
プログラムでレポートやログを出力する時、桁数や位置がバラバラだと非常に読みづらくなります。
Pythonでは、0埋めや空白埋め、左寄せ・中央寄せ・右寄せといった整形を簡単に行うことができます。
本記事では、strメソッド・format・f文字列の3つの観点から、文字列をきれいに揃える具体的な方法を、図解とサンプルコードを交えながら丁寧に解説していきます。
Pythonでの文字列埋めと位置揃えの基本
文字列を0埋め・空白埋めする目的
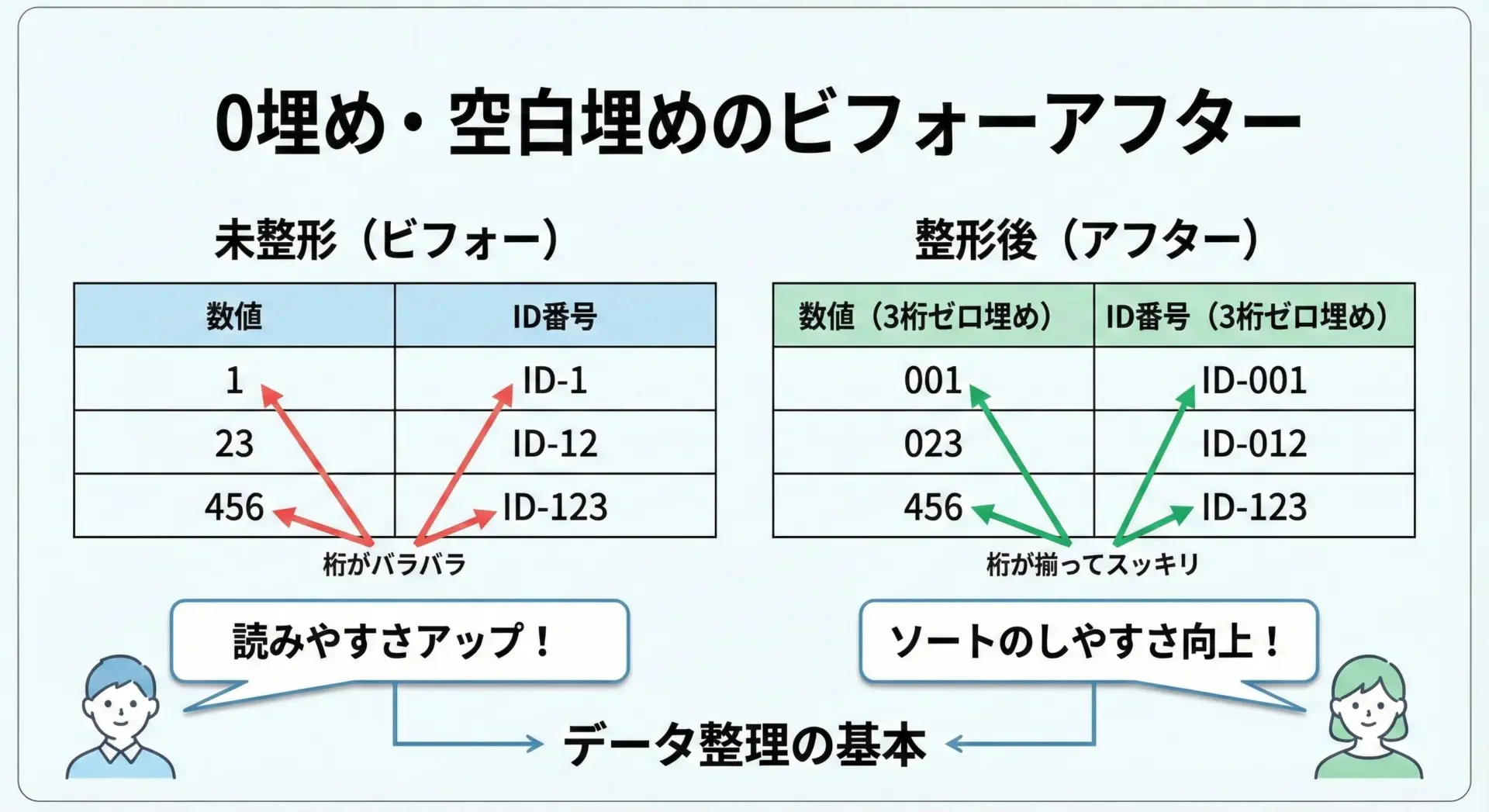
数値やID、ログの出力などで桁数や文字数がバラバラだと、人間が読む時にもプログラムで処理する時にも扱いにくくなります。
そのため、文字列の長さを一定に揃えるために、足りない部分を0や空白(スペース)で埋めることがよく行われます。
実際の目的としては、次のようなものがあります。
数値の桁数をそろえて一覧表示しやすくしたり、IDを「001」「002」のようにして、ソートした時に文字列としても正しい順番になるようにしたりすることです。
また、ログや表形式の出力で列を縦に揃えることで、人間が一目で比較しやすいレイアウトにする効果もあります。
位置揃え(左寄せ・中央寄せ・右寄せ)の基本
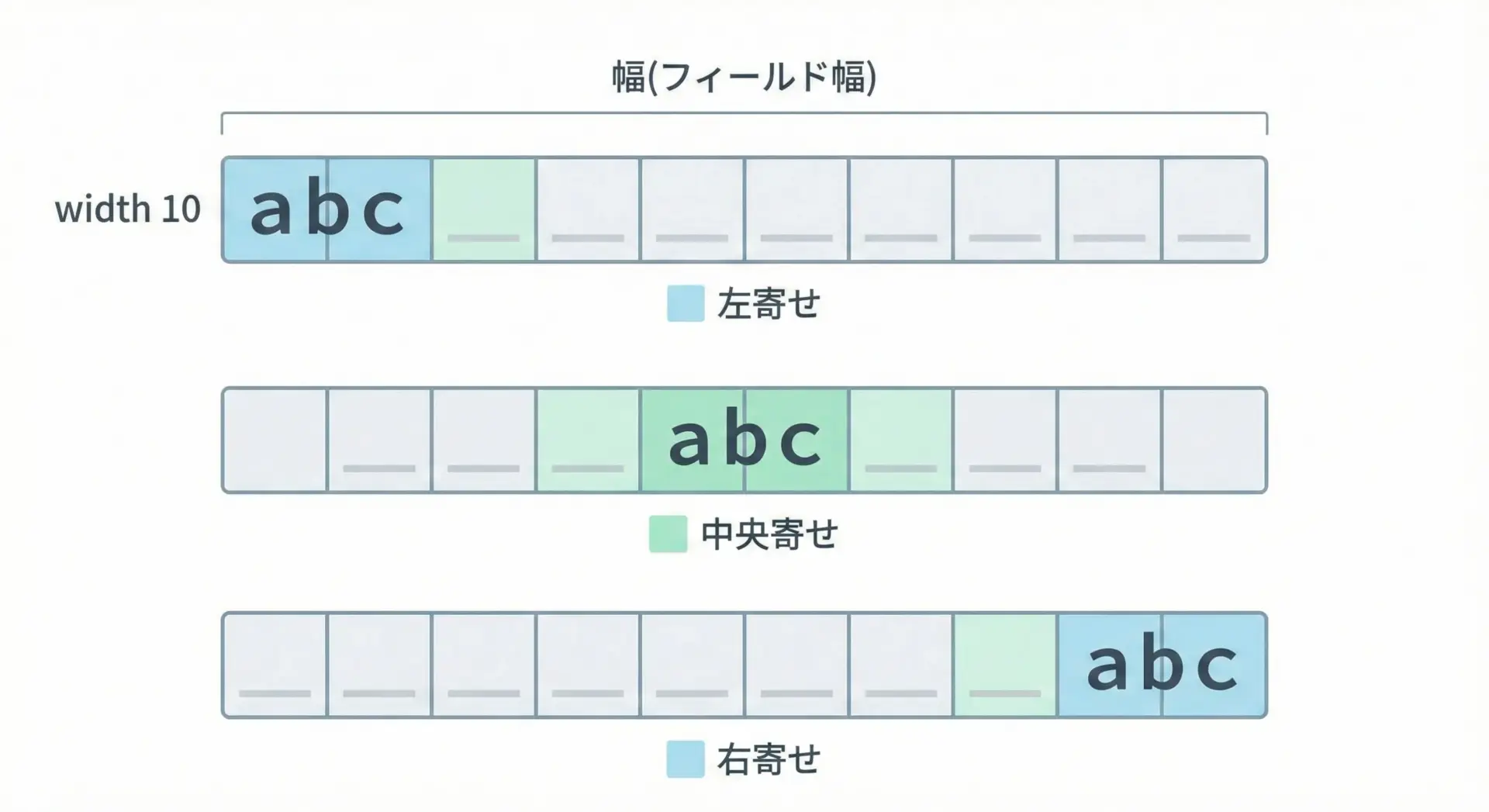
文字をただ埋めるだけでなく、「左に寄せる」「真ん中に寄せる」「右に寄せる」といった位置揃えも重要です。
例えば、表の見出しだけ中央寄せにしたり、数値だけ右寄せにして小数点の位置を揃えたり、ログの時刻を左側に固定したりといった使い方があります。
Pythonでは、「全体の幅(フィールド幅)を決め、その中で文字列をどこに置くか」という考え方で位置揃えを行います。
幅より短い部分には、自動的に空白や指定した文字が詰められます。
Pythonで使える主な文字列整形の方法一覧
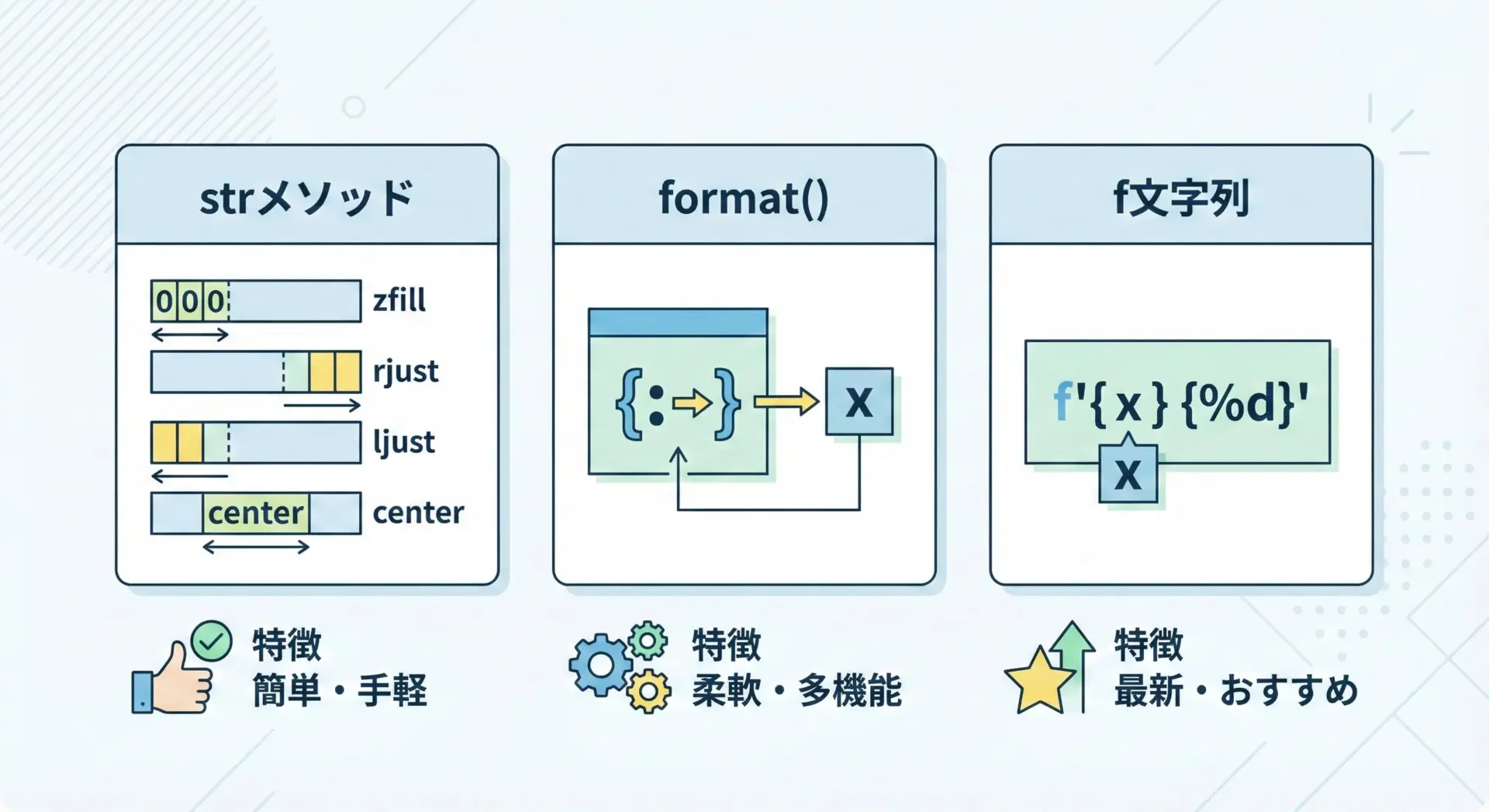
Pythonで文字列を埋めたり位置を揃えたりする代表的な方法は、次の3つです。
| 方法 | 主な用途・特徴 |
|---|---|
str.zfill 等 | 文字列に対して直接使うメソッド。簡単に0埋めや空白埋めができる。 |
str.format | 書式指定文字列を使った汎用的なフォーマット。Python3初期からある方法。 |
f文字列 | Python3.6以降で推奨される書き方。可読性が高く、変数展開・書式指定が1つにまとまる。 |
この記事では、まずstrメソッドでの0埋め・空白埋めから説明し、その後format・f文字列によるより柔軟な整形を解説していきます。
strメソッドでの0埋め・空白埋め
zfillで数値文字列を0埋めする
zfillは「ゼロで埋める(fill)」という意味で、主に数値を表す文字列に対して使います。
指定した幅になるまで、左側を0で埋めてくれます。
# zfillの基本的な使い方
num_str = "42"
# 幅5になるように左側を0で埋める
padded1 = num_str.zfill(5)
# 幅2 (元が2桁なのでそのまま)
padded2 = num_str.zfill(2)
print(padded1) # -> 00042
print(padded2) # -> 4200042
42負の数を表す文字列に対しても、マイナス記号の後ろ側に0を入れてくれるという特徴があります。
negative = "-7"
print(negative.zfill(3)) # 幅3
print(negative.zfill(5)) # 幅5-07
-0007このように数値IDや連番の桁を揃える用途ではzfillが非常に便利です。
rjustで右寄せしながら空白埋めする
rjustは「right justify(右寄せ)」の略です。
指定した幅の中で文字列を右端に寄せ、足りない左側を空白で埋めます。
# rjustの基本
text = "abc"
# 幅10で右寄せ (左側が空白で埋まる)
right_justified = text.rjust(10)
print(f"|{right_justified}|") # | abc|| abc|このとき、カッコの中の空白は見えづらいので、デバッグ時には枠線や区切り文字と一緒に出力すると確認しやすくなります。
ljustで左寄せしながら空白埋めする
ljustは「left justify(左寄せ)」です。
右側を空白で埋めつつ、文字列を左端に配置します。
# ljustの基本
text = "abc"
# 幅10で左寄せ (右側が空白で埋まる)
left_justified = text.ljust(10)
print(f"|{left_justified}|") # |abc ||abc |表形式の出力では、文字列の列は左寄せ、数値の列は右寄せとすることが多く、ljustとrjustを組み合わせることで見やすいレイアウトを作れます。
centerで中央寄せしながら空白埋めする
centerは、指定した幅の中央に文字列を配置し、左右の余白を空白で埋めます。
# centerの基本
text = "title"
# 幅20で中央寄せ
centered = text.center(20)
print(f"|{centered}|")| title |幅が奇数で文字数が偶数など、ピタッと割り切れない場合は、左右の空白の数が1文字分だけ違う場合があります。
この動きは自動で決まるので、中央寄せの大まかな見た目を整えたい時に便利です。
任意の文字で埋める方法
rjust・ljust・centerは、第二引数で埋める文字を1文字だけ指定することができます。
デフォルトでは空白ですが、例えばハイフンやドット、アスタリスクなどを使うと見た目の効果が変わります。
text = "42"
# 右寄せしながら「0」で埋める
print(text.rjust(5, "0")) # -> 00042
# 左寄せしながら「.」で埋める
print(text.ljust(5, ".")) # -> 42...
# 中央寄せしながら「-」で埋める
print(text.center(7, "-")) # -> --42---00042
42...
--42---この方法は「0埋め」もできますが、数値であれば後述するformatやf文字列を使う方が直感的な場合も多いです。
formatとf文字列での文字列整形
formatでの桁数指定と0埋め
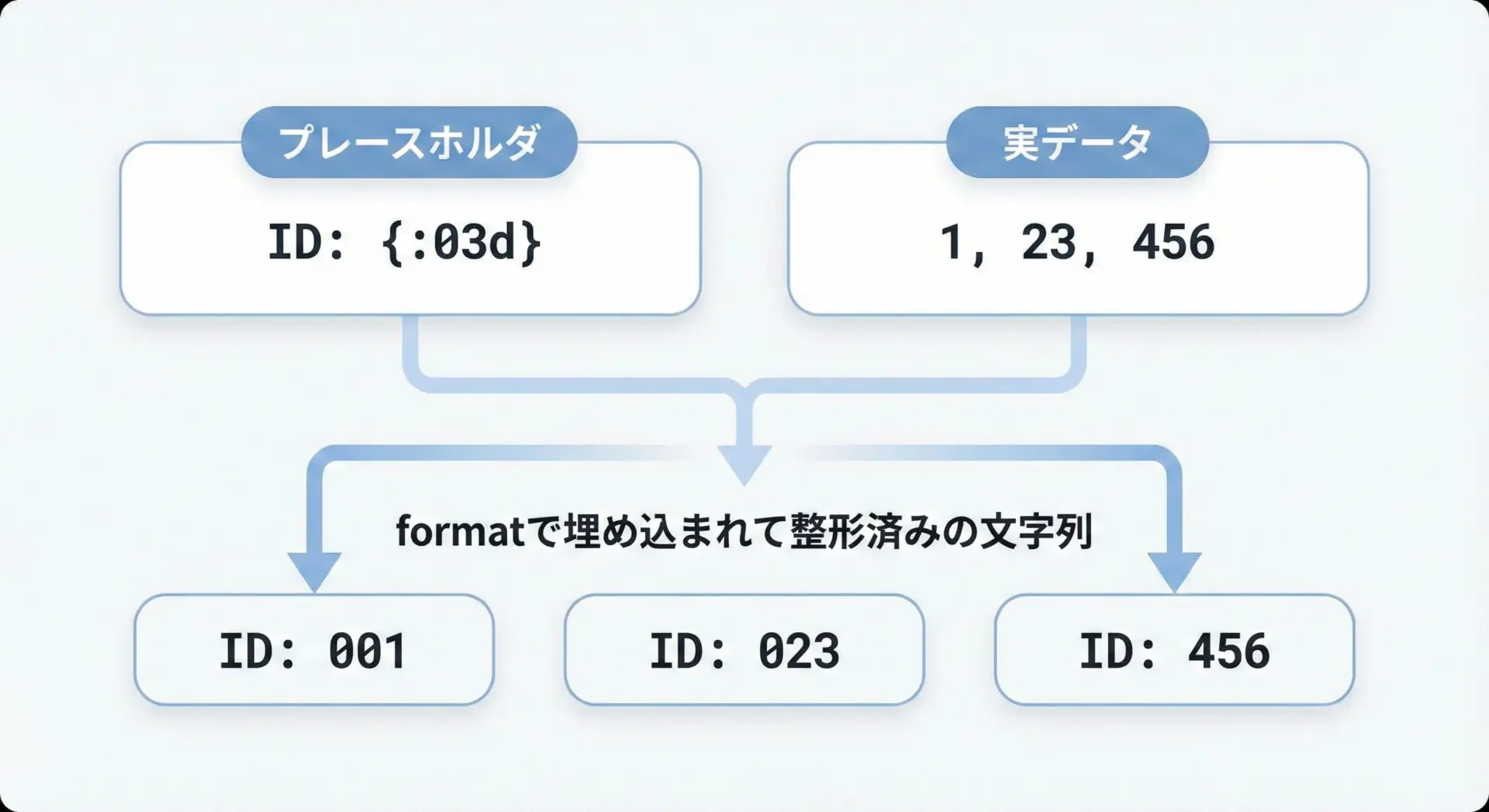
str.formatは、書式を指定しながら値を文字列に埋め込むための古くからある機能です。
中かっこ{}の中に書式指定を記述し、.format(値)で置き換えます。
0埋めをしたい場合は、{:03d}のように書きます。
# formatでの0埋めと桁数指定
num = 7
# 3桁で0埋め (整数)
s1 = "{:03d}".format(num) # 007
# 5桁で0埋め (整数)
s2 = "{:05d}".format(num) # 00007
# 小数も指定可能 (全体の幅と小数点以下の桁数)
pi = 3.14
s3 = "{:06.2f}".format(pi) # 全体6桁、小数点以下2桁 → "003.14"
print(s1, s2, s3)007 00007 003.14<cst-only>書式指定のポイント</cst-only>は、0を付けることで左側を0で埋め、dやfで型(整数・小数)を指定するところです。
f文字列での0埋めと位置揃え

Python3.6以降では、f文字列(f-strings)が推奨されています。
先頭にfを付けた文字列リテラル内で、{変数:書式}の形で書式指定ができます。
num = 42
# 3桁0埋め
s1 = f"{num:03d}"
# 幅10で右寄せ
s2 = f"{num:>10d}"
# 幅10で左寄せ
s3 = f"{num:<10d}"
# 幅10で中央寄せ
s4 = f"{num:^10d}"
print(f"|{s1}|")
print(f"|{s2}|")
print(f"|{s3}|")
print(f"|{s4}|")|042|
| 42|
|42 |
| 42 |書式指定の中では、先頭に0を付けると0埋め、<・^・>で左寄せ・中央寄せ・右寄せを指定できます。
num = 5
# 4桁0埋め (右寄せが暗黙)
print(f"{num:04d}") # 0005
# 幅6で中央寄せ、0埋め (やや特殊な例)
print(f"{num:0^6d}") # 0005000005
0005002番目の例はややトリッキーですが、0^6dのように書くと、0を使って、幅6で中央寄せという指定になります。
数値フォーマットと文字列フォーマットの違い
formatやf文字列の書式指定では、「その値を数値として扱うか、文字列として扱うか」を明示的に指定することができます。
これを意識しておくと、意図しないエラーや不自然な表示を避けられます。
| 種類 | 代表的な書式指定例 | 意味 |
|---|---|---|
| 整数(int) | d | 10進整数として表示 |
| 浮動小数(float) | f | 小数として表示 |
| 文字列(str) | s | 文字列として表示 |
数値フォーマットの例です。
num = 123
# 数値としてフォーマット (d)
print(f"{num:06d}") # 000123
# 文字列としてフォーマット (s)
print(f"{str(num):>6s}") # " 123"000123
123前者は数値そのものに対して0埋めを行い、後者は文字列に変換したあと右寄せだけ行っている点が違います。
0埋めをしたい場合は、数値フォーマット(特にd)を使うのが基本です。
文字列と数値を組み合わせて整形する方法

実際のコードでは、文字列と数値を同時に整形して1行の出力を作ることがよくあります。
f文字列を使うと、このような複合的なフォーマットを1つの式にまとめることができます。
# 商品データの例
items = [
(1, "Apple", 120.0),
(12, "Banana", 98.5),
(123, "Cherry", 1000.0),
]
# 見出し行
print(f"{'No':>4s} {'Name':<10s} {'Price':>8s}")
for no, name, price in items:
# Noは3桁0埋め、Nameは左寄せ、Priceは右寄せで小数点以下2桁
line = f"{no:04d} {name:<10s} {price:8.2f}"
print(line) No Name Price
0001 Apple 120.00
0012 Banana 98.50
0123 Cherry 1000.00このように各列の幅や寄せ方を明示的に指定することで、データが増えてもレイアウトが崩れにくくなります。
実用例で学ぶ0埋め・空白埋め・位置揃え
連番IDや番号を0埋めする
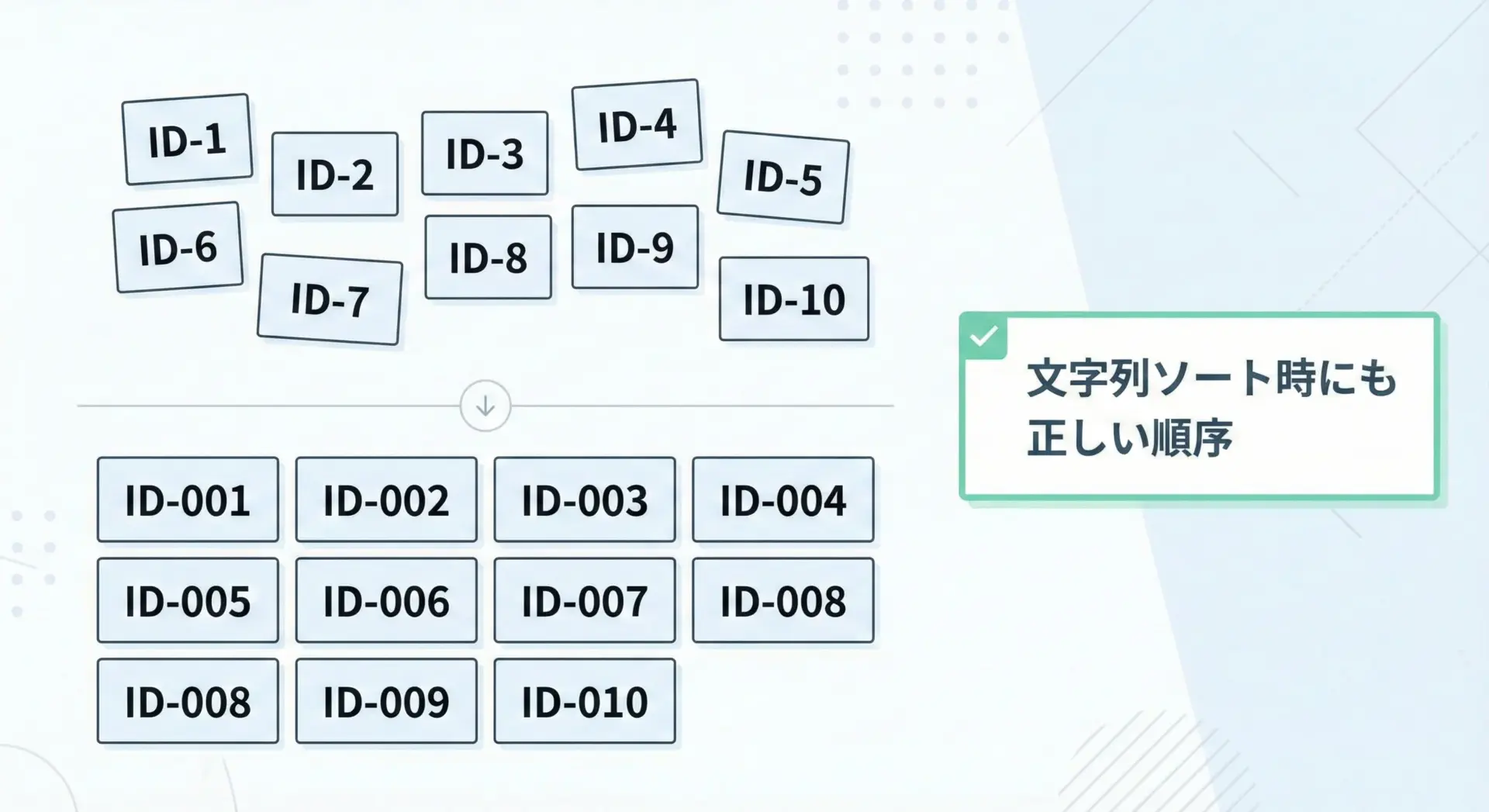
連番IDを扱う時、「1」「2」「10」のように桁数が混在すると、文字列としてソートした場合に「1, 10, 2」のような順序になってしまいます。
そこで固定桁数で0埋めしたIDにしておくと、文字列ソートでも自然な並びを保てます。
# 3桁0埋めのIDを生成する例
def generate_ids(prefix: str, start: int, end: int) -> list[str]:
ids = []
for i in range(start, end + 1):
# 3桁0埋めでIDを作成
id_str = f"{prefix}{i:03d}"
ids.append(id_str)
return ids
ids = generate_ids("USER-", 1, 12)
print(ids)['USER-001', 'USER-002', 'USER-003', 'USER-004', 'USER-005', 'USER-006', 'USER-007', 'USER-008', 'USER-009', 'USER-010', 'USER-011', 'USER-012']このようにプレフィックス(接頭辞)と0埋めした番号を組み合わせると、データベースのキーやログIDとして扱いやすくなります。
表形式の出力で列を揃える

コンソールに簡易的な表を出したい時、各列の最大幅を調べてからljustやrjustで揃えると見やすい出力になります。
# 人物データのテーブルを整形して出力する例
people = [
("Alice", 23, 162.5),
("Bob", 8, 120.0),
("Charlie", 35, 175.2),
]
# 各列の最大幅を計算 (名前と年齢の列を対象)
name_width = max(len(p[0]) for p in people)
age_width = max(len(str(p[1])) for p in people)
# 見出し行
header_name = "Name".ljust(name_width)
header_age = "Age".rjust(age_width)
header_height = "Height"
print(f"{header_name} | {header_age} | {header_height}")
# 区切り線
print("-" * (name_width + age_width + len(header_height) + 6))
# データ行
for name, age, height in people:
line_name = name.ljust(name_width)
line_age = str(age).rjust(age_width)
line_height = f"{height:6.1f}" # 高さは固定幅で小数1桁
print(f"{line_name} | {line_age} | {line_height}")Name | Age | Height
----------------------
Alice | 23 | 162.5
Bob | 8 | 120.0
Charlie | 35 | 175.2このように列ごとに「左寄せか右寄せか」を決めておくと、情報を素早く読み取りやすくなります。
ログやメッセージの見やすい整形
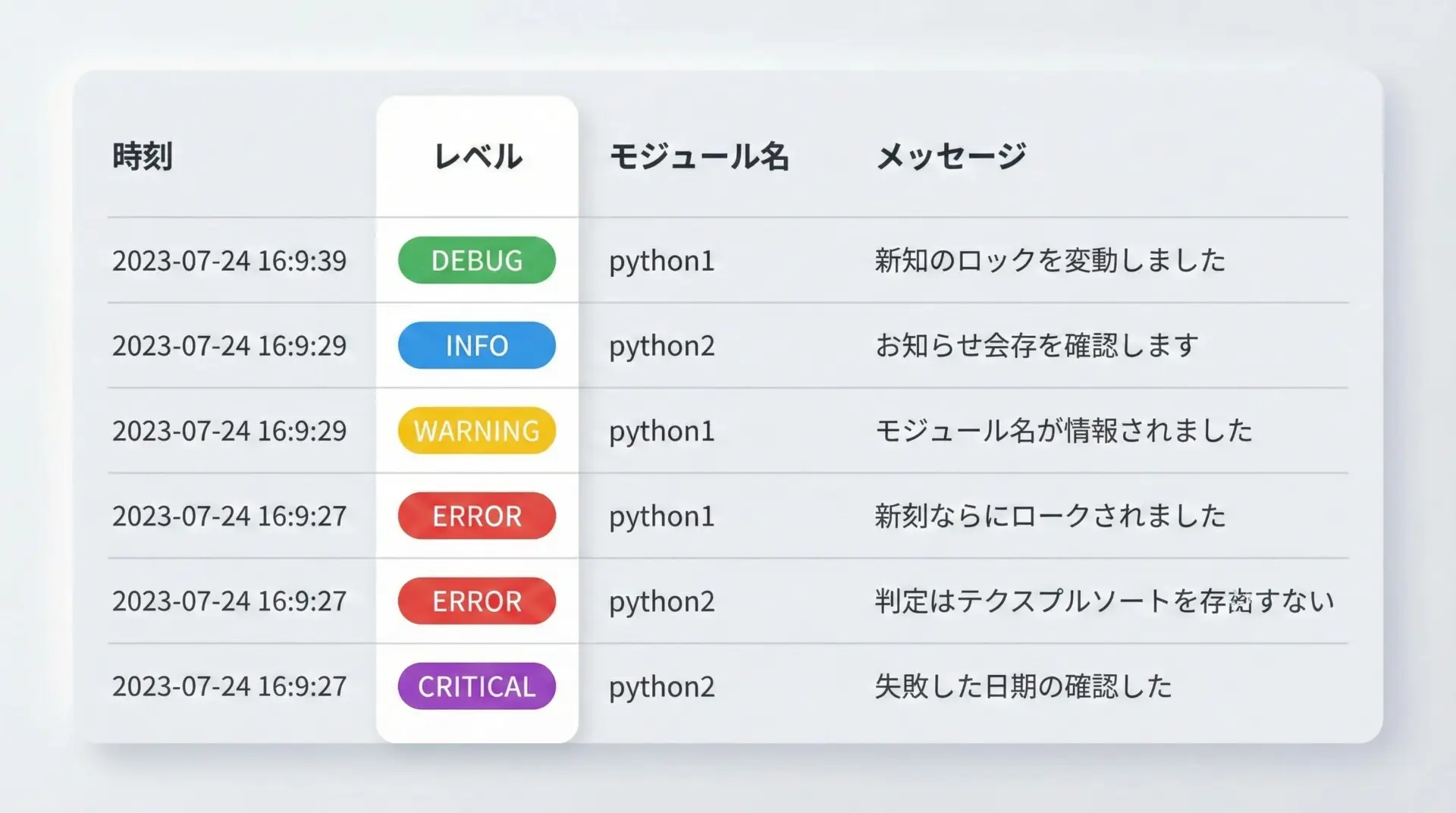
ログやデバッグメッセージを見やすくするには、時刻・ログレベル・メッセージなどを一定幅で揃えるのが有効です。
import datetime
def log(level: str, message: str) -> None:
# 現在時刻
now = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# レベルは幅7で中央寄せ
level_str = f"{level:^7s}"
# 時刻とレベルを固定幅で出力
print(f"{now} [{level_str}] {message}")
log("INFO", "アプリケーションを開始しました。")
log("DEBUG", "設定ファイルを読み込み中...")
log("ERROR", "ファイルが見つかりません。")2025-12-17 12:34:56 [ INFO ] アプリケーションを開始しました。
2025-12-17 12:34:56 [ DEBUG ] 設定ファイルを読み込み中...
2025-12-17 12:34:56 [ ERROR ] ファイルが見つかりません。このようにレベル文字列の幅を固定しておくと、長時間ログを眺めていても視線がブレにくくなり、重要な行を探しやすくなります。
日本語(全角)を含む文字列整形の注意点
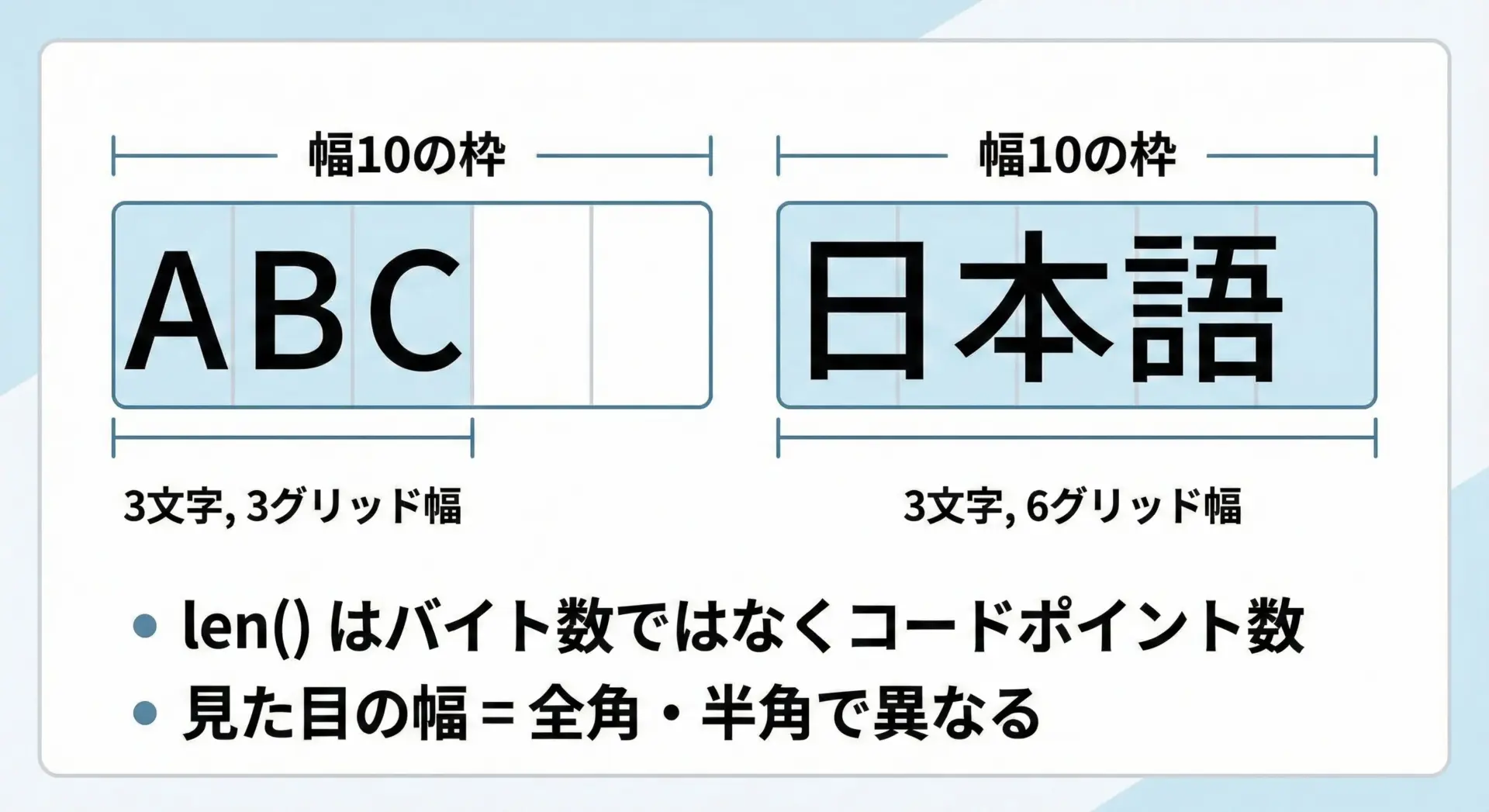
日本語(全角文字)を含む文字列を揃える場合、単純にlen()で長さを測っても、見た目の幅が揃わないという問題があります。
Pythonのlen()は文字数(正確にはコードポイント数)を返しますが、日本語1文字は英数字1文字より横幅が広いためです。
簡易的な対処として、日本語を含む列については、ある程度大きめの幅を指定してljust/rjustする方法がありますが、見た目を正確に揃えたい場合は、unicodedataモジュールなどを使って「全角は2幅、半角は1幅」とみなして計算する必要があります。
以下は、とりあえずの幅固定で整形する例です。
# 日本語を含むテーブルを幅指定で整形する簡易例
rows = [
("山田太郎", "営業部"),
("John", "開発部"),
("佐藤", "人事部"),
]
# とりあえず名前は幅10、部署は幅8で左寄せ
for name, dept in rows:
print(f"{name:<10s} | {dept:<8s}")山田太郎 | 営業部
John | 開発部
佐藤 | 人事部見た目として完全に揃ってはいませんが、最低限、列の開始位置はある程度そろっている状態です。
ターミナルやフォントによっても見え方が変わるため、日本語をきっちりそろえるには、表示環境も含めた調整が必要になります。
まとめ
Pythonでは、strメソッド(zfill・rjust・ljust・center)と、format/f文字列を使うことで、0埋めや空白埋め、左寄せ・中央寄せ・右寄せといった文字列整形を柔軟に行うことができます。
連番IDの生成や表形式の出力、ログ整形など、実用的な場面で活用すると、プログラムの出力がぐっと読みやすくなります。
特にf文字列は、変数展開と書式指定を一箇所にまとめられるため、今から新しくコードを書く場合はf文字列+書式指定を基本スタイルとして身につけておくと良いでしょう。
