私たちの日常生活において、スマートフォンでの文字入力の予測変換、Google翻訳による精度の高い翻訳、そしてChatGPTのような対話型AIとのやり取りは、もはや欠かせないものとなっています。
これらのテクノロジーの根幹を支えているのが、自然言語処理 (NLP:Natural Language Processing) という分野です。
かつてはコンピュータにとって「人間の言葉」を理解することは極めて困難な課題でしたが、近年のディープラーニング (深層学習) の発展、特にTransformerと呼ばれる革新的な技術の登場により、その精度は劇的に向上しました。
現在では、単なるキーワードの処理に留まらず、文脈やニュアンスまでを汲み取った高度な処理が可能になっています。
本記事では、自然言語処理の基礎知識から、コンピュータが言葉を理解する仕組み、最新の活用事例、そしてこれからNLPを学びたい方のための学習ロードマップまでを、専門用語を交えつつも分かりやすく徹底的に解説します。
自然言語処理 (NLP) とは何か
自然言語処理とは、人間が日常的に話したり書いたりしている「自然言語」を、コンピュータに処理・理解させるための技術を指します。
人工知能 (AI) 研究の一分野であり、言語学、計算機科学、統計学などが融合した領域です。
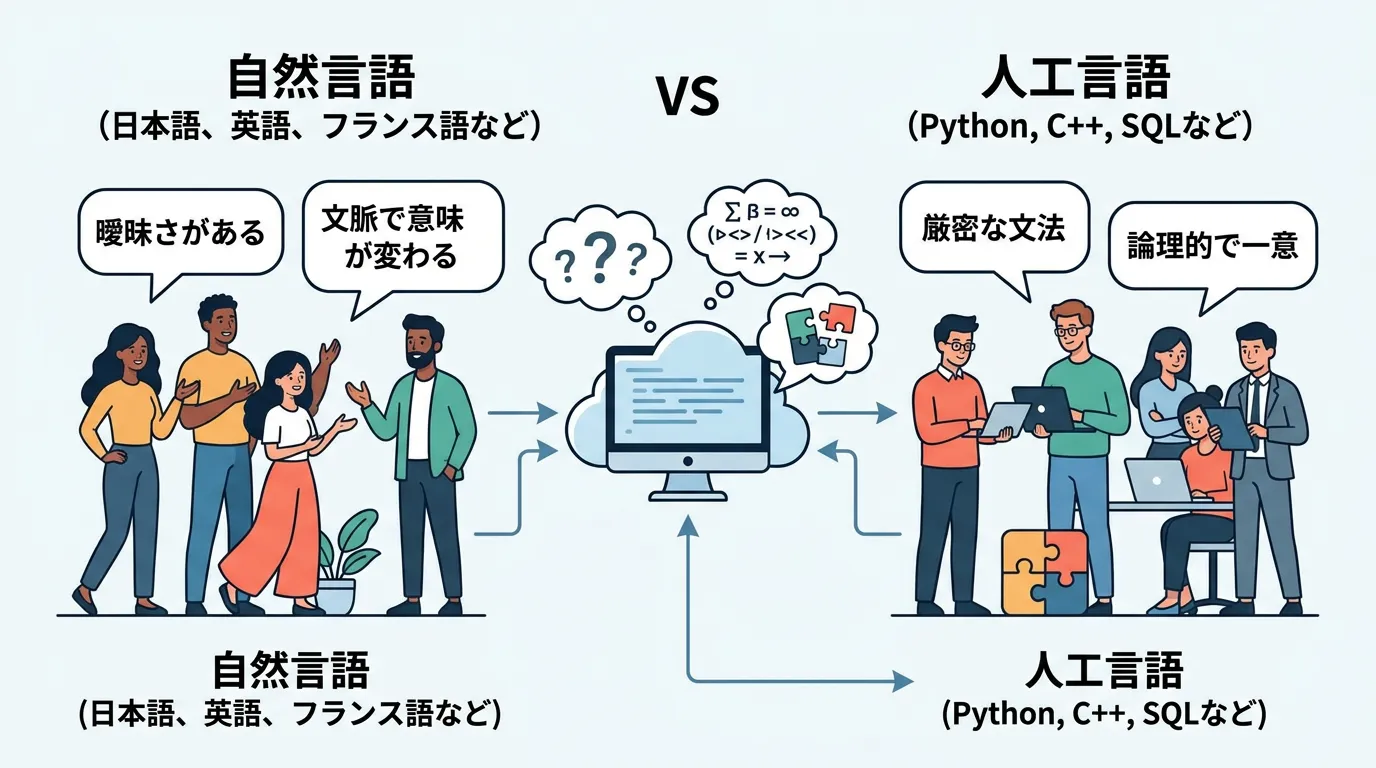
ここでいう「自然言語」とは、日本語や英語のように、長い歴史の中で自然に発生し進化した言語のことです。
これに対し、JavaやPythonといったプログラミング言語は「人工言語」と呼ばれます。
人工言語はコンピュータが誤解なく解釈できるように厳密な文法ルールで作られていますが、自然言語は「曖昧さ」や「省略」、「文脈による意味の変化」が含まれるため、コンピュータにとって処理の難易度が非常に高いのが特徴です。
なぜ今、自然言語処理が注目されているのか
自然言語処理がこれほどまでに注目を集めている最大の理由は、非構造化データの活用にあります。
企業の持つデータの多くはテキスト形式 (メール、議事録、報告書など) です。
これらを自動で分析し、有益な知見を取り出すことができれば、ビジネスの効率は飛躍的に向上します。
また、2022年末に登場した「ChatGPT」に代表される生成AI (Generative AI)の爆発的な普及により、専門家だけでなく一般ユーザーにとってもNLPは身近な存在となりました。
言葉で命令するだけでプログラミングができたり、小説を執筆したりできる今の時代は、まさにNLP技術の集大成と言えるでしょう。
自然言語処理の仕組み:4つの解析ステップ
コンピュータが人間の言葉を理解するプロセスは、大きく分けて4つの段階に分類されます。
これを「解析パイプライン」と呼びます。
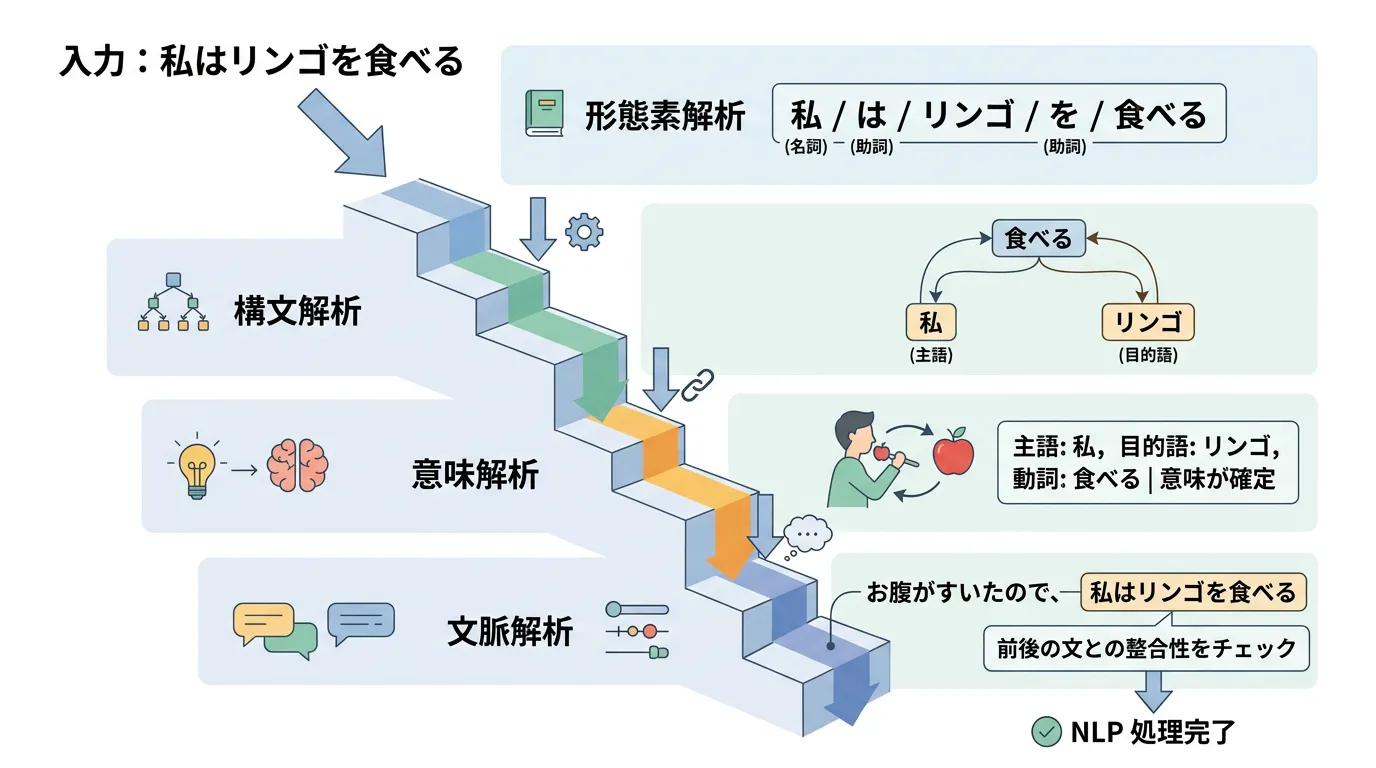
1. 形態素解析 (Morphological Analysis)
自然言語処理の最初の一歩は、文章を意味を持つ最小単位である「形態素 (けいたいそ)」に分割することです。
日本語のように語間にスペースがない言語 (膠着語) においては、この工程が非常に重要になります。
例えば、「すもももももももものうち」という文を、辞書データに基づいて「すもも / も / もも / も / もも / の / うち」と分割し、それぞれの品詞 (名詞、助詞など) を特定します。
代表的なツールには MeCab や Sudachi があります。
2. 構文解析 (Syntactic Analysis)
形態素解析で分割された単語同士が、どのような関係にあるかを分析するのが構文解析です。
主に「係り受け関係」を調べます。
「綺麗な花の絵を描いた」という文があったとき、「綺麗な」が修飾しているのは「花」なのか、それとも「絵」なのか。
この構造を木構造 (ツリー構造) で表現することで、文の骨組みを明らかにします。
3. 意味解析 (Semantic Analysis)
構文解析で得られた構造に対し、実際にどのような意味があるのかを判定します。
ここで課題となるのが「多義性」です。
例えば、「ハシ」という言葉には「箸」「橋」「端」といった複数の意味があります。
文中の他の単語との組み合わせから、どの意味が最も適切かをコンピュータが判断します。
近年では、単語をベクトル (数値の羅列) で表現する「分散表現」という手法を用いることで、意味の近さを計算できるようになりました。
4. 文脈解析 (Contextual Analysis)
単一の文章を超えて、複数の文にまたがる関係性や、代名詞が何を指しているかを分析します。
これを「照応解析」と呼ぶこともあります。
「太郎はリンゴを買った。彼はそれを食べた。」という2つの文がある場合、「彼」が「太郎」を指し、「それ」が「リンゴ」を指していることを理解するのが文脈解析の役割です。
これができて初めて、人間のように自然な対話が可能になります。
自然言語処理を支える主要技術の進化
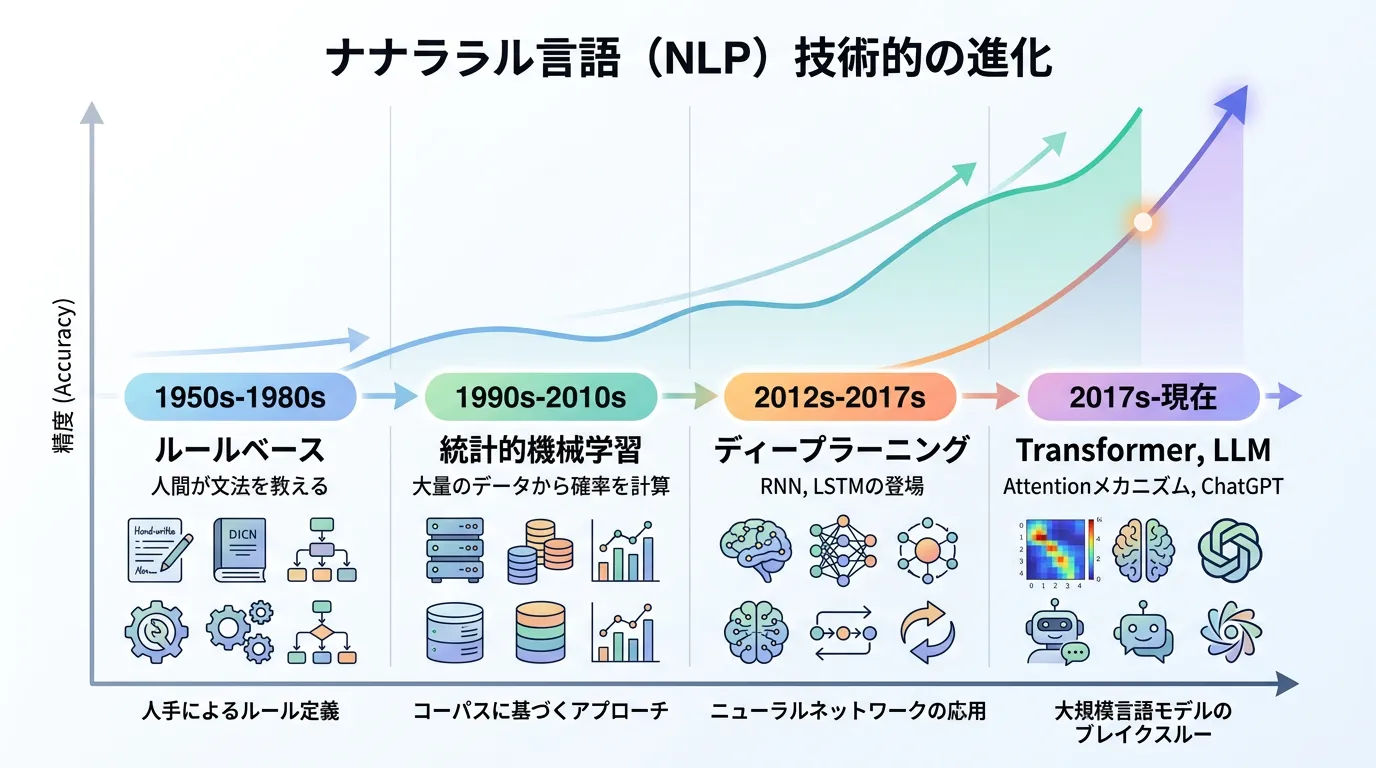
NLPの歴史は、大きく「ルールベース」「統計的機械学習」「ディープラーニング」の3つのパラダイムシフトに分けられます。
伝統的な手法から機械学習へ
初期のNLPは、言語学者が作成した膨大な文法ルールをプログラムに書き込む手法が主流でした。
しかし、言語の例外パターンをすべて網羅することは不可能でした。
1990年代以降、インターネットの普及により大量のテキストデータが利用可能になると、「統計的機械学習」が主流となりました。
これは、ある単語の次にどの単語が来る確率が高いかを計算する手法です。
ディープラーニングの衝撃とWord2Vec
2010年代に入ると、ニューラルネットワークを用いたディープラーニングがNLPに導入されました。
その先駆けとなったのが、単語をベクトル化する Word2Vec です。
これにより、「王様 – 男性 + 女性 = 女王」といった単語の意味を計算で導き出すことが可能になり、コンピュータの「語彙理解」が飛躍的に深まりました。
Transformerと大規模言語モデル (LLM) の登場
現在のNLPにおける最も重要な転換点は、2017年にGoogleが発表した論文「Attention Is All You Need」で提案されたTransformerというモデルの登場です。
Transformerは、文中のどの部分に注目すべきかを計算する「Self-Attention」というメカニズムを持っています。
これにより、長い文章でも文脈を正確に把握できるようになり、学習の並列化も可能になりました。
この技術をベースに開発されたのが、OpenAI のGPTシリーズや、GoogleのBERTといったモデルです。
これらは数千億という膨大なパラメータを持つため、大規模言語モデル (LLM:Large Language Models) と呼ばれ、人間と同等かそれ以上の文章作成能力、要約能力、さらには論理的推論能力を発揮しています。
自然言語処理の具体的な活用事例
NLP技術は、すでに私たちの社会の至る所で実用化されています。
代表的な5つの事例を見てみましょう。
| 活用分野 | 具体的な内容 | 代表的なサービス例 |
|---|---|---|
| 機械翻訳 | 文脈を理解し、自然な訳文を生成する | DeepL, Google翻訳 |
| 対話システム | ユーザーの質問に回答、雑談を行う | ChatGPT, Claude, カスタマーサポートBot |
| 感情分析 | SNSの投稿からポジティブ・ネガティブを判定 | ブランドモニタリングツール |
| 自動要約 | 長い議事録やニュース記事を短くまとめる | ニュースアプリ、文書管理システム |
| 検索エンジン | ユーザーの意図を汲み取った検索結果を出す | Google検索, Bing AI |
1. 機械翻訳
かつての機械翻訳は「直訳」が多く不自然でしたが、現在のニューラル機械翻訳は、文全体の意味を捉えて適切な語順と表現を選択します。
特に専門用語の多い技術文書やビジネスメールにおいて、翻訳作業の効率化に大きく貢献しています。
2. 感情分析 (センチメント分析)
Twitter (X) やECサイトのレビューなど、膨大なテキストデータから「顧客がどう感じているか」を自動で抽出します。
「満足」「不満」「怒り」といった感情を数値化することで、マーケティング戦略や製品改善に役立てられます。
3. スマートスピーカーとAIアシスタント
Amazon AlexaやSiriなどは、音声認識技術で音声をテキストに変換した後、NLPによってユーザーの意図 (インテント) を解釈します。
例えば「明日の天気は?」という問いに対し、それが「天気を知りたい」というリクエストであることを理解し、適切な情報を返します。
4. 医療・法務分野での文書解析
膨大な論文から特定の症例に関する情報を抽出したり、契約書の中に潜むリスク項目を自動で検知したりする用途でもNLPは活躍しています。
高度な専門知識が必要な分野こそ、「見落としを防ぐ」ための強力なサポートツールとして期待されています。
自然言語処理の課題と限界
技術が急速に進歩する一方で、NLPにはまだ解決すべき課題も残されています。
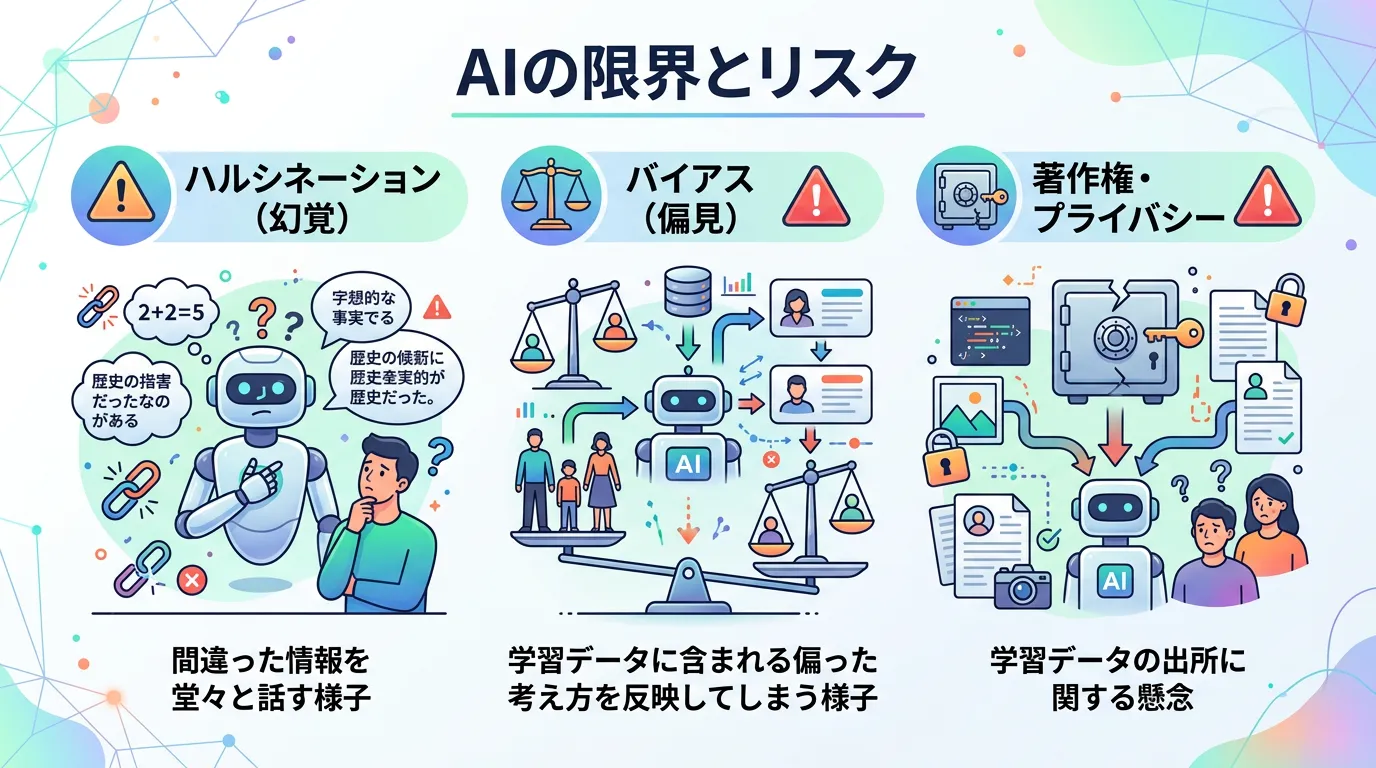
ハルシネーション (幻覚)
最新のLLMであっても、「事実ではないことを、さも真実かのように堂々と回答する」現象が発生します。
これをハルシネーションと呼びます。
NLPモデルは「確率的に尤もらしい言葉」を繋げているに過ぎないため、情報の正確性を担保するためには、人間によるファクトチェックが不可欠です。
バイアスと倫理
AIの学習データは人間が作成したインターネット上の膨大なテキストです。
そのため、データに含まれる人種、性別、文化的な偏見 (バイアス) をそのまま学習してしまうリスクがあります。
公平で倫理的なAIを構築するための「ガードレール」の設計が、現在進行形で議論されています。
自然言語処理を学ぶためのロードマップ
NLPを習得するためには、幅広い知識が必要です。
以下のステップに沿って学習を進めることをお勧めします。
ステップ1:プログラミング言語 (Python) の習得
NLPの世界では、ライブラリが豊富な Python が標準言語です。
基本的な文法に加え、データ処理ライブラリである Pandas や NumPy の使いかたをマスターしましょう。
ステップ2:数学と機械学習の基礎
NLPの深層を探るには、線形代数、微分、確率統計の知識が必要です。
また、教師あり学習、教師なし学習といった機械学習の基本コンセプトを理解しておくと、モデルの仕組みがスムーズに頭に入ります。
ステップ3:NLP専門ライブラリの活用
まずは既存のツールを動かしてみることから始めましょう。
- 日本語解析: MeCab や GiNZA
- 汎用NLPライブラリ: NLTK や spaCy
- ディープラーニング: Hugging Face Transformers
特に、Hugging Faceは世界中の学習済みモデルが公開されており、数行のコードで最新のBERTやGPT系モデルを試すことができます。
ステップ4:実践プロジェクト
理論を学んだら、実際に何かを作ってみることが上達への近道です。
- 「自分のTwitter投稿を感情分析してみる」
- 「ニュースサイトの記事を自動要約するプログラムを作る」
- 「特定のキャラクター風に喋るチャットボットを作る」 : といった小さなプロジェクトに挑戦してみてください。
まとめ
自然言語処理 (NLP) は、コンピュータと人間のコミュニケーションのあり方を根本から変えつつある、現代で最もエキサイティングな技術領域の一つです。
「形態素解析」から始まった基礎的な技術は、ディープラーニングとTransformerの登場を経て、今や「大規模言語モデル (LLM)」という形で社会のインフラへと進化しました。
ハルシネーションや倫理的課題といった克服すべき壁はありますが、その可能性は無限大です。
これからNLPを学ぶ方は、まずはPythonを手に取り、既存のライブラリを使って「言葉がデータとして処理される感覚」を体験することから始めてみてください。
コンピュータが人間の言葉を理解し、それに応えてくれる感動は、あなたのエンジニアとしての、あるいはビジネスパーソンとしてのキャリアに大きな刺激を与えてくれるはずです。
自然言語処理の世界は常にアップデートされています。
常に最新の論文やライブラリの動向に目を向け、このダイナミックな進化を楽しみながら学んでいきましょう。
