C#でプログラミングを行っている際、ファイルパスや正規表現、あるいは複数行にわたるSQLクエリなどを文字列として定義する場面は非常に多いでしょう。
しかし、通常の文字列リテラルでは「\(バックスラッシュ)」がエスケープシーケンスとして解釈されるため、パスを書くたびに \ と二重に記述しなければならず、コードの可読性が著しく低下してしまいます。
このような問題をスマートに解決するのが、C#の逐語的文字列リテラル(Verbatim String Literals)です。
文字列の先頭に @ 記号を付与するだけで、エスケープ処理の煩わしさから解放され、直感的でメンテナンス性の高いコードを記述することが可能になります。
本記事では、逐語的文字列リテラルの基礎から、最新のC#における応用的な使い方までを徹底的に解説します。
逐語的文字列リテラル(@)の基本概念
C#における文字列の定義には、大きく分けて「通常の文字列リテラル」と「逐語的文字列リテラル」の2種類が存在します。
逐語的文字列リテラルは、文字列内の文字をその見た目通り(逐語的)に扱うための仕組みです。
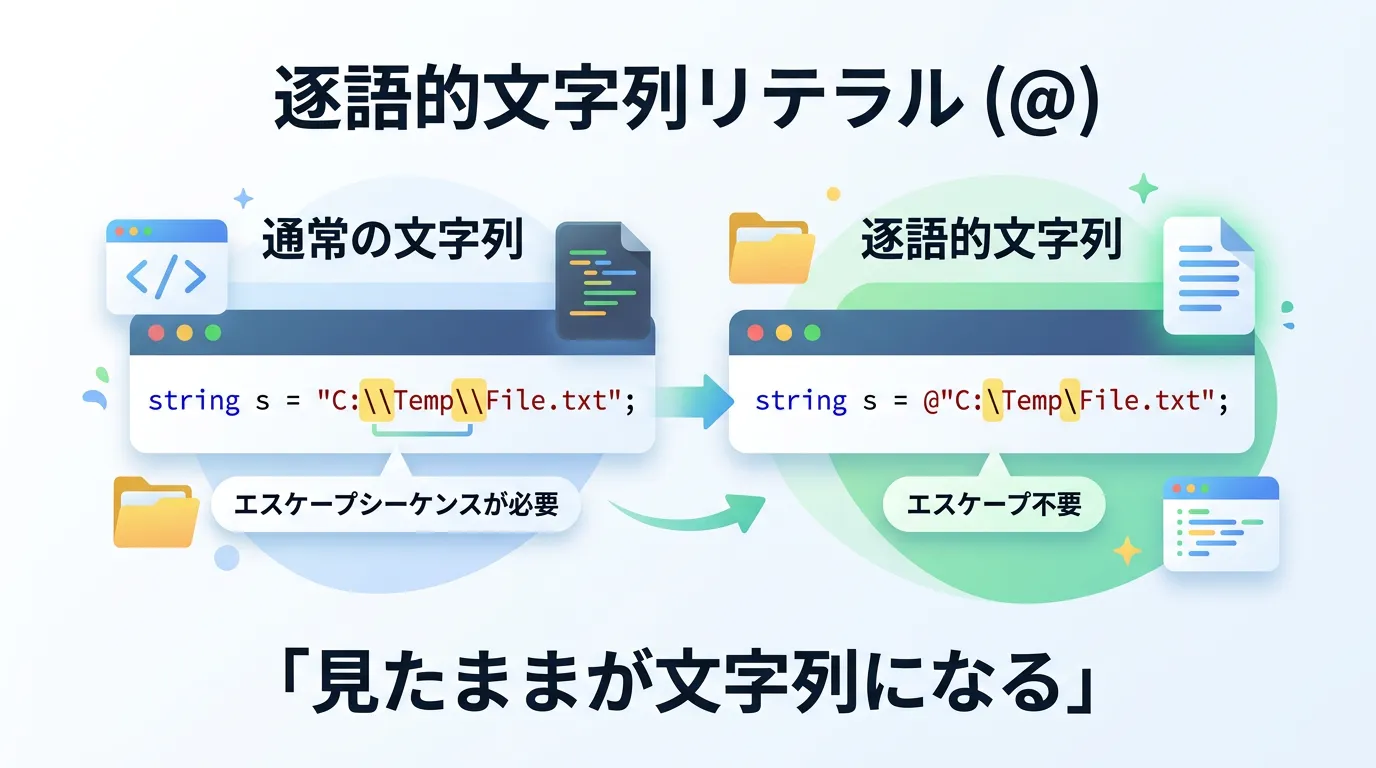
通常の文字列リテラルでは、\n(改行)や \t(タブ)といった特殊な制御文字を表現するためにエスケープシーケンスを使用します。
これ自体は便利な機能ですが、Windowsのファイルパスのように \ 自体を文字として扱いたい場合には、バックスラッシュを2回書く必要があるため、非常に冗長な記述を強いられます。
一方、逐語的文字列リテラル(@"")を使用すると、引用符内のバックスラッシュは単なる文字として解釈されます。
これにより、パスや正規表現のパターンをそのままコピー&ペーストして利用できるようになり、記述ミスを防ぐとともにコードの視認性が劇的に向上します。
メリット1:ファイルパス記述の簡略化
逐語的文字列リテラルが最も威力を発揮する場面の一つが、Windows環境でのファイルパス指定です。
Windowsのパス区切り文字はバックスラッシュであるため、通常のリテラルでは非常に読みづらいコードになりがちです。

以下の表は、通常の文字列リテラルと逐語的文字列リテラルでのパス記述の違いをまとめたものです。
| 項目 | 通常の文字列リテラル | 逐語的文字列リテラル (@) |
|---|---|---|
| ローカルパス | "C:\Users\Documents" | @"C:\Users\Documents" |
| ネットワークパス | "\\\Server\Shared\Folder" | @"\Server\Shared\Folder" |
| 正規表現 | "\d{3}-\d{4}" | @"\d{3}-\d{4}" |
このように、特にネットワーク共有パス(UNCパス)を扱う場合、通常のリテラルではバックスラッシュが4つ並ぶ(\\)など、一目で何を表しているのか判断しにくい状態になります。
逐語的文字列リテラルを使用することで、エクスプローラーのアドレスバーからコピーした文字列をそのまま貼り付けるだけで動作するため、開発効率が大幅に改善されます。
メリット2:複数行にわたる文字列の記述
逐語的文字列リテラルのもう一つの大きな特徴は、ソースコード上の改行をそのまま文字列の改行として保持できる点です。

通常、C#で文字列を複数行にわたって記述する場合、各行の末尾で連結演算子(+)を使用するか、StringBuilderを利用する必要があります。
しかし、逐語的文字列リテラルを使えば、以下のように自然な形で記述できます。
// 逐語的文字列リテラルによる複数行記述
string query = @"
SELECT id, name, email
FROM Users
WHERE IsActive = 1
ORDER BY CreatedDate DESC";この記法は、SQLクエリやHTML、JSON、あるいはメールのテンプレートなどをコード内に埋め込む際に非常に重宝します。
ただし、ソースコード上のインデント(行頭のスペースやタブ)もそのまま文字列に含まれてしまう点には注意が必要です。
もし行頭の余白を排除したい場合は、後述するC# 11の「未加工文字列リテラル」の検討、あるいは Trim() メソッドの併用が必要になります。
特殊なケース:ダブルクォーテーションのエスケープ
逐語的文字列リテラル内ではほとんどの文字がエスケープ不要になりますが、唯一の例外がダブルクォーテーション(”)自体を文字列に含めたい場合です。
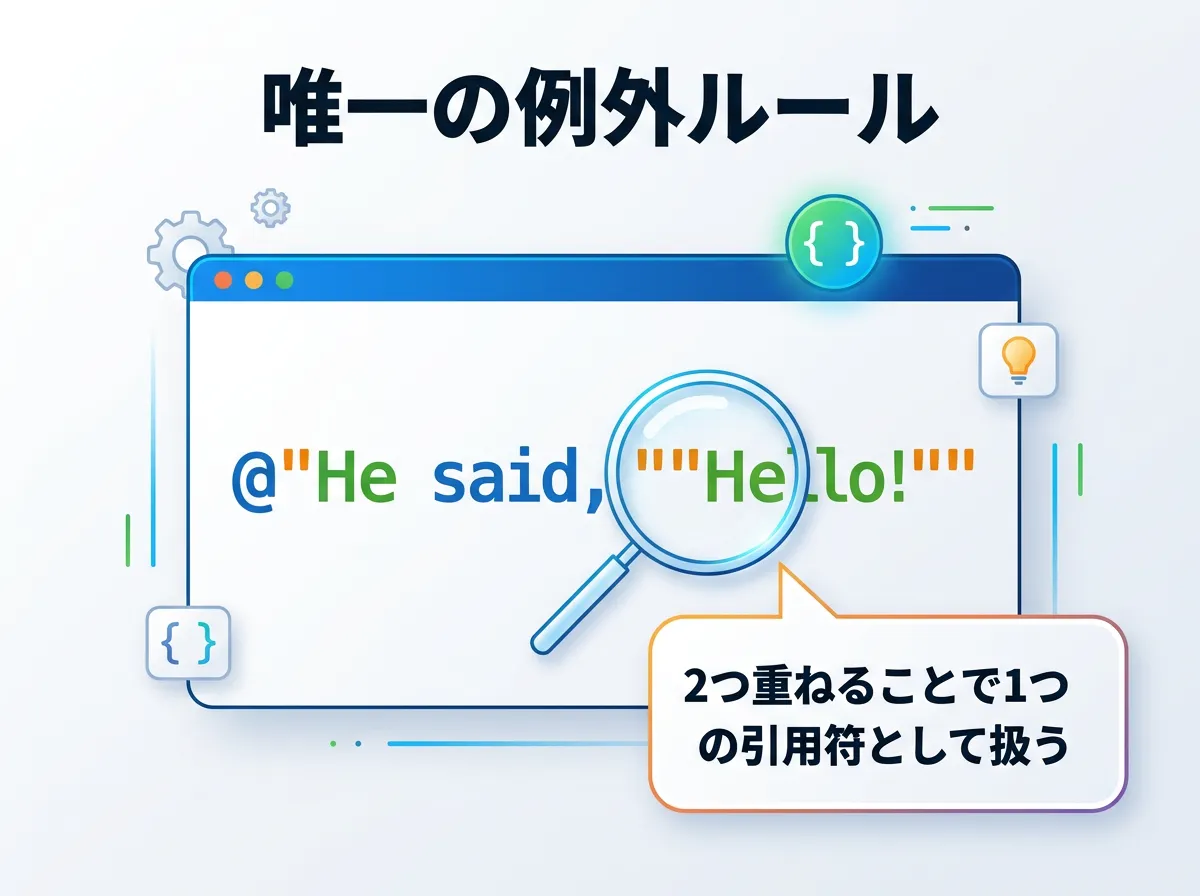
逐語的文字列リテラルの中でダブルクォーテーションを表現するには、ダブルクォーテーションを2つ続けて記述(””)します。
// 実行結果: He said, "Hello!"
string quote = @"He said, ""Hello!""";通常のリテラルでは " と書きますが、逐語的リテラルでは "" となるルールを覚えておきましょう。
これは、CSV形式のデータを扱う際などに頻出するパターンです。
文字列補間($)との組み合わせ
現代のC#開発において、変数の値を文字列に埋め込む「文字列補間($)」は欠かせない機能です。
この文字列補間は、逐語的文字列リテラル(@)と組み合わせて使用することが可能です。
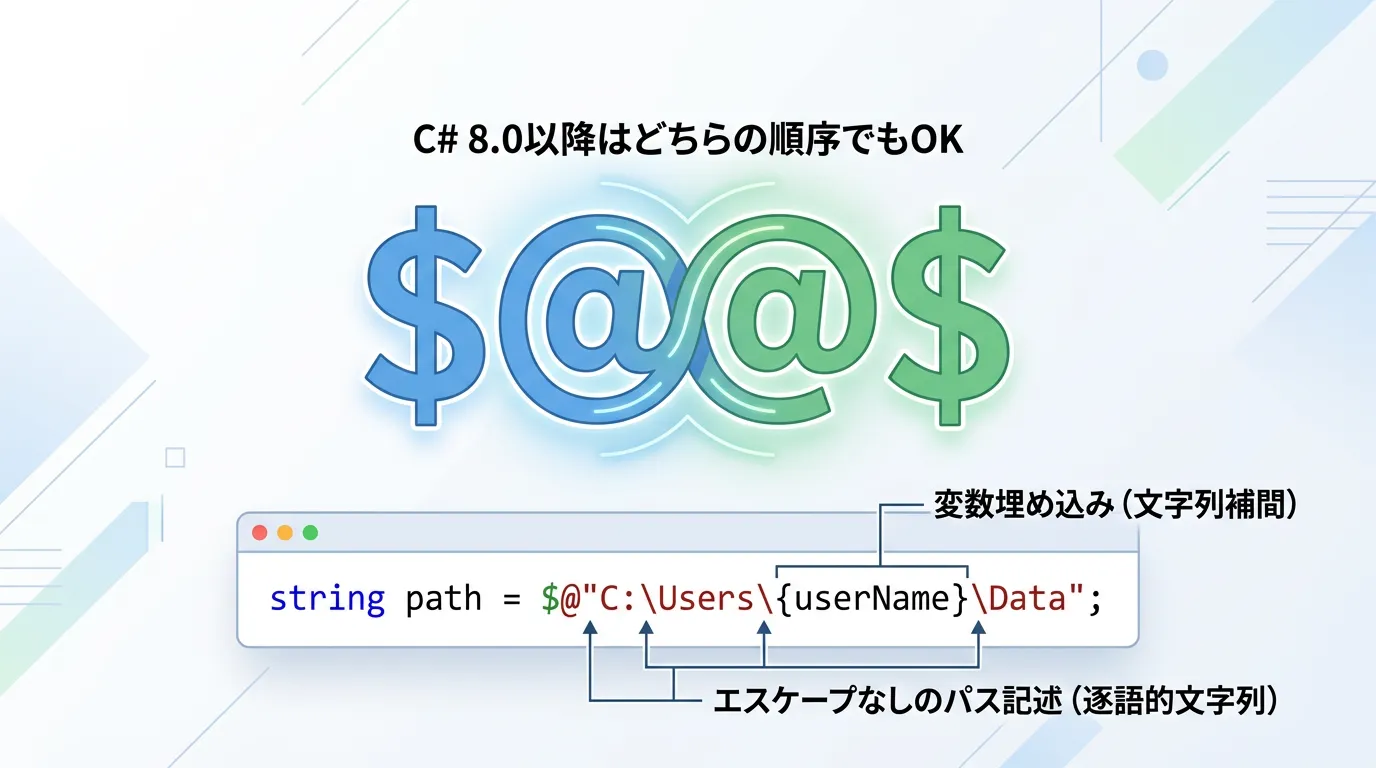
C# 8.0以降では、$@"" と @$"" のどちらの順序で記述しても正しく動作します(それ以前のバージョンでは $@ の順序のみでした)。
string userName = "Taro";
// 文字列補間と逐語的リテラルの併用
string userPath = $@"C:\Users\{userName}\Documents";この組み合わせにより、「バックスラッシュのエスケープを無視しつつ、動的に変数を埋め込む」という極めて強力な表現が可能になります。
ファイルシステムを操作するアプリケーションや、動的にパスを生成するツールを作成する際には必須のテクニックと言えるでしょう。
C# 11以降の新機能:未加工文字列リテラルとの比較
C#の進化に伴い、文字列リテラルの表現方法はさらに進化しました。
C# 11からは、逐語的文字列リテラルよりもさらに柔軟な未加工文字列リテラル(Raw String Literals)が導入されています。
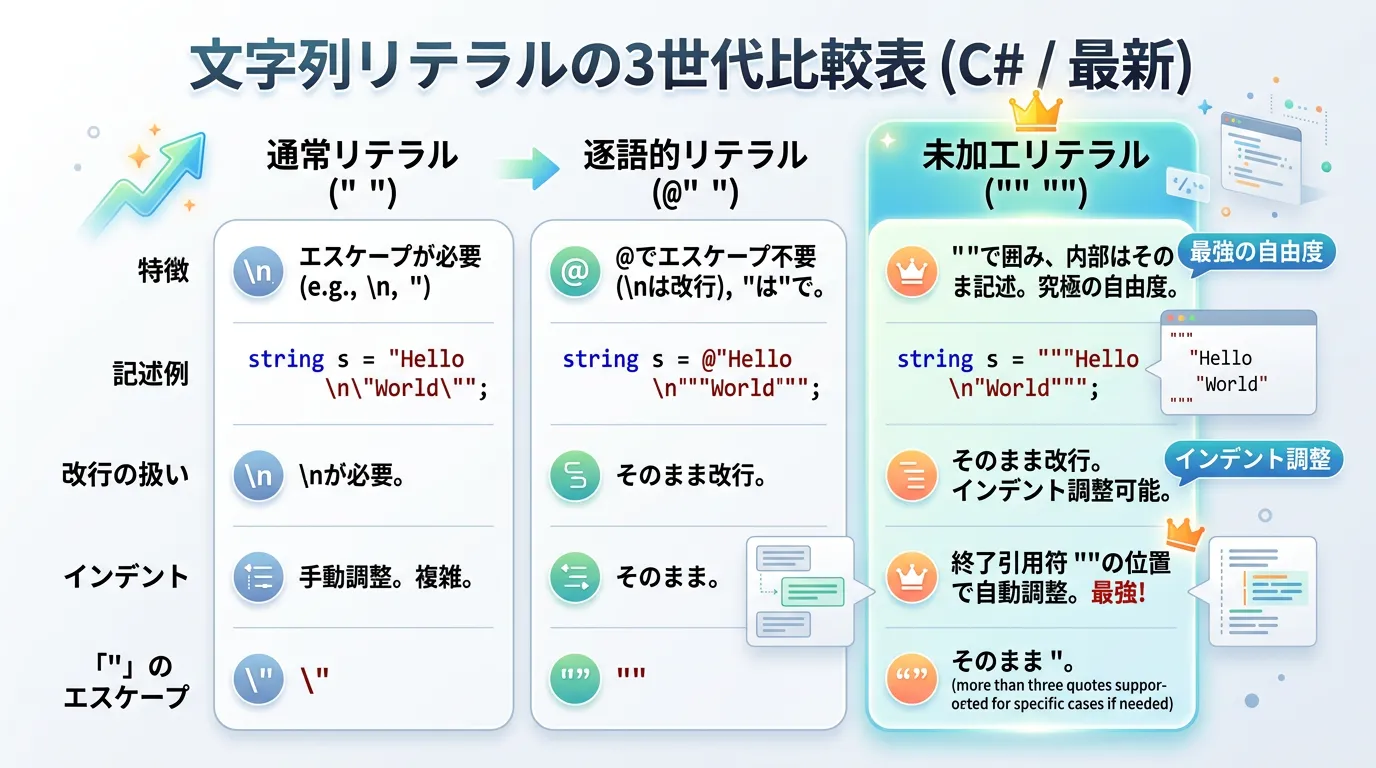
未加工文字列リテラルは、3つ以上のダブルクォーテーション(""")で囲む形式です。
逐語的リテラルとの主な違いは以下の通りです。
| 機能 | 逐語的文字列リテラル (@) | 未加工文字列リテラル (“””) |
|---|---|---|
| 開始・終了記号 | @" … " | """ … """ |
| 引用符(”)の扱い | "" と重ねる必要あり | 重ねずそのまま記述可能 |
| インデントの除去 | 不可(そのまま含まれる) | 終了記号の位置に合わせて自動除去 |
| 推奨される用途 | シンプルなパスや短い複数行 | 複雑なJSON、XML、コード生成 |
逐語的文字列リテラルは、パスの記述などの「単一行または短い複数行」において依然として簡潔で便利です。
一方で、大規模なJSONデータをコード内に貼り付けるようなケースでは、インデントを綺麗に制御できる未加工文字列リテラルの方が適しています。
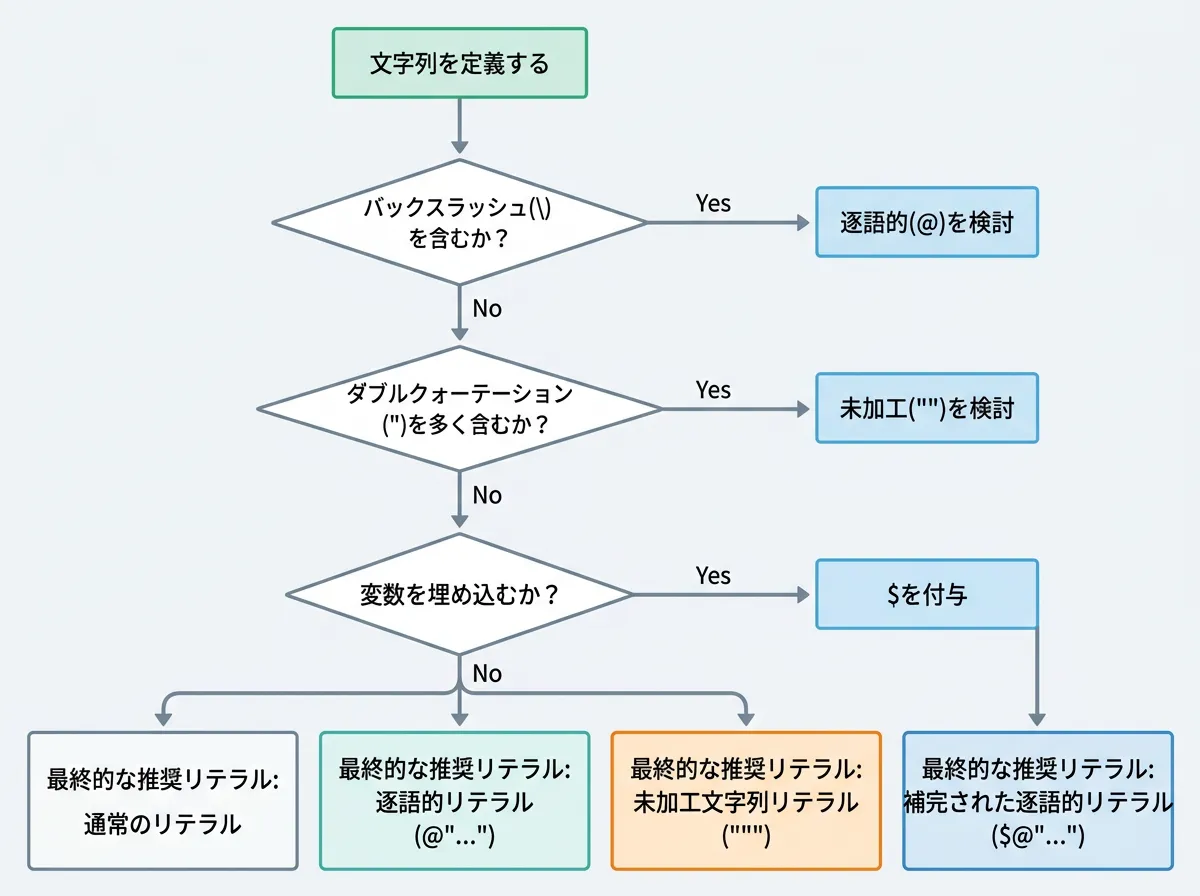
使い分けのベストプラクティス
逐語的文字列リテラルを効果的に使い分けるためのガイドラインを整理します。
- Windowsのパスを記述する場合
常に
@を使用することを検討してください。これにより、バックスラッシュの数え間違いによるバグを根絶できます。
- 正規表現(Regex)を定義する場合
正規表現には
\dや\sといったバックスラッシュを含むパターンが多用されます。逐語的文字列リテラルを使うことで、正規表現のパターンを読みやすく保てます。
- SQL文をハードコードする場合
可読性を確保するために、
@を使って複数行に分けて記述しましょう。- JSONやXMLを扱う場合
引用符(
")が多く含まれる場合は、逐語的リテラルよりも C# 11 の未加工文字列リテラル(""") の方がエスケープが少なく済み、より適しています。
まとめ
C#の逐語的文字列リテラル(@)は、単純ながらも非常に強力な機能です。
エスケープシーケンスによる「コードのノイズ」を取り除き、パスや複数行テキストを直感的に記述できるため、読みやすく、壊れにくいコードを書くための第一歩となります。
最後に、今回学んだポイントを振り返りましょう。
@を付けるとバックスラッシュをエスケープせずに記述できる。- 複数行の文字列をそのままの形で保持できる。
- ダブルクォーテーションを記述するときだけ、
""と2つ重ねる。 - 文字列補間
$と組み合わせて$@""と記述できる。 - より複雑な構造(大量の引用符やインデント保持)が必要な場合は、C# 11の未加工文字列リテラルを検討する。
これらの特性を理解し、適切に使い分けることで、あなたのC#プログラミングはより洗練されたものになるはずです。
特にパス操作やデータ定義が多いプロジェクトでは、積極的に逐語的文字列リテラルを活用していきましょう。
