
C#における引数の受け渡しは、基本的に「値渡し」が標準です。
しかし、大規模なデータ構造を扱う際や、複数の戻り値を返したい場合、パフォーマンスを極限まで最適化したい場合には、参照渡しを制御するref、out、inという3つのキーワードが重要な役割を果たします。
これらのキーワードを正しく理解し使い分けることは、メモリ効率の良い堅牢なアプリケーションを構築する上で欠かせません。
本記事では、これら3つのキーワードの違いから、内部動作、そしてパフォーマンスに与える影響までを詳しく解説します。
参照渡しの基本概念
C#でこれら3つのキーワードを理解するためには、まず「値渡し」と「参照渡し」の違いを明確にする必要があります。
通常、構造体(struct)などの値型をメソッドに渡すと、そのデータのコピーが作成されます。
これに対し、参照渡しではデータのメモリ上の場所(アドレス)を渡すため、コピーが発生しません。
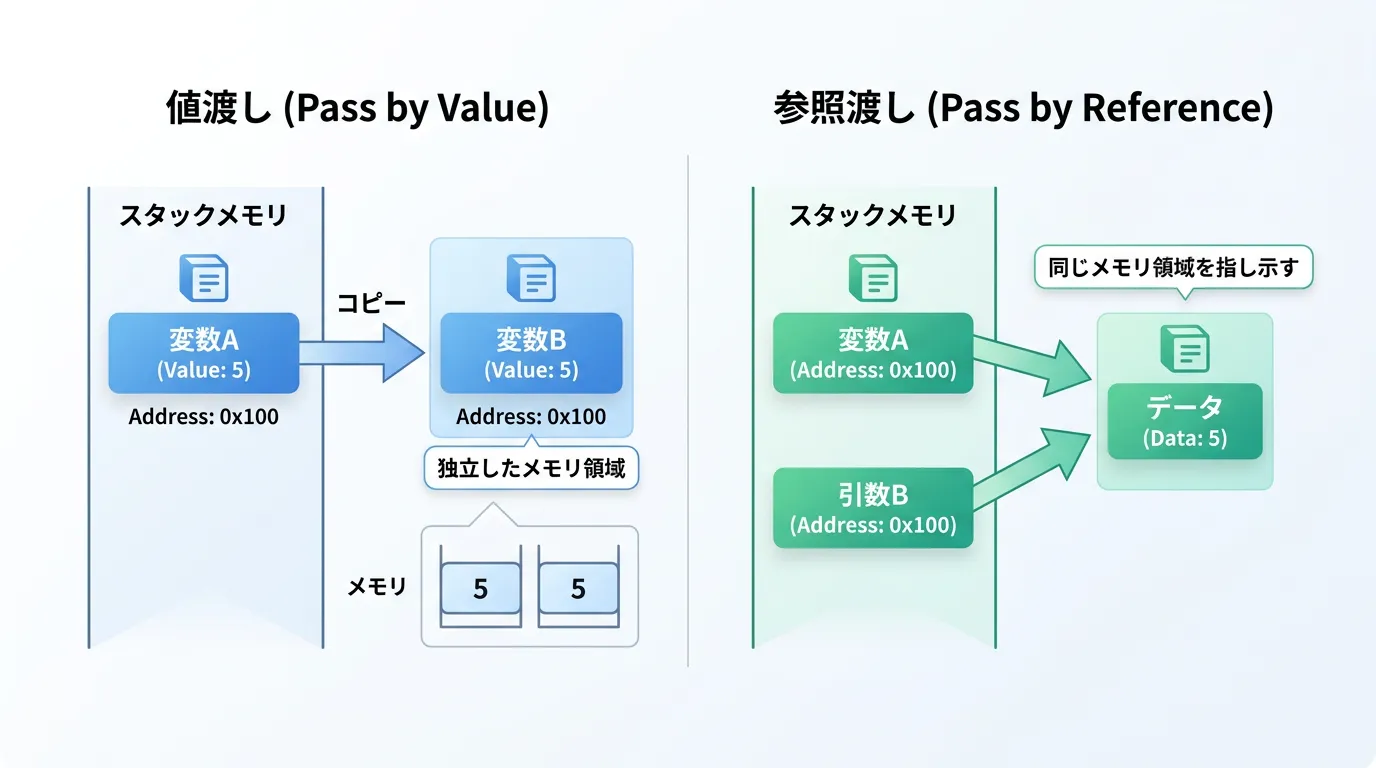
C#では、参照渡しを実現するために主に3つの方法が用意されています。
これらは「データの流れる方向」と「書き込み許可」によって区別されます。
| キーワード | データの方向 | 呼び出し側の初期化 | メソッド内での代入 |
|---|---|---|---|
ref | 双方向(入力・出力) | 必須 | 任意 |
out | 出力のみ | 不要 | 必須 |
in | 入力のみ(読み取り専用) | 必須 | 禁止 |
これらの特性を理解した上で、それぞれの詳細な挙動を見ていきましょう。
refキーワード:双方向の参照渡し
refキーワードは、引数を参照として渡すための最も基本的な方法です。
呼び出し元で初期化された変数をメソッドに渡し、メソッド内でその値を読み取ることも、書き換えることも可能です。
メソッド内で行われた変更は、即座に呼び出し元の変数に反映されます。
refの使用例と動作
以下のコードは、2つの整数の値を入れ替える(Swap)処理をrefを用いて実装した例です。
using System;
class RefExample
{
static void Main()
{
int x = 10;
int y = 20;
Console.WriteLine($"実行前: x = {x}, y = {y}");
// refキーワードを付けてメソッドを呼び出す
Swap(ref x, ref y);
Console.WriteLine($"実行後: x = {x}, y = {y}");
}
// 引数にrefを付けることで、参照を受け取る
static void Swap(ref int a, ref int b)
{
int temp = a;
a = b;
b = temp;
}
}実行前: x = 10, y = 20
実行後: x = 20, y = 10refを使用する場合、呼び出し側とメソッド定義側の両方にrefを記述する必要があります。
これにより、コードを読んでいる人が「この変数はメソッド内で書き換えられる可能性がある」ということを明示的に知ることができます。
注意点として、refで渡す変数は、メソッドに渡す前に必ず初期化されている必要があります。
outキーワード:出力専用の参照渡し
outキーワードは、メソッドから複数の値を返したい場合によく使われます。
戻り値(return)とは別に、引数を通じて結果を呼び出し元に返します。
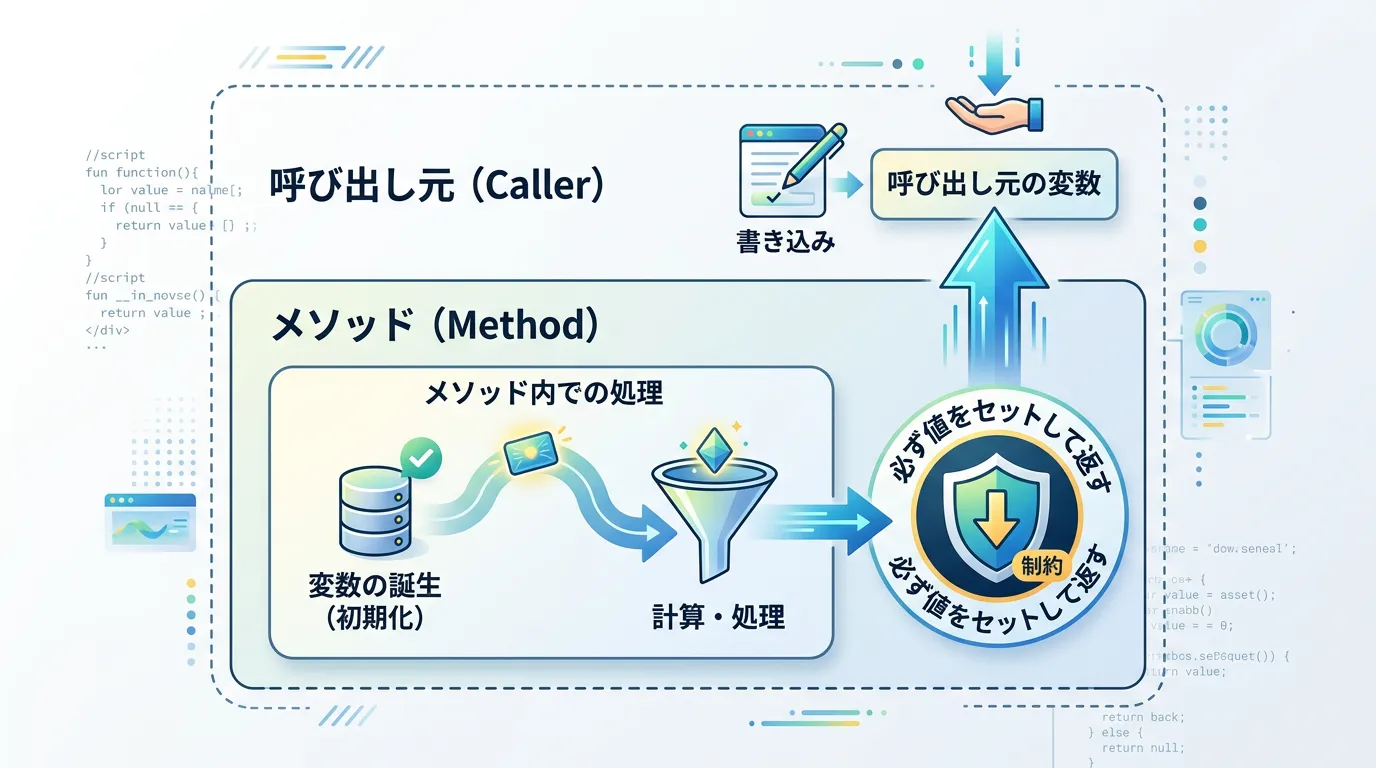
outの使用例と動作
outの最大の特徴は、メソッド内で必ず値を代入しなければならないという点です。
コンパイラはこの制約を厳格にチェックします。
using System;
class OutExample
{
static void Main()
{
// 呼び出し側で初期化していなくても渡せる
if (TryParseDouble("123.45", out double result))
{
Console.WriteLine($"変換成功: {result}");
}
else
{
Console.WriteLine("変換失敗");
}
}
static bool TryParseDouble(string input, out double value)
{
try
{
// out引数には必ず値を代入しなければならない
value = double.Parse(input);
return true;
}
catch
{
// 失敗時でも必ず初期値を代入する必要がある
value = 0;
return false;
}
}
}変換成功: 123.45C# 7.0以降では、上記の例のようにout varという形式で、メソッドの引数リストの中で直接変数を宣言できるようになりました。
これにより、コードの記述が簡潔になります。
inキーワード:読み取り専用の参照渡し
inキーワードは、C# 7.2で導入された比較的新しい機能です。
主な目的はパフォーマンスの向上です。
大きな構造体を引数として渡す際、値渡しによるコピーを避けるために参照として渡しますが、メソッド内での変更を禁止したい場合に使用します。
inの使用例と制限
inを指定した引数は、メソッド内では読み取り専用(ReadOnly)として扱われます。
そのため、メソッド内でその引数に値を代入しようとすると、コンパイルエラーが発生します。
struct LargeStruct
{
public double X, Y, Z;
// 実際にはもっと多くのフィールドがある想定
}
class InExample
{
static void Main()
{
LargeStruct data = new LargeStruct { X = 1, Y = 2, Z = 3 };
PrintData(in data);
}
static void PrintData(in LargeStruct data)
{
// データの読み取りは可能
Console.WriteLine($"X: {data.X}");
// データの書き換えはコンパイルエラーになる
// data.X = 10; // エラー: 読み取り専用変数に割り当てることはできません
}
}inは、特に「読み取り専用の大きな構造体」を扱う際に真価を発揮します。
しかし、使いどころを間違えると逆にパフォーマンスを低下させる可能性があるため、注意が必要です。
パフォーマンス比較と内部動作の最適化
これら3つのキーワードを使用する最大の動機の一つは、パフォーマンスです。
特に値型(struct)の受け渡しにおいて、メモリのコピーコストをいかに抑えるかが鍵となります。
コピーコストの削減
値型をメソッドに渡すと、その中身がすべてスタックにコピーされます。
例えば、16バイトを超えるような大きな構造体の場合、このコピー処理がループ内などで頻繁に発生すると、CPUのキャッシュ効率を下げ、実行速度に影響を与えます。
refやinを使用すると、中身に関わらずポインタ(通常4または8バイト)のみが渡されるため、非常に効率的です。
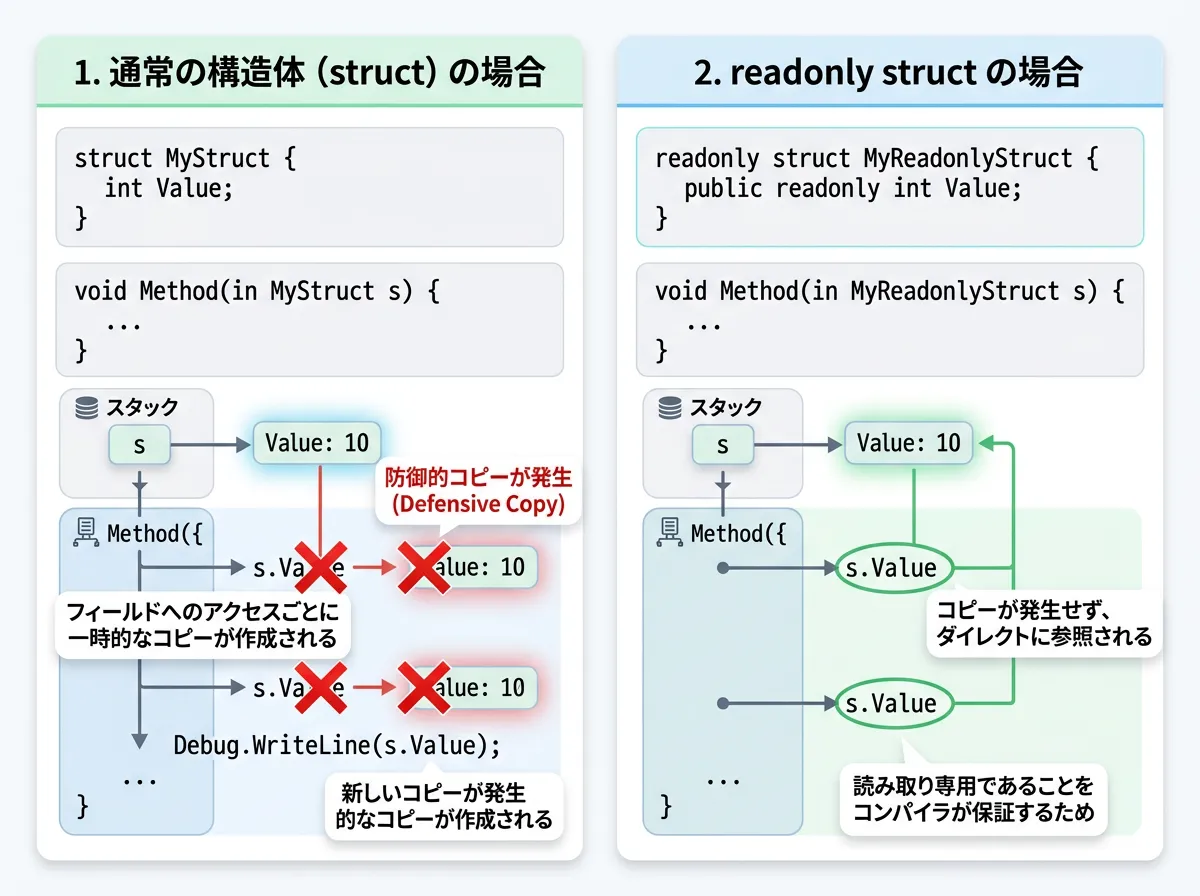
隠れた罠:防御的コピー (Defensive Copy)
inキーワードを使用する際に最も注意すべきなのが「防御的コピー」です。
もしメソッドに渡す構造体がreadonly structとして定義されていない場合、コンパイラは「メソッド内で値が変更されないこと」を保証するために、メソッド内でその構造体のコピーを内部的に作成してから読み取りを行います。
これでは、コピーを避けるためにinを使った意味がなくなってしまいます。
パフォーマンスを最大化する組み合わせ
パフォーマンスを追求する場合、以下のような設計指針が推奨されます。
- 小さな構造体(16バイト以下)
そのまま値渡しを行うのが最適です。
- 大きな構造体
readonly structとして定義し、inで渡します。- 変更が必要な場合
refを使用します。
実行速度のベンチマークイメージ
理論上、大きな構造体を100万回ループで渡すような処理では、以下のような差が生じます。
| 渡し方 | 構造体のサイズ | 実行時間 (相対) | 備考 |
|---|---|---|---|
| 値渡し | 小 (int) | 1.0 | 非常に高速 |
| 値渡し | 大 (struct) | 5.0 – 10.0 | コピー負荷が高い |
ref / in | 大 (struct) | 1.1 – 1.5 | コピーが発生せず安定 |
in (非readonly) | 大 (struct) | 6.0 – 12.0 | 防御的コピーにより最遅の可能性 |
このように、inはreadonly structと組み合わせて初めて最強のパフォーマンスを発揮します。
適切な使い分けのガイドライン
これまでの内容を踏まえ、開発現場でどのように使い分けるべきかを整理します。
refを使うべきケース
refは「既存の変数を直接書き換えたい」という意図が明確な場合に使用します。
- 状態を保持する大きな構造体を更新するメソッド。
- 低レイヤーの最適化が必要な計算アルゴリズム。
- 外部ライブラリ(Win32 APIなど)との相互運用。
outを使うべきケース
outは「メソッドの成功・失敗を返しつつ、追加でデータを返したい」場合に使用します。
TryParseパターンの実装。- 1つのメソッドから複数の異なる計算結果を取得したい場合(ただし、最近は
ValueTupleを使う方が可読性が高いケースも多いです)。
inを使うべきケース
inは「読み取り専用として安全に、かつ高速に大きなデータを渡したい」場合に使用します。
- ベクトル計算、行列演算、3Dグラフィックスなどの大きな構造体を扱う処理。
- 不変(Immutable)なデータ構造を大量に走査する処理。
タプル(ValueTuple)との比較
最近のC#では、複数の戻り値を返す方法としてタプルが推奨されることが多いです。
// outを使う古いスタイル
bool success = GetUser(out User u, out int id);
// タプルを使うモダンなスタイル
var (user, id) = GetUser();可読性を重視するならタプル、パフォーマンスとメモリ再利用を重視するならoutという使い分けが一般的です。
タプルは内部的に構造体ですが、戻り値としてスタックに積まれるため、非常に大きなデータを返す場合はやはり参照渡し系のキーワードが有利になります。
まとめ
C#のref、out、inは、いずれもポインタを介した参照渡しを行うための強力な道具です。
refは読み書き可能な双方向通信、outは初期化を強制する出力専用、そしてinはパフォーマンスに特化した読み取り専用の参照渡しです。
特にinを使用する際は、防御的コピーを避けるためにreadonly structとセットで利用することがパフォーマンス向上の絶対条件となります。
これらを適切に使い分けることで、メモリ消費を抑えつつ、意図が明確で保守性の高いコードを書くことができます。
まずは引数のサイズと「変更の有無」を確認し、最適なキーワードを選択する習慣を身につけましょう。
