C++を深く理解する上で避けては通れない壁が「L値(L-value)」と「R値(R-value)」の概念です。
これらはモダンC++においてプログラムのパフォーマンスを劇的に向上させるムーブセマンティクスを支える非常に重要な要素です。
かつてのC++では単純だった値の分類も、C++11以降は効率化のために細分化されました。
この記事では、初心者から中級者へステップアップするために欠かせないL値とR値の違い、そしてそれらを活用した右辺値参照の仕組みを徹底的に解説します。
L値とR値の基本的な違い
C++の式はすべて、特定の型に属すると同時に、値カテゴリ(Value Category)と呼ばれる属性を持っています。
古くからの定義では「代入式の左側(Left)に置けるものがL値、右側(Right)にしか置けないものがR値」とされてきましたが、現代のC++ではより厳密な定義が存在します。
L値(L-value)とは何か
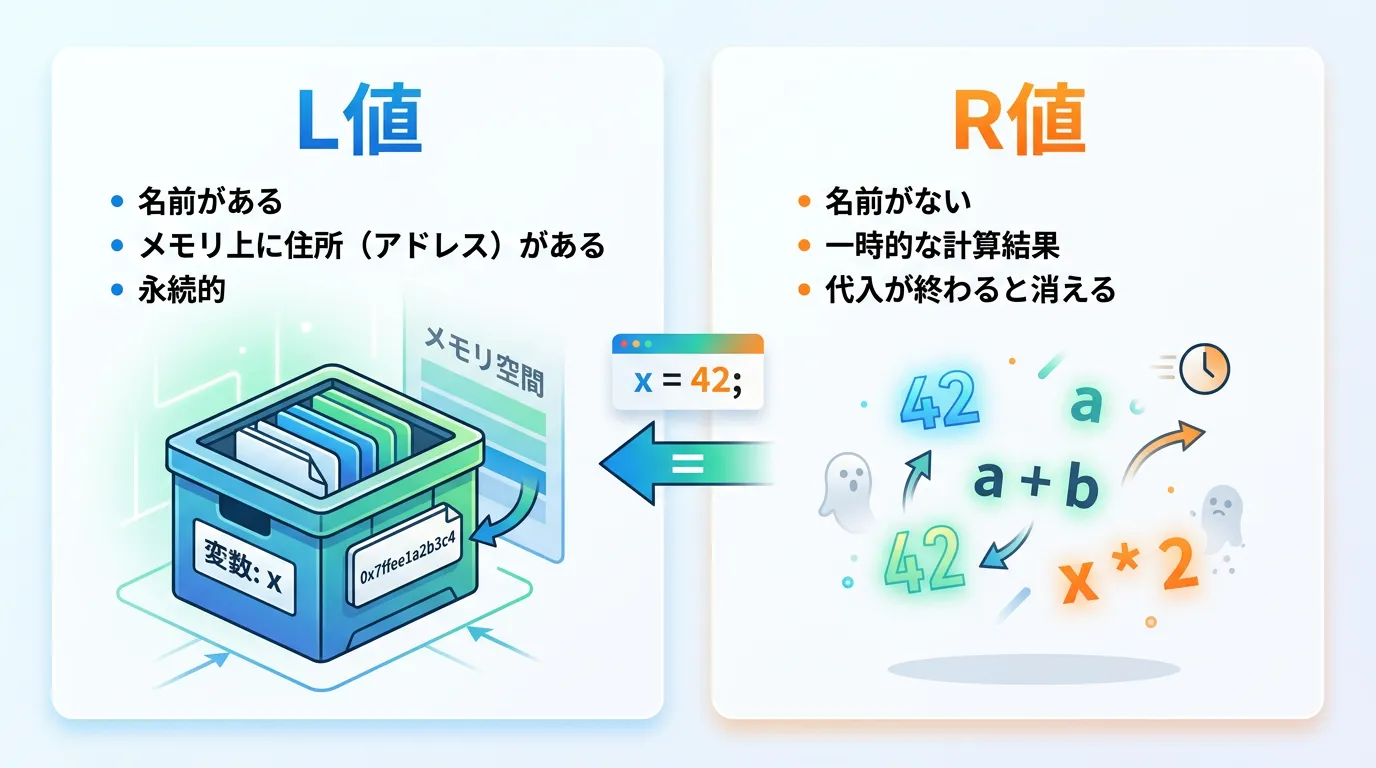
L値とは、平たく言えば「名前が付いていて、メモリ上の特定の場所(アドレス)を占有しているオブジェクト」のことです。
変数を宣言したとき、その変数はプログラムの実行中、スコープを抜けるまでメモリ上に残り続けます。
L値の特徴
L値の最大の特徴は、&演算子を使ってアドレスを取得できる点にあります。
例えば、int x = 10;というコードにおいて、xはL値です。
私たちは&xとしてそのメモリ上の場所を特定できます。
R値(R-value)とは何か
一方でR値とは、「名前を持たず、メモリ上の特定の場所に永続的に存在しない一時的な値」を指します。
計算式の途中で現れる数値や、関数の戻り値として一時的に生成されるオブジェクトなどがこれに該当します。
R値の特徴
R値は、その式が終わるとすぐに破棄されてしまうため、原則としてアドレスを取得することができません。
int x = 10 + 20;という式における10 + 20の結果(30)は、変数xに格納されるための一時的な存在であり、R値です。
#include <iostream>
int main() {
int x = 10; // xはL値、10はR値
int y = 20; // yはL値、20はR値
int z = x + y; // zはL値、(x + y)の結果はR値
// L値はアドレスを取れる
std::cout << "xのアドレス: " << &x << std::endl;
// R値のアドレスは取れない(コンパイルエラーになる)
// std::cout << &(x + y) << std::endl;
return 0;
}xのアドレス: 0x7ffee6b5a8ac右辺値参照(R-value Reference)の登場
C++11以前は、R値を変数にバインド(紐付け)して長生きさせる方法は、const参照(const T&)を使う以外にありませんでした。
しかし、これでは値を変更することができません。
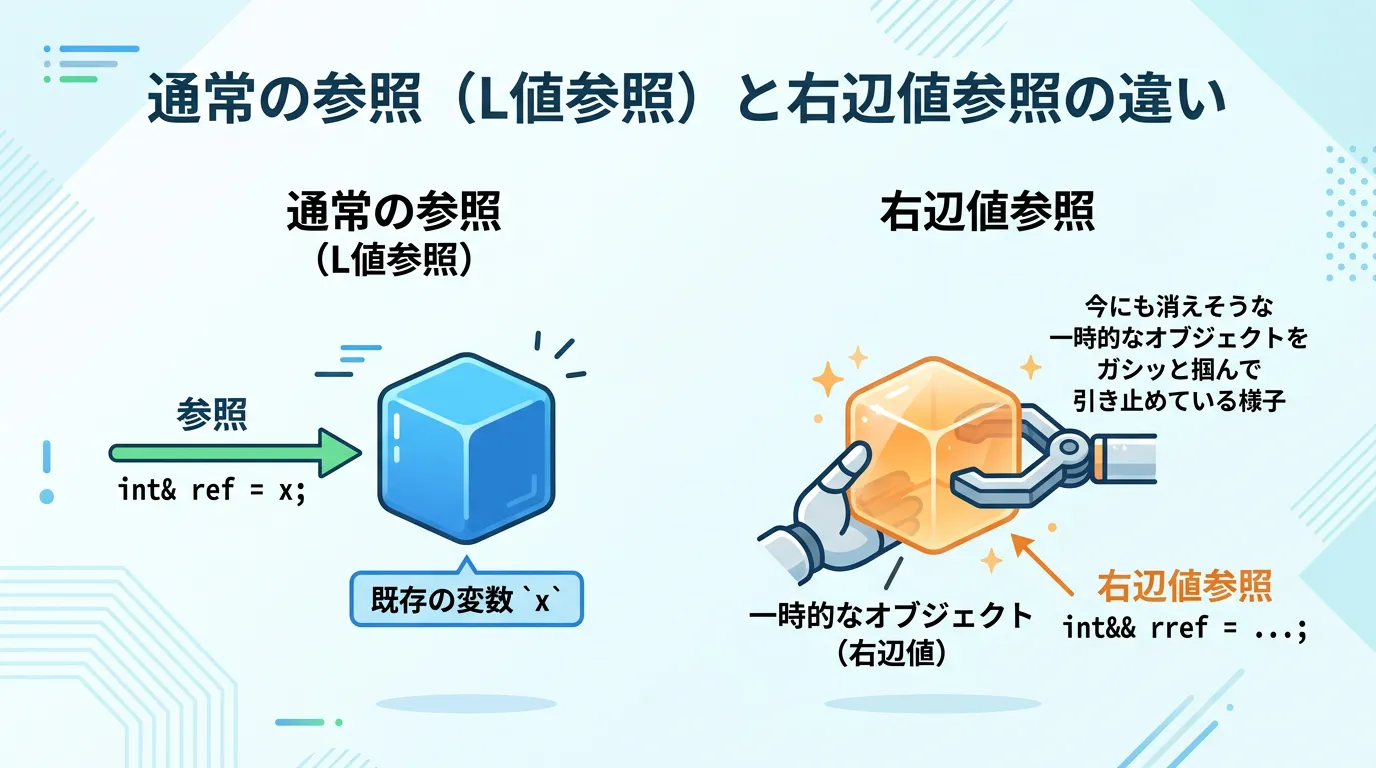
そこで導入されたのが右辺値参照(&&)です。
右辺値参照の書き方
右辺値参照は、型の後ろに&&を付けることで宣言します。
| 参照の種類 | 構文 | 参照できるもの |
|---|---|---|
| L値参照 | T& | L値のみ |
| const L値参照 | const T& | L値とR値の両方(ただし変更不可) |
| 右辺値参照 | T&& | R値のみ |
なぜ右辺値参照が必要なのか
右辺値参照の目的は、「間もなく消えてしまう一時的なオブジェクトから、リソースを効率的に盗み取る」ことにあります。
これが次に説明するムーブセマンティクスの鍵となります。
#include <iostream>
#include <string>
int main() {
std::string s1 = "Hello";
// std::string& r1 = s1 + " World"; // エラー:L値参照はR値を参照できない
const std::string& r2 = s1 + " World"; // OK:const L値参照はR値を参照可能
std::string&& r3 = s1 + " World"; // OK:右辺値参照でR値を直接参照
r3 += "!!!"; // 右辺値参照なので中身を書き換え可能
std::cout << r3 << std::endl;
return 0;
}Hello World!!!ムーブセマンティクスによる最適化
L値とR値の違いを理解する最大のメリットは、「ムーブセマンティクス」を理解できるようになることです。
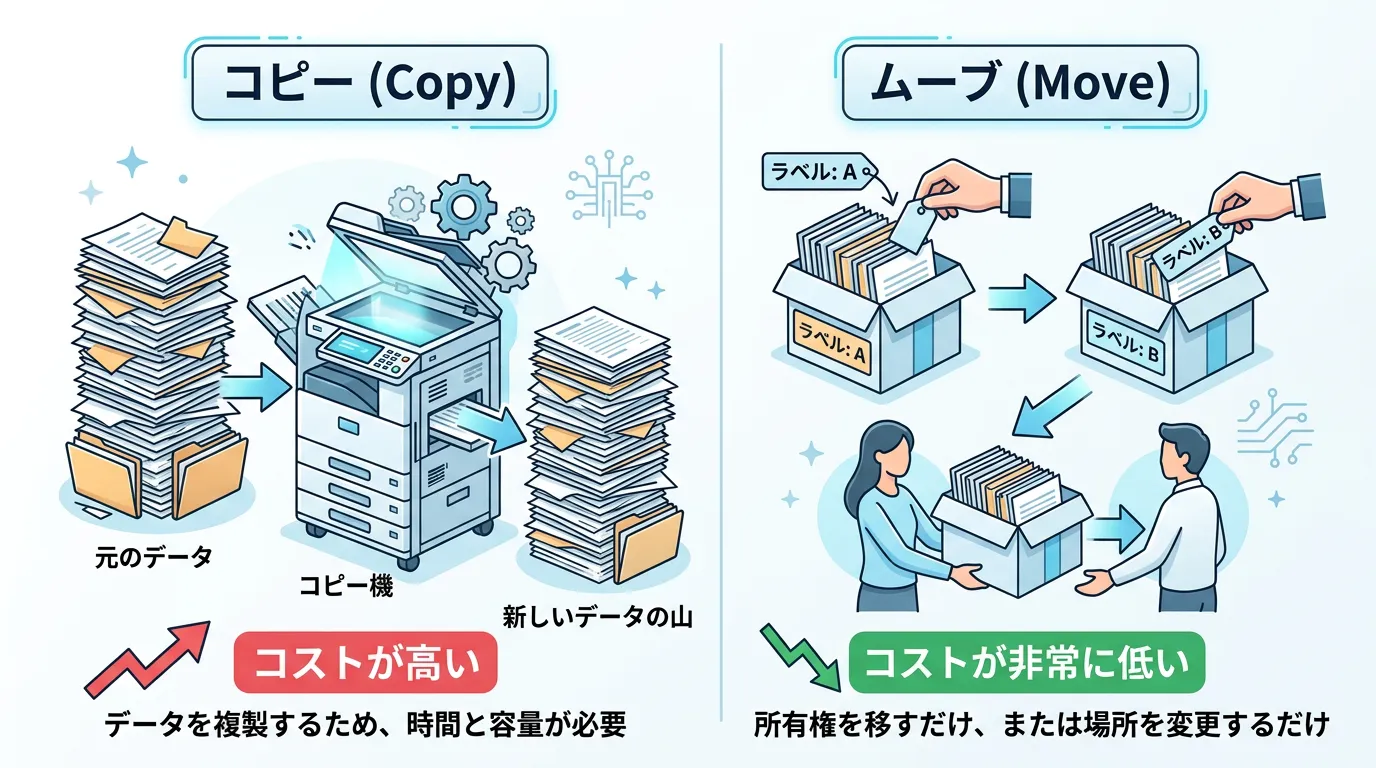
ムーブセマンティクスとは、データの「コピー」ではなく「移動(所有権の移転)」を行う仕組みです。
コピーとムーブの違い
例えば、大量のデータを保持するstd::vectorを別の変数に代入する場合を考えてみましょう。
- コピー: 新しいメモリ領域を確保し、すべての要素を一つずつ複製する。
- ムーブ: 元の変数が持っていたメモリ領域へのポインタを、新しい変数にそのまま渡す。元の変数は「空」の状態にする。
ムーブコンストラクタの実装例
自作クラスでムーブセマンティクスを実装するには、右辺値参照を引数に取るムーブコンストラクタを定義します。
#include <iostream>
#include <utility> // std::moveのために必要
class MyBuffer {
public:
int* data;
size_t size;
// 通常のコンストラクタ
MyBuffer(size_t s) : size(s) {
data = new int[size];
std::cout << "メモリ確保: " << size << "個" << std::endl;
}
// デストラクタ
~MyBuffer() {
delete[] data;
}
// ムーブコンストラクタ
MyBuffer(MyBuffer&& other) noexcept : data(other.data), size(other.size) {
// 元のオブジェクトのリソースを「奪う」
other.data = nullptr;
other.size = 0;
std::cout << "ムーブされました" << std::endl;
}
// コピーは禁止(話を単純にするため)
MyBuffer(const MyBuffer&) = delete;
};
int main() {
MyBuffer buf1(1000);
// buf1はL値なので、そのままではムーブできない
// std::moveを使ってL値をR値にキャストする
MyBuffer buf2(std::move(buf1));
return 0;
}メモリ確保: 1000個
ムーブされましたstd::moveの正体
上記のコードで登場したstd::moveは、名前に反して「何かを移動させる関数」ではありません。
その正体は、「引数を強制的に右辺値にキャストする」だけの機能です。
これにより、コンパイラに対して「この変数はもう使わないから、中身を盗んでもいいよ(ムーブコンストラクタを呼んでいいよ)」というサインを送ります。
現代C++における値カテゴリの分類
C++11以降、値カテゴリはより厳密に分類されるようになりました。
これを知っておくと、テンプレートプログラミングや複雑なエラーメッセージの理解に役立ちます。
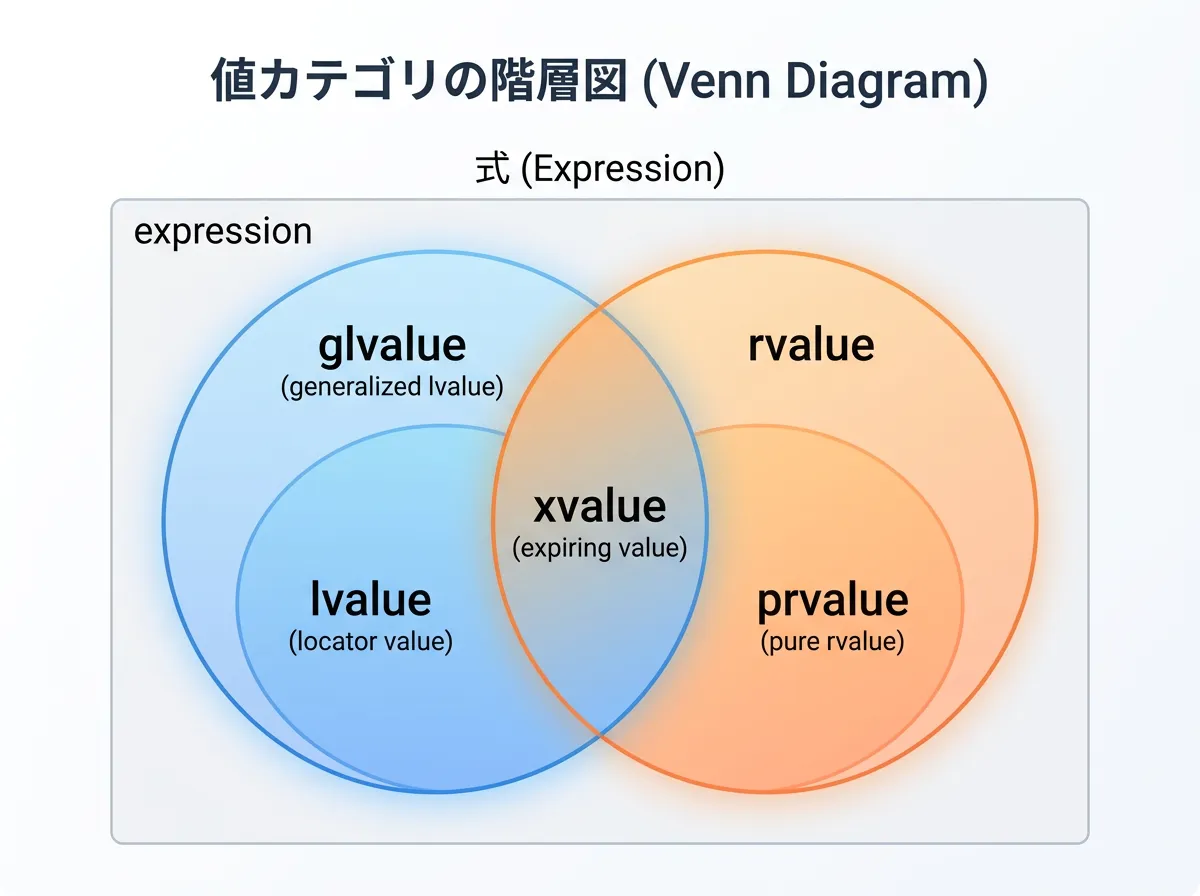
3つの主要なカテゴリ
現代のC++では、すべての式は以下の3つのいずれかに分類されます。
- lvalue(L値): 名前があり、アドレスが取れるもの。
- prvalue(純粋右辺値): 文字列リテラルを除くリテラルや、演算結果、関数の戻り値(非参照)など。
- xvalue(期限切れ値): ムーブされる直前のオブジェクトなど。
std::moveの戻り値がこれに当たります。
また、これらをまとめた概念として以下の用語も使われます。
| 用語 | 構成 | 説明 |
|---|---|---|
| glvalue | lvalue + xvalue | 「場所」を特定できる式の総称。 |
| rvalue | prvalue + xvalue | 「ムーブ可能」な式の総称。 |
この分類により、xvalue(eXpiring value:期限切れ値)という「場所はあるけれど、もうすぐ消えるのでムーブして良い」という絶妙な状態が定義できるようになりました。
まとめ
C++におけるL値とR値の違いを理解することは、単なる文法知識を超えて、プログラムの実行効率を極限まで引き出すための必須スキルです。
L値は「名前があり、アドレスが取れる永続的な存在」であり、R値は「名前がなく、すぐに消え去る一時的な存在」です。
このR値を右辺値参照(&&)で捉え、ムーブセマンティクスを活用することで、メモリ確保やコピーのコストを大幅に削減できます。
std::moveを適切に使用し、値カテゴリを意識したコードを書くことで、よりモダンで高速なC++プログラムを目指しましょう。
特に大規模なデータを扱うクラスを設計する際は、今回解説したムーブの概念が最大の武器になるはずです。
