C#でアプリケーションを開発する際、プログラム内で特殊な文字や、キーボードから直接入力できない文字を扱う場面は多々あります。
例えば、難読漢字や絵文字、制御文字などをソースコード内に直接記述すると、ファイルのエンコーディング設定によっては文字化けの原因となることがあります。
こうした問題を回避し、ソースコードのポータビリティと安全性を高めるための仕組みが「Unicodeエスケープシーケンス」です。
本記事では、C#におけるUnicodeエスケープシーケンスの基本的な書き方から、サロゲートペアを伴う拡張文字の扱い、さらに動的な相互変換コードの実装方法まで、テクニカルな視点で詳しく解説します。
Unicodeエスケープシーケンスとは
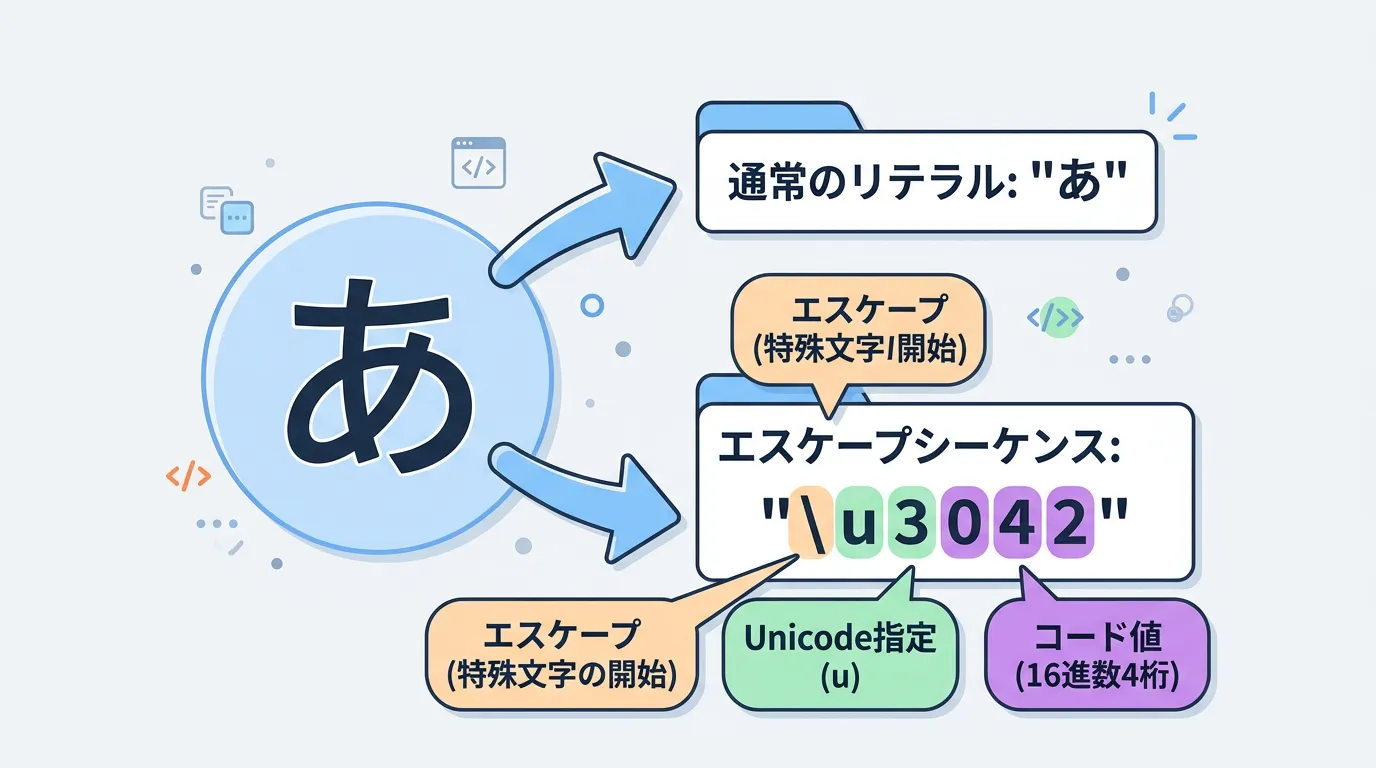
Unicodeエスケープシーケンスとは、特定の文字をその文字そのものではなく、「Unicodeコードポイント(文字に割り当てられた固有の番号)」を用いて表現する記法のことです。
C#において、文字列リテラルや文字リテラルの中でバックスラッシュ \ に続く特定のフォーマットを使用することで、コンパイラに対して「これは特定の文字である」と明示的に伝えることができます。
C#が内部的に採用している文字エンコーディングはUTF-16です。
そのため、基本的には16ビット(2バイト)の範囲で文字を表現しますが、現代のUnicode規格では16ビットに収まらない文字(絵文字など)も存在します。
これらを正しく扱うためには、エスケープシーケンスの複数のバリエーションを理解しておく必要があります。
C#におけるエスケープシーケンスの3つの形式
C#では、Unicodeを表現するために主に3つのエスケープ形式が用意されています。
用途や文字の種類に応じてこれらを使い分けることが重要です。
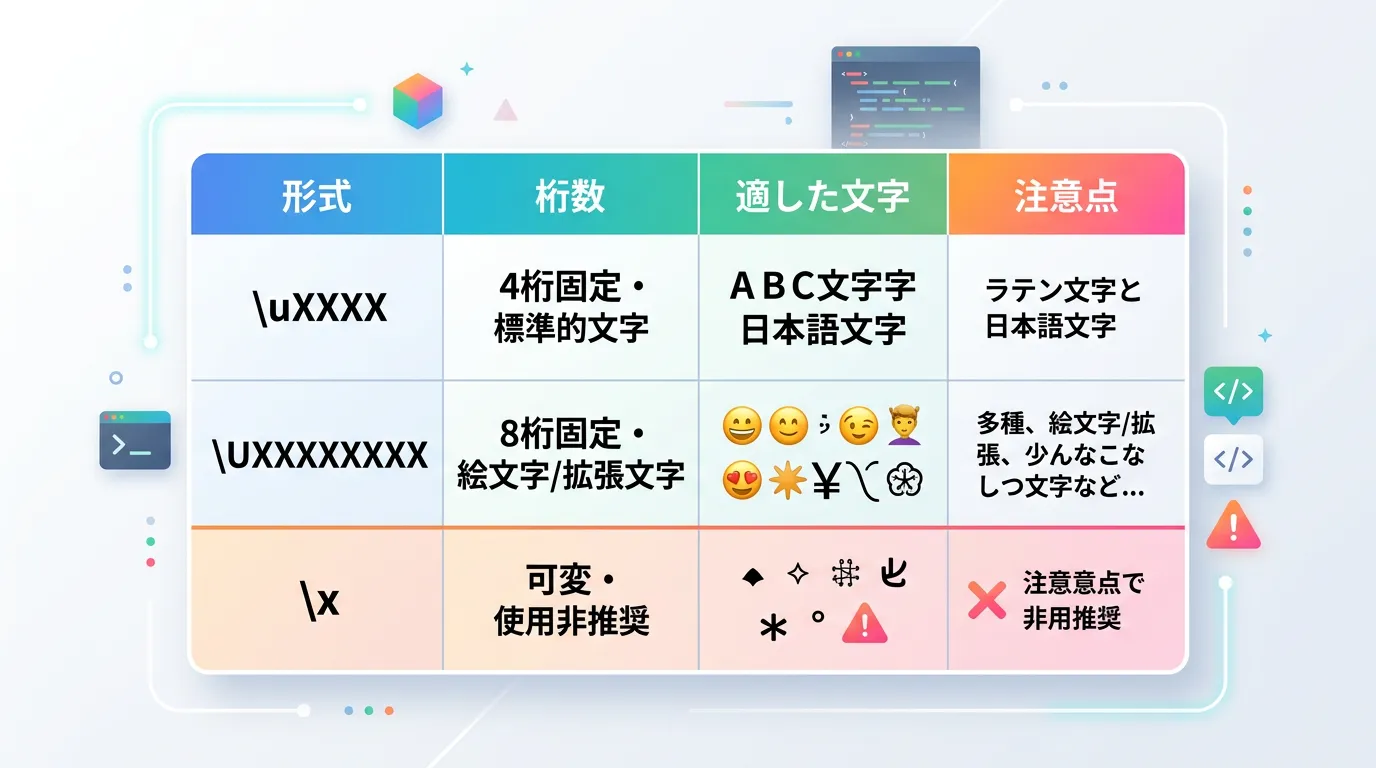
1. \uXXXX 形式 (16進数4桁)
最も一般的に利用される形式です。
\u の後に固定で4桁の16進数を記述します。
これは、Unicodeの「基本多言語面 (BMP: Basic Multilingual Plane)」に属する文字を表現するために使用されます。
'\u0041'→ ‘A’'\u3042'→ ‘あ’'\u00A9'→ ‘©’ (コピーライトマーク)
この形式は必ず4桁である必要があるため、例えば \u41 と書くとコンパイルエラーになります。
必ず \u0041 と記述しなければなりません。
2. \UXXXXXXXX 形式 (16進数8桁)
絵文字や一部の難読漢字など、16ビットの範囲を超えて定義されている文字(追加面)を扱うための形式です。
\U (大文字)の後に固定で8桁の16進数を記述します。
"\U0001F600"→ 😀 (Grinning Face)"\U00020BB7"→ 𠮷 (「よし」の異体字)
C#の char 型は16ビットであるため、'\U0001F600' のように単一の文字リテラルとして定義することはできません。
これらは文字列 string 内で定義するか、後述するサロゲートペアとして扱う必要があります。
3. \xX… 形式 (可変長16進数)
\x の後に16進数を記述する形式ですが、これは使用に注意が必要な「可変長」の記法です。
"\x41"→ “A” と解釈される。"\x0041"→ これも “A” と解釈される。
問題は、"\x411" と書いた場合です。
開発者が「’A’ (0x41) と ‘1’ (文字)」を意図していても、コンパイラは 411 という1つの16進数として解釈しようとします。
予期しない動作を防ぐため、現代のC#開発では \uXXXX 形式を使用することが推奨されます。
サロゲートペアとエスケープシーケンスの関係
C#でUnicodeを扱う上で避けて通れないのが「サロゲートペア」の概念です。
Unicodeのコードポイントが U+FFFF を超える場合、UTF-16では2つの16ビット値のペアで1つの文字を表現します。
例えば、絵文字の「😀」はコードポイント U+1F600 です。
これをエスケープシーケンスで表現する場合、以下の2通りの書き方が可能です。
- 直接指定:
"\U0001F600" - サロゲートペアによる指定:
"\uD83D\uDE00"
サロゲートペアによる指定では、上位サロゲート (\uD83D) と下位サロゲート (\uDE00) を組み合わせています。
C#の string.Length プロパティは「文字数」ではなく「16ビット要素の数」を返すため、サロゲートペア1文字を含む文字列の長さは 2 になるという点に注意してください。
プログラムによる相互変換の実装
実際の開発では、文字列をエスケープシーケンス形式の文字列 (例: “あ” → “\u3042”) に変換したり、その逆を行ったりする処理が必要になることがあります。
文字列からUnicodeエスケープ形式への変換
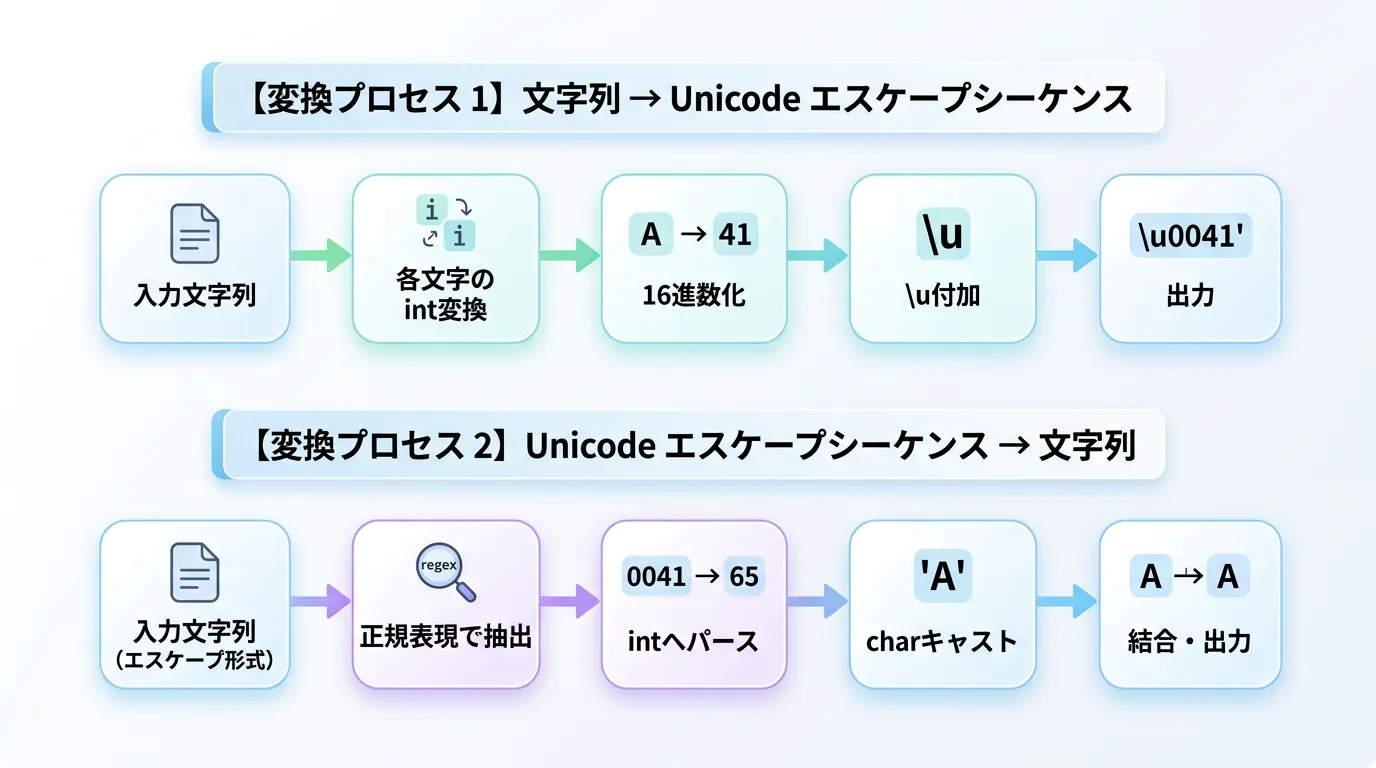
以下のコードは、文字列内の各文字を \uXXXX 形式のテキストに変換する例です。
using System;
using System.Text;
public class UnicodeConverter
{
public static string ToEscapeSequence(string input)
{
var sb = new StringBuilder();
foreach (char c in input)
{
// 16進数4桁の文字列に整形
sb.AppendFormat("\\u{0:X4}", (int)c);
}
return sb.ToString();
}
}
// 使用例
string original = "C#開発";
string escaped = UnicodeConverter.ToEscapeSequence(original);
// 結果: \u0043\u0023\u958B\u767Aこのコードでは、各 char を整数にキャストし、16進フォーマット文字列を使用して整形しています。
ただし、この方法はサロゲートペアを考慮せず、各16ビット要素を個別に変換します。
Unicodeエスケープ形式から文字列への復元
逆に、"\u3042" というテキストを実際の「あ」という文字に変換するには、System.Text.RegularExpressions を使用するのが効率的です。
using System;
using System.Text;
using System.Text.RegularExpressions;
public class UnicodeDecoder
{
public static string UnescapeUnicode(string input)
{
return Regex.Replace(input, @"\\u([0-9a-fA-F]{4})", m =>
{
// マッチした16進数部分を数値に変換し、charにキャスト
return ((char)Convert.ToInt32(m.Groups[1].Value, 16)).ToString();
});
}
}
// 使用例
string input = @"\u3042\u3044\u3046";
string decoded = UnicodeDecoder.UnescapeUnicode(input);
// 結果: あいう正規表現 @"\u([0-9a-fA-F]{4})" を使用することで、文字列内にあるUnicodeエスケープパターンを正確に抽出し、一括で置換処理を行えます。
高度なトピック:System.Text.Rune の活用
.NET Core 3.0 および .NET 5 以降では、Unicode文字をより安全かつ直感的に扱うための System.Text.Rune 構造体が導入されました。
Rune は「Unicodeスカラー値」を表す型であり、サロゲートペアを意識せずに1文字として扱うことができます。
サロゲートペアを伴う複雑な文字列処理を行う場合は、char 単位ではなく Rune 単位でループを回すことが推奨されます。
using System;
using System.Text;
string complexText = "A𠮷😀";
foreach (Rune rune in complexText.EnumerateRunes())
{
Console.WriteLine($"文字: {rune}, コードポイント: U+{rune.Value:X4}");
}この方法を使えば、上位サロゲートと下位サロゲートが泣き別れになるバグを防ぎつつ、正確なUnicode値を抽出できます。
エスケープシーケンスの生成ロジックにおいても、Rune.Value を使用して U+1FFFF 以上の値を取得し、\UXXXXXXXX 形式を生成するといった高度な実装が可能になります。
実務での活用シーンと注意点
Unicodeエスケープシーケンスは、単なる記法以上の役割を果たします。
1. JSON や XML のシリアライズ
Web APIとの通信でデータをやり取りする際、日本語などの非ASCII文字をエスケープして送信することが一般的です。
C#の標準ライブラリである System.Text.Json では、デフォルトで非ASCII文字を Unicodeエスケープシーケンスとしてシリアライズします。
これはセキュリティ上の理由(XSS対策など)や、受信側のエンコーディング依存を最小限にするためです。
2. ソースコードの文字化け防止
共有ライブラリの開発などで、異なるOSやエディタ環境でコードが閲覧される可能性がある場合、著作権マーク © や特殊な記号を "\u00A9" と記述しておくことで、環境依存の文字化けを100%防ぐことができます。
3. 正規表現での利用
正規表現内で特定の文字範囲(例: 全角ひらがなのみ)を指定したい場合、[\u3041-\u3096] のようにエスケープシーケンスを用いることで、視認性と正確性を両立させたパターン定義が可能です。
まとめ
C#におけるUnicodeエスケープシーケンスは、文字コードの壁を越えて正確に情報を扱うための不可欠なツールです。
| 形式 | 記述例 | 用途 |
|---|---|---|
| \uXXXX | \u3042 | BMP内の文字(日本語など)に最適 |
| \UXXXXXXXX | \U0001F600 | 絵文字や追加面の文字に必須 |
| \xX… | \x41 | 可変長のため使用時は注意が必要 |
基本となる \uXXXX 形式をマスターした上で、サロゲートペアが必要な拡張文字には \UXXXXXXXX を使用しましょう。
また、現代的な .NET 開発においては System.Text.Rune を活用することで、より堅牢な文字列操作プログラムを構築できます。
エスケープシーケンスを正しく理解し、適切に使い分けることで、文字化けに強い、プロフェッショナルなC#アプリケーションを目指しましょう。
