C++においてオブジェクト指向プログラミングを行う際、継承と多態性(ポリモーフィズム)は非常に重要な要素です。
その中で、派生クラスが基底クラスの関数を再定義する「オーバーライド」を安全に行うために導入されたのがoverrideキーワードです。
本記事では、このキーワードの意味や具体的な使い方、そしてなぜ現代のC++開発において必須とされるのかを詳しく解説します。
C++におけるoverrideとは
C++におけるoverrideは、C++11から導入された文脈依存のキーワードです。
主に派生クラスで仮想関数を再定義する際に使用され、その関数が「基底クラスの仮想関数を上書きするものであること」をコンパイラに明示的に伝える役割を持っています。
基本的な概念と役割
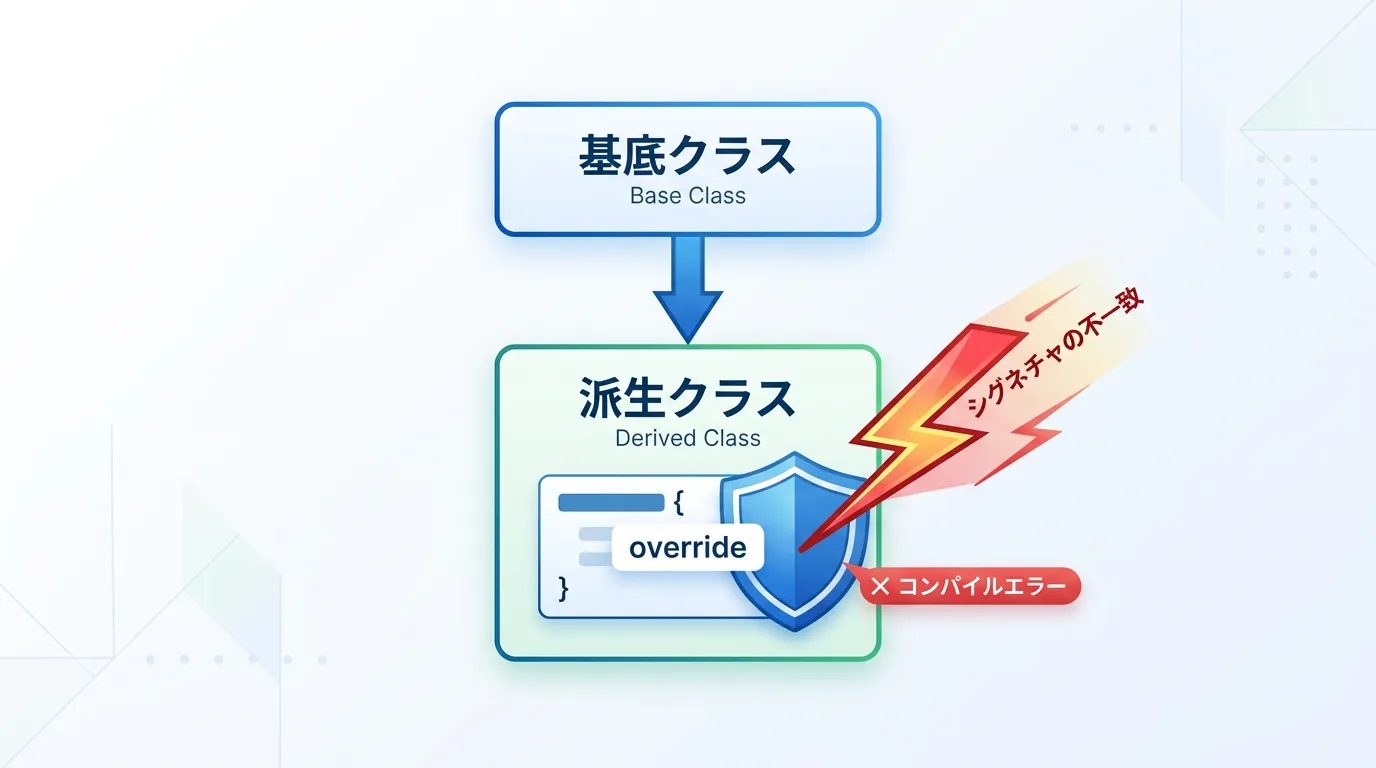
通常、基底クラスでvirtual宣言されたメンバ関数は、派生クラスで同じシグネチャ(関数名、引数の型、const性の組み合わせ)を持つ関数を定義することで上書きできます。
しかし、overrideキーワードがない場合、意図せずシグネチャが異なってしまうと、コンパイラはそれを「新しい別の関数の定義」として解釈してしまい、バグの原因となります。
overrideを記述することで、コンパイラは「本当に基底クラスに同じシグネチャの仮想関数が存在するか」をチェックするようになります。
もし一致する関数が基底クラスに見つからない場合、コンパイルエラーとして報告してくれるため、実行時の予期せぬ動作を未然に防ぐことが可能です。
なぜoverrideが必要なのか
古くからあるC++では、オーバーライドの成否はプログラマの注意深さに依存していました。
例えば、基底クラスの関数の引数がint型であるのに対し、派生クラスで誤ってlong型で定義してしまった場合、これは「オーバーライド」ではなく「関数のオーバーロード(多重定義)」と見なされます。
このようなミスは、プログラムの規模が大きくなるほど発見が困難になります。
実行時に基底クラスのポインタを介して関数を呼び出した際、期待した派生クラスの処理が呼ばれず、基底クラスのデフォルト処理が実行されてしまうからです。
これを防ぐための安全装置として、overrideが誕生しました。
overrideキーワードの基本的な使い方
overrideを使用する際は、関数の宣言または定義の末尾に記述します。
記述場所と構文
基本的な構文は以下の通りです。
class 派生クラス名 : public 基底クラス名 {
public:
void 関数名() override {
// 処理
}
};注意点として、overrideは関数の名前の後、かつ純粋仮想関数の指定子である= 0よりも前に記述します。
基底クラスと派生クラスの定義例
具体的なコードを見てみましょう。
以下の例では、動物を表す基底クラスAnimalと、それを継承したDogクラスを定義しています。
#include <iostream>
#include <string>
// 基底クラス
class Animal {
public:
// 仮想関数として定義
virtual void make_sound() const {
std::cout << "何かの鳴き声" << std::endl;
}
// デストラクタも仮想関数にしておくのが基本
virtual ~Animal() = default;
};
// 派生クラス
class Dog : public Animal {
public:
// overrideを明示して再定義
void make_sound() const override {
std::cout << "ワンワン!" << std::endl;
}
};
int main() {
Animal* my_pet = new Dog();
// Animal型のポインタ経由でもDogの関数が呼ばれる(多態性)
my_pet->make_sound();
delete my_pet;
return 0;
}ワンワン!この例では、Dog::make_soundにoverrideが付与されています。
これにより、もしAnimal::make_soundの名前が変わったり削除されたりした場合、コンパイラが即座にエラーを出して教えてくれます。
overrideを使用する具体的なメリット
overrideを記述することには、単なるエラーチェック以上の価値があります。
コンパイル時における型チェックの強化
最大のメリットは、人間による些細なミスをコンパイラが100%検出できる点です。
以下の表は、overrideがある場合とない場合の違いをまとめたものです。
| 状況 | overrideなし | overrideあり |
|---|---|---|
| 関数名のタイポ | 別の関数として定義される(正常終了) | コンパイルエラー |
| 引数の型の不一致 | オーバーロードとして扱われる(正常終了) | コンパイルエラー |
| const修飾子の忘れ | 別の関数として扱われる(正常終了) | コンパイルエラー |
| 基底関数が仮想でない | 隠蔽(Hiding)が発生する(正常終了) | コンパイルエラー |
コードの可読性と意図の明確化
overrideが書かれていることで、そのコードを読む他の開発者(あるいは将来の自分)に対して、「この関数は継承ツリーのどこかで定義されたものを上書きしている」という意図を明確に伝えることができます。
わざわざ基底クラスの定義まで遡って確認する必要がなくなるため、メンテナンス性が大幅に向上します。
また、モダンC++においては、派生クラスでvirtualを繰り返すよりも、overrideのみを記述する方が推奨されるスタイルとなっています。
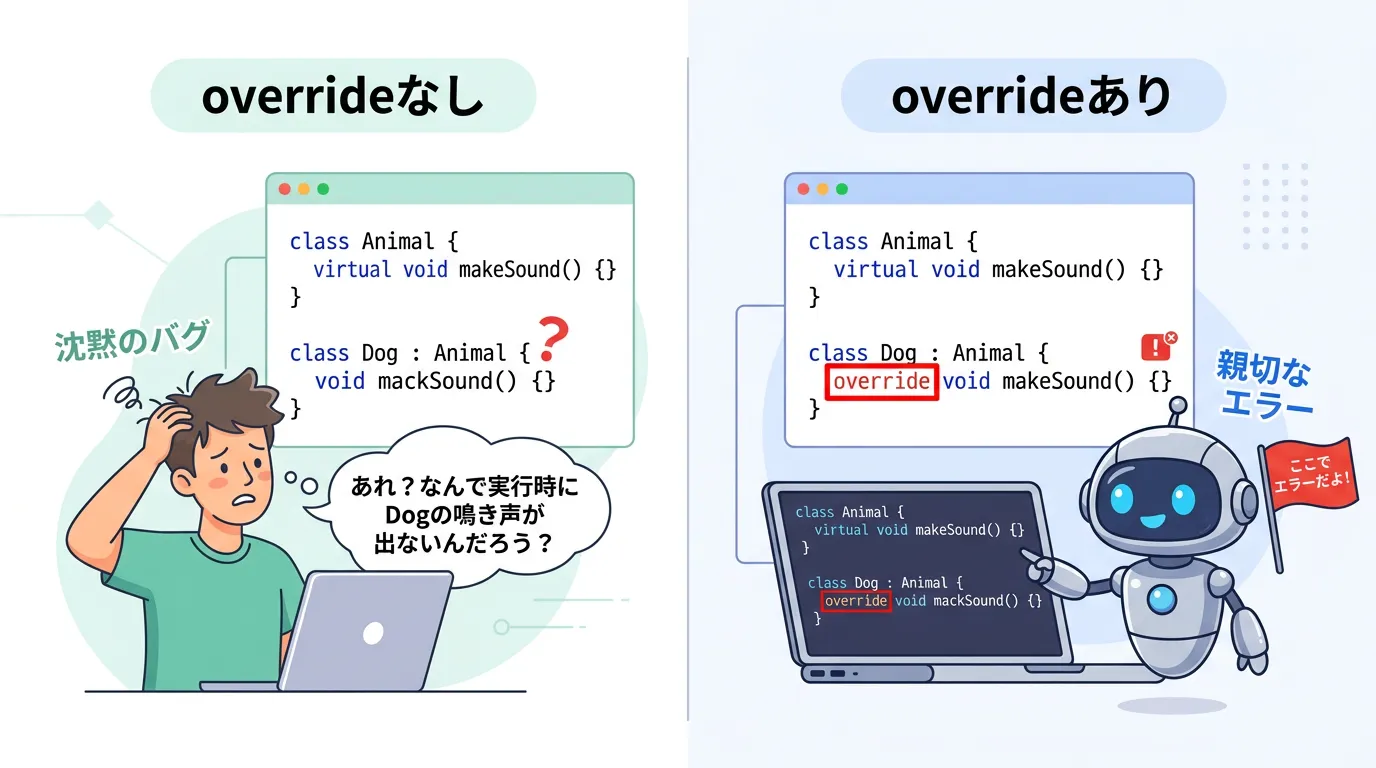
overrideで防げる代表的なミス
実際にどのようなミスが防げるのか、具体的な失敗例を通して見ていきましょう。
関数名のスペルミス
非常に単純ですが、よくあるミスです。
class Base {
public:
virtual void setup_system() {}
};
class Derived : public Base {
public:
// setup_systemをオーバーライドしたいが、'm'を忘れた
void setup_syste() override { // ここでコンパイルエラー!
// 処理
}
};overrideがない場合、setup_systeという新しい関数が定義されただけで終わり、本来のsetup_systemは基底クラスの空の処理が走り続けます。
引数の型や数の不一致
関数のシグネチャが少しでも異なると、それは別物です。
class Base {
public:
virtual void process(int value) {}
};
class Derived : public Base {
public:
// intではなくfloatにしてしまった
void process(float value) override { // ここでコンパイルエラー!
// 処理
}
};C++ではintとfloatは異なる型であるため、これはオーバーロードになります。
overrideを付けていれば、コンパイラが「Baseにfloatを引数に取るprocessなんて無いよ」と教えてくれます。
const修飾子の有無
これは上級者でも陥りやすい罠です。
C++において、constがついている関数とついていない関数は、完全に別物として扱われます。
class Base {
public:
virtual void display() const {} // constあり
};
class Derived : public Base {
public:
void display() override { // constを忘れたのでコンパイルエラー!
// 処理
}
};基底クラスでconstが指定されている場合、派生クラスでも必ずconstを付けなければオーバーライドとは認められません。
実践的なコード例で学ぶoverrideの挙動
ここでは、あえてエラーが発生する状況と、正しく修正された状況を比較して学びます。
正常にオーバーライドされるケース
まずは、正しく実装された美しいコードの例です。
#include <iostream>
class UIElement {
public:
virtual void render() const = 0; // 純粋仮想関数
virtual ~UIElement() = default;
};
class Button : public UIElement {
public:
// 基底クラスの純粋仮想関数を実装
void render() const override {
std::cout << "[ボタンを表示します]" << std::endl;
}
};
void draw(const UIElement& element) {
element.render();
}
int main() {
Button btn;
draw(btn);
return 0;
}[ボタンを表示します]コンパイルエラーが発生するケース
次に、基底クラスの仕様が変更されたことに気づかず、派生クラスの修正を忘れた場合を想定します。
class Database {
public:
// 旧: virtual void connect()
// 新: 引数にタイムアウト値を追加
virtual void connect(int timeout_ms) {}
};
class MyDatabase : public Database {
public:
// 基底クラスの仕様変更により、この定義はオーバーライドではなくなった
void connect() override {
// エラー: 'void MyDatabase::connect()' marked 'override' but does not override any member functions
}
};このように、overrideを付けておくことで、「基底クラスを変更した際の影響範囲」がコンパイルエラーによって浮き彫りになります。
これは大規模なリファクタリングにおいて絶大な威力を発揮します。
overrideに関連する重要な知識
overrideを使いこなす上で、併せて知っておくべき概念がいくつかあります。
virtualキーワードとの関係性
派生クラスでoverrideを記述する場合、その関数にvirtualを重ねて記述する必要はありません。
C++の仕様上、一度仮想関数として定義された関数は、派生クラスでも自動的に仮想関数となります。
// 推奨される書き方
void func() override;
// これでも動くが冗長
virtual void func() override;モダンなコーディング規約(Google C++ Style Guideなど)では、「基底クラスではvirtualを使い、派生クラスではoverrideのみを使う」というスタイルが一般的です。
finalキーワードによる継承の制限
overrideとセットで覚えたいのがfinalキーワードです。
これは、「これ以上のオーバーライドを禁止する」という意思表示に使います。
class Base {
public:
virtual void action() {}
};
class Intermediate : public Base {
public:
// オーバーライドしつつ、さらに下のクラスでの再定義を禁止する
void action() override final {
// 処理
}
};
class Derived : public Intermediate {
public:
// エラー: Intermediate::actionがfinalなのでオーバーライドできない
// void action() override {}
};finalを使用することで、クラス設計の意図をより強固に守ることができます。
また、コンパイラが「これ以上上書きされない」と判断できるため、関数呼び出しの最適化(脱仮想化)が期待できる場合もあります。

C++ Core Guidelinesにおける推奨
C++の生みの親であるBjarne Stroustrup氏らがまとめた「C++ Core Guidelines」では、仮想関数の扱いについて以下のように推奨されています。
- 仮想関数を宣言する場合は、
virtual、override、finalのいずれかちょうど1つを使用すること。 - 基底クラスの最初の宣言には
virtualを使用する。 - 派生クラスでの再定義には
overrideを使用する。 - 再定義を禁止したい場合には
finalを使用する。
この指針に従うことで、コードの意図が最も明確になり、かつ冗長さを排除できます。
| 指定子 | 推奨される使用シーン |
|---|---|
virtual | 基底クラスで初めて仮想関数を定義するとき |
override | 派生クラスで仮想関数を再定義するとき(最も一般的) |
final | これ以上の上書きを許したくないとき |
まとめ
C++におけるoverrideキーワードは、単なる記述のルールではなく、プログラムの安全性と可読性を劇的に向上させるための強力なツールです。
これを活用することで、タイポやシグネチャの不一致といった「静かなバグ」をコンパイル時に確実に排除できるようになります。
また、コードの意図が明確になるため、チーム開発や長期的なメンテナンスにおいても大きなメリットをもたらします。
現代のC++開発においては、派生クラスで仮想関数を再定義する際には必ずoverrideを付けることが標準的な作法となっています。
もし、まだ使っていない古いコードがあれば、積極的に導入して堅牢なクラス設計を目指しましょう。
