近年、ChatGPTをはじめとする生成AI(大規模言語モデル:LLM)の急速な普及に伴い、テクノロジー業界で急速に注目を集めているのが「ベクトルデータベース(Vector Database)」です。
従来のデータベースとは異なり、テキストや画像、音声といった非構造化データを「数値の配列(ベクトル)」として扱うことで、高度な検索やAIへの知識付加を可能にします。
本記事では、ベクトルデータベースの基本的な仕組みから、なぜLLMの活用において不可欠とされているのか、そのメリットや主要な製品比較まで、プロの視点で徹底的に解説します。
AIプロジェクトの基盤構築を検討しているエンジニアやビジネスリーダーにとって、必読の内容となっています。
ベクトルデータベースの基礎知識
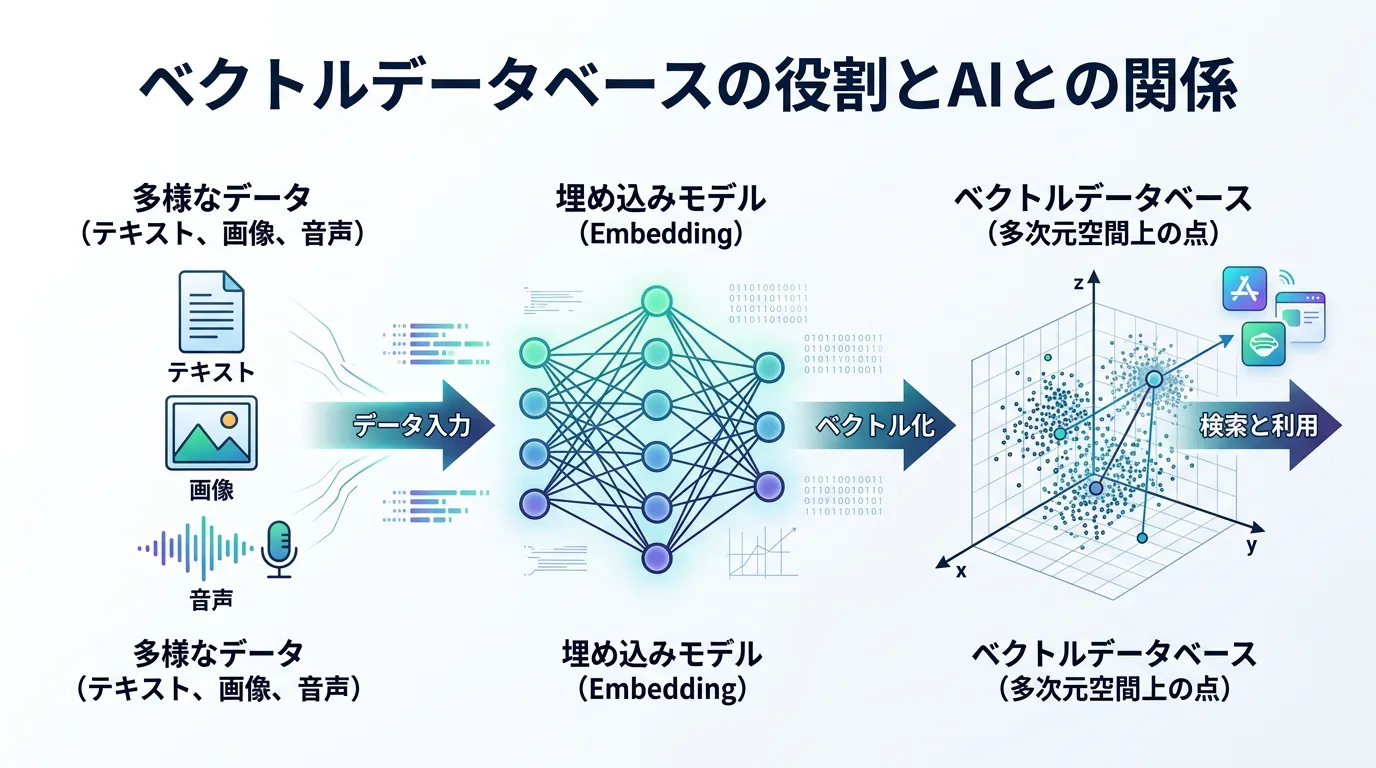
ベクトルデータベースとは、データを「多次元空間上のベクトル(数値列)」として保存し、それらのデータの「意味的な近さ」を高速に検索することに特化したデータベースです。
従来のデータベース(リレーショナルデータベース:RDB)が、名前や数値、日付などの「構造化データ」を管理するのに対し、ベクトルデータベースは、そのままではコンピュータが理解しにくいテキスト、画像、音声、動画などの「非構造化データ」を扱うのが得意です。
ベクトルとは何か
数学におけるベクトルは、向きと大きさを持つ量ですが、コンピュータサイエンスにおけるベクトルは、単なる[0.1, -0.5, 0.8, ...]といった数値のリストを指します。
例えば、「王様」という単語をAIモデル(埋め込みモデル)に通すと、その単語が持つ意味を反映した数百〜数千次元の数値列に変換されます。
これが「ベクトル化(Embedding)」と呼ばれるプロセスです。
なぜ「ベクトル」で保存するのか
データをベクトル化して保存する最大の理由は、「意味の類似性」を計算可能にするためです。
従来のデータベースで「美味しいリンゴ」というキーワードで検索した場合、基本的には「美味しい」と「リンゴ」という文字列が含まれるデータしかヒットしません。
しかし、ベクトル空間上では、「美味しいリンゴ」の近くに「風味豊かなアップル」や「甘い果物」といった、言葉は違えど意味が近いデータが配置されます。
これにより、曖昧な検索や文脈に応じた情報の抽出が可能になります。
ベクトルデータベースの仕組み
ベクトルデータベースがどのようにして膨大なデータから瞬時に最適な回答を見つけ出すのか、その内部メカニズムを詳しく見ていきましょう。
埋め込み(Embedding)のプロセス
ベクトルデータベースにデータを格納する前には、必ず「埋め込み(Embedding)」という工程が発生します。
- 入力データ:ドキュメント、画像、音声ファイルなど。
- 埋め込みモデル:OpenAIの
text-embedding-3-smallや、オープンソースの Hugging Face モデルなどを使用。 - ベクトル生成:データを高次元の数値配列に変換。
- 格納:生成されたベクトルと、元のデータのメタデータ(ID、元の文、URLなど)をセットでデータベースに保存。
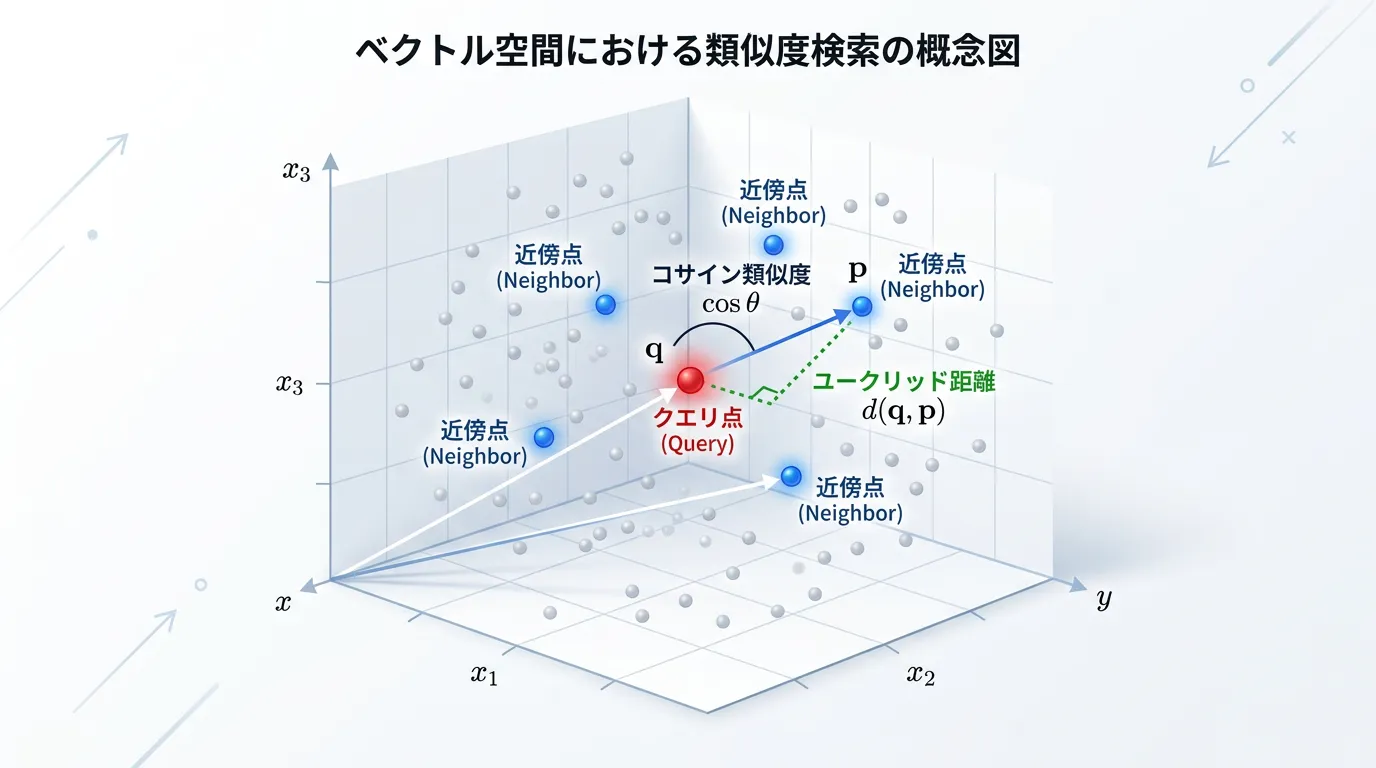
類似性検索(Similarity Search)の指標
ベクトルデータベースは、検索クエリ(質問)も同様にベクトル化し、保存されているデータとの「距離」を計算します。
代表的な計算手法には以下のものがあります。
| 手法 | 特徴 | 主な用途 |
|---|---|---|
| コサイン類似度 | ベクトルの向き(角度)の近さを測定する。 | テキストの意味的類似性の検索に最適。 |
| ユークリッド距離 | ベクトル間の直線距離を測定する。 | データの大きさが重要な場合に使用。 |
| 内積(Dot Product) | ベクトルの大きさと向きの両方を考慮する。 | 推奨システムなどでよく利用される。 |
高速化を実現するインデックスアルゴリズム
数百万、数千万件のベクトルデータから、毎回すべてのデータとの距離を計算(全探索)していては、非常に時間がかかります。
そこで、ベクトルデータベースでは「近似最近傍探索(ANN:Approximate Nearest Neighbor)」というアルゴリズムを用いて高速化を図っています。
HNSW(Hierarchical Navigable Small World)
現在、多くのベクトルデータベースで採用されている最もポピュラーな手法です。
多層構造のグラフネットワークを構築し、上層から下層へと高速に目的のデータ(近傍点)へ辿り着く仕組みです。
精度と速度のバランスが非常に優れています。
IVF(Inverted File Index)
空間をいくつかの領域(クラスタ)に分割し、検索時にクエリが属するクラスタとその周辺だけを探索することで、計算量を劇的に削減します。
従来のデータベースとの違い
ベクトルデータベースと、私たちが長年利用してきたリレーショナルデータベース(RDB)やNoSQLデータベースには、明確な役割の違いがあります。
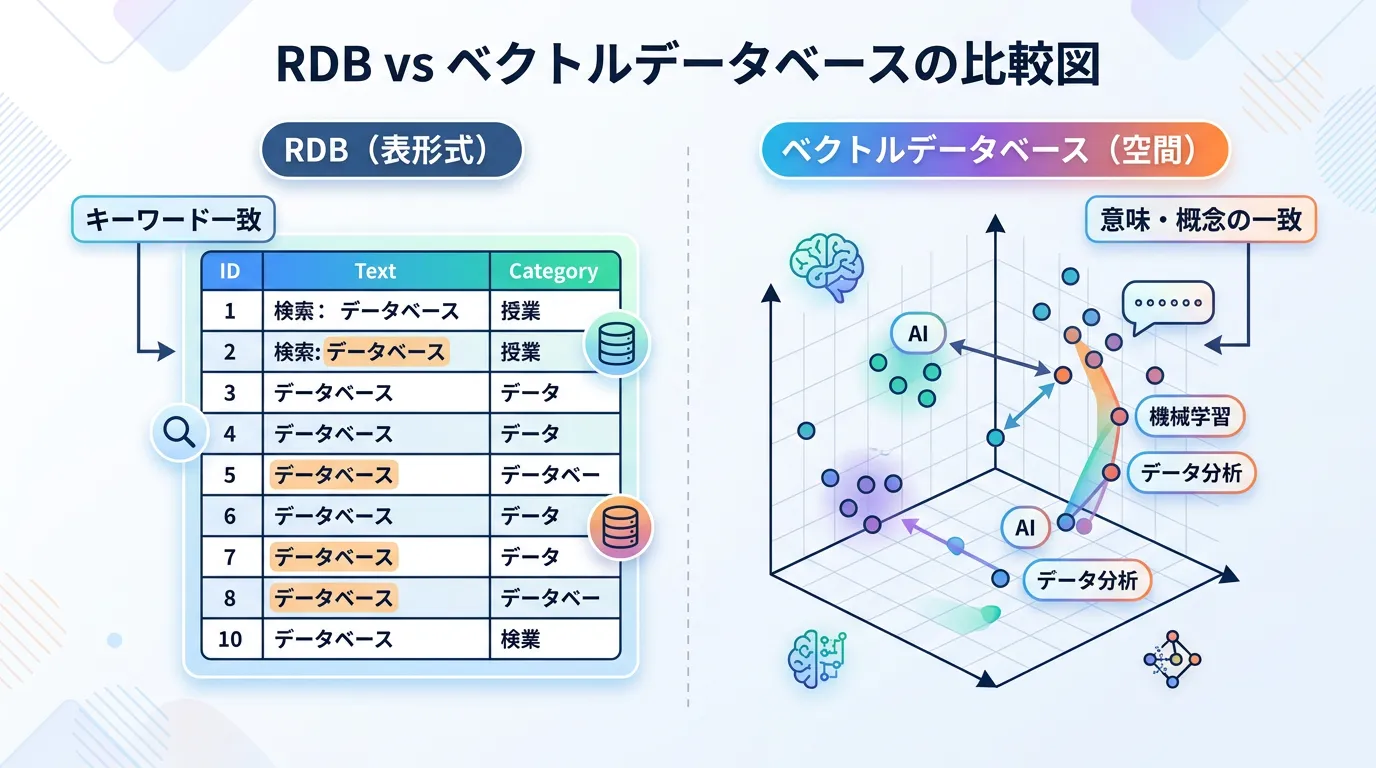
検索精度の違い:完全一致か意味一致か
従来のRDB(MySQL, PostgreSQLなど)は、特定のカラムに対して「キーワードが完全に一致するか」「数値が範囲内か」といった厳密な条件でデータを抽出します。
これは在庫管理やユーザー認証など、正確性が求められる処理に適しています。
一方、ベクトルデータベースは「なんとなく似ているもの」を探し出すのが得意です。
検索ワードが間違っていても、あるいは言語が異なっていても(多言語検索)、意味が近ければ結果を返してくれます。
データの構造
RDBはあらかじめ決められた「スキーマ(表の定義)」に従ってデータを保存します。
これに対し、ベクトルデータベースは非構造化データから抽出された「特徴量」を保存するため、データの形式に縛られず、画像や音声を同一の空間上で扱うことさえ可能です。
以下の表に、主な違いをまとめました。
| 項目 | リレーショナルデータベース(RDB) | ベクトルデータベース |
|---|---|---|
| 格納対象 | 構造化データ(数値、文字列) | ベクトル(非構造化データの特徴量) |
| 検索方式 | キーワード一致、SQLクエリ | 類似性検索(ANN) |
| 検索結果 | 0か1か(条件に合うか否か) | 類似度スコア(似ている順) |
| 主な用途 | 事務処理、Webアプリケーション基盤 | AI、検索エンジン、推薦、RAG |
なぜLLM(大規模言語モデル)にベクトルデータベースが必要なのか
現在、ベクトルデータベースの需要が爆発的に高まっている最大の要因は、ChatGPTのようなLLMの弱点を補完するためです。
その代表的な手法が「RAG(Retrieval-Augmented Generation:検索拡張生成)」です。
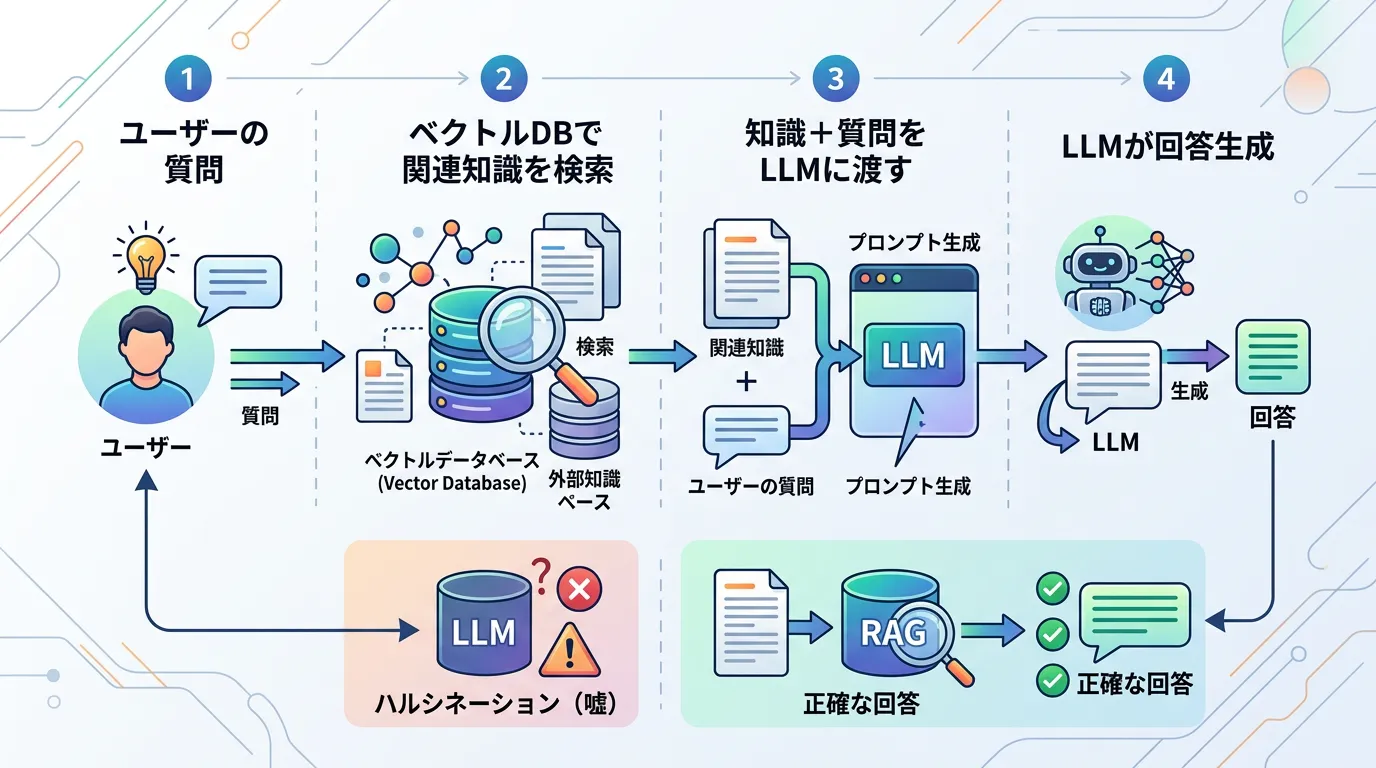
ハルシネーション(幻覚)の防止
LLMは学習データに含まれていない最新の情報や、企業独自の機密情報については回答できません。
無理に答えようとすると、もっともらしい嘘(ハルシネーション)をつくことがあります。
ベクトルデータベースに自社のドキュメントを保存しておき、質問に関連する情報だけをLLMに「参考資料」として渡すことで、事実に基づいた正確な回答を生成させることができます。
トークン制限(コンテキスト窓)の克服
LLMには一度に読み込めるテキスト量(コンテキスト窓)に限界があります。
数千ページの社内マニュアルをすべてLLMに読み込ませることは不可能です。
ベクトルデータベースを使えば、膨大な資料の中から「今、この質問に必要な数行」だけをピンポイントで抽出できるため、効率的にLLMを活用できます。
低コストでの知識アップデート
LLMを特定の知識に特化させる手法として「ファインチューニング(追加学習)」がありますが、これには膨大な計算リソースと時間、コストがかかります。
ベクトルデータベースを用いたRAGであれば、新しいデータをデータベースに追加するだけで、即座にAIの回答に反映させることが可能です。
ベクトルデータベースの主な活用事例
ベクトルデータベースは、LLM以外にも幅広い分野で革新をもたらしています。
1. セマンティック検索(意味検索)
ECサイトやドキュメント管理システムにおいて、ユーザーが入力したキーワードそのものではなく、「ユーザーが何を探しているのか」という意図を汲み取った検索結果を提供します。
例えば、「夏にぴったりの涼しい服」という検索に対し、商品説明にその文言がなくても、リネン素材のシャツやサンダルを表示させることができます。
2. 画像・動画の類似検索
画像ファイルをベクトル化することで、「この写真と似た雰囲気の画像を検索する」といった機能が実現できます。
これは著作権侵害のチェックや、ファッションサイトでの似た商品探し、医療画像の解析などに利用されています。
3. パーソナライズされたレコメンデーション
ユーザーの過去の行動履歴(閲覧した商品、聴いた音楽など)をベクトル化し、それと「意味的に近い」商品を推薦します。
従来の協調フィルタリングよりも、より個人の好みの「文脈」に沿った提案が可能になります。
4. 異常検知
正常なデータ群をベクトル空間上に配置しておき、そこから大きく外れた位置にあるデータを「異常」と判定します。
サイバーセキュリティにおける不正アクセス検知や、工場の製造ラインにおける不良品検知に活用されています。
主要なベクトルデータベース製品の比較
現在、多くのベクトルデータベースが登場しており、プロジェクトの要件に合わせて選択する必要があります。
1. Pinecone
特徴:フルマネージド(SaaS型)のベクトルデータベース。
サーバーの管理が不要で、APIを介して簡単に利用できるため、スタートアップから大企業まで幅広く採用されています。
「運用負荷を最小限に抑えたい」場合に最適です。

2. Milvus
特徴:オープンソースで、圧倒的なスケーラビリティを誇る。
何十億もの大規模なベクトルデータを扱うことが想定されており、Kubernetes上での運用が一般的です。
「大規模・高パフォーマンス」を求めるエンタープライズ用途に適しています。

3. Weaviate
特徴:キーワード検索(BM25)とベクトル検索を組み合わせた「ハイブリッド検索」に強い。
GraphQLを利用した直感的な操作が可能で、データの関連性を構造的に管理しやすいのが特徴です。

4. Chroma
特徴:シンプルで軽量なオープンソース。
Python環境でのセットアップが非常に簡単で、ローカル環境でのプロトタイプ開発や、小規模なプロジェクトで圧倒的な支持を得ています。
5. 既存DBの拡張機能(pgvectorなど)
PostgreSQLの拡張機能である pgvector や、Redis、Elasticsearchなどもベクトル検索機能を備え始めています。
すでにこれらのDBを運用している場合、新たなDBを導入せずにベクトル検索を始められるというメリットがあります。
ベクトルデータベース導入時の注意点
強力なツールであるベクトルデータベースですが、導入にあたっては以下のポイントに留意する必要があります。
ベクトルの精度は使用する埋め込みモデルに依存します。
まずデータの種類(日本語、英語、コード、画像など)を明確にし、それに最適化されたモデルを選んでください。
多言語データには汎用の多言語モデル、コードにはコード特化モデル、画像は画像埋め込みモデルを検討します。
候補モデルごとにサンプルデータでベンチマークを取り、精度(類似度スコア、ダウンストリームタスクの性能)と速度を比較して決定します。
マネージドサービスや自前インフラを使う場合、コストはベクトル次元数、データ量、検索回数に応じて変動します。
特に高次元ベクトルはストレージとメモリを多く消費するため注意が必要です。
コスト抑制策として、次元削減や量子化(PQ)、圧縮、バッチ処理、キャッシュ、古いデータのアーカイブや保持ポリシーの導入、インデックス種類の選択(メモリ効率の良いものを選ぶ)を検討してください。
また、クエリ頻度やSLAに応じてスケーリング戦略を設計し、定期的に使用状況と請求をモニタリングします。
近似最近傍探索(ANN)は高速化のためにわずかな正確性を犠牲にします。
インデックスのパラメータ(例:HNSWのMやef、IVFのnlistやnprobe、PQのサブベクトル数など)を調整して、「速度と精度のバランス」を見つけてください。
検証用データセットでrecall@kや平均精度を測定し、レイテンシやスループットとのトレードオフを評価します。
ビジネス要件(例:許容される誤検出率や応答時間)を基準に反復的にチューニングを行い、必要に応じてハイブリッド検索や再ランク手法を組み合わせます。
まとめ
ベクトルデータベースは、AIが私たちの世界の情報を「意味」として理解するための架け橋となる重要なテクノロジーです。
特にLLMを活用したRAG(検索拡張生成)の構築においては、もはや不可欠なコンポーネントと言っても過言ではありません。
テキスト検索の高度化、画像検索、パーソナライズ、そして社内データのAI活用など、ベクトルデータベースが解決できる課題は多岐にわたります。
まずは小規模なプロジェクトやプロトタイプから導入を検討し、その圧倒的な「意味検索」の力を体感してみてください。
今後、AI技術が進化し続ける中で、ベクトルデータベースはRDBと同じように、ITインフラの「当たり前」の存在になっていくでしょう。
最新の動向を常にチェックし、適切なツールを選択することが、次世代のシステム構築における成功の鍵となります。
