
C#を用いたアプリケーション開発において、文字列のバリデーションやデータの抽出、不要な文字の除去といったテキスト処理は避けて通れないタスクの一つです。
その際、強力な武器となるのが正規表現(Regular Expression)です。
正規表現には「特定の文字に一致させる」だけでなく、「特定の文字以外に一致させる」という否定の概念が存在します。
この記事では、C#の System.Text.RegularExpressions 名前空間における「文字クラスの否定」に焦点を当て、基礎から応用、そしてパフォーマンス面での注意点までを詳しく解説します。
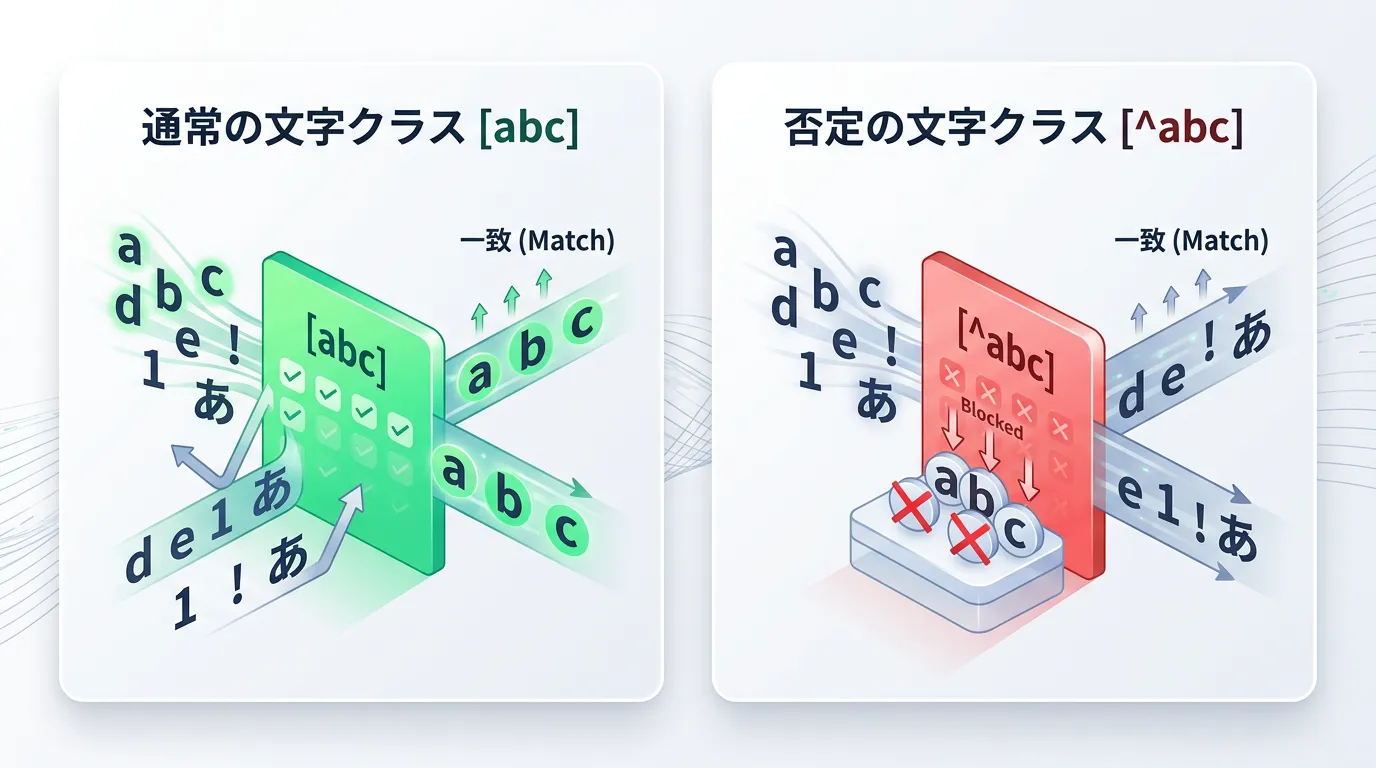
文字クラスの否定「[^…]」の基本概念
正規表現における「文字クラス」とは、[ ](角括弧)の中に記述した文字のいずれかに一致させる仕組みのことです。
この文字クラスの先頭に ^(ハット記号)を記述することで、「その括弧内に含まれない任意の1文字」に一致させる「否定」の意味を持たせることができます。
C#でこの否定の文字クラスを利用する場合、もっとも基本的な書き方は以下のようになります。
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main()
{
string input = "A1-B2_C3";
// 数字「以外」の文字にマッチさせる
string pattern = "[^0-9]";
string result = Regex.Replace(input, pattern, "");
Console.WriteLine(result); // 出力: 123
}
}上記の例では、[^0-9] というパターンを使用しています。
これは「0から9までの数字ではない文字」にマッチするため、アルファベットや記号が置換対象となり、結果として数字だけが抽出されることになります。
ここで注意が必要なのは、^ 記号は必ず角括弧内の先頭に配置しなければならないという点です。
もし [a^bc] のように記述した場合、それは「a、^、b、cのいずれか」という意味になり、否定の意味は失われてしまいます。
複数の文字や範囲の指定
否定の文字クラスでは、単一の文字だけでなく、複数の文字や範囲を組み合わせて指定することが可能です。
[^aeiou]:小文字の母音以外の文字に一致[^a-zA-Z]:英字以外の文字に一致[^0-9\n\r]:数字および改行コード以外の文字に一致
このように、特定の文字セットをブラックリストとして定義し、それ以外をすべて受け入れるという柔軟なフィルタリングが可能になります。
否定形の定義済み文字クラス
C#の正規表現には、よく使われる文字セットを短縮して記述できる「定義済み文字クラス」が用意されています。
これらの中には、最初から否定の意味を含んでいるものが存在します。
これらの定義済みクラスを理解しておくことで、コードの可読性は飛躍的に向上します。
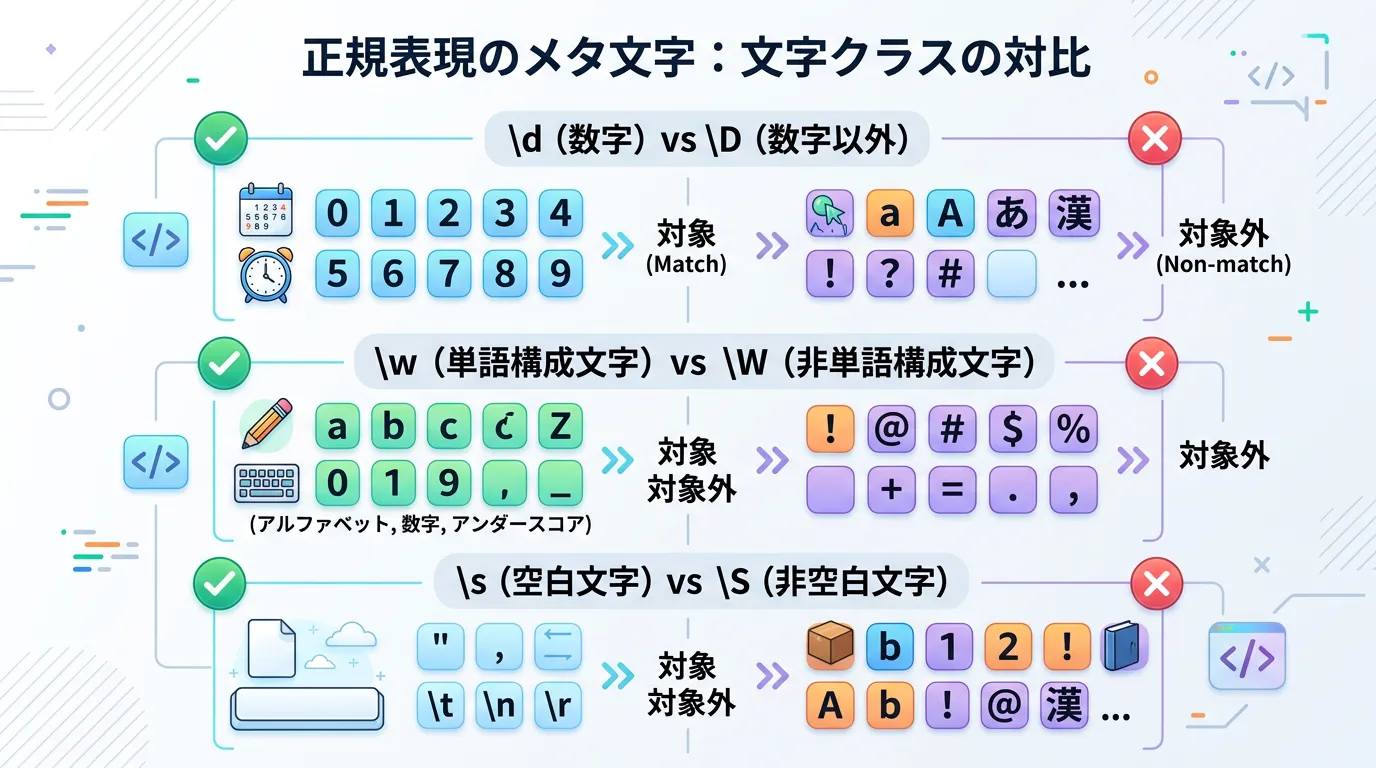
| クラス | 意味 | 解説 |
|---|---|---|
\d | 数字 | [0-9] と同等(Unicode設定により広がる場合あり) |
\D | 数字以外 | [^0-9] と同等 |
\w | 単語構成文字 | アルファベット、数字、アンダースコア。 |
\W | 単語構成文字以外 | 記号やスペース、全角文字などに一致。 |
\s | 空白文字 | スペース、タブ、改行など。 |
\S | 空白文字以外 | 目に見える文字全般に一致。 |
\D, \W, \S の具体的な活用シーン
たとえば、ユーザーが入力した電話番号からハイフンや括弧を取り除き、純粋な数字のみを取得したい場合、\D を使うのがもっともスマートです。
string phoneNumber = "(03) 1234-5678";
// 数字以外すべてを空文字に置換
string cleanNumber = Regex.Replace(phoneNumber, @"\D", "");
Console.WriteLine(cleanNumber); // 出力: 0312345678また、\S+ というパターンを使えば、空白で区切られた単語を抽出する際に便利です。
これは「空白以外の文字が1つ以上続く塊」を意味するため、文章から効率的にトークンを切り出すことができます。
Unicode カテゴリによる否定:\P{…}
C#の正規表現エンジンの大きな特徴の一つに、強力なUnicodeサポートがあります。
\p{...} 構文を使うと、特定のUnicodeカテゴリ(文字種)に一致させることができますが、その否定形として \P{...}(大文字のP) が用意されています。
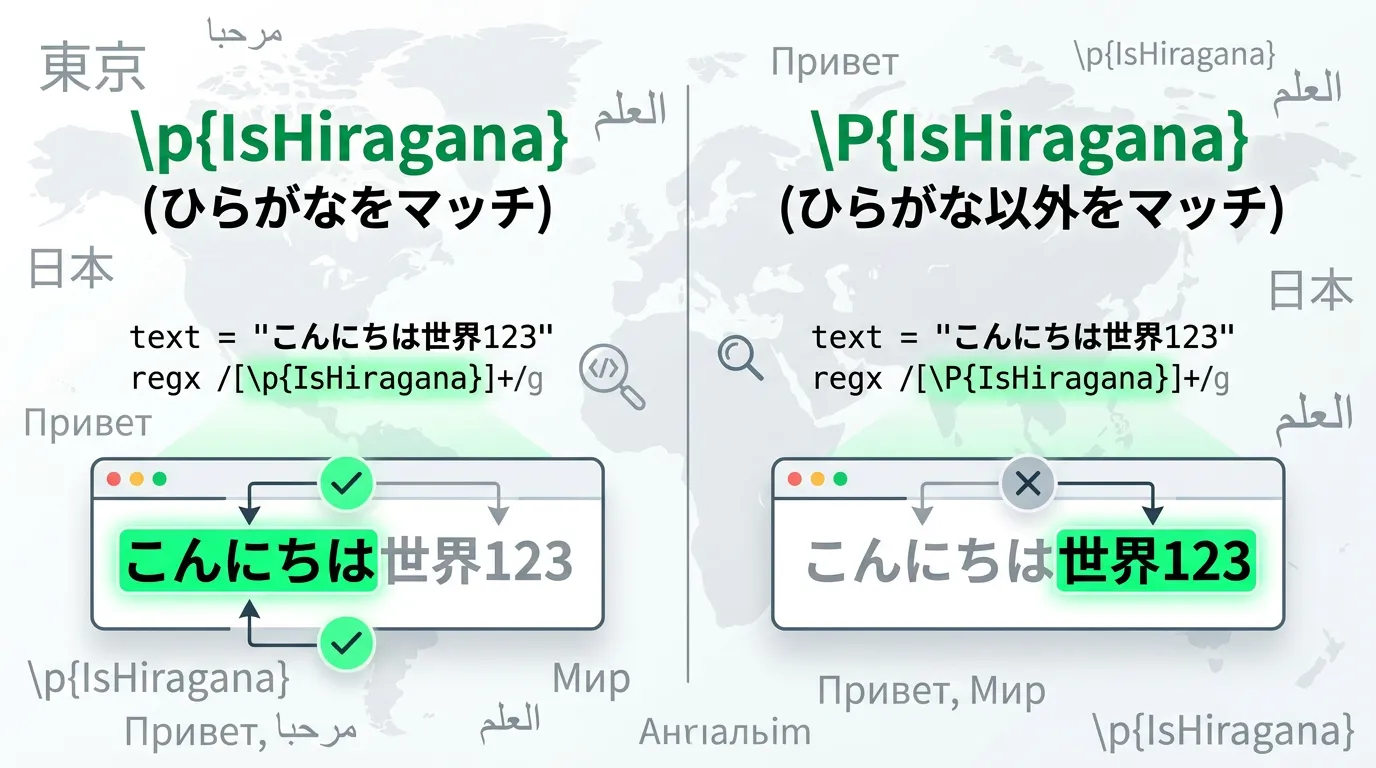
例えば、日本語の「ひらがな」以外の文字をすべて排除したい場合、以下のように記述できます。
string text = "プログラミングC#、楽しい!";
// ひらがな「以外」に一致
string pattern = @"\P{IsHiragana}";
string result = Regex.Replace(text, pattern, "");
Console.WriteLine(result); // 出力: しいこのように、[^...] では定義しきれない膨大なUnicodeの文字集合に対しても、否定のロジックを簡単に適用できるのがC#の強みです。
よく使われるカテゴリには L(文字全般)、N(数値全般)、P(句読点・記号)などがあります。
否定形クラスを使用する際の注意点とTips
否定の文字クラスは非常に便利ですが、直感に反する挙動を示す場合や、パフォーマンスに影響を与える場合があります。
1. 改行文字の扱い
もっとも多いミスの一つが、改行文字の含め忘れです。
[^abc] は「a, b, c以外のすべての文字」に一致しますが、これには改行コード(\n や \r)も含まれます。
もし「1行内にあるa, b, c以外の文字」を検索したい場合は、明示的に改行を否定に含める必要があります(例:[^abc\r\n])。
これを忘れると、意図せず複数行をまたいでマッチしてしまい、データの構造を破壊する恐れがあります。
2. 否定の先読み(Negative Lookahead)との違い
「文字クラスの否定 [^...]」は「特定の1文字」に対する否定ですが、「特定の文字列」を否定したい場合は 否定の先読み (?!...) を使用します。
[^not]: ‘n’, ‘o’, ‘t’ のいずれでもない1文字に一致。(?!not).+: “not” という文字列で始まらない任意の文字列に一致。
文字クラスの否定はあくまで「文字単位」であることを忘れないようにしましょう。
3. パフォーマンスへの影響
否定の文字クラス、特に [^...] に量指定子(* や +)を組み合わせる場合、バックトラックと呼ばれる現象により処理が著しく低速化する可能性があります。
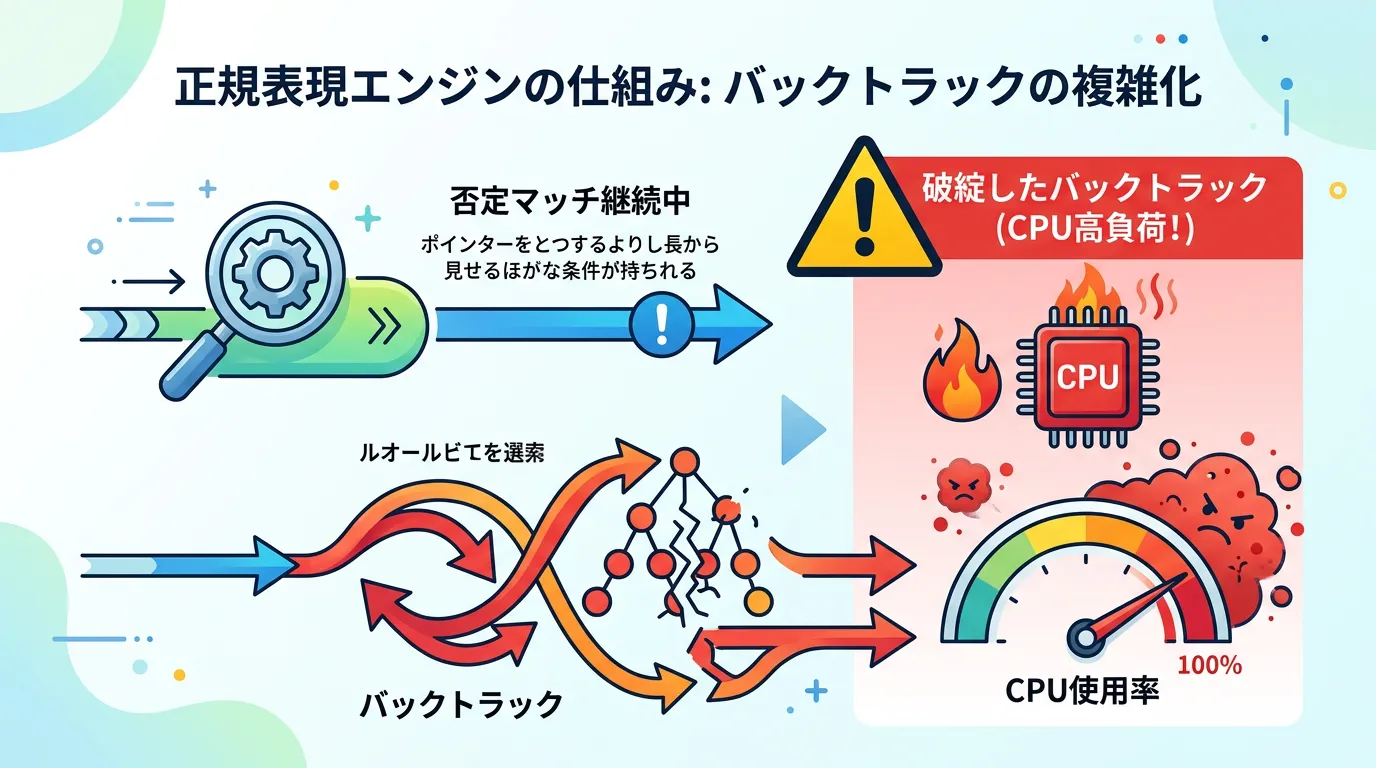
これを防ぐためには、可能な限りマッチの範囲を限定するか、後述する最新のC#の機能を活用するのが有効です。
.NET でのパフォーマンス最適化
C#で正規表現を扱う際、特に大規模なテキストを処理したり高頻度で呼び出したりする場合は、実装方法に工夫が必要です。
RegexOptions.Compiled の活用
古い .NET Framework から続く手法ですが、正規表現オブジェクトを生成する際に RegexOptions.Compiled を指定すると、正規表現をMSILにコンパイルし、実行速度を向上させることができます。
var regex = new Regex(@"[^0-9]+", RegexOptions.Compiled);ただし、コンパイルには初期コストがかかるため、一度しか使わないパターンでは逆に遅くなる点に注意が必要です。
.NET 7以降の GeneratedRegex
最新のC#開発(.NET 7 / .NET 8以降)では、Source Generator を活用した正規表現の生成が推奨されています。
これにより、コンパイル時に正規表現の解析が行われ、実行時のオーバーヘッドがほぼゼロになります。
// パーシャルクラス内で定義
[GeneratedRegex(@"[^a-zA-Z0-9]+")]
private static partial Regex AlphanumericOnlyRegex();
// 使用時
var result = AlphanumericOnlyRegex().Replace(input, "");この方法を用いると、否定の文字クラスを含む複雑なパターンであっても、型安全かつ超高速に動作します。
大規模プロジェクトでは必須のテクニックと言えるでしょう。
実践例:特定の文字を除外するクリーニング処理
最後に、これまでの知識を活かした実践的なコード例を紹介します。
ファイル名として使用できない文字(\ / : * ? " < > |)を、文字クラスの否定を使って一括置換する処理です。
using System;
using System.Text.RegularExpressions;
public class FileSystemHelper
{
// 無効な文字をアンダースコアに置換する
public static string SanitizeFileName(string fileName)
{
// 制御文字と、ファイルシステムで禁止されている文字を否定のロジックで表現
// ここでは「有効な文字以外」にマッチさせる
// 実際には [^...] を使わずとも直接指定したほうが早いが、
// 「特定の許可された文字以外すべて」を消したい場合には [^...] が最強
string pattern = @"[^a-zA-Z0-9_\-\.]";
return Regex.Replace(fileName, pattern, "_");
}
}この例では、英数字、アンダースコア、ハイフン、ドット以外の文字をすべてアンダースコアに置き換えています。
これにより、日本語が含まれていたり、予期せぬ記号が入っていたりしても、安全なファイル名を生成することが可能です。
まとめ
C#の正規表現における文字クラスの否定 [^...] は、単純な除外処理から複雑なデータのクレンジングまで、非常に幅広いシーンで活躍する強力な機能です。
[^...]は「括弧内の文字以外」に一致する。\D,\W,\Sなどの定義済みクラスを使い分けることでコードが読みやすくなる。- Unicodeカテゴリを否定する
\P{...}で多言語対応も容易。 - 改行文字の扱いやバックトラックによるパフォーマンス低下には注意が必要。
- 最新の .NET では
GeneratedRegexを活用して最適化を図る。
これらの特性を正しく理解し、適切に使い分けることで、あなたのC#プログラミングにおける文字列操作の精度と効率は格段に向上するはずです。
正規表現は一見難解ですが、否定の概念をマスターすることは、その強力な力を自在に操るための大きな一歩となるでしょう。
