
C#において、文字列の比較はプログラムのロジックを決定づける非常に重要な要素です。
ユーザー入力の検証、設定値の照合、データのフィルタリングなど、あらゆる場面で文字列が等しいかどうかを判定する必要があります。
しかし、C#には==演算子やstring.Equalsメソッド、さらにはstring.Compareといった複数の比較方法が存在し、どれを使うべきか迷うことも少なくありません。
本記事では、特に柔軟な比較が可能なstring.Equalsメソッドに焦点を当て、演算子との違いや大文字小文字を無視する方法、そして文化圏(カルチャ)を考慮した比較について、初心者から中級者まで納得できるように詳しく解説します。
string.Equalsの基本的な使い方
C#のstring.Equalsは、2つの文字列が内容的に等しいかどうかを判定するためのメソッドです。
このメソッドには「インスタンスメソッド」と「静的(static)メソッド」の2種類が存在します。
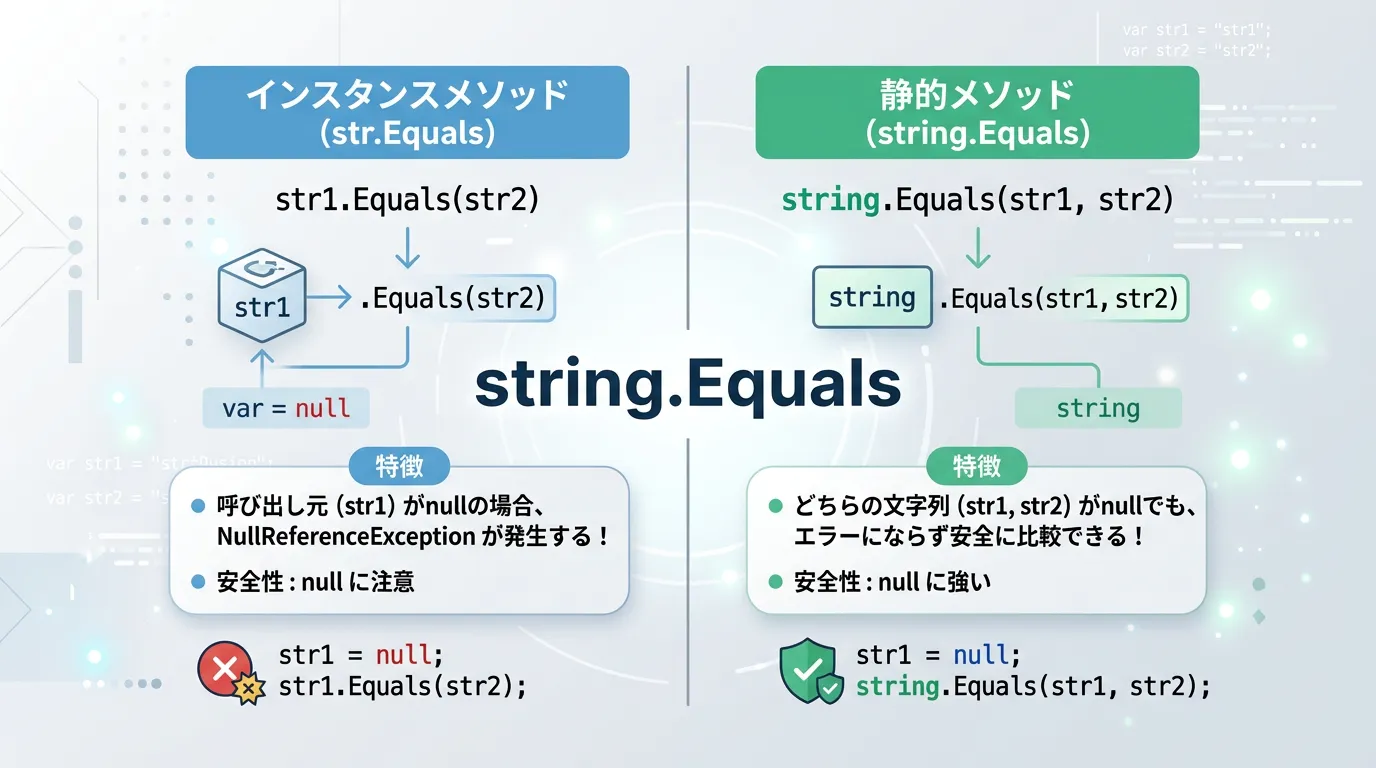
インスタンスメソッドとしてのEquals
インスタンスメソッドは、既存の文字列オブジェクトから呼び出します。
string str1 = "Hello";
string str2 = "Hello";
// インスタンスメソッドによる比較
bool result = str1.Equals(str2);
Console.WriteLine($"比較結果: {result}");比較結果: Trueこの方法は直感的ですが、呼び出し元の変数(上記の例ではstr1)がnullの場合、NullReferenceExceptionが発生するというリスクがあります。
そのため、安全性を考慮すると次に紹介する静的メソッドの方が推奨される場面が多いです。
静的(static)メソッドとしてのEquals
静的メソッドは、クラス名であるstringから直接呼び出し、2つの引数を渡します。
string str1 = null;
string str2 = "Hello";
// 静的メソッドによる比較
bool result = string.Equals(str1, str2);
Console.WriteLine($"比較結果: {result}");比較結果: False静的メソッドの最大の利点は、第一引数がnullであっても例外が発生せず、正しく比較が行われる点にあります。
両方がnullの場合はTrueを返し、片方だけがnullの場合はFalseを返します。
堅牢なコードを書くためには、この静的メソッドの利用を優先的に検討しましょう。
string.Equalsと==演算子の違い
C#では、文字列の比較に==演算子もよく使われます。
一見するとどちらも同じ動作をしますが、内部的な挙動や特定の条件下での動作に違いがあります。
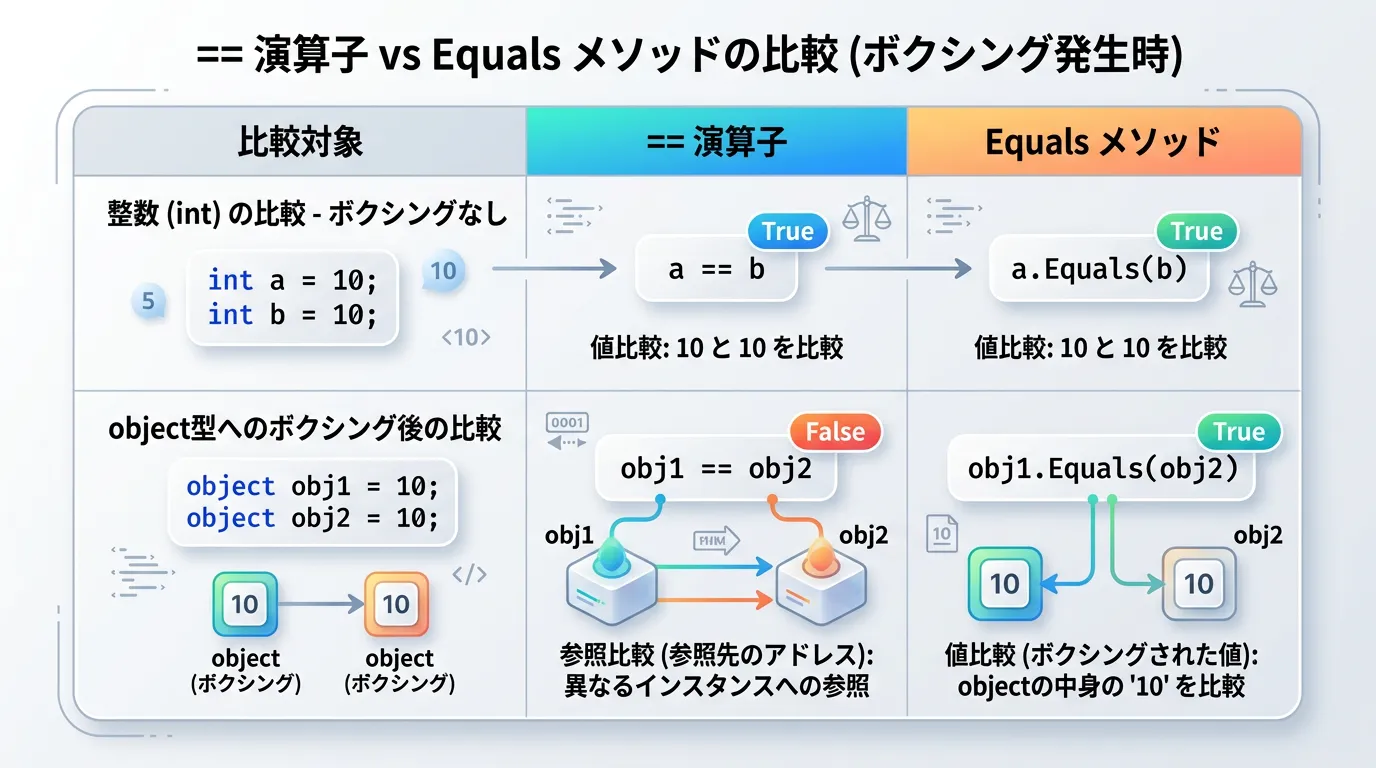
演算子オーバーロードによる値比較
本来、C#の参照型における==演算子は「参照(メモリ上のアドレス)が同じかどうか」を判定します。
しかし、stringクラスではこの演算子がオーバーロード(再定義)されており、「値(文字列の内容)が同じかどうか」を判定するようにカスタマイズされています。
そのため、基本的にはどちらを使っても同じ結果が得られます。
object型にキャストした場合の挙動
違いが顕著に現れるのは、文字列をobject型として扱う場合です。
string str1 = "C#";
object obj1 = str1;
object obj2 = new string("C#".ToCharArray());
// == 演算子での比較(参照比較になる)
Console.WriteLine($"== の結果: {obj1 == obj2}");
// Equals メソッドでの比較(値比較になる)
Console.WriteLine($"Equals の結果: {obj1.Equals(obj2)}");== の結果: False
Equals の結果: True上記のコードでは、obj1とobj2は中身こそ同じ「C#」ですが、別々のインスタンス(参照)です。
==演算子をobject型に対して使うと、文字列としてのオーバーロードが機能せず、純粋な参照比較が行われるため、Falseとなります。
一方でEqualsは仮想メソッドであるため、実行時に実際の型(string)のメソッドが呼ばれ、正しく値の比較が行われます。
大文字・小文字を無視した比較
実務において最もstring.Equalsが重宝される理由は、比較のルール(オプション)を細かく指定できることにあります。
特に「大文字と小文字を区別せずに比較したい」というニーズは非常に多いです。
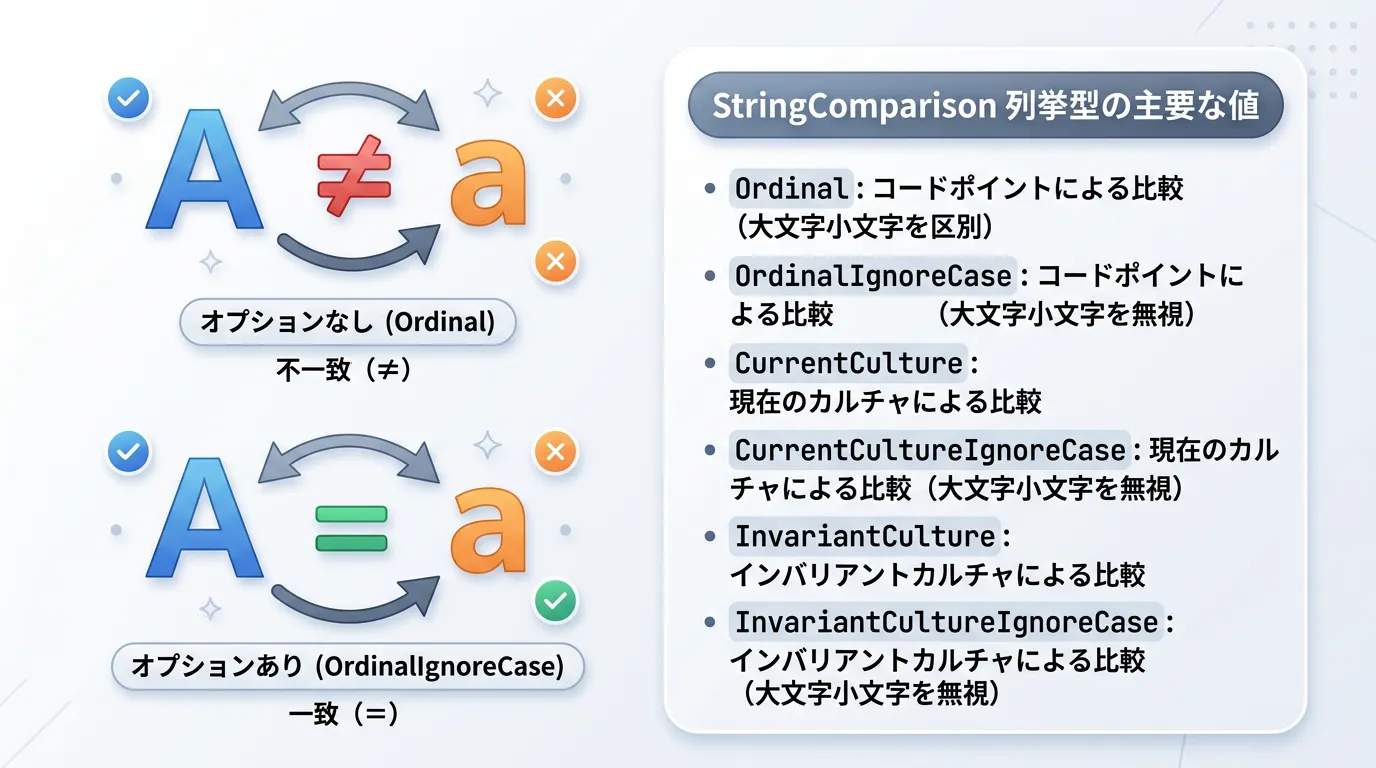
StringComparison列挙型の活用
string.Equalsの第3引数には、StringComparison列挙型を指定できます。
これを利用することで、文字列をわざわざToUpper()やToLower()で変換することなく、効率的に比較できます。
string val1 = "dotnet";
string val2 = "DOTNET";
// 大文字小文字を区別しない比較
bool isEqual = string.Equals(val1, val2, StringComparison.OrdinalIgnoreCase);
Console.WriteLine($"大文字小文字無視の結果: {isEqual}");大文字小文字無視の結果: TrueなぜToUpper()を使ってはいけないのか
初心者のうちは、if (str1.ToUpper() == str2.ToUpper())といったコードを書きがちです。
しかし、この方法は以下の2つの理由から推奨されません。
- パフォーマンスの低下
ToUpper()を呼び出すたびに、新しい文字列メモリが確保(アロケーション)されます。大量のデータをループ内で比較する場合、メモリとCPUのリソースを無駄に消費します。
- 文化圏(カルチャ)の問題
特定の言語(トルコ語など)では、大文字小文字の変換ルールが英語とは異なります。
単純な変換では予期せぬ判定ミスを招く恐れがあります。
StringComparisonを使用すれば、メモリ消費を抑えつつ、意図した通りの比較を安全に行うことができます。
StringComparisonの種類と使い分け
StringComparisonにはいくつかの種類があります。
これらを適切に使い分けることが、バグの少ないプログラムへの第一歩です。
| 設定値 | 説明 | 推奨される用途 |
|---|---|---|
Ordinal | バイナリレベル(文字コード)で比較します。 | 内部的なID、ファイルパス、設定キーなど。 |
OrdinalIgnoreCase | バイナリレベルで、大文字小文字を無視して比較します。 | プログラム内部で扱う名前の比較(最も多用される)。 |
CurrentCulture | 現在の実行環境の言語設定に基づき比較します。 | ユーザーに表示するリストの並び替えや検索など。 |
InvariantCulture | 言語設定に依存しない「不変のカルチャ」で比較します。 | どの国で動かしても同じ結果が必要なデータの永続化。 |
Ordinal比較(序数比較)の重要性
「Ordinal(序数)」比較は、最も高速で予測可能な比較方法です。
これは、文字列を単なる数値(Unicodeコードポイント)の並びとして扱うため、言語学的な複雑さを一切排除します。
プログラムの内部ロジックや、システム間でやり取りする識別子の比較には、必ずOrdinalまたはOrdinalIgnoreCaseを使用するようにしましょう。
文化圏(カルチャ)に依存する比較の罠
例えば、ドイツ語の「ß(エスツェット)」は、カルチャによっては「ss」と等しいと判定されることがあります。
また、トルコ語の「i」の大文字は「İ(点付きのI)」であり、一般的な英語の「I」とは異なります。
// 特定のカルチャを指定した比較(例としてトルコ語)
var culture = new System.Globalization.CultureInfo("tr-TR");
string input1 = "i";
string input2 = "I";
// Ordinal(バイナリ比較)では一致しない
bool resultOrdinal = string.Equals(input1, input2, StringComparison.OrdinalIgnoreCase);
// トルコ語カルチャでの比較(トルコ語のiのペアではないため一致しないケースがある)
// ※実際の挙動は環境や.NETのバージョンにより繊細に変化しますこのように、ユーザーの入力内容を言語的に正しく評価したい場合は、CurrentCulture系のオプションを慎重に選択する必要があります。
実践的な活用シーン
ここでは、実際の開発現場でよく遭遇するstring.Equalsの活用例を紹介します。
ユーザーの入力チェック(コマンド判定)
コンソールアプリケーションやチャットボットなどで、ユーザーが入力したコマンドを判定する場合、大文字小文字の揺れを許容するのが一般的です。
string userInput = Console.ReadLine();
// ユーザーが "quit" や "QUIT"、"Quit" と入力しても終了できるようにする
if (string.Equals(userInput, "quit", StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine("プログラムを終了します。");
}辞書のキーとしての比較
Dictionary<string, T>などのコレクションを使用する場合も、デフォルトでは大文字小文字が区別されます。
ここでもStringComparer(Equalsと密接に関係するクラス)を利用して、比較ルールを注入できます。
// 大文字小文字を区別しない辞書を作成
var settings = new Dictionary<string, string>(StringComparer.OrdinalIgnoreCase);
settings["Theme"] = "Dark";
// "theme"(小文字)でアクセスしても取得できる
if (settings.ContainsKey("theme"))
{
Console.WriteLine($"テーマ: {settings["theme"]}");
}テーマ: Darkパフォーマンスとベストプラクティス
高頻度で呼ばれる処理において、文字列比較のコストは無視できません。
C#において最も高速な文字列比較は、静的な string.Equals に StringComparison.Ordinal を指定することです。
早期リターンによる最適化
string.Equalsの内部実装では、以下のようなステップで最適化が行われています。
参照が同一であるかを確認します。
もし同じであれば、即座に true を返します。
比較対象のいずれかが null であるかを確認します。
文字列の長さ(Length)が一致するかを確認します。
もし長さが異なる場合は、即座に false を返します。
先頭から順番に、1文字ずつ比較を行います。
このため、長大な文字列同士であっても、長さが違えば一瞬で判定が終わります。
自前で比較ロジックを組むよりも、標準のEqualsに任せるのが最も効率的です。
ReadOnlySpan<char>による最新の比較
最新の.NET(.NET 5以降や.NET 8など)では、ReadOnlySpan<char>を使用した比較も一般的になっています。
これはメモリの「切り出し(スライス)」を行っても新しい文字列を生成しないため、非常に高速です。
ReadOnlySpan<char> path = "C:/Users/Admin/Documents/test.txt";
ReadOnlySpan<char> fileName = "test.txt";
// スライス(一部分の抽出)をしても新しい文字列は作られない
if (path.EndsWith(fileName, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine("ファイル名が一致しました。");
}大規模なテキスト処理を行う場合は、string.Equalsの知識をベースに、これらの新しい型も組み合わせていくと、よりハイクオリティなコードになります。
まとめ
C#における文字列比較は、一見単純に見えて非常に奥が深いテーマです。
単に==を使うだけでも多くの場合で動作しますが、「null安全」「大文字小文字の制御」「パフォーマンス」「国際化対応」といったプロフェッショナルな要求に応えるためには、string.Equalsの正しい理解が欠かせません。
基本的には、静的メソッドの string.Equals(s1, s2, StringComparison.OrdinalIgnoreCase) を使うのが、最も安全かつ汎用的な選択肢となります。
今回の内容をまとめると以下の通りです。
- 安全性:静的メソッドなら
nullチェックを自動で行ってくれる。 - 柔軟性:
StringComparisonで大文字小文字や言語ルールを自由に指定できる。 - 正確性:
object型へのキャスト時でも、意図した「値比較」を維持できる。
これらのテクニックを駆使して、堅牢で効率的なC#プログラムを構築していきましょう。
