
Pythonのリストを自在に並び替えられるようになると、データ処理や集計、レポート作成が一気に楽になります。
本記事では、基本的な昇順・降順ソートから、文字列や辞書を含む複雑なカスタムソートまで、Pythonでの並び替えテクニックを体系的に解説します。
sortとsortedの違いやkey引数・lambda式の使い方まで、実務で役立つ知識を丁寧に身につけていきましょう。
Pythonでリストを並び替える基本
リストの並び替えとは
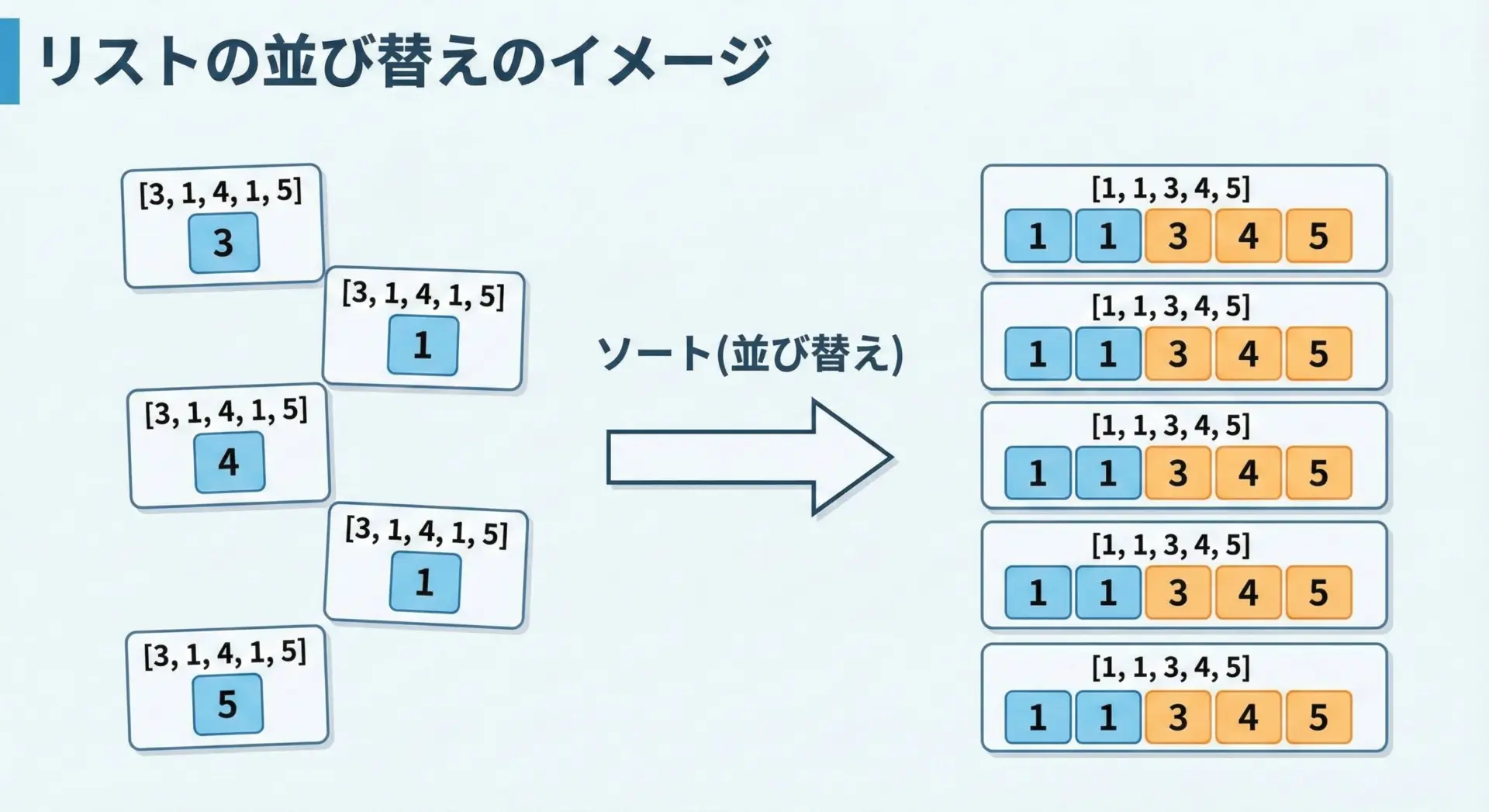
リストの並び替えとは、Pythonで扱う複数の要素を持つデータ構造であるリストの中身を、ある規則に従って並べ替える操作のことです。
典型的には、数値を小さい順に並べる昇順ソートや、大きい順に並べる降順ソートがありますが、実務では次のようなさまざまな並び替えを行います。
文章でいくつか例を挙げると、売上データを売上金額が大きい順に並べる、ユーザー一覧を名前の五十音順やアルファベット順に並べる、オブジェクトや辞書のリストを特定のキー(年齢や更新日時など)で並べる、などです。
Pythonでは、こうした並び替えを標準機能だけで柔軟に実現できます。
ここで重要なキーワードになるのがlist.sort()メソッドとsorted()関数です。
どちらもソートを行いますが、動作と使いどころがはっきりと異なります。
sortとsortedの違いを理解する
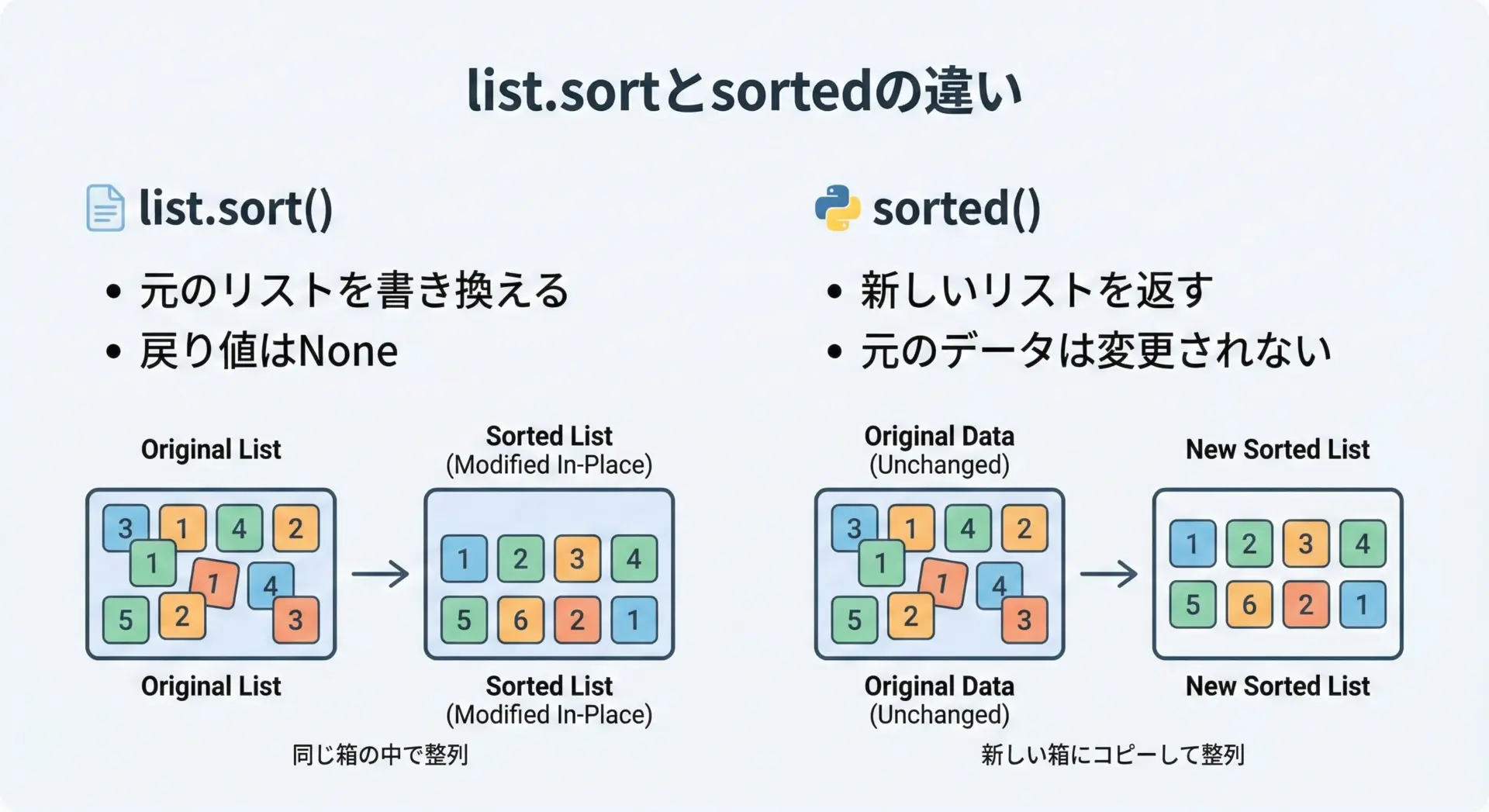
list.sort()とsorted()は、いずれもリストを並び替えるために使いますが、動作の仕組みが根本的に異なります。
まず結論から整理しておきます。
| 項目 | list.sort() | sorted() |
|---|---|---|
| 呼び出し方 | リストのメソッド | 組み込み関数 |
| 戻り値 | None | 並び替え済みの新しいリスト |
| 元のリスト | 書き換わる(破壊的) | 変更されない(非破壊的) |
| 使える対象 | リストのみ | 反復可能オブジェクト(リスト・タプル・集合・辞書など) |
| 主な用途 | 同じリストをそのまま並び替えたいとき | 並び替えた結果だけ欲しいとき、元を残したいとき |
list.sort()はリストのインスタンスメソッドであり、そのリスト自体の順番を変えます。
その代わり、戻り値はNoneです。
一方sorted()は組み込み関数で、元のデータを変更せず、新しいリストを返します。
この違いを理解しておくと、バグを防ぎながら効率的なコードが書けます。
list.sort()の使い方
list.sort()の基本構文と引数
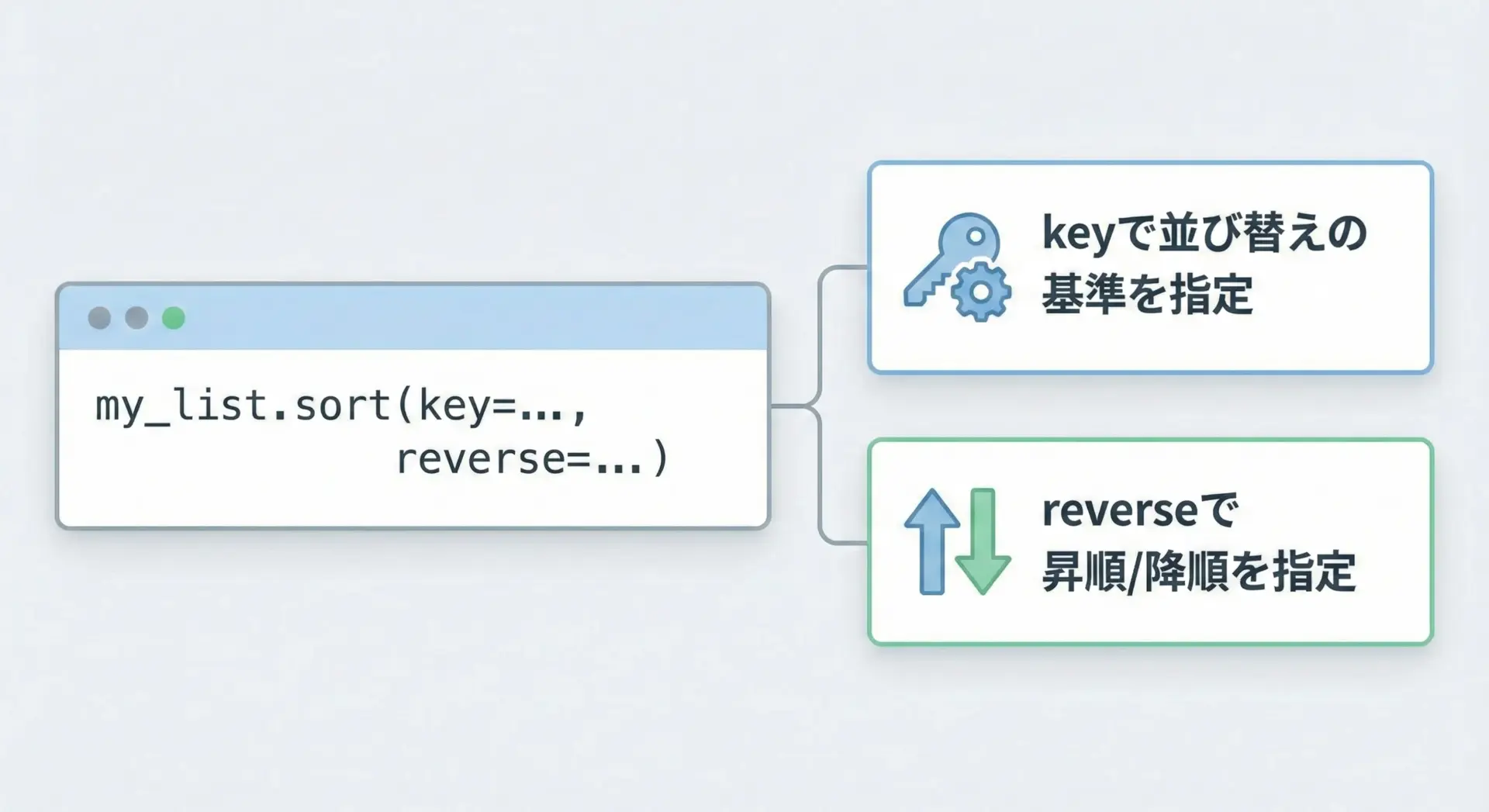
list.sort()はリストのメソッドであり、最も基本的なソート操作を提供します。
基本構文は次のようになります。
# 基本構文
リストオブジェクト.sort(key=None, reverse=False)代表的な引数は2つです。
- key引数
比較の基準となる値を返す関数を指定します。省略すると、リストの要素そのものが比較されます。たとえば、文字列の長さで並び替えたい場合はkey=lenのように指定します。 - reverse引数
ソートの方向を指定します。デフォルトはFalseで昇順、Trueにすると降順で並び替えます。
実際の使用例を見てみます。
# 数値リストをソートする例
numbers = [5, 2, 9, 1, 5, 6]
# 昇順で並び替え (デフォルト)
numbers.sort()
print(numbers) # [1, 2, 5, 5, 6, 9][1, 2, 5, 5, 6, 9]このように、sort()を呼ぶと元のnumbers自体が並び替えられ、戻り値はありません。
昇順ソートと降順ソート
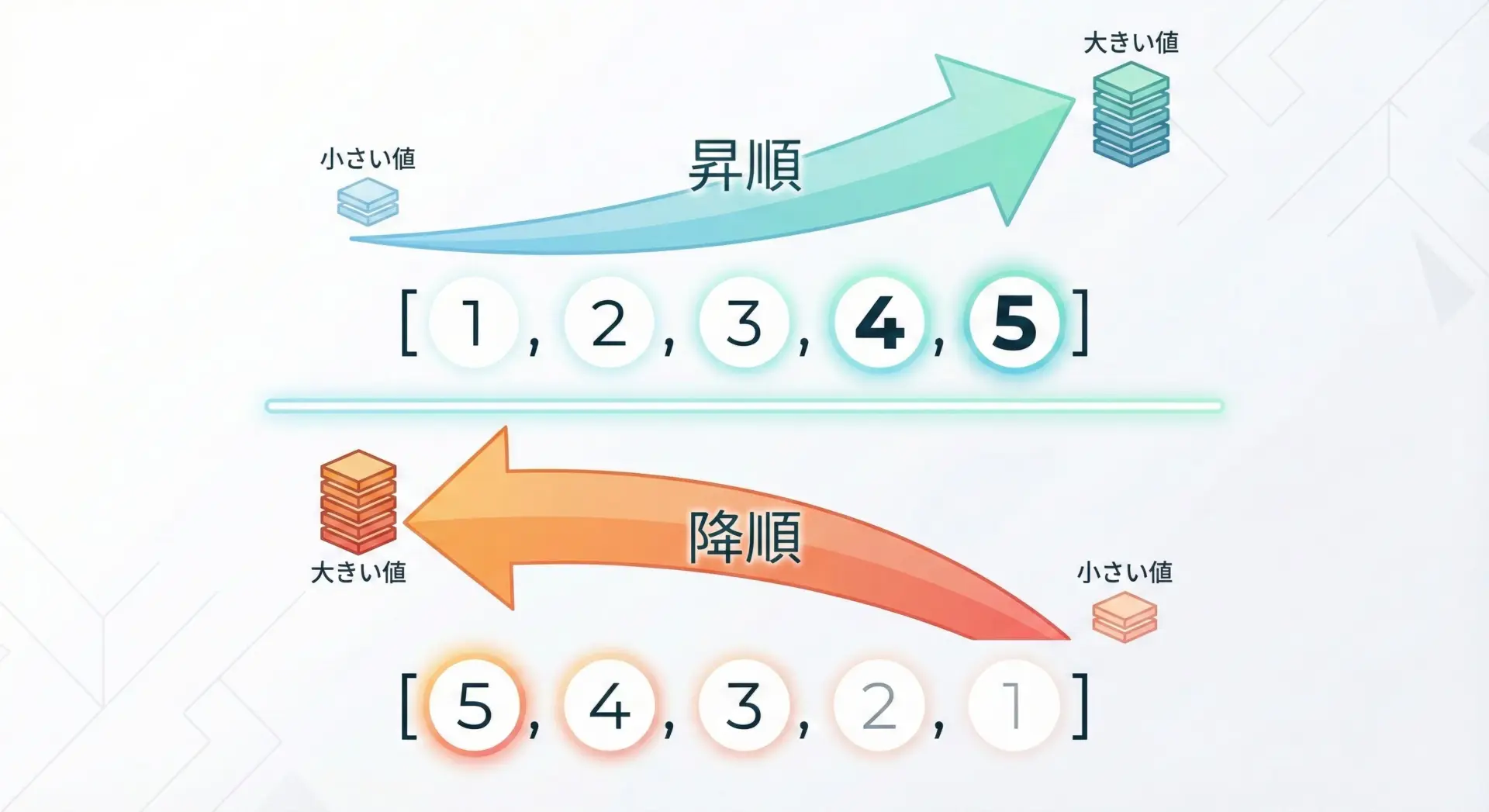
昇順ソートは数値や文字列を小さいものから大きいものへ並べる方法で、sort()のデフォルトの動作です。
降順ソートはその逆で、大きいものから小さいものへ並べます。
以下の例で両方の結果を確認してみます。
# 昇順と降順のソート例
numbers = [5, 2, 9, 1, 5, 6]
# 昇順 (小さい順)
numbers.sort() # reverse=False がデフォルト
print("昇順:", numbers)
# 降順 (大きい順)
numbers.sort(reverse=True)
print("降順:", numbers)昇順: [1, 2, 5, 5, 6, 9]
降順: [9, 6, 5, 5, 2, 1]昇順・降順は、数値だけでなく文字列にも適用できます。
文字列は辞書順(アルファベット順)に比較されるため、名前や商品名リストなどでも同じように扱えます。
破壊的メソッドとしての注意点
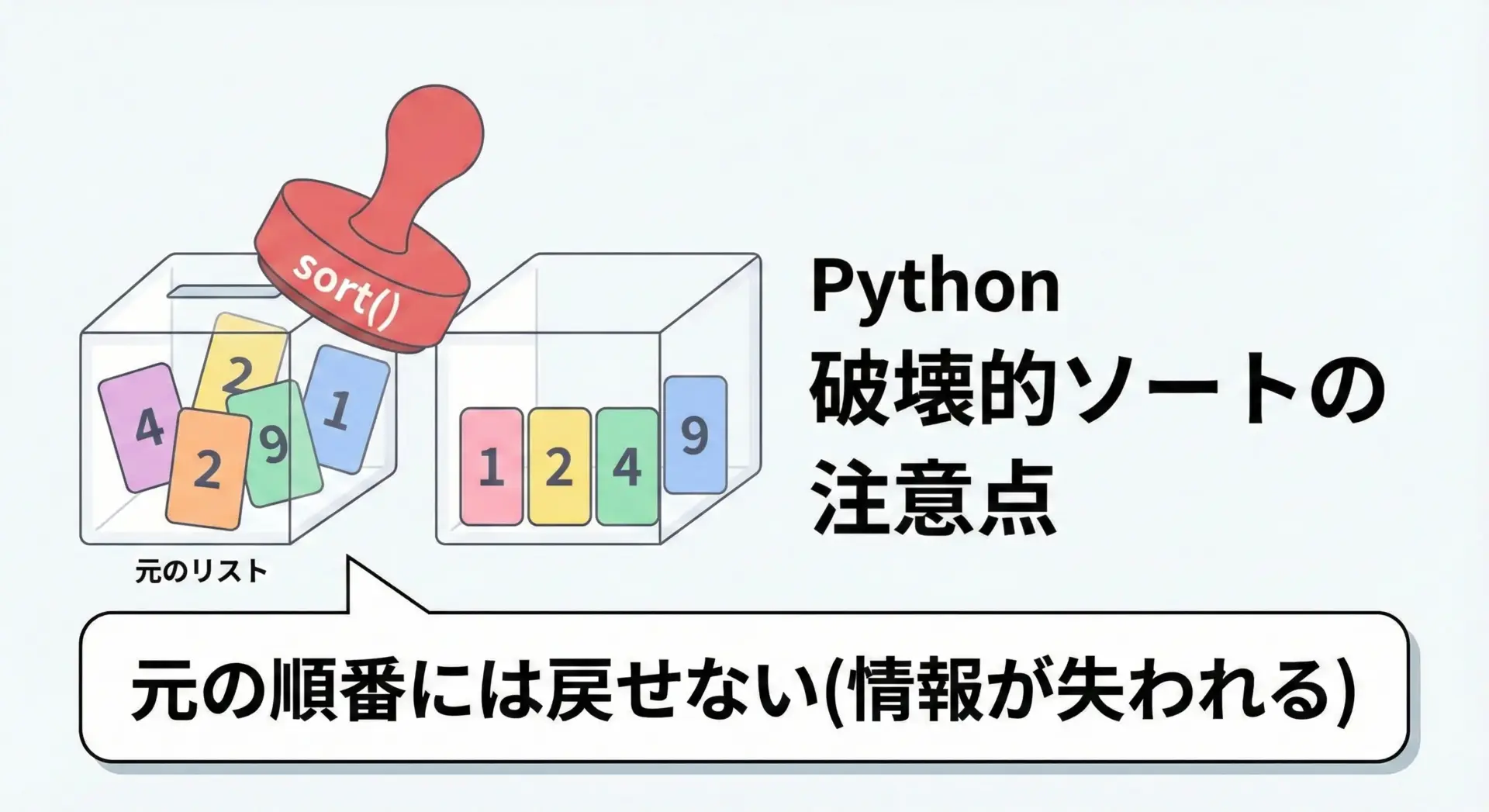
list.sort()は破壊的メソッドです。
つまり、メソッドを呼び出したリストそのものを書き換えてしまいます。
この性質を理解せずに使うと、元の順番を残しておきたかったのに二度と復元できないというトラブルにつながることがあります。
例えば次のコードを見てください。
# sort() の破壊的な動作の例
data = [3, 1, 4]
# 元の順番を残しておきたいと思って、変数を代入
backup = data
# data をソート
data.sort()
print("data:", data)
print("backup:", backup)data: [1, 3, 4]
backup: [1, 3, 4]一見backupにコピーしたように見えますが、実際にはdataとbackupは同じリストオブジェクトを指しているため、両方とも並び替えられてしまいます。
元の順番を保持したいなら、コピーを作ってからsortするか、後述するsorted()を使うべきです。
コピーを明示的に取るには、スライスを使うかlist()コンストラクタを使います。
# 元のリストを残したい場合
data = [3, 1, 4]
# スライスでコピーを作る
backup = data[:] # あるいは backup = list(data)
data.sort()
print("ソート後 data:", data)
print("元の順序 backup:", backup)ソート後 data: [1, 3, 4]
元の順序 backup: [3, 1, 4]このように、sortを使うときは「元のリストが書き換わる」ことを常に意識しておくことが大切です。
sorted()関数の使い方
sorted()の基本構文と引数
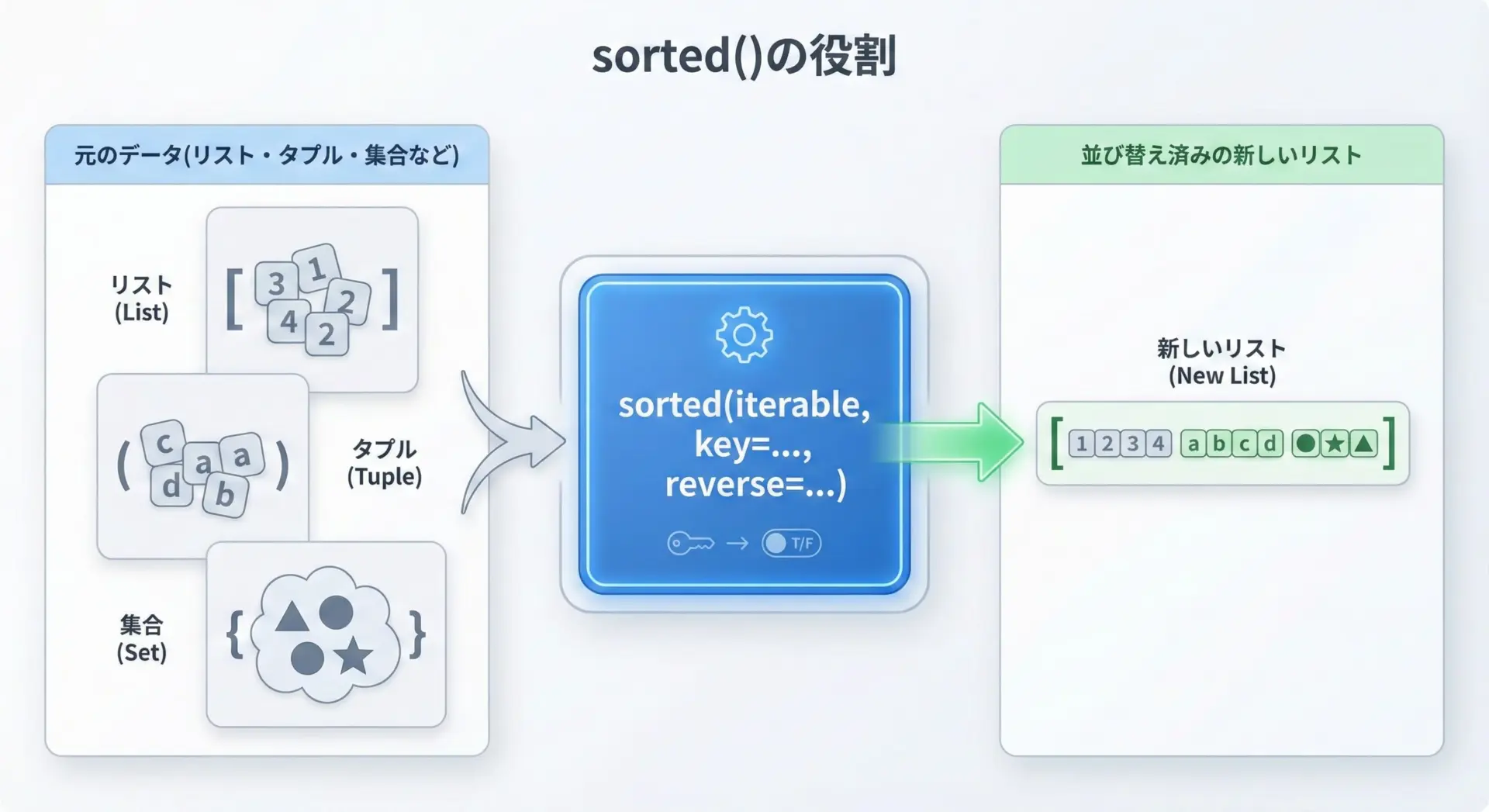
sorted()関数は、元のデータを変更せずに並び替えた新しいリストを返します。
基本構文は次のようになります。
# 基本構文
sorted(反復可能オブジェクト, key=None, reverse=False)反復可能オブジェクト(iterable)とは、リスト・タプル・集合・辞書・ジェネレータなど、for文で順に取り出せるオブジェクト全般を指します。
引数の意味はlist.sort()と同じで、keyでソートの基準、reverseで昇順・降順を指定します。
基本的な例を見てみましょう。
# sorted() の基本動作
numbers = [5, 2, 9, 1, 5, 6]
sorted_numbers = sorted(numbers)
print("元のリスト:", numbers)
print("並び替え後:", sorted_numbers)元のリスト: [5, 2, 9, 1, 5, 6]
並び替え後: [1, 2, 5, 5, 6, 9]元のnumbersはそのまま、sorted_numbersだけが並び替え済みの新しいリストになっていることが分かります。
リスト以外(タプル・辞書・集合)のソート
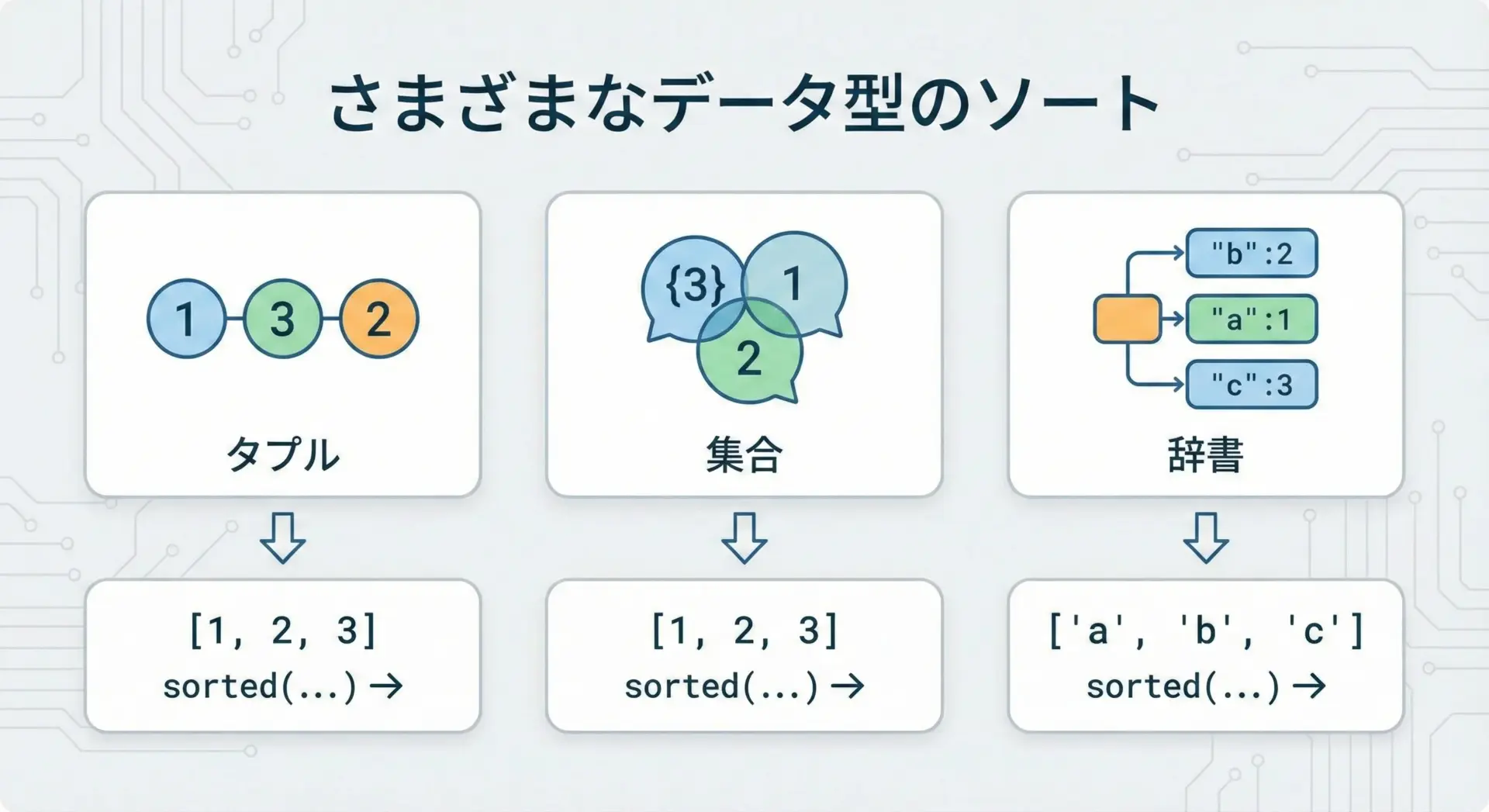
sorted()の強みは、リスト以外もソート対象にできることです。
代表的な例を順に見ていきます。
タプルのソート
タプルは変更不可能(イミュータブル)なシーケンスですが、sorted()を使えば要素を並び替えたリストを得られます。
# タプルを並び替える
t = (3, 1, 4, 1, 5)
result = sorted(t)
print("元のタプル:", t)
print("sorted()の結果:", result)元のタプル: (3, 1, 4, 1, 5)
sorted()の結果: [1, 1, 3, 4, 5]タプルそのものをソートしているわけではなく、要素を並べ替えた新しいリストが作られている点に注意してください。
集合(set)のソート
集合は順序を持たないデータ構造ですが、sorted()で並び替えれば、集合の要素をソートしたリストを得られます。
# 集合を並び替える
s = {3, 1, 4, 1, 5}
result = sorted(s)
print("元の集合:", s)
print("sorted()の結果:", result)元の集合: {1, 3, 4, 5}
sorted()の結果: [1, 3, 4, 5]集合は重複を持たないため、結果のリストにも同じ値は1つしか現れません。
辞書(dict)のソート
辞書をsorted()に渡すと、デフォルトではキーの一覧をソートしたリストが返ってきます。
# 辞書を sorted() に渡した場合
d = {"b": 2, "c": 3, "a": 1}
result = sorted(d)
print("sorted(d) の結果:", result)sorted(d) の結果: ['a', 'b', 'c']値で並び替えたい場合は、d.items()などを使い、key引数を適切に指定する必要があります。
この点については、後半の辞書リストのソートの項目でも詳しく扱います。
非破壊的ソートとしての使いどころ
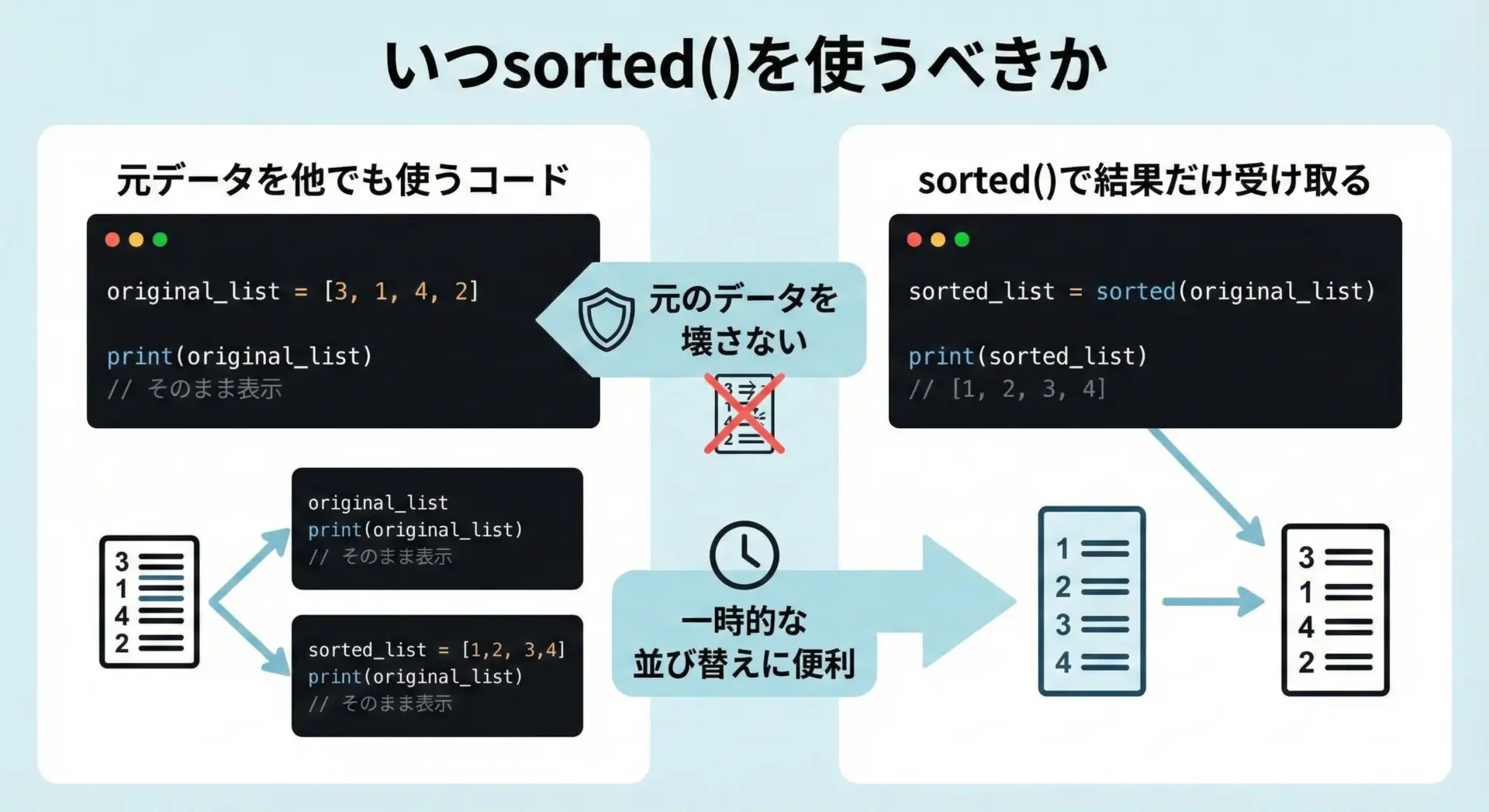
sorted()は非破壊的な関数であるため、次のような場面で特に有用です。
1つ目は、元の順番も意味を持つデータを扱う場合です。
たとえば、時系列データの元順序を保持しつつ、一時的に値の大きさ順で見たいときなどです。
このような場合、元データはそのまま残し、sorted()の結果だけを表示やレポート作成に使うと安全です。
2つ目は、タプルや集合など、そもそも変更できない・順序を持たないデータを並び替えたい場合です。
これらはlist.sort()が使えないため、sorted()が自然な選択肢になります。
3つ目として、関数の戻り値として並び替え済みのリストだけを返したい場合も、sorted()が適しています。
関数の外のデータを暗黙に変更してしまう心配がなく、コードの見通しも良くなります。
Pythonのカスタムソート
key引数でカスタムソートする方法
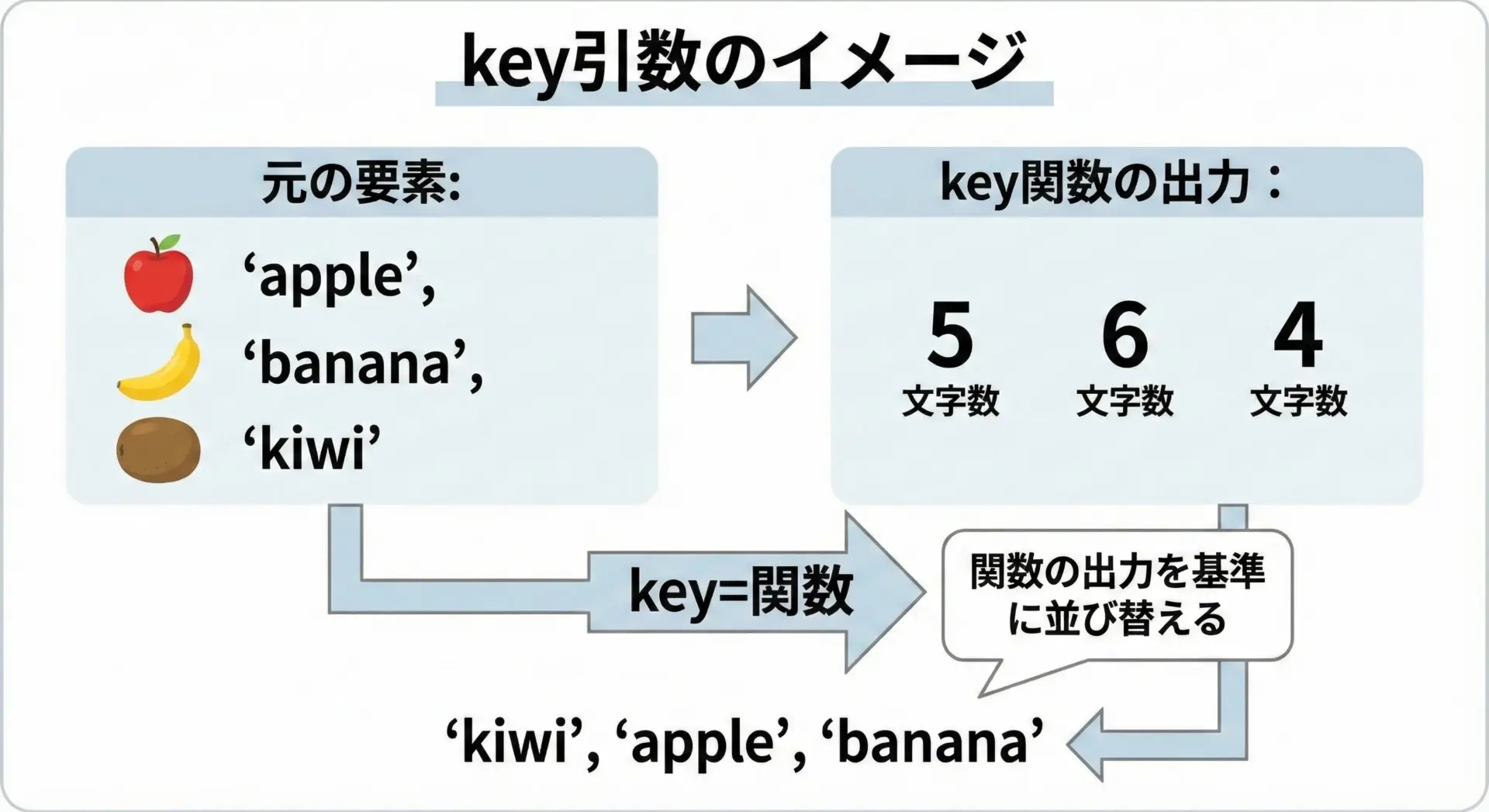
カスタムソートの中心となるのがkey引数です。
keyには「要素を受け取って並び替えの基準となる値を返す関数」を指定します。
ソートのアルゴリズム自体はPythonに任せ、私たちは「何を基準に比較するか」だけを教えるイメージです。
基本的な使い方は次の通りです。
# 文字列を「長さ」で並び替える例
fruits = ["banana", "apple", "kiwi", "strawberry"]
# len 関数を key に指定
fruits.sort(key=len)
print(fruits)['kiwi', 'apple', 'banana', 'strawberry']この例では、各要素に対してlen(要素)が計算され、その結果(文字数)を基準に並び替えが行われます。
実際に比較されているのは、要素そのものではなく、key関数が返した値という点がポイントです。
sorted()でも全く同じようにkeyを指定できます。
# sorted() でも key は同じように指定できる
fruits = ["banana", "apple", "kiwi", "strawberry"]
sorted_fruits = sorted(fruits, key=len)
print("元のリスト:", fruits)
print("sorted() の結果:", sorted_fruits)元のリスト: ['banana', 'apple', 'kiwi', 'strawberry']
sorted() の結果: ['kiwi', 'apple', 'banana', 'strawberry']lambda式を使った実用的なソート例
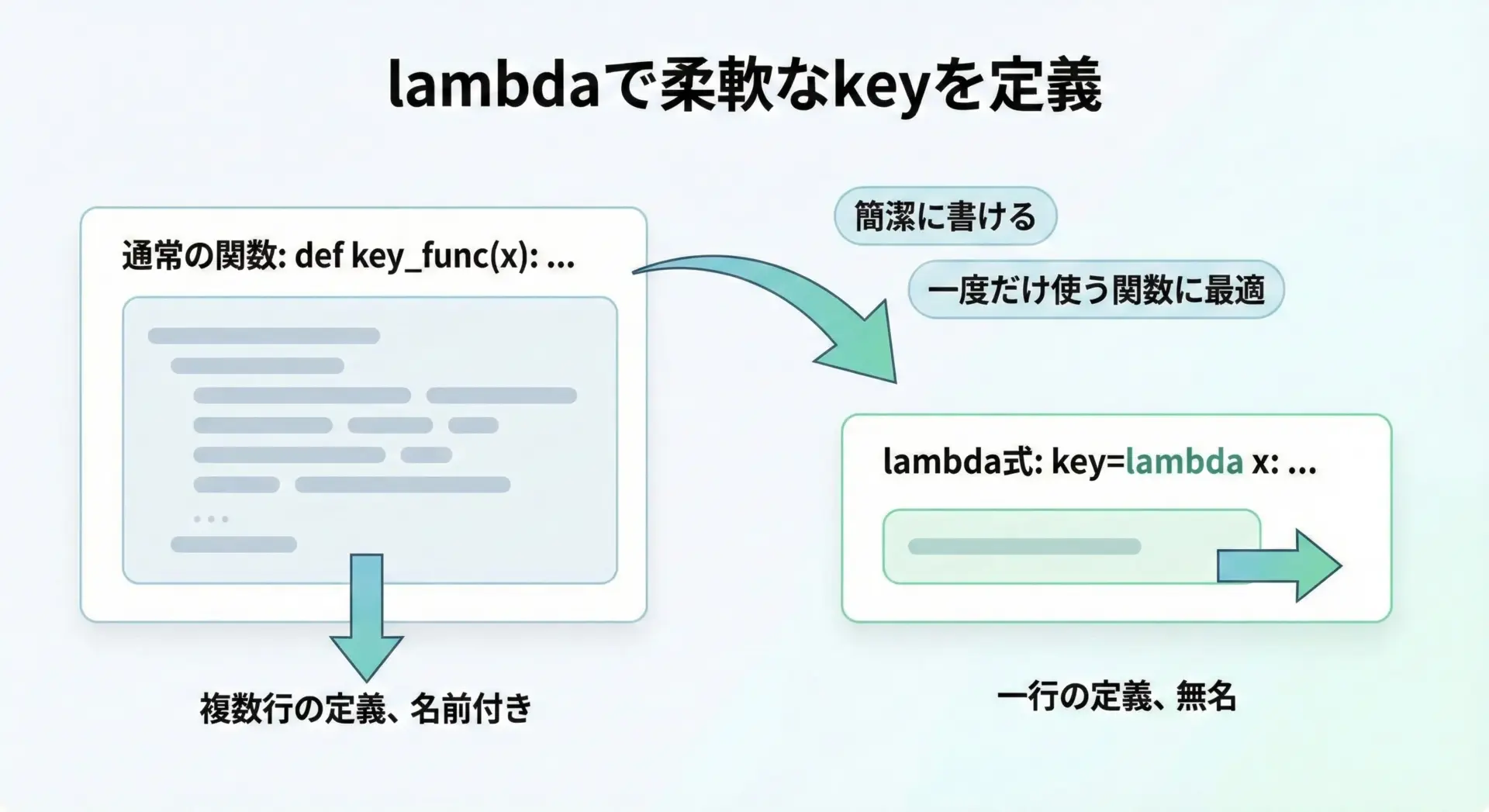
keyには任意の関数を指定できますが、その場限りの簡単な処理であればlambda式を使うとコードがすっきりします。
lambda式は「名前を付けない短い関数」を定義するための構文です。
例えば、タプルのリストを「2番目の要素」でソートしたい場合は次のように書けます。
# タプル (名前, 年齢) のリストを、年齢で並び替える
people = [
("Alice", 25),
("Bob", 19),
("Charlie", 30),
]
# key に lambda を使って、要素[1] (年齢) を基準にする
people.sort(key=lambda person: person[1])
print(people)[('Bob', 19), ('Alice', 25), ('Charlie', 30)]この例では、lambda person: person[1]が「人のタプルを受け取り、その年齢を返す関数」として機能しています。
このように、lambda式を使うことで、わざわざ別途関数を定義せずにカスタムソートが記述できます。
より実務に近い例として、ファイル名リストを「拡張子」で並び替えるコードも挙げておきます。
# ファイル名を拡張子で並び替える例
files = ["report.docx", "image.png", "archive.zip", "data.csv"]
# 拡張子(最後のドット以降)を取得して並び替え
sorted_files = sorted(files, key=lambda name: name.split(".")[-1])
print(sorted_files)['data.csv', 'report.docx', 'image.png', 'archive.zip']ここではlambda name: name.split(".")[-1]が「ファイル名から拡張子文字列を取り出す」関数として働き、その文字列の辞書順でソートが行われています。
文字列リストのソート

文字列リストのソートは、単に辞書順で並べるだけでなく、大文字小文字を無視したり、長さで並べたりといったバリエーションがよく使われます。
デフォルトの辞書順ソート
words = ["banana", "Apple", "cherry", "apple"]
# デフォルトの辞書順 (大文字と小文字は区別される)
result = sorted(words)
print(result)['Apple', 'apple', 'banana', 'cherry']ASCII順では、大文字の方が小文字より先に来るため、このような順番になります。
大文字小文字を無視してソート
検索結果やユーザー表示などでは、大文字・小文字を区別しないソートが自然な場合が多いです。
その場合、key=str.lowerを指定するのが定石です。
words = ["banana", "Apple", "cherry", "apple"]
# 大文字小文字を無視して並び替え
result = sorted(words, key=str.lower)
print(result)['Apple', 'apple', 'banana', 'cherry']ここではstr.lowerが「文字列を小文字に変換する関数」としてkeyに渡され、すべて小文字にそろえた上で辞書順比較が行われています。
文字列の長さでソート
文字列の長さでソートするのもよくあるパターンです。
words = ["banana", "fig", "apple", "kiwi", "strawberry"]
# 文字列の長さで昇順ソート
result = sorted(words, key=len)
print(result)['fig', 'kiwi', 'apple', 'banana', 'strawberry']降順にしたい場合はreverse=Trueを併用します。
# 長い文字列から順に並び替え
result = sorted(words, key=len, reverse=True)
print(result)['strawberry', 'banana', 'apple', 'kiwi', 'fig']数値リストのソート
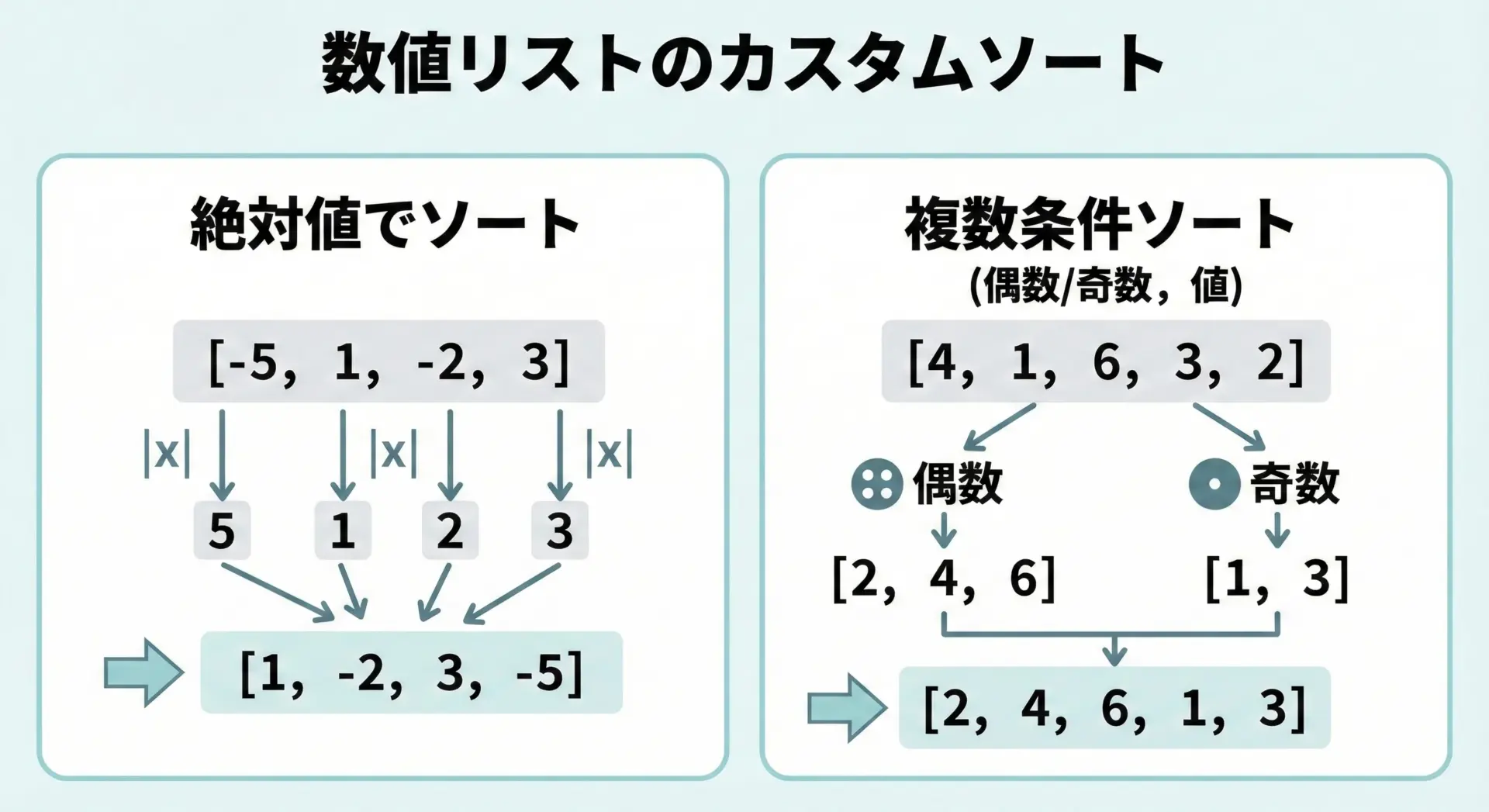
数値リストは単純な昇順・降順だけでなく、絶対値や複数条件によるソートがよく使われます。
絶対値でソート
負の値と正の値が混ざる場合、値そのものではなく絶対値で大小を比べたいことがあります。
numbers = [-5, 3, -2, 1, 0, -10]
# 絶対値を基準に昇順ソート
result = sorted(numbers, key=abs)
print(result)[0, 1, -2, 3, -5, -10]ここではabsが絶対値を計算する関数として、そのままkeyに利用されています。
複数条件でのソート
Pythonのソートは安定ソートであり、またkeyにタプルを返す関数を指定することで、複数の条件を組み合わせたソートが可能です。
例えば、「偶数を先に、その中では値の昇順」「奇数はその後に、値の昇順」で並び替える例を考えます。
numbers = [5, 2, 3, 8, 1, 4, 7, 6]
# (偶数かどうか, 値) のタプルを key にする
result = sorted(numbers, key=lambda x: (x % 2, x))
print(result)[2, 4, 6, 8, 1, 3, 5, 7]x % 2は偶数なら0、奇数なら1になるため、まず偶数(0)が前に集まり、その中で値の昇順、次に奇数(1)が値の昇順で並ぶ、という動きになります。
辞書リストのソート
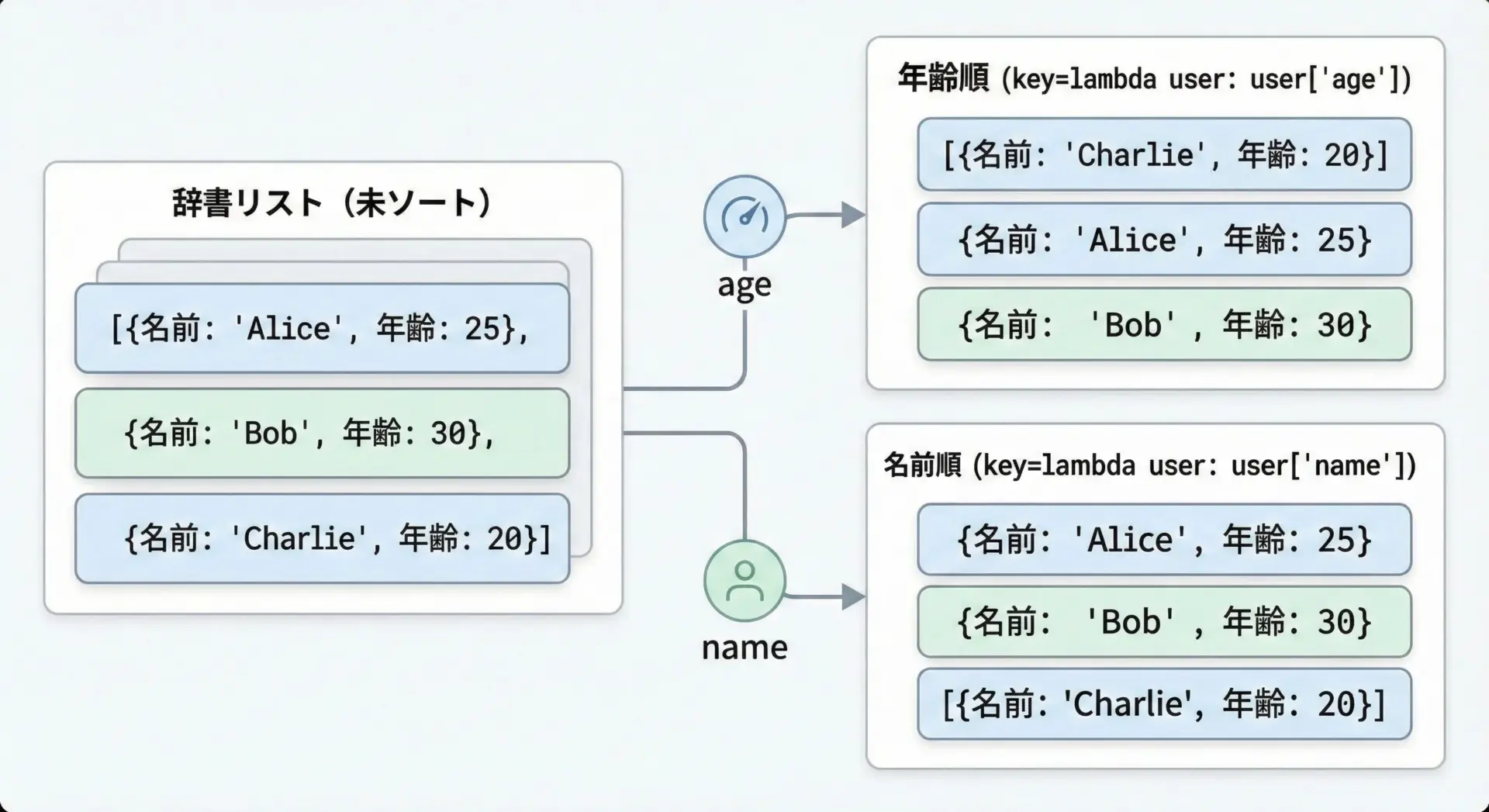
実務では、辞書のリストを扱う場面が非常に多くあります。
たとえば、ユーザー情報の配列やAPIから取得したJSONデータなどです。
これを特定のキー(年齢・点数・日付など)で並び替えるのが、カスタムソートの典型的な用途です。
単一キーでのソート(年齢順など)
# 辞書のリストを年齢順に並び替える例
users = [
{"name": "Alice", "age": 25},
{"name": "Bob", "age": 19},
{"name": "Carol", "age": 30},
]
# 年齢(age)で昇順ソート
sorted_users = sorted(users, key=lambda user: user["age"])
print(sorted_users)[{'name': 'Bob', 'age': 19}, {'name': 'Alice', 'age': 25}, {'name': 'Carol', 'age': 30}]このようにlambda user: user["age"]と書くことで、辞書から特定のキーを取り出して比較基準にできます。
複数キーでのソート(年齢→名前の順など)
同じ年齢のユーザーがいる場合、「年齢が同じなら名前の辞書順で並べる」といった複数条件ソートが必要になることがあります。
この場合も、keyにタプルを返す関数を用いると簡単に実現できます。
# 年齢 → 名前 の順でソートする例
users = [
{"name": "Alice", "age": 25},
{"name": "Bob", "age": 19},
{"name": "Carol", "age": 25},
{"name": "Dave", "age": 19},
]
sorted_users = sorted(
users,
key=lambda user: (user["age"], user["name"])
)
for u in sorted_users:
print(u){'name': 'Bob', 'age': 19}
{'name': 'Dave', 'age': 19}
{'name': 'Alice', 'age': 25}
{'name': 'Carol', 'age': 25}タプルの比較は先頭から順に行われるため、まずageが比較され、同じ場合はnameで比較される、という自然な動作になります。
値で辞書自体をソートする場合(itemsのソート)
「辞書の中身を値でソートしたい」というケースでは、d.items()を並び替えるのが一般的です。
# 辞書のキーと値を、値でソートする例
scores = {"Alice": 85, "Bob": 92, "Carol": 78}
# items() で (キー, 値) のタプルの一覧を取得し、値でソート
sorted_items = sorted(scores.items(), key=lambda item: item[1], reverse=True)
for name, score in sorted_items:
print(name, score)Bob 92
Alice 85
Carol 78このように、辞書そのものではなくitems()の結果(タプルのリスト)を対象にソートすることで、目的に応じた順序付けが行えます。
カスタムソートのパフォーマンスと注意点
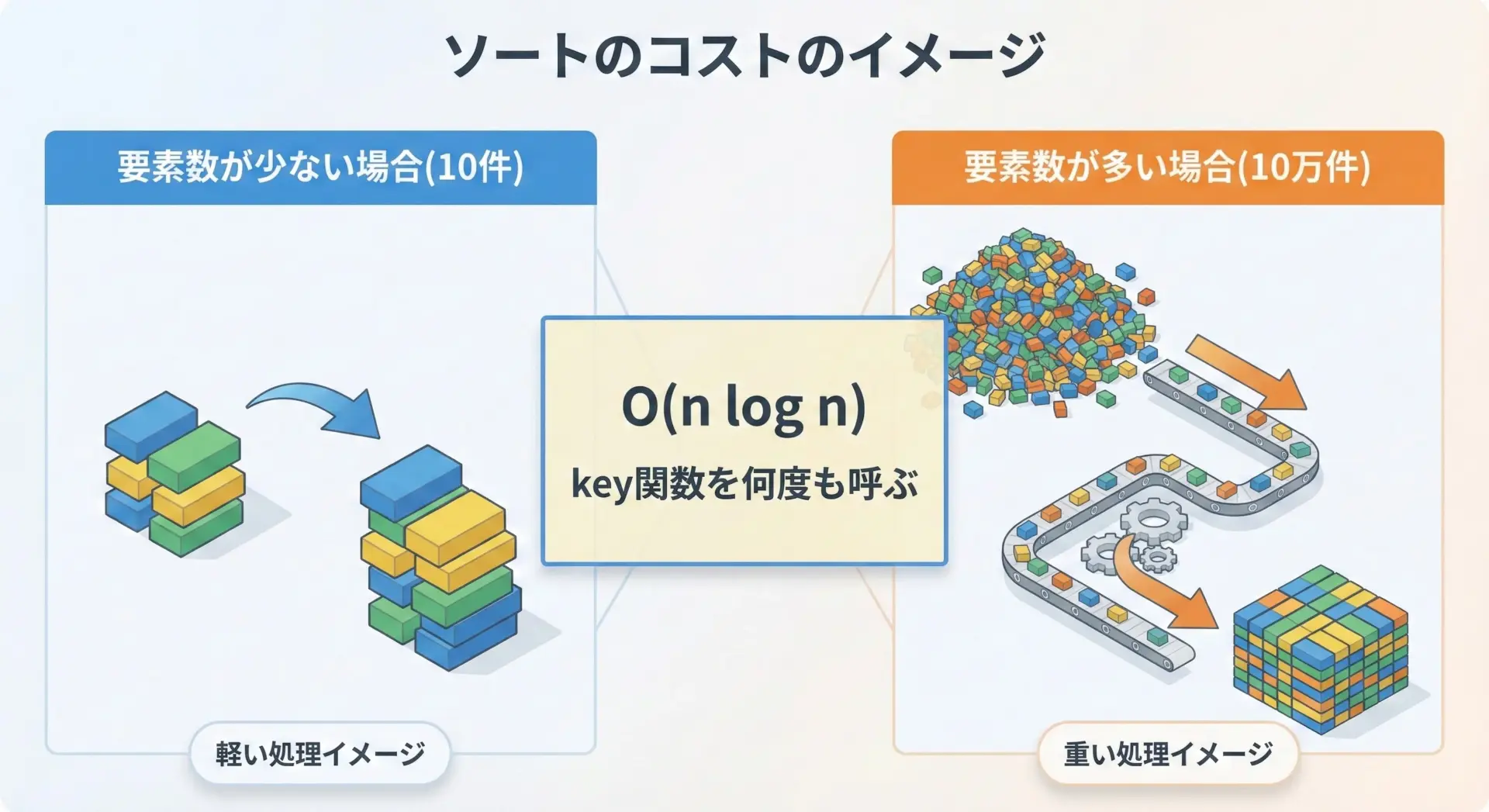
最後に、カスタムソートを実務で使ううえでのパフォーマンス面の注意点をまとめておきます。
PythonのソートアルゴリズムはTimsortと呼ばれ、平均・最悪ともにO(n log n)という十分高速な性能を持っています。
しかし、要素数が数万〜数十万件を超えるような大きなデータを扱うときには、以下の点に注意が必要です。
1つ目は、key関数が何度も呼ばれるという点です。
各要素に対して少なくとも1回、場合によってはそれ以上呼ばれるため、key関数の中で重い処理(例えば、ファイルアクセスや外部API呼び出し、複雑な計算など)を行うと、ソート全体が非常に遅くなります。
この問題を避けるには、事前に比較用の値を別リストに計算しておく、あるいはfunctools.cmp_to_keyのような比較関数ベースのアプローチは避けてkeyを単純にする、といった工夫が有効です。
2つ目は、メモリ使用量です。
sorted()は新しいリストを作るため、元データと合わせてメモリ消費が一時的に増加します。
大規模データでメモリが厳しい場合は、list.sort()を使ってインプレースで並び替える方がメモリ効率が良くなります。
3つ目として、安定ソートであることを活かす設計も重要です。
Pythonのソートは安定であるため、例えば「まず科目ごとにソートし、次に総合点でソートする」といった操作を行うと、同じ総合点の中では科目順が保たれます。
多段階ソートを設計することで、複雑なキー関数を書かずに目的の並びを得られることも多いです。
最後にもう一度強調すると、カスタムソートでは「何をどの順で比較するか」を明確に設計することが最重要です。
そのうえで、keyとlambdaを適切に組み合わせることで、実務に必要なほとんどの並び替えニーズを満たすことができます。
まとめ
本記事では、Pythonでリストを並び替える方法として、破壊的なlist.sort()と非破壊的なsorted()の違いから始め、key引数やlambda式を用いたカスタムソートまで幅広く解説しました。
数値・文字列・タプル・辞書・集合など、どのようなデータでもsorted()を活用すれば柔軟な並び替えが可能です。
実務では、元データを保持したいときはsorted()、メモリ効率を優先したいときはlist.sort()と使い分けつつ、key関数を設計して複雑なソート要件に対応していくのがおすすめです。
