C#におけるメモリ管理や最適化を考える際、「参照渡し(ref)」は非常に強力な武器となります。
しかし、単に「値をコピーしないから速くなる」という単純な理解だけで使い始めると、期待したほどのパフォーマンスが得られなかったり、逆にコードの可読性を損なったりすることもあります。
本記事では、C#における参照渡しの内部的な仕組みから、値渡しとの詳細なコスト比較、そして現代的なC#開発においてどのような場面でrefや関連する修飾子(in, out, readonly ref)を選択すべきかを徹底的に解説します。
パフォーマンスチューニングの核心に迫る内容となっていますので、ぜひ最後までご覧ください。
値渡しと参照渡しの根本的な違い
まず初めに、C#における「値」と「参照」がメモリ上でどのように扱われるかを整理しておきましょう。
ここを正しく理解することが、コスト計算の第一歩となります。
メモリ上での挙動
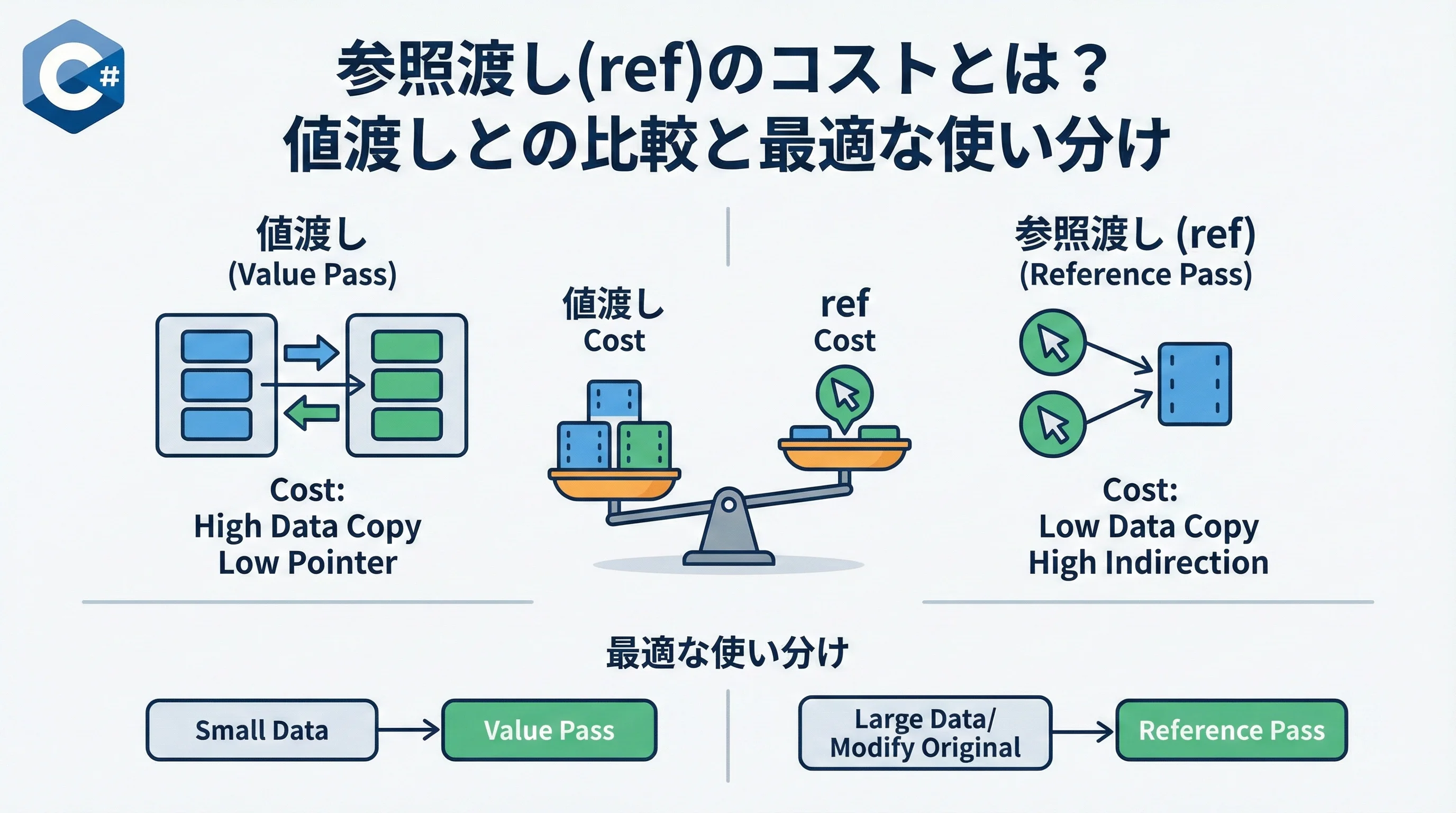
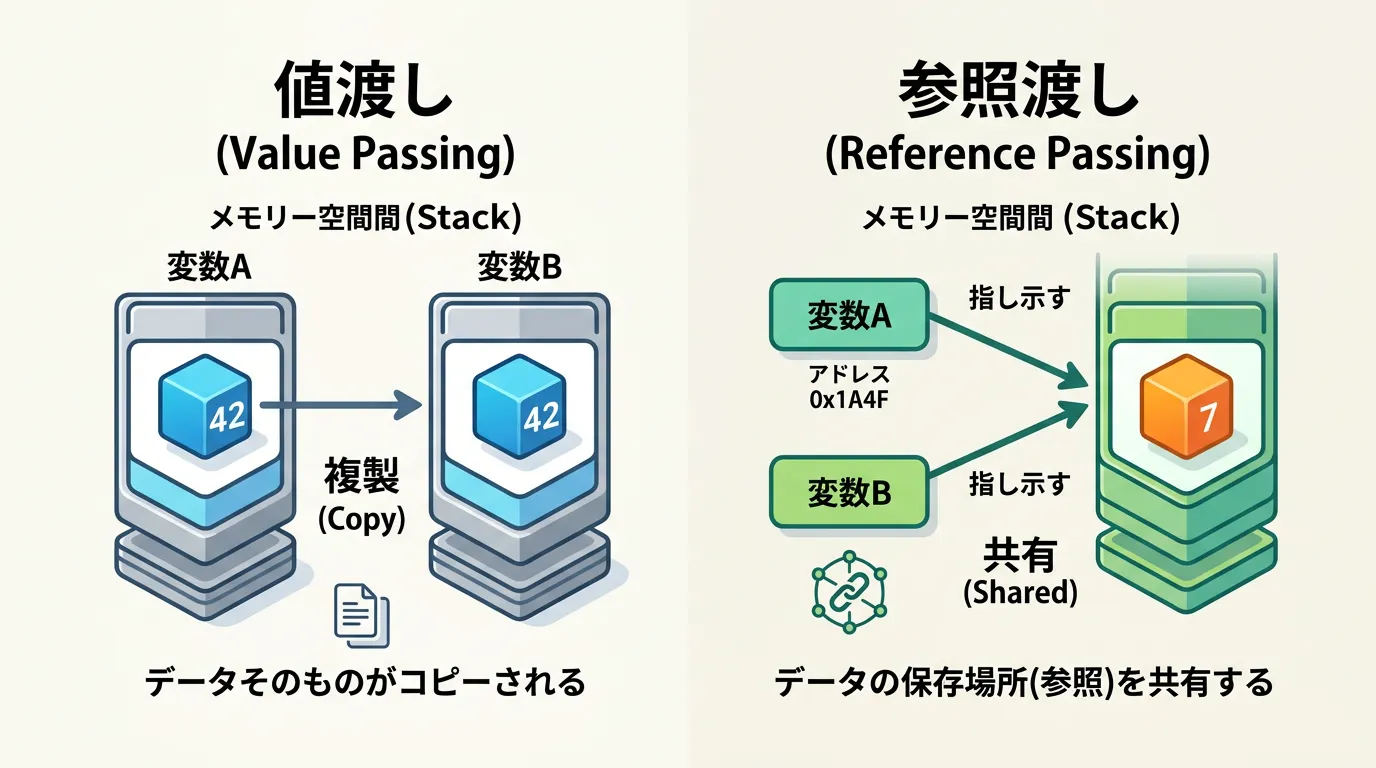
C#の構造体(struct)は、デフォルトでは「値渡し」が行われます。これは、メソッドの引数に渡す際や別の変数に代入する際、その中身が丸ごとコピーされることを意味します。一方で、refキーワードを使用した場合は、データのコピーではなく、そのデータが格納されているメモリ上のアドレス(ポインタ)」が渡されます。
以下のサンプルコードで、その挙動の違いを確認してみましょう。
using System;
struct Point
{
public int X;
public int Y;
}
class Program
{
static void Main()
{
Point p1 = new Point { X = 10, Y = 20 };
// 値渡し(コピーが発生する)
ProcessValue(p1);
Console.WriteLine($"値渡し後: X={p1.X}, Y={p1.Y}");
// 参照渡し(アドレスが渡される)
ProcessRef(ref p1);
Console.WriteLine($"参照渡し後: X={p1.X}, Y={p1.Y}");
}
// 値渡しのメソッド
static void ProcessValue(Point p)
{
p.X = 100; // 元のp1には影響しない
}
// 参照渡しのメソッド
static void ProcessRef(ref Point p)
{
p.X = 100; // 元のp1を直接書き換える
}
}値渡し後: X=10, Y=20
参照渡し後: X=100, Y=20この結果からわかる通り、refを使用すると呼び出し元のデータを直接操作できるため、「副作用を持たせる」という目的でも使用されます。
しかし、パフォーマンスの文脈では、「巨大なデータをコピーしない」という点が注目されます。
参照渡しの「見えないコスト」
「コピーをしないから参照渡しの方が常に速い」と考えるのは危険です。
実は、参照渡しには「間接参照(デリファレンス)」という特有のコストが存在します。
間接参照のオーバーヘッド
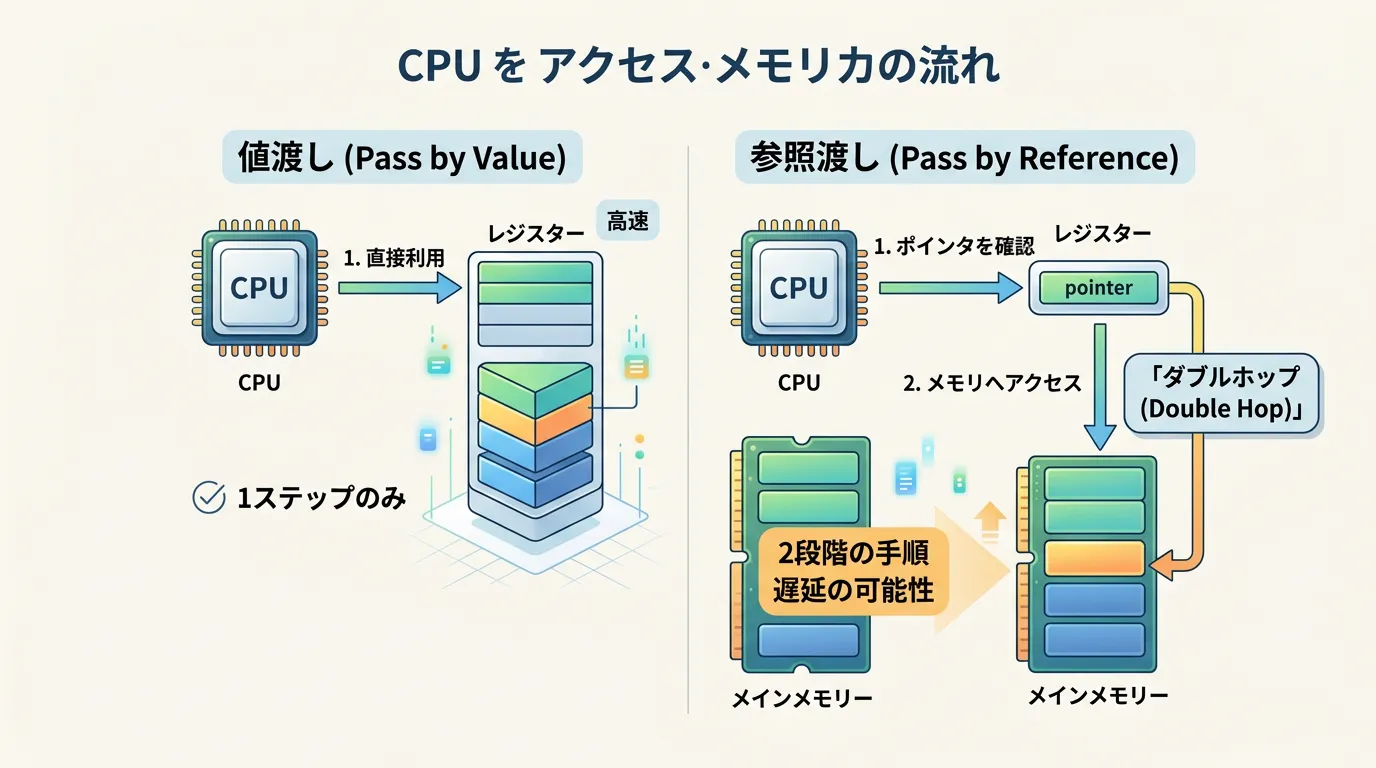
値渡しの場合、CPUはスタック上の値を直接読み取って計算に使用します。
しかし、参照渡しの場合は、まず「アドレス」を読み取り、次にそのアドレスが指し示す先のメモリへアクセスして「実際の値」を取得する必要があります。
この「アドレスを辿る」という操作が、極めて微小ながらオーバーヘッドとなります。
現代のCPUにおいて、メモリへのアクセスは非常に低速な部類に入ります。
そのため、「データのコピーにかかる時間」と「アドレスを辿る手間」のどちらが大きいかが、パフォーマンスの分岐点となります。
CPUキャッシュの影響
さらに重要なのが、CPUキャッシュの存在です。
値渡しで渡されたデータは、スタック上で連続して配置されているため、CPUのL1/L2キャッシュに乗りやすく、高速に処理されます。
一方で、参照渡しで遠くのメモリ番地を指している場合、キャッシュミスを誘発する可能性が高まり、結果としてプログラム全体の実行速度が低下することもあります。
したがって、「小さな構造体(16〜32バイト以下)」を参照渡しにするメリットはほとんどなく、むしろ遅くなるケースが多いのが実情です。
パフォーマンス比較:値渡し vs 参照渡し
では、具体的にどの程度のデータサイズからrefが有利になるのでしょうか。
一般的なベンチマーク傾向を元に解説します。
データサイズによる効率の変化
以下の表は、構造体のサイズに応じたコストの変化をまとめたものです。
| 構造体のサイズ | 推奨される渡し方 | 理由 |
|---|---|---|
| 4〜16バイト (int2つ分など) | 値渡し | コピーコストが非常に小さく、間接参照のオーバーヘッドの方が大きいため。 |
| 17〜64バイト | どちらでも良い | パフォーマンスの差がほとんど現れない境界線。 |
| 65バイト以上 | 参照渡し | メモリコピーのコストが無視できなくなり、参照渡しの方が高速になる。 |
ベンチマークによる検証コード例
実際にどれくらいの差が出るかを測定するためのコードイメージです。
ここでは、非常に大きな構造体をループ内で回す例を考えます。
using System;
using System.Diagnostics;
// 128バイトの巨大な構造体
struct LargeStruct
{
public decimal d1, d2, d3, d4, d5, d6, d7, d8;
}
class Benchmark
{
static void Main()
{
LargeStruct data = new LargeStruct();
const int iterations = 100_000_000;
// 値渡しの測定
Stopwatch sw1 = Stopwatch.StartNew();
for (int i = 0; i < iterations; i++)
{
PassByValue(data);
}
sw1.Stop();
// 参照渡しの測定
Stopwatch sw2 = Stopwatch.StartNew();
for (int i = 0; i < iterations; i++)
{
PassByRef(ref data);
}
sw2.Stop();
Console.WriteLine($"値渡し: {sw1.ElapsedMilliseconds}ms");
Console.WriteLine($"参照渡し: {sw2.ElapsedMilliseconds}ms");
}
static void PassByValue(LargeStruct s) { /* 何もしない */ }
static void PassByRef(ref LargeStruct s) { /* 何もしない */ }
}実行結果(環境による)
値渡し: 450ms
参照渡し: 85msこのように、構造体がある程度の大きさ(例えば行列データやセンサーのバッファなど)を持つ場合、参照渡しによる高速化の恩恵は顕著になります。
現代的なC#における参照渡しのバリエーション
C# 7.0以降、参照渡しをより安全かつ効率的に扱うための機能が次々と追加されました。
単なるref以外の手法を知ることで、バグを抑えつつ高速なコードを書くことができます。
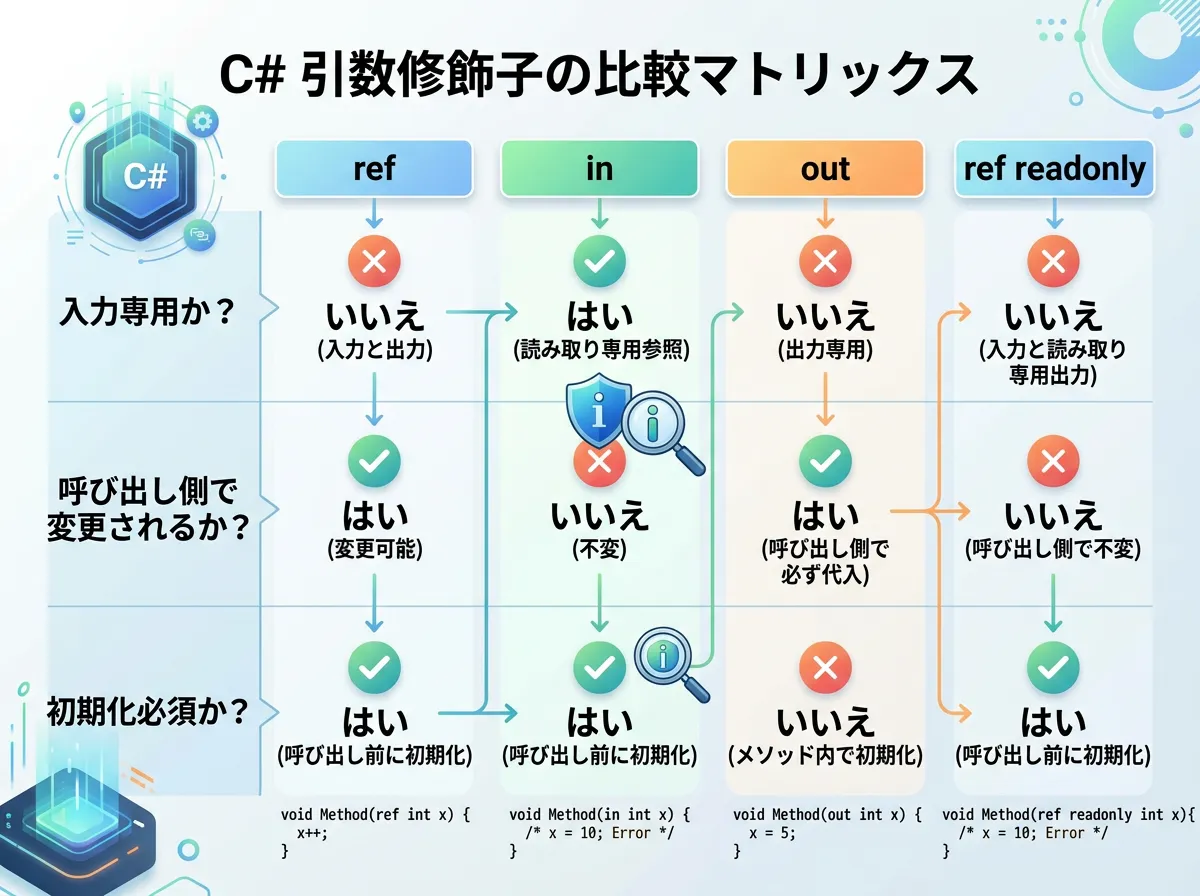
1. in 引数 (読み取り専用参照渡し)
in修飾子は、C# 7.2で導入された非常に強力な機能です。
これは「参照渡しをするが、メソッド内で値を変更させない」という制約を設けます。
- 利点: 大きな構造体のコピーを防ぎつつ、呼び出し元の変数が書き換えられる心配がない。
- 注意点: メソッド内で読み取り専用のフィールドにアクセスする際、コンパイラが「防御的コピー(Defensive Copy)」を作成してしまい、かえって遅くなることがあります。
// 大きな構造体を安全に、かつ高速に渡す
static void Calculate(in LargeStruct data)
{
// data.d1 = 100; // コンパイルエラー(読み取り専用)
Console.WriteLine(data.d1);
}2. ref readonly return (参照戻り値)
メソッドの戻り値を参照として返す機能です。
これにより、クラスや構造体の内部にある大きなデータをコピーせずに外部へ公開できます。
class DataContainer
{
private LargeStruct _data;
// 内部データをコピーせずに参照として返す
public ref readonly LargeStruct GetData() => ref _data;
}3. ref struct
ref structは、スタック上にのみ配置されることが保証される構造体です。
これを使用すると、ヒープへの割り当て(ボックス化)を完全に禁止できるため、超高頻度で呼ばれる低レイヤの処理で極めて有効です。
代表的な例としてSpan<T>があります。
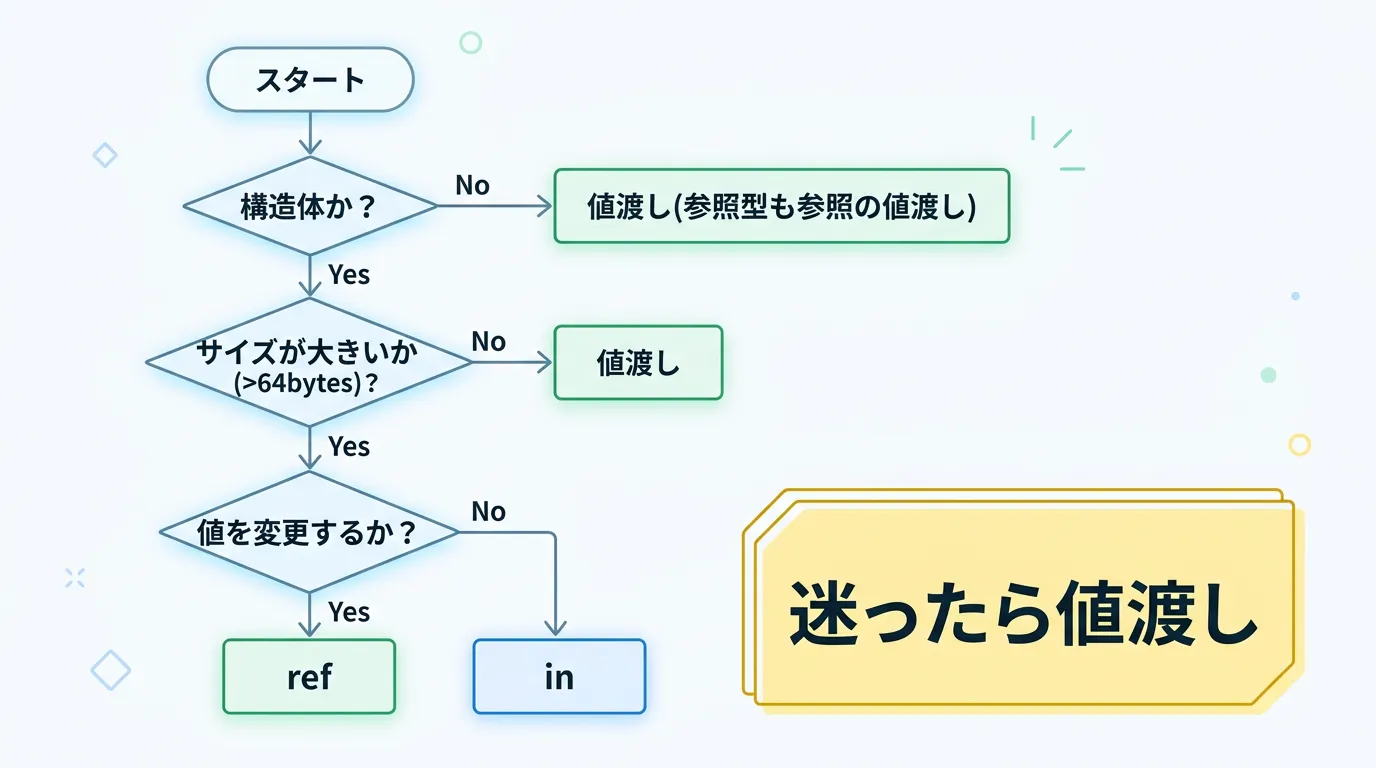
実践的な使い分けガイドライン
これまでの内容を踏まえ、日々の開発でどのように使い分けるべきかの指針を示します。
いつ ref / in を使うべきか?
- 構造体のサイズが64バイトを超える場合
引数として渡す回数が多いのであれば、inまたはrefを検討してください。
- メソッド内で呼び出し元の値を更新する必要がある場合
これはパフォーマンスではなくロジックの都合ですが、明確にrefを使用します。
- スタック上のメモリを直接操作する場合
Span<T>
などを活用し、refで受け渡しを行うことでGCへの負荷を最小限に抑えられます。
いつ使うべきではないか? (アンチパターン)
- プリミティブ型(int, float, bool など)
これらを ref にするのは、ほとんどのケースでパフォーマンスを低下させます。
- 不変ではない小さな構造体
読み取り専用にするために in を多用すると、防御的コピーが発生し、意図せず低速化する原因になります。
- 参照渡し(ref)
可読性が著しく低下する場合、参照渡しはメソッドの外側に影響を与える可能性があるため、多用しすぎるとコードの追いかけが難しくなります。
参照渡しとJITコンパイラの関係
C#のコードは実行時にJIT(Just-In-Time)コンパイルされます。
最近の.NET環境(Core以降)では、JITコンパイラが非常に賢くなっており、「インライン化」という最適化を行います。
メソッドがインライン化されると、引数の受け渡し自体が省略され、レジスタ上で直接計算が行われるようになります。
この場合、値渡しか参照渡しかという議論自体が無意味になることもあります。
しかし、メソッドの規模が大きく、インライン化の対象から外れる場合、明示的なref指定が大きな意味を持ってきます。
低レイヤのライブラリ開発でない限り、まずは可読性を優先し、プロファイリング結果に基づいて後からrefを適用するのが健全な開発スタイルと言えるでしょう。
まとめ
C#のrefによる参照渡しは、メモリコピーを回避してパフォーマンスを向上させるための強力な手段です。
しかし、間接参照のコストやキャッシュ効率、コンパイラの挙動など、考慮すべき点は多岐にわたります。
結論として、以下の3点を意識してください。
- 小さなデータ(プリミティブ型や数個のフィールドを持つ構造体)は「値渡し」が最速である。
- 巨大な構造体を扱う場合や、特定のメモリ領域を操作する場合に限り「ref/in」を活用する。
- パフォーマンスがボトルネックになっていない箇所で「ref」を乱用せず、コードの明確さを優先する。
現代のC#は、inやSpan<T>といった「安全に参照を扱う仕組み」が整っています。
これらを正しく理解し使い分けることで、安全かつ高速なアプリケーションを構築できるようになります。
最適化の第一歩は、魔法を信じることではなく、メモリの動きを正しく把握することから始まります。
