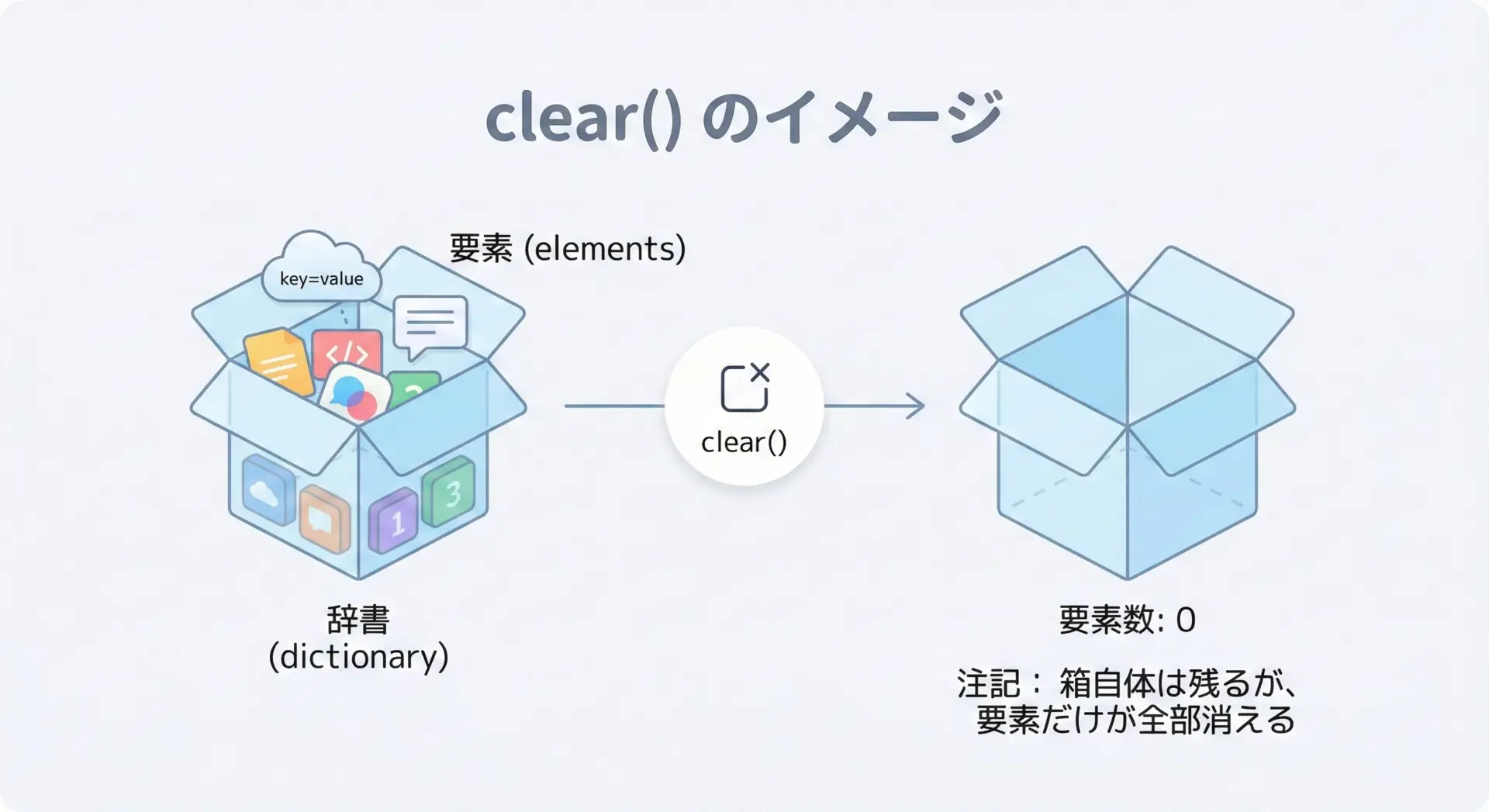
辞書の中身をすべて削除して、空の辞書にしたいときはclear()メソッドを使います。
辞書オブジェクト自体はそのままで、中身だけが消えるイメージです。
user = {
"name": "Taro",
"age": 25,
}
user.clear()
print(user){}このようにclear()は、初期化やリセットを行いたいときに便利です。
辞書型のループと便利メソッド
forループで辞書を回す基本
辞書をforループで回すときの基本は、「辞書をそのまま回すとキーだけが取り出される」というルールを理解することです。
user = {
"name": "Taro",
"age": 25,
"city": "Tokyo",
}
# 辞書をそのまま for で回すとキーが取り出される
for key in user:
print(key)name
age
cityキーから値を取り出したい場合は、ループの中でuser[key]と書きます。
for key in user:
value = user[key]
print(key, "=>", value)name => Taro
age => 25
city => Tokyoこの書き方でも問題ありませんが、より効率的で読みやすい方法として、次に紹介するkeys()、values()、items()メソッドの利用が推奨されます。
keys, values, itemsで効率よくループする
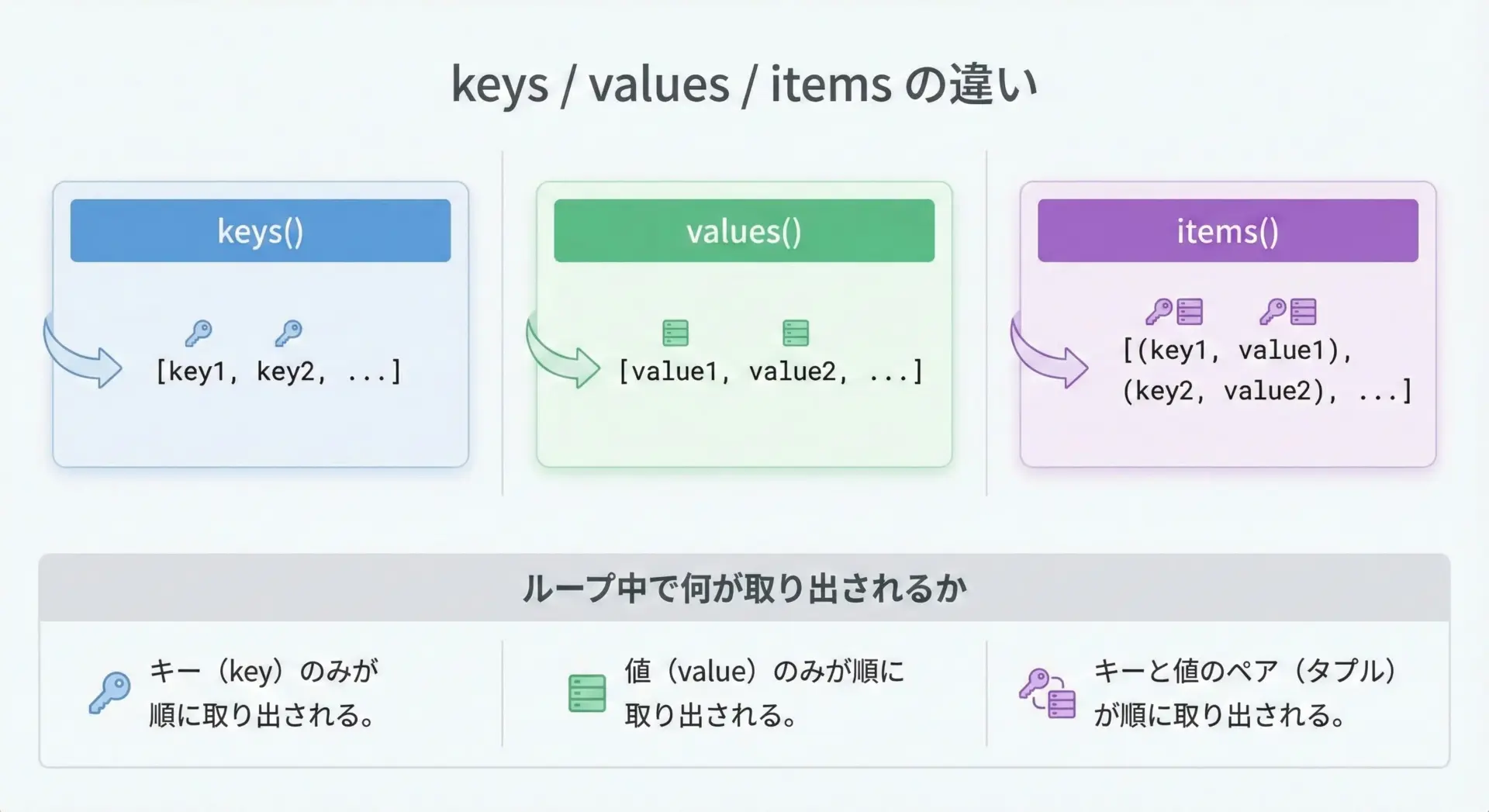
辞書には、キーだけ、値だけ、両方をペアで取り出すためのメソッドが用意されています。
keys()でキーを取り出す
user = {
"name": "Taro",
"age": 25,
}
for key in user.keys():
print("key:", key)key: name
key: agefor key in user:と結果は同じですが、「キーを回している」ことが明示されるので可読性が上がります。
values()で値を取り出す
user = {
"name": "Taro",
"age": 25,
}
for value in user.values():
print("value:", value)value: Taro
value: 25値だけを扱えればよい場合にはvalues()を使うとシンプルです。
items()でキーと値を同時に取り出す
最もよく使われるのがitems()です。
これは、(キー, 値)のペアを1つずつ返します。
user = {
"name": "Taro",
"age": 25,
}
for key, value in user.items():
# key と value に同時に展開される
print(key, "=>", value)name => Taro
age => 25items()を使うことで、キーと値をペアとして直感的に扱えるため、辞書をループするときの定番パターンとなっています。
辞書同士の結合
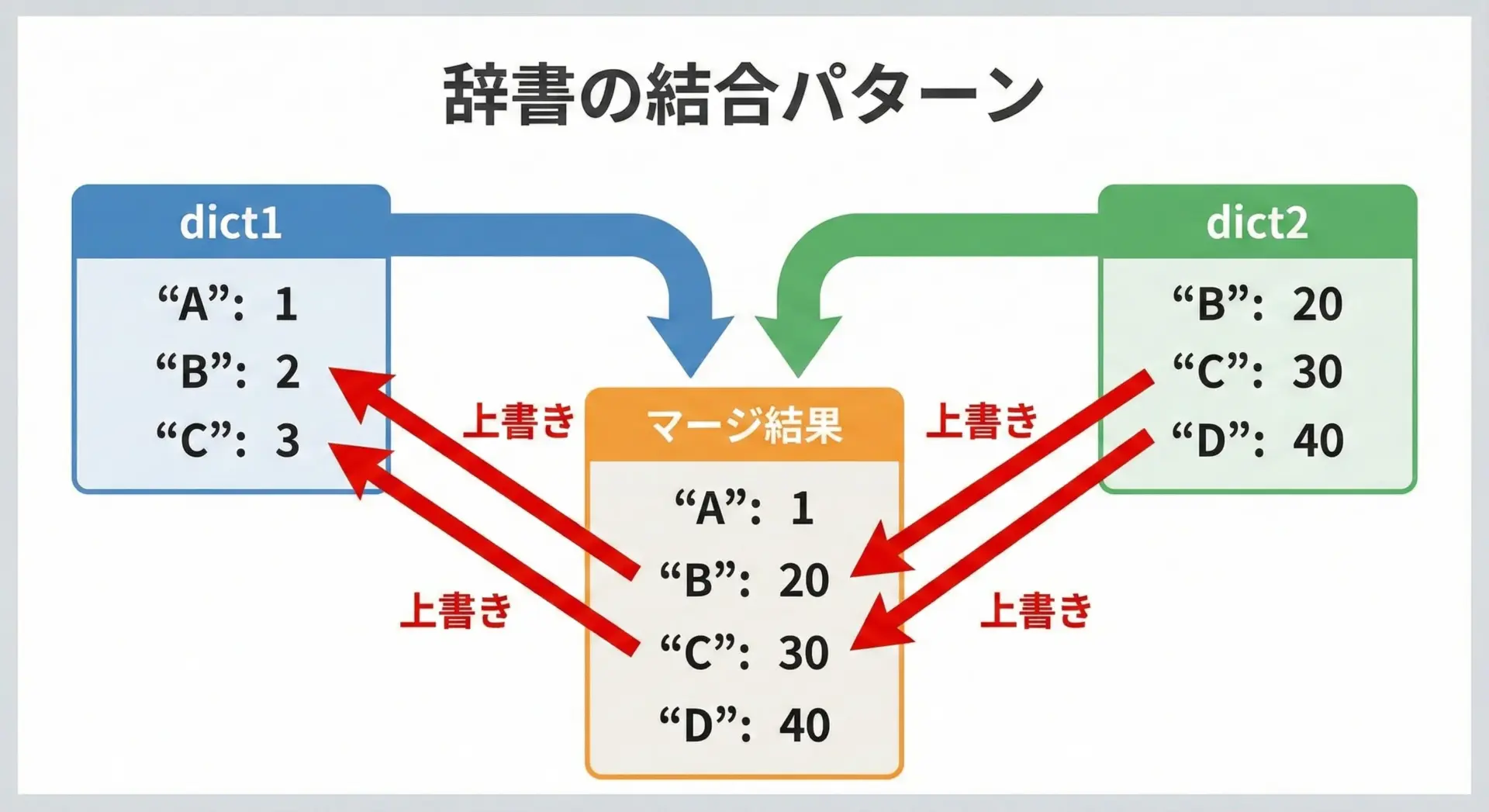
複数の辞書を結合して1つにまとめたい場面もよくあります。
Pythonではいくつかの方法が用意されています。
update()メソッドで結合する
dict.update()を使うと、一方の辞書にもう一方の辞書の内容をマージできます。
user = {
"name": "Taro",
"age": 25,
}
extra = {
"city": "Tokyo",
"age": 26, # 既存キーと重複
}
# user を上書き更新
user.update(extra)
print(user){'name': 'Taro', 'age': 26, 'city': 'Tokyo'}同じキーがある場合、後から渡した辞書の値で上書きされることに注意してください。
Python 3.9以降の「|」演算子で新しい辞書を作る
Python 3.9以降では、|演算子で辞書同士を結合し、新しい辞書を作ることができます。
元の辞書は変更されません。
user = {
"name": "Taro",
"age": 25,
}
extra = {
"city": "Tokyo",
"age": 26,
}
merged = user | extra # 新しい辞書を生成
print("user:", user)
print("extra:", extra)
print("merged:", merged)user: {'name': 'Taro', 'age': 25}
extra: {'city': 'Tokyo', 'age': 26}
merged: {'name': 'Taro', 'age': 26, 'city': 'Tokyo'}|演算子は「元の辞書を壊さずに新しい辞書を作りたい」場合に便利です。
Python 3.8以前を使っている場合は、代わりに{**dict1, **dict2}という書き方が使えます。
# Python 3.8 以前でも使える結合方法
user = {"name": "Taro", "age": 25}
extra = {"city": "Tokyo", "age": 26}
merged = {**user, **extra}
print(merged){'name': 'Taro', 'age': 26, 'city': 'Tokyo'}辞書型を使うときの注意点とベストプラクティス

辞書型は非常に便利ですが、使い方を誤るとバグの原因にもなります。
ここでは、実務でもよく意識される注意点とベストプラクティスをまとめます。
意味の分かるキー名を使う
キーは「データのラベル」なので、人が読んで意味が分かる名前にすることが重要です。
良い例:
user = {
"name": "Taro",
"age": 25,
"email": "taro@example.com",
}悪い例:
user = {
"n": "Taro",
"a": 25,
"e": "taro@example.com",
}後から読む人(過去の自分も含む)が理解しやすいように、説明的なキー名を心がけましょう。
get()で安全にアクセスする
「キーがあるかもしれないし、ないかもしれない」ような入力データや外部データでは、get()を使ってエラーを避けるのが定石です。
user = {"name": "Taro"}
# KeyError を避けたい場合
age = user.get("age", 0) # なければ 0 にする一方で、必ず存在するべきキーに対しては、エラーを出した方がバグに気づきやすい場合もあります。
「本当に必須の項目かどうか」で使い分けるとよいです。
ミュータブルな値の扱いに注意(リストや辞書の共有)
辞書の値に、リストや別の辞書など変更可能(ミュータブル)なオブジェクトを入れる場合、別名参照による思わぬ副作用に注意が必要です。
# 同じリストオブジェクトを2つのキーで共有している例
shared_list = []
data = {
"a": shared_list,
"b": shared_list,
}
data["a"].append(1)
print(data){'a': [1], 'b': [1]}「aだけ変えたつもりが、bも変わってしまう」といった状況を避けるため、必要に応じてcopy()やdeepcopy()を使うことも検討してください。
辞書のネストを深くしすぎない
辞書の中に辞書、その中にさらに辞書…という構造を過度に使うと、アクセスが複雑になり可読性が落ちます。
# ネストが深すぎる例
config["services"]["web"]["auth"]["methods"]["password"]["min_length"]こうした場合は、構造を見直してクラスを導入したり、キーのグルーピング方法を変えたりして、「人間が理解しやすい深さ」に抑えることが大切です。
まとめ
辞書型(dict)は、Pythonで最も重要なデータ型の1つであり、「キーと値のペア」でデータを管理できる柔軟さが大きな特徴です。
本記事では、辞書の基本構造から、作成・追加・更新・削除、ループ処理、そして辞書同士の結合や実務でのベストプラクティスまでを一通り紹介しました。
まずは{}で辞書を作り、dict[key]、get()、items()、update()あたりを自然に使えるようになることを目標にすると良いです。
辞書を使いこなせるようになれば、設定管理、API連携、データ加工など、Pythonで扱う多くの処理がぐっと書きやすくなります。
