
Pythonで多数の文字を一括で置換・削除したい場面は意外と多いです。
例えば、英字の大文字小文字をまとめて変換したり、不要な記号だけを一気に取り除いたりといった処理です。
そのようなときに活躍するのがstr.translateです。
本記事では、複数文字を一括で変換・削除する実用的な使い方を、基礎から応用パターンまで丁寧に解説します。
str.translateとは?Pythonでの基本仕様
str.translateの役割と特徴
Pythonのstr.translateは、「1文字単位のマッピング表(変換テーブル)に従って、文字列を変換する」ためのメソッドです。
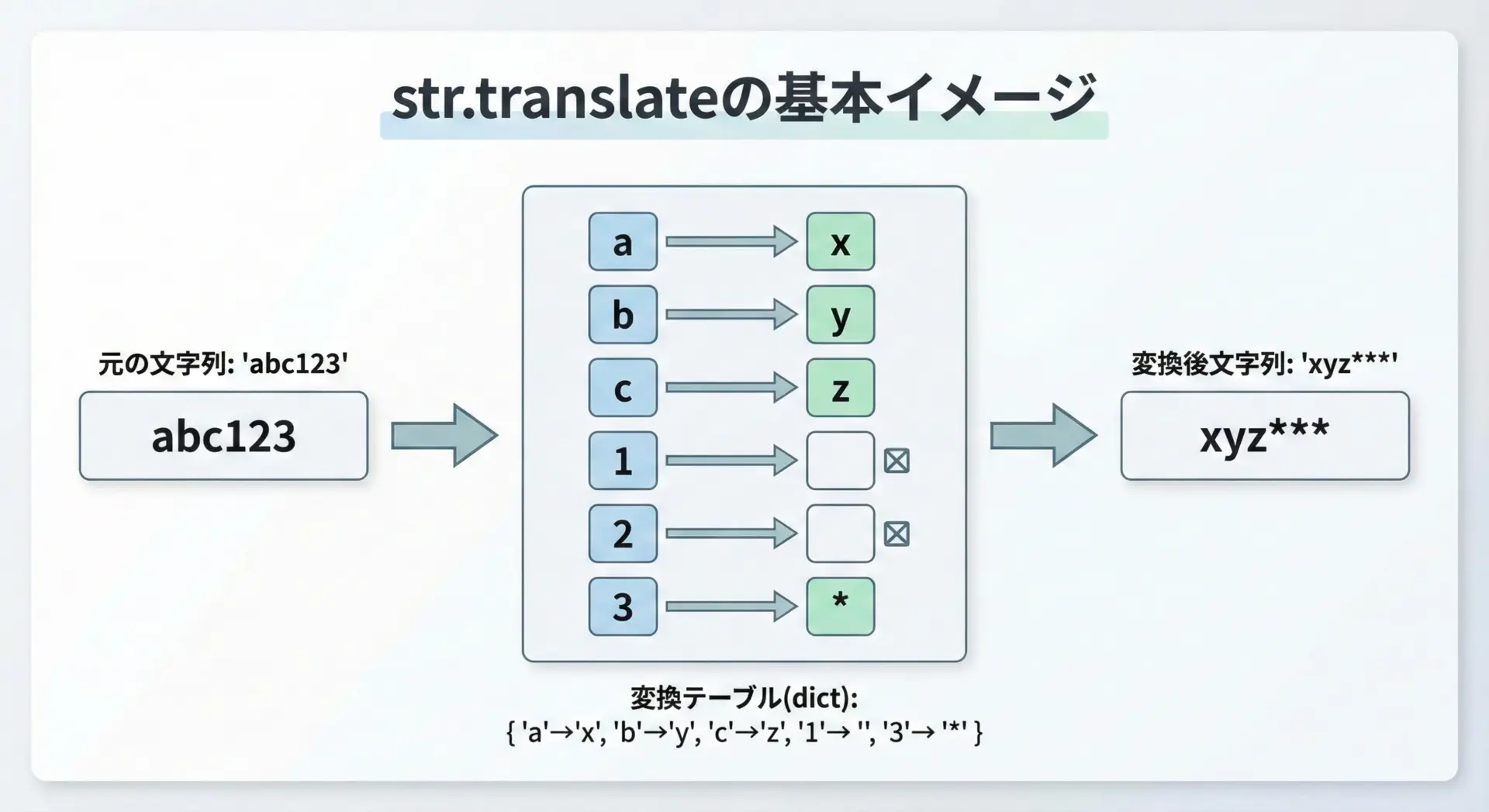
str.translateの基本的な特徴を、文章で整理します。
まず、第1に文字ごとの変換を一括で行えることです。
複数のreplaceを連続で書く代わりに、変換テーブルを1つ用意して一度にまとめて変換します。
次に、第2に「どのコードポイント(Unicodeコード)を、どの文字列に変換するか」を辞書で指定するという点が重要です。
Python内部では、各文字がUnicodeの整数コードポイントで表現されるため、translateは整数キーと文字列の値からなるテーブルを使います。
さらに、第3に指定した文字を「削除」することも可能です。
変換テーブルの値にNoneを指定することで、その文字をまるごと削除できます。
この「変換」と「削除」を同時に扱えるのが大きな利点です。
str.maketransで変換テーブルを作成する理由
str.translateを直接使うには、「Unicodeコードポイント(int)をキーとする辞書」が必要です。
しかし毎回整数コードポイントを調べて辞書を書くのは現実的ではありません。
そこで役立つのがstr.maketransです。
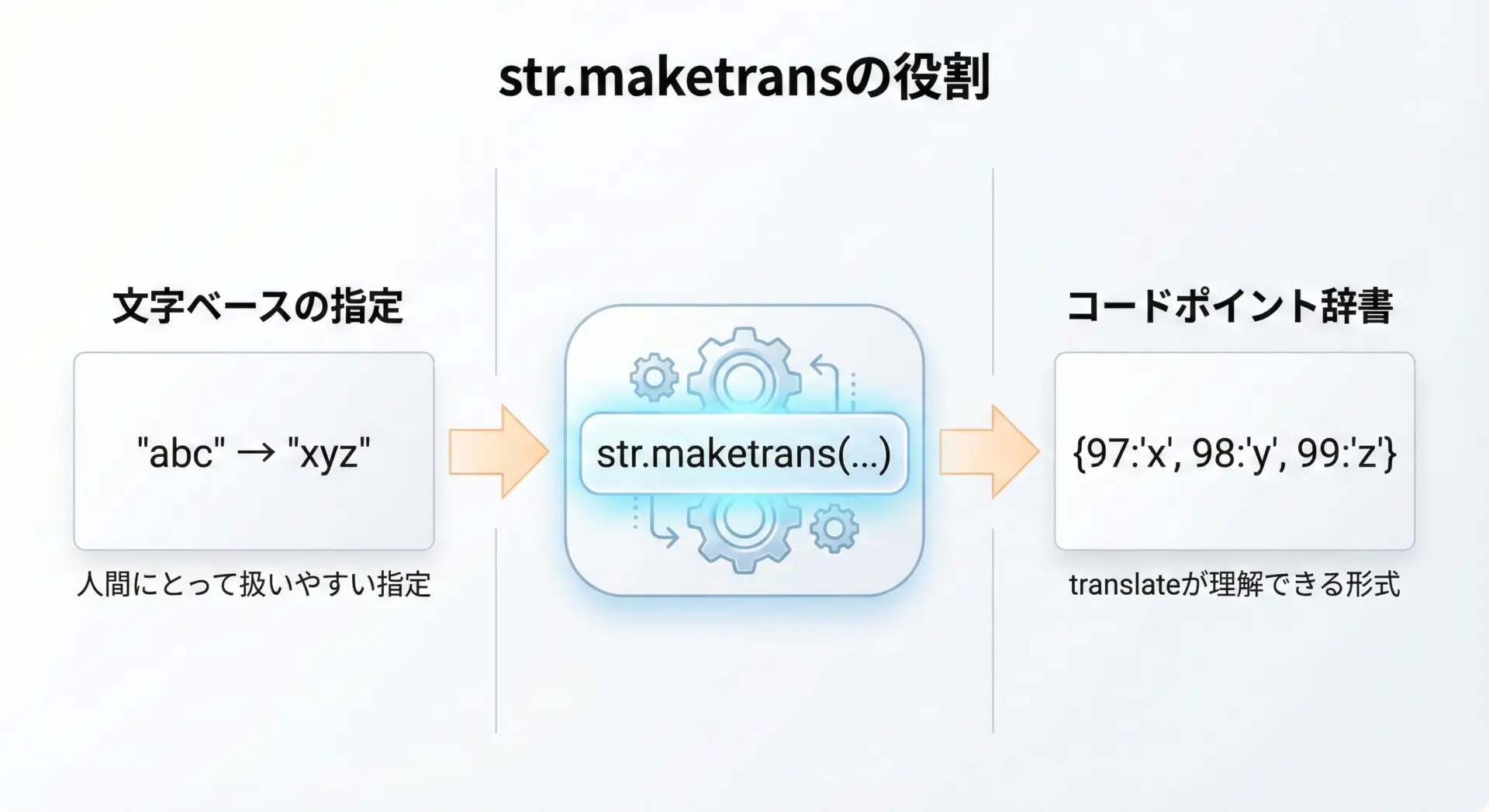
str.maketransを使うと、次のような書き方で簡単に変換テーブルを作れます。
- 文字列同士を渡して「1対1のマッピング」を作る
- 辞書形式で「文字(またはコードポイント)→文字列/None」を直接指定する
- 3つ目の引数で「削除したい文字集合」をまとめて指定する
このように「人間が書きやすい指定」から「translateが理解できる変換テーブル」へ変換してくれるのがstr.maketransの役割です。
具体例をC言語風ではなくPythonで示します。
# 基本的な使い方の例
# 「abc」を「xyz」にそれぞれ変換するテーブルを作る
table = str.maketrans("abc", "xyz")
text = "abracadabra"
# 変換テーブルに従って文字列を変換
result = text.translate(table)
print(result) # => xyrxczdxyrx (のような結果になります)上記のように、Pythonではstr.maketransが辞書作成の煩雑さを隠蔽してくれるため、通常はこちらを経由してテーブルを作るのが実務的です。
str.replaceとの違いと使い分け
str.replaceも文字列を置換するためによく使われますが、str.translateとは設計思想が異なります。
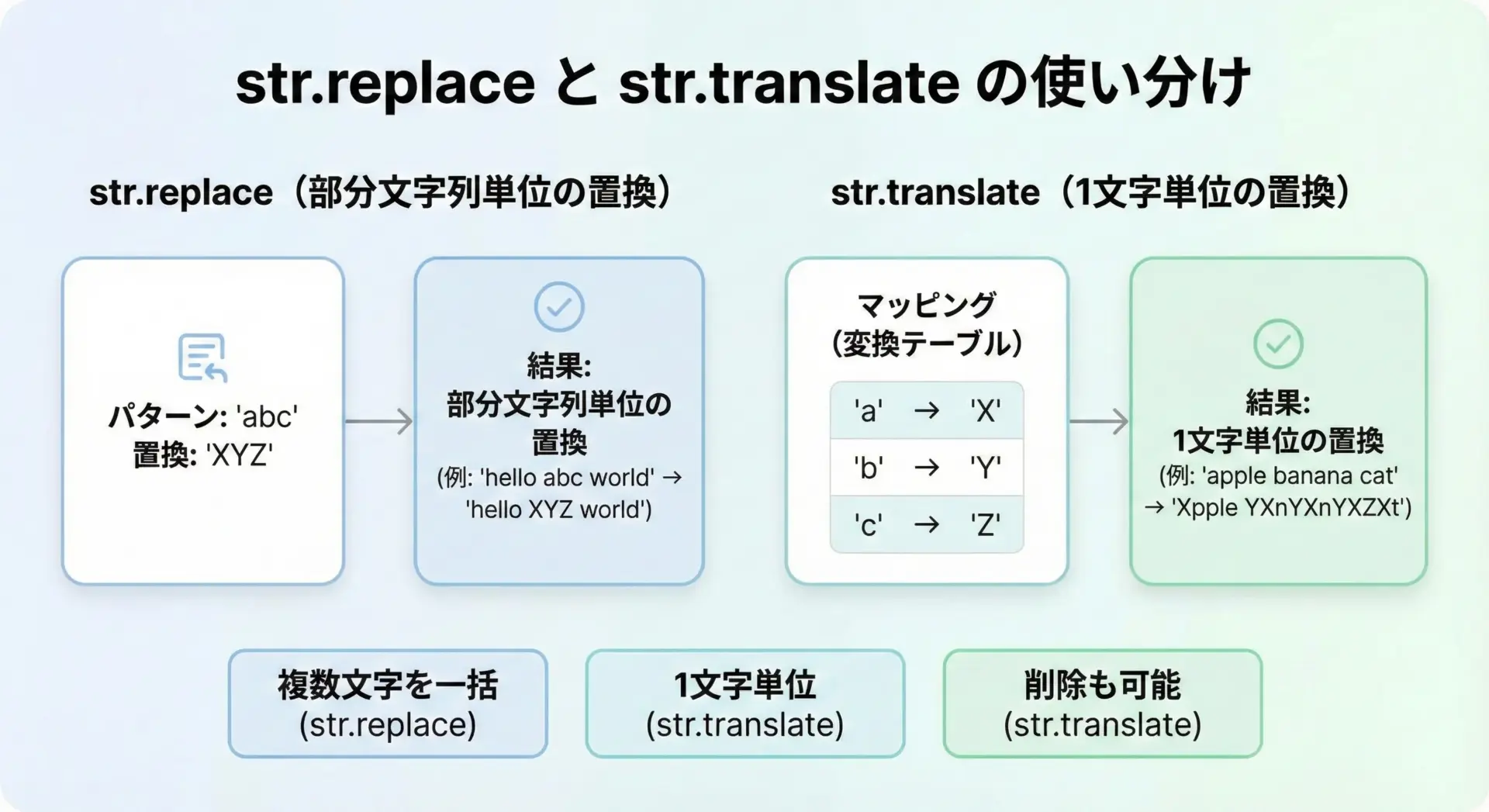
str.replaceは、「部分文字列」単位での置換を行います。
つまり、text.replace("abc", "XYZ")のように、連続した文字列をまとめて違う文字列に置き換えます。
一方でstr.translateは「各文字」単位での変換に特化しており、1文字ごとに変換テーブルを参照します。
そのため、次のように使い分けるとよいです。
- 文中の特定の「単語」や「複数文字の連なり」を別の文字列に変えたい場合は
replace - 多数の異なる文字を一括で変換・削除したい場合や、性能を重視する場合は
translate
例えば、複数の不要記号を削除する処理をreplaceで書くと次のようになります。
text = "Hello, World!! (Python3)"
# replaceを何度も呼び出している例
cleaned = (
text.replace(",", "")
.replace("!", "")
.replace("(", "")
.replace(")", "")
)
print(cleaned)Hello World Python3このようにreplaceでも書けますが、置換対象が増えるとコードがどんどん長くなり、パフォーマンスも低下しがちです。
このような状況ではtranslateの出番となります。
str.translateで複数文字を一括置換する基本パターン
1文字ずつの複数置換
最も基本的なパターンとして、複数の文字をそれぞれ別の1文字に置き換える方法から見ていきます。
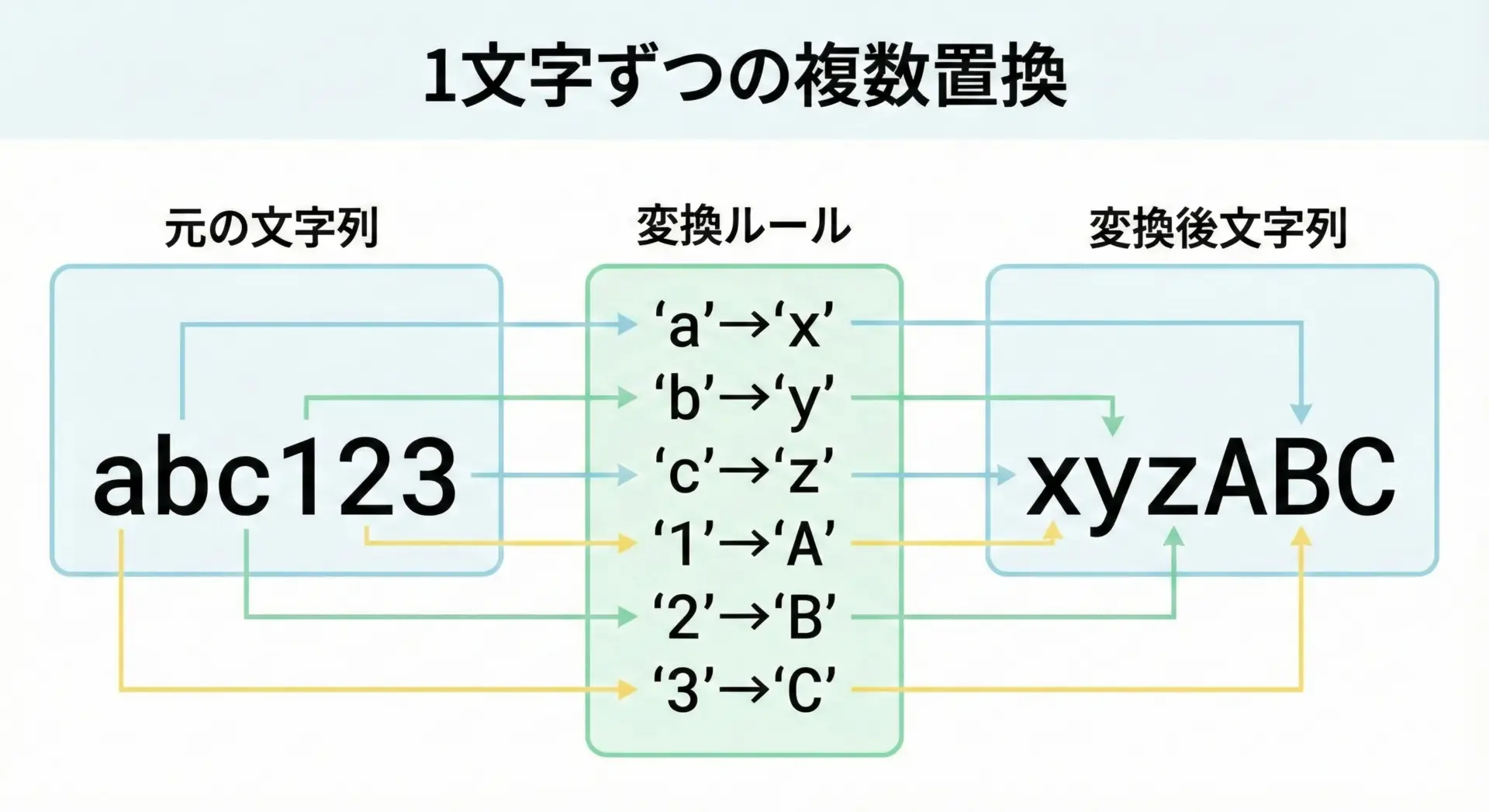
次のサンプルコードでは、アルファベットと数字の一部を別の文字に置き換えています。
# 複数の文字を1文字ずつまとめて置換する例
text = "abc123abc"
# "abc123" の各文字をそれぞれ "xyzABC" に対応させる
# a→x, b→y, c→z, 1→A, 2→B, 3→C という対応になります
table = str.maketrans("abc123", "xyzABC")
result = text.translate(table)
print("元の文字列:", text)
print("変換後文字列:", result)元の文字列: abc123abc
変換後文字列: xyzABCxyzここでのポイントは、変換したい文字を左側、対応する文字を右側に同じ順番で並べるという点です。
長さが一致していないとValueErrorになるため注意が必要です。
複数文字を別の1文字にまとめて変換
次に、複数の異なる文字を同じ1文字にまとめて変換するパターンです。
例えば、「a」「ä」「â」をすべて「a」に統一したい場合などが該当します。
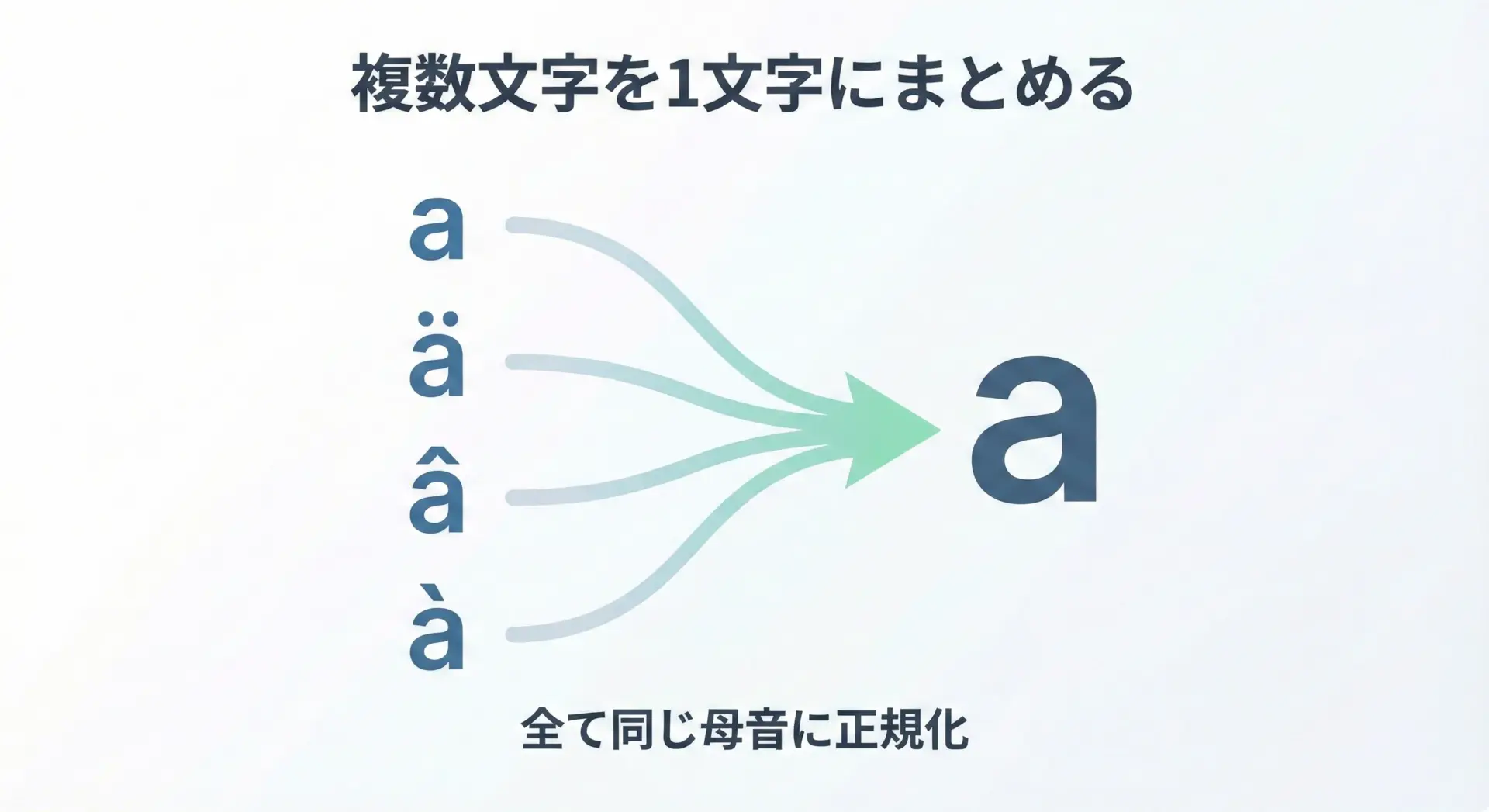
str.maketransの「文字列同士」指定では「1対1」しか書けませんが、辞書形式で指定すれば、複数文字を同じ1文字に集約できます。
# 複数の類似文字を1つの文字にまとめる例
text = "café, cafè, cafê, cafe"
# それぞれのアクセント付き「e」をプレーンな "e" に統一する
table = str.maketrans({
"é": "e",
"è": "e",
"ê": "e",
})
result = text.translate(table)
print("元の文字列:", text)
print("正規化後文字列:", result)元の文字列: café, cafè, cafê, cafe
正規化後文字列: cafe, cafe, cafe, cafeこのように辞書指定を使うと、「似た文字をまとめて1種類に揃える」といった正規化処理が簡潔に書けます。
複数文字を削除する
translateのもう1つの武器が、特定の文字を一括削除できる点です。
削除には次の2通りの方法があります。
str.maketransの第3引数に「削除したい文字列」を渡す方法- 変換テーブルの値に
Noneを指定する方法
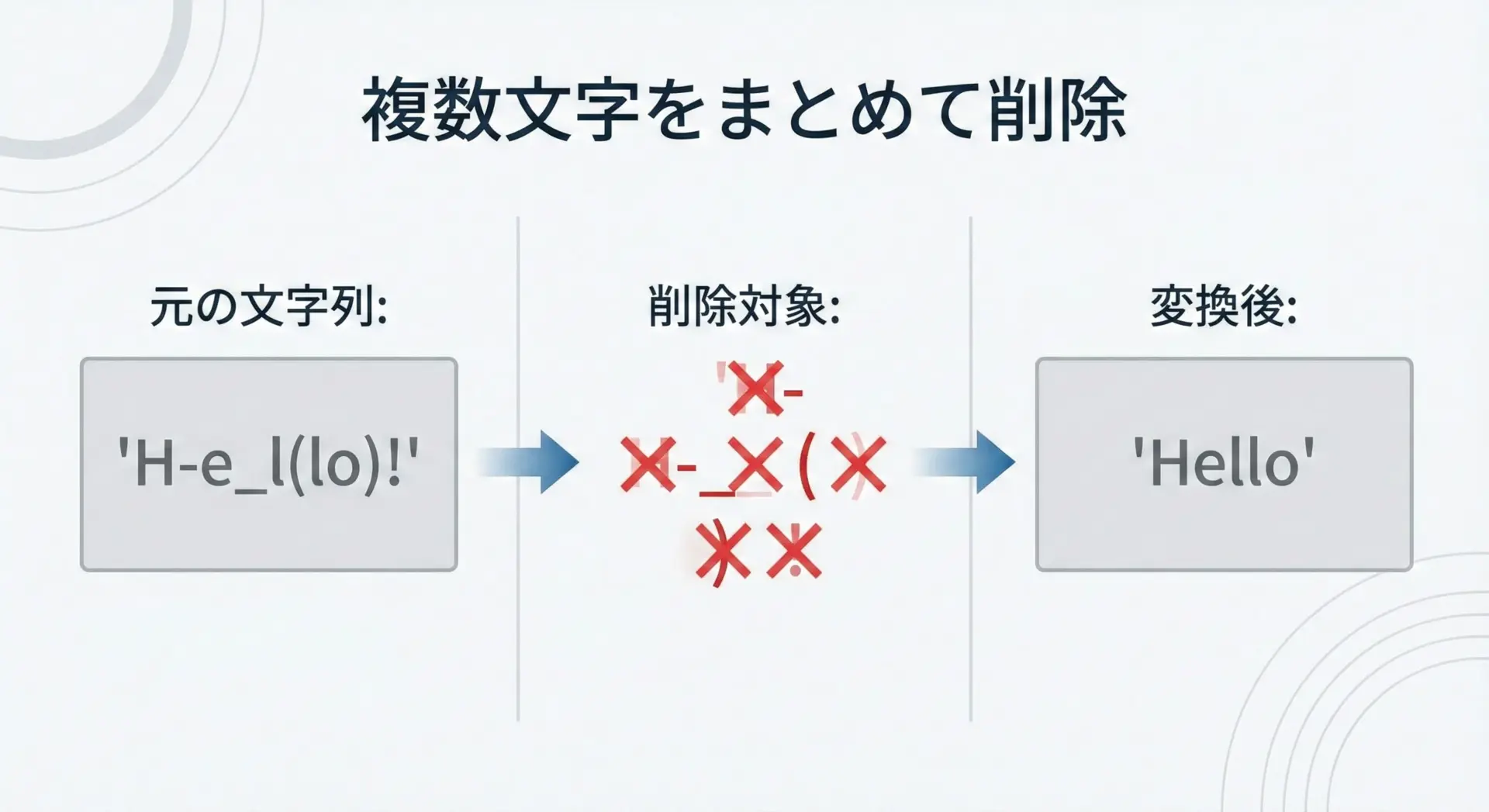
まずは、第3引数を用いる簡潔な書き方から示します。
# 句読点や記号をまとめて削除する例
text = "Hello, World!! (Python3)"
# 第3引数に削除したい文字の列を渡します
delete_chars = ",!()"
table = str.maketrans("", "", delete_chars)
result = text.translate(table)
print("元の文字列:", text)
print("削除後文字列:", result)元の文字列: Hello, World!! (Python3)
削除後文字列: Hello World Python3同じことを、辞書形式でNoneを指定して表現することもできます。
# dictを用いて削除指定をする例
text = "Hello, World!! (Python3)"
table = str.maketrans({
",": None,
"!": None,
"(": None,
")": None,
})
result = text.translate(table)
print("元の文字列:", text)
print("削除後文字列:", result)どちらの方法でも意味は同じですが、「単純に削除だけを指定したい」場合は第3引数、「削除と変換を混在させたい」場合は辞書形式が読みやすくなる傾向があります。
応用パターンで理解するstr.translateの使い方
大文字小文字変換と不要文字削除を同時に行う
実務でよくあるニーズとして、「文字の正規化(大文字小文字の統一)」と「不要な記号の除去」を同時に行いたいというケースがあります。
translateを使うと、これを1回の処理でまとめて実現できます。
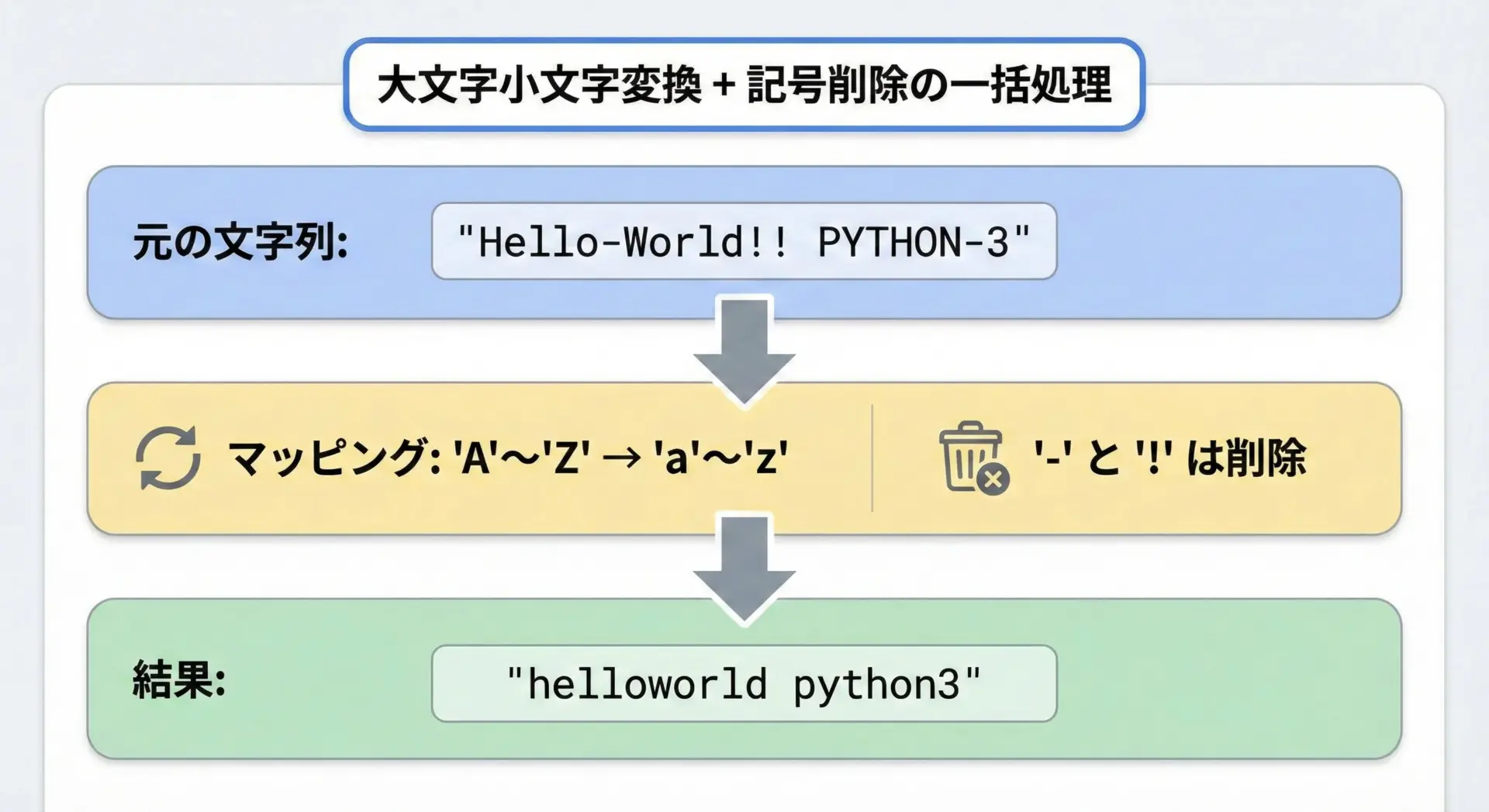
ここでは、アルファベットをすべて小文字にしつつ、ハイフン-と!を削除する例を示します。
# 大文字を小文字に変換しつつ、特定記号を削除する例
import string
text = "Hello-World!! PYTHON-3"
# まず、A-Z → a-z のマッピングを作成します
upper = string.ascii_uppercase # "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
lower = string.ascii_lowercase # "abcdefghijklmnopqrstuvwxyz"
# 大文字→小文字の変換テーブル(一部)を作る
table = str.maketrans(upper, lower)
# さらに、一部の記号を削除したいので辞書を上書きする
# str.maketransが返すのは辞書なので、updateで追記できます
table.update({
ord("-"): None, # "-" を削除
ord("!"): None, # "!" を削除
})
result = text.translate(table)
print("元の文字列:", text)
print("変換後文字列:", result)元の文字列: Hello-World!! PYTHON-3
変換後文字列: helloworld python3このように1つのtranslate呼び出しで「変換」と「削除」を同時に行えるため、処理の見通しがよくなり、パフォーマンス面でも有利です。
なお、大文字小文字の変換だけであればlower()やupper()でも十分ですが、「同時に他の変換もしたい」ときにはtranslateが選択肢になります。
全角・半角変換などのマッピングに使う
translateは、文字種のマッピングにも向いています。
例えば全角英数字を半角に統一したり、一部の記号だけを半角に変えたい場合などです。
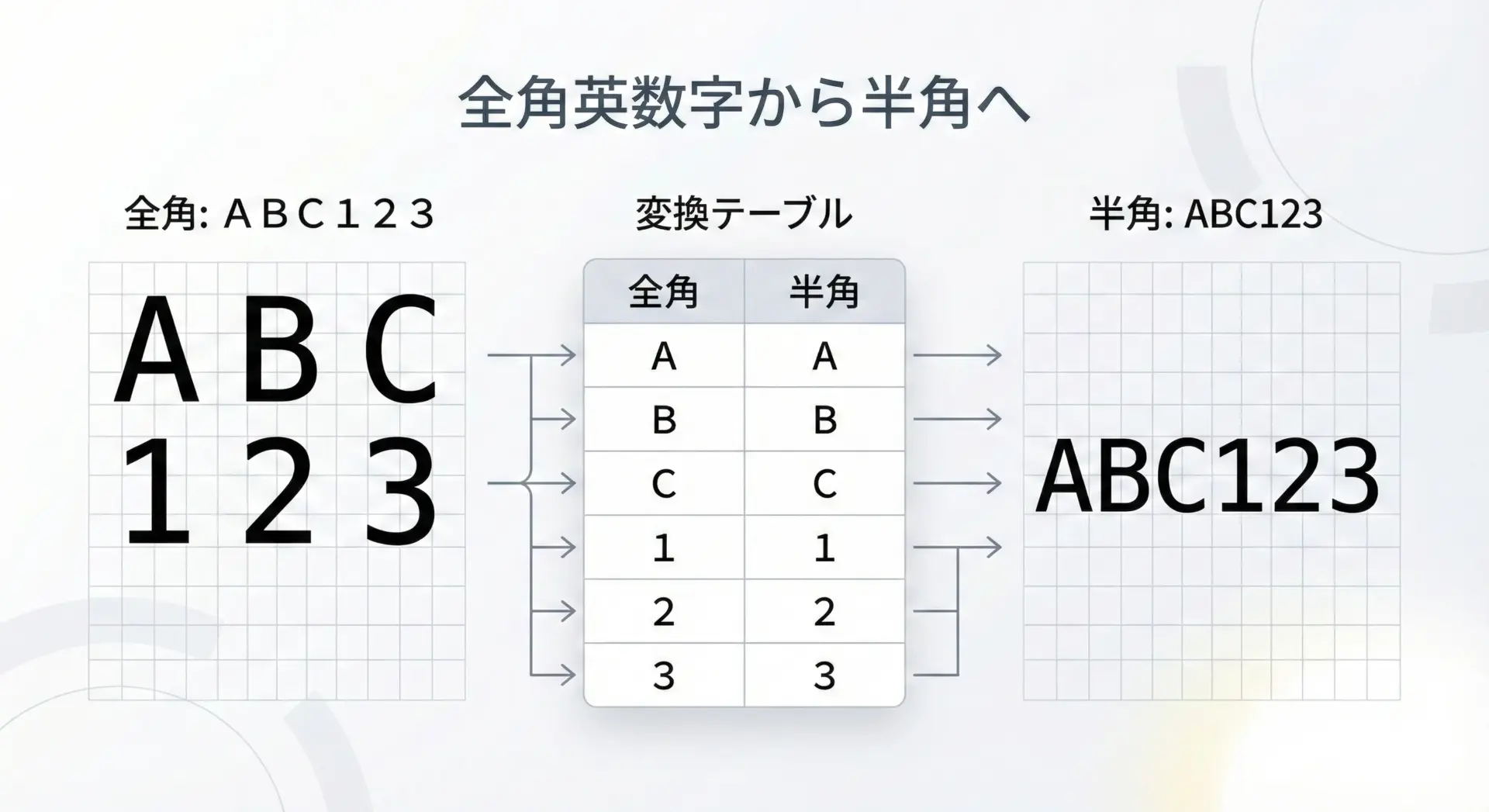
Python標準には「完全な全角・半角変換関数」はありませんが、translateで必要な範囲だけマッピングするのは実用的です。
# ごく簡単な全角→半角変換の例(数字のみ)
text = "商品番号:12345、価格:980円"
# 全角数字と半角数字の対応を辞書で定義
full_width_digits = "0123456789"
half_width_digits = "0123456789"
table = str.maketrans(full_width_digits, half_width_digits)
result = text.translate(table)
print("元の文字列:", text)
print("変換後文字列:", result)元の文字列: 商品番号:12345、価格:980円
変換後文字列: 商品番号:12345、価格:980円このように限定的な範囲の全角・半角変換であれば、translateで十分実用に耐えます。
英字や記号も含んだ本格的な全角・半角変換を行いたい場合は、外部ライブラリ(例: jaconvなど)と組み合わせることもありますが、「自分でマッピングを定義できる」こと自体がtranslateの大きな強みです。
絵文字や記号など特定の文字セットを一括除去
SNSやチャットログの前処理では、絵文字や装飾記号など、特定の文字セットを丸ごと除去したいことがよくあります。
これもtranslateで効率よく実現できます。
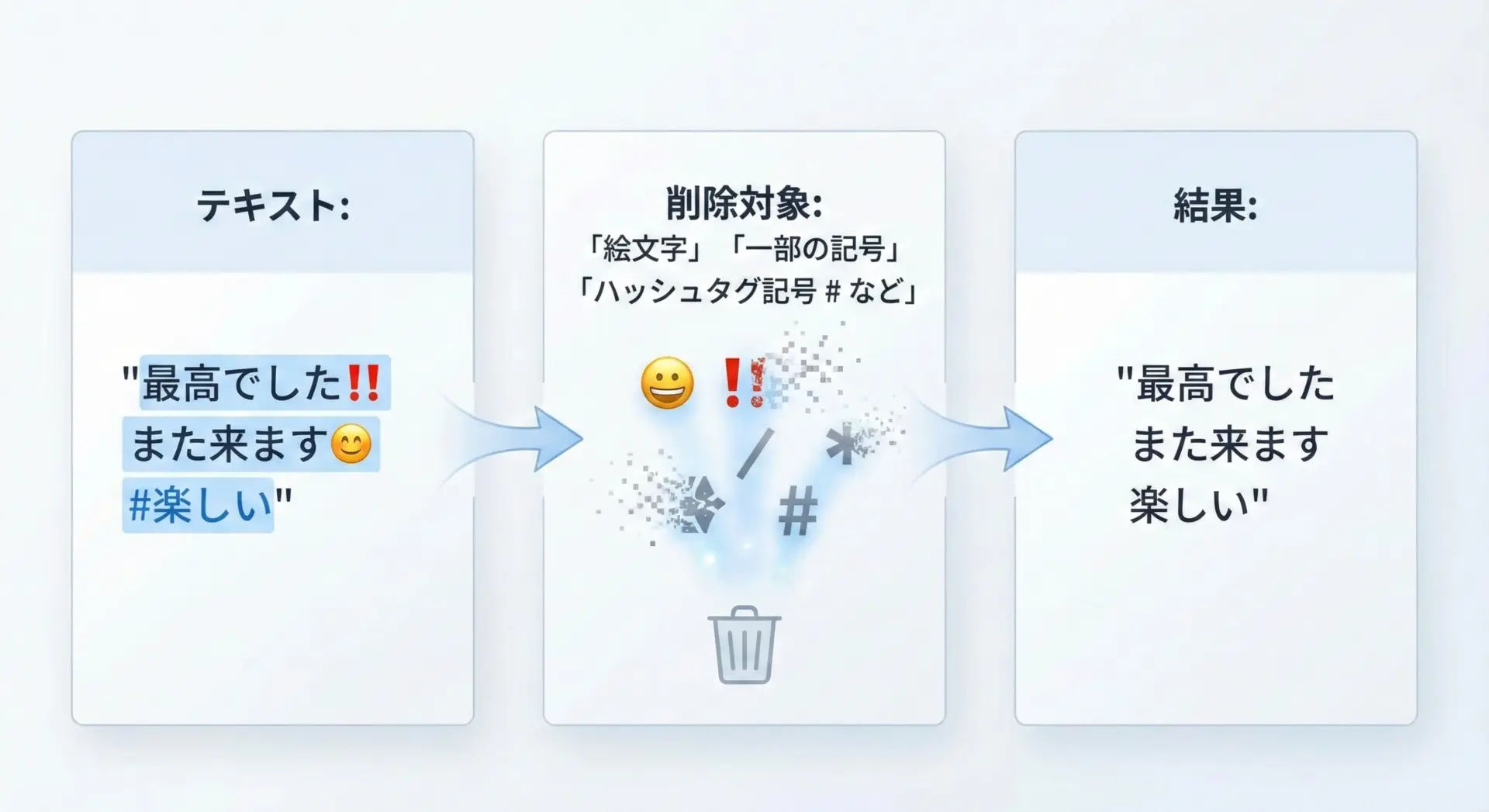
絵文字はUnicode上では幅広い範囲に散らばっているため、「完全に」消すにはやや工夫が必要ですが、ここでは簡易的に「よく出てくる絵文字や記号」を対象とした例を示します。
# 一部の絵文字・記号をまとめて削除する簡易例
text = "最高でした‼️ また来ます😊 #楽しい"
# 削除したい文字を並べる
delete_chars = "‼️😊#"
# 第3引数に削除対象を指定
table = str.maketrans("", "", delete_chars)
result = text.translate(table)
print("元の文字列:", text)
print("絵文字・記号削除後:", result)元の文字列: 最高でした‼️ また来ます😊 #楽しい
絵文字・記号削除後: 最高でした また来ます 楽しいより本格的に絵文字全般を削除したい場合は、Unicodeのカテゴリ(例えば「Symbol」や「Emoji」)に基づいて削除対象を生成し、translate用のテーブルに組み込む、といった方法も考えられます。
このようなケースでも「どのコードポイントを消すか」を辞書で明示できるtranslateは扱いやすいです。
文字列正規化処理でのstr.translate活用例
テキストの前処理では、入力をできるだけ一定の形式に揃える「正規化」が重要です。
translateは次のような正規化で活用されます。
- アクセント付き文字の除去・単純化
- 特定の句読点を統一(例: 「.」「。」「.」をすべて「。」に)
- 制御文字や不可視文字の削除
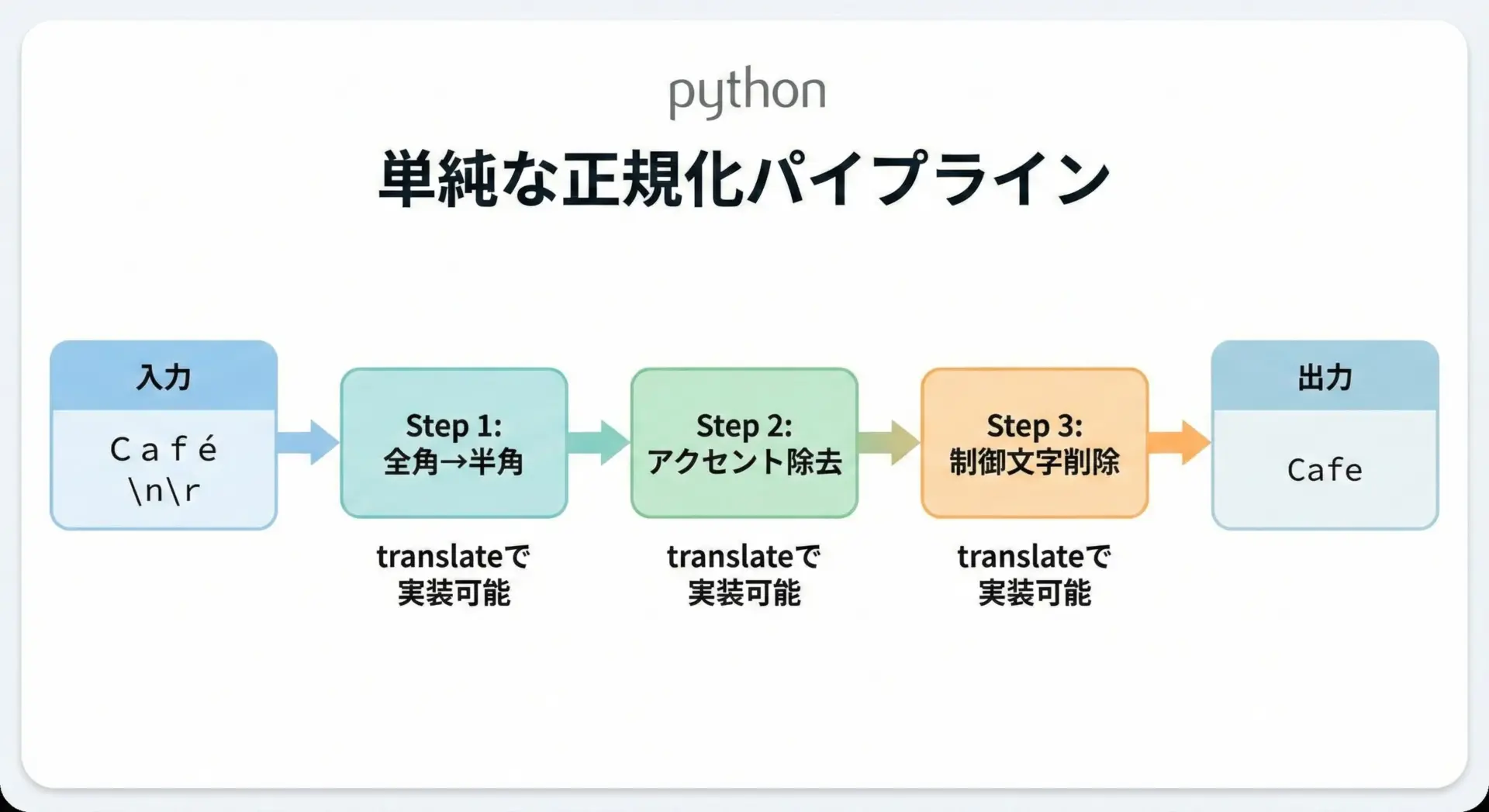
ここでは、アクセント付き文字の一部を単純化し、制御文字を取り除く簡単な正規化関数の例を示します。
# translateを使った簡易的な正規化関数の例
def simple_normalize(text: str) -> str:
# 1. 一部のアクセント付き文字を単純化
accent_map = {
"é": "e",
"è": "e",
"ê": "e",
"á": "a",
"à": "a",
"ñ": "n",
}
# 2. 不要な制御文字を削除(ここでは改行とタブだけ例示)
delete_chars = "\n\t\r"
table = str.maketrans(accent_map)
# 第3引数の削除指定を併用したいので、再度maketransを呼び出して統合する
# dict(table, **str.maketrans("", "", delete_chars)) のようにマージする手もありますが
# ここではupdateを利用します
table.update(str.maketrans("", "", delete_chars))
return text.translate(table)
text = "Café\n\tmañana\r"
print("元の文字列:", repr(text))
print("正規化後文字列:", repr(simple_normalize(text)))元の文字列: 'Café\n\tmañana\r'
正規化後文字列: 'Cafe manana'このように複数の正規化ルールを1つのtranslateテーブルに統合しておくと、文字列処理のパイプラインをすっきり書くことができます。
str.translateと他の方法の比較と注意点
str.replaceとのパフォーマンス・コード量の比較
replaceとtranslateのどちらを使うべきか悩む場合、主な判断材料は「置換対象の数」と「処理量」です。
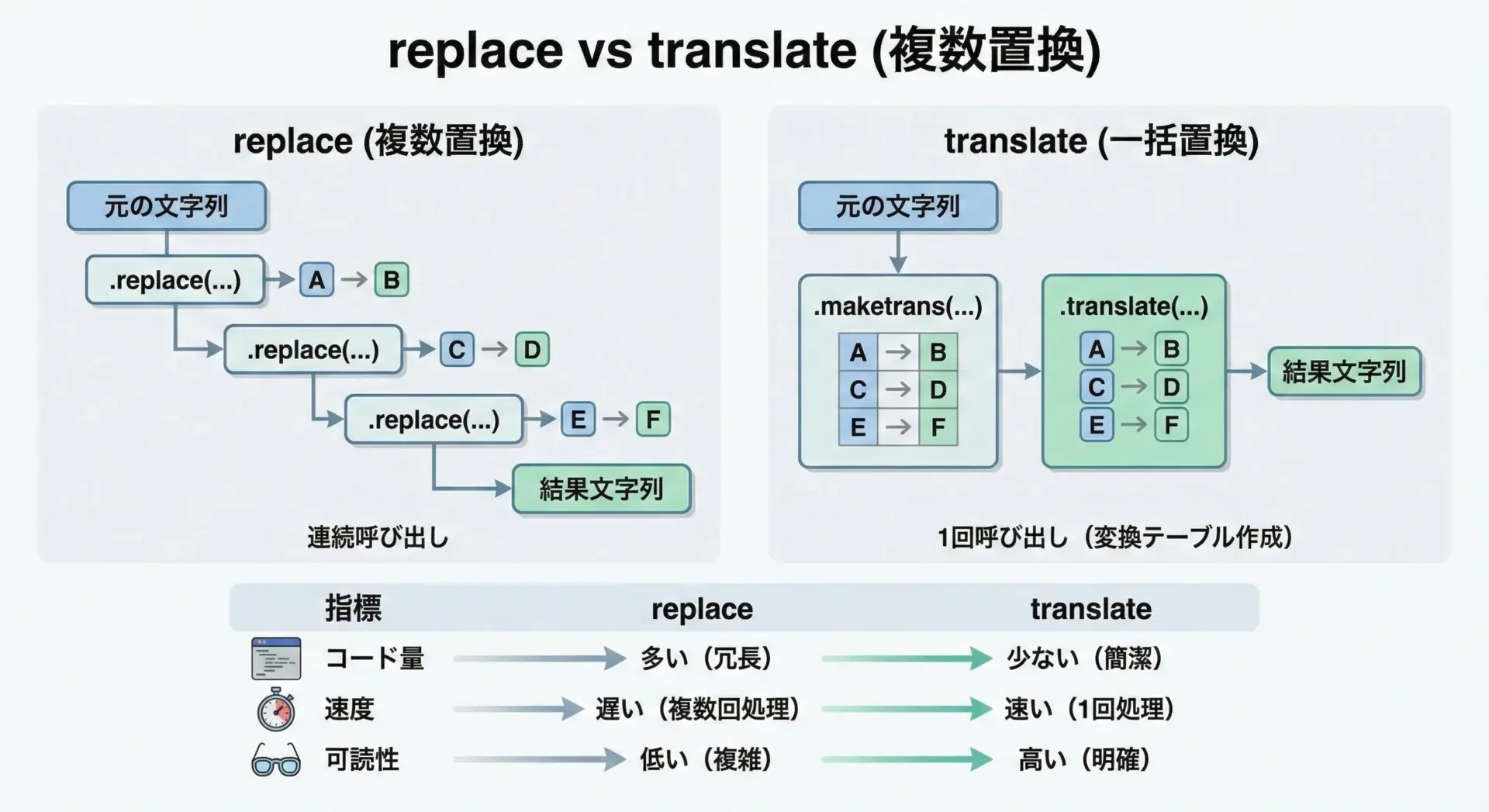
replaceを複数回呼ぶ場合のイメージです。
# replaceを複数回使って複数文字を置換する例
text = "abc123abc"
result = (
text.replace("a", "x")
.replace("b", "y")
.replace("c", "z")
.replace("1", "A")
.replace("2", "B")
.replace("3", "C")
)
print(result)これと同じ処理は、translateなら次のように書けます。
# translateで同じ処理をまとめて行う例
text = "abc123abc"
table = str.maketrans("abc123", "xyzABC")
result = text.translate(table)
print(result)一般に、多くの文字を置換・削除する場合はtranslateの方が高速になりやすく、コードも短く読みやすくなります。
一方、置換したいパターンが少なく、かつ単純な場合にはreplaceで十分なことも多いです。
パフォーマンスを厳密に測りたい場合は、実際のデータと処理内容でベンチマークを取る必要がありますが、複数置換・大量テキストが絡む場合にはtranslateを検討する価値があります。
正規表現(re.sub)との違いと向き不向き
re.subは、「パターン」にマッチした部分を置換するための関数です。
translateとの一番の違いは、次の点に集約されます。
- translate: 個々の文字ごとに「この文字はこう変える/消す」という静的なマッピング
- re.sub: 正規表現にマッチした部分を動的・柔軟に置換
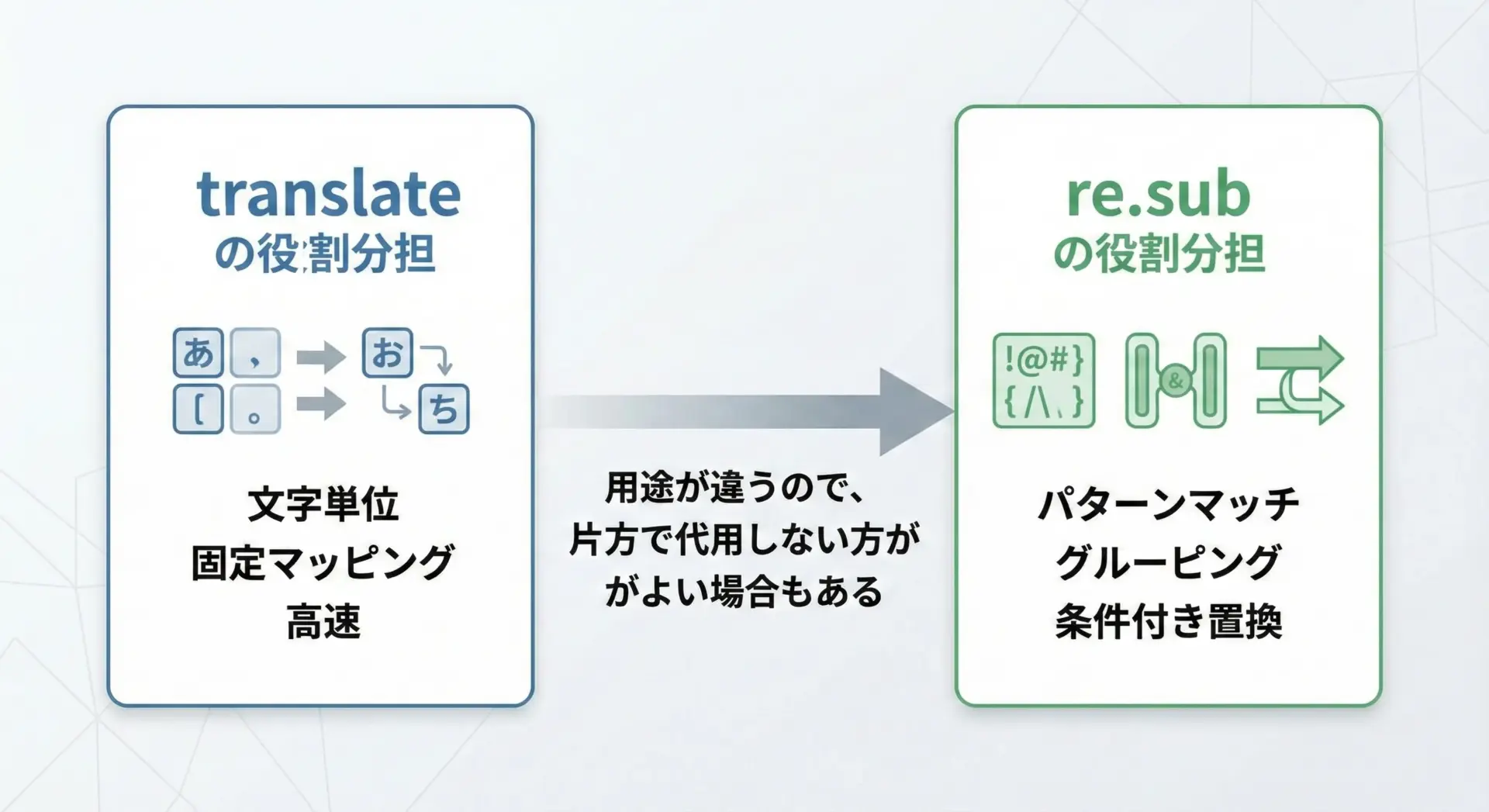
re.subは、例えば「数字が3つ以上続いたところだけを置換する」といった複雑な条件に基づく置換が可能です。
しかし、単純な文字の置換・削除であればtranslateの方がシンプルで高速になることが多いです。
次の例は、数字以外の文字を削除するという処理を、re.subとtranslateでそれぞれ書いたものです。
import re
import string
text = "注文ID: AB-1234-XY, 数量: 56個"
# 1. re.subで「数字以外」を削除する例
digits_only_re = re.sub(r"[^0-9]", "", text)
# 2. translateで「数字以外」を削除する例
# まず、削除したい文字を列挙する(ここでは簡略化し、数字以外のASCII文字を削除)
delete_chars = string.ascii_letters + string.punctuation + " :個,"
table = str.maketrans("", "", delete_chars)
digits_only_tr = text.translate(table)
print("re.sub:", digits_only_re)
print("translate:", digits_only_tr)ここではやや強引にASCII文字だけを対象としましたが、要件に応じてどこまで細かく制御したいかによって、translateとre.subのどちらが向いているかが変わります。
まとめると、次のような使い分けが目安になります。
- translateが向いている場合
- 1文字単位の単純な置換・削除
- 同時に多くの文字を処理したい
- 性能やコードの簡潔さを優先したい
- re.subが向いている場合
- 文脈や隣接文字に依存する複雑な条件付き置換
- グループキャプチャや後方参照を使う必要がある
- 文字列の一部だけを抽出・再構成するような高度な処理
マルチバイト文字・Unicode扱いの注意点
Python 3の文字列はUnicodeベースなので、translateも当然Unicodeコードポイントを扱います。
ここで注意したい点がいくつかあります。
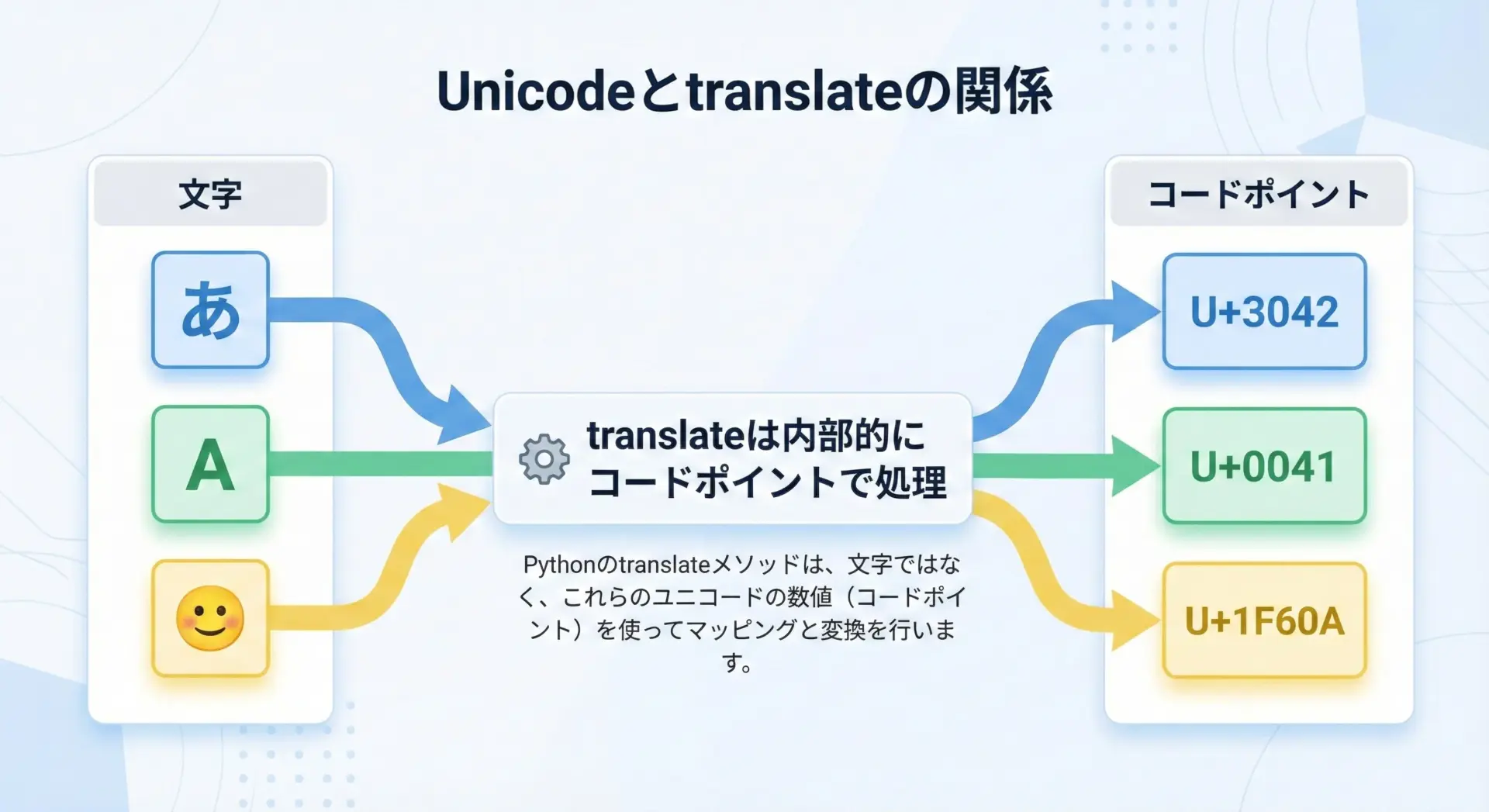
まず、キーが「文字」でも「整数(コードポイント)」でも動作するという仕様があります。
次の2つは等価です。
# 文字をキーにする
table1 = str.maketrans({"あ": "ア"})
# コードポイント(整数)をキーにする
table2 = {ord("あ"): "ア"}
text = "あいうえお"
print(text.translate(table1))
print(text.translate(table2))アイウエオ
アイウエオこのように、str.maketransは内部でord()を使って文字をコードポイントに変換してくれます。
通常は文字をキーに書けばよく、コードポイント(整数)を直接扱う必要はありません。
一方で、結合文字(アクセント記号)やサロゲートペアを含む文字では、見た目1文字でも内部構造が複数のコードポイントから成る場合があります。
このような場合、translateは「コードポイント単位」で動作することに注意が必要です。
例えば、"é"は「1つのコードポイント」として表現されることもあれば、「e + 結合アクセント」の2つで表現されていることもあります。
前者だけに対するマッピングを定義しても、後者には効かない場合があります。
そのため、Unicode正規化(NFC, NFDなど)と組み合わせてからtranslateを適用するという手法がよく用いられます。
# Unicode正規化とtranslateを組み合わせる例
import unicodedata
text = "Cafe\u0301" # "e" + 結合アクセントで構成された "é" 相当
print("元の文字列:", text, "長さ:", len(text))
# NFKDで分解(ここでは例示のため)
normalized = unicodedata.normalize("NFKD", text)
# 結合記号(カテゴリ "Mn")をすべて削除するテーブルを作る
delete_chars = "".join(
ch for ch in normalized
if unicodedata.category(ch) == "Mn"
)
table = str.maketrans("", "", delete_chars)
result = normalized.translate(table)
print("正規化後:", normalized, "長さ:", len(normalized))
print("結合文字削除後:", result, "長さ:", len(result))このように、Unicodeの世界は「見た目1文字」が必ずしも「内部1文字(1コードポイント)」ではないという点を理解しておくと、translateをより安全に扱えるようになります。
まとめ
str.translateは、「1文字単位の変換・削除を一括で行う」ための強力なメソッドです。
str.maketransと組み合わせることで、複数文字の置換や削除を短く、そして高速に記述できます。
単純な部分文字列置換にはreplaceが便利ですが、多数の文字を同時処理する場面や、正規化・前処理のパイプラインではtranslateが真価を発揮します。
Unicodeの仕組みやマルチバイト文字の点にだけ注意しながら、日常的な文字列処理に積極的に活用してみてください。
