
C#を使用したアプリケーション開発において、特定のパターンに一致する文字列をテキスト中からすべて抽出したい場面は頻繁に発生します。
ログファイルの解析、HTMLのスクレイピング、ユーザー入力のバリデーションなど、その用途は多岐にわたります。
こうしたニーズに応えるのが、System.Text.RegularExpressions名前空間に用意されているRegex.Matchesメソッドです。
このメソッドは、指定した正規表現パターンに一致するすべての箇所を一度に検索し、その結果をコレクションとして返却します。
単一の箇所のみを検索するRegex.Matchとは異なり、テキスト全体を走査して合致するすべての情報を取得できるため、一括処理において非常に強力な力を発揮します。
本記事では、Regex.Matchesの基本的な使い方から、最新の.NETにおけるパフォーマンス最適化、実戦的なテクニックまでを詳しく解説します。
Regex.Matchesの基本概念と構文
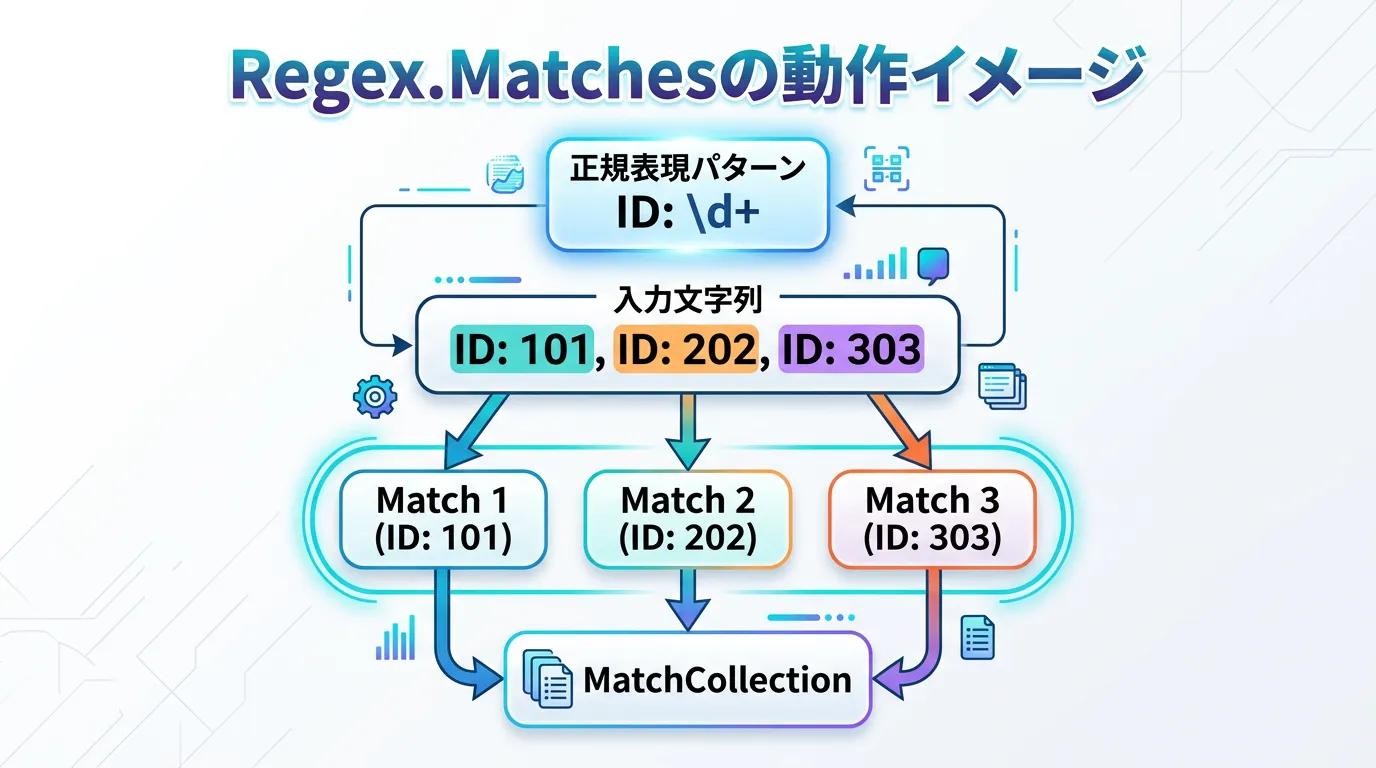
Regex.Matchesは、入力文字列の中から特定のパターンに一致するすべての部分を探し出し、MatchCollectionというオブジェクトで結果を返すメソッドです。
Regex.Matchesを使用する際の最も基本的なシグネチャは以下の通りです。
public static MatchCollection Matches (string input, string pattern);第一引数には検索対象となる入力文字列、第二引数には正規表現パターンを渡します。
このメソッドは静的メソッド(static)として定義されているため、インスタンス化せずに直接呼び出すことが可能です。
ただし、同じパターンを何度も繰り返し使用する場合は、Regexクラスのインスタンスを生成して実行するほうが効率的です。
MatchCollectionの仕組み
返却されるMatchCollectionは、見つかったすべてのMatchオブジェクトを保持しています。
ここで重要なのは、MatchCollectionは遅延評価(Lazy Evaluation)に近い挙動を示すという点です。
すべてのマッチング結果が即座にメモリ上に完全に展開されるわけではなく、コレクションを反復処理(列挙)する際に順次マッチングが行われます。
実践的な使用方法:全一致文字列の取得
実際にコードを書いて、どのように全一致文字列を取得するのかを見ていきましょう。
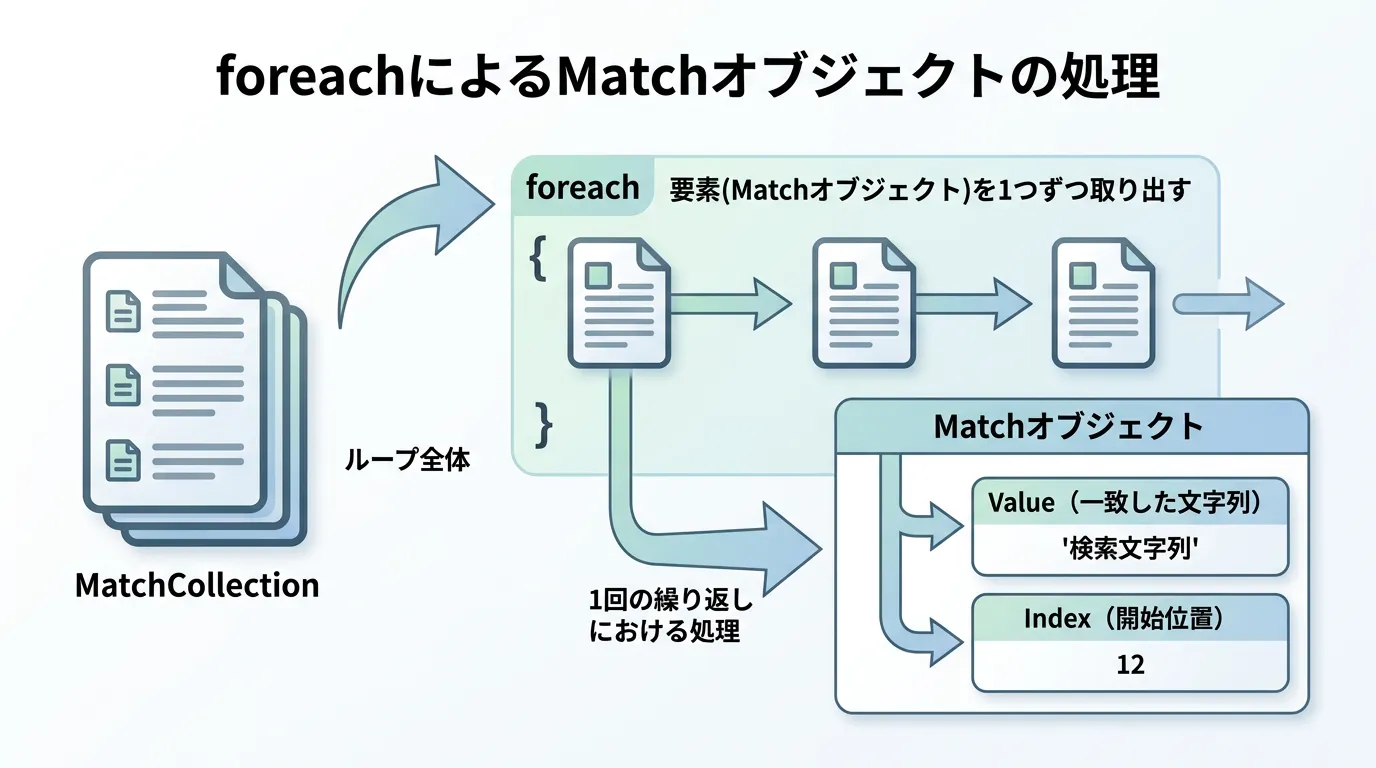
最も一般的な方法は、foreach文を使用してコレクションを走査することです。
using System;
using System.Text.RegularExpressions;
public class Example
{
public static void Main()
{
string input = "apple, orange, banana, grape";
string pattern = @"\b\w+\b"; // 単語全体に一致するパターン
// Regex.Matchesで一致するものをすべて取得
MatchCollection matches = Regex.Matches(input, pattern);
Console.WriteLine($"{matches.Count} 個の単語が見つかりました。");
foreach (Match match in matches)
{
// match.Valueで一致した文字列を取得
Console.WriteLine($"Found: {match.Value} at index {match.Index}");
}
}
}上記のコードでは、カンマ区切りの文字列から個々の単語をすべて抽出しています。
match.Valueプロパティを参照することで、実際に一致した文字列をstring型として取得できます。
また、match.Indexを使えば、その文字列が元の文章のどの位置から始まっているかも把握可能です。
LINQを活用したスマートな取得
現代的なC#開発では、foreachの代わりにLINQを使用して、より簡潔にリスト化やフィルタリングを行うのが一般的です。
以前の.NETではMatchCollectionが古いインターフェース(IEnumerable)しか実装していなかったため、Cast<Match>()を呼び出す必要がありましたが、現在の.NETではよりスムーズに記述できます。
using System.Linq;
using System.Text.RegularExpressions;
using System.Collections.Generic;
// LINQを使用して一致した文字列のリスト(List<string>)を直接作成する
List<string> results = Regex.Matches(input, pattern)
.Select(m => m.Value)
.ToList();このように記述することで、正規表現の結果を後続の処理で扱いやすいList<string>やIEnumerable<string>へ1行で変換できます。
RegexOptionsによる動作の制御
Regex.Matchesを使用する際、第3引数にRegexOptionsを指定することで検索の挙動を細かく制御できます。
| オプション | 内容 |
|---|---|
RegexOptions.IgnoreCase | 大文字と小文字を区別せずに検索します。 |
RegexOptions.Multiline | ^ と $ の動作を変更し、各行の先頭と末尾に一致させます。 |
RegexOptions.Singleline | ドット . が改行文字 \n を含むすべての文字に一致するようになります。 |
RegexOptions.Compiled | 正規表現をMSILコードにコンパイルし、実行速度を向上させます(起動コストは増大)。 |
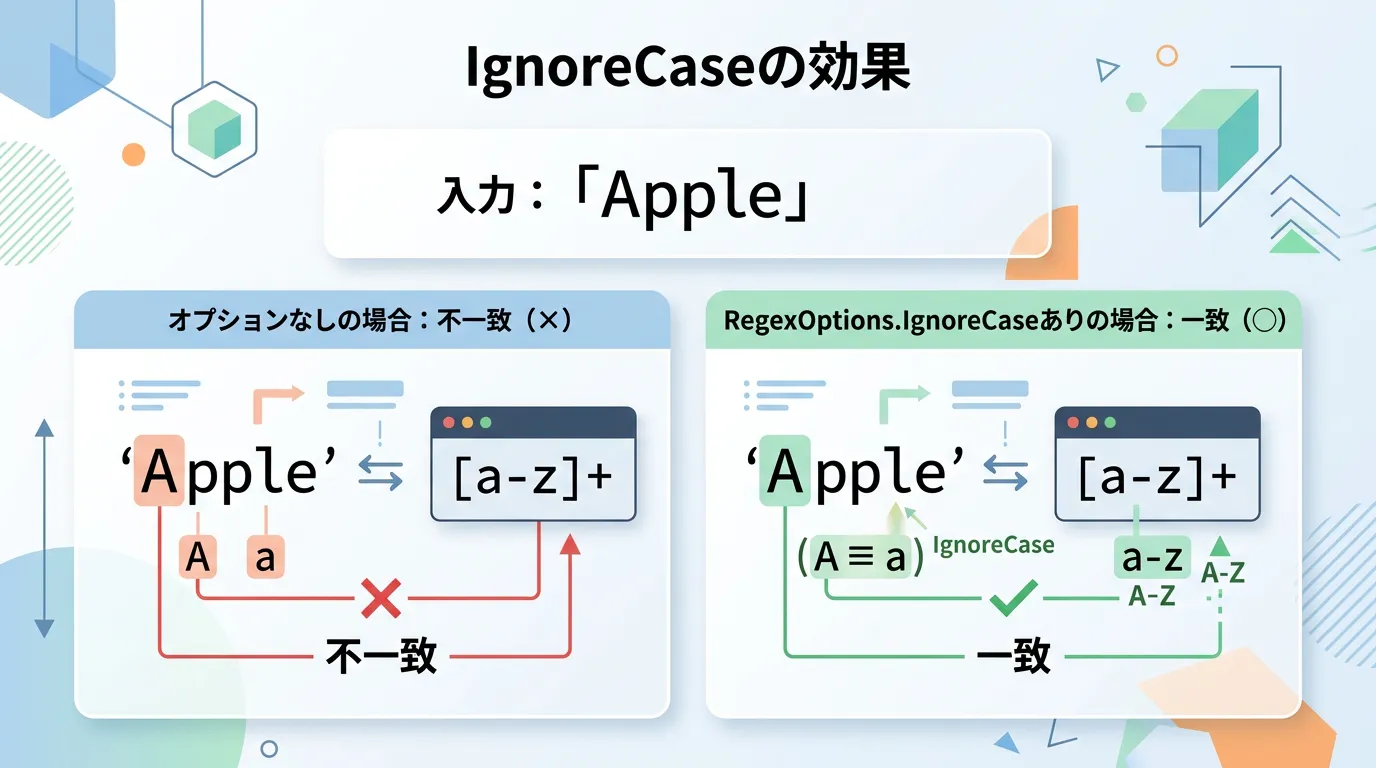
例えば、HTMLタグなどの大文字小文字が混在する可能性があるものを探す場合は、RegexOptions.IgnoreCaseを併用するのが鉄則です。
string html = "<div>Content</div><DIV>More Content</DIV>";
string tagPattern = @"<div.*?>";
var matches = Regex.Matches(html, tagPattern, RegexOptions.IgnoreCase);グループ化を利用した詳細情報の取得
単に一致した文字列全体(match.Value)を取得するだけでなく、パターン内の一部をグルーピング(カッコで囲む)して抽出したいケースがあります。
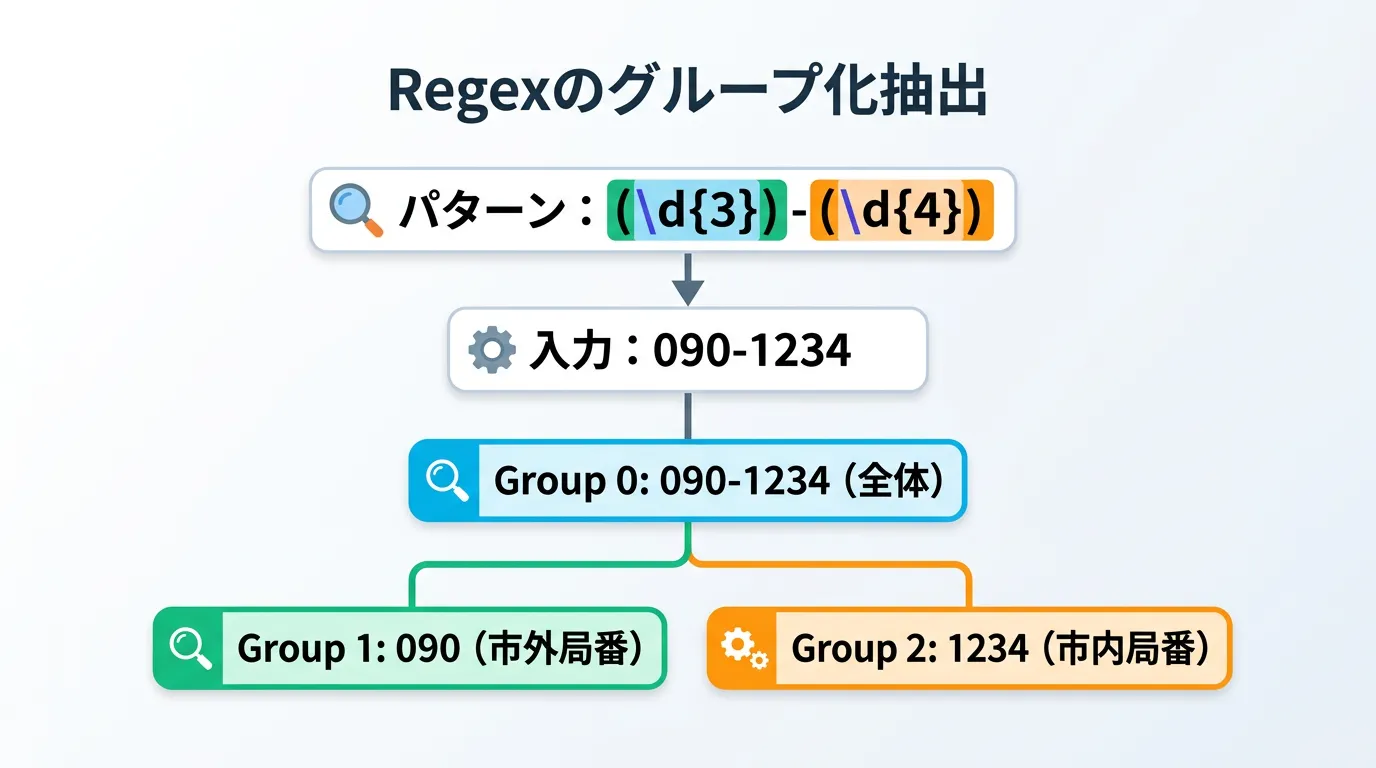
string input = "TEL: 03-1234-5678, FAX: 06-9876-5432";
string pattern = @"(\d{2,3})-(\d{4})-(\d{4})";
var matches = Regex.Matches(input, pattern);
foreach (Match match in matches)
{
// match.Groups[0] は一致した全体
// match.Groups[1] は最初のカッコの内容
string areaCode = match.Groups[1].Value;
Console.WriteLine($"市外局番: {areaCode}");
}Regex.Matchesで取得した各Matchオブジェクトの中には、Groupsプロパティが含まれています。
これを利用することで、複雑な文字列構造の中から特定のデータ(日付の「年」の部分だけ、URLの「ドメイン」の部分だけなど)をピンポイントで抽出することが可能です。
パフォーマンスとメモリ管理の最適化
大規模なテキストデータを扱う際、正規表現はCPUとメモリに大きな負荷をかける可能性があります。
特に「全一致」を取得する場合、一致箇所が多いとそれだけオブジェクトの生成コストがかさみます。
CompiledフラグとSource Generator
.NETにおいて正規表現を高速化する手段は主に2つあります。
- RegexOptions.Compiled
実行時に正規表現をコンパイルします。
同じパターンを数百回、数千回と繰り返し利用するループ内などで有効です。
- GeneratedRegex(.NET 7以降)
コンパイル時に正規表現の解析コードを生成する最新の推奨手法です。
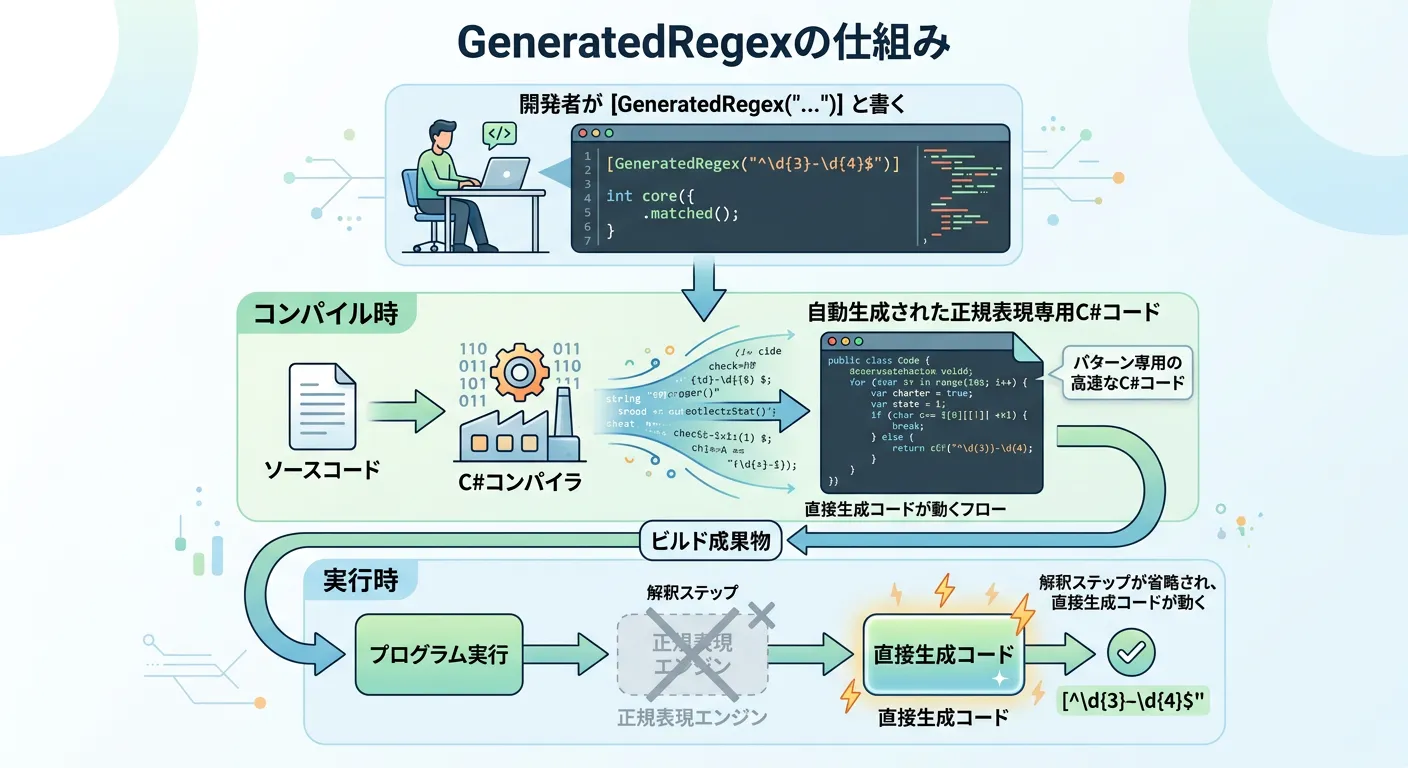
// .NET 7以降の推奨される書き方
partial class MyScanner
{
[GeneratedRegex(@"\b\d{4}-\d{2}-\d{2}\b")]
private static partial Regex DateRegex();
public void Process(string text)
{
var matches = DateRegex().Matches(text);
// ...
}
}GeneratedRegexを使用すると、実行時の解析オーバーヘッドがゼロになり、さらにトリミング(未使用コードの削除)やAOTコンパイルとの相性も抜群です。
2020年代後半のモダンな開発においては、可能な限りSource Generatorを活用することが推奨されます。
重複のない検索
Regex.Matchesは、デフォルトでは重複するマッチングを回避します。
例えば、「aaaa」という文字列に対して「aa」というパターンで検索した場合、結果は2つ([0,1]のaaと[2,3]のaa)になります。
[1,2]にある「aa」は、最初のマッチングで消費された文字を含んでいるため、スキップされます。
もし重なりを許容して取得したい場合は、肯定先読み(Positive Lookahead)などの高度な正規表現テクニックが必要になりますが、通常の用途ではこの挙動が直感的で安全です。
MatchとMatchesの使い分け
初心者が混同しやすいのがMatchメソッドとMatchesメソッドの違いです。
| メソッド名 | 戻り値 | 挙動 |
|---|---|---|
Match | Match | 最初に見つかった1件のみを返す。 |
Matches | MatchCollection | 見つかったすべての箇所をリスト形式で返す。 |
「設定ファイルの中に1つだけあるはずのキーを探す」場合はMatchを、「文章の中からすべてのメールアドレスを抜き出す」場合はMatchesを選択するというように、目的の「個数」に合わせて使い分けましょう。
まとめ
C#のRegex.Matchesは、複雑なテキスト処理をわずか数行のコードに凝縮できる非常に強力なメソッドです。
- MatchCollectionを通じて、すべての合致箇所を一括で取得できる。
- LINQを組み合わせることで、抽出後のデータ加工も容易。
- Groupsプロパティを活用し、パターン内の特定部位だけを取り出すことが可能。
- パフォーマンスが求められる場面では、GeneratedRegex(Source Generator)を利用するのが最新のベストプラクティス。
正規表現はその柔軟性ゆえに、正しく使いこなせば開発効率を飛躍的に向上させます。
一方で、複雑すぎるパターンは可読性を下げる原因にもなるため、Regex.Matchesを利用する際は、誰が見ても意図が伝わるシンプルなパターン設計と、適切なオプション選択を心がけてください。
