
C#を用いてアプリケーションを開発する際、テキストデータをファイルに保存したり、ネットワーク経由で送信したりする場面が多々あります。
その際、コンピューターが理解できる形式であるバイト配列(byte[])への変換は避けて通れません。
逆に、受け取ったバイナリデータを人間が読める文字列に復元する処理も同様に重要です。
本記事では、現代のC#開発において標準的かつ効率的な「文字列とバイト配列の相互変換」について、文字コードの基礎知識から最新のパフォーマンス最適化手法まで徹底的に解説します。
文字列とバイト配列の変換が必要な理由
C#の内部では、文字列(string)はUTF-16という形式で保持されています。
しかし、インターネットの世界ではUTF-8が標準であり、Windowsの古いファイルシステムではShift_JIS(CP932)が使われていることもあります。
これらの異なる「言葉のルール」を橋渡しするのが、文字エンコーディングの役割です。
エンコーディングの基本概念
文字列をバイト配列に変換することをエンコード(符号化)と呼び、その逆をデコード(復号)と呼びます。
この変換を行う際に最も重要なのが「どの文字コード(Encoding)を使用するか」という点です。
例えば、同じ「あ」という文字でも、UTF-8では3バイト(0xE3, 0x81, 0x82)になりますが、Shift_JISでは2バイト(0x82, 0xA0)になります。
変換時と復元時で異なるエンコーディングを使用すると、いわゆる文字化けが発生するため、常にペアを意識する必要があります。
文字列からバイト配列へ変換する(GetBytes)
C#で文字列をバイト配列に変換する最も一般的な方法は、System.Text.EncodingクラスのGetBytesメソッドを使用することです。
標準的な変換方法
以下のコードは、文字列をUTF-8形式のバイト配列に変換する基本的な例です。
using System;
using System.Text;
class Program
{
static void Main()
{
// 変換対象の文字列
string sourceString = "C#文字列変換のテスト";
// UTF-8エンコーディングを使用してバイト配列に変換
byte[] byteArray = Encoding.UTF8.GetBytes(sourceString);
// 結果を表示
Console.WriteLine($"元の文字列: {sourceString}");
Console.WriteLine("変換後のバイト配列(16進数):");
foreach (byte b in byteArray)
{
Console.Write($"{b:X2} ");
}
Console.WriteLine();
Console.WriteLine($"バイト長: {byteArray.Length}バイト");
}
}元の文字列: C#文字列変換のテスト
変換後のバイト配列(16進数):
43 23 E6 96 87 E5 AD 97 E5 88 97 E5 A4 89 E6 8F 9B E3 81 AE E3 83 86 E3 82 B9 E3 83 88
バイト長: 30バイトこの例では、Encoding.UTF8プロパティを使用してUTF-8のインスタンスを取得しています。
現代のWeb開発や多くのアプリケーションではUTF-8が推奨されるため、特に理由がない限りはこの設定を利用するのが無難です。
特定の文字コード(Shift_JISなど)を指定する
日本のレガシーシステムやExcel向けのCSV出力などでは、Shift_JISが必要になる場合があります。
ただし、モダンな.NET(Core/5以降)では、標準でShift_JISがサポートされていないため、CodePagesEncodingProviderを登録する必要があります。
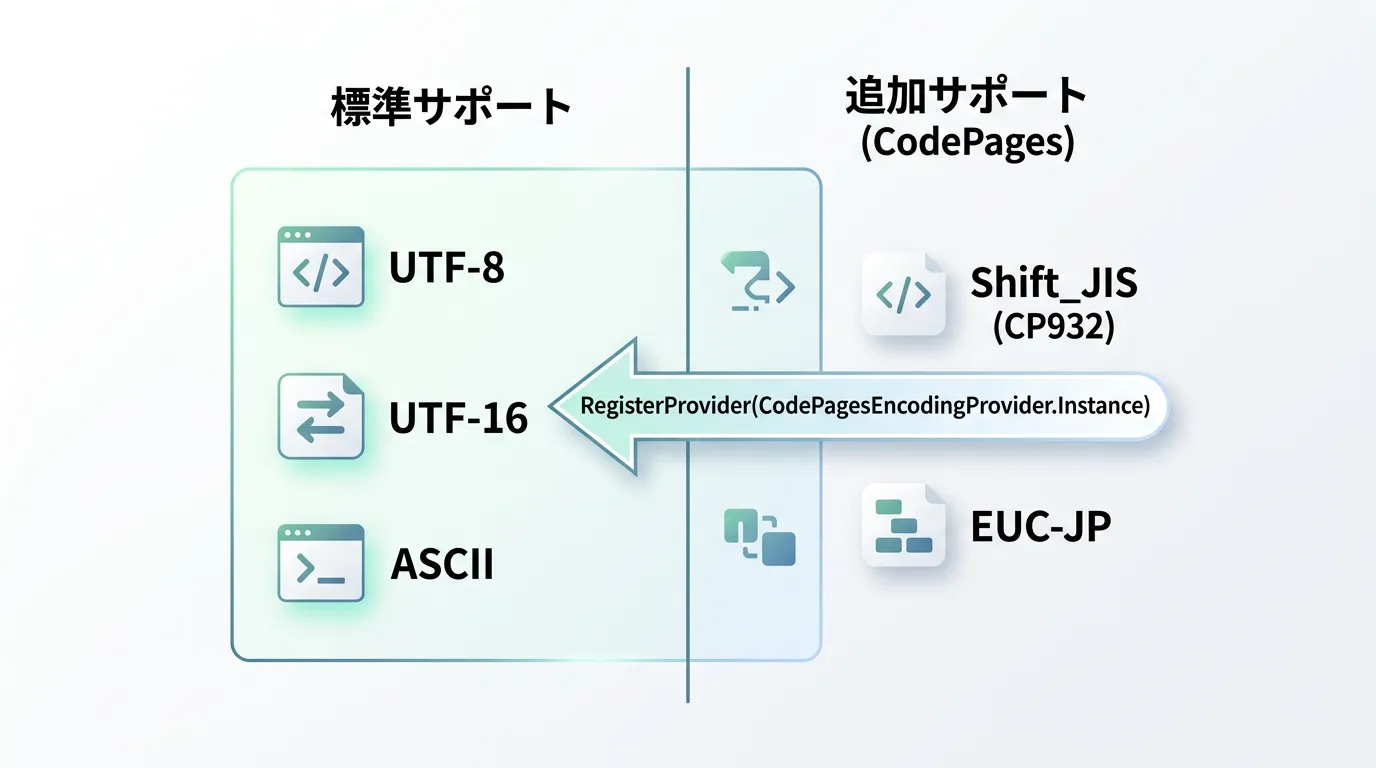
using System;
using System.Text;
class Program
{
static void Main()
{
// .NET Core/5以降でShift_JISを扱うためにプロバイダーを登録
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
string text = "こんにちは";
// Shift_JIS(コードページ932)を指定
Encoding sjis = Encoding.GetEncoding("shift_jis");
byte[] bytes = sjis.GetBytes(text);
Console.WriteLine($"Shift_JISでのバイト数: {bytes.Length}バイト");
// 「こんにちは」は全角5文字なのでShift_JISでは10バイトになる
}
}Shift_JISでのバイト数: 10バイトEncoding.GetEncoding("shift_jis")を呼び出す前に、必ずEncoding.RegisterProviderを実行してください。
これを忘れるとNotSupportedExceptionが発生し、プログラムが停止してしまいます。
バイト配列から文字列へ変換する(GetString)
受け取ったバイナリデータを文字列に戻すには、GetStringメソッドを使用します。
このとき、必ずエンコード時と同じ文字コードを指定してください。
基本的なデコード処理
using System;
using System.Text;
class Program
{
static void Main()
{
// サンプルのバイト配列 (UTF-8での「Hello」)
byte[] utf8Bytes = { 0x48, 0x65, 0x6C, 0x6C, 0x6F };
// バイト配列を文字列に復元
string result = Encoding.UTF8.GetString(utf8Bytes);
Console.WriteLine($"復元された文字列: {result}");
}
}復元された文字列: Hello配列の一部だけを変換する場合
ネットワーク通信などで、大きなバッファの一部にだけデータが入っている場合、開始位置(インデックス)と長さを指定して変換できます。
これにより、不要なメモリコピーを抑えることが可能です。
byte[] buffer = new byte[1024];
// ... 何らかの通信処理でbufferにデータが入る ...
int receivedLength = 13; // 実際に受け取ったサイズ
// 0番目からreceivedLength分だけを文字列にする
string data = Encoding.UTF8.GetString(buffer, 0, receivedLength);主要なEncodingクラスのプロパティ
C#のEncodingクラスには、よく使われる文字コードがあらかじめプロパティとして用意されています。
それぞれの特徴を整理しました。
| プロパティ | 文字コード | 特徴 |
|---|---|---|
Encoding.UTF8 | UTF-8 | 現在の標準。多くの環境で推奨される。 |
Encoding.Unicode | UTF-16 (LE) | C#の内部表現に最も近い。Windowsアプリ内部で多用。 |
Encoding.ASCII | ASCII | 7ビット文字のみ。日本語はすべて「?」に化ける。 |
Encoding.Default | OS依存 | .NET Core以降は常にUTF-8。古い.NET Frameworkでは環境依存。 |
Encoding.Defaultは実行環境によって挙動が変わる可能性があるため、明示的にEncoding.UTF8などを指定することが、バグを防ぐための鉄則です。
高度な変換手法:パフォーマンスとメモリ効率
大量のデータを扱う場合や、高頻度で変換を行うリアルタイム処理では、byte[]の新規作成によるメモリ確保(アロケーション)がパフォーマンスのボトルネックになることがあります。
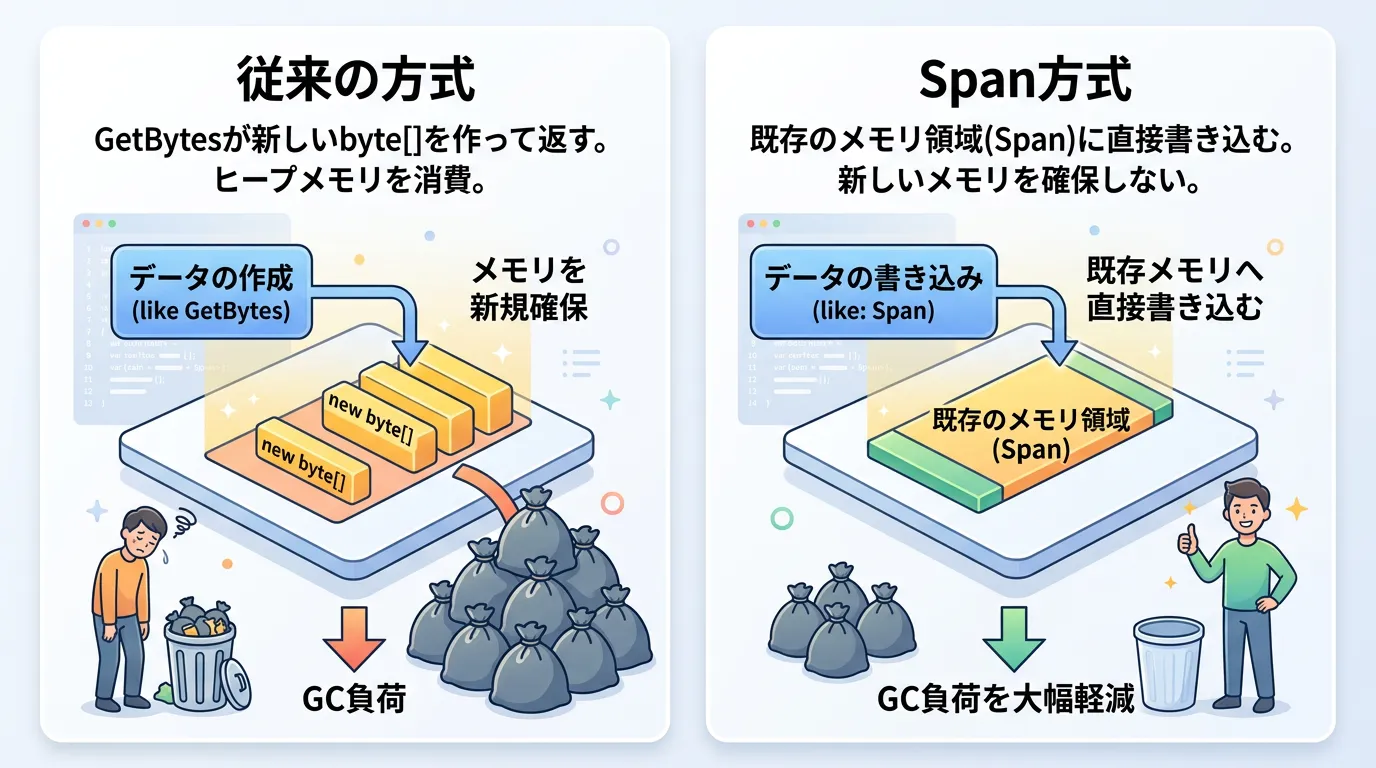
Span<T>を利用した変換
.NET Core 2.1以降で導入されたSpan<T>やReadOnlySpan<T>を利用すると、スタック領域や既存のバッファを利用して高速に変換できます。
using System;
using System.Text;
class Program
{
static void Main()
{
string text = "高速な変換処理";
// 必要なバイト数を計算
int byteCount = Encoding.UTF8.GetByteCount(text);
// スタック上にメモリを確保 (非常に高速だがサイズ制限に注意)
Span<byte> buffer = stackalloc byte[byteCount];
// Spanに直接書き込む
int written = Encoding.UTF8.GetBytes(text, buffer);
Console.WriteLine($"書き込まれたバイト数: {written}");
}
}この方法では、new byte[]を行わないため、ガベージコレクション(GC)の発生を抑え、スループットを向上させることができます。
特殊な形式への変換:Base64と16進数
文字列とバイト配列の変換において、もう一つ重要なのが「バイナリデータのテキスト化」です。
これは文字コードの変換とは異なり、バイナリそのものを文字列として表現する手法です。
Base64への変換
Base64は、任意のバイナリデータを64種類の英数字のみで表現する方式です。
メールの添付ファイルや、JSONの中に画像を埋め込む際によく使われます。
using System;
using System.Text;
class Program
{
static void Main()
{
byte[] data = Encoding.UTF8.GetBytes("C# Base64 Test");
// バイト配列 -> Base64文字列
string base64String = Convert.ToBase64String(data);
Console.WriteLine($"Base64: {base64String}");
// Base64文字列 -> バイト配列
byte[] decodedBytes = Convert.FromBase64String(base64String);
string decodedString = Encoding.UTF8.GetString(decodedBytes);
Console.WriteLine($"復元: {decodedString}");
}
}Base64: QyMgQmFzZTY0IFRlc3Q=
復元: C# Base64 Test16進数文字列への変換
デバッグ時など、バイト配列の中身を「FF 00 AB」のような形式で確認したい場合には、BitConverterや最新のConvert.ToHexStringが便利です。
byte[] bytes = { 255, 0, 171, 205 };
// モダンな方法 ( .NET 5以降 )
string hex = Convert.ToHexString(bytes);
Console.WriteLine($"HEX: {hex}"); // FF00ABCD文字化けと例外への対策
変換時に対応していない文字が含まれている場合、デフォルトでは「?」などの代替文字に置き換わります。
しかし、データ整合性が重要な場合は、エラーとして検知したいこともあるでしょう。
エンコーディングフォールバックの設定
変換に失敗したときに例外を投げるようにするには、EncoderFallbackを設定します。
// 変換できない文字がある場合に例外を投げる設定
Encoding asciiWithException = Encoding.GetEncoding(
"us-ascii",
new EncoderExceptionFallback(),
new DecoderExceptionFallback()
);
try
{
// ASCIIで表現できない日本語を含む文字列を変換
byte[] b = asciiWithException.GetBytes("あ");
}
catch (EncoderFallbackException ex)
{
Console.WriteLine("エラー: ASCIIに変換できない文字が含まれています。");
}このように、要件に応じてエラーハンドリングを適切に行うことが、堅牢なシステム開発への第一歩となります。
まとめ
C#における文字列とバイト配列の変換は、System.Text.Encodingクラスを軸に展開されます。
基本となるGetBytesとGetStringを使いこなすことはもちろん、利用シーンに応じて適切な文字コードを選択する能力が求められます。
Web標準のUTF-8、WindowsレガシーなShift_JIS、そしてデータ転送用のBase64など、それぞれの特性を理解しておくことが重要です。
また、現代的な開発においては、Span<T>を用いた低アロケーションな実装を検討することで、よりパフォーマンスの高いアプリケーションを構築できるでしょう。
今回紹介したコード例や注意点を参考に、正確で効率的なデータ変換処理を実装してください。
