
C#でのアプリケーション開発において、文字列の操作は避けては通れない非常に重要な要素です。
ユーザー入力の検証、ファイルパスの解析、ログデータの抽出など、特定の文字列があるパターンで始まっているか、あるいは特定の拡張子で終わっているかを確認するシーンは数多く存在します。
このような文字列の「接頭辞」と「接尾辞」を判定するために用意されているのが、StartsWithメソッドとEndsWithメソッドです。
これらのメソッドは非常にシンプルで使いやすいものですが、大文字・小文字の区別や言語環境(カルチャ)に応じた比較など、詳細な仕様を理解しておくことで、より堅牢でパフォーマンスの高いコードを記述できるようになります。
本記事では、初心者から中級者までを対象に、C#におけるStartsWithおよびEndsWithの基本的な使い方から応用、さらには最新のパフォーマンス最適化手法まで徹底的に解説します。
StartsWithメソッドによる先頭文字列の判定
文字列が特定の文字や文字列から始まっているかどうかを確認したい場合、string.StartsWithメソッドを使用します。
このメソッドは、指定した文字列が対象の文字列の先頭に一致すればtrueを、そうでなければfalseを返却します。
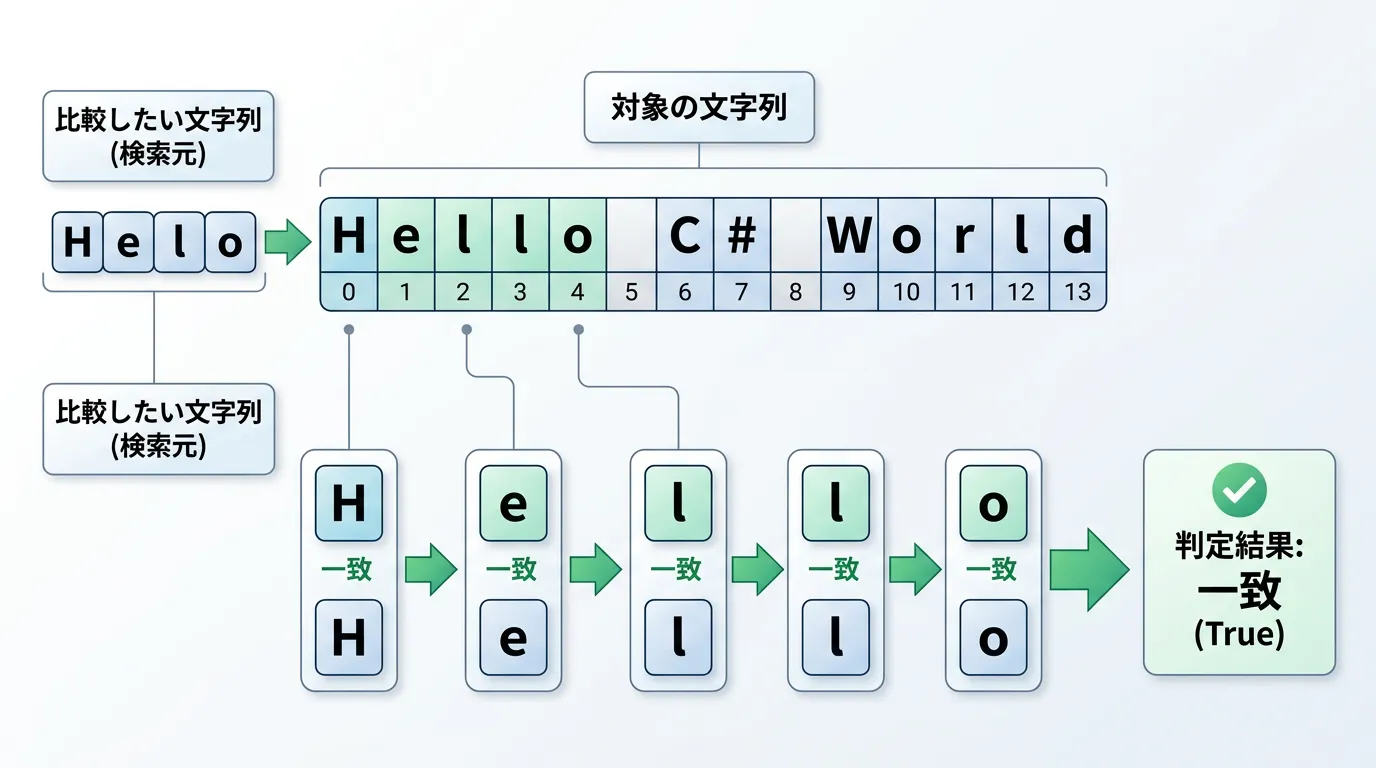
基本的な使い方
もっともシンプルな使い方は、引数に判定したい文字列を一つだけ渡す方法です。
デフォルトでは、現在実行されている環境のカルチャ設定を使用し、大文字と小文字を厳密に区別して比較を行います。
using System;
public class Example
{
public static void Main()
{
string text = "C# Programming is fun!";
// "C#" で始まるか判定
bool result1 = text.StartsWith("C#");
// "c#" で始まるか判定(小文字)
bool result2 = text.StartsWith("c#");
Console.WriteLine($"'C#' で始まるか: {result1}");
Console.WriteLine($"'c#' で始まるか: {result2}");
}
}'C#' で始まるか: True
'c#' で始まるか: False上記のコードでは、大文字と小文字が異なるため、result2はFalseになります。
このように、単純な呼び出しでは厳密な比較が行われることを覚えておきましょう。
指定した文字(char型)での判定
C#の比較的新しいバージョン(.NET Core 2.0以降や.NET 5/6/7/8/9など)では、文字列ではなく単一の文字(char型)を引数に取るオーバーロードも追加されています。
特定の1文字から始まるかどうかを調べたい場合、文字列を指定するよりもメモリ消費を抑え、高速に動作する傾向があります。
string fileName = "Report.pdf";
// 文字(char)での判定
if (fileName.StartsWith('R'))
{
Console.WriteLine("ファイル名は 'R' で始まります。");
}ファイル名は 'R' で始まります。EndsWithメソッドによる末尾文字列の判定
EndsWithメソッドは、文字列が特定の文字列で終わっているかどうかを判定します。
ファイル拡張子のチェックや、URLの末尾が「/」で終わっているかどうかの確認などによく使われます。
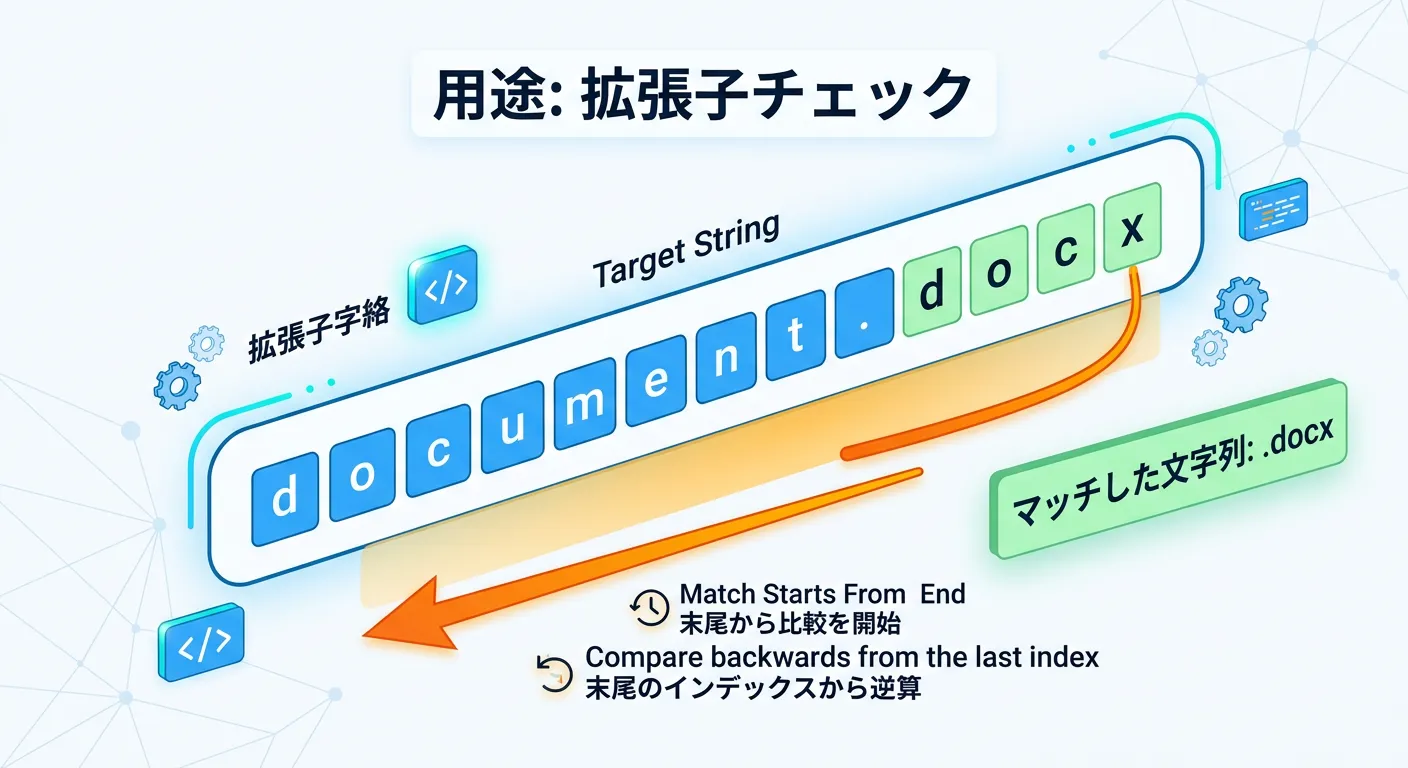
基本的な使い方
StartsWithと同様に、引数に比較したい文字列を指定します。
こちらもデフォルトでは大文字・小文字を区別します。
using System;
public class Example
{
public static void Main()
{
string url = "https://example.com/index.html";
// ".html" で終わるか判定
bool isHtml = url.EndsWith(".html");
// ".HTML" で終わるか判定(大文字)
bool isHtmlUpper = url.EndsWith(".HTML");
Console.WriteLine($"'.html' で終わるか: {isHtml}");
Console.WriteLine($"'.HTML' で終わるか: {isHtmlUpper}");
}
}'.html' で終わるか: True
'.HTML' で終わるか: False拡張子判定の実例
実際の開発現場では、ユーザーがアップロードしたファイルの形式をチェックする際に重宝します。
string[] files = { "image.png", "data.csv", "notes.txt", "PHOTO.PNG" };
foreach (var file in files)
{
// 大文字小文字を区別しない判定(後述のStringComparisonを使用)
if (file.EndsWith(".png", StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"{file} は画像ファイルです。");
}
}image.png は画像ファイルです。
PHOTO.PNG は画像ファイルです。大文字・小文字を無視する比較(StringComparison)
C#の文字列比較で最も注意すべき点は、デフォルトの比較挙動が常に最適とは限らない点です。
特にユーザー入力を扱う場合、大文字と小文字を区別せずに判定したいことが多々あります。
その際に使用するのがStringComparison列挙型です。
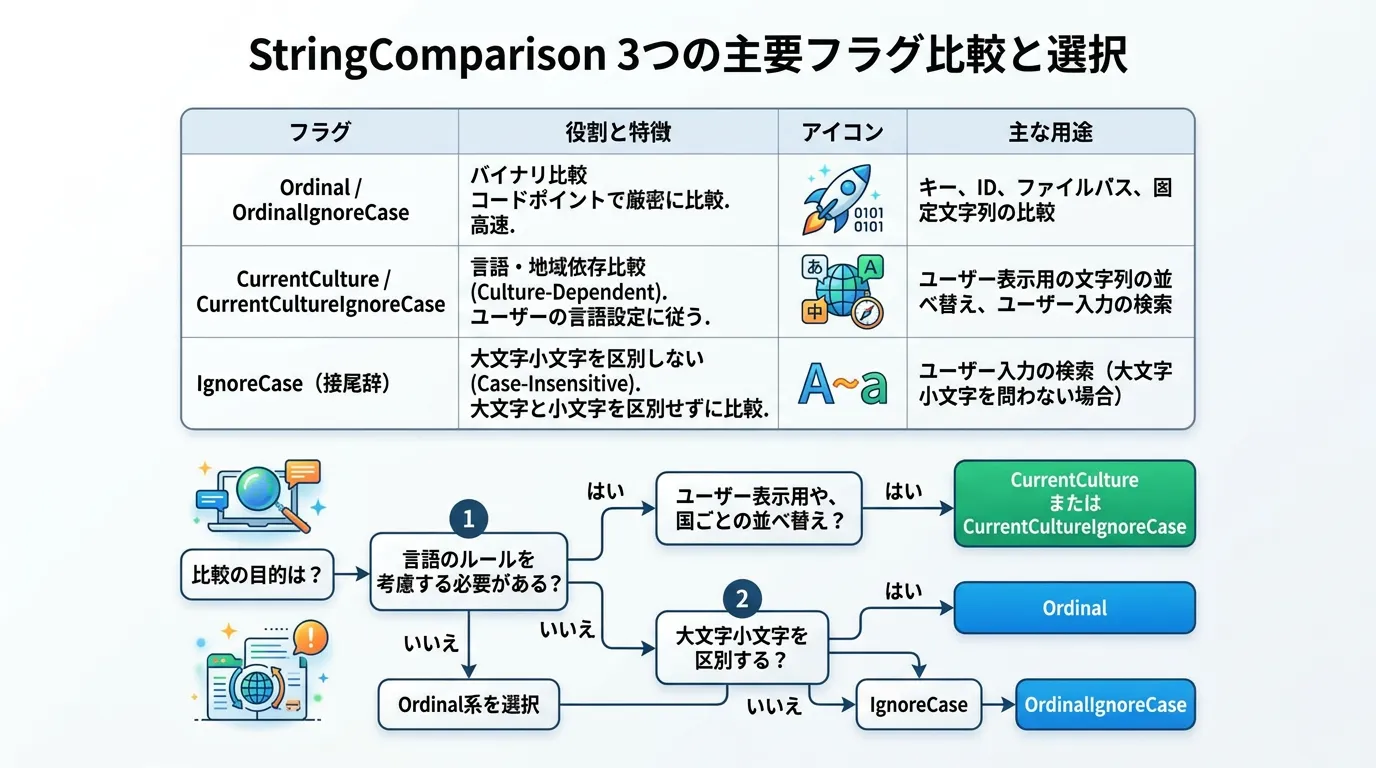
StringComparisonの種類と使い分け
StartsWithおよびEndsWithの第2引数(または第3引数)には、StringComparisonを指定できます。
主な値は以下の通りです。
| 設定値 | 説明 |
|---|---|
Ordinal | 文字のコードポイント(バイナリ値)で比較します。デフォルトの動作に近く、最も高速です。 |
OrdinalIgnoreCase | バイナリ比較を行いながら、大文字と小文字を区別しません。識別子の比較などに最適です。 |
CurrentCulture | 現在のスレッドのカルチャ(言語設定)を使用して比較します。言語特有の並び替え規則が適用されます。 |
CurrentCultureIgnoreCase | 現在のカルチャを使用し、かつ大文字小文字を区別しません。 |
InvariantCulture | 特定の言語に依存しない「不変のカルチャ」を使用します。データの保存や通信のプロトコル判定に有効です。 |
推奨される使い分け
- システム的な判定(ファイル拡張子、URLスキーム、設定キーなど)
常に
StringComparison.OrdinalまたはStringComparison.OrdinalIgnoreCaseを使用してください。カルチャ設定によって挙動が変わるリスクを避け、パフォーマンスを最大化できます。
- ユーザーに表示するテキストの検索・ソート
StringComparison.CurrentCultureIgnoreCaseなどのカルチャ依存のオプションを検討します。
OrdinalIgnoreCaseの使用例
string command = "START Server";
// 大文字小文字を無視して先頭が "start" かチェック
if (command.StartsWith("start", StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine("コマンドが認識されました。");
}コマンドが認識されました。特定のカルチャと言語ルールに基づく判定
文字列の比較は、国や言語によって異なるルールを持つことがあります。
たとえば、トルコ語などの特定の言語では、アルファベットの「i」の大文字化のルールが英語とは異なります。
C#では、明示的にカルチャを指定して比較することも可能です。
CultureInfoを使用した詳細な比較
CultureInfoオブジェクトを渡すことで、特定の言語環境での判定をシミュレートできます。
using System;
using System.Globalization;
public class Example
{
public static void Main()
{
string title = "İSTANBUL"; // トルコ語の「I」は点付き
// トルコ語(tr-TR)のカルチャで判定
bool result = title.StartsWith("i", true, new CultureInfo("tr-TR"));
Console.WriteLine($"トルコ語カルチャでの 'i' 開始判定: {result}");
}
}トルコ語カルチャでの 'i' 開始判定: Trueこのように、多言語対応が必要なアプリケーションでは、単なる文字列比較も慎重に行う必要があります。
ただし、通常のビジネスロジックではOrdinalIgnoreCaseを利用するのが最も安全で一般的です。
Containsメソッドとの違いと使い分け
「特定の文字列が含まれているか」を判定するメソッドとしてContainsがあります。
よくある間違いとして、先頭や末尾を調べたいのにContainsを使ってしまうケースがあります。
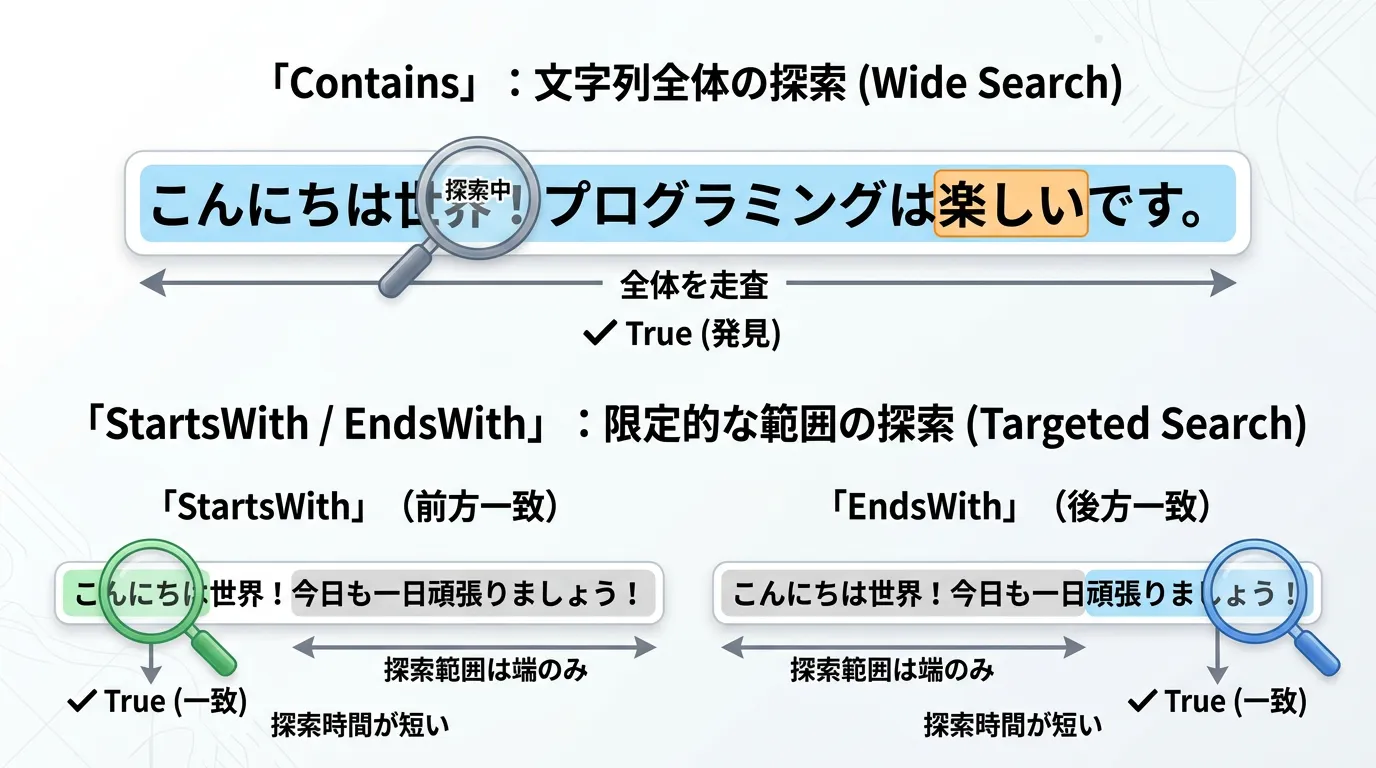
なぜStartsWith/EndsWithを使うべきか
- 意図の明確化
「文字列のどこかにあれば良い」のか「最初にあるべき」なのかを、コードを読む人に明確に伝えられます。
- 誤判定の防止
例えば、ファイルのフルパスから「C:」で始まるか確認したい場合、Containsを使うとフォルダ名に「C:」が含まれているだけで誤検知してしまいます。
- パフォーマンス
Containsは内部で文字列全体をスキャンする可能性がありますが、StartsWithは最初の数文字をチェックするだけで終わるため、より効率的です。
string path = @"C:\Users\Admin\Documents\C_Drive_Backup.txt";
// 誤った使い方:どこかに "C:\" があれば True になってしまう
if (path.Contains(@"C:\")) { /* ... */ }
// 正しい使い方:ドライブレターが C であることを厳密に判定
if (path.StartsWith(@"C:\", StringComparison.Ordinal)) { /* ... */ }最新のC#におけるパフォーマンス最適化(ReadOnlySpan)
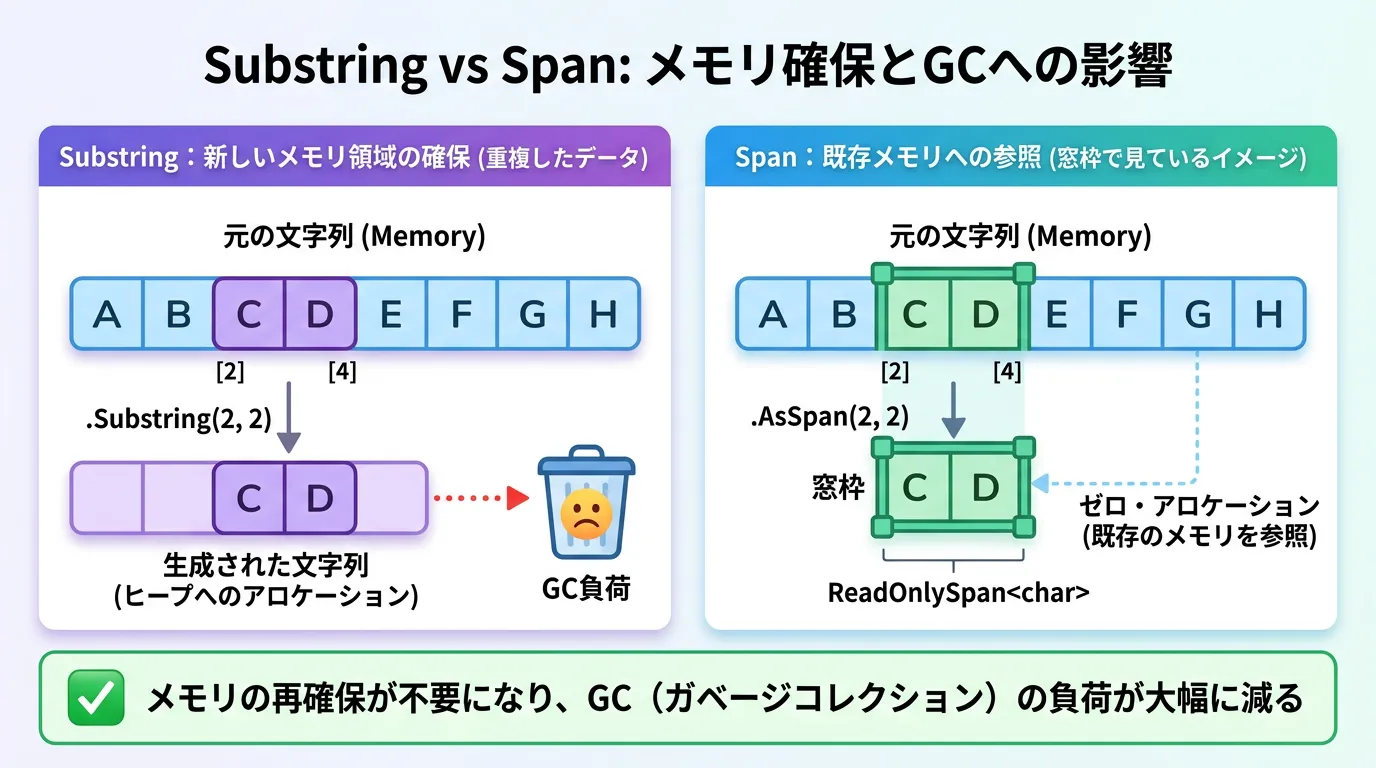
大規模なテキスト処理や、高頻度で呼ばれるループ内での文字列判定では、メモリ割り当て(アロケーション)を削減することが重要です。
最新のC#では、ReadOnlySpan<char>を利用して、文字列のコピーを作成せずに高速な判定を行うことができます。
Span<char>を使用した判定
文字列の一部を切り取って判定したい場合、従来はSubstringを使用していました。
しかし、Substringは新しい文字列オブジェクトをメモリ上に作成するため、パフォーマンスに悪影響を及ぼします。
using System;
public class PerformanceExample
{
public static void Main()
{
string data = "ORDER_12345_PROCESSED";
// 最初の6文字をスライス(メモリコピーが発生しない)
ReadOnlySpan<char> span = data.AsSpan();
ReadOnlySpan<char> prefix = span.Slice(0, 5);
// Spanの状態でも StartsWith が使える
if (prefix.StartsWith("ORDER"))
{
Console.WriteLine("これは注文データです。");
}
}
}これは注文データです。ReadOnlySpan<char>にもStartsWithおよびEndsWithメソッドが定義されており、文字列型と同様の感覚で使用できます。
これにより、大量のログ解析やリアルタイム通信処理において、ガベージコレクションの発生を劇的に抑えることが可能です。
実践的な活用シーン
ここでは、開発でよく遭遇する具体的なシナリオに基づいたサンプルコードを紹介します。
1. URLのプロトコルチェック
Webアプリにおいて、安全な接続(https)のみを許可するフィルタリングの例です。
public bool IsSecureUrl(string url)
{
if (string.IsNullOrEmpty(url)) return false;
// 先頭が https:// かどうかを大文字小文字無視で判定
return url.StartsWith("https://", StringComparison.OrdinalIgnoreCase);
}2. ファイルのフィルタリング
特定の拡張子を持つファイルだけをリストアップする例です。
using System;
using System.Collections.Generic;
using System.Linq;
public class FileFilter
{
public static void Main()
{
List<string> files = new List<string> { "data.json", "config.xml", "script.py", "output.JSON" };
// JSONファイルだけを抽出
var jsonFiles = files.Where(f => f.EndsWith(".json", StringComparison.OrdinalIgnoreCase));
foreach (var file in jsonFiles)
{
Console.WriteLine($"見つかったJSON: {file}");
}
}
}見つかったJSON: data.json
見つかったJSON: output.JSON3. コメント行の読み飛ばし
テキストファイルなどを一行ずつ読み込み、特定の記号(#や//)で始まる行をコメントとして除外する処理です。
string[] lines = {
"# 設定ファイル",
"Timeout=30",
"// デバッグ用",
"LogLevel=Verbose"
};
foreach (var line in lines)
{
// 複数のパターンをチェック
if (line.StartsWith("#") || line.StartsWith("//"))
{
continue; // スキップ
}
Console.WriteLine($"処理中: {line}");
}処理中: Timeout=30
処理中: LogLevel=Verboseよくある落とし穴と注意点
便利なメソッドですが、いくつか注意すべき「罠」が存在します。
Null判定を忘れない
StartsWithやEndsWithを呼び出す対象の文字列がnullである場合、NullReferenceExceptionが発生します。
また、引数に渡す比較文字列がnullであっても、ArgumentNullExceptionがスローされます。
string input = null;
// これは例外が発生する
// bool error = input.StartsWith("A");
// 安全な書き方
if (!string.IsNullOrEmpty(input) && input.StartsWith("A"))
{
// 処理
}空文字列に対する挙動
比較対象が空文字列("")の場合、StartsWith("")は常にtrueを返します。
これは「すべての文字列は空文字列から始まる」という数学的な定義に基づいています。
string text = "Hello";
Console.WriteLine(text.StartsWith("")); // True を返すこの仕様を理解していないと、条件分岐で予期せぬ挙動を招くことがあるため、引数が空になる可能性がある場合は注意が必要です。
正規表現(Regex)との使い分け
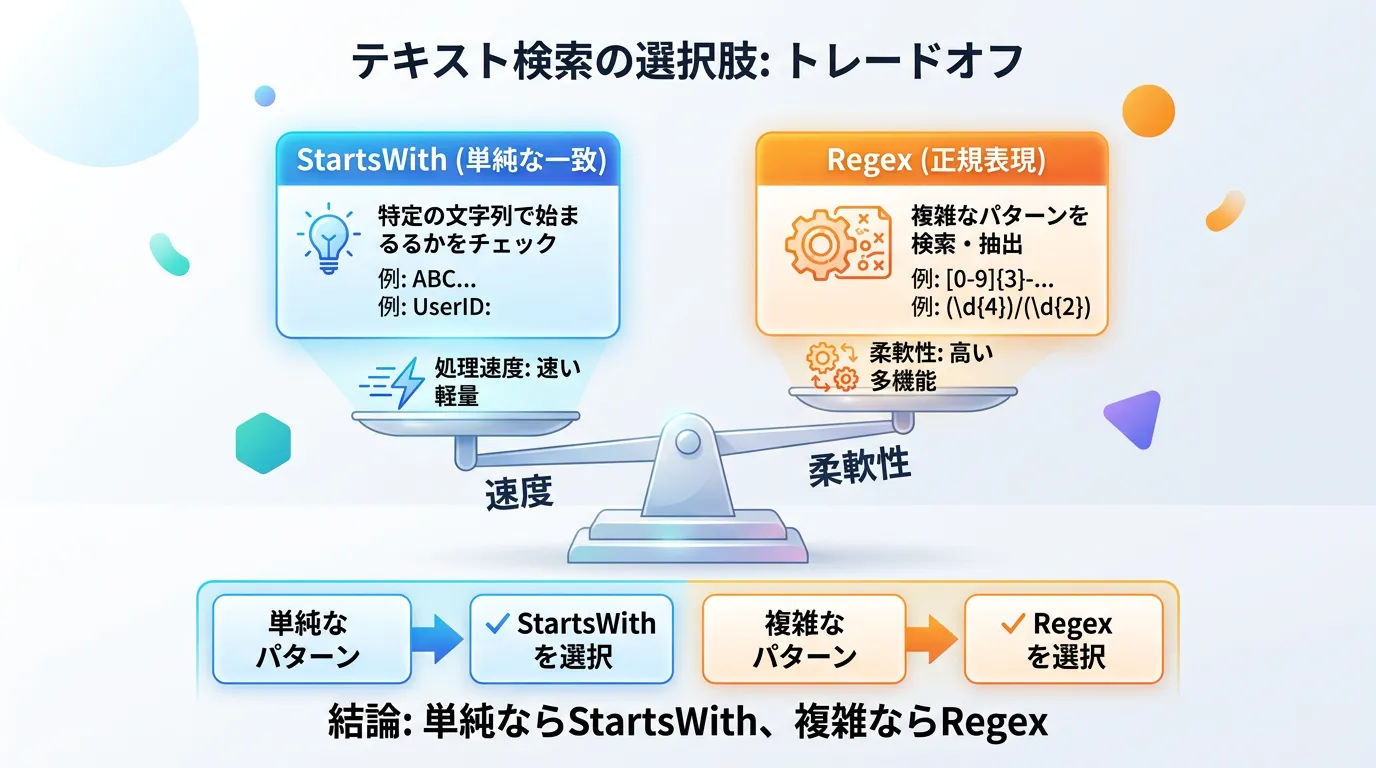
複雑なパターン(例:数字3桁で始まり、その後に特定の文字が続くなど)を判定したい場合は、StartsWithではなく正規表現を使用します。
正規表現の例
using System.Text.RegularExpressions;
string code = "123-ABC";
// 「数字3桁 + ハイフン」で始まるか
if (Regex.IsMatch(code, @"^\d{3}-"))
{
Console.WriteLine("パターンに一致しました。");
}単純な固定文字列の判定であれば、正規表現よりも StartsWith/EndsWith の方が圧倒的に高速です。
正規表現はエンジンの初期化コストや解析コストがかかるため、使い分けが重要です。
まとめ
C#のStartsWithおよびEndsWithメソッドは、文字列判定の基本でありながら、非常に奥が深い機能です。
単に一致を確認するだけでなく、StringComparisonを適切に選択して大文字・小文字やカルチャの影響を制御することが、バグの少ないプログラムを書くための第一歩となります。
また、最新の.NET環境ではReadOnlySpan<char>を活用することで、パフォーマンスを犠牲にすることなく高度な文字列解析が可能です。
まずは基本的な使い方をマスターし、徐々にパフォーマンスや多言語対応を意識した実装へとステップアップしていきましょう。
今回の内容を参考に、日々のコーディングにおける文字列操作をより洗練されたものにしてみてください。
