C#を用いたアプリケーション開発において、文字列の検索、抽出、置換、バリデーション(入力チェック)は避けては通れない非常に重要な処理です。
これらの操作を効率的かつ高度に行うために欠かせないのが正規表現 (Regular Expression) です。
正規表現は特定の文字のパターンを表現するための共通言語のようなものであり、その中核を成すのが「メタ文字」と呼ばれる特殊記号です。
C#では、System.Text.RegularExpressions名前空間に含まれるRegexクラスを使用することで、強力な正規表現エンジンをフル活用できます。
本記事では、C#で利用可能な正規表現のメタ文字を体系的に網羅し、初心者から中級者までが実戦で活用できるよう、詳細な解説とコードサンプル、そして視覚的な図解を交えて徹底的に解説します。
C#における正規表現の基本概念
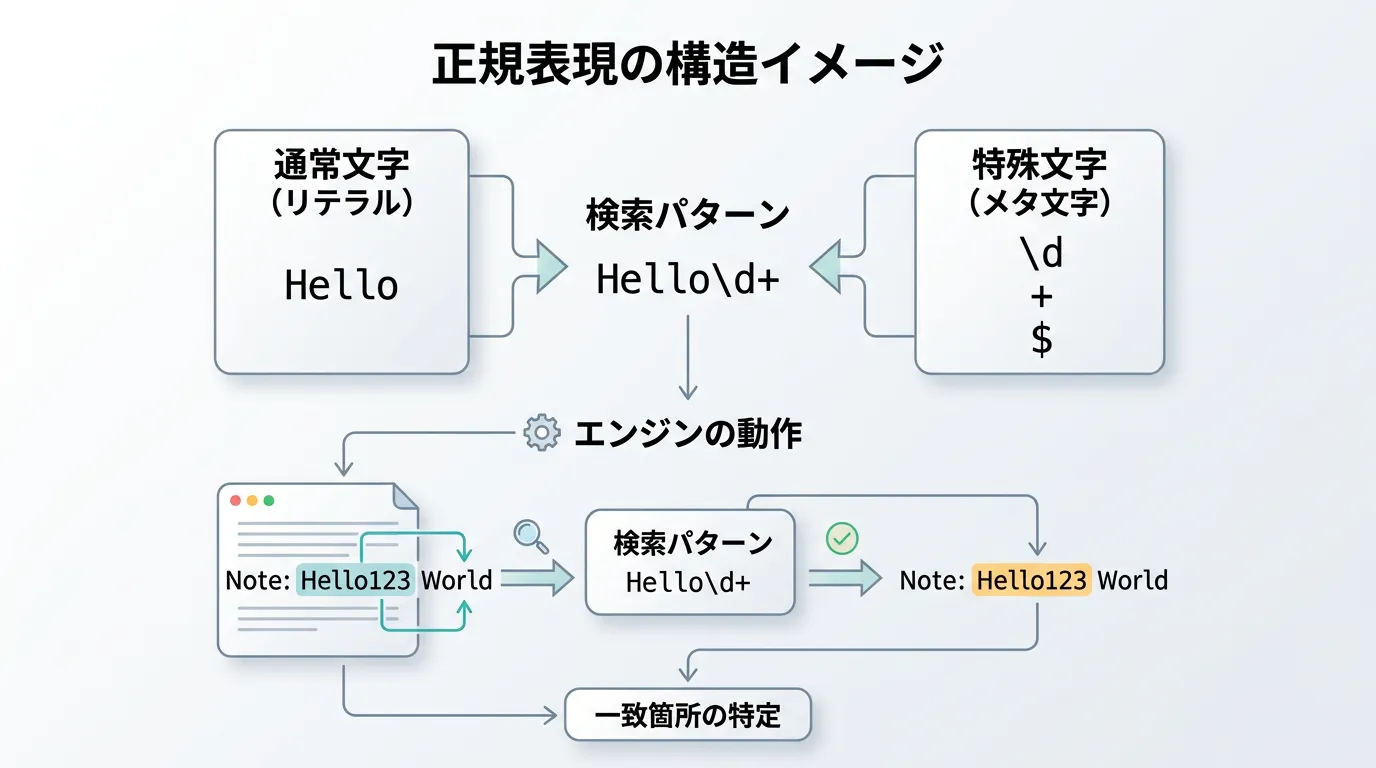
正規表現を使いこなす第一歩は、「リテラル」と「メタ文字」の違いを理解することです。
リテラルとは「a」や「1」といった、その文字自体を指す通常の文字です。
対してメタ文字は、正規表現エンジンに対して「何らかの特殊なルール」を指示するための記号です。
C#の正規表現エンジンは非常に高機能で、Unicode規格に準拠している点が大きな特徴です。
これにより、日本語の全角文字や特殊な記号に対しても、一貫した動作を期待できます。
また、C# 11以降では「生文字列リテラル」の導入により、バックスラッシュ(\)を多用する正規表現の記述が飛躍的に楽になりました。
まずは、最も頻繁に使用されるメタ文字の一覧を早見表で確認しましょう。
【早見表】C# 正規表現のメタ文字一覧
C#でよく使われるメタ文字をカテゴリ別にまとめました。
この表をブックマークしておくだけでも、実装時の効率が大幅に向上します。
| カテゴリ | メタ文字 | 説明 | 例 |
|---|---|---|---|
| 文字クラス | . | 改行以外の任意の1文字 | a.c → abc, arc |
\d | 任意の数字 (Digit) | \d\d → 12, 99 | |
\D | 数字以外の任意の文字 | \D\D → AB, !! | |
\w | 任意の単語構成文字 (英数字+アンダースコア) | \w+ → user_1 | |
\W | 単語構成文字以外の文字 | \W → @, # | |
\s | 任意の空白文字 (スペース, タブ等) | \s | |
[abc] | a, b, c のいずれか1文字 | [A-Z] → 大文字1文字 | |
| 境界指定 | ^ | 文字列の先頭 (または行頭) | ^Start |
$ | 文字列の末尾 (または行末) | End$ | |
\b | 単語の境界 | \bcat\b | |
| 量指定子 | * | 直前の文字の0回以上の繰り返し | a* |
+ | 直前の文字の1回以上の繰り返し | a+ | |
? | 直前の文字が0回または1回出現 | https? | |
{n} | 直前の文字のn回の繰り返し | \d{3} | |
{n,m} | 直前の文字のn回以上m回以下の繰り返し | \d{2,4} | |
| グループ化 | () | 複数の文字をグループ化し、後で参照可能にする | (abc)+ |
\| | いずれかのパターンに一致 (OR) | cat\|dog |
文字クラス:特定の文字セットを指定する
文字クラスは、「どのような種類の文字にマッチさせるか」を定義するメタ文字群です。
C#のバリデーション処理で最も多用されます。
任意の1文字を表すドット .
ドットは「改行(\n)を除くすべての1文字」にマッチします。
例えば、a.c というパターンは、「abc」「arc」「a1c」「a-c」など、aとcの間に何か1文字挟まっているすべてのケースに合致します。
プリセットされた文字クラス (\d, \w, \s)
これらは「ショートハンド(略記法)」と呼ばれ、頻出するパターンを簡潔に記述できます。
- \d:Digit(数字)。
[0-9]と同義です。 - \w:Word(単語構成文字)。英大文字・小文字、数字、およびアンダースコア
_にマッチします。 - \s:Space(空白)。半角スペース、タブ、改行などにマッチします。
注意点: C#のデフォルト設定では、これらはUnicodeベースで動作します。
例えば \d は全角の「1」にもマッチする可能性があります。
厳密に半角数字のみを対象にしたい場合は、[0-9] と記述するか、RegexOptions.ECMAScript オプションを指定します。
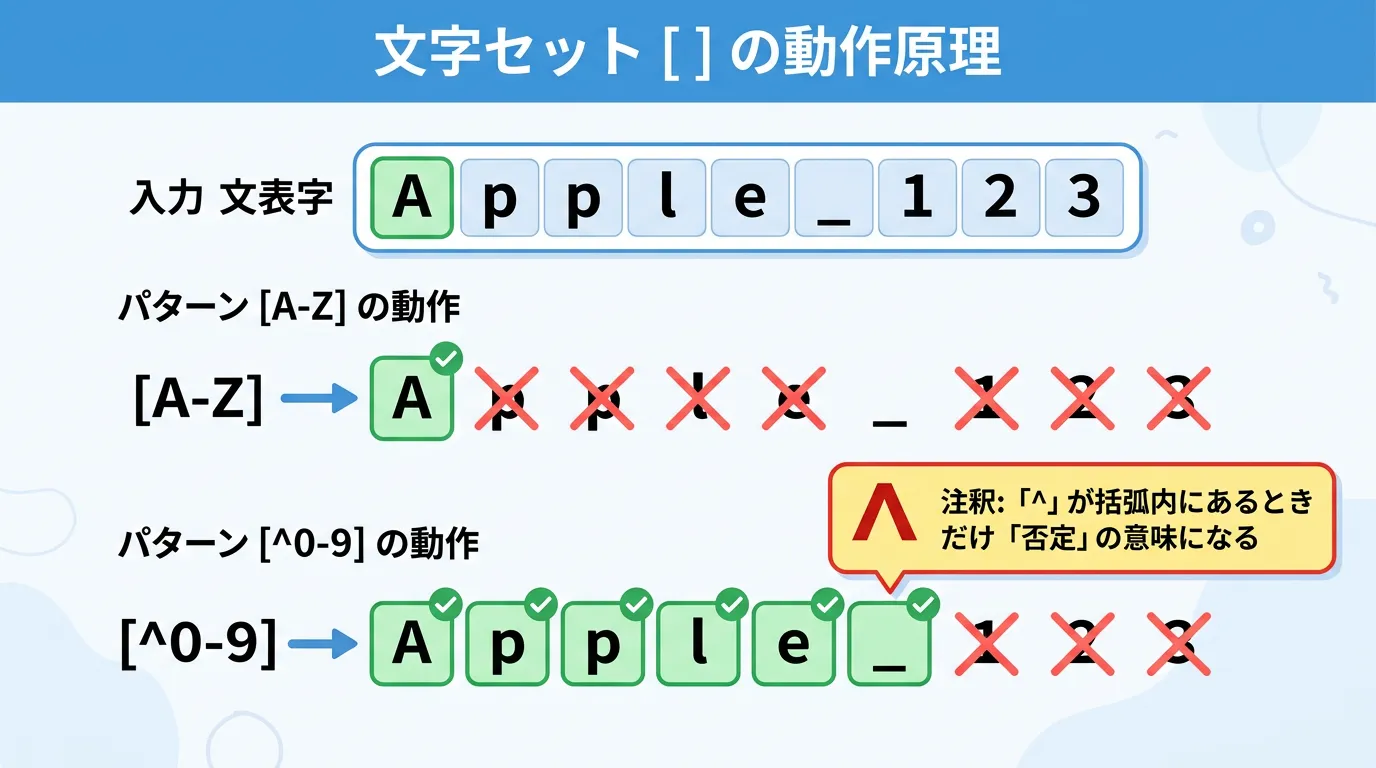
文字セット [] と否定 [^ ]
角括弧を使用すると、特定の文字の集合を指定できます。
[aeiou]:母音のいずれか1文字。[a-z]:aからzまでの小文字いずれか1文字(範囲指定)。[^0-9]:数字以外の1文字。
量指定子:繰り返しの回数を制御する
量指定子は、直前の文字やグループが「何回出現するか」を定義します。
基本的な量指定子
*:0回以上。あってもなくても良く、いくつあっても良い。+:1回以上。最低1つは必要。?:0回または1回。オプション扱いの文字に使用。
回数の詳細指定 {n,m}
{3}:ちょうど3回。{3,}:3回以上。{1,5}:1回から5回まで。
欲張りなマッチと控えめなマッチ
正規表現には「最長一致(Greedy/欲張り)」という性質があります。
デフォルトでは、条件を満たす限り最も長い範囲を検索しようとします。
例えば、<div>Hello</div><div>World</div> という文字列に対し、<div>.*</div> というパターンを適用すると、最初の <div> から最後の </div> までが一本の大きな塊としてマッチしてしまいます。
各タグごとにマッチさせたい場合は、量指定子の後ろに ? を付け加えます(最短一致)。
<div>.*?</div>:最小単位のタグごとにマッチ。

アンカー:マッチする位置を固定する
アンカーは特定の「文字」ではなく、「位置」にマッチします。
^:文字列の先頭。$:文字列の末尾。
これらを使用することで、「部分一致」ではなく「完全一致」のバリデーションが可能になります。
例えば、5桁の数字の入力チェックを行う場合、\d{5} だけでは「123456」という6桁の入力の冒頭5桁にマッチしてしまいます。
これを防ぐには ^\d{5}$ と記述し、「先頭から末尾までがちょうど5桁の数字であること」を強制します。
単語境界 \b
\b は、英数字と非英数字の境界(単語の切れ目)にマッチします。
例えば、\bcat\b は “The cat sits” にはマッチしますが、”category” や “copycat” の中の “cat” にはマッチしません。
特定の単語のみを抽出したい場合に非常に強力です。
グループ化と後方参照
丸括弧 () を使うと、複数の文字を一つのユニットとして扱うことができます。
グループ化の効果
- 量指定子の適用:
(abc)+と書けば “abc”, “abcabc” にマッチします。 - キャプチャ:マッチした部分を後でプログラムから取り出せます。
- 選択(OR演算):
(jpg|png|gif)のように、いずれかの文字列にマッチさせます。
名前付きグループ
C#独自の強力な機能として「名前付きグループ」があります。
(?<year>\d{4})-(?<month>\d{2})
このように記述すると、マッチした結果から「year」や「month」という名前で値を抽出でき、コードの可読性が劇的に向上します。
C# での正規表現の実装方法
理論を学んだところで、実際に C# のコードでどのようにメタ文字を扱うかを見ていきましょう。
1. Regex.IsMatch (バリデーション)
入力された文字列がパターンに従っているかを bool で返します。
using System;
using System.Text.RegularExpressions;
string input = "090-1234-5678";
// 郵便番号や電話番号のチェックに最適
string pattern = @"^\d{2,4}-\d{2,4}-\d{4}$";
if (Regex.IsMatch(input, pattern))
{
Console.WriteLine("有効な電話番号形式です。");
}2. Regex.Match / Matches (抽出)
特定のパターンに合致する部分を取り出します。
string text = "価格は1,500円、送料は500円です。";
string pattern = @"\d{1,3}(,\d{3})*"; // 桁区切りカンマ対応の数字
// 最初に見つかったもの
Match match = Regex.Match(text, pattern);
if (match.Success)
{
Console.WriteLine($"最初の数値: {match.Value}");
}
// すべて抽出
MatchCollection matches = Regex.Matches(text, pattern);
foreach (Match m in matches)
{
Console.WriteLine($"見つかった数値: {m.Value}");
}3. Regex.Replace (置換)
パターンに一致する箇所を別の文字列に置き換えます。
string html = "<div>テスト</div>";
// タグをすべて削除する
string result = Regex.Replace(html, @"<[^>]*>", string.Empty);
Console.WriteLine(result); // 出力: テストC# 11以降の新機能:Source Generators
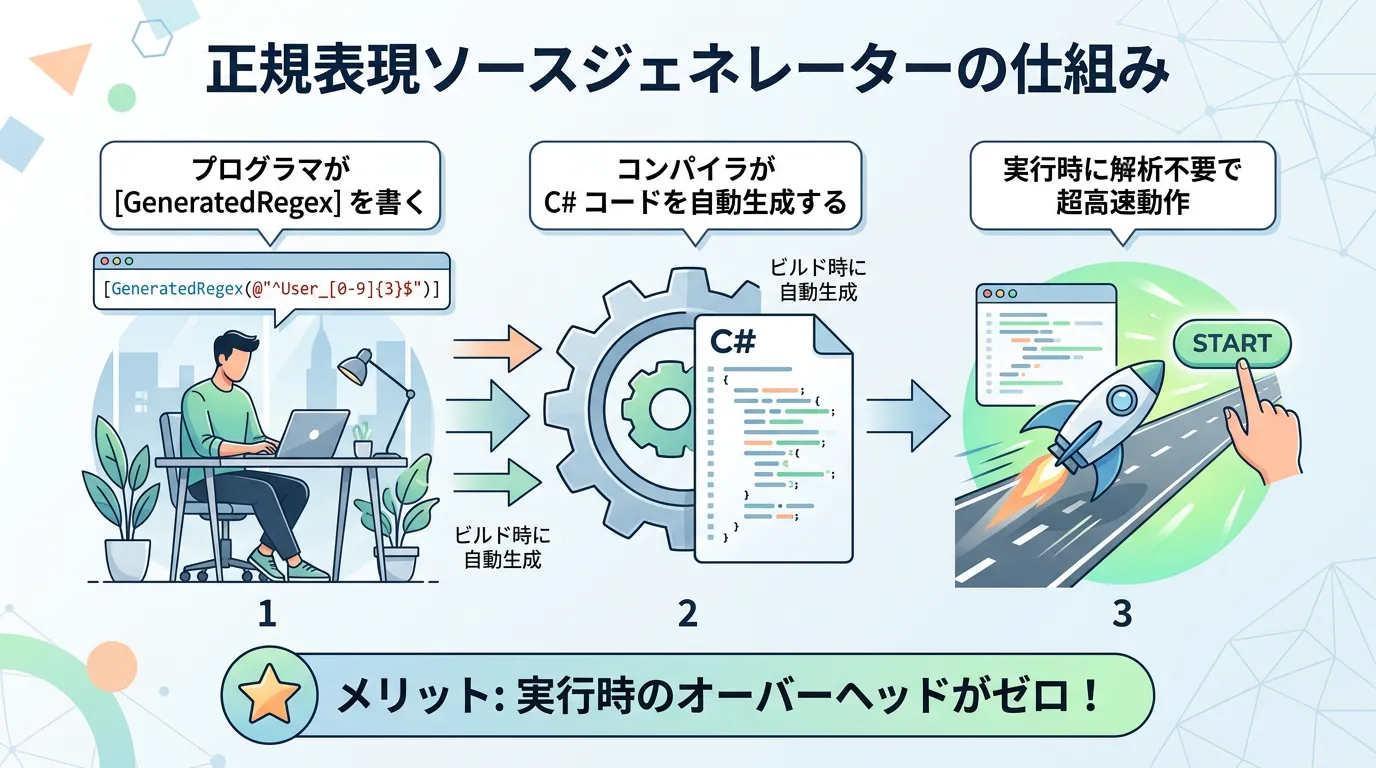
高パフォーマンスが求められるWebサーバーや大規模アプリでは、実行時に正規表現を解析するコストが無視できない場合があります。
最新の C# ( .NET 7以降 ) では、正規表現ソースジェネレーターが導入されました。
これにより、コンパイル時に正規表現の解析コードを自動生成し、実行時のパフォーマンスを最大化できます。
// クラスは partial である必要があります
public partial class MyValidator
{
// 属性を付与するだけで、コンパイル時に効率的なコードが生成される
[GeneratedRegex(@"^\w+([-+.']\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$")]
private static partial Regex EmailRegex();
public bool IsEmailValid(string email) => EmailRegex().IsMatch(email);
}
正規表現を使用する際のベストプラクティス
正規表現は強力ですが、一歩間違えると「メンテナンス不能なコード」や「パフォーマンス低下」を招きます。
以下の点に注意しましょう。
- 逐次リテラル(@マーク)を使用する
C#ではバックスラッシュがエスケープ文字として扱われます。
正規表現の
\dを書くとき、通常は"\d"と書く必要がありますが、@"\d"と書けばそのまま記述できます。- タイムアウトを設定する
悪意のある複雑な入力(正規表現の脆弱性:ReDoS)を避けるため、必ずタイムアウトを指定することを検討してください。
<br>
new Regex(pattern, RegexOptions.None, TimeSpan.FromMilliseconds(100))- 読みやすさを優先する
複雑なパターンには
RegexOptions.IgnorePatternWhitespaceを使い、正規表現内にコメントや改行を入れられるようにすると保守性が向上します。
まとめ
C#の正規表現は、強力なメタ文字を組み合わせることで、複雑な文字列処理をわずか数行のコードで解決できる魔法のようなツールです。
- 文字クラス(\d, \w, [ ])で種類を選別
- 量指定子(+, *, { })で回数を制御
- アンカー(^, $)で位置を固定
- グループ化(( ))で構造化
これらの基本を抑え、さらに最新の GeneratedRegex などの機能を活用することで、堅牢で高速なアプリケーションを構築できます。
まずは簡単なバリデーションから正規表現を取り入れ、その便利さを実感してみてください。
正規表現をマスターすることは、C#エンジニアとしてのスキルを一段上のステージへ引き上げる大きな武器となるはずです。
