
Pythonではリストを「逆順に並べ替える」方法がいくつも用意されていますが、挙動や目的が少しずつ異なります。
本記事では代表的な4つの書き方(list.reverse(), スライス[::-1], reversed(), sorted(reverse=True))を比較しながら、使いどころと注意点を丁寧に解説します。
サンプルコードを通して、実務でも迷わず選べるようになりましょう。
Pythonでリストを逆順・反転する基本
Pythonでリストを逆順・反転する4つの方法
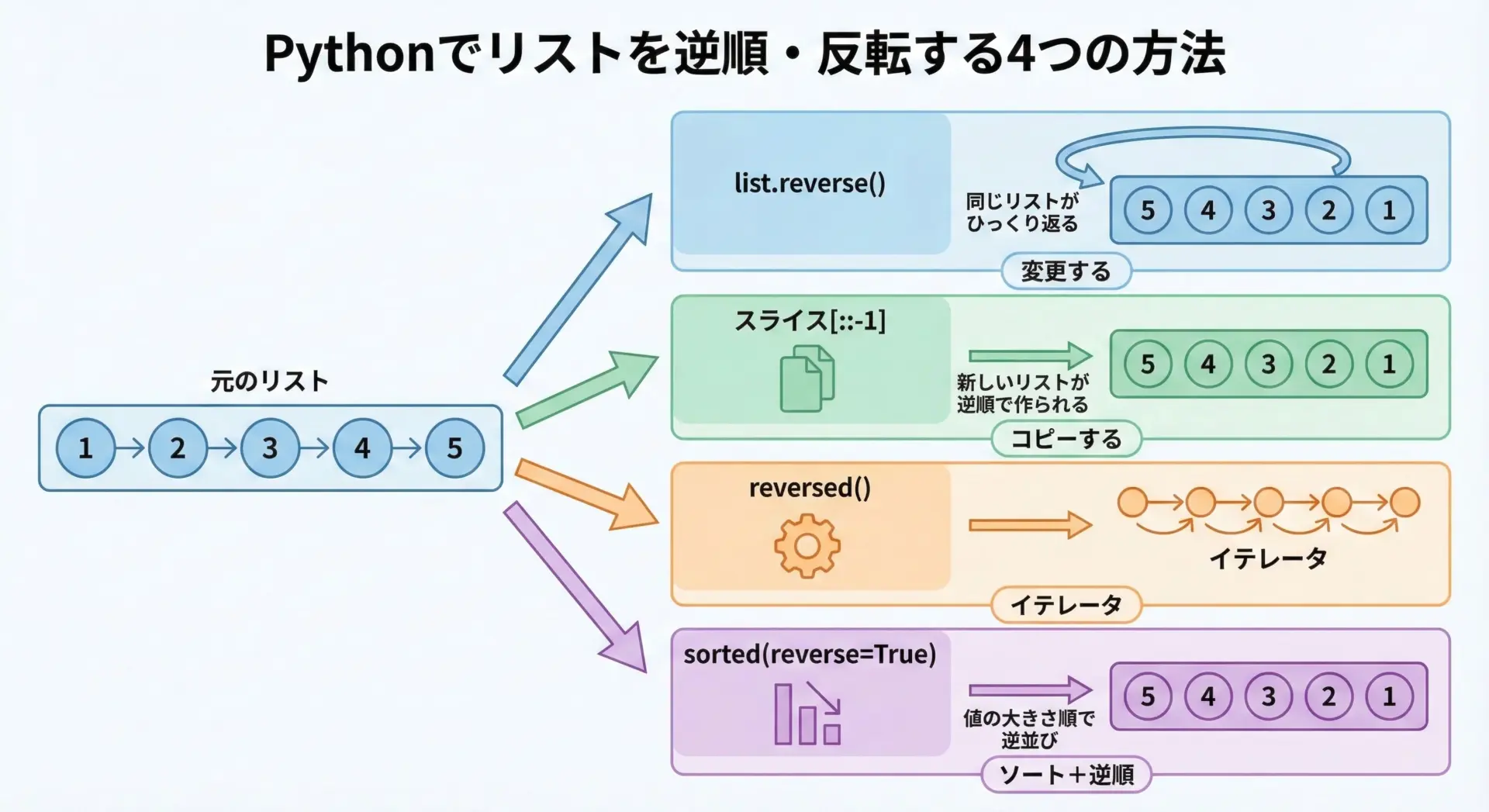
Pythonでリストを逆順にする代表的な方法は、次の4つです。
1つ目はlist.reverse()で、リストオブジェクト自身を書き換えて反転します。
2つ目はスライス構文(リスト[::-1])で、元のリストから逆順のコピーを作ります。
3つ目はreversed()で、リストを反転順に走査するイテレータを得ます。
4つ目はsorted(reverse=True)で、値の大小に基づくソートと逆順を同時に行います。
これらは見た目が似ていても、「元のリストを書き換えるか」「新しいリストができるか」「そもそもソートなのか」などの違いがあります。
リストを逆順にする際の注意点
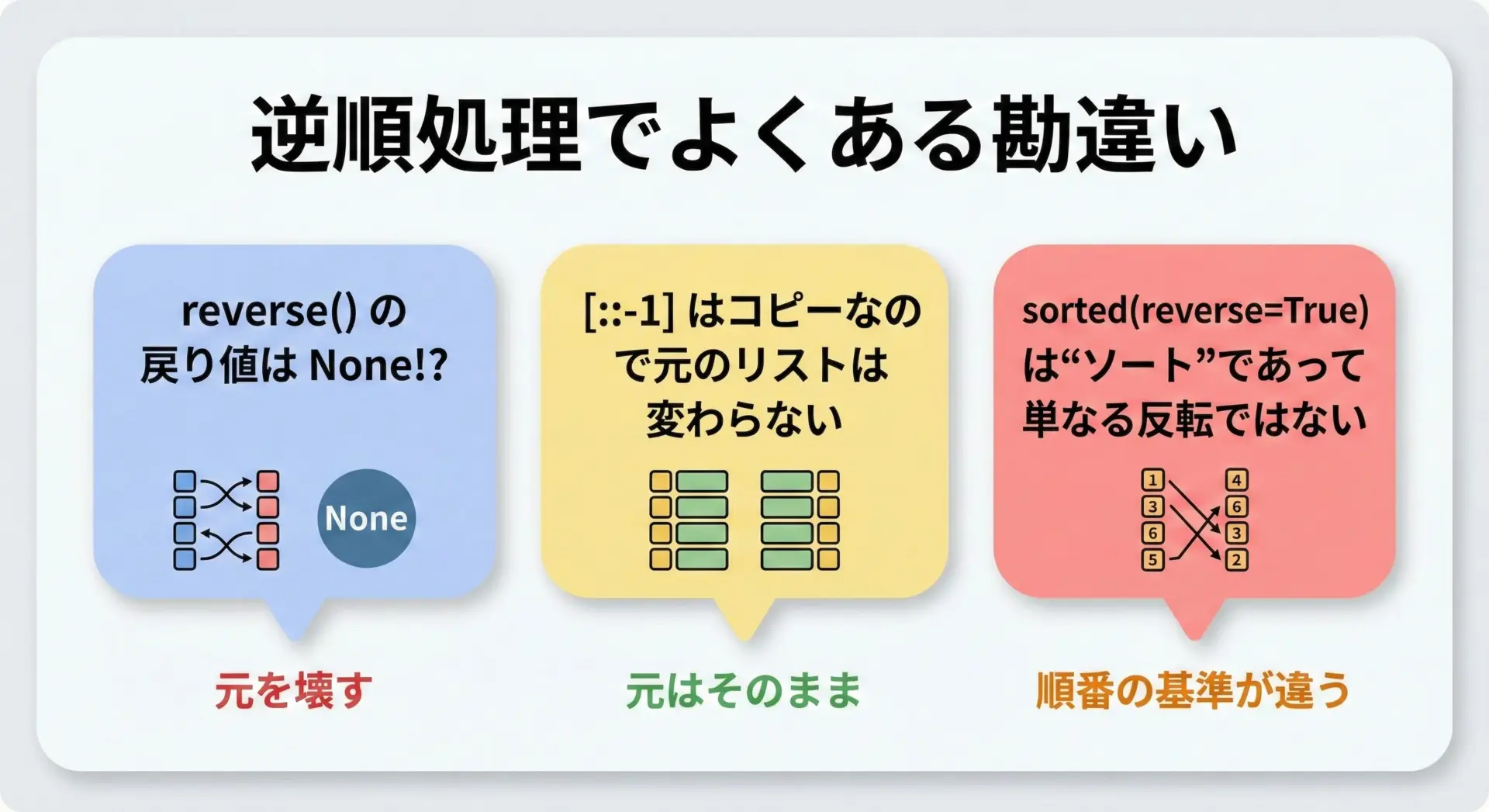
リストを逆順にするときに、特に注意したい点をまとめます。
まず、list.reverse()の戻り値はNoneです。
メソッド呼び出しの結果をそのまま変数に代入してしまうと、変数がNoneになってしまうため注意が必要です。
次に、スライス構文は常に「コピー」を返すので、元のリストは変わりません。
元のリストを維持したい場合は便利ですが、大きなリストではメモリ使用量が増える点も意識する必要があります。
さらに、sorted(reverse=True)はあくまで「ソート+降順」です。
リストのもともとの並びをひっくり返すだけではなく、値の大小に従って並び替えてから逆順にします。
そのため、「今の順番をそのままひっくり返したいだけ」のケースと混同しないようにしましょう。
用途に応じた使い分けの考え方
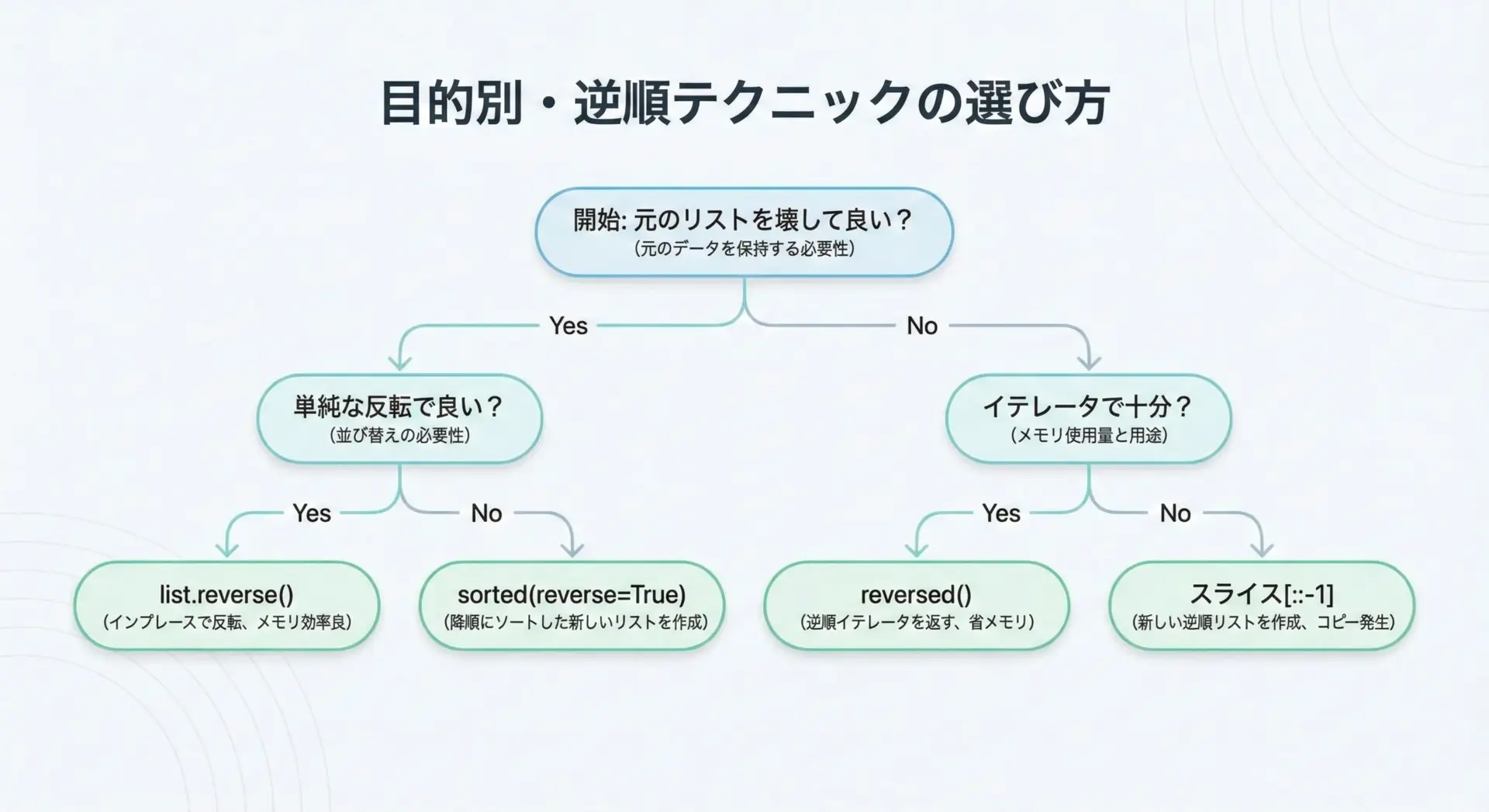
用途による使い分けは、次のように考えると整理しやすくなります。
1つ目の軸は「元のリストを書き換えてよいかどうか」です。
リストをその場で反転してよいならlist.reverse()、元のリストを保持したいなら[::-1]かreversed()のどちらかを使うことになります。
2つ目の軸は「イテレータで足りるか、それとも新しいリストが必要か」です。
ループで逆順に処理したいだけならreversed()で十分ですし、値として逆順のリストが必要ならスライスまたはlist(reversed())を使うとよいでしょう。
3つ目の軸は「単純な反転か、それともソート(大小順)したいのか」です。
「単純に今の順番を逆さまにしたい」のか、「値を大きい順に並べたい」のかを明確に意識することで、reverse()系とsorted(reverse=True)系のどちらを使うべきかが決まります。
list.reverse()でリストをインプレースで反転
list.reverse()の基本的な使い方
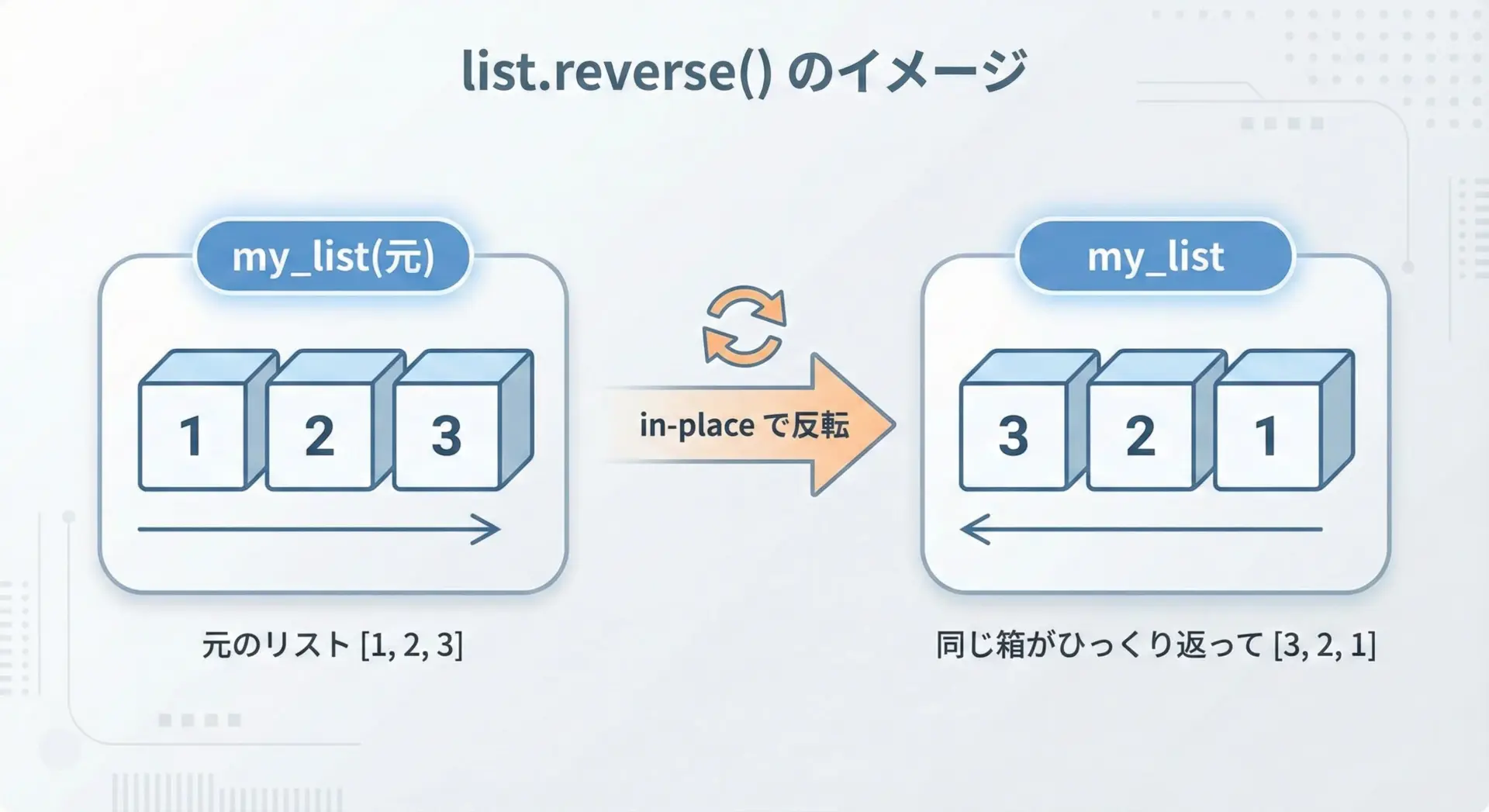
list.reverse()は、リスト自身をその場で反転(インプレース反転)するメソッドです。
新しいリストは作らず、対象となるリストの要素の順番がそのまま入れ替わります。
# list.reverse() によるインプレース反転の例
numbers = [1, 2, 3, 4, 5]
print("反転前:", numbers)
# リスト自身を反転する
numbers.reverse()
print("反転後:", numbers)反転前: [1, 2, 3, 4, 5]
反転後: [5, 4, 3, 2, 1]このように、reverse()メソッドを呼び出すだけで、同じ変数numbersの中身が反転します。
list.reverse()の戻り値と注意点

list.reverse()の戻り値は必ずNoneです。
この仕様を知らないと、次のような書き方でハマりやすくなります。
# よくある間違い例: reverse() の戻り値をそのまま使ってしまう
numbers = [1, 2, 3]
result = numbers.reverse() # ここで result には None が入る
print("numbers:", numbers)
print("result:", result) # None になってしまうnumbers: [3, 2, 1]
result: Noneこの例では、numbers自体は正しく反転していますが、resultにはNoneが代入されています。
つまり、numbers.reverse()を式として値を返す関数のように扱ってはいけないということです。
連鎖して書くこともできません。
例えば次のようなコードはエラーになります。
# これも NG の例: reverse() の戻り値をさらに処理しようとする
numbers = [1, 2, 3]
# reversed_numbers = numbers.reverse().append(4) # AttributeError になるreverse()は「何かを返す」のではなく、「対象のリストの状態を変える」メソッドであることを覚えておくと安全です。
list.reverse()を使うべきケース・避けるべきケース
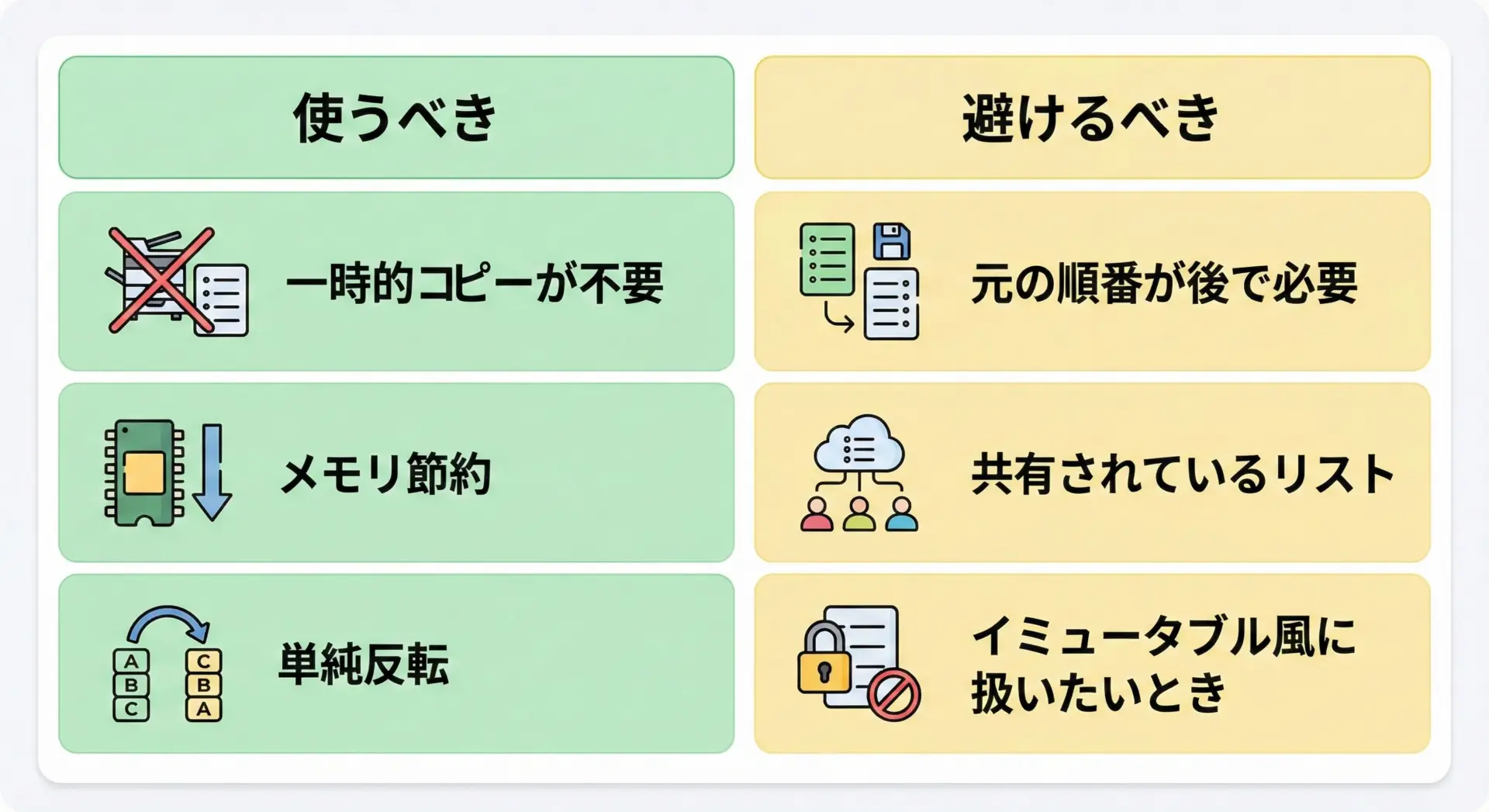
list.reverse()を使うかどうかは、次の観点で判断するとよいです。
使うべきケースとしては、まず「元のリストの順番を二度と使わない」場面が挙げられます。
処理の途中で順番を逆にして、そのまま最後まで使い切るようなケースでは、とてもシンプルで高速です。
また、大きなリストを扱っていてコピーを作りたくない場合にも有利です。
逆に避けるべきケースは、「元の順番も後から必要になる」ときです。
あとで元の順番と比較したり、別の用途で使ったりする可能性があるなら、reverse()で破壊的変更を加えるのは危険です。
また、他のコードとリストを共有しているような場面では、思わぬ副作用を生むため避けた方が安全です。
スライス構文でリストを逆順コピーする方法
スライス[::-1]でリストを反転コピーする書き方
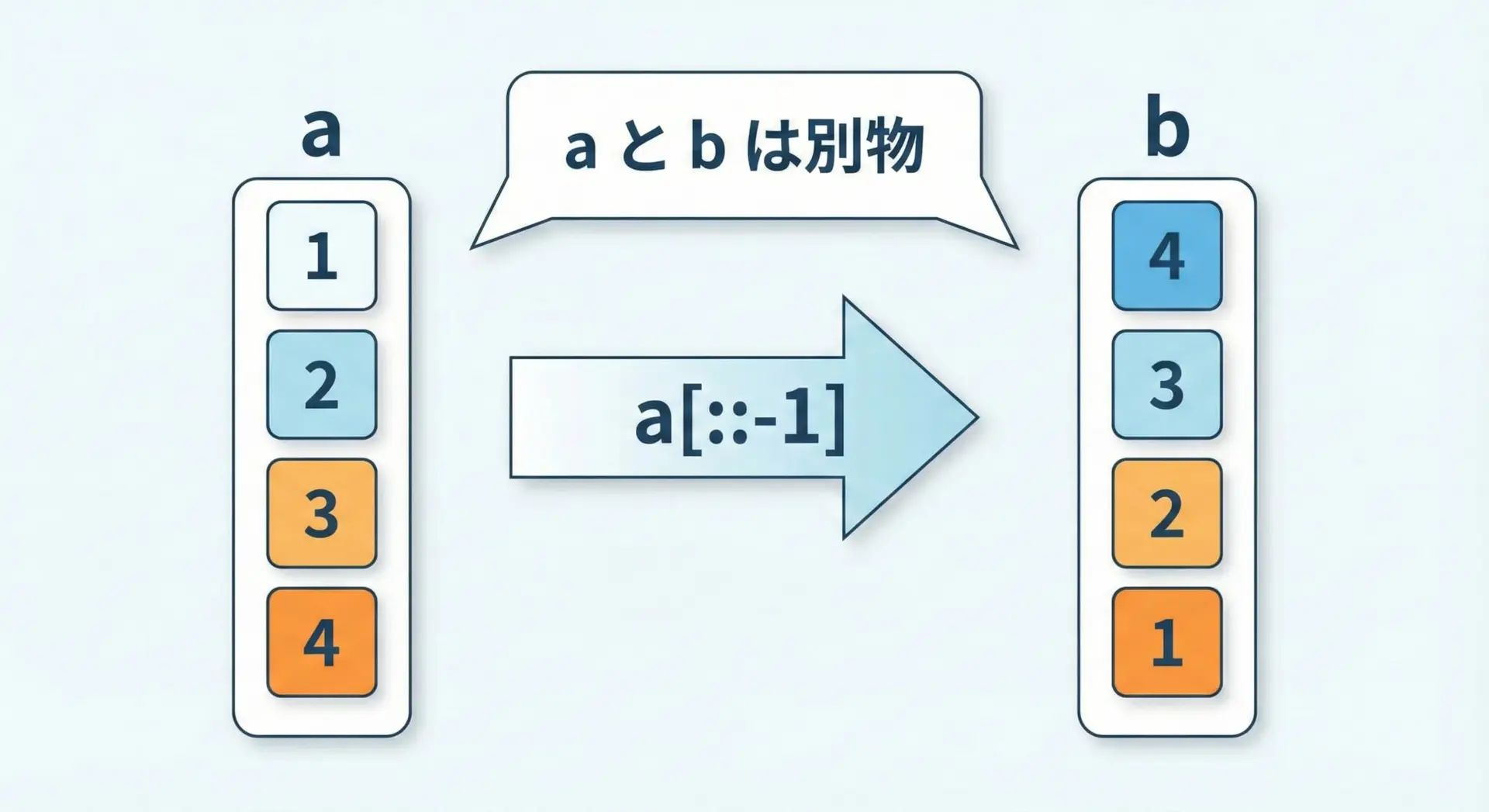
スライス構文[::-1]を使うと、元のリストはそのままに、逆順に並んだ新しいリストを作成できます。
# スライス構文による逆順コピー
numbers = [1, 2, 3, 4, 5]
reversed_copy = numbers[::-1]
print("元のリスト:", numbers)
print("逆順コピー:", reversed_copy)元のリスト: [1, 2, 3, 4, 5]
逆順コピー: [5, 4, 3, 2, 1]スライスの一般形はseq[start:end:step]ですが、[::-1]という書き方はstartとendを省略し、step=-1だけを指定して「逆方向にすべての要素を走査する」という意味になります。
スライスでのリスト反転のメリット・デメリット

スライスによる反転コピーには、明確な長所と短所があります。
まずメリットとして、元のリストを一切変更しない点が挙げられます。
元のデータを保ちつつ、必要な場面だけ逆順で扱いたい場合に非常に便利です。
また、構文が短く直感的であるため、Pythonらしい書き方とも言えます。
一方でデメリットは、常に全要素をコピーすることです。
巨大なリストを何度も[::-1]でコピーしていると、そのたびにメモリと時間を消費します。
特に、「ただ逆順に走査したいだけ」の場合には過剰なコストになるため、後述するreversed()を検討した方がよいこともあります。
スライスとlist.reverse()の違い

list.reverse()とスライス[::-1]は、一見同じ結果を生みますが、性質は大きく異なります。
代表的な違いを表にまとめます。
| 項目 | list.reverse() | スライス[::-1] |
|---|---|---|
| 変更対象 | 元のリストを直接変更 | 新しいリストを生成 |
| 戻り値 | None | 逆順の新しいリスト |
| メモリ使用 | 追加コピーなし | 全要素分のコピーを作成 |
| 安全性(副作用の少なさ) | 共有リストだと危険 | 元を壊さないので安全 |
| 主な用途 | 一度きりの反転、メモリ節約 | 元を保持したまま逆順を利用したい場合 |
このように、「元を壊してもよいか」「コピーコストをどう評価するか」で選び分けるのが基本方針になります。
reversed()で反転イテレータを使う方法
reversed()でリストを逆順にループする
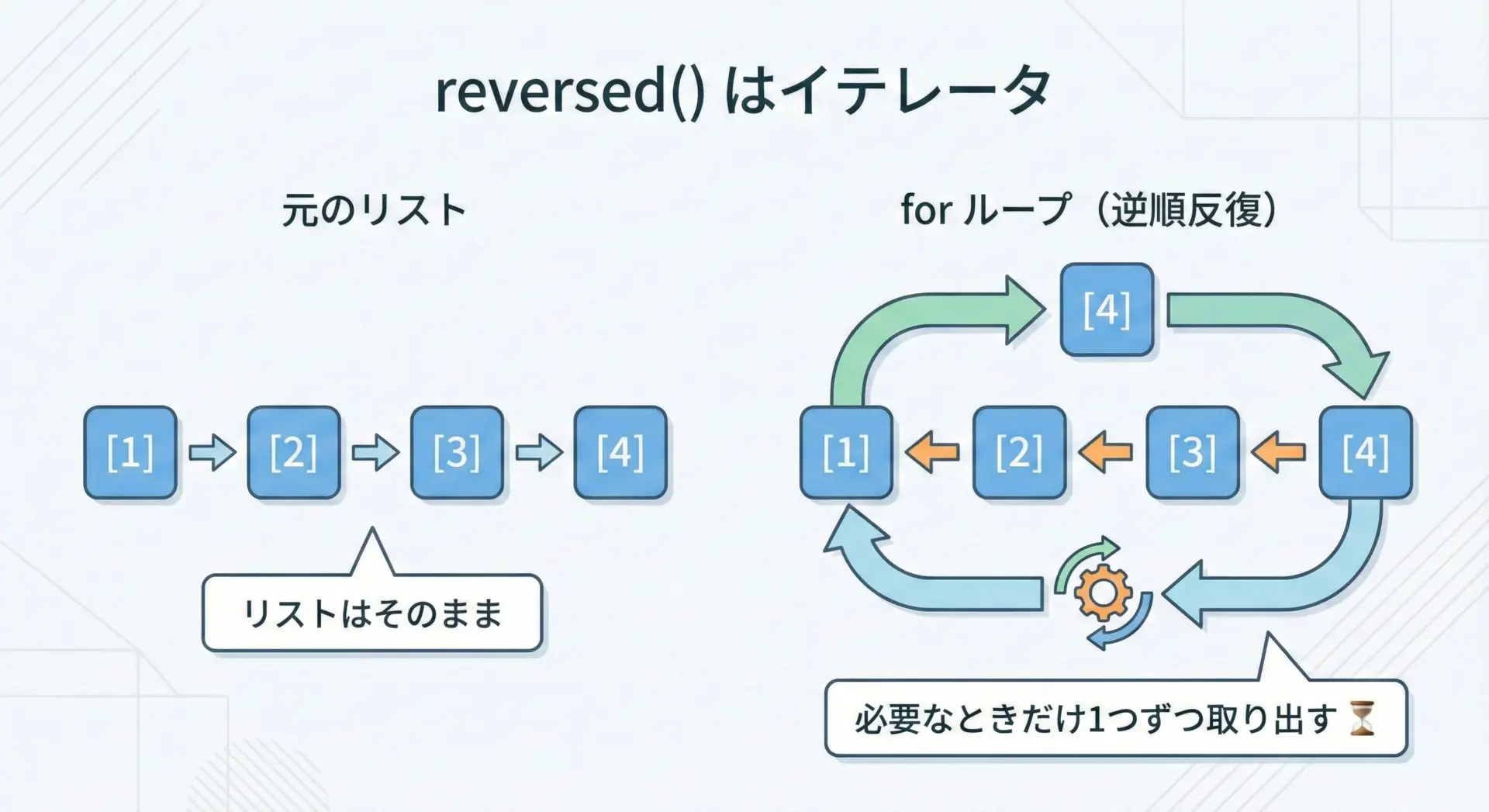
reversed()は、与えられたシーケンス(多くの場合リスト)を逆順に走査するイテレータを返します。
元のリストを書き換えず、かつ全体のコピーも作りません。
# reversed() でリストを逆順にループする例
numbers = [10, 20, 30, 40, 50]
print("逆順にループ:")
for n in reversed(numbers):
print(n)逆順にループ:
50
40
30
20
10このように、reversed(numbers)はリストnumbersから、必要になった要素を逆順に1つずつ取り出す仕組みを提供します。
元のリストnumbersは、一切変更されません。
reversed()からリストを生成する(list(reversed()))書き方
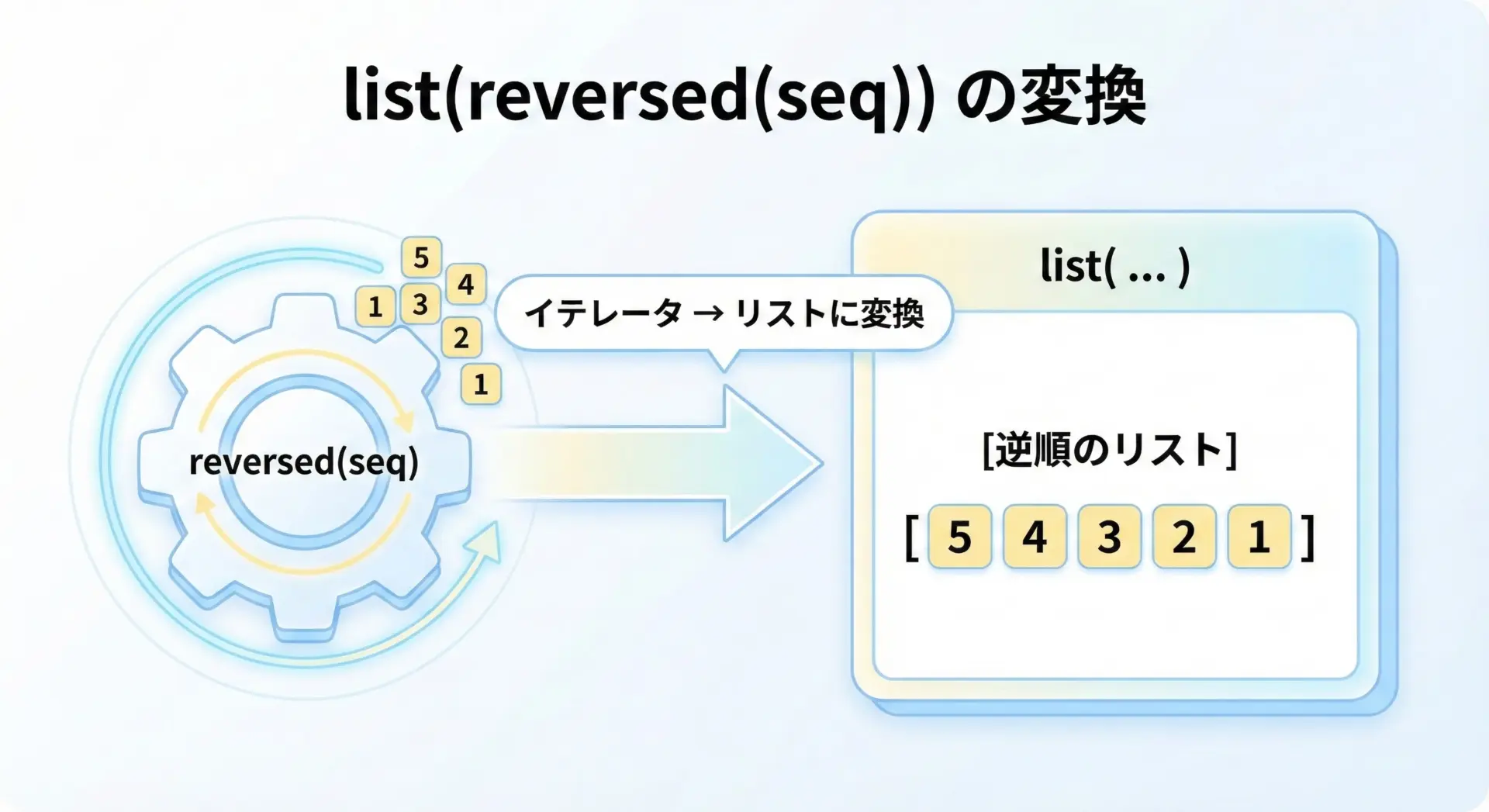
reversed()はイテレータを返すため、その結果をリストとして扱いたい場合はlist()で包んであげます。
# reversed() の結果から新しいリストを作る
numbers = [1, 2, 3, 4, 5]
reversed_iter = reversed(numbers) # イテレータ
reversed_list = list(reversed_iter) # リストに変換
print("元のリスト:", numbers)
print("逆順リスト:", reversed_list)元のリスト: [1, 2, 3, 4, 5]
逆順リスト: [5, 4, 3, 2, 1]見た目の結果はnumbers[::-1]と同じですが、reversed()はイテレータとしても活用できるため、「まずはループで使い、必要なら後からリスト化する」といった柔軟な使い方が可能です。
reversed()が便利なケース
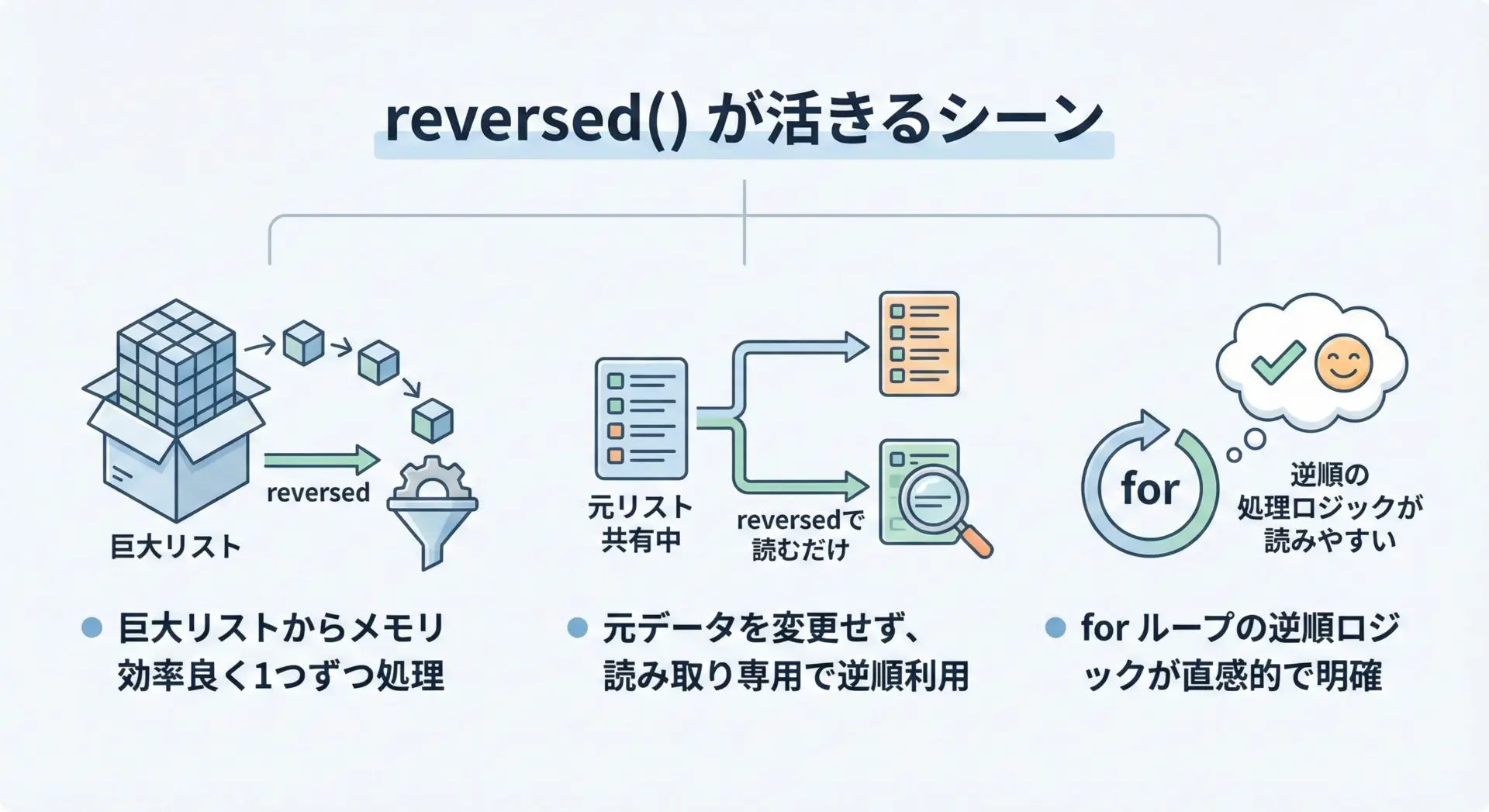
reversed()が特に便利なのは、「逆順に処理したいが、リスト全体のコピーは作りたくない」場面です。
例えば、巨大なリストを逆順に走査しながら条件に合う要素を探すような場合、numbers[::-1]でコピーを作ってしまうと、それだけで多くのメモリと時間を消費します。
これに対してreversed(numbers)なら、その都度1要素ずつ取り出して処理するだけなので、非常に効率的です。
また、元のリストを他の処理と共有しており、順番を書き換えたくない場合にも好適です。
forループのヘッダにfor x in reversed(lst):と書かれていれば、「逆順で処理している」ことが一目で分かり、コードの読みやすさという点でも優れています。
sorted(reverse=True)で並び替えと反転を同時に行う方法
sorted(reverse=True)でリストを逆順ソートする
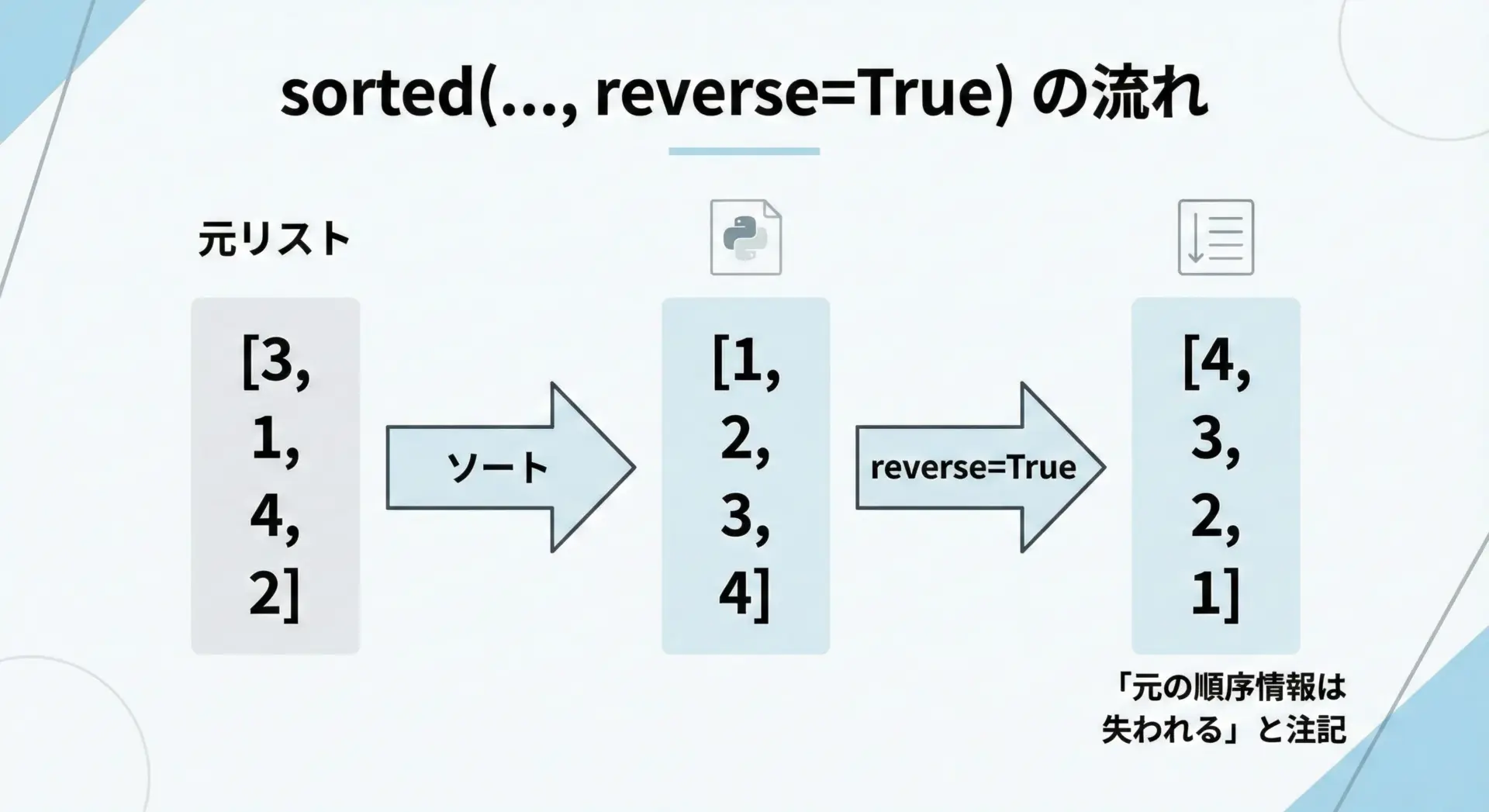
sorted()関数にreverse=Trueを指定すると、「ソートした結果を逆順(降順)にした新しいリスト」が得られます。
# sorted(reverse=True) による逆順ソート
numbers = [3, 1, 4, 2, 5]
desc = sorted(numbers, reverse=True)
print("元のリスト:", numbers)
print("降順ソート:", desc)元のリスト: [3, 1, 4, 2, 5]
降順ソート: [5, 4, 3, 2, 1]ここでのポイントは、単に元の順序を反転しているのではなく、「値の大小に従って並び替えた上で、降順にしている」という点です。
元の並び順の情報は、この処理で完全に失われます。
反転とソートの違いを理解する
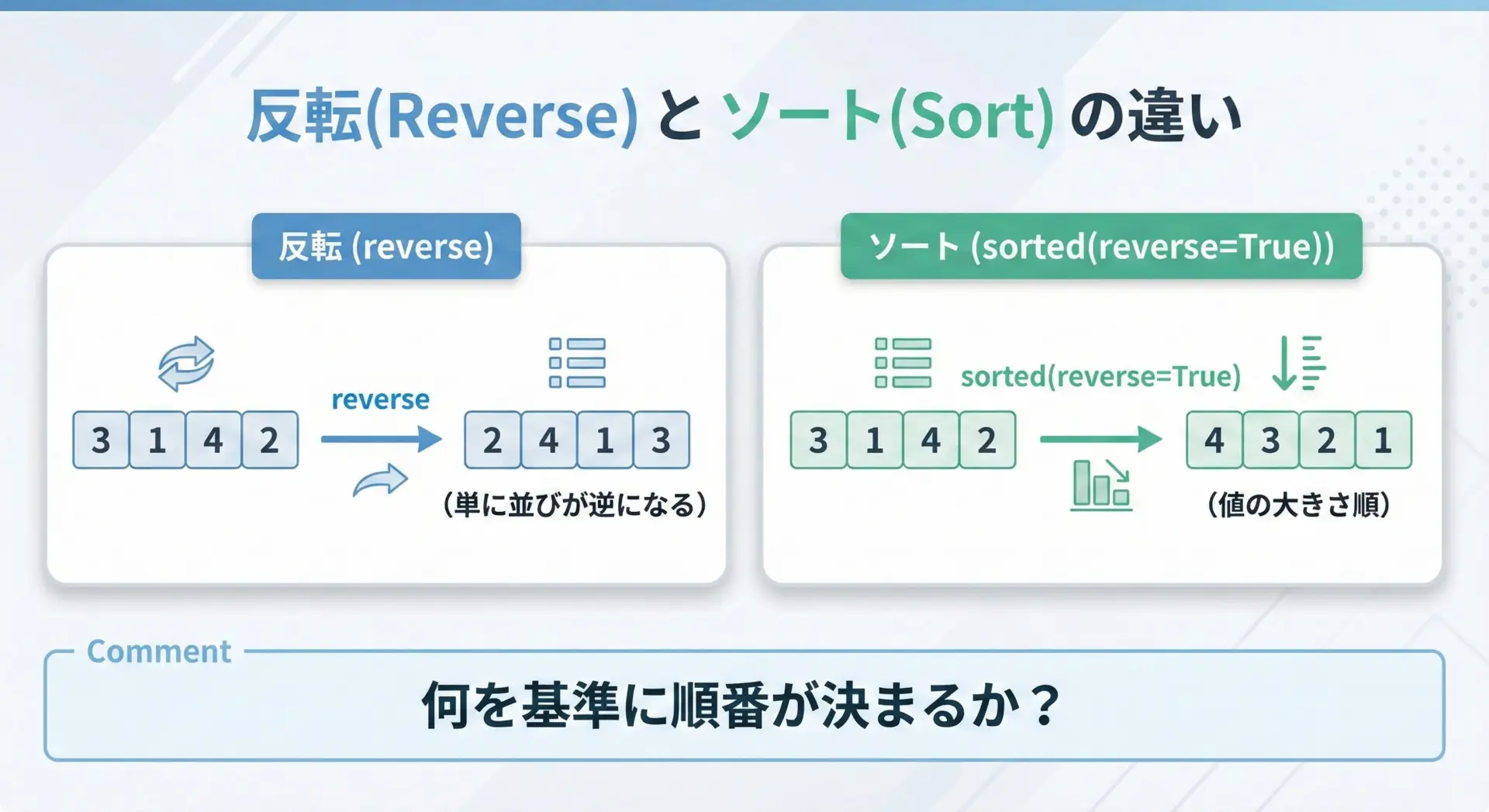
「反転」と「ソート」は似て非なる操作です。
反転(list.reverse(), [::-1], reversed())は、「今の並びを単に逆から読む」だけです。
値の大小は一切考慮しません。
一方ソート(sorted, list.sort())は、「値の大小や指定したキーに基づいて、並び順を決め直す」処理です。
reverse=Trueは、その結果を「逆の向きにする」という意味であって、「元の順番を逆にする」という意味ではありません。
# 反転とソートの違いを確認する例
data = [3, 1, 4, 1, 5]
reversed_data = data[::-1] # 反転コピー
sorted_desc = sorted(data, reverse=True) # 降順ソート
print("元のリスト:", data)
print("反転だけ:", reversed_data)
print("降順ソート:", sorted_desc)元のリスト: [3, 1, 4, 1, 5]
反転だけ: [5, 1, 4, 1, 3]
降順ソート: [5, 4, 3, 1, 1]この違いを理解しておかないと、「逆順にしたいから reverse=True を付ければよいだろう」と安易に使って、意図しないソートになってしまうことがあります。
key引数とreverse=Trueを組み合わせた応用例
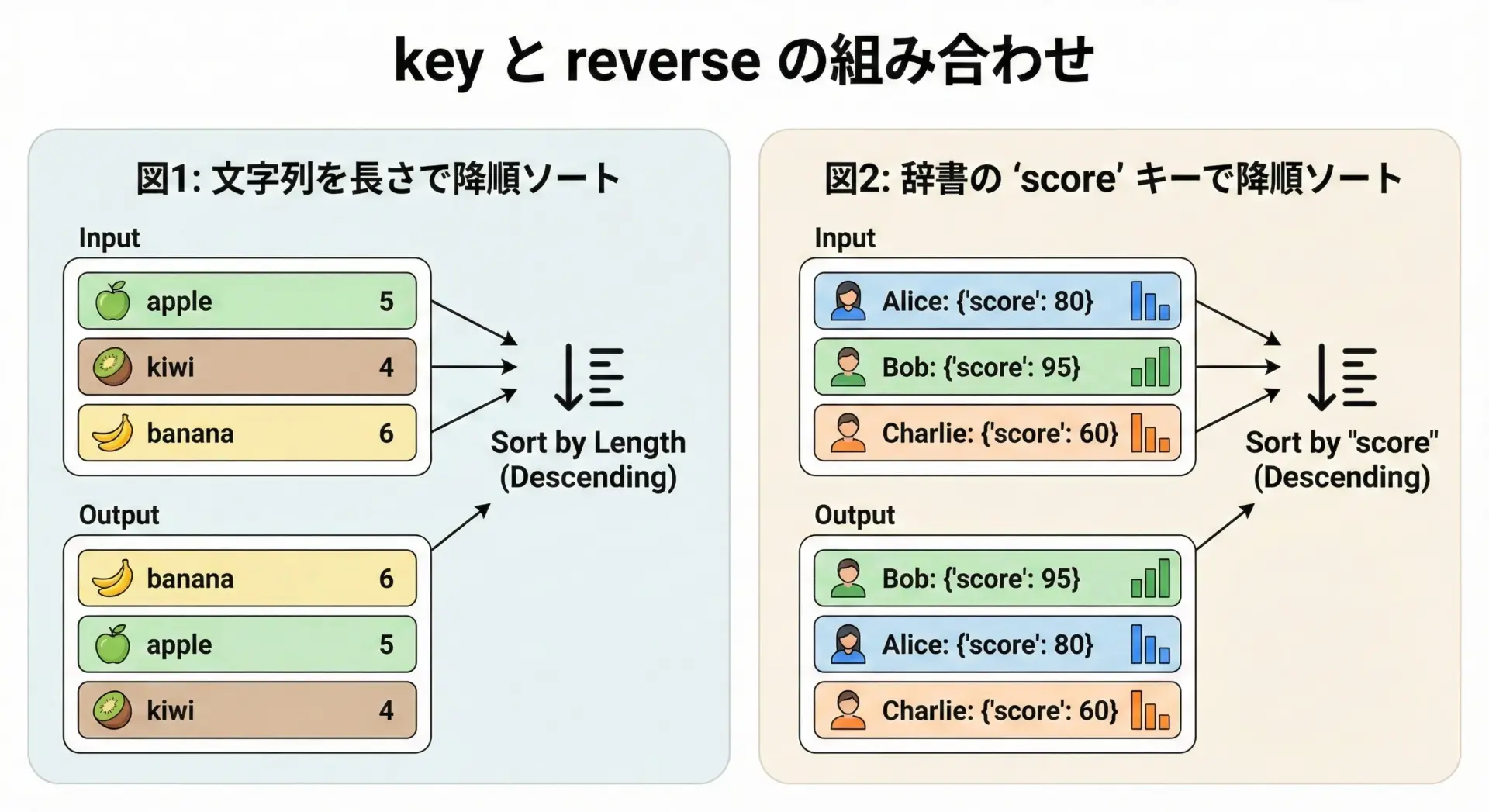
sorted()はkey引数とreverse=Trueを組み合わせることで、さまざまな基準での「降順ソート」を実現できます。
文字列の長さに基づいて、長いものから順に並べる例を見てみます。
# 文字列を長さに基づいて降順ソート
words = ["apple", "banana", "kiwi", "strawberry"]
# len をキーにし、reverse=True で長い順に並べる
sorted_by_length = sorted(words, key=len, reverse=True)
print("元のリスト:", words)
print("長い順ソート:", sorted_by_length)元のリスト: ['apple', 'banana', 'kiwi', 'strawberry']
長い順ソート: ['strawberry', 'banana', 'apple', 'kiwi']次に、辞書のリストを特定のキー(ここでは'score')に基づいて降順ソートする例です。
# 辞書のリストを score の値で降順ソートする例
students = [
{"name": "Alice", "score": 80},
{"name": "Bob", "score": 95},
{"name": "Carol", "score": 70},
]
# score の値をキーにして降順ソート
sorted_students = sorted(students, key=lambda s: s["score"], reverse=True)
print("元のリスト:")
for s in students:
print(s)
print("\nscore の高い順:")
for s in sorted_students:
print(s)元のリスト:
{'name': 'Alice', 'score': 80}
{'name': 'Bob', 'score': 95}
{'name': 'Carol', 'score': 70}
score の高い順:
{'name': 'Bob', 'score': 95}
{'name': 'Alice', 'score': 80}
{'name': 'Carol', 'score': 70}このように、sorted(reverse=True)は単なる「逆順」ではなく、「任意の基準での降順ソート」を行う強力なツールです。
リストを「評価値の高い順」「日付の新しい順」などに並べたい場面で役立ちます。
まとめ
Pythonでリストを逆順・反転する方法は、list.reverse(), スライス[::-1], reversed(), sorted(reverse=True)の4つが代表的です。
「元のリストを壊してよいか」「コピーが必要か」「単純な反転かソートか」という3つの観点で選び分けるとよいでしょう。
単純なインプレース反転にはlist.reverse()、元を保持したいならスライス、ループ中心ならreversed()、値に基づく降順並び替えにはsorted(reverse=True)が向いています。
目的に合った方法を選ぶことで、読みやすく効率的なコードを書けるようになります。
