
C++11ではポインタの初期化や比較にnullptrが導入されました。
従来のNULLや0でも一見問題なく動きますが、実はオーバーロード解決や型安全性などで微妙なバグを生みやすい要因になっていました。
この記事では、なぜC++11以降はnullptrが推奨されるのかという本質的な理由と、基本的な使い方、移行時のポイントを丁寧に解説します。
C++11で導入されたnullptrとは何か
nullptrの正体と型
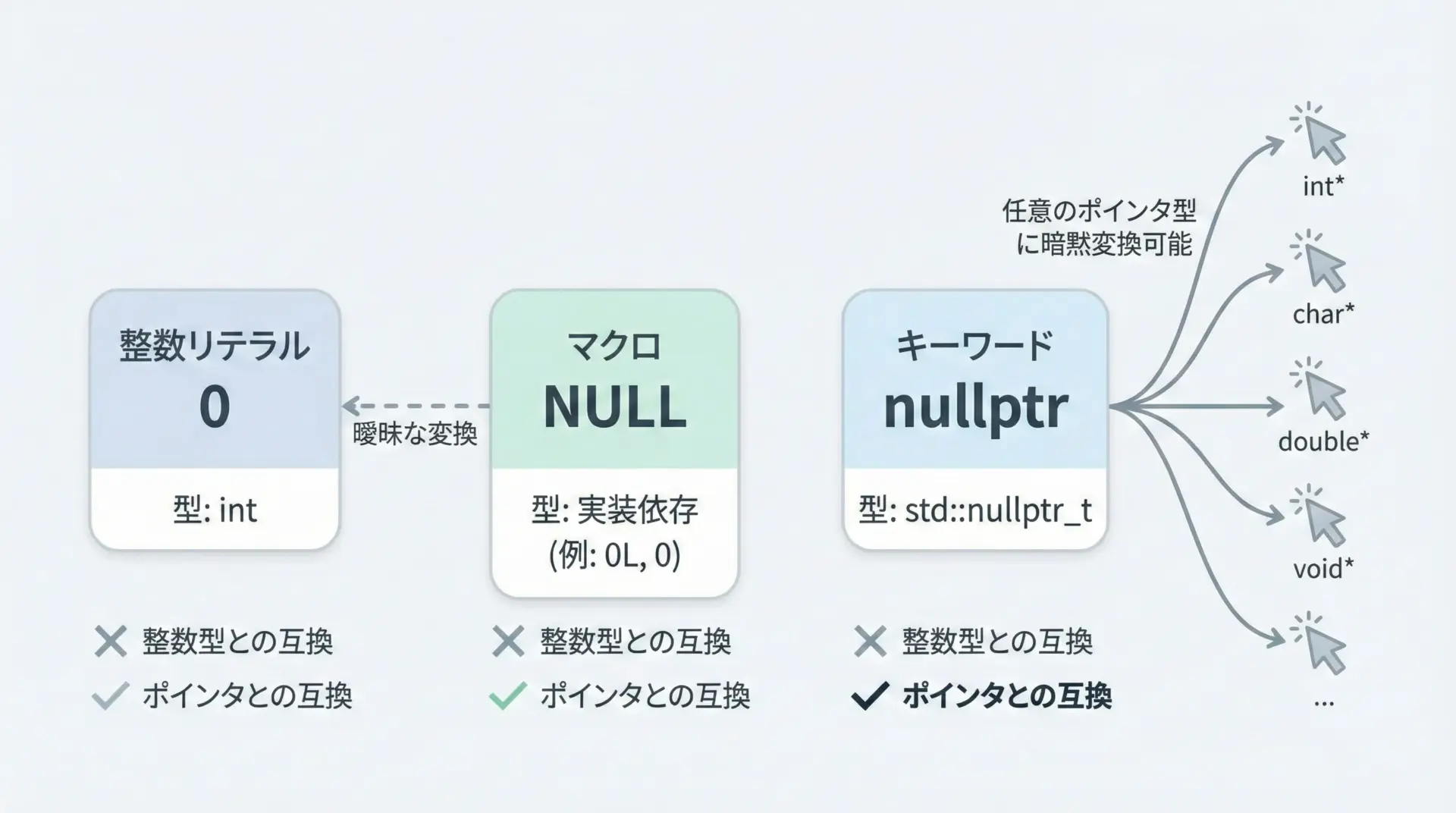
C++11で導入されたnullptrは、ヌルポインタ専用のリテラルです。
型はstd::nullptr_tという特殊な型で、次の特徴があります。
- 任意のポインタ型(例:
int、void)に暗黙変換可能です。 - しかし整数型(
intやlong)には暗黙変換されません。 - 「これはヌルポインタを表している」ことが型レベルで明確になります。
一方でNULLは多くの処理系で0または0Lとして定義されたマクロにすぎず、型としては整数型です。
そのため、関数オーバーロードなどでNULLを渡すと、本当はポインタとして扱いたいのに整数として解釈されてしまう可能性があります。
NULLとnullptrの簡単な比較
次の表に、0・NULL・nullptrの違いを簡単に整理します。
| リテラル | 主な型 | 用途 | 主な問題点 |
|---|---|---|---|
| 0 | int | 整数/ヌルポインタ(旧来) | 整数と区別できない |
| NULL | 実装依存(多くは0か0L) | ヌルポインタ(旧来) | 実体は整数マクロ、オーバーロードであいまいさ |
| nullptr | std::nullptr_t | ヌルポインタ専用 | C++11以降でのみ利用可能 |
「ヌルポインタであることを明示し、整数と確実に区別したい」という目的に対して、nullptrは最も素直な解決策になっています。
なぜnullptrが推奨されるのか
理由1: オーバーロード解決のあいまいさを避ける
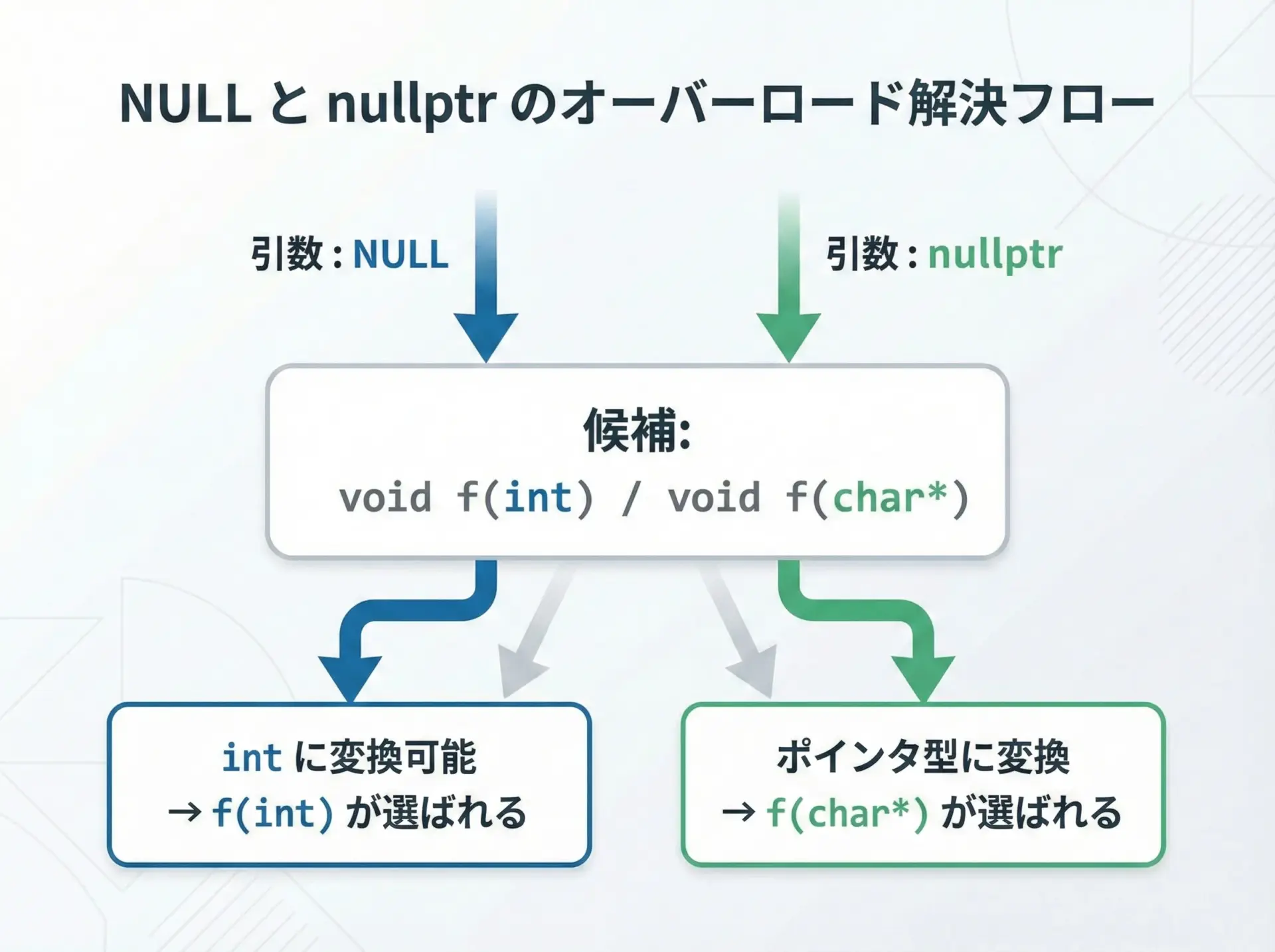
次のような関数オーバーロードを考えます。
#include <iostream>
// 整数を受け取るオーバーロード
void f(int x) {
std::cout << "f(int) が呼ばれました\n";
}
// 文字列ポインタを受け取るオーバーロード
void f(const char* p) {
std::cout << "f(const char*) が呼ばれました\n";
}
int main() {
f(0); // どちらが呼ばれるか
f(NULL); // どちらが呼ばれるか
f(nullptr);// どちらが呼ばれるか
}f(int) が呼ばれました
f(int) が呼ばれました
f(const char*) が呼ばれましたこれは、多くの処理系でNULLが0(整数)として定義されており、f(NULL)がf(int)に束縛されるためです。
本来は「ポインタとしてヌルを渡したかった」のに、意図せず整数オーバーロードが呼ばれるという紛らわしい動作になっています。
一方でnullptrはヌルポインタ専用の型であり、const charへの変換が最も自然なため、f(const char)が呼ばれます。
これにより、コードの意図と実際の挙動を一致させやすくなります。
理由2: 型安全性が向上する
nullptrは整数型には自動変換されないため、次のようなコードはコンパイルエラーになります。
int main() {
int n = nullptr; // コンパイルエラー
return 0;
}NULLを使っていると、うっかり整数として代入してしまってもコンパイルが通ってしまうことがあります。
バグを早期に検出できるという意味でも、nullptrは安全です。
理由3: 可読性が高く、意図が明確になる
nullptrは「ヌルポインタである」ことが見ただけで明確です。
0やNULLは整数かもしれませんし、マクロかもしれません。
p = 0;p = NULL;p = nullptr;
この3つを比べると、最後のnullptrが最も意図がはっきり読み取れます。
大規模なコードベースやレビューを行う現場では、「読む人にとって誤解されにくい表現」を選ぶことが重要です。
nullptrの基本的な使い方
ポインタの初期化・代入
ポインタを「どこも指していない状態」で初期化するには、C++11以降ではnullptrを使うことが推奨されます。
#include <iostream>
int main() {
int* p1 = nullptr; // ヌルポインタで初期化
int* p2 = nullptr; // 途中で代入する場合も同様
if (p1 == nullptr) { // ヌルチェックもnullptrで行う
std::cout << "p1 はどこも指していません\n";
}
int x = 10;
p1 = &x; // 有効なアドレスを代入
if (p1 != nullptr) {
std::cout << "p1 が指す値: " << *p1 << "\n";
}
return 0;
}想定される実行結果は次のようになります。
p1 はどこも指していません
p1 が指す値: 10初期化・代入・比較のすべてをnullptrで統一すると、コードの一貫性が高まり、バグ発見もしやすくなります。
関数への引数として使う
関数に「ポインタが存在しない」ことを明示したいときにもnullptrを使います。
#include <iostream>
void print_or_default(const char* str) {
if (str == nullptr) {
std::cout << "デフォルト表示です\n";
} else {
std::cout << "入力文字列: " << str << "\n";
}
}
int main() {
print_or_default(nullptr); // ヌルポインタを渡す
print_or_default("Hello"); // 有効な文字列リテラルを渡す
}実行結果の一例は次の通りです。
デフォルト表示です
入力文字列: Hellonullptrを使うことで、「ここには有効なポインタが来ないかもしれない」というインターフェースの意図が、呼び出し側にも伝わりやすくなります。
nullptrと関数オーバーロードの例をもう少し詳しく
典型的な問題パターン
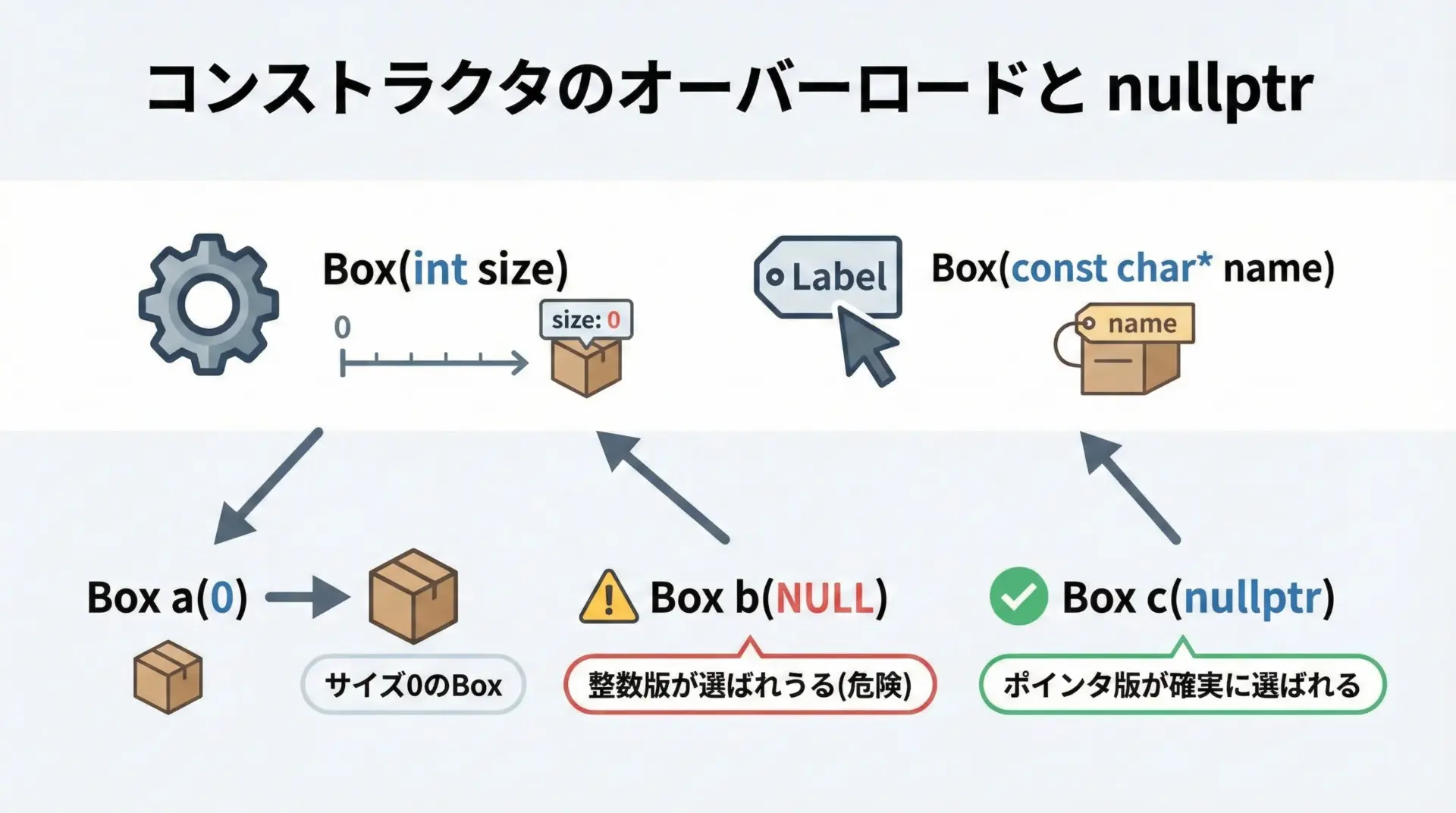
次のようにコンストラクタがオーバーロードされているクラスを考えます。
#include <iostream>
class Box {
public:
Box(int size) {
std::cout << "Box(int) コンストラクタ\n";
}
Box(const char* name) {
std::cout << "Box(const char*) コンストラクタ\n";
}
};
int main() {
Box a(0); // 整数として明確
Box b(NULL); // 実装によってはBox(int)が選ばれる可能性
Box c(nullptr); // Box(const char*) が選ばれる
}想定される出力例は次の通りです。
Box(int) コンストラクタ
Box(int) コンストラクタ
Box(const char*) コンストラクタBox b(NULL); が「文字列名なしのBox」を意図していたとしても、整数版が呼ばれてしまう可能性があります。
これがNULLを使い続けることの危険性です。
nullptrを使えば、ポインタを受け取るオーバーロードを確実に選択できるため、この種のバグを防止できます。
nullptrへの移行と実務上のポイント
既存コードからの移行指針
既存のC++コードでは、ポインタの初期化や比較にNULLや0が多用されていることが一般的です。
C++11以降の環境が前提であれば、次のような方針で段階的にnullptrへ移行するとよいです。
- ヌルポインタを表す
0やNULLはnullptrに置き換える。 - 数値としての
0(例: ループカウンタ)はそのまま維持する。 - ライブラリのインターフェース(公開API)では、ドキュメントにも「引数が
nullptrの場合の振る舞い」を明記する。
単純置換だけではなく、「本当にヌルポインタとして使われているか」を確認してから置き換えることが重要です。
nullptrとbool文脈
nullptrは、if文などのbool文脈でも自然に使うことができます。
これはポインタ型に変換されたあと、boolに変換されるためです。
#include <iostream>
int main() {
int* p = nullptr;
if (p) { // p != nullptr と等価
std::cout << "有効なポインタです\n";
} else {
std::cout << "ヌルポインタです\n";
}
return 0;
}ヌルポインタです可読性の観点から、「存在チェック」をしていることを明示したい場合はp != nullptrと書くこともよくあります。
プロジェクト内でスタイルを統一するとよいです。
nullptrとスマートポインタの関係
C++11以降ではstd::unique_ptrやstd::shared_ptrなどのスマートポインタが標準的に使われます。
これらもnullptrで初期化したり、比較したりできます。
#include <iostream>
#include <memory>
int main() {
std::unique_ptr<int> up; // デフォルト構築はヌルポインタ相当
std::shared_ptr<int> sp(nullptr); // 明示的にnullptrを渡す
if (up == nullptr) {
std::cout << "unique_ptr は空です\n";
}
sp = std::make_shared<int>(42);
if (sp != nullptr) {
std::cout << "shared_ptr の値: " << *sp << "\n";
}
}unique_ptr は空です
shared_ptr の値: 42スマートポインタも「ポインタらしく扱える」ように設計されているため、nullptrを使った書き方が自然に適用できます。
まとめ
C++11で導入されたnullptrは、単なる新しい記法ではなく、ヌルポインタを型安全かつ明確に表現するための中核的な機能です。
従来のNULLや0は整数として扱われるため、オーバーロード解決の誤りや意図しない代入を招くリスクがありました。
nullptrを使えば、こうした問題をコンパイル時に防ぎ、コードの可読性と保守性を高めることができます。
C++11以降の環境が前提であれば、新規コードはもちろん、既存コードのヌルポインタ表現も可能な範囲でnullptrに統一することを強くおすすめします。
