
C#における文字列操作は、アプリケーション開発において避けては通れない非常に重要な要素です。
ユーザー入力の検証やデータのパース、特定のパターン抽出など、その用途は多岐にわたります。
その中でも「特定の文字列がどこにあるか」を特定するためのIndexOfメソッドは、最も基本的かつ強力なツールの一つです。
本記事では、IndexOfメソッドの基本的な使い方から、検索範囲の指定、大文字・小文字の区別といった応用的なテクニックまで、詳細に解説していきます。
IndexOfメソッドの基本概念
IndexOfメソッドは、文字列(string)や文字の配列の中から、指定した文字列や文字が最初に出現する位置を「0から始まるインデックス(整数)」で返すメソッドです。
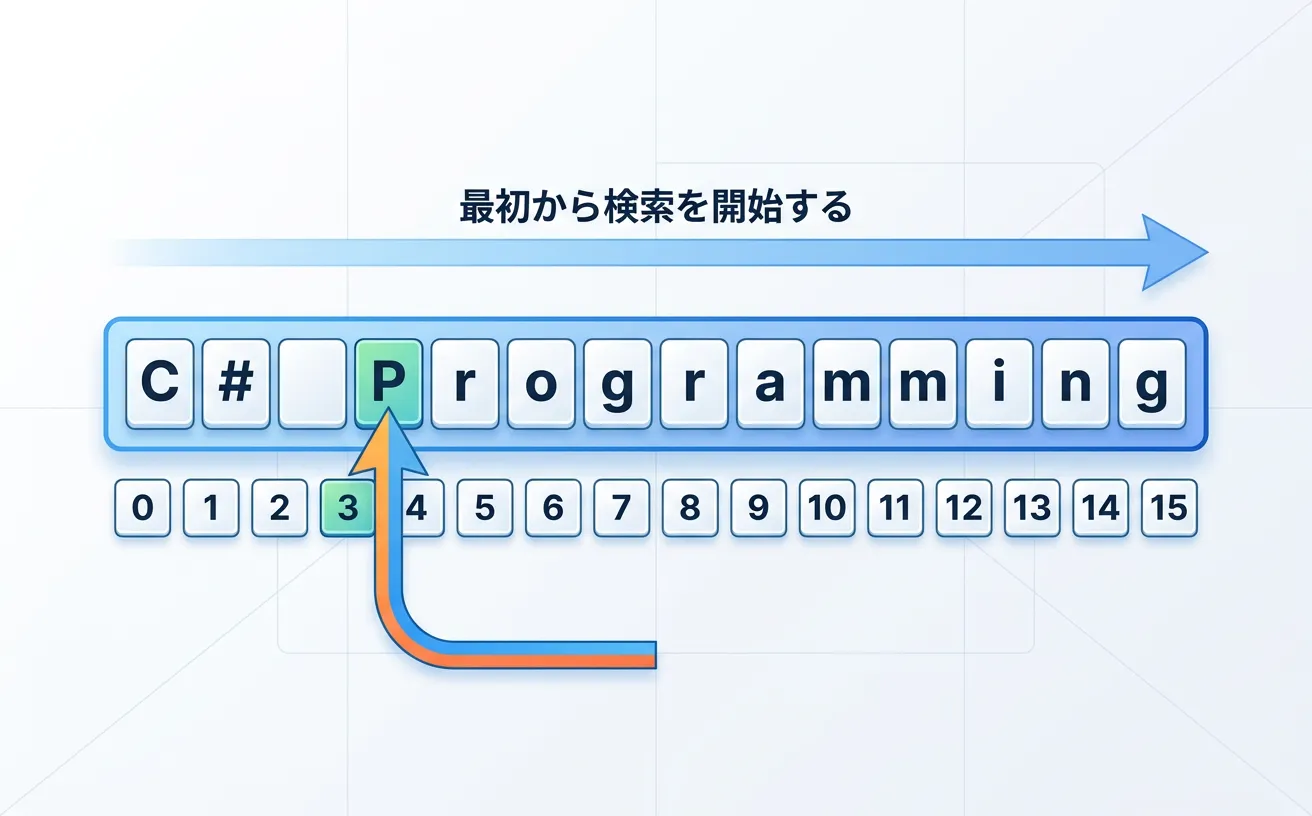
C#の文字列は、先頭の文字を「0番目」としてカウントします。
この概念を理解することが、IndexOfを正しく使いこなすための第一歩となります。
もし検索した結果、対象が見つからなかった場合には、-1という特別な値が返されます。
これは「存在しない」という状態をプログラムで判定するための重要なサインです。
基本的な戻り値のルール
IndexOfの戻り値について、以下の表に整理しました。
| 検索結果 | 戻り値 | 説明 |
|---|---|---|
| 見つかった場合 | 0以上の整数 | 最初に見つかった文字のインデックス |
| 見つからなかった場合 | -1 | 指定した文字列が対象内に存在しない |
| 検索文字列が空(“”)の場合 | 0 | 空文字は常に先頭で見つかったとみなされる |
文字列を検索する基本的な使い方
最も一般的な使い方は、ある文字列の中に別の文字列が含まれているかを調べ、その位置を取得する方法です。
単純な文字列検索のサンプルコード
以下のコードは、文章の中から特定の単語を探す基本的な例です。
using System;
public class IndexOfExample
{
public static void Main()
{
string message = "Welcome to C# Programming World!";
string target = "C#";
// 文字列 "C#" が最初に出現する位置を検索
int index = message.IndexOf(target);
if (index != -1)
{
// 見つかった場合
Console.WriteLine($"「{target}」が見つかりました。位置: {index}");
}
else
{
// 見つからなかった場合
Console.WriteLine($"「{target}」は見つかりませんでした。");
}
}
}「C#」が見つかりました。位置: 11この例では、messageの11番目のインデックスから「C#」が始まっているため、11という数値が返されています。
スペースも1文字としてカウントされる点に注意してください。
検索の開始位置と範囲を指定する
IndexOfメソッドは、単に最初から最後まで探すだけでなく、検索を開始する位置や、検索する文字数を指定することができます。
これにより、2番目以降に出現する文字列を探したり、特定の範囲内だけを効率的に検索したりすることが可能になります。
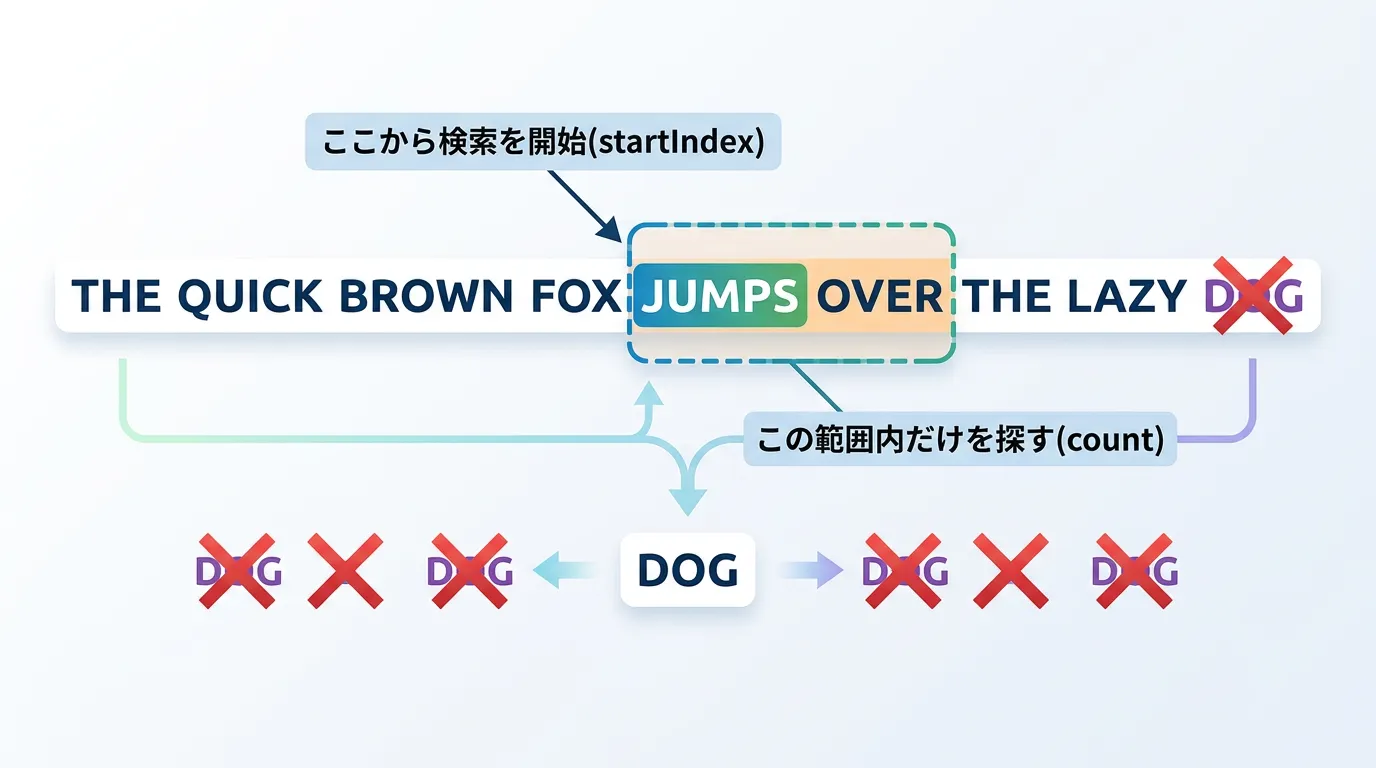
検索開始位置の指定 (startIndex)
特定のインデックス以降から検索を開始したい場合は、第2引数にstartIndexを指定します。
using System;
public class StartIndexExample
{
public static void Main()
{
string text = "apple, orange, apple, banana";
string searchItem = "apple";
// 1つ目の apple を検索
int firstIndex = text.IndexOf(searchItem);
Console.WriteLine($"1つ目の位置: {firstIndex}");
// 1つ目の位置の次から検索を開始して、2つ目の apple を探す
if (firstIndex != -1)
{
int secondIndex = text.IndexOf(searchItem, firstIndex + 1);
Console.WriteLine($"2つ目の位置: {secondIndex}");
}
}
}1つ目の位置: 0
2つ目の位置: 15このように、firstIndex + 1を引数に渡すことで、最初に見つかった場所をスキップして次に出現する位置を特定できます。
検索する文字数の指定 (count)
さらに、検索する文字の範囲(文字数)を制限することもできます。
これは、巨大なテキストデータの一部分だけを高速にチェックしたい場合に有効です。
using System;
public class CountExample
{
public static void Main()
{
string data = "ID:12345, Name:SampleItem, Category:Food";
// "Name" という文字列を、インデックス10から15文字の範囲内だけで探す
int index = data.IndexOf("Name", 10, 15);
if (index != -1)
{
Console.WriteLine($"指定範囲内に見つかりました。位置: {index}");
}
else
{
Console.WriteLine("指定範囲内には存在しませんでした。");
}
}
}指定範囲内に見つかりました。位置: 10大文字・小文字を区別せずに検索する
デフォルトのIndexOfは、大文字と小文字を厳密に区別</cst-redします。
しかし、実務においては「Apple」と「apple」を同じものとして扱いたい場面が多いでしょう。
そのような場合は、StringComparison列挙型を使用します。
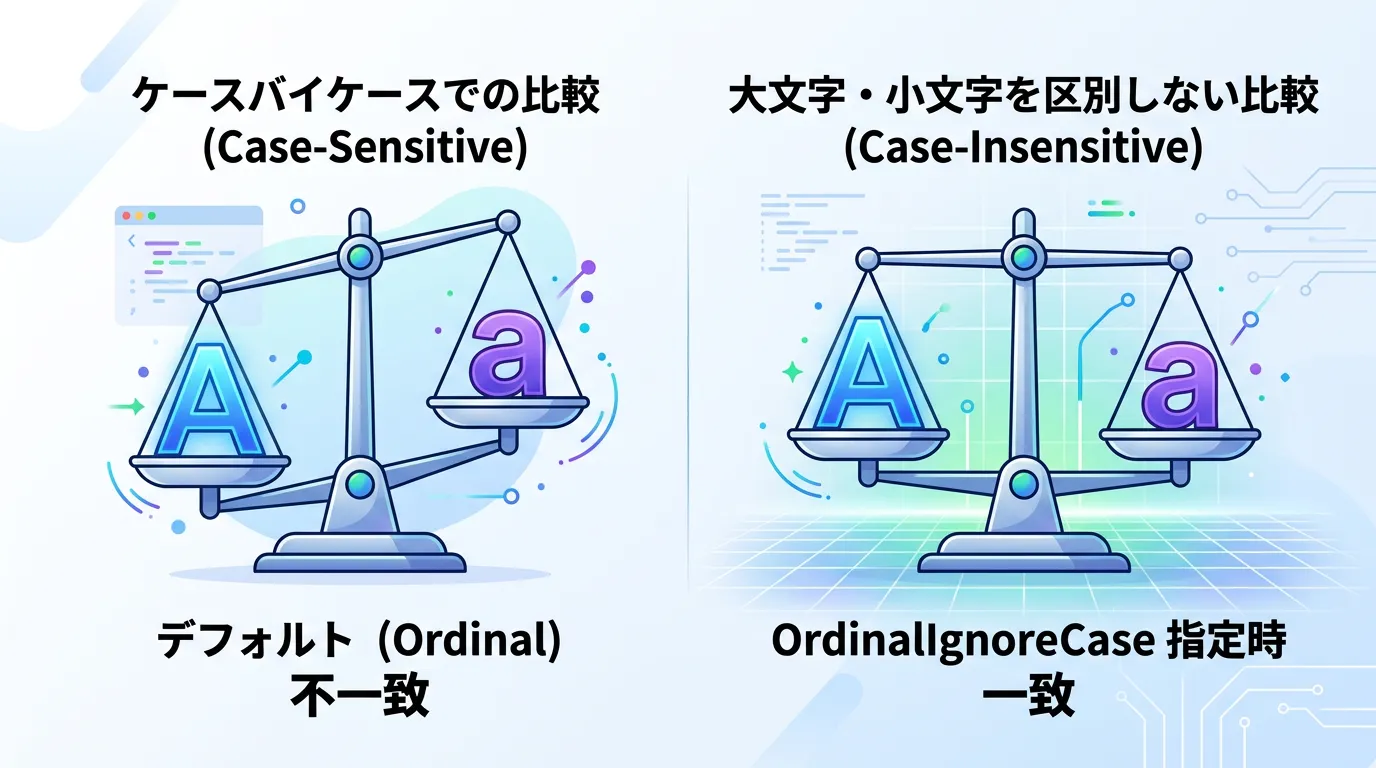
StringComparisonの活用
C#では、比較ルールを明示的に指定することが推奨されます。
using System;
public class CaseInsensitiveExample
{
public static void Main()
{
string source = "C# is a POWERFUL language.";
string keyword = "powerful";
// 通常の検索(見つからない)
int indexDefault = source.IndexOf(keyword);
Console.WriteLine($"デフォルト検索の結果: {indexDefault}");
// 大文字小文字を区別しない検索
int indexIgnoreCase = source.IndexOf(keyword, StringComparison.OrdinalIgnoreCase);
Console.WriteLine($"無視検索の結果: {indexIgnoreCase}");
}
}デフォルト検索の結果: -1
無視検索の結果: 10StringComparisonの種類
比較オプションにはいくつかの種類があります。
状況に応じて最適なものを選択してください。
| 値 | 説明 |
|---|---|
Ordinal | バイナリ値で比較。最も高速で、デフォルトの動作。 |
OrdinalIgnoreCase | バイナリ値で比較するが、大文字小文字は無視する。 |
CurrentCulture | 現在のユーザーの言語(カルチャ)設定に従って比較。 |
CurrentCultureIgnoreCase | カルチャ設定に従い、かつ大文字小文字を無視。 |
基本的には、プログラム内部の処理であればパフォーマンスに優れるOrdinalIgnoreCaseを使用し、ユーザーの言語感覚に合わせる必要がある表示関連の処理であればCurrentCultureIgnoreCaseを使用するのがベストプラクティスです。
1文字(char)を検索する場合
IndexOfは文字列だけでなく、char型(1文字)を引数に取ることもできます。
動作は文字列検索とほぼ同じですが、内部的な処理がより軽量です。
using System;
public class CharSearchExample
{
public static void Main()
{
string csv = "user01,admin,tokyo";
char targetChar = ',';
// カンマの位置を探す
int index = csv.IndexOf(targetChar);
Console.WriteLine($"最初のカンマの位置: {index}");
}
}最初のカンマの位置: 6カンマ区切りのデータや、特定の区切り文字を基準に文字列を分割したい際、Substringメソッドと組み合わせてよく使われます。
IndexOfと関連メソッドの使い分け
C#には、IndexOfに似た機能を持つメソッドがいくつか存在します。
目的によってこれらを使い分けることで、コードの可読性が向上します。
Containsとの違い
「位置はどうでもいいから、含まれているかどうかだけ知りたい」という場合は、Containsメソッドの方が適しています。
Containsは戻り値がbool型(true/false)であるため、if文での記述がスッキリします。
LastIndexOfとの違い
IndexOfが「最初から」検索するのに対し、LastIndexOfは「最後から」逆順に検索します。
ファイルパスから拡張子を特定する場合など、後ろにある要素を探したい時に便利です。

StartsWith / EndsWithとの違い
「特定の文字で始まっているか」「終わっているか」だけを確認したい場合は、StartsWithやEndsWithを使います。
これらはインデックスを意識する必要がないため、意図が伝わりやすいコードになります。
実践的な活用例:URLからドメインを抽出する
IndexOfを実務でどのように使うかの具体例として、URL文字列から特定のセグメントを抽出する処理を見てみましょう。
using System;
public class PracticalExample
{
public static void Main()
{
string url = "https://example.com/products/item123";
// "://" の後ろから検索を開始するためのオフセット
int protocolEnd = url.IndexOf("://");
if (protocolEnd != -1)
{
// プロトコルの直後(インデックス3つ分後ろ)から最初の "/" を探す
int startSearch = protocolEnd + 3;
int domainEnd = url.IndexOf("/", startSearch);
if (domainEnd != -1)
{
// ドメイン部分だけを切り出す
string domain = url.Substring(startSearch, domainEnd - startSearch);
Console.WriteLine($"ドメイン名: {domain}");
}
}
}
}ドメイン名: example.comこのコードでは、まずIndexOfでプロトコルの終わりを見つけ、その位置を基準に次のスラッシュを探すという「段階的な検索」を行っています。
高度なトピック:ReadOnlySpan<char>による高速化
最新のC#(.NET 8や9など)では、パフォーマンスが重視される場面においてReadOnlySpan<char>という型が頻繁に使われます。
実は、このSpanに対してもIndexOfを呼び出すことが可能です。
文字列そのものを操作するのではなく、メモリ上のデータとして扱うことで、ヒープメモリの割り当て(アロケーション)を抑えつつ高速に検索ができます。
using System;
public class SpanExample
{
public static void Main()
{
string largeText = "Performance is key in modern C# development.";
ReadOnlySpan<char> span = largeText.AsSpan();
// Spanに対しても同様にIndexOfが使える
int index = span.IndexOf("modern");
Console.WriteLine($"Span内での位置: {index}");
}
}大量のテキストデータをループ内で処理するような高度なアプリケーションを開発する場合は、このSpan版のIndexOfの存在を覚えておくと役立ちます。
まとめ
C#のIndexOfメソッドは、文字列内の特定の位置を特定するための基本中の基本となるメソッドです。
ただ位置を返すだけでなく、開始位置の指定や比較ルールの指定(StringComparison)を組み合わせることで、非常に柔軟な検索が可能になります。
開発時には以下のポイントを意識しましょう。
- 見つからない場合は-1が返ることを前提に、必ずチェックを行う。
- 大文字小文字を区別しない場合は、
StringComparison.OrdinalIgnoreCaseを明示する。 - 検索の目的(有無の確認、末尾からの検索)に応じて、
ContainsやLastIndexOfと使い分ける。
これらの知識を活用して、より正確で効率的な文字列処理を実装してください。
