
Pythonのコードは、書いた本人ですら時間が経つと読み解くのが大変になることがあります。
そこで役立つのが「型ヒント」です。
本記事では、Pythonの型ヒントの基本から、実務でよく使うtypingモジュールの実例、そしてmypyによる型チェックまでを、図解とサンプルコードを交えながら丁寧に解説していきます。
Pythonの型ヒントとは
型ヒントとは何か
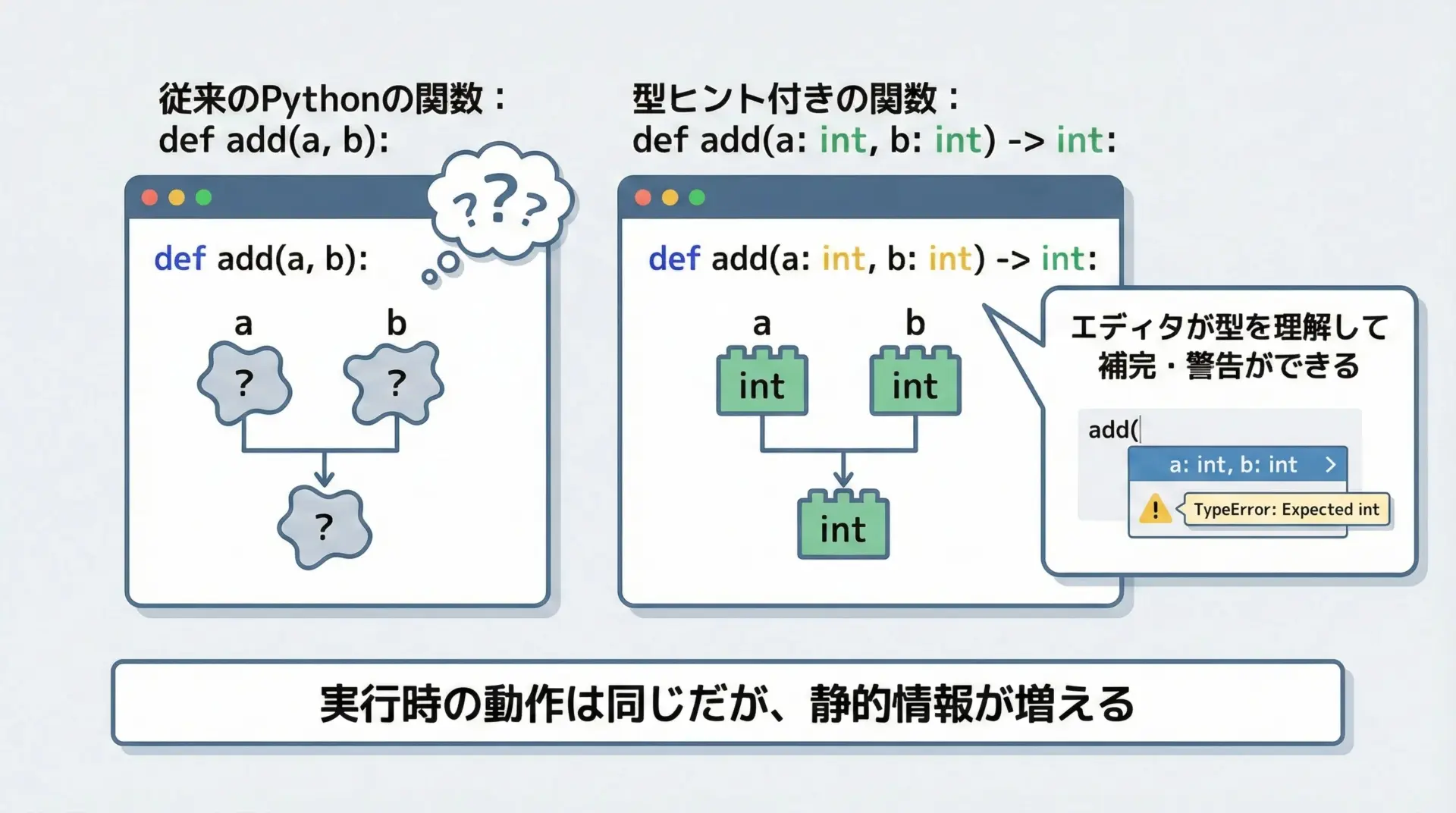
Pythonの型ヒントとは、「変数や関数の引数・戻り値などがどのような型であることを意図しているか」をコード上に明示する仕組みです。
Pythonは動的型付け言語なので、型ヒントを書いても実行時の挙動は変わりません。
あくまで開発者やツール(mypyなど)が、コードを静的に解析しやすくするための「注釈」の役割を果たします。
具体的には、次のようなスタイルで記述します。
def add(a: int, b: int) -> int:
"""2つの整数を足し合わせる関数"""
return a + b
x: str = "hello"ここでは、引数aとbがintであり、戻り値もintであることを示しています。
また変数xがstrであることも明示しています。
型ヒントを使うメリット
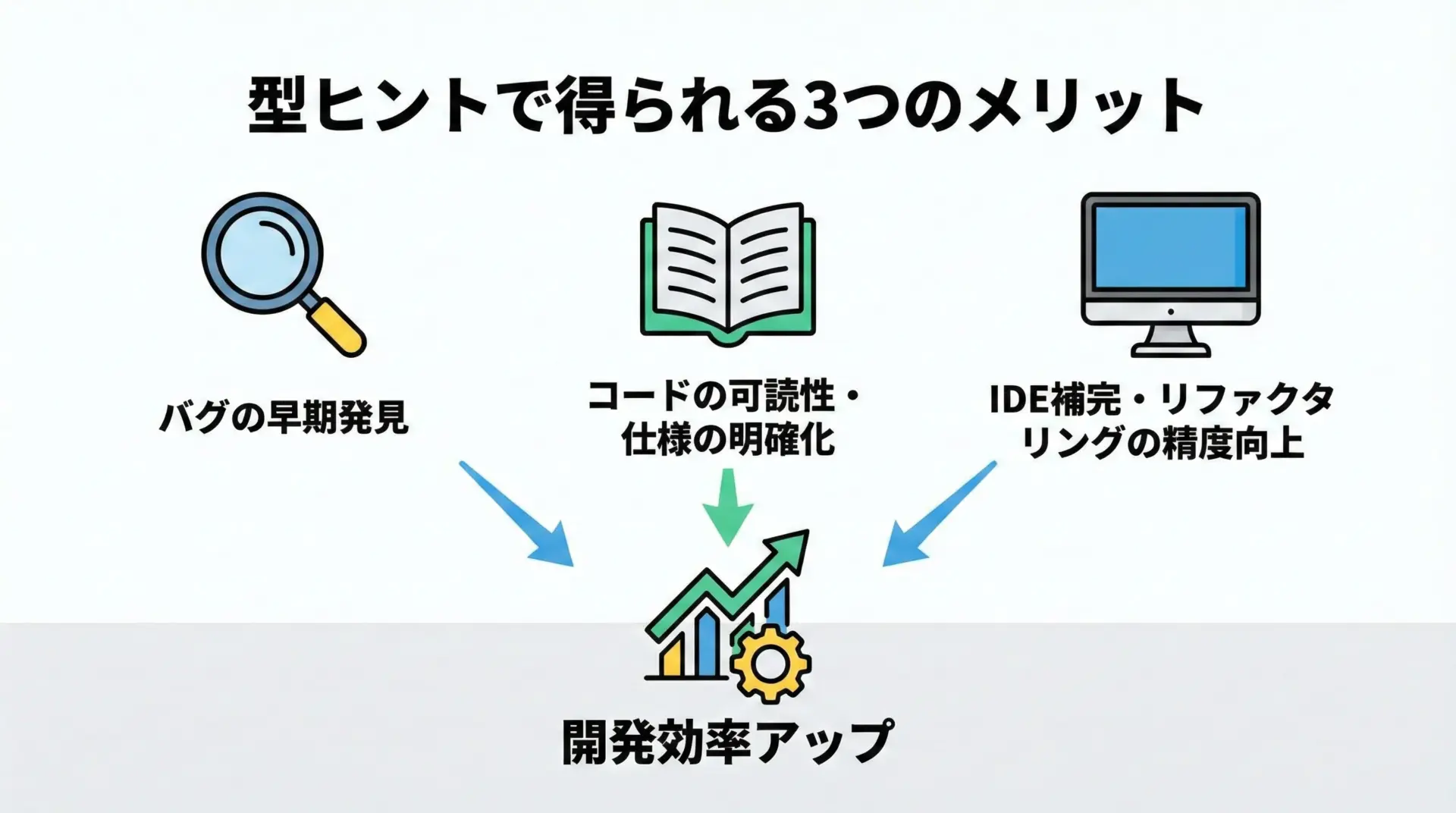
型ヒントを使うと、次のようなメリットがあります。
まずバグを早期に検出しやすくなることです。
例えば、本来は整数を渡すべき関数に誤って文字列を渡しているようなコードを、実行前の静的解析段階で検出してくれるようになります。
これにより、実行してみるまで気づきにくい型関連のバグを、事前に洗い出すことができます。
次に、コードの意図や仕様が明確になります。
例えばget_user(id: int) -> Userと書かれていれば、「整数IDを受け取り、User型のオブジェクトを返す関数なのだな」と一目で分かります。
ドキュメントやコメントを読まなくても、関数の使い方が理解しやすくなります。
さらに、エディタやIDEの補完機能が賢くなるという実利もあります。
VSCodeやPyCharmなどは、型情報を基にメソッド補完や入力候補を提示できるため、大規模なプロジェクトでも快適にコーディングできます。
Pythonの動的型付けとの違い
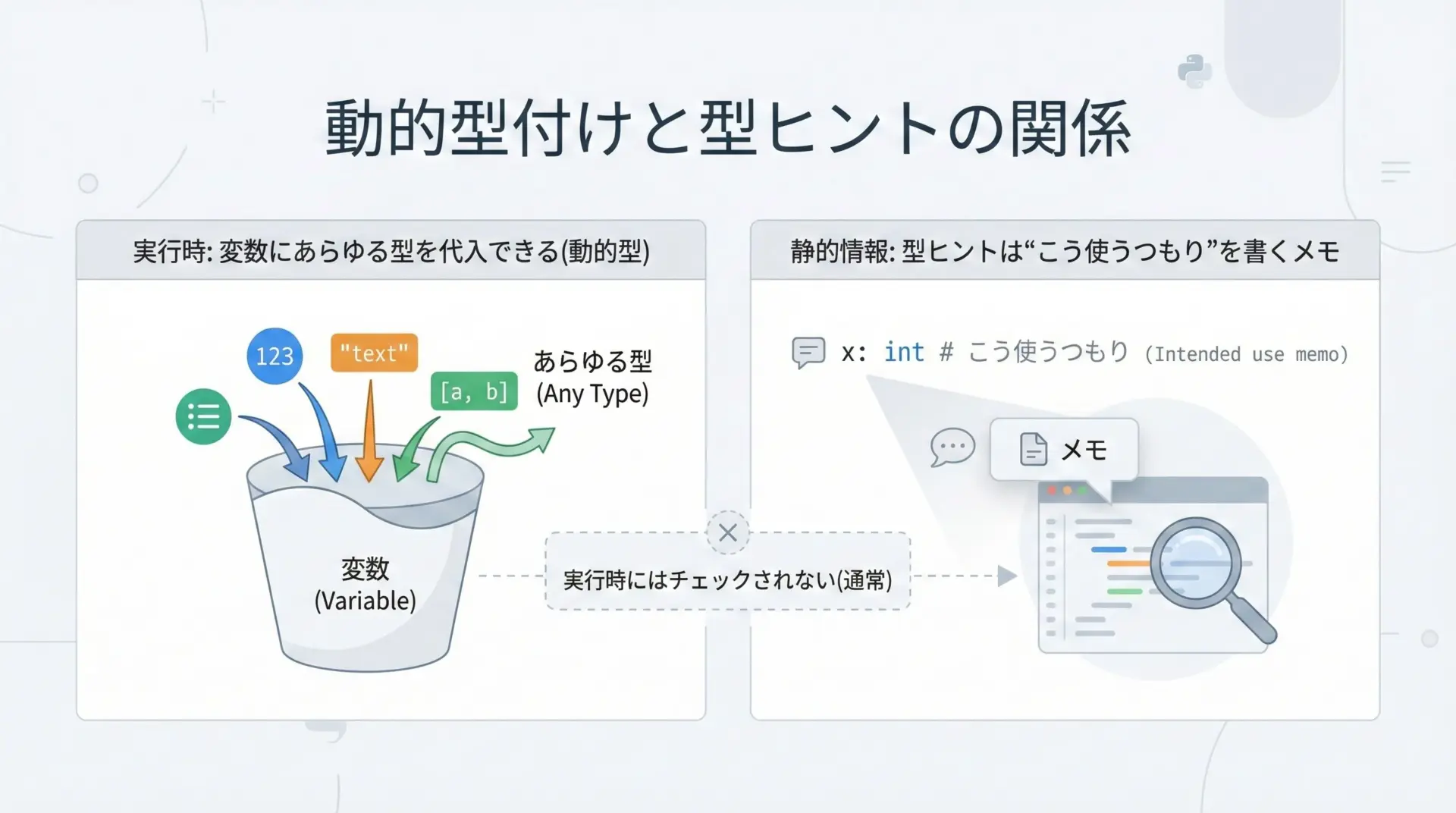
Pythonは動的型付け言語です。
つまり、変数に束縛されるオブジェクトの型は実行時に決まり、同じ変数に異なる型の値を代入することも可能です。
x = 1 # いまは int
x = "text" # 後から str を代入してもエラーにならない型ヒントは、こうした動的な性質を変えるものではありません。
あくまで、「本来はどういう型で使うべきか」という開発者の意図を静的に記述するだけです。
そのため、型ヒントを書いても、Pythonインタプリタは原則として実行時に型チェックを行いません。
実行前にmypyなどのツールで検査してはじめて、型の不整合に気づけるようになります。
typingモジュールの基礎
基本の型ヒント
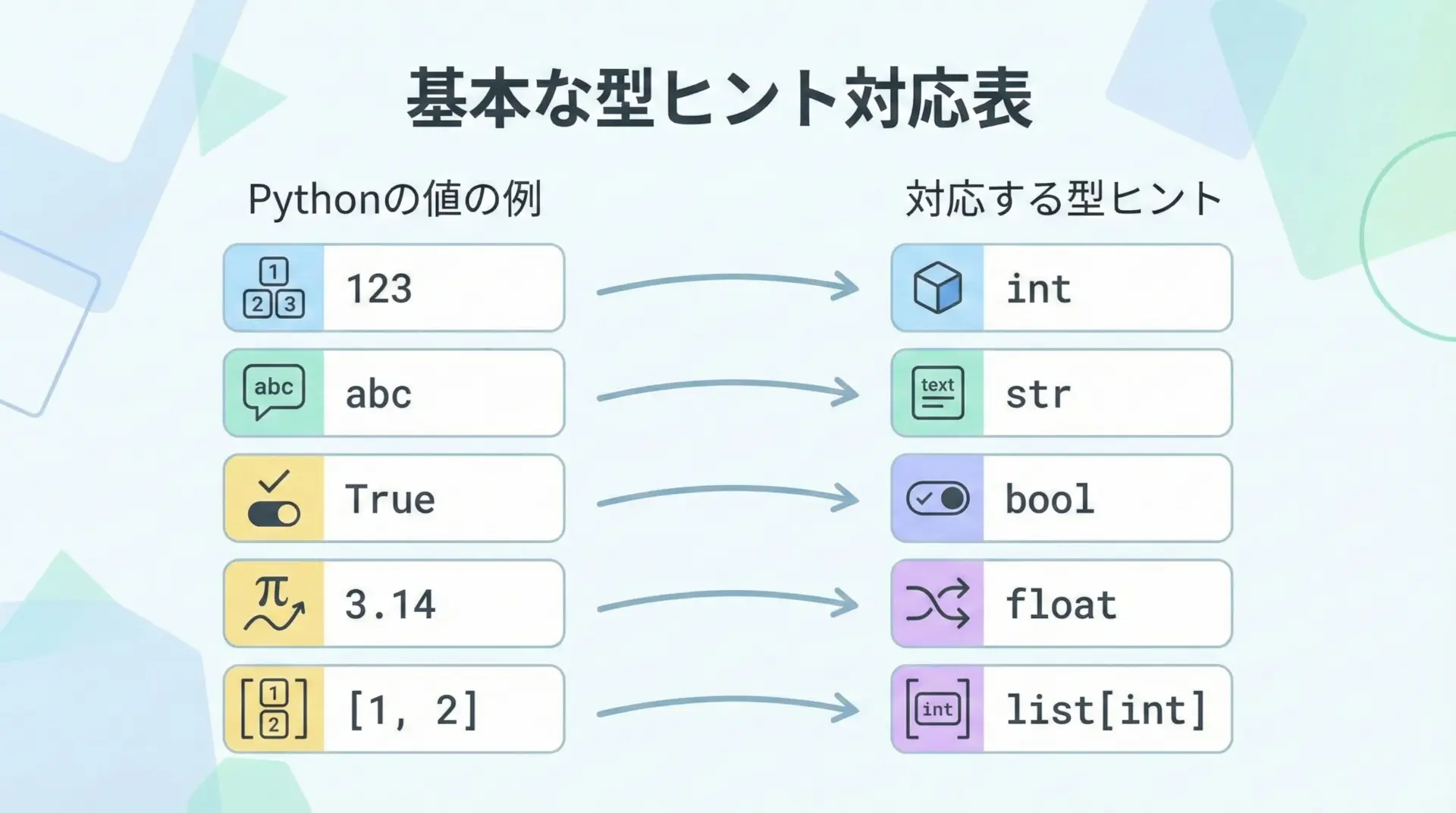
Pythonの型ヒントでは、組み込みの基本型はそのまま型として使用します。
代表的なものとして、int、float、bool、str、bytesなどがあります。
少し前まではtypingモジュールからListやDictをインポートして使うスタイルが主流でしたが、Python 3.9以降では、組み込みのlistやdictなどにジェネリクス構文を直接使うことが推奨されています。
# Python 3.9 以降で推奨される書き方
numbers: list[int] = [1, 2, 3]
mapping: dict[str, int] = {"one": 1, "two": 2}変数・関数・メソッドへの型ヒントの付け方
変数への型ヒント
変数には、変数名: 型という形式で型を注釈できます。
# 変数の型ヒント
age: int = 30
name: str = "Alice"
scores: list[float] = [98.5, 87.0, 92.5]代入と同時に型ヒントを書くのが一般的ですが、必要であれば別行に分けて書くことも可能です。
from typing import Optional
user_name: Optional[str]
user_name = None関数への型ヒント
関数では、引数ごとに引数名: 型、戻り値に-> 型の形式で書きます。
def greet(name: str, times: int) -> str:
"""nameをtimes回だけ挨拶文として繰り返す"""
return f"Hello, {name}! " * times戻り値がNoneの関数は、次のように書きます。
def log(message: str) -> None:
print(f"[LOG] {message}")メソッドへの型ヒント
クラスのメソッドにも、関数と同様に型ヒントを付けられます。
selfには通常型ヒントを付けません。
class User:
def __init__(self, name: str, age: int) -> None:
self.name = name
self.age = age
def is_adult(self) -> bool:
return self.age >= 20OptionalとUnionの使い方
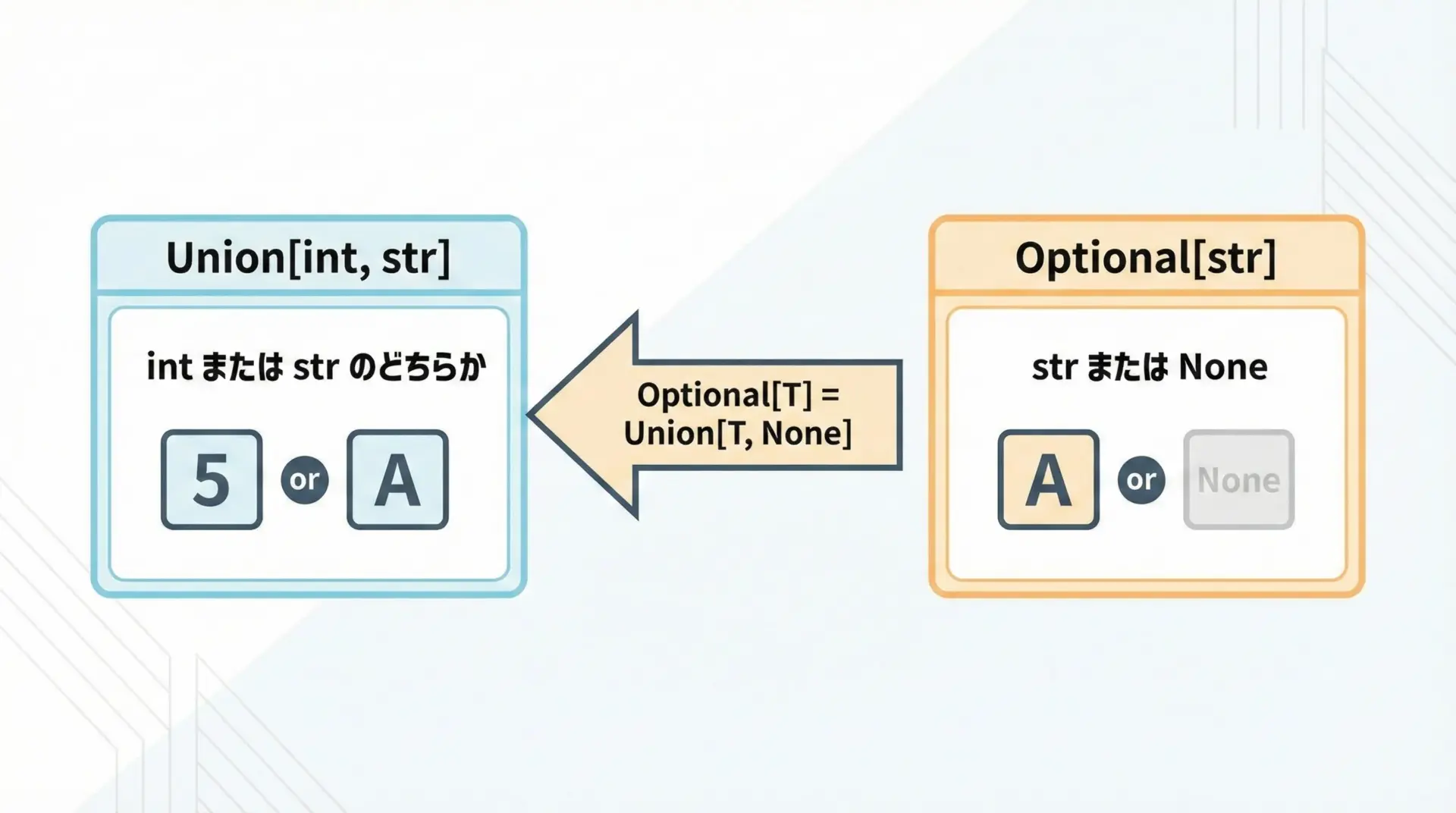
複数の型のいずれかを許容する場合には、Unionを使います。
代表的なのが「値がある場合はstr、ない場合はNone」というパターンで、このときに便利なのがOptionalです。
from typing import Union, Optional
# int または str を受け取る
def to_str(value: Union[int, str]) -> str:
return str(value)
# str または None を返す (Optional[str] は Union[str, None] と同じ意味)
def find_user_name(user_id: int) -> Optional[str]:
if user_id == 1:
return "Alice"
return NonePython 3.10以降では、Unionの代わりに|演算子を使う省略記法がサポートされています。
def to_str(value: int | str) -> str: # Union[int, str] と同じ
return str(value)List・Dict・Tupleなどコレクション型の書き方
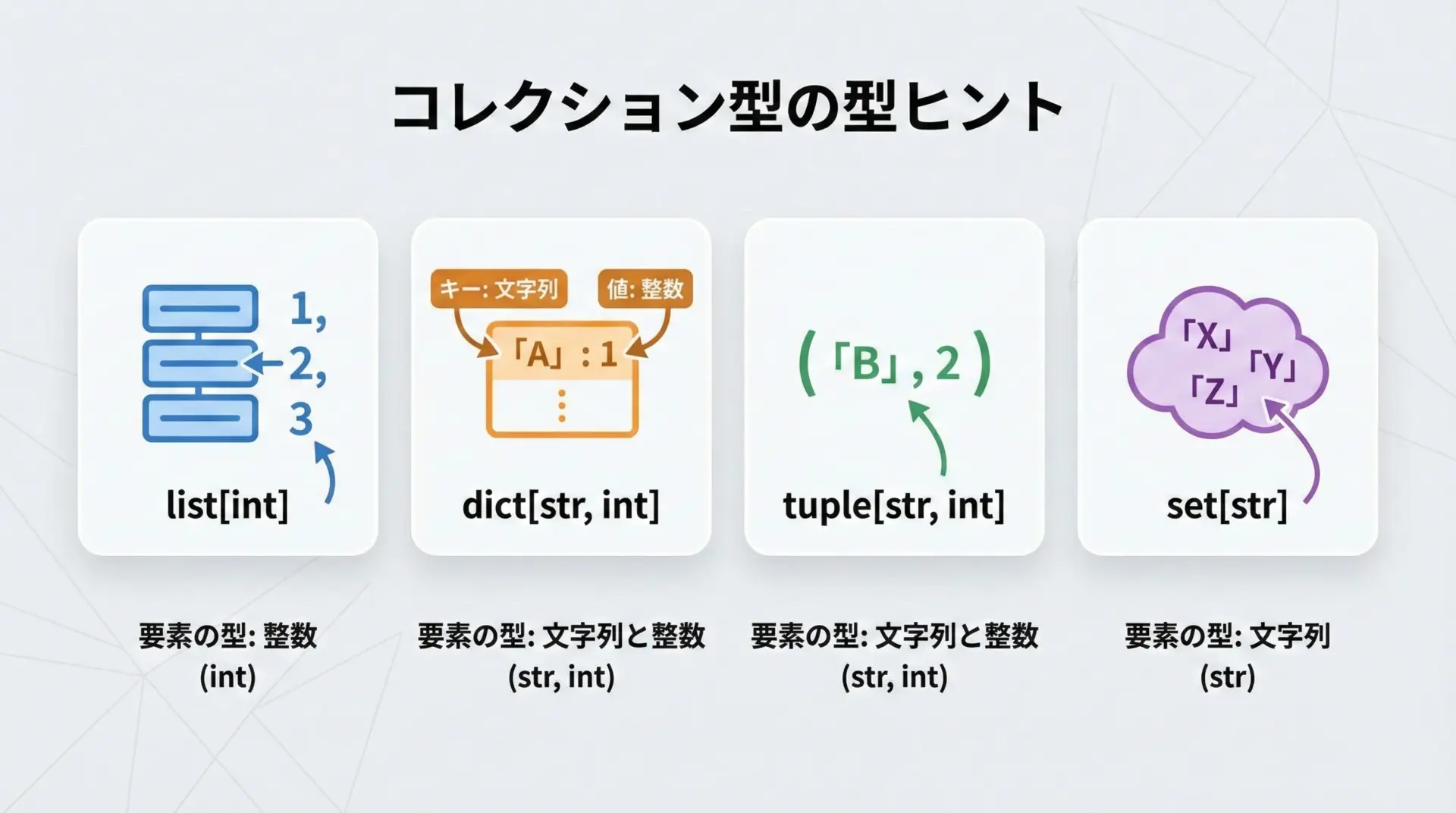
コレクション型の書き方は、Pythonのバージョンによって少し表記が異なります。
Python 3.9以降であれば、組み込みのコレクションに直接ジェネリクスを使う書き方がシンプルでおすすめです。
# リスト型 (要素がすべてint)
numbers: list[int] = [1, 2, 3]
# 辞書型 (キーがstr、値がfloat)
price_table: dict[str, float] = {"apple": 120.0, "banana": 98.0}
# タプル型 (最初がstr、次がintの2要素タプル)
user_info: tuple[str, int] = ("Alice", 30)
# 集合型 (要素がstr)
tags: set[str] = {"python", "typing"}Python 3.8以前では、typingモジュールからList、Dictなどをインポートして使用します。
from typing import List, Dict, Tuple, Set
numbers: List[int] = [1, 2, 3]
price_table: Dict[str, float] = {"apple": 120.0}
user_info: Tuple[str, int] = ("Alice", 30)
tags: Set[str] = {"python", "typing"}型エイリアス(TypeAlias)でわかりやすくする
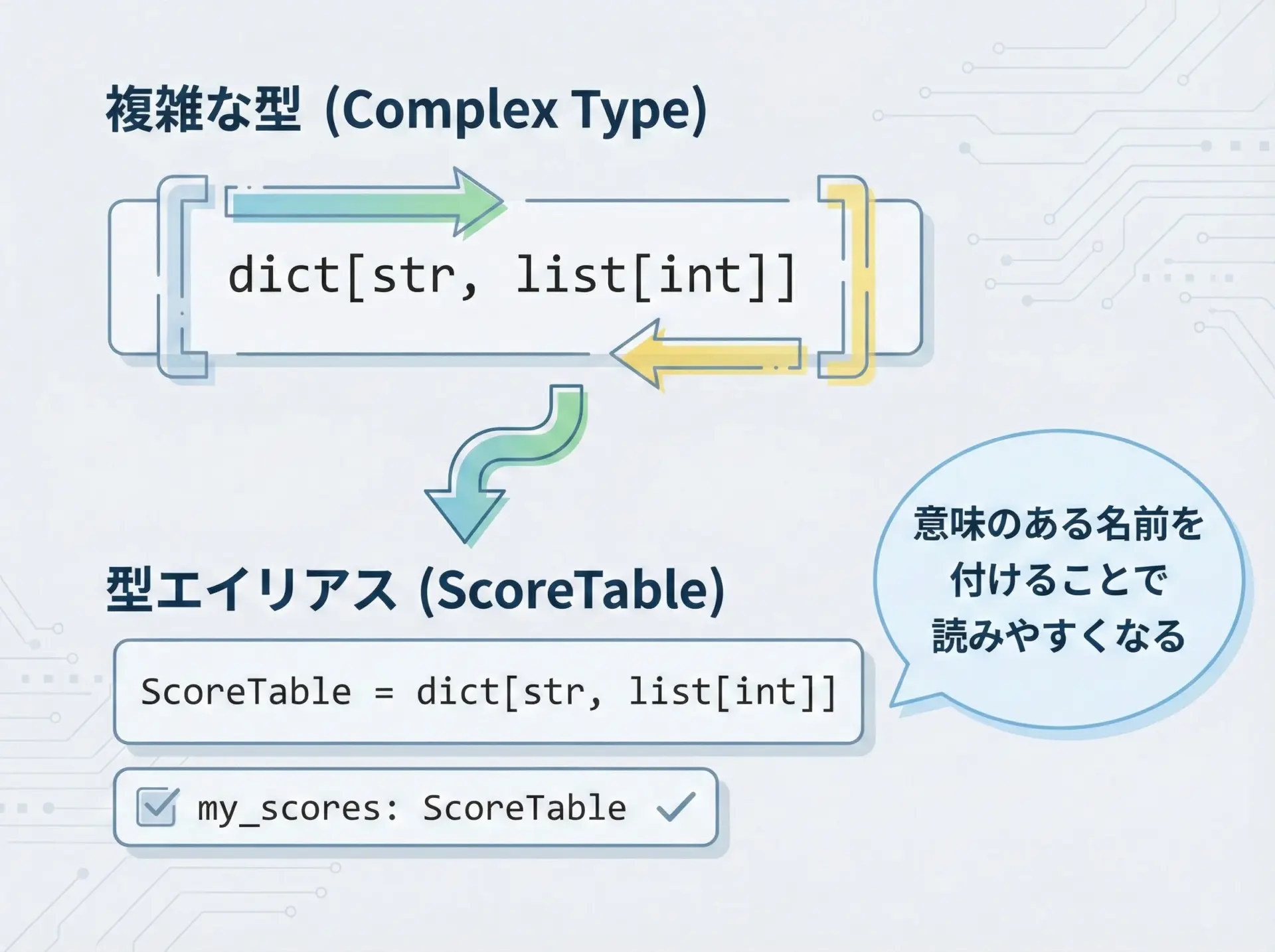
型が複雑になってくると、そのままの表記では可読性が落ちてしまいます。
そこで型エイリアスを使って、意味のある名前を付けると分かりやすくなります。
from typing import TypeAlias
# 学生名をキー、テストスコアのリストを値にする辞書
ScoreTable: TypeAlias = dict[str, list[int]]
def average_score(scores: ScoreTable) -> float:
total = 0
count = 0
for user_scores in scores.values():
total += sum(user_scores)
count += len(user_scores)
return total / countTypeAliasを使う目的は、「その型が何を意味するのか」を名前で表現することです。
同じdict[str, list[int]]でも、ScoreTableという名前が付くことで「誰の何の値が入っているのか」が読み手に伝わりやすくなります。
Literalで値を限定する
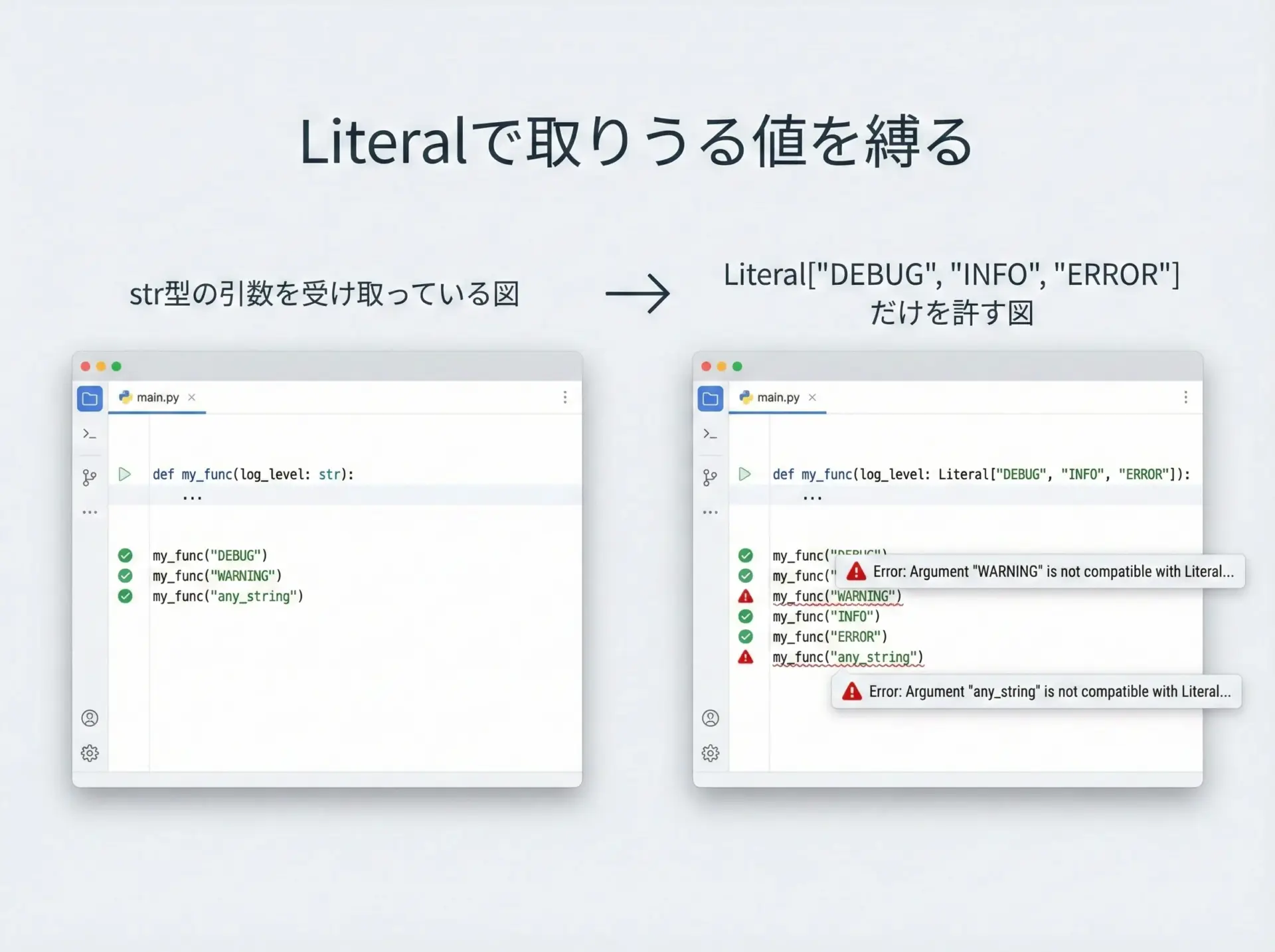
Literalを使うと、「特定の値の集合だけを許可する」という型ヒントを表現できます。
例えばログレベルを"DEBUG"、"INFO"、"ERROR"のいずれかに限定したいような場合です。
from typing import Literal
LogLevel = Literal["DEBUG", "INFO", "WARNING", "ERROR"]
def log(message: str, level: LogLevel) -> None:
print(f"[{level}] {message}")この関数に対してlevel="TRACE"のような文字列を渡すと、mypyなどの型チェックツールが警告を出してくれるようになります。
設定値やモード指定など、事前に取りうる値が決まっている場合に非常に有効です。
typingの実用的な使い方
関数の引数と戻り値に型ヒントを付ける例
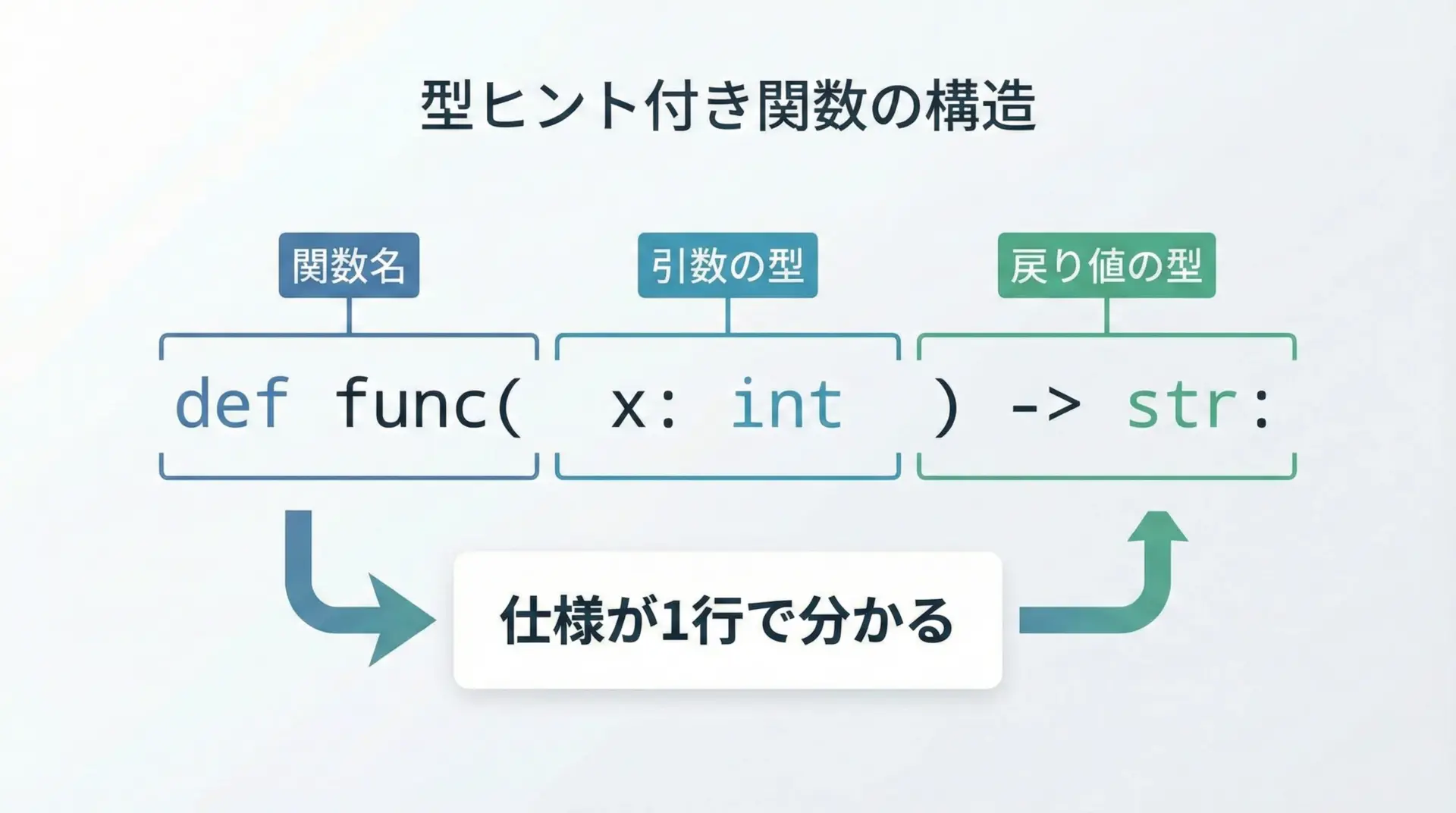
実際の関数に型ヒントを付けると、関数の「入出力の仕様」が宣言的に表現されます。
from typing import Optional
def find_max(values: list[int]) -> Optional[int]:
"""整数のリストから最大値を返す。空リストならNone。"""
if not values:
return None
return max(values)この定義から、「整数リストを受け取り、最大値(整数)またはNoneを返す」という仕様がひと目で分かります。
呼び出し側も、それを前提に安全なコードを書けるようになります。
実務では、「外部から呼ばれる関数・メソッド」や「ビジネスロジックの中核となる関数」から優先的に型ヒントを付けていくと、全体像が把握しやすくなります。
クラスとメソッドでの型ヒントの実例
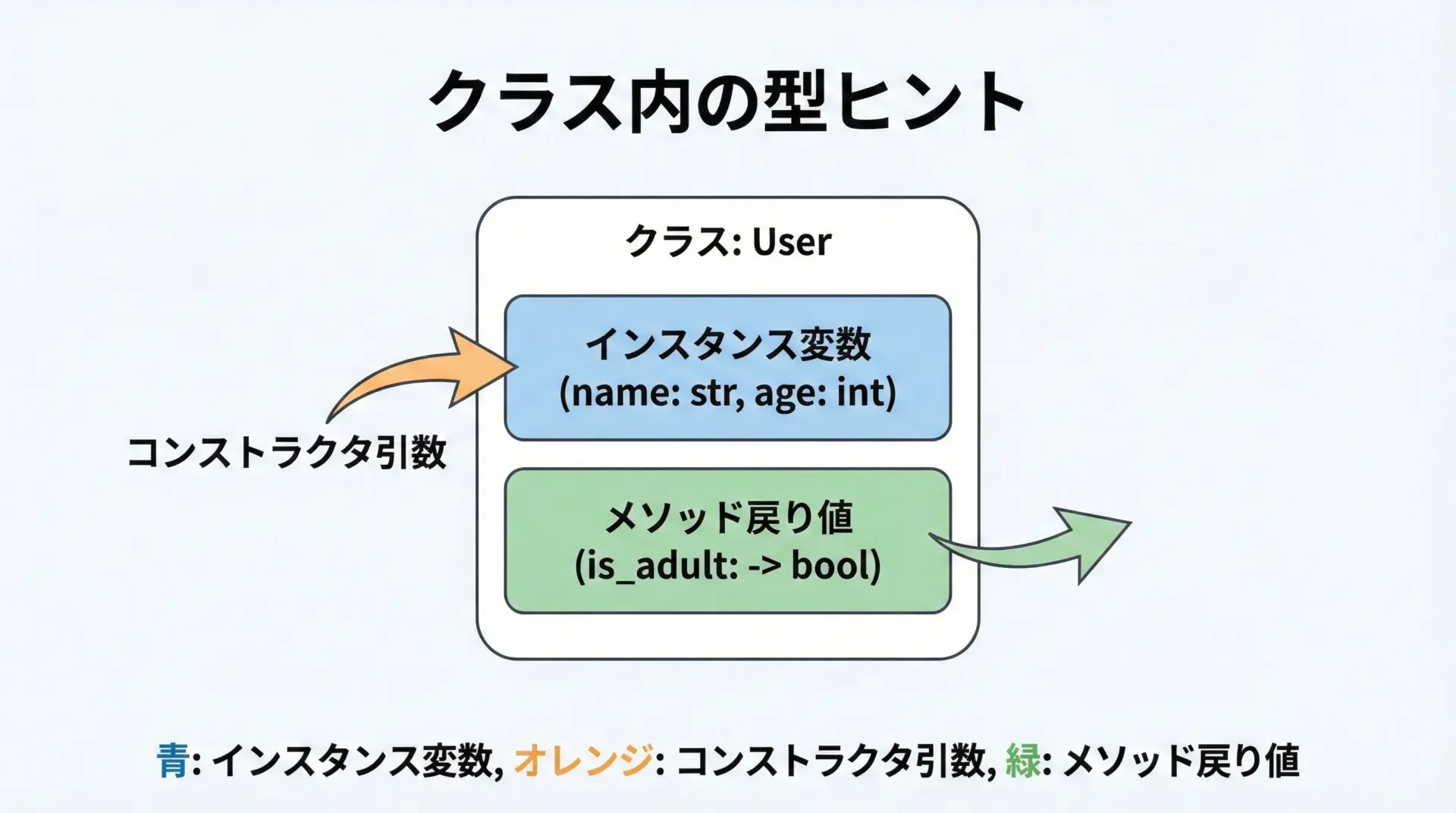
クラスでは、コンストラクタの引数、インスタンス変数、メソッドなど、様々な場所に型ヒントを付けることができます。
from __future__ import annotations # Python 3.7〜3.10で前方参照を使うときに便利
class User:
def __init__(self, name: str, age: int) -> None:
# インスタンス変数にも型を明示できる (Python3.6+)
self.name: str = name
self.age: int = age
def is_adult(self) -> bool:
return self.age >= 20
def friend_with(self, other: "User") -> str:
"""他のユーザーとの関係を説明する文字列を返す"""
return f"{self.name} is friends with {other.name}"ここではfriend_withメソッドのother引数に"User"と文字列で型を書いています。
これは前方参照と呼ばれ、クラス自体の定義がまだ完了していない時点で自分自身の型を参照したい場合に用います。
Python 3.11以降では、from __future__ import annotationsなしでも前方参照がより柔軟に扱えるようになっています。
ジェネリクス(Generic)とTypeVarの基本例
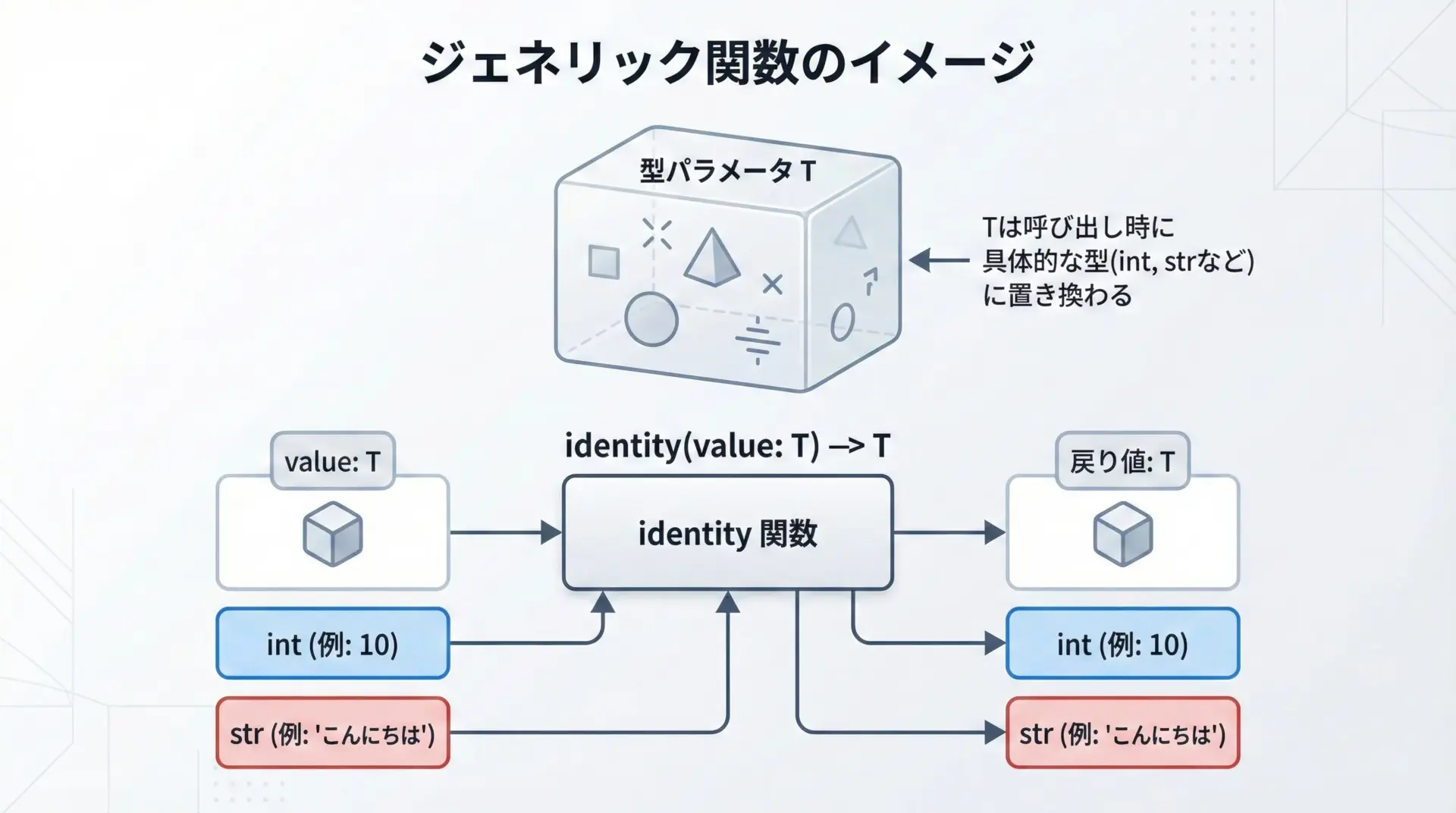
ジェネリクス(Generic)は、型パラメータを持つ関数やクラスを定義する仕組みです。
PythonのTypeVarを使うと、「任意の型だが、引数と戻り値で同じ型である」といった関係を表現できます。
from typing import TypeVar
T = TypeVar("T")
def identity(value: T) -> T:
"""受け取った値をそのまま返す汎用関数"""
return value
num = identity(123) # num は int と推論される
text = identity("hello") # text は str と推論されるまた、TypeVarに制約を付けることで、「この型パラメータは数値型に限定したい」といった指定もできます。
from typing import TypeVar
Number = TypeVar("Number", int, float)
def add(a: Number, b: Number) -> Number:
return a + bここではaとbはintまたはfloatである必要があり、mypyなどがそれをチェックしてくれます。
Callableで関数オブジェクトに型ヒントを付ける
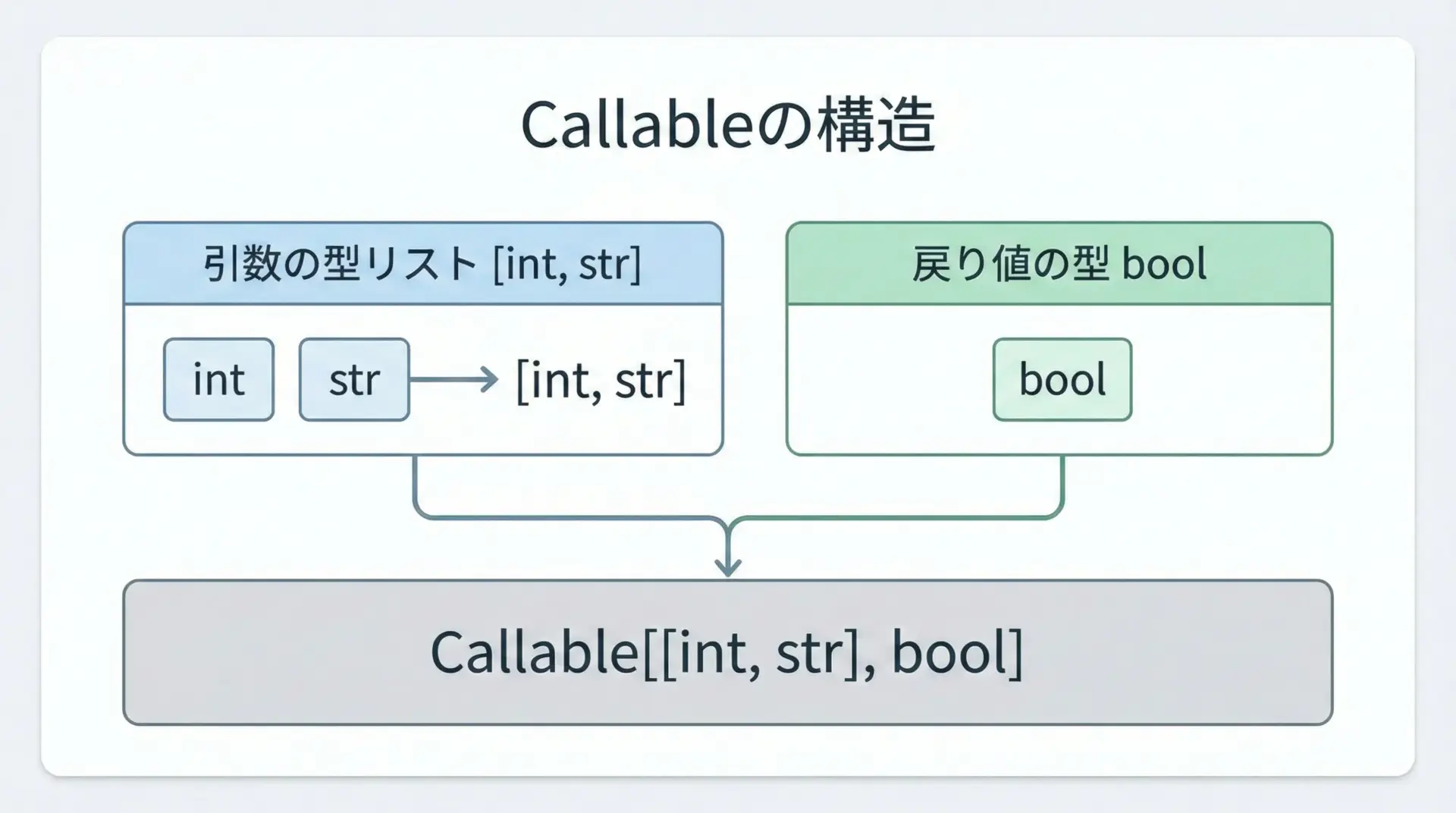
関数やメソッドを引数として受け取る場合、その「受け取る関数」の引数・戻り値にも型ヒントを付けられます。
そこで使うのがCallableです。
from typing import Callable
# int を受け取って bool を返す関数を引数に取る
def filter_numbers(values: list[int], predicate: Callable[[int], bool]) -> list[int]:
result: list[int] = []
for v in values:
if predicate(v):
result.append(v)
return result
def is_even(n: int) -> bool:
return n % 2 == 0
numbers = [1, 2, 3, 4, 5]
even_numbers = filter_numbers(numbers, is_even)
print(even_numbers)上記のコードでは、「intを受け取りboolを返すような関数オブジェクト」だけをpredicateとして許可しています。
このようにCallableを使うことで、コールバック関数や戦略パターンなどを安全に扱うことができます。
[2, 4]Iterable・Iterator・Generatorの型ヒント
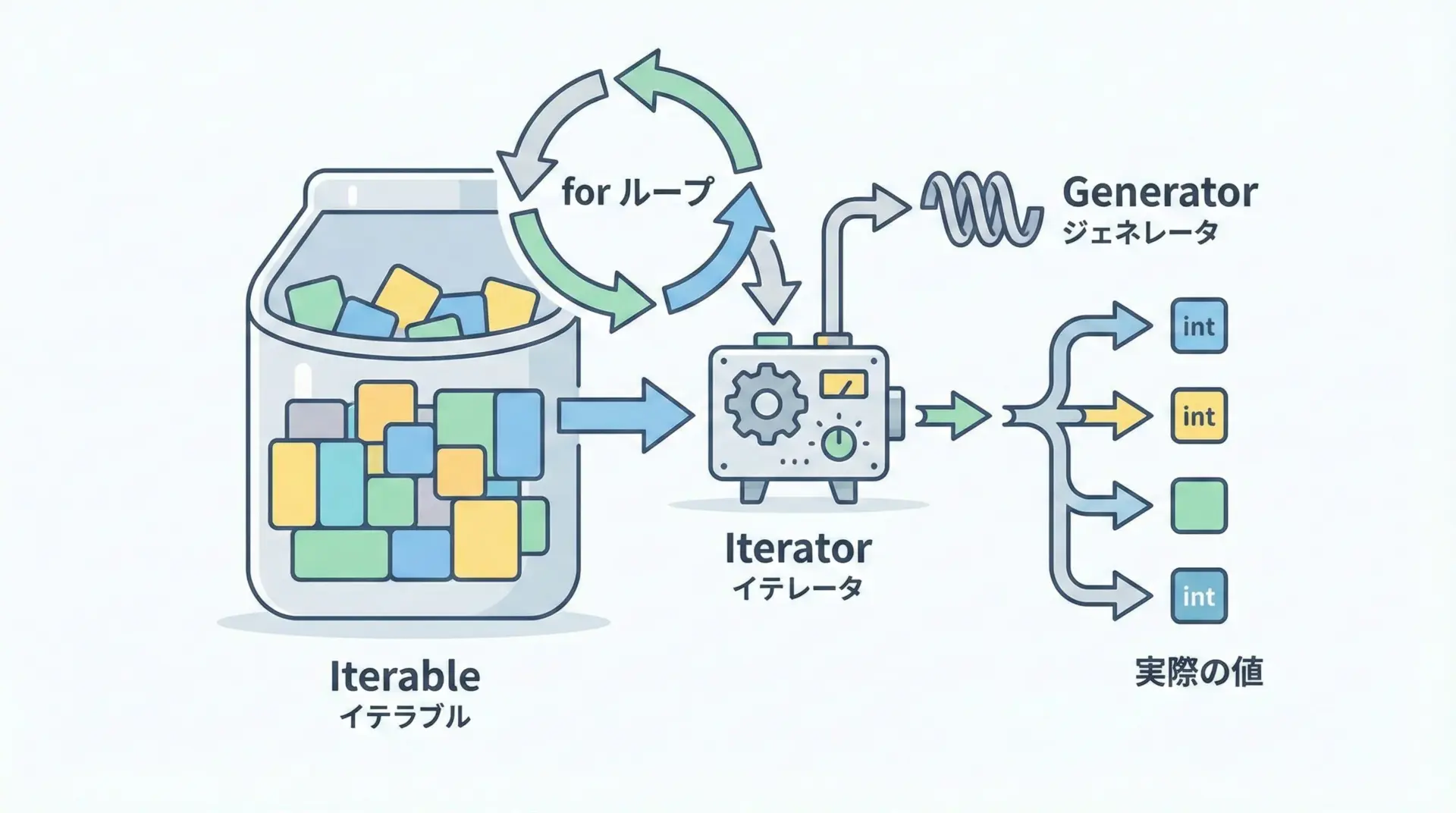
Iterable、Iterator、Generatorは、繰り返し処理でよく登場するインターフェースです。
これらにも型ヒントを付けることで、「何の要素を繰り返しているのか」を明確にできます。
from typing import Iterable, Iterator, Generator
def sum_all(values: Iterable[int]) -> int:
"""intのIterableから合計を計算する"""
total = 0
for v in values:
total += v
return total
def count_up(limit: int) -> Iterator[int]:
"""0 から limit-1 までの整数を順に返すイテレータ"""
i = 0
while i < limit:
yield i
i += 1
def gen_numbers() -> Generator[int, None, None]:
"""イールドする値・送信される値・戻り値に型を付けたGenerator"""
yield 1
yield 2
yield 3Generator[Y, S, R]は、それぞれY: yieldする値の型、S: sendされる値の型、R: return文の戻り値の型を意味します。
通常はGenerator[int, None, None]のように、sendやreturnを使わない場合はNoneを指定します。
dataclassと型ヒントの組み合わせ
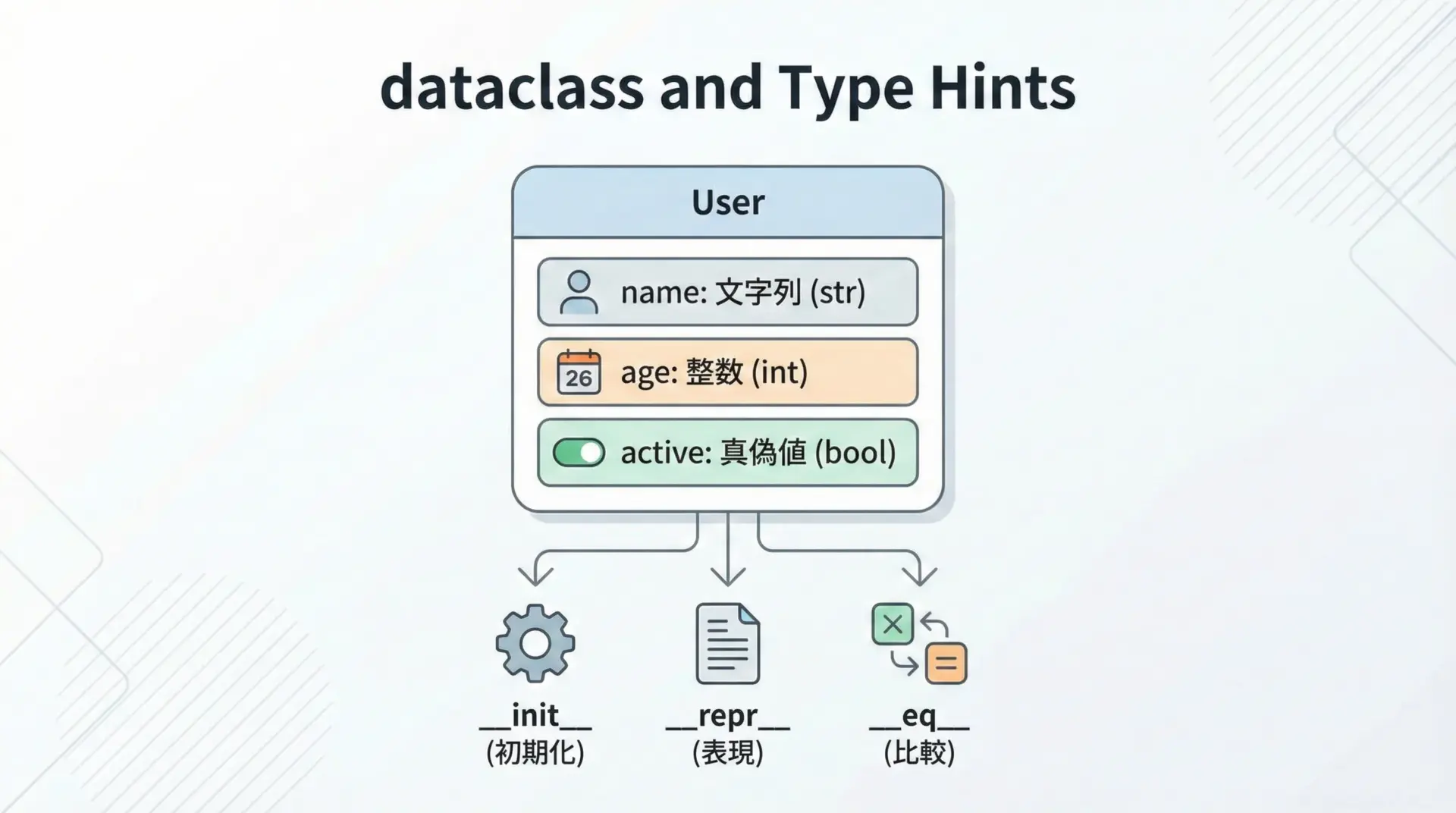
dataclassesモジュールの@dataclassは、型ヒントと非常に相性が良い仕組みです。
フィールドの型ヒントを書くだけで、コンストラクタなどを自動生成してくれるため、データ構造を簡潔に定義できます。
from dataclasses import dataclass
@dataclass
class User:
name: str
age: int
active: bool = True
def is_active_adult(user: User) -> bool:
return user.active and user.age >= 20
u = User(name="Alice", age=30)
print(u)
print(is_active_adult(u))実行結果の例は以下のとおりです。
User(name='Alice', age=30, active=True)
Trueこのように、データを表現するクラスは、基本的にdataclass + 型ヒントで書くと、コードがすっきりして扱いやすくなります。
外部ライブラリ(pandas・requestsなど)を使うときの型ヒント
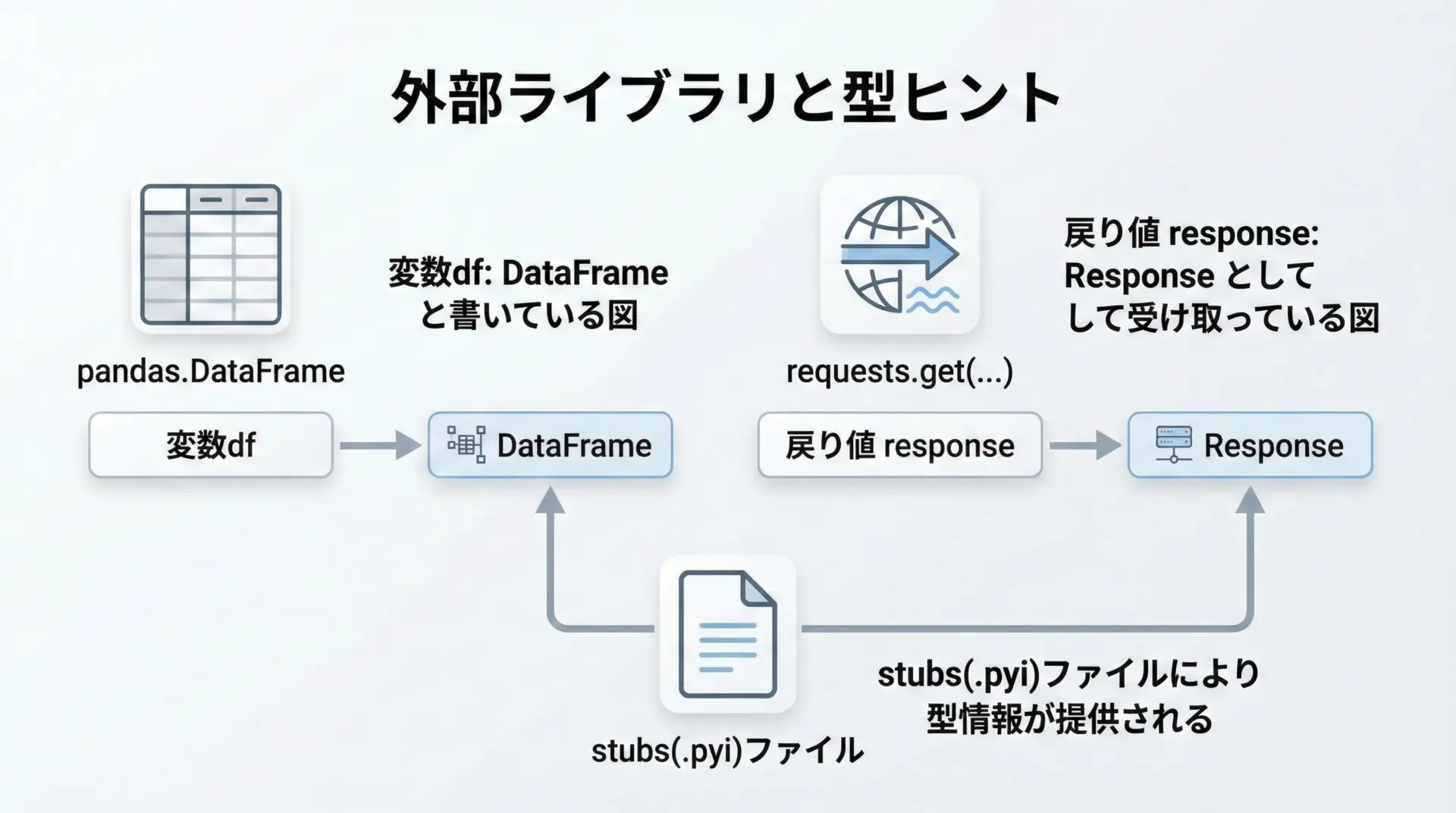
近年の主要な外部ライブラリは、多くが型ヒントに対応しています。
pandasやrequestsも例外ではなく、ライブラリ自身が型定義を内蔵しているか、別途型スタブパッケージが提供されていることが多いです。
例えばpandasの場合、次のように書くと、DataFrameやSeriesに対して補完や型チェックが効くようになります。
import pandas as pd
from pandas import DataFrame, Series
def load_and_filter(path: str) -> DataFrame:
df: DataFrame = pd.read_csv(path)
# boolのSeriesを使ってフィルタリング
adult_mask: Series = df["age"] >= 20
return df[adult_mask]requestsでも同様です。
import requests
from requests import Response
def fetch_json(url: str) -> dict:
response: Response = requests.get(url)
response.raise_for_status()
return response.json()これらの型情報はIDEにも認識されるため、メソッド名やプロパティ名の補完がより精度よく効くようになります。
必要に応じてpip install pandas-stubsやtypes-requestsなどの型スタブパッケージを追加することも検討すると良いでしょう。
型チェックとベストプラクティス
mypyでPython型ヒントをチェックする方法
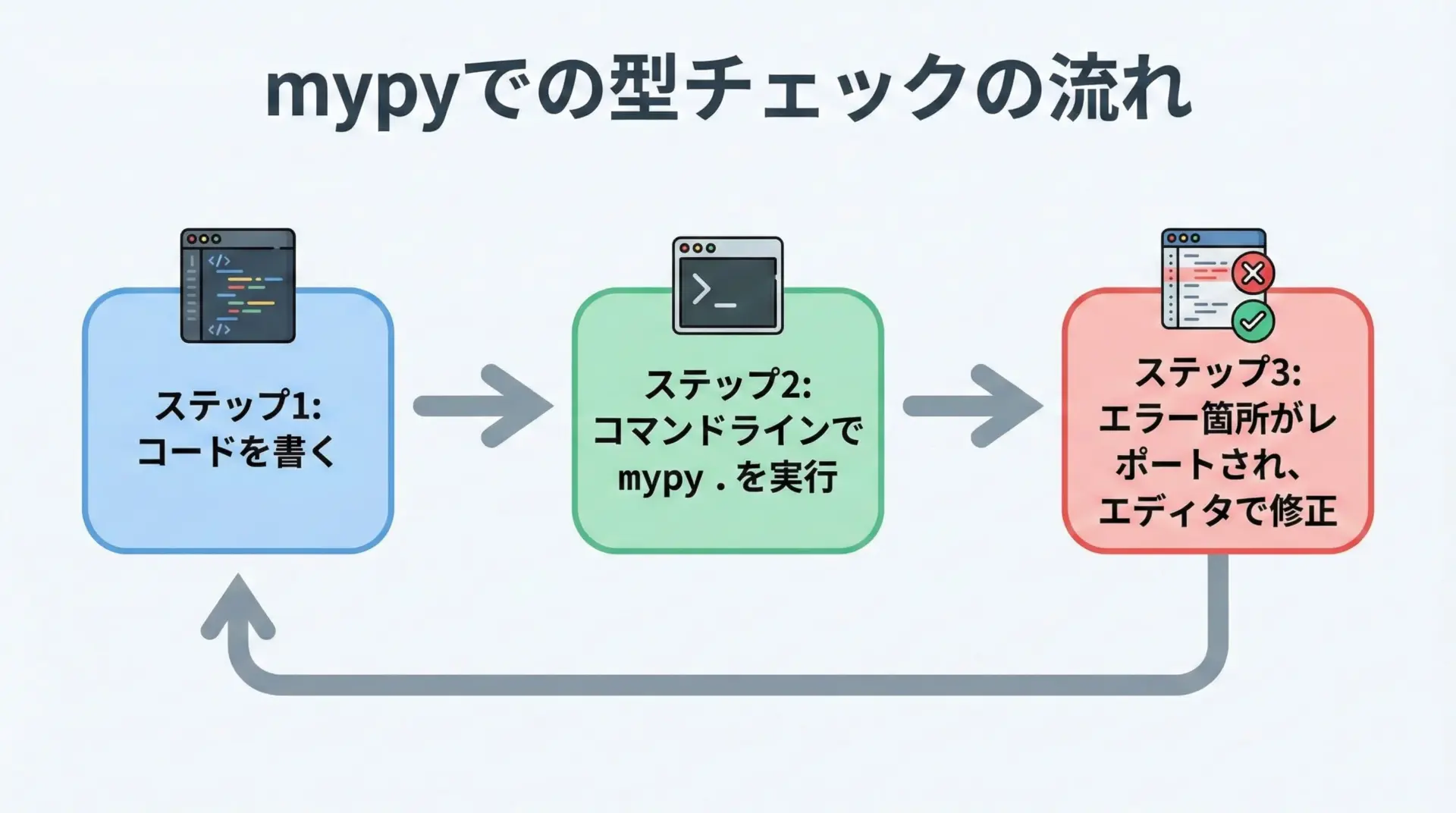
型ヒントは、書くだけではなく、ツールでチェックしてはじめて真価を発揮します。
代表的な型チェッカーがmypyです。
まずはインストールします。
pip install mypy次に、簡単なサンプルコードに対してmypyを実行してみましょう。
# sample.py
def add(a: int, b: int) -> int:
return a + b
result: str = add(1, 2) # わざと型を間違えるこのファイルに対してmypyを実行します。
mypy sample.pysample.py:4: error: Incompatible types in assignment (expression has type "int", variable has type "str")
Found 1 error in 1 file (checked 1 source file)実行してみる前に、明らかな型の不整合を検出できるのが、mypyを導入する大きな価値です。
CIにmypyを組み込んで、プルリクエスト時に自動チェックする運用もよく行われます。
VSCodeで型ヒントと補完を活用する
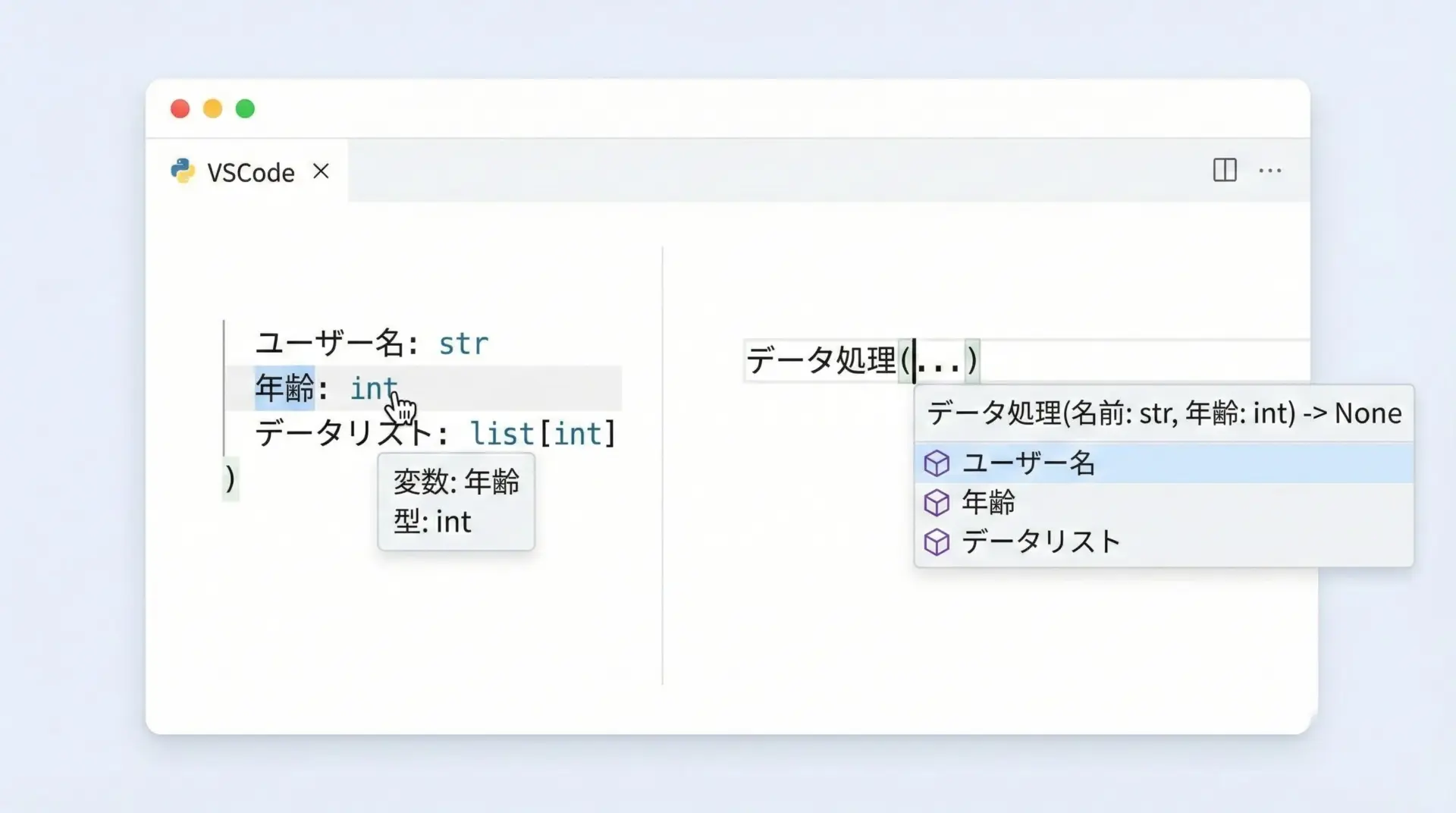
VSCodeなどのモダンなIDEは、型ヒントを理解してくれるため、補完・ジャンプ・リファクタリングの精度が大きく向上します。
VSCodeでPythonの型補完を最大限活用するには、以下のようなポイントがあります。
まず、Python拡張(Pylance)を有効にします。
Pylanceは高速な型解析エンジンを備えており、型ヒントを利用して静的解析を行います。
設定でpython.analysis.typeCheckingModeを"basic"または"strict"にすると、より多くの型エラーを検出できるようになります。
型ヒントの付いたコードであれば、変数名や関数名にカーソルを合わせるだけで、推論された型や定義位置が即座に分かります。
これにより、他人が書いたコードや巨大なコードベースでも、構造を把握しやすくなります。
型ヒントを導入する際のベストプラクティス
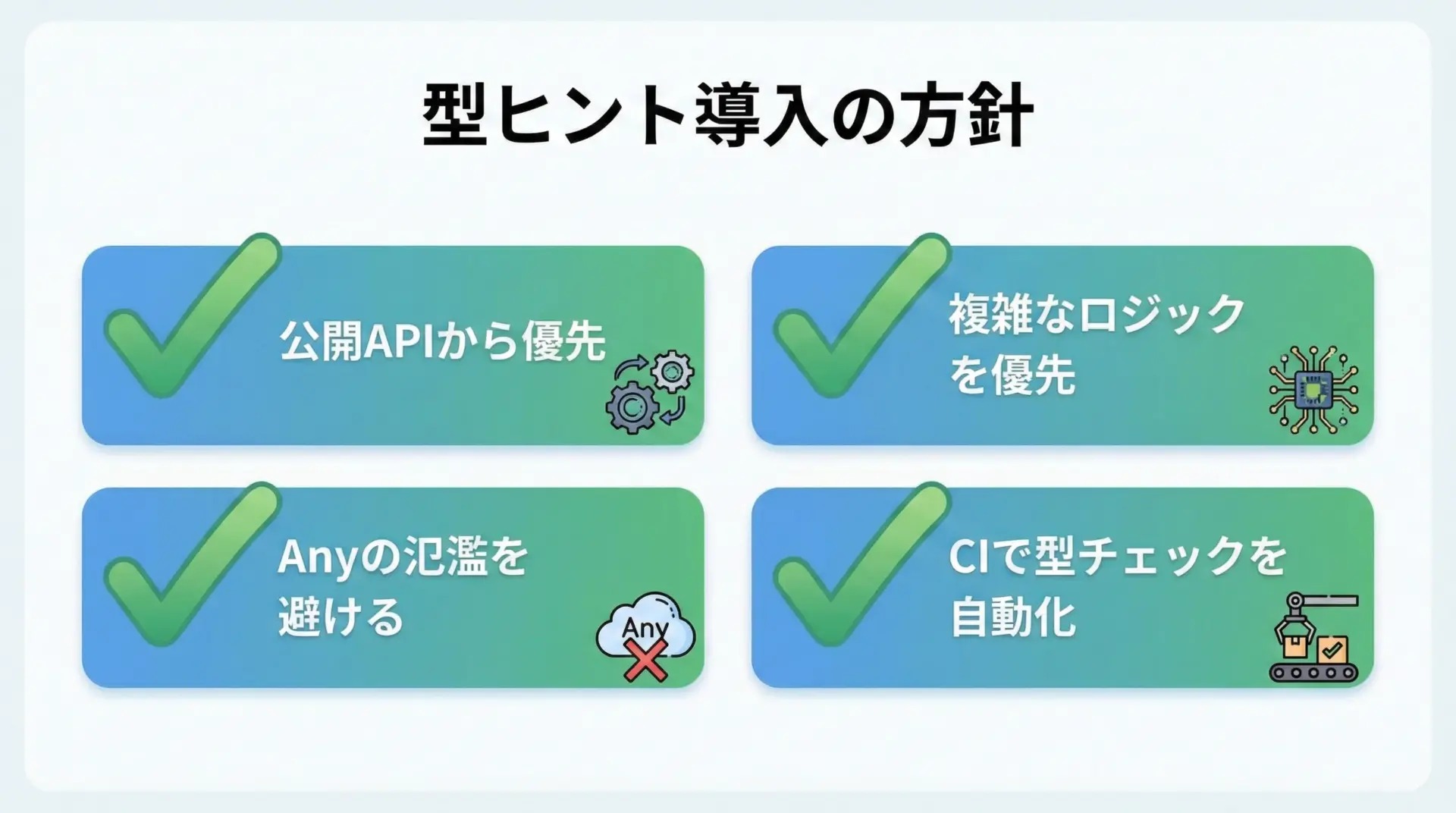
型ヒントは「とりあえず全部の変数に付ける」よりも、戦略的に重要な部分から導入していくのが現実的です。
一般的なベストプラクティスとしては、次のような方針が挙げられます。
まず、モジュールやクラスの「公開API」に優先的に型を付けることです。
外部から呼ばれる関数・メソッドのインターフェースが固まれば、その内部実装の型も自然と決まりやすくなります。
次に、ビジネスロジックや、扱うデータ構造が複雑な箇所にも積極的に型ヒントを入れます。
ここを型でしっかり表現しておくと、将来的な改修時にも仕様を見失いにくくなります。
一方で、Any型を安易に多用すると、型チェックの恩恵が薄まってしまいます。
どうしても型を絞り込めない場合を除き、できるだけ具体的な型を与えることを意識すると良いでしょう。
最後に、mypyやPyrightなどの型チェッカーをCIに組み込むことで、開発チーム全体として型の整合性を維持しやすくなります。
既存コードベースに型ヒントを徐々に導入するコツ
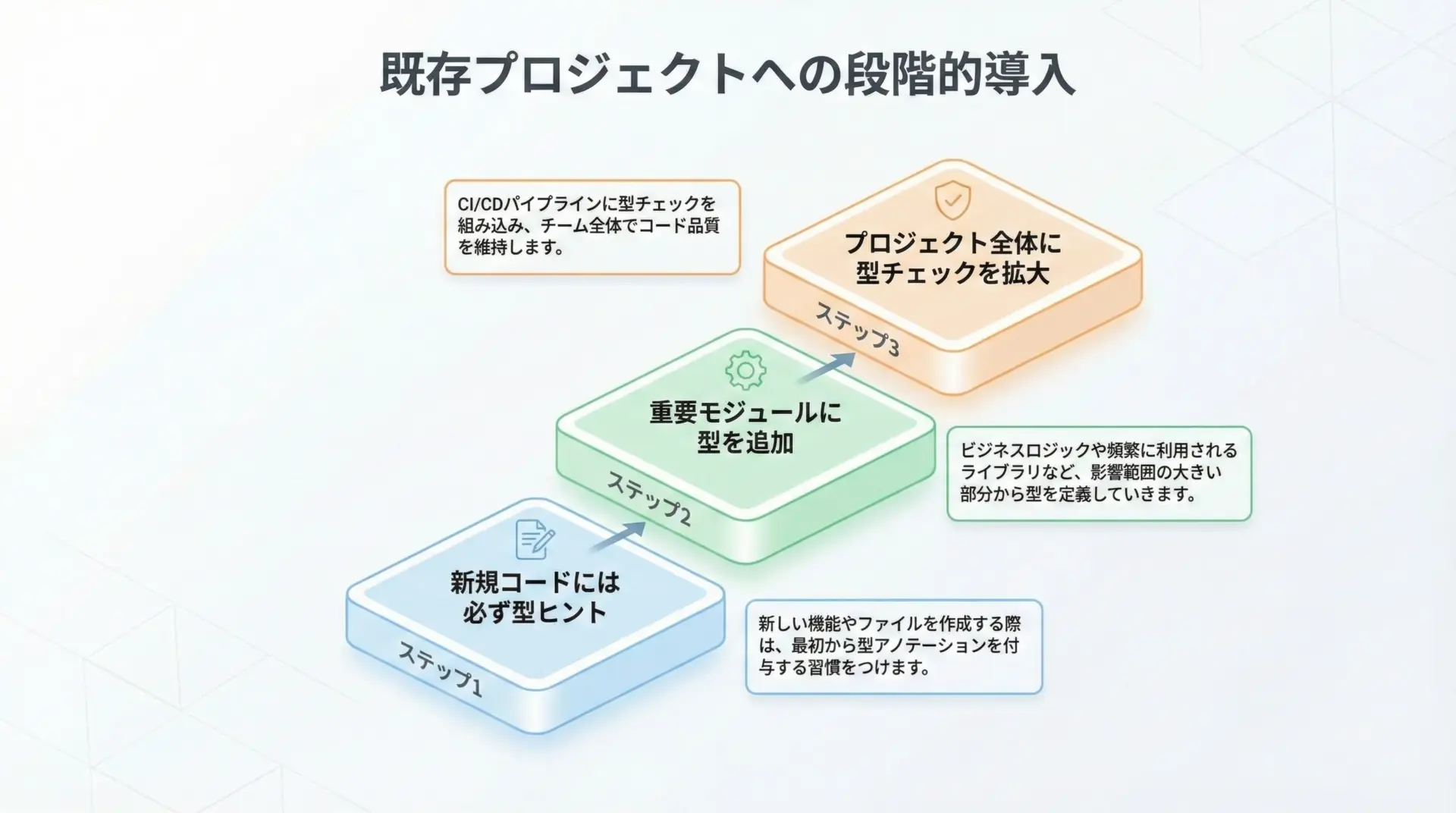
既存の大規模なコードベースに、一気に型ヒントを導入するのは現実的ではありません。
そのため、段階的な導入戦略が重要になります。
まず、「これから書く新しいコードには、原則として型ヒントを付ける」というルールを決めます。
これだけでも、時間の経過とともに型付きコードの割合は増えていきます。
次に、ビジネス的に重要なモジュールや、外部とインターフェースする部分(APIクライアント、データアクセス層など)を選び、重点的に型ヒントを追加していきます。
このとき、# type: ignoreコメントをピンポイントで使うことで、一時的に問題のある箇所をスキップしながら、徐々に型の整合性を整えていく方法もあります。
mypy側でも、部分的なチェックを許容する設定があります。
例えばmypy.iniやpyproject.tomlで、チェック対象のモジュールを限定したり、未注釈の関数を許容したりできます。
これにより、開発の妨げにならない範囲で、型チェックのカバー範囲を徐々に広げることができます。
まとめ
Pythonの型ヒントは、動的型付けの柔軟さを保ちながら、コードの意図を明確にし、バグの早期発見と開発効率向上に寄与する強力な仕組みです。
typingモジュールの基本的な使い方(基本型、Optional・Union、コレクション型、Literal、Genericなど)と、mypyやVSCodeと組み合わせた運用を理解すれば、日常の開発で大きなメリットを得られます。
既存コードには、まず公開APIや重要モジュールから段階的に導入し、型チェックツールと連携しながら、少しずつ型安全なコードベースへと育てていくことをおすすめします。
