現代のビジネスシーンやテクノロジーのニュースにおいて、「AI (人工知能)」「機械学習 (マシンラーニング)」「ディープラーニング (深層学習)」という言葉を耳にしない日はありません。
これらはしばしば同義語のように扱われることがありますが、実際には明確な包含関係と技術的な違いが存在します。
本記事では、プロの視点からこれら3つの概念の相関関係を整理し、特に混同されやすい機械学習とディープラーニングの違いについて、図解を交えながら専門的かつ分かりやすく解説します。
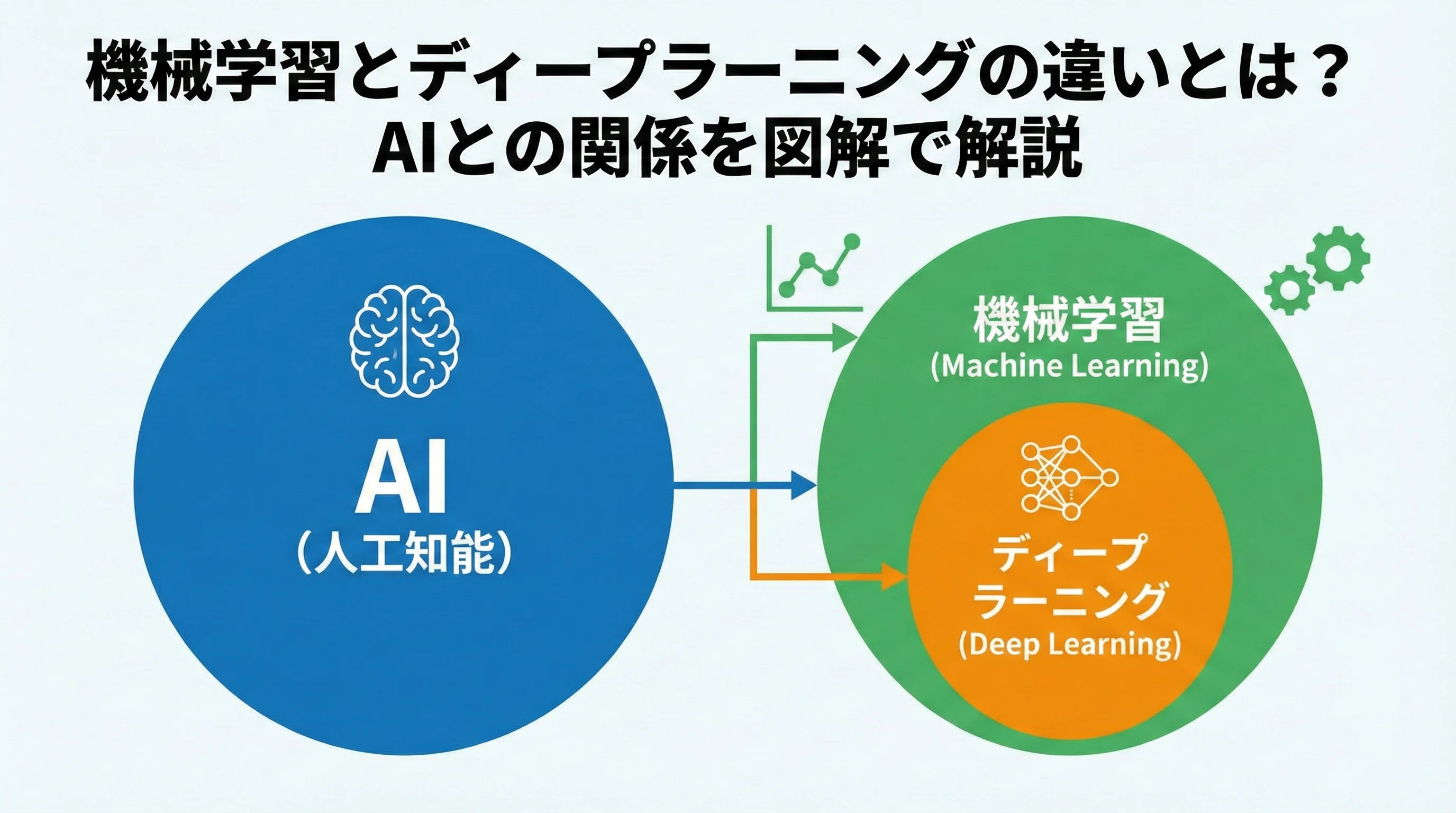
AI・機械学習・ディープラーニングの相関図
まず最初に理解すべきは、AI、機械学習、ディープラーニングは別々の独立した技術ではなく、入れ子構造 (階層構造)になっているという点です。
[イメージ作成の指示]
- AIという大きな円の中に、機械学習という中くらいの円があり、さらにその中にディープラーニングという小さな円があるベン図。
- 各階層の関係性が一目でわかるように、外側から「AI (人工知能)」「機械学習 (Machine Learning)」「ディープラーニング (Deep Learning)」とラベルを付ける。
- 背景は清潔感のある白または薄いグレー、円は青系のグラデーションを用いる。
上の図が示す通り、最も広い概念がAI (人工知能)であり、その中の一部に機械学習が含まれます。
そして、機械学習の手法の一つとして、近年目覚ましい発展を遂げているのがディープラーニングです。
これらを一言で定義するならば、以下のようになります。
- AI (人工知能)
コンピュータに人間のような知能を持たせる技術の総称。
- 機械学習 (Machine Learning)
データから学習し、特定のタスクを実行するためのアルゴリズムを自動的に構築する技術。
- ディープラーニング (Deep Learning)
人間の脳の神経回路を模した「ニューラルネットワーク」を多層化し、高度な判断を可能にする機械学習の発展形。
この関係性を念頭に置いた上で、それぞれの詳細な仕組みと違いを掘り下げていきましょう。
AI (人工知能) とは:広義の概念
AI (Artificial Intelligence) は、1950年代から研究されている非常に歴史の長い分野です。
その定義は専門家の間でも多岐にわたりますが、一般的には「学習、推論、判断といった人間の知的なふるまいをソフトウェアによって模倣する技術」を指します。
初期のAIは、人間がルールをあらかじめすべて記述する「ルールベース (エキスパートシステム)」が主流でした。
例えば、「もしAならばBせよ」という膨大なIF-THEN形式のルールを人間が教え込む手法です。
しかし、現実世界の複雑な事象をすべてルール化することには限界がありました。
そこで登場したのが、コンピュータ自らがデータからルールを見つけ出す機械学習の技術です。
機械学習 (Machine Learning) の仕組みと特徴
機械学習は、大量のデータを読み込ませることで、データの中に潜むパターンや統計的なルールをコンピュータに自力で発見させる手法です。
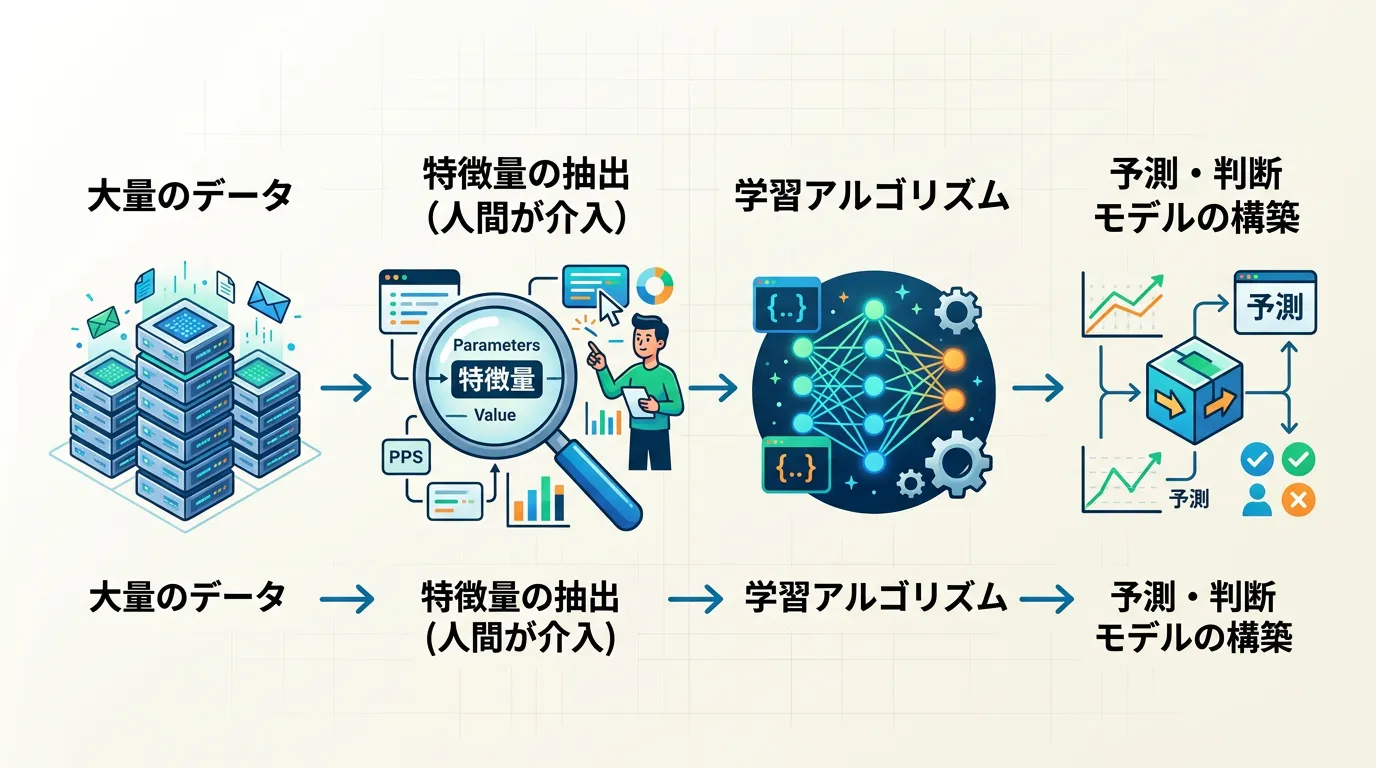
機械学習において最も重要なキーワードは「特徴量 (Feature)」です。
特徴量とは、予測や分類を行う際に「データのどこに注目すべきか」という変数のことです。
例えば、メールがスパムかどうかを判定する機械学習モデルを作る場合、人間が「特定の怪しい単語の出現頻度」や「送信ドメインの信頼性」といった特徴量をあらかじめ定義し、それをコンピュータに学習させます。
このように、「どの情報が重要か」を人間が設計するのが、従来の機械学習の大きな特徴です。
機械学習の主な3つの学習手法
機械学習は、学習の進め方によって大きく3つに分類されます。
- 教師あり学習 (Supervised Learning)
正解 (ラベル) 付きのデータを用いて学習させる手法です。
「この画像は猫である」という正解を与え続けることで、未知のデータに対しても正解を予測できるようになります。
回帰分析や分類問題に使用されます。
- 教師なし学習 (Unsupervised Learning)
正解を与えず、データそのものの構造や傾向を分析させる手法です。
顧客のクラスタリング (グループ分け) や、異常検知などに活用されます。
- 強化学習 (Reinforcement Learning)
システムが試行錯誤を通じて、最も報酬が得られる行動を学習する手法です。
チェスや囲碁などのゲームAI、自動運転の制御などに用いられます。
ディープラーニング (Deep Learning) とは:機械学習の進化形
ディープラーニングは、機械学習の一部でありながら、従来の機械学習が抱えていた「特徴量の設計を人間が行わなければならない」という限界を打破した革新的な技術です。
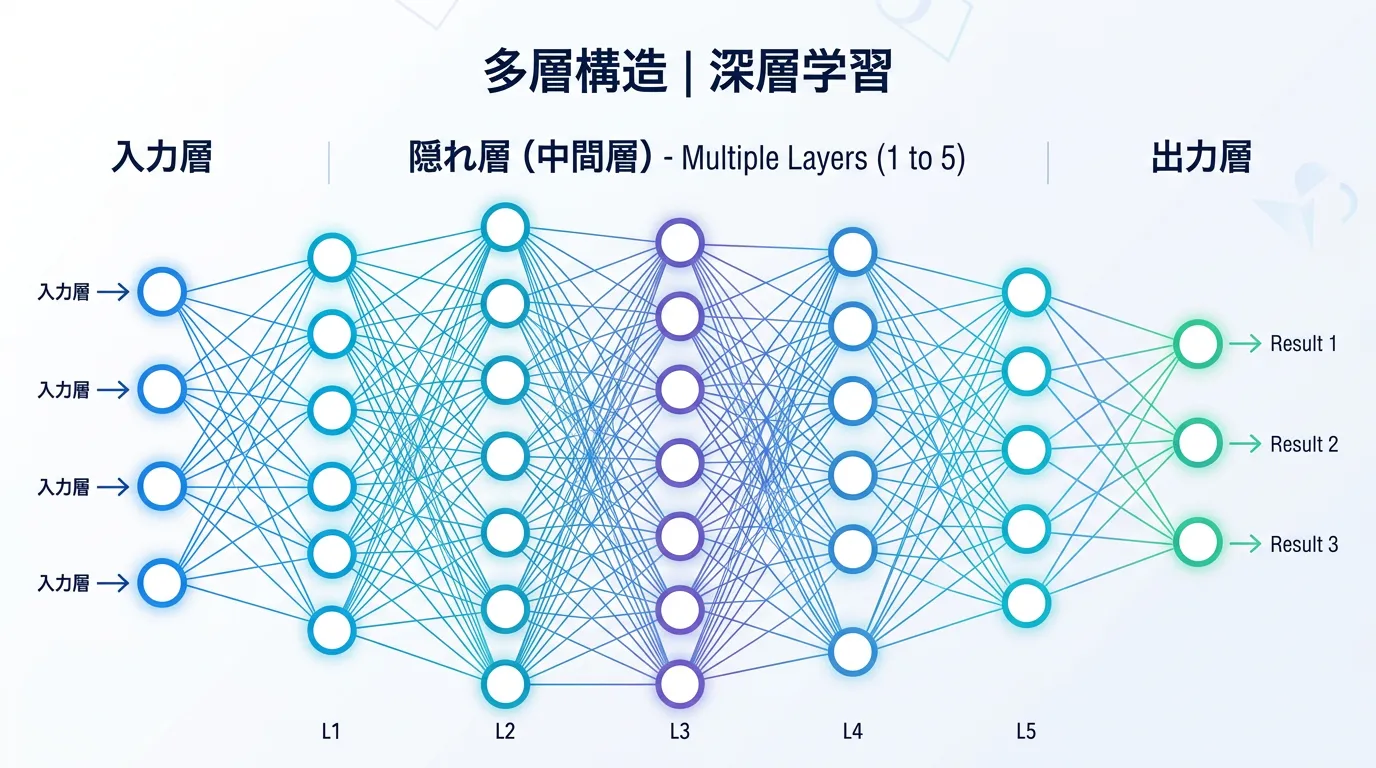
ディープラーニングは、人間の脳にある神経細胞 (ニューロン) の仕組みを模した「ニューラルネットワーク」というモデルをベースにしています。
このネットワークを何層にも深く (Deep) 重ねることで、複雑なデータの背後にある本質的な特徴を段階的に抽出していきます。
最大の特徴は、「何に注目すべきか (特徴量)」をコンピュータが自ら発見する点にあります。
例えば、画像認識において、従来の機械学習では「耳の形」や「色のコントラスト」を人間が指定していましたが、ディープラーニングでは大量の画像を見る過程で、コンピュータが勝手に「猫を認識するにはこのエッジのパターンが重要だ」といった特徴を見つけ出します。
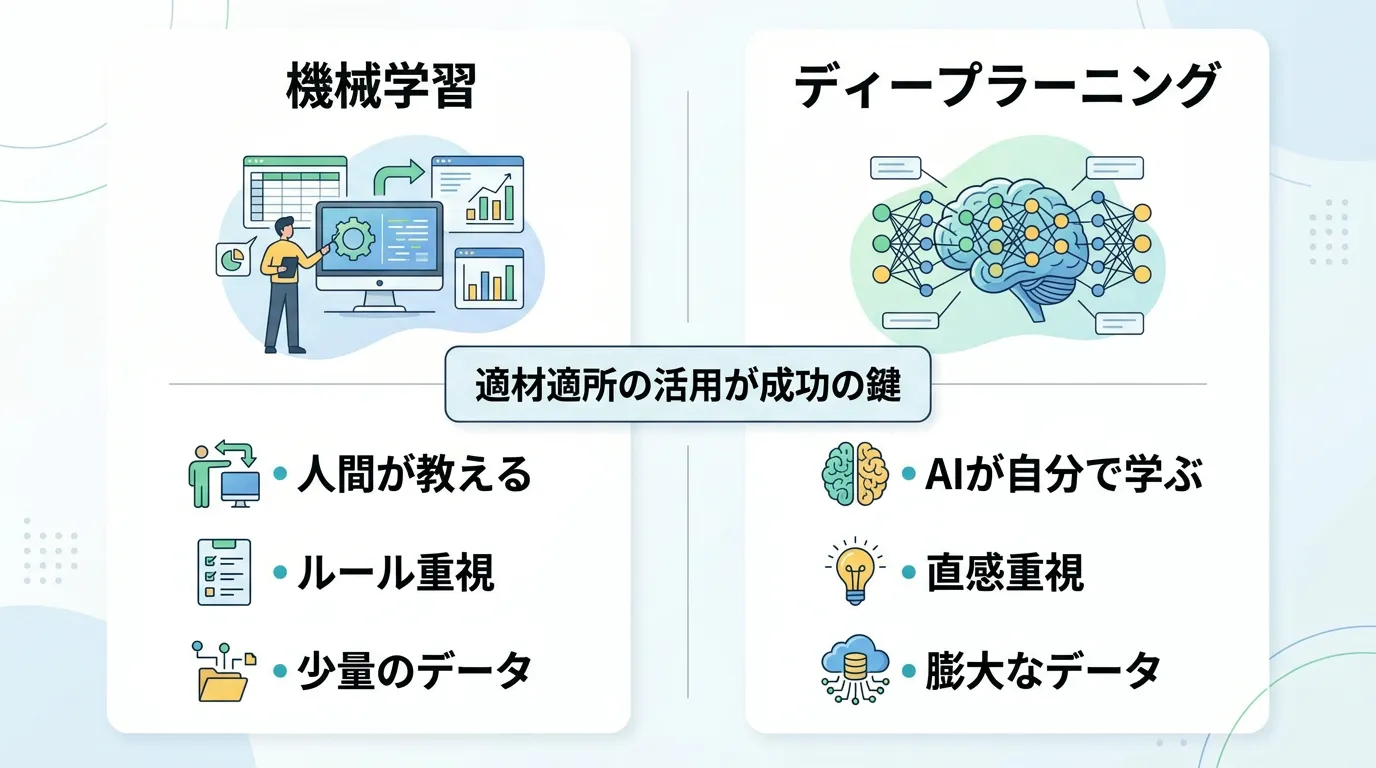
機械学習とディープラーニングの決定的な違い
それでは、具体的にどのような点が異なるのか、主要な4つの観点から比較してみましょう。
1. 特徴量の抽出方法
これが最も本質的な違いです。
- 機械学習
人間がデータの特徴を定義し、それをアルゴリズムに教える必要がある。
- ディープラーニング
データから自動的に特徴を抽出する。
人間が気づかないような微細なパターンも学習可能。
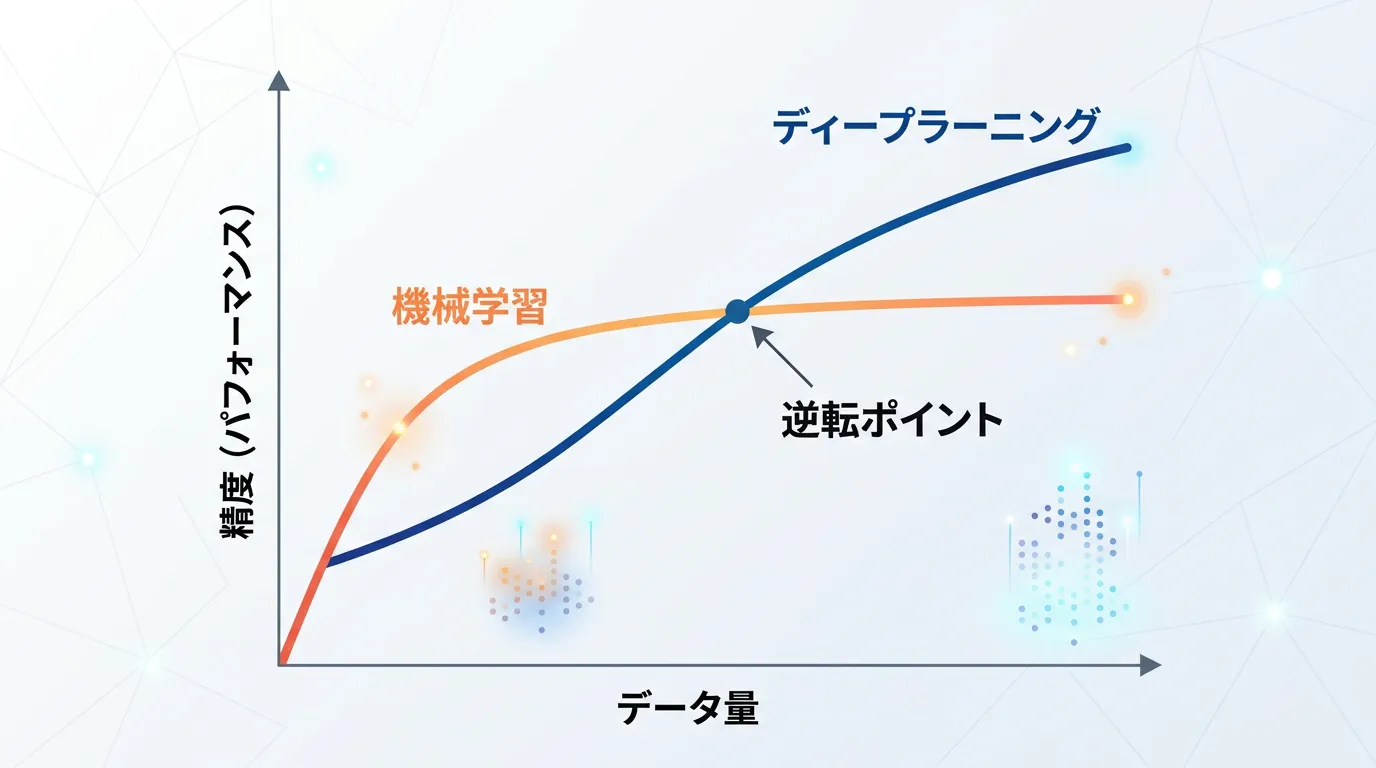
2. 必要なデータ量
- 機械学習
数百から数千程度の比較的少ないデータ量でも、ある程度の精度を出すことが可能。
- ディープラーニング
性能を最大限に発揮するためには、数万、数百万単位の膨大なデータ (ビッグデータ)が必要。
データが少ないと、過学習 (学習データにだけ適合しすぎて汎用性がなくなる状態) を起こしやすい。
3. ハードウェアのリソース
- 機械学習
一般的なビジネスPCの
CPUでも実行可能なモデルが多い。- ディープラーニング
膨大な行列演算を高速に行う必要があるため、
GPU(画像処理装置)を搭載した高スペックな計算環境が不可欠。
4. 判断の根拠 (ブラックボックス問題)
- 機械学習
どの特徴量が結果に影響を与えたのかを人間が把握しやすく、説明性が高い。
- ディープラーニング
ニューラルネットワークの内部でどのような計算が行われ、なぜその結論に至ったのかを人間が論理的に説明することが困難。
これを「ブラックボックス化」と呼び、医療や金融など説明責任が求められる分野での課題となっている。
比較まとめ表
| 比較項目 | 機械学習 (Machine Learning) | ディープラーニング (Deep Learning) |
|---|---|---|
| 特徴量の抽出 | 人間が手動で行う | コンピュータが自動で行う |
| データ量 | 少量〜中量でも動作可能 | 膨大な量が必要 |
| 計算リソース | 低スペックでも可 | 高スペック (GPU) が必須 |
| 学習時間 | 比較的短い | 非常に長い (数日〜数週間かかることも) |
| 精度の限界 | ある程度のデータ量で頭打ちになる | データ量に応じて精度が向上し続ける |
| 説明性 | 高い (根拠が明確) | 低い (ブラックボックス化) |
どちらを採用すべきか?使い分けの基準
「ディープラーニングの方が高度なら、常にディープラーニングを使えばいいのでは?」と思われるかもしれません。
しかし、実務においては必ずしもそうではありません。
プロジェクトの目的や予算に応じて最適な手法を選択することが重要です。
機械学習が適しているケース
- データ量が限られている場合
数千件程度の顧客データから売上予測を行うなど、ビッグデータが確保できない場合。
- 予測の根拠を説明する必要がある場合
なぜその融資審査が落ちたのか、なぜその部品を交換すべきなのかといった、「納得感」が求められるビジネスシーン。
- コストを抑えたい場合
計算リソースが少なく済むため、低コストで迅速にプロトタイプを開発したい場合。
代表的なアルゴリズム:ロジスティック回帰、ランダムフォレスト、SVM (サポートベクターマシン)
ディープラーニングが適しているケース
- 非構造化データを扱う場合
画像、音声、自然言語 (文章) など、人間がルールを言語化しにくい複雑なデータ。
- 精度を極限まで高めたい場合
自動運転の障害物検知や、医療画像の診断支援など、わずかなミスが許されない高度なタスク。
- 生成AIを活用する場合
ChatGPTのような文章生成や、画像生成などのクリエイティブなタスクは、ディープラーニングの独壇場です。
代表的なモデル:CNN (畳み込みニューラルネットワーク)、RNN (回帰型ニューラルネットワーク)、Transformer
実社会における具体的な活用事例
イメージをより具体的にするため、私たちの身の回りでどのように使い分けられているかを見ていきましょう。
機械学習の事例:ECサイトのレコメンド
AmazonなどのECサイトで「この商品を買った人はこんな商品も買っています」と表示される機能は、主に機械学習が担っています。
過去の購買履歴や閲覧履歴という構造化されたデータに基づき、相関関係の強い商品を提示します。
ディープラーニングの事例:顔認証システム
スマートフォンのロック解除や空港の入国審査で使われる顔認証は、ディープラーニングの得意分野です。
照明の当たり方や表情の変化、メガネの有無にかかわらず、画像データから本質的な「顔の特徴」を抽出して本人を識別します。
機械学習の事例:スパムメールフィルター
メールの内容から特定のキーワードや送信元のパターンを分析し、迷惑メールフォルダに振り分ける機能です。
シンプルかつ軽量な動作が求められるため、ナイーブベイズなどの機械学習アルゴリズムが長年活用されています。
ディープラーニングの事例:自動翻訳
DeepLやGoogle翻訳などの高精度な翻訳サービスは、ディープラーニング (特にTransformerモデル) によって支えられています。
文脈を理解し、より自然な言葉の並びを生成することが可能です。
これからのAI活用に求められる視点
機械学習とディープラーニングの違いを理解することは、単なる用語の整理に留まりません。
今後、ビジネスにAIを導入する際には、「持っているデータの質と量は十分か」「結果に説明性が求められるか」「運用コストに見合う効果が得られるか」を冷静に判断するリテラシーが求められます。
また、近年では「生成AI (Generative AI)」の普及により、ディープラーニングを直接開発するのではなく、既存の巨大なモデル (大規模言語モデル:LLM) をAPI経由で活用するケースも増えています。
しかし、その根底にある「データから学習する」という機械学習の基本原則は変わりません。
まとめ
本記事では、AI、機械学習、そしてディープラーニングの違いについて詳しく解説しました。
最後に重要なポイントを振り返りましょう。
- AI (人工知能)は最も広い概念であり、人間の知能を模倣する技術全般を指します。
- 機械学習はAIの一分野で、人間が特徴量を設計してデータから学習させる手法です。
- ディープラーニングは機械学習の進化形で、ニューラルネットワークを用いてコンピュータが自ら特徴量を抽出します。
- 両者の使い分けは、データの量、種類 (構造化か非構造化か)、計算リソース、そして「説明性」の必要性によって決まります。
技術は日々進化していますが、それぞれの特性を正しく理解することで、過度な期待や誤解を避け、AIという強力なツールを最大限に活用できるようになります。
まずは自社が抱える課題が「ルール化できるものか」それとも「膨大なデータからパターンを見出すべきものか」を検討することから始めてみてはいかがでしょうか。
