
Pythonでリストの要素が存在するかを調べるとき、最初に覚えるべきなのがin演算子です。
インデックスで無理にアクセスしようとしてエラーを出してしまうより、inで「あるかどうか」を先に確かめる方が安全です。
本記事では、リストに特化しつつ、シーケンス型全般で使えるinの基本から、実務で役立つテクニック、パフォーマンスの考え方まで丁寧に解説します。
in演算子とは
in演算子でできること
in演算子は、Pythonで「ある値が、ある入れ物(コンテナ)の中に含まれているか」を判定するための演算子です。
反対に「含まれていないか」を調べるnot inもセットで覚えておくと便利です。
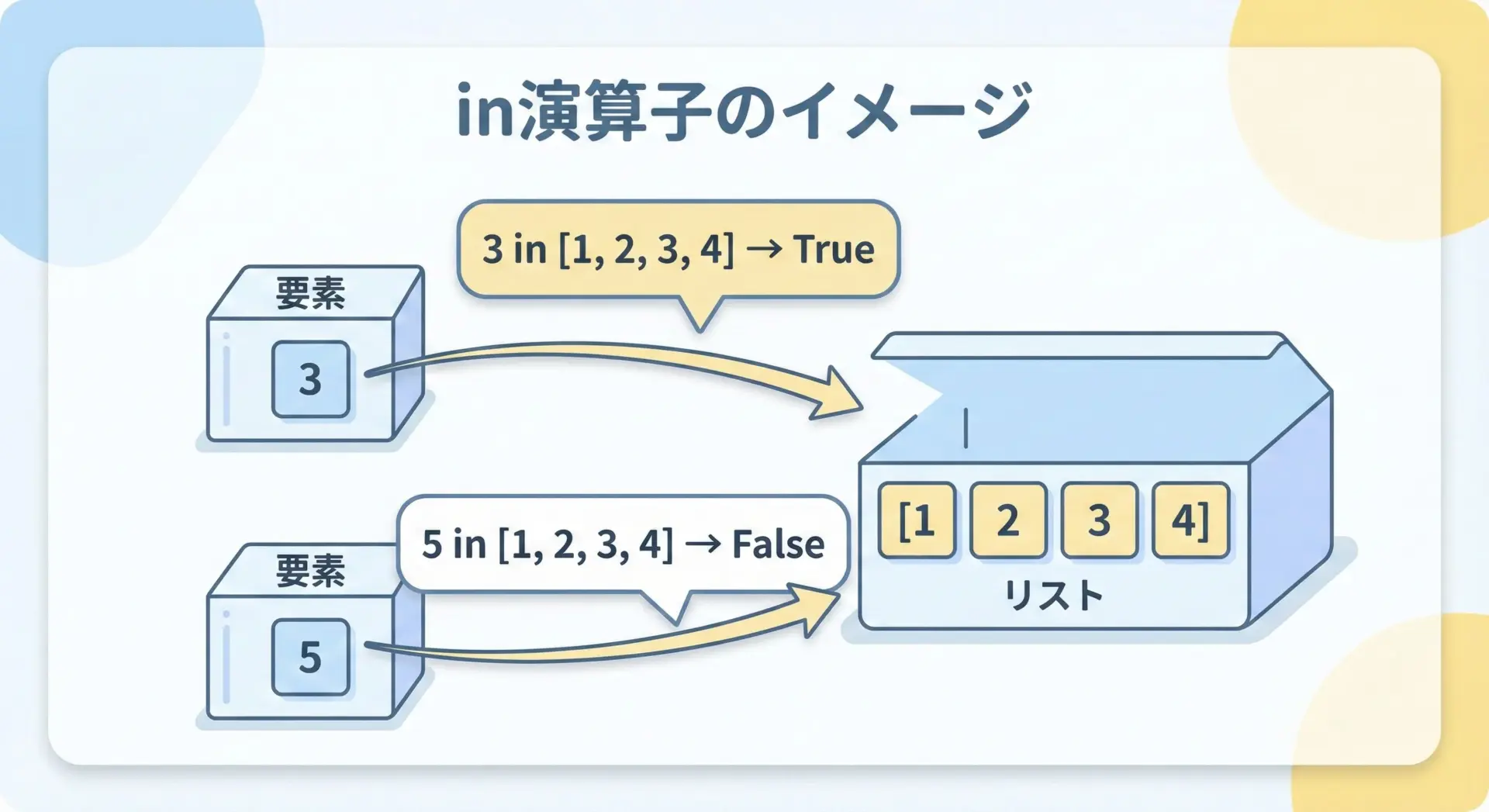
inは、次のようなさまざまな場面で活躍します。
- リストやタプルなどのシーケンス型に、特定の値が含まれているかをチェック
- 文字列の中に、ある部分文字列が含まれているかをチェック
- 辞書で、特定のキーが存在するかをチェック
- 集合(set)で、要素の存在を高速に確認
具体的なイメージを掴むため、簡単なサンプルをいくつか見てみます。
# 数値リストでの in
numbers = [1, 2, 3, 4, 5]
print(3 in numbers) # True
print(10 in numbers) # False
# 文字列での in (部分文字列の存在チェック)
text = "Python programming"
print("Python" in text) # True
print("java" in text) # False (大文字小文字も区別されます)
# 辞書での in (キーの存在チェック)
user = {"name": "Alice", "age": 20}
print("name" in user) # True (キー"name"が存在する)
print("Alice" in user) # False (値は対象外)
# 集合(set)での in
colors = {"red", "green", "blue"}
print("red" in colors) # True
print("yellow" in colors) # FalseTrue
False
True
False
True
False
True
Falseこのように、inは「入れ物の中をざっと探して、あったかどうか」を真偽値で返す演算子です。
Pythonのリストとシーケンス型の基本
リスト(list)は、Pythonで最もよく使われるシーケンス型です。
シーケンス型とは、要素が順番に並んでいて、インデックスでアクセスできるデータのまとまりのことです。
Pythonで代表的なシーケンス型には、次のようなものがあります。
| 型名 | 例 | 特徴 |
|---|---|---|
| list | [1, 2, 3] | 変更可能(要素の追加・削除ができる) |
| tuple | (1, 2, 3) | 変更不可(イミュータブル) |
| str | “python” | 文字の並びを表す |
| range | range(0, 10) | 整数の連続した範囲 |
このうち、リストは次のような特徴があります。
- 複数の値をひとつの変数で扱える
- 型の異なる値を混在させることも可能
- 添字(インデックス)でアクセスできる
in演算子で、要素の存在確認ができる
fruits = ["apple", "banana", "orange"]
# インデックスアクセス
print(fruits[0]) # "apple"
print(fruits[1]) # "banana"
# in による存在チェック
print("banana" in fruits) # True
print("grape" in fruits) # Falseapple
banana
True
Falseこの記事では、このリストを中心にinの使い方を深掘りしていきます。
リストの要素が存在するかをinで確認する方法
リスト内の要素をinで検索する基本構文
リストに特定の要素が含まれているかを確認する基本構文は、とてもシンプルです。
要素 in リスト
この式は、要素がリストの中にあればTrue、なければFalseを返します。
# 基本形: 要素 in リスト
animals = ["cat", "dog", "bird"]
print("cat" in animals) # "cat"があるか → True
print("lion" in animals) # "lion"があるか → False
# 数値リストでも同様
scores = [10, 20, 30, 40]
print(20 in scores) # True
print(25 in scores) # FalseTrue
False
True
Falseここで重要なのは、inは「位置」ではなく「存在の有無」だけを返すという点です。
リストのどこにあるかを知りたい場合は、list.index()メソッドなど別の手段が必要になります。
inとnot inで存在・非存在を判定する書き方
inには対になる演算子not inがあります。
「含まれないこと」を確認したいときはnot inを使うと読みやすくなります。
users = ["alice", "bob", "charlie"]
# in: 存在すれば True
print("alice" in users) # True
# not in: 存在しなければ True
print("david" not in users) # True
# 否定の否定とくらべて読みやすい
# 悪い例:
print(not ("david" in users)) # 読みづらい
# 良い例:
print("david" not in users) # 「david は users に含まれていない」True
True
True
True条件を自然な日本語で読み上げたときに意味が通るかを意識して、inとnot inを選ぶと、後からコードを読むときに理解しやすくなります。
if文と組み合わせた安全な存在チェック
リストの存在チェックは、実務ではほとんどの場合if文と組み合わせて使います。
よくあるパターンを見てみましょう。
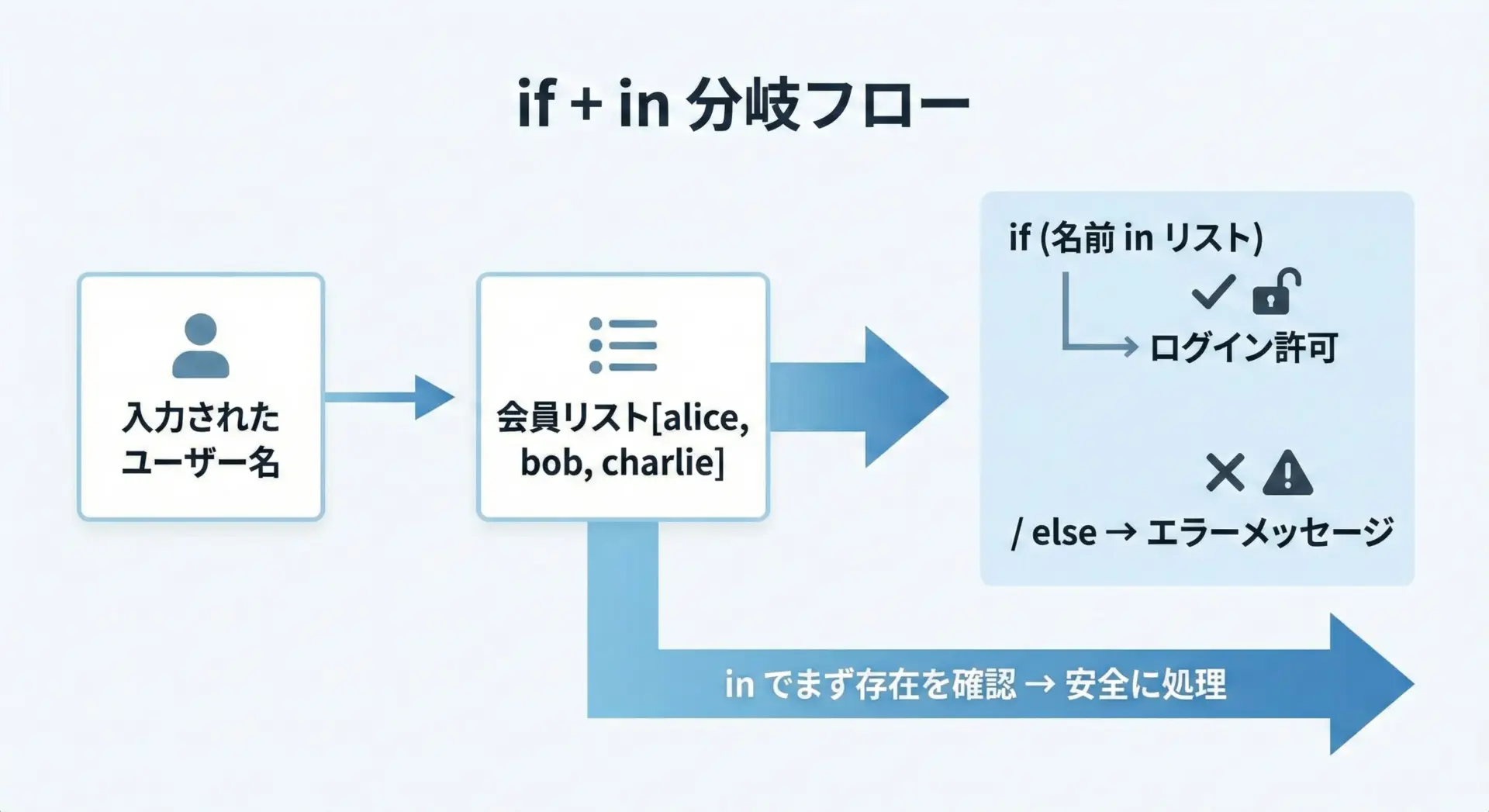
# if と in を組み合わせた安全な存在チェック
members = ["alice", "bob", "charlie"]
name = input("ユーザー名を入力してください: ")
if name in members:
print(f"{name} さんはメンバーです。ログインを許可します。")
else:
print(f"{name} さんはメンバーではありません。新規登録してください。")ユーザー名を入力してください: alice
alice さんはメンバーです。ログインを許可します。「存在チェックをしてから、インデックスアクセスや処理を行う」という流れを徹底すると、例外を未然に防ぎやすくなります。
たとえば、次のように「存在を確認せずにindex()を呼ぶ」とエラーになることがあります。
fruits = ["apple", "banana", "orange"]
# "grape" が存在しない状態で index() を呼ぶと ValueError
position = fruits.index("grape") # ここでエラー
print(position)Traceback (most recent call last):
File "example.py", line X, in <module>
position = fruits.index("grape")
ValueError: 'grape' is not in listこのような場合は、次のようにinで存在チェックを挟むと安全です。
fruits = ["apple", "banana", "orange"]
target = "grape"
if target in fruits:
position = fruits.index(target)
print(f"{target} は {position} 番目にあります。")
else:
print(f"{target} はリストに存在しません。")grape はリストに存在しません。inを使った安全な書き方のポイント
インデックスアクセスとの違いとエラー回避
インデックスアクセスlist[i]は「その位置に必ず要素がある」という前提で使うため、範囲外を指定するとIndexErrorが発生します。
一方inは範囲外という概念がなく、常にTrueかFalseを返すだけなので、安全性が高いです。
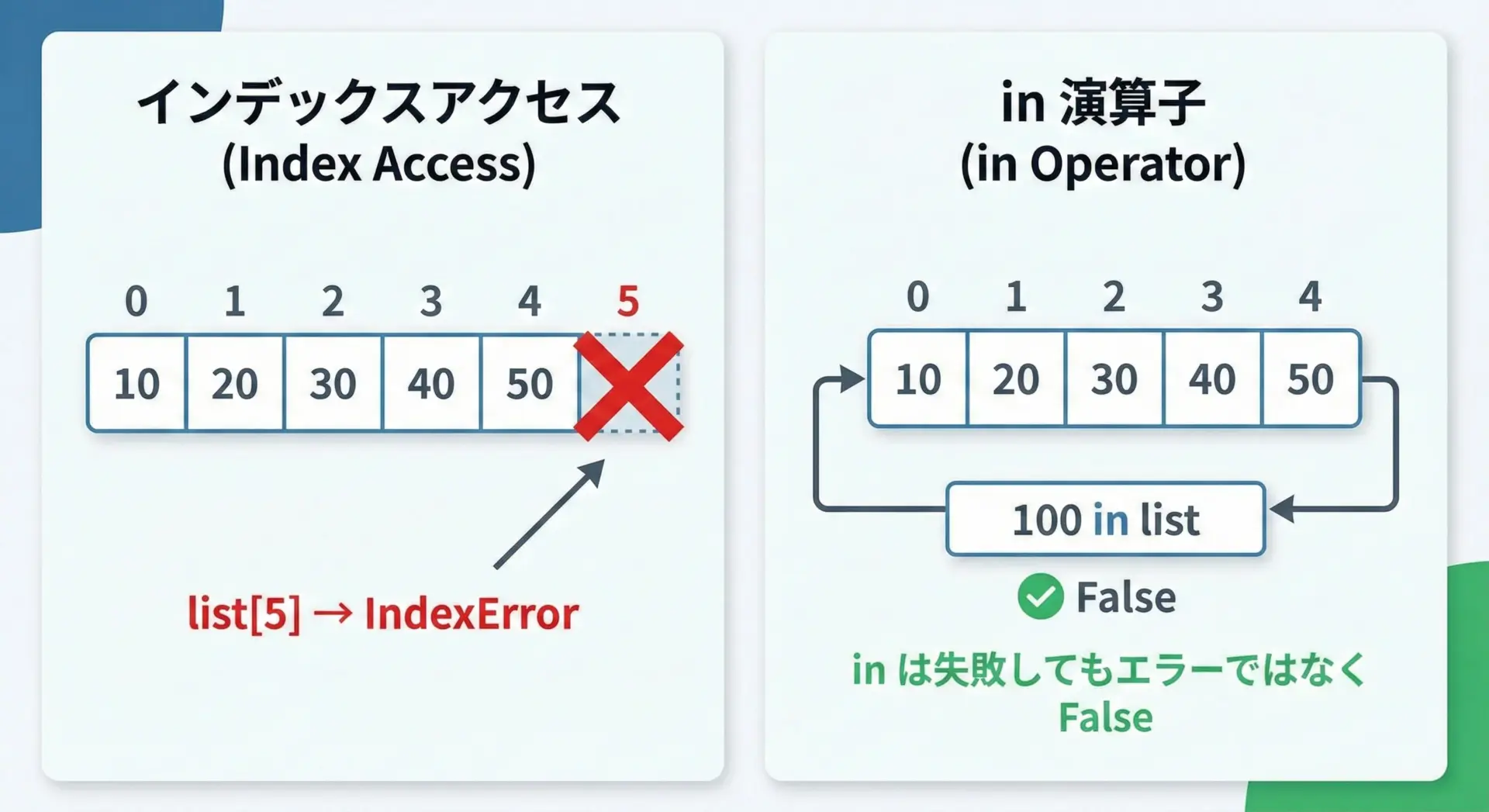
numbers = [10, 20, 30]
# 1. インデックスアクセスは範囲外でエラー
# print(numbers[5]) # IndexError: list index out of range
# 2. in は常に True/False を返すので安全
print(10 in numbers) # True
print(40 in numbers) # False
# 3. 条件分岐と組み合わせると、より安全
idx = 2
if 0 <= idx < len(numbers):
print(numbers[idx])
else:
print("指定した位置には要素がありません。")True
False
30「位置を指定して取り出す前に、inで存在そのものを確認する」という考え方は、実務でのバグを減らす上で非常に重要です。
Noneや空文字が含まれる場合の注意点
リストの中にNoneや空文字""が入ることもよくあります。
このときinは、「同じ値が含まれているかどうか」だけを見ているので、Noneかどうかの判定と混同しないように気を付けます。
values = [None, "", "text", 0]
print(None in values) # True
print("" in values) # True
print(0 in values) # True
# それぞれ、実際にその値が要素として含まれているかどうかだけを見ますTrue
True
Trueよくある勘違いの例として、if value:のように「真偽値の評価」で判定してしまうケースがあります。
Noneや""や0はFalseと評価されるため、「存在しているが空」「0 が入っている」ことと、「まったく存在しない」ことを混同してしまうことがあります。
values = [None, "", "text", 0]
# value が「空」でも「0」でも False と評価されてしまう
for v in values:
if v:
print(f"{v!r} は True と評価されます。")
else:
print(f"{v!r} は False と評価されます。")None は False と評価されます。
'' は False と評価されます。
'text' は True と評価されます。
0 は False と評価されます。「リストの中にNoneが含まれているか確認したい」のであればNone in valuesとし、「要素がNoneでないものだけを処理したい」のであればif v is not None:のように明示的に比較するのが安全です。
values = [None, "", "text", 0]
# None が含まれているかどうか
if None in values:
print("リストには None が含まれています。")
# None 以外だけを処理する
for v in values:
if v is not None:
print(f"None ではない値: {v!r}")リストには None が含まれています。
None ではない値: ''
None ではない値: 'text'
None ではない値: 0ネストしたリストでinを使うときの挙動
ネストしたリスト(リストの中にリストが入っている構造)では、inの「比較の単位」に注意が必要です。
inは、リストの「直接の要素」と比較します。
つまり、「二重リストの中にある値」までは自動で潜って探してくれません。
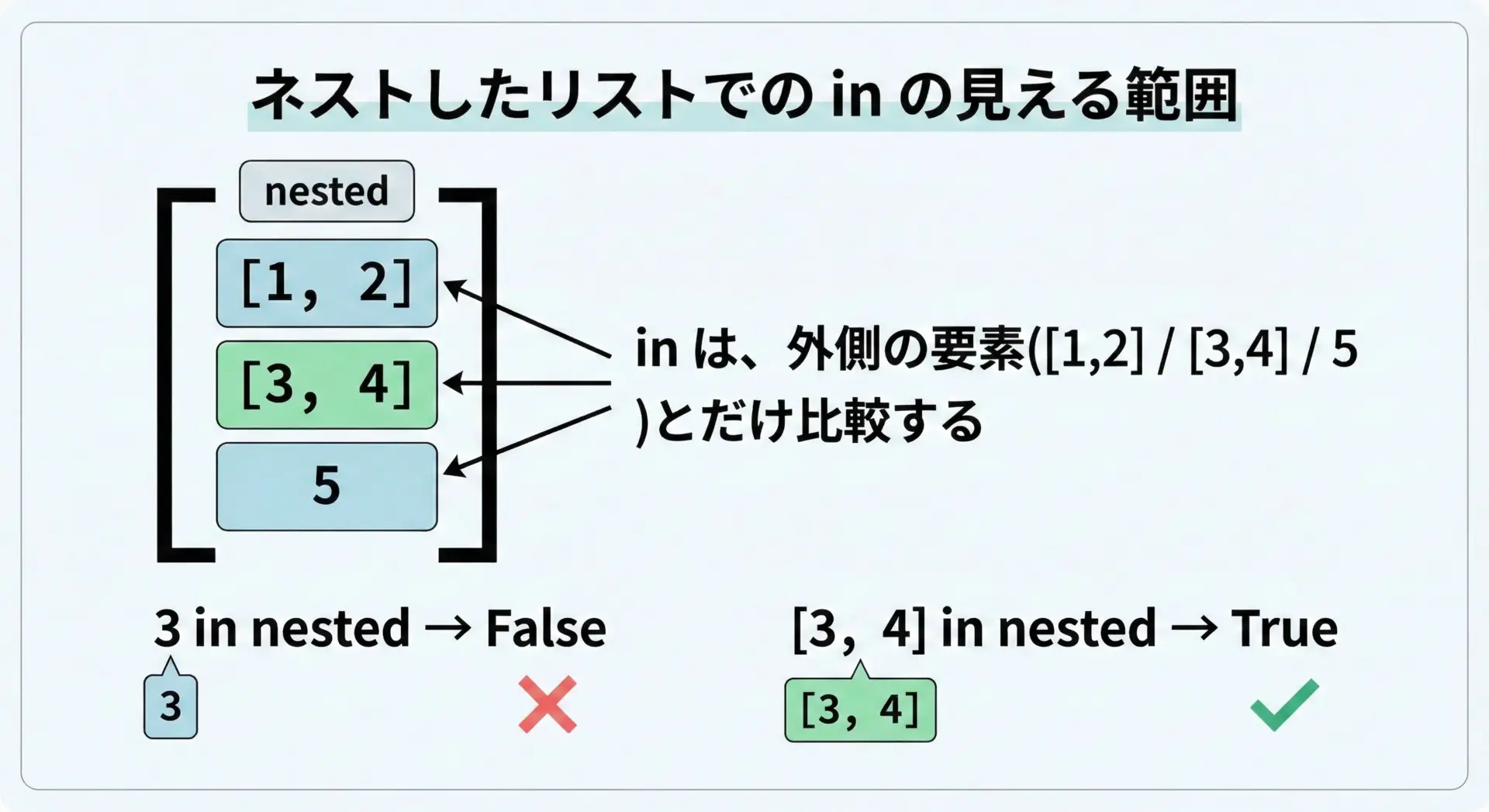
nested = [[1, 2], [3, 4], 5]
print([1, 2] in nested) # True: 要素として [1, 2] がそのまま入っている
print(1 in nested) # False: 1 は「外側の要素」ではない
print(5 in nested) # True: 5 は外側の要素
# 「内側のリストの要素も含めて探したい」場合は工夫が必要True
False
Trueもし「内側も含めてすべての要素を検索したい」場合は、ループで回したり、内包表記で平坦化したりする必要があります。
nested = [[1, 2], [3, 4], 5]
target = 3
# 1. ループで内側も調べる簡易版
found = False
for item in nested:
if isinstance(item, list):
if target in item:
found = True
break
else:
if item == target:
found = True
break
print(found) # True
# 2. 内包表記で平坦化してから in を使う例 (内側が1段だけの場合)
flat = [x for item in nested for x in (item if isinstance(item, list) else [item])]
print(flat) # [1, 2, 3, 4, 5]
print(target in flat) # TrueTrue
[1, 2, 3, 4, 5]
Trueネストの深い構造になるほど、単純なinでは足りなくなるため、「どの深さまで探すのか」「何をもって存在とみなすのか」を明確にしてから実装するのがポイントです。
パフォーマンスと応用テクニック
大きなリストでinを使うときの処理速度の考え方
inをリストに対して使うとき、Pythonは先頭から順に要素を1つずつ比較していきます。
そのため、リストが大きくなるほど、最悪の場合の処理時間は線形に増えます。
リストの長さ = n のとき、最悪 O(n)

# 大きなリストでの in の動作を簡易的に計測する例
import time
# 0〜999999 までのリストを作成
numbers = list(range(1_000_000))
target_head = 0 # 先頭にも存在しない値
target_tail = 999_999 # 一番最後の要素
start = time.time()
_ = target_head in numbers
end = time.time()
print(f"先頭にも存在しない値の検索時間: {end - start:.6f} 秒")
start = time.time()
_ = target_tail in numbers
end = time.time()
print(f"末尾の値の検索時間: {end - start:.6f} 秒")先頭にも存在しない値の検索時間: 0.0xxx 秒
末尾の値の検索時間: 0.0yyy 秒実際の秒数は環境によって異なりますが、「見つからない場合」や「末尾にある場合」ほど時間がかかることがわかります。
要素数が数万程度なら問題にならないことも多いですが、数十万〜数百万を超えるような場合は、次に紹介するsetなど、より高速なデータ構造の利用を検討します。
リスト以外(setやdict)でのin活用方法
存在確認がメインの用途なら、リストではなくsetやdictを使う方が圧倒的に高速です。
これらは内部でハッシュテーブルという仕組みを使っており、平均するとO(1)(要素数にほとんど依存しない時間)で存在を確認できます。

# list / set / dict での in の違いイメージ
users_list = ["alice", "bob", "charlie"]
users_set = {"alice", "bob", "charlie"} # 集合
users_dict = {"alice": 1, "bob": 2, "charlie": 3} # 辞書
target = "bob"
# 1. list: 先頭から順に比較
print(target in users_list) # True
# 2. set: ハッシュテーブルで高速に検索
print(target in users_set) # True
# 3. dict: キーの存在チェックとして使う
print(target in users_dict) # True (値ではなくキーを見ています)True
True
True特徴を整理すると次のようになります。
| 型 | in の意味 | 速度の目安 | 向いている用途 |
|---|---|---|---|
| list | 要素の存在 | O(n) | 小〜中規模データ、順序が重要なとき |
| set | 要素の存在 | 平均 O(1) | 重複なしの集まり、存在チェックが主用途 |
| dict | キーの存在 | 平均 O(1) | キー→値の対応、設定値やマスタの参照など |
「順序が重要」「同じ値を重ねて持ちたい」ならリスト、「とにかく存在を高速に調べたい」ならセットというように、目的に合わせて型を選ぶと、パフォーマンスもコードの意図も明確になります。
実務で使えるPythonのin演算子のサンプルコード
最後に、実務でそのまま応用しやすいin演算子のサンプルをいくつか紹介します。
サンプル1: 禁止ワードチェック
入力テキストに禁止ワードが含まれていないか、inとany()を組み合わせて確認する例です。
# 禁止ワードチェックの例
def contains_ng_word(text: str) -> bool:
# set にしておくと「その単語そのもの」の判定は速いですが、
# ここでは部分文字列として含まれているかを調べるためリストを使います。
ng_words = ["禁止", "ダメ", "NG"]
# どれか1つでも含まれていれば True
return any(ng in text for ng in ng_words)
user_input = "この表現はちょっと禁止ワードに触れます。"
if contains_ng_word(user_input):
print("禁止ワードが含まれています。文章を修正してください。")
else:
print("OK な文章です。")禁止ワードが含まれています。文章を修正してください。any(条件 for 要素 in シーケンス)とinの組み合わせは、複数条件の存在チェックによく使われるパターンです。
サンプル2: ユーザー権限の判定(リスト→set で高速化)
ユーザーがある操作を行えるかどうか、権限リストを使って判定するコードです。
ユーザー数や権限が増えてきたら、リストからセットへの置き換えを検討します。
# ユーザー権限の判定例
# もともと list で管理していたケース
allowed_roles_list = ["admin", "editor", "viewer"]
def can_delete_article(role: str) -> bool:
# 削除できるのは admin と editor のみ
return role in ["admin", "editor"]
print(can_delete_article("admin")) # True
print(can_delete_article("viewer")) # False
# 役割が増え、存在チェックが増えてきたら set で管理
allowed_roles_set = {"admin", "editor", "viewer"}
def can_access_dashboard(role: str) -> bool:
# set での in は高速
return role in allowed_roles_set
print(can_access_dashboard("editor")) # True
print(can_access_dashboard("guest")) # FalseTrue
False
True
Falseこのように、最初は書きやすいリストで実装し、必要になった段階でsetやdictに置き換えるという段階的な改善も現実的なアプローチです。
サンプル3: 設定値のバリデーション
ユーザーからの入力や設定ファイルの値が、許可された選択肢の中に入っているかをinで検証するパターンです。
# 設定値のバリデーション例
VALID_ENVIRONMENTS = {"dev", "staging", "prod"} # set で管理
def validate_env(env: str) -> None:
if env not in VALID_ENVIRONMENTS:
raise ValueError(
f"env は {VALID_ENVIRONMENTS} のいずれかである必要があります (指定値: {env})"
)
# 正しい値
validate_env("dev")
# 誤った値 (例外が発生)
try:
validate_env("local")
except ValueError as e:
print("設定エラー:", e)設定エラー: env は {'dev', 'staging', 'prod'} のいずれかである必要があります (指定値: local)このように「許可された集合に含まれているかどうか」をinでチェックするのは、バリデーションの定番パターンです。
まとめ
Pythonのin演算子は、リストをはじめとするシーケンス型で「要素が存在するか」を安全に確認する、非常に重要な道具です。
インデックスアクセスと違い、範囲外でも例外を出さずTrue/Falseを返すため、if文と組み合わせた堅牢な存在チェックに向いています。
ネスト構造やNone、空文字などの扱いに注意しつつ、リストが大きくなってきたらsetやdictへの移行も検討すると、読みやすく高速なコードになります。
まずは日常の存在確認をすべてinで書いてみるところから始めてみてください。
