ChatGPTやClaudeといった生成AI(大規模言語モデル:LLM)が急速に普及する中で、ビジネスシーンにおいて「AIを自社専用にカスタマイズしたい」というニーズが高まっています。
そのための主要な手法として注目されているのが、ファインチューニング(Fine-tuning)です。
しかし、ファインチューニングが具体的にどのような仕組みで、どのような場面で活用すべきなのか、また近年話題のRAG(検索拡張生成)とどう使い分けるべきなのか、正しく理解するのは容易ではありません。
本記事では、プロの視点からファインチューニングの定義や仕組み、メリット・デメリット、そしてRAGとの決定的な違いまで、初心者の方にもわかりやすく徹底解説します。
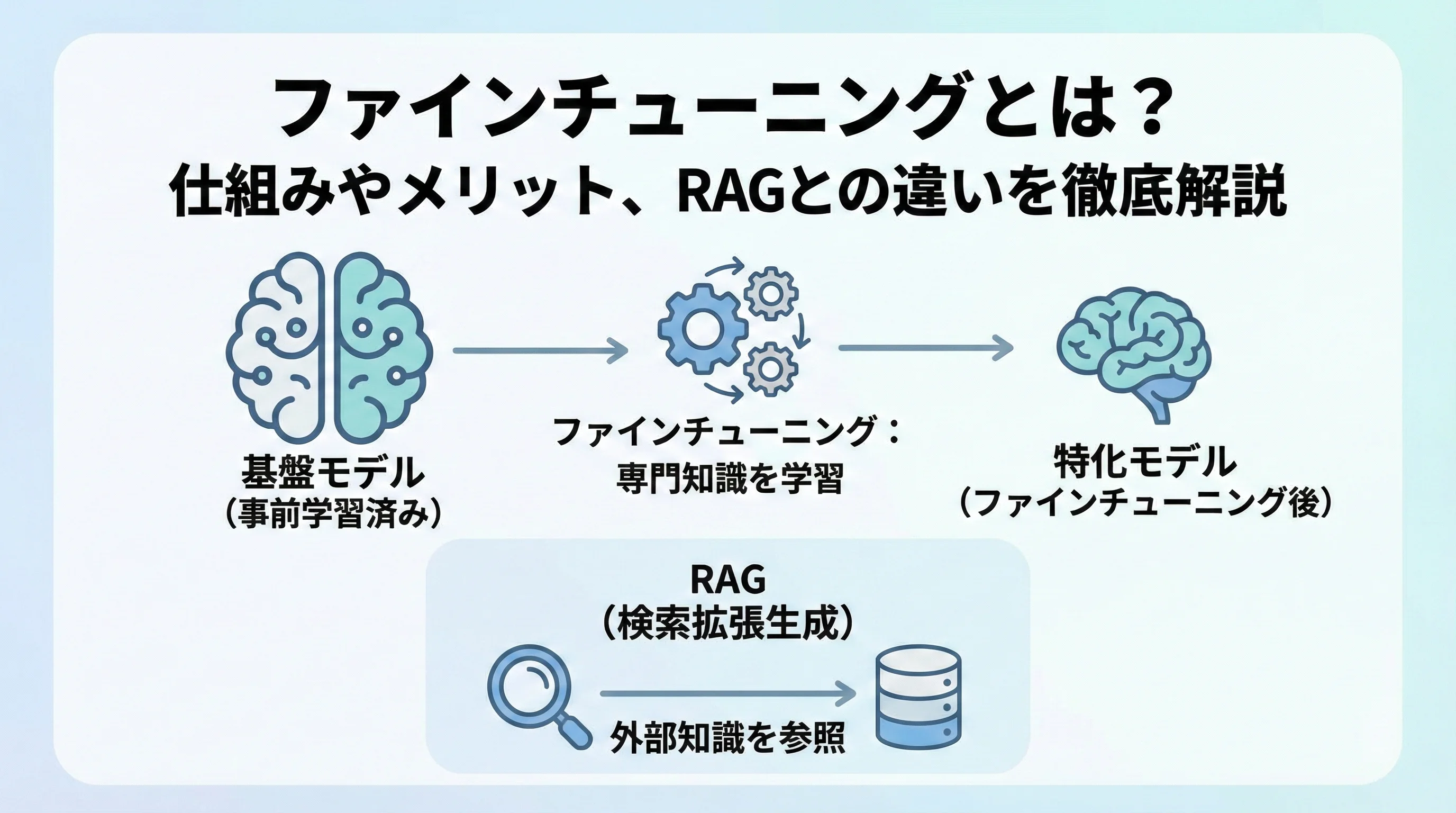
ファインチューニングとは?
ファインチューニングとは、一言で言えば「学習済みのモデルに、特定のデータセットを用いて追加学習を行い、特定のタスクやドメインに特化させる手法」のことを指します。
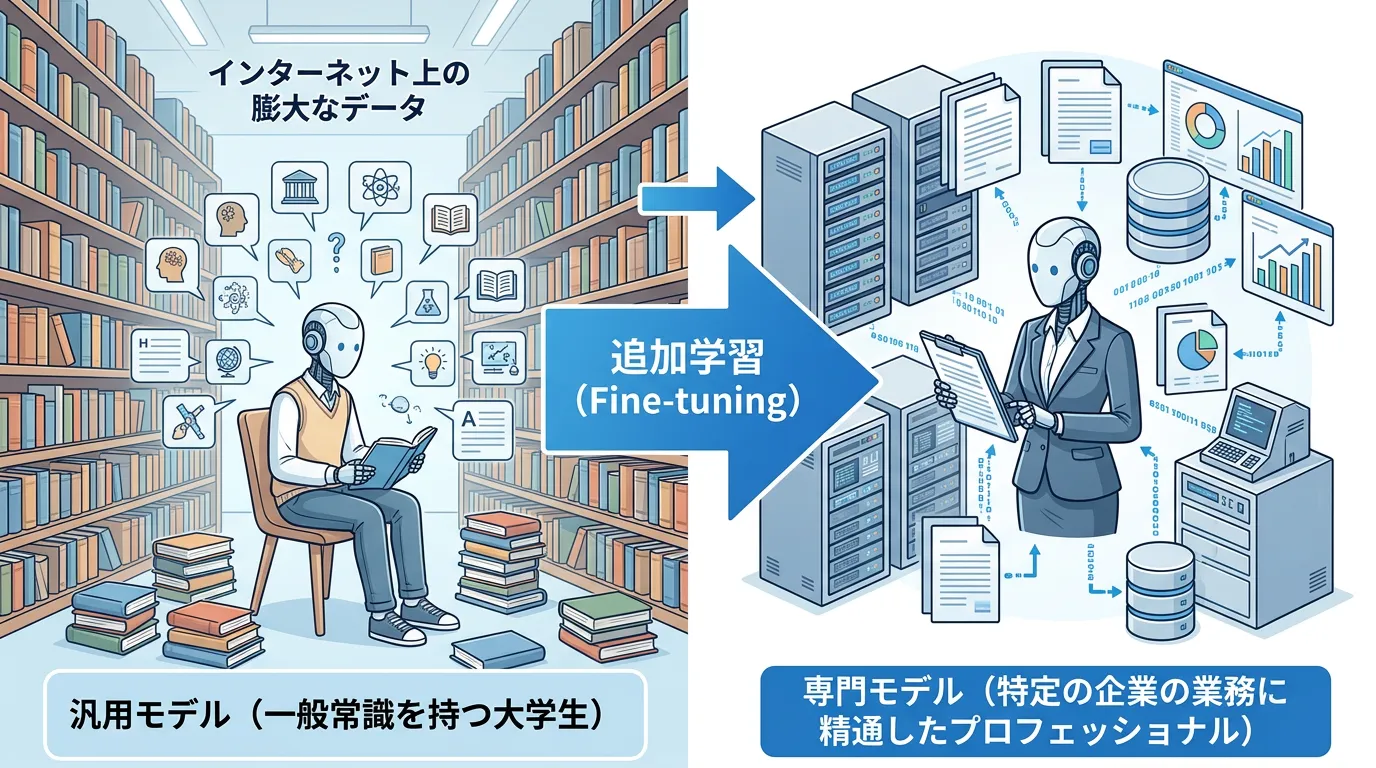
大規模言語モデル(LLM)は、インターネット上の膨大なテキストデータを使用して「事前学習(Pre-training)」が行われています。
この段階で、モデルは言語の構造や一般的な知識、論理的思考能力を身につけます。
例えるなら、「あらゆる分野の基礎知識を網羅した大学生」のような状態です。
しかし、特定の企業の社内規定、専門的な医療用語、あるいは独特なブランドトーン(口調)に合わせた回答を求める場合、汎用的な知識だけでは不十分です。
そこで、「特定の目的に合わせた追加データ」を学習させることで、モデルのパラメータを微調整し、特定の領域において高いパフォーマンスを発揮できるようにするのがファインチューニングの役割です。
事前学習とファインチューニングの関係
AIモデルの構築プロセスは、大きく以下の2つのステップに分けられます。
数テラバイトという膨大なデータ(Wikipedia、ニュース、書籍、Webサイトなど)を使い、言葉のつながりや世界的な知識を学習させます。
これには膨大な計算リソースと時間が必要です。
事前学習済みのモデルをベースにし、比較的小規模な「質の高い専門データ」を追加で学習させます。
これにより、モデルは汎用的な能力を維持したまま、特定のタスク(例:法律相談、プログラミング支援、特定の文体でのメール作成など)に最適化されます。
ファインチューニングの仕組み
ファインチューニングの技術的な本質は、モデル内部の「パラメータ(重み)」を更新することにあります。
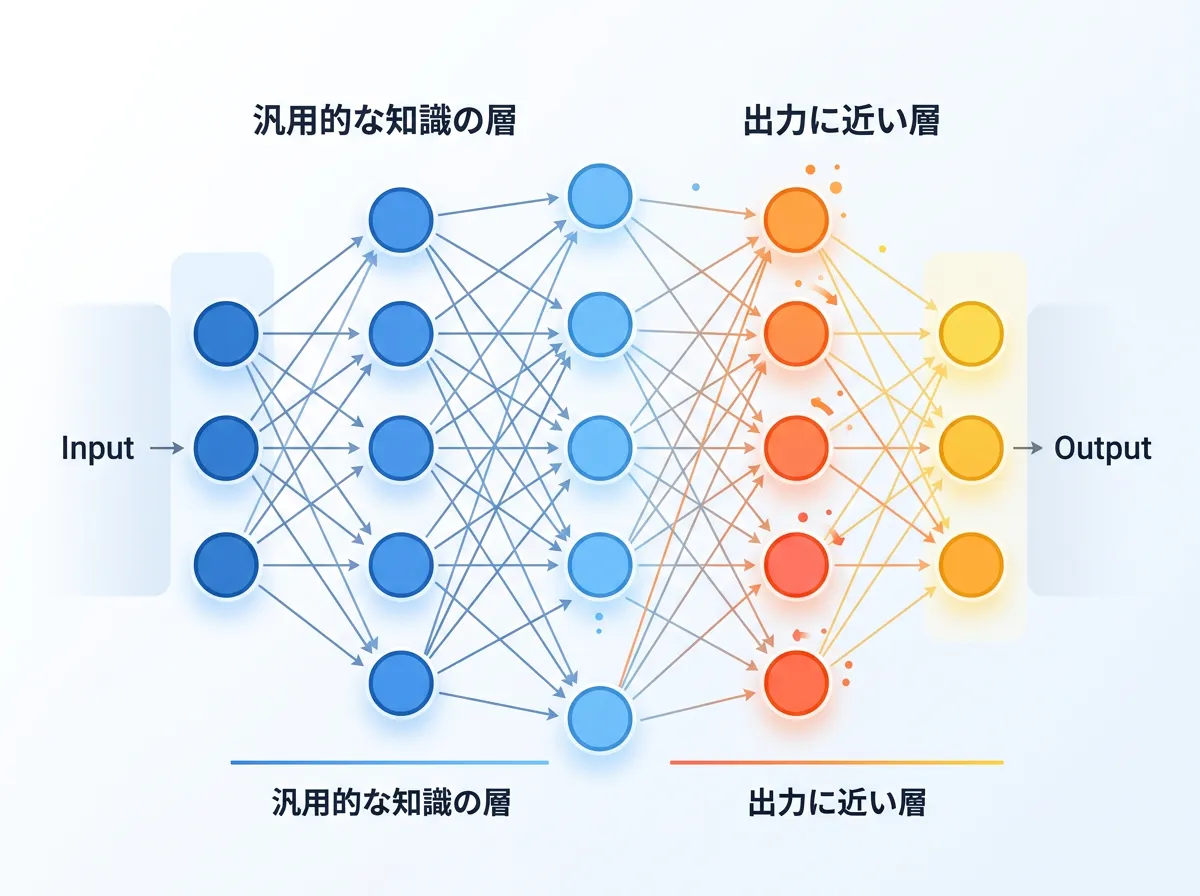
LLMは数千億ものパラメータを持つ巨大なニューラルネットワークです。
ファインチューニングを行う際、モデルに対して「質問(プロンプト)」と「期待される回答」のペアを与えます。
- データの入力: 特定ドメインのデータをモデルに入力します。
- 誤差の計算: モデルが生成した回答と、正解データ(教師データ)との間の「ズレ(誤差)」を計算します。
- 重みの更新: その誤差を最小にするように、バックプロパゲーション(誤差逆伝播法)を用いて、モデル内部のパラメータを少しずつ調整します。
このプロセスを繰り返すことで、モデルは「この種類の質問に対しては、このように答えるのが正解である」というパターンや振る舞いを学習します。
フルファインチューニングとPEFT
かつてはモデルの全パラメータを更新する「フルファインチューニング」が一般的でしたが、近年の巨大なLLMでは膨大なメモリと計算コストがかかるため、非効率的になっています。
そこで現在主流となっているのがPEFT(Parameter-Efficient Fine-tuning)という手法です。
PEFTの代表的な手法であるLoRA (Low-Rank Adaptation)などは、元のモデルの大部分は凍結(固定)し、一部の小さな層(アダプター)のみを学習させます。
これにより、消費メモリを劇的に抑えつつ、フルファインチューニングに近い精度を実現できるようになりました。
ファインチューニングとRAG(検索拡張生成)の違い
AIのカスタマイズを検討する際、必ず比較対象となるのがRAG(Retrieval-Augmented Generation / 検索拡張生成)です。
この2つは「外部知識を利用する」という点では似ていますが、アプローチが根本的に異なります。
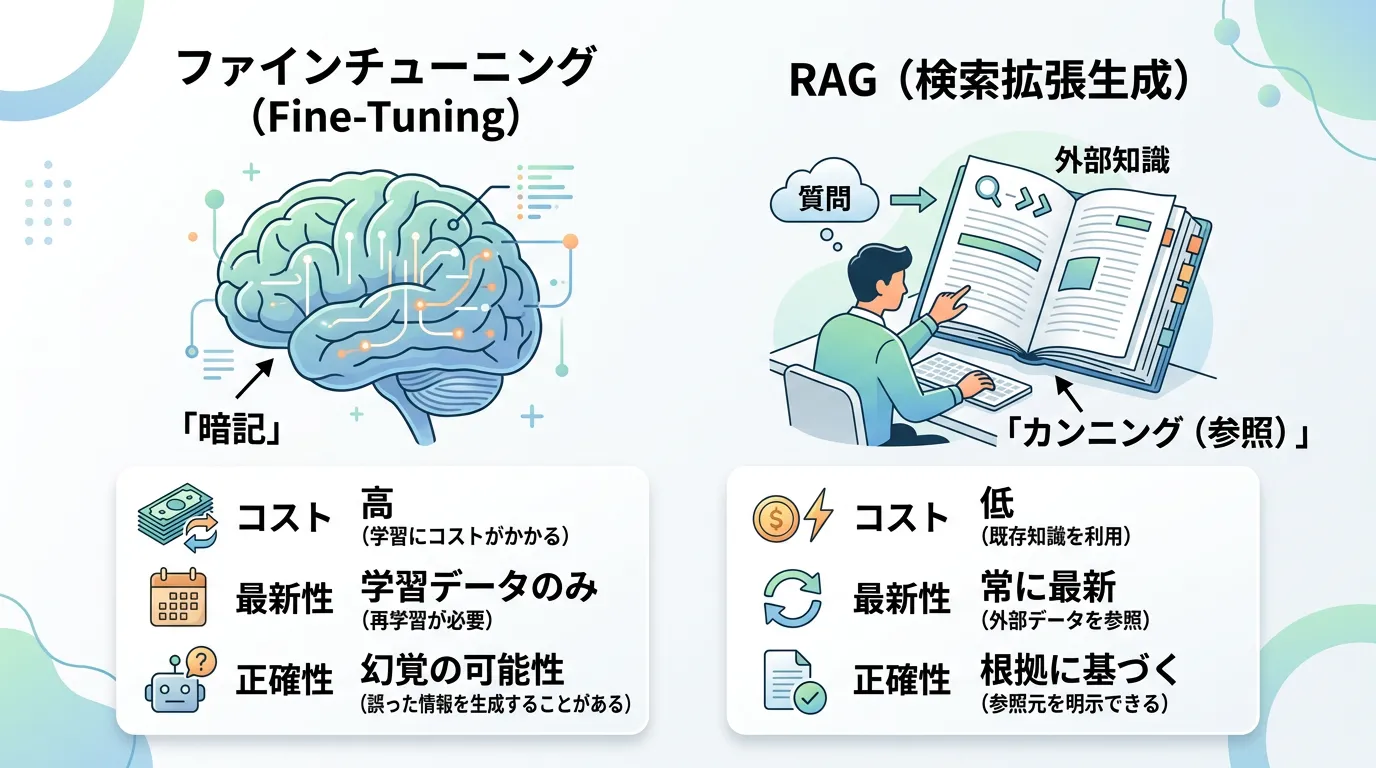
RAGの仕組み
RAGはモデルを再学習させるのではなく、「外部のデータベースから必要な情報を検索し、それをプロンプトに含めてモデルに渡す」手法です。
例えば、社内ドキュメントを検索システムに入れ、ユーザーの質問に関連する箇所を瞬時に探し出し、「この情報を元に答えてください」とAIに指示を出します。
比較表:ファインチューニング vs RAG
| 比較項目 | ファインチューニング | RAG (検索拡張生成) |
|---|---|---|
| 主な目的 | 文体、口調、形式、専門用語の習得 | 最新情報や事実情報の参照 |
| 知識の更新 | 再学習が必要(コスト高・時間かかる) | データベースの更新のみ(即時・低コスト) |
| ハルシネーション | 発生しやすい(古い知識が混ざる) | 抑制しやすい(根拠を明示できる) |
| データの透明性 | 回答の根拠が不明確 | 参照元を提示できる(エビデンスがある) |
| コスト | 高い(GPUリソースが必要) | 比較的低い(検索インフラの構築) |
「振る舞いや形式を教え込みたいならファインチューニング」、「事実に基づいた正確な回答をさせたいならRAG」というのが現在のAI活用の定石となっています。
ファインチューニングのメリット
ファインチューニングを導入することで、汎用モデルでは達成できない高度なカスタマイズが可能になります。
1. 文体やトーンの完全な制御
企業のブランドイメージに合わせた「丁寧な接客口調」や、特定のキャラクターのような「独特な言い回し」を徹底させたい場合、ファインチューニングは非常に有効です。
プロンプトエンジニアリング(指示出しの工夫)だけでは限界がある細かなニュアンスも、数千件のサンプルデータを学習させることでモデルの「性格」として定着させることができます。
2. 出力形式の固定
JSON形式や特定のプログラミング構文など、厳格な出力フォーマットが求められる業務システムとの連携において、ファインチューニングは威力を発揮します。
汎用モデルが時折起こす「余計な前置きや解説」を排除し、必要なデータのみを確実に返答するように最適化できます。
3. 特定ドメインの専門用語への対応
医学、法律、金融、あるいは特定の製造現場で使われる業界用語や社内用語は、一般的なAIでは誤認されることが多々あります。
これらの用語を文脈とともに学習させることで、業界特有の複雑なニュアンスを理解した回答が可能になります。
4. 推論コストの削減(短いプロンプト)
ファインチューニング済みのモデルは、指示(プロンプト)の中に大量の例示(Few-shotプロンプト)を含める必要がありません。
モデル自体が既にやり方を「知っている」ため、短い入力で精度の高い出力が得られます。
これは、トークン消費量の削減につながり、長期的な運用コストを抑える要因になります。
ファインチューニングのデメリットと課題
メリットが多い一方で、ファインチューニングには無視できない課題も存在します。
1. 高品質な学習データの準備
「Garbage In, Garbage Out(ゴミを入れたらゴミが出てくる)」の原則通り、ファインチューニングの成否はデータの質に100%依存します。
誤った情報や矛盾する回答を含むデータを学習させてしまうと、モデルの性能はかえって低下します。
データの収集・クレンジング(整形)・アノテーション(ラベル付け)には膨大な労力が必要です。
2. ハルシネーション(もっともらしい嘘)のリスク
ファインチューニングはモデルに「知識」を焼き付けますが、それが最新の情報であるとは限りません。
学習後に情報が変わった場合、モデルは古い情報を自信満々に回答してしまいます。
また、事実関係の学習よりも「それらしい回答の生成」が優先されることがあり、根拠のない嘘(ハルシネーション)を生むリスクがRAGよりも高くなります。
3. 計算リソースと費用の発生
モデルをトレーニングするためには、高性能なGPU(NVIDIA H100やA100など)が必要です。
クラウドサービスを利用する場合でも、OpenAIのAPI経由での学習や、自前でのサーバー構築には相応のコストがかかります。
また、学習が完了するまでには数時間から数日の待ち時間が発生します。
4. 破滅的忘却(Catastrophic Forgetting)
特定のタスクを過度に学習させると、モデルが元々持っていた「汎用的な推論能力」や「他の知識」を失ってしまう現象が起こることがあります。
これを防ぐためには、学習率の調整やデータの混ぜ方の工夫など、専門的なノウハウが求められます。
ファインチューニングの主要な手法
現代のLLM開発において、効率的にファインチューニングを行うための代表的な手法を紹介します。
LoRA(Low-Rank Adaptation)
現在最も普及している手法です。
前述の通り、全パラメータを更新するのではなく、小さな行列(重み)を追加してそこだけを学習させます。
これにより、計算コストを1/1000程度に抑えつつ、モデルの性能を最適化できます。
Hugging FaceのPEFTライブラリなどで簡単に実装可能です。
QLoRA (Quantized LoRA)
LoRAをさらに進化させ、モデルを4ビットなどに量子化(軽量化)した状態で学習させる手法です。
これにより、家庭用のゲーミングPCクラスのGPUでも、巨大なモデルのファインチューニングが可能になりました。
指示チューニング(Instruction Fine-tuning)
「〇〇してください」という命令形式のデータセットを用いて学習させる手法です。
これにより、ユーザーの意図を汲み取り、タスクを遂行する能力が飛躍的に向上します。
ChatGPTのような対話型AIの構築には欠かせないプロセスです。
ファインチューニングの具体的な活用事例
医療・ヘルスケア
医師の診断補助や論文の要約など、高度な専門知識が求められる分野です。
医学用語や症例データをファインチューニングすることで、一般的なAIでは不可能な精度での文章作成や分析が可能になります。
カスタマーサポート・接客
自社製品の仕様書や過去の問い合わせ対応ログを学習させることで、まるで熟練のオペレーターのような回答を生成します。
ブランドイメージを損なわない言葉遣いを徹底させるのに最適です。
独自コードの生成
企業内で独自に開発しているフレームワークやライブラリのコードを学習させることで、その企業専用の「コーディングアシスタント」を構築できます。
汎用的なGitHubのデータにはない、社内独自の規約に則ったコードを提案させることが可能です。
ファインチューニングを成功させるための手順
実際にファインチューニングを行う際の標準的な流れは以下の通りです。
なぜRAGではなくファインチューニングが必要なのかを定義します。
GPT-4o-mini、Llama 3.1、Mistralなど、用途に適したモデルを選びます。
質問と回答のペアをJSONL形式などで準備します(最低数百〜数千件推奨)。
LoRAなどの手法を用い、ハイパーパラメータを調整しながらトレーニングします。
学習済みモデルにテストデータを入力し、精度やハルシネーションの有無を検証します。
アプリケーションに組み込み、運用を開始します。
まとめ
ファインチューニングは、AIを「汎用ツール」から「自社専用の強力な武器」へと進化させるための鍵となる技術です。
RAGが「外部資料を参照する能力」を強化するものであるのに対し、ファインチューニングは「AIそのものの振る舞いや専門性を内面から変える手法」と言えます。
導入には高品質なデータの準備や計算コストといった壁もありますが、一度最適化されたモデルは、ブランドトーンの統一や業務効率化において計り知れない価値をもたらします。
まずは、実現したいタスクが「情報の参照(RAG)」で解決できるのか、それとも「振る舞いの最適化(ファインチューニング)」が必要なのかを見極めることから始めましょう。
AI技術の進化は非常に速いため、PEFTやLoRAといった最新の効率的な手法を取り入れながら、スモールスタートで検証を進めることが成功への近道です。
