
生成AIの普及により、私たちの業務効率は飛躍的に向上しました。
しかし、その利便性の裏で無視できない課題となっているのが「ハルシネーション(幻覚)」です。
AIがもっともらしい嘘をつくこの現象は、ビジネスの現場において重大なリスクを招く可能性があります。
本記事では、ハルシネーションが発生するメカニズムから、その具体的なリスク、そしてAIの信頼性を最大化するための実践的な対策までを専門的な視点で詳しく解説します。
ハルシネーションとは何か
ハルシネーション(Hallucination)とは、人工知能、特に ChatGPT や Claude などの大規模言語モデル(LLM)が、事実に基づかない、あるいは文脈的に矛盾した情報を、あたかも真実であるかのように生成する現象を指します。

ハルシネーションは、単なる「間違い」とは少し性質が異なります。
LLMは統計的な確率に基づいて次の単語を予測するため、論理構成が非常に自然で、文章としての完成度が高いのが特徴です。
そのため、専門知識のないユーザーが読むと、それが誤情報であることに気づきにくいという非常に厄介な性質を持っています。
具体的には、以下のようなパターンが挙げられます。
- 実在しない文献や論文のタイトルを引用する
- 歴史的事実の日付や人物の行動を捏造する
- 存在しないプログラムのライブラリや関数を提案する
- 企業の内部規定や法律について誤った解釈を述べる
ビジネスにおいてAIを活用する場合、このハルシネーションを完全にゼロにすることは現在の技術では困難ですが、その発生率を極限まで下げ、リスクを管理することが運用の鍵となります。
なぜAIはハルシネーションを起こすのか
ハルシネーションが発生する理由は、LLMの設計思想そのものに深く関わっています。
AIは人間のように「思考」して回答しているのではなく、膨大なデータから「確率的に最もらしい文字列」を生成しているに過ぎないからです。
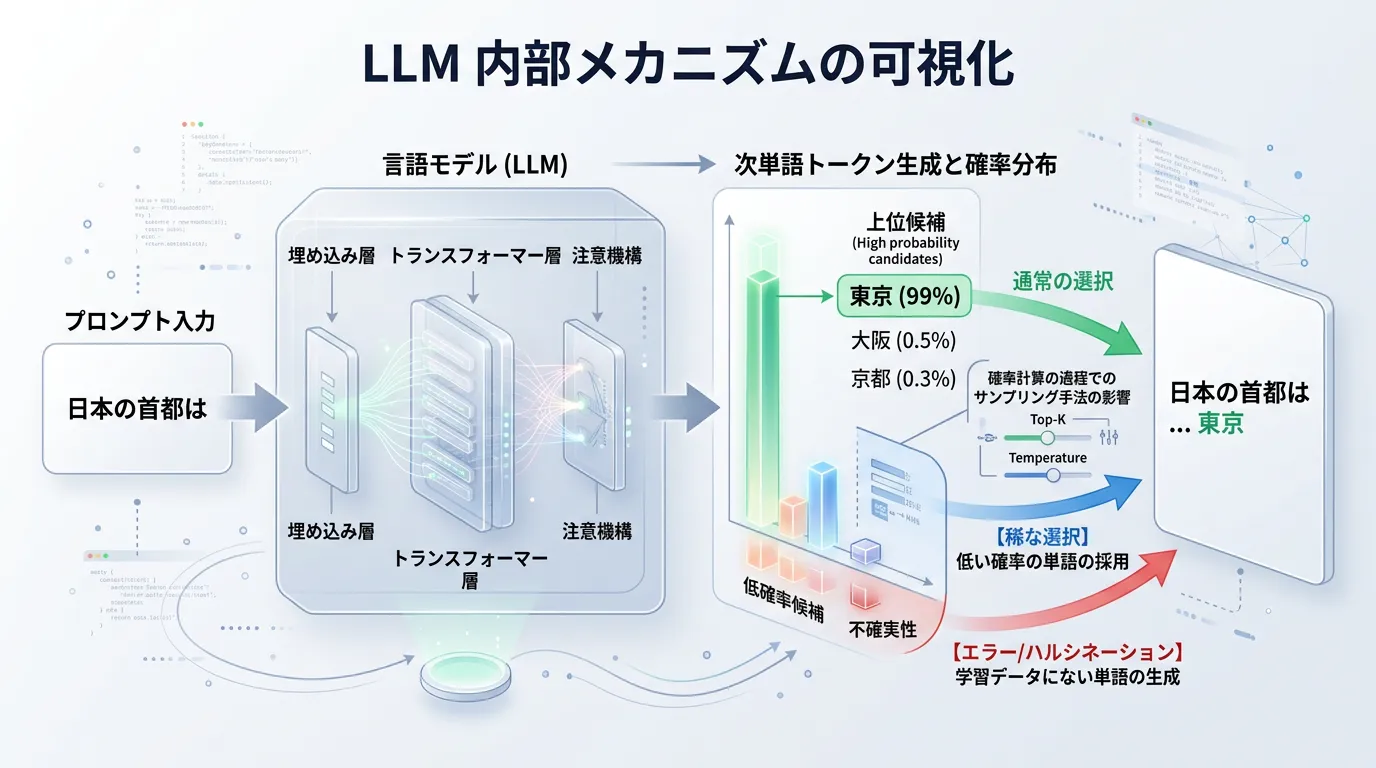
主な原因は、以下の3点に集約されます。
1. 学習データの限界とノイズ
AIの学習データには、インターネット上の膨大なテキストが含まれています。
これらの中には、もともと誤った情報やバイアスが含まれていることがあり、AIが「誤った知識」を正解として学習してしまうことがあります。
また、学習データに含まれない最新の情報について問われた際、AIは「わかりません」と答えるよりも、手持ちの知識を組み合わせて回答を「創作」してしまう傾向があります。
2. 次単語予測(Next Token Prediction)の仕組み
LLMの根本的な仕組みは、文脈から次にくる単語を予測することです。
このプロセスにおいて、AIは「事実としての正確性」よりも「文章としての滑らかさ」を優先してしまうことがあります。
特に複雑な論理展開を求められる質問に対し、一貫性を保とうとするあまり、途中で事実から逸脱した情報を補完してしまうのです。
3. 学習データのカットオフ(情報の鮮度)
多くのAIモデルには、学習データの収集を終了した「カットオフ日」が存在します。
それ以降に発生した出来事について質問すると、AIは過去のデータから推測して回答しようとし、結果として現状とは異なるハルシネーションを引き起こします。
ハルシネーションがもたらすビジネスリスク
ハルシネーションを放置したままAIを業務に導入することは、企業にとって極めて大きなリスクとなります。

具体的にどのようなリスクがあるのか、以下の表にまとめました。
| カテゴリ | 具体的なリスク内容 |
|---|---|
| 法的・権利リスク | 存在しない法律の引用による規約違反、他者の著作権を侵害する創作物の生成、プライバシー侵害。 |
| 社会的信頼の損失 | 誤った情報を顧客に提供することによるクレーム、企業ブランドの毀損、フェイクニュースの拡散。 |
| 意思決定の誤り | 捏造された市場データや競合分析に基づいた戦略立案による、多大な経済的損失。 |
| セキュリティリスク | 存在しないソフトウェアライブラリ(悪意のある第三者が同名で公開したもの)を推奨され、マルウェアに感染する。 |
特に、2023年にはアメリカの弁護士が ChatGPT を使って作成した書面に、実在しない判例が多数含まれていたとして制裁を科された事例は有名です。
このように、専門職であってもAIの嘘を見抜けず、法的な責任を問われるケースが現実に起きています。
実践的なハルシネーション対策:技術的アプローチ
ハルシネーションを防ぐためには、AIモデル単体に頼るのではなく、適切な「仕組み」を構築することが重要です。
現在、最も効果的とされるのが以下の手法です。
RAG(検索拡張生成)の導入
ハルシネーション対策として、現在ビジネスで主流となっているのが RAG(Retrieval-Augmented Generation / 検索拡張生成) です。
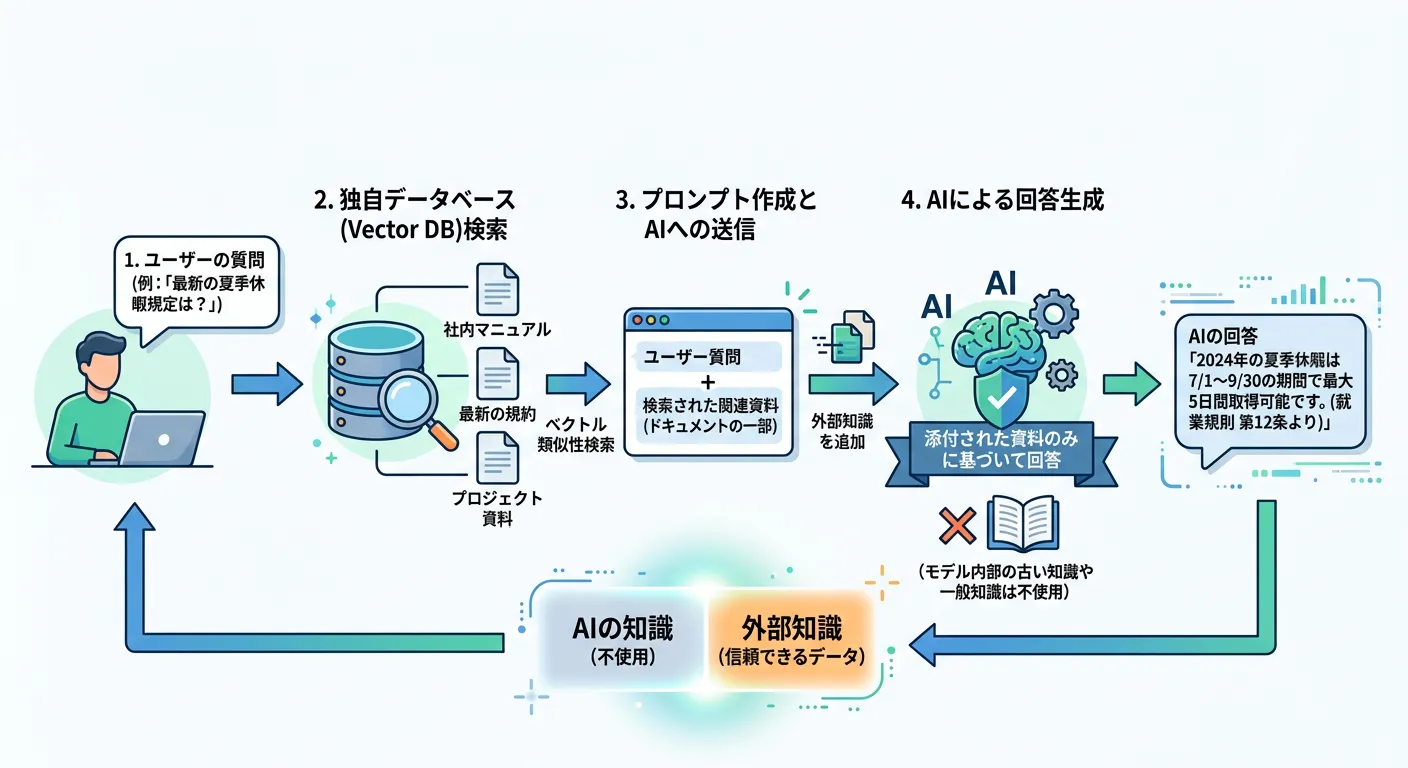
RAGは、AIが回答を生成する直前に、信頼できる外部データベースから関連情報を取得し、その情報をベースに回答を作成させる手法です。
これにより、AIは「自分の記憶(学習データ)」ではなく「提示された資料」に基づいて回答するため、事実に基づかない回答を劇的に減らすことができます。
特に社内ドキュメントや最新の情報を扱う場合には、RAGの導入は必須と言えるでしょう。
グラウンディング(Grounding)の強化
グラウンディングとは、AIの回答を特定の「根拠」に結びつける技術です。
回答の末尾に、参照した資料のページ数やURLを明示させることで、ユーザーが情報の正確性を即座に検証できるようにします。
温度感(Temperature)パラメーターの調整
AIモデルには、生成の「多様性」や「創造性」をコントロールする Temperature という設定値があります。
Temperatureが高い(例: 1.0以上): 回答が創造的になるが、ハルシネーションが起きやすくなる。Temperatureが低い(例: 0.1以下): 回答が決定論的(常に同じような硬い回答)になり、ハルシネーションを抑制できる。
事実確認が必要な業務では、この値を限りなく 0 に近づける設定が推奨されます。
実践的なハルシネーション対策:プロンプトエンジニアリング
開発環境を整えるだけでなく、AIへの「指示の出し方(プロンプト)」を工夫することでも、精度を大幅に向上させることができます。
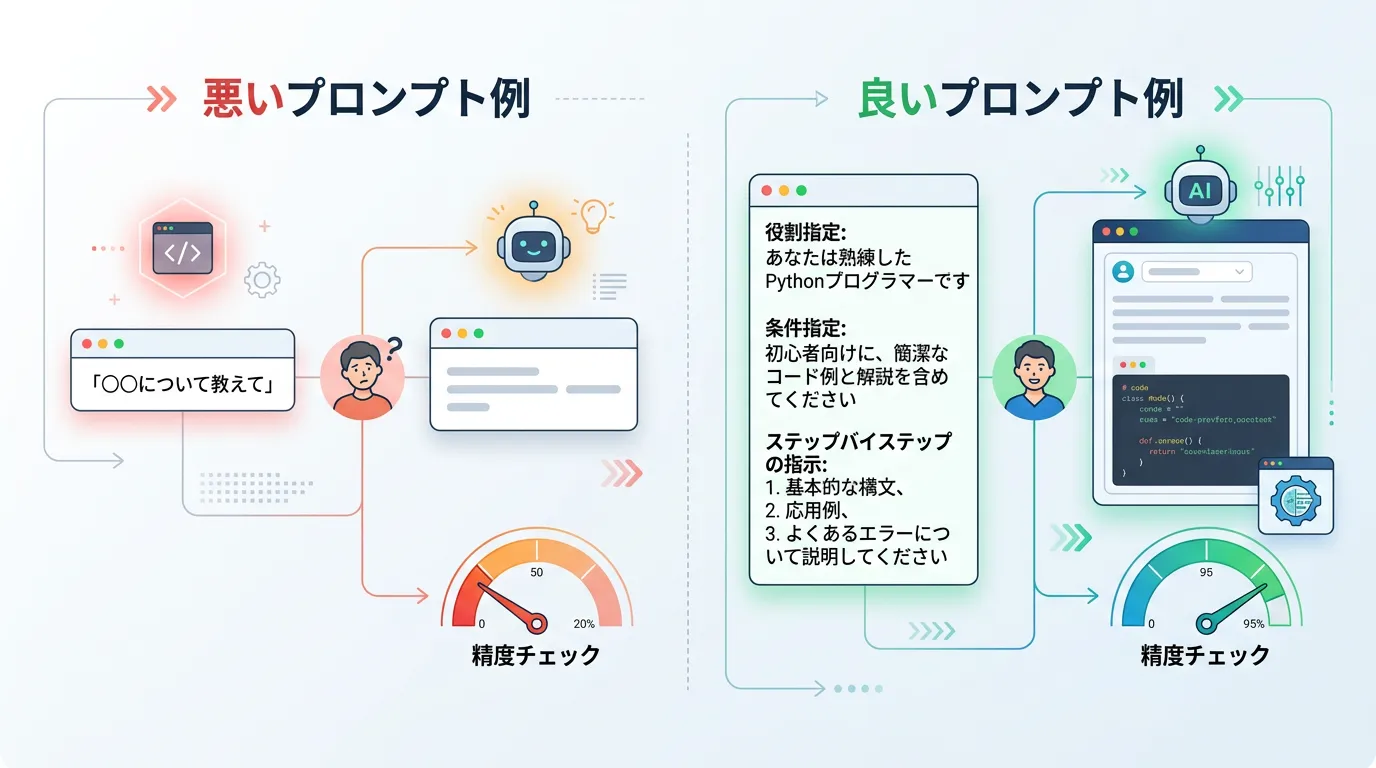
Chain of Thought(思考の連鎖)
AIに対して「順を追って考えてください」と指示する手法です。
いきなり結論を出させるのではなく、中間的な推論プロセスを出力させることで、論理的な破綻(ハルシネーション)を防ぐことができます。
Few-shot プロンプティング
指示の中に、いくつかの「質問と回答の具体例」を含める手法です。
AIに対して期待する回答の型や正確性のレベルを事前に学習させることで、迷走を防ぎます。
「わからない場合は正直に答える」という指示
プロンプトの最後に、「もし確かな情報がない場合は、推測で答えずに『分かりません』と回答してください」という一文を付け加えるだけでも、無理な創作を抑える効果があります。
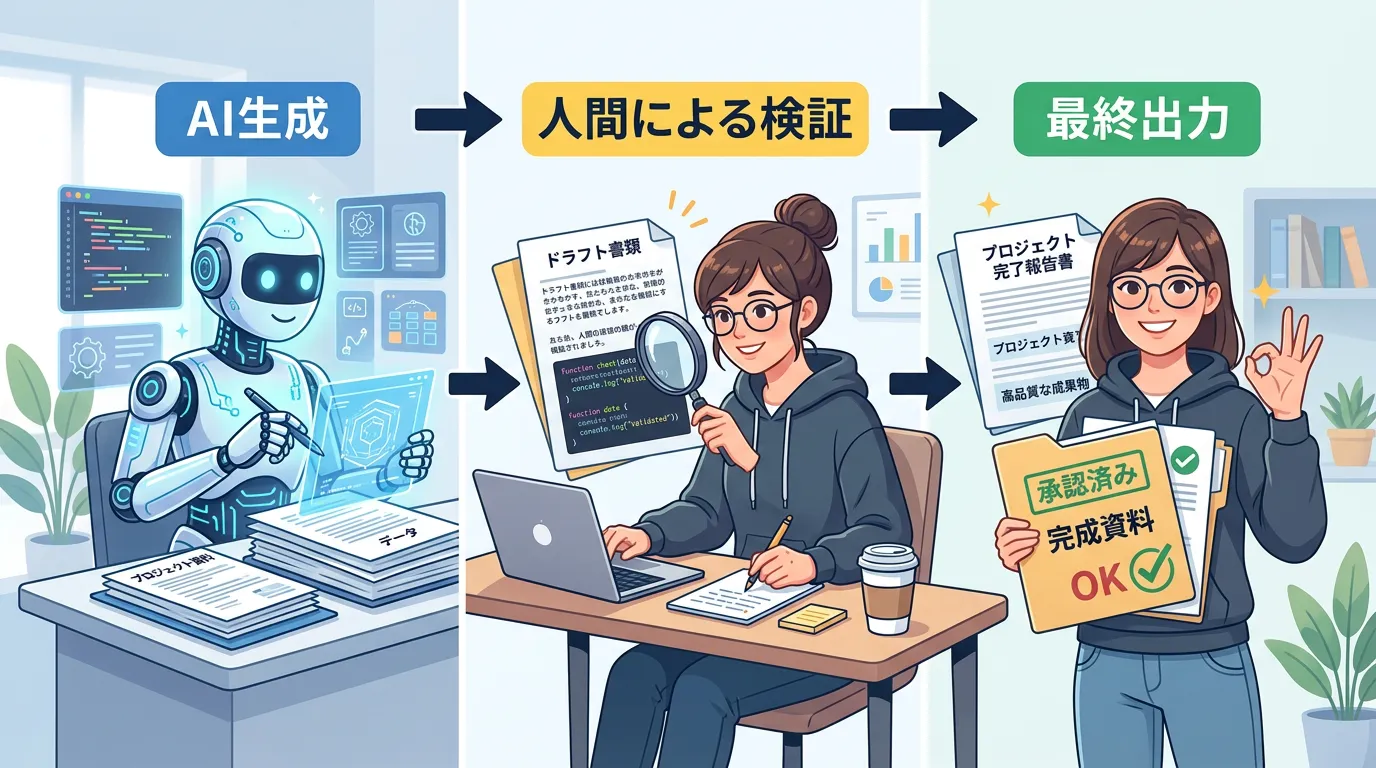
運用でカバーする:ヒューマン・イン・ザ・ループ(HITL)
技術的な対策を講じても、ハルシネーションの可能性を完全にゼロにすることはできません。
そのため、最終的な出力結果を人間が確認する Human-in-the-Loop(HITL) の体制構築が不可欠です。
AIはあくまで「下書き担当」や「検索補助」として位置づけ、重要な判断が伴う業務では必ず専門知識を持つ人間がクロスチェックを行う運用フローを設計してください。
精度を評価するための指標とツール
対策を実施した後は、実際にハルシネーションが減っているかどうかを定量的に測定する必要があります。
| 評価手法 | 内容 |
|---|---|
| G-Eval | 高性能なLLM(GPT-4など)を「評価者」として使い、別のAIの回答の正確性を採点させる手法。 |
| RAGAS | RAG(検索拡張生成)の精度に特化した評価フレームワーク。忠実性、関連性などをスコア化する。 |
| Self-Correction | AI自身に「自分の回答に誤りがないか」を再チェックさせるステップを組み込む。 |
LangChain や LlamaIndex などのフレームワークを活用すると、これらの評価プロセスを自動化しやすくなります。
まとめ
ハルシネーションは生成AIの宿命とも言える現象ですが、その原因を正しく理解し、適切な対策を講じることで、ビジネスにおけるリスクを最小限に抑えることが可能です。
本記事で解説した対策のポイントを振り返ります。
- RAG(検索拡張生成)の導入により、信頼できる外部データを参照させる。
- Temperature設定の最適化や、プロンプトでの「思考の連鎖」活用により、生成プロセスを制御する。
- 人間による最終確認(HITL)を運用プロセスに組み込み、AIを過信しない。
- 継続的な評価と改善を行い、ハルシネーションの発生率をモニタリングする。
AIは魔法の杖ではありませんが、正しく制御されたAIは強力なパートナーとなります。
ハルシネーション対策を徹底し、安全かつ効果的にAIの恩恵を享受しましょう。
