
C#でアプリケーションを開発している際、文字列の中に特定のワードが含まれているかを確認するためにContainsメソッドは頻繁に利用されます。
しかし、デフォルトのContainsメソッドは大文字と小文字を厳密に区別する仕様となっており、例えば「Apple」という文字列に対して「apple」で検索をかけても一致しないという結果になります。
ユーザー入力の検索機能やファイルパスの比較など、実務では大文字小文字を区別せずに判定したい場面が多々あります。
本記事では、最新のC#(.NET)環境において、最も効率的で推奨される「大文字小文字を区別しないContains」の実装方法を、パフォーマンス面やコードの可読性の観点から詳しく解説します。
C#における文字列比較の基本仕様
C#のstring.Containsメソッドは、引数に文字列のみを渡した場合、序数比較(Ordinal Comparison)という方式で判定が行われます。
これは文字のコードポイントを直接比較する方式であり、大文字の「A」と小文字の「a」は全く別のデータとして扱われます。
まずは、デフォルトの挙動を確認するためのサンプルコードを見てみましょう。
using System;
class Program
{
static void Main()
{
string text = "C# Programming Guide";
string searchWord = "programming";
// デフォルトのContainsは大文字小文字を区別する
bool result = text.Contains(searchWord);
Console.WriteLine($"検索対象: {text}");
Console.WriteLine($"検索語: {searchWord}");
Console.WriteLine($"結果: {result}"); // Falseになる
}
}検索対象: C# Programming Guide
検索語: programming
結果: Falseこのように、人間にとっては同じ単語に見えても、プログラム上ではFalseと判定されてしまいます。
これを解決するために、適切な引数やメソッドを選択する必要があります。
StringComparisonを指定する標準的な手法
現代のC#(.NET Core 2.0以降、.NET 5/6/7/8以降)において、最も推奨される方法は、Containsメソッドの第2引数にStringComparison列挙体を指定する方法です。
この方法はコードがシンプルになり、意図も明確に伝わります。
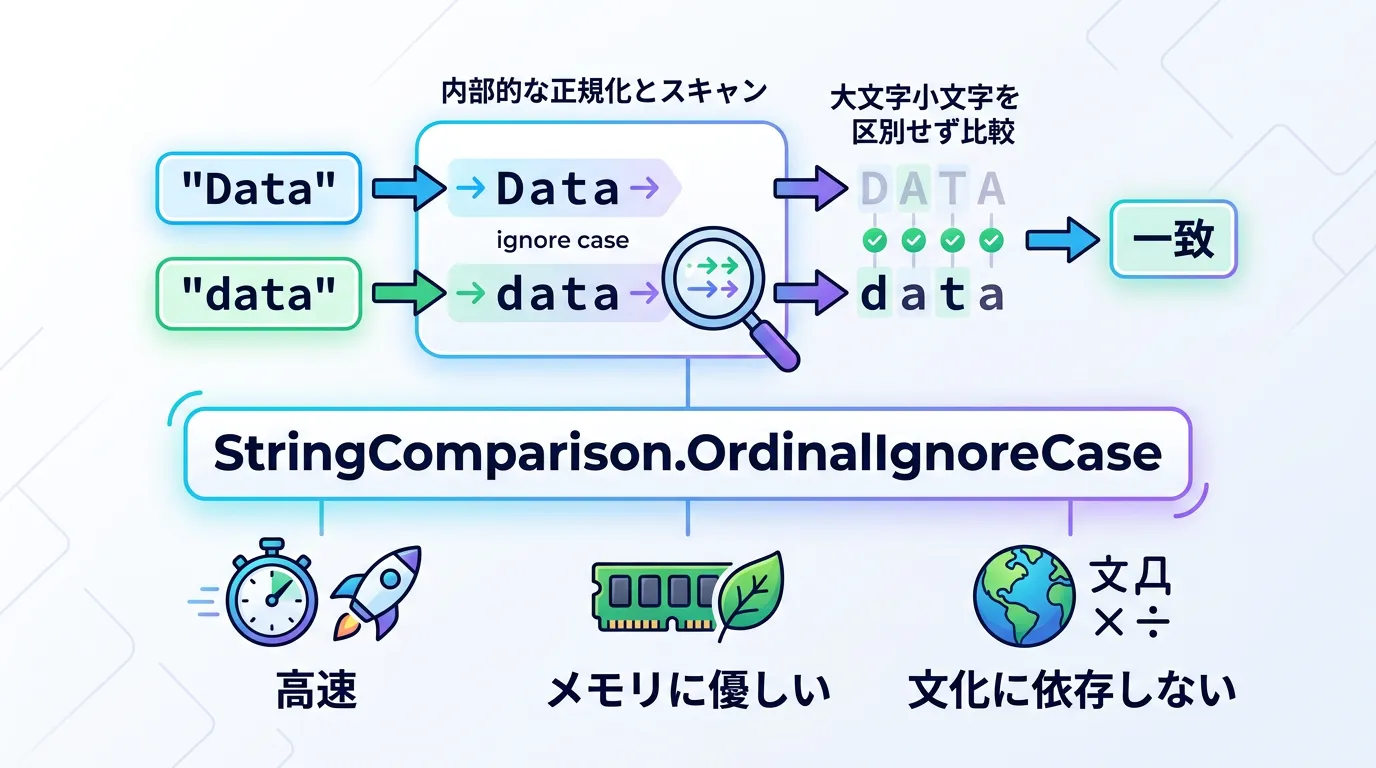
StringComparison.OrdinalIgnoreCaseの利用
最も一般的に使われるのがStringComparison.OrdinalIgnoreCaseです。
これは「序数比較を行い、かつ大文字小文字を無視する」という設定です。
using System;
class Program
{
static void Main()
{
string text = "C# Programming Guide";
string searchWord = "PROGRAMMING";
// 第2引数にStringComparison.OrdinalIgnoreCaseを指定
bool isFound = text.Contains(searchWord, StringComparison.OrdinalIgnoreCase);
Console.WriteLine($"大文字小文字を無視した結果: {isFound}"); // Trueになる
}
}大文字小文字を無視した結果: Trueこの書き方の利点は、新しい文字列インスタンスを生成しない点にあります。
後述するToLowerなどのメソッドを使う方法と比較して、メモリ効率が非常に高く、パフォーマンスが求められるループ処理内などでも安心して使用できます。
各種StringComparisonの違い
用途に合わせて以下のオプションを選択できますが、基本的にはOrdinalIgnoreCaseを選択しておけば間違いありません。
| 列挙値 | 特徴 | 用途 |
|---|---|---|
| Ordinal | 完全に一致するか判定(デフォルト) | 厳密な比較が必要な場合 |
| OrdinalIgnoreCase | バイナリレベルで大文字小文字を無視 | 最も推奨(一般的、高速) |
| CurrentCultureIgnoreCase | 現在のOSの言語設定に従って無視 | ユーザーの地域性に合わせた検索 |
| InvariantCultureIgnoreCase | 言語に依存しない不変の文化設定で無視 | 永続的な設定データの比較など |
ToLowerやToUpperを使用する方法とその注意点
以前のC#バージョンや、一部の古いフレームワークではStringComparisonを引数に取るContainsが実装されていなかったため、ToLower()(小文字化)やToUpper()(大文字化)を適用してから比較する手法がよく使われていました。
サンプルコードと問題点
string text = "C# Programming";
string search = "PROGRAM";
// 両方を小文字に変換してから判定
if (text.ToLower().Contains(search.ToLower()))
{
Console.WriteLine("見つかりました");
}このコードは一見正しく動作しますが、2つの大きなデメリットがあります。
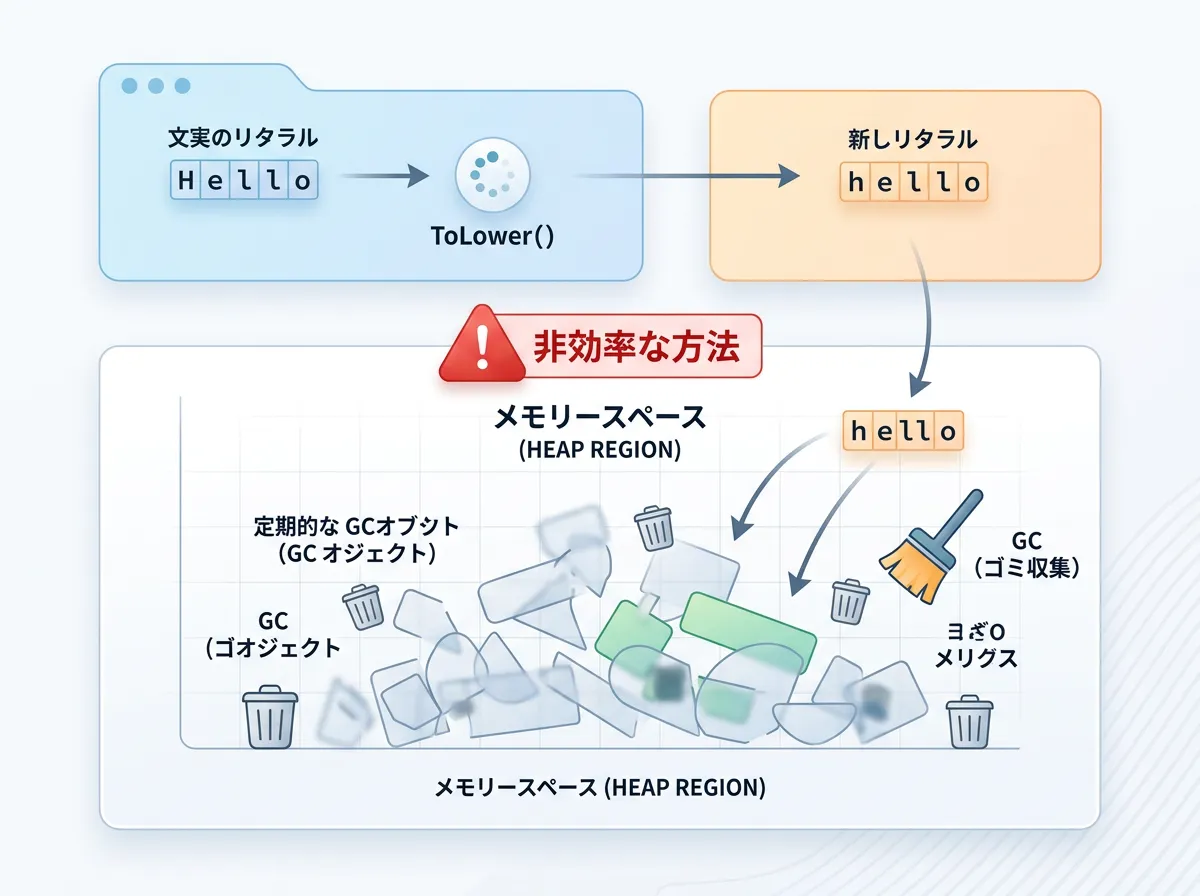
- メモリ効率の低下
ToLower()を呼び出すたびに、元の文字列とは別に新しい文字列オブジェクトがメモリ(ヒープ領域)に作成されます。大量のデータを処理する場合、ガベージコレクション(GC)の負荷が高まり、アプリのパフォーマンスが低下します。
- Null参照のリスク
もし
textがnullだった場合、text.ToLower()を実行した瞬間に例外(NullReferenceException)が発生します。
そのため、現在の開発環境ではStringComparison引数を使う方法に書き換えることを強く推奨します。
String.IndexOfを活用した判定
Containsメソッドが内部的に行っていることと同じですが、IndexOfメソッドを使用することでも大文字小文字を区別しない検索が可能です。
これは、かなり古いバージョンの.NET(.NET Frameworkなど)をメンテナンスしている場合に有効な手段です。
string text = "Hello World";
string search = "world";
// IndexOfが0以上を返せば、その文字列が含まれている
bool exists = text.IndexOf(search, StringComparison.OrdinalIgnoreCase) >= 0;
Console.WriteLine(exists); // TrueTrueIndexOfは、見つかった位置を整数で返します。
見つからない場合は-1を返すため、>= 0という比較演算子と組み合わせて判定します。
最新のC#であればContainsの方が読みやすいため、あえてIndexOfを使うメリットは少ないですが、知識として持っておくと古いコードの解読に役立ちます。
正規表現(Regex)を使用した柔軟な検索
単なる部分一致だけでなく、「単語の境界を意識したい」場合や「特定のパターンを含めて検索したい」場合には、正規表現(Regular Expression)が非常に強力です。
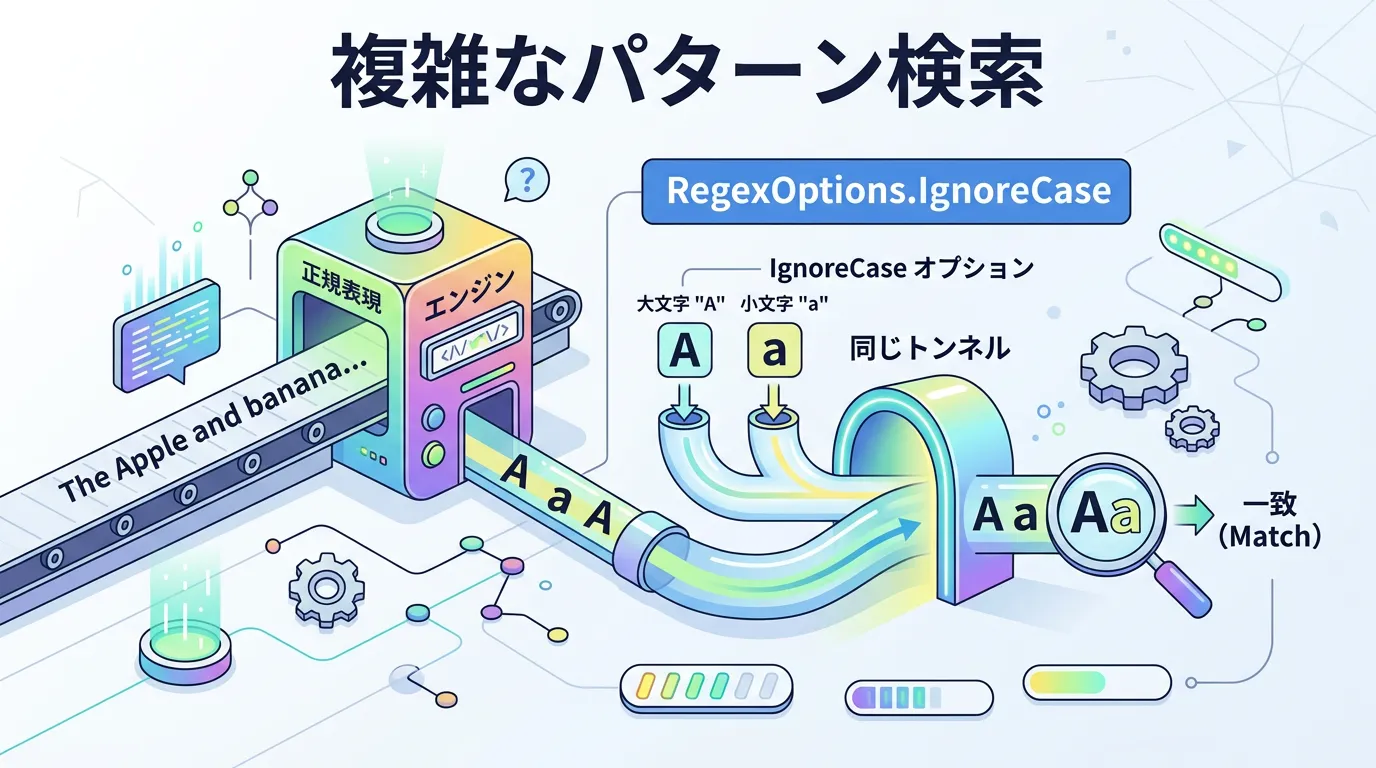
RegexOptions.IgnoreCaseの利用
System.Text.RegularExpressions名前空間を使用し、Regex.IsMatchメソッドにRegexOptions.IgnoreCaseフラグを渡します。
using System;
using System.Text.RegularExpressions;
class Program
{
static void Main()
{
string text = "The quick brown Fox";
string pattern = "fox";
// RegexOptions.IgnoreCaseで大文字小文字を無視
bool isMatch = Regex.IsMatch(text, pattern, RegexOptions.IgnoreCase);
Console.WriteLine($"正規表現での判定結果: {isMatch}"); // True
}
}正規表現での判定結果: True正規表現は、単純なContainsに比べると処理が重いという特徴があります。
そのため、大文字小文字を区別しないだけの単純な判定であればContains(..., StringComparison.OrdinalIgnoreCase)を使い、複雑なルールが必要な場合にのみ正規表現を採用するのがベストプラクティスです。
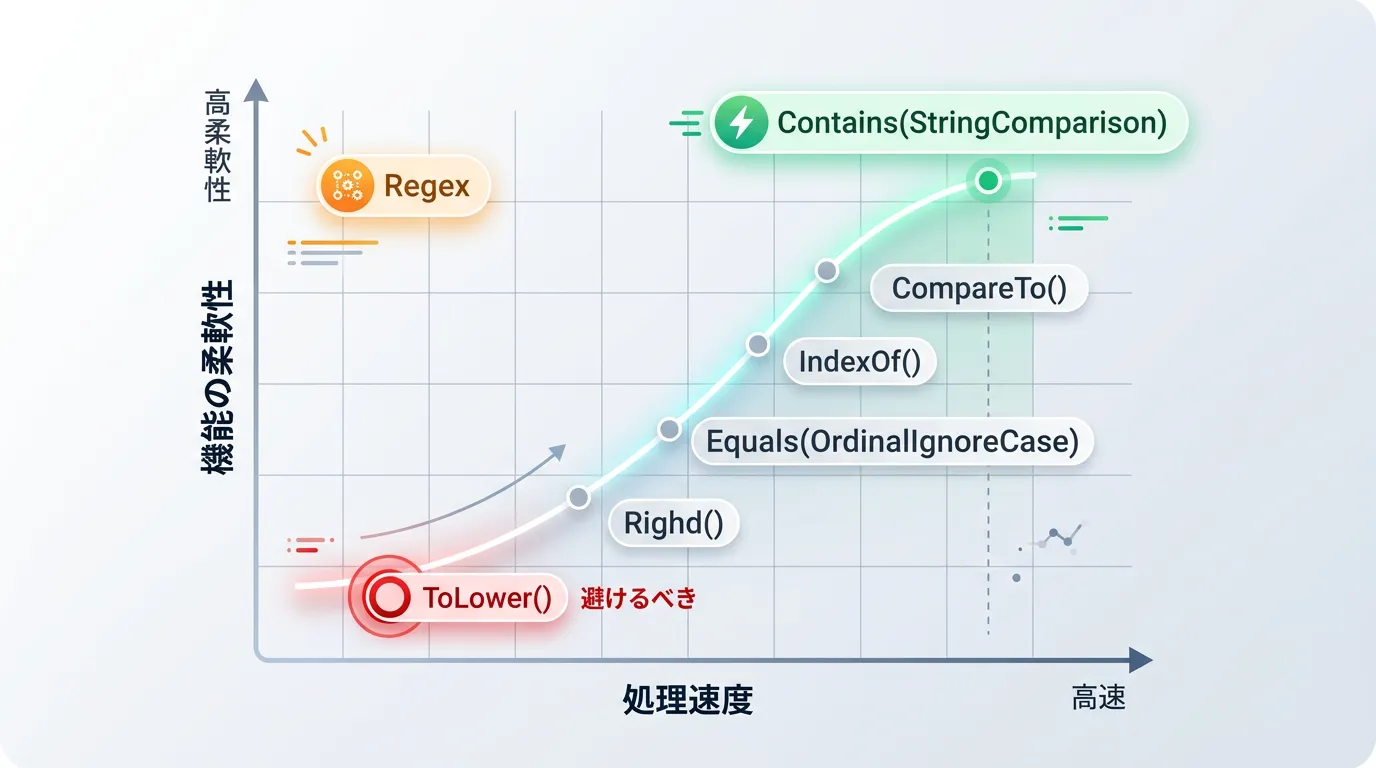
パフォーマンスの比較と最適な使い分け
どの手法を選択すべきか、パフォーマンスと可読性の観点からまとめます。
大量の文字列データを扱うシステムでは、この選択一つで処理速度が大きく変わることもあります。
| 手法 | パフォーマンス | 推奨度 | 特徴 |
|---|---|---|---|
| Contains(str, StringComparison) | 非常に高い | 最高 | 最も標準的で高速。メモリ消費も最小限。 |
| ToLower().Contains() | 低い | 低い | 文字列コピーが発生するため、ループ内では厳禁。 |
| IndexOf() >= 0 | 高い | 中 | 古い.NET環境(Framework等)ではこれ一択。 |
| Regex.IsMatch() | やや低い | 中 | 複雑なパターンが必要な時のみ使用する。 |
プログラミングにおいては、「意図が明確で、かつリソースを浪費しないコード」が優れたコードとされます。
C#において大文字小文字を無視したい場合は、迷わずStringComparison.OrdinalIgnoreCaseを引数に取るContainsを選択しましょう。
また、リスト(List<string>)の中に特定の文字列が含まれているかを一括で確認したい場合などは、LINQのAnyメソッドと組み合わせることもできます。
using System;
using System.Collections.Generic;
using System.Linq;
class Program
{
static void Main()
{
var fruits = new List<string> { "Apple", "Banana", "Orange" };
string target = "apple";
// LINQとStringComparisonの組み合わせ
bool hasFruit = fruits.Any(f => f.Contains(target, StringComparison.OrdinalIgnoreCase));
Console.WriteLine($"リスト内の存在確認: {hasFruit}"); // True
}
}このように、応用範囲は非常に広いです。
まとめ
C#で大文字小文字を区別せずに文字列が含まれているかを判定するには、「Contains(searchWord, StringComparison.OrdinalIgnoreCase)」を使用するのが現代のC#における正解です。
かつて主流だったToLower()による変換比較は、不要なメモリ割り当てを発生させ、アプリケーションのパフォーマンスを損なう原因となります。
「パフォーマンス」と「安全性」、そして「可読性」のすべてにおいて優れているStringComparison引数の活用を習慣化しましょう。
もし、より複雑な条件(特定の単語から始まるか、正規表現パターンに合うかなど)が必要な場合に限り、Regexの利用を検討してください。
適切なメソッド選択によって、バグが少なく高速なC#プログラムを構築できるようになります。
