
Pythonのオブジェクト指向では、メソッドのオーバーライドを理解することで、コードの再利用性や拡張性が一気に高まります。
本記事では、継承の基本からsuper()の使い方、多重継承や抽象クラスまで、初心者の方でも迷わないように図解とコード例を交えながら丁寧に解説します。
Pythonならではの注意点やベストプラクティスもまとめて確認していきましょう。
メソッドオーバーライドとは
メソッドオーバーライドの基本とPythonの特徴
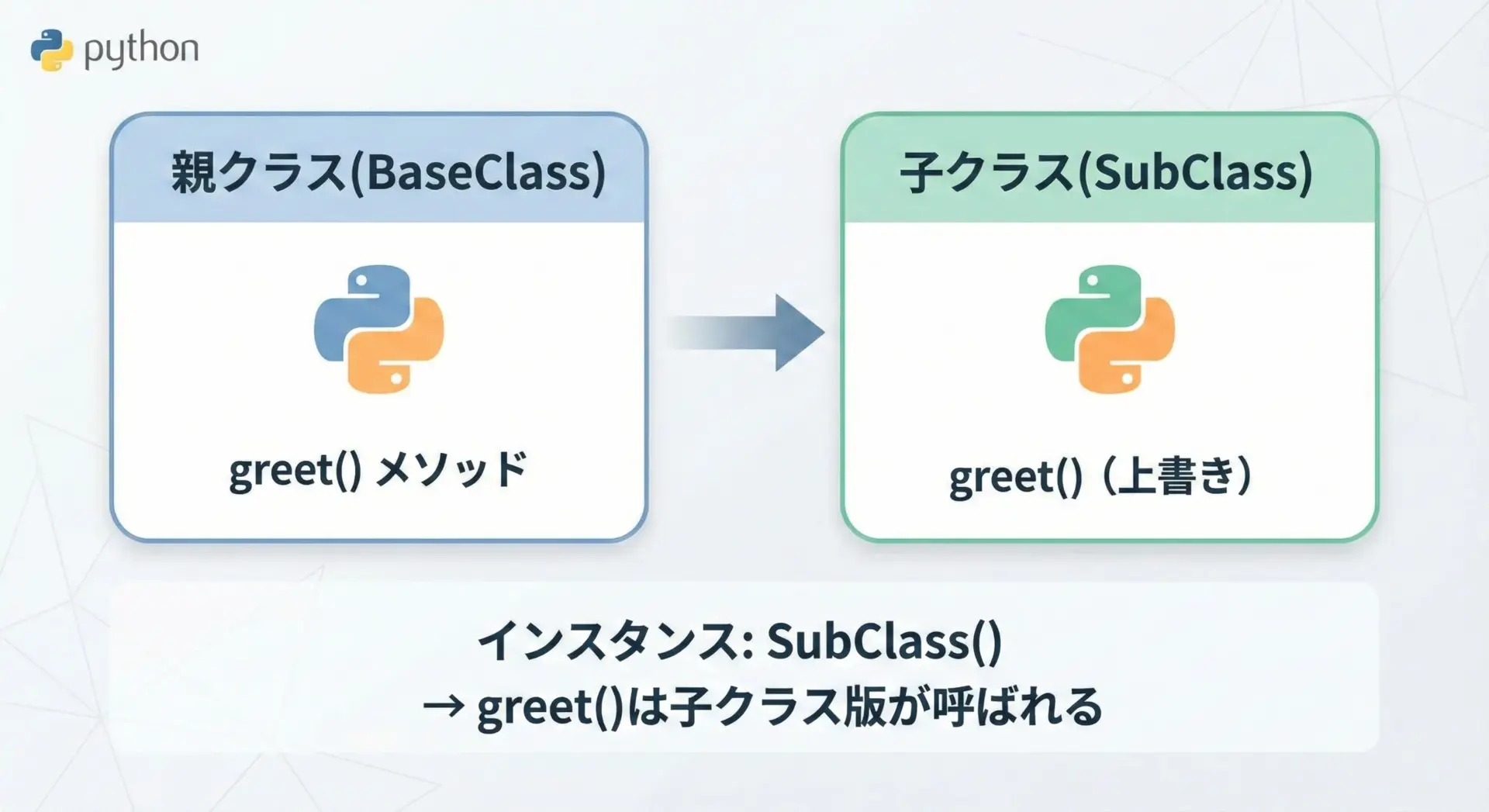
メソッドオーバーライドとは、親クラス(スーパークラス)で定義されたメソッドを、子クラス(サブクラス)で同じ名前で再定義して振る舞いを上書きすることを指します。
Pythonでは、特別なキーワードなしに同じメソッド名を定義し直すだけでオーバーライドが行われます。
具体的には、次のようなイメージです。
- 親クラスに
speak()メソッドがある - 子クラスでも
def speak(...):と定義し直す - 子クラスのインスタンスで
obj.speak()を呼ぶと、親ではなく子クラス版が実行される
Pythonでは静的な型宣言が必須ではないため、オーバーライドは非常に柔軟です。
その一方で、間違った引数や戻り値を定義してもコンパイルエラーにならないため、注意して設計する必要があります。
シンプルなオーバーライドの例
class Animal:
# 親クラスのメソッド
def speak(self):
print("Animal is making a sound")
class Dog(Animal):
# メソッドをオーバーライド(上書き)
def speak(self):
print("Woof!")
# インスタンスを生成
animal = Animal()
dog = Dog()
animal.speak() # 親クラス版が呼ばれる
dog.speak() # 子クラス版が呼ばれるAnimal is making a sound
Woof!このように、同じspeak()という名前ですが、どのクラスのインスタンスかによって実行される処理が変化します。
オーバーライドとオーバーロードの違い
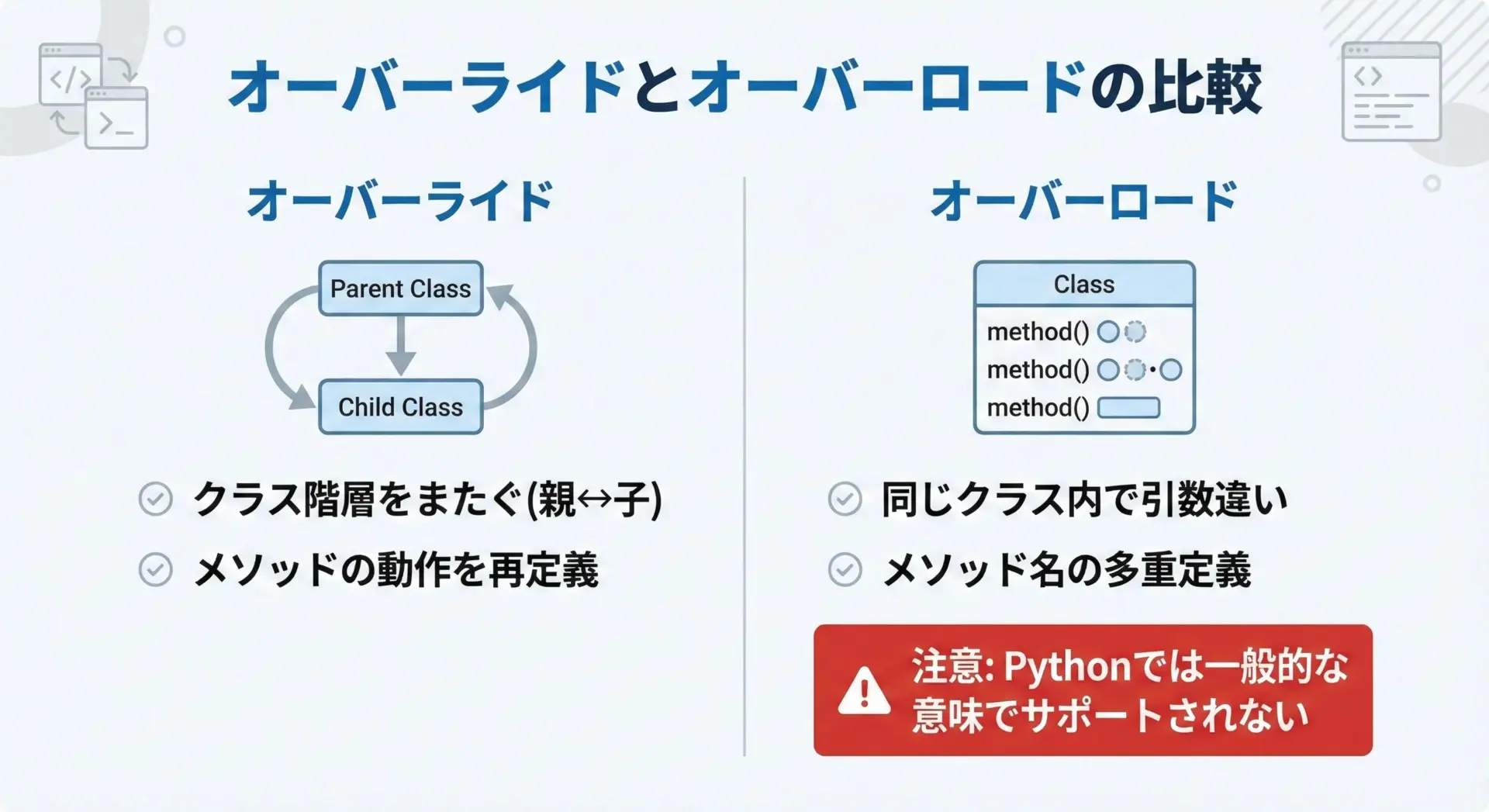
オーバーライドとよく混同される概念にオーバーロードがあります。
両者の違いを整理しておきます。
- オーバーライド: 親クラスのメソッドを、子クラスで同じ名前で上書きすること
- オーバーロード: 同じクラスの中で、同じメソッド名だが引数リストが異なるメソッドを複数定義すること
JavaやC++などではオーバーロードが言語機能としてサポートされていますが、Pythonでは引数リストの違いによるメソッドの多重定義はサポートされていません。
Pythonで「オーバーロードしようとしても」上書きになる例
class Sample:
def greet(self, name):
print(f"Hello, {name}")
# これでオーバーロードしたつもりでも…
def greet(self):
print("Hello")
s = Sample()
s.greet()Helloこのコードでは、2つ目のgreet()が1つ目を完全に上書きしてしまいます。
Pythonで複数パターンの引数を扱いたい場合は、*argsや**kwargs、デフォルト引数を使って1つのメソッドで引数バリエーションを吸収する設計を行います。
Pythonの継承とメソッドオーバーライド
クラス継承の基本構文と仕組み
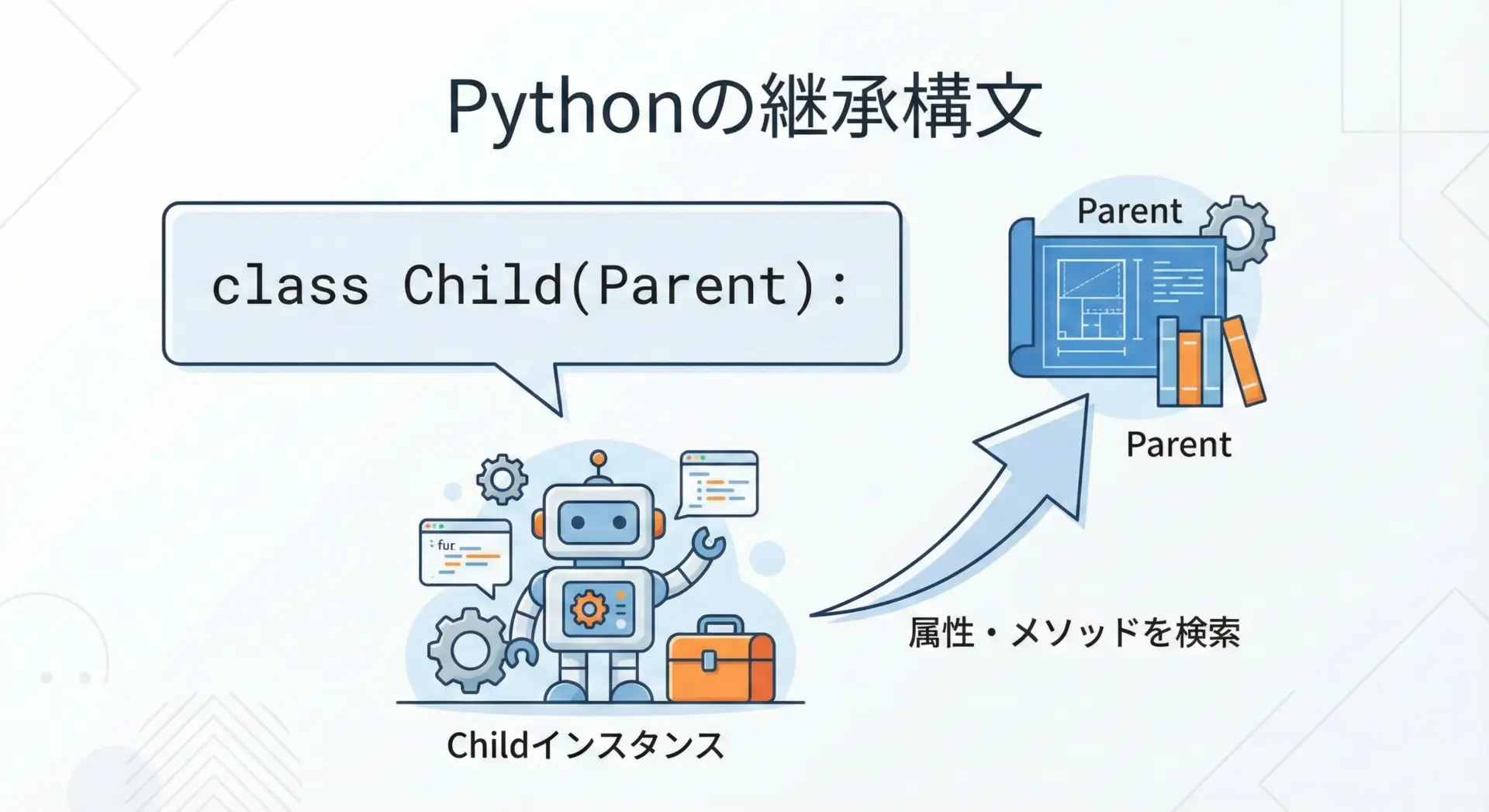
Pythonで継承を行う基本構文はとてもシンプルです。
親クラスを()の中に指定するだけで、そのクラスを継承した子クラスを定義できます。
class Parent:
def hello(self):
print("Hello from Parent")
# Parentを継承したChildクラス
class Child(Parent):
pass # まだ何も追加しない
p = Parent()
c = Child()
p.hello()
c.hello() # Parentで定義したメソッドをそのまま使えるHello from Parent
Hello from Parentこのように、Childクラスではhello()を定義していないにもかかわらず、親クラスのメソッドを呼び出せます。
これは、インスタンスからメソッドを探す際に、まず自分のクラス、次に親クラスへと順に探索するという仕組みによるものです。
サブクラスでメソッドをオーバーライドする方法
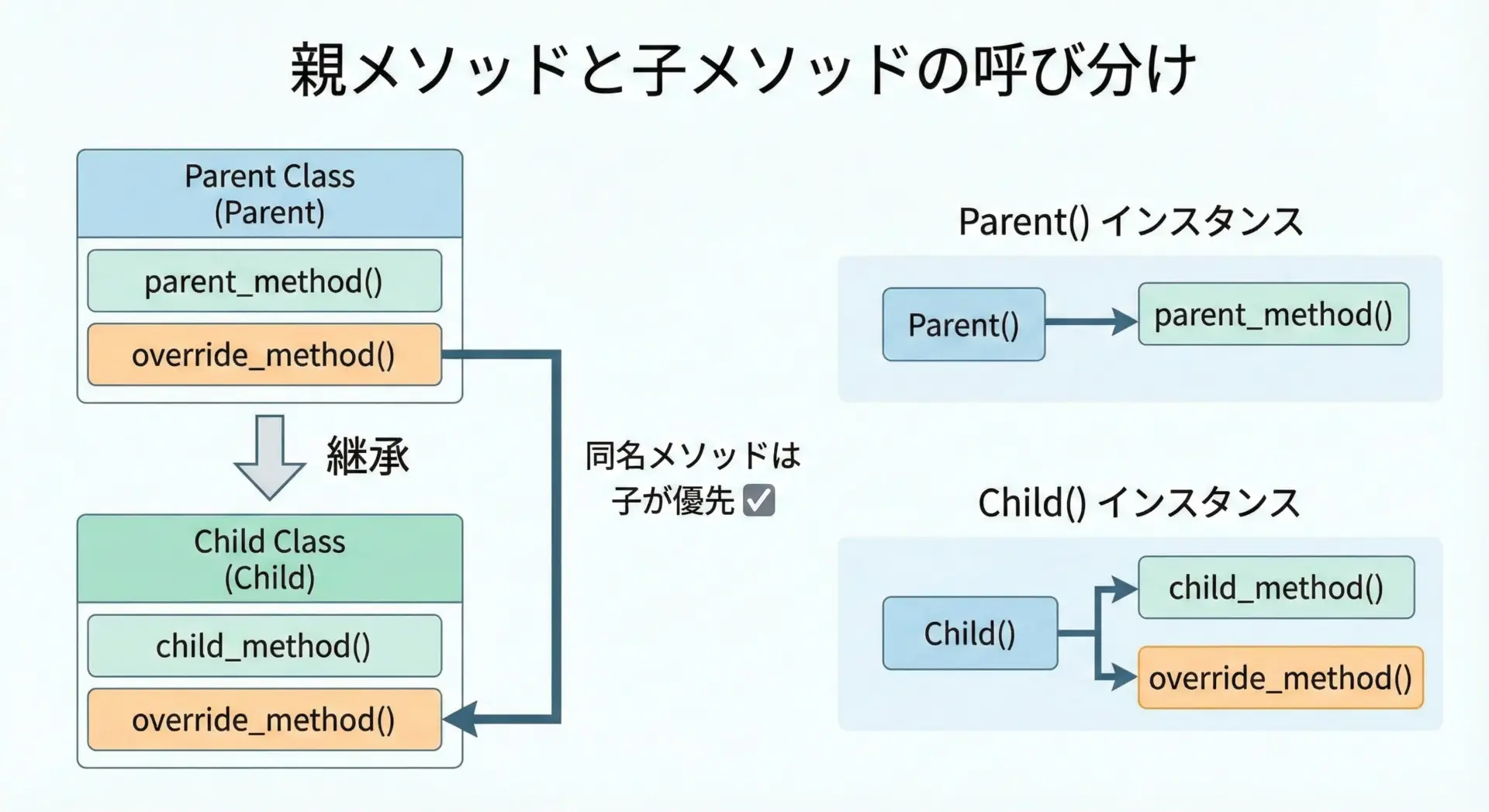
サブクラス(子クラス)でメソッドをオーバーライドするには、同じメソッド名で再定義するだけです。
引数や戻り値も基本的には同じにするのが望ましいです。
基本的なオーバーライド例
class Parent:
def greet(self):
print("Hello from Parent")
class Child(Parent):
# greetをオーバーライド
def greet(self):
print("Hello from Child")
parent = Parent()
child = Child()
parent.greet() # Parent版
child.greet() # Child版Hello from Parent
Hello from Childこのとき、Childクラスのインスタンスからgreet()を呼ぶと、親クラスではなく子クラスの実装が優先されます。
オーバーライド時の引数と戻り値の扱い
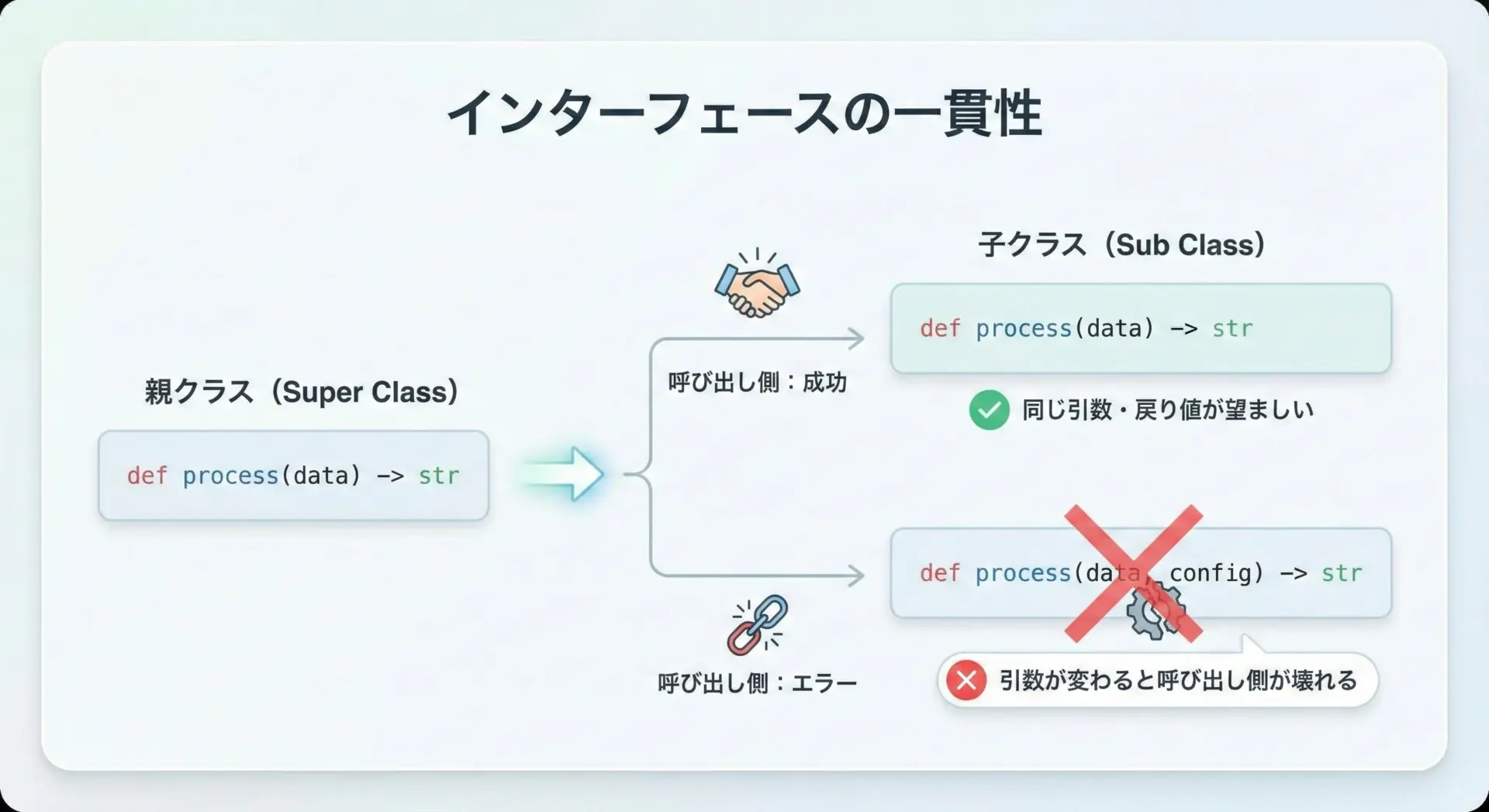
メソッドをオーバーライドする際には、引数や戻り値の扱いを親クラスと整合させることが大切です。
Pythonは動的型付けなので、引数の型や個数が変わってもエラーにはなりませんが、呼び出し側のコードが想定通りに動かなくなる可能性があります。
引数を変えてしまうとどうなるか
class Parent:
def add(self, x, y):
return x + y
class Child(Parent):
# 親とは違う引数にしてしまった例(あまり良くない)
def add(self, x, y, z):
return x + y + z
c = Child()
# 呼び出し側は「Parentと同じつもり」で2引数で呼び出す
# c.add(1, 2) # TypeError になるTypeError: Child.add() missing 1 required positional argument: 'z'このように、同じインターフェースだと思って呼び出したコードが突然エラーになることがあります。
そのため、基本的には次のような指針を守ると安全です。
- 引数の数や意味は親クラスと合わせる
- 親クラスよりも「多くの引数を必須にしない」
- 戻り値の型や意味も基本的に合わせる
正しい形でのオーバーライド例
class Parent:
def format_name(self, first_name, last_name):
return f"{first_name} {last_name}"
class Child(Parent):
# 引数・戻り値の形はそのまま、実装だけ変更
def format_name(self, first_name, last_name):
# 例: 大文字にして返す
full = super().format_name(first_name, last_name)
return full.upper()
c = Child()
print(c.format_name("Taro", "Yamada"))TARO YAMADAこのように、インターフェース(引数・戻り値の約束)は維持しながら、内部の処理だけ変えるのが、良いオーバーライドの基本です。
super()で親クラスのメソッドを呼び出す
super()の基本的な使い方と書き方
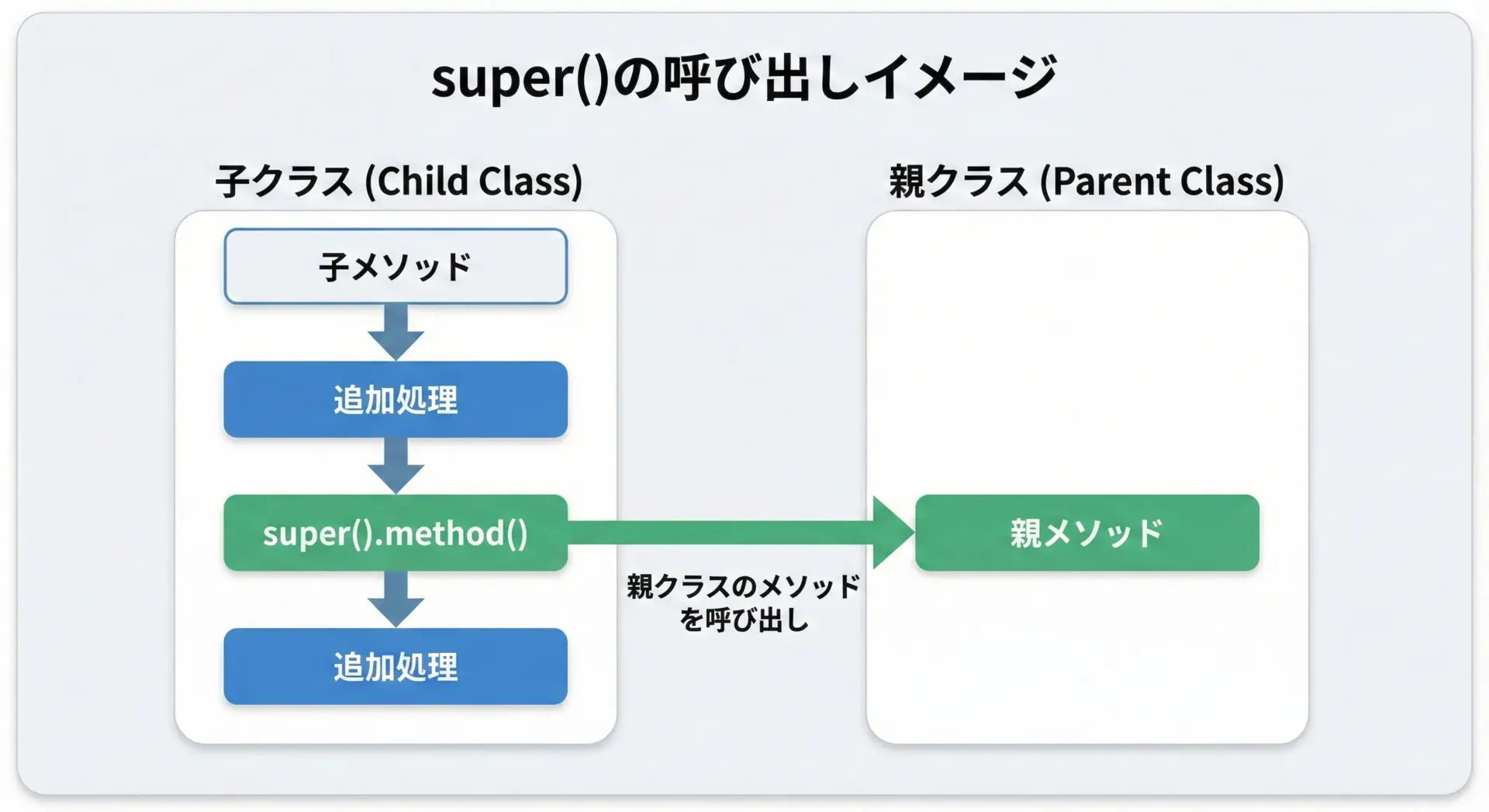
オーバーライドしたメソッドの中で、親クラスの元の処理も一部利用したいというケースはよくあります。
そのときに使うのがsuper()です。
super()は、簡単に言うと「今いるクラスの親クラスを指すオブジェクト」を返す仕組みです。
もっと正確には、メソッド解決順序(MRO)に従って1つ前のクラスを探す仕組みですが、単一継承では「親クラス」だと理解して問題ありません。
super()の基本例
class Animal:
def speak(self):
print("Animal is making a sound")
class Dog(Animal):
def speak(self):
# まず親クラスの処理を呼ぶ
super().speak()
# そのあとで追加の処理をする
print("Woof!")
dog = Dog()
dog.speak()Animal is making a sound
Woof!このようにsuper().speak()を呼び出すことで、親クラスのspeak()を実行した上で、子クラス独自の処理を追加できます。
コンストラクタでのsuper()の利用
コンストラクタ__init__()のオーバーライドでは、親クラスの初期化処理を忘れずに呼び出すことが重要です。
class User:
def __init__(self, name):
self.name = name
print("User initialized")
class AdminUser(User):
def __init__(self, name, level):
# 親クラスの初期化を必ず呼ぶ
super().init(name) # ← この行はわざと間違い
self.level = level
print("AdminUser initialized")このままだとエラーなので、正しくは以下のように書きます。
class User:
def __init__(self, name):
self.name = name
print("User initialized")
class AdminUser(User):
def __init__(self, name, level):
# 正しい書き方
super().__init__(name)
self.level = level
print("AdminUser initialized")
admin = AdminUser("Alice", 5)
print(admin.name, admin.level)User initialized
AdminUser initialized
Alice 5コンストラクタのオーバーライドではsuper().__init__()を呼び出すことを、基本ルールとして覚えておくと良いです。
super()を使うべきケースと使わないケース
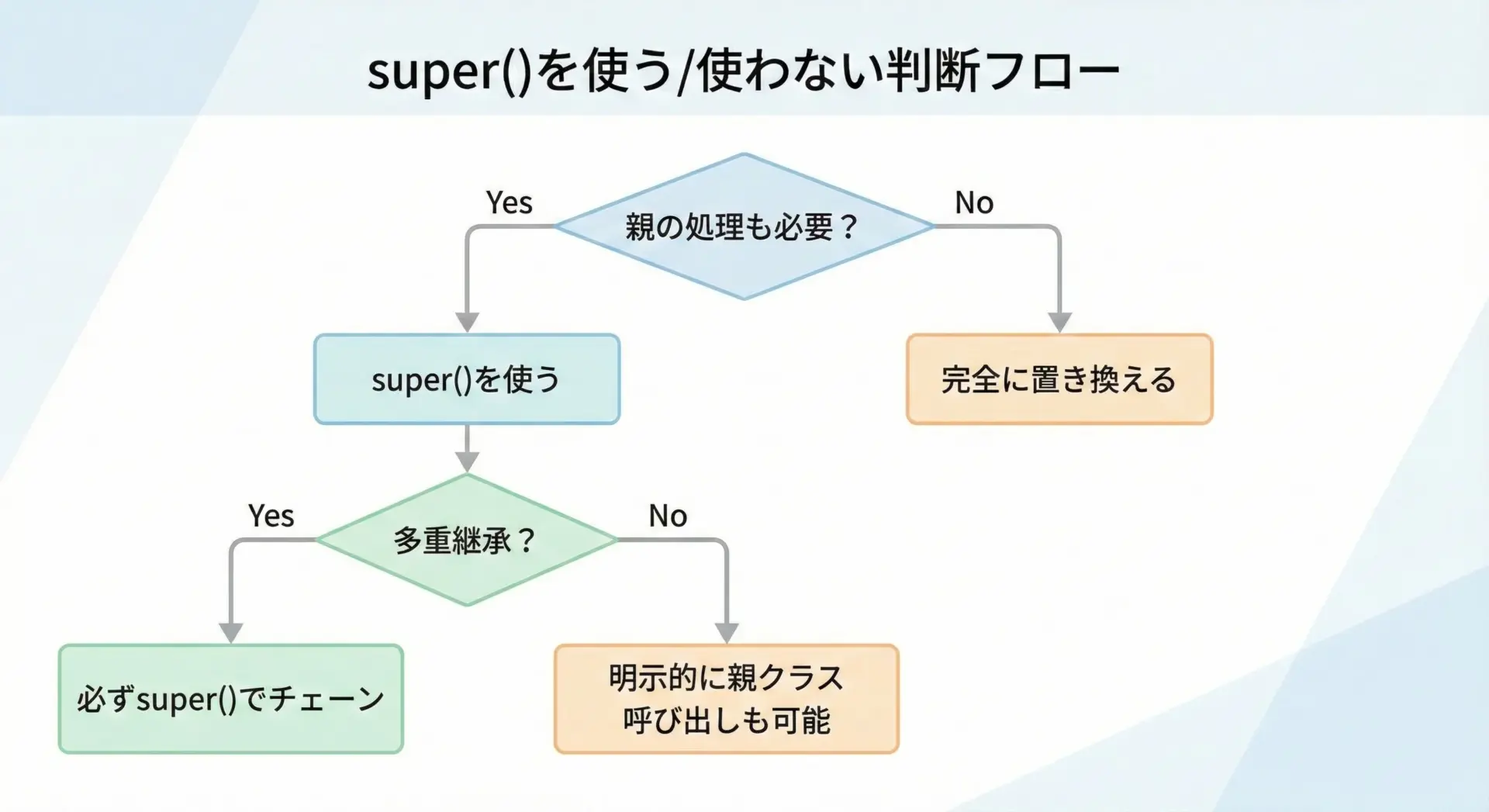
親クラスの処理を部分的に再利用したい場合は、基本的にsuper()を使うべきです。
特にコンストラクタやフレームワークのコールバックメソッドでは、親クラス側に重要な初期化や共通処理が書かれていることが多く、その処理を飛ばしてしまうとバグの原因になります。
super()を使うべき主なケースとしては、次のようなものがあります。
- 親クラスの
__init__()で初期化している属性がある - 親クラスのメソッドに共通ロジックがあり、そこに子クラスの処理を追加したい
- 多重継承をしている、または将来拡張する可能性がある
一方で、親クラスの処理を完全に無効にして、まったく別の振る舞いに変えたい場合には、あえてsuper()を呼び出さないこともあります。
ただし、その場合でも「親の機能を絶対に使わない」という意図をコメントやドキュメントで明示しておくと、後から読んだ人にとって理解しやすくなります。
完全に処理を置き換えるオーバーライド例
class Logger:
def log(self, message):
print(f"[LOG] {message}")
class SilentLogger(Logger):
def log(self, message):
# 何も出力しない(親の処理は呼ばない)
pass
l1 = Logger()
l2 = SilentLogger()
l1.log("hello")
l2.log("hello")[LOG] helloこのように、子クラスでpassにしてしまえば、親クラスのログ処理を完全に無効化することができます。
多重継承とsuper()の動作
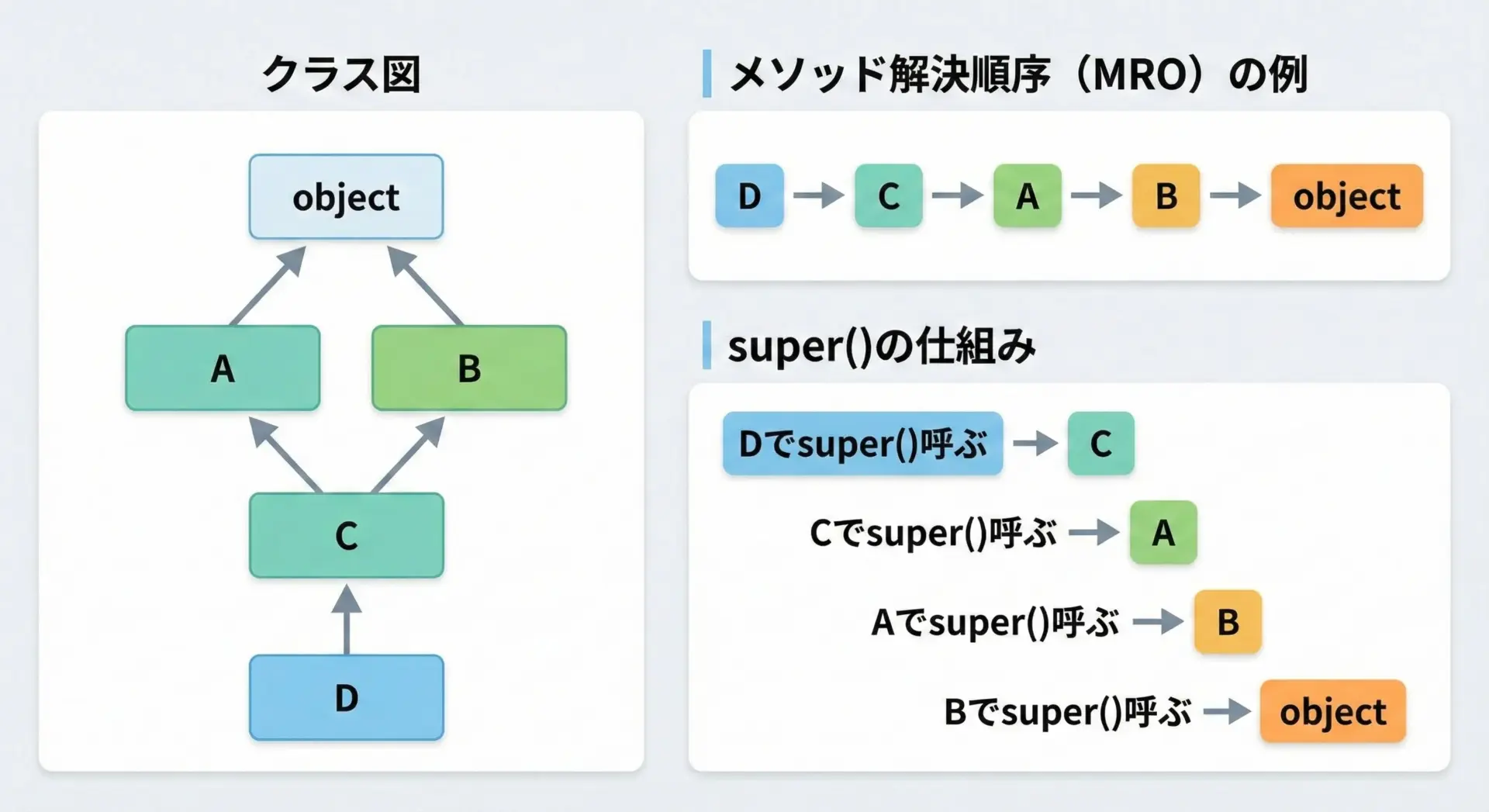
Pythonは多重継承をサポートしており、1つのクラスが複数の親クラスを持つことができます。
このとき、どの親クラスのメソッドが呼ばれるかを決めるのがメソッド解決順序(MRO: Method Resolution Order)です。
super()は、このMROにしたがって「次に呼び出すべきクラス」を決定します。
単一継承では直感通り「親クラス」が呼ばれますが、多重継承では「親クラスの親」など、MROに沿ったチェーンになっていきます。
多重継承でのsuper()チェーンの例
class Base:
def process(self):
print("Base.process")
class MixinA(Base):
def process(self):
print("MixinA.process - before")
super().process()
print("MixinA.process - after")
class MixinB(Base):
def process(self):
print("MixinB.process - before")
super().process()
print("MixinB.process - after")
class Concrete(MixinA, MixinB):
pass
obj = Concrete()
print(Concrete.mro()) # MROを確認
obj.process()[<class '__main__.Concrete'>, <class '__main__.MixinA'>, <class '__main__.MixinB'>, <class '__main__.Base'>, <class 'object'>]
MixinA.process - before
MixinB.process - before
Base.process
MixinB.process - after
MixinA.process - afterこの例では、クラスの定義順により、MROはConcrete → MixinA → MixinB → Base → objectとなっています。
super()はこの順序に従って「次のクラス」のprocess()を呼び出していくため、各クラスが自分の処理を前後に挟みながら、チェーンのように処理を積み上げていく形になります。
多重継承を行う場合、特定の親クラスを直接呼び出す(例: Base.process(self)のように)とMROチェーンが崩れてしまうため、基本的にはsuper()を使って呼び出すことが重要です。
メソッドオーバーライドの注意点とベストプラクティス
オーバーライド時に起こりがちなバグと回避策
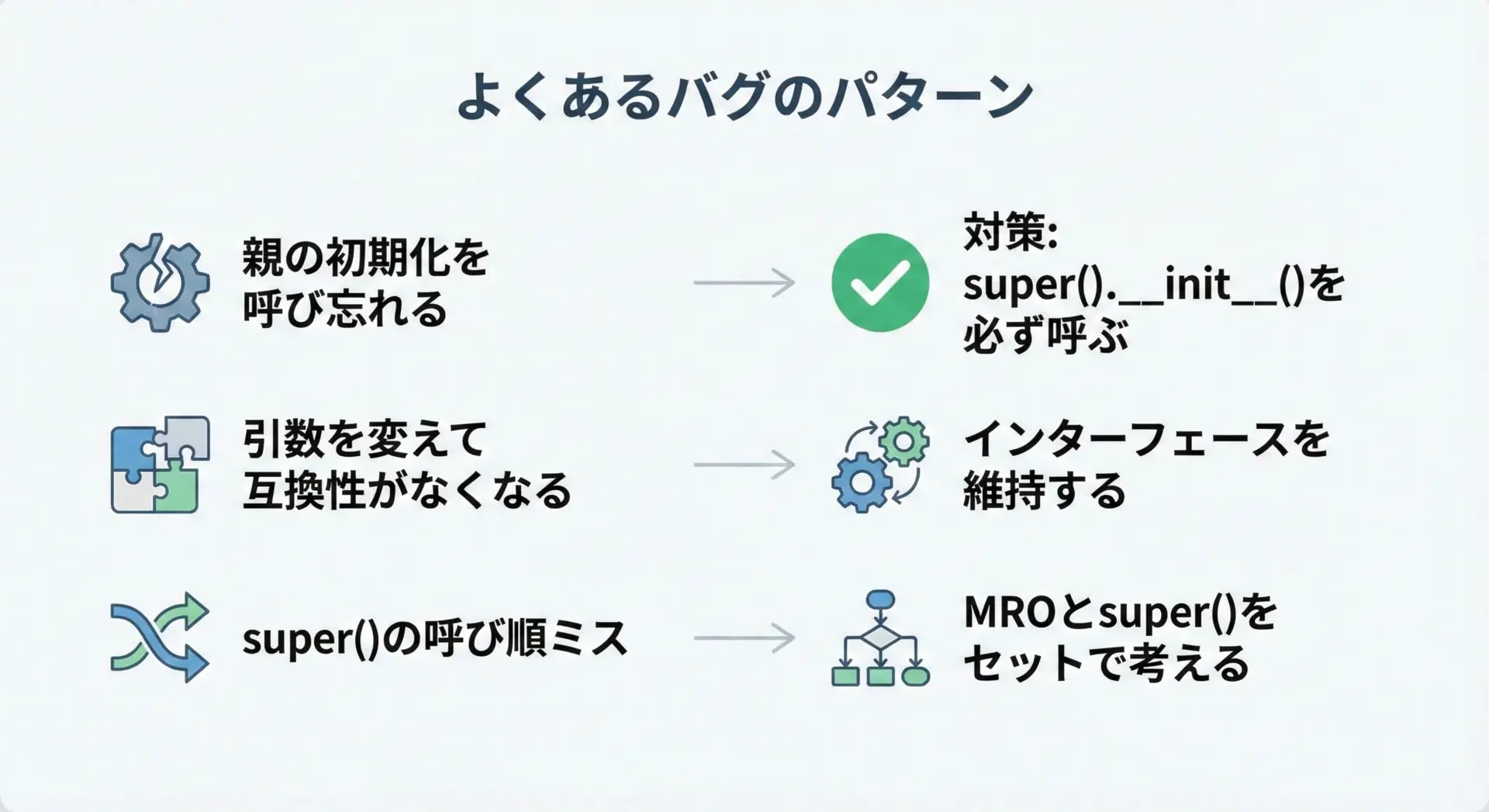
メソッドオーバーライドは強力な一方で、使い方を誤ると気づきにくいバグにつながりやすいです。
よくある失敗例と、その回避策を整理しておきます。
よくあるパターンとしては、次のようなものがあります。
- 親クラスの
__init__()を呼び忘れて、必要な属性が初期化されない - 引数リストを変えてしまい、親クラスと互換性がなくなる
- 多重継承で
super()を使わずに親クラスを直接呼んでしまう - 親クラスの仕様変更に追随できず、サブクラスとの整合性が崩れる
親の初期化を呼び忘れる例と対策
class BaseRepository:
def __init__(self):
self.connected = True
class UserRepository(BaseRepository):
def __init__(self):
# 親の__init__を呼び忘れ
self.users = []
repo = UserRepository()
print(repo.connected) # AttributeError になるAttributeError: 'UserRepository' object has no attribute 'connected'このようなバグを防ぐために、次のようなルールを設けると良いです。
- コンストラクタをオーバーライドするときは必ず
super().__init__()を呼ぶ - テストで親クラスの期待する属性がサブクラスでも存在するかを確認する
親クラスとのインターフェースを崩さないコツ
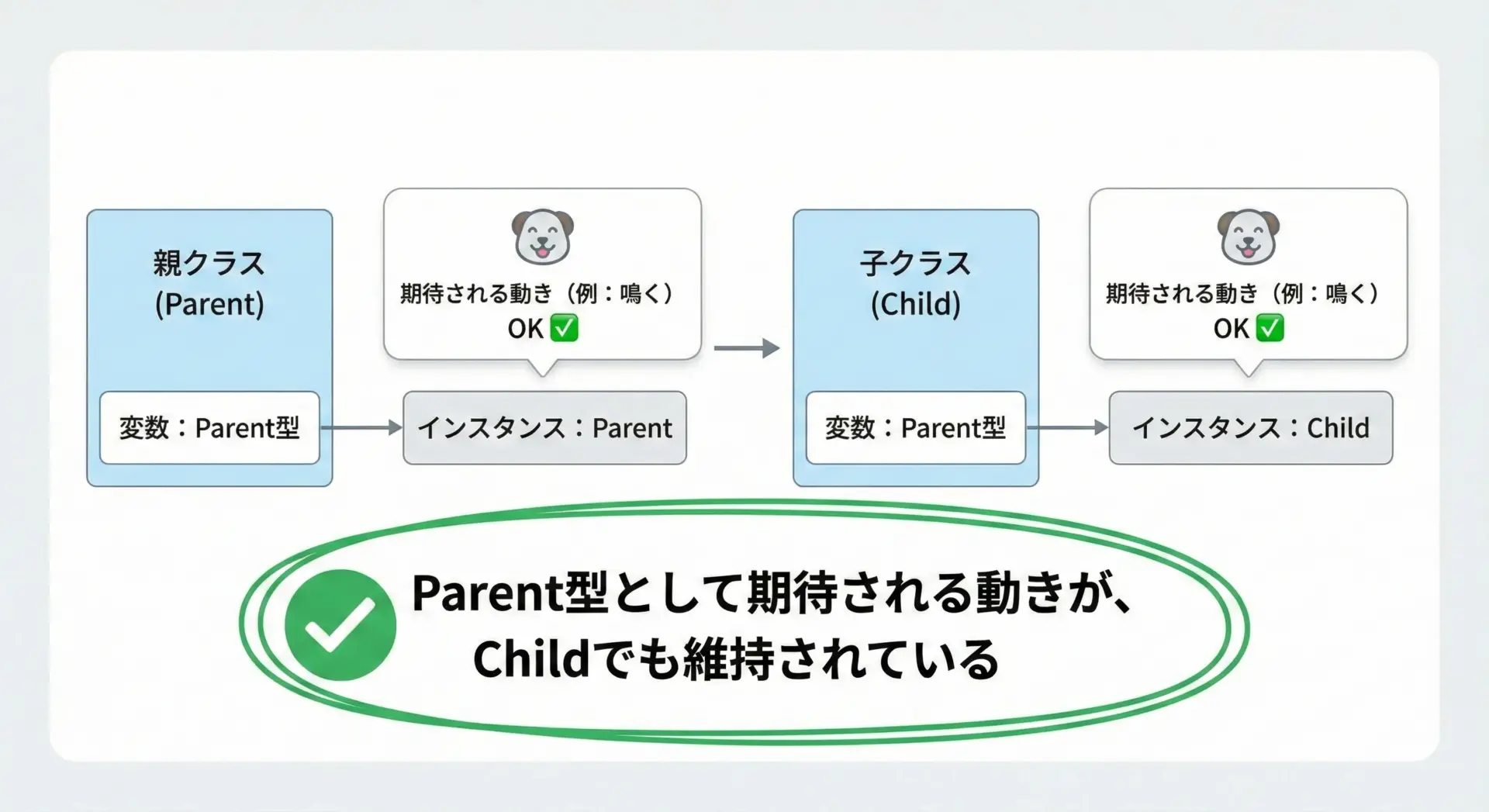
オーバーライド時には親クラスとサブクラスのインターフェース(使い方の約束)を崩さないことが大切です。
これはオブジェクト指向の原則である「LSP(リスコフの置換原則)」に対応する考え方で、「親クラスの代わりに子クラスを使ってもプログラムが正しく動くべき」という意味になります。
具体的に守るべきポイントは次の通りです。
- メソッド名はそのままにする
- 引数の数・意味・順序を変えない
- 例外の出方も大きくは変えない
- 戻り値の型や意味を大きく変えない
インターフェースを維持しながら挙動だけ変える例
class Calculator:
def divide(self, x, y):
return x / y
class SafeCalculator(Calculator):
def divide(self, x, y):
# y が 0 の場合は None を返す(使い手がそう期待している前提)
if y == 0:
return None
return super().divide(x, y)
c1 = Calculator()
c2 = SafeCalculator()
print(c1.divide(10, 2))
print(c2.divide(10, 2))
print(c2.divide(10, 0))5.0
5.0
Noneこのように、呼び出し側から見て「divideという名前で2つの引数を取り、何らかの結果を返す」という約束は崩れていません。
親クラスと同じインターフェースを維持することで、コードの再利用性とテストのしやすさが大きく向上します。
抽象クラスとオーバーライド
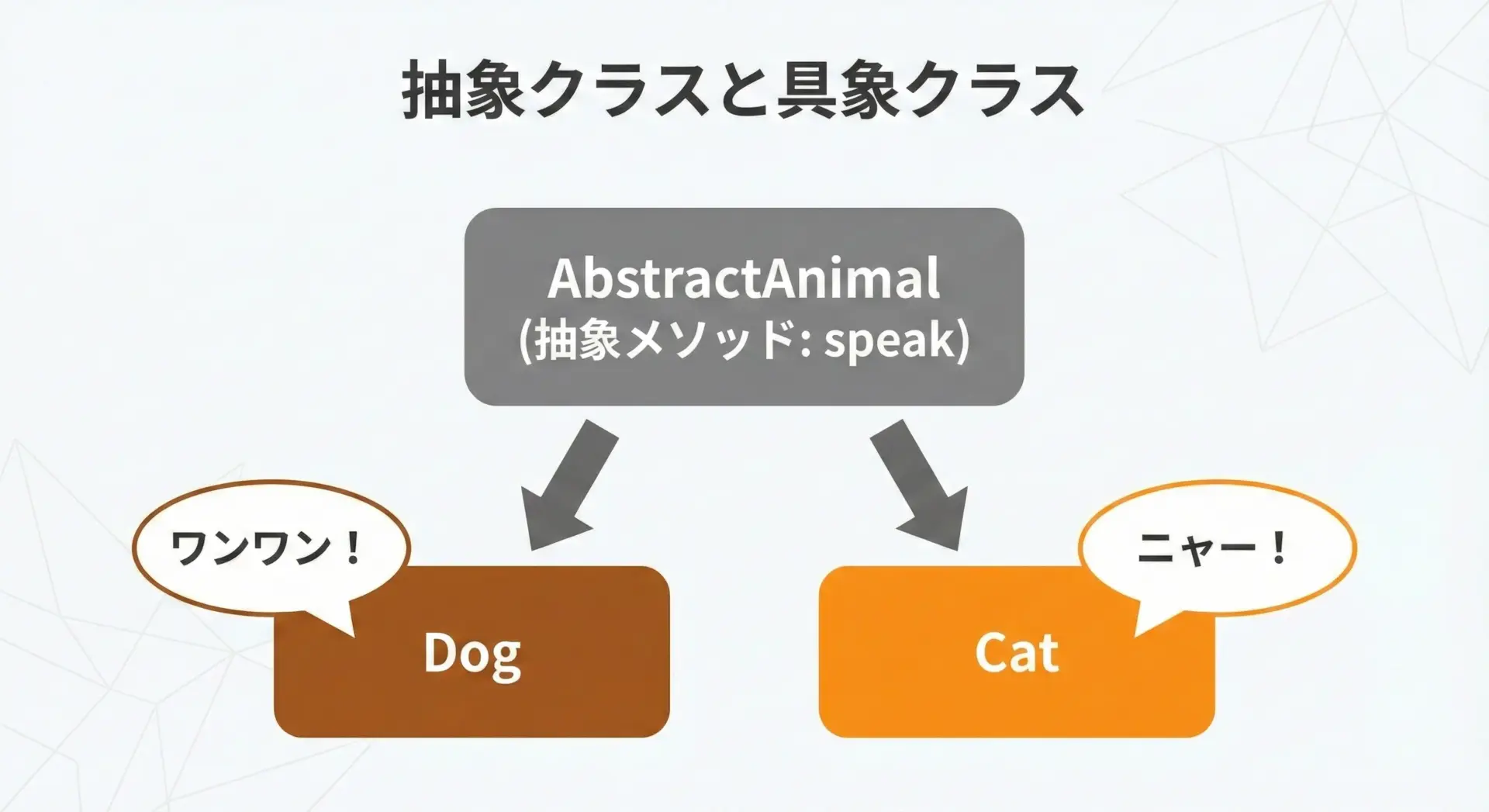
Pythonではabcモジュールを使うことで抽象クラスを定義できます。
抽象クラスは「このクラスを継承するサブクラスは、必ずこのメソッドを実装(オーバーライド)してね」という契約を表現する仕組みです。
抽象クラスと抽象メソッドの定義
from abc import ABC, abstractmethod
class Animal(ABC):
@abstractmethod
def speak(self):
"""鳴き声を出す抽象メソッド"""
pass
class Dog(Animal):
def speak(self):
print("Woof!")
class Cat(Animal):
def speak(self):
print("Meow!")
dog = Dog()
cat = Cat()
dog.speak()
cat.speak()Woof!
Meow!抽象メソッドを1つでも実装していないクラスのインスタンスは生成できないため、オーバーライド漏れをコンストラクタで検出できるというメリットがあります。
大規模なプロジェクトやチーム開発では、重要なインターフェースには抽象クラスを使って「必ずオーバーライドさせる」設計にしておくと、安全性が高まります。
テストしやすいオーバーライド設計のポイント
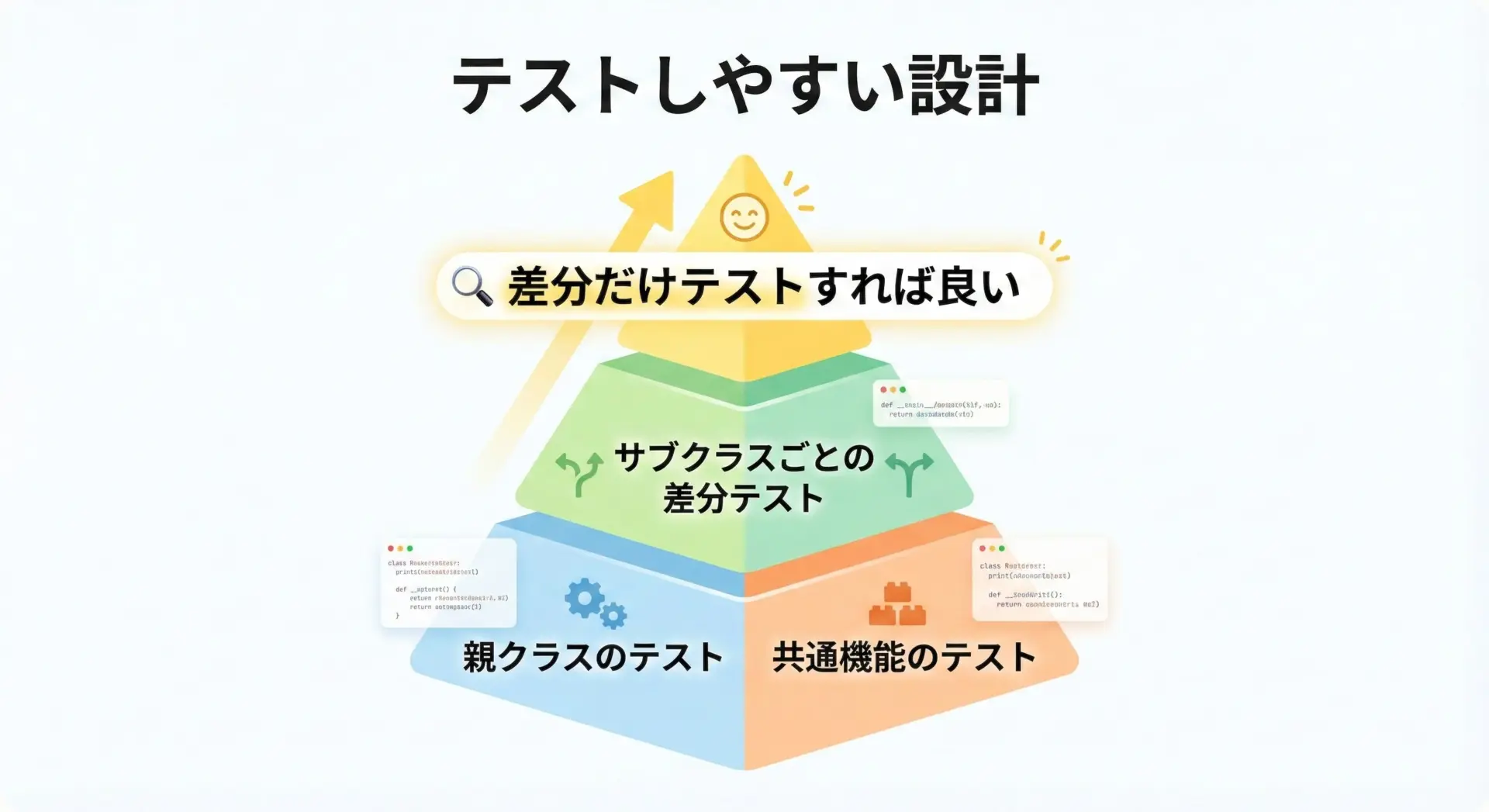
メソッドオーバーライドを多用すると、テストが複雑になりやすい印象を持たれるかもしれませんが、設計を少し工夫するだけでテストがしやすくなります。
ポイントは次の通りです。
- 親クラスに共通ロジックをまとめ、よくテストしておく
- サブクラスでは「差分」に集中してテストする
- 複雑な処理はメソッドを分割し、オーバーライド部分を小さく保つ
- 依存関係をコンストラクタ引数やプロパティで受け取り、モックしやすくする
共通部分と差分部分を分ける例
class DiscountCalculator:
def calculate(self, price):
# 基本の検証ロジック
if price < 0:
raise ValueError("price must be non-negative")
# ここから先の「割引率の決め方」だけをサブクラスに任せる
rate = self.get_discount_rate(price)
return int(price * (1 - rate))
def get_discount_rate(self, price):
# デフォルトでは割引なし
return 0.0
class StudentDiscountCalculator(DiscountCalculator):
def get_discount_rate(self, price):
# 学生は常に20%オフ
return 0.2
class VipDiscountCalculator(DiscountCalculator):
def get_discount_rate(self, price):
# VIPは価格に応じて割引率を変える
if price >= 10000:
return 0.3
return 0.15
calc = StudentDiscountCalculator()
print(calc.calculate(10000))
vip_calc = VipDiscountCalculator()
print(vip_calc.calculate(8000))
print(vip_calc.calculate(12000))8000
6800
8400この設計では、入力チェックや割引率の適用方法といった共通ロジックは親クラスDiscountCalculatorに集中し、「割引率の決め方」だけをオーバーライドの対象にしています。
これにより、テスト戦略は次のように整理できます。
- 親クラス
calculate()のテストで、価格がマイナスのときの例外や割引率の適用ロジックをしっかり検証する - サブクラスのテストでは、
get_discount_rate()の動作に集中する - サブクラスごとに、「特定の価格に対して期待される割引率」をテーブル形式で検証する
このように、オーバーライドする範囲を限定し、共通部分と差分部分を明確に分離することで、テストしやすく理解しやすい継承構造を作ることができます。
まとめ
メソッドオーバーライドは、Pythonのオブジェクト指向を使いこなすうえで避けて通れない重要な機能です。
本記事では、継承の基本構文から、super()による親メソッドの呼び出し、多重継承におけるMRO、抽象クラスによる「実装の強制」まで、一通りの知識を整理しました。
引数や戻り値のインターフェースを守りつつ、親クラスの共通ロジックとサブクラスの差分をうまく分担することで、再利用性が高くテストしやすい設計が実現できます。
まずは小さなクラス階層から、実際にオーバーライドを試して感覚をつかんでみてください。
