
エンジニアの業務において、生成AI(GitHub Copilot、ChatGPT、Claudeなど)は今や欠かせないパートナーとなりました。
コードの自動生成やバグの特定、ドキュメント作成の効率化など、その恩恵は計り知れません。
しかし、その一方で「AIが生成したコードの著作権は誰にあるのか」「他者の著作権を侵害するリスクはないのか」といった法的な懸念が、開発現場の大きな課題となっています。
本記事では、プロのエンジニアが知っておくべき生成AIと著作権の基本構造から、具体的な開発リスク、そして法的トラブルを回避するための実践的なガイドラインまでを徹底的に解説します。
技術革新のスピードに法整備が追いつこうとしている過渡期だからこそ、正しい知識を身につけ、「守りのDX」を固めることが、エンジニアとしての価値を高めることにつながります。
生成AIと著作権の全体像:3つのフェーズで理解する
生成AIに関連する著作権の問題は、非常に複雑に見えますが、エンジニアリングのプロセスに当てはめて考えると整理しやすくなります。
日本の文化庁の見解によれば、著作権の問題は大きく分けて「AIの開発・学習段階」と「生成・利用段階」の2つに分類されます。
さらに、エンジニアの実務に即して「入力(プロンプト)」のフェーズを加えた3つの視点で捉えることが重要です。
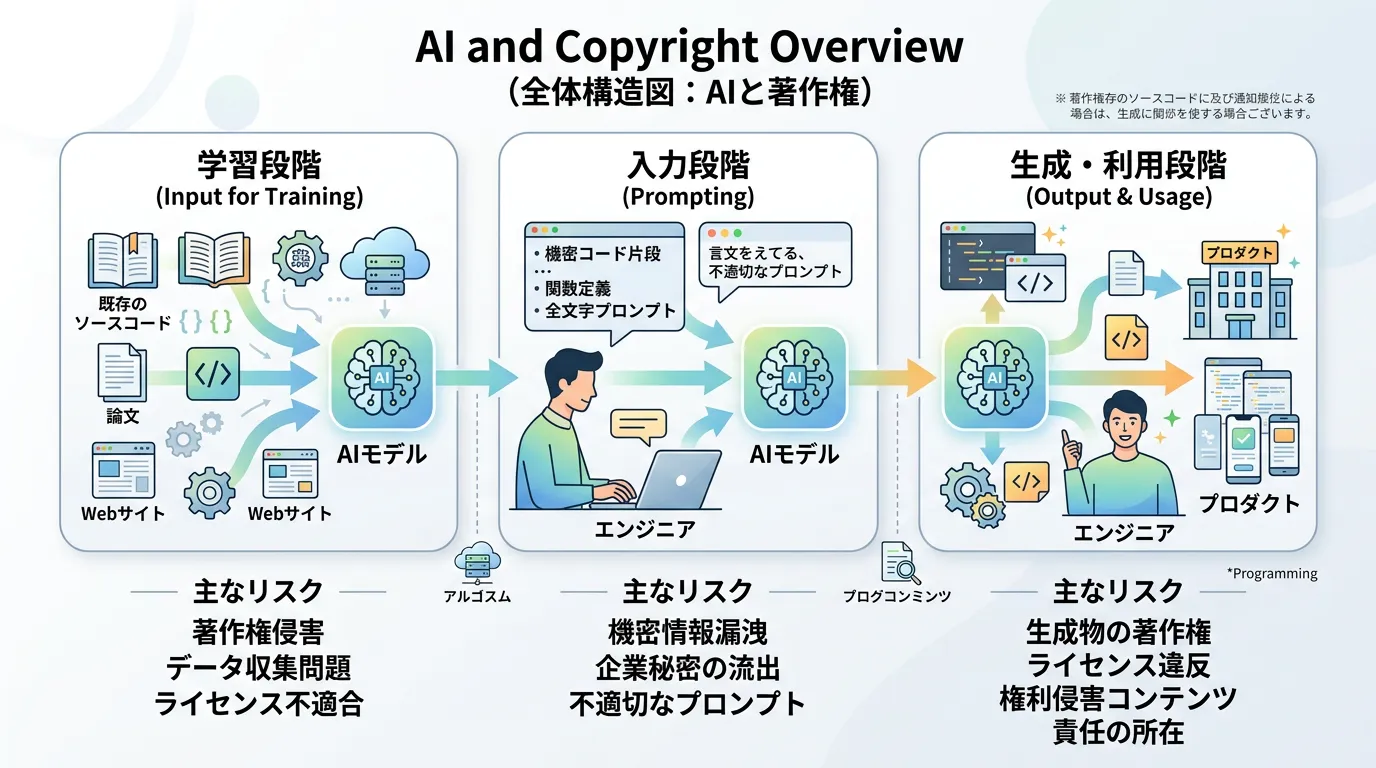
1. AIの開発・学習段階(学習データの利用)
AIモデルが構築される際、インターネット上の膨大なソースコードやドキュメントが学習データとして使用されます。
ここで問題になるのは、「他人の著作物を勝手に学習に使っても良いのか」という点です。
日本では、著作権法第30条の4という規定により、原則として「情報解析を目的とする場合、著作権者の許諾なく著作物を利用できる」とされています。
これは世界的に見ても非常に「AI開発に寛容な法律」と言われており、日本のAI産業を支える法的根拠となっています。
ただし、著作権者の利益を不当に害する場合(例:海賊版サイトから意図的に収集するなど)は例外となるため、完全に自由というわけではありません。
2. 入力段階(プロンプトと機密保持)
エンジニアがAIに指示を出す際、既存のソースコードの一部をプロンプトとして入力することがあります。
ここで懸念されるのは著作権よりも、むしろ機密保持契約(NDA)や営業秘密の漏洩です。
入力したデータがAIの学習に再利用される設定になっている場合、自社のコアロジックが他者の回答として出力されるリスクが生じます。
多くの商用AIツール(GitHub Copilotの法人版など)では、入力データを学習に使用しない設定が可能ですが、個人用アカウントでの利用には十分な注意が必要です。
3. 生成・利用段階(アウトプットの法的性質)
最も議論が活発なのが、AIが生成したコードを自社の製品に組み込む段階です。
ここでは以下の2つの問いが重要になります。
- AIが生成したコードに著作権は発生するのか?
- AIが生成したコードが、既存のコード(他者の著作物)に酷似していた場合、著作権侵害になるのか?
現在の日本の法解釈では、人間が創作的寄与(具体的な指示や修正)を行っていない「AIによる自動生成物」には、原則として著作権が発生しないと考えられています。
一方で、生成されたコードが既存の著作物と「類似性」があり、かつその著作物を学習したことによる「依拠性」が認められる場合、著作権侵害が成立する可能性があります。
日本の著作権法第30条の4とエンジニアへの影響
エンジニアが日本の法律下で開発を行う際、最も重要なのが著作権法第30条の4の理解です。
この条文は「機械学習パラダイス」とも呼ばれる日本独自の強力な規定です。
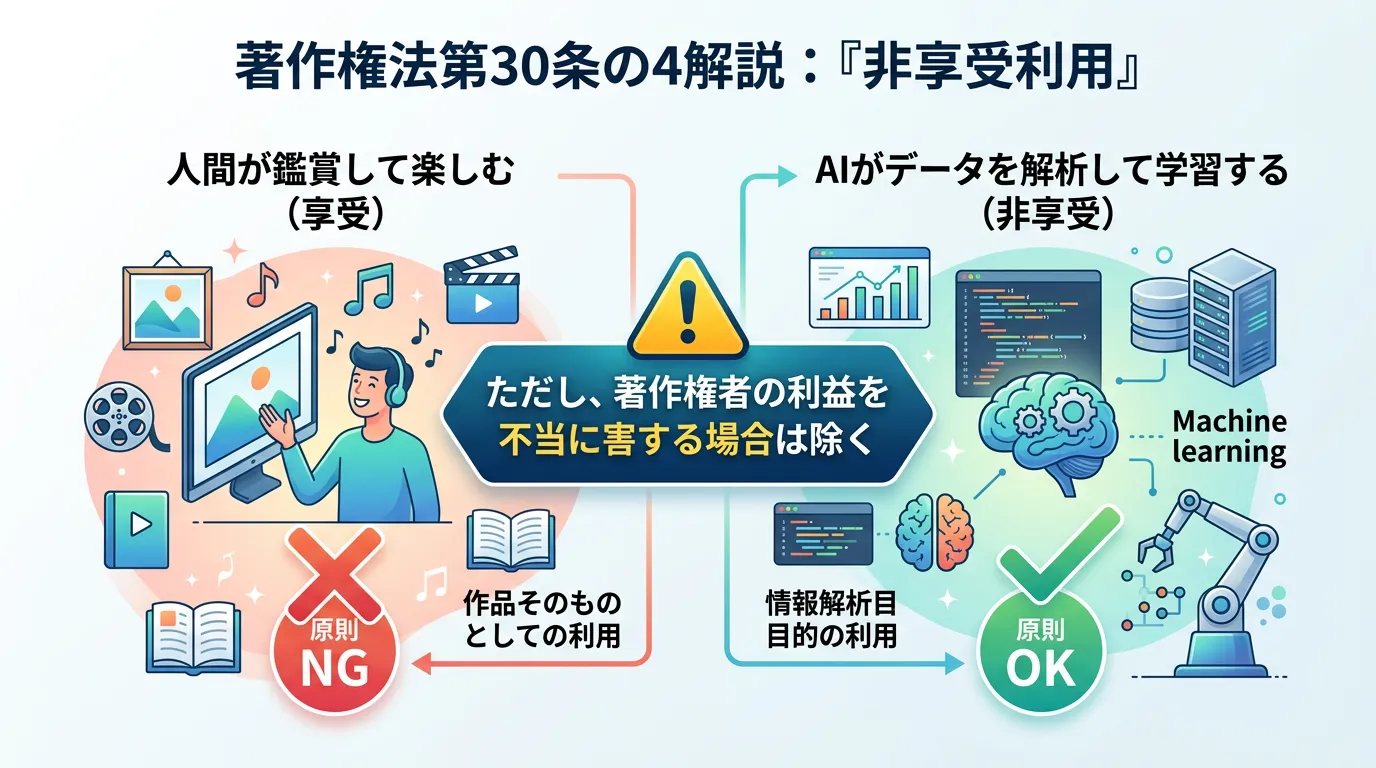
非享受利用の原則
著作権法は本来、思想や感情を表現した著作物を保護するためのものです。
AIが機械的にデータを読み取り、統計的なパターンを抽出する行為(情報解析)は、人間が作品の芸術性を楽しむ「享受」とは異なります。
そのため、「思想や感情を享受することを目的としない利用(非享受利用)」であれば、著作権者の許可なく利用できるというのが日本のスタンスです。
エンジニアが自前でLLM(大規模言語モデル)をファインチューニングする場合、この条文が強力なバックアップとなります。
「著作権者の利益を不当に害する場合」の解釈
ただし、この規定には「著作権者の利益を不当に害することとなる場合は、この限りでない」という但し書きがあります。
例えば、以下のようなケースはリスクが高いと考えられます。
- 特定のエンジニアのコードスタイルを完全に模倣させるために、そのエンジニアの非公開リポジトリを不当に取得して学習させる。
- プログラムのデータベース(APIリファレンス等)を、そのまま競合サービスとして提供する目的で解析する。
エンジニアとしては、「学習目的であれば何でも許されるわけではない」という境界線を意識する必要があります。
開発現場における具体的な法的リスク
生成AIを利用した開発において、エンジニアが直面するリスクは主に3つに集約されます。
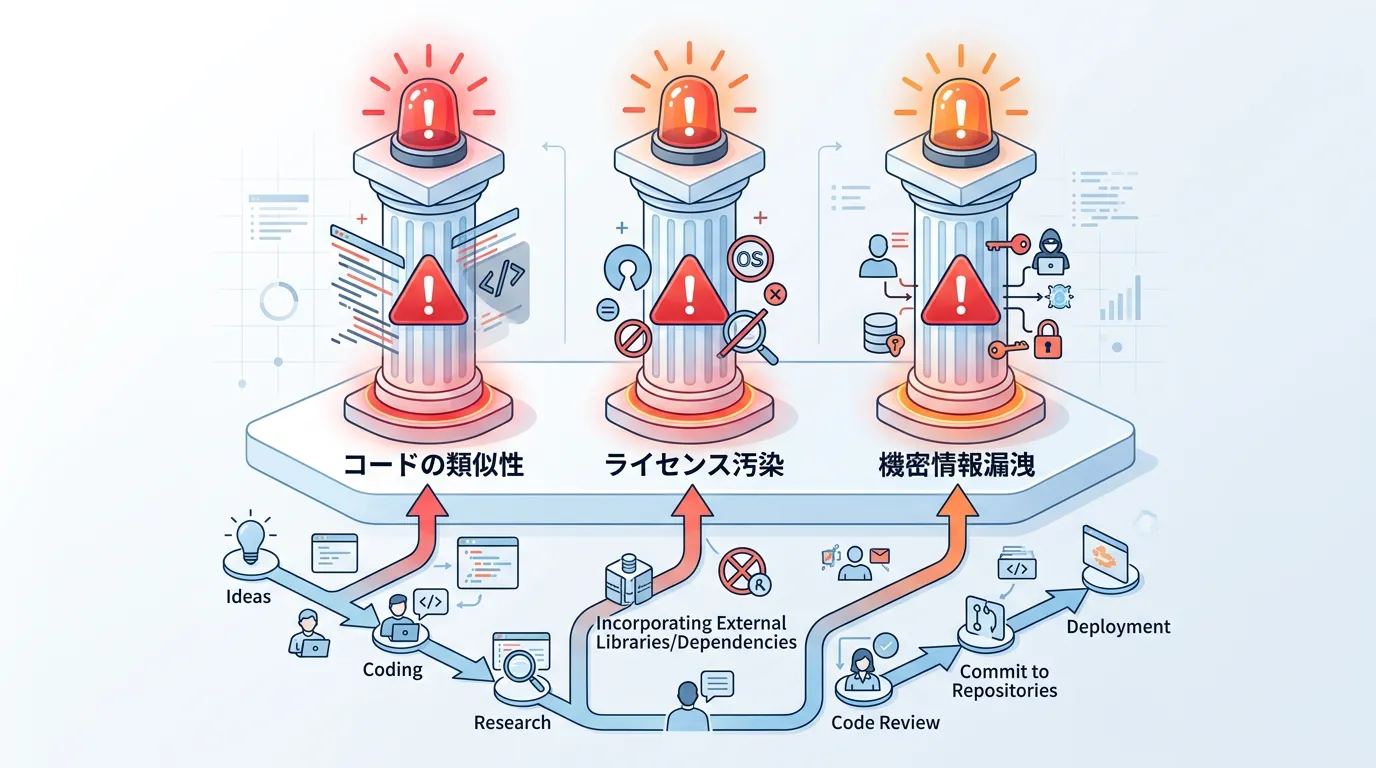
1. 著作権侵害(類似性と依拠性)
AIが生成したコードが、既存のオープンソースソフトウェア(OSS)や他社の製品コードと酷似している場合、著作権侵害を問われる可能性があります。
- 類似性: 生成されたコードが、既存の著作物の表現上の本質的な特徴を直接感じ取れるほど似ていること。
- 依拠性: AIがその既存の著作物を学習しており、それに基づいて生成されたこと。
近年のAIモデルは膨大なデータを学習しているため、特定のコードをそのまま出力する「丸暗記(Memorization)」現象が報告されています。
特に、非常にユニークなアルゴリズムや複雑なロジックがそのまま出力された場合、侵害のリスクが高まります。
2. ライセンス汚染(OSSライセンスの遵守)
エンジニアにとって最も現実的な脅威が「ライセンス汚染」です。
AIは、MIT、Apache 2.0、GPLといった様々なライセンスが適用されたコードを学習しています。
もし、AIがGPLライセンスのコードを一部引用して生成し、それを自社の商用プロダクトに組み込んでしまった場合、自社のソースコード全体を公開しなければならない(コピーレフト特性)というリスクが生じます。
AIツール側は通常「ライセンスの保証」をしてくれないため、利用側の責任でこれをチェックする必要があります。
3. 企業秘密・営業秘密の流出
ChatGPTなどのチャット型AIに、自社の未発表のアルゴリズムやAPIキー、顧客データを含むコードを貼り付けてリファクタリングを依頼するケースです。
入力されたデータがモデルの再学習に利用される設定になっている場合、その機密情報が「他者の回答」として世界中に公開されるリスクがあります。
一度流出した情報は回収が困難であり、法的な損害賠償だけでなく、企業の社会的信用を大きく失墜させます。
主要なAI開発ツールの利用規約と法的保護
エンジニアが利用する主要なツールが、著作権やデータ利用についてどのようなスタンスを取っているか把握しておくことは必須です。
| サービス名 | 入力データの学習利用 | 著作権の帰属先 | 法的補償(インデムニティ) |
|---|---|---|---|
| GitHub Copilot (Business/Enterprise) | 原則として学習に利用しない | ユーザーに帰属 | 条件付きで著作権侵害の補償あり |
| ChatGPT (Enterprise/Team) | 学習に利用しない | ユーザーに帰属 | 著作権侵害の法的保護あり |
| Claude (Pro/Team) | オプトアウト設定等で回避可能 | ユーザーに帰属 | 商用利用向けの補償プランあり |
GitHub Copilotについては、パブリックコードとの一致を検出し、ブロックするフィルタリング機能が提供されています。
これを利用することで、意図しないライセンス侵害のリスクを大幅に低減できます。
実践ガイド:エンジニアが守るべき「安全なAI利用」の5か条
リスクを正しく理解した上で、どのように開発フローに組み込むべきか。
現場で即実践できるガイドラインを提案します。
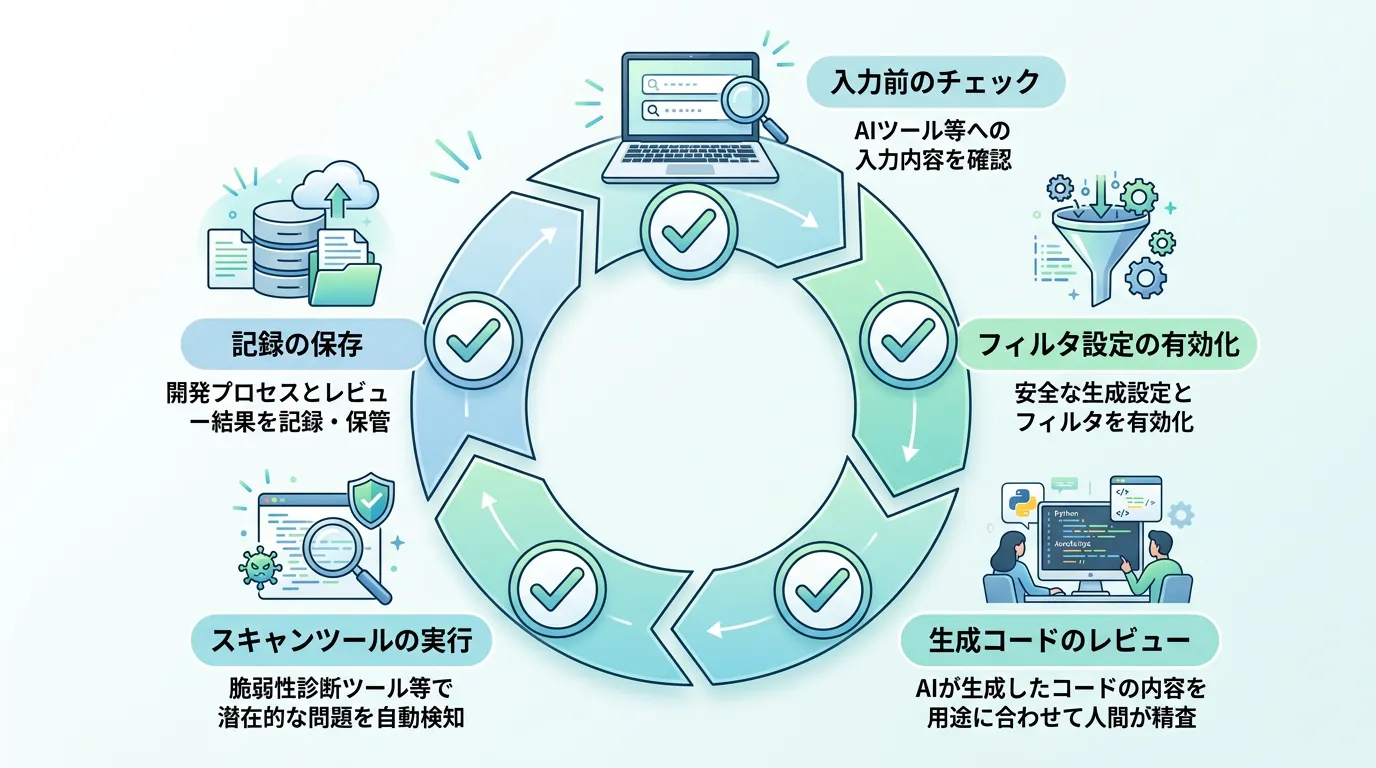
第1条:法人向け(Enterprise/Business)プランを原則とする
個人向けの無料プランや安価なプランでは、入力データが学習に利用されることがデフォルト設定になっている場合があります。
法人の業務で行う開発であれば、必ず「入力データを学習に利用しない」ことが明記された法人契約のアカウントを使用してください。
第2条:フィルター機能を必ず「ON」にする
GitHub Copilotなどのツールには、パブリックコード(公開されているソースコード)と一致するコードを提案しないようにする設定があります。
これをBlockに設定しておくことで、既存のOSSコードをそのままコピー&ペーストしてしまうリスクを物理的に遮断できます。
第3条:生成されたコードは「外部ライブラリ」として扱う
AIが生成したコードを、自分が書いたコードと同じ感覚で扱ってはいけません。
AIの出力はあくまで「提案」であり、「出所不明のサードパーティ製ライブラリ」を導入する際と同じレベルの警戒感を持つべきです。
- ロジックが正しいか?
- 非効率な処理が含まれていないか?
- 脆弱性(セキュリティホール)がないか?
- 既存の有名なライブラリに酷似していないか?
これらを人間が必ずレビューする必要があります。
第4条:SCA(ソフトウェア組成分析)ツールを活用する
AIを使って大量のコードを生成する場合、目視のレビューだけでは限界があります。
SnykやBlack DuckなどのSCA(Software Composition Analysis)ツールをCI/CDパイプラインに組み込み、混入したコードが既存のOSSライセンスに抵触していないかを自動でスキャンする仕組みを構築しましょう。
第5条:プロンプトに機密情報を直接書かない
たとえ学習に利用されない設定であっても、クラウドサービスに機密情報を送信すること自体が、企業のセキュリティポリシーに抵触する場合があります。
- 変数名や関数名を抽象化する。
- 独自のビジネスロジックそのものではなく、汎用的なアルゴリズムの書き方を尋ねる。
- 個人情報やパスワード、APIキーは絶対に含めない。
このように、「情報の抽象化」を意識したプロンプトエンジニアリングが、身を守るためのスキルとなります。
AI生成コードの著作権帰属:誰が「著者」になるのか?
開発したプロダクトの権利を主張するためには、著作権がどこに帰属するかを知っておく必要があります。
創作的寄与がある場合
エンジニアが詳細な仕様を定義し、AIに対して「この変数をこう使い、このアルゴリズムで、こういうエラーハンドリングを行え」といった具体的な指示を積み重ね、出力されたコードに対して大幅な修正やリファクタリングを行った場合、そのコードには人間の「創作的寄与」が認められ、人間に著作権が発生する可能性が高くなります。
創作的寄与がない場合(単なる自動生成)
逆に、「〇〇な機能のコードを書いて」という一行のプロンプトで出力されたコードをそのまま使用した場合、それは「思想や感情を創作的に表現したもの」とはみなされず、著作権が発生しない(パブリックドメインに近い状態になる)可能性があります。
これは、競合他社にそのコードを模倣されても、著作権法で保護できないリスクを意味します。
自社のコア技術をAIに書かせる場合は、必ず人間によるブラッシュアップ(創作性の追加)のプロセスを挟むようにしましょう。
最新の法的動向とエンジニアが注視すべきニュース
AIと著作権のルールは現在進行形で変化しています。
エンジニアとしてアンテナを張っておくべきトピックを整理しました。
米国での集団訴訟(GitHub, OpenAIなど)
アメリカでは、GitHub Copilotが「ライセンス表示(著作権表記)を無視してコードを提示している」として、開発者たちが集団訴訟を起こしています。
この裁判の結果次第では、AIツールの提供形態やフィルタリングの基準が大きく変わる可能性があります。
EU AI法(EU AI Act)
世界で初めての包括的なAI規制法である「EU AI法」が成立しました。
ここでは、生成AI(汎用AI)に対して「学習データの詳細な要約を公開すること」や「著作権法の遵守」を求めています。
グローバルなプロダクトを開発するエンジニアにとって、EUの規制は避けて通れない基準となります。
文化庁「AIと著作権に関する考え方」のアップデート
日本でも文化庁が定期的に議論を重ね、ガイドラインを更新しています。
最新の議論では「生成AIが特定のクリエイターの利益を害する場合」の解釈がより具体化されています。
まとめ
生成AIは、エンジニアの生産性を劇的に向上させる魔法の杖ですが、その裏には「著作権侵害」「ライセンス汚染」「機密漏洩」という3つの大きな落とし穴が潜んでいます。
法的トラブルを回避し、AIを真の武器にするためには、以下の3点を徹底しましょう。
- 仕組みを知る: 日本の著作権法(第30条の4)の特殊性と、AIが学習・生成するメカニズムを理解する。
- ツールを選ぶ: 学習利用をオフにできる法人向けプランや、フィルタリング機能のあるツールを正しく設定する。
- プロセスを作る: AI生成コードを盲信せず、人間によるレビューとSCAツールによる自動検知を開発フローに組み込む。
法律は技術を縛るためのものではなく、安心して技術を活用するための「ルール」です。
正しく恐れ、正しく活用することで、次世代のエンジニアリングをリードしていきましょう。
